1. Introduction
Over the last two decades, there has been an increasing interest in functional data analysis due to its extensive application in biometrics, chemometrics, econometrics, medical research as well as other fields. The functional data are intrinsically infinite in dimension; thus, the classical methods for multivariate observations are no longer applicable. The functional linear model is an important model in functional data analysis, and has been extensively investigated. Ramasy and Silverman [
1] systematically introduced the statistical analysis methods for the functional data and described regression relationship between functional covariates and scalar responses by the functional linear models; further investigations include Cardot et al. [
2], Cardot and Sarda [
3], Li and Hsing [
4], and Hall and Horowitz [
5], who constructed estimator of slope function in the functional linear model and established its convergence with rates based on the functional principal component analysis (FPCA) technique. For more analysis on the functional data, refer to Hall and Hosseini-Nasab [
6], Horváth and Kokoszka [
7], Hsing and Eubank [
8], Ferraty and Vieu [
9], and others.
In real data, the response variable is also affected by other covariates. Shin [
10] proposed the following partial functional linear model:
where
is the response variable,
is a
d-dimensional covariate vector with
,
is a square integrable stochastic process on [0, 1] with
,
is an unknown
d-dimensional parametric vector,
is a square integrable unknown coefficient function and
V is the regression error, which is independent of
.
The spline method, which is frequently employed to investigate functional data, were used in many papers that studied functional data. Based on B-spline, Yuan and Zhang [
11] used the residual sum of squares to construct the test statistic of the
in the model (
1); Hu and Liang [
12] considered the empirical likelihood in the single-index partially functional linear model when the observations are missing at random; Jiang and Huang [
13]) discussed single-index partially functional linear quantile regression and used B-spline to approximate the link function and the slope function and further establish the convergence rates and asymptotic normality of the estimators. Bouka et al. [
14] employed a smoothing spline to study the estimators with a spatial functional linear regression.
However, the spline method has some drawbacks, such as the fact that shifting a control point causes the entire curve to change, making it hard to regulate the curve’s trend locally. Then, in recent years, many researchers have developed an interest in the FPCA approach for analyzing functional data, since this approach enables finite dimensional study of a topic that is inherently infinitely dimensional. The estimation and testing of a partially functional linear varying coefficient model were covered by Feng and Xue [
15]. Based on FPCA, Xie et al. [
16] examined the rank-based test’s asymptotic characteristics while considering the hypothesis test for the
in the model (
1). In addition, Hu et al.’s [
17] research also concentrated on the estimation issues for additive partial functional linear models with skew-normal errors. Tang et al. [
18] proposed a two-step estimation procedure with FPCA in the partial functional partially linear additive model. At the same time, we find there are several papers to discuss penalized estimators related to the partially functional linear model based on FPCA. For instance, Kong et al. [
19] applied a group penalty to reduce the effect of significant functional predictors in a high dimension setting; Du et al. [
20] analysed estimation and variable selection; Yao et al. [
21] selected the important variables based on the SCAD penalty in partially functional linear quantile model; Wu et al. [
22] concentrated on building the estimators for the parameter and slope function with the responses being right-censored and the censoring indicators being missing at random, and proposed a variable selection procedure by the method of adaptive lasso penalty.
It is known that the independence assumption for the model errors, in practical applications, is not always appropriate, especially for sequentially collected economic data, which often exhibit dependence in the errors. Up to now, we have found that Wang et al. [
23] established asymptotic normality and weak convergence with rates of the estimators for
and
, respectively, in model (
1) when the errors form a stationary
-mixing sequence, while Hu and Liang [
24] used the reproducing kernel Hilbert space technique to study the parameter estimator and the convergence rate of the estimator for the slope function with missing observations under under correlated errors
, which is called linear process, with
, and further defined the penalized estimator of the parameter by the SCAD penalty and a test statistic for check a linear hypothesis.
Motivated by the discussion in Hu and Liang [
24], we, in this paper, focus on the partially functional linear model (
1) when the regression error
V is a linear process deduced by not necessarily independent random variables by using FPCA method. In particular, we give the estimators
and
of
and
, investigate the asymptotic normality of
and discuss the weak convergence with rates of
and
. At the same time, the penalized estimator of
is defined based on the SCAD penalty introduced by Fan and Li [
25] and its oracle property is established. Finite sample behavior of the proposed estimators is also investigated via simulations.
The rest of the paper is organized as follows. In
Section 2, we construct the estimators of the parameter and slope function including the penalized estimator of the parameter. The main results are described in
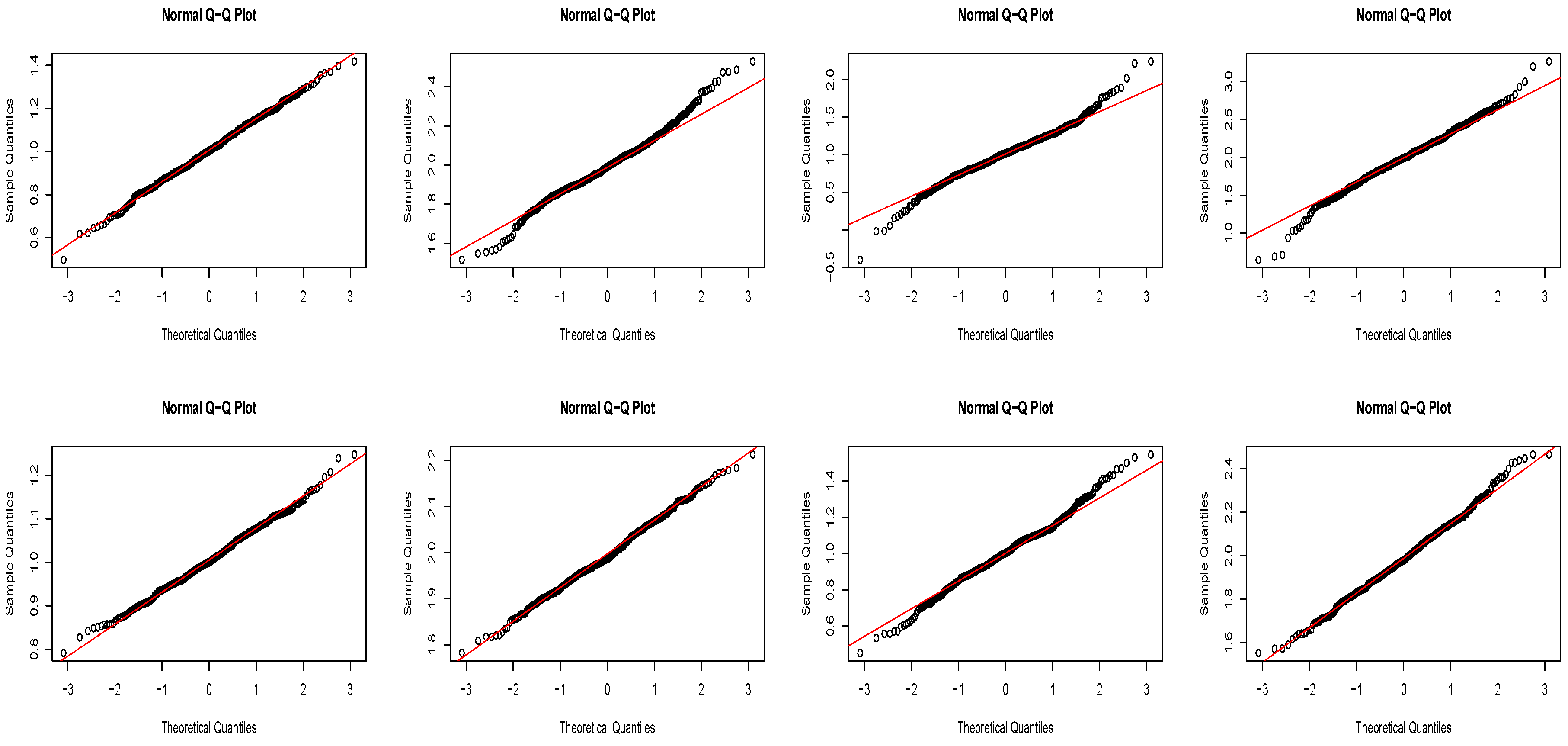
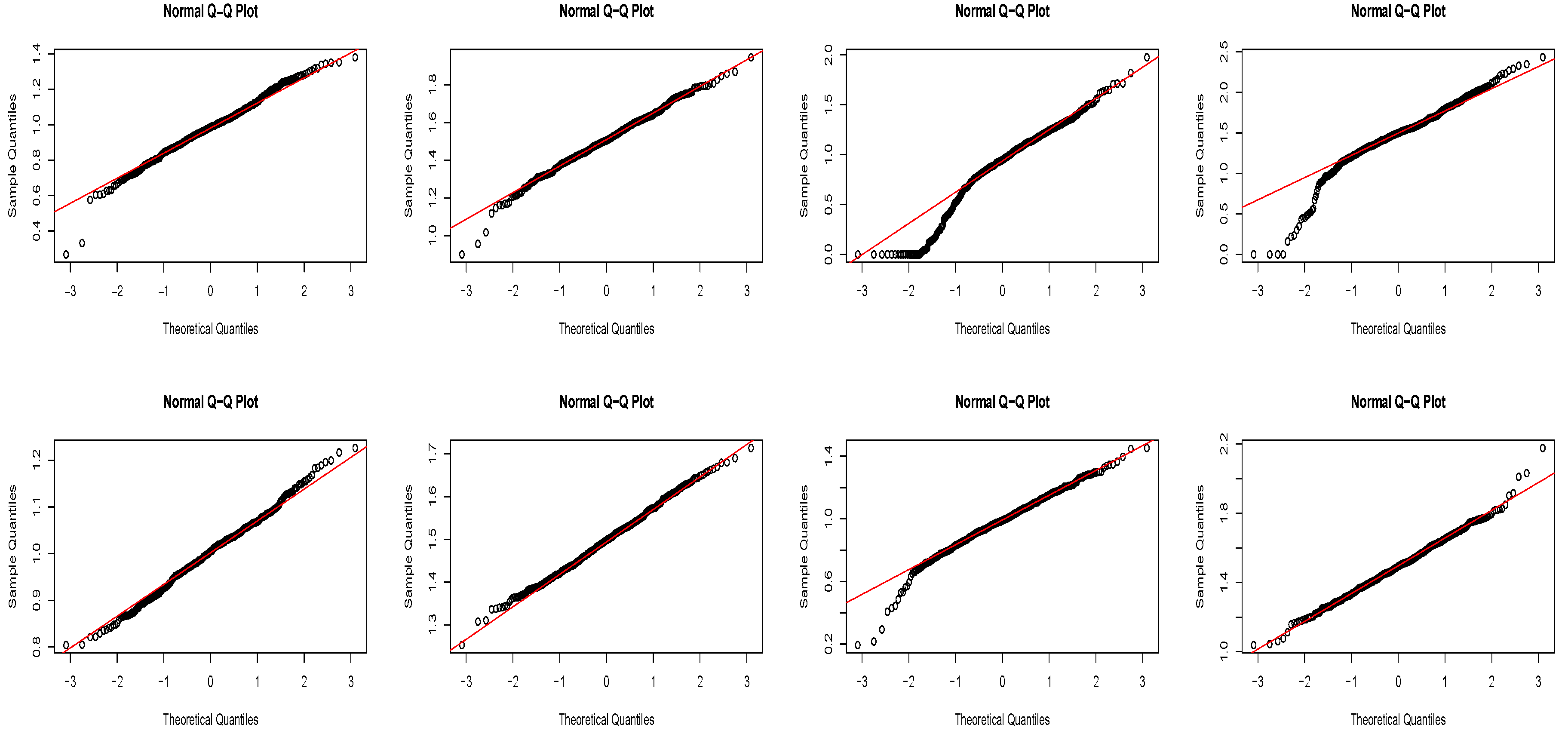
Section 3. A simulation study is presented in
Section 4. Conclusions are put into
Section 5. All proofs are put in
Section 6.
5. Conclusions
By using the least square method, based on FPCA, we construct the estimators of parameter and coefficient function in the partially functional linear models with linear process errors and establish asymptotic normality of parameter estimator and the rate of convergence of the estimator for the coefficient function. Additionally, we use the SCAD penalty to define the estimator of the parameter and discuss its oracle property.
However, the proposed method has some limitations. First, in this study, we approximate the expansion of the function part into partial sum form by using the FPCA method, which may leave out data information due to the truncation value m. Second, while, in practice, there exists missing data, this work considers the scenario of complete data. Therefore, in the event of missing data, our proposed method may be inapplicable. In the future, we are interested in figuring out a way to reduce data information loss and take missing data into account.
6. Proof of Main Results
In proof below, we use the following notations: for linear operator
T, let
,
for
;
for matrix
; for
, set
,
,
,
and
.
Lemma 1 - (1)
Let , then , and for
- (2)
Suppose that (A1), (A3), (A4)(i), (A5) and (A6) are satisfied. Then Further, if are identical distributed with or square uniformly integrable,
Lemma 2 (Pollard [26], page 171). Let be a sequence of random variables and be increasing sequence of σ-fields such that is measurable with respect to , and for . Assume that and for some constant and every . Then . Lemma 3. For , let be random variables with and . Set with . Assume that is independent of , and that are identical distributed with or square uniformly integrable. Then
Proof. Note that So which yields □
Lemma 4. If (A1) and for each k hold, then and , where , .
Proof. From
, using (A1) we have
□
Lemma 5. Let and be two sequences of independent random variables, then for any and we have Proof. Using independence between
and
, it follows that
□
Proof of Theorem 1. We write (cf. the proof of Theorem 3.1 in Shin [
10])
Lemma 1 implies
. Thus, it suffices to show that
,
and
Step 1. We prove
. By applying Lemmas 1 and 3, it follows
which yields
.
Step 2. We prove
. From
, we know that the
k-th (
) element of
is
Since
,
Then, to prove
, we need only to prove that
Here, we only prove (
8) and (
10), the proof for (
9) is similar by Remark 2(c).
To do these, we need the following results (i) and (ii), their proofs can be found in Hall and Horowitz [
5]:
- (i)
If we have .
- (ii)
. Furthermore, let , then .
Note that
, then, from
, we have
Using
we get
The result (ii) implies
on
, hence using (
11) and
, On
we have
By and , we find
When
and using the conclusion
and Lemma 4
The inequation (5.16) in Hall and Horowitz [
5] shows
, thus, from
we have
On
, we have
Obviously, from
we have
and
for
. Then, in view of (A3), (A4) and Lemma 4, we obtain
According to (A3) and (A4), by using Lemma 4 we have
So, on
, we have
. Thus, using results (i) and (ii), as
,
which yields (
8). As for (
10), we have
Step 3. We verify (
7). It suffices to show that for nonzero vector
,
Write
By
and using
, it follows that, for any
which implies
.
Now, we use Lemma 2 to prove
. In fact,
, where
. Set
Then
is measurable with respect to
, and for
,
. Thus, from Lemma 2, we only need to verify that
We first prove (
13). Applying
a.s., we can write
The law of large numbers implies , hence from we obtain
Since
is a sequence of independent random vectors with
, we have
which gives
. Therefore, (
13) is proved.
We next prove (
14). Using Lemma 5, we write
According to the moment inequality for sum of independent random variables, we can write
When
are identical distributed, from
we have
; when
are square uniformly integrable, we have
. Hence
. Therefore,
, further we verify (
14). □
Proof of Theorem 2. Applying Lemmas 1 and 3 and
, following the proof line in the proof of Theorem 3.2 in Shin [
10], one can prove this result. □
Proof of Theorem 3. (1) Let
and
. we first prove that for any
and a large constant
,
which implies there exists a local minimizer
such that
.
In fact,
. Let
. Using the Taylor expansion, we have
and from
, it follows that
where
,
and
. (
8), (
10) and (
9) imply
. Hence, from Theorem 2 and
we have
Next, we consider
. Clearly,
, where
and
is defined in the proof of Theorem 1 and further in the proof of Theorem 1, it holds that
and
. Thus,
.
From Lemma 1, we have , which implies .
As for
, from (A7) we get
Therefore, for
, we have
, which yields (
15) since
is a positive definite matrix.
Note that
Then
where
. Thus, for any
satisfying
, by (A7) and Theorem 2,
and
we find
then the sign of
is dominated by the sign of
. Note that
is the estimator of
. Then
as
.
(2) From the proof in (1) above, we know
and
. Hence, from (
16) we get
where
,
and
. Due to Lemma 1, we can obtain
. Then, by (A7),
Thus, by (
8), (
10) and (
9), (
17) can be rewritten as
Similar to the proof of Theorem 1, we have , where and are similarly defined as and , which are related to for . Then, following the proof line in Step 2 and Step 3 of the proof of Theorem 1, one can verify □



{kind=link}
{kind=link}