Abstract
Negation of a discrete probability distribution was introduced by Yager. To date, several papers have been published discussing generalizations, properties, and applications of negation. The recent work by Wu et al. gives an excellent overview of the literature and the motivation to deal with negation. Our paper focuses on some technical aspects of negation transformations. First, we prove that independent negations must be affine-linear. This fact was established by Batyrshin et al. as an open problem. Secondly, we show that repeated application of independent negations leads to a progressive loss of information (called monotonicity). In contrast to the literature, we try to obtain results not only for special but also for the general class of -entropies. In this general framework, we can show that results need to be proven only for Yager negation and can be transferred to the entire class of independent (=affine-linear) negations. For general -entropies with strictly concave generator function , we can show that the information loss increases separately for sequences of odd and even numbers of repetitions. By using a Lagrangian approach, this result can be extended, in the neighbourhood of the uniform distribution, to all numbers of repetition. For Gini, Shannon, Havrda–Charvát (Tsallis), Rényi and Sharma–Mittal entropy, we prove that the information loss has a global minimum of 0. For dependent negations, it is not easy to obtain analytical results. Therefore, we simulate the entropy distribution and show how different repeated negations affect Gini and Shannon entropy. The simulation approach has the advantage that the entire simplex of discrete probability vectors can be considered at once, rather than just arbitrarily selected probability vectors.
Keywords:
negation; Gini entropy; Shannon entropy; Havrda–Charvát (Tsallis) entropy; ϕ-entropy; Rényi entropy; Sharma–Mittal entropy; (h,ϕ)-entropy; Dirichlet distribution; Monte Carlo simulation MSC:
62E10; 94A16
1. Introduction
In knowledge-based systems, terms with n categories can be characterized by probability distributions. Let us consider the term ”conservative” and assume that we know how the conservative population is distributed among the three categories ”right-wing conservative”, ”conservative” and ”liberal-conservative”. Can we learn anything about the non-conservative population from this distribution by looking at the negation of the original distribution? If so, does this not necessarily involve a loss of information, because the original distribution makes no explicit statement about non-conservatism? Can the loss of information be measured by any information measure? These are questions that are still the subject of intense debate that starts with the seminal work of Yager [1]. He proposed to define negation of a probability distribution by subtracting the probability distribution from 1 and distributing the sum of negated probabilities equally among the n categories. The equal distribution can be motivated by Dempster–Shafer theory and a maximal entropy argument. Technically, the equal distribution means that the negation of one category’s probability must not depend on the probabilities of the other categories. Batyrshin et al. [2] call a negation with this property ”independent”. Yager negation and all other affine-linear negations are independent. Batyrshin [3] stated this as an open problem to show that independent negations must be affine-linear. One of our technical remarks concerns the solution of this open problem.
In particular, for Yager negation, information content and information loss have been measured by different entropies. Yager [1] discussed Gini entropy. This entropy is very popular because no complicated calculations are required. However, the question arises whether the results obtained for Gini entropy can be transferred to other entropies. Therefore, Gao and Deng [4,5] have considered Shannon and Havrda–Charvát entropy. Zhang et al. [6] also studied Havrda–Charvát entropy and Wu et al. [7] Shannon entropy for exponential negations. Srivastava and Maheswari [8] introduced a new kind of entropy tailored for Yager negation. Their proposal is also based on Shannon entropy. All authors concluded that negation leads to an information loss. They use a Lagrangian approach to reach this conclusion. Because the articles mentioned mostly deal with the application of negations in various scientific fields, the more technical aspects seem to be of less interest. In particular, the sufficient conditions for optimization have not been investigated. Therefore, our technical remarks are intended to complete the proofs and generalise the results to the class of -entropies with strictly concave generating function .
Negations can be applied not only to the original probability vector, but also to the negation of a probability vector because negation again gives a probability distribution. For example, consider a sequence of recursive application of negation of length . Then, Yager [1] showed for Yager negation and Batyrshin et al. [3] proved for general affine-linear negations that the -times recursively applied negation is given by a recursion relation that updates the k-times recursively repeated negation by the uniform distribution. Convergence against the uniform distribution with is easy to show. We ask whether this updating rule also applies to entropy of negation. In the tradition of Yager’s work, we focus on Gini entropy as the preferred information measure. We show that Gini entropy of -times repeated independent negations is a convex combination of the Gini entropy of the uniform distribution and the Gini entropy of the k-times recursively repeated negations. It is well known that the uniform distribution maximises the Gini entropy and represents the point of minimum information, maximum dispersion, or maximum uncertainty. Therefore, this updating formula ensures that negation leads to an information loss as suspected in the introductory discussion of “conservatism”.
The work of Gao and Deng [4,5], Zhang et al. [6] and Wu et al. [7] illustrates the entropy behaviour in terms of negation by numerical examples. Typical probability vectors were selected and Yager or exponential negation were applied to this vector. As an alternative, we propose a numerical procedure to compare -entropies for all possible probability vectors. The numerical way is to draw probability vectors of size n from the Dirichlet distribution and to simulate the entropy distribution. This procedure is particularly recommended for dependent negations. In our opinion, there seems to be no analytical way to discuss the behaviour of dependent negations and the corresponding -entropies. For all negations considered, the entropy distribution is more or less concentrated below the entropy’s maximum value. What we can learn is that negations that lie above Yager negation (like exponential negation discussed in [7]) give more concentrated and peaked entropy distributions and negations that lie below the Yager negation (like the Tsallis negation with parameter [6]) give more spread and less peaked distributions. This confirms the statement of Wu et al. [7] that recursively repeated exponential negations converge faster to the uniform distribution than recursively repeated Yager negations.
The specific aims of our paper are as follows.
- It will be proven that independent negations have to be affine-linear.
- It will be proven that the uniform distribution maximizes all -entropies with strictly concave generating function .
- It will be proven that the Yager negation minimizes any -entropy in the class of affine-linear negations, with the consequence that the information loss has to be discussed only for Yager negation.
- It will be proven that the information loss, measured by the difference of -entropies, increases separately for odd and even sequences of repetition numbers of Yager negation.
- It will be proven that the uniform distribution yields a local minimum of the information loss produced by the Yager negation for each -entropy.
- It will be proven that the uniform distribution yields the global minimum of the information loss produced by the Yager negation for Gini, paired Shannon, Shannon and Havrda–Charvát entropy.
- An explicit formula for Yager negation’s information loss in the case of the Gini entropy will be given.
- It will be shown that results concerning the information loss of Havrda–Charvát entropy can be transferred to Rényi and Sharma–Mittal entropies by using the concept of -entropies with h strictly increasing.
- An impression of how the information loss behaves for dependent negations when analytical results do not seem to be available will be given.
The paper is organised along the lines of the abovementioned objectives. After some definitions in the first section, we show in the second section that independent negations must be affine-linear. The third section introduces -entropies and shows that they are maximized for the uniform distribution. Moreover, the Yager negation will be identified as a minimum entropy representation of the class of affine-linear negations. The remainder of the section discusses the information loss of Yager negation for general -entropies. Approaches based on the strict concavity of as well as the Lagrangian approach will be considered. In the fourth section, we elaborate on the results concerning the information loss for some prominent -entropies. The impression could be given that all -entropies behave similarly with respect to a negation. Therefore, we present some examples of entropies wherein negations behave differently. In the fifth section, we discuss the information loss for -entropies with strictly increasing function h. In the sixth section, we present the results of a simulation study for the information loss of dependent negations. The seventh section summarizes the main results. Three proofs refer to the same bordered Hessian matrix. For this reason, this matrix is dealt with in Appendix A. Three proofs are moved out to Appendix B to improve the readability.
2. Definitions
Let
be the probability simplex of size . It contains all discrete probability distributions with support of size n. A probability transformation maps a discrete probability distribution to a new discrete probability distribution with support of the same size.
Definition 1.
- A probability transformation maps into such thatwith , and for all .
- The probability transformation is independent, if there exists a function such thatfor all .
For an independent transformation, the function depends exactly on the i-th component and not on the other probabilities , for .
Three examples, to be discussed in detail later, are the exponential, the cosine, and the affine-linear transformation. The first two are not and the last is independent.
Example 1.
- In Wu et al. [7] an exponential probability transformation withwas considered.
- Another example could be the cosinus transformation
- Affine-linear probability transformations are given byfor a and b such that , .
The transformations (4), (5) and the affine-linear transformation (6) with are negative transformations (called negations) in the following sense.
Definition 2.
- The probability transformation withis called a negation, iffor all and .
- For independent negations there exists a function withN will be called a negator [3].
We will highlight two affine-linear negations that play a central role in what follows.
Example 2.
An affine-linear negator is given by
with . Yager [1] discussed the special case which is now called Yager negator. For , we obtain the uniform negator characterizing the uniform distribution .
The transformations (4), (5) and (6) are of the form
generated by a function . The division by ensures that the image of the transformation again results in a discrete probability distribution.
If f has a negative slope, f generates a negation
Even though (9) is a function of the whole vector of probabilities, Batyrshin [3] defines
and calls the N negator as well. This small formal incorrectness simplifies the notation and will be used in the following. Furthermore, we speak of an independent negator if the corresponding negation is independent. This formulation also follows Batyrshin [3].
3. Independence and Linearity
The constant c can be characterized more precisely if the special discrete probability distribution is inserted into (12):
Batyrshin et al. [2] and Batyrshin [3] showed many properties of independent negators and of affine-linear negators with generating function with and . It is easy to verify that affine-linear negators are independent. Batyrshin et al. [2] identified this as an open problem to show that the converse is also true. The following theorem gives a proof that independent negators must be affine-linear. For simplicity, we assume that f is continuous. The proof can be based on weaker assumptions.
Theorem 1.
Let be a continuous function. Then the unique independent negator is generated by
with .
Proof.
Consider with and , this results in
Define , and then we get the Cauchy functional equation
for . If f and therefore g are continuous, it is well-known that the Cauchy functional equation has the unique solution ([9], p. 51) . This gives for with k determined by
as . The unique independent negator is generated by
□
The corresponding affine-linear negator generated by (14) is
The following collection of properties for affine-linear negators has already been proven by Batyrshin et al. [2]. These properties are needed to show some results concerning the entropy of negations. Set
and then for .
Remark 1.
- .
- for , for . This means that, depending on n, an independent negator takes on values in a very small interval.
- can be equivalently represented as the convex combination of the constant (or uniform) negator and the Yager negator for . This means, there exists an such that
For an affine-linear negator N, there is an alternative representation as difference between the negator and the uniform distribution:
Yager [1] already considered the repeated use of negation. According to Batyrshin [3], denotes the negator after -times repeated use of N. By using (18) and by induction it is easy to show
or, equivalently,
for [2]. The recursion relation (20) starts with . From Remark 1, we know that , such that for . This means that is an alternating sequence converging to 0.
4. Information Loss for Independent Negations and General -Entropies
4.1. -Entropies
Yager [1] decided to discuss the Gini entropy based on its simple formula. This leads to the question whether the results proven for the Gini entropy also apply to other entropies. In the literature, the Shannon and the so-called Havrda–Charvát (or Tsallis) entropy have been the focus of discussion. These entropies are special cases of a broader class of entropies. In a recent paper, Ilić et al. [10]) gave an excellent overview of what they call ”generalized entropic forms”. For our purposes, it is sufficient to consider -entropies introduced by Burbea and Rao [11] and -entropies introduced by Salicrú et al. [12].
Definition 3.
Let be strictly concave on with for . Then,
is called ϕ-entropy with generating function ϕ.
Examples for -entropies are
Example 3.
- Gini (or quadratic) entropy: [13,14,15,16].
- Shannon entropy: [17].
- Havrda–Charvát (or Daróczy or Tsallis) entropy: [18,19,20].
- Paired Shannon entropy: [11].
- Paired Havrda–Charvát (or Tsallis) entropy: [11].
- Modified paired Shannon entropy: [8].
- Leik entropy: [21,22].
- Entropy introduced by Shafee: [23].
Notice that the entropy-generating functions of the Leik entropy is only concave and not strictly concave, and the entropy-generating function of the entropy introduced by Shafee is strictly concave only for . We will discuss both entropies in detail in the Examples 4 and 5.
A basic axiom that all entropies should satisfy is that they must be maximal for the uniform distribution , . This axiom is part of the Shannon–Khinchin axioms that justify Shannon entropy. However, we do not choose an axiomatic approach. To show that the definition of an entropy is useful, we have at least to prove that the uniform distribution maximizes this entropy. This will be done for -entropies. It seems useful to unify the partially incomplete proofs given separately in the literature for individual entropies [7,8].
Theorem 2.
Let be strictly concave on with for and the corresponding ϕ entropy. Then,
and .
Proof.
Consider the Lagrangian function
and the derivatives
resp.
for and . The necessary condition for an optimum (for a stationary point) is , . has to be strictly decreasing because , . This means that the inverse function exists. It is
All probabilities are identical and add up to 1 such that , . The uniform distribution is the only stationary point of the Lagrangian function (22). To show that this stationary point belongs to a global maximum of (22) we consider the bordered Hessian matrix (see Lemma A1) with , . Let denote the determinant of the upper left -matrix for . For a local maximum, we have to show that for [24] (p. 203). In the appendix (see Lemma A1), we prove that
with
for . For m odd, it is and . For m even, we get and such that for . Therefore, the uniform distribution is not only a stationary point, but also the point where (22) has a global maximum. □
The importance of the fact that the entropy-generating function is strictly concave shall be illustrated by two examples.
Example 4.
We consider the Leik entropy [21,22]
The generating function corresponding to (23) is , . ϕ is concave but not strictly concave. If for , then it is . For independent negators N we know from Remark 1 that , and . This means that the Leik entropy cannot distinguish between the information content of different independent negations and different numbers of repetitions of independent negations.
Example 5.
Let us consider an entropy introduced by Shafee [23] as
This entropy is part of the family of Sharma–Taneja–Mittal entropies [10] and a simple generalization of Shannon entropy (. The entropy generating function is
with derivatives
and
ϕ is strictly concave for .
Now, we want to show that (24), depending on n, has a local maximum or a local minimum for . If we solve then
Consider . Then it is with for and for .
If n is large enough such that , then and, following the proof of Theorem 2, gives a local maximum of (24). For , we get such that for .
For smaller n with , it is . We again consider the bordered Hessian matrix (see Lemma A1). denotes the determinant of the upper left -matrix for . For a local minimum, we have to show that for [24] (p. 203) with
and
for . With , we immediately see that for .
For , for and for . By using this property, a similar argument can be applied to show that the uniform distribution can be a point at which (24) has either a local maximum or a local minimum.
The important overall result is that the uniform distribution does not maximize (24) for all n.
Let be a negation, and then we want to check the property of monotonicity
in a most general setting. In other words, this means that the information loss caused by the negation
is non-negative.
From (25) we can conclude
can be considered as a new vector of probabilities for which (25) holds and so on.
Table 1 gives an overview about the results concerning (25) that will be proven in the following. Without loss of generality, we can restrict the discussion to Yager negations as will be shown in the next section.

Table 1.
Property of monotonicity for several entropies H.
4.2. Yager Negation Minimizes -Entropies
In Remark 1 we quote a result proven by [2]. Any affine-linear negator can be represented as a convex combination of the uniform and the Yager negator. This means that uniform and Yager negators are the vertices for each independent negator. The uniform negator is known to maximize any entropy. Therefore, it is not surprising that the convex combination can be used to show that the Yager negator minimizes any -entropy with strictly concave generating function in the class of all affine-linear negators.
Theorem 3.
Let be strictly concave, an independent (= affine-linear) negation with negator N and
the Yager negation for . Then, the following applies:
Proof.
From the strict concavity of follows for :
This implies that the -entropy of is greater than the convex combination of the -entropies of the uniform and the Yager negator:
The maximum property of the uniform negator leads to
such that
follows. □
From Theorem 3, we can conclude that the property of monotonicity (25) must only be investigated for the Yager negation. Monotonicity for the Yager negation implies monotonicity for any independent (=affine-linear) negation:
Corollary 1.
Let be strictly concave, an independent (=affine-linear) negation. Then, it is
Proof.
Let , . From (28) follows
□
4.3. -Entropy and Yager Negation
In the literature, in addition to Gini entropy, Havrda–Charvát (or Tsallis) entropy was considered for Yager negation [4,5,6]. Srivastava and and Maheshwari [8] discussed a modified version of the Shannon entropy and Gao and Deng [4] Shannon entropy for Yager negation. We want to investigate whether the property of monotonicity (25) applies to all -entropies. Without further assumptions on the entropy-generating function , we can only prove a weaker version of (25), as Theorem 4 shows.
Theorem 4.
Let be strictly concave. Then, it holds
Proof.
The Yager negation is affine-linear with . From (20), we get for
Due to strict concavity of and (see Remark 1) it is
Inserting into the entropy formula (21) gives
Again, we have such that
□
The difference to (25) is that -entropy increases separately for sequences of odd numbers and sequences of even numbers of repeated uses of negation. This means that and and so on. We have no general proof that, for example, holds. This result is not surprising considering that only an odd number of applications of a negation lead back to a negation. Both the original probability vector (= identical transformation) and all even numbers of repeated applications of a negation are non-negative transformations.
4.4. Lagrangian Approach
To see whether the property of monotonicity (25) does not hold only for sequences of odd and even k separately, we choose a Lagrangian approach with the aim to show that the uniform distribution is a stationary point where the information loss
is minimal. The minimum value is 0, because . Then (30) must be non-negative and the property of monotonicity (25) is satisfied in the neighbourhood of the uniform distribution.
Theorem 5.
Let , ϕ be twice differentiable and . Then
has a local minimum for .
Proof.
The necessary condition of optimality is
Set
and then the necessary condition of optimality means that
One solution of (33), and therefore stationary point of (31), is with , . With it is , . To show that the uniform distribution is the point where (31) has a local minimum, we need to investigate the second derivatives of (31):
and
For we get
Again, consider the bordered Hessian matrix in the appendix (see Lemma A1). Let denote the determinant of the upper left -matrix of the bordered Hessian matrix for . For a local minimum we have to show that for [24] (p. 203). From
with
for , we can conclude that (31) has a local minimum for = . □
The question is whether there are more points where (31) has a local minimum. If not, the uniform distribution characterizes a global minimum of (31). Because the minimum is 0, the difference (30) is non-negative for all and the -entropy has the property of monotonicity (25). Two criteria are taken into account. If one of these criteria is satisfied, there is no further local minimum.
- The first criterion is that the function (32) is strictly monotone on . In this case, one can conclude from that , . In Section 5.1, it will be shown that this criterion can be applied to paired Shannon entropy.
- The second criterion allows (32) to be non-monotone. In principle, there could be other candidates satisfying (33). If we can show that these candidates violate the restriction that the probabilities add to 1, we are left with the uniform distribution as the only point where (31) has a local minimum. This criterion can be applied for Shannon and Havrda–Charvát entropy (see Section 5.2 and Section 5.3).
5. Information Loss for Special Entropies
5.1. Paired Shannon Entropy and Yager Negation
The paired Shannon entropy
is given by a generating function being twice differentiable such that
As announced, we investigate the monotonicity of the function (32). The proof is given in Appendix B.
Lemma 1.
Then it follows that for the paired Shannon entropy and the Yager negation, the condition of monotonicity holds.
Theorem 6.
Let be the paired Shannon entropy and be the Yager negation. Then, it holds that
Proof.
From Theorem 5, we know that the uniform distribution is the point where the difference has a local minimum with value 0 under the restriction . By Lemma 1, g is strictly increasing, so can only hold for , . This means that there are no other local minima and the difference has a global minimum for the uniform distribution. □
Srivastava and Maheshwari [8] discussed a modified version of paired Shannon entropy. They considered the generating function
Let be Yager negator, and then this modification is motivated by the fact that , . The maximal upper bound 1 can only be assumed for . However, there are at least two drawbacks to this choice for . The first is that this entropy depends on the length n of the probability vector. A variation of n means to define a new entropy. The second concerns the property of monotonicity (25). The entropy of the Yager negation has to be compared with the entropy of the original probability vector :
For , this entropy difference is not well-defined.
5.2. Shannon Entropy and Yager Negation
The Shannon entropy is given by
The corresponding generating function is twice differentiable with
Again, we consider the function (32). Unlike Lemma 1, this function is no longer strictly increasing as the following lemma shows. Again, you can find the proof in Appendix B.
Lemma 2.
Let and , .
The function (32) is given by
g is strictly increasing on the interval and strictly decreasing on . Let with , then for .
With this result, we can conclude that Shannon entropy satisfies the property of monotonicity (25).
Theorem 7.
Let denote Shannon entropy. Then, it holds that
Proof.
Again, we learn from Theorem 5 that the uniform distribution is the point where the difference has a local minimum. From Lemma 2 we conclude that can only be if , . This means that there are no other local minima, and the difference (37) has a global minimum for the uniform distribution. □
The Lagrangian approach has already been proposed by Gao and Deng [4,5] to show that the condition of monotonicity holds for the Shannon entropy. But their proof does not seem to be quite complete. The sufficient condition of local minimum was not considered. The discussion of the global minimum is also missing. This research gap is now filled by the Theorem 7.
5.3. Havrda–Charvát Entropy and Yager Negation
Havrda–Charvát (or Tsallis) entropy [18,20] is given by
for and . The generating function is
with
for and . is negative on for . We again consider the function (32). The function (32) is not strictly increasing. One can apply a similar reasoning as in Lemma 2 by distinguishing three different ranges for the parameter q. For the proof, see Appendix B.
Lemma 3.
For Havrda–Charvát entropy and Yager negation the property of monotonicity (25) is satisfied.
Theorem 8.
Let be Havrda–Charvát entropy with . Then, it holds
Proof.
We can use the same arguments as in the proof of Theorem 7. □
There again are some results proven by Gao and Deng [4,5] concerning Havrda–Charvát entropy. With Theorem 8, we fill a gap in their reasoning.
5.4. Gini Entropy and Independent Negations
Yager [1] showed that Gini entropy of cannot be larger than Gini entropy of . Therefore, the property of monotonicity has already been proven for Gini entropy. We want to show that Gini entropy plays a special role because it is the only entropy such that the negation’s information loss can be calculated explicitly. To see this, we show that Gini entropy of is a convex combination of Gini entropy of the uniform distribution and Gini entropy of . This means that in every repetition Gini entropy will be updated by Gini entropy of the uniform distribution. To get the information loss (26) not only for Yager negation, we consider a general independent (= affine-linear) negation .
Theorem 9.
Let be an independent (= affine-linear) negation with negator N, and . For Gini entropy of applies
for .
Proof.
□
A simple consequence of this theorem is that the Gini entropy cannot increase from one repetition to the next. The information loss is given by
for . It is really a loss because the uniform distribution maximizes Gini entropy such that the difference of Gini entropies is non-negative. This proves the following theorem without the help of the Lagrangian approach.
Theorem 10.
Consider an independent (= affine-linear) negation . Then, for Gini entropy of applies
This means that Gini entropy also satisfies the property of monotonicity (25).
5.5. Information Loss If Is Not Strictly Concave
The discussion so far seems to give the impression that negation leads to an information loss for all -entropies. To show that this impression is misleading, let us again consider Leik entropy (23) and the entropy (24).
Example 6.
The information loss of Yager negation measured by Leik entropy is given by
The information loss is
This means that the property of monotonicity (25) is indeed satisfied. However, applying Yager negation twice or more often cannot increase the information loss. This property is not desirable.
Example 7.
Remember the entropy (24). By counterexamples we are able show to that the difference
can be negative for suitable choices of α and . For example, consider , and the probability vector . Then the difference (45) is . To see that this can also happen for larger n, we choose and . The corresponding difference (45) is .
Example 7 shows that negations do not automatically lead to a loss of information for every entropy. It is the rule, but there are exceptions.
6. Strictly Increasing Relationship between Entropies
6.1. -Entropies
In the following lemma, we state the fact that the property of monotonicity (25) can be transferred from a entropy to an entropy , if and are related by an strictly increasing transformation h.
Lemma 4.
Let be a negation and , two entropies such that for with strictly increasing. Then, it holds
Proof.
The statement immediately follows from the fact that h is strictly increasing. □
In addition to -entropies, there are many other entropies. We have already mentioned the overview given by Ilić et al. [10]. By Lemma 4, the property of monotonicity (25) can be transferred from -entropies to entropies which are strictly increasing functions of -entropies. This leads us to -entropies.
Salicrú et al. [12] generalized -entropies to -entropies
where either is strictly concave and h is strictly increasing or is strictly convex and h is strictly decreasing. For , we get the class of -entropies.
In [10,12], it was shown that the famous Rényi entropy and the Sharma–Mittal entropy are -entropies with suitable chosen h and . Both do not belong to the class of -entropies, but are closely related to Havrda–Charvát entropy by a strictly increasing function h.
6.2. Rényi Entropy, Havrda–Charvát Entropy and Yager Negation
Rényi [25] introduced the entropy
with parameter . For we get Shannon entropy. Rényi entropy (47) does not belong to the class of -entropies. Nevertheless, Rényi entropy satisfies the property of monotonicity (25) for Yager negation.
Theorem 11.
Let denote Rényi entropy. Then, it holds
for .
Proof.
There is a functional relationship h between Rényi and Havrda–Charvát entropy given by
with
where . According to
for , h is strictly increasing. In Theorem 8 we proved that Havrda–Charvát entropy has the property of monotonicity (25). By using Lemma 4 we see that Rényi entropy also satisfies the property of monotonicity (25). □
6.3. Sharma–Mittal Entropy, Harvda–Charvát Entropy and Yager Negation
We can go a step further and consider Sharma–Mittal entropy [10,26] with two parameters and :
Special cases are Shannon (), Rényi () and Havrda–Charvát () entropy. Again, we can find a strictly increasing functional relation h between Sharma–Mittal entropy and Havrda–Charvát entropy to prove the following theorem.
Theorem 12.
Let be Sharma–Mittal entropy. Then, it follows that
for with and .
Proof.
It is
Substituting in (48) gives
Differentiating Sharma–Mittal entropy with regard to Havrda–Charvát entropy and using (49) leads to
Therefore, h is strictly increasing and the property of monotonicity (25) is valid for Sharma–Mittal entropy and Yager negation. □
Remark 2.
This results can be generalized to entropies of the form
with f strictly increasing on and . This class (50) was considered by Uffink [27] and intensively discussed in a recent paper of Jizba and Korbel [28]. Similar to Theorem 11 and Theorem 12, can be substituted by Havrda–Charvát entropy such that (50) is a strictly increasing function of Havrda–Charvát entropy. This means that (50) also satisfies the property of monotonicity (25).
7. -Entropy in the Dependent Case
Wu et al. [7] used the rudimentary arguments of Gao and Deng [4,5] to show that Gini entropy of the exponential negation cannot be smaller than Gini entropy of the original probability vector. For dependent negators, the bordered Hessian matrix is still more complex such that it is doubtful whether a proof that (30) is non-negative will be possible.
We consider negators of the form (9) with generating function f decreasing on .
Some examples are given in the introduction and will be repeated here.
- Yager negator [1] with
- exponential negator [7] with
- cosinus negator with
- and square root negator (special case of the Tsallis negator discussed by Zhang et al. [6]):, and are generating functions for dependent negations. For dependent negations, it is not easy to prove properties of their entropies. Wu et al. [7] discussed the exponential negation. They considered the Shannon entropy for this negator. In their numerical examples, they compared Yager und exponential negators for different concrete probability vectors and a different number of categories n. Their general result is that exponential negator converges faster to the uniform distribution than Yager negator.
We choose another approach to get an idea how Gini and Shannon entropies behave for dependent negators and how fast the convergence is. We obtain 1,000,000 different probability vectors by drawing random samples from a Dirichlet distribution. For each probability vector, the entropy (Gini or Shannon) is calculated. From the resulting 1,000,000 entropy values we estimate the entropy density. The same procedure is applied for the probability vectors transformed by the negators , . We use the random generator rdirichlet from the R-package ”MCMCpack” of [29] and density estimation by the standard R routine ”density”. Walley [30] discussed the Dirichlet distribution as a model for probabilities. The Dirichlet distribution has a vector of hyperparameters that has to be chosen before starting the simulation. Following [30], the decision falls on a noninformative prior setting with , . Note that other choices affect the graphical representation, but not the general results.
Figure 1 and Figure 2 show the results for the Gini resp. the Shannon entropy. The number of categories is in both cases . For a higher number of categories, the results are even more pronounced. The top left panel presents the generating functions of the four negators. The top right panel shows the density estimation for the entropy of the original (non-transformed) probability vector. The bottom left panel compares the estimated entropy densities for the Yager negation applied once () and twice (). The bottom right panel presents a comparison of the estimated entropy densities when the four negators are applied exactly once.
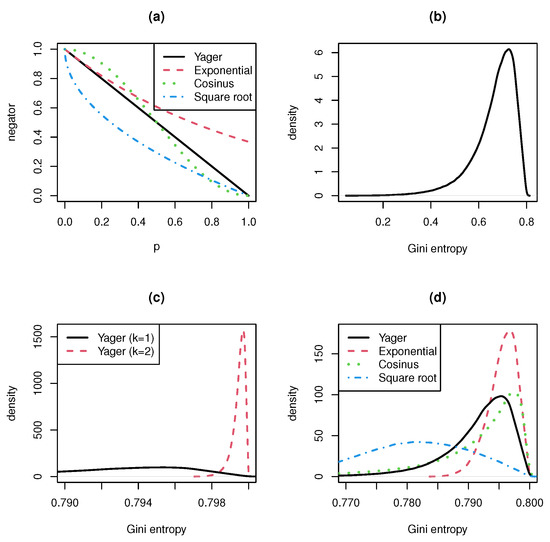
Figure 1.
Gini entropy for different negations and . (a) Generating functions of negators. (b) Density of Gini entropy. (c) Density of Gini entropy for Yager negation applied once (k = 1) and twice (k = 2). (d) Density of Gini entropy for four negators.
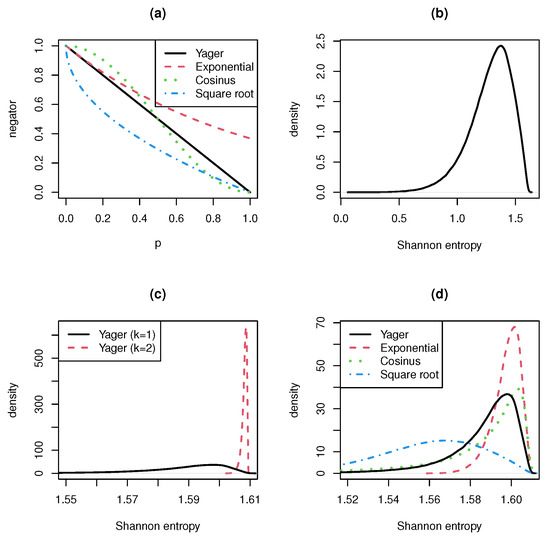
Figure 2.
Shannon entropy for different negations and . (a) Generating functions of negators. (b) Density of Shannon entropy. (c) Density of Shannon entropy for Yager negation applied once (k = 1) and twice (k = 2). (d) Density of Shannon entropy for four negators.
We can see that there is not much difference between the results for the Gini and the Shannon entropy. For , the Gini entropy has the maximum value and the Shannon entropy the maximum value . This explains the range of the abscissae.
The main results are:
- A single application of the negation already results in a very concentrated and strongly peaked entropy distribution. This confirms the fact stated in Remark 1 that the range of negations is very narrow.
- The double or multiple use of a negation leads to a distribution that resembles a singular distribution concentrated at the entropy’s maximum value. Therefore, the convergence rate to the uniform distribution is very high.
- The convergence rate is even higher when we consider negations with generating function f with for . The reverse is also true. Negations with generating function , give lower convergence rates.
- In the interval , the generating function of the cosinus negation is greater and in smaller than the generating function of the Yager negation. Nevertheless, the cosinus negation produces entropy distributions looking similar to the entropy distribution of the Yager negation. The entropy formula seems to eliminate the difference between the cosinus and the Yager negator.
8. Conclusions
First, we can prove that independent negations must be affine-linear. Due to Batyrshin [2] this was an open problem. The property of monotonicity means that the entropy cannot decrease by applying negation to a probability vector. This is equivalent to the fact that negations imply an information loss. We show that the property of monotonicity is satisfied for -entropies and Yager negation. It is sufficient to consider Yager negation because we can prove that the monotonicity of entropies of Yager negation can be transferred to all affine-linear (=independent) negations. We try to prove the monotonicity of -entropies by means of strict concavitiy of the entropy generating function. This procedure is only partially successful. The monotonicity holds for odd and even sequences for the number of negation repetitions k separately. Alternatively, following some examples from the literature, we try to prove monotonicity by a Lagrangian approach based on the difference of the -entropies for Yager negation and the original probability vector. For general -entropies, this approach is also only partially successful. We can prove monotonicity in the neighbourhood of the uniform distribution as the point where the difference of the -entropies has a local minimum. To show monotonicity for all probability vectors, we have to consider concrete -entropies like the Gini, the Shannon or the Havrda–Charvát (Tsallis) entropy. For the Gini entropy, it is not necessary to use the Lagrangian approach. The Gini entropy of an affine-linear negation can be represented as a convex combination of maximal Gini entropy and Gini entropy of the original probability vector. This updating formula can be applied to arbitrary k-times the negation is repeated. This leads to a sequence of non-decreasing values for Gini entropy converging towards the maximum value generated by the uniform distribution. Such an argument does not seem to apply for Shannon entropy. For this reason, we again take up the Lagrangian approach and show that the uniform distribution is the unique point at which the Lagrange function of Shannon entropy difference has a global minimum. The same can be shown for the difference of Havrda–Charvát (Tsallis) entropies. This means that the property of monotonicity is valid for Gini, Shannon and Havrda–Charvát (Tsallis) entropy. -entropies generalize -entropies. If h is a strictly increasing function and the condition of monotonicity holds for a -entropy, we show that the property of monotonicity is also satisfied for -entropy. With this argument, the property of monotonicity can easily be checked for Rényi and Sharma–Mittal entropy. For dependent negations, it is not easy to get analytical results. Therefore, we simulate the entropy distribution and show how different repeated negations affect Gini and Shannon entropy. The simulation approach has the advantage that the whole simplex of discrete probability vectors can be considered at once and not just arbitrarily selected probability vectors. When Yager negation is used as a point of reference, we see that negations with generating functions larger (smaller) than the generating function of Yager negation produce larger (smaller) information loss and a (lower) higher speed of convergence to the uniform distribution.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
I thank Christian Weiss for introducing me to the concept of negation and two anonymous reviewers for their helpful comments.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A
The Lagangian approach is used to prove that the uniform distribution gives a global maximum for -entropies and a local minimum for the difference of the -entropy of the Yager negation and the -entropy of the original probability vector, in each case under the restriction that the probabilities add up to 1. The corresponding bordered Hessian matrices and their determinants are considered in Lemma A1.
Lemma A1.
Let be a vector with for and
a -matrix. denotes the determinant of the upper left -matrix for . Then,
with
for .
Proof.
The statement is true for : Laplace expansion [24] (p. 292) along the third row gives
with
Assume that the statement is true for m. Laplace expansion of the upper left -matrix along the -th row gives
Inserting
leads to
such that
with
□
Appendix B
Proof of Lemma 1.
It is
for . After some simple calculations, the derivative of g is
for . Therefore, g is strictly increasing on . □
Proof of Lemma 2.
Consider the derivative
for . Then it is for and for . Let . It is and such that
for . Let and with then
g is strictly increasing on . means and . This contradicts the fact that and are probabilities. Therefore, it must be , if . □
Proof of Lemma 3.
follows immediately by inserting . The derivative is
with for
For , we get the Gini entropy already discussed by Yager [1].
- Case 1: . We haveIt is
- -
- Subcase 1.1: . For it holdsConsider such that and with .We have such that and .
- -
- Subcase 1.2: : First, reformulate asThis gives for andThe rest follows the arguments from subcase 1.1.
- Case 2: means that holds. Then, since for . Now, we haveFrom this and it followsConsider such that and with . Because g is strictly decreasing in we have such that and . This contradicts the fact that and are probabilities.
□
References
- Yager, R. On the maximum entropy negation of a probability distribution. IEEE Trans. Fuzzy Syst. 2014, 23, 1899–1902. [Google Scholar] [CrossRef]
- Batyrshin, I.; Villa-Vargas, L.A.; Ramirez-Salinas, M.A.; Salinas-Rosales, M.; Kubysheva, N. Generating negations of probability distributions. Soft Comput. 2021, 25, 7929–7935. [Google Scholar] [CrossRef]
- Batyrshin, I. Contracting and involutive negations of probability distributions. Mathematics 2021, 9, 2389. [Google Scholar] [CrossRef]
- Gao, X.; Deng, Y. The generalization negation of probability distribution and its application in target recognition based on sensor fusion. Int. J. Distrib. Sens. Netw. 2019, 15, 1–8. [Google Scholar] [CrossRef]
- Gao, X.; Deng, Y. The negation of basic probability assignment. IEEE Access 2019, 7, 107006–107014. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, R.; Zhang, J.; Kang, B. Extension of Yager’s negation of a probability distribution based on Tsallis entropy. Int. J. Intell. Syst. 2020, 35, 72–84. [Google Scholar] [CrossRef]
- Wu, Q.; Deng, Y.; Xiong, N. Exponential negation of a probability distribution. Soft Comput. 2022, 26, 2147–2156. [Google Scholar] [CrossRef]
- Srivastava, A.; Maheshwari, S. Some new properties of negation of a probability distribution. Int. J. Intell. Syst. 2018, 33, 1133–1145. [Google Scholar] [CrossRef]
- Aczél, J. Vorlesungen über Funktionalgleichungen und ihre Anwendungen; Birkhauser: Basel, Switzerland, 1961. [Google Scholar]
- Ilić, V.; Korbel, J.; Gupta, S.; Scarfone, A. An overview of generalized entropic forms. Europhys. Lett. 2021, 133, 50005. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C. On the convexity of some divergence measures based on entropy functions. IEEE Trans. Inf. Theory 1982, 28, 489–495. [Google Scholar] [CrossRef]
- Salicrú, M.; Menéndez, M.; Morales, D.; Pardo, L. Asymptotic distribution of (h,Φ)-entropies. Commun. Stat. Theory Methods 1993, 22, 2015–2031. [Google Scholar] [CrossRef]
- Gini, C. Variabilità e Mutabilità: Contributo alla Distribuzioni e delle Relazioni Statistiche; Tipografia di Paolo Cuppin: Bologna, Italy, 1912. [Google Scholar]
- Onicescu, O. Théorie de l’information énergie informationelle. Comptes Rendus l’Academie Sci. Ser. AB 1966, 263, 841–842. [Google Scholar]
- Vajda, I. Bounds on the minimal error probability and checking a finite or countable number of hypotheses. Inf. Transm. Probl. 1968, 4, 9–17. [Google Scholar]
- Rao, C. Diversity and dissimilarity coefficients: A unified approach. Theor. Popul. Biol. 1982, 21, 24–43. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Havrda, J.; Charvát, F. Quantification method of classification processes. Concept of structural α-entropy. Kybernetika 1967, 3, 30–35. [Google Scholar]
- Daróczy, Z. Generalized information functions. Inf. Control. 1970, 16, 36–51. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Leik, R. A measure of ordinal consensus. Pac. Sociol. Rev. 1966, 9, 85–90. [Google Scholar] [CrossRef]
- Klein, I.; Mangold, B.; Doll, M. Cumulative paired ϕ-entropy. Entropy 2016, 18, 248. [Google Scholar] [CrossRef]
- Shafee, F. Lambert function and a new non-extensive form of entropy. IMA J. Appl. Math. 2007, 72, 785–800. [Google Scholar] [CrossRef]
- Mosler, K.; Dyckerhoff, R.; Scheicher, C. Mathematische Methoden für Ökonomen; Springer: Berlin, Germany, 2009. [Google Scholar]
- Rényi, A. On measures of entropy and information. In Proceedings 4th Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Sharma, B.; Mittal, D. New nonadditive measures of entropy for discrete probability distributions. J. Math. Sci. 1975, 10, 28–40. [Google Scholar]
- Uffink, J. Can the maximum entropy principle be explained as a consistency requirement? Stud. Hist. Philos. Sci. Part B Stud. Hist. Philos. Mod. Phys. 1995, 26, 223–261. [Google Scholar] [CrossRef]
- Jizba, P.; Korbel, J. When Shannon and Khinchin meet Shore and Johnson: Equivalence of information theory and statistical inference axiomatics. Phys. Rev. E 2020, 101, 042126. [Google Scholar] [CrossRef] [PubMed]
- Martin, A.; Quinn, K.; Park, J. MCMCpack: Markov Chain Monte Carlo in R. J. Stat. Softw. 2011, 42, 22. [Google Scholar] [CrossRef]
- Walley, P. Inferences From multinomal data: Learning sbout a bag of marbles (with discussion). J. R. Stat. Soc. Ser. B 1996, 58, 3–57. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).