Abstract
This study presents a wearable haptic feedback system designed to support speech training for individuals with speech and hearing impairments. The system provides real-time tactile cues based on detected phonemes, helping users correct their pronunciation independently. Unlike prior approaches focused on passive reception or therapist-led instruction, our method enables active, phoneme-level feedback using a multimodal interface combining audio input, visual reference, and spatially mapped vibrotactile output. We validated the system through three user studies measuring pronunciation accuracy, phoneme discrimination, and learning over time. The results show a significant improvement in word articulation accuracy and user engagement. These findings highlight the potential of real-time haptic pronunciation tools as accessible, scalable aids for speech rehabilitation and second-language learning.
1. Introduction
Hearing and speech impairments pose significant challenges to millions of individuals worldwide, affecting their ability to communicate effectively and integrate into society. According to the World Health Organization (WHO), approximately 430 million people globally experience disabling hearing loss, with projections indicating that this number could rise to over 700 million by 2050 [1,2]. Additionally, speech impairments affect a substantial portion of the population, with an estimated 8% of children aged 3 to 17 in the United States having a communication disorder related to voice, speech, language, or swallowing [3]. These impairments can stem from various factors, including genetic conditions, injuries, diseases, and natural aging processes [4]. The impact on quality of life is significant, affecting education, employment, and social interactions [5,6]. Traditional interventions, such as speech therapy provided by Speech–Language Pathologists (SLPs), are crucial in improving communication abilities [7]. However, these methods often require significant human resources and time, limiting access and scalability [8].
To address these challenges, there is a growing need for innovative, automated solutions that can provide real-time feedback and assist in learning correct pronunciation without constant professional supervision [9,10]. Despite these promising developments, a notable gap remains in the domain of real-time, phoneme-level feedback for active speech production. Most existing systems are designed for passive perception (e.g., tactile word recognition or captioning), offer only partial phoneme coverage, or are tightly coupled with therapist-guided protocols. As such, there is a pressing need for solutions that support independent, scalable, and complete pronunciation training, particularly for users who cannot rely on auditory or visual feedback. Recent advancements in haptic feedback technologies have shown promising results in enhancing communication and interaction for individuals with sensory impairments [11,12]. Several haptic feedback devices have been developed to aid in communication and language acquisition [13,14]. For instance, the TActile Phonemic Sleeve (TAPS) translates phonemic elements of speech into tactile stimuli on the forearm, enabling users to learn and recognize English words through haptic feedback [15]. Other approaches, such as skin reading and vibrotactile information encoding, have demonstrated the potential to use tactile patterns to convey complex information [16,17]. Additionally, an intuitive cognition-based approach was introduced for generating speech through hand gestures, bridging the gap between physical movement and speech production [18]. Despite these advancements, significant gaps remain in existing solutions. Many current technologies provide either limited real-time assistance or focus on specific aspects of communication without offering comprehensive support. There is a need for integrated, user-responsive solutions to address the diverse and evolving needs of individuals with hearing and speech impairments. Recent studies highlight the value of cost-effective, real-time technologies—such as camera-based systems—for supporting motor rehabilitation in accessible, everyday settings [19].
Our Contribution
This research aims to develop a haptic feedback system to improve word pronunciation among people with speech and hearing impairments. By translating heard words into tactile information and comparing the tactile cues received from the device with the correct pronunciation, we seek to enable users to improve their pronunciation and speech production in a cognitively informed and effective manner. This approach can potentially enhance communication skills and ultimately improve the quality of life for individuals with hearing and speech impairments. By combining full phoneme coverage, spatially intuitive tactile encoding, and real-time closed-loop feedback, our system fills a critical gap in the assistive technology landscape. It is the first to support independent pronunciation learning through touch alone, without relying on speech therapists, vision, or hearing. This differentiates our work from previous approaches such as TAPS [20] or HAPOVER [4], which either lack production feedback, cover only a subset of phonemes, or focus on receptive learning tasks.
2. Related Work
2.1. Clinical Interventions: Speech–Language Pathologists
Speech–Language Pathologists (SLPs) are the cornerstone of therapeutic intervention, using structured exercises and real-time correction to guide patients toward improved articulation, fluency, and phonological awareness [21,22,23,24]. Clinical evidence supports their effectiveness in individualized care plans [21,22], but accessibility is constrained by cost, therapist availability, and geographic limitations, particularly for disadvantaged or remote populations [23]. Moreover, the reliance on face-to-face interaction limits scalability.
2.2. Real-Time Translation and Captioning Technologies
Technologies such as automatic speech recognition (ASR) and sign language translation have been developed to assist individuals with hearing disabilities by converting spoken language into readable or visual formats [25]. These tools are effective in enhancing communication comprehension, particularly in educational and public settings. However, they are one-directional: while they help users understand speech, they do not assist in producing or correcting speech, nor do they offer phoneme-specific feedback.
2.3. Haptic Feedback Systems for Language Support
Haptic feedback has emerged as a promising modality for sensory substitution, allowing tactile stimuli to carry linguistic information [26,27,28,29,30]. Recent frameworks for haptic language communication suggest that systems must go beyond basic vibration cues and consider perceptual, cognitive, and linguistic dimensions of tactile feedback. For instance, Reed et al. [14] conducted a comprehensive review of haptic language systems, classifying them by their encoding strategies (spatial, temporal, and intensity-based), user perceptual thresholds, and learning demands. They emphasized that effective tactile communication must align with linguistic salience and user learning curves, principles that directly informed our design, particularly the spatial mapping of distinct phonemes to vibration loci.
Several research efforts have explored its application in language learning:
- TActile Phonemic Sleeve (TAPS): A wearable system that encodes English phonemes into tactile patterns on the forearm. Tan et al. [20] demonstrated the acquisition of over 500 English words through repeated haptic exposure. However, TAPS is optimized for vocabulary comprehension, not for pronunciation output or real-time correction.
- HAPOVER System: Ilhan and Kaçanoğlu [4] introduced HAPOVER, a wearable pronunciation training device utilizing eight vibration motors to provide phoneme-level feedback. The system captures speech, extracts Mel-Frequency Cepstral Coefficients (MFCC), and compares them with reference templates using Dynamic Time Warping (DTW). If a mismatch is detected, it delivers corrective haptic signals to guide users toward accurate articulation. Their pilot study reported an 80.74% improvement in word pronunciation accuracy among second-language learners after training. Despite its promising results, HAPOVER uses a limited number of actuators and covers only a subset of phonemes, without a scalable design for full language production support.
- Skin Reading Interfaces: Luzhnica et al. [31] proposed encoding textual information using six-channel haptic displays. While innovative, the system focuses on passive reception and requires high cognitive training for interpretation.
- Vibrotactile Encoding Capacity: Novich and Eagleman [32] investigated how spatial and temporal patterns of vibration can encode complex information, estimating the throughput capacity of human skin. Their results highlight the potential—but also the limitations—of tactile systems for detailed language feedback.
- Tactile Vocoder with Envelope Expansion: Fletcher et al. [33,34] proposed an audio-to-tactile substitution approach using amplitude envelope expansion across multiple frequency bands. Their system demonstrated enhanced phoneme identification accuracy—especially for vowels and consonants—under noisy conditions, achieving an average improvement of 9.6%. The authors emphasized the clinical potential of such compact, low-power devices for real-time feedback. However, while promising for passive perception, this system does not provide active pronunciation correction or phoneme-level feedback tailored to speech production.
- Phoneme-Based Tactile Display: Jung et al. [35] developed a 4 × 6 tactile actuator array that maps 39 English phonemes to unique vibration patterns, allowing users to receive words and short messages via touch. In their study, participants achieved an average word recognition accuracy of 87% for trained four-phoneme words and 77% for novel words after 3–5 h of training. Additionally, a longitudinal experiment demonstrated two-way tactile communication with 73% phoneme-level and 82% word-level accuracy, albeit at a limited transmission rate (approximately one message per minute). While this system effectively supports connected phoneme-level reception and real-world communication scenarios, it does not offer active feedback for pronunciation correction or real-time speech training.
- Phoneme-Based Tactile Display: Jung et al. [35] developed a tactile actuator array that maps 39 English phonemes (their chosen inventory) to unique vibration patterns, allowing users to receive words and short messages via touch. In their study, participants achieved an average word recognition accuracy of 87% for trained four-phoneme words and 77% for novel words after 3–5 h of training. Additionally, a longitudinal experiment demonstrated two-way tactile communication with 73% phoneme-level and 82% word-level accuracy, albeit at a limited transmission rate (approximately one message per minute). While this system effectively supports connected phoneme-level reception and real-world communication scenarios, it does not offer active feedback for pronunciation correction or real-time speech training.
2.4. Limitations in Existing Approaches
Despite advancements, current systems tend to address only one dimension of the communication challenge. Table 1 provides a comparative summary of existing methods.

Table 1.
Comparison of different approaches for speech communication systems.
Most notably, no existing system fully supports real-time, closed-loop tactile feedback for speech correction. Systems like TAPS lack bidirectional feedback. Others focus on comprehension rather than production. Furthermore, few devices adapt to users dynamically or support comprehensive phoneme training based on International Phonetic Alphabet (IPA) standards.
2.5. Summary and Gap Analysis
Existing solutions for individuals with speech and hearing impairments include clinical therapy, translation systems, and haptic technologies. While SLPs [21,22,23,24] provide effective treatment, they are not scalable. Real-time translation tools [25] improve comprehension but do not support speech production.
Haptic systems—such as TAPS [20], HAPOVER [4], Fletcher’s tactile vocoder [33,34], and Jung et al.’s phoneme display [35]—demonstrate the potential of tactile feedback for language learning. Some support passive recognition; others offer limited correction or communication. However, key limitations remain:
- Most systems lack real-time, corrective feedback.
- Phoneme coverage is often partial.
- Few are designed for active pronunciation training or broad scalability.
Our system addresses these gaps by providing:
- Real-time, closed-loop feedback;
- Full phoneme coverage;
- A scalable, therapist-free design aligned with cognitive and perceptual principles.
3. Method
This study examines whether users can learn to interpret phoneme-level haptic cues and pronounce words accurately in real time. We focus on two main questions: (1) Can participants reliably associate phonemes with specific tactile locations? (2) Does performance improve as phoneme set size increases?
We addressed these questions using a custom-built haptic system and a series of structured experiments, as detailed below.
3.1. System Overview
We developed a table-mounted device that delivers real-time vibrotactile cues corresponding to spoken output. The system integrates the following:
- Raspberry Pi 5 for speech processing and experiment control, running Python-based algorithms (ver 3.8).
- Arduino Uno to individually control up to 26 vibration motors.
- A microphone (speech input; not used during core haptic feedback phases).
- A speaker (optional auditory feedback; not used in the main experiments).
- A 3D-printed ergonomic hand rest for consistent contact and user comfort.
This configuration supports accurate haptic encoding of phonemes for speech learning and correction. The overall system architecture is shown in Figure 1.
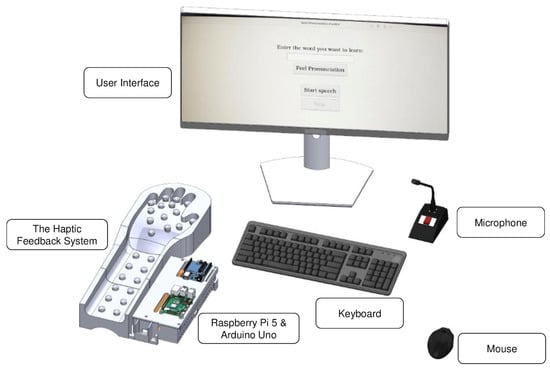
Figure 1.
Block diagram of the haptic feedback system illustrating the information flow from speech input to vibrotactile output.
To assess system responsiveness, we measured the latency from word selection to the onset of the first haptic vibration. The average latency was ≈1.5 s, which was sufficient to maintain the perception of synchronicity for real-time pronunciation training tasks.
3.2. Phonemes and the International Phonetic Alphabet (IPA)
Spoken language consists of discrete sound units called phonemes, the smallest sounds that differentiate words within a language. For example, “pin” and “bin” differ by only one phoneme: /p/ versus /b/. English includes a distinct inventory of consonant and vowel phonemes, such as /t/, /s/, /m/, /i/, /æ/, and /o/.
To represent these sounds precisely, linguists use the International Phonetic Alphabet (IPA), a standardized set of symbols that directly encode pronunciation regardless of spelling. For instance, the word “sit” is written as /sIt/ in IPA, making it clear how each letter should sound. IPA is widely used in linguistics, speech therapy, and language education for its clarity and universality.
In this study, all words and haptic patterns were selected and described using their IPA transcriptions. This ensured unambiguous communication of target sounds to both experimenters and participants, eliminating confusion from irregular spelling or pronunciation differences.
3.3. Haptic Feedback Selection
Multiple actuator types were evaluated; vibration motors were chosen for their
- Compactness and cost-effectiveness;
- Clear, discriminable tactile sensation;
- imple integration with microcontrollers.
Unlike prior protocols, each phoneme used in the experiment was mapped to a unique motor location. For each word, its phonemes were encoded as brief (250 ms) vibrations at corresponding spatial locations, with 50 ms pauses. Each vibration motor was a compact 10 mm diameter, 2 mm height coin-type actuator operating at – V. At 3 V, it delivered a rotational speed of RPM with a nominal current of 60 mA, ensuring clear and responsive tactile feedback suitable for wearable applications. Motors were run at a fixed frequency (approximately 130 Hz) and intensity, so spatial location alone cued phoneme identity. International Phonetic Alphabet (IPA) notation was used throughout to ensure clarity and avoid orthographic ambiguity. Words with ambiguous spelling or pronunciation were excluded.
3.4. Phoneme Conversion and Haptic Mapping Procedure
Each word used in the experiment was first converted into its International Phonetic Alphabet (IPA) transcription to ensure a precise, language-independent representation of pronunciation. This conversion was performed offline using automated tools, including the OpenAI API and the open-source phonemizer library [38]. The resulting phoneme sequences were manually verified for accuracy and consistency across all participants.
Importantly, no phoneme recognition or speech analysis was performed on participants’ spoken responses. Instead, the IPA transcription served as a reliable foundation for generating the vibrotactile sequences, while pronunciation correctness was evaluated by a human operator during the experiment. Each unique phoneme from the IPA transcription was mapped to a specific vibration motor and spatial location on the haptic device. During each trial, the word’s phonemes were delivered as a sequence of brief (approximately 250 ms) vibrations at the corresponding locations, separated by short pauses (about 50 ms). All motors operated at the same frequency and intensity, so the only distinguishing feature for each phoneme was its spatial position. Words with ambiguous spelling or multiple valid pronunciations were excluded to ensure clarity and reproducibility.
This systematic, automated mapping enabled this study to handle complex word lists while maintaining full experimental control over the haptic cues experienced by participants. Although English is variously analyzed as having 39–44 phonemes (depending on how diphthongs and rhotic vowels are treated), we adopted a 44-phoneme inventory in this work. Our device utilized 26 vibration motors. (An earlier prototype from our lab used the same actuator count for letter-level encoding; in the present work, we redesigned the mapping to operate at the phoneme level.) This motor count reflected practical constraints of the wearable form factor, power consumption, and user comfort rather than a one-to-one mapping to orthographic units.
To make the encoding intuitive, we followed three simple rules: vowels were placed on fingertip motors (higher tactile acuity), high-frequency phonemes were allocated to the most salient regions (e.g., palm, proximal digits), and low-frequency phonemes were assigned pragmatically—either grouped or encoded with two-motor combinations—without imposing further articulatory or spatial regularities. Accordingly, phonemes were mapped based on their relative frequency in English; for example, /I/, /n/, and /t/ occur at , , and , respectively [39], whereas the least frequent phonemes appear in less than of words. This frequency-aware, rule-based scheme enabled scalable encoding of all required phonemes within the 26-motor constraint.
3.5. Mechanical Design and Assembly
Raspberry Pi controlled the experiment, converting each target word to an IPA phoneme sequence and relaying phoneme indices to Arduino, which activated the assigned motors in order. Motors were powered by a 9 V Li-ion battery for portability. The device was table-mounted; the user rested their hand for maximal contact with all vibration points. Mechanical parts were designed in SolidWorks V.2024 and 3D-printed with heat-resistant PLA+. Key features included
- Ergonomic hand fixture for comfortable, repeatable placement;
- Precise motor mounts to avoid vibratory overlap;
- Ventilation for electronics cooling.
Wiring was stabilized on perfboard. The assembled device is shown in Figure 2.

Figure 2.
The assembled -printed hand and forearm model was designed to deliver localized vibrotactile feedback across the fingers, palm, and lower forearm up to the wrist joint.
To clarify the user experience and operational flow, Figure 3 presents two complementary views of a participant interacting with the system during a pronunciation task. The setup included a visual display of target words, a calibrated microphone for speech input, and a tactile user interface that delivered immediate vibrotactile feedback. This physical arrangement supported the real-time feedback loop described above and enabled closed-loop pronunciation training.

Figure 3.
Dual-angle view of a participant using the system during a real-time pronunciation task. The user read a target word on the display, spoke into a calibrated microphone, and received immediate vibrotactile feedback via the tactile interface. The two perspectives highlight key components of the setup: the tactile unit, speech input, and visual guidance.
3.6. Experiment Protocol and Participants
In total, 20 adults (ages 22–49; 15 men, 5 women) participated. All were native Hebrew speakers and reported no formal training in phonetics/linguistics or speech therapy or prior experience with haptic phoneme-encoding systems. A brief pre-experiment questionnaire documented education level and prior exposure to phoneme instruction. All participants were undergraduate or graduate students or university staff members holding an academic degree. All gave informed consent and the protocol was IRB-approved. This initial study was conducted with participants without visual and hearing disabilities to evaluate the system’s usability and decoding feasibility in a controlled environment prior to clinical testing.
Sessions were conducted in a quiet lab. Participants wore noise-canceling headphones playing white noise to eliminate auditory self-feedback (as can be seen in Figure 3). Each experimental phase (see Results for phoneme and word lists) included the following:
- Familiarization: Participants learned the phoneme-to-motor mapping via isolated haptic cues.
- Production Task: The experimenter delivered each word’s phoneme sequence as haptic cues; participants pronounced the word aloud, relying solely on touch.
- Correction: Incorrect attempts were met with a “not correct” prompt; repetition continued until success.
- Timing: The researcher measured time from cue onset to successful pronunciation with a stopwatch.
No visual or software interface was used; all timing and feedback were manual.
The primary mode of feedback during the experiments was verbal confirmation from the experimenter. After each spoken response, the operator informed the participant whether their pronunciation was correct. No additional visual indicators (e.g., accuracy icons or success cues) were used. This setup ensured that participants relied solely on tactile input for pronunciation and auditory feedback only for correctness.
Pronunciation detection time (phase 4) was recorded and logged manually. One outlier—a participant whose phase 1 timing exceeded the group mean by more than two standard deviations—was removed from the dataset. Descriptive statistics (mean, SD) for the cleaned data appear in Section 4. The integration of a speech recognition engine, tactile encoding module, and visual interface enabled a closed-loop system for pronunciation correction. Together, these components formed the basis for real-time, user-guided articulation feedback. The following section presents the experimental validation of this system, including the evaluation protocol, key performance metrics, and participant outcomes.
In summary, the system integrates tactile encoding, controlled phoneme mapping, and live operator feedback to form a closed-loop platform for real-time pronunciation training. The design emphasizes simplicity, scalability, and cognitive alignment with the user’s learning process. The following section presents the experimental validation of this approach, including performance metrics, learning curves, and participant outcomes.
4. Results
In this section, we report results from two experiments. Experiment 1 (Word Recognition Task) tested initial learnability and decoding using a limited six-phoneme inventory and five words, with all 20 participants. Experiment 2 (Learning Curves with Expanding Phoneme Sets) examined adaptation over time as the phoneme set and word list expanded across three sessions on separate days, with 10 participants (a subset of the original cohort). The procedural template (Familiarization, Production, Correction, Timing) was identical in both experiments; only the phoneme inventory, word sets, and number of participants differed.
4.1. Experiment 1—Word Recognition Task
The first experiment assessed the ability of participants to learn and recognize a set of five words, each constructed exclusively from a limited phoneme inventory (see Table 2). Twenty adult participants with no reported hearing or speech impairments took part in this phase. Each participant was sequentially trained to recognize the words sit, pan, nap, pin, and satin. For each word, the corresponding sequence of phoneme-coded haptic cues was delivered, and the participant had to correctly produce the spoken word.
Table 2.
Phoneme inventory and word list for Phase 1, with IPA transcription.
Each word is listed alongside its IPA transcription to eliminate any ambiguity regarding pronunciation. The “Phonemes” row in the table highlights the complete inventory of phoneme sounds included in this phase; all selected words were composed solely from these six phonemes (/p/, /æ/, /n/, /I/, /s/, /t/), which were mapped to specific spatial locations on the haptic device. This careful selection ensured that participants could focus exclusively on learning a limited, consistent set of haptic cues while minimizing confounding effects due to unfamiliar or ambiguous sounds. The inclusion of both monosyllabic (e.g., sit, pan, pin, nap) and a disyllabic word (satin) was designed to probe the effects of word length and phoneme sequence complexity on recognition and learning speed.
The average time (in seconds) required to successfully pronounce each word was as follows: 27.54 for sit, 39.70 for pan, 15.51 for nap, 19.14 for pin, and 51.94 for satin.
Figure 4 plots detection times for each Phase 1 word. The word satin stood out with the highest median and the widest spread, showing that the learning time was the longest and varied most across participants. By contrast, shorter words like *nap* and *pin* have lower, tighter boxes, meaning that they were detected faster and more consistently.
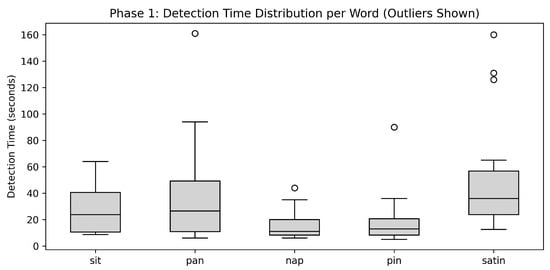
Figure 4.
The box plot shows how long each Phase 1 word took to detect. The line in each box is the middle time, the box itself covers most of the scores, and dots are the rare extremes.
4.2. Experiment 2—Learning Curves with Expanding Phoneme Sets
The second experiment focused on how participants adapted to increasing complexity in the phoneme-to-haptic mapping task. This study involved 10 adult participants over three separate sessions, with each session (phase) conducted on a different day to allow for consolidation and to observe learning effects over time.
The first phase, described previously, used a foundational set of six phonemes and five corresponding words. In the subsequent phases, two additional phonemes were introduced at each stage, along with five new words constructed from the expanded phoneme inventory (including previous phonemes). The complete progression of phonemes and words for all phases is detailed in Table 3.
Table 3.
Phoneme inventory and word list for each experimental phase, with IPA transcription.
For each phase, the mean detection time for every participant was recorded, allowing us to calculate both the overall mean and standard deviation for each phase. This statistical summary provides insight into both the average performance and the consistency of recognition times as task complexity increased. By examining these values, one can also extract the learning curve across phases and observe how participants adapted to the expanding phoneme set. The summarized results for all phases are presented in Table 4.
Table 4.
Summary of pronunciation times (in seconds) by phase and gender.
The key finding from this experiment was that despite the increasing number of phonemes and the corresponding rise in word complexity, participants’ average recognition time did not increase across phases. This suggests that once participants became familiar with the core principles of the haptic-phoneme mapping, they were able to generalize their skills to new, more complex word sets without any loss in speed.
These results underscore the intuitive and scalable nature of the haptic feedback system. Even as the task became more challenging, participants were able to maintain or even improve their performance, demonstrating effective learning and adaptation across sessions.
Key findings:
- Learning effect: Mean times dropped by from Phase 1 to 2, indicating rapid adaptation. Phase 3 times increased slightly but remained faster than initial performance.
- Outliers: One slow participant was excluded; the fastest individual achieved times below 12 s per word.
4.3. Qualitative Observations
Most participants reported that the phoneme–haptic code became intuitive after a short familiarization period as they quickly learned to associate specific spatial locations with particular speech sounds. In addition, the following was observed:
- Native English advantage. Participants who were native in both Hebrew and English—or who had native-level proficiency in English—consistently achieved faster and more accurate detections. They were already accustomed to the mismatch between spelling and pronunciation; for example, they could segment candle as kændəl, whereas almost all native Hebrew speakers cannot distinguish sheep from ship.
- Phoneme-load effect with learning curve. As predicted, tasks containing a larger inventory of phonemes posed a greater initial challenge; mean detection times fell across successive sessions, indicating a clear learning effect.
- Gender parity. No statistically significant performance differences were observed between male and female participants ().
- Zero-detection group. In addition to the 20 participants, four volunteers (two men and two women) failed to detect even a single word. None of these four were native English speakers, implying that some people—particularly those with little to no phonological experience in English—may find the task nearly impossible.
- Usability impressions. Participants provided positive feedback regarding the usability of the system. Even those who did not successfully complete the tasks expressed appreciation for the intuitiveness of the tactile interface. Notably, it became evident that the hand’s placement on the tactile platform played a crucial role in performance. Each participant naturally adjusted their hand to a position that felt most comfortable and effective for detecting the vibrations. This self-guided adjustment suggests that future designs may benefit from incorporating adaptable or user-customizable hand rests to enhance tactile perception and learning outcomes.
5. Conclusions and Future Work
The proposed haptic feedback system offers a novel approach to real-time pronunciation training through tactile cues. By mapping phonemes to spatial vibration patterns, users were able to interpret and articulate words without relying on hearing or vision. Across multiple sessions, participants showed consistent learning effects, with improved recognition speed and accuracy despite increasing task complexity.
Quantitative findings indicate a clear learning effect: mean completion times dropped by from Phase 1 to Phase 2, with only a slight increase in Phase 3 despite added task complexity. Overall, performance in Phase 3 remained faster than the initial phase, suggesting rapid adaptation to the phoneme-to-vibration mapping. These results demonstrate the feasibility and efficiency of real-time haptic pronunciation guidance, even under increasing cognitive and linguistic load.
While our system is designed for individuals with speech and hearing impairments, the current study was conducted with adults without visual and hearing disabilities to evaluate the core haptic encoding strategy in a controlled setting. This early-stage validation approach, common in assistive technology research, necessarily limits the generalizability of the results, a limitation we acknowledge.
Future trials with individuals from the target population, conducted in collaboration with speech therapists and educators, will assess the system’s practical effectiveness, adaptability, and usability in therapeutic and educational contexts. We also plan to explore adaptations for reduced phoneme sets (e.g., Hebrew or early language acquisition) to better match the needs of different user groups. The tactile encoding can be reconfigured accordingly, allowing the system to support a wider range of languages and proficiency levels. For multilingual users, future versions could explore standardized tactile layouts across language phoneme sets, reducing the need to relearn mappings per language and improving cross-linguistic usability. This interdisciplinary direction will incorporate linguistic and physiological considerations into future system design.
Additional directions include enhancing the ergonomic design, increasing the resolution and perceptual clarity of the tactile signals, and integrating adaptive learning algorithms for personalized feedback. These steps aim to establish the system as a scalable, therapist-independent solution that improves pronunciation training and communication outcomes for individuals with speech and hearing impairments, as well as for second-language learners.
Author Contributions
Conceptualization, A.S. and E.H.; methodology, R.Y. and E.H.; software, A.S.; validation, E.H. and R.Y.; formal analysis, R.Y. and E.H.; investigation, A.S.; resources, E.H. and R.Y.; data curation, R.Y.; writing—original draft preparation, R.Y.; writing—review and editing, E.H. and R.Y.; visualization, A.S.; supervision, E.H.; project administration, E.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kushalnagar, R. Deafness and hearing loss. In Web Accessibility: A Foundation for Research; Springer: Berlin/Heidelberg, Germany, 2019; pp. 35–47. [Google Scholar]
- Graydon, K.; Waterworth, C.; Miller, H.; Gunasekera, H. Global burden of hearing impairment and ear disease. J. Laryngol. Otol. 2019, 133, 18–25. [Google Scholar] [CrossRef] [PubMed]
- Guo, R. Advancing real-time close captioning: Blind source separation and transcription for hearing impairments. Appl. Comput. Eng. 2024, 30, 125–130. [Google Scholar] [CrossRef]
- Ilhan, R.; Kaçanoğlu, K. HAPOVER: A Haptic Pronunciation Improver Device. IEEJ Trans. Electr. Electron. Eng. 2024, 19, 985–992. [Google Scholar] [CrossRef]
- Greenwell, T.; Walsh, B. Evidence-based practice in speech-language pathology: Where are we now? Am. J. Speech Lang. Pathol. 2021, 30, 186–198. [Google Scholar] [CrossRef]
- Tambyraja, S.R. Facilitating parental involvement in speech therapy for children with speech sound disorders: A survey of speech-language pathologists’ practices, perspectives, and strategies. Am. J. Speech Lang. Pathol. 2020, 29, 1987–1996. [Google Scholar] [CrossRef]
- CATy, M.È.; Kinsella, E.A.; DOyLE, P.C. Reflective practice in speech-language pathology: A scoping review. Int. J. Speech Lang. Pathol. 2015, 17, 411–420. [Google Scholar] [CrossRef]
- Gomez-Risquet, M.; Cáceres-Matos, R.; Magni, E.; Luque-Moreno, C. Effects of Haptic Feedback Interventions in Post-Stroke Gait and Balance Disorders: A Systematic Review and Meta-Analysis. J. Pers. Med. 2024, 14, 974. [Google Scholar] [CrossRef]
- Bogach, N.; Boitsova, E.; Chernonog, S.; Lamtev, A.; Lesnichaya, M.; Lezhenin, I.; Novopashenny, A.; Svechnikov, R.; Tsikach, D.; Vasiliev, K.; et al. Speech processing for language learning: A practical approach to computer-assisted pronunciation teaching. Electronics 2021, 10, 235. [Google Scholar] [CrossRef]
- Pennington, M.C.; Rogerson-Revell, P.; Pennington, M.C.; Rogerson-Revell, P. Using technology for pronunciation teaching, learning, and assessment. In English Pronunciation Teaching and Research: Contemporary Perspectives; Palgrave Macmillan: London, UK, 2019; pp. 235–286. [Google Scholar]
- Raghul, J.; Sreya, M.; Maithreye, S.; Durga Devi, K. Mobility Stick with Haptic Feedback for People with Vision Impairments. In Proceedings of the 2024 International Conference on Signal Processing, Computation, Electronics, Power and Telecommunication (IConSCEPT), Karaikal, India, 4–5 July 2024; pp. 1–6. [Google Scholar]
- Kleinberg, D.; Yozevitch, R.; Abekasis, I.; Israel, Y.; Holdengreber, E. A haptic feedback system for spatial orientation in the visually impaired: A comprehensive approach. IEEE Sens. Lett. 2023, 7, 1–4. [Google Scholar] [CrossRef]
- Emami, M.; Bayat, A.; Tafazolli, R.; Quddus, A. A survey on haptics: Communication, sensing and feedback. IEEE Commun. Surv. Tutor. 2024, 27, 2006–2050. [Google Scholar] [CrossRef]
- Reed, C.M.; Tan, H.Z.; Jones, L.A. Haptic communication of language. IEEE Trans. Haptics 2023, 16, 134–153. [Google Scholar] [CrossRef]
- Xia, J.; Pei, S.; Chen, Z.; Wang, L.; Hu, J.; Wang, J. Effects of Conventional Speech Therapy with Liuzijue Qigong, a Traditional Chinese Method of Breath Training, in 70 Patients with Post-Stroke Spastic Dysarthria. Med. Sci. Monit. Int. Med. J. Exp. Clin. Res. 2023, 29, e939623-1–e939623-10. [Google Scholar] [CrossRef] [PubMed]
- de Groot, A.; Eijsvoogel, N.; van Well, G.; van Hout, R.; de Vries, E. Evidence-based decision-making in the treatment of speech, language, and communication disorders in Down syndrome; a scoping review. J. Intellect. Disabil. 2024, 17446295241283659. [Google Scholar]
- Martins, G.d.S.; Santos, I.R.D.d.; Brazorotto, J.S. Validation of an educational resource for speech therapists on the use of video feedback in training families of hearing-impaired children. Audiol. Commun. Res. 2024, 29, e2928. [Google Scholar] [CrossRef]
- Holdengreber, E.; Yozevitch, R.; Khavkin, V. Intuitive cognition-based method for generating speech using hand gestures. Sensors 2021, 21, 5291. [Google Scholar] [CrossRef] [PubMed]
- Yozevitch, R.; Frenkel-Toledo, S.; Elion, O.; Levy, L.; Ambaw, A.; Holdengreber, E. Cost-Effective and Efficient Solutions for the Assessment and Practice of Upper Extremity Motor Performance. IEEE Sens. J. 2023, 23, 23494–23499. [Google Scholar] [CrossRef]
- Tan, H.Z.; Reed, C.M.; Jiao, Y.; Perez, Z.D.; Wilson, E.C.; Jung, J.; Martinez, J.S.; Severgnini, F.M. Acquisition of 500 English words through a TActile phonemic sleeve (TAPS). IEEE Trans. Haptics 2020, 13, 745–760. [Google Scholar] [CrossRef]
- Weidner, K.; Lowman, J. Telepractice for adult speech-language pathology services: A systematic review. Perspect. Asha Spec. Interest Groups 2020, 5, 326–338. [Google Scholar] [CrossRef]
- Powell, R.K. Unique contributors to the curriculum: From research to practice for speech-language pathologists in schools. Lang. Speech Hear. Serv. Sch. 2018, 49, 140–147. [Google Scholar] [CrossRef]
- Thomas, S.; Schulz, J.; Ryder, N. Assessment and diagnosis of Developmental Language Disorder: The experiences of speech and language therapists. Autism Dev. Lang. Impair. 2019, 4, 2396941519842812. [Google Scholar] [CrossRef]
- Raina, S. Schizophrenia: Communication disorders and role of the speech-language pathologist. Am. J. Speech Lang. Pathol. 2024, 33, 1099–1112. [Google Scholar] [CrossRef] [PubMed]
- Otoom, M.; Alzubaidi, M.A. Ambient intelligence framework for real-time speech-to-sign translation. Assist. Technol. 2018, 30, 119–132. [Google Scholar] [CrossRef] [PubMed]
- Shull, P.B.; Damian, D.D. Haptic wearables as sensory replacement, sensory augmentation and trainer—A review. J. Neuroeng. Rehabil. 2015, 12, 1–13. [Google Scholar] [CrossRef]
- Giri, G.S.; Maddahi, Y.; Zareinia, K. An application-based review of haptics technology. Robotics 2021, 10, 29. [Google Scholar] [CrossRef]
- Irigoyen, E.; Larrea, M.; Graña, M. A Narrative Review of Haptic Technologies and Their Value for Training, Rehabilitation, and the Education of Persons with Special Needs. Sensors 2024, 24, 6946. [Google Scholar] [CrossRef]
- Levy, L.; Ambaw, A.; Ben-Itzchak, E.; Holdengreber, E. A real-time environmental translator for emotion recognition in autism spectrum disorder. Sci. Rep. 2024, 14, 31527. [Google Scholar] [CrossRef]
- Levy, L.; Blum, Y.; Ambaw, A.; Yozevitch, R.; Holdengreber, E. Harnessing Haptic Technology for Real-Time Emotion Detection. IEEE Sens. Lett. 2025, 9, 5500804. [Google Scholar] [CrossRef]
- Luzhnica, G.; Veas, E.; Pammer, V. Skin reading: Encoding text in a 6-channel haptic display. In Proceedings of the 2016 ACM International Symposium on Wearable Computers, Heidelberg, Germany, 12–16 September 2016; pp. 148–155. [Google Scholar]
- Novich, S.D.; Eagleman, D.M. Using space and time to encode vibrotactile information: Toward an estimate of the skin’s achievable throughput. Exp. Brain Res. 2015, 233, 2777–2788. [Google Scholar] [CrossRef]
- Fletcher, M.D.; Akis, E.; Verschuur, C.A.; Perry, S.W. Improved tactile speech perception and noise robustness using audio-to-tactile sensory substitution with amplitude envelope expansion. Sci. Rep. 2024, 14, 15029. [Google Scholar] [CrossRef]
- Fletcher, M.D.; Verschuur, C.A.; Perry, S.W. Improving speech perception for hearing-impaired listeners using audio-to-tactile sensory substitution with multiple frequency channels. Sci. Rep. 2023, 13, 13336. [Google Scholar] [CrossRef]
- Jung, J.; Reed, C.M.; Martinez, J.S.; Tan, H.Z. Tactile Speech Communication: Reception of Words and Two-Way Messages through a Phoneme-Based Display. Virtual Worlds 2024, 3, 184–207. [Google Scholar] [CrossRef]
- Anazia, E.K.; Eti, E.F.; Ovili, P.H.; Ogbimi, O.F. Speech-To-Text: A Secured Real-Time Language Translation Platform for Students. FUDMA J. Sci. 2024, 8, 329–338. [Google Scholar] [CrossRef]
- Sanaullah, M.; Ahmad, B.; Kashif, M.; Safdar, T.; Hassan, M.; Hasan, M.H.; Aziz, N. A real-time automatic translation of text to sign language. Comput. Mater. Contin. 2022, 70, 2471–2488. [Google Scholar] [CrossRef]
- Bernard, M.; Titeux, H. Phonemizer: Text to Phones Transcription for Multiple Languages in Python. J. Open Source Softw. 2021, 6, 3958. [Google Scholar] [CrossRef]
- Hayden, R.E. The relative frequency of phonemes in General-American English. Word 1950, 6, 217–223. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).