Abstract
In this paper, we study a constrained optimal control on pollution accumulation where the dynamic system was governed by a diffusion process that depends on unknown parameters, which need to be estimated. As the true values are unknown, we intended to determine (adaptive) policies that maximize a discounted reward criterion with constraints, that is, we used Lagrange multipliers to find optimal (adaptive) policies for the unconstrained version of the optimal control problem. In the present context, the dynamic system evolves as a diffusion process, and the cost function is to be minimized by another function (typically a constant), which plays the role of a constraint in the control model. We offer solutions to this problem using standard dynamic programming tools under the constrained discounted payoff criterion on an infinite horizon and the so-called principle of estimation and control. We used maximum likelihood estimators by means of a minimum least square error approximation in a pollution accumulation model to illustrate our results. One of the advantages of our approach compared to others is the intuition behind it: find optimal policies for an estimated version of the problem and let this estimation tend toward the real version of the problem. However, most risk analysts will not be as used to our methods as they are to, for instance, the model predictive control, MATLAB’s robust control toolbox, or the polynomial chaos expansion method, which have been used in the literature to address similar issues.
Keywords:
consistent estimators; discounted cost; control with restrictions; maximum likelihood estimators; least square errors MSC:
93E10; 93E20; 93E24; 60J60
1. Introduction
This work studies the problem of the optimal control of pollution accumulation with an unknown parameter, which needs to be statistically estimated, in a constrained context. We aim to construct adaptive policies for the discounted reward criterion on an infinite horizon. We assumed that the stock of pollution is driven by an Itô’s diffusion and used the discounted criterion. We consider the presence of constraints on the reward function. We estimated the unknown parameter and followed the principle of estimation and control (PEC) to use standard dynamic programming tools to find optimal solutions.
We kept the presentation at the application level to the pollution accumulation problem while attempting to maximize a utility function. However, the theory is general enough to be exploited in other contexts. The goal of pollution accumulation models is to examine how some things are managed for society’s consumption. It is commonly acknowledged that this consumption produces two by-products: pollution and social welfare. The latter term refers to the distinction between the benefits and harms connected with pollution. The theory studied here enables the decision-maker to identify a consumption policy that maximizes anticipated social welfare for society, subject to a limitation that may reflect, for example, that some environmental clean-up expenditures will not surpass a certain number over time, while (for instance) the rate at which nature cleans itself is unknown. One of the features of the discounted optimality criterion used in this paper is that emphasis is placed on the utility of consumption for the present generations, which is mirrored by the value functions that we obtained. This characteristic renders the problem a rather flexible one and enables us to use standard dynamic programming tools.
We employ the PEC, which has roots in Kurano (1972) [1] and Mandl (1974) [2], to analyze the adaptive control problem with constraints. The goal of the PEC is to estimate parameter , replace the unknown with its estimated value, and then solve the optimal control problem with constraints. Refer to [1,3,4], and the references therein for studies developing asymptotically optimal adaptive strategies. For instance, Kurano and Mandl introduce the idea of estimation and control when thinking about Markov decision models with constrained rewards and a finite-state space. Based on a consistent estimator for the unknown parameter that is uniformly optimal in the parameter, they demonstrate the existence of an optimal policy. Reference [4] works with discrete-time stochastic control systems.
In the late 1990s and early 2000s, the stochastic optimization issue with constraints was addressed, under the assumption that all the coefficients—the diffusion itself, the reward function, and the restrictions—are bounded (see, for example, [5,6,7,8]). Related publications include Borkar and Ghosh’s foundational publication on constrained optimum control under discounted and ergodic criteria, the work of Mendoza-Pérez, Jasso-Fuentes, Prieto-Rumeau, and Hernandez-Lerma (see [9,10]), and the paper of Jasso-Fuentes, Escobedo-Trujillo, and Mendoza-Pérez [11].
The adaptive control of a linear diffusion process (of the sort we use here) with regard to the discounted cost criterion is studied in [12]. In [13], an adaptive optimal control for continuous-time linear systems is investigated. The use of statistical tools is common when modeling control problems. For instance, Bayesian adaptive techniques for ergodic diffusions are considered in [14], and ref. [15] uses the method of maximum likelihood estimation of parameters to study a self-tuning scheme for a diffusion process with the long-term average cost criterion. The main idea is to estimate the unknown parameter online so that the most recent estimate is used to determine the true parameter when choosing each control (see [16]). The estimation of parameters for diffusion processes using discrete observations was studied in several papers, including [17,18,19,20,21] and the references therein.
The issue of pollution accumulation has previously been studied from the perspective of dynamic optimization; for instance, refs. [22,23] use a linear-quadratic model to explain this phenomenon, ref. [24] deals with the average payoff in a deterministic framework, refs. [25,26] extends the former’s approach to a stochastic context, ref. [27] uses a robust stochastic differential game to characterize the situation, ref. [28] studies the problem from the perspective of constrained stochastic optimization, and ref. [29] is a statistical survey of the effects of air pollution on public health. The main contribution of our paper is as follows: a statistical estimation procedure is used to find ; we construct adaptive policies that are almost certainly optimal for the constrained optimization problem under the discounted payoff on an infinite horizon. These adaptive policies were obtained by substituting the estimates into optimal stationary controls (or PEC); see [1,2]. In this sense, our findings resemble those presented in [30], for most risk analysts will not be as used to our methods as they are to, for instance, the model predictive control, the robust control toolbox or the polynomial chaos expansion method, which have been used in the literature to address similar issues.
Our work lies at the intersection of three important classes of optimal control problem. The first is the problem of controlling pollution accumulation, as presented in [22,29,30,31,32]; the second class deals with constrained optimal control problems (references [11,33,34] study this type of problem, considering that all parameters are known); the third class concerns the adaptive optimal control problems, as presented in [14,15,20,35,36]. Reference [30] belongs to the first and third classes. Our work is an extension of [11,22,28,31,32,36] to the adaptive constrained optimal control framework. Reference [22] builds a robust control to explore the normative maxim that, in the presence of uncertainty, society must guard against worst-case outcomes; [11] studies a constrained optimal control problem where all the parameters are known, while [28,32] study the same in the context of pollution accumulation; Refs. [31,36] study an unconstrained adaptive optimal control problem. In addition, a numerical example is given for demonstration purposes.
The rest of the paper is organized as follows. We present the theoretical preliminaries in the next Section. Then, we devote Section 3 to our main results and we illustrate them in Section 4. We provide our conclusions in Section 5. Please note that, for the sake of self-completeness of the presentation and acknowledgement of our sources, we have included references at the end of this article. However, we recognize that these might diverge the reader. We apologize for this inconvenience.
Throughout our work, we use the following notations. All in and matrices we denote by the usual Euclidean norm , and we let , where and , denote the transpose and the trace of a square matrix, respectively. Sometimes, we use the notation , and .
2. Problem Statement
In our model, the stock of pollution is modeled as an n-dimensional controlled stochastic differential equation (SDE) of the form:
where and are given functions, and is an -adapted d-dimensional Wiener process, such that and are pairwise independent. The compact set U is assumed to be contained in a suitable metric space and is called the control set. Here, represents the flow of consumption at time t; this is a stochastic process that takes values from U, which, in turn, is bounded to represent the consumption restrictions imposed by worldwide protocols. In this work, we assume that the pollution decay rate is an unknown parameter taking values from a compact set called the parameter set. Assumption A1 in Appendix A ensures the existence and uniqueness of a strong solution to (1).
2.1. Control Policies and Stability Assumptions
Although we manage to illustrate our theoretical developments using the so-called stationary Markovian policies, we need to introduce the concept of randomized policies (also known as relaxed controls). To this end, we used the following nomenclature:
- is the Borel -algebra spawned by the Borel set B.
- is, as usual, the space of all real-valued continuous functions on a bounded, open and connected subset .
- stands for the space of all real-valued continuous bounded functions f on the bounded, open and connected subset .
- is the space of all real-valued continuous functions f on the bounded, open and connected subset , with continuous derivatives up to order .
- is, as is customary, the Lebesgue space of functions g on such that , with a suitable measure space, and .
- is the family of probability measures on B endowed with the topology of weak convergence.
Definition 1.
A randomized policy is a family of stochastic kernels on , satisfying:
- (a)
- for each and , , and for each and , is a Borel function on ;
- (b)
- for each and , the function is Borel-measurable in .
A randomized policy is said to be stationary if there is a probability measure , such that for all and . The set of randomized stationary policies is denoted by Π.
Let be the family of measurable functions . A strategy for some is said to be a stationary Markov policy.
For each randomized stationary policy , we write the drift coefficient b defined in (1) as
Note that inherits the same continuity and Lipschitz properties from b, given in Assumption A1.
Remark 1.
Under Assumption A1, for each policy and , there exists a weak solution of (1) which is a Markov–Feller process in the probability space . See Theorem 2.2.6 in [37].
Topology of relaxed controls. We will need the limit and continuity concepts. For this reason, we topologized the set of randomized stationary policies , as in [38]. This topology renders a compact metric space, and is determined by the following convergence criterion (see [37,38,39]).
Definition 2.
A sequence in Π converges to , if
for all , and , where
We denote this type of convergence as .
For , and let
where is the i-th component of b, and is the -component of the matrix , defined in Assumption A1(d). Again, for each randomized stationary policy , we write the infinitesimal generator defined in (3) as
Note that the application of Dynkin’s formula to the function , and Assumption A2(b) yields
where stands for the conditional expectation of ·, given that (1) starts at x, the controller uses the randomized stationary policy , and the unknown parameter is fixed at . That is, is the expectation of · taken with respect to the probability measure when starts at x.
2.2. Reward, Cost and Constraint Rates
We will consider that the reward and the cost rates, along with the constraints of our model, can be unbounded from above and below, but are dominated by the Lyapunov function w given in Assumption A2. Namely, they are in the Banach space of real-valued measurable functions on with the finite w-norm, which is defined as follows.
Definition 3.
Let denote the Banach space of real-valued measurable functions v on with finite w-norm, which is defined as
Let be measurable functions that will be identified as the social welfare (also called payoff or reward) rate and the cost rate, respectively, and let be another measurable function that will be referred to as the constraint rate. In the present context, this restriction stands for the fact that, in some situations, due to each country’s legal framework, the cost of cleaning the environment must not exceed a given quantity. Both functions are supposed to meet Assumption A3.
When the controller uses policy , we write the reward and cost rates in a similar way as (2); that is,
3. Main Results
3.1. Discounted Control with Constraints
In the sequence, we work in the space , where stands for the Sobolev space of real-valued measurable functions on the open and connected subset whose generalized derivatives up to order are in for .
Definition 4.
Given the initial state x, a parameter value and a discount rate , we define the total expected α-discounted reward and cost when the controller uses a policy π in Π, as
Propositions 1–3 below state the properties of the functional for all . Under Assumption A3 and inequality (4), a direct computation yields the following result. This estabilishes that the expected -discounted reward are dominated by a Lyapunov function.
Proposition 1.
If Assumptions A1–A3 hold, the functions and belong to the space for each π in Π; in fact, for each x in and , we have
Here, c and d are as in Assumption A2, and M is the constant in Assumption A3(b).
The following result is an extension of Proposition 3.1.5 in [40] to the topology of the relaxed controls. This shows that both the expected discounted reward and the expected cost are solutions to the linear version of the dynamic programming partial differential equation. This can be regarded as a necessary condition for the optimality of the value function. Its proof mimics the steps of the original, replacing the control sets with those used here while keeping fixed.
Proposition 2.
Let Assumptions A1–A3 hold, and let be a measurable function satisfying Assumption A3. Then, for every , the associated expected α-discounted function is in , and is such that
Conversely, if some function verifies (6), then
Moreover, if the equality in (6) is replaced by “≤” or “≥”, then (7) holds, with the respective inequality.
Definition 5.
Let . The total expected α-discounted constraint when the controller uses a policy , given the initial state and , is defined by
Remark 2.
The function belongs to the space for each . Moreover, for each , we have
For each , and , assume we are given a constraint function satisfying Assumption A3(c). In this way, we define the set
We assume that is nonempty.
Definition 6 (The discounted problem with constraints (DPC)).
We say that a policy is optimal for the DPC with initial state , given that is the true parameter value if and, in addition,
In this case, is called the -discount optimal reward for the DPC.
3.2. Lagrange Multipliers Approach
We mimic the technique we used in [32] to transform the original DPC into an unconstrained problem. To this end, take and consider the new reward rate
Using the same notation of (5), we can write (8) as
Observe that, for each and , is in uniformly in and . In fact,
where , and M, as in Assumption A3(b).
For all and , define
The discounted unconstrained problem is defined as follows.
Definition 7 (-Discounted unconstrained problem (-DUP)).
A policy for which
is called discounted optimal for the λ-DUP, and is referred to as the optimal discounted reward for the λ-DUP.
Let be a measurable function satisfying similar conditions as those given in Assumption A3. The following is called a verification result in the literature. It shows that is the unique solution of the Hamilton–Jacobi–Bellman (HJB) Equation (11), and also proves the existence of stationary policies . Observe that, by virtue of Definition 7, the functional to which it refers can be the optimal discounted reward for the -DUP. Its proof can be found in [11,15,41], considering as fixed.
Proposition 3.
Suppose that Assumptions A1–A3 hold. Then:
Remark 3.
- (a)
- Notice that
- (b)
- By Definitions 4 and 5,
- (c)
- Given that the cost and constraint rates satisfy Assumption A3, we deduceThus,
- (d)
- The function is locally Lipschitz on In fact,for each , and for all . The last inequality in (12) is met since we assume that Assumption A3 holds.
- (e)
- Parts (c) and (d) imply that the function satisfies Assumption A3. Thus, the rate is Lipschitz-continuous and . Furthermore, by virtue of (9) and Proposition 1,implying that .
3.3. Convergence of Value Functions and
Definition 8.
A sequence of measurable functions is said to be a sequence of uniformly strongly consistent (USC) estimators of if, as ,
where is the probability measure referred to by Remark 1.
For ease of notation, we write . Let be a measurable function satisfying similar conditions to those given in Assumption A3.
Remark 4.
- (a)
- If Assumptions A1–A3 hold, then by Proposition 3.4 in [11], the mappings , and are continuous on Π for each and
- (b)
- Let be a sequence of USC estimators of . Then, using Theorem 4.5 in [36], for every measurable function that satisfies the Assumptions A1–A3, the sequence converges to -a.s., for each and .
- (c)
- Let be a sequence in Π. Since Π is a compact set, there exists a subsequence such that , thus, combining parts (a) and (b), and using the following triangular inequality:we deduce that, for every measurable function satisfying Assumption A3, we have that
- (d)
- The optimal discount reward for the -DUP, satisfies Proposition 3. In addition, Proposition 3(ii) ensures the existence of stationary policy .
- (e)
- For each , and , we denoteSince can be seen as an embedding of Π, Proposition 3(ii) ensures that the set is nonempty.
- (f)
- Under the hypotheses of Proposition 3, Lemma 3.15 in [11] ensures that for each fixed and any sequence in converging to some ; if there exists a sequence for each , such that it converges to a policy , then . That is, π satisfies
- (g)
- Lemma 3.16 in [11] ensures that the mapping is differentiable on , for any and ; in fact, for each and
3.4. Estimation Methods for Our Application
Pedersen [42] describes the approximate maximum likelihood estimator in the following manner. The unknown parameter is estimated by means of some function that measures the likelihood of different values of . If for each fixed, the function has a unique maximum point , then is estimated by .
Under the assumption that, for and , is a measurable function of and is also continuously differentiable in for all and almost all , it is proven that the function is continuous and has a unique maximum point for each fixed. The number is the index of a sequence of random experiments on the measurable space .
In our application, the outcomes of the random experiments will be represented by a sequence of a trajectory at times on and the function will be called the least square function (LSE), i.e.,
In practice, in (1) can only be observed in a finite horizon; for example, T. Actually, this is one of the hypotheses of the so-called model predictive control. However, at least from a theoretical point of view, our version of the PEC makes no such assumption, but still chooses T to be as large as practically possible (with regard to computer power, measurement instruments, computation time, etc.) so that we can define LSE as:
with b as in (1). The LSE function generates the least square estimator, ,
Consistency and asymptotic normality of are studied in [18,19,42]. Shoji [18] demonstrates that the optimization based on the LSE function is identical to the optimization based on the discrete approximate likelihood ratio function when a one-dimensional stochastic differential equation with a constant diffusion coefficient is taken into account:
with b and as in (1). The MLR function generates the discrete approximate likelihood ratio estimator:
We establish our main result considering Remarks 3 and 4.
Theorem 1.
Let be a sequence of USC estimators of , and let be a critical point of . Assume that there is a sequence that converges to . Then, π is optimal for the DPC. Moreover, the equalities and hold -a.s.
Proof.
-a.s., as .
On the other hand, note that
thus, by Remark 4(a) we can obtain that the term in (19) converges to zero as ; whereas, using Remark 4(b), we can deduce that the term in (20) converges to zero -a.s. So,
As is a critical point of , we obtain, from (14), that for every ,
Therefore, from (21) and (22), we obtain
This last result, along with (18) yields
Using Remark 4(g), is in ,
We have that, for all ,
This implies that , which, in turn, together with (10), (24), (25) and Remark 3(a), lead to
Thus,
Finally, by (25) we obtain that . Therefore, (26), along with (24) and (25) show that
in other words, is optimal for the DPC, and coincides with the optimal reward for the DPC -a.s. □
4. Numeric Illustration
To exemplify our results, we substitute (1) by
where . We assume that the reward and cost rates , as well as the constraint rate , are defined by
with , , satisfying and where q is a positive constant. Here, represents the social welfare, where and represent the social utility of the consumption u and the social disutility of the pollution x, respectively.
Remark 5.
Assumptions A1–A3 given in this work hold for the controlled diffusion (27); see Lemma 5.2 in [11]. In fact, the Lyapunov function in Assumption A2 is taken as .
4.1. The -DUP
Lemma 5.3 in [11] ensures that, under the conditions imposed on the constants , , , and q given above, for every and , the optimal reward in (10) with , becomes
where
and the discounted optimal policy for the (), which maximizes the right-hand side of (11) for this example, is the constant function given by
4.2. The Dpc
Using Theorem 5.5 in [11], for a fixed point such that
If , then the mapping admits a critical point satisfying
Hence, every is -optimal for the DPC and ; in particular, the corresponding -optimal policy for the DPC is
and the -optimal value for the DPC is given by
4.3. Numerical Results for the Optimal Accumulation Problem
To implement the optimal controller (28), we estimate the unknown parameter with LSE (15) and (16). By replacing in (15), a direct computation yields:
where
Assume that the true parameter value of the parameter is , and take , , , , , , , , and . We next obtained discrete observations of the stochastic differential Equation (27) by simulating the equation using the Euler–Maruyama technique on . Based on this information, we obtained observations with different values of the diffusion coefficient
4.3.1. Numerical Results for the -DUP
In Table 1 and Table 2, we denote the root mean square error (RMSE) between the predicted process and the real process by , and the RMSE between the predicted optimal discount cost and the real optimal discount cost , by .

Table 1.
RMSE and absolute error between the estimated processes and the real processes () with .
Table 2.
RMSE and absolute error between the estimated processes and the real processes () with .
Table 1 and Table 2 take and 1200 and display the information on the different values of . As can be seen, as m increases, the estimator approaches the true parameter value , and the RMSEs between the predicted processes , , and the real processes , decrease, thus implying a good fit (see Figure 1 and Figure 2). We can also see that, as the amount of data increases, the absolute error between the predicted optimal control , and the real optimal control decreases. Therefore, the predicted optimal control approaches the true optimal control.
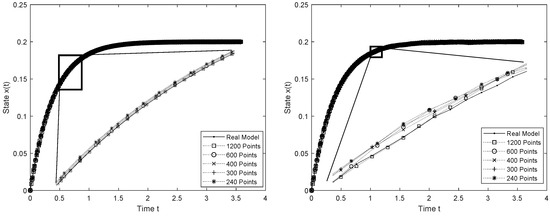
Figure 1.
Asymptotic behavior of with (left) and (right).
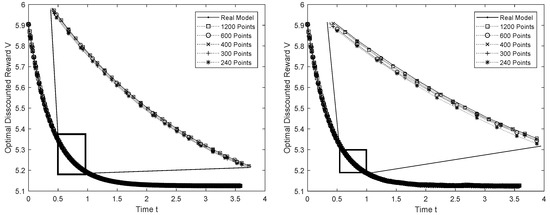
Figure 2.
Asymptotic behavior of the optimal discount cost for (left) and (right).
The diffusion process (27) with showed the best fit because, with 1200 data, and its RMSE is , which suggests that the lower the noise in the measured data, the more accurate the least square estimator.
4.3.2. Numerical Results for the DPC
Table 3 and Table 4 show the predicted optimal controls defined in (29), as well as the predicted -optimal rewards for the DPC given in (30) and denoted by . As m increases, the estimator approaches the true parameter value , and the predicted optimal controls and rewards converge to the real optimal control and reward , respectively, implying a good fit. Again, showed the best fit, which suggests that the lower the noise in the measured data, the more accurate the LSE.
Table 3.
Estimated processes and the real processes () with .
Table 4.
Estimated processes and the real processes () with .
5. Concluding Remarks
This paper concerns controlled stochastic differential equations of the form (1), where the drift coefficient depends on an unknown parameter . Using a statistical estimation procedure to find , we constructed adaptive policies, which are almost certainly optimal for the constrained optimization problem under the discounted payoff on an infinite horizon. To this end, we let , and be the optimal discounted rewards for the DUP and the DPC, respectively. Our results are our own version of the PEC, and can be summarized as follows:
- 1.
- For each m, there are optimal control policies for the -DUP and -DPC.
- 2.
- For each initial state , and , and is almost certainly .
- 3.
- For the DUP, there is a subsequence of and a policy , such that converges to in the topology of relaxed controls, and, moreover, is optimal for the -DUP. Moreover, if is a critical point of , then is optimal for the -DCP.
Some of the techniques we use are standard in the context of dynamic programming, and our use of the discounted payoff criterion on the infinite horizon renders the problem a rather flexible one. This criterion emphasizes the weight of the rewards and costs on the present generations while tending to overlook their effects on future generations. One way to prevent this from happening is to use the ergodic criterion by means of the so-called vanishing technique, which has been used in, for instance [43]. To obtain some insight as to how this method would alter the value function and the overall results presented here, we invite the reader to let .
There are many ways to obtain a sequence of USC estimators of the unknown parameter (see [18]). However, when implementing the approximation algorithms for , one needs to check the type numerical approximation of the derivative that is required. In our case, we replaced with its central difference, instead of the backward difference, because our applications yield more accurate approximations.
The PEC requires knowledge and storage of the optimal policies for all values of , which may require considerable off-line computation and considerable storage. Therefore, for optimal control problems with closed-form solutions (), such as, for example, LQ problems (linear systems with quadratic costs), the PEC works well. In this sense, our model resembles the model predictive control. However, the fact that the horizon has to be finite in the latter is a serious limitation that is surpassed by our proposal. In fact, the numeric illustration from Section 4 is another example of the distinction between our version of the PEC, and the polynomial chaos expansion method. While the latter aims to approximate the probability densities of finite-variance random variables, our goal is to obtain an optimal control while making estimations of the infinite-total variation processes (1). This is particularly true in the case of (27), regardless of how small the diffusion coefficient is in our illustration. There, the focus point should be that the lower the noise in the measured data, the more accurate the LSE.
One of the downfalls of our method is that a closed-form solution of is virtually impossible for many optimal control problems with or without constraints. Another limitation is that, for each application, there is a large number of assumptions and constraints that need to be verified. We believe this deflection from the main problem could be eased by the inclusion of our method in (for instance) MATLAB’s robust control.
The second part of this project will approximate the adaptive original problem using a sequence of discrete-time adaptive optimal control problems of controlled Markov switching diffusions.
Author Contributions
Conceptualization, methodology, and writing/original draft preparation of this research are due to B.A.E.-T., F.A.A.-H. and J.D.L.-B.; software, validation, visualization, and data curation are original of F.A.A.-H.; formal analysis, investigation, writing/review and editing are due to C.G.H.-C.; project administration, funding acquisition are due to J.D.L.-B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Universidad Anáhuac México grant number 00100575.
Data Availability Statement
Not applicable.
Acknowledgments
The authors wish to sincerely thank Ekaterina Viktorovna Gromova for her kind invitation to publish this work.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Appendix A. Technical Assumptions
The following hypothesis ensures the existence and uniqueness of a strong solution to (1). For more details, see Theorem 3.1 in [43] and Chapter III.2 in [44].
Assumption A1.
- (a)
- The random process (1) belongs to a complete probability space . Here, is a filtration on , such that each is complete relative to ; and is the law of the state process given the parameter and the control .
- (b)
- The drift coefficient in (1) is continuous and locally Lipschitz in the first and third arguments uniformly in u; that is, for each , there exist nonnegative constants and such that, for all , all and ,Moreover, is continuous on U.
- (c)
- The diffusion coefficient satisfies a local Lipschitz condition; that is, for each , there is a positive constant such that, for all ,
- (d)
- The coefficients b and σ satisfy a global linear growth condition of the formwhere is a positive constant.
- (e)
- (Uniform ellipticity). The matrix satisfies that, for some constant ,
The following hypothesis is a standard Lyapunov stability condition for the solution of the dynamic system (1) (see [37,41]). It gives the following inequality (4).
Assumption A2.
There exists a function in and constants , such that
- (a)
- .
- (b)
- for all , and x in .
The reward and cost functions are supposed to meet the next hypothesis.
Assumption A3.
- (a)
- The payoff rate the cost rate and the constraint rate are continuous on and , respectively. Moreover, they are locally Lipschitz on , uniformly on U and Θ; that is, for each , there are positive constants and such that for all
- (b)
- The rates , and are in uniformly on U and Θ; in other words, there exists such that, for all
References
- Kurano, M. Discrete-time Markovian decision processes with an unknown parameter-average return criterion. J. Oper. Res. Soc. Jpn. 1972, 15, 67–76. [Google Scholar]
- Mandl, P. Estimation and control in Markov chains. Adv. Appl. Probab. 1974, 6, 40–60. [Google Scholar] [CrossRef]
- Hernández-Lerma, O.; Marcus, S. Technical note: Adaptive control of discounted Markov Decision chains. J. Optim. Theory Appl. 1985, 46, 227–235. [Google Scholar] [CrossRef]
- Hilgert, N.; Minjárez-Sosa, A. Adaptive control of stochastic systems with unknown disturbance distribution: Discounted criteria. Math. Methods Oper. Res. 2006, 63, 443–460. [Google Scholar] [CrossRef]
- Broadie, M.; Cvitanic, J.; Soner, H.M. Optimal replication of contingent claims under portfolio constraints. Rev. Fin. Stud. 1998, 11, 59–79. [Google Scholar] [CrossRef]
- Cvitanic, J.; Pham, H.; Touzi, N. A closed-form solution for the super-replication problem under transaction costs. Financ. Stochastics 1999, 3, 35–54. [Google Scholar] [CrossRef]
- Cvitanic, J.; Pham, H.; Touzi, N. Superreplication in stochastic volatility models under portfolio constraints. J. Appl. Probab. 1999, 36, 523–545. [Google Scholar] [CrossRef]
- Soner, M.; Touzi, N. Super replication under gamma constraints. SIAM J. Control Optim. 2000, 39, 73–96. [Google Scholar] [CrossRef]
- Mendoza-Pérez, A.; Jasso-Fuentes, H.; Hernández-Lerma, O. The Lagrange approach to ergodic control of diffusions with cost constraints. Optimization 2015, 64, 179–196. [Google Scholar] [CrossRef]
- Prieto-Rumeau, T.; Hernández-Lerma, O. The vanishing discount approach to constrained continuous-time controlled Markov chains. Syst. Control Lett. 2010, 59, 504–509. [Google Scholar] [CrossRef]
- Jasso-Fuentes, H.; Escobedo-Trujillo, B.A.; Mendoza-Pérez, A. The Lagrange and the vanishing discount techniques to controlled diffusion with cost constraints. J. Math. Anal. Appl. 2016, 437, 999–1035. [Google Scholar] [CrossRef]
- Bielecki, T. Adaptive control of continuous-time linear stochastic systems with discounted cost criterion. J. Optim. Theory Appl. 1991, 68, 379–383. [Google Scholar] [CrossRef]
- Vrabie, D.; Pastravanu, O.; Abu-Khalaf, M.; Lewis, F. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica 2009, 45, 477–484. [Google Scholar] [CrossRef]
- Di Masp, G.; Stettner, L. Bayesian ergodic adaptive control of diffusion processes. Stochastics Stochastics Rep. 1997, 60, 155–183. [Google Scholar] [CrossRef]
- Borkar, V.; Ghosh, M. Ergodic Control of Multidimensional Diffusions II: Adaptive Control. Appl. Math. Optim. 1990, 21, 191–220. [Google Scholar] [CrossRef]
- Borkar, V.; Bagchi, A. Parameter estimation in continuous-time stochastic processes. Stochastics 1982, 8, 193–212. [Google Scholar] [CrossRef]
- Huzak, M. Estimating a class of diffusions from discrete observations via approximate maximum likelihood method. Statistics 2018, 52, 239–272. [Google Scholar] [CrossRef]
- Shoji, I. A note on asymptotic properties of the estimator derived from the Euler method for diffusion processes at discrete times. Stat. Probab. Lett. 1997, 36, 153–159. [Google Scholar] [CrossRef]
- Ralchenko, K. Asymptotic normality of discretized maximum likelihood estimator for drift parameter in homogeneous diffusion model. Mod. Stochastics Theory Appl. 2015, 2, 17–28. [Google Scholar] [CrossRef]
- Duncan, T.; Pasik-Duncan, B.; Stettner, L. Almost self-optimizing strategies for the adaptive control of diffusion processes. J. Optim. Theory Appl. 1994, 81, 479–507. [Google Scholar] [CrossRef]
- Durham, G.; Gallant, A. Numerical Techniques for Maximum Likelihood Estimation of Continuous-Time Diffusion Processes. J. Bus. Econ. Stat. 2002, 20, 297–316. [Google Scholar] [CrossRef]
- Athanassoglou, S.; Xepapadeas, A. Pollution control with uncertain stock dynamics: When, and how, to be precautious. J. Environ. Econ. Manag. 2012, 63, 304–320. [Google Scholar] [CrossRef]
- Jiang, K.; You, D.; Li, Z.; Shi, S. A differential game approach to dynamic optimal control strategies for watershed pollution across regional boundaries under eco-compensation criterion. Ecol. Indic. 2019, 105, 229–241. [Google Scholar] [CrossRef]
- Kawaguchi, K. Optimal Control of Pollution Accumulation with Long-Run Average Welfare. Environ. Resour. Econ. 2003, 26, 457–468. [Google Scholar] [CrossRef]
- Kawaguchi, K.; Morimoto, H. Long-run average welfare in a pollution accumulation model. J. Econ. Dyn. Control 2007, 31, 703–720. [Google Scholar] [CrossRef]
- Morimoto, H. Optimal Pollution Control with Long-Run Average Criteria. In Stochastic Control and Mathematical Modeling: Applications in Economics; Encyclopedia of Mathematics and its Applications, Cambridge University Press: Cambridge, UK, 2010; pp. 237–251. [Google Scholar] [CrossRef]
- Jasso-Fuentes, H.; López-Barrientos, J.D. On the use of stochastic differential games against nature to ergodic control problems with unknown parameters. Int. J. Control 2015, 88, 897–909. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, Z.; Cui, Y.; Yuan, C. Game Model of Enterprises and Government Based on the Tax Preference Policy for Energy Conservation and Emission Reduction. Filomat 2016, 30, 3963–3974. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, G.; Su, B. The spatial impacts of air pollution and socio-economic status on public health: Empirical evidence from China. Socio-Econ. Plan. Sci. 2022, 83, 101167. [Google Scholar] [CrossRef]
- Cox, L.A.T., Jr. Confronting Deep Uncertainties in Risk Analysis. Risk Anal. 2012, 32, 1607–1629. [Google Scholar] [CrossRef]
- López-Barrientos, J.D.; Jasso-Fuentes, H.; Escobedo-Trujillo, B.A. Discounted robust control for Markov diffusion processes. Top 2015, 23, 53–76. [Google Scholar] [CrossRef]
- Escobedo-Trujillo, B.A.; López-Barrientos, J.D.; Garrido-Meléndez, J. A Constrained Markovian Diffusion Model for Controlling the Pollution Accumulation. Mathematics 2021, 9, 1466. [Google Scholar] [CrossRef]
- Borkar, V.; Ghosh, M. Controlled diffusions with constraints. J. Math. Anal. Appl. 1990, 152, 88–108. [Google Scholar] [CrossRef]
- Borkar, V. Controlled diffusions with constraints II. J. Math. Anal. Appl. 1993, 176, 310–321. [Google Scholar] [CrossRef]
- Duncan, T.; Pasik-Duncan, B. Adaptive control of continuous time linear stochastic systems. Math. Control. Signals Syst. 1990, 3, 45–60. [Google Scholar] [CrossRef]
- Escobedo-Trujillo, B.; Hernández-Lerma, O.; Alaffita-Hernández, F. Adaptive control of diffusion processes with a discounted criterion. Appl. Math. 2020, 47, 225–253. [Google Scholar] [CrossRef]
- Arapostathis, A.; Borkar, V.; Ghosh, M. Ergodic control of diffusion processes. In Encyclopedia of Mathematics and its Applications; Cambridge University Press: Cambridge, UK, 2012; Volume 143. [Google Scholar]
- Warga, J. Optimal Control of Differential and Functional Equations; Academic Press: New York, NY, USA, 1972. [Google Scholar]
- Fleming, W.; Nisio, M. On the stochastic relaxed control for partially observed diffusions. Nagoya Mathhematical J. 1984, 93, 71–108. [Google Scholar] [CrossRef]
- Jasso-Fuentes, H.; Yin, G. Advanced Criteria for Controlled Markov-Modulated Diffusions in an Infinite Horizon: Overtaking, Bias, and Blackwell Optimality; Science Press: Beijing, China, 2013. [Google Scholar]
- Jasso-Fuentes, H.; Hernández-Lerma, O. Characterizations of overtaking optimality for controlled diffusion processes. Appl. Math. Optim. 2007, 57, 349–369. [Google Scholar] [CrossRef]
- Pedersen, A.R. Consistency and asymptotic normality of an approximate maximum likelihood estimator for discretely observed diffusions process. Bernoulli 1995, 1, 257–279. [Google Scholar] [CrossRef]
- Ghosh, M.K.; Arapostathis, A.; Marcus, S.I. Ergodic control of switching diffusions to flexible manufacturing systems. SIAM J. Control Optim. 1993, 31, 1183–1204. [Google Scholar] [CrossRef]
- Rogers, L.; Williams, D. Diffusions, Markov Processes and Martingales, Vol.1, Foundations; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).