


Fuzzy Logic Prediction of Hypertensive Disorders in Pregnancy Using the Takagi–Sugeno and C-Means Algorithms

 ,
,  ,
,  , , , ,
, , , , 
Abstract
1. Introduction
2. Fuzzy C-Means (FCM) Algorithm
2.1. Business and Data Understanding
2.2. Data Pre-Processing
2.2.1. Outliers
2.2.2. Data Invariants
2.2.3. Multicollinearity
- First, an ordinary regression of least squares is performed, with as a function of all other explanatory variables, using Equation (4), as follows:where is constant and e represents a deviation from observation (error).
- Subsequently, the VIF for is calculated using Equation (4), as follows:where is the coefficient of determination of the regression equation in the first step.
2.2.4. Factor Analysis and Principal Component Analysis (PCA)
2.2.5. Feature Importance and Random Forest
2.2.6. Clustering Variables
2.2.7. Recursive Feature Elimination
2.3. Fuzzy Modeling
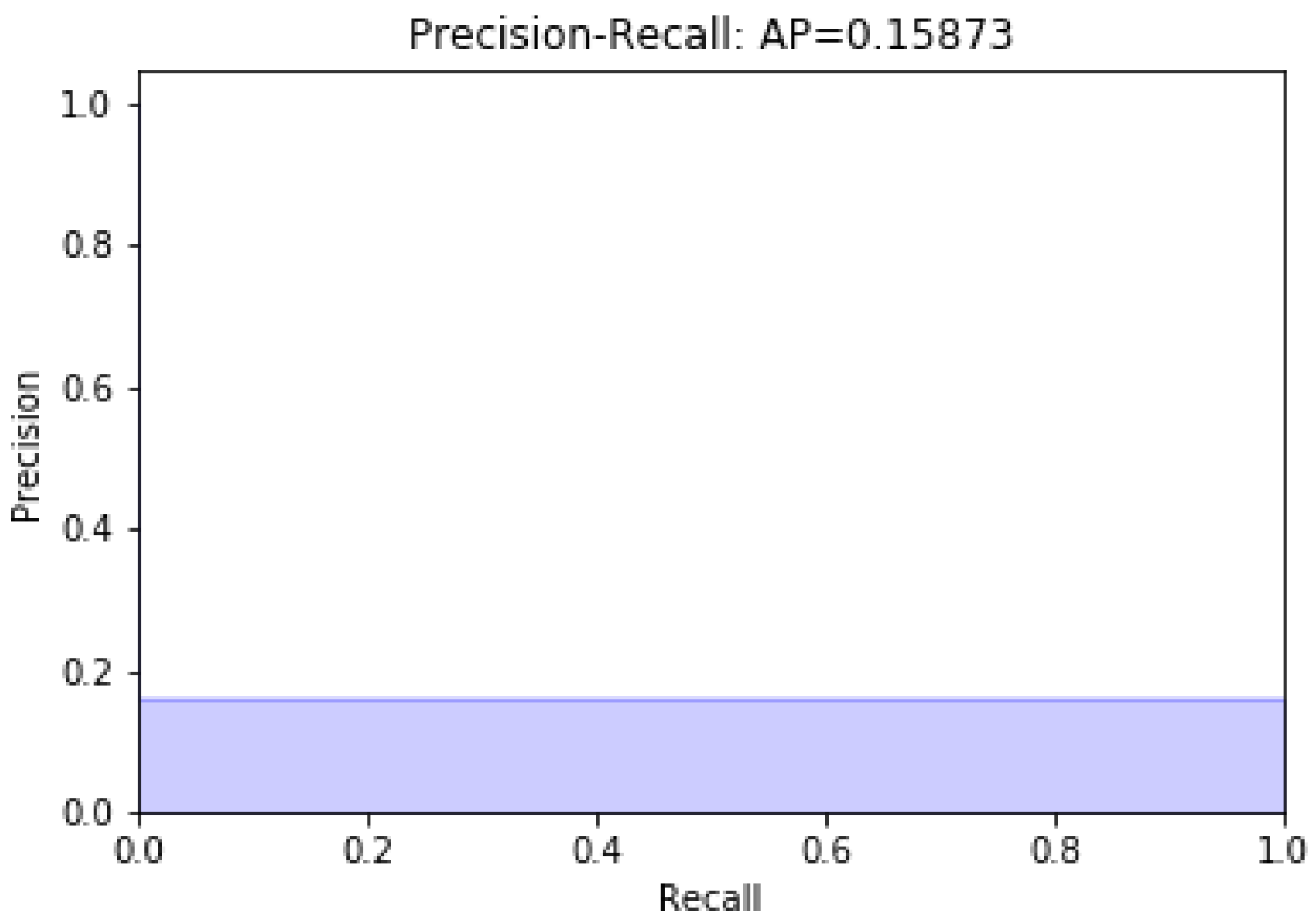
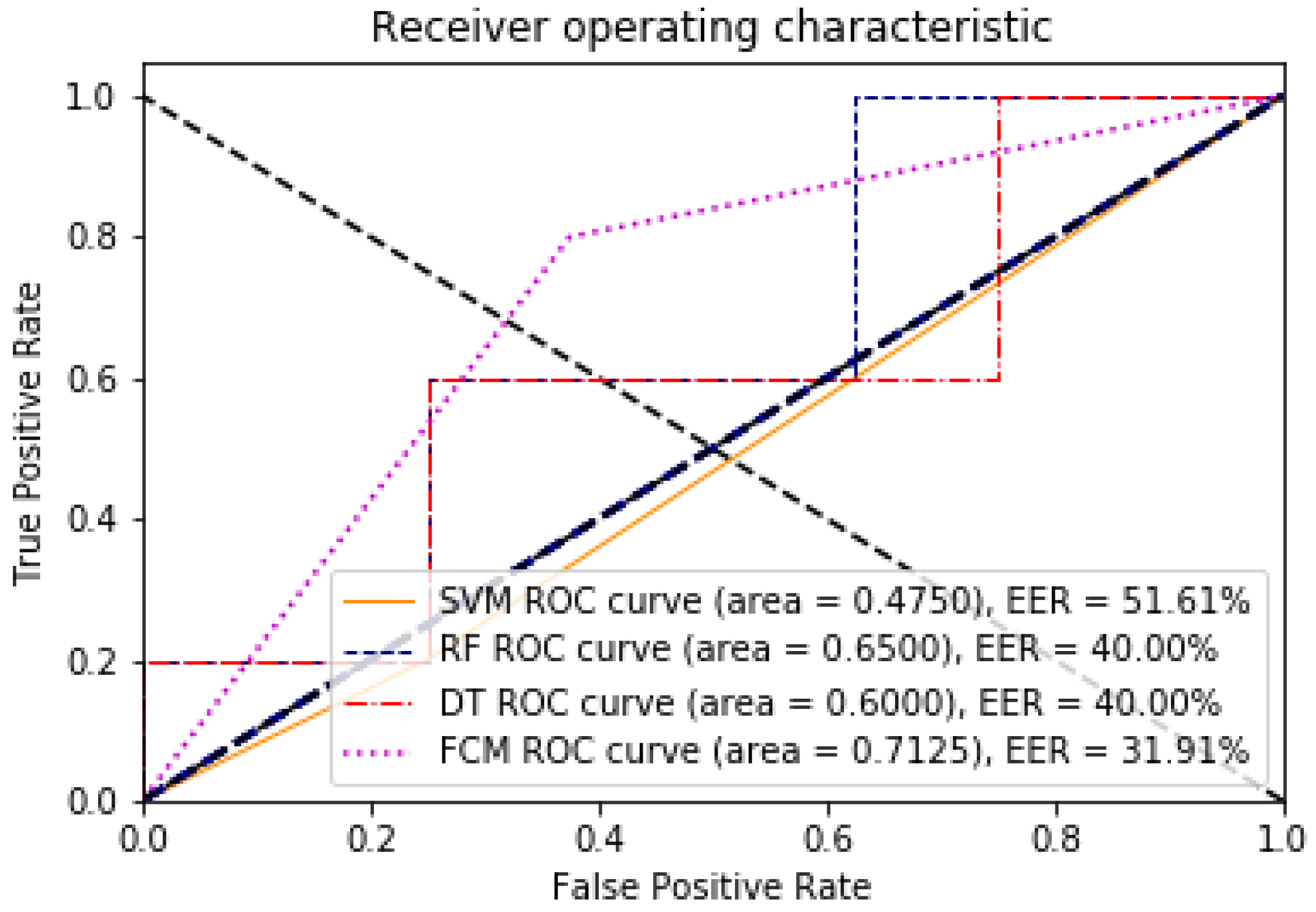
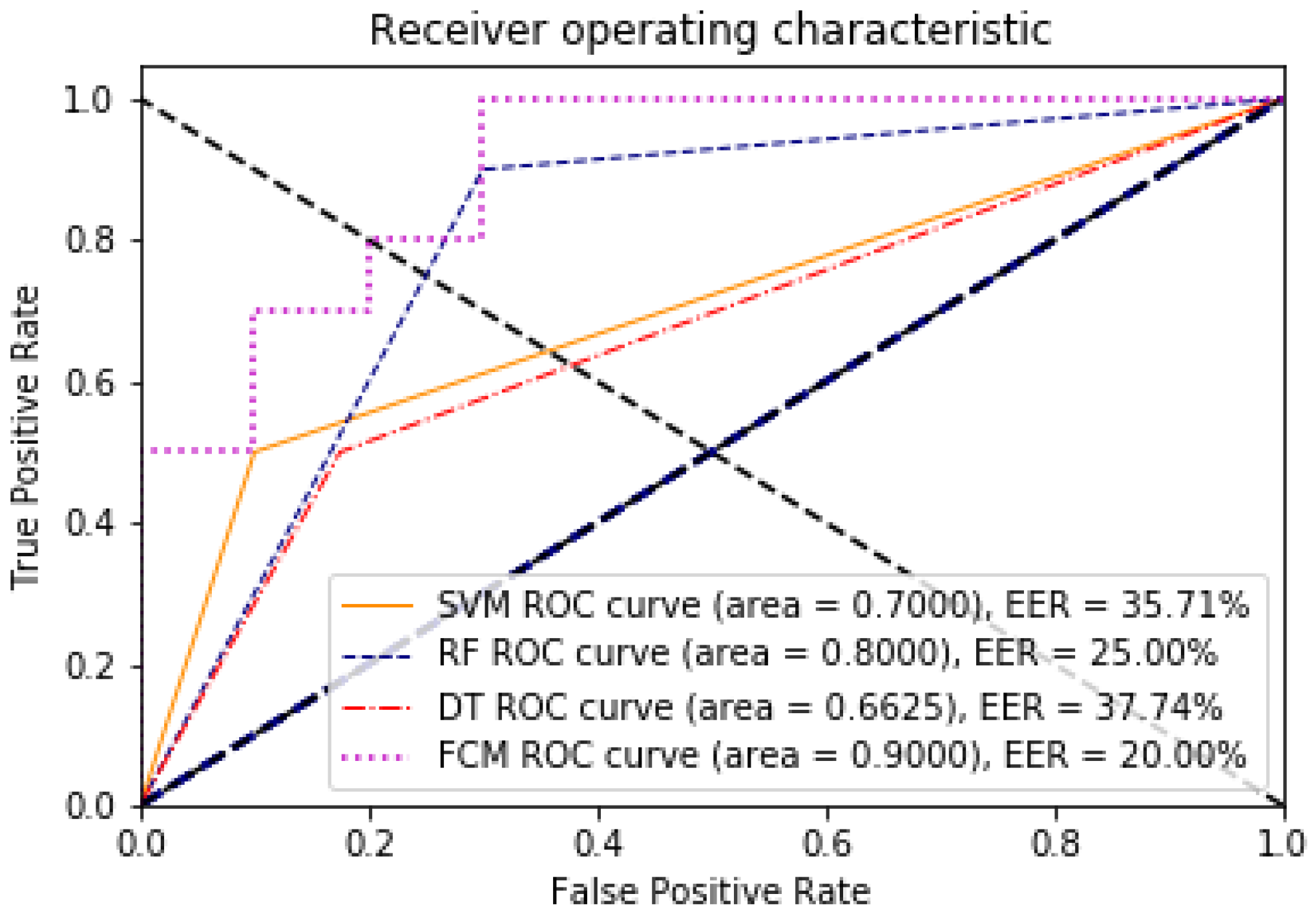
3. Results
Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| TPR | True positive rate |
| TNR | True negative rate |
| EER | Equal error rate |
| PE | Preeclampsia |
| FCM | Fuzzy c-means |
| T-S | Takagi–Sugeno |
| AUC | Area under the curve |
| OOB | Out-of-bag |
| RFE | Recursive feature elimination |
| PCA | Principal component analysis |
| ROC | Receiver operating characteristic |
References
- Steegers, E.A.; Von Dadelszen, P.; Duvekot, J.J.; Pijnenborg, R. Pre-eclampsia. Lancet 2010, 376, 631–644. [Google Scholar] [CrossRef]
- Davey, D.A.; MacGillivray, I. The classification and definition of the hypertensive disorders of pregnancy. Am. J. Obstet. Gynecol. 1988, 158, 892–898. [Google Scholar] [CrossRef] [PubMed]
- Özsezer, G.; Mermer, G. Prevention of Maternal Mortality: Prediction of Health Risks of Pregnancy with Machine Learning Models. 2023. Available online: https://www.researchgate.net/publication/368845364_Prevention_of_Maternal_Mortality_Prediction_of_Health_Risks_of_Pregnancy_with_Machine_Learning_Models (accessed on 1 July 2024).
- Raza, A.; Siddiqui, H.U.R.; Munir, K.; Almutairi, M.; Rustam, F.; Ashraf, I. Ensemble learning-based feature engineering to analyze maternal health during pregnancy and health risk prediction. PLoS ONE 2022, 17, e0276525. [Google Scholar] [CrossRef]
- Ramla, M.; Sangeetha, S.; Nickolas, S. Fetal health state monitoring using decision tree classifier from cardiotocography measurements. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 1799–1803. [Google Scholar]
- Irfan, M.; Basuki, S.; Azhar, Y. Giving more insight for automatic risk prediction during pregnancy with interpretable machine learning. Bull. Electr. Eng. Inform. 2021, 10, 1621–1633. [Google Scholar] [CrossRef]
- Alam, M.S.B.; Patwary, M.J.; Hassan, M. Birth mode prediction using bagging ensemble classifier: A case study of bangladesh. In Proceedings of the 2021 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021; pp. 95–99. [Google Scholar]
- Haldar, N.A.H.; Khan, F.A.; Ali, A.; Abbas, H. Arrhythmia classification using Mahalanobis distance based improved Fuzzy C-Means clustering for mobile health monitoring systems. Neurocomputing 2017, 220, 221–235. [Google Scholar] [CrossRef]
- Neocleous, C.K.; Anastasopoulos, P.; Nikolaides, K.H.; Schizas, C.N.; Neokleous, K.C. Neural networks to estimate the risk for preeclampsia occurrence. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2221–2225. [Google Scholar]
- American College of Obstetricians and Gynecologists. Hypertension in pregnancy. Report of the American College of Obstetricians and Gynecologists’ task force on hypertension in pregnancy. Obstet. Gynecol. 2013, 122, 1122. [Google Scholar]
- Moreira, M.W.; Rodrigues, J.J.; Oliveira, A.M.; Ramos, R.F.; Saleem, K. A preeclampsia diagnosis approach using Bayesian networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–5. [Google Scholar]
- Moreira, M.W.; Rodrigues, J.J.; Oliveira, A.M.; Saleem, K.; Neto, A.J.V. Predicting hypertensive disorders in high-risk pregnancy using the random forest approach. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–5. [Google Scholar]
- Espinilla, M.; Medina, J.; García-Fernández, Á.L.; Campaña, S.; Londoño, J. Fuzzy intelligent system for patients with preeclampsia in wearable devices. Mob. Inf. Syst. 2017, 2017, 7838464. [Google Scholar] [CrossRef]
- Babuška, R. Fuzzy Modeling for Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998; Volume 12. [Google Scholar]
- Velikova, M.; van Scheltinga, J.T.; Lucas, P.J.; Spaanderman, M. Exploiting causal functional relationships in Bayesian network modelling for personalised healthcare. Int. J. Approx. Reason. 2014, 55, 59–73. [Google Scholar] [CrossRef]
- Tejera, E.; Jose areias, M.; Rodrigues, A.; Ramoa, A.; Manuel nieto villar, J.; Rebelo, I. Artificial neural network for normal, hypertensive, and preeclamptic pregnancy classification using maternal heart rate variability indexes. J. -Matern.-Fetal Neonatal Med. 2011, 24, 1147–1151. [Google Scholar] [CrossRef] [PubMed]
- Kelleher, J.D.; Mac Namee, B.; D’arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Garcia Asuero, A.; Sayago, A.; González, G. The Correlation Coefficient: An Overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Mansfield, E.R.; Helms, B.P. Detecting multicollinearity. Am. Stat. 1982, 36, 158–160. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Guo, X.; Yu, H. Variable selection using mean decrease accuracy and mean decrease gini based on random forest. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; pp. 219–224. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Altfeld, S.; Handler, A.; Burton, D.; Berman, L. Wantedness of pregnancy and prenatal health behaviors. Women Health 1998, 26, 29–43. [Google Scholar] [CrossRef]
- Mehlsen, J.; Pagh, K.; Nielsen, J.; Sestoft, L.; Nielsen, S. Heart rate response to breathing: Dependency upon breathing pattern. Clin. Physiol. 1987, 7, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Selvin, E.; Marinopoulos, S.; Berkenblit, G.; Rami, T.; Brancati, F.L.; Powe, N.R.; Golden, S.H. Meta-analysis: Glycosylated hemoglobin and cardiovascular disease in diabetes mellitus. Ann. Intern. Med. 2004, 141, 421–431. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R.; Famili, F. Feature selection for high-dimensional class-imbalanced data sets using Support Vector Machines. Inf. Sci. 2014, 286, 228–246. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R. A wrapper method for feature selection using support vector machines. Inf. Sci. 2009, 179, 2208–2217. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- Setnes, M.; Babuska, R.; Verbruggen, H.B. Rule-based modeling: Precision and transparency. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 1998, 28, 165–169. [Google Scholar] [CrossRef]
- Díez, J.L.; Navarro, J.L.; Sala, A. Algoritmos de agrupamiento en la identificación de modelos borrosos. Rev. Iberoam. de Automática e Informática Ind. 2010, 1, 32–41. [Google Scholar]
- Babuška, R. Fuzzy Systems, Modeling and Identification; Delft University of Technology, Department of Electrical Engineering Control Laboratory, Mekelweg: Delft, The Netherlands, 1996; Volume 4. [Google Scholar]
- Kruse, R.; Gebhardt, J.E.; Klowon, F. Foundations of Fuzzy Systems; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Powers, D. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. Mach. Learn. Technol. 2008, 2. [Google Scholar]
- Melamed, I.D.; Green, R.; Turian, J.P. Precision and recall of machine translation. In Proceedings of the HLT-NAACL, Stroudsburg, PA, USA, 31 May 2003; pp. 61–63. [Google Scholar]
- Yap, B.W.; Rani, K.A.; Rahman, H.A.A.; Fong, S.; Khairudin, Z.; Abdullah, N.N. An application of oversampling, undersampling, bagging and boosting in handling imbalanced datasets. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013); Springer: Berlin/Heidelberg, Germany, 2014; pp. 13–22. [Google Scholar]
- Carter, J.V.; Pan, J.; Rai, S.N.; Galandiuk, S. ROC-ing along: Evaluation and interpretation of receiver operating characteristic curves. Surgery 2016, 159, 1638–1645. [Google Scholar] [CrossRef] [PubMed]
- Al-Nima, R.R.O.; Dlay, S.S.; Woo, W.L.; Chambers, J.A. A novel biometric approach to generate ROC curve from the probabilistic neural network. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), IEEE, Zonguldak, Turkey, 16–19 May 2016; pp. 141–144. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, ACM, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Program, National High Blood Pressure Education. Report of the national high blood pressure education program working group on high blood pressure in pregnancy. Am. J. Obstet. Gynecol. 2000, 183, s1–s22. [Google Scholar] [CrossRef]
- Caritis, S.; Sibai, B.; Hauth, J.; Lindheimer, M.D.; Klebanoff, M.; Thom, E.; VanDorsten, P.; Landon, M.; Paul, R.; Miodovnik, M.; et al. Low-dose aspirin to prevent preeclampsia in women at high risk. N. Engl. J. Med. 1998, 338, 701–705. [Google Scholar] [CrossRef] [PubMed]
- Sjónsdóttir, L.; Arngrimsson, R.; Geirsson, R.T.; Slgvaldason, H.; Slgfússon, N. Death rates from ischemic heart disease in women with a history of hypertension in pregnancy. Acta Obstet. Gynecol. Scand. 1995, 74, 772–776. [Google Scholar] [CrossRef]
- Savitz, D.A.; Zhang, J. Pregnancy-induced hypertension in North Carolina, 1988 and 1989. Am. J. Public Health 1992, 82, 675–679. [Google Scholar] [CrossRef]
- Bodnar, L.M.; Catov, J.M.; Klebanoff, M.A.; Ness, R.B.; Roberts, J.M. Prepregnancy body mass index and the occurrence of severe hypertensive disorders of pregnancy. Epidemiology 2007, 18, 234–239. [Google Scholar] [CrossRef]
- Kaufman, F.R. Type 2 diabetes mellitus in children and youth: A new epidemic. J. Pediatr. Endocrinol. Metab. 2002, 15, 737–744. [Google Scholar] [CrossRef]
- Arslanian, S.A. Type 2 diabetes mellitus in children: Pathophysiology and risk factors. J. Pediatr. Endocrinol. Metab. 2000, 13, 1385–1394. [Google Scholar] [CrossRef] [PubMed]
- Carty, D.M.; Delles, C.; Dominiczak, A.F. Novel biomarkers for predicting preeclampsia. Trends Cardiovasc. Med. 2008, 18, 186–194. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Classifiers | Dataset | Achieved Accuracy |
|---|---|---|---|
| [3] | KNN, XGBoost, Light GBM, ANN, LR, CatBoost, RF, SVM, GBM, and CART | Kaggle | 88% LightGBM and CatBoost |
| [4] | DTC, LR, KNN, ETC, RFC, and SVM | Kaggle | 98% SVM with DT-BiLTCN feature |
| [5] | CART, and DT | UCI | 88% DT |
| [6] | RF, NB, KNN, and XGBoost with three feature selection methods (CFS, C5.0, KSPR) | Cipto Mulyo Malang Public Health Center, dataset | 94% XGBoost |
| [7] | NB, NB (Bagging), k-NN, k-NN (Bagging), DT, DT (Bagging), SVM, and SVM (Bagging) | BDHS-2014 dataset | 87% DT (Bagging) |
| Models | Advantages | Disadvantages |
|---|---|---|
| Fuzzy C-Means (FCM) | Handles uncertainty and overlapping data effectively. Models complex relationships more accurately. | Increased complexity in model interpretation and tuning. Requires careful parameterization to optimize performance. |
| Random Forest (RF) | Robust against over-fitting, especially in highly dimensional data. Provides a measure of the importance of features. | Less effective in direct interpretation. Requires more computational power. |
| Decision Tree (DT) | Easy to understand and interpret. Good for feature selection. | Prone to over-fitting with noisy data. Less ability to handle complex and overlapping data. |
| Support Vector Machine (SVM) | Effective in high-dimensional spaces. Resistant to over-fitting, especially in binary sorting tasks. | Less interpretative. Does not handle large datasets with many overlapping classes well. |
| Query number | Date | Current weight | Systolic blood pressure | Diastolic blood pressure | Uterine height |
| Heart rate | Respiratory rate | Temperature | Glucose | Pulse | Fetal heart rate |
| Chronic High Blood Pressure | Pregnancy-Induced Hypertension | Preeclampsia | Eclampsia | Heart Disease |
|---|---|---|---|---|
| Nephropathy | Gestational diabetes | Risk of bleeding | High cholesterol | Risk of abortion |
| Leukorrhea | Urinary tract infection | Amenorrhea | Surgical risk | Low glucose |
| Colitis | Thyroid problem | Edemas | Anemia |
| Method Combinations | Dimensions | |||
|---|---|---|---|---|
| Factors | RF | Clustering | RFE | 8 |
| RFE | Factors | RF | Clustering | 12 |
| RF | RFE | Clustering | Factors | 12 |
| Clustering | RFE | Factors | RF | 10 |
| Factor No. | Factor Variance | Factor No. | Factor Variance | Factor No. | Factor Variance | Factor No. | Factor Variance |
|---|---|---|---|---|---|---|---|
| 1 | 10 | 19 | 28 | ||||
| 2 | 11 | 20 | 29 | ||||
| 3 | 12 | 21 | 30 | ||||
| 4 | 13 | 22 | 31 | ||||
| 5 | 14 | 23 | 32 | ||||
| 6 | 15 | 24 | 33 | ||||
| 7 | 16 | 25 | 34 | ||||
| 8 | 17 | 26 | 35 | ||||
| 9 | 18 | 27 | 36 |
| Feature Ranking (Decreasing Order) | ||
|---|---|---|
| 1. Diastolic blood pressure (0.112585) | 14. Hypertension (0.022374) | 27. 0 (0.000515) |
| 2. Body mass index (0.102220) | 15. Cardiovascular (0.012199) | 28. 2 (0.000418) |
| 3. Heart rate (0.090110) | 16. Maternal cardiovascular (0.011442) | 29. 10 (0.000410) |
| 4. Systolic blood pressure (0.083825) | 17. 4 (0.010270) | 30. 15 (0.000399) |
| 5. Childbirth (0.082424) | 18. 29 (0.010259) | 31. 9 (0.000375) |
| 6. Age (0.082059) | 19. 16 (0.006717) | 32. 14 (0.000353) |
| 7. Respiratory rate (0.076504) | 20. 6 (0.004902) | 33. 24 (0.000320) |
| 8. Temperature (0.068116) | 21. 5 (0.002286) | 34. 30 (0.000229) |
| 9. Previous pregnancies (0.062942) | 22. 23 (0.002166) | 35. 22 (0.000213) |
| 10. Sexual partners (0.042248) | 23. 21 (0.000919) | 36. 8 (0.000210) |
| 11. Currently living children (0.041399) | 24. 7 (0.000816) | 37. 18 (0.000139) |
| 12. Maternal diabetes (0.033450) | 25. 20 (0.000560) | 38. 13 (0.000100) |
| 13. Number of fetuses (0.032931) | 26. 17 (0.000559) | 39. 19 (0.000039) |
| Step | Number of Clusters | Similarity Level | Distance Level | Cluster Joined | New Cluster | Number of Objects in New Cluster |
|---|---|---|---|---|---|---|
| 1 | 15 | 90.6540 | 0.18692 | 9 11 | 9 | 2 |
| 2 | 14 | 79.6475 | 0.40705 | 1 4 | 1 | 2 |
| 3 | 13 | 72.9477 | 0.54105 | 6 9 | 6 | 3 |
| 4 | 12 | 66.5169 | 0.66966 | 1 2 | 1 | 3 |
| 5 | 11 | 61.3923 | 0.77215 | 3 7 | 3 | 2 |
| 6 | 10 | 60.7389 | 0.78522 | 14 15 | 14 | 2 |
| 7 | 9 | 55.8924 | 0.88215 | 5 6 | 5 | 4 |
| 8 | 8 | 55.6662 | 0.88668 | 8 16 | 8 | 2 |
| 9 | 7 | 53.2323 | 0.93535 | 8 12 | 8 | 3 |
| 10 | 6 | 52.6070 | 0.94786 | 10 13 | 10 | 2 |
| 11 | 5 | 50.0891 | 0.99822 | 1 5 | 1 | 7 |
| 12 | 4 | 49.0337 | 1.01933 | 3 10 | 3 | 4 |
| 13 | 3 | 48.0947 | 1.03811 | 8 14 | 8 | 5 |
| 14 | 2 | 46.2200 | 1.07560 | 3 8 | 3 | 6 |
| 15 | 1 | 43.1843 | 1.13631 | 1 3 | 1 | 16 |
| RFE Using SVM for Unbalanced Classes | |
|---|---|
| True | Diastolic blood pressure |
| True | Body mass index |
| True | Heart rate |
| True | Systolic blood pressure |
| False | Childbirth |
| True | Age |
| False | Temperature |
| False | Previous pregnancies |
| False | Sexual partners |
| True | Maternal diabetes |
| True | Number of fetuses |
| True | Hypertension |
| False | Cardiovascular |
| Parameters Rule 1 | Parameters Rule 2 | |
|---|---|---|
| − | ||
| − | − | |
| − | ||
| − | − | |
| − | ||
| − | ||
| − |
| Variable | Center 1 | Center 2 |
|---|---|---|
| Diastolic blood pressure | 65.2358 | 62.3517 |
| Heart rate | 77.5245 | 76.1068 |
| Systolic blood pressure | 102.5317 | 98.5688 |
| Age | 24.5329 | 23.7132 |
| Diabetes maternal | 0.2740 | 0.2678 |
| Number of fetuses | 1.0194 | 1.0199 |
| Hypertension | 0.0377 | 0.03529 |
| Body mass index | 26.7199 | 25.9533 |
| Variable | Mean | St. Dev. | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|---|
| Diastolic blood pressure | 66.38 | 10.86 | 24 | 60 | 60 | 70 | 100 |
| Heart rate | 77.69 | 11.48 | 20 | 70 | 78 | 84 | 103 |
| Systolic blood pressure | 101.79 | 13.76 | 60 | 90 | 100 | 110 | 150 |
| Age | 24.316 | 7.059 | 14 | 18.75 | 24 | 28 | 43 |
| Diabetes materna | 0.2551 | 0.4382 | 0 | 0 | 0 | 1 | 1 |
| Number of fetuses | 1.102 | 0.3043 | 1 | 1 | 1 | 1 | 2 |
| Hypertension | 0.0408 | 0.1989 | 0 | 0 | 0 | 0 | 1 |
| Body mass index | 28.061 | 6.534 | 15.111 | 22.843 | 27.018 | 32.234 | 46.382 |
| Model | Precision | Recall | F-Score | Sample Weight | |||
|---|---|---|---|---|---|---|---|
| To Sample Weight = None | Class 0 | Class 1 | Class 0 | Class 1 | Class 0 | Class 1 | |
| SVM | 0.6 | 0.3333 | 0.75 | 0.2 | 0.6666 | 0.25 | None |
| 0.46666 | 0.5384 | 0.5384 | Macro | ||||
| 0.5384 | 0.5384 | 0.5384 | Micro | ||||
| 0.4974 | 0.5384 | 0.5064 | Weighted | ||||
| DT | 0.6666 | 0.4285 | 0.5 | 0.6 | 0.5714 | 0.5 | None |
| 0.5476 | 0.55 | 0.5357 | Macro | ||||
| 0.5384 | 0.5384 | 0.5384 | Micro | ||||
| 0.5750 | 0.5384 | 0.5439 | Weighted | ||||
| FCM | 0.8333 | 0.5714 | 0.625 | 0.8 | 0.7142 | 0.6666 | None |
| 0.7023 | 0.7125 | 0.6904 | Macro | ||||
| 0.6923 | 0.6923 | 0.6923 | Micro | ||||
| 0.7326 | 0.6923 | 0.6959 | Weighted | ||||
| RF | 0.75 | 0.4444 | 0.375 | 0.8 | 0.5 | 0.5714 | None |
| 0.5972 | 0.5875 | 0.5357 | Macro | ||||
| 0.53844 | 0.5384 | 0.5384 | Micro | ||||
| 0.6324 | 0.5384 | 0.5274 | Weighted | ||||
| Model | Precision | Recall | F-Score | Sample Weight | |||
|---|---|---|---|---|---|---|---|
| To Sample Weight = None | Class 0 | Class 1 | Class 0 | Class 1 | Class 0 | Class 1 | |
| SVM | 0.6428 | 0.8333 | 0.9 | 0.5 | 0.75 | 0.625 | None |
| 0.7380 | 0.7 | 0.6875 | Macro | ||||
| 0.7 | 0.7 | 0.7 | Micro | ||||
| 0.7380 | 0.7 | 0.6875 | Weighted | ||||
| DT | 0.9166 | 0.3 | 0.825 | 0.5 | 0.8684 | 0.375 | None |
| 0.6083 | 0.6625 | 0.6217 | Macro | ||||
| 0.7826 | 0.7826 | 0.78260 | Micro | ||||
| 0.7362 | 0.7826 | 0.7040 | Weighted | ||||
| FCM | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | None |
| 0.8 | 0.8 | 0.8000 | Macro | ||||
| 0.8 | 0.8 | 0.8000 | Micro | ||||
| 0.8 | 0.8 | 0.8000 | Weighted | ||||
| RF | 0.805 | 0.75 | 0.7 | 0.8 | 0.7777 | 0.7181 | None |
| 0.8125 | 0.8 | 0.7979 | Macro | ||||
| 0.8 | 0.8 | 0.8000 | Micro | ||||
| 0.7925 | 0.8 | 0.7979 | Weighted | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Campero-Jurado, I.; Robles-Camarillo, D.; Ruiz-Vanoye, J.A.; Xicoténcatl-Pérez, J.M.; Díaz-Parra, O.; Salgado-Ramírez, J.-C.; Marroquín-Gutiérrez, F.; Ramos-Fernández, J.C. Fuzzy Logic Prediction of Hypertensive Disorders in Pregnancy Using the Takagi–Sugeno and C-Means Algorithms. Mathematics 2024, 12, 2417. https://doi.org/10.3390/math12152417
Campero-Jurado I, Robles-Camarillo D, Ruiz-Vanoye JA, Xicoténcatl-Pérez JM, Díaz-Parra O, Salgado-Ramírez J-C, Marroquín-Gutiérrez F, Ramos-Fernández JC. Fuzzy Logic Prediction of Hypertensive Disorders in Pregnancy Using the Takagi–Sugeno and C-Means Algorithms. Mathematics. 2024; 12(15):2417. https://doi.org/10.3390/math12152417
Chicago/Turabian StyleCampero-Jurado, Israel, Daniel Robles-Camarillo, Jorge A. Ruiz-Vanoye, Juan M. Xicoténcatl-Pérez, Ocotlán Díaz-Parra, Julio-César Salgado-Ramírez, Francisco Marroquín-Gutiérrez, and Julio Cesar Ramos-Fernández. 2024. "Fuzzy Logic Prediction of Hypertensive Disorders in Pregnancy Using the Takagi–Sugeno and C-Means Algorithms" Mathematics 12, no. 15: 2417. https://doi.org/10.3390/math12152417
APA StyleCampero-Jurado, I., Robles-Camarillo, D., Ruiz-Vanoye, J. A., Xicoténcatl-Pérez, J. M., Díaz-Parra, O., Salgado-Ramírez, J.-C., Marroquín-Gutiérrez, F., & Ramos-Fernández, J. C. (2024). Fuzzy Logic Prediction of Hypertensive Disorders in Pregnancy Using the Takagi–Sugeno and C-Means Algorithms. Mathematics, 12(15), 2417. https://doi.org/10.3390/math12152417