Abstract
We consider an optimal control problem with the discounted and average payoff. The reward rate (or cost rate) can be unbounded from above and below, and a Markovian switching stochastic differential equation gives the state variable dynamic. Markovian switching is represented by a hidden continuous-time Markov chain that can only be observed in Gaussian white noise. Our general aim is to give conditions for the existence of optimal Markov stationary controls. This fact generalizes the conditions that ensure the existence of optimal control policies for optimal control problems completely observed. We use standard dynamic programming techniques and the method of hidden Markov model filtering to achieve our goals. As applications of our results, we study the discounted linear quadratic regulator (LQR) problem, the ergodic LQR problem for the modeled quarter-car suspension, the average LQR problem for the modeled quarter-car suspension with damp, and an explicit application for an optimal pollution control.
MSC:
49N05; 49N10; 49N30; 49N90; 93C41
1. Introduction
In recent years, there has been more attention to a class of optimal control problems where the dynamic systems are governed means switching diffusions in which the switching is modeled by a continuous-time Markov chain () with unobservable hidden states (also known as partially observed optimal control problems). In these problems, an observable process y whose outcomes are “influenced” by the outcomes of in a known way is assumed. Since cannot be observed directly, the goal is to learn about by observing y. Following the last mentioned, this article concerns with an optimal control problem with discounted and ergodic payoff in which the dynamic system evolves according to a Markovian regime-switching diffusion for given continuous functions f and . The reward rate is allowed to be unbounded from above and from below. In this paper, the Wonham filter to estimate the states of the Markov chain from the observable evolution of a given process (y) is used. As a result, the original system is converted to a completely observable one .
Our main results extend the dynamic programming technique to this family of stochastic optimal control problems with reward (or cost) rate per unit of time unbounded and Markovian regime-switching diffusions. The regime switching is modeled by a continuous-time Markov chain () with unobservable states. Early works include research on an optimal control problem with an ergodic payoff, considering that the dynamic system evolves according to Markovian switching diffusions. However, this diffusion does not depend on a hidden Markov chain [1]. Research on deriving the dynamic programming principle for a partially observed optimal control problem in which the dynamic system is governed by a discrete-time Markov control process taking values in a finite-dimensional space has also been proposed [2]. Finally, one paper studied the optimal control with Markovian switching that is completely observable and rewards rate unbounded [3]. As an application of our results, we study the discounted linear quadratic regulator (LQR) problem, the ergodic LQR problem for the modeled quarter-car suspension, the average (ergodic) LQR problem for the modeled quarter-car suspension with damp, and an explicit application for an optimal pollution control. Other applications with bounded payoff different from those studied in this work are found in [4,5,6].
The objective of the theory of controlled regime-switching diffusions is to model controlled diffusion systems whose dynamics are affected by discrete phenomena. In these systems, the discrete phenomena are modeled by a Markov chain in continuous time, whose states represent the discrete phenomenon involved. There is an extensive list of references dealing with the case of completely observable stochastic optimal control in which a switching diffusion governs the stochastic systems. A literature review includes the textbooks [7,8] and the papers [9,10,11,12,13,14], with several applications, including optimization portfolios, wireless communication systems, and wind turbines, among others.
Generally, to solve unobserved optimal control problems, where the dynamic systems are governed by a hidden Markovian switching diffusion, it is necessary to transform them into completely observed ones, which in our case is done using a Wonham filter.
This Wonham filter estimates the hidden state of the Markov chain from the observable evolution of the process y. When these estimates are replaced in the original system, this becomes a completely observable system [15,16] and ([17], Section 22.3). The numerical results for Wonham’s filter are given in [18].
The paper is organized as follows: in Section 1, an introduction is given. In Section 2, the main assumptions are given. In this section, the partially observable system is converted into an observable system. The conditions to ensure the existence of optimal solutions for the optimal control problem with discounted payoff are given in Section 3. In Section 4, the conditions to ensure the existence of optimal solutions for the optimal control problem with average payoff are deduced. To illustrate our results, four applications are developed: an application on a linear quadratic regulator (LQR) with discounted payoff (Section 5); the development of a model of a quarter-car suspension LQR with an average payoff (Section 6); the study of an optimal control of a vehicle active suspension system with damp (Section 7); and an explicit application for an optimal pollution control (Section 8).
2. Formulation of the Problem
This work focuses on controlled hybrid stochastic differential Equations (HSDE) under partial observation. To explain this, first, we consider the stochastic differential equations of the form:
where and in (1) depend on a finite state and time-continuous irreducible and aperiodic Markov chain taking values in . For all the transition probabilities are given by:
where the constants are the transition rates from i to j and satisfy that , the transition matrix is denoted by . The control component is with a compact set of , and W is a d-dimensional standard Brownian motion independent of . Throughout the work, it is considered that both the Markov chain and the Brownian motion W are defined on a complete filtered probability space that satisfies the usual conditions.
Until now, the switching diffusion (1) seems to be formulated as a classical switching diffusion, as in [11,12,13,14,19], among others. However, we propose that the process is a hidden Markov chain, i.e., at any given instant of time, the exact state of the Markov chain cannot be observed directly. Instead, we can only observe the process y given by:
whose dynamics depends on the value of . In Equation (2), is a bounded function, whereas B is a one-dimensional Brownian motion independent of W and , and is a positive constant.
Under partial observation, the best way to work is through nonlinear filtering. This technique studies the conditional distribution of given the observed data accumulated up to time t, namely:
where is the -algebra generated by the process and Taking into account the following notation:
and using the Wonham filtering techniques, we know that the process in (3) satisfies the following Equation (see for instance [15] or ([17], Section 22.3)):
where is the identity matrix. If we introduce the process:
then Equation (4) can be rewritten as:
Remark 1.
Note that the unique solution of (5) exists up to an explosion time τ (see, for instance [20]). However, a.s. since for all and .
At this point, we have defined the controlled HSDE with partial observation. To fulfill the objective of this work, that is, to solve an optimal control problem with the discounted and average payoff with partial observation, we will transform this problem into one with complete observation (see for instance [5,6,16]). First, we will establish the following notational convention.
For the coefficients and
we have their filtered estimates:
and with equalities (6)–(7), we establish the new coefficients:
With the use of above functions and Equation (1), we introduce the components of a new diffusion process as:
and therefore, we obtain from (5) and (8) the following controlled system with complete observation:
where with:
Throughout this work, we will use the following Assumption 1.
Assumption 1.
- (a)
- The control setis compact.
- (b)
- is a continuous function that satisfies the Lipschitz continuous property on x uniformly in, that is, there exists a constantsuch that:
- (c)
- There exists constantssuch that,satisfies:for alland for all.
- (d)
- There existswith:forand.
Under Assumption 1 and taking into account Remark 1, we know that the system (9) has a unique solution.
For , we denote by and the gradient and the Hessian matrix of x, respectively, and the scalar product. For a sufficiently smooth real-valued function . Let:
with
the operator associated with Equation (9). In order to carry out the aim of this work, we define the control policies.
Definition 1.
A function of the formfor some measurable function, is called a Markov policy, whereasfor some measurable functionis said to be a stationary Markov policy. The stationary Markov policies set is denote by.
The following assumption represents a Lyapunov-like condition.
Assumption 2.
There exists a function, and constants, such that:
- (i)
- and
- (ii)
- for eachand.
It is important to point out that since the is irreducible and aperiodic, we can ensure the existence of a unique invariant measure for the Markov–Feller process (see [21,22]). Moreover, the Assumption 2 allows us to conclude that the Markov process , where is positive recurrent and there exists a unique invariant probability measure for which is satisfied:
Note that for every , the measure belongs to the space defined as follows.
Definition 2.
The w-norm is defined as:
where ν is the real-valued measurable function onand w is the Lyapunov function given in Assumption 2. The normed linear space of real-valued measurable functions ν with finite w-norm is denoted by. Moreover, the normed linear space of finite signed measures μ onsuch that:
whereis the total variation of μ is denoted by.
Remark 2.
For eachand, we get:
that is, the integralis finite.
The next result will be useful later.
Lemma 1.
The conditionin Assumption 2 implies that:
- (a)
- ;
- (b)
- for all,, and;
- (c)
- for all.
Proof.
(a) After applying Dynkin’s formula to the function , we use case of Assumption 2 to get:
Finally, if we multiply the inequality (12) by , we obtain the result. To prove , it is enough take the limit from the inequality (12). Integrating both sides of (12) with respect to the invariant probability , we obtain , i.e., ; thus, the result follows. □
In this work, the reward rate is a measurable function that satisfies the following conditions:
Assumption 3.
- (a)
- The functionis continuous on; moreover, for each, there exists a constantsuch that:i.e., r is locally Lipschitz in x uniformly with respect toand.
- (b)
- is in the normed linear space of real-valued functionsuniformly in u; that is, there existssuch that for all:
Notation. The rate reward is vector form is given by:
and its estimation is:
Henceforth, for each stationary Markov policy , we write:
3. The Discounted Case
The objective of this section is to give conditions that guarantee the existence of discounted optimal policies for the -discounted payoff criterion we are concerned with.
Definition 3.
Let r be as in Assumption 3 and α a positive constant. Given a stationary Markov policyand an initial state, the total expected discount payoff (or discounted payoff, for short) is defined as:
Observe that the value function does not depend on the time at which the optimal control problem is studied to get the stationarity of the problem.
The following result shows a bound of the total expected discount payoff given in Definition 3. We will omit its proof because it is a direct consequence of Assumption 3 and inequality in Lemma 1a.
Proposition 1.
Suppose that Assumptions 2 and 3b hold. Then, for each x in, andwe have:
implying that α-discounted payoff, belongs to the space. Here, q and p are as in Assumption 2 and M is the constant in Assumption 3b.
-discounted optimal problem. The optimal control problem with discounted payoff consists of finding a policy such that:
The function is referred to as the optimal discount payoff, whereas the policy is called the discounted optimal.
Definition 4.
We say that a function, and a policyverify (are a solution of) the-discounted payoff optimality equations (or Hamilton–Jacobi–Bellman (HJB) equation) if, for everyand:
Proposition 2.
If Assumptions 1, 2, and 3 hold, then:
Proof.
- (a)
- (b)
- By Dynkin’s formula for all , and :Observe that:This yields:Now, as a consequence of v is in and Lemma 1 (a),(b), we have that:Therefore:Thus, . In particular, if we take satisfying (14) and proceed as above, we get:
- (c)
- The if part. Suppose that satisfies Equations (14) and (15). Then, proceeding as in part (b), we obtain that is an optimal policy.The only if part. By mimic the same procedure of part (b), we can obtain that for any fixed:On the other hand, by part (b) we can assert that:
□
4. Average Optimality Criteria
As in (10), let for every .
Assumption 4.
Next, we define the long-run average optimality criterion.
Definition 5.
For each, , and, let:
The long-run expected average reward given the initial stateis:
The function:
is referred to as the optimal gain or the optimal average reward. If there is a policyfor whichfor all, thenis called average optimal.
Remark 4.
In some optimal control problems, the limit of as might not exist. To avoid this difficulty, in optimal control problems, it defines the average payoff as a liminf as in (21), which be interpreted as the worst average payoff that is to be maximized.
For each , let:
with as in (10). Now, observe that defined in (20) can be expressed as:
therefore, multiplying (23) by and letting we obtain, by (19):
Therefore, by Lemma 1c:
thus, the reward is uniformly bounded on . From (24) and (25) we obtain that the following:
has a finite value.
Thus, under the Assumptions 1, 2, and 4, it follows from (19) (w-exponential ergodicity) and (22) that the long-run expected average reward (21) coincides with the constant for every . Indeed, note that defined in (20) can be expressed as:
Definition 6.
(a) A pairconsisting of a constantand a functionis said to be a solution of the average reward HJB-equation if:
then f is called a canonical policy.
The following theorem shows that if a policy satisfies the average reward HJB-equation, then it is an optimal average policy.
Theorem 1.
If Assumptions 1, 2, and 3 hold, then:
Proof.
The steps for the proof of this incise are essentially the same given in proof of Theorem 6.4 in [24]; thus, we omit the proof.
Since and are continuous functions on the compact set , we obtain that is a continuous function on ; thus, the existence of a canonical policy follows from standard measurable selection theorems; see [25] (Theorem 12.2).
Observe that, by (27):
Therefore, for any , using Dynkin’s formula and (29) we obtain:
Thus, multiplying by in (30) we have:
To obtain the reverse inequality, similar arguments show that if:
then for all . This last inequality together with (29) yields that if is a canonical policy, which satisfies (28), then we obtain that , and by (26):
Similar arguments to those given in lead us to that if is a canonical policy, then it is an average optimal. □
Theorem 1 indicates that if a policy satisfies the HJB Equation (27), then this policy is an optimal policy for the optimal control problem associated with the HJB equation. The difficulty with this approach is how to get a solution of the HJB equation. The most common form of the solve the HJB equation is based on variants on the vanishing discount approach (see [11,24,26] for details).
Remark 5
([1]). In the optimality criteria known as bias optimality, overtaking optimality, sensitive discount optimality, and Blackwell optimality, the early returns and the asymptotic returns are both relevant; thus, to study them, we need first to analyze the discounted and average optimality criteria. These optimality criteria will be studied in future work.
Remark 6.
- On Assumption 1, ([7], Theorems 3.17 and 3.18). The uniform Lipschitz and linear growth conditions of b and σ ensure the existence and uniqueness of the global solution of the SDE with Markovian switching (1). The uniform Lipschitz condition,) imply that the change rates of the functionsandare minor or equal to the change rate of a linear function of x. This gives, in particular, the continuity of b and σ in x for all. Thus, the uniform Lipschitz condition excludes the functions b and σ that are discontinuous concerning x. It is important to note that although a function let continuous, it does not guarantee that it satisfies the uniform Lipschitz condition; for example, the continuous functiondoes not satisfy this condition. Uniform Lipschitz condition can be replaced by the local Lipschitz condition. In fact, the local Lipschitz condition allows us to include a great variety of functions, such as functions. However, the linear growth condition (Assumption 1 (d)) also excludes some important functions, such as. Assumption 1 (d) is quite standard but may be restrictive for some applications. As far as the results of this paper are concerned, the uniform Lipschitz condition may be replaced by the weaker condition:where K is a positive constant. This last condition allows us to include many functions as the coefficients b and. For example:withsuch thatand for some continuous functiongiven. It is possible to check that a diffusion process with the parameters given above satisfies the local Lipschitz condition but the linear growth condition is not satisfied. On the other hand, note that:withand a compact control set U. That is, the condition (33) is fulfilled. Thus, ([7], Theorem 3.18) guarantees that the SDE with Markovian switching with these coefficients has a unique global solution on.
- On Assumption 2, ([7], Theorem 5.2). This assumption guarantees the positive recurrence and the existence of an invariant measurefor the Markov–Feller process. Moreover, if this assumption holds together with the inequalityfor positive numbers, then, the diffusion process (1) satisfies:that is,is asymptotically bounded inth moment. Some Lyapunov functions are, for example:considering that the coefficients b andin (1) satisfy the Lipschitz condition and:withandbe constants. In fact, using the inequalityand (35), we get:where.If we set:thenNow, taking the Lyapunov function (34) we define:Considering that,,anda similar procedure to that given in (37) allows us to obtain that W is also a Lyapunov function. That is:
- On Assumption 3.This assumption allows us that the reward rate (or cost rate) can be unbounded from above and below. For the Lyapunov function, a reward rate of the form:for some continuous functionsatisfies the Assumption 3. In fact:withand U a compact set.
- On Assumption 4.This assumption indicates asymptotic behavior ofwhen t goes to infinite. Sufficient conditions for the w-exponentially ergodicity of the processcan be seen in ([1], Theorem 2.8). In fact, in the proof of this theorem, Assumptions 1 and 2 are required. Note that, for the optimal control problem with discounted optimality criterion, the w-exponentially ergodicity of the processis not required. This assumption is only necessary to study the average reward optimality criterion.
Remark 7.
In the following sections, our theoretical results are implemented in three applications. The dynamic system in the three applications evolves according to linear stochastic differential equations, namely, Assumption 1. The state numbers of the Markov chain is 2, that is,. The payoff rate is of the formwithand,. Takingwe get:
with; thus, Assumption 3 also holds. A few calculations allow us to obtain the Assumption 2 with. In fact:
Let, and rewriteas:
where
where the last inequality is obtained from fact that the functionis continuous on the compact set U for alland that the termis negative. Thus,and Assumption 2b follows.
5. Application 1: Discounted Linear Quadratic Regulator (LQR)
In this subsection, we consider the -discounted linear quadratic regulator. To this end, we suppose that the dynamic system evolves according to the linear stochastic differential equations:
with , , , is a m-dimensional Brownian motion, and is a positive constant. The expected cost is:
where , , and . The optimality equation or HJB-equation for the -discounted partially observed LQR-optimal control problem is:
where the infinitesimal generator for the process applied to is:
where
By Proposition 2, if there exist a function and a policy such that (14) and (15) hold, then v coincides with the value function and is the -discount optimal policy. Thus, we propose that the function that solves the HJB-Equation (40) has the form:
where is a twice differentiable continuous function, c is a constant, and K is a positive definite matrix. Inserting the derivative of in (43) we get the optimal control:
where the equality (40) holds if the matrix K satisfies the algebraic Riccati equation:
and satisfies the partial differential equation:
where is as in (42), is the identity matrix of , and and are the gradient and the Hessian of the n, respectively.
Simulation results. In the following figures, we assume that the Markov chain has two states, namely, and the dynamic system . We have computed the Wonham filter, the states of the dynamic system (39) with initial condition , the value function (44), and the optimal control (45) for the following data: , , , , , , , :
and the transition matrix:
To solve the Wonhan filter, we use the numerical method given in ([18], Section 8.4), considering that the Markov chain can only be observed through .
Figure 1 shows the solution of the filter Wonham equation and the states of the hidden Markov chain . As can be noted, in s , implying that the Markov chain with a higher probability to is in state 2 in (). The evolution of the dynamic system (39) is given in Figure 2 (top); in this figure, we can note that the optimal control (45) moves the initial point to the point in s, indicating the good performance of the optimal control (45). The asymptotic behavior of the optimal control (45) is given in Figure 2 (bottom); this control stabilizes at zero around s, since also stabilizes at zero around s.
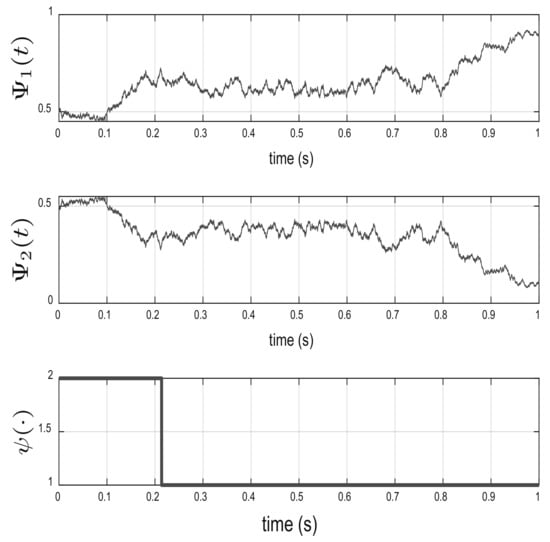
Figure 1.
Wonham filter for the -discounted LQR.
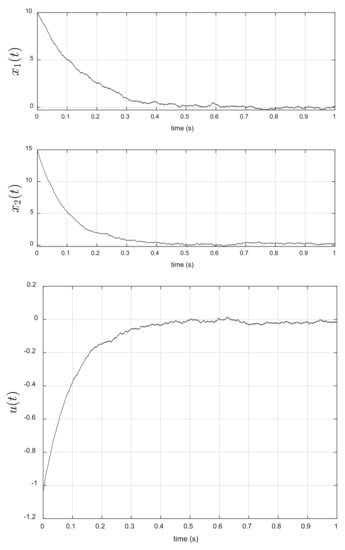
Figure 2.
Asymptotic behavior of the state of dynamic system (top) and optimal control -discount LQR (bottom).
6. Application 2: Average LQR: Modeling of a Quarter-Car Suspension
In this section, the basic quarter-car suspension model analyzed in [27] is considered, see Figure 3. The parameters are: the sprung mass (), the unsprung mass (), the suspension spring constant (), and the tire spring constant (k). Let , and be the vertical displacements of the sprung mass, the unsprung mass, and the road profile, respectively. The equations of motion for this model are given by:
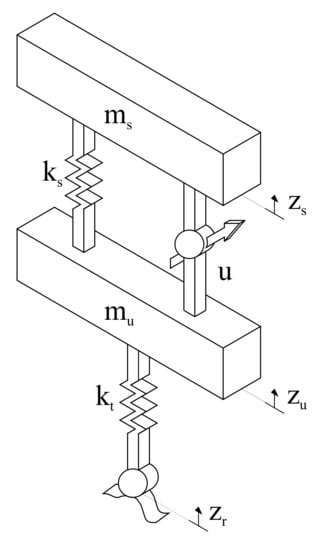
Figure 3.
Schematic of a quarter-car suspension.
Now, defining , , , and , the equations of motion (46) and (47) can be expressed in matrix form as:
where , and in the time domain, the road profile, , can be represented as the output of a linear first-order filter to white noise as follows:
where V is the vehicle speed (assumed constant), is a positive constant, and a is the road roughness coefficient depending on the type of road. Here, we assume that a depends on a hidden Markov chain, that is, with In our case, we consider that the dynamic system (48) evolves with additional white noise, that is:
The experts introduced the following performance index in order to trade off between the ride comfort and the handling while maintaining the constraint on suspension deflection:
Defining and , we can rewrite (50) as:
Now, from the equations of motion in (46) and (47), note that with and Thus, replacing this matrix form of y in (51) we can rewrite (50) again as:
where , , .
The optimal control problem (OCP). The OCP in this application consists of finding such that it minimizes the performance index (52) considering that the dynamic system evolves according to the stochastic differential Equation (49).
In the dynamic programming technique, we need the infinitesimal generator of the process applied to ; in this case, this generator is:
where , whereas the Hamilton–Jacobi–Bellman Equation (or dynamic programming equation) associated with this problem is:
see [28] for more details.
Proposition 3.
Assume thatevolves according to (49). Then, the control that minimizes the long-run cost (52) is:
whereas the corresponding function v that solves the HJB Equation (54) is given by:
where K is a positive semi-definite matrix that satisfies the Ricatti differential equation
andsatisfies the differential equation:
andsatisfies the partial differential equation:
whereis as in (41) and and denote the gradient and the Hessian of the n, respectively. The optimal cost is given by:
Proof.
The HJB-equation for the partially observed LQR optimal control problem with evolves according to (49) and finite cost (52) is (54), where is the infinitesimal generator given in (53). We are looking for a candidate solution to (54) in the form:
for some continuous functions , and K a positive semi-definite matrix. We assume that for all and is positive definite, so that the function is convex.
Now, the function is strictly convex on the compact set U, and thus, attains its minimum at:
Inserting and the partial derivatives of v with respect to x, , and in the HJB-Equation (54), we obtain:
For equality (61) to hold, it is necessary that the functions g and h satisfy (57) and (58), respectively, and the matrix K satisfies the Ricatti differential Equation (56), whereas the constant . Finally, from the Theorem 1, it follows that is an optimal Markovian control and the value function is equal to (59). That is:
□
Simulation results. To solve the Wonhan filter, we use the numerical method given in ([18], Section 8.4), considering that the Markov chain has two states that can only be observed through . The following data were used: , , , , , , , , × , , , kg, kg, N/m, N/m, m/s, , , and:
The solution of the Wonham filter equation and the states of the hidden Markov chain are shown in Figure 4. As can be noted, in s, , implying that the Markov Chain with a probability greater than is in state 1 at .
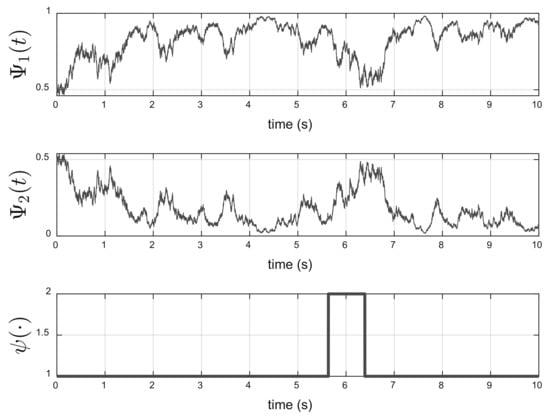
Figure 4.
Wonham filter and hidden Markov chain (in t = 1 s).
The asymptotic behavior of the optimal control (55) is given in Figure 5 (bottom). It is interesting to note that this control minimizes the magnitude of the sprung mass velocity, and unsprung mass velocity, after s, see Figure 5 (top). This behavior implies that the magnitude of the sprung mass acceleration, and unsprung mass acceleration are also minimized, considering that the stochastic differential equation that models the road profile depends on a hidden Markov chain. These results agree with the obtained by authors in [27]. These authors mentioned that two important objectives of a suspension system are ride comfort and handling performance. The ride comfort requires that the car body be isolated from road disturbances as much as possible to provide a good feeling for passengers. In practice, we are looking to minimize the acceleration of the sprung mass.
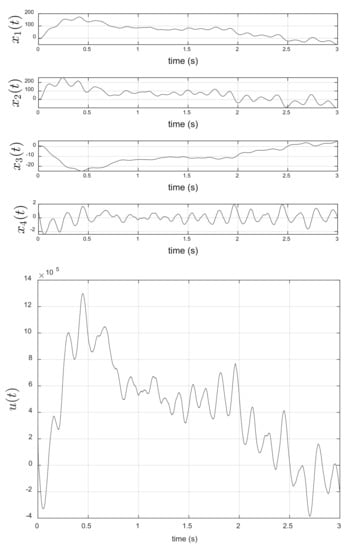
Figure 5.
Asymptotic behavior of the state of dynamic system (top) and optimal control (bottom).
7. Application 3: Optimal Control of a Vehicle Active Suspension System with Damp
The model analyzed in this subsection is given in [29]. In this application, a damp is added to the quarter-car suspension given in Section 6, see Figure 6. The parameters in Figure 6 are: the sprung mass (), the unsprung mass (), the suspension spring constant (), and the tire spring constant (k). Let , and r be the vertical displacements of the sprung mass, the unsprung mass, and the road disturbance, respectively. The equations of motion are given by:
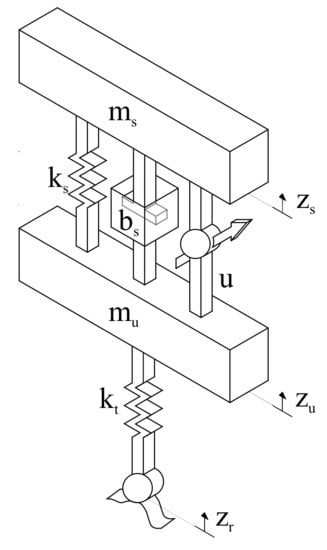
Figure 6.
Quarter vehicle model of active suspension system.
Now, defining , , , and , the equations of motion in (62) and (63) can be expressed in matrix form as:
where , and we assume that the road profile is represented by a function with hidden Markovian switchings:
where (road bump height is 10 cm), (road bump height is 16 cm), and , are the random jump times of . In our case, we consider that the dynamic system (64) evolves with additional white noise, that is:
and we wish to minimize the discounted expected cost:
subject to (66) and (65). Considering the infinitesimal generator given in (53) with and the Hamilton–Jacobi–Bellman equation associated as the following problem:
similar arguments to these given in Section 5 and Section 6 allow us to find the optimal control and the value function for this setting. In fact:
where is a twice differentiable continuous function, c is a constant, is a twice differentiable continuous function, and K is a positive definite matrix. Inserting the derivative of in (43), we get the optimal control:
where the matrix K satisfies the algebraic Riccati equation:
the function satisfies the differential equation:
and satisfies the partial differential equation:
where is as in (42), is the identity matrix of , and and are the gradient and the Hessian of the n, respectively.
Simulation results. To solve the Wonhan filter, we use the numerical method given in ([18], Section 8.4) considering that the Markov chain has two states and that can be only observed through . The following data were used: , , , , , , , , , kg, kg, N/m, N/m, N/m, and:
Figure 7 shows the solution of the Wonham filter equation and the states of the hidden Markov chain . As can be seen, in the time interval , , implying that the Markov chain with a probability greater than is in state 1.
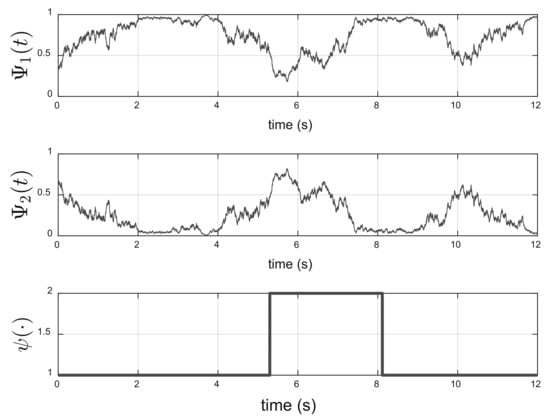
Figure 7.
Wonham filter and hidden Markov chain (time interval [2, 4]).
The asymptotic behavior of the optimal control (67) is given in Figure 8 (bottom). It is interesting to note that this control minimizes the magnitude of the sprung mass, , and unsprung mass, , al well as their velocities, and , after s, see Figure 8 (top).
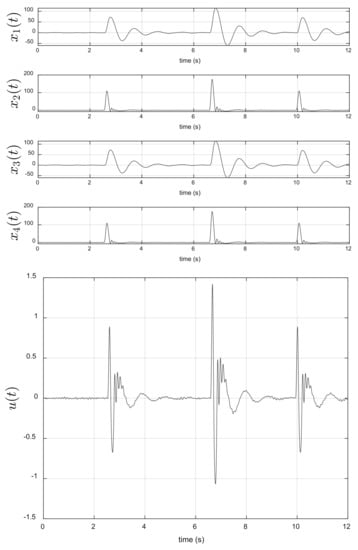
Figure 8.
Asymptotic behavior of the state of the dynamic system (top) and optimal control (bottom).
8. Application 4: Optimal Pollution Control with Average Payoff
The application studies the pollution accumulation incurred by the consumption of a certain product, such as gas or petroleum, see [30]. The stock of pollution is governed by the controlled diffusion process:
where represents the pollution flow generated by an entity due to the consumption of the product, represents the decay rate of pollution, chosen at each time by nature, and k is a positive constant. We shall assume that is bounded and the parameter represents the consumption/production restriction. Let be a Markov chain with two states and a generator Q given by:
The reward rate in this example represents the social welfare and is defined as:
where and is the social utility of the consumption u and the social disutility of the pollution , respectively. We assume that the function F in (69) satisfies:
Clearly, (68) is a liner stochastic differential equation, and satisfies Assumption 1.
Now, we define the Banach space and use , . Hence, and Assumption 2i holds. On the other hand, since the utility function is continuous on the compact interval , then:
where ; thus, Assumption 3 holds. Note that:
Thus, taking and we obtain:
Therefore, Assumption 2(ii) holds. It can be proven that the process (68) satisfies Assumption 2.6 in [1]; thus, by ([1], Theorem 2.8), is exponentially ergodic (Assumption 4). In this application, we seek a policy u that maximizes the long-run average welfare :
We propose , where and as a solution that verify the HJB Equation (27) associated with this pollution control problem. Simple calculations allow us to conclude that the policy on consumption/pollution takes the form:
where is the inverse function of derivative , .
9. Concluding Remarks
Under hypotheses such as uniform ellipticity in Assumption 1c, the Lyapunov-like conditions in Assumption 2, and the w-exponential ergodicity in (4) for the average criterion, this work shows the existence of optimal controls for the control problems with discounted and average payoffs, where the dynamic system evolves according to switching diffusion with hidden states. To conclude, we conjecture that the results obtained in this work still hold (with obvious changes) if the hidden Markov chain () in (1) is replaced with any other diffusion process. Furthermore, these results can be extended to constrained and unconstrained nonzero-sum stochastic differential games with additive structures, which will allow us to model a larger class of practical systems. This will be a topic in future works.
Author Contributions
Conceptualization, B.A.E.-T.; Formal analysis, B.A.E.-T. and J.G.-M.; Investigation, B.A.E.-T., J.G.-M. and G.A.; Methodology, B.A.E.-T., J.G.-M. and J.D.R.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Escobedo-Trujillo, B.A.; Hernández-Lerma, O. Overtaking optimality for controlled Markov-modulated diffusions. J. Optim. 2011, 61, 1405–1426. [Google Scholar] [CrossRef]
- Borkar, V.S. The value function in ergodic control of diffusion processes with partial observations. Stoch. Stoch. Rep. 1999, 67, 255–266. [Google Scholar] [CrossRef]
- Borkar, V.S. Dynamic programming for ergodic control with partial observations. Stoch. Process. Their Appl. 2003, 103, 293–310. [Google Scholar] [CrossRef]
- Rieder, U.; Bäuerle, N. Portfolio optimization with unobservable Markov-modulated drift Process. J. Appl. Probab. 2005, 362–378. [Google Scholar] [CrossRef] [Green Version]
- Tran, K. Optimal exploitation for hybrid systems of renewable resources under partial observation. Nonlinear Anal. Hybrid Syst. 2021, 40, 101013. [Google Scholar] [CrossRef]
- Tran, K.; Yin, G. Stochastic competitive Lotka–Volterra ecosystems under partial observation: Feedback controls for permanence and extinction. J. Frankl. Inst. 2014, 351, 4039–4064. [Google Scholar] [CrossRef]
- Mao, X.; Yuan, C. Stochastic Differential Equations with Markovian Switching; World Scientific Publishing Co.: London, UK, 2006; Available online: https://www.worldscientific.com/doi/pdf/10.1142/p473 (accessed on 20 March 2022). [CrossRef]
- Yin, G.G.; Zhu, C. Hybrid Switching Diffusions. In Stochastic Modelling and Applied Probability; Properties and Applications; Springer: New York, NY, USA, 2010; Volume 63, p. xviii+395. [Google Scholar] [CrossRef]
- Yin, G.; Mao, X.; Yuan, C.; Cao, D. Approximation methods for hybrid diffusion systems with state-dependent switching processes: Numerical algorithms and existence and uniqueness of solutions. SIAM J. Math. Anal. 2009, 41, 2335–2352. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Zhang, Q.; Yin, G. Asset allocation for regime-switching market models under partial observation. Dynam. Syst. Appl. 2014, 23, 39–61. [Google Scholar]
- Ghosh, M.K.; Arapostathis, A.; Marcus, S.I. Optimal control of switching diffusions with application to flexible manufacturing systems. SIAM J. Control Optim. 1993, 31, 1183–1204. [Google Scholar] [CrossRef]
- Ghosh, M.K.; Marcus, S.I.; Arapostathis, A. Controlled switching diffusions as hybrid processes. In Proceedings of the International Hybrid Systems Workshop, New Brunswick, NJ, USA, 22–25 October 1995; Springer: Berlin/Heidelberg, Germany, 1995; pp. 64–75. [Google Scholar]
- Zhang, X.; Zhu, Z.; Yuan, C. Asymptotic stability of the time-changed stochastic delay differential equations with Markovian switching. Open Math. 2021, 19, 614–628. [Google Scholar] [CrossRef]
- Zhu, C.; Yin, G. Asymptotic properties of hybrid diffusion systems. SIAM J. Control Optim. 2007, 46, 1155–1179. [Google Scholar] [CrossRef]
- Wonham, W.M. Some applications of stochastic differential equations to optimal nonlinear filtering. J. SIAM Control Ser. A 1965, 2, 347–369. [Google Scholar] [CrossRef]
- Elliott, R.J.; Aggoun, L.; Moore, J.B. Hidden Markov Models: Estimation and Control; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Cohen, S.N.; Elliott, R.J. Stochastic Calculus and Applications, 2nd ed.; Probability and Its Applications; Springer: Cham, Switzerland, 2015; p. xxiii+666. [Google Scholar] [CrossRef]
- Yin, G.; Zhang, Q. Discrete-Time Markov Chains: Two-Time-Scale Methods and Applications; Stochastic Modelling and Applied Probability; Springer: New York, NY, USA, 2006. [Google Scholar]
- Yin, G.G.; Zhu, C. Hybrid Switching Diffusions: Properties and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 63. [Google Scholar]
- Protter, P.E. Stochastic integration and differential equations. In Stochastic Modelling and Applied Probability, 2nd ed.; Version 2.1, Corrected Third Printing; Springer: Berlin/Heidelberg, Germany, 2005; Volume 21, p. xiv+419. [Google Scholar] [CrossRef]
- Chigansky, P. An ergodic theorem for filtering with applications to stability. Syst. Control Lett. 2006, 55, 908–917. [Google Scholar] [CrossRef]
- Kunita, H. Asymptotic behavior of the nonlinear filtering errors of Markov processes. J. Multivar. Anal. 1971, 1, 365–393. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Yin, G.; Guo, X. Infinite Horizon Controlled Diffusions with Randomly Varying and State-Dependent Discount Cost Rates. J. Optim. Theory Appl. 2017, 172, 535–553. [Google Scholar] [CrossRef]
- Ghosh, M.K.; Arapostathis, A.; Marcus, S.I. Ergodic control of switching diffusions. SIAM J. Contr. Optim 1997, 35, 1962–1988. [Google Scholar] [CrossRef]
- SchÄl, M. Conditions for optimality and for the limit of n-stage optimal policies to be optimal. Z. Wahrs. Verw. Gerb. 1975, 32, 179–196. [Google Scholar] [CrossRef]
- Ghosh, M.K.; Marcus, S.I. Stochastic differential games with multiple modes. Stoch. Anal. Appl. 1998, 16, 91–105. [Google Scholar] [CrossRef]
- Nguyen, L.H.; Seonghun, P.; Turnip, A.; Hong, K.S. Application of LQR Control Theory to the Design of Modified Skyhook Control Gains for Semi-Active Suspension Systems. In Proceedings of the ICROS-SICE International Joint Conference 2009, Fukuoka, Japan, 18–21 August 2009; pp. 4698–4703. [Google Scholar]
- Escobedo-Trujillo, B.; Garrido-Meléndez, J. Stochastic LQR optimal control with white and colored noise: Dynamic programming technique. Rev. Mex. Ing. QuÍmica 2021, 20, 1111–1127. [Google Scholar] [CrossRef]
- Maurya, V.K.; Bhangal, N.S. Optimal Control of Vehicle Active Suspension System. J. Autom. Control. Eng. 2018, 6, 1111–1127. [Google Scholar] [CrossRef]
- Kawaguchi, K.; Morimoto, H. Long-run average welfare in a pollution accumulation model. J. Econom. Dynam. Control 2007, 31, 703–720. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).