
Credit Card Fraud Detection Using a New Hybrid Machine Learning Architecture


Abstract
:1. Introduction
- The distribution of the data is highly imbalanced as the number of fraudulent transactions is very small.
- The data is continually evolving over time.
- Lack of real-world dataset due to privacy concerns.
2. Related Works
3. Materials and Methods
3.1. Data Collection
3.2. Data Preparation
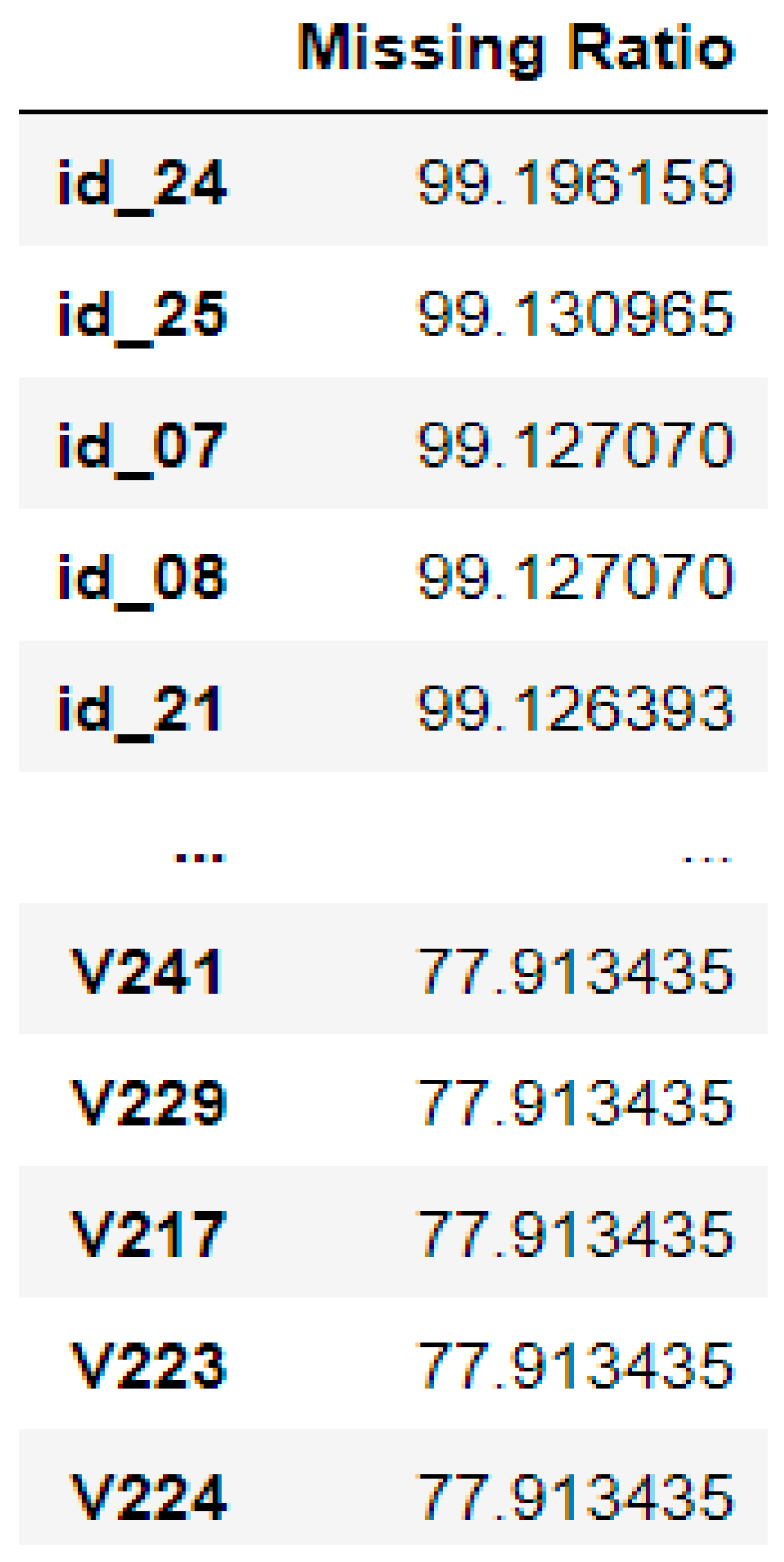
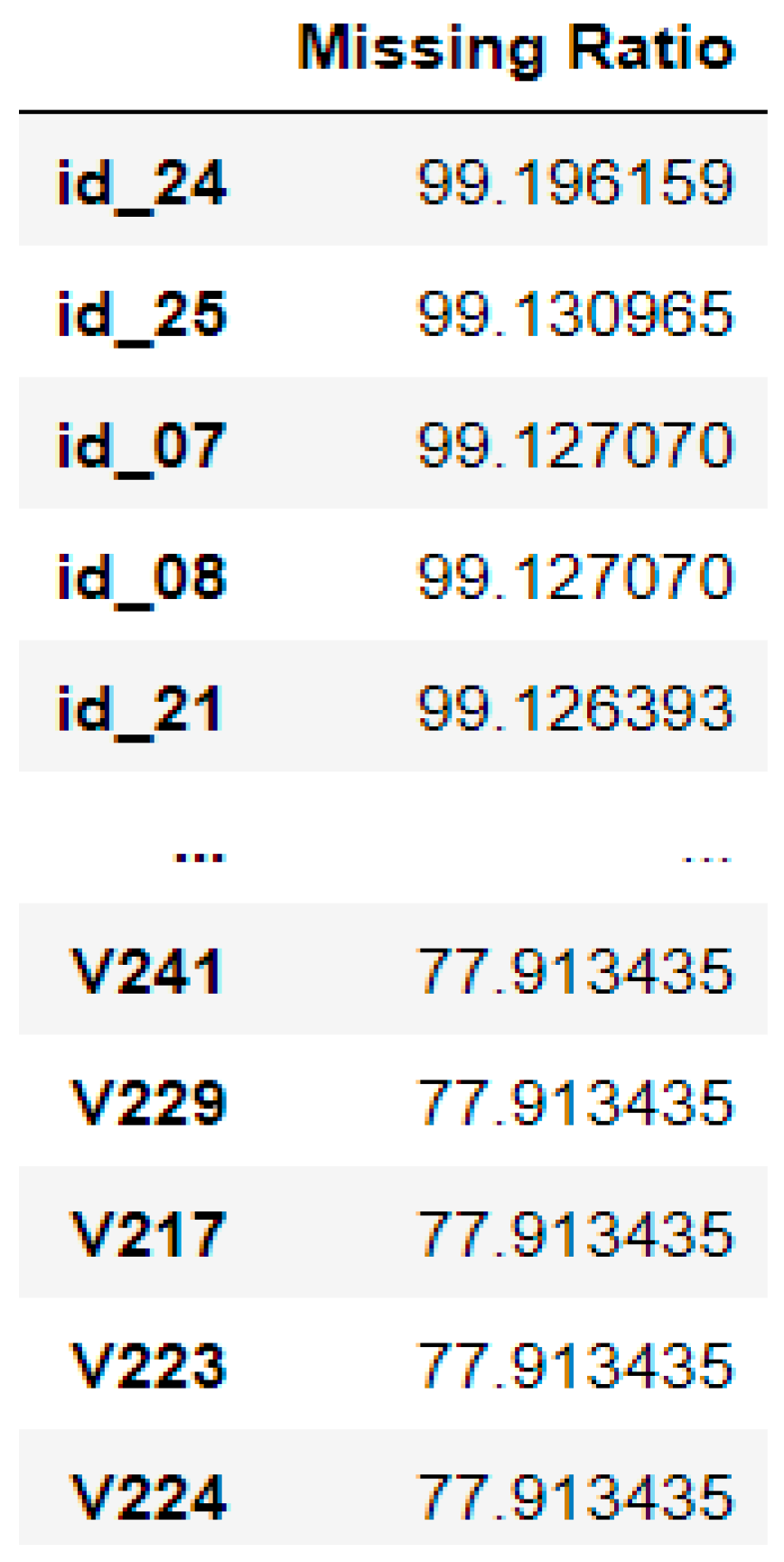
3.2.1. Missing Values
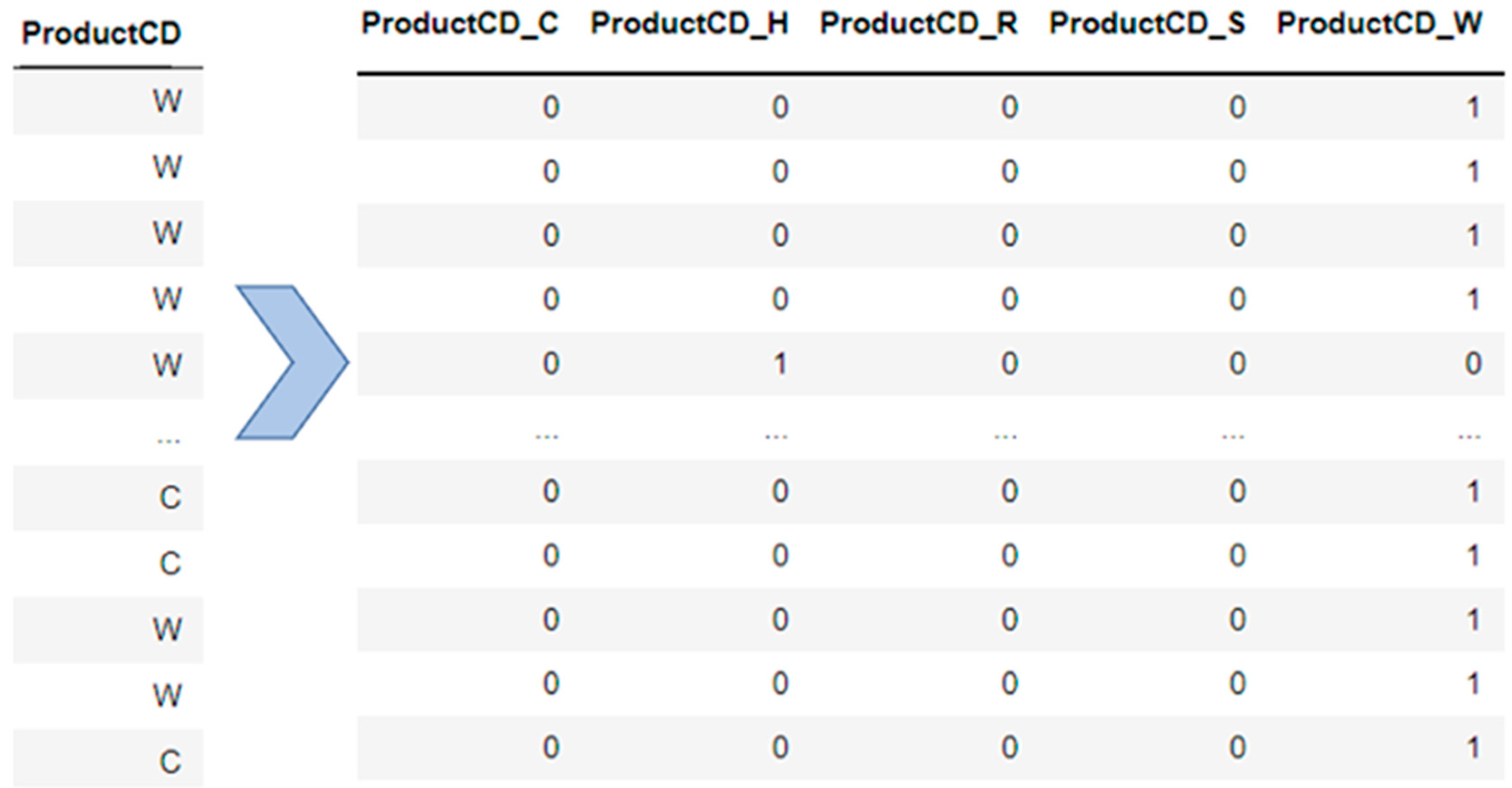
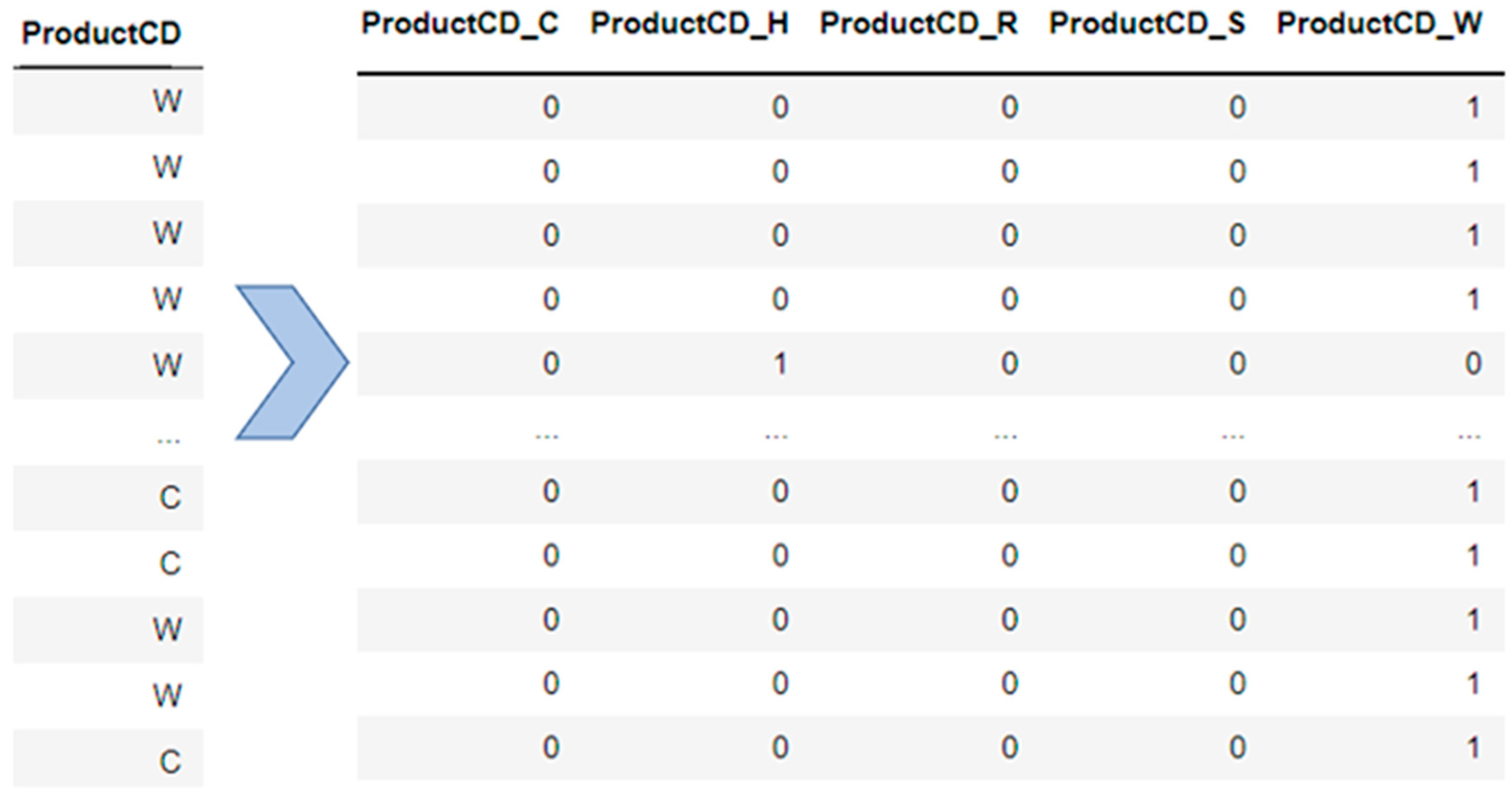
3.2.2. Encoding Categorical Features
3.2.3. Feature Scaling
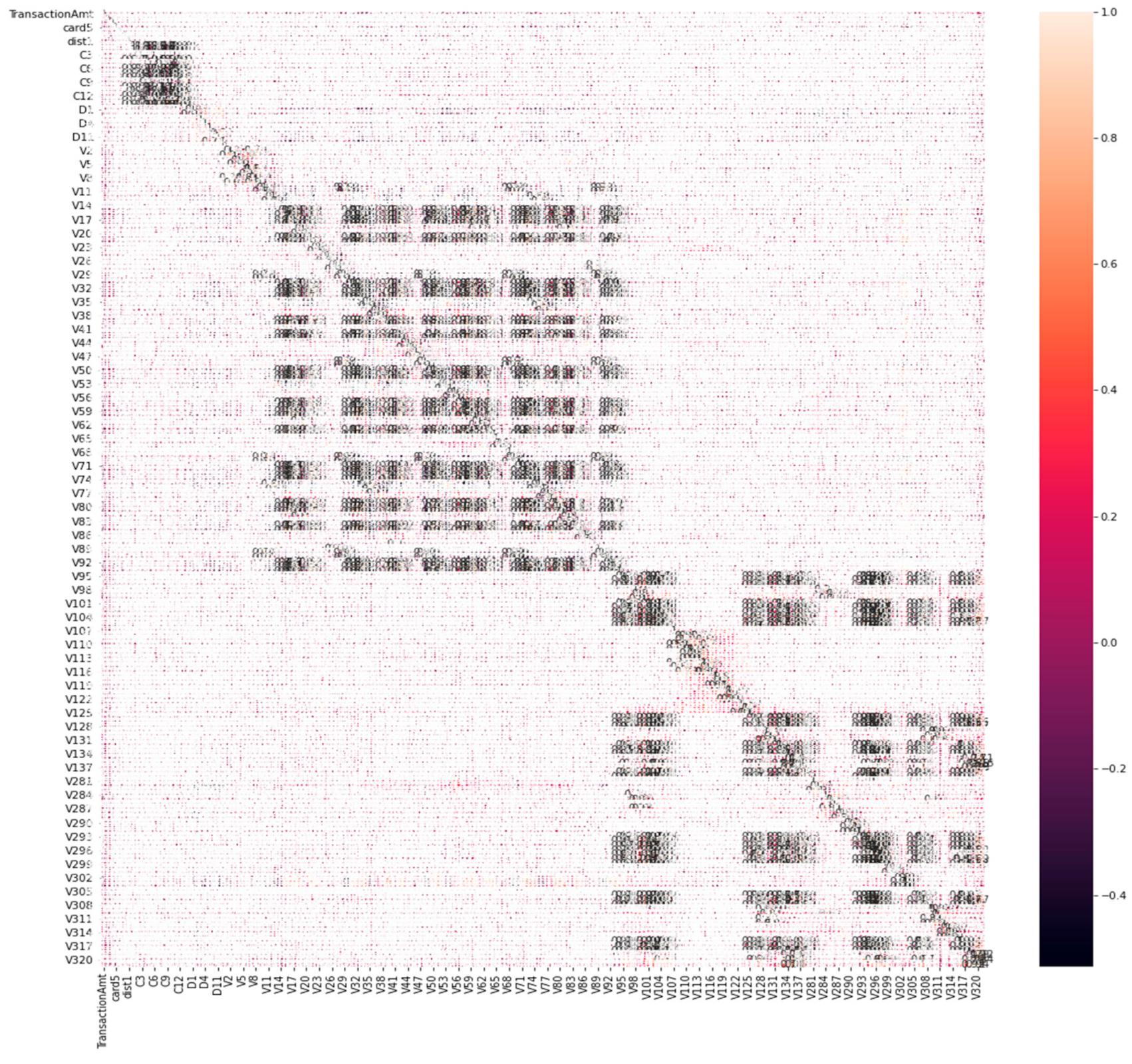
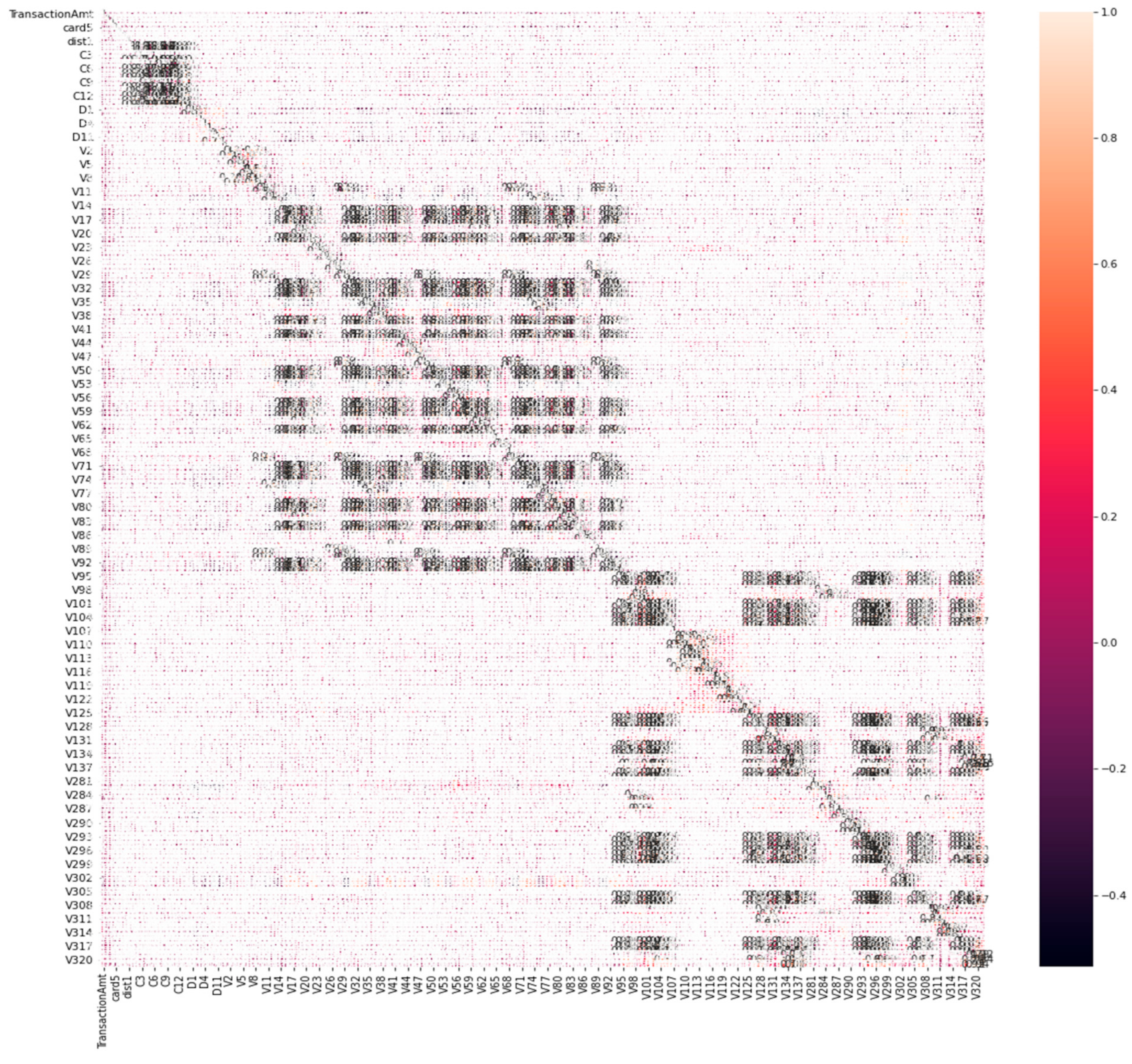
3.2.4. Feature Selection
3.2.5. Data Resampling
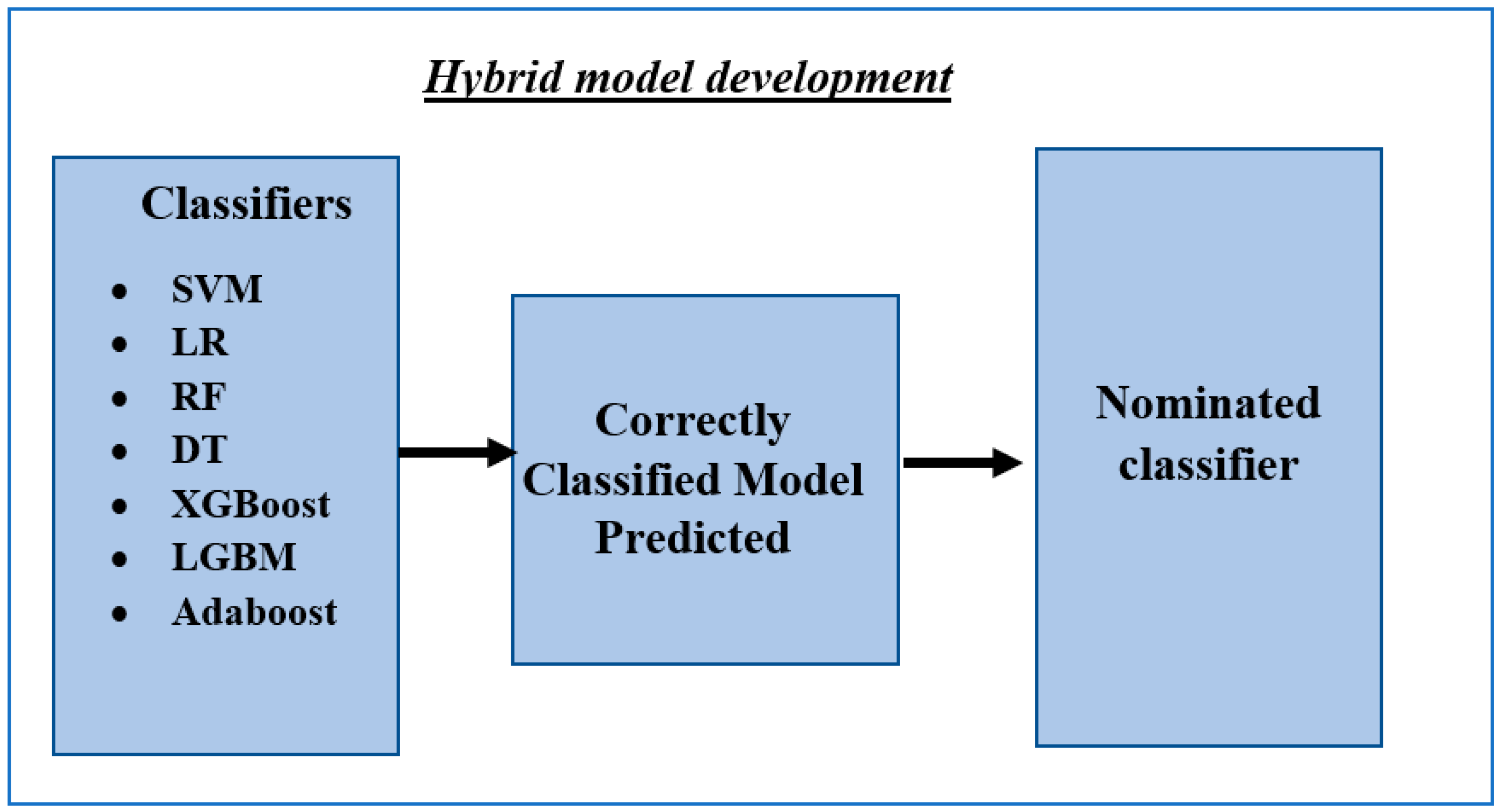
4. Model Development
- (1)
- The best baseline single model + LR;
- (2)
- The best baseline single model + RF;
- (3)
- The best baseline single model + DT;
- (4)
- The best baseline single model + XGBOOST;
- (5)
- The best baseline single model + SVM;
- (6)
- The best baseline single model + NB;
- (7)
- The best baseline single model + LGBM.
5. Model Evaluation
- True positive (TP) implies the number of correctly classified data as fraudulent credit card transactions.
- True negative (TN) implies the number of correctly classified data as legitimate credit card transactions.
- False positive (FP) denotes the number of legitimate credit card transactions classified as fraudulent.
- False Negative (FN) denotes the number of fraudulent credit card transactions classified as legitimate.
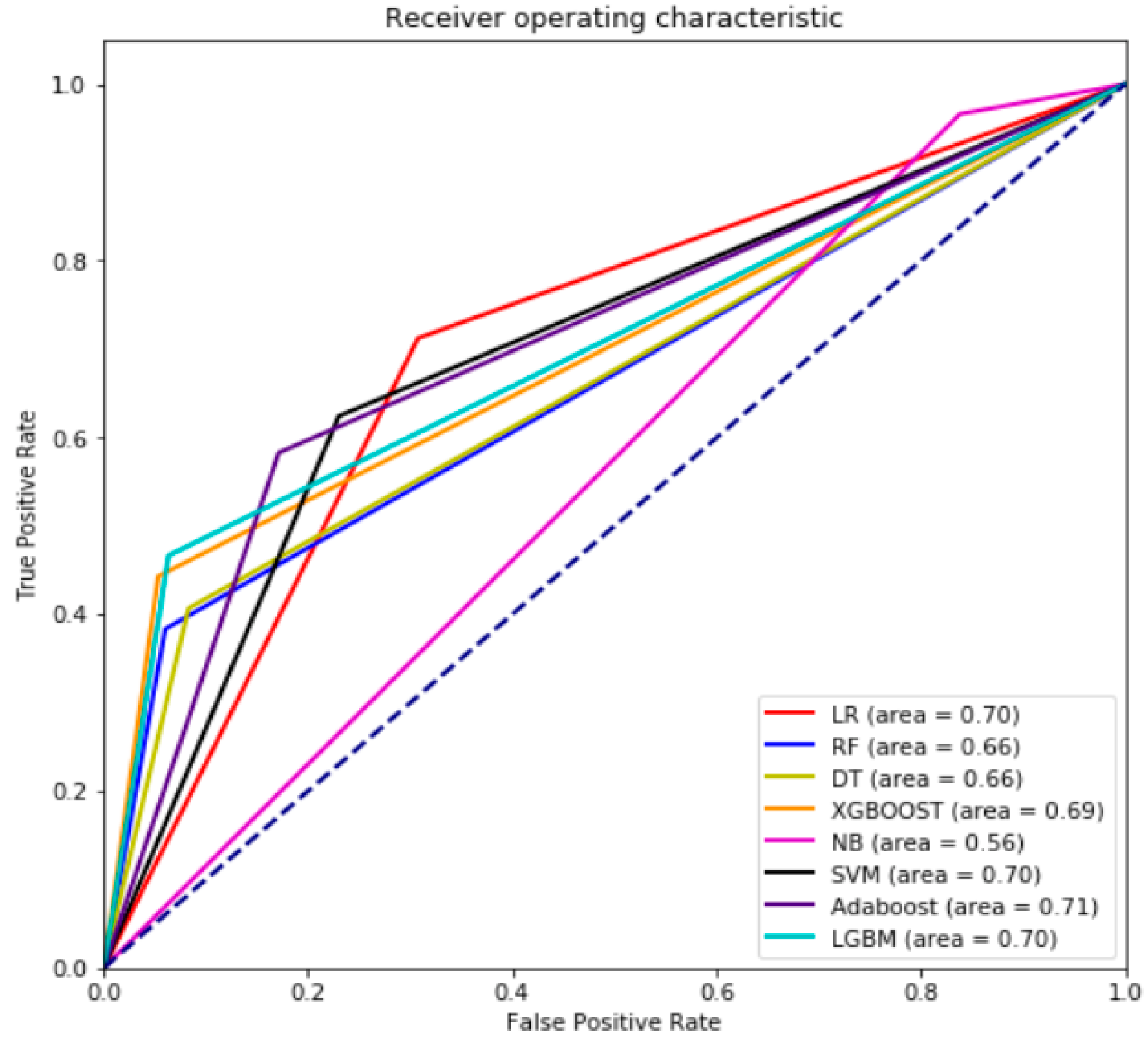
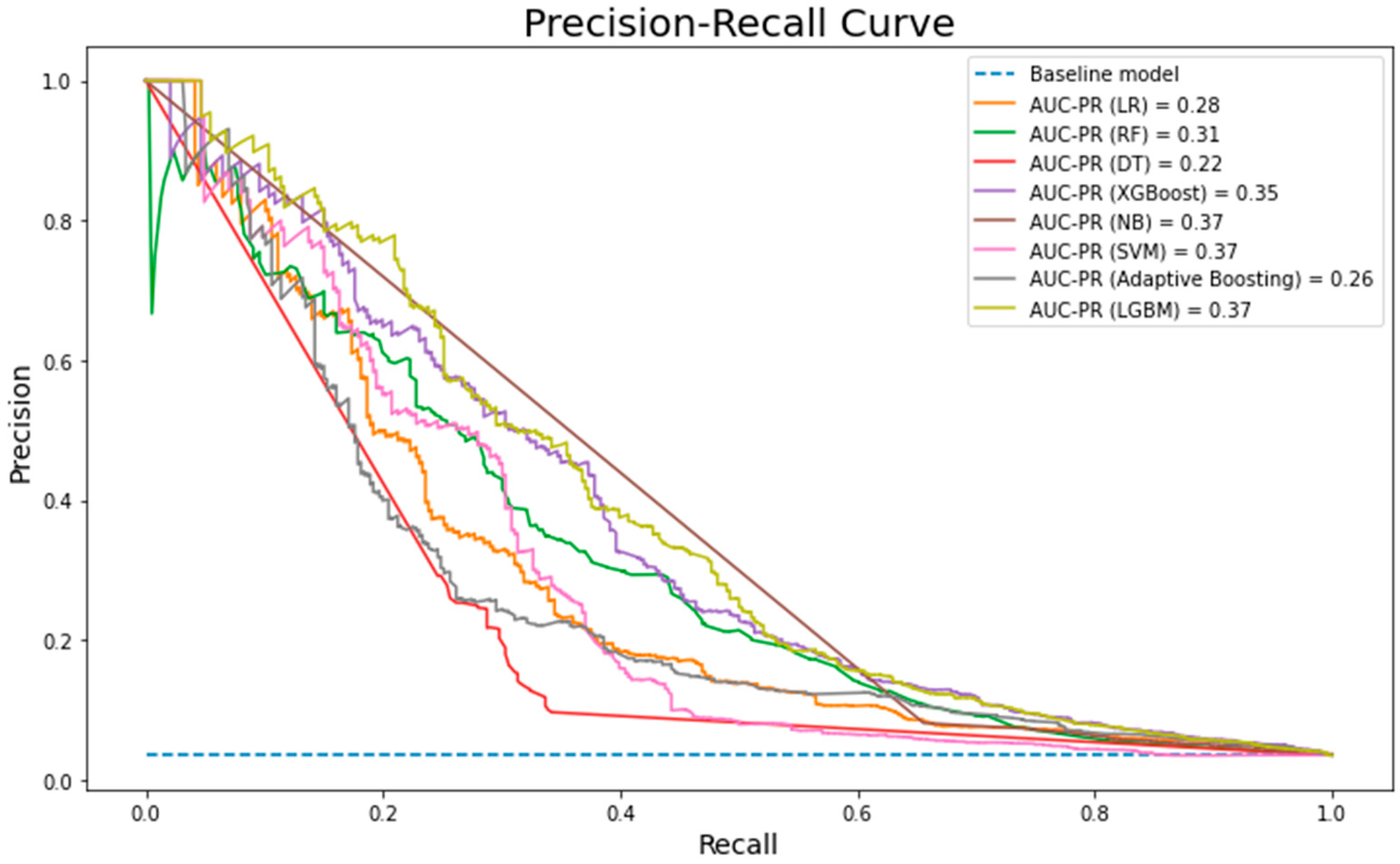
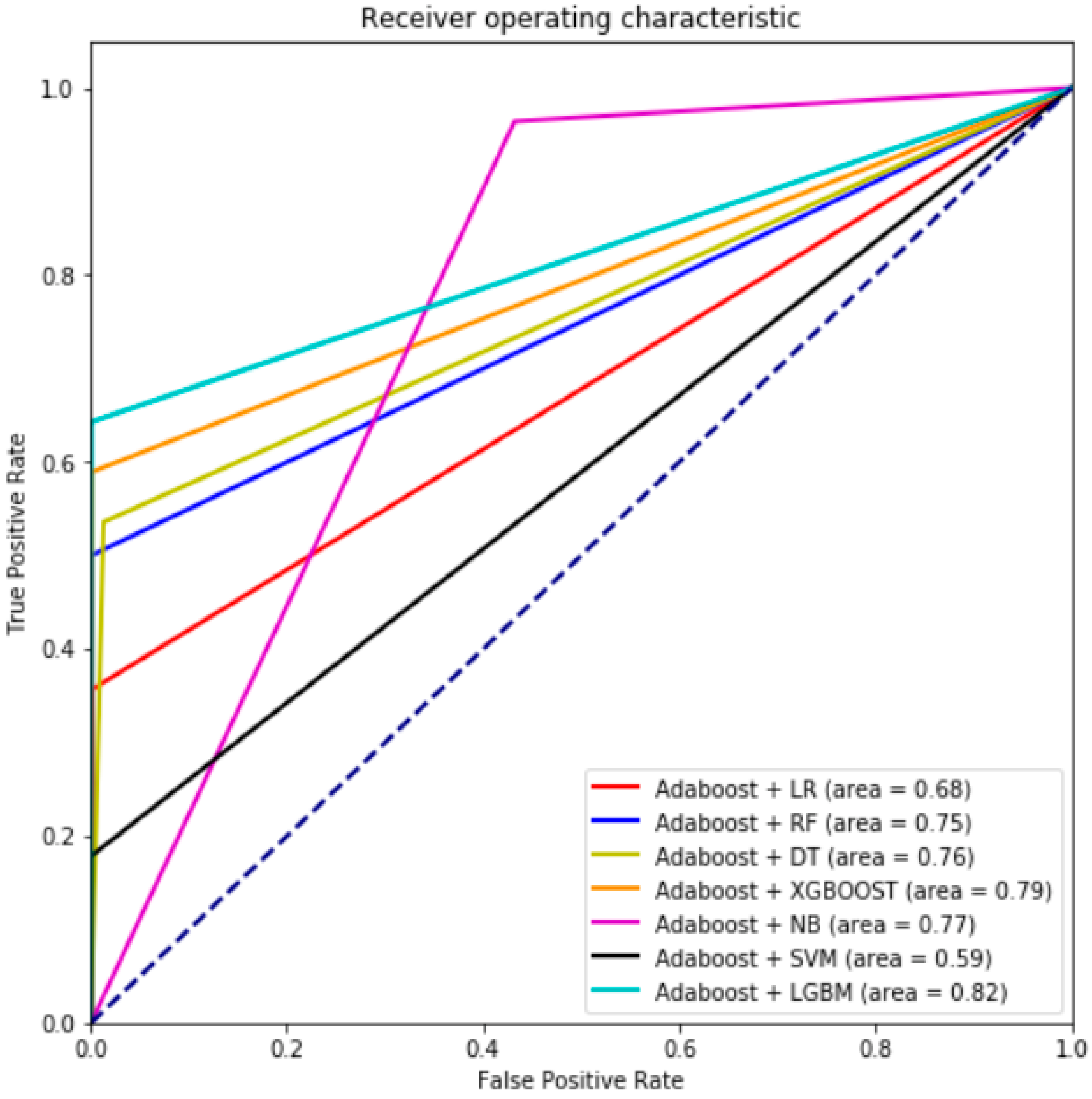
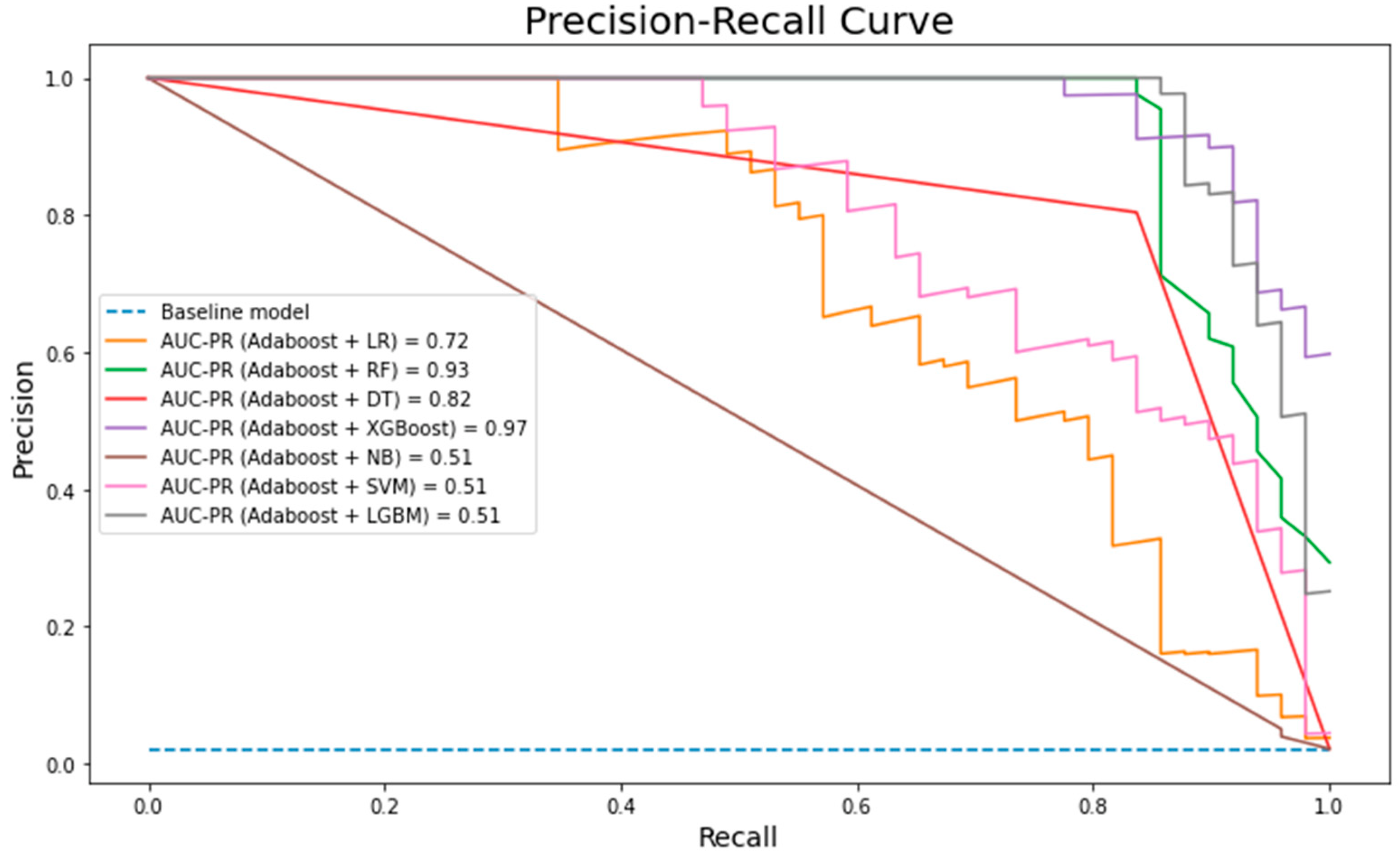
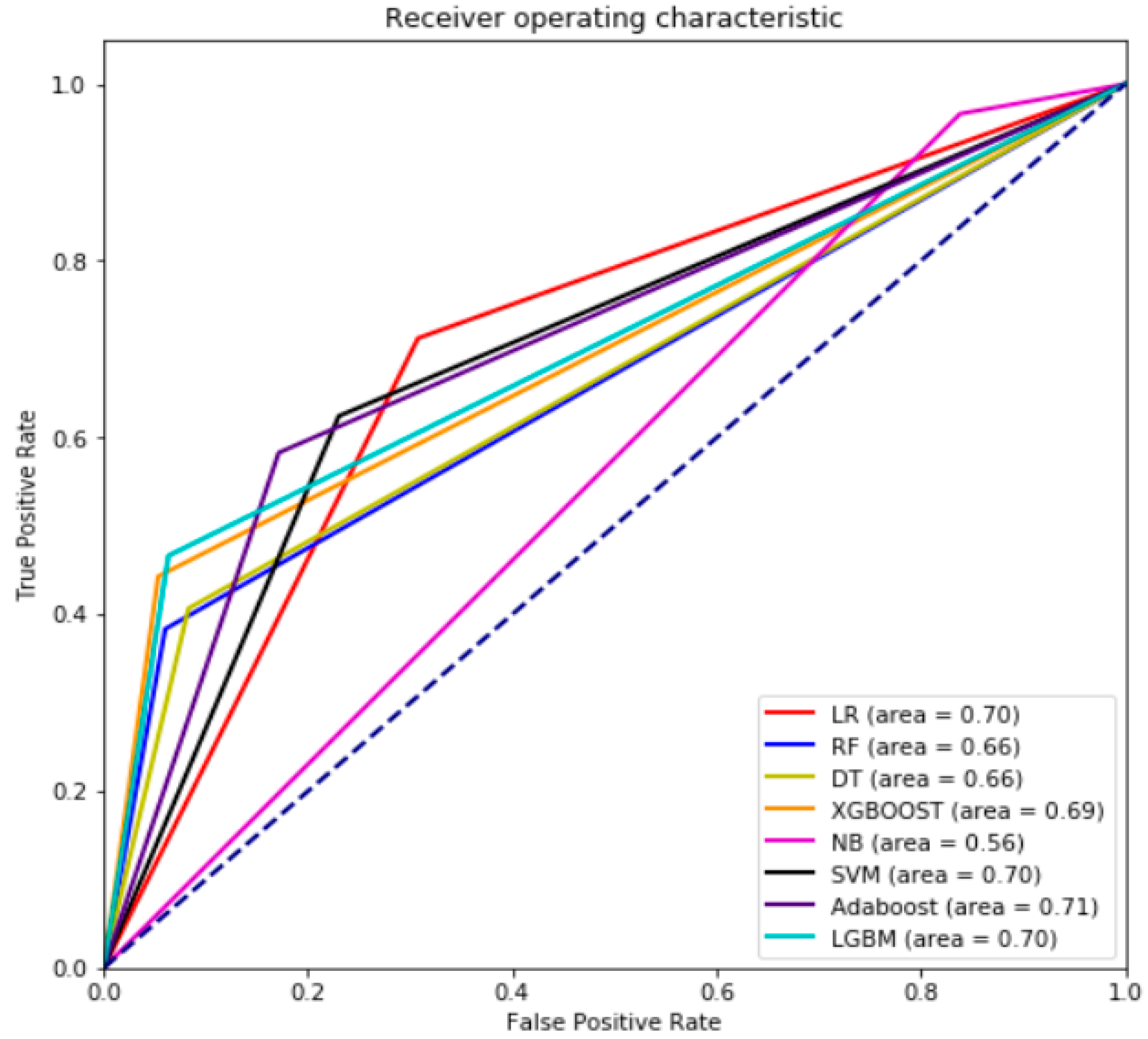
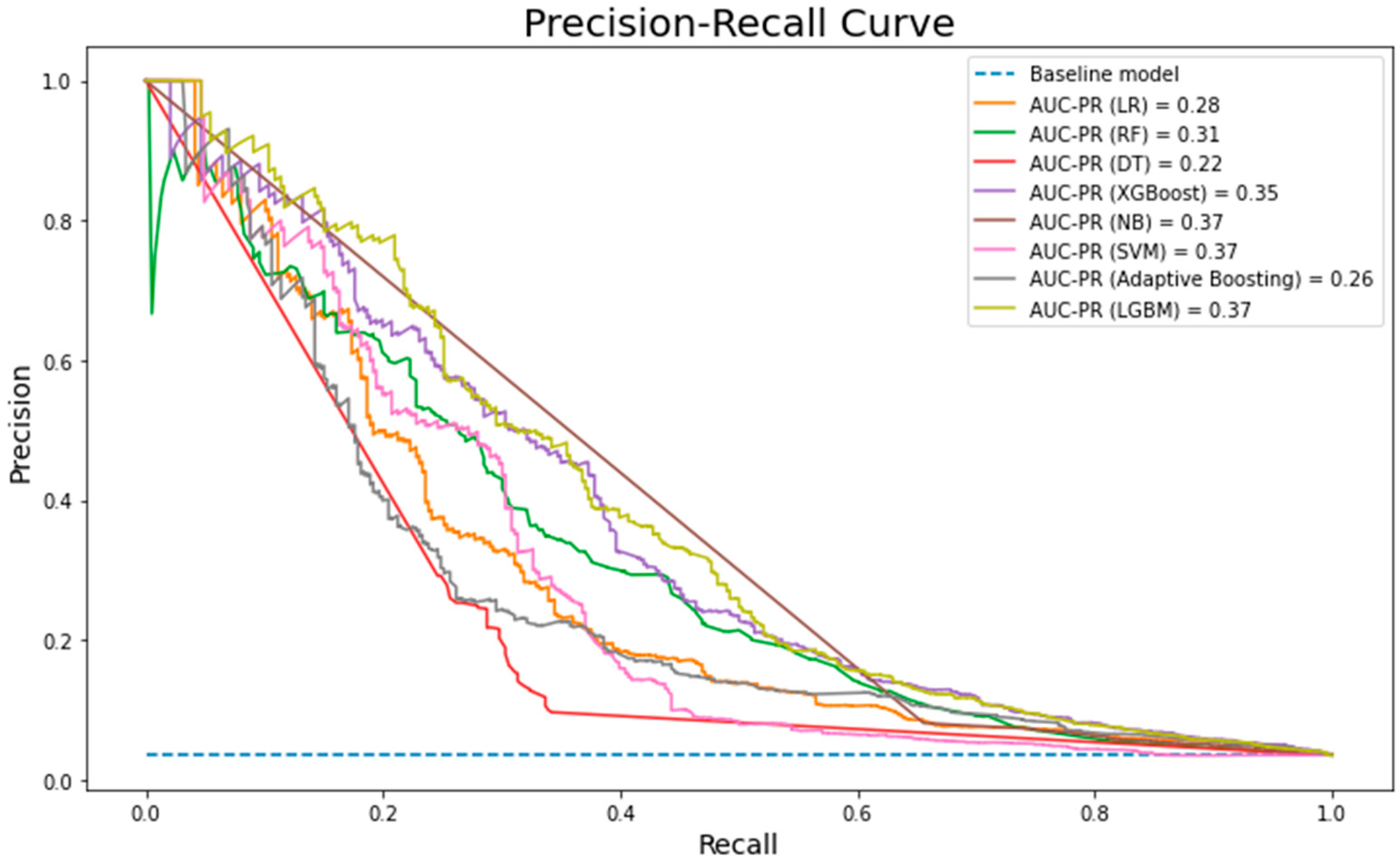
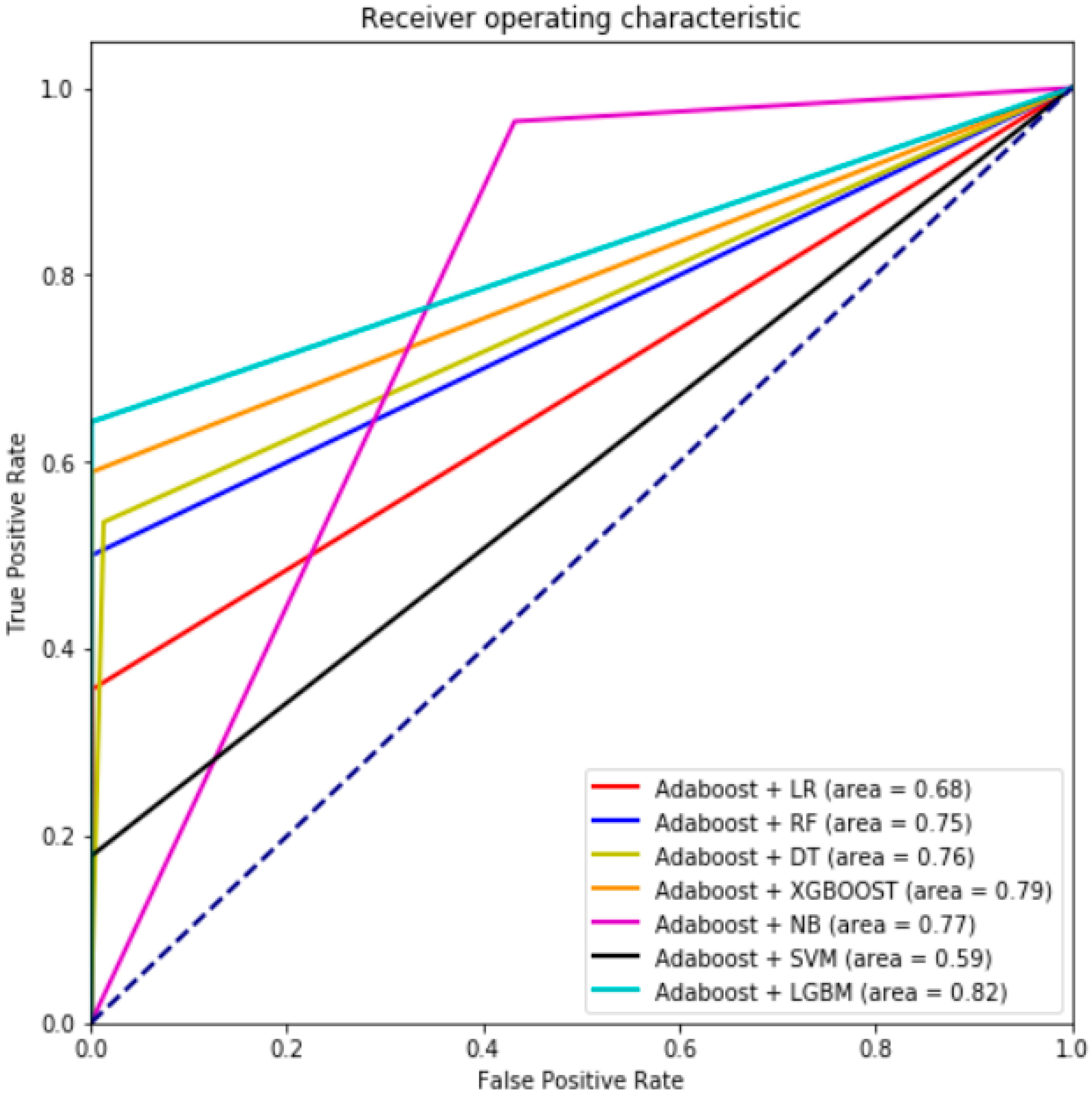
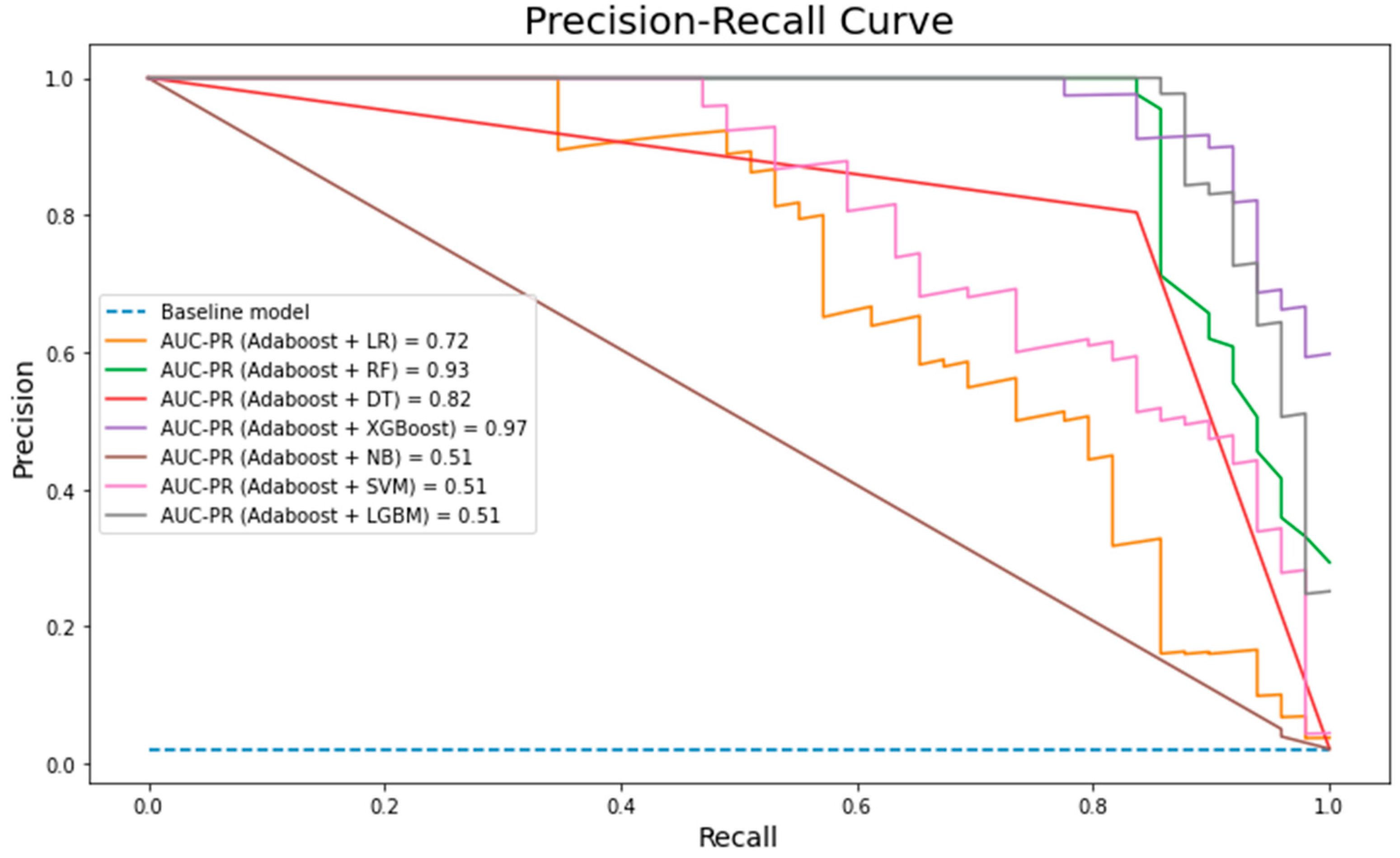
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- PWC. Fighting Fraud: A Never-Ending Battle; PWC: London, UK, 2020. [Google Scholar]
- Garner, B.A. Black’s Law Dictionary, (Black’s Law Dictionary (Standard Edition)), 8th ed.; Thomson West: Toronto, ON, Canada, 2004; p. 1805. [Google Scholar]
- Kültür, Y.; Çağlayan, M.U. Hybrid approaches for detecting credit card fraud. Expert Syst. 2017, 34, 1–13. [Google Scholar] [CrossRef]
- Kurshan, E.; Shen, H. Graph Computing for Financial Crime and Fraud Detection: Trends, Challenges and Outlook. Int. J. Semant. Comput. 2020, 14, 565–589. [Google Scholar] [CrossRef]
- West, J.; Bhattacharya, M. Intelligent Financial Fraud Detection: A Comprehensive Review. Comput. Secur. 2015, 57, 47–66. [Google Scholar] [CrossRef]
- Ethem, A. Introduction to Machine Learning, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Mater, A.C.; Coote, M.L. Deep Learning in Chemistry. J. Chem. Inf. Model. 2019, 59, 2545–2559. [Google Scholar] [CrossRef]
- Hossain, M.A.; Islam, S.M.S.; Quinn, J.M.W.; Huq, F.; Moni, M.A. Machine learning and bioinformatics models to identify gene expression patterns of ovarian cancer associated with disease progression and mortality. J. Biomed. Inform. 2019, 100, 103313. [Google Scholar] [CrossRef]
- Abdelrahman, O.; Keikhosrokiani, P. Assembly Line Anomaly Detection and Root Cause Analysis Using Machine Learning. IEEE Access 2020, 8, 189661–189672. [Google Scholar] [CrossRef]
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S.A.C. Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists. Diagnostics 2020, 10, 1–19. [Google Scholar] [CrossRef]
- Cruz, J.A.; Wishart, D.S. Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2006, 2, 59–77. [Google Scholar] [CrossRef]
- Lalmuanawma, S.; Hussain, J.; Chhakchhuak, L. Applications of machine learning and artificial intelligence for COVID-19 (SARS-CoV-2) pandemic: A review. Chaos Solitons Fractals 2020, 139, 110059. [Google Scholar] [CrossRef]
- Angermueller, C.; Pärnamaa, T.; Parts, L.; Stegle, O. Deep learning for computational biology. Mol. Syst. Biol. 2016, 12, 878. [Google Scholar] [CrossRef]
- Taha, A.A.; Malebary, S.J. An Intelligent Approach to Credit Card Fraud Detection Using an Optimized Light Gradient Boosting Machine. IEEE Access 2020, 8, 25579–25587. [Google Scholar] [CrossRef]
- Khandani, A.E.; Kim, A.J.; Lo, A.W. Consumer credit-risk models via machine-learning algorithms. J. Bank. Financ. 2010, 34, 2767–2787. [Google Scholar] [CrossRef] [Green Version]
- Randhawa, K.; Loo, C.K.; Seera, M.; Lim, C.P.; Nandi, A.K. Credit Card Fraud Detection Using AdaBoost and Majority Voting. IEEE Access 2018, 6, 14277–14284. [Google Scholar] [CrossRef]
- Krivko, M. A hybrid model for plastic card fraud detection systems. Expert Syst. Appl. 2010, 37, 6070–6076. [Google Scholar] [CrossRef]
- Alharbi, A.; Alshammari, M.; Okon, O.D.; Alabrah, A.; Rauf, H.T.; Alyami, H.; Meraj, T. A Novel text2IMG Mechanism of Credit Card Fraud Detection: A Deep Learning Approach. Electronics 2022, 11, 756. [Google Scholar] [CrossRef]
- Behera, T.K.; Panigrahi, S. Credit Card Fraud Detection: A Hybrid Approach Using Fuzzy Clustering & Neural Network. In Proceedings of the 2015 2nd IEEE International Conference on Advances in Computing and Communication Engineering, Dehradun, India, 1–2 May 2015; pp. 494–499. [Google Scholar] [CrossRef]
- Seeja, K.R.; Zareapoor, M. FraudMiner: A novel credit card fraud detection model based on frequent itemset mining. Sci. World J. 2014, 2014, 252797. [Google Scholar] [CrossRef]
- Sarno, R.; Dewandono, R.D.; Ahmad, T.; Naufal, M.F. Hybrid Association Rule Learning and Process Mining for Fraud Detection. IAENG Int. J. Comput. Sci. 2015, 42, 59–72. [Google Scholar]
- Carcillo, F.; Le Borgne, Y.A.; Caelen, O.; Kessaci, Y.; Oblé, F.; Bontempi, G. Combining unsupervised and supervised learning in credit card fraud detection. Inf. Sci. 2019, 557, 317–331. [Google Scholar] [CrossRef]
- Li, S.H.; Yen, D.C.; Lu, W.H.; Wang, C. Identifying the signs of fraudulent accounts using data mining techniques. Comput. Hum. Behav. 2012, 28, 1002–1013. [Google Scholar] [CrossRef] [Green Version]
- Sivanantham, S.; Dhinagar, S.R.; Kawin, P.A.; Amarnath, J. Hybrid Approach Using Machine Learning Techniques in Credit Card Fraud Detection. In Advances in Smart System Technologies; Springer: Singapore, 2021. [Google Scholar]
- IEEE Computational Intelligence Society. IEEE-CIS Fraud Detection Can You Detect Fraud from Customer Transactions? 2019. Available online: https://www.kaggle.com/c/ieee-fraud-detection/overview (accessed on 5 December 2021).
- Aoife, D.; Brian, M.; John, D.K. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Cerda, P.; Varoquaux, G.; Kégl, B. Similarity encoding for learning with dirty categorical variables. Mach. Learn. 2018, 107, 1477–1494. [Google Scholar] [CrossRef] [Green Version]
- Qi, Z.; Zhang, Z. A hybrid cost-sensitive ensemble for heart disease prediction. BMC Med. Inform. Decis. Mak. 2020, 21, 73. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Al Khaldy, M.; Kambhampati, C. Resampling imbalanced class and the effectiveness of feature selection methods for heart failure dataset. Int. Robot. Autom. J. 2018, 4, 37–45. [Google Scholar] [CrossRef] [Green Version]
- Lavanya, D.; Rani, D.K.U. Analysis of Feature Selection with Classification: Breast Cancer Datasets. Indian J. Comput. Sci. Eng. 2011, 2, 756–763. [Google Scholar]
- Zhang, Y.; Wang, Z. Customer Transaction Fraud Detection Using Xgboost Model. In Proceedings of the 2020 International Conference on Computer Engineering and Application, Guangzhou, China, 18–20 March 2020; pp. 554–558. [Google Scholar] [CrossRef]
- Sanz, H.; Valim, C.; Vegas, E.; Oller, J.M.; Reverter, F. SVM-RFE: Selection and visualization of the most relevant features through non-linear kernels. BMC Bioinform. 2018, 19, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Prati, R.C.; Batista, G.E.; Monard, M.-C. Class Imbalances versus Class Overlapping: An Analysis of a Learning System Behavior. In Proceedings of the Mexican International Conference on Artificial Intelligence, Mexico City, Mexico, 26–30 April 2004; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Le, T.; Vo, M.T.; Vo, B.; Lee, M.Y.; Baik, S.W. A Hybrid Approach Using Oversampling Technique and Cost-Sensitive Learning for Bankruptcy Prediction. Complexity 2019, 2019, 8460934. [Google Scholar] [CrossRef] [Green Version]
- Al-Hashedi, K.G.; Magalingam, P. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Tsai, C.F.; Lin, W.C. Feature selection and ensemble learning techniques in one-class classifiers: An empirical study of two-class imbalanced datasets. IEEE Access 2021, 9, 13717–13726. [Google Scholar] [CrossRef]
- Tsai, C.F.; Chen, M.L. Credit rating by hybrid machine learning techniques. Appl. Soft Comput. J. 2010, 10, 374–380. [Google Scholar] [CrossRef]
- Bhattacharyya, S.; Jha, S.; Tharakunnel, K.; Westland, J.C. Data mining for credit card fraud: A comparative study. Decis. Support Syst. 2011, 50, 602–613. [Google Scholar] [CrossRef]
- Vieira, S.; Pinaya, W.H.L.; Mechelli, A. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Harrington, P. Machine Learning in Action; Manning Publications, Co.: Shelter Island, NY, USA, 2012. [Google Scholar]
- Faraji, Z. A Review of Machine Learning Applications for Credit Card Fraud Detection with A Case study. J. Manag. 2022, 5, 49–59. [Google Scholar] [CrossRef]
- Lim, K.S.; Lee, L.H.; Sim, Y.-W. A Review of Machine Learning Algorithms for Fraud Detection in Credit Card Transaction. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2021, 21, 31–40. [Google Scholar]
- Hooda, N.; Bawa, S.; Rana, P.S. Fraudulent Firm Classification: A Case Study of an External Audit. Appl. Artif. Intell. 2018, 32, 48–64. [Google Scholar] [CrossRef]
- Gepp, A.; Kumar, K.; Bhattacharya, S. Lifting the numbers game: Identifying key input variables and a best-performing model to detect financial statement fraud. Account. Financ. 2021, 61, 4601–4638. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Observations for Fraud Cases | Number of Observations for Non-Fraud Cases | |
|---|---|---|
| Before SMOTE-ENN | 1157 | 32,060 |
| After SMOTE-ENN | 28,689 | 27,155 |
| Algorithm | Strength | Limitation |
|---|---|---|
| LR | Simple parametric approach and ease of implementation | Poor classification performance |
| DT | Easy to understand and interpret, not requiring complicated data preparation, provides a strong indicator of which features are most relevant for the classification model | Vulnerable to overfitting and impossibility of performing prediction for numeric labels |
| NB | Robust to noisy and irrelevant data points, computationally efficient and easily understood | The Independence assumption may not hold for some features |
| SVM | High tolerance to noisy features, effective in high dimensional spaces and memory-efficient | Computationally expensive in training and weak interpretability |
| LGBM | High training speed and performance and low memory utilization | Has a high chance of overfitting |
| Adaboost | Ease of use, less parameter tweaking and less susceptible to overfitting | Sensitive to outliers and noisy |
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | 8798 | 1889 |
| Actual Negative | 161 | 225 |
| ROC | Recall (TPR) | Precision | F-Measure | Misclassification Rate | TNR | Type-I Error | Type-II Error | |
|---|---|---|---|---|---|---|---|---|
| state-of-the-Art | ||||||||
| LR | 0.70 | 0.71 | 0.08 | 0.14 | 0.30 | 0.68 | 0.31 | 0.28 |
| RF | 0.66 | 0.38 | 0.19 | 0.25 | 0.07 | 0.93 | 0.06 | 0.59 |
| DT | 0.66 | 0.41 | 0.15 | 0.22 | 0.10 | 0.91 | 0.08 | 0.57 |
| XGBOOST | 0.69 | 0.44 | 0.23 | 0.30 | 0.07 | 0.93 | 0.06 | 0.52 |
| NB | 0.56 | 0.97 | 0.04 | 0.08 | 0.81 | 0.15 | 0.84 | 0.03 |
| SVM | 0.70 | 0.62 | 0.09 | 0.16 | 0.23 | 0.74 | 0.25 | 0.35 |
| Adaboost | 0.71 | 0.58 | 0.11 | 0.18 | 0.17 | 0.82 | 0.17 | 0.41 |
| LGBM | 0.70 | 0.47 | 0.21 | 0.29 | 0.07 | 0.92 | 0.07 | 0.52 |
| Hybrid Models | ||||||||
| Adaboost+LR | 0.67 | 0.36 | 0.83 | 0.50 | 0.004 | 0.999 | 0.0004 | 0.52 |
| Adaboost+RF | 0.74 | 0.50 | 0.97 | 0.66 | 0.003 | 0.999 | 0.0004 | 0.33 |
| Adaboost+DT | 0.76 | 0.54 | 0.51 | 0.52 | 0.006 | 0.990 | 0.0099 | 0.29 |
| Adaboost+XGBOOST | 0.79 | 0.59 | 0.94 | 0.73 | 0.002 | 0.996 | 0.0031 | 0.31 |
| Adaboost+NB | 0.76 | 0.96 | 0.05 | 0.10 | 0.105 | 0.579 | 0.5791 | 0.05 |
| Adaboost+SVM | 0.58 | 0.18 | 0.91 | 0.30 | 0.005 | 1.0 | 0.0000 | 0.66 |
| Adaboost+LGBM | 0.82 | 0.64 | 0.97 | 0.77 | 0.002 | 0.998 | 0.0018 | 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malik, E.F.; Khaw, K.W.; Belaton, B.; Wong, W.P.; Chew, X. Credit Card Fraud Detection Using a New Hybrid Machine Learning Architecture. Mathematics 2022, 10, 1480. https://doi.org/10.3390/math10091480
Malik EF, Khaw KW, Belaton B, Wong WP, Chew X. Credit Card Fraud Detection Using a New Hybrid Machine Learning Architecture. Mathematics. 2022; 10(9):1480. https://doi.org/10.3390/math10091480
Chicago/Turabian StyleMalik, Esraa Faisal, Khai Wah Khaw, Bahari Belaton, Wai Peng Wong, and XinYing Chew. 2022. "Credit Card Fraud Detection Using a New Hybrid Machine Learning Architecture" Mathematics 10, no. 9: 1480. https://doi.org/10.3390/math10091480
APA StyleMalik, E. F., Khaw, K. W., Belaton, B., Wong, W. P., & Chew, X. (2022). Credit Card Fraud Detection Using a New Hybrid Machine Learning Architecture. Mathematics, 10(9), 1480. https://doi.org/10.3390/math10091480