
A New Text-Mining–Bayesian Network Approach for Identifying Chemical Safety Risk Factors


Abstract
1. Introduction
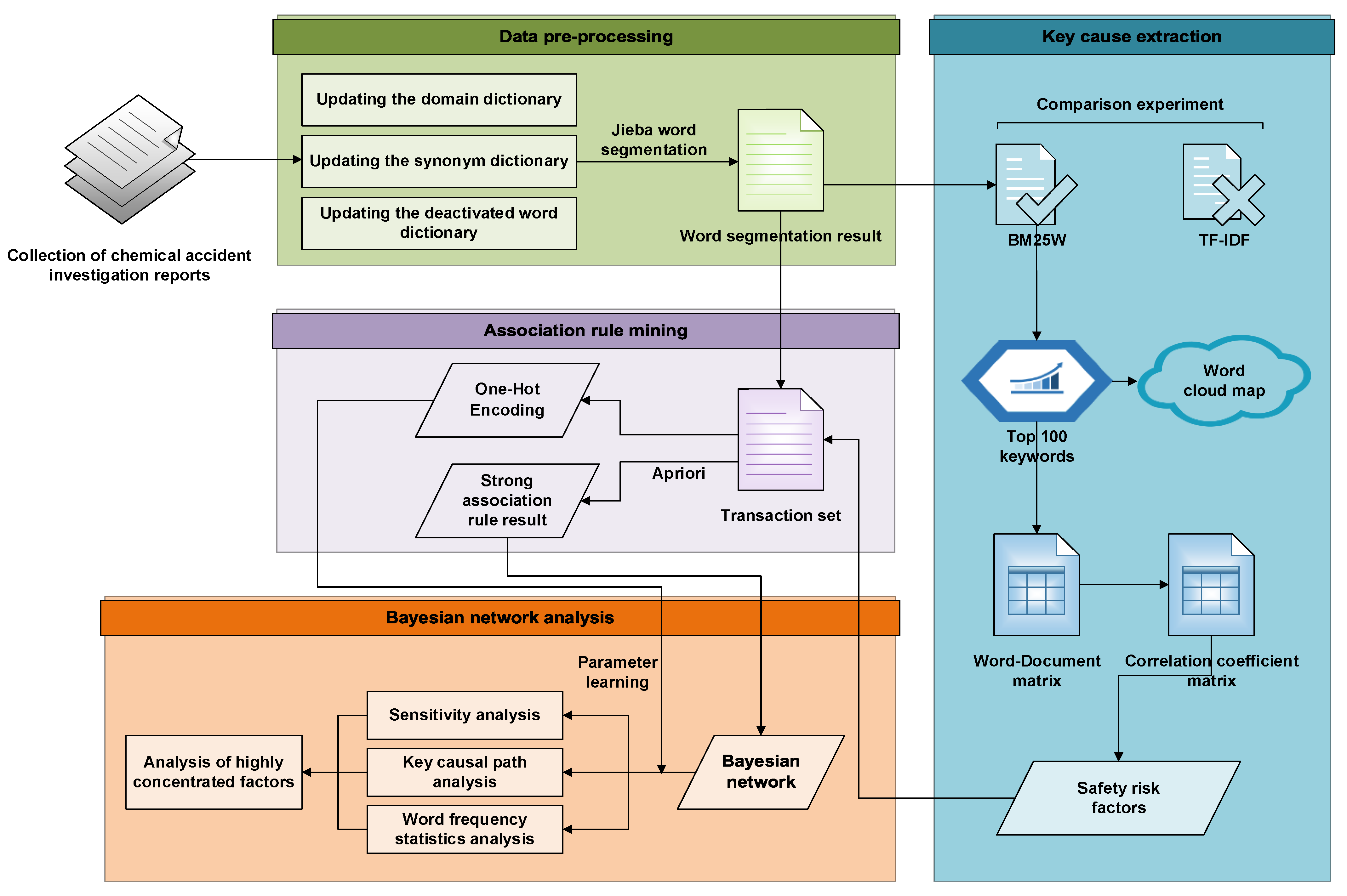
2. Materials and Methods
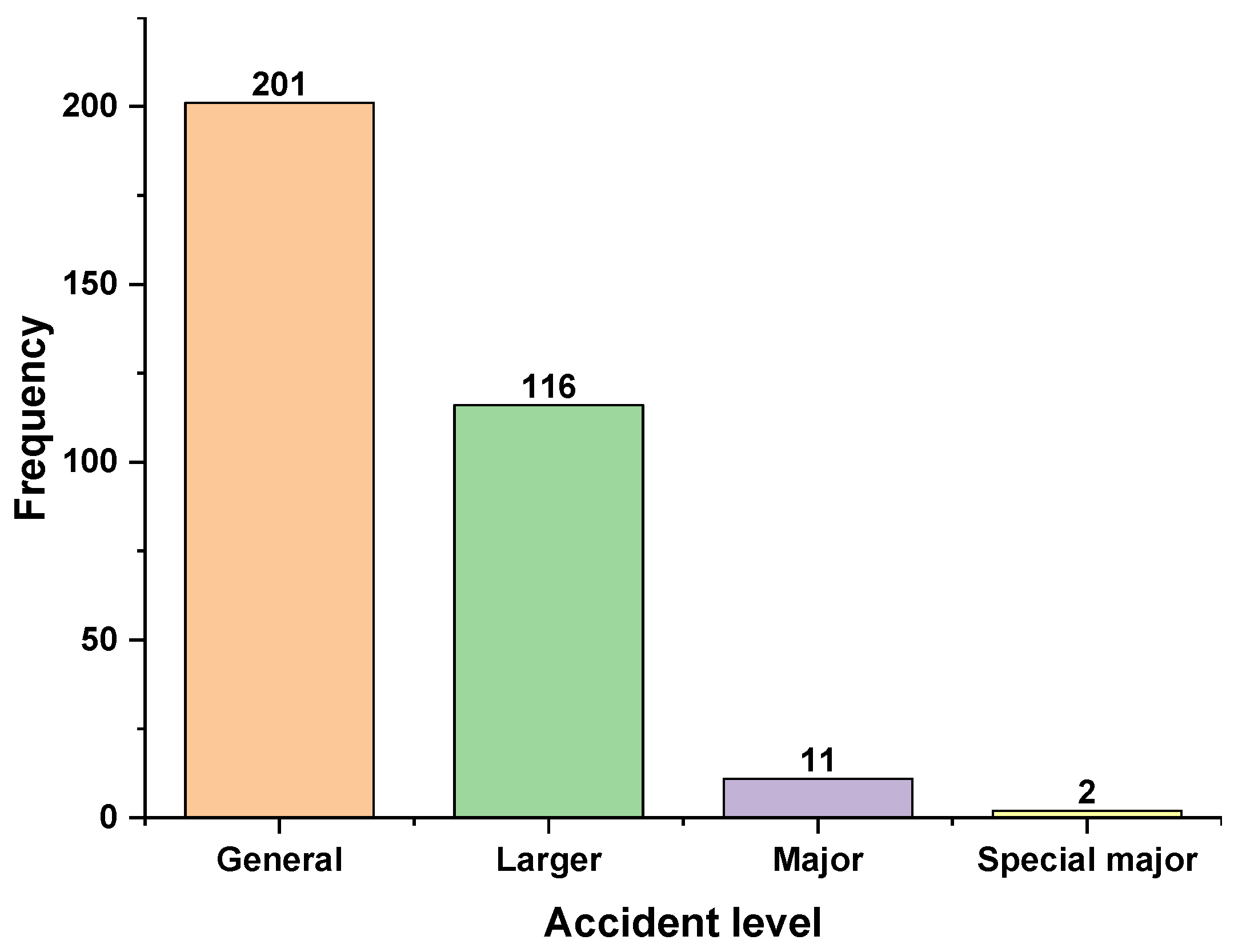
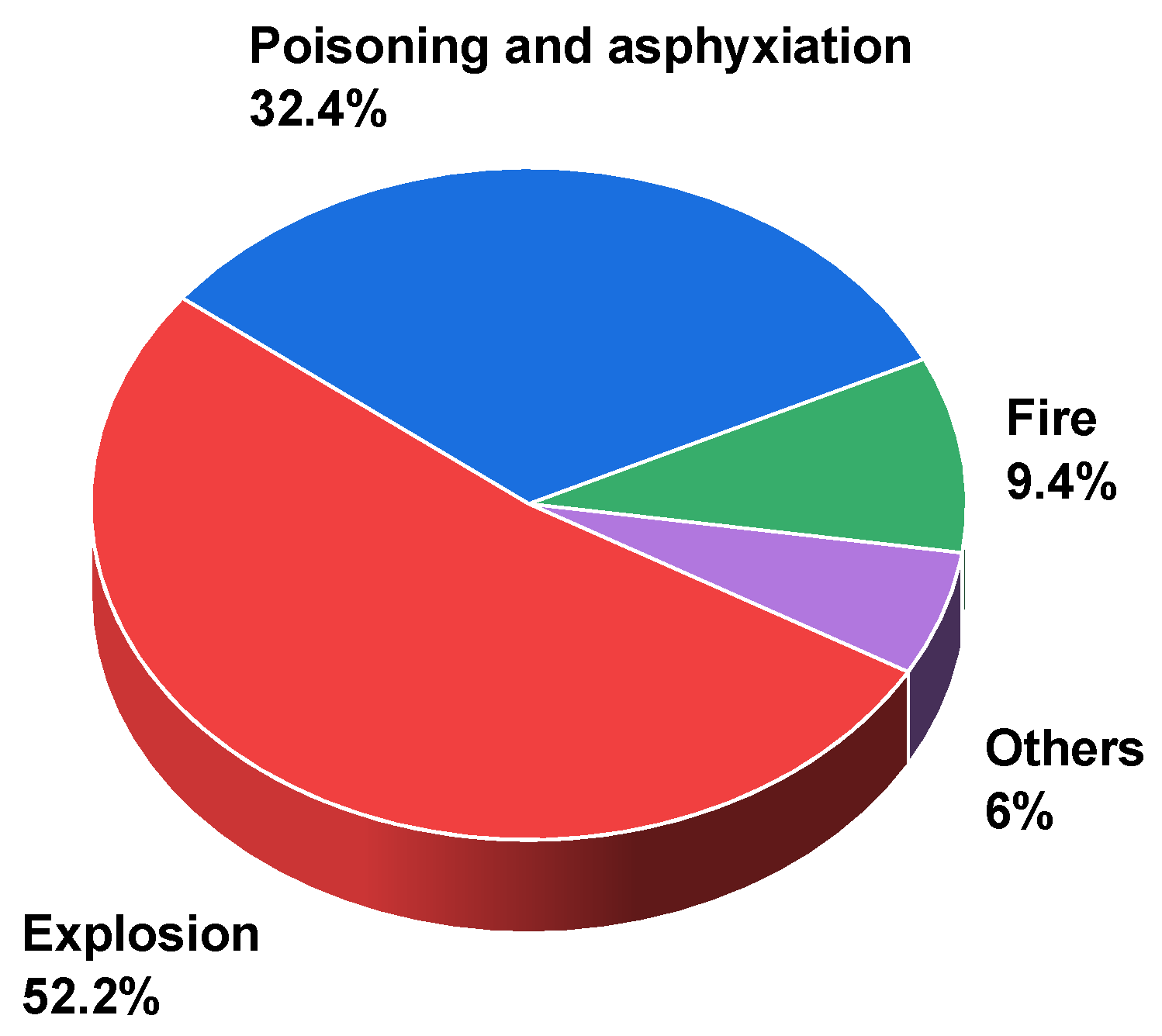
2.1. Dataset
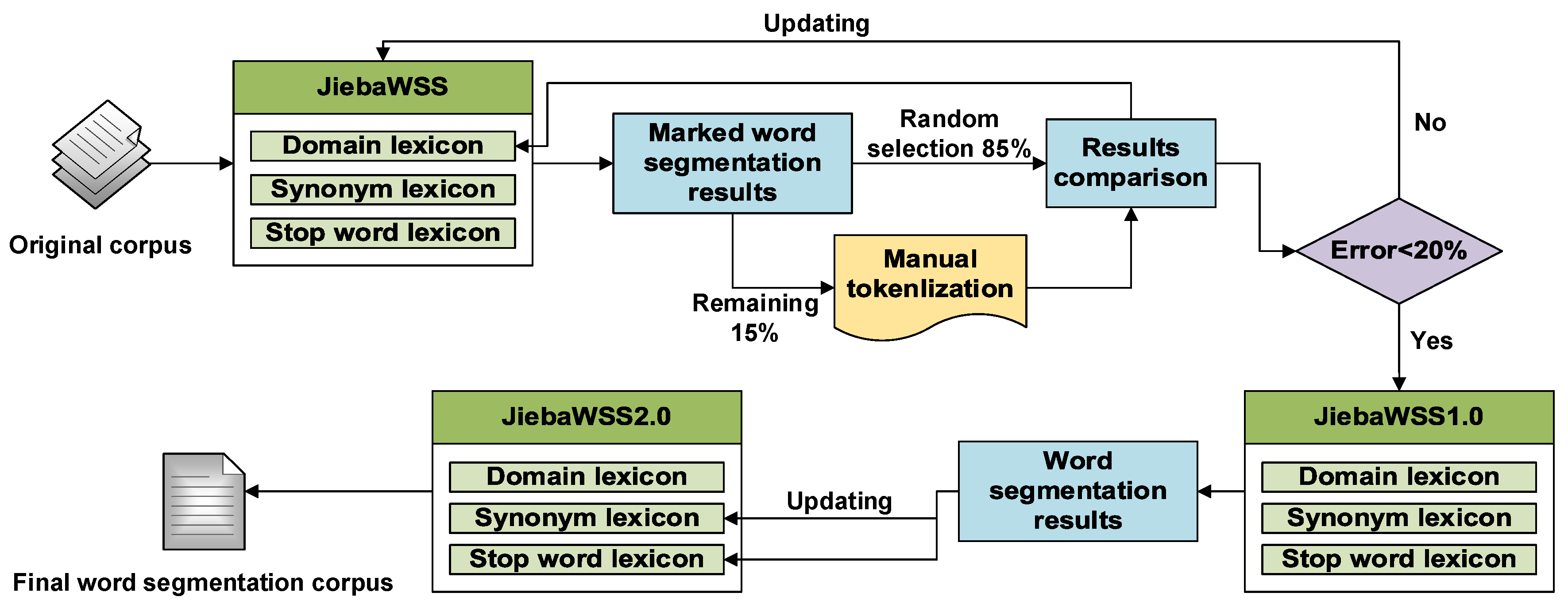
2.2. Data Pre-Processing
- (1)
- Domain lexicon: Although JiebaWSS comes with a dictionary that contains most of the commonly used words (e.g., reactor, piping, etc.) for segmenting words, there are many industry-specific words that cannot be identified, such as distillation column, middle operating chamber, steam valve, and gas detector. When it comes to these words, JiebaWSS may split the whole proprietary word into two or more words. This requires prior integration of these industry-specific words into a domain dictionary and adding the dictionary to JiebaWSS.
- (2)
- Synonym lexicon: There are many synonyms in accident investigation reports, and a large number of these synonyms can make the word segmentation results too discrete. We can replace all the synonyms with one of the words; for example, pipe, pipeline, steam pipe, pressure pipe, etc., can be replaced by the pipe.
- (3)
- Discontinued word lexicon: The accident investigation report also contains a large number of meaningless words, numbers, and symbols, such as “we”, “actually”, “exactly”, “3”, “6”, “,”, “.”, “!”, etc. These words have no practical significance for the analysis of this study and can be added to the dictionary of discontinued words for elimination.
2.2.1. Creation and Update of Domain Lexicon
2.2.2. Creation and Update of Synonym Lexicon and Stop Word Lexicon
2.3. Extraction of Key Causes
2.3.1. Keyword Extraction Method
2.3.2. Improved BM25 Model—BM25W
2.3.3. Generation of Key Causes
2.4. Association-Rule Analysis
2.5. Bayesian Network Analysis
3. Results and Discussion
3.1. Data Pre-Processing Result
3.2. Key Cause Extraction Result
3.2.1. The Comparative Study of Keyword Extraction Algorithms
3.2.2. Keyword Extraction Result
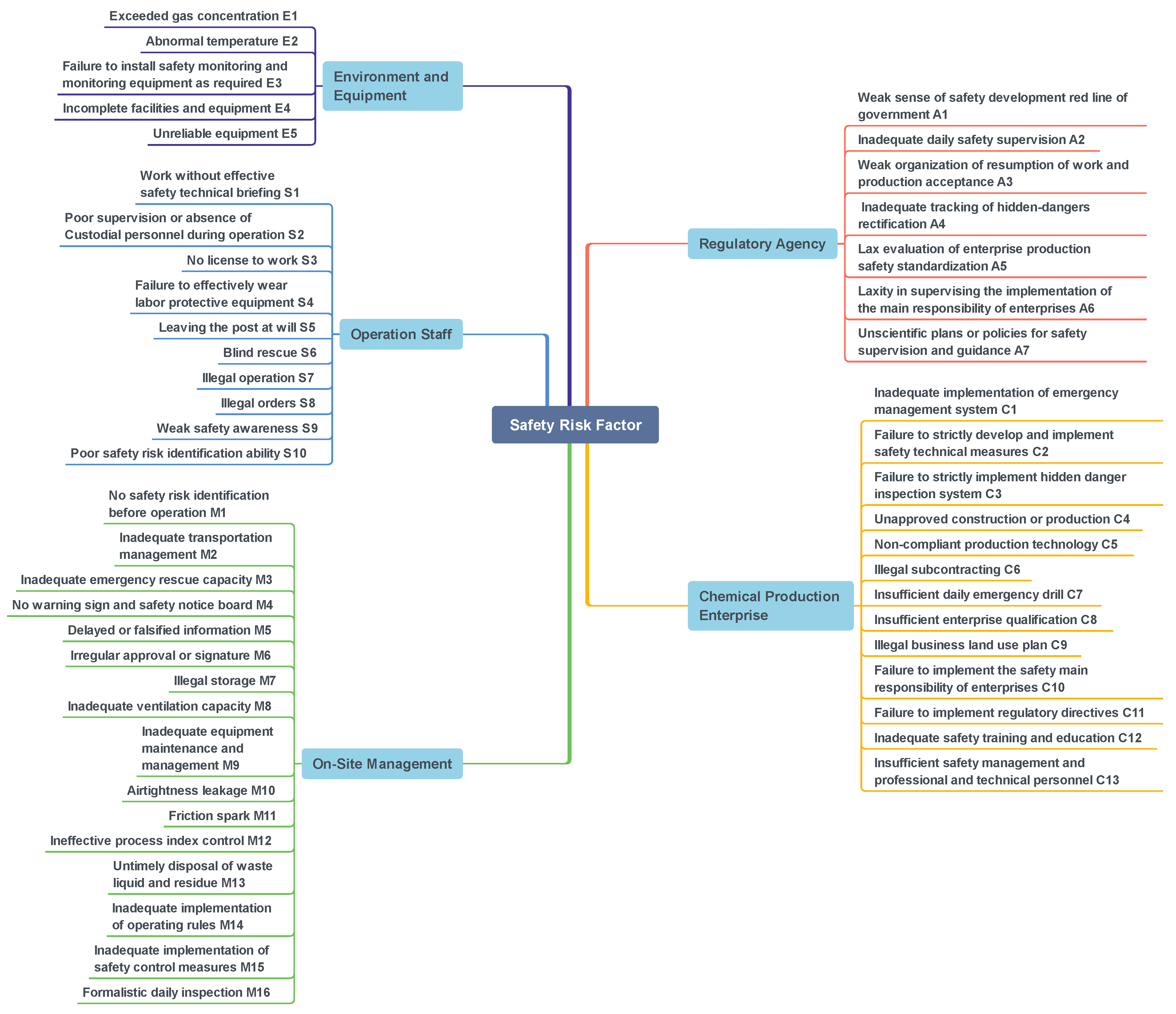
3.2.3. Result of Key Causes Generation
3.3. Association-Rule Analysis Result
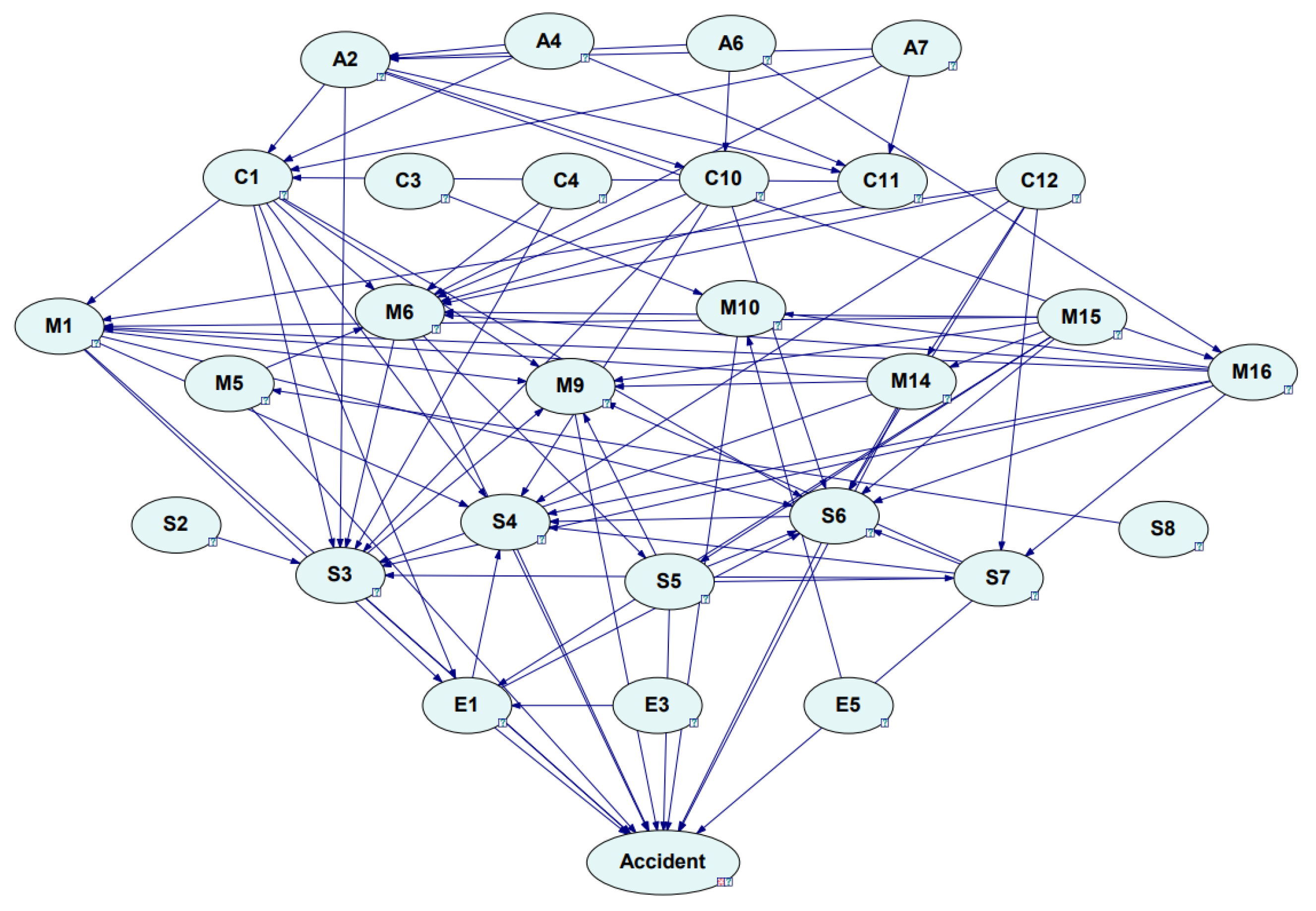
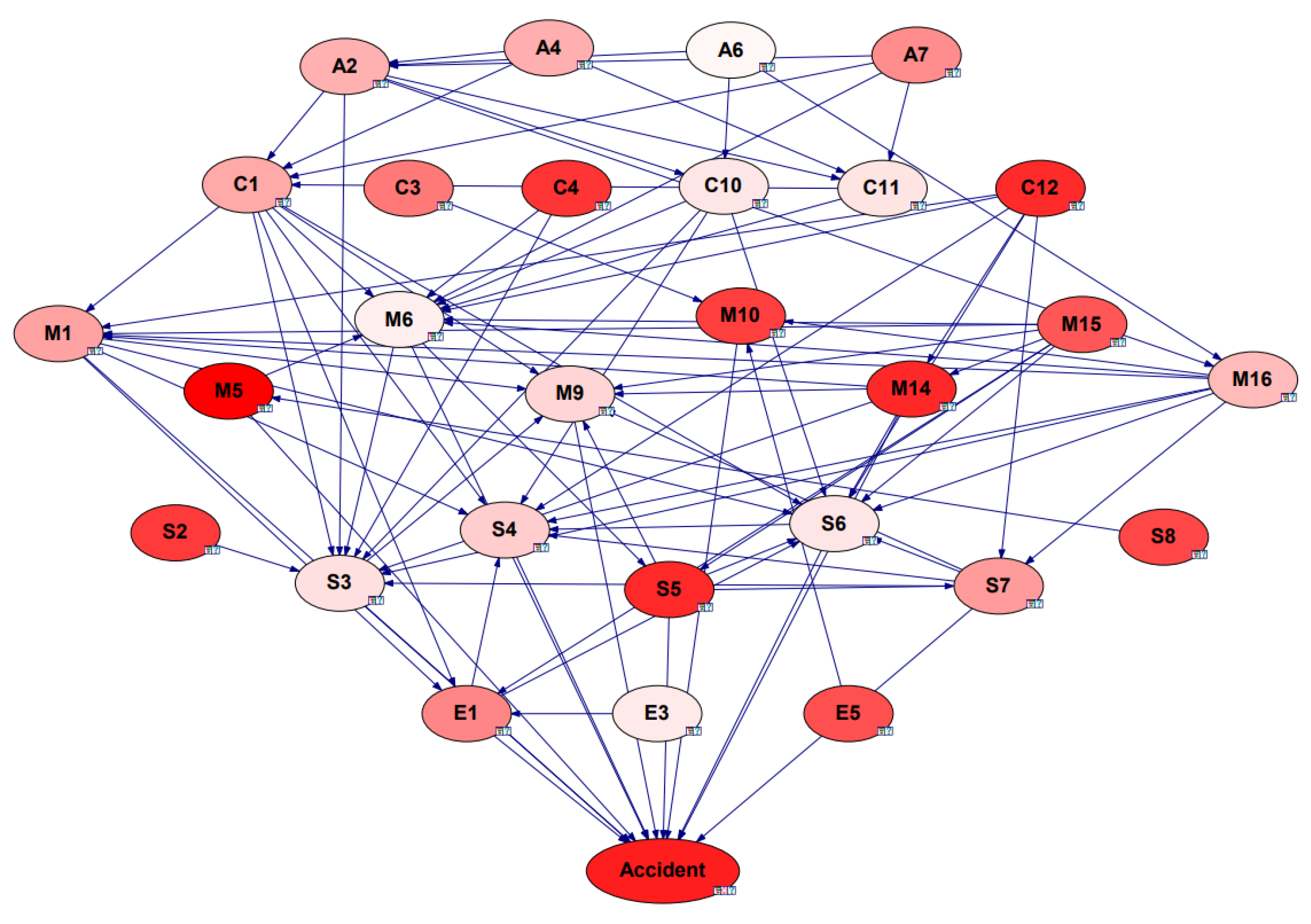
3.4. Bayesian Network Analysis Result
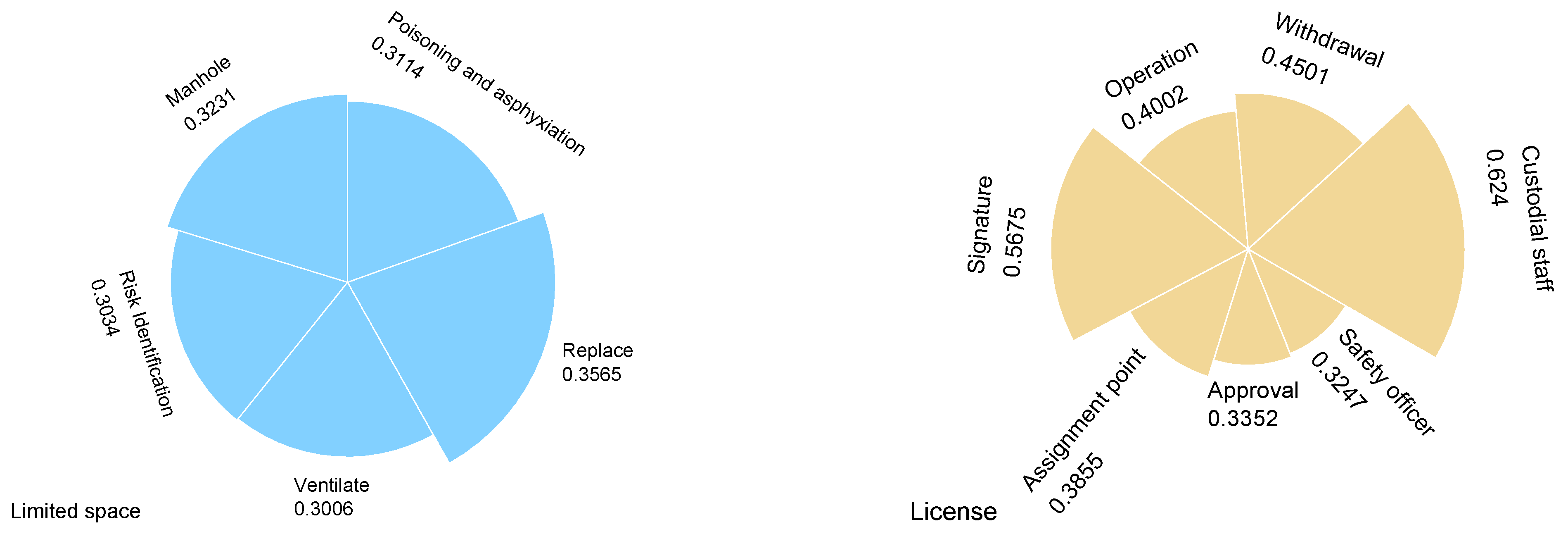
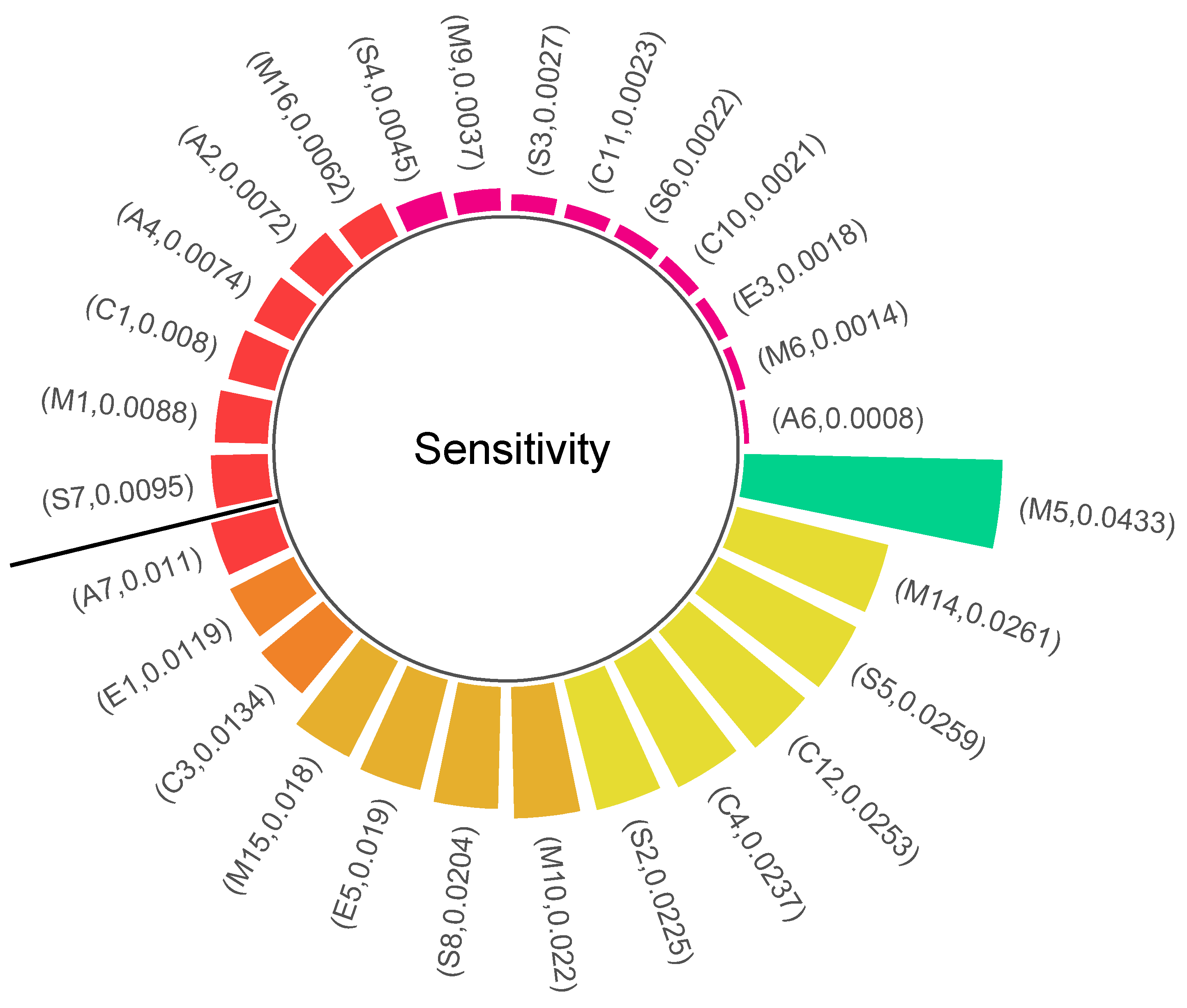
3.4.1. Sensitivity Analysis
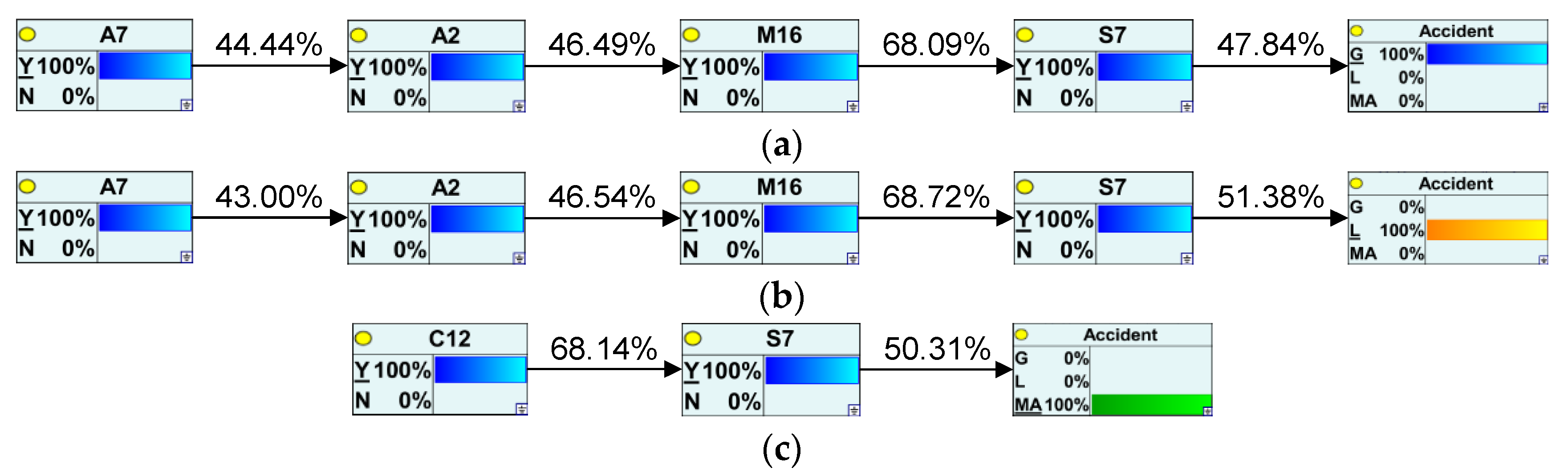
3.4.2. Key Cause Path Analysis
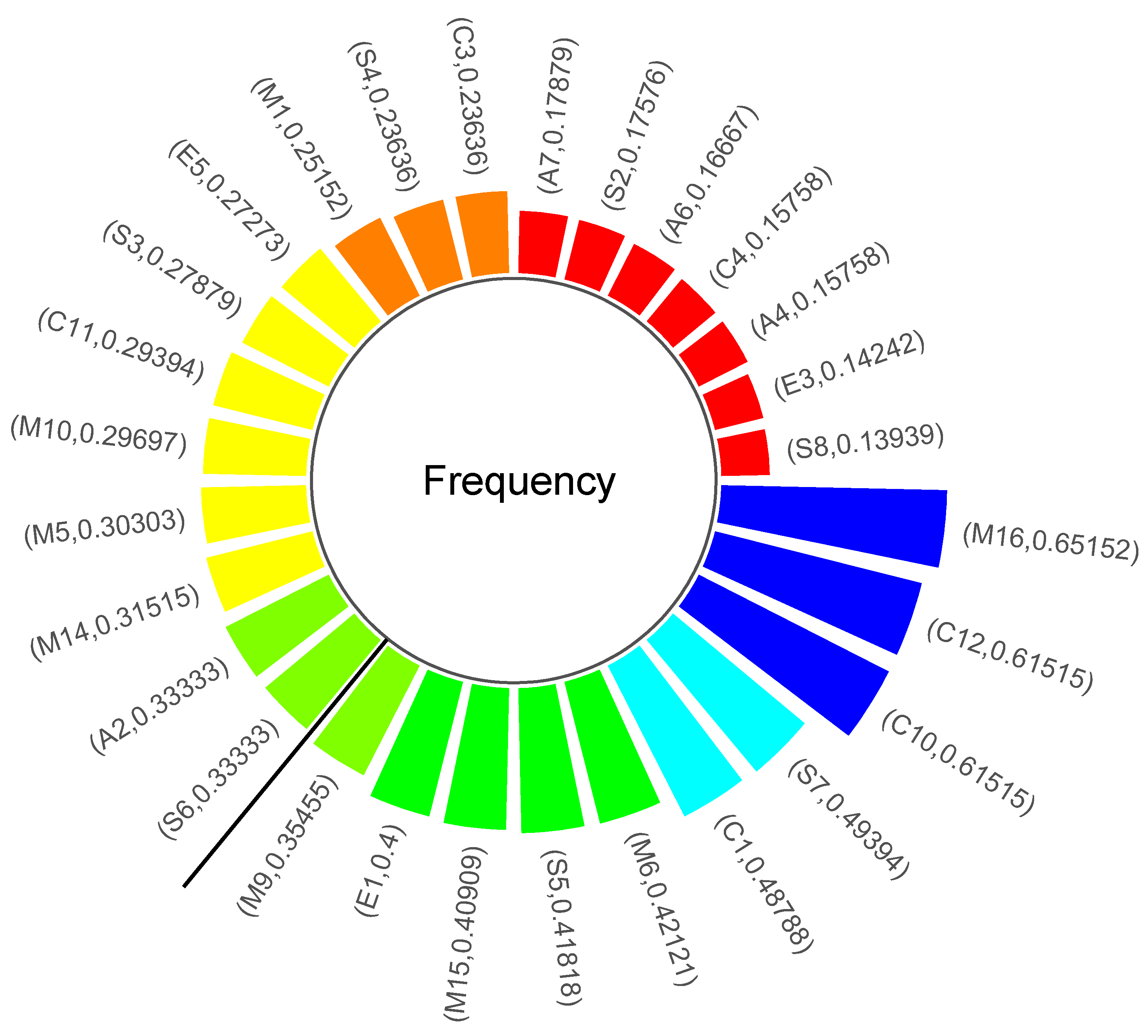
3.4.3. Frequency Statistical Analysis
3.4.4. Other Discovery
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- China’s Chemical Industry: New Strategies for a New Era. Available online: https://www.mckinsey.com/industries/chemicals/our-insights/chinas-chemical-industry-new-strategies-for-a-new-era (accessed on 29 June 2022).
- Southern Metropolis Daily. The Number of Larger Chemical Accidents in China Dropped to Single Digits for the First Time in 2021. Available online: https://www.mem.gov.cn/xw/xwfbh/2022n2y15rxwfbh/mtbd_4262/202202/t20220218_408142.shtml (accessed on 18 July 2022).
- National Chemical Accident Statistics: 620 Cases in Three Years, 728 People Died. Available online: https://news.sina.com.cn/c/2019-03-22/doc-ihsxncvh4721344.shtml (accessed on 18 July 2022).
- Chen, C.; Reniers, G.; Khakzad, N. Cost-benefit management of intentional domino effects in chemical industrial areas. Process Saf. Environ. Protect. 2020, 134, 392–405. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, G.; Chen, P. The probability prediction method of domino effect triggered by lightning in chemical tank farm. Process Saf. Environ. Protect. 2018, 116, 106–114. [Google Scholar] [CrossRef]
- Zhou, D.; Zhang, M. The integrated safety assessment on chemical industry park. In Proceedings of the 2017 9th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 26–27 August 2017. [Google Scholar]
- Zhao, J.; Suikkanen, J.; Wood, M. Lessons learned for process safety management in China. J. Loss Prev. Process Ind. 2014, 29, 170–176. [Google Scholar] [CrossRef]
- Wang, J.; Fu, G.; Yan, M. Comparative analysis of two catastrophic hazardous chemical accidents in China. Process Saf. Prog. 2020, 39, e12137. [Google Scholar] [CrossRef]
- Wang, B.; Wu, C.; Reniers, G.; Huang, L.; Kang, L.; Zhang, L. The future of hazardous chemical safety in China: Opportunities, problems, challenges and tasks. Sci. Total Environ. 2018, 643, 1–11. [Google Scholar] [CrossRef]
- Xu, N.; Ma, L.; Liu, Q.; Wang, L.; Deng, Y. An improved text mining approach to extract safety risk factors from construction accident reports. Saf. Sci. 2021, 138, 105216. [Google Scholar] [CrossRef]
- Nonaka, I. The Knowledge-Creating Company, 1st ed.; Harvard Business Review Press: Boston, MA, USA, 2008; pp. 1–72. [Google Scholar]
- Wang, B.; Li, D.; Wu, C. Characteristics of hazardous chemical accidents during hot season in China from 1989 to 2019: A statistical investigation. Saf. Sci. 2020, 129, 104788. [Google Scholar] [CrossRef]
- Fyffe, L.; Krahn, S.; Clarke, J.; Kosson, D.; Hutton, J. A preliminary analysis of Key Issues in chemical industry accident reports. Saf. Sci. 2016, 82, 368–373. [Google Scholar] [CrossRef]
- Zhang, H.; Zheng, X. Characteristics of hazardous chemical accidents in China: A statistical investigation. J. Loss Prev. Process Ind. 2012, 25, 686–693. [Google Scholar] [CrossRef]
- Chen, C.; Reniers, G. Chemical industry in China: The current status, safety problems, and pathways for future sustainable development. Saf. Sci. 2020, 128, 104741. [Google Scholar] [CrossRef]
- Liu, Q.; Meng, X.; Li, X.; Luo, X. Risk precontrol continuum and risk gradient control in underground coal mining. Process Saf. Environ. Protect. 2019, 129, 210–219. [Google Scholar] [CrossRef]
- Kumari, P.; Lee, D.; Wang, Q.; Karim, M.N.; Sang-Il Kwon, J. Root cause analysis of key process variable deviation for rare events in the chemical process industry. Ind. Eng. Chem. Res. 2020, 59, 10987–10999. [Google Scholar] [CrossRef]
- Miner, G.; Elder IV, J.; Fast, A.; Hill, T.; Nisbet, R.; Delen, D. Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications, 1st ed.; Academic Press: Waltham, MA, USA, 2012; pp. 921–1023. [Google Scholar]
- Zanasi, A. Virtual weapons for real wars: Text mining for national security. In Proceedings of the International Workshop on Computational Intelligence in Security for Information Systems CISIS’08, Genoa, Italy, 23–24 October 2008. [Google Scholar]
- Coussement, K.; Van den Poel, D. Integrating the voice of customers through call center emails into a decision support system for churn prediction. Inf. Manag. 2008, 45, 164–174. [Google Scholar] [CrossRef]
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Automated content analysis for construction safety: A natural language processing system to extract precursors and outcomes from unstructured injury reports. Autom. Constr. 2016, 62, 45–56. [Google Scholar] [CrossRef]
- Pavlinek, M.; Podgorelec, V. Text classification method based on self-training and LDA topic models. Expert Syst. Appl. 2017, 80, 83–93. [Google Scholar] [CrossRef]
- Zhong, B.; Pan, X.; Love, P.E.; Sun, J.; Tao, C. Hazard analysis: A deep learning and text mining framework for accident prevention. Adv. Eng. Inform. 2020, 46, 101152. [Google Scholar] [CrossRef]
- Chen, J.; Du, S.; Yang, S. Mining and evolution analysis of network public opinion concerns of stakeholders in hot social events. Mathematics 2022, 10, 2145. [Google Scholar] [CrossRef]
- Esmaeili, B.; Hallowell, M. Attribute-based risk model for measuring safety risk of struck-by accidents. In Proceedings of the Construction Research Congress 2012, West Lafayette, IN, USA, 21–23 May 2012. [Google Scholar]
- Rodrigues, R.S.; Balestrassi, P.P.; Paiva, A.P.; Garcia-Diaz, A.; Pontes, F.J. Aircraft interior failure pattern recognition utilizing text mining and neural networks. J. Intell. Inf. Syst. 2012, 38, 741–766. [Google Scholar] [CrossRef]
- Fan, H.; Li, H. Retrieving similar cases for alternative dispute resolution in construction accidents using text mining techniques. Autom. Constr. 2013, 34, 85–91. [Google Scholar] [CrossRef]
- Sanmiquel, L.; Rossell, J.M.; Vintró, C. Study of Spanish mining accidents using data mining techniques. Saf. Sci. 2015, 75, 49–55. [Google Scholar] [CrossRef]
- Tanguy, L.; Tulechki, N.; Urieli, A.; Hermann, E.; Raynal, C. Natural language processing for aviation safety reports: From classification to interactive analysis. Comput. Ind. 2016, 78, 80–95. [Google Scholar] [CrossRef]
- Yang, L. Causes Analysis of Rail Transit Accidents and Risk Research Based on Text Data. Doctoral Dissertation, Beijing Jiaotong University, Beijing, China, 2021. [Google Scholar]
- Esmaeili, B.; Hallowell, M.R.; Rajagopalan, B. Attribute-based safety risk assessment. II: Predicting safety outcomes using generalized linear models. J. Constr. Eng. Manag. 2015, 141, 04015022. [Google Scholar] [CrossRef]
- Wang, X.; Yang, L.; Wang, D.; Zhen, L. Improved TF-IDF keyword extraction algorithm. Comput. Sci. Appl. 2013, 3, 64–68. [Google Scholar]
- Wang, J.; Wang, S.; Cui, Q.; Wang, Q. Local-based active classification of test report to assist crowdsourced testing. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016. [Google Scholar]
- Ma, Y.; Xie, Z.; Li, G.; Ma, K.; Huang, Z.; Qiu, Q.; Liu, H. Text visualization for geological hazard documents via text mining and natural language processing. Earth Sci. Inform. 2022, 15, 439–454. [Google Scholar] [CrossRef]
- Sun, J.; Lei, K.; Cao, L.; Zhong, B.; Wei, Y.; Li, J.; Yang, Z. Text visualization for construction document information management. Autom. Constr. 2020, 111, 103048. [Google Scholar] [CrossRef]
- Qiu, Z.; Liu, Q.; Li, X.; Zhang, J.; Zhang, Y. Construction and analysis of a coal mine accident causation network based on text mining. Process Saf. Environ. Protect. 2021, 153, 320–328. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993. [Google Scholar]
- Li, S.; You, M.; Li, D.; Liu, J. Identifying coal mine safety production risk factors by employing text mining and Bayesian network techniques. Process Saf. Environ. Protect. 2022, 162, 1067–1081. [Google Scholar] [CrossRef]
- Ouali, A.; Cherif, A.R.; Krebs, M.O. Data mining based Bayesian networks for best classification. Comput. Stat. Data Anal. 2006, 51, 1278–1292. [Google Scholar] [CrossRef]
- Chen, J.; Li, K.; Yang, S. Electric vehicle fire risk assessment based on WBS-RBS and fuzzy BN coupling. Mathematics 2022, 10, 3799. [Google Scholar] [CrossRef]
- Yang, S.; Su, K.; Wang, B.; Xu, Z. A Coupled mathematical model of the dissemination route of short-term fund-raising fraud. Mathematics 2022, 10, 1709. [Google Scholar] [CrossRef]
- Chen, Z.; Yin, D.; Zeng, J.; Li, H.; Li, Z. Human factors inference of safety accidents in coal mine based on Bayesian network. J. Saf. Sci. Technol. 2014, 11, 145–150. [Google Scholar]
- Uusitalo, L. Advantages and challenges of Bayesian networks in environmental modelling. Ecol. Model. 2007, 203, 312–318. [Google Scholar] [CrossRef]
- Heckerman, D. Bayesian networks for data mining. Data Min. Knowl. Discov. 1997, 1, 79–119. [Google Scholar] [CrossRef]
- GeNIe Modeler. Available online: https://support.bayesfusion.com/docs/GeNIe/introduction_genie.html (accessed on 16 September 2022).
- Chen, L.; Huang, S.; Sun, J.; Hui, Z.; Wu, K. Bug report quality detection based on the BM25 algorithm. J. Tsinghua Univ. 2020, 60, 829–836. [Google Scholar]
- Yang, X.; Haugen, S. Implications from major accident causation theories to activity-related risk analysis. Saf. Sci. 2018, 101, 121–134. [Google Scholar] [CrossRef]

















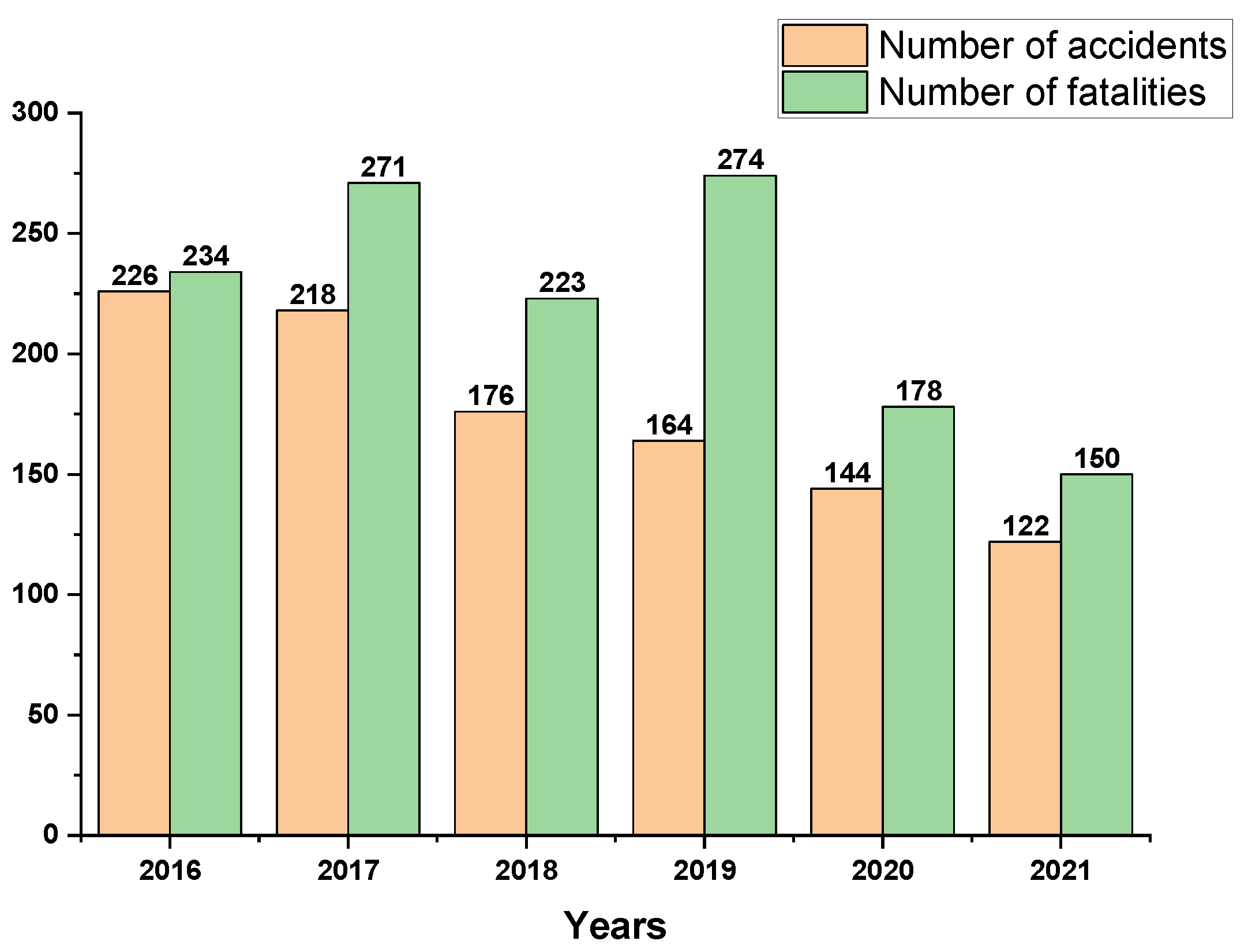{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Updating Times | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Error | ∞ | 0.70 | 0.37 | 0.17 |
| Corpus Number | Word Segmentation Result |
|---|---|
| 1 | <Enterprise> <Sewage> <Production technology> <Production technology> <Wastewater> < Sampling > <Check>…<Manager> < Safety measure> |
| 2 | <Workshop> <Production technology> <Production> <Warehouse> <Stop production> <Inspect and repair> <Dilute> <Production technology>…<Operating rule> <Check> |
| … | … |
| 330 | <On duty> <Operate> <Dimethylformamide> <Methanol> <High level tank> <Valve> <Rinse> <High level tank>…<Staff> <Operate> |
| Corpus | Accuracy | Recall | ||
|---|---|---|---|---|
| TF-IDF | BM25W | TF-IDF | BM25W | |
| Art (10) | 0.1511 | 0.1724 | 0.5004 | 0.5720 |
| Sports (10) | 0.2544 | 0.3168 | 0.5967 | 0.7417 |
| Politics (10) | 0.2130 | 0.1544 | 0.8267 | 0.6117 |
| Economy (10) | 0.1592 | 0.1670 | 0.6983 | 0.5917 |
| Agriculture (10) | 0.1712 | 0.1375 | 0.7250 | 0.6083 |
| Environment (10) | 0.2582 | 0.3734 | 0.4433 | 0.7150 |
| Computer (10) | 0.2776 | 0.5226 | 0.3733 | 0.6667 |
| History (10) | 0.1148 | 0.2299 | 0.4229 | 0.7731 |
| Space (10) | 0.1517 | 0.5453 | 0.2750 | 0.8083 |
| Energy (10) | 0.3567 | 0.5383 | 0.3789 | 0.5900 |
| average | 0.2108 | 0.3158 | 0.5240 | 0.6678 |
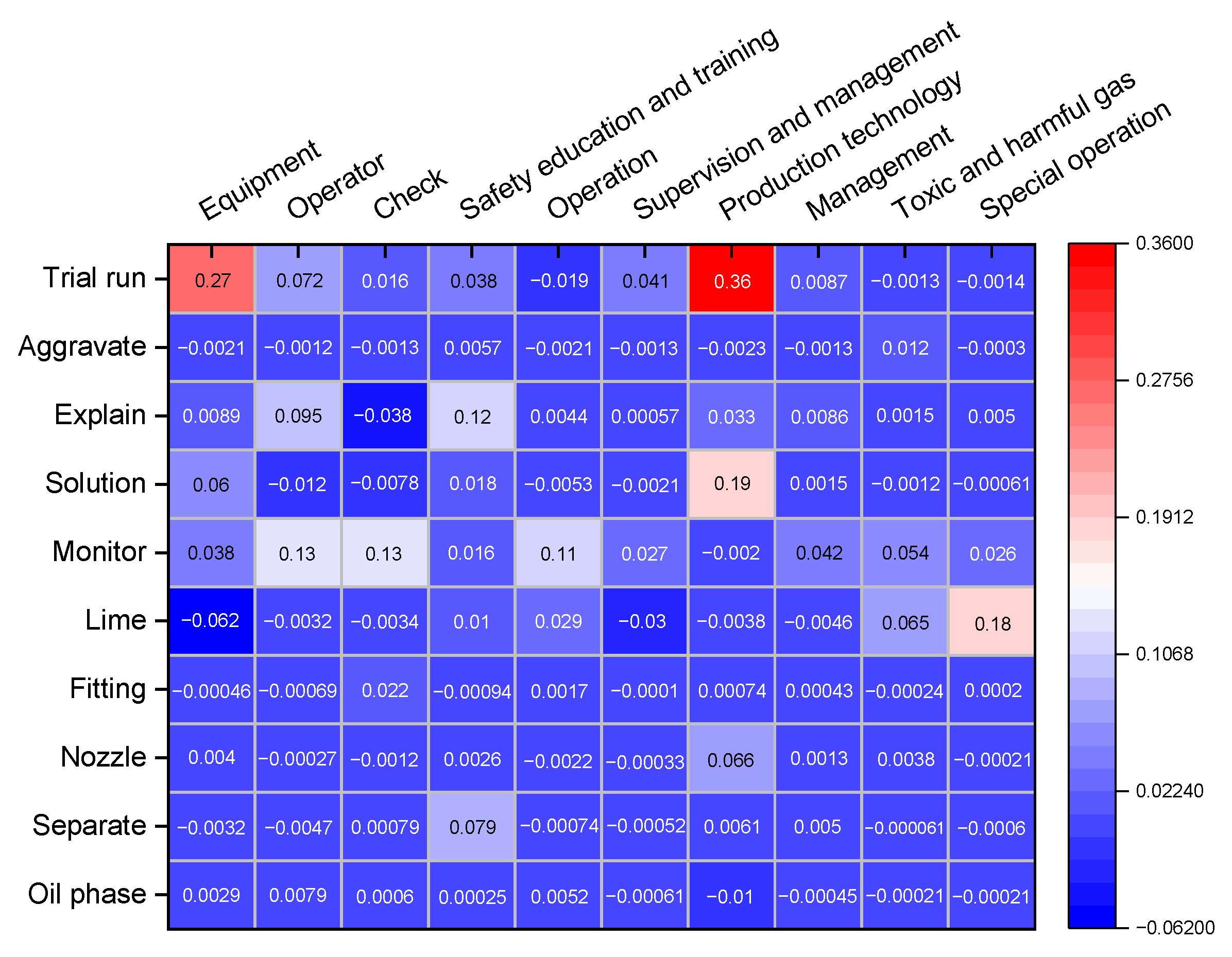
| Number | TF-IDF | BM25W |
|---|---|---|
| 1 | Enterprise | Equipment |
| 2 | Operation | Operator |
| 3 | Workshop | Check |
| 4 | Equipment | Safety education and training |
| 5 | Tank | Operation |
| 6 | Supervision and management | Supervision and management |
| 7 | Production | Production technology |
| 8 | Personnel | Management |
| 9 | Locale | Toxic and harmful gas |
| 10 | Check | Special operation |
| … | … | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | … | 5 | 0 | 1 | 0 | … | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | … | 3 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 0 | 0 | 0 | 0 | … | 12 | 0 | 1 | 0 | … | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | … | 3 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 0 | 0 | 0 | 0 | … | 4 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 |
| Association Rule | Support | Confidence | Lift |
|---|---|---|---|
| {S4, C12}⇒{S6} | 0.1545 | 0.8361 | 2.5082 |
| {C10, S6}⇒{S4} | 0.1273 | 0.5915 | 2.5027 |
| {E1, M15}⇒{M1} | 0.1121 | 0.6271 | 2.4934 |
| {A7, C1}⇒{C11} | 0.0939 | 0.7209 | 2.4526 |
| {M16, S6}⇒{S4} | 0.1394 | 0.5750 | 2.4327 |
| {S4, S5}⇒{S6} | 0.1030 | 0.8095 | 2.4286 |
| {E1, S5}⇒{S4} | 0.1000 | 0.5323 | 2.2519 |
| {C11, M16}⇒{A7} | 0.1000 | 0.4024 | 2.2509 |
| {M6, M14}⇒{S3} | 0.0970 | 0.6275 | 2.2506 |
| {C1, A2}⇒{C11} | 0.1303 | 0.6615 | 2.2506 |
| {E1, S7}⇒{S4} | 0.1152 | 0.5278 | 2.2329 |
| {E1, C12}⇒{S4} | 0.1394 | 0.5227 | 2.2115 |
| {M15, M14}⇒{M1} | 0.0939 | 0.5439 | 2.1623 |
| {M1, E1}⇒{S6} | 0.1091 | 0.7200 | 2.1600 |
| {S4, S6}⇒{E1} | 0.1727 | 0.8636 | 2.1591 |
| {S8}⇒{M5} | 0.0909 | 0.6522 | 2.1522 |
| {M9, E1}⇒{S6} | 0.1152 | 0.7170 | 2.1509 |
| {C4, M16}⇒{A2} | 0.0909 | 0.7143 | 2.1429 |
| {C11, M6}⇒{M5} | 0.0939 | 0.6458 | 2.1313 |
| {A7, A2}⇒{C11} | 0.0939 | 0.6200 | 2.1093 |
| … | … | … | … |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Huang, J.; Lu, Y.; Ma, H.; Li, W.; Chen, J. A New Text-Mining–Bayesian Network Approach for Identifying Chemical Safety Risk Factors. Mathematics 2022, 10, 4815. https://doi.org/10.3390/math10244815
Zhou Z, Huang J, Lu Y, Ma H, Li W, Chen J. A New Text-Mining–Bayesian Network Approach for Identifying Chemical Safety Risk Factors. Mathematics. 2022; 10(24):4815. https://doi.org/10.3390/math10244815
Chicago/Turabian StyleZhou, Zhiyong, Jianhui Huang, Yao Lu, Hongcai Ma, Wenwen Li, and Jianhong Chen. 2022. "A New Text-Mining–Bayesian Network Approach for Identifying Chemical Safety Risk Factors" Mathematics 10, no. 24: 4815. https://doi.org/10.3390/math10244815
APA StyleZhou, Z., Huang, J., Lu, Y., Ma, H., Li, W., & Chen, J. (2022). A New Text-Mining–Bayesian Network Approach for Identifying Chemical Safety Risk Factors. Mathematics, 10(24), 4815. https://doi.org/10.3390/math10244815