
Data Quality-Aware Client Selection in Heterogeneous Federated Learning


Abstract
1. Introduction
2. Related Works
2.1. Federated with Data Heterogeneity
2.2. Federated Client Selection
3. Notations and Preliminaries
3.1. General FL Framework
3.2. Heterogeneous Federated Learning
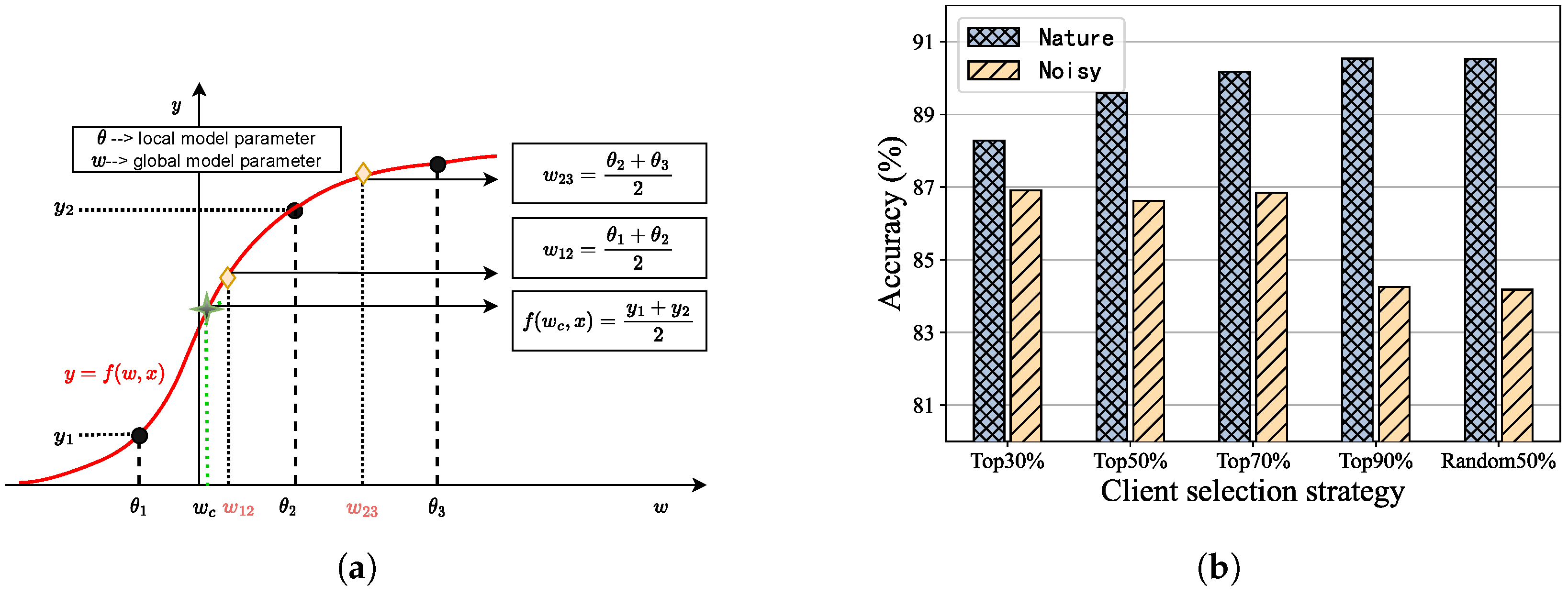
4. Loss Sharpness in Federated Learning
5. FedDQA
- L1: Local training. Train local model by .
- L2: Data quality-aware with loss sharpness. Perceive client data quality during training and obtain the quality score .
- R1: Client selection. Client selection using quality score to obtain a subset of users .
- R2: Model aggregation. A global model is aggregated based on client subset .
- R3: Global model broadcast. Distribute the global model parameters obtained from aggregation to clients for the next round of updating.
6. Performance Evaluation
6.1. Evaluation Setup
6.1.1. System Settings and Datasets
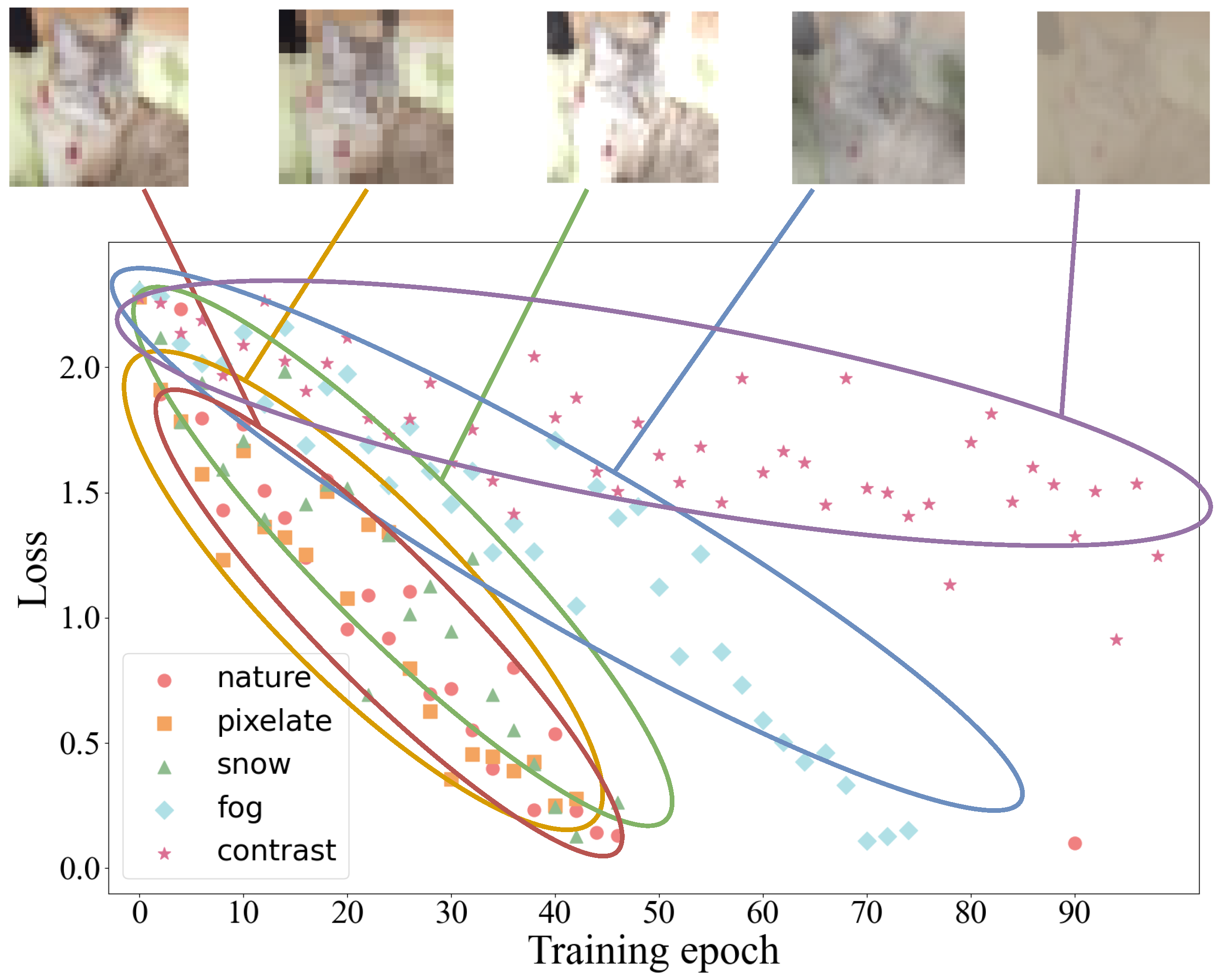
6.1.2. Noisy Environment Setup
- (1)
- Single noise type and multiple noise levels (1-M). We choose the Emnist and Fashion datasets. We split the training dataset into n parts as independent homogeneous distributions and add different Gaussian noise levels to each data part, assigning them to different clients i. Specifically, there are , when .
- (2)
- Multiple noise types and single noise level (M-1). We choose the CIFAR-10 and CIFAR-10-C datasets. Among them, the noiseless natural data of client0 comes from the dataset CIFAR-10. client1∼client19 each comes with one different type of noise data, and the data come from 19 types of noise (level 5) in CIFAR-10-C.
- (3)
- Multiple noise types and noise levels (M-M). We choose the CIFAR-10 and CIFAR-10-C datasets. Among them, the noiseless natural data of client0 comes from the dataset CIFAR-10. client1∼client9 each carries a different type of noise data, and the data come from 9 types of noise in CIFAR-10-C (level 3). client10∼client19 each carries a different type of noise data from the FedDQA parameter .
6.1.3. Benchmark Algorithms
- (1)
- (2)
- (3)
- WGD: Weights Gradient Differences prioritizes the clients with the most significant parameter gradient of model updates. The method considers that the global model that receives more parameter updates during the local training process is considered to learn more; this metric has been applied in studies such as [23,46,47].
- (4)
- FAST: This method prioritizes the client with the fastest decreasing loss. The method considers that the faster the loss decreases during the local training process, the more content updates it has; this metric is applied in the study [48].
- (5)
- DQA: The method used in this paper.
6.1.4. Experimental Settings for Clients Selection
| Algorithm 1: Client selection with dynamic thresholds |
Data: client set C, DQA ordered set , thresholds parameters , client sub set size Result: selected client sub set ; ; select according to and ; 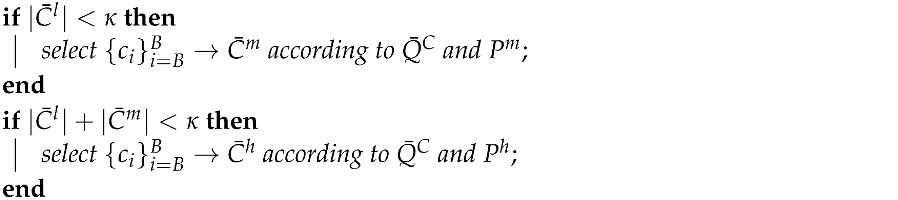 combine |
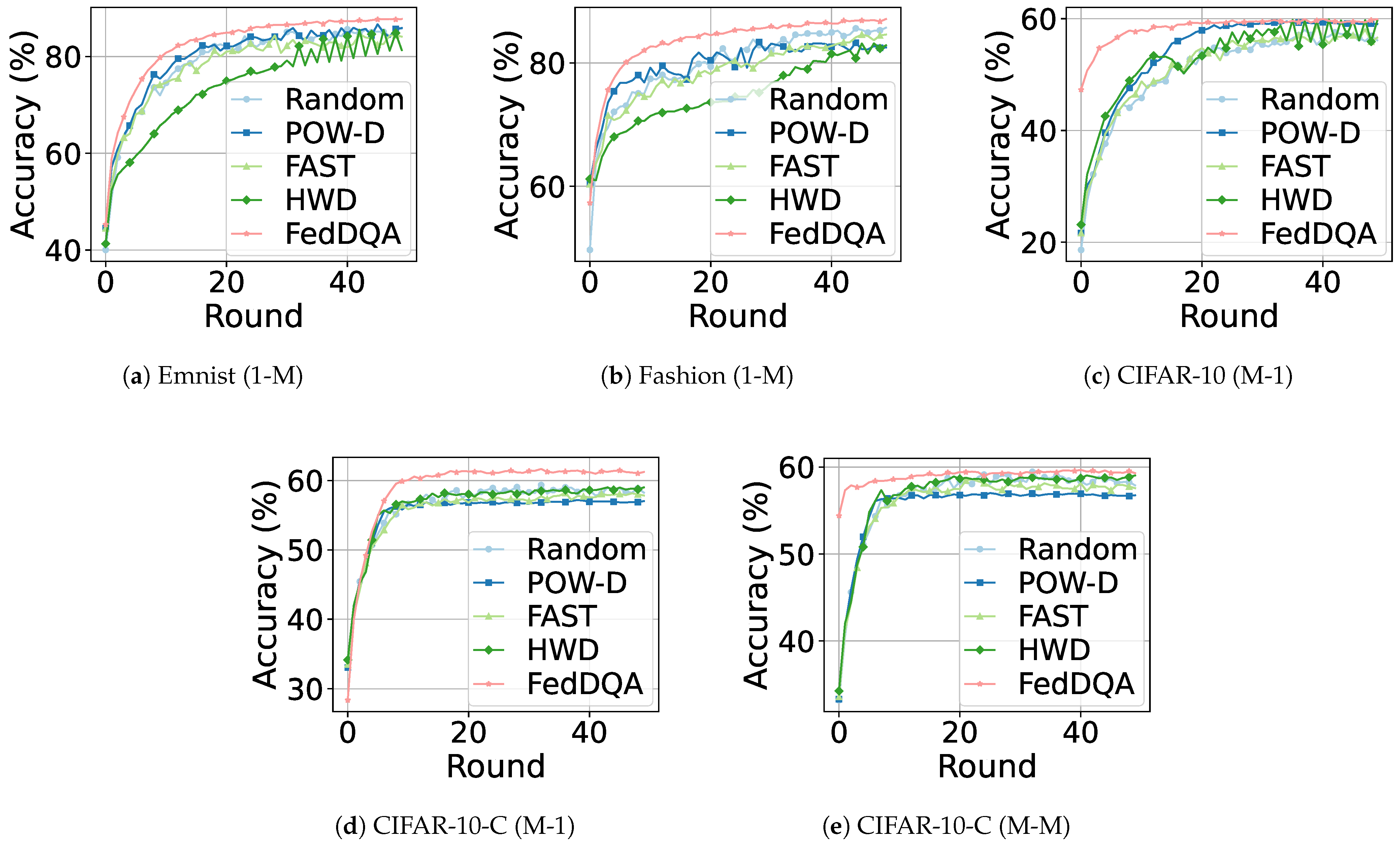
6.2. Effecient and Convergence Analysis
6.3. Flexibility in Parameter Choices
6.4. Impact of Feature Skew
6.5. Conjunction with Popular Federal Learning Methods
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| N | Total number of clients |
| Global dataset | |
| Local dataset of client i | |
| Noisy dataset of client i | |
| Noise added to data sample | |
| Parameters of the global model | |
| Optimal global model parameters | |
| Parameters of the local model on nature data of client i | |
| Parameters of the model trained on noisy data of client i | |
| Empirical loss on the global dataset | |
| Local empirical loss on the dataset | |
| Loss function for dataset with model | |
| Set of loss values of client i | |
| Subset of clients selected in the t-th communication round | |
| Slow-start loss threshold | |
| Number of epochs to reach the loss threshold | |
| Data-Quality-Aware (DQA) score for client i | |
| Ordered set of DQA scores for client set | |
| f | Non-linear transformation function |
| Data distribution of client i | |
| Selection probabilities for clients |
References
- Li, X.; Jiang, M.; Zhang, X.; Kamp, M.; Dou, Q. Fedbn: Federated learning on non-iid features via local batch normalization. arXiv 2021, arXiv:2102.07623. [Google Scholar]
- Zhu, Z.; Hong, J.; Zhou, J. Data-Free Knowledge Distillation for Heterogeneous Federated Learning. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 12878–12889. [Google Scholar]
- Zhang, J.; Chen, C.; Li, B.; Lyu, L.; Wu, S.; Ding, S.; Shen, C.; Wu, C. DENSE: Data-Free One-Shot Federated Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 21414–21428. [Google Scholar]
- Qi, P.; Zhou, X.; Ding, Y.; Zhang, Z.; Zheng, S.; Li, Z. FedBKD: Heterogenous Federated Learning via Bidirectional Knowledge Distillation for Modulation Classification in IoT-Edge System. IEEE J. Sel. Top. Signal Process. 2023, 17, 189–204. [Google Scholar] [CrossRef]
- Fang, X.; Ye, M. Robust Federated Learning With Noisy and Heterogeneous Clients. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10072–10081. [Google Scholar]
- Zhang, L.; Wu, D.; Yuan, X. FedZKT: Zero-Shot Knowledge Transfer towards Resource-Constrained Federated Learning with Heterogeneous On-Device Models. In Proceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), Bologna, Italy, 10–13 July 2022; pp. 928–938. [Google Scholar]
- Zhang, L.; Shen, L.; Ding, L.; Tao, D.; Duan, L.-Y. Fine-Tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10174–10183. [Google Scholar]
- Huang, W.; Ye, M.; Du, B. Learn from Others and Be Yourself in Heterogeneous Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10133–10143. [Google Scholar]
- Tang, Z.; Zhang, Y.; Shi, S.; He, X.; Han, B.; Chu, X. Virtual Homogeneity Learning: Defending against Data Heterogeneity in Federated Learning. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 June 2022; pp. 21111–21132. [Google Scholar]
- Zhang, J.; Hua, Y.; Wang, H.; Song, T.; Xue, Z.; Ma, R.; Guan, H. FedALA: Adaptive Local Aggregation for Personalized Federated Learning. Proc. AAAI Conf. Artif. Intell. 2023, 37, 11237–11244. [Google Scholar] [CrossRef]
- He, Y.; Chen, Y.; Yang, X.; Yu, H.; Huang, Y.-H.; Gu, Y. Learning Critically: Selective Self-Distillation in Federated Learning on Non-IID Data. IEEE Trans. Big Data 2022, 1–12. [Google Scholar] [CrossRef]
- Marfoq, O.; Neglia, G.; Vidal, R.; Kameni, L. Personalized Federated Learning through Local Memorization. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 June 2022; pp. 15070–15092. [Google Scholar]
- Gao, L.; Fu, H.; Li, L.; Chen, Y.; Xu, M.; Xu, C.-Z. FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10112–10121. [Google Scholar]
- Alam, S.; Liu, L.; Yan, M.; Zhang, M. FedRolex: Model-Heterogeneous Federated Learning with Rolling Sub-Model Extraction. Adv. Neural Inf. Process. Syst. 2022, 35, 29677–29690. [Google Scholar]
- Mendieta, M.; Yang, T.; Wang, P.; Lee, M.; Ding, Z.; Chen, C. Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8397–8406. [Google Scholar]
- Qu, Z.; Li, X.; Duan, R.; Liu, Y.; Tang, B.; Lu, Z. Generalized Federated Learning via Sharpness Aware Minimization. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 June 2022; pp. 18250–18280. [Google Scholar]
- Tuor, T.; Wang, S.; Ko, B.J.; Liu, C.; Leung, K.K. Overcoming Noisy and Irrelevant Data in Federated Learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5020–5027. [Google Scholar]
- Yang, M.; Wang, X.; Zhu, H.; Wang, H.; Qian, H. Federated Learning with Class Imbalance Reduction. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 2174–2178. [Google Scholar]
- Xu, J.; Chen, Z.; Quek, T.Q.S.; Chong, K.F.E. Fedcorr: Multi-Stage Federated Learning for Label Noise Correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10184–10193. [Google Scholar]
- Tam, K.; Li, L.; Han, B.; Xu, C.; Fu, H. Federated Noisy Client Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Aguera y Arcas, B. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20–22 April 2017; PMLR: Fort Lauderdale, FL, USA, 2017; pp. 1273–1282. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning; Now Foundations and Trends: Norwell, MA, YSA, 2021; Volume 14, pp. 1–210. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated Learning with Matched Averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Li, Q.; He, B.; Song, D. Model-Contrastive Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10713–10722. [Google Scholar]
- Shoham, N.; Avidor, T.; Keren, A.; Israel, N.; Benditkis, D.; Mor-Yosef, L.; Zeitak, I. Overcoming Forgetting in Federated Learning on Non-IID Data. arXiv 2019, arXiv:1910.07796. [Google Scholar]
- Dinh, C.T.; Tran, N.; Nguyen, J. Personalized Federated Learning with Moreau Envelopes. Adv. Neural Inf. Process. Syst. 2020, 33, 21394–21405. [Google Scholar]
- Reisizadeh, A.; Farnia, F.; Pedarsani, R.; Jadbabaie, A. Robust Federated Learning: The Case of Affine Distribution Shifts. Adv. Neural Inf. Process. Syst. 2020, 33, 21554–21565. [Google Scholar]
- Andreux, M.; du Terrail, J.O.; Beguier, C.; Tramel, E.W. Siloed Federated Learning for Multi-Centric Histopathology Datasets. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning: Second MICCAI Workshop, DART 2020, and First MICCAI Workshop, DCL 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 4–8 October 2020, Proceedings 2; Springer: Cham, Switzerland, 2020; pp. 129–139. [Google Scholar]
- Li, X.; Gu, Y.; Dvornek, N.; Staib, L.H.; Ventola, P.; Duncan, J.S. Multi-Site fMRI Analysis Using Privacy-Preserving Federated Learning and Domain Adaptation: ABIDE Results. Med. Image Anal. 2020, 65, 101765. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Huang, Z.; Zhu, Y.; Saenko, K. Federated Adversarial Domain Adaptation. arXiv 2019, arXiv:1911.02054. [Google Scholar]
- Liu, Q.; Chen, C.; Qin, J.; Dou, Q.; Heng, P.A. FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1013–1023. [Google Scholar]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing Federated Learning on Non-IID Data with Reinforcement Learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; IEEE: New York, NY, USA, 2020; pp. 1698–1707. [Google Scholar]
- Tang, M.; Ning, X.; Wang, Y.; Sun, J.; Wang, Y.; Li, H.; Chen, Y. FedCor: Correlation-Based Active Client Selection Strategy for Heterogeneous Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10102–10111. [Google Scholar]
- Qin, Z.; Yang, L.; Wang, Q.; Han, Y.; Hu, Q. Reliable and Interpretable Personalized Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 20422–20431. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An Extension of MNIST to Handwritten Letters. arXiv 2017, arXiv:1702.05373. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Tech. Rep. 2009, 1, 1–60. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. arXiv 2019, arXiv:1903.12261. [Google Scholar]
- Lee, J.; Ko, H.; Seo, S.; Pack, S. Data Distribution-Aware Online Client Selection Algorithm for Federated Learning in Heterogeneous Networks. IEEE Trans. Veh. Technol. 2022, 72, 1127–1136. [Google Scholar] [CrossRef]
- Fang, X.; Ye, M.; Yang, X. Robust Heterogeneous Federated Learning under Data Corruption. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 5020–5030. [Google Scholar]
- Deng, Y.; Lyu, F.; Ren, J.; Wu, H.; Zhou, Y.; Zhang, Y.; Shen, X. Auction: Automated and Quality-Aware Client Selection Framework for Efficient Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 1996–2009. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 5132–5143. [Google Scholar]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Cho, Y.J.; Wang, J.; Joshi, G. Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Wu, H.; Wang, P. Node Selection Toward Faster Convergence for Federated Learning on Non-IID Data. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3099–3111. [Google Scholar] [CrossRef]
- Amiri, M.M.; Gündüz, D.; Kulkarni, S.R.; Poor, H.V. Convergence of Update Aware Device Scheduling for Federated Learning at the Wireless Edge. IEEE Trans. Wirel. Commun. 2021, 20, 3643–3658. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and Robust Federated Learning Through Personalization. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 6357–6368. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Letters (1-M) | Fashion (1-M) | cifar-10 (M-1) | cifar-10-C (M-1) | cifar-10-C (M-M) |
|---|---|---|---|---|---|
| Random | 85.37 ± 0.3 | 85.72 ± 0.01 | 57.11 ± 0.75 | 59.19 ± 0.66 | 59.02 ± 0.8 |
| POW-D | 86.08 ± 0.58 | 82.89 ± 0.3 | 59.5 ± 0.38 | 57.17 ± 0.48 | 57.25 ± 0.69 |
| WGD | 84.42 ± 2.2 | 83.22 ± 0.34 | 58.51 ± 1.64 | 59.44 ± 0.59 | 59.38 ± 0.3 |
| FAST | 83.92 ± 0.37 | 84.72 ± 0.23 | 58.03 ± 1.02 | 58.93 ± 0.81 | 58.76 ± 0.86 |
| DQA | 87.33 ± 0.34 | 86.88 ± 0.33 | 59.82 ± 0.15 | 60.24 ± 0.76 | 59.34 ± 0.07 |
| Metric | Emnist (1-M) | CIFAR-10-C (M-1) |
|---|---|---|
| 0.1 | 86.93 | 60.24 |
| 0.5 | 87.18 | 59.84 |
| 1.0 | 87.75 | 59.32 |
| 1.5 | 87.96 | 59.65 |
| 2.0 | 87.75 | 61.23 |
| Avg | 87.51 | 60.06 |
| Method | 1-M | M-1 | M-M |
|---|---|---|---|
| FedAVG | 56.15 | 58.26 | 57.89 |
| +Ours(FedDQA) | 59.92 | 59.32 | 59.29 |
| FedProx | 55.34 | 57.9 | 57.43 |
| +Ours(FedDQA) | 60.59 | 59.84 | 60.23 |
| Ditto | 57.93 | 55.01 | 55.29 |
| +Ours(FedDQA) | 59.69 | 58.57 | 59.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, S.; Li, Y.; Wan, J.; Fu, X.; Jiang, J. Data Quality-Aware Client Selection in Heterogeneous Federated Learning. Mathematics 2024, 12, 3229. https://doi.org/10.3390/math12203229
Song S, Li Y, Wan J, Fu X, Jiang J. Data Quality-Aware Client Selection in Heterogeneous Federated Learning. Mathematics. 2024; 12(20):3229. https://doi.org/10.3390/math12203229
Chicago/Turabian StyleSong, Shinan, Yaxin Li, Jin Wan, Xianghua Fu, and Jingyan Jiang. 2024. "Data Quality-Aware Client Selection in Heterogeneous Federated Learning" Mathematics 12, no. 20: 3229. https://doi.org/10.3390/math12203229
APA StyleSong, S., Li, Y., Wan, J., Fu, X., & Jiang, J. (2024). Data Quality-Aware Client Selection in Heterogeneous Federated Learning. Mathematics, 12(20), 3229. https://doi.org/10.3390/math12203229