Abstract
In this paper, we present a new class of distributions called the modified power family by adding an extra shape parameter. Some of its structural properties are derived. Three special cases of the new family are considered and estimated using the method of maximum likelihood. The validity of the method of maximum likelihood is illustrated via Monte Carlo simulations. The importance and flexibility of the new family are empirically illustrated, partly due to efficient modeling of several real data. We compare the proposed family with some distributions and special models generated from other classes using classical statistical measures.
MSC:
62E10; 62F10; 60E05; 62P10
1. Introduction
Several papers introduced, in the last three decades, new classes of continuous distributions with desirable properties and motivations from a baseline cumulative distribution function (cdf) . Ref. [1] proposed the Marshall–Olkin-G family, with applications to the exponential and Weibull distributions, using an extra shape parameter to make more flexible the generated distributions. Based on the Marshall–Olkin-G family, several models were investigated: Marshall–Olkin–Weibull [2], Marshall–Olkin–Lomax [3], Marshal–Olkin–Fréchet [4], Marshall– Olkin Burr XII [5] and modified-power-function [6] distributions, among others.
Another method to generate a new cdf [7] is the beta-G family by composing the cdf of the beta distribution with , i.e., , where is the incomplete beta function ratio. Several articles were published on sub-models of the beta-G family such as the beta-exponential [8], beta-generalized-exponential [9] and beta-Dagum [10], among several others.
This composition procedure was extended to a function of (), instead of , in [11,12,13,14], to generate the gamma-G, Kumaraswamy-G, gamma-G and log-gamma-G (I and II). For more details about composition of cdfs, see, for example, [15,16,17].
Recently, Refs. [18,19] followed the same proposal by [1], and starting with a monotone increasing function of , defined the alpha-power-G classes with cdfs including one and two extra parameters, respectively, given by
In this paper, we present a new family with one extra parameter based on the parent cdf . Our aim is to show its utility to achieve adequate flexibility to real data in many fields. The new family is motivated by the ability to fit real data. The cdf and probability density function (pdf) of the new family have simple expressions. The density shapes can be decreasing or unimodal (right-skewed or symmetrical). The hazard rate function (hrf) exhibits monotone, non-monotone (bathtub and upside-down bathtub) or decreasing–increasing–decreasing shapes.
The rest of the paper is structured as follows. Section 2 defines a new one-parameter family, provides some of its properties and discusses the estimation method. Three sub-models are addressed in Section 3. Section 4 examines the efficiency of the estimators via Monte Carlo simulations, and performs real applications of these sub-models. Finally, Section 5 concludes the paper.
2. Materials and Methods
2.1. The New Family
Definition 1.
For every continuous cdf , the cdf of the modified power (MPo) family is defined by the monotonic increasing cdf (for )
It is clear that and . For , .
The pdf corresponding to (1) is
where is the baseline density corresponding to .
Proposition 1.
Equation (2) is a weighted function of the baseline density , where
is the weight. Note that is increasing for , and decreasing for . Equation (2) leads to
For the parent random variable (rv) by integrating both sides of (3) gives .
These weights play an important role in distribution theory [20]. The weighted distributions are very important, because they consider the method of ascertainment by adjusting the probabilities of actual occurrence of events. Ref. [21] introduced the concept of a weighted distribution as a method of adjustment applicable to many situations. We may arrive at the wrong conclusions, while failing to make such an adjustment.
Many authors have employed weighted distributions for different purposes, see [22,23]. They occur frequently in reliability, meta analysis and analysis of intervention data, biomedicine and several other areas, for the improvement of proper statistical models.
We denote the hrfs corresponding to F and G by and , respectively. From Equation (3), the following results compare some measures of the weighted rv with those of the unweighted [24]:
- (i)
- If is monotone increasing and then for all x.
- (ii)
- If is monotone decreasing, and then for all x.
- (iii)
- if .
- (iv)
- if .
Properties (i) and (ii) are illustrated in Figure 1 for the exponential baseline distribution. For two monotone increasing weights and and two monotone decreasing weights and .
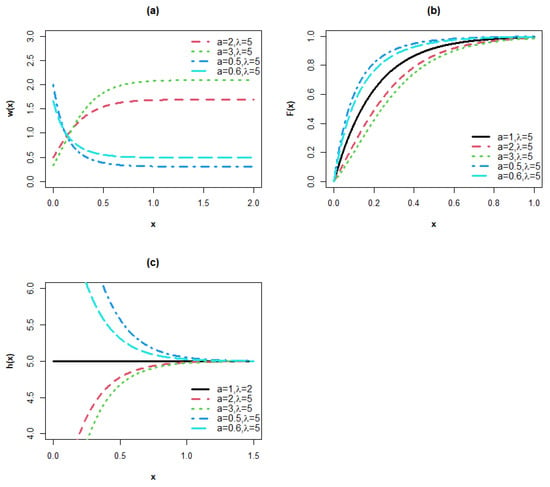
Figure 1.
Plots of the (a) weight, (b) cdf and (c) hrf for the MPoE model.
Several others interesting connections between measures of X and T in the context of reliability and life testing were addressed by [22].
The cdf of the “exponentiated-G” (exp-G) class is simply given by , where is the baseline cdf and is a power parameter. So, the pdf of the exp-G class is , where is the parent pdf. Twenty eight different exp-G models were reported in Table 1 of [16] with a complete and accurate bibliography until this date.
Proposition 2.
The density of X is an infinite linear combination of exponentiated densities with weights
Proof.
Using the power series for , Equation (1) reduces to
and the density of X can be written as
where is the exp-G density with power . □
Hence, based on the linear representation (4), some properties of the new family follow from those exp-G properties reported in several papers; see Table 1 of [16]. Henceforth, denotes a rv with density .
2.2. Moments
If X has density (2), the rth ordinary moment of X (for ) can be found from (4) and the moments of the exp-G distribution as
The first incomplete moment is useful for determining the mean deviations from any location of X, and the Bonferroni and Lorenz curves.
2.3. Generating Function
The generating function (gf) of X can be found from (4)
where is the gf of Alternatively, the gf of X can be written as
By expanding in power series gives
2.4. Quantiles
There is no explicit form for the quantile function (qf) of X, but it can be approximated using a one-dimensional root-finding algorithm from (1) such as Newton’s method in , where . We can write the iterative process as
and starting with a suitable guess and keep repeating the process (for ) until terminate at for a specified accuracy level. So, we obtain . Further, the solution of z in is given by (Using the Mathematica software)
where is the principal branch of the Lambert W function, which has a known power series
So, the qf of X follows from the baseline qf as
2.5. Mode
The mode m of the MPo family can be found by maximizing the log-pdf from (2). At , the derivative of with respect to x vanishes. We can obtain m by solving the equation
which has no explicit solution for m. So, the mode of the MPo family does not have a closed form. Given and , direct maximization of using a numerical optimization algorithm or one-dimensional root-finding algorithm of (5) can be used to approximate the mode.
2.6. Hazard Rate
The hrf of X is
Proposition 3.
It is straightforward to show that:
2.7. Estimation
Let be n independent realizations from the MPo model, , where is the parameter vector of the parent distribution. The log-likelihood function for is
By differentiating with respect to the parameters, we obtain the score components:
and
Since we can not solve these equations analytically to find the maximum likelihood estimates (MLEs) of , these estimates can be determined by numerical algorithms, such as the BFGS algorithm. This algorithm with analytical derivatives can be used for maximizing using the R software library AdequacyModel [25], which provides a general optimization method for maximizing or minimizing an arbitrary objective function.
3. Sub-Models
3.1. Modified Power Exponential (MPoE)
For the exponential parent with rate , the cdf of the MPoE model (for and ) is
Plots of the pdf, cdf and hrf of the MPoE are displayed in Figure 2.
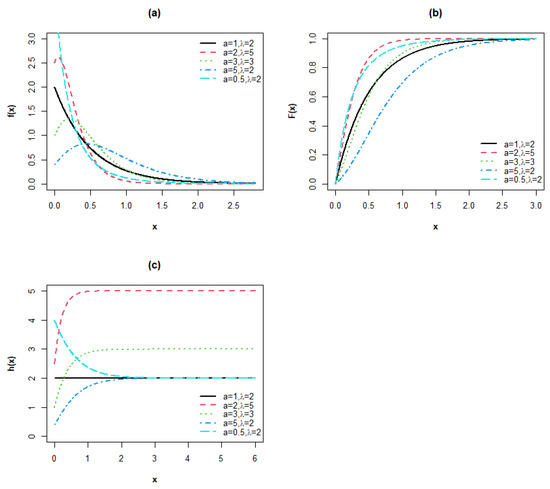
Figure 2.
Plots of the (a) pdf, (b) cdf and (c) hrf for the MPoE model.
3.2. Modified Power Weibull (MPoW)
For the Weibull with shape and scale , the cdf of the MPoW model (for and ) is
Plots of the pdf, cdf and hrf of the MPoW are reported in Figure 3.
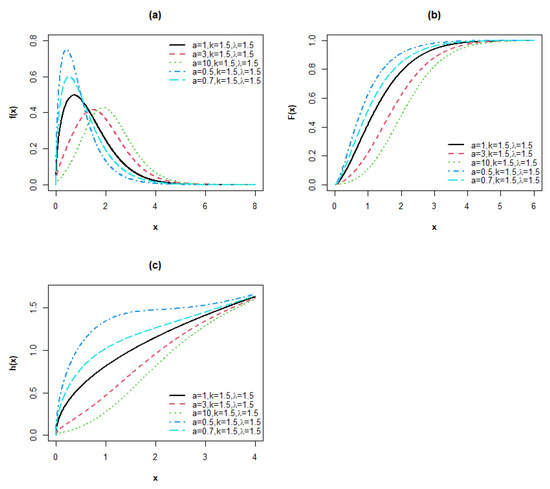
Figure 3.
Plots of the (a) pdf, (b) cdf and (c) hrf for the MPoW model.
3.3. Modified Power Fréchet (MPoF)
For the Fréchet with shape and scale , the cdf of the MPoF model (for and ) is
Plots of the pdf, cdf and hrf of the MPoF are displayed in Figure 4.
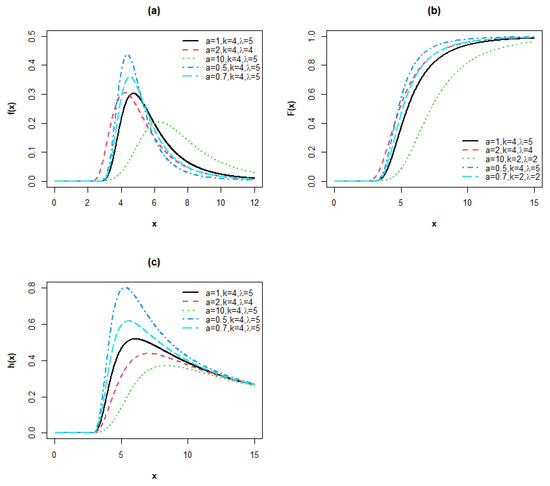
Figure 4.
Plots of the (a) pdf, (b) cdf and (c) hrf for the MPoF model.
4. Applications
4.1. Simulation Results
A simulation was conducted to examine the accuracy of the MLEs for the MPoE and MPoW distributions. Their averages, absolute biases (ABs) and mean square errors (MSEs) are calculated from 1000 samples of sizes n = 50, 100, 150 and 250 with different values of parameters. Table 1 and Table 2 provide the results. The MLEs and ABs in Table 1 and Table 2 indicate that the ML method provides parameter estimates, which converge to the true parameter values and the MSEs decrease when n increases. These results reflect the appropriateness of the ML method to provide good estimates of the parameters of the MPo distribution.

Table 1.
Simulation results for the MPoE distribution.
Table 2.
Simulation results for the MPoW distribution.
4.2. Real Data
4.2.1. Breast Cancer Data
We fit the sub-models defined in Section 3 to the data sets available in the UC Irvine Machine Learning Repository at the Diagnostic Wisconsin Breast Cancer Data [26]. The data contain 30 features (V3, V4, ..., V32). The MPoE model is adopted for fitting to V19, V20, V28 and V29. The MPoW model is used for fitting to V7, V11, V14, V18, V24 and V27. The MPoF model is chosen for fitting to V3, V5, V13 and V21.
Table 3, Table 4 and Table 5 report the MLEs and 95% confidence intervals (CIs) of the parameters. To test whether the data sets are drawn from these sub-models, Cramér–von Mises (CvM) and Kolmogorov–Smirnov (KS) statistics and their p-values are given in Table 6, Table 7 and Table 8. These findings prove that the hypothesis that the data come from the MPo distribution (with the corresponding estimates given in Table 3, Table 4 and Table 5) can not be rejected and then the three sub-models are good choices for modeling these data.
Table 3.
MLEs and 95% CIs of the MPoE parameters.
Table 4.
MLEs and 95% CIs of the MPoW parameters.
Table 5.
MLEs and 95% CIs of the MPoF parameters.
Table 6.
Kolmogorov–Smirnov and Cramér–von Mises tests for the MPoE model.
Table 7.
Kolmogorov–Smirnov and Cramér–von Mises tests for the MPoW model.
Table 8.
Kolmogorov–Smirnov and Cramér–von Mises tests for the MPoF model.
To illustrate the adequacy of the fitted distributions, Figure 5, Figure 6 and Figure 7 compare the fitted MPoE, MPoW and MPoF models with the empirical distribution of the data, respectively, by giving: (a) the histogram, empirical and estimated densities, (b) empirical and estimated cdfs, (c) the P-P plot, and (d) the Q-Q plot. From Figure 5, Figure 6 and Figure 7, there is a clear evidence of the closeness of the estimated MPo pdfs and cdfs to the empirical pdfs and cdfs, and the P-P and Q-Q plots are close to the first bisector. These perceptions support the goodness of the MPo model for fitting these data.
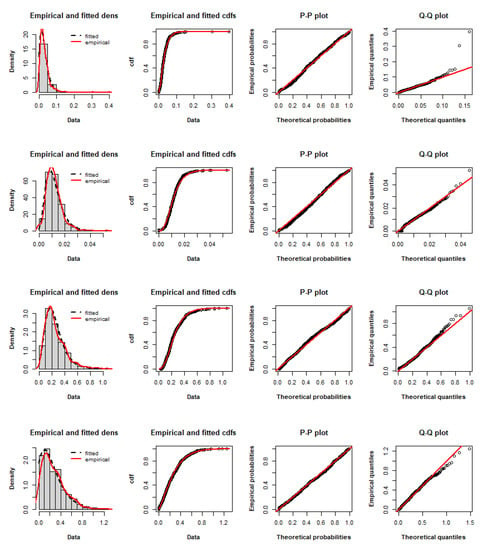
Figure 5.
Empirical densities, empirical cdfs, P-P plots and Q-Q plots of the fitted MPoE distribution to the V19, V20, V28 and V29 sets.
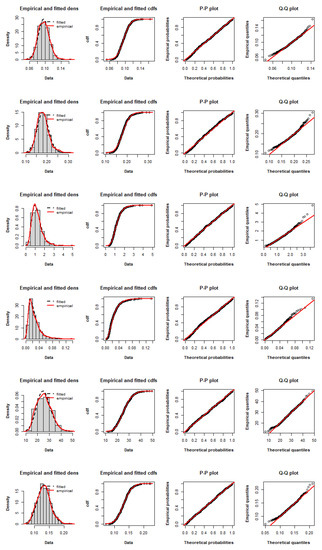
Figure 6.
Empirical densities, empirical cdfs, P-P plots and Q-Q plots of the fitted MPoW distribution to the V7, V11, V14, V18, V24 and V27 sets.
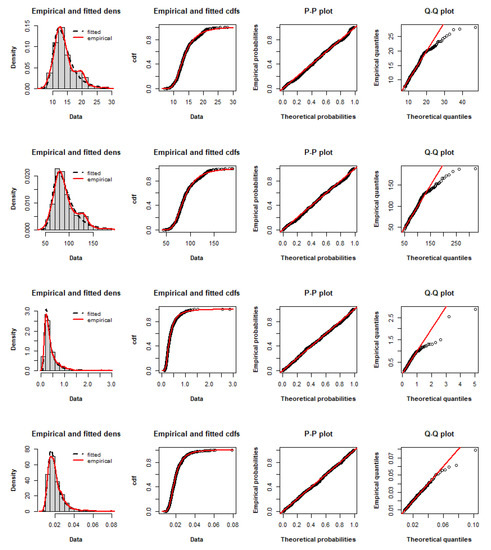
Figure 7.
Empirical densities, empirical cdfs, P-P plots and Q-Q plots of the fitted MPoF distribution to the V3, V5, V13 and V21 sets.
4.2.2. Coal-Mining Data
The data set represents the time intervals in days between explosions in mines, involving more than 10 men killed in Great Britain, for the period 1875–1951, published by [27]. The data are:
1, 4, 4, 7, 11, 13, 15, 15, 17, 18, 19, 19, 20, 20, 22, 23, 28, 29, 31, 32, 36, 37, 47, 48, 49, 50, 54, 54, 55, 59, 59, 61, 61, 66, 72, 72, 75, 78, 78, 81, 93, 96, 99, 108, 113, 114, 120, 120, 120, 123, 124, 129, 131, 137, 145, 151, 156, 171, 176, 182, 188, 189, 195, 203, 208, 215, 217, 217, 217, 224, 228, 233, 255, 271, 275, 275, 275, 286, 291, 312, 312, 312, 315, 326, 326, 329, 330, 336, 338, 345, 348, 354, 361, 364, 369, 378, 390, 457, 467, 498, 517, 566, 644, 745, 871, 1312, 1357, 1613, 1630.
We fit the MPoE distribution to these data and compare with the exponential (Exp) distribution with rate parameter , the Weibull distribution with shape parameter a and scale parameter , the Marshall–Olkin exponential (MOE) distribution with parameters a and as defined by [1], the exponentiated exponential (Exp-E) distribution with parameters a and as given by [28], the gamma exponential I (GE-I) distribution as given by [11] and the log-expo exponential (LET-E) distribution as defined by [29].
Table 9 provides the MLEs and 95% CIs of the model parameters. Table 10 reports the adequacy of the models through a combination of several statistics (AIC, CAIC, BIC, HQIC, minus maximized log-likelihood function (), Kolmogorov–Smirnov test statistic (KS) and its p-values), which measure the relative quality of fit of these models to a data set.
Table 9.
Estimation results for coal mining data set.
Table 10.
Adequacy measures for coal mining data set.
Based on adequacy statistics introduced in Table 10, the MPoE model fits the data sets with minimum AIC, CAIC, BIC, HQIC, log-likelihood and maximum p-value among the other distributions. Thus, it can be a a good choice for modeling these data. This result is illustrated graphically in Figure 8 by comparing the empirical distribution of the data with the fitted MPoE distribution, respectively, by displaying (a) the histogram and fitted MPoE distribution, (b) the fitted MPoE survival function and the empirical survival (c) the P-P plot and (d) the Q-Q plot.
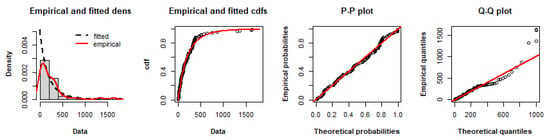
Figure 8.
Empirical density, empirical cdf, P-P plot and Q-Q plot of the fitted MPoE distribution to coal-mining data.
5. Conclusions
We studied a new family of continuous distributions with a single extra parameter and showed its usefulness in practice by means of several applications. The new model is a mixture distribution, which can arise in a wide variety of fields. The new model is discussed from the weighted distributions’ viewpoint. Connections between measures of the new family and the parent distribution are addressed. The extra parameter boosted the flexibility of the family to cope with several types of data sets. We compare the proposed family with some distributions and special models generated from other classes using classical statistical measures. The new family can generate models that are powerful to represent and predict real-world data.
Author Contributions
Conceptualization, M.H. and G.M.C.; methodology, M.H. and G.M.C.; software, M.H.; investigation, M.H. and G.M.C.; writing—original draft preparation, M.H.; writing—review and editing, G.M.C. and M.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available data sets were analyzed in this study. These data can be found at (UCI Machine Learning Repository: (Accessed on 12 September 2021) http://archive.ics.uci.edu/ml).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AB | absolute bias |
| cdf | cumulative distribution function |
| CI | confidence interval |
| CvM | Cramér–von Mises |
| hrf | hazard rate function |
| KS | Kolmogorov–Smirnov |
| MLE | maximum likelihood estimate |
| P-P | probability vs. probability |
| probability distribution function | |
| Q-Q | quantile vs. quantile |
References
- Marshall, A.W.; Olkin, I. A New Method for Adding a Parameter to a Family of Distributions with Application to the Exponential and Weibull Families. Biometrika 1997, 84, 641–652. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Hussaini, E.K.; Al-Jarallah, R.A. Marshall-Olkin Extended Weibull Distribution and Its Application to Censored Data. J. Appl. Stat. 2005, 32, 1025–1034. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Awadh, F.A.; Alkhalfan, L.A. Marshall-Olkin Extended Lomax Distribution and Its Application to Censored Data. Commun. Stat. Theory Methods 2007, 36, 1855–1866. [Google Scholar] [CrossRef]
- Krishna, E.; Jose, K.K.; Alice, T.; Ristic, M.M. Marshall-Olkin Frechet Distribution. Commun. Stat. Theory Methods 2013, 42, 4091–4107. [Google Scholar] [CrossRef]
- Al-Saiari, A.Y.; Baharith, L.A.; Mousa, S.A. Marshall-Olkin Extended Burr Type XII Distribution. Int. J. Stat. Probab. 2014, 3, 78–84. [Google Scholar] [CrossRef] [Green Version]
- Okorie, I.E.; Akpanta, A.C.; Ohakwe, J.; Chikezie, D.C. The modified Power function distribution. Cogent Math. 2017, 4, 1319592. [Google Scholar] [CrossRef]
- Eugene, N.; Lee, C.; Famoye, F. Beta-Normal Distribution and Its Applications. Commun. Stat.-Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. The Beta Exponential Distribution. Reliab. Eng. Syst. Saf. 2006, 91, 689–697. [Google Scholar] [CrossRef]
- Barreto-Souza, W.; Santos, A.H.S.; Cordeiro, G.M. The Beta Generalized Exponential Distribution. J. Stat. Comput. Simul. 2010, 80, 159–172. [Google Scholar] [CrossRef] [Green Version]
- Domma, F.; Condino, F. The Beta-Dagum Distribution: Definition and Properties. Commun. Stat. Theory Methods 2013, 42, 4070–4090. [Google Scholar] [CrossRef]
- Zografos, K.; Balakrishnan, N. On Families of Beta- and Generalized Gamma-Generated Distributions and Associated Inference. Stat. Methodol. 2009, 6, 344–362. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; de Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 2011, 81, 883–898. [Google Scholar] [CrossRef]
- Ristić, M.M.; Balakrishnan, N. The Gamma Exponentiated Exponential Distribution. J. Stat. Comput. Simul. 2012, 82, 1191–1206. [Google Scholar] [CrossRef]
- Amini, M.; MirMostafaee, S.; Ahmadi, J. Log-Gamma-Generated Families of Distributions. Stat. A J. Theor. Appl. Stat. 2013, 48, 913–932. [Google Scholar] [CrossRef]
- AL-Hussani, E.K. Composition of Cumulative Distribution Functions. J. Stat. Thoery Appl. 2012, 11, 323–336. [Google Scholar]
- Tahir, M.H.; Nadarajah, S. Parameter induction in continuous univariate distributions: Well-established G families. An. Acad. Bras. Ciênc 2015, 87, 539–568. [Google Scholar] [CrossRef] [PubMed]
- Barakat, H.M.; Khaled, O.M. Toward the establishment of a family of distributions that may fit any dataset. Commun. Stat. -Simul. Comput. 2017, 46, 6129–6143. [Google Scholar] [CrossRef]
- Mahdavi, A.; Kundu, D. A New Method for Generating Distributions with an Application to Exponential Distribution. Commun. Stat.-Theory Methods 2017, 46, 6543–6557. [Google Scholar] [CrossRef]
- Hussein, M.; Elsayed, H.; Cordeiro, G.M. A New Family of Continuous Distributions: Properties and Estimation. Symmetry 2022, 14, 276. [Google Scholar] [CrossRef]
- Patil, G.P. Weighted Distributions. In Wiley StatsRef: Statistics Reference Online; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]
- Rao, C.R. On Discrete Distributions Arising out of Methods of Ascertainment. Sankhyā Indian J. Stat. 1965, 27, 311–324. [Google Scholar]
- Gupta, R.C.; Kirmani, S.N.U.A. The role of weighted distributions in stochastic modeling. Commun. Stat.-Theory Methods 1990, 19, 3147–3162. [Google Scholar] [CrossRef]
- Saghir, A.; Hamedani, G.G.; Tazeem, S.; Khadim, A. Weighted Distributions: A Brief Review, Perspective and Characterizations. Int. J. Stat. Probab. 2017, 6, 109–133. [Google Scholar] [CrossRef] [Green Version]
- Jain, K.; Singh, H.; Bagai, I. Relations for reliability measures of weighted distributions. Commun. Stat.-Theory Methods 1987, 18, 4393–4412. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- William, H.; Wolberg, W.; Street, N.; Olvi, L. Mangasarian UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 12 September 2021).
- Maguire, B.A.; Pearson, E.S.; Wynn, A.H.A. The Time Intervals Between Industrial Accidents. Biometrika 1952, 39, 168–180. [Google Scholar] [CrossRef]
- Gupta, R.C.; Gupta, P.L.; Gupta, R.D. Modeling Failure Time Data by Lehman Alternatives. Commun. Stat.-Theory Methods 1998, 27, 887–904. [Google Scholar] [CrossRef]
- Aslam, M.; Ley, C.; Hussain, Z.; Shah, S.F.; Asghar, Z. A new generator for proposing flexible lifetime distributions and its properties. PLoS ONE 2020, 15, e0231908. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).