Abstract
In this paper, we develop and study a novel testing procedure that has more a powerful ability to detect mean difference for functional data. In general, it includes two stages: first, splitting the sample into two parts and selecting principle components adaptively based on the first half-sample; then, constructing a test statistic based on another half-sample. An extensive simulation study is presented, which shows that the proposed test works very well in comparison with several other methods in a variety of alternative settings.
MSC:
62G10; 62G20
1. Introduction
In the recent literature, there has been an increasing interest in functional data analysis, with its extensive application in biometrics, chemometrics, econometrics, and medical research, as well as other fields. Functional data have intrinsically infinite dimensions and thus, classical methods for multivariate observations are not applicable. Therefore, it is necessary to develop special techniques for this type of data. There has intensive methodological and theoretical development in function data analysis; see [1,2,3,4,5] and so on.
In functional data analysis, a functional data set or curve can be modeled as independent realizations of an underlying stochastic process:
where is the mean function of the stochastic process, is the ith individual function variation from , and is the ith measurement error process. In general, we assume and are independent, and i.i.d. sample from and , respectively, where, , , and SP denotes a stochastic process with mean function and covariance function .
The mean function reflects the underlying trend and can be used as an important index for population response, such as in drug and biomedical purposes, among other. One important statistical inference other than estimation is related to testing of various hypotheses about the mean function. Therefore, we focus on the problem of testing the equality of mean functions in two random samples independently drawn from two functional random variables. There have been some approaches proposed so far to address this problem. For instance, Ref. [6] proposed an adaptive Neyman test, but in the case when the sampling information is in a “discrete” format. Ref. [7] discussed two methods: multivariate analysis-based and bootstrap-based testing.
However, these methods have only been applied in narrow fields and not available for a global testing result. Refs. [8,9] proposed an -norm based statistic to test the equality of mean functions. Ref. [10] proposed and studied a so-called Globalized Pointwise F-test, abbreviated as GPF test. The GPF test is in general comparable with the -norm-based test and the F-type test adopted for the one-way ANOVA problem. Then, Ref. [11] proposed the -test; via some simulation studies, it was found that in terms of both level accuracy and power, the -test outperforms the Globalized Pointwise F (GPF) test of [10] when the functional data are highly or moderately correlated, and its performance is comparable with the latter otherwise. Ref. [5] proposed a statistic based on the functional principal component emi-distances. Furthermore, they gave a normalized version of the functional principal components that has a chi-square limit distribution. The statistic is scale-invariant. However, this method require pre-specifying a threshold to choose the leading principal components (PCs), where PCs are ranked based on eigenvalues. They chose the number of PCs, for example, d, based on the percentage of variance explained for the functional covariates. This method has two drawbacks: one is that it can only detect mean differences in this d-dimensional subspace; the other is that different thresholds often lead to different tests, whose power depends on the particular simple alternative hypothesis.
In this paper, we develop and study a novel testing procedure that overcomes the drawback that many tests can only detect mean difference in the d-dimensional subspace. Furthermore, the novel testing procedure is very powerful in the cases when there are differences in middle part and latter part of two function sequences. Additionally, we derived the asymptotic distribution of the new test statistics under the alternative hypothesis, which is the key difficulty in the current approach. In general, the novel testing procedure includes two stages: first, split the sample into two parts and select PCs adaptively based on the first half-sample; then, construct the test statistic based on another half-sample. Sample splitting is often used in high-dimension regression problems because most computationally efficient selection algorithms cannot guard against inclusion of noise variables. Asymptotically valid p-values are not available. Ref. [12] adopted this technology to reduce the number of variables to a manageable size using the first split sample and apply classical variable selection techniques with the remaining variables, using the data from the second split.
In our procedure, we mainly adopt two methods to select PCs in the first stage: the adaptive Neyman test [6] and the adaptive ordered Neyman test. At the same time, we also consider selecting PCs based on pre-specifying a threshold; however, this threshold is an association–projection index that combines both the variation and the projection along each direction. The purpose of splitting the sample is two-fold: (1) to decrease the random noise effect in the first stage; (2) to derive the asymptotic distribution of the test statistic. From simulation results, we can see that our testing procedure asymptotically achieves the pre-specified significance level, and enjoys certain optimality in terms of its power, even when the population is a non-Gaussian process.
This paper is organized as follows. In Section 2, we introduce the test problem and briefly review the existing global two-sample test methods. Section 3 proposes our testing procedure. Simulation studies are given in Section 4. A real-data example is analyzed in Section 5. Section 6 concludes the present work. The derivations are given in Appendix A.
2. The Testing Problem for Functional Data
2.1. Preliminary
Let () denote a stochastic process with mean function and covariance function , where . Suppose we have the following two independent function samples:
where denotes the covariance function of the function data and denotes the covariance function of the function data . However, we do not know if and are equal. We want to test whether the two mean functions are equal:
Let denote the sample mean functions of the two samples, respectively. First, we have
and
where . can be written as , where are the eigenvalues and are eigenfunctions satisfying and .
It is easy to see that , and .
can also be written in as an eigen-decomposition
where the nonincreasing sequence is the sample eigenvalues and are the corresponding eigenfunctions forming an orthonormal basis of .
To simplify notation, we use the symbol for both the kernel and the operator. Now, the functional Mahalanobis semi-distance between and is defined as:
Plugging (6) into (7), we have
2.2. Existing Global Testing Methods
Although there is significant literature discussing the equality of means for two functional data sets, they can be roughly grouped into a few broad categories, as follows.
- (1)
- -norm-based test
The test is based on the -norm of the difference between and :
Ref. [8] proved that , , where denotes that X and Y have the same distribution, and Furthermore, they use the two-cumulant matched approximation method and obtained an approximate distribution of , which is, , where
Then, they have
- (2)
- Projection-based Test
Ref. [5] considered projecting the observed mean difference onto the space spanned by , where d is determined based on the percentage of eigenvalues, constructed the following test statistic:
Given d, the asymptotic distribution of under the null hypothesis is the distribution of , where are independent standard normal random variables. Alternately, they proposed a normalized version of which is given by
Then, under the null hypothesis, has an asymptotic distribution.
- (3)
- F-test
Finally, we describe the testing procedure proposed by [13]. Although they proposed a functional F test in a functional linear regression setting, the method can be specified for our two sample test as follows.
The F-test statistic for our setting is
where
Ref. [13] also presented the distribution of the F-test as In practice, they also applied the idea of [14] approximation to derive approximate distribution of F-statistic, that is, , which is an ordinary F distribution with degrees of freedom and , where , .
3. Our Testing Procedure
In order to determine the number of PCs adaptively and find significant parts to construct a more powerful test statistic, we propose a two-stage procedure via a data-splitting technique. With the help of this technique, we can derive the distribution of the test statistic.
First, we assume that the sample size is even for simplicity and randomly split samples into two groups: and . In the first stage, we choose based on the adaptively truncated Hotelling order statistic via the first group sample . In the second stage, we construct the test statistic via the second group sample and .
Next, we show three methods of choosing in a general case.
Denote In practice, since many of the trailing eigenvalues are close to zero and will be very large for a large k. Hence, we generally give the cutoff a high threshold, for example, . For most inference problems, there is no optimal test, but the adaptive Neyman tests have been shown to work well against a broad range of alternatives. Therefore, we choose adaptively based on the following adaptive Neyman test methods. One method is maximizing normalized (8) (in the Appendix A we have proven has an approximate distribution), that is,
Considering some possible nonsignificant terms, we propose another method that maximizes the sun of normalized order statistic , that is,
where is the k-th order statistic of in decreasing order. Unfortunately, there is no closed form since it involves order statistics. However, empirical approximations of this maximum value can be conducted by very fast Monte Carlo approximations. The third method is a hard threshold truncation method, but we truncate at the d-th term based on the percentage of , which combines both the variation and the projection along each direction. In our simulation, we set a truncation threshold as [5] projection-based test for comparison.
Remark 1.
and are chosen adaptively based on the first group data. For the convenience of follow-up theoretical analysis, we denote them as uniformly.
After we derive in the first stage, we construct the following statistic based on the second group sample as follows:
where
To derive the asymptotic distribution of , , , and , we make the following assumptions:
Assumption 1.
There exist constants and C such that for and
Assumption 2.
Assumption 3.
Assumption 4.
, where
Assumptions 1 and 2 are regular in functional principle component analysis (FPCA). Assumption 1 implies that . Because the covariance functions are bounded, one has . Assumption 1 essentially assumes that all the eigenvalues are positive, but decay exponentially. Assumption 3 requires that the two sample sizes tend to ∞ proportionally. Assumption 4 specifies the growing rate of . In related literature e.g., [15], to guarantee estimation consistency, is usually assumed to satisfy .
Theorem 1.
Under , , where G is a Gaussian process with mean zero and covariance function Γ, where
The proof of Theorem 1 follows the trivial central limit of the stochastic process and we omit it.
Remark 2.
We can write G as , where are i.i.d centered real Gaussian random variables with variance 1.
Theorem 2.
Under Assumptions 1–4, there exist some increasing sequences such that under
where denotes the cumulative distribution function (cdf) of standard normal distribution.
Theorem 3.
Under Assumptions 1–4, the test statistic is approximately equivalent to (1) under , where are order statistics (in a decreasing order) of random variables.
Remark 3.
The asymptotic null distribution of is affected not only by the values of , but also by the order of them. In practice, empirical approximations of quantiles and tail probability of the null distribution of can be deduced by very fast Monte Carlo approximations.
Theorem 4.
Under Assumptions 1–4 and ,
where denotes the cdf of the standard normal distribution.
To obtain the asymptotic distribution of under the alternative in (3), we choose the local alternative, as defined in the following assumption:
Assumption 5.
where is any fixed real function such that
Then, we have the following asymptotic power of :
Theorem 5.
Under Assumptions 1–6, the asymptotic distribution of the is given by
where P denotes that the distribution have been obtained under the alternative, and is the upper point of the standard normal distribution.
Theorem 6.
Under Assumptions 1–5, the distribution of the is approximately equivalent to a noncentral distribution , where
and
4. Simulations
In this section, we report some Monte Carlo simulation results to compare the finite samples performance of the classical and proposed methods on the two sample mean testing problem under different settings, including a fixed simple alternative and sparse signals with varying locations.
4.1. Fixed Simple Alternative
In this subsection, we first look at a simple setting where the alternatives are fixed. We generate curves from two populations that are generated by 40 Fourier bases as
Here, are independent standard normal random variables. In each case, we take for and generate the data on a discrete grid of 100 equispaced points in [0, 1]. We took . We choose and depending on the property that we want to illustrate (see below). We compare power and size under three different methods: Ref. [8] -norm based test (); Ref. [13]’s F-test ; Ref. [5]’s projection-based test () with fixed truncation and our two methods. We choose the commonly used threshold to determine the truncated term in [5]’s projection-based test (). The results are based on 1000 Monte Carlo replications. In all scenarios, we set the nominal size .
To cover as many different scenes as possible, we set five different settings referring to the mean difference: (1) the mean differences arise early in the sequence and , that is, and for , for , for ; (2) the mean differences arise in the middle of the sequence and , that is, and for other k, for , for other k; (3) the mean differences arise in the latter part of the sequence and , that is, and for other k, for , for other k; (4) the mean differences are scattered in the first, middle and latter part, that is, and for other k, for , for other k; (5) the tiny differences appear in all the principal components. In this case, we set as independent random variables, and .
From Table 1, Table 2, Table 3, Table 4 and Table 5, we can see that these are obvious different performances in different settings. From Table 1, we can see that when the mean difference lies in early part in the sequence, Ref. [5]’s projection-based test () has most powerful performance. This should not be surprising, because their method just chooses projection space spanned by the first few eigenfunctions, where the mean difference lies. From Table 2 we observe that when mean difference lies in the middle part in the sequence, our method has very high power compared to , and . Particularly, we notice that Ref. [5]’s projection-based test () has a dramatic power loss. From Table 3, we can see that when the mean difference lies in the latter part of the sequence, our method still has the best performance. At the same time, we can find that and have higher power then in this case. This illustrates that and are sensitive to divergence degree and is more sensitive to location of mean difference. Furthermore, we notice that the power of and outperform our method only on large sample sizes and large discrepancies between the null hypothesis and alternative hypothesis. This is understandable, because our method also depends on mean difference projection on space spanned by the eigenfunction, excluding last few eigenfunctions. Table 4 and Table 5 illustrate more general cases. Table 4 demonstrates that when there are tiny differences in all directions, our method is still the most powerful, while and are useless. Table 5 demonstrates the performance of each method when there are differences in the early part, middle part, and latter part. From the simulation results, we can see that in this general case, our method has the most satisfactory performance.

Table 1.
Size and power of five methods in Setting 1 (mean difference lies in early part ).
Table 2.
Size and power of five methods in Setting 2 (mean difference lies in middle part ).
Table 3.
Size and power of five methods in Setting 3 (mean difference lies in latter part ).
Table 4.
Size and power of five methods in Setting 4 (mean difference lies in separable part , , ).
Table 5.
Size and power of five methods in Setting 5 (difference averaged in total vector ).
We also conducted simulation studies under other similar scenarios. As they demonstrated similar patterns to those discussed above, we omit them here to save space.
It is worth noting that the proposed method has a first stage with randomly split data. There could be a potential limitation with large randomness. In order to understand the robustness for this splitting, we perform some supporting simulation studies, again considering multi-fold cross validation (CV), including two-fold CV, five-fold CV, and ten-fold CV. For convenience, we use the same data setting of Table 5. The results are shown in Table 6. From Table 6, we can see that in most cases, the hypothesis is robust for this splitting.
Table 6.
Size and power of in Setting 5 (difference averaged in total vector ).
4.2. Sparse Signals with Varying Locations
In this section, we demonstrate the performance of different tests under signals with varying locations. We set as independent random variables, and , where k is six random locations out of 40. In Setting 1, the signal of difference appears randomly in six of the first twenty principal components; we denote . In Setting 2, the signal of difference appears in six of forty principal components; we denote . The simulation results are illustrated in Table 7 and Table 8. From the simulation results, we can see that in these cases, our method also have the most satisfactory performance.
Table 7.
Size and power of five methods under randomized signal in Setting 1 .
Table 8.
Size and power of five methods under randomized signal in Setting 2 .
We also compare our method with the full-sample adaptive methods, including the adaptive Neyman–Pearson test () and the ordered adaptive test . In the full sample, the distribution of adaptive Neyman–Pearson test () and ordered adaptive test is notable, that is,
We use permutation method to calculate size and power. Table 9 illustrates the simulation results, where Time1 is the time of running once and and Time2 is the time to run and once. The unit is seconds. From Table 9, we can see that our splitting sample methods have a slight power loss compared to the adaptive Neyman–Pearson test and the ordered adaptive test . However, we can save significant time in real computing.
Table 9.
Size and power of seven methods under randomized signal in Setting 2 .
5. Application
In this section, we apply our proposed hypothesis testing procedures to a real PM 2.5 dataset in Beijing, Tianjin, and Shijiazhuang between January 2017 and December 2019. The dataset was downloaded from the website http://www.tianqihoubao.com/aqi/, accessed on 10 June 2021. The data readings were taken every day, so the total data size is 1085 for every city. Beijing is surrounded by Tianjin and Shijiazhuang. Therefore, we want to know more about the average PM 2.5 difference in these three areas. The following Figure 1 and Figure 2 show the mean PM 2.5 (g/m) in Beijing, Tianjin, and Hebei Province in different time periods. There are some missing days in some cycles. Note that Figure 1 shows negative values at the beginning for a measure that is always greater than zero because of B-spline approximation.
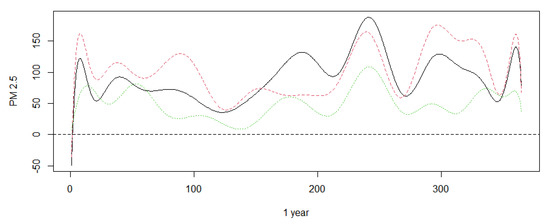
Figure 1.
The mean PM 2.5 (μg/m) of Beijing, Tianjin, and Shijiazhuang from December 2019 to January 2019. The black line stands for Beijing. The red dasehed line stands for Tianjin. The green dotted line stands for Shijiazhuang.
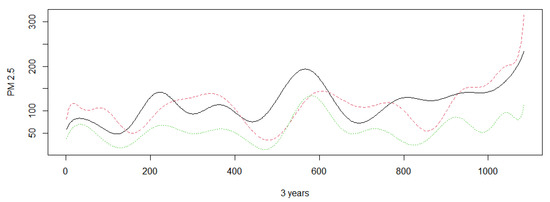
Figure 2.
The mean PM 2.5 (μg/m) of Beijing, Tianjin, and Shijiazhuang from December 2019 to January 2017. The black line stands for Beijing. The red asehed line stands for Tianjin. The green dotted line stands for Shijiazhuang.
It is obvious that PM 2.5 changes over individual periods. Here, we test whether there is a significant difference in PM 2.5 among the three cities using the method we proposed. First, the sample is divided into two data sets: the training sample is the dataset in 2017; the test sample is the dataset in 2018–2019. The principle components are adaptively based on the training sample. Then, the test statistic is constructed via the test sample and the principle components are selected by the training sample. To test whether there is significant difference in PM 2.5 between the three cities, we carry out permutations 1000 times within each group to calculate the rejection proportions; then, we obtain the p-value of the test. The results are shown in Table 10.
Table 10.
p-value of two tests.
From Table 10, we can see that all p-values are less than 0.05. The tests are statistically significant and suggest that the average PM 2.5 in these three areas are different from each other at a 0.05 level of significance.
6. Conclusions and Discussions
In this paper, we consider the problem of testing the equality of mean functions in two random samples independently drawn from two functional random variables. We develop and study a novel testing procedure that has a more powerful ability to detect mean difference. In general, it includes two stages: first, splitting the sample into two parts and selecting principle components adaptively based on the first half-sample; then, constructing the test statistic based on another half-sample. An extensive simulation study is presented, which shows that the proposed test works very well in comparison with several other methods in a variety of settings. Our future project is to detect differences in the covariance functions of independent sample curves. There have been some approaches proposed so far to address this problem, for instance, the factor-based test proposed by [4] and the regularized M-test introduced by [16].
Author Contributions
Data curation, S.F.; Funding acquisition, S.F.; Investigation, J.Z.; Methodology, J.Z.; Project administration, Y.H.; Validation, Y.H.; Writing—original draft, J.Z.; Writing—review & editing, Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by China National Institute of Standardization through the “Special funds for basic R.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs of the Main Results
Before proving the main results, we introduce the following useful lemmas. Furthermore, for the convenience of notation, we give proofs in the full sample.
Lemma A1.
Under Assumptions 1–4, we have
Proof.
Denote ; note that provided holds, we have
It can be proven easily that , ; then,
According to central limit theory, we have
Then, , which means is bounded in probability.
Notice that ; therefore
Ref. [15] has proven that as ; thus, Lemma A1 holds. □
Lemma A2.
Under Assumptions 1–4, we have
Proof.
First,
Then,
where
It is obvious that
It can also be easily proven that . According to the result of [17], we have under corresponding conditions. Then, we have
Similarly, we can prove . □
Lemma A3.
Under Assumptions 1–4, we have
which converges in distribution to a centered Gaussian random variable g with variance 1.
The proof of Lemma A3 is similar to the techniques used by [18], so we omit it here.
Proof of Theorem 2.
Combine Lemmas A1 and A2 with Lemma A3; then, can proof Theorem 2. □
Proof of Theorem 3.
According to Theorem 1, Lemmas A1 and A2, we have and . Then, the conclusion is obvious. □
Proof of Theorem 5.
We note that
where Then
Observe that
According to (A2), we have
By Assumptions 1–5 and Lemma A1, we have that
Under Assumptions 4 and 5, we have
From Theorem 2 and the above results, we have
From (A2) we can obtain ; then,
Combined with (A4), we have
□
Proof of Theorem 6.
By Lemma A2, we have as Define as decreasing orders of and as decreasing orders of . Ref. [19] have proven that the random orders in the selection procedure are asymptotically equivalent to fixed orders . □
References
- Besse, P.; Ramsay, J. Principal components analysis of sampled functions. Psychometrika 1986, 51, 285–311. [Google Scholar] [CrossRef]
- Rice, J.A.; Silverman, B.W. Estimating the mean and covariance structure nonparametrically when the data are curves. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1991, 53, 233–243. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis; Springer Press: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Ferraty, F.; Vieu, P.; Viguier-Pla, S. Factor-based comparison of groups of curves. Comput. Stat. Data Anal. 2007, 51, 4903–4910. [Google Scholar] [CrossRef]
- Horváth, L.; Kokoszka, P. Inference for Functional Data with Applications; Springer Press: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Fan, J.Q.; Lin, S.K. Test of significance when data are curves. J. Am. Stat. Assoc. 1998, 93, 1007–1021. [Google Scholar] [CrossRef]
- Faraway, J.J. Regression analysis for a functional response. Technometrics 1997, 39, 254–261. [Google Scholar] [CrossRef]
- Zhang, C.Q.; Peng, H.; Zhang, J.T. Two samples tests for functional data. Commun. Stat.-Methods 2010, 39, 559–578. [Google Scholar] [CrossRef]
- Zhang, J.T. Statistical inferences for linear models with functional responses. Stat. Sin. 2011, 21, 1431–1451. [Google Scholar] [CrossRef]
- Zhang, J.T.; Liang, X. One-way ANOVA for functional data via globalizing the pointwise F-test. Scand. J. Stat. 2014, 45, 51–71. [Google Scholar] [CrossRef]
- Zhang, J.T.; Cheng, M.Y.; Wu, H.T.; Zhou, B. A new test for functional one-way ANOVA with applications to ischemic heart screening. Comput. Stat. Data Anal. 2019, 132, 3–17. [Google Scholar] [CrossRef]
- Wasserman, L.; Roeder, K. High dimensional variable selection. Ann. Stat. 2009, 37, 2178–2201. [Google Scholar] [CrossRef] [PubMed]
- Shen, Q.; Faraway, J.L. An F test for linear models with functional responses. Stat. Sin. 2004, 14, 1239–1257. [Google Scholar]
- Satterthwaites, F.E. Synthesis of variance. Psychometrika. 1941, 6, 309–3167. [Google Scholar] [CrossRef]
- Hall, P.; Hosseini-Nasab, M. On properties of functional principal components analysis. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2006, 68, 109–126. [Google Scholar] [CrossRef]
- Kraus, D.; Panaretos, V.M. Dispersion operators and resistant second-order functional data analysis. Biometrika 2012, 99, 813–832. [Google Scholar] [CrossRef]
- Kong, D.; Xue, K.; Yao, F.; Zhang, H.H. Partially functional linear regression in high dimensions (supplementary material). Biometrika 2016, 103, 147–159. [Google Scholar] [CrossRef]
- Shang, Y.L. A central limit theorem for randomly indexed m-dependent random variables. Filomat 2012, 26, 713–717. [Google Scholar] [CrossRef]
- Su, Y.R.; Di, C.Z.; Li, H. Hypothesis testing in functional linear models. Biometrics 2017, 73, 551–561. [Google Scholar] [CrossRef] [PubMed]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).