Abstract
The main goal of this paper is to propose a two-step method for the estimation of parameters in non-linear mixed-effects models. A first-step estimate of the vector of parameters is obtained by solving estimation equations, with a working covariance matrix as the identity matrix. It is shown that is consistent. If, furthermore, we have an estimated covariance matrix, , by , a second-step estimator can be obtained by solving the optimal estimation equations. It is shown that maintains asymptotic optimality. We establish the consistency and asymptotic normality of the proposed estimators. Simulation results show the improvement of over . Furthermore, we provide a method to estimate the variance using the method of moments; we also assess the empirical performance. Finally, three real-data examples are considered.
MSC:
62F12
1. Introduction
Non-linear mixed-effects models (NLMEMs) have been described in the literature, and have been used particularly in pharmacokinetics to identify sources of variability in drug concentration in the patient population [1,2]. For example, in [3] (Section 20.3), the authors discussed a toxicokinetic model, involving 15 parameters for each of the six persons in a pharmacokinetics experiment. Some methods for the estimation of fixed effects and variance components in NLMEMs have been described. The marginal density of the response variable does not have a closed-form expression, so some approximation methods have also been proposed, for example, taking a first-order Taylor expansion of the non-linear function for the conditional modes of the random effects model [4], Laplacian approximation [5], importance sampling [5,6], and Gaussian quadrature approximation [7].
Iterative estimation equations (IEEs) [8,9] have been investigated in the context of a semi-parametric regression model for longitudinal data with an unspecified covariance matrix; consistency and asymptotic efficiency have also been demonstrated [10]. However, it is time-consuming or difficult to obtain the convergence using the iterative method when the sample size is too large. Here, we improve and extend this method to the non-linear mixed-effects model.
This paper is structured as follows: In Section 2, we discuss a two-step method for estimating the parameters of non-linear mixed effects models. In Section 3, we study the asymptotic properties of the estimators. Section 4 contains details of the simulation results. In Section 5, we propose a method to estimate the variance . The analysis of real data is considered in Section 6. All of the technical results can be found in the Appendix A, Appendix B, Appendix C and Appendix D.
2. Estimation in a Non-linear Mixed-Effects Model
2.1. Non-linear Mixed-Effects Model
A non-linear mixed-effects (NLME) model can be expressed as follows:
where is the response or observation vector for the observation of the individual, f is a known non-linear function, is the vector of covariates, is a population parameter vector, is a vector of the unobserved latent variables that are random across subjects, and represents the error, independent of [11]. We assume that and , and that they are independent of each other [2,4,11].
Next, we describe a method for estimating the parameter .
2.2. Parameter Estimation
Let the responses be , the sample size be N, and be the parameter space; and are the vectors of the true parameter.
As in the iterative estimation equation, we now use the estimation equation to estimate the parameter, as follows:
where , and is a sequence of positive constants, , where r represents the dimensions of parameter . The notation represents dependence on the sample size, N.
For longitudinal data, Equation (1) can be expressed as
where
Note that the generalized estimation equation (GEE) [8] corresponds to , , which is the true covariance matrix, but which is usually unknown. Hence, we propose a two-step estimation method.
Let ; then, the first-step estimator is the solution to the equation
For the second-step estimator, we derive an estimate for using the first-step estimator . Then, letting , we use the equation to obtain the second-step estimator .
If we iterate until convergence, the iterative equation estimator (IEE) is obtained. However, it will sometimes be difficult to obtain convergence.
It is shown in the next section that, under suitable conditions, and are consistent. Furthermore, our simulations show that outperforms in terms of efficiency. Furthermore, our simulation results show that the estimated efficiency of the second-step estimate is not much different from that of the GEE method.
A challenging task during computation is solving the estimation equation, which, under such a model, typically does not have an analytic expression. We tried to solve equations with the most popular methods, such as the Newton–Raphson iterative algorithm [12], but failed. Finally, we solved the estimation equation using the non-linear Gauss–Seidel algorithm, whose convergence has been established [13].
Remark 1.
The method can only estimate the parameters involved in . In the case of the linear mixed-effects model, the method can only estimate the fixed effects. For example, for the linear mixed-effects model , we assume the random effect and independent error ϵ, . As can be seen, in order to use our method, we need to know ; then, we can estimate parameter β but cannot estimate the variance of random effects, R. However, under a non-linear mixed-effects model, the method can be used to estimate both the fixed effects and the variance of the random effects, as is the case for our simulation.
Remark 2.
The matrix V can occasionally be singular. In this case, we suggest using the Moore–Penrose generalized inverse of V in place of .
3. Asymptotic Properties of the Estimator
In this section, we study the consistency and asymptotic normality of first- and second-step estimators.
We assume that the first-step() estimator is the solution to Equation (3). Let
Consider as a map from to a subset of . Let be the image of under .
For and , define . represents the complement of A.
Let be a sequence of non-negative random variables. We say that with a probability tending to one if for any there is such that for large n. Note that this is equivalent to [14].
Theorem 1.
(i) Suppose that,
in probability, as .
Theorem 2.
(i) Suppose that
in probability, as .
(ii) Suppose for any , there is and , such that, for large N,
Let be the covariance matrix of y.
Write ,
is the element of , lies between and .
.
Theorem 3.
Suppose that
(i) The components of are three-time continuously differentiable;
(ii) satisfies (3) with a probability tending to one and is consistent;
(iii) There exists such that
in probability, where
(iv)
in distribution.
(v) is bounded in probability,
is bounded in probability.
where , is the element of .
Then, is asymptotically normal with mean and asymptotic covariance matrix
4. Simulation
Example 1.
Consider a simple case of a non-linear mixed-effects model that can be expressed as
, where and are independent, with and . We consider as a nuisance parameter whose estimation is not considered. Let ; we consider the estimation of the unknown parameters β and τ.
In this model, it is easy to see that has the same (joint) distribution, hence, for an unspecified covariance matrix, . For the second-step estimate, is estimated by the method of moments (MoM) as follows:
Consider a set of unbalanced data. Table 1 shows the results of a simulation in which m = 500, for , the true parameters are , and generated from N(0, 1). The results are based on 500 simulations. We find a 13.21% improvement in the second-step estimator over the first-step estimator in terms of the total mean squared error, and the second-step estimator is very close to the GEE estimator in efficiency.

Table 1.
Simulation result: non-linear model.
Example 2.
Consider the following non-linear mixed-effects model, an exponential model, which may be used to model changes in drug concentration. Let
where is the random effect with a distribution , and is the error, which is independent of , with distribution . and are fixed parameters. represents the time of observation. Assuming that is known, we estimate parameter .
Let and , with the true parameters . The results, based on 500 simulation runs, are presented in Table 2. We see an improvement of approximately 12.5% in the second-step estimator over the first-step estimator in terms of the total mean squared error. Furthermore, we see that the second-step estimate is comparable to the GEE method.
Table 2.
Simulation estimation result.
5. Estimate of Variance
We have so far not discussed how to estimate the variance . Now, we propose a method to estimate this parameter and study its empirical performance.
For a non-linear mixed-effects model
we assume the same conditions as in Section 2.1. Let , , we have
The summation of both sides of over leads to
where . If were observable, by removing the expectation sign on the left side of , and replacing and by their available estimators, and , respectively, an empirical method of moments (EMM) estimator of would be obtained, that is,
The difficulty is, of course, that are unobserved. To handle this situation, we replace on the right side of with their conditional expectations given y, and , respectively, that is,
To compute the conditional expectations, we need to know the parameters, and . The is replaced by the current estimator, . As for , we use an idea similar to the EM algorithm. Let be the current estimator of . Then, the conditional expectations are computed under and , denoted by . We then use
to update , from to . We continue until convergence, that is, when (e.g., ). The final estimator, , is denoted by . The initial estimator, , is obtained by the right side of with . We now consider an example.
Example 3.
(Example 1 Continued). In this model, we obtain
and
where is the condition probability density function, and it is obvious that .
The parameter is replaced by the estimator , either the first-step estimate or second-step estimate. Then, using the same simulation design as Example 1, we iterate and to obtain the estimator . Based on 500 simulation runs, we found that some solutions did not converge, so we used the converge solution to obtain the results, which are shown in Table 3. The results show that there is little difference using a different method, but the estimation result is good. We can use either the first-step estimate or second-step estimate for the next step.
Table 3.
Estimate .
Remark 3.
The results in Table 3 are based on the converged solutions only. An implication is that, if the solution converges one may expect a good estimate from this procedure. In our real-data analysis results, the solution converged in all cases. A topic of future work would be to improve the estimator with better convergence.
6. Real Data
6.1. Height of Girls
The data are from the Longitudinal Studies of Child Health Development project, initiated in 1929 at the Harvard School of Public Health (the full description of the project is given by Stuart and Reed, 1929 [15]), which consists of the heights of 67 girls and 67 boys aged from 7 to 18, as described in chapter 8, Demidenko (2013) [16]. Here, we only consider the data for the girls, see Figure 1; the data from the boys are similar.
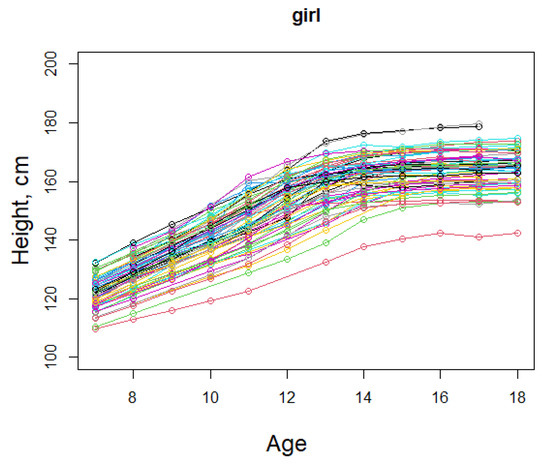
Figure 1.
The height of girls aged from 7 to 18.
We use a non-linear mixed-effects model to describe the growth trend. For example, assuming that one parameter is subject-specific, the NLME model is
where and represents the random effect with distribution . Furthermore, we assume the random errors are independent from , and are distributed as . is the age for girl at time. We first estimate the parameter .
For simplicity of notation, let . Under this model, we can obtain It is convenient to use the expression , where . Then, we have
In order to estimate parameter , we use the first-step estimation equation
The parameter estimate is , which is solved using the Gauss–Seidel iteration method.
The second-step estimation equation is
where , but this value is unknown, so we need an estimate to approximate it. Because the dataset consists of unbalanced data, the estimators of the covariances are obtained component-wise [10]. The estimates are .
Next, we use our method to estimate the parameter . In this model, ; then, we can obtain the first-step estimator and second-step estimator .
6.2. Indomethacin Concentration
Pinheiro and Bates (2000) [17] presented a dataset on the drug indomethacin for six patients. Every patient was injected with intravenous indomethacin before the commencement of the study. The plasma concentration of the indomethacin level (mcg/mL) of the patients was measured 11 times at the following points (hr): t = (0.25, 0.5, 0.75, 1, 1.25, 2, 3, 4, 5, 6, 8). Let represent the plasma concentration for patients at point. We can plot the concentration change, as shown in Figure 2.
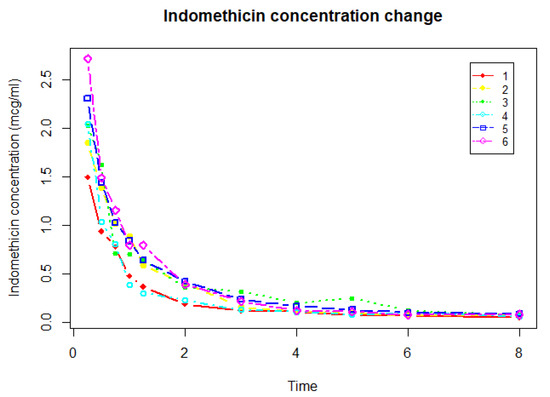
Figure 2.
Indomethicin concentration (mcg/mL) of six individuals measured 11 times after injection.
From the plot, we can see that the initial decrease in the plasma concentration of the drug level is dramatic due to the movement of the drug from the body circulation system into the tissue, until an equilibrium is reached. We establish a non-linear mixed-model to describe the change. , where we assume to be random effects, which are independent and distributed as . are i.i.d random errors distributed as , and and s are independent of each other. We use our method to estimate the parameter . The first-step estimate is and the second-step estimate is . The results show that the first-step estimate is comparable to the second-step estimate.
Then, we estimate the parameter . In this model, . Then, we can obtain the first-step estimator and second-step estimator . The two-step estimator returns the same estimate, so the first-step estimates are the ones to be used.
6.3. Orange Trees
We consider the data on the growth of orange trees over time given in Draper and Smith ([18] Exercise 24.N, p.559), described in [4]. The data are presented in Figure 3 and consist of seven measurements of the trunk circumferences (in millimeters) of five trees on seven occasions.
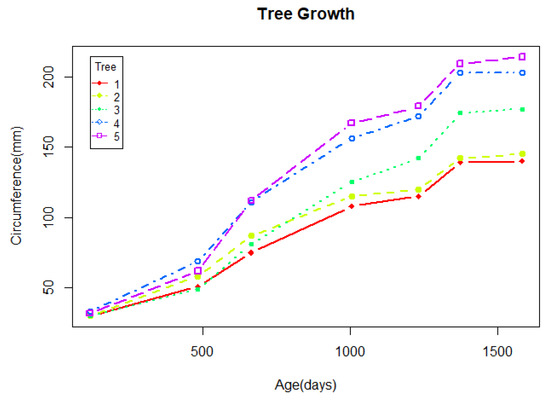
Figure 3.
Trunk circumference (in millimeters) of five orange trees.
Each of the five trees was measured at 118, 484, 664, 1004, 1231, 1372, and 1582 days after December 31, 1968, when the study started. Let be the trunk circumferences (in millimeters) for the tree at time. We consider a non-linear model as follows:
where represents the day corresponding to the measurement; are independent random effects, identically distributed as ; and are the random errors, assumed to be independent and distributed as . and are independent of each other. We use our method to estimate the parameter . The first-step estimate is , and the second-step estimate is . If the iteration converges, we can obtain the estimate . The results show that the two-step estimate is similar to the converged estimate. We use the second-step estimate for subsequent work. For , we can obtain the first-step estimator and second-step estimator . It is shown that the two-step estimate is very close.
7. Concluding Remarks
In this paper, we propose a two-step method to estimate the parameters, and we study the asymptotic properties of the estimators. This method is very convenient to use because it depends only on and we do not have to know the special distribution of . On the other hand, this method can only estimate the parameters related to . Thus, we need some other method to estimate other parameters. Here, we provide a method to estimate the variance using the method of moments.
We found that the second-step estimate is sometimes not more efficient than the first-step estimate, or that it demonstrates little improvement. In such a case, we choose to use the first-step estimate, which is simpler and computationally more attractive.
In this paper, the numerical solution is also an important topic. Hence, we will attempt to improve our numerical solution method in future work; see [19,20,21].
Author Contributions
Conceptualization, J.W. and J.J.; methodology, J.W., Y.L. and J.J.; software, J.W.; validation, J.W., Y.L. and J.J.; formal analysis, J.J. and Y.L.; investigation, J.W., Y.L. and J.J.; resources, J.W., Y.L. and J.J.; data curation, J.W. and J.J.; writing—original draft preparation, J.W.; writing—review and editing, Y.L. and J.J.; visualization, J.W.; supervision, Y.L.and J.J.; project administration, J.W., Y.L. and J.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key R&D Program of China, Grant No. 2018YFA0703900, and the National Science Foundation of China, Grant No. 11971264.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All the data included in this study are available upon request from the corresponding author.
Acknowledgments
We are thankful to the reviewers for their constructive comments, which helped us to improve the manuscript.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Appendix A
Appendix B
Proof of Theorem 2.
For any ,
by (6), there is and such that
by (4), there is , any such that as .
by Theorem 1, there is such that for ,
Then, for ,, such that
On the other hand, by (7), there is and , such that
Then, for any , there is , such that
The result follows because with a probability tending to one and by the above argument.
Appendix C
Lemma A1.
We find that (4) holds provided that, as ,
where .
Proof.
By Chebyshev’s Inequality, we know that
Then, by (L1), we can obtain , followed by (4). □
Proof.
For any :
By condition (1), there is such that ,
By condition (2), for any , there is such that
Then, let , as , by triangle inequality we have
Then, (5) holds. □
Lemma A3.
Suppose that
there are continuous functions , such that
(1) with a probability tending to one.
(2) For any , such that
(3) If, as , is bounded in probability.
Then, there is a compact subset such that (6) holds with .
Proof.
For any :
By condition (1), there is such that , .
By condition (2), for any (),there is such that if and uniformly in N; there is such that if and uniformly in N.
Then, for any , there is , such that
if and . Similarly, we can obtain if and .
By condition (3), there is such that , let ,then ,
So for any there is if . Then,, ,so . Furthermore, are continuous functions. If they are uniformly continuous in a compact set, then
Then, there is , if such that
Similarly, if , then .
So, for any , let compact subset . Then, if , there is , such that . Then, (6) holds. □
Lemma A4.
Suppose is continuously differentiable,
(1)
means the smallest eigenvalue.
(2) For any ,
(3)
where , is ,
lies between θ and .
is , the (k,l) element is
(4) Suppose there is a compact set such that , and ,
, as
Then, there is a compact such that ,
as , where is any compact subset of Θ that includes as an interior point.
Proof.
by Taylor expansion,
where the element of is
where lies between and .
Then, , where
So
so,
Let
we have
by , we can obtain
By (2), there is , , as , such that , let ; therefore,
For any , by condition (3), for any there is , as .
So, there is , as , such that
So, for any , there is , as , such that
Suppose is a compact subset that includes as an interior point, as say, there is ,
Let , when then there is , as , such that
Let , there is , as such that
Then, there is a compact such that ,
as , where is any compact subset of that includes as an interior point. □
Appendix D
Proof of Theorem 3.
By the Taylor expansion, it is easy to show that
Take into the equation,
Now, we have
where
Write . Then,
by (iv)(v)(vi),
so
in distribution. Furthermore, we have
where
so
then
in probability, in distribution, so
Then, is an asymptotically normal with mean and asymptotic covariance matrix
□
References
- FDA US. Guidance for Industry: Population Pharmacokinetics; FDA: Rockville, MD, USA, 1999. [Google Scholar]
- Jiang, J.; Ge, Z. Mixed models: An overview. In Frontiers of Statistics in Honor of Professor Peter J. Bickel’s 65th Birthday; Fan, J., Koul, H., Eds.; Imperial College Press: London, UK, 2006; pp. 445–466. [Google Scholar]
- Gelman, A.; Carlin, J.; Stern, H.; Rubin, D. Bayesian Data Analysis, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Lindstrom, M.; Bates, D. Nonlinear mixed effects models for repeated measures data. Biometrics 1990, 46, 673–687. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, J.; Bates, D. Approximations to the Log-likelihood function in Nonlinear Mixed Effects Models. J. Comput. Graph. Stat. 1995, 4, 12–35. [Google Scholar]
- Geweke, J. Bayesian Inference in Econmetric Models Using MonteCarlo Integration. Econometrica 1989, 57, 1317–1339. [Google Scholar] [CrossRef]
- Davidian, M.; Gallant, A.R. Smooth Nonparametric Maximum Likelihood Estimation for Population Pharmacokinetics, with Application to Quinidine. J. Pharmacokinet. Biopharm. 1992, 20, 529–556. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J. Linear and Generalized Linear Mixed Models and Their Applications; Springer: New York, NY, USA, 2007. [Google Scholar]
- Jiang, J.; Nguyen, T. Linear and Generalized Linear Mixed Models and Their Applications, 2nd ed.; Springer: New York, NY, USA, 2021. [Google Scholar]
- Jiang, J.; Luan, Y.; Wang, Y.G. Iterative Estimating Equations: Linear Convergence and Asymptotic Properties. Ann. Stat. 2007, 35, 2233–2260. [Google Scholar] [CrossRef]
- Jiang, J. Asymptotic Analysis of Mixed Effects Models. Theory, Applications, and Open Problems; Chapman & Hall/CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- McCullagh, P. ; Nelder, J A. Generalised Linear Modelling; Chapman and Hall: New York, NY, USA, 1989. [Google Scholar]
- Jiang, J. A nonlinear Gauss–Seidel algorithm for inference about GLMM. Comput. Stat. 2000, 15, 229–241. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, W. Robust estimation in generalised linear mixed models. Biometrika 2001, 88, 753–765. [Google Scholar] [CrossRef]
- Stuart, H.C.; Reed, R.B. Longitudinal studies of child health and development, Harvard School of Public Health, Series II, No. 1, Description of project. Pediatrics 1929, 24, 875–885. [Google Scholar] [CrossRef]
- Demidenko, E. Mixed Models: Theory and Applications with R; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Pinheiro, J.; Bates, D. Mixed-Effects Models in S and S-PLUS; Statistics and Computing Series; Springer: New York, NY, USA, 2000. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis, 3rd ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Qalandarov, A.A.; Khaldjigitov, A.A. Mathematical and numerical modeling of the coupled dynamic thermoelastic problems for isotropic bodies. TWMS J. Pure Appl. Math. 2020, 11, 119–126. [Google Scholar]
- Shokri, A.; Saadat, H. Trigonometrically fitted high-order predictor–corrector method with phase-lag of order infinity for the numerical solution of radial Schrödinger equation. J. Math. Chem. 2014, 52, 1870–1894. [Google Scholar] [CrossRef]
- Shokri, A.; Saadat, H. P-stability, TF and VSDPL technique in Obrechkoff methods for the numerical solution of the Schrodinger equation. Bull. Iran. Math. Soc. 2016, 42, 687–706. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).