
A Study on Computational Algorithms in the Estimation of Parameters for a Class of Beta Regression Models




Abstract
1. Introduction
2. Methodology
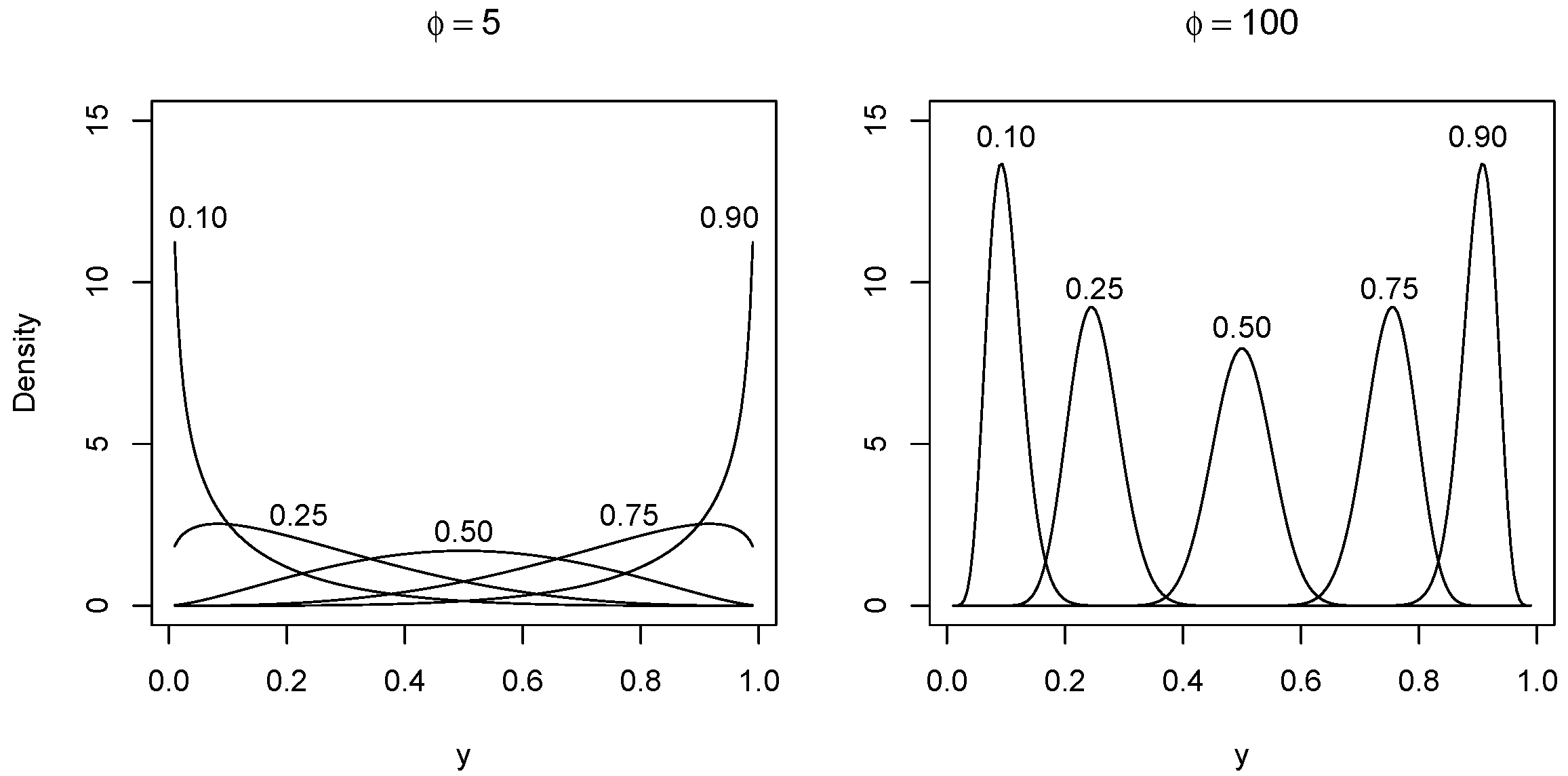
2.1. Beta Models
2.2. Optimization Algorithms
- Genetic algorithm: This is a heuristic inspired by the basic principle of biological evolution and natural selection, simulating evolution so that the fittest individuals survive, imitating its mechanisms such as the processes of selection, crossing, and mutation. The ga function that implements this algorithm is available in an R package named GA [44].
- Differential evolutionary algorithm: This method is similar to the genetic algorithm indicated to find the global optimum of real-valued functions with real-valued parameters as well [45]. Such an algorithm does not need the function to be optimized that is continuous or differentiable and is available by the DEoptim command of an R package named DEoptim [46].
- Self-adapted evolutionary algorithm: This method proposed in [47] is a strategy of self-adaptation of the covariance matrix that is implemented in the cma_es function of the cmaes package of R. This is also an evolutionary method, which uses a covariance matrix approximation to be more efficient in the generation of next generations.
- Simulated annealing algorithm: This is a metaheuristic based on the thermodynamic annealing process that performs a probabilistic local search replacing the current solution with a solution in its vicinity, obtaining good solutions regardless of the chosen starting point. The GenSA function is available in an R package named GenSA [48]. A general strategy to improve the simulated annealing (SANN) algorithm is to inject noise via the Markov chain Monte Carlo algorithms (noise-boosted) to sample high probability regions of the search space and to accept solutions that increase the search breadth [49,50,51]. Another approach is based on hybridized search gradient methods or genetic algorithms for cases of difficulties in the convergence with SANN [52,53].
- Controlled random search algorithm: This is a direct search heuristic [54] that tries to balance the fulfillment of constraints and convergence by storing possible trial points by the nloptr_crs function. Such a function has implemented this algorithm and is available in an R package named nloptr [55].
- DIRECT algorithm: This is a deterministic method based on the division of the search space into increasingly smaller hyperrectangles and was proposed in [56]. The nloptr_d function has implemented such an algorithm and is available in the nloptr package of R.
- DIRECT_L algorithm: This is a variation of DIRECT containing certain randomness and was proposed in [57]. The nloptr_d_l function is available in the nloptr package.
- Evolutionary algorithm: A common practice in evolutionary methods is to apply a penalty function to bias the search for viable solutions. This method is a strategy improved by stochastic ranking that proposes a way to eliminate subjectivity in the configuration of penalty parameters and was proposed in [58]. The nloptr_i function implements this algorithm and is available in the nloptr package of R.
- Memetic algorithm: This technique does a search locally combining the evolutionary method with a local search algorithm. The alschains function has implemented this algorithm and is available in the malschains package of R [59].
- Particle swarm algorithm: This is a heuristic that considers the movement of a swarm of particles through the search space, using formulas for position and velocity that depend on the state of other particles. The PSopt function that implements this algorithm is available in an R package named NMOF [60,61,62,63].
- Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm: This is a quasi-Newton optimization method that applies analytical gradients for parameter estimation and uses as initial guesses values obtained through an auxiliary linear regression of the transformed response. The BFGS algorithm is employed in the optim function of the betareg package [16].
3. Results and Discussion
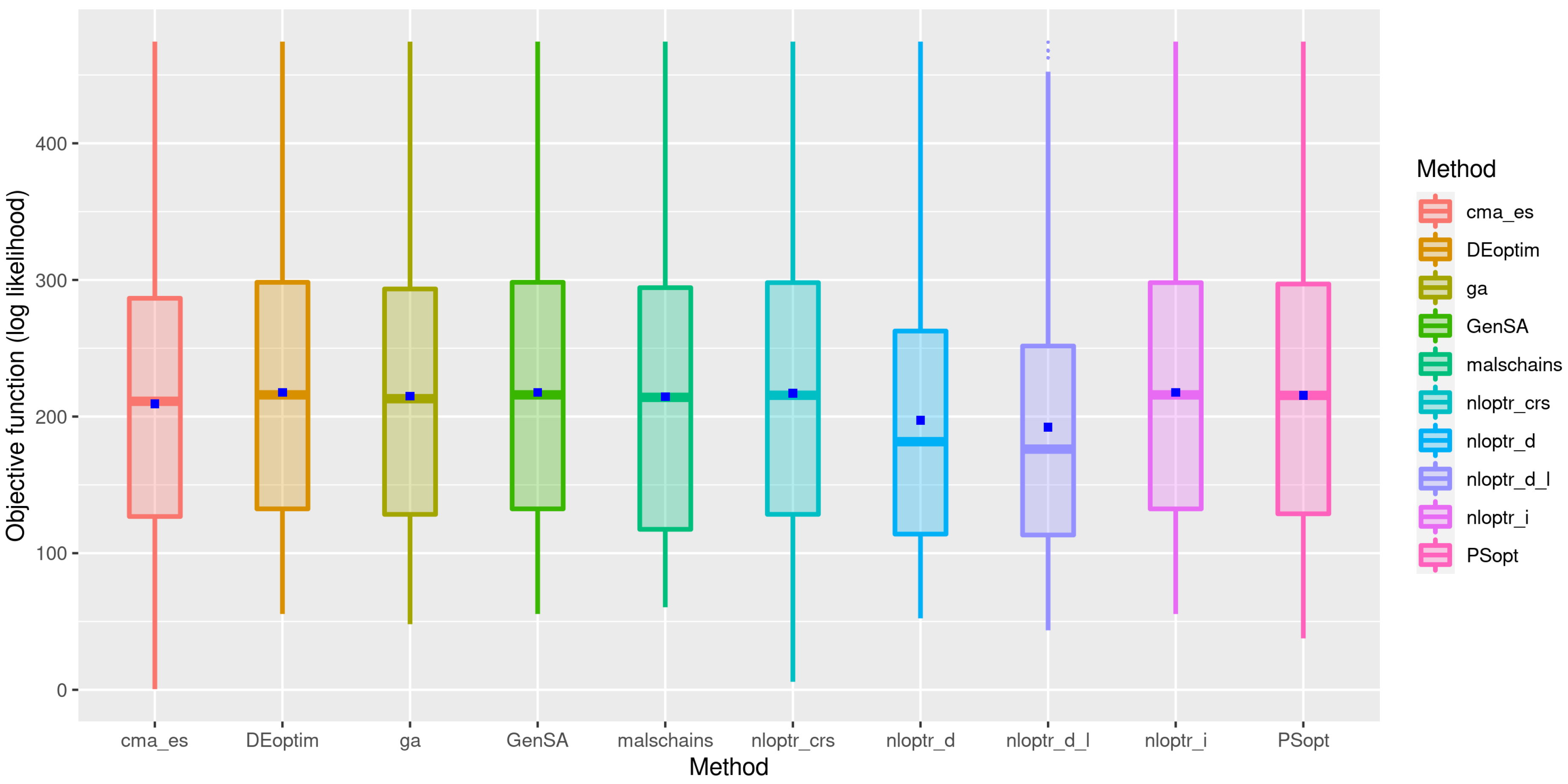
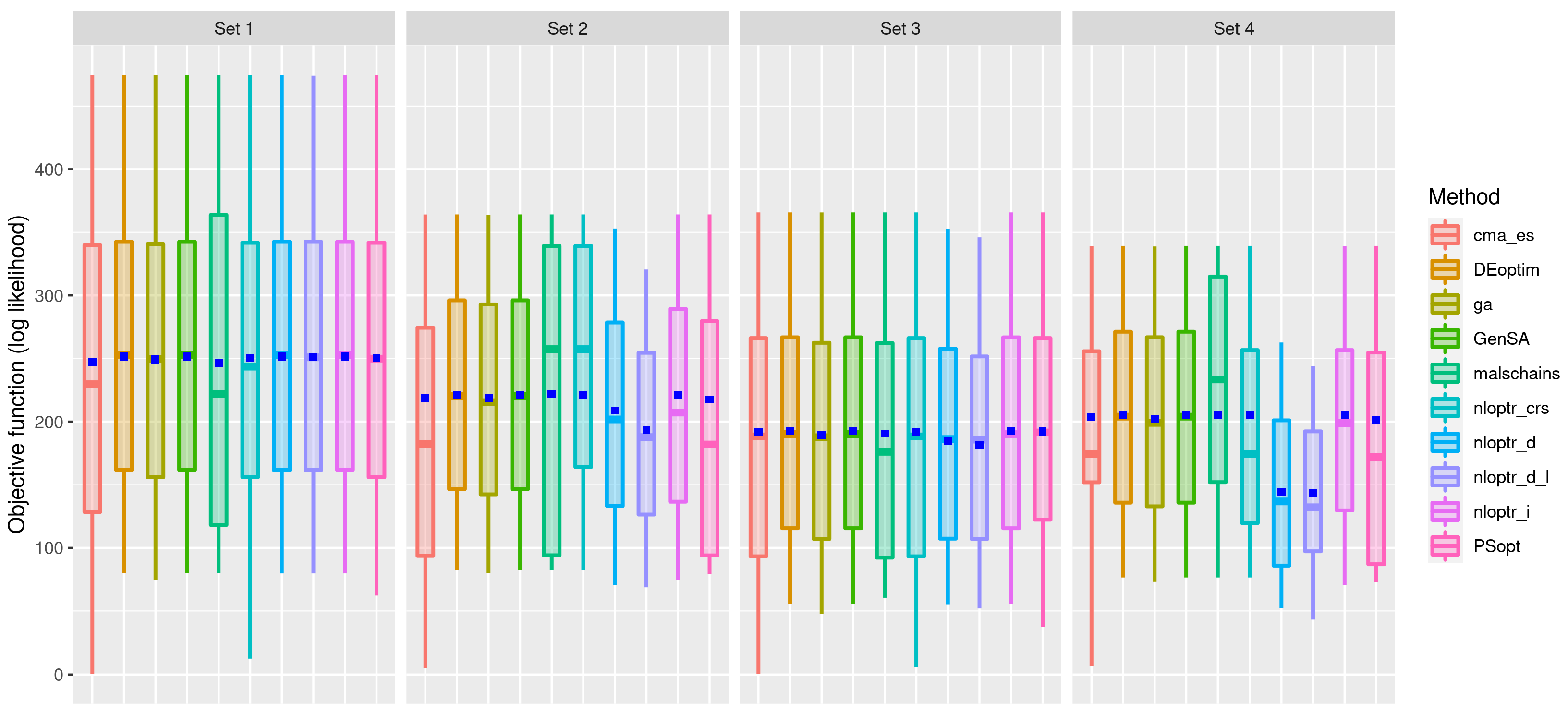
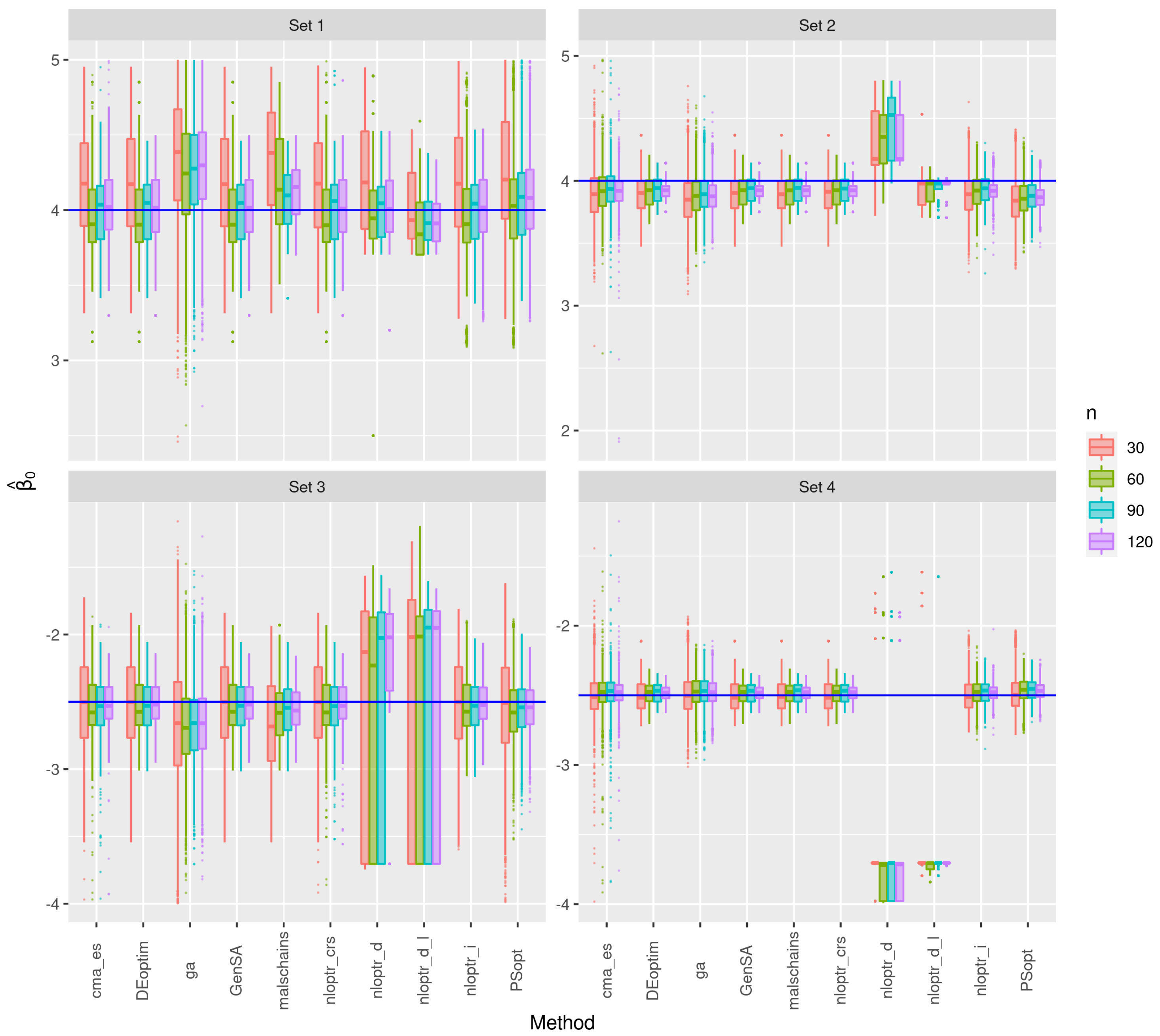
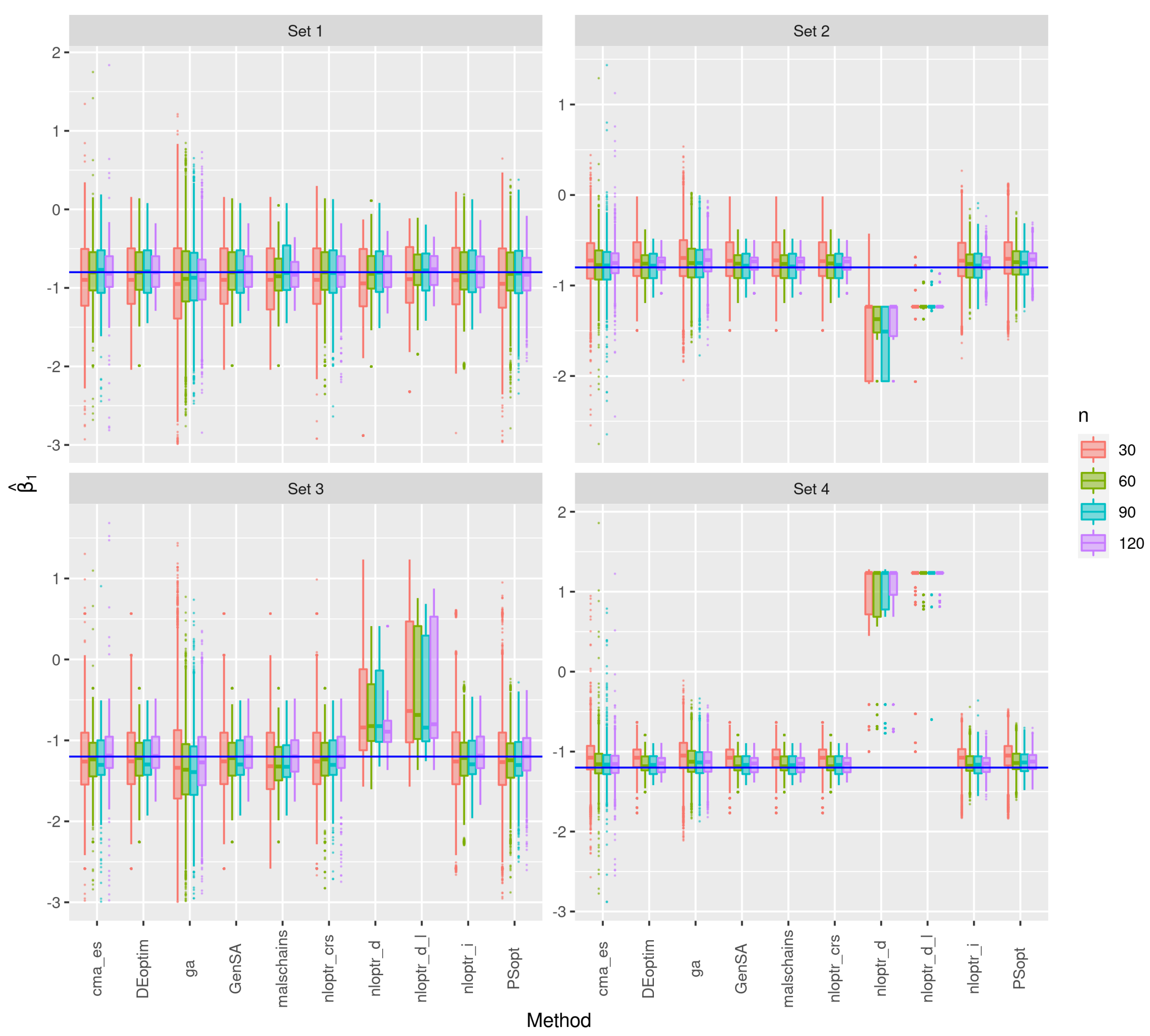
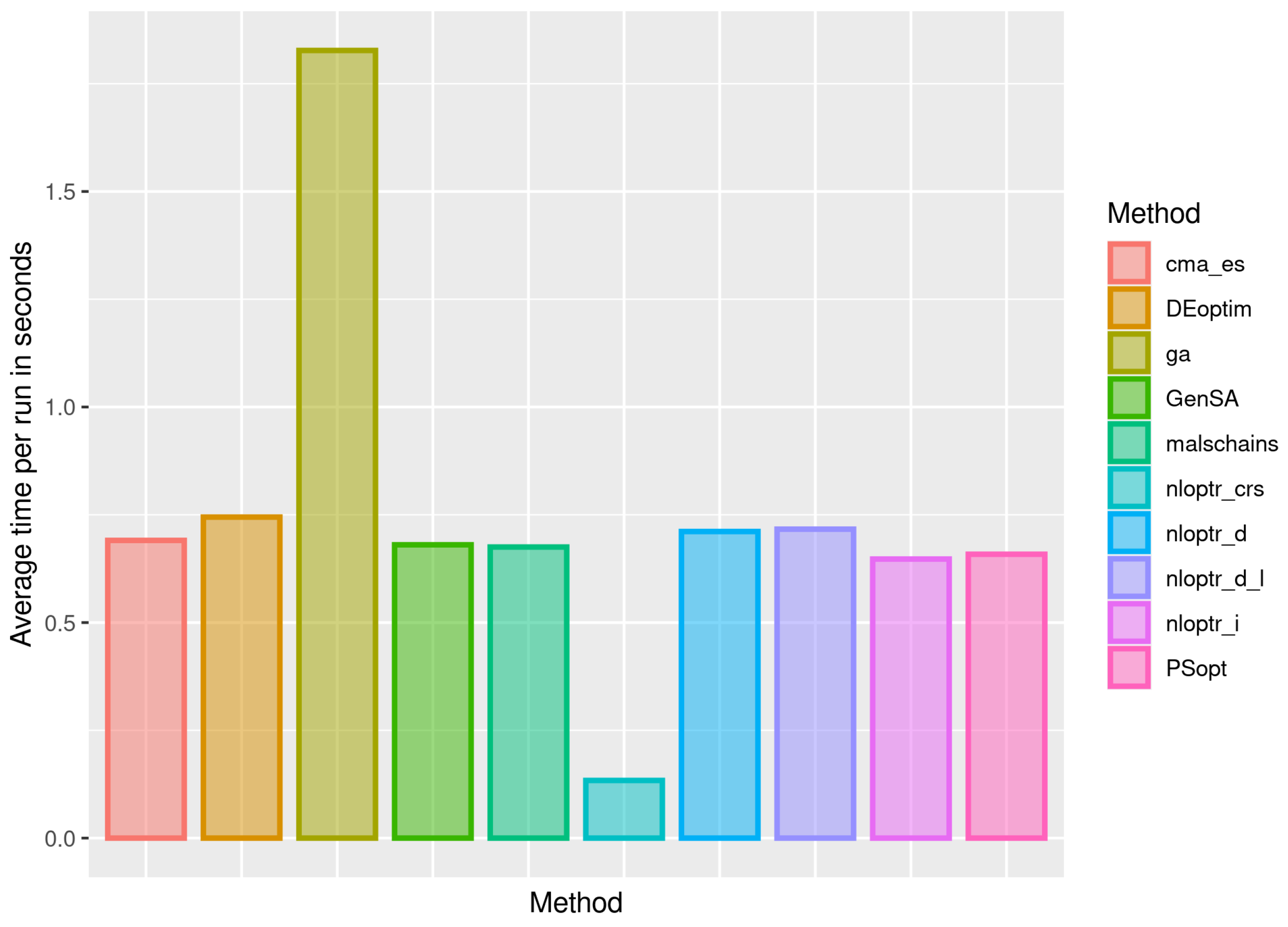
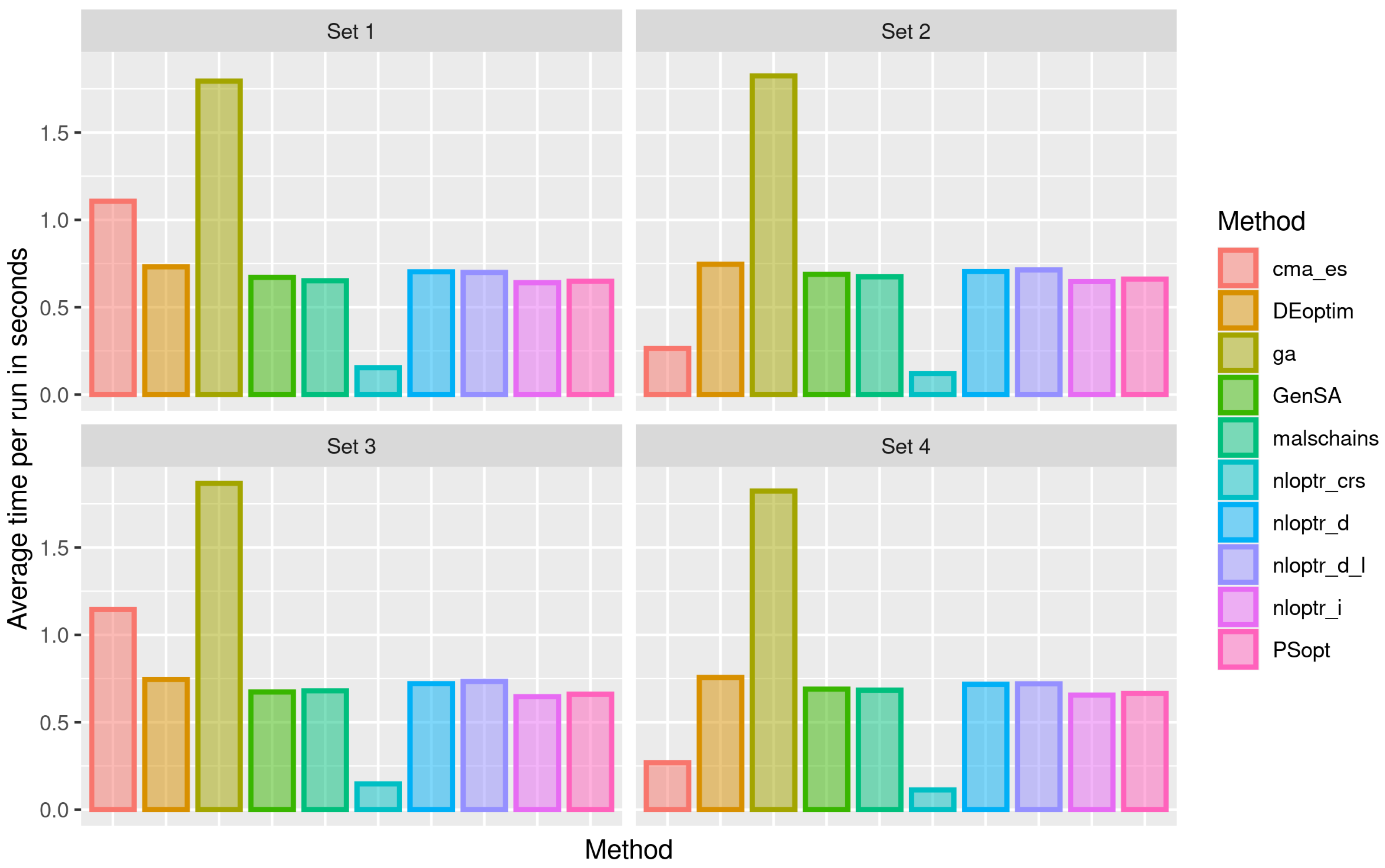
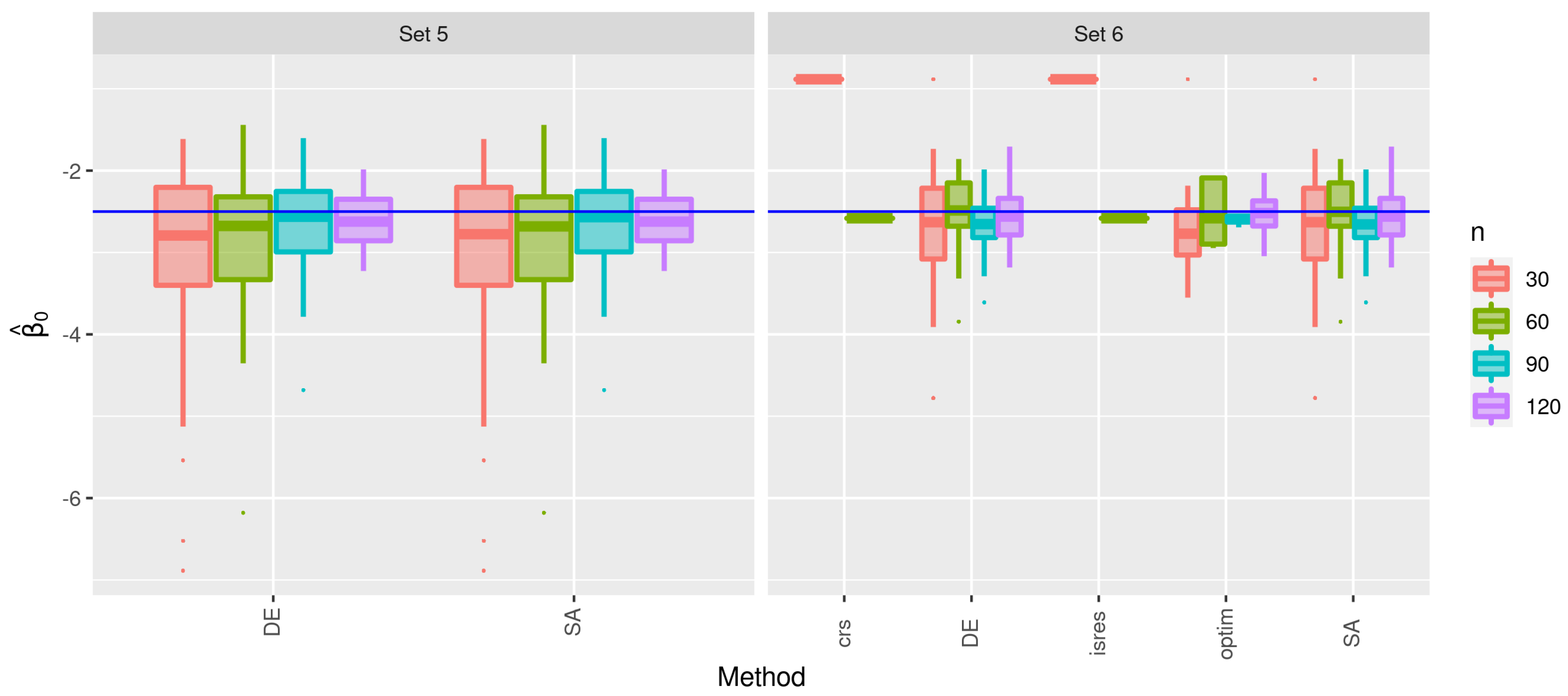
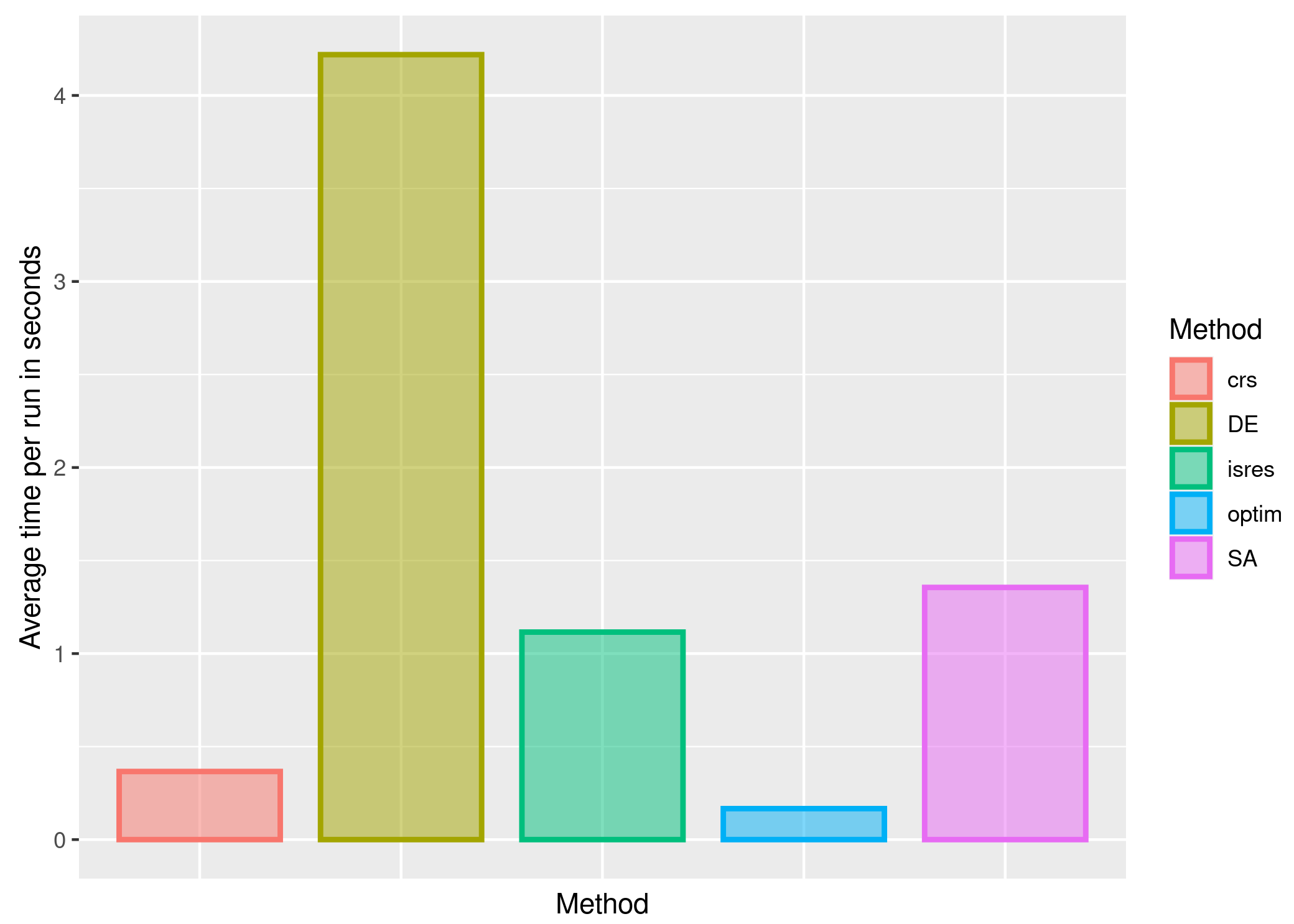
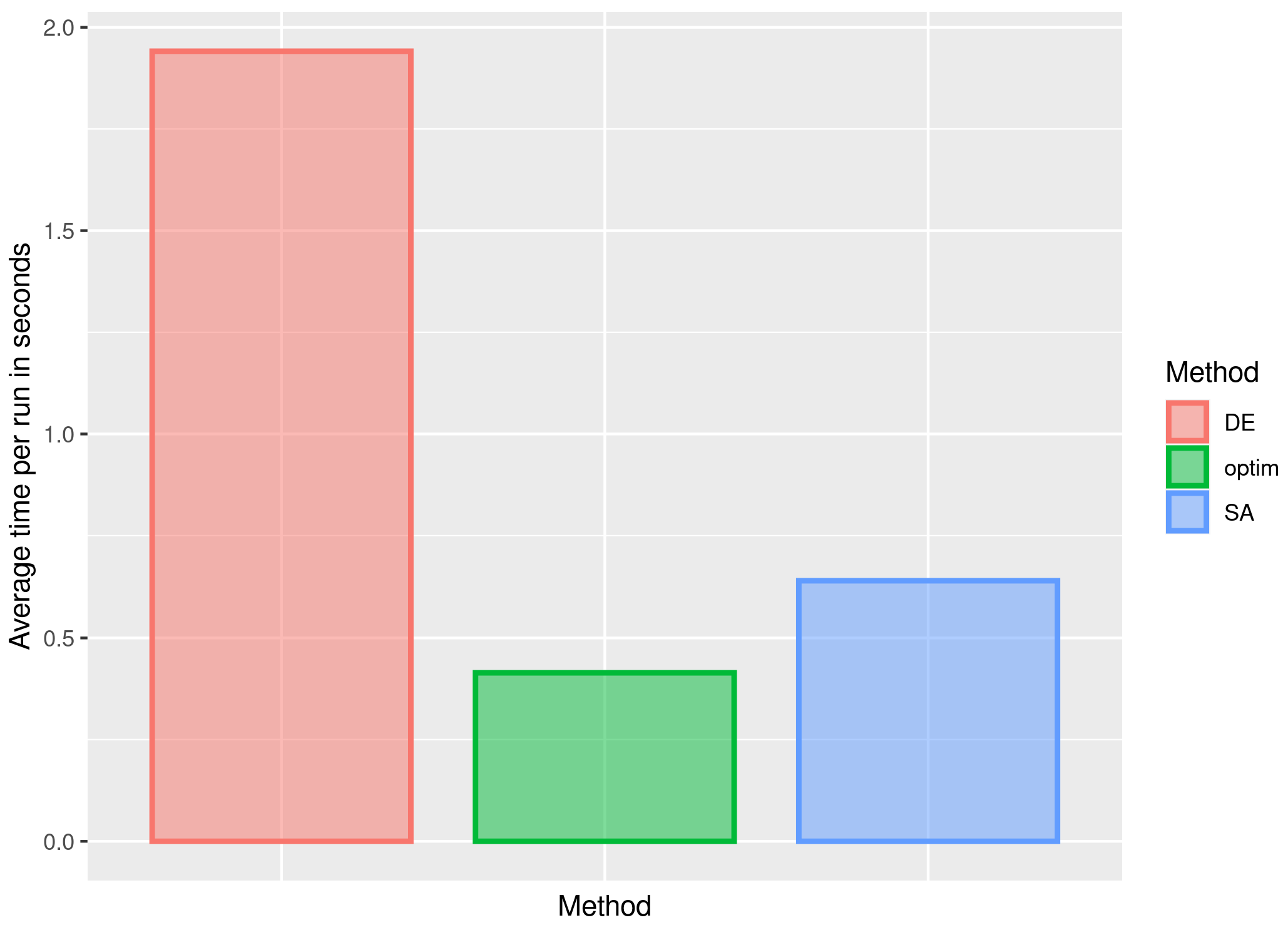
3.1. First Stage of the Simulation
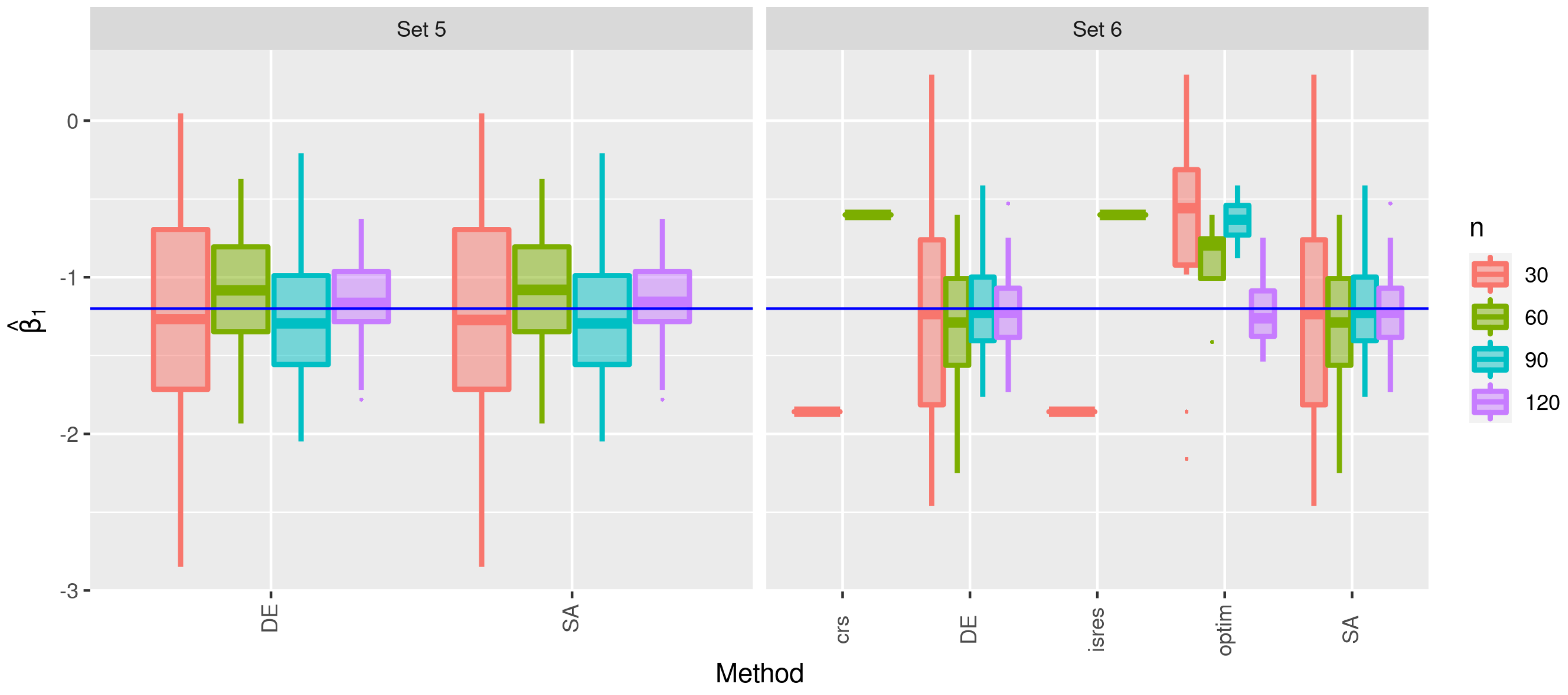
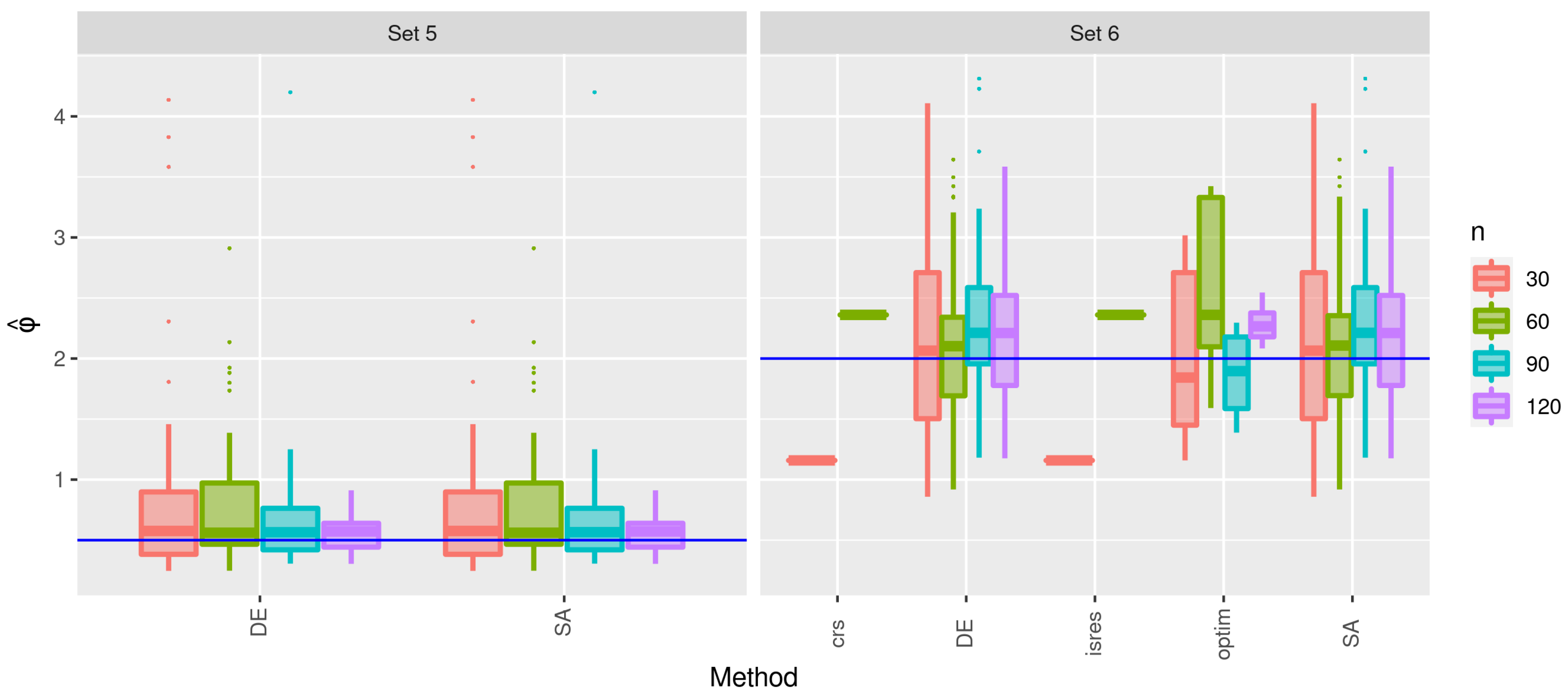
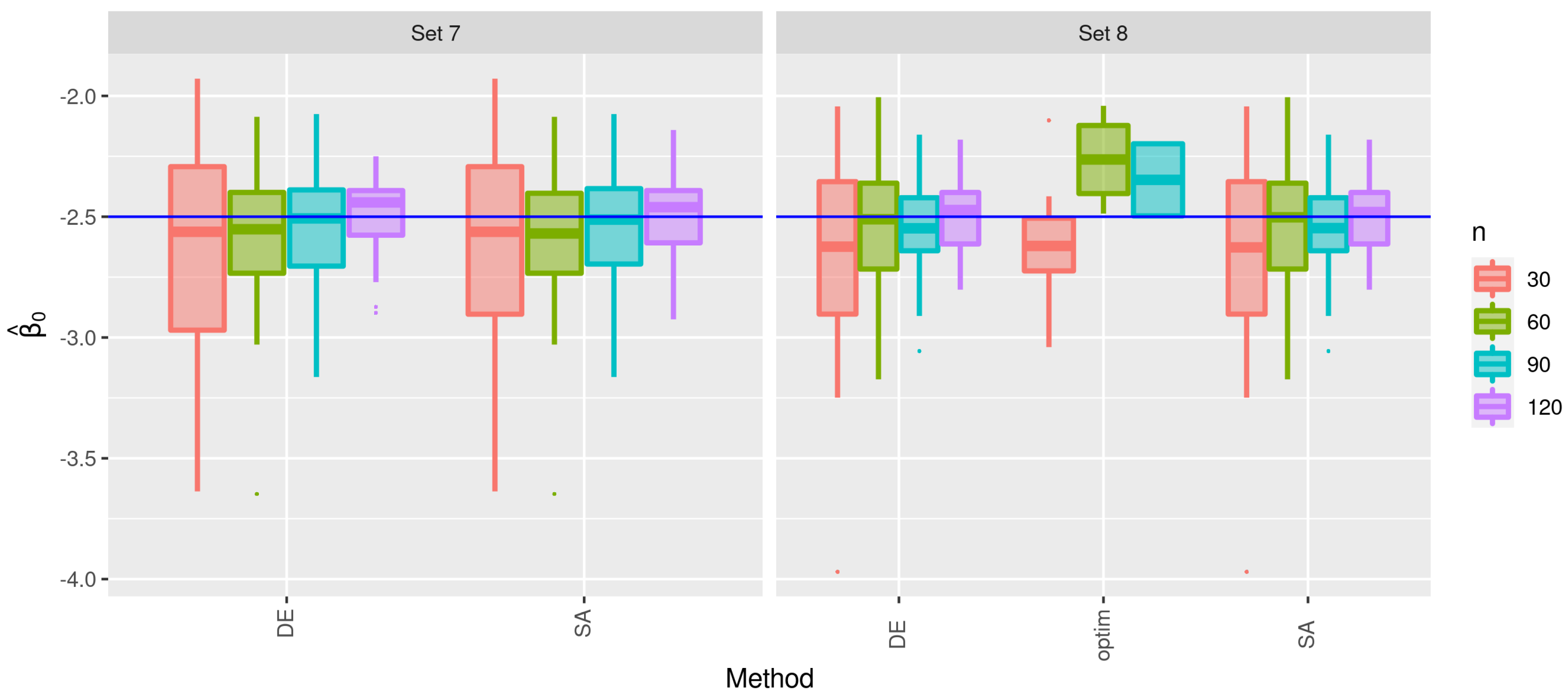
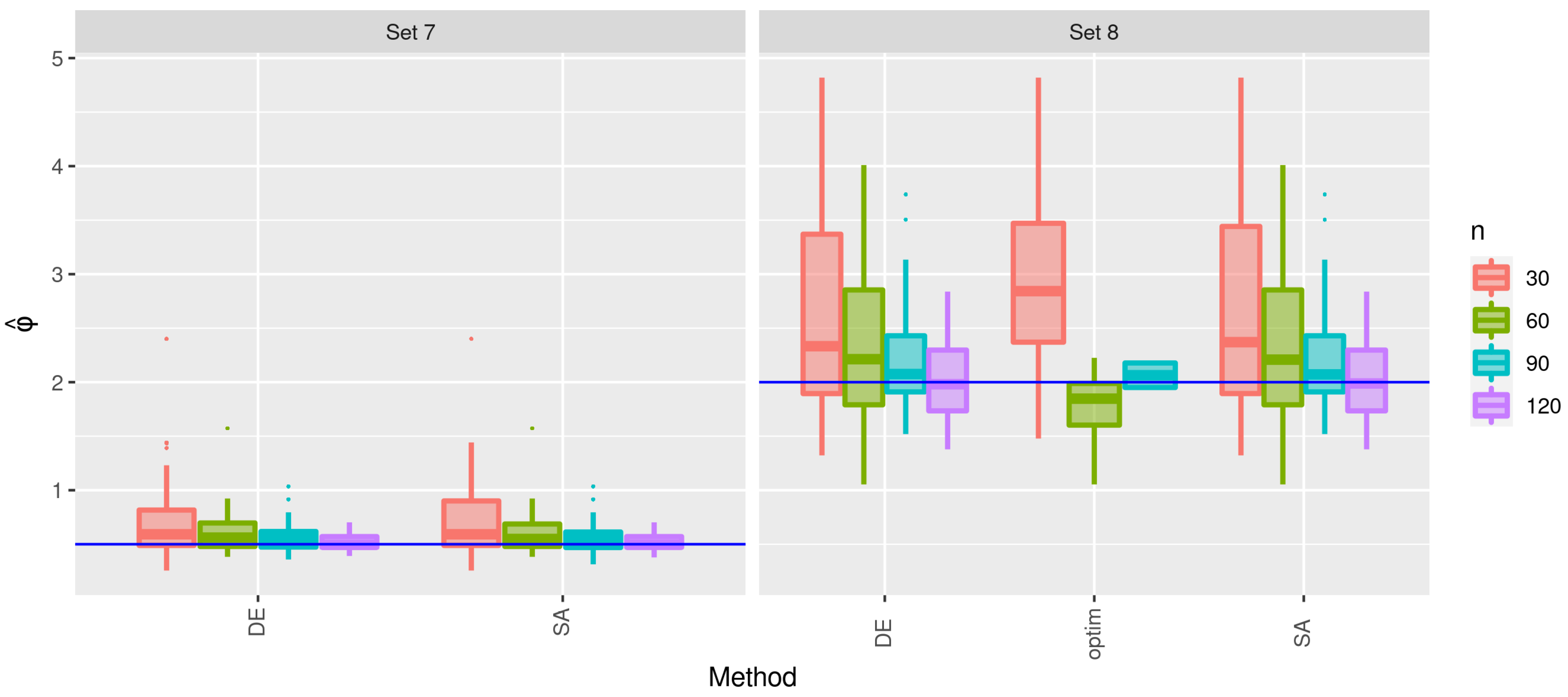
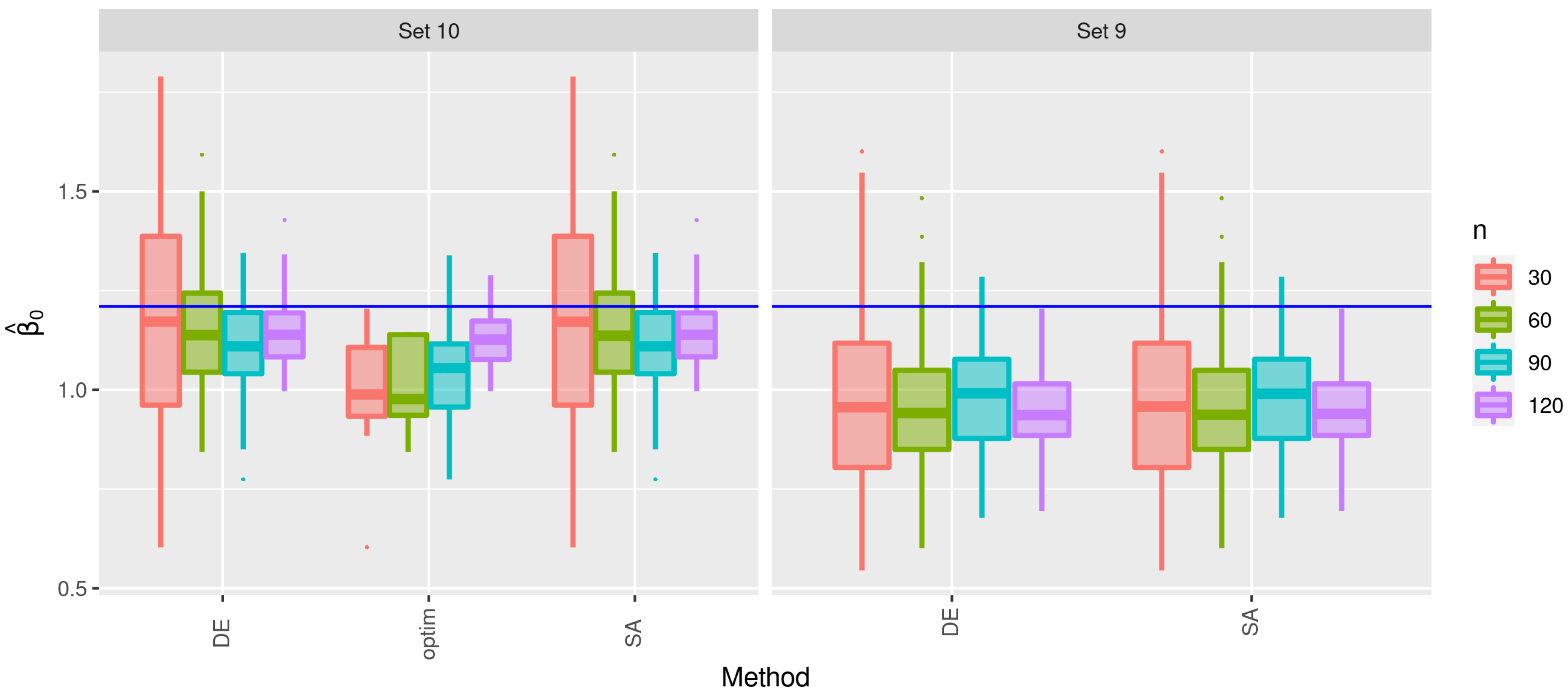
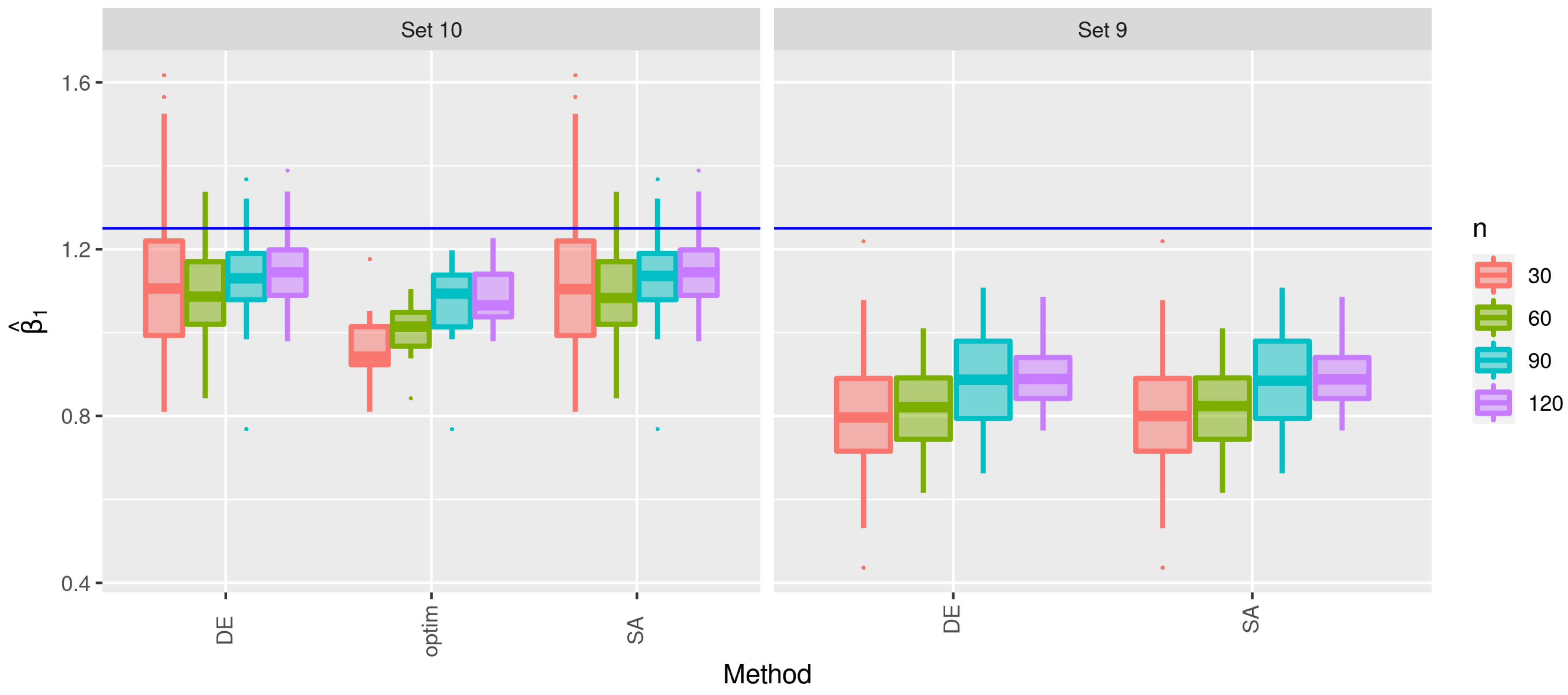
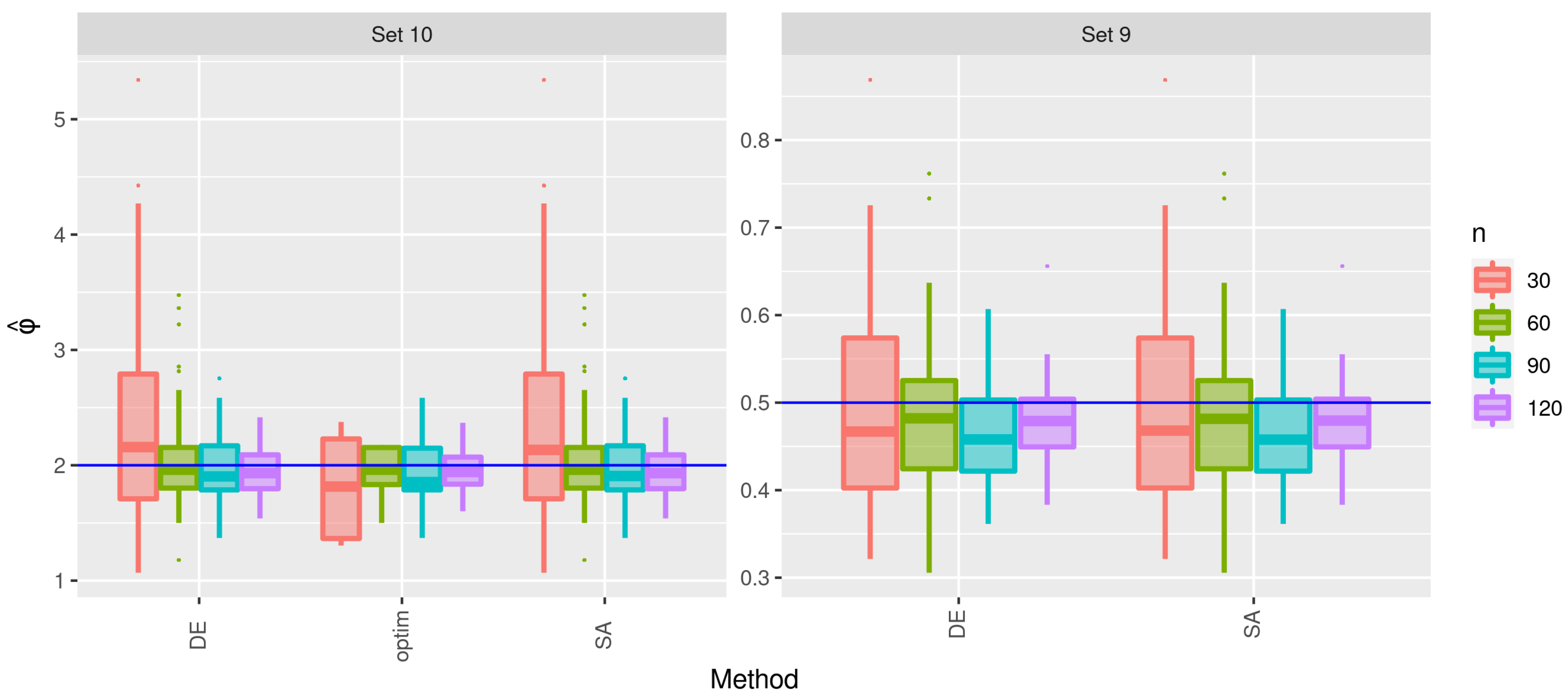
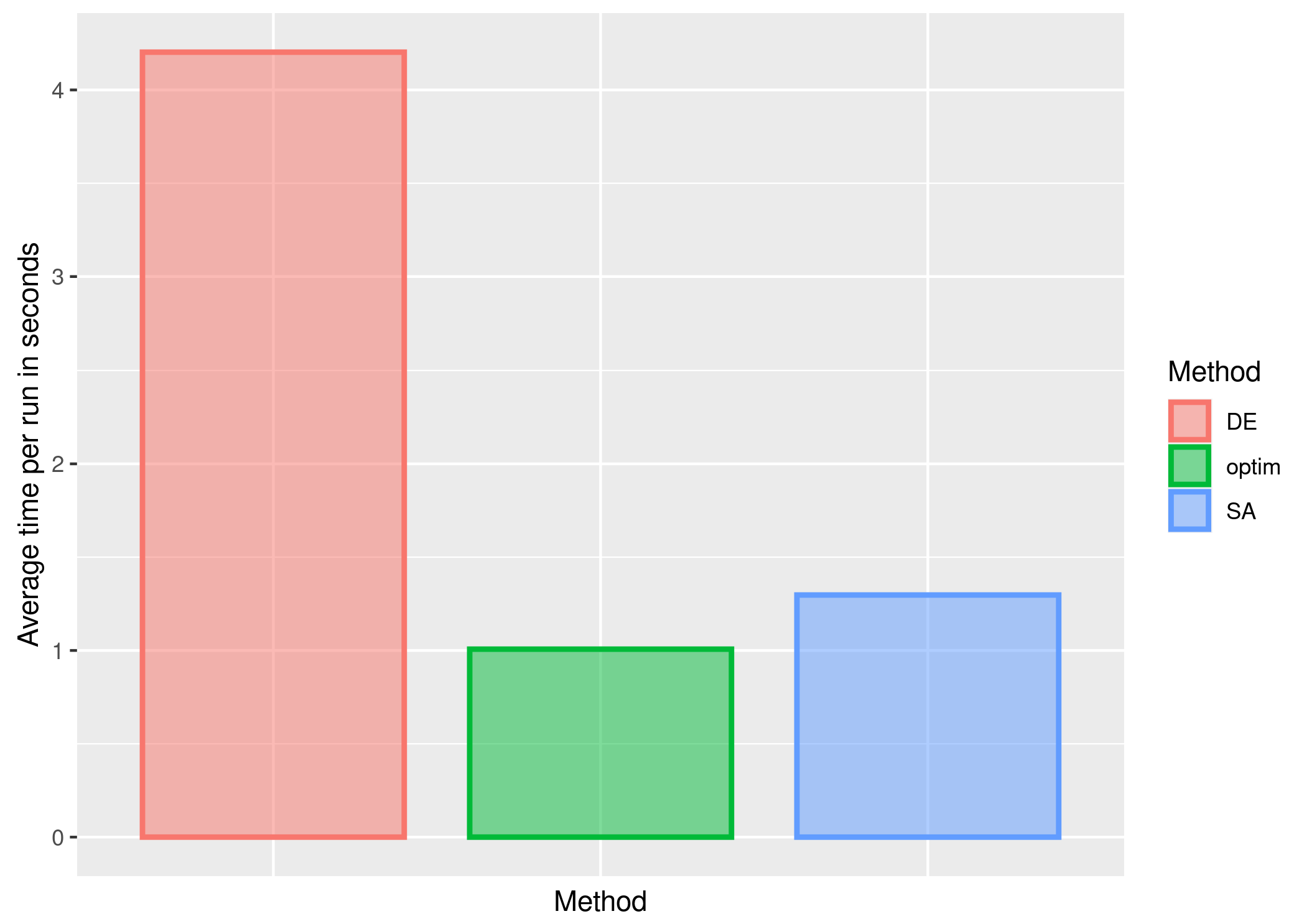
3.2. Second Stage of the Simulation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Berggren, N.; Daunfeldt, S.O.; Hellström, J. Social trust and central-bank independence. Eur. J. Political Econ. 2014, 34, 425–439. [Google Scholar] [CrossRef]
- Buntaine, M.T. Does the Asian development bank respond to past environmental performance when allocating environmentally risky financing? World Dev. 2011, 39, 336–350. [Google Scholar] [CrossRef]
- Castellani, M.; Pattitoni, P.; Scorcu, A.E. Visual artist price heterogeneity. Econ. Bus. Lett. 2012, 1, 16–22. [Google Scholar] [CrossRef]
- De Paola, M.; Scoppa, V.; Lombardo, R. Can gender quotas break down negative stereotypes? Evidence from changes in electoral rules. J. Public Econ. 2010, 94, 344–353. [Google Scholar] [CrossRef]
- Huang, X.; Oosterlee, C. Generalized beta regression models for random loss-given-default. J. Credit. Risk 2011, 7, 1–27. [Google Scholar] [CrossRef]
- Figueroa-Zúniga, J.; Bayes, C.L.; Leiva, V.; Liu, S. Robust beta regression modeling with errors-in-variables: A Bayesian approach and numerical applications. Stat. Pap. 2022. [Google Scholar] [CrossRef]
- Martinez-Florez, G.; Leiva, V.; Gomez-Deniz, E.; Marchant, C. A family of skew-normal distributions for modeling proportions and rates with zeros/ones excess. Symmetry 2020, 12, 1439. [Google Scholar] [CrossRef]
- Mazucheli, J.; Bapat, S.R.; Menezes, A.F.B. A new one-parameter unit Lindley distribution. Chil. J. Stat. 2019, 11, 53–67. [Google Scholar]
- Huerta, M.; Leiva, V.; Lillo, C.; Rodriguez, M. A beta partial least squares regression model: Diagnostics and application to mining industry data. Appl. Stoch. Model. Bus. Ind. 2018, 34, 305–321. [Google Scholar] [CrossRef]
- Figueroa-Zúniga, J.; Niklitschek, S.; Leiva, V.; Liu, S. Modeling heavy-tailed bounded data by the trapezoidal beta distribution with applications. Revstat, 2022, in press.
- Smithson, M.; Verkuilen, J. A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychol. Methods 2006, 11, 54–71. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Souza, T.C. Religious belief and intelligence: Worldwide evidence. Intelligence 2013, 41, 482–489. [Google Scholar] [CrossRef]
- Souza, T.C.; Cribari-Neto, F. Intelligence and religious disbelief in the united states. Intelligence 2018, 68, 48–57. [Google Scholar] [CrossRef]
- Mazucheli, M.; Leiva, V.; Alves, B.; Menezes, A.F.B. A new quantile regression for modeling bounded data under a unit Birnbaum–Saunders distribution with applications in medicine and politics. Symmetry 2021, 13, 682. [Google Scholar] [CrossRef]
- Ferrari, S.; Cribari-Neto, F. Beta regression or modeling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Zeileis, A. Beta regression in R. J. Stat. Softw. 2010, 34, 1–24. [Google Scholar] [CrossRef]
- Paolino, P. Maximum likelihood estimation of models with beta-distributed dependent variables. Political Anal. 2001, 9, 325–346. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Vasconcellos, K. Nearly unbiased maximum likelihood estimation for the beta distribution. J. Stat. Comput. Simul. 2002, 72, 107–118. [Google Scholar] [CrossRef]
- Ospina, R.; Cribari-Neto, F.; Vasconcellos, K. Improved point and interval estimation for a beta regression model. Comput. Stat. Data Anal. 2006, 51, 960–981. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing, Vienna, Austria. 2021. Available online: https://www.R-project.org (accessed on 6 January 2022).
- Dunn, P.K.; Smyth, G.K. Generalized Linear Models with Examples in R; Springer: New York, NY, USA, 2018. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Chapman and Hall: London, UK, 1989. [Google Scholar]
- Hilbe, J. Logistic Regression Models; Chapman and Hall: New York, NY, USA, 2009. [Google Scholar]
- McCullagh, P. Tensor Methods in Statistics; Chapman and Hall: London, UK, 2018. [Google Scholar]
- Rydlewski, J.; Mielczarek, D. On the maximum likelihood estimator in the generalized beta regression model. Opusc. Math. 2012, 32, 761–774. [Google Scholar] [CrossRef]
- Simas, A.; Barreto-Souza, W.; Rocha, A.V. Improved estimators for a general class of beta regression models. Comput. Stat. Data Anal. 2010, 54, 348–366. [Google Scholar] [CrossRef]
- Rustagi, J. Optimization Techniques in Statistics; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Kosmidis, I.; Firth, D. A generic algorithm for reducing bias in parametric estimation. Electron. J. Stat. 2010, 4, 1097–1112. [Google Scholar] [CrossRef]
- Espinheira, P.; Silva, L.; Silva, A.; Ospina, R. Model selection criteria on beta regression for machine learning. Mach. Learn. Knowl. Extr. 2019, 1, 427–449. [Google Scholar] [CrossRef]
- Grün, B.; Kosmidis, I.; Zeileis, A. Extended beta regression in R: Shaken, stirred, mixed, and partitioned. J. Stat. Softw. 2012, 48, 1–25. [Google Scholar] [CrossRef]
- Rocha, A.; Simas, A.B. Influence diagnostics in a general class of beta regression models. TEST 2011, 20, 95–119. [Google Scholar] [CrossRef]
- Billio, M.; Casarin, R. Beta autoregressive transition Markov-switching models for business cycle analysis. Stud. Nonlinear Dyn. Econom. 2011, 15, 4. [Google Scholar] [CrossRef]
- Pumi, G.; Valk, M.; Bisognin, C.; Bayer, F.; Prass, T. Beta autoregressive fractionally integrated moving average models. J. Stat. Plan. Inference 2019, 200, 196–212. [Google Scholar] [CrossRef]
- Silva, C.; Migon, H.; Correia, L. Dynamic Bayesian beta models. Comput. Stat. Data Anal. 2011, 55, 2074–2089. [Google Scholar] [CrossRef]
- Bayer, F.; Cintra, R.; Cribari-Neto, F. Beta seasonal autoregressive moving average models. J. Stat. Comput. Simul. 2018, 88, 2961–2981. [Google Scholar] [CrossRef]
- Galvis, D.; Bandyopadhyay, D.; Lachos, V. Augmented mixed beta regression models for periodontal proportion data. Stat. Med. 2014, 33, 3759–3771. [Google Scholar] [CrossRef] [PubMed]
- Ospina, R.; Ferrari, S. A general class of zero-or-one inflated beta regression models. Comput. Stat. Data Anal. 2012, 56, 1609–1623. [Google Scholar] [CrossRef]
- Pereira, G.; Botter, D.; Sandoval, M. The truncated inflated beta distribution. Commun. Stat. Theory Methods 2012, 41, 907–919. [Google Scholar] [CrossRef]
- Bonat, W.; Ribeiro, P., Jr.; Zeviani, W. Likelihood analysis for a class of beta mixed models. J. Appl. Stat. 2015, 42, 252–266. [Google Scholar] [CrossRef]
- de Brito Trindade, D.; Espinheira, P.; Pinto Vasconcellos, K.; Farfán Carrasco, J.; Lima, M. Beta regression model nonlinear in the parameters with additive measurement errors in variables. PLoS ONE 2021, 16, e0254103. [Google Scholar] [CrossRef] [PubMed]
- Carrasco, J.; Ferrari, S.; Arellano-Valle, R. Errors-in-variables beta regression models. J. Appl. Stat. 2014, 41, 1530–1547. [Google Scholar] [CrossRef]
- Figueroa-Zúñiga, J.; Arellano-Valle, R.; Ferrari, S. Mixed beta regression: A Bayesian perspective. Comput. Stat. Data Anal. 2013, 61, 137–147. [Google Scholar] [CrossRef]
- Mullen, K.M. Continuous global optimization in R. J. Stat. Softw. 2014, 60, 1–45. [Google Scholar] [CrossRef]
- Scrucca, L. GA: A package for genetic algorithms in R. J. Stat. Softw. 2013, 53, 1–37. [Google Scholar] [CrossRef]
- Dünder, E.; Cengíz, M. Model selection in beta regression analysis using several information criteria and heuristic optimization. J. New Theory 2020, 33, 76–84. [Google Scholar]
- Mullen, K.; Ardia, D.; Gil, D.; Windover, D.; Cline, J. DEoptim: An R package for global optimization by differential evolution. J. Stat. Softw. 2011, 40, 1–26. [Google Scholar] [CrossRef]
- Hansen, N.; Ostermeier, A. Adapting arbitrary normal mutation distributions in evolution strategies: The covariance matrix adaptation. In Proceedings of the IEEE International Conference on Evolutionary Computation, Nagoya, Japan, 20–22 May 1996; pp. 312–317. [Google Scholar] [CrossRef]
- Xiang, Y.; Gubian, S.; Suomela, B.; Hoeng, J. Generalized simulated annealing for efficient global optimization: The GenSA package for R. R J. 2013, 5, 13–21. [Google Scholar] [CrossRef]
- Franzke, B.; Kosko, B. Noise can speed Markov chain Monte Carlo estimation and quantum annealing. Phys. Rev. E 2019, 100, 053309. [Google Scholar] [CrossRef] [PubMed]
- Geyer, C. Markov chain Monte Carlo maximum likelihood. In Computing Science and Statistics, Proceedings of 23rd Symposium on the Interface, Fairfax Station, Seattle, WA, USA, 21–24 April 1991; Interface Foundation of North America: Fairfax Station, VA, USA, 1991; pp. 156–163. [Google Scholar]
- Martino, L.; Elvira, V.; Luengo, D.; Corander, J.; Louzada, F. Orthogonal parallel MCMC methods for sampling and optimization. Digit. Signal Process. 2016, 58, 64–84. [Google Scholar] [CrossRef]
- El-Alem, M.; Aboutahoun, A.; Mahdi, S. Hybrid gradient simulated annealing algorithm for finding the global optimal of a nonlinear unconstrained optimization problem. Soft Comput. 2021, 25, 2325–2350. [Google Scholar] [CrossRef]
- Xu, P.; Sui, S.; Du, Z. Application of Hybrid Genetic Algorithm Based on Simulated Annealing in Function Optimization. Int. J. Math. Comput. Sci. 2015, 9, 695–698. [Google Scholar]
- Kaelo, P.; Ali, M. Some variants of the controlled random search algorithm for global optimization. J. Optim. Theory Appl. 2006, 130, 253–264. [Google Scholar] [CrossRef]
- Johnson, S.G. The Nlopt Package. Version 1.2.2.2. 2020. Available online: https://nlopt.readthedocs.io/en/latest/ (accessed on 6 January 2022).
- Jones, D.; Perttunen, D.; Stuckman, E. Lipschitzian optimisation without the Lipschitz constant. J. Optim. Theory Appl. 1993, 79, 157–181. [Google Scholar] [CrossRef]
- Gablonsky, J.; Kelley, C. A locally-biased form of the direct algorithm. J. Glob. Optim. 2001, 21, 27–37. [Google Scholar] [CrossRef]
- Runarsson, T.; Yao, X. Search biases in constrained evolutionary optimization. IEEE Trans. Syst. Man Cybern. C 2005, 35, 233–243. [Google Scholar] [CrossRef]
- Bergmeir, C.; Molina, D.; Benítez, J.M. Memetic algorithms with local search chains in R: The Rmalschains package. J. Stat. Softw. 2016, 75, 1–33. [Google Scholar] [CrossRef]
- Gilli, M.; Maringer, D.; Schumann, E. Numerical Methods and Optimization in Finance; Academic Press: Waltham, MA, USA, 2011. [Google Scholar]
- Martin-Barreiro, C.; Ramirez-Figueroa, J.A.; Cabezas, X.; Leiva, V.; Martin-Casado, A.; Galindo-Villardón, M.P. A new algorithm for computing disjoint orthogonal components in the parallel factor analysis model with simulations and applications to real-world data. Mathematics 2021, 9, 2058. [Google Scholar] [CrossRef]
- Ramirez-Figueroa, J.A.; Martin-Barreiro, C.; Nieto, A.B.; Leiva, V.; Galindo-Villardón, M.P. A new principal component analysis by particle swarm optimization with an environmental application for data science. Stoch. Environ. Res. Risk Assess. 2021, 35, 1969–1984. [Google Scholar] [CrossRef]
- Martin-Barreiro, C.; Ramirez-Figueroa, J.A.; Nieto, A.B.; Leiva, V.; Martin-Casado, A.; Galindo-Villardón, M.P. A new algorithm for computing disjoint orthogonal components in the three-way Tucker model. Mathematics 2021, 9, 203. [Google Scholar] [CrossRef]
- Espinheira, L.; Ferrari, S.; Cribari-Neto, F. On beta regression residuals. J. Appl. Stat. 2008, 35, 407–419. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | |||
|---|---|---|---|
| Set | |||
| 1 | 12 | ||
| 2 | 148 | ||
| 3 | 12 | ||
| 4 | 148 | ||
| Method | |||
|---|---|---|---|
| Indicator | cma_es | malschains | PSopt |
| Number of failures | |||
| Percentage of failures | |||
| Parameter | ||||
|---|---|---|---|---|
| Set | Distribution | |||
| 5 | Uniform(0,1) | |||
| 6 | Uniform(0,1) | |||
| 7 | Normal(0,1) | |||
| 8 | Normal(0,1) | |||
| 9 | Student-t(3) | |||
| 10 | Student-t(3) | |||
| Method | ||||||
|---|---|---|---|---|---|---|
| Sets | Indicator | crs | DEoptim | isres | optim | GenSA |
| 5–6 | Number of failures | 0 | 19 | |||
| Percentage of failures | ||||||
| 7–8 | Number of failures | 0 | 19 | |||
| Percentage of failures | ||||||
| 9–10 | Number of failures | 0 | 19 | |||
| Percentage of failures | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Couri, L.; Ospina, R.; Silva, G.d.; Leiva, V.; Figueroa-Zúñiga, J. A Study on Computational Algorithms in the Estimation of Parameters for a Class of Beta Regression Models. Mathematics 2022, 10, 299. https://doi.org/10.3390/math10030299
Couri L, Ospina R, Silva Gd, Leiva V, Figueroa-Zúñiga J. A Study on Computational Algorithms in the Estimation of Parameters for a Class of Beta Regression Models. Mathematics. 2022; 10(3):299. https://doi.org/10.3390/math10030299
Chicago/Turabian StyleCouri, Lucas, Raydonal Ospina, Geiza da Silva, Víctor Leiva, and Jorge Figueroa-Zúñiga. 2022. "A Study on Computational Algorithms in the Estimation of Parameters for a Class of Beta Regression Models" Mathematics 10, no. 3: 299. https://doi.org/10.3390/math10030299
APA StyleCouri, L., Ospina, R., Silva, G. d., Leiva, V., & Figueroa-Zúñiga, J. (2022). A Study on Computational Algorithms in the Estimation of Parameters for a Class of Beta Regression Models. Mathematics, 10(3), 299. https://doi.org/10.3390/math10030299