
Matching Ontologies through Multi-Objective Evolutionary Algorithm with Relevance Matrix



Abstract
:1. Introduction
- The multi-objective ontology matching problem is formally defined;
- A MOEA-RM is presented to address the ontology matching problem, which uses RM-based initialization, crossover and mutation to adaptively maintain population’s diversity and improve the algorithm’s converging speed;
- The proposed MOEA-RM is employed on 39 different ontology matching tasks, and the experimental results show its effectiveness.
2. Related Work
3. Ontology Matching Problem
4. Multi-Objective Evolutionary Algorithm with Relevance Matrix
| Algorithm 1 The framework of multi-objective evolutionary algorithm with relevance matrix |
|
4.1. Initialization
| Algorithm 2 Initialization |
|
4.2. Relevance Matrix Based Evolutionary Operator
| Algorithm 3 Relevance matrix-based crossover and mutation |
|
5. Experiment
5.1. Experimental Setup
5.2. Experimental Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guarino, N.; Oberle, D.; Staab, S. What is an ontology? In Handbook on Ontologies; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–17. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Cardoso, J.; Sheth, A. The Semantic Web and its applications. In Semantic Web Services, Processes and Applications; Springer: Berlin/Heidelberg, Germany, 2006; pp. 3–33. [Google Scholar]
- Shishehchi, S.; Banihashem, S.Y.; Zin, N.A.M. A proposed semantic recommendation system for e-learning: A rule and ontology based e-learning recommendation system. In Proceedings of the 2010 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 15–17 June 2010; Volume 1, pp. 1–5. [Google Scholar]
- Gauch, S.; Chaffee, J.; Pretschner, A. Ontology-based personalized search and browsing. Web Intell. Agent Syst. Int. J. 2003, 1, 219–234. [Google Scholar]
- Altman, R.B.; Buda, M.; Chai, X.J.; Carillo, M.W.; Chen, R.O.; Abernethy, N.F. RiboWeb: An ontology-based system for collaborative molecular biology. IEEE Intell. Syst. Their Appl. 1999, 14, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Shvaiko, P.; Euzenat, J. Ontology matching: State of the art and future challenges. IEEE Trans. Knowl. Data Eng. 2011, 25, 158–176. [Google Scholar] [CrossRef] [Green Version]
- Xue, X.; Liu, W. Integrating Heterogeneous Ontologies in Asian Languages through Compact Genetic Algorithm with Annealing Re-sample Inheritance Mechanism. Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Naya, J.M.V.; Romero, M.M.; Loureiro, J.P.; Munteanu, C.R.; Sierra, A.P. Improving ontology alignment through genetic algorithms. In Soft Computing Methods for Practical Environment Solutions: Techniques and Studies; IGI Global: Hershey, PA, USA, 2010; pp. 240–259. [Google Scholar]
- Rijsberge, C.J.V. Information Retrieval; University of Glasgow: Glasgow, UK, 1975. [Google Scholar]
- Tan, Z.; Wang, H.; Liu, S. Multi-stage dimension reduction for expensive sparse multi-objective optimization problems. Neurocomputing 2021, 440, 159–174. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, Y.; Liang, J.; Slowik, A. A self-adaptive mutation neural architecture search algorithm based on blocks. IEEE Comput. Intell. Mag. 2021, 16, 67–78. [Google Scholar] [CrossRef]
- Ma, X.; Liu, F.; Qi, Y.; Wang, X.; Li, L.; Jiao, L.; Yin, M.; Gong, M. A multiobjective evolutionary algorithm based on decision variable analyses for multiobjective optimization problems with large-scale variables. IEEE Trans. Evol. Comput. 2015, 20, 275–298. [Google Scholar] [CrossRef]
- Zille, H.; Ishibuchi, H.; Mostaghim, S.; Nojima, Y. A framework for large-scale multiobjective optimization based on problem transformation. IEEE Trans. Evol. Comput. 2017, 22, 260–275. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, X.; Wang, C.; Jin, Y. An evolutionary algorithm for large-scale sparse multiobjective optimization problems. IEEE Trans. Evol. Comput. 2019, 24, 380–393. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Zhang, X. Improved SparseEA for sparse large-scale multi-objective optimization problems. Complex Intell. Syst. 2021, 1–16. [Google Scholar] [CrossRef]
- Xue, Y.; Zhu, H.; Liang, J.; Słowik, A. Adaptive crossover operator based multi-objective binary genetic algorithm for feature selection in classification. Knowl.-Based Syst. 2021, 227, 107218. [Google Scholar] [CrossRef]
- Bento, A.; Zouaq, A.; Gagnon, M. Ontology matching using convolutional neural networks. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 5648–5653. [Google Scholar]
- Khoudja, M.A.; Fareh, M.; Bouarfa, H. Ontology matching using neural networks: Survey and analysis. In Proceedings of the 2018 International Conference on Applied Smart Systems (ICASS), Medea, Algeria, 24–25 November 2018; pp. 1–6. [Google Scholar]
- Zhang, Y.; Wang, X.; Lai, S.; He, S.; Liu, K.; Zhao, J.; Lv, X. Ontology matching with word embeddings. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data; Springer: Cham, Switzerland, 2014; pp. 34–45. [Google Scholar]
- Xue, X.; Huang, Q. Generative adversarial learning for optimizing ontology alignment. In Expert Systems; Wiley: Hoboken, NJ, USA, 2022; pp. 1–12. [Google Scholar]
- Belhadi, H.; Akli-Astouati, K.; Djenouri, Y.; Lin, J.C.W. Data mining-based approach for ontology matching problem. Appl. Intell. 2020, 50, 1204–1221. [Google Scholar] [CrossRef]
- David, J. Association rule ontology matching approach. Int. J. Semant. Web Inf. Syst. 2007, 3, 27–49. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Acampora, G.; Kaymak, U.; Loia, V.; Vitiello, A. Applying NSGA-II for solving the ontology alignment problem. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 1098–1103. [Google Scholar]
- Acampora, G.; Ishibuchi, H.; Vitiello, A. A comparison of multi-objective evolutionary algorithms for the ontology meta-matching problem. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 413–420. [Google Scholar]
- Xue, X.; Tsai, P.W.; Zhuang, Y. Matching Biomedical Ontologies through Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm. Biology 2021, 10, 1287. [Google Scholar] [CrossRef]
- Xue, X.; Lu, J.; Chen, J. Ternary Compound Matching of Biomedical Ontologies with Compact Multi-Objective Evolutionary Algorithm Based on Adaptive Objective Space Decomposition. In Proceedings of the 2020 16th International Conference on Computational Intelligence and Security (CIS), Nanning, China, 27–30 November 2020; pp. 121–125. [Google Scholar]
- Lv, Q.; Jiang, C.; Li, H. An interactive multi-objective ontology matching technique. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications, Cairo, Egypt, 20–22 March 2021; pp. 955–964. [Google Scholar]
- Xue, X.; Chen, J. A preference-based multi-objective evolutionary algorithm for semiautomatic sensor ontology matching. Int. J. Swarm Intell. Res. 2018, 9, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Acampora, G.; Loia, V.; Vitiello, A. Enhancing ontology alignment through a memetic aggregation of similarity measures. Inf. Sci. 2013, 250, 1–20. [Google Scholar] [CrossRef]
- Xue, X.; Wang, Y. Optimizing ontology alignments through a Memetic Algorithm using both MatchFmeasure and Unanimous Improvement Ratio. Artif. Intell. 2015, 223, 65–81. [Google Scholar] [CrossRef]
- Jean-Mary, Y.R.; Shironoshita, E.P.; Kabuka, M.R. Ontology matching with semantic verification. J. Web Semant. 2009, 7, 235–251. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xue, X.; Wang, Y. Using memetic algorithm for instance coreference resolution. IEEE Trans. Knowl. Data Eng. 2015, 28, 580–591. [Google Scholar] [CrossRef]
- Wang, J.; Ding, Z.; Jiang, C. Gaom: Genetic algorithm based ontology matching. In Proceedings of the 2006 IEEE Asia-Pacific Conference on Services Computing (APSCC’06), Guangzhou, China, 12–15 December 2006; pp. 617–620. [Google Scholar]
- Caraciolo, C.; Euzenat, J.; Hollink, L.; Ichise, R.; Isaac, A.; Malaisé, V.; Meilicke, C.; Pane, J.; Shvaiko, P.; Stuckenschmidt, H.; et al. Results of the ontology alignment evaluation initiative 2008. In Proceedings of the 3rd ISWC Workshop on Ontology Matching (OM), Karlsruhe, Germany, 26 October 2008; pp. 73–119. [Google Scholar]
- Xue, X.; Chen, J. Matching Biomedical Ontologies through Compact Differential Evolution Algorithm with Compact Adaption Schemes on Control Parameters. Neurocomputing 2021, 458, 526–534. [Google Scholar] [CrossRef]
- Lima, B.; Faria, D.; Couto, F.M.; Cruz, I.F.; Pesquita, C. OAEI 2020 Results for AML and AMLC. In Proceedings of the Fifteenth International Workshop on Ontology Matching, Athens, Greece, 2 November 2020; pp. 154–160. [Google Scholar]
- Jiménez-Ruiz, E.; Grau, B.C.; Cross, V. LogMap family participation in the OAEI 2017. Ceur Workshop Proc. 2017, 2032, 1–5. [Google Scholar]
- Djeddi, W.E.; Khadir, M.T.; Yahia, S.B. XMap: Results for OAEI 2015. In Proceedings of the Tenth International Workshop on Ontology Matching, Bethlehem, PA, USA, 12 October 2015; pp. 216–221. [Google Scholar]
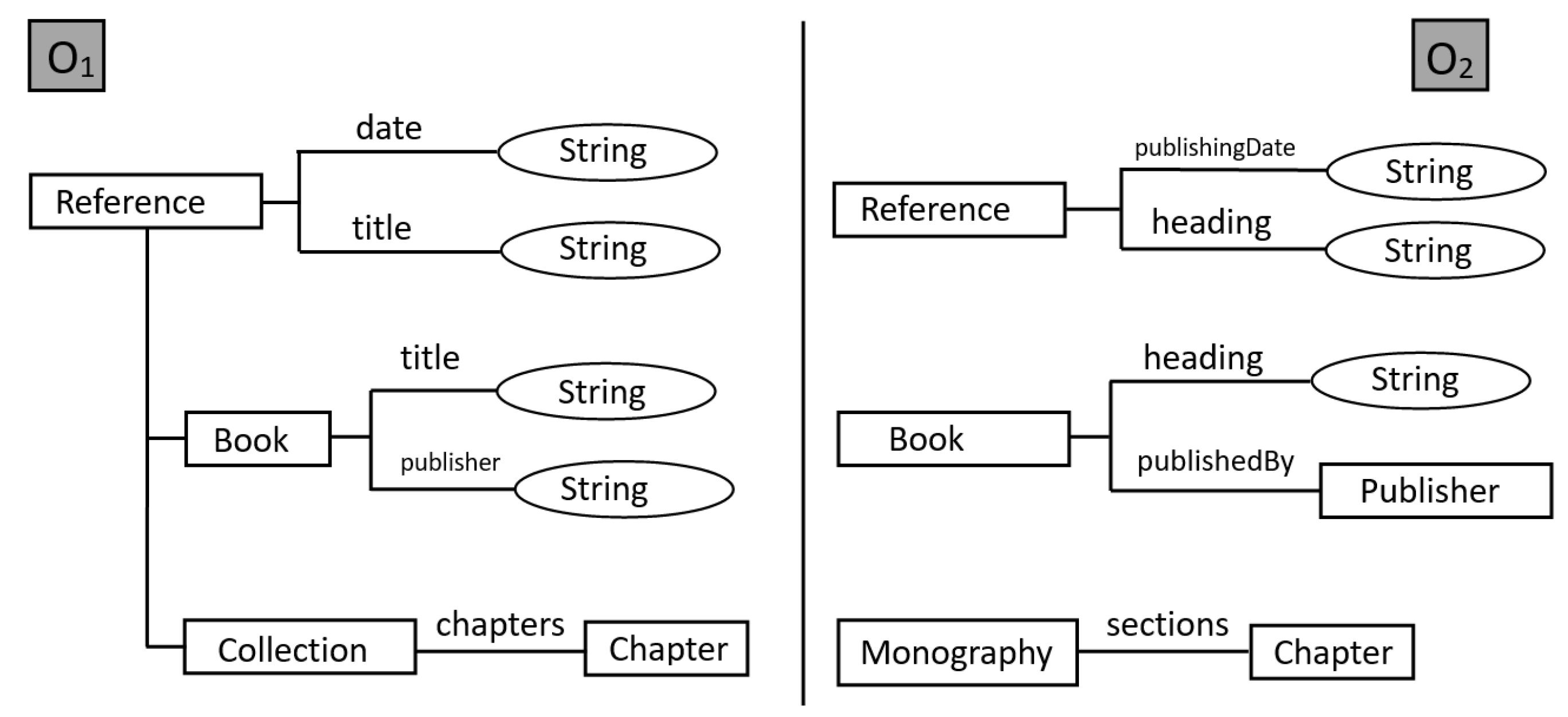
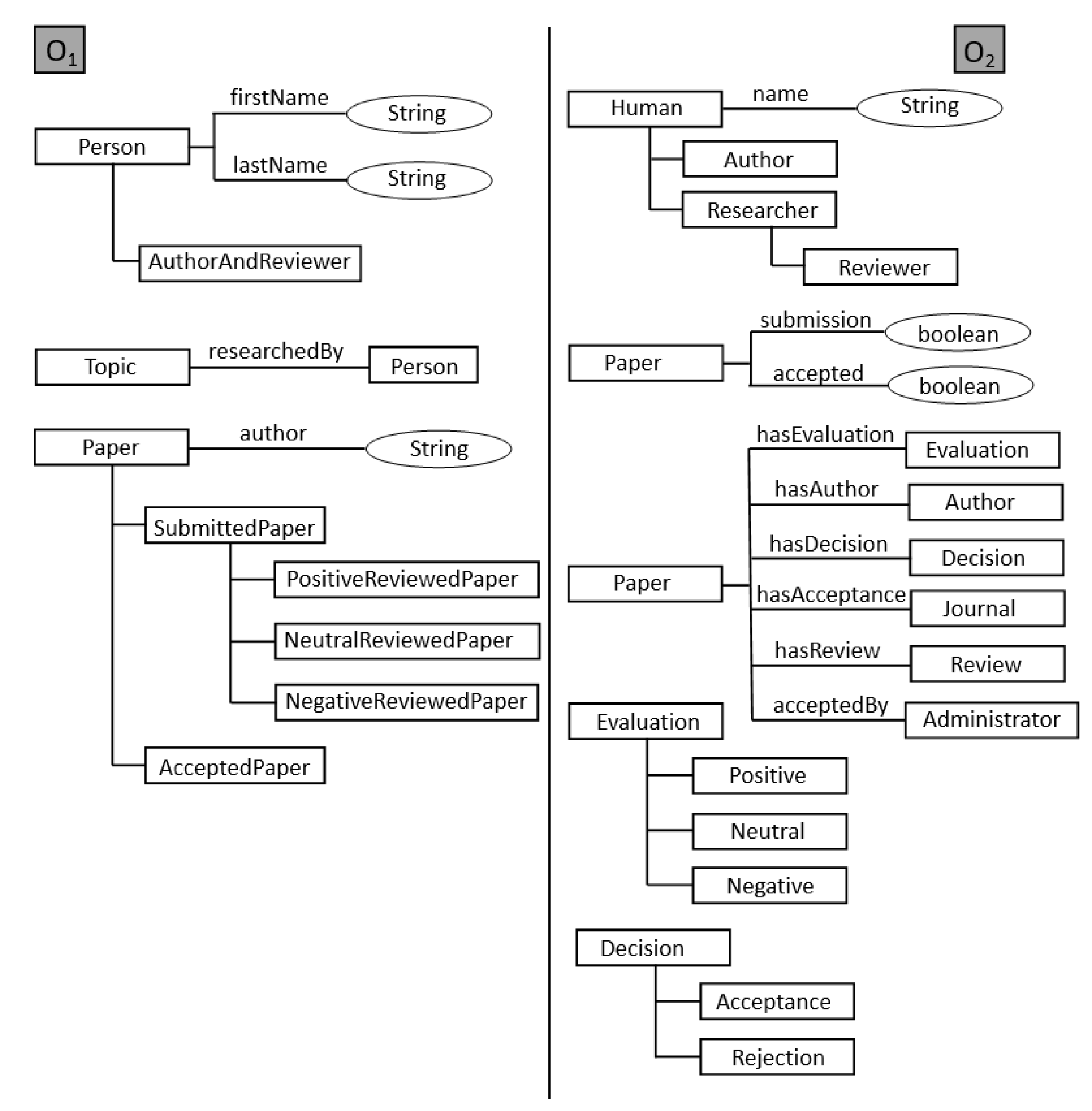

{kind=link}
{kind=link}
| 0 | 1 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 |
| OAEI’s Benchmark Track | |||||||
|---|---|---|---|---|---|---|---|
| Testing Case | AMLC [39] | LogMap [40] | LogMapLt [40] | XMap [41] | EA | NSGA-II | MOEA-RM |
| () | () | () | () | () | () | () | |
| 101 | 1.00 (1.00) | 0.88 (0.96) | 0.78 (0.64) | 0.93 (1.00) | 0.78 (0.84) | 1.00 (1.00) | 1.00 (1.00) |
| 202 | 0.80 (0.92) | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 0.72 (0.87) | 0.80 (0.91) | 0.95 (0.95) |
| 221 | 0.49 (0.53) | 0.87 (0.98) | 0.76 (0.69) | 0.95 (1.00) | 0.87 (0.87) | 0.97 (0.92) | 1.00 (1.00) |
| 222 | 0.71 (0.32) | 0.00 (0.00) | 0.76 (0.69) | 0.80 (0.75) | 0.78 (0.85) | 0.97 (0.92) | 1.00 (1.00) |
| 223 | 0.40 (0.62) | 0.90 (0.98) | 0.76 (0.69) | 0.98 (0.96) | 0.87 (0.87) | 0.86 (0.95) | 1.00 (1.00) |
| 224 | 0.58 (0.45) | 0.90 (0.98) | 0.82 (0.98) | 0.98 (0.96) | 0.94 (0.85) | 0.86 (0.95) | 1.00 (1.00) |
| 225 | 0.51 (0.52) | 0.92 (0.97) | 0.76 (0.69) | 0.98 (0.96) | 0.78 (0.85) | 0.82 (0.87) | 1.00 (1.00) |
| 228 | 1.00 (1.00) | 0.92 (0.97) | 0.58 (0.40) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| 232 | 0.51 (0.52) | 0.87 (0.98) | 0.88 (0.93) | 0.98 (0.96) | 0.81 (0.95) | 0.86 (0.95) | 1.00 (1.00) |
| 233 | 1.00 (1.00) | 0.92 (0.97) | 0.58 (0.40) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| 236 | 1.00 (1.00) | 0.92 (0.97) | 0.72 (0.87) | 1.00 (1.00) | 0.82 (0.88) | 0.92 (0.92) | 1.00 (1.00) |
| 237 | 0.42 (0.58) | 0.00 (0.00) | 0.88 (0.93) | 0.80 (0.75) | 0.87 (0.80) | 0.82 (0.87) | 0.93 (0.98) |
| 238 | 0.51 (0.52) | 0.96 (0.93) | 0.88 (0.93) | 0.98 (0.96) | 0.82 (0.92) | 0.86 (0.95) | 1.00 (1.00) |
| 239 | 1.00 (1.00) | 0.91 (0.93) | 0.58 (0.40) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| 240 | 1.00 (1.00) | 0.91 (0.93) | 0.58 (0.40) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| 241 | 1.00 (1.00) | 0.91 (0.93) | 0.72 (0.87) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| 246 | 1.00 (1.00) | 0.88 (0.96) | 0.72 (0.87) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| 247 | 1.00 (1.00) | 0.88 (0.96) | 0.72 (0.87) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
| average | 0.77 (0.77) | 0.75 (0.80) | 0.69 (0.68) | 0.91 (0.90) | 0.89 (0.91) | 0.93 (0.95) | 0.99 (0.99) |
| OAEI’s Conference Track | |||||||
| Testing Case | AMLC | LogMap | LogMapLt | XMap | EA | NSGA-II | MOEA-RM |
| () | () | () | () | () | () | () | |
| cmt-conference | 0.53 (0.67) | 0.53 (0.73) | 0.33 (0.56) | 0.00 (0.00) | 0.68 (0.76) | 0.68 (0.76) | 0.83 (0.86) |
| cmt-confOf | 0.56 (0.90) | 0.31 (0.83) | 0.38 (0.67) | 0.44 (0.88) | 0.65 (0.68) | 0.65 (0.68) | 0.75 (0.81) |
| cmt-edas | 0.77 (0.91) | 0.62 (0.89) | 0.62 (0.73) | 0.69 (0.75) | 0.65 (0.72) | 0.68 (0.76) | 0.80 (0.86) |
| cmt-ekaw | 0.55 (0.75) | 0.55 (0.75) | 0.45 (0.56) | 0.64 (0.70) | 0.65 (0.68) | 0.65 (0.68) | 0.82 (0.89) |
| cmt-iasted | 1.00 (0.80) | 0.84 (0.80) | 0.90 (0.89) | 0.93 (0.80) | 0.75 (0.89) | 0.83 (0.87) | 0.91 (0.94) |
| cmt-sigkdd | 0.92 (0.92) | 0.88 (0.95) | 0.67 (0.89) | 0.83 (0.91) | 0.75 (0.75) | 0.87 (0.90) | 0.95 (0.95) |
| conference-confOf | 0.87 (0.87) | 0.73 (0.85) | 0.60 (0.90) | 0.80 (0.71) | 0.78 (0.67) | 0.80 (0.88) | 0.88 (0.87) |
| conference-edas | 0.65 (0.73) | 0.65 (0.85) | 0.53 (0.75) | 0.65 (0.79) | 0.78 (0.67) | 0.68 (0.78) | 0.86 (0.85) |
| conference-ekaw | 0.72 (0.78) | 0.48 (0.60) | 0.32 (0.62) | 0.60 (0.58) | 0.74 (0.66) | 0.70 (0.78) | 0.84 (0.85) |
| conference-iasted | 0.36 (0.83) | 0.50 (0.88) | 0.29 (0.80) | 0.36 (0.62) | 0.68 (0.52) | 0.75 (0.60) | 0.75 (0.74) |
| conference-sigkdd | 0.73 (0.85) | 0.73 (0.85) | 0.53 (0.80) | 0.60 (0.58) | 0.75 (0.75) | 0.75 (0.75) | 0.92 (0.85) |
| confOf-edas | 0.58 (0.92) | 0.53 (0.77) | 0.58 (0.58) | 0.53 (0.91) | 0.65 (0.72) | 0.65 (0.72) | 0.71 (0.76) |
| confOf-ekaw | 0.80 (0.94) | 0.70 (0.93) | 0.50 (0.77) | 0.80 (0.76) | 0.88 (0.75) | 0.88 (0.75) | 0.85 (0.90) |
| confOf-iasted | 0.44 (0.80) | 0.54 (0.89) | 0.54 (0.90) | 0.67 (0.43) | 0.62 (0.51) | 0.69 (0.51) | 0.72 (0.78) |
| confOf-sigkdd | 0.88 (0.95) | 0.81 (0.90) | 0.68 (0.88) | 0.57 (0.80) | 0.88 (0.73) | 0.89 (0.78) | 0.93 (0.95) |
| edas-ekaw | 0.48 (0.79) | 0.52 (0.75) | 0.43 (0.59) | 0.52 (0.75) | 0.65 (0.68) | 0.65 (0.68) | 0.84 (0.75) |
| edas-iasted | 0.47 (0.82) | 0.37 (0.88) | 0.37 (0.88) | 0.42 (0.57) | 0.63 (0.57) | 0.62 (0.82) | 0.70 (0.85) |
| edas-sigkdd | 0.75 (0.84) | 0.47 (0.88) | 0.47 (0.88) | 0.62 (0.81) | 0.75 (0.75) | 0.68 (0.76) | 0.78 (0.82) |
| ekaw-iasted | 0.70 (0.84) | 0.70 (0.78) | 0.60 (0.60) | 0.70 (0.58) | 0.68 (0.76) | 0.82 (0.74) | 0.80 (0.80) |
| ekaw-sigkdd | 0.73 (0.80) | 0.70 (0.78) | 0.70 (0.78) | 0.64 (0.78) | 0.78 (0.67) | 0.70 (0.81) | 0.75 (0.82) |
| iasted-sigkdd | 0.87 (0.81) | 0.88 (0.82) | 0.73 (0.73) | 0.87 (0.68) | 0.76 (0.75) | 0.80 (0.85) | 0.85 (0.86) |
| average | 0.68 (0.83) | 0.62 (0.82) | 0.53 (0.75) | 0.61 (0.68) | 0.70 (0.69) | 0.73 (0.55) | 0.82 (0.84) |
| OAEI’s Benchmark Track | |||||||
|---|---|---|---|---|---|---|---|
| Testing Case | AMLC | LogMap | LogMapLt | XMap | EA | NSGA-II | MOEA-RM |
| 101 | 1.00 | 0.95 | 0.71 | 0.97 | 0.81 | 1.00 | 1.00 |
| 202 | 0.86 | 0.00 | 0.00 | 0.00 | 0.79 | 0.85 | 0.95 |
| 221 | 0.51 | 0.94 | 0.72 | 0.97 | 0.87 | 0.95 | 1.00 |
| 222 | 0.50 | 0.00 | 0.72 | 0.78 | 0.82 | 0.95 | 1.00 |
| 223 | 0.51 | 0.94 | 0.72 | 0.97 | 0.87 | 0.90 | 1.00 |
| 224 | 0.51 | 0.94 | 0.90 | 0.97 | 0.90 | 0.90 | 1.00 |
| 225 | 0.51 | 0.95 | 0.72 | 0.97 | 0.82 | 0.85 | 1.00 |
| 228 | 1.00 | 0.92 | 0.48 | 1.00 | 1.00 | 1.00 | 1.00 |
| 232 | 0.51 | 0.94 | 0.90 | 0.97 | 0.88 | 0.90 | 1.00 |
| 233 | 1.00 | 0.92 | 0.48 | 1.00 | 1.00 | 1.00 | 1.00 |
| 236 | 1.00 | 0.92 | 0.80 | 1.00 | 0.85 | 0.92 | 1.00 |
| 237 | 0.50 | 0.00 | 0.91 | 0.78 | 0.84 | 0.85 | 0.95 |
| 238 | 0.51 | 0.95 | 0.90 | 0.97 | 0.87 | 0.90 | 1.00 |
| 239 | 1.00 | 0.92 | 0.48 | 1.00 | 1.00 | 1.00 | 1.00 |
| 240 | 1.00 | 0.92 | 0.48 | 1.00 | 1.00 | 1.00 | 1.00 |
| 241 | 1.00 | 0.92 | 0.80 | 1.00 | 1.00 | 1.00 | 1.00 |
| 246 | 1.00 | 0.92 | 0.80 | 1.00 | 1.00 | 1.00 | 1.00 |
| 247 | 1.00 | 0.92 | 0.80 | 1.00 | 1.00 | 1.00 | 1.00 |
| average | 0.77 | 0.78 | 0.68 | 0.91 | 0.91 | 0.94 | 0.99 |
| OAEI’s Conference Track | |||||||
| Testing Case | AMLC | LogMap | LogMapLt | XMap | EA | NSGA-II | MOEA-RM |
| cmt-conference | 0.59 | 0.62 | 0.42 | 0.00 | 0.72 | 0.72 | 0.84 |
| cmt-confOf | 0.69 | 0.45 | 0.48 | 0.58 | 0.66 | 0.66 | 0.78 |
| cmt-edas | 0.83 | 0.73 | 0.67 | 0.72 | 0.68 | 0.72 | 0.83 |
| cmt-ekaw | 0.63 | 0.63 | 0.50 | 0.67 | 0.68 | 0.72 | 0.85 |
| cmt-iasted | 0.89 | 0.89 | 0.89 | 0.89 | 0.82 | 0.85 | 0.92 |
| cmt-sigkdd | 0.92 | 0.91 | 0.76 | 0.87 | 0.75 | 0.89 | 0.95 |
| conference-confOf | 0.87 | 0.79 | 0.72 | 0.75 | 0.78 | 0.83 | 0.87 |
| conference-edas | 0.69 | 0.73 | 0.62 | 0.71 | 0.73 | 0.73 | 0.82 |
| conference-ekaw | 0.75 | 0.53 | 0.42 | 0.59 | 0.70 | 0.74 | 0.86 |
| conference-iasted | 0.50 | 0.64 | 0.42 | 0.45 | 0.59 | 0.68 | 0.74 |
| conference-sigkdd | 0.79 | 0.79 | 0.64 | 0.69 | 0.75 | 0.75 | 0.83 |
| confOf-edas | 0.71 | 0.62 | 0.58 | 0.67 | 0.68 | 0.68 | 0.79 |
| confOf-ekaw | 0.86 | 0.80 | 0.61 | 0.78 | 0.82 | 0.82 | 0.88 |
| confOf-iasted | 0.57 | 0.62 | 0.62 | 0.52 | 0.58 | 0.60 | 0.75 |
| confOf-sigkdd | 0.92 | 0.83 | 0.73 | 0.67 | 0.80 | 0.85 | 0.94 |
| edas-ekaw | 0.59 | 0.62 | 0.50 | 0.62 | 0.66 | 0.62 | 0.70 |
| edas-iasted | 0.60 | 0.52 | 0.52 | 0.48 | 0.60 | 0.66 | 0.77 |
| edas-sigkdd | 0.80 | 0.61 | 0.61 | 0.64 | 0.75 | 0.72 | 0.80 |
| ekaw-iasted | 0.78 | 0.74 | 0.60 | 0.64 | 0.72 | 0.78 | 0.80 |
| ekaw-sigkdd | 0.76 | 0.74 | 0.74 | 0.70 | 0.73 | 0.76 | 0.78 |
| iasted-sigkdd | 0.84 | 0.85 | 0.73 | 0.76 | 0.76 | 0.82 | 0.85 |
| average | 0.74 | 0.70 | 0.61 | 0.64 | 0.71 | 0.74 | 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Xue, X.; Wang, H. Matching Ontologies through Multi-Objective Evolutionary Algorithm with Relevance Matrix. Mathematics 2022, 10, 2077. https://doi.org/10.3390/math10122077
Zhu H, Xue X, Wang H. Matching Ontologies through Multi-Objective Evolutionary Algorithm with Relevance Matrix. Mathematics. 2022; 10(12):2077. https://doi.org/10.3390/math10122077
Chicago/Turabian StyleZhu, Hai, Xingsi Xue, and Hongfeng Wang. 2022. "Matching Ontologies through Multi-Objective Evolutionary Algorithm with Relevance Matrix" Mathematics 10, no. 12: 2077. https://doi.org/10.3390/math10122077
APA StyleZhu, H., Xue, X., & Wang, H. (2022). Matching Ontologies through Multi-Objective Evolutionary Algorithm with Relevance Matrix. Mathematics, 10(12), 2077. https://doi.org/10.3390/math10122077