Abstract
In this paper, we explore a distributionally robust reinsurance problem that incorporates the concepts of Glue Value-at-Risk and the expected value premium principle. The problem focuses on stop-loss reinsurance contracts with known mean and variance of the loss. The optimization problem can be formulated as a minimax problem, where the inner problem involves maximizing over all distributions with the same mean and variance. It is demonstrated that the inner problem can be represented as maximizing either over three-point distributions under some mild condition or over four-point distributions otherwise. Additionally, analytical solutions are provided for determining the optimal deductible and optimal values.
Keywords:
glue value-at-risk; distributional robustness reinsurance; uncertainty; four-point distribution; stop-loss MSC:
90C17; 91B05; 91G70
1. Introduction
Reinsurance has played a crucial role in facilitating the transfer of risks from insurers to reinsurers. The optimization of reinsurance strategies has been the subject of extensive research, with significant contributions made by [1,2]. Since then, numerous extensions and advancements have been proposed in this field.
Some researchers have devoted their attention to identifying the most favorable reinsurance contract through the examination of multiple criteria. These criteria encompass minimizing regulatory capital and mitigating the insurer’s risk exposure with respect to specific risk measures. The first proposal of the optimal reinsurance problem for VaR and CVaR risk measures was put forward by [3]. They analyzed the class of stop-loss policies based on the expected value premium principle. Ref. [4] expanded the scope of optimal reinsurance selection to a broader set. Additionally, Refs. [5,6,7] have investigated various approaches and models to determine the optimal reinsurance contract in accordance with the selected risk measure. For a comprehensive overview of optimal reinsurance design with a focus on risk measures, we highly recommend consulting the survey paper [8].
Given the practical difficulties in obtaining the precise distribution of losses, a widely adopted approach to tackle model uncertainty is the utilization of a moment-based uncertainty set. This approach entails considering distributions that adhere to particular moment constraints. An example of this is seen in [9], where optimal reinsurance incorporating stop-loss contracts was examined while accounting for incomplete information regarding the loss distribution. In a similar vein, Ref. [10] examined model uncertainty in the insurance context by maximizing over a finite set of probability measures. In the research conducted in [11], the investigation of VaR-based and CVaR-based reinsurance took place, while taking into account model uncertainty related to stop-loss reinsurance contracts. The authors successfully provided an analytical solution to the reinsurance problem. Moreover, in the study conducted in [12], a distributionally robust reinsurance problem incorporating expectiles was examined, and the optimization problem was numerically solved.
In this paper, we investigate a reinsurance problem incorporating the risk measure Glue Value-at-Risk (GlueVaR) under the framework of distributional robustness. GlueVaR, initially introduced in [13] as a function with four parameters, enables the customization of risk measures to specific contexts by adjusting these parameters. The practical aspects of tail-subadditivity were analyzed by the authors of [14], who also examined the subadditivity and tail-subadditivity of risk aggregation. In a recent study, Ref. [15] examined the optimal reinsurance problem using a novel combination of risk measures and derived closed-form solutions for optimal reinsurance policies. They also explored the application of VaR and GlueVaR as specific instances of risk management. However, it is important to note that their analysis assumed knowledge of the risk distribution. In our research, we possess partial knowledge about the distribution of losses, specifically, regarding the mean and variance. The primary contribution of this paper is to establish that the worst-case distribution falls within the category of three-point or four-point distributions, thereby transforming the infinite-dimensional inner problem into a finite-dimensional one. As a result, we obtain closed-form solutions for the optimal deductible and optimal value. Our findings build upon the conclusions presented in [11], thus extending their implications.
The remaining sections of this paper are structured as follows. Section 2 presents the definition and properties of GlueVaR and formulates our distributionally robust reinsurance problem as a minmax problem. In Section 3, we address the distributionally robust reinsurance problem by identifying the optimal deductibles and optimal values. Section 4 provides an in-depth discussion on the optimal solution, and concludes the paper with closing remarks. Some detailed proofs can be found in the Appendix A and Appendix B.
2. Preliminaries
2.1. Risk Measures
A risk measure is a mathematical function that assigns a non-negative real number to a specific level of risk. Within the financial and insurance sectors, two commonly utilized risk measures are Value-at-Risk (VaR) and Conditional Value-at-Risk (CVaR). For a deeper understanding of CVaR, please consult the discussion provided in [16].
For a random variable X, VaR is defined in two versions: left-continuous VaR () and right-continuous VaR (VaR). They are defined as
and
respectively. Specifically, let and . Both of these measures serve as a scientific foundation for determining the initial capital required by a company to withstand risks. However, it should be noted that and VaR do not satisfy subadditivity, and they cannot accurately calculate extreme risks.
CVaR, also known as expected shortfall, satisfies the property of subadditivity, which was defined as
provided the integral exists. Ref. [17] proposed at levels , as follows:
RVaR includes right-continuous VaR and CVaR as its limiting cases, and the two versions of VaR do not impact the values of RVaR and CVaR.
Moving on to another perspective, Ref. [18] defines a family of risk measures using the concept of a distortion function. A distortion function is an non-decreasing function such that and . The corresponding distortion risk measure, denoted as , is defined as follows:
where is the survival function of X. For a more comprehensive understanding of distortion risk measures, see [19,20].
Ref. [13] introduced GlueVaR, denoted by , which utilizes a distortion function defined as follows:
where such that and . By [13], GlueVaR can be expressed as
where
The GlueVaR family can exhibit great flexibility by imposing appropriate conditions on and . For instance, risk managers may choose parameters such that . This implies that GlueVaR has the potential to address the limitation of VaR’s tendency to underestimate risks. On the contrary, unlike CVaR, GlueVaR is not overly conservative. Additionally, it is important to note that GlueVaR encompasses (right-continuous) Value-at-Risk (VaR), Conditional Value-at-Risk (CVaR), and Range Value-at-Risk (RVaR) as specific cases. The corresponding distortion functions for these measures are , , and , respectively. The graphs of these distortion functions are clearly illustrated in Figure 1.
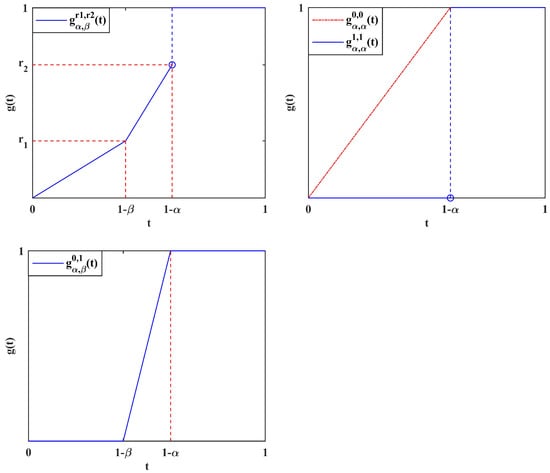
Figure 1.
The distortion function of , , , and : , , , and .
2.2. Distributionally Robust Reinsurance with GlueVaR
Suppose we have a non-negative ground-up loss, denoted as X, defined on an atomless probability space . The insurer has the option to transfer a portion of the loss, denoted as , to a reinsurer in exchange for a reinsurance premium, denoted as . A stop-loss reinsurance contract is defined as , where is referred to as the deductible. When , the identity function is equal to X, which signifies that stop-loss reinsurance defaults to full reinsurance. Conversely, if , equals 0, indicating that no reinsurance is purchased. In a stop-loss reinsurance arrangement, the total retained loss for the insurer can be expressed as . Here, denotes a loading factor.
Given a pair of non-negative mean and standard deviation, denoted as , we define the uncertainty set as follows:
The distributionally robust reinsurance problem based on the risk measure is defined as
where is the loss with distribution function F. An optimal solution to (2) is called an optimal deductible, denoted by . A distribution that solves
is referred to as a worst-case distribution, and is called the worst-case value corresponding to a given d. In other words, we have .
The distributionally robust reinsurance with and has been studied by [11], and when is an expectile-based risk measure, it was studied by [12]. Since GlueVaR can incorporate more information about agents’ attitudes towards risk, we consider the distributionally robust reinsurance problem with GlueVaR. By utilizing the translation invariance of GlueVaR, model (2) can be reduced to
where with and .
From the expression in Equation (1), and represent the levels of riskiness in GlueVaR. The larger the values of and , the more risk the insurer will transfer to the reinsurer. Conversely, if and are small enough, the insurer will assume all the risk, aligning with the following proposition.
Proposition 1.
Proof.
- (i)
- If , we have . Taking the derivative with respect to d, we haveFrom this, we can observe that . This implies that is decreasing for , and is increasing for . Since , it follows that . Consequently, is decreasing in .
- (ii)
- If , which implies , we haveThus, the derivative with respect to d isWe will demonstrate that is decreasing in d by considering the following three subcases.Subcase 1: .In this subcase, is decreasing for if and only if , whereBy Condition (4), we have and . Consequently, we can conclude that .Subcase 2: .In this subcase, is decreasing in if and only if . By utilizing condition (4), we can verify that .Subcase 3: .In this subcase, we have
- (iii)
- If , thenFrom this, we can observe that . Therefore, is decreasing for .
Combining the above three cases, we conclude that is decreasing for . □
Noting that , we can derive the following corollary as an immediate consequence of Proposition 1.
Corollary 1.
If , then the optimal deductible of problem (2) with is .
3. Main Results
As indicated by Proposition 1, the optimal deductible under certain moderate conditions is for the case where , implying a scenario with no reinsurance purchase. However, practical instances often present values near 1 and relatively minor values. This makes the condition rarely satisfied. Consequently, our primary focus in this section is on cases where .
Moving forward, we employ a methodological approach in examining the issue. In Section 3.1, we transform problem (3) into a finite-dimensional and more computationally amenable problem. Subsequently, in Section 3.2, we deduce the worst-case scenario for problem (5). Lastly, within Section 3.2, we present the optimal deductible for the optimization problem represented by (3).
3.1. The Problem Formulation
We first consider the inner problem of (3), which is defined as follows:
We demonstrate that under mild conditions, if , the worst-case distribution of the problem (5) can be restricted to the class of three-point distributions . Conversely, when , the worst-case distribution of problem (5) can be confined to the class of four-point distributions .
We first present the following two lemmas, which will be utilized in the proof of the subsequent propositions.
Lemma 1.
For and , let be a distribution with . Suppose . Then there exists such that
Similar to the proof of Lemma 1, we can obtain the following Lemma.
Lemma 2.
For , let with and . There exists such that
The next proposition states that if , then the worst-case distribution of optimization problem (5) can be limited to the set of three-point distributions .
Proposition 2.
Suppose and . The optimization problem (5) is equivalent to
Proof.
It suffices to show that for each , there exists a distribution such that . One can verify that
To construct , we consider the following three cases.
- (i)
- If , let be a uniform random variable such that U and X are comonotonic. Let , . Denote by for . Define a discrete random variableWe state that and . Indeed, obviously holds. Using Hölder’s inequality, we obtain thatHence, . By the definition of as in (7), we obtainwithand . By (7), , where . Consequently, . In a similar manner, we can confirm that and . Noting that implies , we conclude thatThe second equality holds because . Combining with the result follows. If , then , and . If , by Lemma 1, there exists a three-point distribution such that .
- (ii)
- If , let , and . Denote by . Define a discrete random variable as in Equation (7). Similar to the proof of (i), it is easy to show , , andwhere the inequality follows from . Noting that , the result follows. If , then , and . If , by Lemma 1, there exists a three-point distribution such . Then, the result follows.
- (iii)
- If , define a two-point random variableSimilar to case (i), we have and . For , definewhere . Note that , is continuous and increasing in . Next, we consider the following two subcases.
- (iii.a)
- If there exists an such that , then the distribution of is the desired two-point distribution.
- (iii.b)
- Otherwise, we have with . In this case, for , we definewith . Then and have the same distribution and . Noting that the variance is continuous in and , there exists an such that . Then the distribution of is the desired distribution .
□
Since , we derive the following results for from the proof of Proposition 2. These results generalize Proposition 1 in [11].
Corollary 2.
For , we have
From the proof of Proposition 2, we can obtain the explicit form of the worst-case distributions. Specifically, we have the following result as a corollary of Proposition 2.
Corollary 3.
Proof.
In the proof of Proposition 2 case (iii.b), for the founded in the proof, we consider the following three cases.
- (i)
- If , then . By applying case (i) of the proof of Proposition 2, we obtain a three-point distribution in .
- (ii)
- If , then if , if , and . In this case, by applying case (ii) of the proof of Proposition 2, we obtain a three-point distribution in .
- (iii)
- If , then . In this case, we can apply case (iii) of the proof of Proposition 2. Specifically, we obtain a random variable defined by (9) with . By iterating this process, we can obtain a distribution in case (i), (ii), or case (iii.a) of the proof of Proposition 2, such that the objective function is not less than that of the original one.
□
The proposition below asserts that if , then the worst-case distribution of optimization problem (5) can be limited to the set of four-point distributions .
Proposition 3.
For , we assume that . The optimization problem (5) can be equivalently represented as follows:
Proof.
To prove this, it is sufficient to demonstrate that for every , there exists a distribution such that . We can derive the following expression:
To construct , we consider the following three cases.
- (i)
- If , let be a uniform random variable that is comonotonic with X. Define the events , , , and . Denote by for . We define a discrete random variable as follows:It can be stated that , , and . By applying the Hölder inequality, we obtain thatThus, . From the definition of , it follows thatSinceit follows that .If , then , and . If , by Lemma 2, there exists a four-point distribution such that and . Thus, we have .
- (ii)
- If , let be comonotonic with X. Let . Denote by for . Define a discrete random variable as in (7), and we can determine that .If , then , and . If , by Corollary 2, there exists a three-point distribution such that .
- (iii)
- If , the proof is similar to the proof of (iii) in Proposition 2, so we omit it here.
□
3.2. Worst-Case Value
In this subsection, we first present the worst-case value of problem (5) when . Subsequently, we derive the worst-case value for as a corollary.
Corollary 3 implies that when , we have
Define . Then, , and we can express the supremum as follows:
Next, we demonstrate that is increasing with respect to . This implies that the uncertainty set can be substituted with the following set:
Specifically, we can state the following result.
Lemma 3.
For , and , if , we have
where is any uncertainty set satisfying
In the following theorem, we provide the worst-case value for problem (5) under the conditions and .
Theorem 1.
Let , for and .
- (i)
- If , then the worst-case value of problem (5) is
- (ii)
- If , then the worst-case value of problem (5) iswhere
Since and , we can derive the following corollary from Theorem 1.
Corollary 4.
For , let us define the following functions:
Next, we define the constants:
It can be shown that and . Additionally,
Since , we can show that for . Then, we have
According to Corollary 4, we have . Therefore, we rewrite the above equation as
Theorem 2.
For , under the conditions and , we have
3.3. Optimal Deductible
In this subsection, we provide the explicit solutions for the optimization problems (3) and (5). From Proposition 1, we know that the worst-case value is decreasing in d, and the optimal deductible is . Based on this, we can state the following theorem.
Theorem 3.
If and , then an optimal deductible of the optimization problem (3) is , and the optimal value is given by
Proof.
By Proposition 1, the optimal deductible of the optimization problem is . Therefore, based on Proposition 2, we obtain the optimal value given by (19). □
When , regardless of whether or not, the optimal deductibles are the same, and the optimal values are equal. Specifically, we have the following theorem.
Theorem 4.
If , then the optimal deductible for the optimization problem (3) is given by
and the optimal value is given by
Proof.
For and , we consider the following cases.
- (i)
- For , we havewhich is increasing and continuous in d for . Therefore, the optimal deductible is , and the optimal value is as follows:
- (ii)
- If , we haveThus, the derivative with respect to d iswhere and . Since and , we can derive the inequality . This can also be expressed equivalently as . Then, we can prove that for all . This implies that , and .
- (iii)
- If and , then we can conclude that , and the expression for is as follows:Then, the derivative with respect to d is given byOne can observe that is continuous for ; we will now consider the two subcases.
- (iii.1)
- If , which is equivalent to , then we have for all . Therefore, the optimal deductible is , and .
- (iii.2)
- If , or equivalently , we see that the second-order differentiation of with respect to d isNoting thatwith . Then, in the interval , there exists a unique such that . Furthermore, we have that for , and for . Consequently, initially decreases for and then increases for . Therefore, the minimum value of is attained at . Solving the equation , we can determine the value of , and
- (iv)
- If and , the proof is similar to case (iii), with the same optimal deductible and optimal value.
4. Conclusions
In this paper, we examine a distributionally robust reinsurance problem with the risk measure, GlueVaR (Generalized Value-at-Risk), under model uncertainty. As demonstrated in the main results, the parameters and significantly impact the optimal reinsurance design. If is sufficiently large such that and , then the insurer will not transfer any risk to the reinsurer. A smaller value of leads to a lower optimal deductible. The parameters and represent the levels of GlueVaR used to measure riskiness. Higher values of and indicate that the insurer transfers more risk to the reinsurer. This observation aligns with the results stated in Proposition 1 and Theorem 4. The values of and determine the weights of , , and . When and , the optimal deductible is infinite (). This means that the insurer will not purchase reinsurance. When , regardless of whether holds or not, the optimal deductible is zero () when .
By demonstrating that the worst-case distribution must fall within the set of four-point distributions or three-point distributions, we have effectively transformed the infinite-dimensional minimax problem into a finite-dimensional optimization problem. This reduction allows us to solve the problem in a tractable manner. We have provided closed-form optimal deductibles and optimal values for the distributionally robust reinsurance problem with GlueVaR. Our result generalizes the result in [11], although our proof differs from that in [11].
Author Contributions
Conceptualization, W.L.; methodology, W.L.; software, W.L. and L.W.; validation, W.L.; formal analysis, W.L. and L.W.; investigation, W.L.; resources, W.L.; writing—original draft preparation, W.L.; writing—review and editing, W.L. and L.W.; visualization, W.L. and L.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Scientific Research Project of Chuzhou University (No.zrjz2021019) and Scientific Research Program for Universities in Anhui Province (Project Nos. 2023AH051573, 2023AH051582).
Data Availability Statement
The data that support the analysis of this study are openly available in https://cn.investing.com/ (accessed on 12 May 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs of Lemma 1 and Lemma 3
Proof of Lemma 1.
Let represent a uniform random variable that is comonotonic with . We define the following sets: ,, and , where . We define a random variable with a three-point distribution as follows:
It is easy to verify that , , and . By the continuity of with respect to , there exists an such that . Suppose is the distribution of . Then
and
where and . Similarly, we can show that
Thus, we have
where
For , noting that and , we can show that
For , taking the derivative with respect to yields
where the inequality follows from . Thus, is decreasing in . Since , we obtain . When , we determine that
Thus, for . Noting that , we obtain that for . Combining above three cases, we determine that
This completes the proof. □
Proof of Lemma 3.
To establish (13), it is sufficient to demonstrate that
For any distribution with , as shown in the proof of Proposition 2, there exists a three-point distribution such that . Consequently, we obtain that
Since , the reverse inequality is trivially satisfied. Thus, we have completed the proof of Lemma 3. □
Appendix B. Proof of Theorem 1
The proof procedure of Theorem 1 follows a similar idea as Theorem 1 of [11], so it is included in the appendix.
Proof.
Define . By Lemma 3, we prove the theorem in the following two cases.
- (i)
- For any , we have . Then, the optimization problem is equivalent to maximizingsubject toSolving the first two equations in (A6), we obtain thatAs , we have . Hence, the optimization problem (A5) is reduced tosubject towhere . The first- and second-order differentiations of with respect to d areandrespectively. Solving yields .
- (i.a)
- If , the feasible set in problem (A7) is empty. Therefore, we obtain
- (i.b)
- If , it can be verified that . We consider the following subcases:
- (1)
- (2)
- (3)
- (4)
- (ii)
- For any , we havewhereandThen, the optimization problem is equivalent to maximizing (A17) subject toDenoteBy , we can obtain thatSince and , we can deduce that . Therefore, the functionis a concave function. By conventional calculation, we find thatwhereIt can be easily verified that belongs to . Noting thatandwe can conclude that the optimization problem can be reduced tosubject toSolving the first constraint condition of (A19), the optimization problem (A18) can be further simplified towith . Next, we solve problem (A20) in two cases.
- (ii.a)
- If , then , and the maximum value of problem (A20) isThe corresponding distribution of X is
- (ii.b)
- If , then . If , the feasible set of equation (A20) is empty, and the maximum value is . If , since is decreasing in x, the maximizer of (A20) is , and the maximum value isThe corresponding distribution isIf , the maximizer is still , and the maximum value of (A20) isThen, if , the maximum value of h is given byIf , selecting the larger value between Equations (A15) and (A21) gives us the worst-case value as stated in Equation (14). If , we can confirm thatandChoosing the larger one between Equations (A16) and (A23), we obtain the worst-case value as stated in Equation (15).
□
References
- Borch, K. An attempt to determine the optimum amount of stop loss reinsurance. In Proceedings of the Transactions of the 16th International Congress of Actuaries I; 1960; pp. 597–610. [Google Scholar]
- Arrow, K.J. Uncertainty and the welfare economics of medical care. Am. Econ. Rev. 1963, 53, 941–973. [Google Scholar]
- Cai, J.; Tan, K.S. Optimal retention for a stop-loss reinsurance under the VaR and CTE risk measures. ASTIN Bullet. 2007, 37, 93–112. [Google Scholar] [CrossRef]
- Chi, Y.; Tan, K.S. Optimal reinsurance under VaR and CVaR risk measures: A simplified approach. ASTIN Bullet. 2011, 41, 487–509. [Google Scholar]
- Cui, W.; Yang, J.; Wu, L. Optimal reinsurance minimizing the distortion risk measure under general reinsurance premium principles. Insur. Math. Econ. 2013, 53, 74–85. [Google Scholar] [CrossRef]
- Cheung, K.C.; Sung, K.C.J.; Yam, S.C.P.; Yung, S.P. Optimal reinsurance under general law-invariant risk measures. Scand. Actuar. J. 2014, 72–91. [Google Scholar] [CrossRef]
- Cai, J.; Lemieux, C.; Liu, F. Optimal reinsurance from the perspectives of both an insurer and a reinsurer. ASTIN Bullet. 2016, 46, 815–849. [Google Scholar] [CrossRef]
- Cai, J.; Chi, Y. Optimal reinsurance designs based on risk measures: A review. Stat. Theor. Relat. Field. 2020, 4, 1–13. [Google Scholar] [CrossRef]
- Hu, X.; Yang, H.; Zhang, L. Optimal retention for a stop-loss reinsurance with incomplete information. Insur. Math. Econ. 2015, 65, 15–21. [Google Scholar] [CrossRef]
- Asimit, A.V.; Bignozzi, V.; Cheung, K.C.; Hu, J.; Kim, E.S. Robust and pareto optimality of insurance contracts. Eur. J. Oper. Res. 2017, 262, 720–732. [Google Scholar] [CrossRef]
- Liu, H.; Mao, T. Distributionally robust reinsurance with Value-at-Risk and Conditional Value-at-Risk. Insur. Math. Econ. 2022, 107, 393–417. [Google Scholar] [CrossRef]
- Xie, X.; Liu, H.; Mao, T.; Zhu, X.B. Distributionally robust reinsurance with expectile. ASTIN Bullet. 2023, 53, 129–148. [Google Scholar] [CrossRef]
- Belles-Sampera, J.; Guillén, M.; Santolino, M. Beyond Value-at-Risk: GlueVaR Distortion Risk Measures. Risk. Anal. 2014, 34, 121–134. [Google Scholar] [CrossRef] [PubMed]
- Belles-Sampera, J.; Guillén, M.; Santolino, M. The use of flexible quantile-based measures in risk assessment. Commun. Stat. Theor. M. 2016, 45, 1670–1681. [Google Scholar] [CrossRef]
- Zhu, D.; Yin, C. Optimal reinsurance policy under a new distortion risk measure. Commun. Stat. Theory Methods 2023, 52, 4151–4164. [Google Scholar] [CrossRef]
- Wang, R.; Zitikis, R. An axiomatic foundation for the expected shortfall. Manag. Sci. 2020, 67, 1413–1429. [Google Scholar] [CrossRef]
- Cont, R.; Deguest, R.; Scandolo, G. Robustness and sensitivity analysis of risk measurement procedures. Quant. Financ. 2010, 10, 593–606. [Google Scholar] [CrossRef]
- Wang, S. Premium calculation by transforming the layer premium density. ASTIN Bullet. 1996, 26, 71–92. [Google Scholar] [CrossRef]
- Denuit, M.; Dhaene, J.; Goovaerts, M.J.; Kaas, R. Actuarial Theory for Dependent Risks: Measures, Orders and Models; John Wiley & Sons: Ltd.: London, UK, 2005. [Google Scholar]
- Dhaene, J.; Vanduffel, S.; Goovaerts, M.J.; Kaas, R.; Tang, Q.; Vyncke, D. Risk measures and comonotonicity: A review. Stoch. Model. 2006, 22, 573–606. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).