
Efficient Automatic Subdifferentiation for Programs with Linear Branches
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Related Works
2. Problem Setup
2.1. Notations
2.2. Programs with Branches
2.3. Pieces of Programs
2.4. Reverse-Mode Automatic Differentiation
| Algorithm 1 Forward pass of reverse-mode automatic differentiation |
|
| Algorithm 2 Backward pass of reverse-mode automatic differentiation |
|
3. Efficient Automatic Subdifferentiation
3.1. Assumptions on Primitive Functions
- .
- is linear, i.e., there exists such that .
- is analytic on .
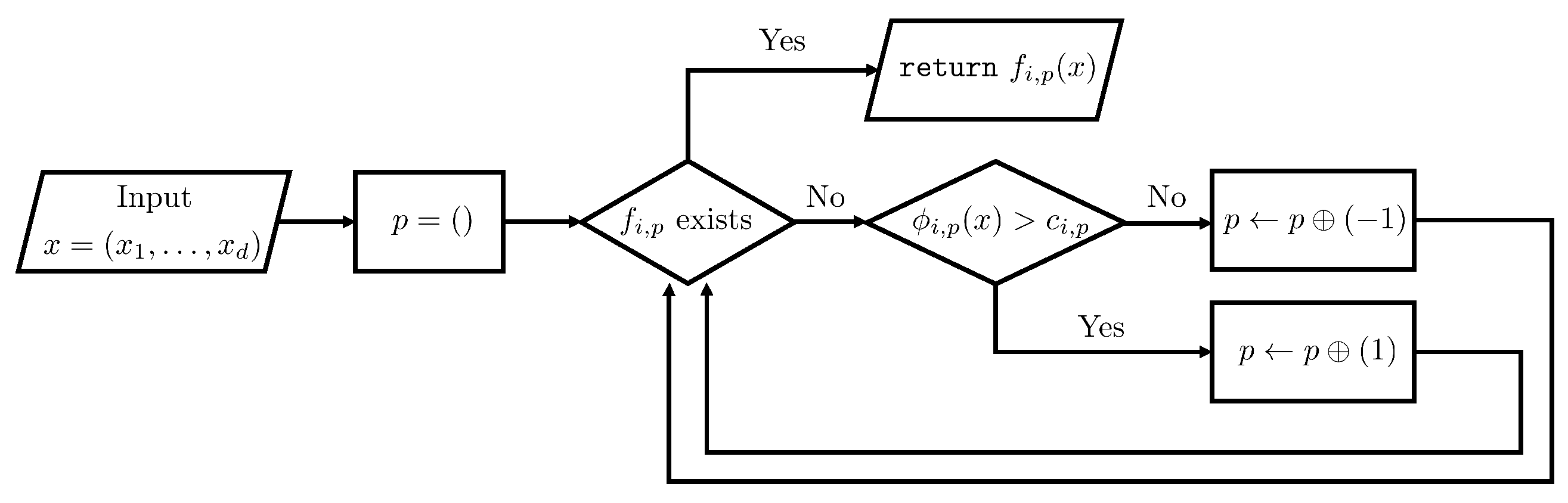
3.2. Intuition Behind Efficient Automatic Subdifferentiation
| Algorithm 3 Forward pass of our algorithm |
|
3.3. Forward Pass for Efficient Automatic Subdifferentiation
3.4. Computational Cost
4. Proof of Theorem 1
4.1. Additional Notations
4.2. Technical Claims
4.3. Technical Assumptions
4.4. Technical Lemmas
- ;
- .
4.5. Key Lemmas
- If , then is open since is strictly monotone on ;
- If , then are constant functions (i.e., is a constant) due to Assumption 2.
| Algorithm 4 Construction of and |
|
4.6. Proof of Theorem 3
5. Proof of Theorem 2
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 1 November 2023).
- Frostig, R.; Johnson, M.; Leary, C. Compiling machine learning programs via high-level tracing. In Proceedings of the SysML Conference, Stanford, CA, USA, 15–16 February 2018; Volume 4. [Google Scholar]
- Speelpenning, B. Compiling Fast Partial Derivatives of Functions Given by Algorithms; University of Illinois at Urbana-Champaign: Champaign, IL, USA, 1980. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 84–90. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Griewank, A.; Walther, A. Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, 2nd ed.; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
- Pearlmutter, B.A.; Siskind, J.M. Reverse-mode AD in a functional framework: Lambda the ultimate backpropagator. ACM Trans. Program. Lang. Syst. 2008, 30, 1–36. [Google Scholar] [CrossRef]
- Baur, W.; Strassen, V. The complexity of partial derivatives. Theor. Comput. Sci. 1983, 22, 317–330. [Google Scholar] [CrossRef]
- Griewank, A. On automatic differentiation. Math. Program. Recent Dev. Appl. 1989, 6, 83–107. [Google Scholar]
- Bolte, J.; Boustany, R.; Pauwels, E.; Pesquet-Popescu, B. Nonsmooth automatic differentiation: A cheap gradient principle and other complexity results. arXiv 2022, arXiv:2206.01730. [Google Scholar]
- Griewank, A. Who invented the reverse mode of differentiation. Doc. Math. Extra Vol. ISMP 2012, 389400, 389–400. [Google Scholar]
- Kakade, S.M.; Lee, J.D. Provably Correct Automatic Sub-Differentiation for Qualified Programs. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 7125–7135. [Google Scholar]
- Lee, W.; Yu, H.; Rival, X.; Yang, H. On Correctness of Automatic Differentiation for Non-Differentiable Functions. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 6719–6730. [Google Scholar]
- Nesterov, Y. Lexicographic differentiation of nonsmooth functions. Math. Program. 2005, 104, 669–700. [Google Scholar] [CrossRef]
- Khan, K.A.; Barton, P.I. Evaluating an element of the Clarke generalized Jacobian of a composite piecewise differentiable function. ACM Trans. Math. Softw. 2013, 39, 1–28. [Google Scholar]
- Khan, K.A.; Barton, P.I. A vector forward mode of automatic differentiation for generalized derivative evaluation. Optim. Methods Softw. 2015, 30, 1185–1212. [Google Scholar] [CrossRef]
- Barton, P.I.; Khan, K.A.; Stechlinski, P.; Watson, H.A.J. Computationally relevant generalized derivatives: Theory, evaluation and applications. Optim. Methods Softw. 2018, 33, 1030–1072. [Google Scholar] [CrossRef]
- Khan, K.A. Branch-locking AD techniques for nonsmooth composite functions and nonsmooth implicit functions. Optim. Methods Softw. 2018, 33, 1127–1155. [Google Scholar] [CrossRef]
- Griewank, A. Automatic directional differentiation of nonsmooth composite functions. In Proceedings of the Recent Developments in Optimization: Seventh French-German Conference on Optimization, Dijon, France, 27 June–2 July 1995; Springer: Berlin/Heidelberg, Germany, 1995; pp. 155–169. [Google Scholar]
- Sahlodin, A.M.; Barton, P.I. Optimal campaign continuous manufacturing. Ind. Eng. Chem. Res. 2015, 54, 11344–11359. [Google Scholar] [CrossRef]
- Sahlodin, A.M.; Watson, H.A.; Barton, P.I. Nonsmooth model for dynamic simulation of phase changes. AIChE J. 2016, 62, 3334–3351. [Google Scholar] [CrossRef]
- Hanin, B. Universal function approximation by deep neural nets with bounded width and relu activations. Mathematics 2019, 7, 992. [Google Scholar] [CrossRef]
- Alghamdi, H.; Hafeez, G.; Ali, S.; Ullah, S.; Khan, M.I.; Murawwat, S.; Hua, L.G. An Integrated Model of Deep Learning and Heuristic Algorithm for Load Forecasting in Smart Grid. Mathematics 2023, 11, 4561. [Google Scholar] [CrossRef]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Rehman, H.U.; Kumam, P.; Argyros, I.K.; Shutaywi, M.; Shah, Z. Optimization based methods for solving the equilibrium problems with applications in variational inequality problems and solution of Nash equilibrium models. Mathematics 2020, 8, 822. [Google Scholar] [CrossRef]
- Davis, D.; Drusvyatskiy, D.; Kakade, S.; Lee, J.D. Stochastic subgradient method converges on tame functions. Found. Comput. Math. 2020, 20, 119–154. [Google Scholar] [CrossRef]
- Bolte, J.; Pauwels, E. Conservative set valued fields, automatic differentiation, stochastic gradient methods and deep learning. Math. Program. 2021, 188, 19–51. [Google Scholar] [CrossRef]
- Scholtes, S. Introduction to Piecewise Differentiable Equations; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Griewank, A.; Bernt, J.U.; Radons, M.; Streubel, T. Solving piecewise linear systems in abs-normal form. Linear Algebra Its Appl. 2015, 471, 500–530. [Google Scholar] [CrossRef]
- Bolte, J.; Pauwels, E. A mathematical model for automatic differentiation in machine learning. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020; pp. 10809–10819. [Google Scholar]
- Lee, W.; Park, S.; Aiken, A. On the Correctness of Automatic Differentiation for Neural Networks with Machine-Representable Parameters. arXiv 2023, arXiv:2301.13370. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Mityagin, B. The zero set of a real analytic function. arXiv 2015, arXiv:1512.07276. [Google Scholar] [CrossRef]
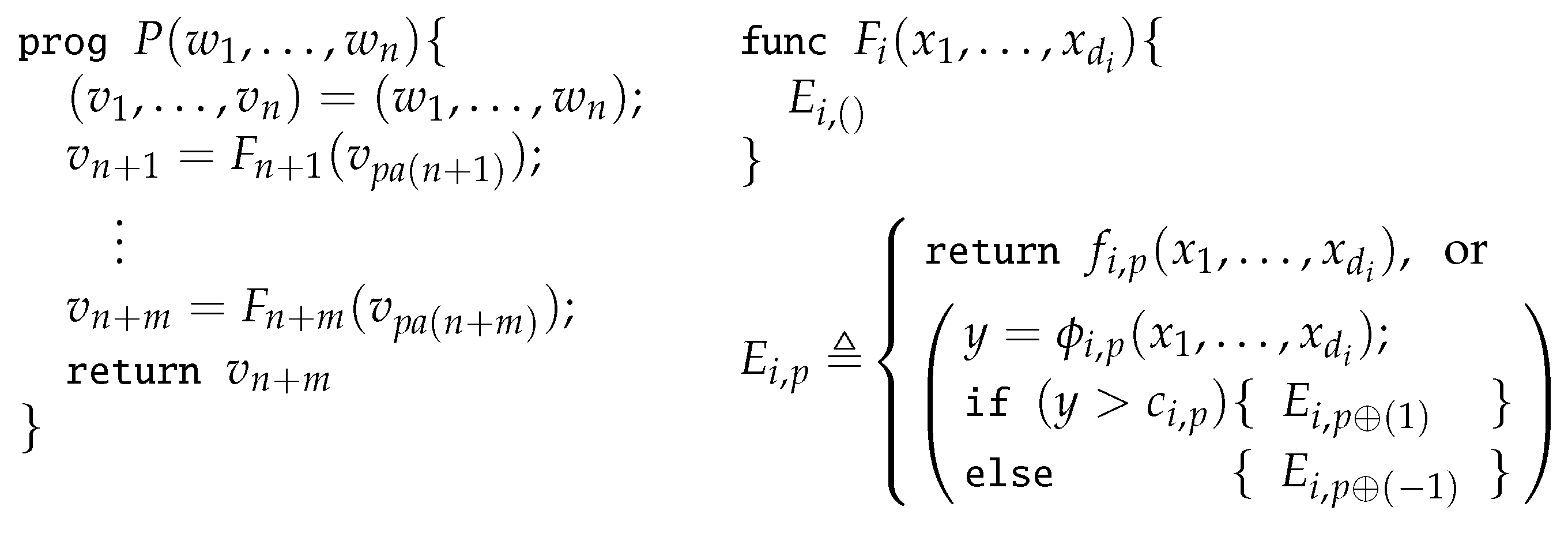



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S. Efficient Automatic Subdifferentiation for Programs with Linear Branches. Mathematics 2023, 11, 4858. https://doi.org/10.3390/math11234858
Park S. Efficient Automatic Subdifferentiation for Programs with Linear Branches. Mathematics. 2023; 11(23):4858. https://doi.org/10.3390/math11234858
Chicago/Turabian StylePark, Sejun. 2023. "Efficient Automatic Subdifferentiation for Programs with Linear Branches" Mathematics 11, no. 23: 4858. https://doi.org/10.3390/math11234858
APA StylePark, S. (2023). Efficient Automatic Subdifferentiation for Programs with Linear Branches. Mathematics, 11(23), 4858. https://doi.org/10.3390/math11234858