

Relation Extraction from Videos Based on IoT Intelligent Collaboration Framework

Abstract
:1. Introduction
- We propose an edge computing framework to reduce latency by leveraging edge and cloud nodes’ cooperative processing capabilities on AI algorithms;
- To achieve more accuracy for video analysis, two AI algorithms are proposed based on multi-granularity GCN and ensemble learning in the cloud. In addition, some tasks are processed at edge nodes to prevent network congestion;
- We experiment on some video datasets to demonstrate that our framework and AI algorithms can optimize the accuracy and latency of the relation extraction and analysis from massive videos.
2. Related Work
2.1. Edge Computing
2.2. Relation Extraction and Recognition
2.3. Relation Graph Analysis
3. The Proposed Edge-Cloud Intelligence Framework
3.1. Framework Overview
3.2. Definition
- Edge devices: These may be static camera devices fixed in the surveillance area such as city streets, public places, mobile phones, or drones, which invoke video tasks, divide them into smaller sub-tasks, compress videos and transmit them to the edge nodes. Besides, essential information and videos are sent to the cloud for high-level planning and decision with Deep Neural Networks (DNN), e.g., relation recognition and video analysis algorithms;
- Edge intelligence: It reflects the core functions of edge computing. The edge nodes can run lightweight AI algorithms, have some storage capacity, and are closer to the edge device to generate faster query responses. It helps execute some sub-tasks, e.g., feature extraction and entity detection, and transmits these results to cloud computing nodes through the network for further analysis;
- Cloud intelligence: The cloud computing platform undertakes the storage and computing capacity of the overall video in the system, which is a fixed device far from the edge node. The cloud node receives videos and operation results from edge devices and edge nodes to perform more detailed analysis and training, such as relation graph construction, relation recognition, and community detection.
3.3. Collaboration and Workflow
4. AI Algorithms for Relation Extraction and Analysis
4.1. Problem Description
4.2. Tasks in Edge Intelligence
4.2.1. Partition Schemes for Entity Detection
4.2.2. Person Identification
| Algorithm 1 Person Set A |
| Input: face and body features and . Output: person set A. //Concatenate feature vectors and perform normalization operations.
|
4.3. Tasks in Cloud Intelligence
4.3.1. The Architecture of the MGM
4.3.2. Relation Recognition
4.3.3. Relationship Graph Analysis
| Algorithm 2 Fusion algorithm for CDEL |
| Input: structure and attribute partitions and . Output: The final community partition . //Traverse the two partitions. If the node pair is not in the same partition, we ignore it. Otherwise, we calculate its weighted co-association matrix M.
|
5. Experiment
5.1. Dataset Description
5.2. Evaluation Metrics
5.2.1.
5.2.2. BalAccuracy
5.2.3. Subset Accuracy
5.2.4. NMI
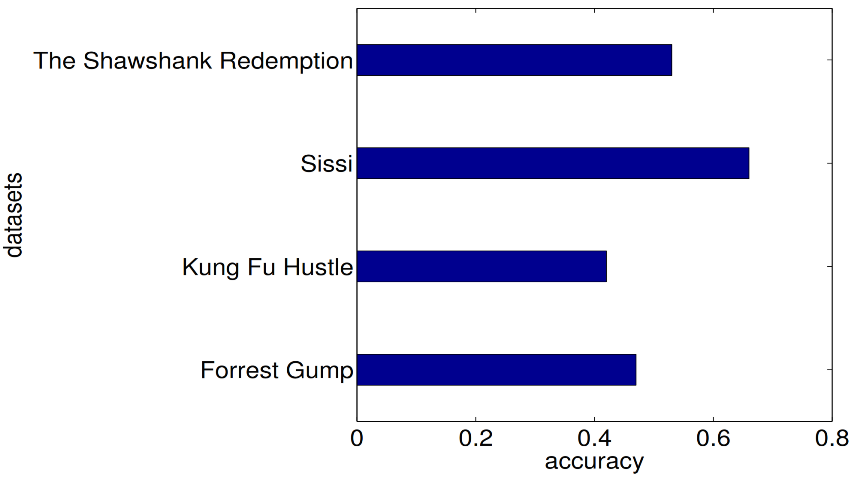
5.3. Entity Detection in Edge Intelligence
5.4. Relation Recognition in the Cloud Intelligence
5.5. Community Detection in the Cloud Intelligence
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, X.; Yu, F.R.; Song, T.; Leung, V.C. A survey on multi-access edge computing applied to video streaming: Some research issues and challenges. IEEE Commun. Surv. Tutor. 2021, 23, 871–903. [Google Scholar] [CrossRef]
- Alfonso, G.P. Application of HMM and Ensemble Learning in Intelligent Tunneling. Mathematics 2022, 10, 1785. [Google Scholar]
- Patrikar, D.R.; Parate, M.R. Anomaly detection using edge computing in video surveillance system: Review. Int. J. Multimed. Inf. Retr. 2022, 11, 85–110. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Liu, W.; Zhang, M.; Chen, J.; Gao, L.; Yan, C.; Mei, T. Social relation recognition from videos via multi-scale spatial-temporal reasoning. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 6–16 June 2019; pp. 3566–3574. [Google Scholar]
- Sun, H.; Shi, W.; Liang, X.; Yu, Y. VU: Edge computing-enabled video usefulness detection and its application in large-scale video surveillance systems. IEEE Internet Things J. 2020, 7, 800–817. [Google Scholar] [CrossRef]
- Xu, K.; Jiang, X.; Sun, T. Anomaly detection based on stacked sparse coding with intraframe classification strategy. IEEE Trans. Multimed. 2018, 20, 1062–1074. [Google Scholar] [CrossRef]
- Georgiou, T.; Liu, Y.; Chen, W.; Lew, M.S. A survey of traditional and deep learning-based feature descriptors for high dimensional data in computer vision. Int. J. Multimed. Inf. Retr. 2020, 9, 135–170. [Google Scholar] [CrossRef]
- Long, C.; Cao, Y.; Jiang, T.; Zhang, Q. Edge computing framework for cooperative video processing in multimedia iot systems. IEEE Trans. Multimed. 2018, 20, 1126–1139. [Google Scholar] [CrossRef]
- Ghosh, A.M.; Grolinger, K. Edge-cloud computing for internet of things data analytics: Embedding intelligence in the edge with deep learning. IEEE Trans. Ind. Inform. 2020, 17, 2191–2200. [Google Scholar]
- Rong, C.; Wang, J.H.; Liu, J.; Wang, J.; Li, F.; Huang, X. Scheduling massive camera streams to optimize large-scale live video analytics. IEEE/ACM Trans. Netw. 2022, 30, 867–880. [Google Scholar] [CrossRef]
- Zhang, B.; Jin, X.; Ratnasamy, S.; Wawrzynek, J.; Lee, E.A. Awstream: Adaptive wide-area streaming analytics. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 236–252. [Google Scholar]
- Zhang, X.; Wang, Y.; Lu, S.; Liu, L.; Shi, W. Openei: An open framework for edge intelligence. In Proceedings of the 39th IEEE International Conference on Distributed Computing Systems, Dallas, TX, USA, 7–10 July 2019; pp. 1840–1851. [Google Scholar]
- Angadi, S.; Nandyal, S. Human identification using histogram of oriented gradients (HOG) and non-maximum suppression (NMS) for atm video surveillance. Int. J. Inn. Res. Com. Sci. Tech. 2021, 9, IRP1143. [Google Scholar] [CrossRef]
- Yu, H.; Li, H.; Mao, D.; Cai, Q. A relationship extraction method for domain knowledge graph construction. World Wide Web 2020, 23, 735–753. [Google Scholar] [CrossRef]
- Shashank, G.; Ajay, R.S. Maximum correlation based mutual information scheme for intrusion detection in the data networks. Expert Syst. Appl. 2022, 189, 116089. [Google Scholar]
- Xiong, Z.; Wu, Y.; Ye, C.; Zhang, X.; Xu, F. Color image chaos encryption algorithm combining CRC and nine palace map. Multimed. Tools Appl. 2019, 78, 35–55. [Google Scholar] [CrossRef]
- Zellers, R.; Bisk, Y.; Farhadi, A.; Choi, Y. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 6–16 June 2019; pp. 6720–6731. [Google Scholar]
- Lin, D.; Wang, L.; Shi, G.; Xu, H. Social relationship recognition based on relational self-attention mechanism. In Proceedings of the 25th IEEE International Conference on Computer Supported Cooperative Work in Design, Hangzhou, China, 4–6 May 2022; pp. 798–803. [Google Scholar]
- Lv, J.; Liu, W.; Zhou, L.; Wu, B.; Ma, H. Multi-stream fusion model for social relation recognition from videos. In Proceedings of the MultiMedia Modeling—24th International Conference, Bangkok, Thailand, 5–7 February 2018; pp. 355–368. [Google Scholar]
- Dai, P.; Lv, J.; Wu, B. Two-stage model for social relationship understanding from videos. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 1132–1137. [Google Scholar]
- Xu, T.; Zhou, P.; Hu, L.; He, X. Socializing the videos: A multimodal approach for social relation recognition. ACM Trans. Multimed. Comput. 2021, 17, 23. [Google Scholar] [CrossRef]
- Kukleva, A.; Tapaswi, M.; Laptev, I. Learning interactions and relationships between movie characters. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9849–9858. [Google Scholar]
- Vicol, P.; Tapaswi, M.; Castrejón, L.; Fidler, S. Moviegraphs: Towards understanding human-centric situations from videos. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8581–8590. [Google Scholar]
- Li, S.; Jiang, S.; Xu, X.; Han, W.; Zhao, D.; Wang, Z. A weighted network community detection algorithm based on deep learning. Appl. Math. Comput. 2021, 401, 126012. [Google Scholar] [CrossRef]
- Ma, C.X.; Song, J.C.; Zhu, Q.; Maher, K.; Huang, Z.Y.; Wang, H.A. Emotionmap: Visual analysis of video emotional content on a map. J. Comput. Sci. Technol. 2020, 35, 576–591. [Google Scholar] [CrossRef]
- Donta, P.K.; Srirama, S.N.; Amgoth, T.; Annavarapu, C.S.R. Survey on recent advances in iot application layer protocols and machine learning scope for research directions. Digit. Commun. Netw. 2021. [Google Scholar] [CrossRef]
- Yang, P.; Lyu, F.; Wu, W.; Zhang, N.; Yu, L.; Shen, X.S. Edge coordinated query configuration for low-latency and accurate video analytics. IEEE Trans. Ind. Inform. 2019, 16, 4855–4864. [Google Scholar] [CrossRef]
- Fathy, C.; Saleh, S.N. Integrating deep learning-based iot and fog computing with software-defined networking for detecting weapons in video surveillance systems. Sensors 2022, 22, 5075. [Google Scholar] [CrossRef]
- Taghavi, S.; Shi, W. Edgemask: An edge-based privacy preserving service for video data sharing. In Proceedings of the 5th IEEE/ACM Symposium on Edge Computing, San Jose, CA, USA, 12–14 November 2020; pp. 382–387. [Google Scholar]
- Dave, M.; Rastogi, V.; Miglani, M.; Saharan, P.; Goyal, N. Smart fog-based video surveillance with privacy preservation based on blockchain. Wirel. Pers. Commun. 2022, 124, 1677–1694. [Google Scholar] [CrossRef]
- Yuan, K.; Yao, H.; Ji, R.; Sun, X. Mining actor correlations with hierarchical concurrence parsing. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 798–801. [Google Scholar]
- Lv, J.; Wu, B.; Zhou, L.; Wang, H. Storyrolenet: Social network construction of role relationship in video. IEEE Access 2018, 6, 958–969. [Google Scholar] [CrossRef]
- Labatut, V.; Bost, X. Extraction and analysis of fictional character networks: A survey. ACM Comput. Surv. 2019, 52, 89. [Google Scholar] [CrossRef]
- Gao, J.; Qing, L.; Li, L.; Cheng, Y.; Peng, Y. Multi-scale features based interpersonal relation recognition using higher-order graph neural network. Neurocomputing 2021, 456, 243–252. [Google Scholar] [CrossRef]
- Li, L.; Qing, L.; Wang, Y.; Su, J. HF-SRGR: A new hybrid feature-driven social relation graph reasoning model. Vis. Com. 2021, 1–14. [Google Scholar] [CrossRef]
- Teng, Y.; Song, C.; Wu, B. Toward jointly understanding social relationships and characters from videos. Appl. Intell. 2022, 52, 5633–5645. [Google Scholar] [CrossRef]
- Lv, J.; Wu, B. Spatio-temporal attention model based on multi-view for social relation understanding. In Proceedings of the MultiMedia Modeling—25th International Conference, Thessaloniki, Greece, 8–11 January 2019; pp. 390–401. [Google Scholar]
- Feng, L.; Bhanu, B. Understanding dynamic social grouping behaviors of pedestrians. IEEE J. Sel. Top. Signal Process. 2015, 9, 317–329. [Google Scholar] [CrossRef]
- Lee, O.J.; Jung, J.J. Story embedding: Learning distributed representations of stories based on character networks. Artif. Intell. 2020, 281, 103235. [Google Scholar] [CrossRef]
- Wang, W.; Du, H.Y.; Bai, L. An overlapping community detection algorithm based on centrality measurement of network node. J. Comput. Dev. 2018, 55, 1619. [Google Scholar]
- Li, Y.; He, K.; Kloster, K.; Bindel, D.; Hopcroft, J. Local spectral clustering for overlapping community detection. ACM Trans. Knowl. Discov. Data 2018, 12, 17. [Google Scholar] [CrossRef]
- Abbe, E. Community detection and stochastic block models: Recent developments. J. Mach. Learn. Res. 2017, 18, 1–86. [Google Scholar]
- Sun, H.; He, F.; Huang, J.; Sun, Y.; Li, Y.; Wang, C.; He, L.; Sun, Z.; Jia, X. Network embedding for community detection in attributed networks. ACM Trans. Knowl. Discov. Data. 2020, 14, 36. [Google Scholar] [CrossRef]
- Su, X.; Xue, S.; Liu, F.; Wu, J. A comprehensive survey on community detection with deep learning. IEEE T. Neur. Net. Lear. 2022. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Cao, Y.; Jiang, T.; Chen, X.; Zhang, J. Social-aware video multicast based on device-to-device communications. IEEE Trans. Mob. Comput. 2016, 15, 1528–1539. [Google Scholar] [CrossRef]
- Hu, C.; Bao, W.; Wang, D.; Liu, F. Dynamic adaptive DNN surgery for inference acceleration on the edge. In Proceedings of the 2019 IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1423–1431. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sze, V.; Chen, Y.H.; Yang, T.J. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Zhou, L.; Wu, B.; Lv, J. Sre-net model for automatic social relation extraction from video. In Proceedings of the 6th CCF Conference, Xi’an, China, 11–13 October 2018; pp. 442–460. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10, 10008. [Google Scholar] [CrossRef] [Green Version]
- Vazquez, A.F.; Dapena, A.; Souto-Salorio, M.J. Calculation of the Connected Dominating Set Considering Vertex Importance Metrics. Entropy 2019, 20, 87. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Luo, S.; Zhang, Z.; Ma, Y.; Shu, W. Co-association matrix-based multi-layer fusion for community detection in attributed networks. Entropy 2019, 21, 95. [Google Scholar] [CrossRef]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 9, P09008. [Google Scholar] [CrossRef]
- Du, T.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Findler, N.V. Short note on a heuristic search strategy in long-term memory networks. Inform. Process. Lett. 1972, 1, 191–196. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Girvan, M.; Newman, M. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Contribution | Scope | ||
|---|---|---|---|---|
| EC | RE | CD | ||
| Fathy et al. [28] | Proposed an intelligent adaptive QoS framework for video stream | yes | no | no |
| Yang et al. [27] | Deployed an end-edge-cloud collaboration framework for video queries | yes | no | no |
| Zhang et al. [12] | Defined edge intelligent computing and reviewed the relevant systems | yes | no | no |
| Taghavi et al. [29] | Proposed an EdgeMask to solve real-time object segmentation | yes | no | no |
| Dave et al. [30] | Used an event-driven and resource-efficient surveillance system | yes | no | no |
| Lv et al. [32] | Extracted the relation graph of the persons using coarse-grained features | no | yes | no |
| Li et al. [35] | Proposed a social relation graph reasoning model based on server | no | yes | no |
| Teng et al. [36] | Proposed a character and relationship joint learning framework on standard dataset | no | yes | no |
| Lv et al. [37] | Proposed an attentive sequences recurrent network on standard dataset | no | yes | no |
| Wang et al. [40] | Proposed an overlapping CD algorithm based on Non-attribute Network | no | no | yes |
| Sun et al. [24] | Proposed a community detection algorithm based on a deep sparse autoencoder | no | no | yes |
| Sun et al. [44] | Propose an algorithm named Network Embedding for node Clustering (NEC) | no | no | yes |
| Our work | Relation extraction and analysis based on edge computing | yes | yes | yes |
| Notation | Definition |
|---|---|
| A | The person set, |
| Att(A) | The person attributes set |
| RG(A) | Relation graph extracted from video |
| The concatenation of feature vectors | |
| The normalization operation | |
| The entity features in the MGM | |
| The global features in the MGM | |
| The attribute features in the MGM | |
| The community partition based on structure | |
| The community partition based on attribute | |
| M(A) | The adjacency matrix of the entity graph, |
| An element of , |
| Method | F1 | BalAcc | SubAcc |
|---|---|---|---|
| C3D [59] | 0.3886 | 0.0556 | 0.0357 |
| LSTM [60] | 0.5776 | 0.6667 | 0.2797 |
| TSN [52] | 0.6142 | 0.7089 | 0.3482 |
| Multi-Stream [19] | 0.6383 | 0.6136 | 0.5291 |
| STMV [37] | 0.6492 | 0.6322 | 0.5311 |
| TSM [20] | 0.7293 | 0.7125 | 0.6032 |
| Ours (+GAT) | 0.7431 | 0.7173 | 0.6114 |
| Ours (+GAT+Audio) | 0.7450 | 0.7183 | 0.6147 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, J.; Shen, Q.; Lv, M.; Shi, L. Relation Extraction from Videos Based on IoT Intelligent Collaboration Framework. Mathematics 2022, 10, 3308. https://doi.org/10.3390/math10183308
Lv J, Shen Q, Lv M, Shi L. Relation Extraction from Videos Based on IoT Intelligent Collaboration Framework. Mathematics. 2022; 10(18):3308. https://doi.org/10.3390/math10183308
Chicago/Turabian StyleLv, Jinna, Qi Shen, Mingzheng Lv, and Lei Shi. 2022. "Relation Extraction from Videos Based on IoT Intelligent Collaboration Framework" Mathematics 10, no. 18: 3308. https://doi.org/10.3390/math10183308
APA StyleLv, J., Shen, Q., Lv, M., & Shi, L. (2022). Relation Extraction from Videos Based on IoT Intelligent Collaboration Framework. Mathematics, 10(18), 3308. https://doi.org/10.3390/math10183308