Abstract
This paper proposes a clustering method based on a randomized representation of an ensemble of possible clusters with a probability distribution. The concept of a cluster indicator is introduced as the average distance between the objects included in the cluster. The indicators averaged over the entire ensemble are considered the latter’s characteristics. The optimal distribution of clusters is determined using the randomized machine learning approach: an entropy functional is maximized with respect to the probability distribution subject to constraints imposed on the averaged indicator of the cluster ensemble. The resulting entropy-optimal cluster corresponds to the maximum of the optimal probability distribution. This method is developed for binary clustering as a basic procedure. Its extension to t-ary clustering is considered. Some illustrative examples of entropy-randomized clustering are given.
Keywords:
randomized clustering; Boltzmann and Fermi entropies; indicator matrix; binary clustering; t-ary clustering; finite-dimensional and functional problems MSC:
62H30; 68T10
1. Introduction
Cluster analysis of different objects is a branch of machine learning where the teacher’s labels are replaced by some internal characteristics of objects or external characteristics of clusters. The internal ones include the distances between objects within the cluster [1,2] and the similarity of objects [3]. Among the external characteristics, we mention the distances between the clusters [4]. As a mathematical problem, clustering has no universal statement. Therefore, clustering algorithms are often heuristic [5,6].
A highly developed area of research is cluster analysis of large text arrays. As a rule, latent features are first detected based on latent semantic analysis [7]. Subsequently, they are used for clustering [8,9]. Recently, there have appeared works based on the concept of ensemble clustering [10,11].
Most clustering algorithms involve the distance between objects, measured in an accepted metric, and enumerative search algorithms with heuristic control [12]. Clustering results significantly depend on the metric. Therefore, it is very important to quantify the quality of clustering [13,14,15].
This paper proposes a clustering method based on a randomized representation of an ensemble of possible clusters with a probability distribution [16]. The concept of a cluster indicator is introduced as the average distance between the objects included in the cluster. Since clusters are treated as random objects, the indicators averaged over the entire ensemble are considered the latter’s characteristics. The optimal distribution of clusters is determined using the randomized machine learning approach: an entropy functional is maximized with respect to the probability distribution subject to constraints imposed on the averaged indicator of the cluster ensemble. The resulting entropy-optimal cluster corresponds in size and composition to the maximum of the optimal probability distribution.
The optimal distribution of clusters is based on the method of the randomized maximum entropy estimation (MEE method) described in [16]. The method turns out to be effective in many machine learning and data mining problems. Among other features, it introduces the problem of entropy-randomized clustering. This article is devoted to a more detailed presentation of this problem in terms of proving the convergence of the multiplicative algorithm and the logical scheme of the clustering procedures.
2. An Indicator of Data Matrices
Consider a set of n objects characterized by row vectors from the feature space . Using these vectors, we construct the following n-row matrix:
Let the distance between the ith and jth rows be defined as
where denotes an appropriate metric in the feature space . Next, we construct the distance matrix
We introduce an indicator of the matrix as the average value of the elements of the distance matrix :
Below, the objects will be included in clusters depending on the distances in (2). Therefore, the important characteristics of the matrix are the minimum and maximum elements of the distance matrix :
Note that the elements of the distance matrices of the clusters belong to the interval
3. Randomized Binary Clustering
The binary clustering problem is to arrange n objects between two clusters and of sizes and respectively:
It is required to find the size and composition of the cluster
For each fixed cluster size the clustering procedure consists of selecting a submatrix of some rows from the matrix If the matrix is selected, then the remaining rows form the matrix and the set of their numbers form the cluster
Clearly, the matrix can be formed from the rows of the original matrix in different ways (the number of s-combinations from the set of n elements). For each of them, the matrices can be formed in a corresponding number of ways.
According to the principle of randomized binary clustering, the matrix is a random object and its particular images are the realizations of this object. The sets of its elements and the number of rows s are therefore random.
A realization of the random object is a set of row vectors from the original matrix:
We renumber this set as follows:
Thus, the randomization procedure yields a finite ensemble of the form
Recall that the matrices in this ensemble are random. Hence, we assume the existence of probabilities for realizing the ensemble elements, where s and k denote the cluster size and cluster realization number, respectively:
Then, the randomized binary clustering problem reduces to determining a discrete probability distribution , which is appropriate in some sense.
Let such a function be obtained; according to the general variational principle of statistical mechanics, the realized matrix will be
This matrix corresponds to the most probable cluster of objects with the numbers
The other cluster consists of the remaining objects with the numbers
Generally speaking, there are many such clusters but they all contain the same objects.
4. Entropy-Optimal Distribution
Consider the cluster of size the associated matrix
and the distance matrix
We define the matrix indicator in (4) for the cluster as
Since the matrices are supposed random objects, their ensemble has a probability distribution . We introduce the average indicator in the form
5. Parametrical Problems (18)–(20)
We treat Equations (18)–(20) as finite-dimensional: the objective function (entropy) and the constraints both depend on the finite-dimensional vector composed of the values of the two-dimensional probability distribution :
The dimension of this vector is
The constraints in (19) can be omitted by considering the Fermi entropy [18] as the objective function. Performing standard transformations, we arrive at a finite-dimensional entropy-linear programming problem [19] with the form
To solve this problem, we employ the Karush–Kuhn–Tucker theorem [20], expressing the optimality conditions in terms of Lagrange multipliers and a Lagrange function. For Equation (23), the Lagrange function has the form
The optimality conditions for the saddle point of the Lagrange function in (24) are written as
The first condition in (25) is analytically solvable with respect to the components of the vector :
The second condition in (25) yields the inequalities
and the condition in (26) yields the following equations:
The non-negative solution of these inequalities and equations can be found using a multiplicative algorithm [19] with the form
Here, is a parameter assigned based on the -convergence conditions of the iterative process in (30).
The algorithm in (30) is said to be -convergent if there exists a set in the space and scalars and such that, for all and this algorithm converges to the solution of Equation (30), and the rate of convergence in the neighborhood of is linear.
Proof.
Consider an auxiliary system of differential equations obtained from (30) as :
First, we have to establish its stability in the large, i.e., under any initial deviations in the space
Second, we have to demonstrate that the algorithm in (30) is a Euler difference scheme for Equation (31) with an appropriate value
Let us describe some details of the proof. We define the following function in :
The function is strictly convex in . Its Hessian is
Hence, and it is achieved at the point . Thus, , and .
By the general principle of statistical mechanics, the realized cluster corresponds to the maximum of the probability distribution:
5.1. Randomized Binary Clustering Algorithms
In this section, the algorithms of the clustering procedures in terms of logical schemes are proposed.
5.1.1. Algorithm with a Given Cluster Size s
- 1.
- Calculating the numerical characteristics of the data matrix
- 2.
- Forming the matrix ensemble
- (a)
- Forming the correspondence table
- (b)
- Constructing the matrices
- (c)
- Calculating the elements of the distance matrices in (15):
- (d)
- Calculating the indicator of the matrix :
- 3.
- Determining the Lagrange multipliers and for the finite-dimensional problem
- (a)
- Specifying the initial values for the Lagrange multipliers:
- (b)
- (c)
- Determining the optimal probability distribution:
- (d)
- Determining the most probable cluster :
- (e)
- Determining the cluster :
5.1.2. Algorithm with an Unknown Cluster Size
- 1.
- Applying step 1 of
- 2.
- Organizing a loop with respect to the cluster size
- (a)
- Applying step 2 of
- (b)
- Applying step 3 of
- (c)
- Putting into the memory.
- (d)
- Calculating the conditionally maximum value of the entropy:
- (e)
- Putting in the memory.
- (f)
- If , then returning to Step 2a.
- (g)
- Determining the maximum element of the array :
- (h)
- Extracting the probability distribution
- (i)
- Executing Steps 3d and 3e of :
6. Functional Problems (18)–(20)
Consider a parametric family of all constrained entropy maximization problems with the form
The solutions of (22) and (23) will coincide under an unknown value of the parameter It can be determined by solving Equation (23) and fixing the values of the entropy functional. Its maximum value will correspond to the desired value
Let us turn to Equation (23) with a fixed value of the parameter It belongs to the class of Lyapunov-type problems [21]. We define a Lagrange functional as
Using the technique of Gâteaux derivatives, we obtain the stationarity conditions for the functional in (24) in the primal (functional) and dual (scalar) variables; for details, see [22,23]. The resulting optimal distribution parameterized by the Lagrange multiplier is given by
The Lagrange multiplier satisfies the equation
The solution of this equation belongs to and depends on Hence, the value of the entropy functional depends on We choose
The randomized binary clustering procedure can be repeated times to form t clusters. At each stage, two new clusters are generated from the remaining objects of the previous stage.
7. Illustrative Examples
Consider the binary clustering of iris flowers using Fisher’s Iris dataset (in this dataset, iris flowers are described by the petal width and the petal length ). The database contains this feature information for three types of flowers: “setosa” (1), “versicolor” (2), and “virginica” (3), in the amount of 50 two-dimensional points for each species. Below, we study types 1 and 2 and 10 data points for each type.
Example 1.

The data matrix contains the numerical values of the two features for types 1 and 2; see Table 1.
Table 1.
Data matrix.
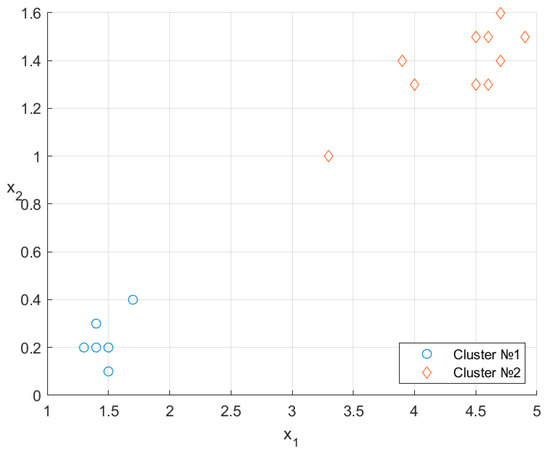
Figure 1 shows the arrangement of the data points on the plane.
Figure 1.
Data points on the two-dimensional plane.
First, we apply the algorithm see Section 5.1.
The minimum and maximum elements are
The data matrix indicator is Let .
The ensemble of possible clusters has the size . The cluster with number has the form . The distance matrix is presented in Table 2.
Table 2.
Distance matrix for cluster .
The indicator of the matrix corresponding to the cluster is
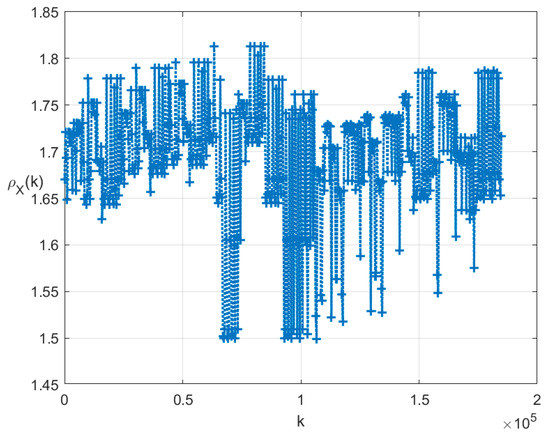
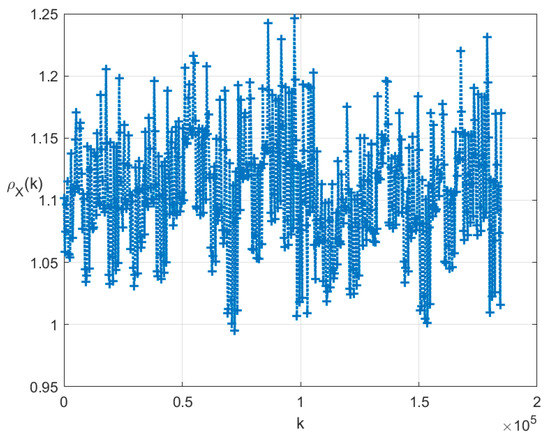
The indicators for the clusters are shown in Figure 2.
Figure 2.
Indicators for .
The entropy-optimal probability distribution for has the form
The cluster with the maximum probability is numbered by
The cluster consists of the following data points: .
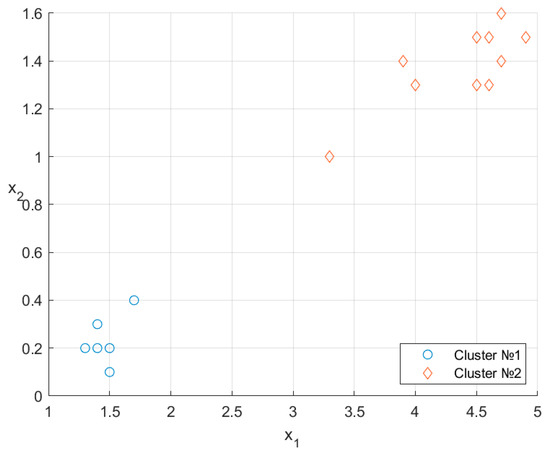
The arrangement of the clusters and is shown in Figure 3.
Figure 3.
Randomized clustering results.
A direct comparison with Figure 1 indicates a perfect match of 10/10: no clustering errors.
Example 2.
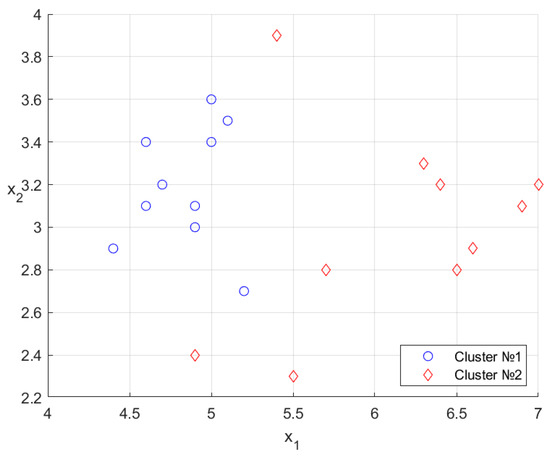
Consider another data matrix from the same dataset (Table 3).
Table 3.
Data matrix.
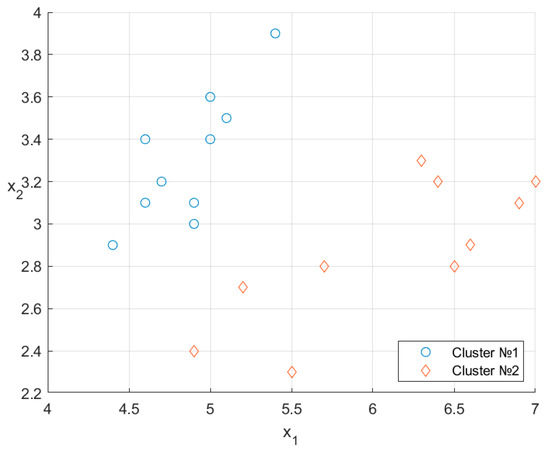
Figure 4 shows the arrangement of the data points.
Figure 4.
Data points on the two-dimensional plane.
Similar to Example 1, we apply the algorithm
We construct the distance matrix and find the minimum and maximum elements:
Let .
The ensemble of possible clusters has the size . The indicators for the clusters are shown in Figure 5.
Figure 5.
Indicators for .
The entropy-optimal probability distribution for has the form
The cluster with the maximum probability is numbered by
It consists of the following data points: The cluster consists of the following data points:
The arrangement of the clusters and is shown in Figure 6. A direct comparison with Figure 4 indicates a match of 8/10.
Figure 6.
Randomized clustering results.
8. Discussion and Conclusions
This paper has developed a novel concept of clustering. Its fundamental difference from the conventional approaches is the generation of an ensemble of random clusters, accompanied by the matrices of inter-object distances averaged over the entire ensemble (the so-called indicators). Random clusters are parameterized by the number of objects s and their set . Therefore, the ensemble’s characteristic is the probability distribution of the clusters in the ensemble, which depends on s and k. A generalized variational principle of statistical mechanics has been proposed to find this distribution. It consists of the conditional maximization of the Boltzmann–Shannon entropy. Algorithms for solving the finite-dimensional and functional optimization problems have been developed.
An advantage of the novel randomized clustering method is complete algorithmization, independent of the properties of the clustered objects data. All existing clustering methods involve, more or less, various empirical techniques related to data properties.
However, this method requires high computational resources to form an ensemble of random clusters and their indicators.
Author Contributions
Conceptualization, Y.S.P.; Data curation, A.Y.P.; Methodology, Y.S.P., A.Y.P., and Y.A.D.; Software, A.Y.P. and Y.A.D.; Supervision, Y.S.P.; Writing—original draft, Y.S.P., A.Y.P. and Y.A.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Higher Education of the Russian Federation, project no. 075-15-2020-799.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mandel, I.D. Klasternyi Analiz (Cluster Analysis); Finansy i Statistika: Moscow, Russia, 1988. [Google Scholar]
- Zagoruiko, N.G. Kognitivnyi Analiz Dannykh (Cognitive Data Analysis); GEO: Novosibirsk, Russia, 2012. [Google Scholar]
- Zagoruiko, N.G.; Barakhnin, V.B.; Borisova, I.A.; Tkachev, D.A. Clusterization of Text Documents from the Database of Publications Using FRiS-Tax Algorithm. Comput. Technol. 2013, 18, 62–74. [Google Scholar]
- Jain, A.; Murty, M.; Flynn, P. Data Clustering: A Review. ACM Comput. Surv. 1990, 31, 264–323. [Google Scholar] [CrossRef]
- Vorontsov, K.V. Lektsii po Algoritmam Klasterizatsii i Mnogomernomu Shkalirovaniyu (Lectures on Clustering Algorithms and Multidimensional Scaling); Moscow State University: Moscow, Russia, 2007. [Google Scholar]
- Lescovec, J.; Rajaraman, A.; Ullman, J. Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Deerwester, S.; Dumias, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1999, 41, 391–407. [Google Scholar] [CrossRef]
- Zamir, O.E. Clustering Web Documents: A Phrase-Based Method for Grouping Search Engine Results. Ph.D. Thesis, The Univeristy of Washington, Seattle, WA, USA, 1999. [Google Scholar]
- Cao, G.; Song, D.; Bruza, P. Suffix-Tree Clustering on Post-retrieval Documents Information; The Univeristy of Queensland: Brisbane, QLD, Australia, 2003. [Google Scholar]
- Huang, D.; Wang, C.D.; Lai, J.H.; Kwoh, C.K. Toward multidiversified ensemble clustering of high-dimensional data: From subspaces to metrics and beyond. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Khan, I.; Luo, Z.; Shaikh, A.K.; Hedjam, R. Ensemble clustering using extended fuzzy k-means for cancer data analysis. Expert Syst. Appl. 2021, 172, 114622. [Google Scholar] [CrossRef]
- Jain, A.; Dubs, R. Clustering Methods and Algorithms; Prentice-Hall: Hoboken, NJ, USA, 1988. [Google Scholar]
- Pal, N.R.; Biswas, J. Cluster Validation Using Graph Theoretic Concept. Pattern Recognit. 1997, 30, 847–857. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On Clustering Validation Techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concept and Techniques; Morgan Kaufmann Publishers: Burlington, MA, USA, 2012. [Google Scholar]
- Popkov, Y.S. Randomization and Entropy in Machine Learning and Data Processing. Dokl. Math. 2022, 105, 135–157. [Google Scholar] [CrossRef]
- Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. Introduction to the Theory of Randomized Machine Learning. In Learning Systems: From Theory to Practice; Sgurev, V., Piuri, V., Jotsov, V., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 199–220. [Google Scholar] [CrossRef]
- Popkov, Y.S. Macrosystems Theory and Its Applications (Lecture Notes in Control and Information Sciences Vol 203); Springer: Berlin, Germany, 1995. [Google Scholar]
- Popkov, Y.S. Multiplicative Methods for Entropy Programming Problems and their Applications. In Proceedings of the 2010 IEEE International Conference on Industrial Engineering and Engineering Management, Xiamen, China, 29–31 October 2010; pp. 1358–1362. [Google Scholar] [CrossRef]
- Polyak, B.T. Introduction to Optimization; Optimization Software: New York, NY, USA, 1987. [Google Scholar]
- Joffe, A.D.; Tihomirov, A.M. Teoriya Ekstremalnykh Zadach (Theory of Extreme Problems); Nauka: Moscow, Russia, 1974. [Google Scholar]
- Tihomirov, V.M.; Alekseev, V.N.; Fomin, S.V. Optimal Control; Nauka: Moscow, Russia, 1979. [Google Scholar]
- Popkov, Y.; Popkov, A. New methods of entropy-robust estimation for randomized models under limited data. Entropy 2014, 16, 675–698. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).