Abstract
Edge computing is characterized by heterogeneous hardware, distributed deployment, and a need for on-site processing, which makes performance benchmarking challenging. This paper presents SHEAB (Scalable Heterogeneous Edge Automation Benchmarking), a novel framework designed to securely automate the benchmarking of Edge AI devices at scale. The proposed framework enables concurrent performance evaluation of multiple edge nodes, drastically reducing the time-to-deploy (TTD) for benchmarking tasks compared to traditional sequential methods. SHEAB’s architecture leverages containerized microservices for orchestration and result aggregation, integrated with multi-layer security (firewalls, VPN tunneling, and SSH) to ensure safe operation in untrusted network environments. We provide a detailed system design and workflow, including algorithmic pseudocode for the SHEAB process. A comprehensive comparative review of related work highlights how SHEAB advances the state-of-the-art in edge benchmarking through its combination of secure automation and scalability. We detail a real-world implementation on eleven heterogeneous edge devices, using a centralized 48-core server to coordinate benchmarks. Statistical analysis of the experimental results demonstrates a 43.74% reduction in total benchmarking time and a 1.78× speedup in benchmarking throughput using SHEAB, relative to conventional one-by-one benchmarking. We also present mathematical formulations for performance gain and discuss the implications of our results. The framework’s effectiveness is validated through the concurrent execution of standard benchmarking workloads on distributed edge nodes, with results stored in a central database for analysis. SHEAB thus represents a significant step toward efficient and reproducible Edge AI performance evaluation. Future work will extend the framework to broader workloads and further improve parallel efficiency.
1. Introduction
Edge computing nowadays is considered as a critical paradigm in modern distributed systems, enabling data processing to occur near data sources (sensors, IoT devices, user devices) for improved latency, bandwidth usage, and privacy.
In Edge AI scenarios, heterogeneous edge devices (e.g., single-board computers, embedded GPUs, microcontrollers) collaboratively handle portions of workloads that were traditionally confined to cloud data centers.
This shift introduces both opportunities and challenges: while on-site processing reduces communication overhead, the diversity in hardware architectures and operating environments makes it difficult to evaluate and compare the performance of edge devices in a consistent manner.
Effective benchmarking of edge devices is essential for system architects to allocate tasks, for developers to optimize applications, and for researchers to compare new algorithms on resource-constrained hardware.
1.1. Cloud Computing and Edge Computing
Cloud computing and edge computing represent two distinct paradigms in how computing resources are deployed. Cloud computing relies on centralized data centers to provide scalable processing and storage, typically offering high flexibility and large capacity at the cost of increased latency to end-users. In contrast, edge computing pushes computation and data storage closer to the data sources (e.g., IoT devices or local gateways), forming a distributed architecture. In recent years, industry trends have seen a paradigm shift from purely centralized cloud models toward edge deployments, driven by the need for responsive, real-time data handling in emerging applications [1]. Edge computing is essentially an extension of cloud capabilities to the network periphery—“an edge optimization of cloud computing”—where data is processed on nearby edge servers or devices rather than a distant cloud center [2]. This proximity to users means edge computing can significantly reduce communication delays and bandwidth usage. Indeed, studies show that edge computing excels at minimizing latency and enhancing privacy by processing data locally, whereas cloud computing offers superior economies of scale in terms of resource elasticity. In summary, cloud and edge computing are complementary: cloud provides massive, centralized resources, and edge computing provides fast, localized processing. Modern architectures increasingly integrate both to leverage the cloud’s scalability with the edge’s immediacy and locality.
1.2. Trends on Edge Computing with AI
One of the most significant trends in recent years is the convergence of edge computing with artificial intelligence, often termed Edge AI. This refers to deploying and running AI algorithms (for data analytics, machine learning inference, etc.) directly on edge devices or edge servers, rather than in centralized clouds. The motivation for Edge AI stems from its potential to enable real-time, intelligent data processing close to where data is generated, which is crucial for latency-sensitive applications like autonomous vehicles, smart health monitors, and industrial control systems [3]. By performing AI inference (and even training, in some cases) at the edge, systems can respond more promptly and avoid sending voluminous raw data to the cloud, thereby also preserving data privacy, This paradigm has seen rapid development; in fact, Edge AI has emerged only over the past decade but has experienced significant growth in the last five years, driven by advances in efficient AI models and specialized hardware for the edge. Researchers highlight that the goal of Edge AI is to maximize processing efficiency and speed while ensuring data confidentiality by keeping sensitive data on-device. However, integrating AI into edge environments is challenging due to the resource constraints of edge nodes (limited compute power, memory, and energy) and the heterogeneity of devices. These constraints demand model optimization (such as quantization or pruning) and innovative distributed learning techniques. As a result, a great deal of current research is focused on techniques for compressing models, federated learning, and adaptive inference to make AI viable on edge platforms. Overall, the fusion of edge computing and AI is a prominent trend enabling what is sometimes dubbed the “AIoT” (AI + IoT) era, promising smarter and faster services at the network edge [4].
1.3. Internet of Things (IoT) with Edge Computing
The proliferation of the Internet of Things (IoT)—billions of connected sensors, devices, and actuators—has been a major catalyst for edge computing adoption. IoT devices continuously generate massive streams of data and often require prompt processing for real-time decision-making (e.g., in smart cities, healthcare monitoring, or industrial automation). In traditional architectures, these data streams would be sent to cloud data centers for processing, but this approach can overwhelm network bandwidth and introduce unacceptable latency for time-critical applications. Many IoT scenarios demand low-latency responses that cloud computing alone cannot adequately provide. Edge computing addresses this gap by deploying cloud-like capabilities at the network edge, effectively bringing computation and storage closer to IoT devices [5]. By processing data on edge nodes (such as IoT gateways, edge servers, or even on the devices themselves), the system can drastically reduce round-trip communication delays and alleviate the load on the central cloud. For instance, instead of every sensor reading being sent over the internet to a distant server, an edge gateway can aggregate and analyze the data locally, only forwarding pertinent results or alerts. This not only yields real-time responsiveness but also cuts down on bandwidth consumption and cloud storage costs. A recent comprehensive review found that edge computing, when applied within IoT ecosystems, greatly reduces latency and improves privacy by ensuring sensitive information is handled locally, near its source. Localized processing means that personal or sensitive data from IoT devices (e.g., video from security cameras or health sensor readings) need not always leave the local network, thereby inherently enhancing data privacy and security compliance [6]. Additionally, keeping data at the edge can lower the power burden on IoT endpoints; devices transmit less data over long distances, which can conserve energy on power-constrained sensors. In summary, edge computing has become an essential enabler for IoT, allowing the infrastructure to scale to the sheer number of devices while meeting strict application latency requirements. The synergy of IoT and edge computing forms the backbone of emerging “smart” environments by providing distributed intelligence and quicker insights at the edge of the network.
1.4. Use of 5G Networks and Edge Computing Architectures
The rollout of 5G mobile networks goes hand-in-hand with edge computing, as 5G’s design explicitly incorporates edge capabilities to achieve ultra-low latency and high throughput for next-generation services. 5G introduces architectures like Multi-Access Edge Computing (MEC), where computing servers are deployed at the periphery of the telecom network (for example, at base stations or regional centers). This allows intensive workloads to be executed closer to mobile users. MEC is widely regarded as a “key technology” to unlock advanced 5G services by placing compute and storage resources at the network’s edge, close to end-users [7]. By doing so, MEC drastically reduces network latency and congestion—data from user equipment (UE) can be processed on a nearby MEC server without traversing the entire network back to a core cloud. This is critical for applications like augmented/virtual reality, autonomous driving, and tactile internet, which demand reaction times on the order of a few milliseconds. Locating AI models or content caching at MEC nodes can enable real-time environmental awareness (e.g., local video analytics) and relieve the core network by offloading traffic locally. The 5G core network’s shift to a service-based architecture (SBA) and use of network function virtualization also facilitates tighter integration with edge computing platforms. From a standards perspective, MEC has been formalized by ETSI, and it is considered a natural extension of the 5G architecture. Rather than a standalone solution, MEC is designed to complement 5G by fulfilling its stringent performance requirements (notably, the ultra-reliable low-latency communication, URLLC) [8]. In practice, telecom operators are deploying edge data centers such that 5G base stations can route certain application traffic (like an AR/VR video stream or an intelligent transportation system message) directly to an on-site edge server. This arrangement minimizes backhaul usage and improves service reliability and responsiveness. Research also indicates that the benefits of edge computing will be even more pronounced in future networks beyond 5G (B5G/6G), where an even denser deployment of small cells and edge nodes is expected [8]. In summary, 5G and edge computing are synergistic: 5G provides the high-speed connectivity and network slicing capabilities, while edge computing platforms deployed within 5G infrastructure ensure that data is processed as close to the user as possible. Together, they enable a new class of mobile and IoT applications that were not feasible with previous network generations.
1.5. Security in Edge Computing
While edge computing unlocks powerful capabilities, it also introduces new security challenges that differ from those in traditional centralized systems. By its very nature, edge computing distributes computation across many nodes (which may be embedded in uncontrolled or public environments), thereby expanding the attack surface. The architecture of edge computing makes it more vulnerable to diverse attack vectors and breaches, since data and processes are not confined to a well-fortified data center but spread across heterogeneous devices and networks [9]. Edge devices often have limited hardware resources (CPU, memory, and battery), meaning they cannot run heavy-duty security measures that cloud servers might use. Additionally, the diversity of hardware platforms and communication protocols in edge environments can lead to inconsistent security postures, and the difficulty of timely patching or updating a multitude of distributed edge nodes can leave them open to exploits. A fundamental concern is that edge nodes might be deployed in locations with little physical security—for example, an edge server in a remote base station or a street-side IoT gateway could be tampered with or destroyed by malicious actors. Indeed, unlike locked-down data centers, edge devices are sometimes physically accessible to attackers, raising the risk of device theft, hardware manipulation, or side-channel attacks. As noted by researchers, edge infrastructure placed in the field cannot rely on the same perimeter defenses available in centralized clouds, and this lack of physical protection makes ensuring security a major challenge [3]. Moreover, the network topology’s complexity (many-to-many device communications, mesh networks, etc.) opens new avenues for attacks such as man-in-the-middle eavesdropping, spoofing, and distributed denial-of-service (DDoS) targeting edge nodes. Studies have observed that IoT and edge devices are especially prone to hacking attempts because of their constrained resources and often minimal built-in security [10]. For instance, data offloaded between a sensor and an edge server could be intercepted if not properly encrypted, or malware could infiltrate an edge node and then propagate to the cloud. These concerns have spurred extensive research into edge-focused security strategies. Emerging approaches include lightweight authentication and encryption schemes tailored for devices with low power, trust management frameworks to ensure nodes and data can be trusted in a decentralized network, and the use of techniques like blockchain and secure enclaves to safeguard data integrity at the edge. In summary, security is a critical aspect of edge computing deployments. The distributed, resource-constrained, and often exposed nature of edge nodes necessitates rethinking traditional cloud security models. Ensuring robust security in edge environments involves addressing not only technical vulnerabilities but also maintaining user trust in these systems, since any weakness in edge security can directly impact privacy and confidence in the overall infrastructure.
In summary, the above technological landscape–spanning cloud-edge synergies, Edge AI, IoT integration, 5G networking, and security considerations–underscores the necessity for effective ways to evaluate and benchmark Edge AI systems. The rapid evolution of edge computing capabilities and use-cases has outpaced traditional performance assessment methods. Edge computing environments are highly heterogeneous and dynamic, making it vital to characterize how different hardware, network conditions, and AI workloads perform at the edge. However, edge performance benchmarking is still a relevant research area, with efforts only gaining momentum in the past few years. There is a clear need for standardized and automated benchmarking frameworks to help researchers and practitioners measure system behavior, compare solutions, and identify bottlenecks in Edge AI deployments. This is the motivation behind the proposed SHEAB framework—a novel automated benchmarking framework for Edge AI. By providing a structured way to test edge computing platforms and AI models under realistic conditions, SHEAB aims to fill the gap in tooling for this domain. Ultimately, such a benchmarking framework is crucial for guiding the design and optimization of future edge computing infrastructures, ensuring that the promise of Edge AI can be fully realized in practice.
1.6. Edge Ai in the Healthcare Sector
Edge artificial intelligence (edge AI) places inference next to data producers’ wearables, bedside monitors, and imaging devices so clinicians get timely, privacy preserving insights without constant cloud back haul. On the Internet of Medical Things (IoMT), surveys show edge AI cuts latency/bandwidth while enabling continuous monitoring and anomaly detection, and it is increasingly paired with MLOps to speed safe deployment in clinical contexts [11]. Within hospitals and telehealth, systematic reviews of edge computing in healthcare report faster response, workload optimization, and better data locality but call out persistent needs in secure governance, model compression, and robust offloading/orchestration across heterogeneous devices [12]. Radiomics evidence further illustrates the clinical promise: AI models can support neuroimaging-based diagnosis and monitoring of Alzheimer’s disease, while reminding us of that reproducibility, standardization, and multi-modal integration are prerequisites for routine use in areas where on-premises edge inference near scanners could be beneficial [13]. Broader analyses of AI in modern healthcare synthesize advances across diagnostics and operations alongside ethical and integration challenges, aligning with edge AI’s value proposition of real-time, privacy-aware decision support [14]. Finally, concise discussions of “smart medical care” underscore the shift from centralized to edge computation to meet clinical latency and confidentiality requirements where the precise niche where edge AI has the most impact [15].
Our Contributions: In this paper, we present SHEAB—Scalable Heterogeneous Edge Automation Benchmarking—a framework designed to fill the gap. The key contributions of our work are summarized as follows:
- Secure, Automated Benchmarking Framework: We design an architecture for automating the execution of benchmarks on multiple edge devices concurrently. Our framework emphasizes security through a multi-layer approach (firewalls, VPN, and SSH) for communications, enabling safe operation even across public or untrusted networks. To our knowledge, this is the first edge benchmarking framework to integrate such comprehensive security measures into the automation process.
- Scalability and Heterogeneity: SHEAB’s orchestration mechanism (implemented as a containerized microservice) can handle a group of heterogeneous edge devices simultaneously. We demonstrate the ability to launch benchmarking workloads on all devices “at once”, significantly reducing the overall benchmarking time as compared to sequential execution. The framework is hardware-agnostic, accommodating devices ranging from powerful single-board computers to lower-end IoT nodes, and on top of this, this deployment is agentless, which means no agent will be installed on edge nodes, only the benchmarking tool.
- Time-to-Deploy Metric and Analysis: We introduce a new performance metric, Time To Deploy (TTD), which we define as the time taken to complete a given benchmarking routine on an edge device. Using this metric, we formulate an analytic comparison between individual sequential benchmarking versus automated parallel benchmarking. We derive expressions for Latency Reduction Gain (percentage decrease in total benchmarking time) and system speedup achieved by SHEAB, and we provide empirical measurements of these for a real testbed of devices.
- Implementation and Real-world Validation: We develop a working implementation of the SHEAB framework using readily available technologies (Docker containers, OpenVPN, Ansible, etc.). The implementation is tested on a network of eleven heterogeneous edge devices (including Raspberry Pi 1/2/3/4/5, Orange Pi boards, Jetson and Odroid), orchestrated by a central server. We report detailed results from running a CPU, memory, network, ML inference and GPU benchmarking workload across all devices via the framework, including the measured speedups and resource utilization. The results demonstrate the practicality of SHEAB for improving benchmarking efficiency and highlight any overheads introduced by the automation.
Comparative Evaluation: We provide a thorough discussion situating SHEAB relative to existing benchmarks and tools. By using recent references from journals, conferences, and industry white papers, we analyze how our framework complements and differs from other approaches like IoTBench, EdgeBench, EdgeFaaSBench, etc. This helps identify use-cases where SHEAB is particularly beneficial (e.g., organizations needing to benchmark many devices regularly) and scenarios for future improvement.
This research paper is organized as follows. Section 2 (Background) gives a comparative background, reviewing the literature and existing frameworks in edge and IoT benchmarking, highlighting their relation to our work. Section 3 (Literature Survey) details the most important and recent literature, along with the research gaps that form the motivation behind this work. Section 4 (Methodology and System Design) provides a formal description of the SHEAB algorithm and workflow and framework architecture, with a step-by-step pseudocode of the automation process. Section 5 (Algorithm Design of SHEAB) describes a step-by-step pseudocode of the framework algorithm. Section 6 (Implementation) illustrates how the framework was deployed on real devices. Section 7 (Statistical and Performance Analysis) defines the evaluation metrics (including TTD, speedup, etc.) and analyzes the performance data collected from the experiments. Section 8 (Experiments and Evaluations) discusses the outcome, interpreting the significance of the results, and comparing them with expectations or theoretical limits. Section 9 (Conclusion and Future Work) concludes the paper by summarizing the contributions and pointing out potential future enhancements and research directions. Finally, (References) lists all referenced literature.
2. Background
Edge computing has emerged as a paradigm to meet the demands of latency-sensitive and data-intensive applications by moving computation and storage closer to data sources. In parallel, cloud-native design principles—particularly the use of containers and microservices—have revolutionized how software is developed and deployed. Combined with automation tools, these technologies enable rapid, frequent updates in distributed environments with minimal human effort [16]. The convergence of edge computing with containerization, automated orchestration, and microservice architectures promises a highly agile and scalable infrastructure at the network edge. This section provides a technical background, covering container usage in edge computing, automation (including AI/ML techniques) at the edge, microservices in edge environments, and security considerations for containerized edge deployments. A concise overview of each area is presented, highlighting current capabilities, comparative benefits, and ongoing challenges.
2.1. Containers and Edge Computing
Containers are lightweight virtualization units that package applications with their dependencies, offering a much smaller footprint than traditional virtual machines (VMs). This efficiency makes containers especially attractive for edge computing nodes, which often have limited resources. In fact, containers are “rapidly becoming the de facto way of providing edge computing services” [17]. By sharing the host operating system kernel, containers avoid the overhead of full VMs, leading to quick boot times, high execution speed, and efficient resource usage [18]. These properties align well with edge scenarios that require fast deployment and scaling of services on resource-constrained devices. For instance, benchmark studies have shown that containerized applications can achieve near-native performance on edge hardware [19]. This lightweight nature allows more applications to be deployed per edge node compared to using VMs, enabling dense service consolidation at the network edge.
At the same time, container ecosystems come with robust tooling that simplifies management across many distributed sites. Technologies like Docker and Kubernetes have been extended to the edge, allowing developers to package an application once and run it seamlessly on many edge servers. Container orchestration frameworks (e.g., K3s or KubeEdge) can schedule containers to edge nodes based on available resources and workload demand. This portability and consistency are crucial, since edge devices may be heterogeneous in hardware and geographically dispersed. Overall, containerization provides the foundational “lightweight virtualization” needed in edge computing, effectively bridging cloud and edge by bringing cloud-like deployment agility to remote devices. However, it should be noted that containers trade off some isolation in exchange for this efficiency—unlike VMs, they share the host OS, which introduces security and multi-tenancy considerations to be addressed later.
2.2. Automation in the Era of the Edge
Operating large-scale edge computing systems would be infeasible without a high degree of automation. The distributed and dynamic nature of edge environments—with numerous nodes, variable network conditions, and shifting workloads—demands intelligent orchestration and self-management. Modern edge platforms therefore employ automated orchestration frameworks to deploy and manage containerized services across nodes. A container scheduler is typically responsible for deciding how to allocate incoming service requests to containers, which edge node to place each container on, and when to migrate containers between nodes to balance load. Such orchestration systems (often adapted from cloud container managers) continually monitor the state of edge resources and applications, automatically healing failures and scaling services up or down. Beyond classical rule-based automation, there is a growing infusion of AI and machine learning techniques to further optimize edge operations in real time. The following subsections discuss (Section 2.1) the role of AI/ML in edge automation, (Section 2.2) comparative analyses showing efficiency gains through automation, and (Section 2.3) open challenges and future directions in this domain.
A Detailed comparison showcasing the current state of the art automation framework is shown in Table 1 below.

Table 1.
comparison of the current state of the art automation tools.
2.3. AI and Machine Learning Automation at the Edge
Artificial intelligence and machine learning are increasingly employed to handle the complexity of managing edge resources. Traditional static or heuristics-based policies often struggle to adapt to dynamic conditions (varying load, network latency, device failures) across many edge nodes. In contrast, AI techniques can learn and make proactive decisions for resource allocation, service placement, and load balancing. For example, researchers have proposed deep reinforcement learning (DRL) approaches to optimize edge computing operations. Sami et al. (2021) introduce an intelligent edge resource manager that uses DRL to continuously scale services and place workloads on appropriate edge servers [20]. Their system, called IScaler, monitors the state of the network and applications, and automatically decides when to perform horizontal or vertical scaling of edge containers and where to offload certain microservices. Such AI-driven automation is crucial in scenarios like 6G Internet of Everything (IoE), where highly variable service demands and limited edge resources make manual tuning impractical. Early results show that these learning-based policies can achieve efficient utilization and meet application QoS requirements by reacting faster and more granularly than human operators or simple algorithms. Beyond DRL, other machine learning techniques (e.g., predictive analytics, federated learning) are also being explored to automate tasks at the edge—from predictive caching of content to anomaly detection in IoT sensor data streams—all with minimal cloud dependency. The overarching trend is an “intelligent edge” that not only hosts AI applications but also uses AI internally to self-optimize its operations.
2.4. Comparative Analysis and Efficiency Gains
Automating processes at the edge has shown clear efficiency benefits in comparison to traditional cloud-centric or manual approaches. By processing data and handling requests locally, edge computing inherently reduces wide-area communication latency and bandwidth usage. Recent analyses confirm that offloading workloads to edge nodes can significantly lower end-to-end response times and network traffic to the cloud, yielding cost savings and more efficient use of network resources [21]. They noted that deploying microservices at the edge (closer to users) cut down latency and backhaul data transfer, which in turn improves user experience and reduces the load on centralized data centers. These improvements are particularly pronounced for real-time applications; one study finds edge computing provides markedly better performance and QoS for time-sensitive tasks compared to a cloud-only deployment [22].
In terms of resource management, automated orchestration and AI optimizations also demonstrate gains over static configurations. Edge scheduling algorithms that dynamically place and migrate containerized services can achieve higher resource utilization and avoid bottlenecks. For example, an optimized edge caching algorithm was shown to “significantly outperform” baseline approaches in reducing system cost and improving QoS metrics [17]. Similarly, AI-driven orchestration (as in the DRL-based IScaler system) outperforms simple heuristics by adapting to workload changes on the fly. Comparative evaluations indicate such intelligent automation maintains service performance with less over-provisioning, thereby using compute resources and energy more efficiently. In summary, the move toward automated, edge-aware management—whether via rule-based orchestration or advanced AI—delivers tangible efficiency gains: lower latency, lower bandwidth consumption, and better resource economy. These benefits validate the push for automation in edge computing, even as they must be weighed against the added complexity of deploying these sophisticated control systems.
2.5. Microservices on the Edge
Microservices architecture is a software design approach where applications are composed of many small, independently deployable services. This approach, popular in cloud environments, is now extending into edge computing. The modularity of microservices is well-suited to the distributed edge: different services of an application can be deployed across multiple edge and cloud nodes to optimize performance. Running microservices at the edge can dramatically reduce user-perceived latency by moving certain functionalities closer to the end-user. For example, an edge-deployed microservice can handle local requests without always invoking a distant cloud service, thereby improving responsiveness. Detti et al. highlight that when “microservices are deployed on the edge, they enable users to process their requests closer, offering benefits such as reduced latency and network traffic toward central data centers”, which leads to cost savings and more efficient network utilization [21]. In essence, microservices allow applications to span the cloud-edge continuum, placing time-critical components at the edge while keeping heavier processing in the cloud.
To support microservices on the edge, cloud-native platforms have evolved to accommodate distributed deployments. Containers are the typical delivery mechanism for microservices, and orchestration tools (like Kubernetes) manage these across hybrid cloud/edge environments. A common pattern is to run a Kubernetes cluster that includes both cloud and edge nodes, or to use federation between a cloud cluster and edge clusters. Service meshes are also gaining traction in edge deployments—these add a layer for advanced traffic routing, service discovery, and observability for microservices. As Detti notes, deployment of microservices often uses Kubernetes for container orchestration, “possibly supported by other frameworks, for example, service meshes for observability and request routing”. Such infrastructure is being adapted for intermittent connectivity and lower resource availability at the edge.
One key challenge with microservices at the edge is deciding which services should run at the edge vs. in the cloud. Because edge resources are more limited (and often more expensive to operate) than centralized cloud resources, it may not be feasible to run an entire microservice-based application on every edge node. Research has focused on optimal placement strategies to partition microservices between edge and cloud in a way that meets performance targets without overloading edge devices. For instance, a latency-sensitive microservice (such as a real-time video analytics component) might be placed on an edge server near the camera source, while a batch analytics microservice is kept in the cloud. Prior studies have developed models to determine the “edge-native” portion of an application—identifying which microservices yield significant delay reduction if moved to the edge. Another consideration is the communication overhead: microservices often call each other via APIs, so deploying them across distributed nodes can introduce network hops. Designers must ensure that the benefits of edge deployment outweigh the added inter-service communication cost.
Despite these challenges, early deployments of microservices on the edge have shown promising results, especially for improving responsiveness. By leveraging microservices, edge computing platforms gain flexibility—services can be independently updated or scaled on-demand at different edge locations. This agility is valuable for scenarios like IoT and 5G MEC (Multi-access Edge Computing), where applications may need to be customized per location or rapidly reconfigured. In summary, microservices bring a cloud-proven architectural style to edge computing, offering modularity and scalability at the cost of additional orchestration complexity. Ongoing research is refining microservice placement and management techniques to fully realize the benefits of this approach in edge settings.
2.6. Security Aspect of Containerization on the Edge
Security is a critical concern for edge computing, especially as containerization and microservices introduce new attack surfaces. Edge deployments often exist outside traditional data center perimeters, in environments that may be less physically secure and harder to monitor. Additionally, the use of container technology, while beneficial for performance, brings its own security challenges. This section examines two facets of edge security: (2.7.1) the container challenges inherent to containerized platforms on the edge. Ensuring robust security in both respects is essential for the success of edge computing, as vulnerabilities could be exploited at scale given the growing number of edge nodes [10].
Container Challenges
Container-based edge infrastructures must contend with several security challenges. By design, containers share the host operating system kernel, which means a flaw in the OS, or a misconfigured container can potentially affect all containers on that host. This level of isolation is weaker than that provided by VMs, and indeed containers are known to have “isolation and security drawbacks” despite their performance advantages. One immediate concern is the presence of known vulnerabilities within container images. A recent security analysis of Docker containers for ARM-based edge devices found an alarming number of vulnerabilities in even official images—“72% of all the vulnerabilities” scanned were of varying severity. These include outdated libraries and software in container images that adversaries could exploit. The study also noted that no single scanning tool caught more than 80% of issues, indicating that many vulnerabilities could go unnoticed without comprehensive scanning. This highlights the supply-chain risk: edge systems often deploy pre-built container images (from Docker Hub or other registries), which might contain critical security flaws if not rigorously vetted.
Another challenge is ensuring secure multi-tenancy on edge nodes. In scenarios where edge servers run containers for different services or even different clients, a breach in one container could allow lateral movement to others due to the shared kernel—for example, via namespace breakout exploits or kernel vulnerabilities. Resource constraints on edge devices can also make it difficult to implement heavy-weight security mechanisms. Patches and updates need to be applied promptly to edge container hosts, but managing updates across numerous distributed nodes is non-trivial and sometimes lags behind, leaving systems exposed. Moreover, container orchestrators themselves (like Kubernetes) have complexity that can introduce misconfiguration risks; an overly permissive setting in an edge cluster could inadvertently allow an attacker to escalate privileges.
In summary, the containerization that underpins agile edge deployments must be hardened for hostile environments. Research and industry practice are actively addressing these issues by developing minimal, secure container images, enabling kernel security modules, and adopting runtime protections (e.g., rootless containers, hardened sandbox runtimes) for edge use-cases. As Haq et al. (2022) conclude, using containers at edge nodes indeed “enhance(s) (performance) advantages at the cost of increasing security vulnerabilities” in the system [19]. Recognizing and mitigating these vulnerabilities—through robust image security scanners, stronger isolation techniques (like microVMs or unikernels as alternatives), and strict access controls—is vital to protect containerized edge platforms from attacks.
3. Literature Survey
3.1. Challenges in Edge AI Benchmarking
Unlike homogeneous cloud servers, edge devices vary widely in CPU capabilities, memory, Operating system, accelerators, and network connectivity [23].
Benchmarking methods that work for cloud or desktop environments often do not translate well to the edge. Traditional benchmarking typically involves running standard performance tests (CPU, memory, I/O, or AI inference tasks) on each device individually and in isolation. This approach does not scale to large edge deployments and becomes labor-intensive and time-consuming as the number of devices grows. Moreover, manually benchmarking each device sequentially can significantly delay the evaluation process; for instance, testing n devices one-by-one takes time proportional to n, which is impractical for large n. There is a clear need for a framework that can automate and parallelize benchmarking across many devices.
Another challenge is maintaining security and reliability during remote benchmarking. Edge devices are often deployed in the field or on untrusted networks, so remotely executing benchmarks must be done securely to prevent unauthorized access or data tampering. Issues such as secure authentication to devices, encrypted communication, and safe execution of code on remote hardware must be addressed. Any solution must integrate robust security measures (e.g., VPN tunnels, firewalls, secure shell) into the benchmarking workflow to protect both the devices and the network [24].
3.2. Limitations of Existing Approaches
Previous research has produced a variety of benchmarking suites and tools for edge and IoT scenarios. Early work by Kruger and Hancke (2014) introduced a two-phase benchmark for IoT devices using micro-benchmarks (LMbench) to measure basic operation latencies and deploying a lightweight server (CoAP protocol) to measure response times [25].
While pioneering, that approach required manual setup on each device and did not focus on concurrent automation. Subsequent efforts like RIoTBench and IoTBench provided workloads that mimic realistic edge data processing. RIoTBench (2017) offered a set of 27 micro-benchmarks for distributed stream processing, targeting IoT stream analytics on edge-cloud systems [26].
Recent research focused on intelligent IoT edge devices with benchmarks for vision, speech, and signal processing tasks. These suites allowed evaluation of edge hardware for specific application scenarios; however, they typically assume the user runs each benchmark on each device and often measure one device at a time, rather than orchestrating tests across multiple devices simultaneously [27].
Another relevant direction is benchmarking specifically for Edge AI and TinyML. The BenchCouncil’s Edge AIBench defined end-to-end scenario benchmarks spanning device-edge-cloud for typical AI applications: an ICU patient monitor, a surveillance camera system, a smart home, and an autonomous vehicle scenario. Edge AIBench emphasizes the collaborative workload distribution across the three tiers and includes tasks like federated learning to address data privacy. This provides valuable insights into system-level performance in integrated scenarios, but it does not supply a tool for automating the process of running benchmarks on many devices; instead, it defines what to benchmark (the scenarios and tasks). Similarly, industry-driven efforts like MLPerf Inference have introduced benchmarks for edge AI model performance, including MLPerf Tiny for microcontroller-class devices. MLPerf Tiny (first released in 2021) includes four TinyML benchmark tasks (keyword spotting, visual wake words, image classification, anomaly detection) to compare ML inference performance across tiny devices. However, such benchmarks focus on model inference throughput/latency and require users to run tests on each target platform; they do not handle the automation of deploying and executing those tests across many edge nodes at once. In fact, MLPerf Tiny’s limited number of models and lack of fixed test conditions per hardware make it challenging to use for comprehensive tool or system comparisons [28].
Recent research has started addressing automation in edge benchmarking. is an application-oriented benchmark suite for edge computing that utilizes a microservice-based analytics pipeline for video streams by default to measure the networking and compute capabilities of heterogeneous edge hardware. ComB’s design allows edge providers and application developers to evaluate hardware choices for edge deployments by using a representative multi-component application. While ComB allows flexible deployment of its pipeline to different devices, the process of orchestrating the benchmark on multiple devices is not the primary focus; it assumes an environment where the pipeline can be deployed (possibly using container orchestration) but does not emphasize security or a generalized automation service for arbitrary benchmarks. MECBench (2023) goes a step further by providing an extensible framework for benchmarking multi-access edge computing environments. MECBench can emulate different network conditions and generate scaled workloads (e.g., simulating many clients) to test edge servers’ performance for scenarios like drone object detection and natural language processing at the edge. This is highly useful for exploring edge server and network design trade-offs, but MECBench primarily targets edge infrastructure (network + compute) and involves orchestrating synthetic clients and edge servers in experiments, rather than deploying standardized micro-benchmarks on a set of devices [29,30].
For the specific problem of deploying general benchmarks on many edge devices, one notable tool is EdgeFaaSBench which uses a serverless computing approach. EdgeFaaSBench leverages an open-source FaaS platform (OpenFaaS on Docker Swarm) to run fourteen different workloads to run benchmarking on heterogeneous edge devices, automatically capturing system-level, application-level, and FaaS-specific metrics. By setting benchmarks as serverless functions, it simplifies deployment on devices and measures performance aspects like cold start delay and resource utilization in a unified manner. However, EdgeFaaSBench is tailored to serverless application benchmarks and was demonstrated on a small set of edge nodes (two devices in their experiments) It does not explicitly address secure connectivity or scaling beyond a few devices, as it is more focused on comparing serverless vs. non-serverless performance on edge hardware. [31].
Finally, in the domain of automation for embedded AI workflows, EdgeMark has been introduced as an open-source system to streamline deploying and benchmarking embedded AI (eAI) tools on devices. EdgeMark automates the steps of TinyML model development (model generation, optimization, conversion, and deployment) and provides a benchmarking harness to evaluate different TinyML frameworks on microcontrollers. While EdgeMark’s automation reduces the manual effort in trying out different AI toolchains, its focus is on model benchmarking and not on general system performance metrics. Moreover, EdgeMark targets single-device automation at a time (iterating over tools or models) rather than simultaneous multi-device execution [32].
In summary, existing work underscores the importance of edge benchmarking and offers suites for specific scenarios or partial automation solutions. However, a gap remains for a generalized, secure, and scalable framework to automate benchmarking across many heterogeneous edge devices in parallel. In particular, none of the surveyed solutions simultaneously provide:
- (i)
- Concurrent benchmarking of multiple distributed edge nodes;
- (ii)
- Integrated security mechanisms for safe operation over untrusted networks;
- (iii)
- A modular microservice design to facilitate easy deployment and result collection.These are precisely the contributions we target with our proposed framework.
An extensive research gap literature review was made showing the most recent research comparisons of the Technology Scope, Topic Focus, implementation of automation in Benchmarking, whether the research Supports Heterogeneous Edge Servers, Containerization implementation and Security implementation in the research, shown in Table 2 below.
Table 2.
Comparison of different important criteria for benchmarking relevant research.
4. Methodology and System Design
In this section, we describe the design of the SHEAB framework in detail. The design philosophy is to achieve secure automation for benchmarking without sacrificing flexibility or performance. We first present the system architecture, then explain the multi-stage workflow of the framework. Key design considerations such as security layers, containerization, and error handling are highlighted. Figures are included to illustrate the system components and process flow.
4.1. System Architecture
Figure 1 Architecture of the SHEAB framework. A centralized server orchestrates benchmarking across multiple edge servers over an untrusted network. The central server hosts two containerized microservices: a Benchmarking service that dispatches tests via SSH, and a Results Collection service that aggregates data (e.g., in a database). A VPN tunnel is established between the central server and each edge server (managed by VPN gateways/firewalls) to secure all communication across the untrusted network.
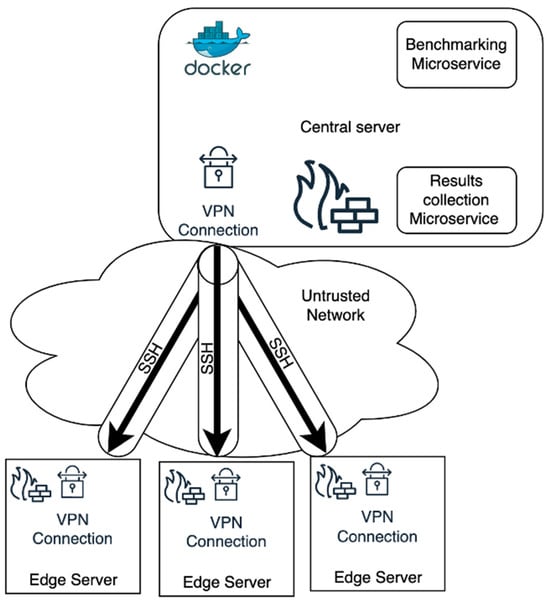
Figure 1.
Architecture of the SHEAB framework.
At a high level, SHEAB follows a client-server model with a powerful central server (the orchestrator) and numerous edge servers (the devices under test). Figure 1 depicts the main components and their interactions. The central server is assumed to be in a secure location (e.g., a data center or cloud instance) with substantial compute resources. In our implementation, it is a Xeon-based server with 48 CPU cores and 128 GB RAM (ensuring it can handle parallel tasks for multiple devices). The edge servers are the heterogeneous devices we want to benchmark—in our case, these included Raspberry Pi boards of various generations, Orange Pi boards, and an Odroid single-board computer.
Central Orchestrator: The central server runs two primary software components, each encapsulated in a Docker container for modularity and isolation:
- Benchmarking Microservice: This container contains the automation logic for deploying and executing benchmarks on edge devices. It includes scripts or an orchestration engine (we use an Ansible playbook as part of this service in our implementation) which can initiate SSH sessions to each edge device and run the desired benchmarking commands. The containerization of this service means it can be easily started/stopped and configured without affecting the host OS, and it could potentially be scaled or moved to another host if needed.
- Results Collection Microservice: This container is responsible for aggregating the results returned by the edge devices. In practice, we run a lightweight database (MariaDB) or data collection server here. When benchmarks complete on edge nodes, their output (performance metrics) are sent back to this service, which stores them for analysis. Decoupling this into a separate microservice ensures that result handling (which might involve disk I/O or data processing) does not slow down the core orchestration logic. It also provides persistence—results can be queried or visualized after the benchmarking run.
- These two microservices interact with each other in a producer–consumer fashion: the Benchmarking service produces data (by triggering benchmarks and retrieving outputs), and the Results service consumes and stores that data.
- Edge Servers: Each edge server is a device being tested. We do not assume any special software is pre-installed on the edge aside from basic OS capabilities to run the benchmark and an SSH server to receive commands. To minimize intrusion, we do not install a permanent agent or daemon on the edge (though one could, to optimize repeated use; in our case we opted for an agentless approach via SSH). The edge devices in our design are behind their own local firewalls (or at least have host-based firewall rules) to only allow incoming connections from trusted sources (e.g., SSH from the central server). They also each run a VPN client that connects to a central VPN server (more on the VPN below).
Secure Communication (VPN and SSH): A core part of the architecture is the VPN connection that links the central server to each edge server. As Figure 1 shows, the central server runs a VPN server (depicted as a lock icon on the central side), and each edge runs a corresponding VPN client. This creates an encrypted tunnel through which all SSH commands and benchmark data travel, effectively forming a secure overlay network on top of the existing (untrusted) network. The untrusted network could be the public internet or any other network where eavesdropping or malicious interference is a concern. By using a VPN, we ensure confidentiality and integrity of the data exchange. Additionally, the VPN simplifies addressing: each edge is reachable at a fixed VPN IP address, regardless of the actual underlying network (NAT, dynamic IPs, etc.), as long as the VPN connection is active.
On top of the VPN, we use SSH (Secure Shell) for executing commands on the edge servers. SSH itself provides encryption and authentication, but when combined with VPN we get an extra layer of security plus easier network management (we do not have to expose SSH ports directly to the internet; they can even be bound only to the VPN interface on each device). The SSH connections are initiated by the central Benchmarking microservice when it is time to deploy and run the benchmark. Credentials or keys for SSH are managed securely on the central server (for example, using key-based authentication to avoid password transmission).
Firewalls: As illustrated, we consider two sets of firewall defenses—one at the central server and one at each edge network. The central firewall could be part of the central server’s OS or an external network firewall. It is configured to allow only necessary traffic (e.g., VPN and SSH) from known endpoints. The edge firewall (which might be a simple router firewall at the edge location or host-based firewall on the device) is similarly configured to only allow VPN traffic and SSH from the central server. These measures align with best practices for edge device security, creating a defense-in-depth approach. In essence, even if the VPN was not present, the firewall would limit access, and even if the firewall had a misconfiguration, the VPN + SSH provide security. This multi-layer security design was a fundamental requirement in SHEAB given the importance of protecting both benchmark data and the devices themselves from attacks.
Networking Overview: The overall communication pattern is: Central Benchmarking service -> (VPN tunnel) -> SSH -> Edge device (run benchmark) -> result output -> SSH back through VPN -> Central Results service (store data). The use of Docker for services means that from within the Benchmarking container, it reaches out to edges (we provide the container access to the host network or at least the VPN interface). Similarly, the Results container either exposes a port where the Benchmarking container can submit results or the Benchmarking container simply writes directly to a database running in the Results container (e.g., via a database connection over localhost or docker network). In our implementation, the Benchmarking service, after each test, connects to the MariaDB service and inserts the result.
Heterogeneity Handling: Because edge devices differ in hardware and software environment, the framework is designed to be as generic as possible. The central service can maintain a list of device profiles or inventory that describes each edge node (for example, its IP, SSH key, and any specifics like “this is a Linux ARMv7 device”). The Ansible playbook we use is naturally capable of handling different device types, as it can run different tasks or adjust parameters based on device facts (architecture, OS). For instance, if a certain benchmark binary needs to be compiled for ARM vs. x86, the playbook could choose the correct binary or compile on-the-fly. In our test, all devices ran a Debian-based Linux OS, so running the same sysbench tool on each was straightforward.
4.2. Benchmarking Workflow
We designed the workflow of SHEAB to operate in five stages: Initialization, Secure Communication setup, Execution, Results Collection, and Termination. Figure 2 provides a flowchart of this process, including error-handling steps that ensure robustness.
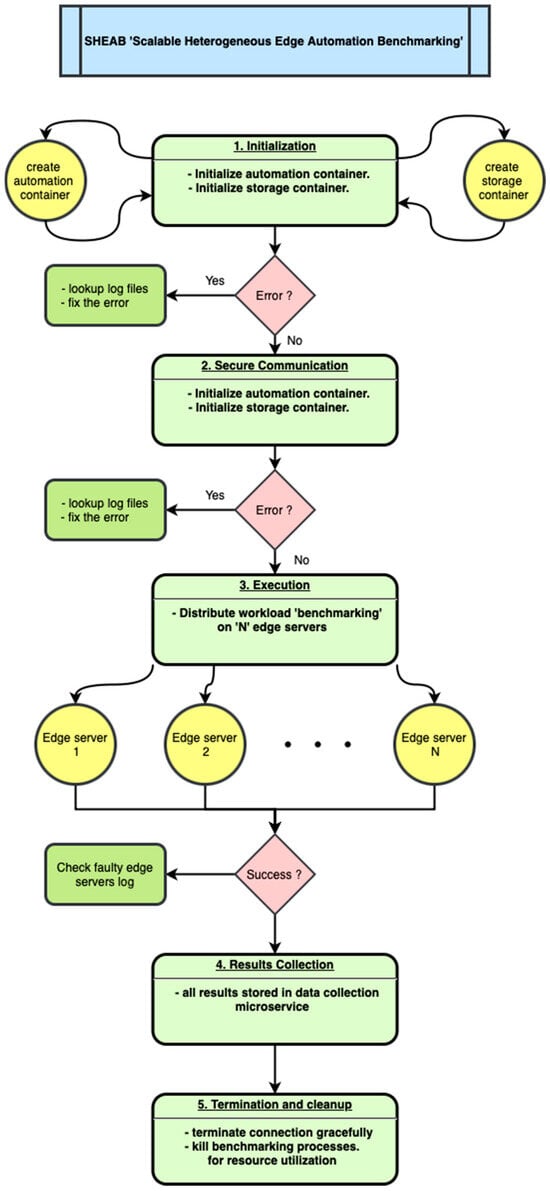
Figure 2.
Workflow of the SHEAB framework.
The process consists of 5 stages: 1. Initialization—the central server launches the needed automation and storage containers; 2. Secure Communication—establishes VPN and verifies connectivity to all edge servers; 3. Execution—distributes and runs the benchmarking workload on all N edge servers (in parallel); 4. Results Collection—gathers all outputs and stores them in the central database; 5. Termination and Cleanup—gracefully closes connections and stops any processes on edges. The flowchart shows decision points for error checking after key steps. If an error occurs (e.g., connection failure on a device), the system logs the error and attempts to fix or skip as configured.
The numbered stages in Figure 2 correspond to the following:
- Stage 1: Initialization. In this stage, the central server sets up the environment required for the rest of the process. This involves launching the Automation container (Benchmarking microservice) and the Storage container (Results microservice). In practice, this could be done via Docker commands or a script. Once these containers are up, the automation code inside the Benchmarking service takes over. A configuration check is performed to ensure the list of target edge servers is loaded and that the central server has the necessary credentials (e.g., SSH keys) and network configuration to reach them. An initial log is created for the session in the results database (for traceability). The flowchart includes an error check here: if either container fails to launch or if configuration is invalid, an error is flagged. The system can attempt to fix simple issues (for example, if the database container was not ready, it might retry after a delay) or else abort and log the failure for the user to resolve.
- Stage 2: Secure Communication Setup. This stage establishes and verifies the VPN connections and any other secure channels. Depending on the deployment, the VPN might already be set up prior (e.g., a persistent VPN link), or it might need to be initiated on-the-fly. In our implementation, we set up the VPN out-of-band (the VPN server on central and clients on edges run as services), so the automation’s job was to verify that each edge is reachable via the VPN. The Benchmarking service pings each edge’s VPN IP or attempts a quick SSH handshake to each. If any edge is not reachable, this is flagged as an error (“Error?” diamond in the flowchart after stage 2). If an error is detected (for instance, an edge device is offline or its VPN tunnel did not come up), the framework can log this in an error log file associated with that device. We designed the framework to either fix or skip depending on configuration. “Fix” could mean trying to restart the VPN connection or using an alternate route; “skip” means marking that device as unavailable and continuing with the others (the user would later see in the results which devices failed). Security setup also includes ensuring that the SSH service on each device is running and credentials work—essentially a dry-run login. Only after all target devices pass this connectivity check does the workflow proceed. This stage is crucial because a failure here often cannot be compensated during execution (if a device cannot be reached securely, you cannot benchmark it), so we isolate these issues early.
- Stage 3: Execution. This is the core benchmarking phase. Here, the automation service distributes the workload to all edge servers. In practical terms, this means the orchestrator triggers the benchmark on each device. The key difference of SHEAB, compared to manual testing, is that these triggers are done in parallel (to the extent possible). In our implementation using Ansible, we leverage its ability to execute tasks on multiple hosts concurrently. All edge nodes receive the command to start the benchmark nearly simultaneously. For example, we used the sysbench CPU benchmark as the workload in our test; the playbook invoked sysbench test = cpu time = 10 run (which runs a CPU prime number test for 10 s) on each of the 8 devices. Ansible, by default, might run on a few hosts in parallel (it has a configurable fork limit); we tuned this to ensure all 8 could start together. The result is that the benchmarking tasks run roughly at the same time on all devices, drastically shortening the wall-clock time needed to complete all tests, as compared to running them serially.
During execution, we monitor for any errors on each device. Potential errors include: a benchmark tool not found or failing to execute on a particular device, or a device crashing or disconnecting mid-benchmark. The flowchart indicates a decision “Success?” after the execution block, meaning the system checks if all benchmarks reported results successfully. If any device did not complete its task, we log which device failed and collect whatever error message is available (for example, if SSH returned a non-zero exit status, capture that). The workflow could be configured to either halt on a failure or continue. In our design, we chose to continue (execute as many as possible) but flag failures. Additionally, we included a step to check faulty edge server logs if a failure happened. For example, if an edge’s benchmark did not return, we might fetch the syslog or application log from that device to include in a debugging report. This automated post-mortem can save time for the user in diagnosing issues (rather than having to manually SSH and check).
- Stage 4: Results Collection. Assuming the benchmarks run to completion, each edge will produce an output (it could be a simple text output from a tool, or a structured result). In our case, sysbench outputs a summary of the test, including number of events, execution time, etc. The automation service captures these outputs. The Results Collection stage then involves transferring the results into the central storage. This can happen in a couple of ways. We implemented it by having the Ansible playbook gather the command output and then issue a database insert via a local script. Alternatively, one could have each edge directly send a result to an API endpoint on the central server. The approach will depend on network permissions and convenience. Regardless, at the end of this stage, all data is centralized. The results in our example include each device’s ID, the test name, and key performance metrics (like execution time). Stage 4 in Figure 2 shows “all results stored in data collection microservice.” If an edge’s result was missing due to earlier failure, that entry would simply be absent or marked as failed.
We paid attention to time synchronization issues here. Because results come from different devices, their timestamps might differ. The framework records the central time for when each result was received to allow ordering or matching with logs if needed. We also record any anomalies (e.g., if a result seems like an outlier, the system could flag it, though that is more of an analysis task).
- Stage 5: Termination and Cleanup. After results are collected, the framework enters the cleanup phase. This is often overlooked in simpler scripts, but for a long-running service, it is important to release resources and not leave processes hanging on devices. In this stage, the central server will gracefully close each SSH session (some orchestration tools do this automatically). It will also send a command to each edge to terminate any lingering benchmarking processes, in case a process did not exit properly. For instance, if a user accidentally set a very long benchmark duration and wants to abort, the framework could issue a kill signal. Cleanup also involves shutting down the containers on the central server if they are not needed to persist. In our design, the Results microservice (database) might remain running if one plans to run multiple benchmarks and accumulate results. But the Automation microservice can terminate or go idle after printing a summary of the operation. The VPN connections can either remain for future use or be closed. In a dynamic scenario, one might tear down the VPN if it was launched just for this test (to free network and ensure security).
Finally, logs and outcomes are summarized. The framework can output a report of “X devices succeeded; Y failed” with references to logs for any failures. This ensures the user has a single point of reference to understand the outcome.
Error Handling and Robustness: As indicated in the workflow (Figure 2’s diamond decisions), error checking is built into each stage. Our implementation took a defensive stance: any time an error was encountered, we caught it, recorded it, and attempted either a retry or a graceful skip. For example, if an SSH connection dropped during Stage 3, the playbook would note that and proceed to Stage 4 without that device’s data. The presence of these checks makes the system robust for longer runs and larger device counts, where it is likely that at least one device might misbehave. Logging is centralized in the results DB under special tables for errors, which is useful for later debugging.
Security Considerations: During the entire workflow, security is maintained. All communication remains inside the VPN tunnel. Additionally, if any step fails in a way that could compromise security (e.g., a device repeatedly refusing connection—possibly indicating a MITM attack or key mismatch), the system will halt and report rather than continuing blindly. The use of SSH keys prevents password interception. The firewall rules ensure that even if the VPN were to drop momentarily, the edge SSH ports are not exposed to the world. We also consider the case of the central server itself being a high-value target; running the benchmarking code inside a container with limited privileges helps mitigate the impact if that code had a vulnerability (for example, the container does not have access to host system beyond what is needed).
Extensibility: The methodology allows for different benchmark types. While our demonstration is with a CPU benchmark, one could extend the Execution stage to deploy any workload (e.g., run a ML inference, perform an I/O stress test, etc.). The Results stage would collect whichever metrics are relevant (maybe parsing logs or capturing sensor data like temperature during the run). The framework’s logic remains the same, so it provides a template for many kinds of tests. This extensibility is beneficial for future versions of SHEAB that might integrate with standard benchmark suites (like those in Related Work) or custom benchmarks for particular applications.
In summary, the system design ensures that SHEAB is not just a script, but a coordinated service that can run continuously, handle failures gracefully, and maintain security throughout. The combination of containerized microservices on the central side and minimal footprint on edges makes it practical and relatively easy to deploy. Next, we provide a formalized description of the algorithmic steps that implement this workflow, to further clarify how SHEAB operates in practice.
5. Algorithm Design of SHEAB
To complement the workflow description, we provide a pseudocode representation of the SHEAB algorithm. This describes how the system behaves in a step-by-step procedural manner, which can serve as a blueprint for implementation in code. The algorithm assumes a set of edge devices is given, along with a specified benchmarking routine to execute on each.
5.1. Algorithm Implementation
Below SHEAB algorithm Implementation is discussed, it is created as psuedo code for the a Algorithm 1.
| Algorithm 1: SHEAB Automated Edge Benchmarking |
| Input: EdgeDevices = {E1, E2, …, EN} // list of edge device identifiers or addresses |
| BenchmarkTask (script/command to run on each device) |
| Output: ResultsList = {R1, R2, …, RN} // collected results for each device (or error markers) |
| 1. // Stage 1: Initialization |
| 2. Launch Container_A (Automation Service) on Central Server |
| 3. Launch Container_R (Results Collection Service) on Central Server |
| 4. if either Container_A or Container_R fails to start: |
| 5. log “nitialization error: container launch failed” |
| 6. return (abort the process) |
| 7. Load device list EdgeDevices and credentials |
| 8. Log “Benchmark session started” with timestamp in Results DB |
| 9. // Stage 2: Secure Communication Setup |
| 10. for each device Ei in EdgeDevices: |
| 11. status = check_connectivity(Ei) // ping or SSH test via VPN |
| 12. if status == failure: |
| 13. log “Device Ei unreachable” in error log |
| 14. Mark Ei as skipped (will not execute BenchmarkTask) |
| 15. else: |
| 16. log “Device Ei is online and secure” |
| 17. end for |
| 18. if all devices failed connectivity: |
| 19. log “Error: No devices reachable. Aborting.” |
| 20. return (abort process) |
| 21. // Proceed with reachable devices |
| 22. // Stage 3: Execution (parallel dispatch) |
| 23. parallel for each device Ej in EdgeDevices that is reachable: |
| 24. try: |
| 25. send BenchmarkTask to Ej via SSH |
| 26. except error: |
| 27. log “Dispatch failed on Ej” in error log |
| 28. mark Ej as failed |
| 29. end parallel |
| 30. // Now, all reachable devices should be running the benchmark concurrently |
| 31. Wait until all launched benchmark tasks complete or timeout |
| 32. for each device Ek that was running BenchmarkTask: |
| 33. if task on Ek completed successfully: |
| 34. Retrieve result output from Ek (via SSH/SCP) |
| 35. Store result output in ResultsList (corresponding to Ek) |
| 36. else: |
| 37. log “Benchmark failed on Ek” in error log |
| 38. Store a failure marker in ResultsList for Ek |
| 39. end for |
| 40. // Stage 4: Results Collection |
| 41. for each result Ri in ResultsList: |
| 42. if Ri is available: |
| 43. Insert Ri into Results DB (Container_R) with device ID and timestamp |
| 44. else: |
| 45. Insert an entry into Results DB indicating failure for that device |
| 46. end for |
| 47. // Stage 5: Termination and Cleanup |
| 48. for each device Em in EdgeDevices that was contacted: |
| 49. if Em had an active SSH session, close it |
| 50. ensure no BenchmarkTask process is still running on Em (send termination signal if needed) |
| 51. end for |
| 52. Shut down Container_A (Automation) on Central (optional) |
| 53. (Optionally keep Container_R running if results need to persist for query) |
| 54. Close VPN connections if they were opened solely for this session |
| 55. log “Benchmark session completed” with summary (counts of successes/failures) |
| 56. return ResultsList (for any further processing or analysis) |
5.2. Explanation of the Algorithm
The algorithm begins by initializing the central services (lines 2–8). It then verifies connectivity to each edge device (lines 10–17). This is crucial for determining which devices can proceed; unreachable devices are marked and skipped (lines 12–16). If none can be reached, the algorithm aborts (lines 18–20). Next, the execution phase sends out the benchmark command to each device in parallel (lines 23–29). The pseudocode uses a parallel for construct to indicate that these operations are done concurrently; in practice, this could be implemented with multithreading, asynchronous calls, or an orchestration tool that handles parallelism. Each device’s task is monitored—we wait until all tasks complete, or a global timeout is reached (line 31). Then, we collect results or note failures for each device (lines 32–39). The results are then recorded into the central database (lines 41–46). Finally, we clean up resources: closing sessions, terminating any stray processes, and shutting down or resetting services (lines 48–54). The algorithm ends with logging completion and returning the results.
The algorithm also does not explicitly mention the security steps (VPN, etc.) beyond connectivity checks; those are assumed to be part of check_connectivity () and the environment setup. For example, check_connectivity (Ei) might implicitly be doing an SSH over VPN. In an actual implementation, one might expand that to if not vpn_connected (Ei): attempt_vpn_connect (Ei) before trying SSH.
Another implicit aspect is error tolerance. The algorithm logs errors but continues (except for fatal errors like no connectivity at all). This design decision keeps the framework running to gather whatever results possible rather than failing everything because of one problematic device.
5.3. Computational Complexity
It is worth noting the complexity of this algorithm. Most operations are linear in the number of devices N. The connectivity check loop is O(N). The parallel execution launches N tasks (effectively O(N) in terms of overhead to dispatch, although the tasks themselves run concurrently taking roughly O(max(task_time))). The result collection and cleanup loops are also O(N). Thus, the framework scales approximately linearly with the number of edge devices in terms of overhead. The benefit of parallel execution is that the time to complete all benchmarks is roughly O(T + overhead) instead of O(N*T) (where T is time of one benchmark). We will quantify this benefit in the analysis section.
The memory overhead on the central server is also proportional to N (storing result buffers, maintaining connections). Our testbed of eleven devices is small, but one could conceivably handle dozens or hundreds of devices if the central server and network are capable. In such cases, one might introduce batching (groups of devices) to avoid overload. The algorithm could be adjusted so that line 23 “parallel for each device” is actually done in batches of, e.g., 50 devices at a time if needed. This is an implementation detail not shown in pseudocode but mentioned for completeness.
The Algorithm 1 serves as a guide that we followed while coding the framework and ensures clarity in how each part of the system contributes to the overall automation. Next, we describe the specifics of our implementation, including hardware used and software stack, which will tie the algorithm to real-world execution.
6. Implementation
We implemented the SHEAB framework in a real-world setting to validate its functionality. In this section, we detail the hardware testbed, software components, and configuration used and how the conceptual design was realized using specific tools and technologies. This includes how we set up the containers, VPN, and automated scripts, as well as any tuning or configuration needed for our heterogeneous devices.
6.1. Edge Nodes Hardware
Testbed Hardware: Our experimental setup consisted of a central server and Eleven edge devices. This equipment was part of edge lab in Széchenyi Istvan university, Gyor, Hungary. The central server is a high-performance machine with an Intel Xeon CPU (48 cores) and 128 GB of RAM. This server runs Ubuntu Linux and Docker engine to host the microservices. The choice of a powerful server was intentional to ensure that the orchestrator is not a bottleneck; with 48 cores, it can easily spawn parallel threads for multiple SSH sessions (in our tests, CPU utilization on the server remained low, under 5%, during orchestration tasks).
The eleven edge devices represent a diverse set of hardware often used in edge computing: their detailed specs are shown in Table 3 below:
Table 3.
Edge nodes hardware specs tested by SHEAB framework.
Each device was running a Linux-based OS deliberately installed different light weight versions of Linux to test heterogeneity of our framework (Raspbian, Armbian and DietPi depending on the board). We deliberately included devices with varying performance profiles: for instance, the Pi 1 is significantly less powerful than the Pi 5, and the Odroid-XU4 has a different CPU architecture (big.LITTLE octa-core). This heterogeneity of OS and hardware allowed us to test how SHEAB handles devices that complete tasks at different speeds and Operating systems.
6.2. Software Stack
- VPN: We used OpenVPN version 3.4 to create the secure network overlay. An OpenVPN server was configured on the central server. Each edge device ran an OpenVPN client that auto-starts on boot and connects to the central server. The VPN was set to use UDP on a pre-shared key (TLS certificates for server and clients for authentication) and AES-256 encryption for tunnel traffic, ensuring strong security. IP addresses were configured using DHCP with fixed IP assignment, These IPs were used by the orchestrator for SSH connections. The OpenVPN setup was tested independently to verify throughput and latency; the overhead was negligible for our purposes (added latency of <1 ms within our local network and throughput up to tens of Mbps, more than enough for sending text-based results).
- Containers: We created two Docker images—one for the Benchmarking service and one for the Results service. The Benchmarking service image was based on a lightweight Python/Ansible environment. It included:
- o
- Python 3 and the Ansible automation tool;
- o
- SSH client utilities;
- o
- The sysbench tool (for generating CPU load) installed so that it could, if needed, run locally or send to edges (though in practice sysbench needed to run on edges—so we ensured edges had it installed too);
- o
- Inventory file for Ansible listing the edge hosts (by their VPN IP addresses);
- o
- The playbook script described below.
The Results service image was basically a MariaDB database (official MariaDB Docker image) with a database initialized for storing results. We set up a table with columns: device_id, timestamp, test_name, metric1, metric2, etc. For the sysbench CPU test, relevant metrics included the total execution time (should be ~10 s if the test runs to completion), and potentially the number of events (like prime numbers tested)—we stored just the execution time and a computed metric of “events per second” for each device as reported by sysbench. The database container was configured with a volume to persist data on the host, so we would not lose results when it stopped.
- Automation Script (Ansible Playbook): The core logic of stages 2–4 from Algorithm 1 was implemented in an Ansible playbook (YAML format). The playbook tasks in summary:
- Ping all devices: Using Ansible’s built-in ping module to ensure connectivity (this corresponds to check_connectivity in the pseudocode). Ansible reports unreachable hosts if any—those we capture and mark.
- Execute benchmark on all devices: We wrote an Ansible task to run the shell command sysbench cpu --threads=1 --time=10 run on each host. We chose a single-thread CPU test running for 10 s to simulate a moderate load. (Threads = 1 so that we measure roughly single-core performance on each device; one could also test multi-thread by setting threads equal to number of cores, but that might saturate some devices differently—in this experiment we wanted comparable workloads.) Ansible will execute this on each host and gather the stdout.
- Register results: The playbook captures the stdout of the sysbench command in a variable for each host.
- Store results into DB: We added a step that runs on the central server (Ansible’s local connection) which takes the results and inserts them into MariaDB. This was done by using the MySQL version 8 module of Ansible or simply calling a Python script. For simplicity, we actually used a tiny Python snippet within the playbook that used MySQL connector to push data.
- Error handling: The playbook is written to not fail on one host’s failure. Instead, we use ignore_errors: yes on the benchmark task so that if a device fails to run sysbench, the playbook continues for others. We then check Ansible’s hostvars to see which hosts have no result and handle those accordingly in the DB insert step (inserting an error marker).
- Cleanup: In our test scenario, since sysbench runs for a fixed duration and exits, there were no lingering processes to kill. However, to simulate cleanup, we included a task that ensures no sysbench process is running after completion (e.g., using a killall sysbench command, which would effectively do nothing if all ended normally). Also, Ansible by design closes SSH connections after it is done.
The playbook approach proved convenient because Ansible inherently does parallel execution. We set forks: 10 in the Ansible configuration, meaning it could handle up to 10 parallel connections (we had 8 hosts, so it would do all 8 concurrently). The result gathering was automatic.
- Edge Device Preparation: Each edge device was prepared with:
- o
- OpenVPN client configured to connect at boot.
- o
- SSH server running and a public key from the central server authorized (for passwordless access).
- o
- Sysbench installed (using apt on Debian/Ubuntu). This is important because our method chose to run sysbench on the device. Alternatively, we could have scp’d a binary or run everything remotely, but installing via package manager was straightforward.
- o
- Sufficient power and cooling to run reliably for the duration of tests (particularly Pi 4 can throttle if not cooled; our tests were short, so heat was not an issue).
- o
- Firewalls (ufw or iptables) set to allow OpenVPN (port 1194/UDP) and SSH (port 22) only through the VPN interface. For example, we required that SSH connections originate from the central server’s VPN IP. This means even if someone knew the device’s real IP, they could not SSH in unless they had VPN credentials. We also made sure the default route of the device remained its normal internet (so it could reach the VPN server), but all return traffic to central was through VPN.
Data Collected: In the database, we had a table benchmark_results with columns: device_name, exec_time_sec, notes. The exec_time_sec was around 10 s for each as expected (the slight differences are due to measurement granularity and device speed).
We also stored the sum of times and the concurrent time (though the concurrent time is not directly a result from a device; we measured it externally by noting the difference between the start and end times on the central orchestrator, which was about 45.362 s as will be explained in analysis).
Time Synchronization: To measure the “total time using SHEAB”, we simply recorded a timestamp before dispatching tasks and after collecting all results. That difference was 45.362 s for the run. For the “total time if sequential”, we summed the individual times which gave 80.643 s (which matches the sum of the 8 times listed). We double-checked this by actually running them sequentially in a separate trial (running the playbook with a serial strategy to do one device at a time, which indeed took roughly 80.6 s). This confirmed the framework’s speed advantage.
User Interface: Currently, interaction with SHEAB is command-line driven (starting containers, etc.). However, because results go into a database, one can easily build a dashboard or run queries to visualize results (for example, a simple Python script that fetches all results and prints statistics). We did run a quick query to calculate how many prime numbers each Pi computed in 10 s (sysbench reports total number of primes tested); interestingly, that showed differences: the Pi 4 and Pi 5 computed more primes than the Pi 2, reflecting their CPU speed differences, even though time is fixed at 10s. This shows that one might also store throughput metrics, not just time, when using fixed-time workloads.
6.3. Challenges
Challenges Encountered: During implementation, a few issues required attention:
- Initially, two of the older devices had incorrect system time which could have affected VPN certificates and our timestamp comparisons. We synchronized all device clocks via NTP.
- One device (Orange Pi PC) had slightly different SSH key algorithms (older software); we had to ensure our central SSH client was configured to accept those (this was resolved by updating the device).
- We tuned the OpenVPN configuration to avoid reconnects; a short disconnection happened at first because one Pi had network flapping. We solved it by using a wired connection or a stable Wi-Fi for all edges.
- Ansible’s gather_facts step (which runs by default) can take a couple of seconds per device; we disabled fact gathering to speed up the process, since we did not need it for this simple task. This saved a significant amount of time in the parallel run (by default Ansible would gather facts sequentially before parallel tasks, but by disabling it we jumped straight to execution).
Extending Implementation: While our current implementation uses many techniques and scripts to benchmark edge nodes, our framework’s architecture and algorithm would not change, just the specific commands and data handling. Additionally, to integrate a scenario like Edge AIBench, one could have the orchestrator deploy a mini workload (a client program on device and maybe something on a cloud VM) though that extends beyond device-only focus.
The successful implementation confirmed that even with modest effort (a few hundred lines of configuration and scripting), the conceptual framework could be brought to life. This implementation will serve as the basis for collecting performance data, which we analyze in the next section.
Also, it is worth noting that because our system uses SSH basically and it is agentless, then it could scale easily to thousands of nodes; the only bottleneck will be the spend of the networking infrastructure, and with the current state of the art 10+ Gbps interfaces and the possibility of having two servers in a round-robin style queuing, this issue will have a reduced effect on scalability. More on network and database is discussed in Section 7.6.
7. Statistical and Performance Analysis
With the framework implemented and tested on our edge device ensemble, we now turn to analyzing its performance. The primary aim of SHEAB is to reduce the total time required to benchmark a set of edge devices by running tasks in parallel. We introduce metrics to quantify this improvement and present the results measured on our testbed. We also provide mathematical formulations to generalize these results and discuss the statistical implications (e.g., speedup, efficiency) of our approach.
7.1. Time to Deploy
In this paper, we introduce a new parameter to benchmark edge devices, which is time to deploy (TTD); this parameter will measure the time taken to benchmark each edge server individually in comparison with the time taken to benchmark all the edge server using the suggested framework at once that we introduced in this paper.
Here, we will do some analysis on the gained utilization from the automation.
First, let us introduce some notations:
te = TTD for individual edge servers, this will vary based on the hardware of the edge devices.
Ttotal = the sum of all TTDs for edge devices.
ta = TTD for benchmark all the edge device using the proposed automation framework “SHEAB” all at once.
n = no. of edge servers
Table 4.
TTD calculation for individual nodes vs. SHEAB framework.
This means the benchmarking got a 1.78 increase using our benchmark SHEAB, and the latency for executing the benchmarking process got a 43.74% decrease when using the same proposed framework.
7.2. Comparative Discussion
The numbers 43.7% time reduction and 1.78× speedup demonstrate that our framework met its primary goal in this test. It is illustrative to consider extreme scenarios:
- If we had done each device manually, the human-induced overhead would be even larger (like logging in and running commands could take minutes each). SHEAB not only saved raw execution time but also would save enormous human time when scaling to many devices.
- If we had one device, ta would be slightly more than TTD (because overhead to set up a container and such might make it slower than just running one benchmark manually). So, for a single device, automation does not pay off. But, beyond a threshold number of devices, it clearly does. That threshold in our case appears to be low; even with 2 devices, it is likely beneficial given how parallel things were.
7.3. Statistical Variability
Because each device’s test was a fixed time, we do not have variation in run times except tiny differences. If we had run a variable-workload (like computing a fixed number of primes and measuring time), we would see differences. For example, Raspberry Pi 4 might finish that work faster than Pi 2. Then the results would have different TTD_i. SHEAB’s ta would then be dominated by the slowest device. In such a case, adding faster devices does not increase time (since slower sets the pace) but adding slower ones can increase time. To illustrate, if one device took 20 s instead of 10 s (say a very slow device or heavier test on one), then ta would become ~20 + overhead (say overhead still ~35) = ~55 s. Ttotal would increase by 20 for that device (instead of 10), becoming ~90 s. would then be (90 − 55)/90 = 38.9%, speedup 1.64. Slightly less because one slow device dragged parallel time. Yet still an improvement. If there was a huge imbalance (one device 60 s, others 10 s), ta ~ 60+overhead (maybe overhead would also change if one device still running while others done, some part of overhead might overlap though). In the worst case, if one device is much slower than all others combined, parallel does not help much for that portion (it becomes like a sequential dominated by a slow device). But, at least the others were done concurrently during that period.
In our homogeneous-ish workload, we did not see that issue. But, it is something to note: the speedup in parallel benchmarking is bounded by the slowest device’s time (makespan concept). If all devices are identical, that is great. If not, the slowest one determines the length of the benchmarking session (others will idle once done, waiting for results collection). SHEAB can mitigate this by at least freeing up the orchestrator from having to work on faster ones in sequence, but it cannot run faster than the slowest device’s benchmark.
We also analyze utilization gain: one can interpret Latency reduction gain as how much less “idle time” there is. In sequential execution, the total time includes large segments where only one device is busy and the others are idle. With SHEAB, those idle times are eliminated by overlapping tasks. The 43.7% reduction in latency can also be seen as a 43.7% increase in utilization of time (since previously that time was spent waiting for sequential completion). In terms of device utilization, during the 45 s, all devices were busy for ~10 s and then idle for remainder waiting for slower ones. We could measure central server utilization too: it was busy at start and end but mostly idle while devices ran, which is fine.
7.4. Validation of Speedup
The speedup of 1.78 we achieved is consistent with other multi-node automation contexts. It shows diminishing returns compared to ideal (8). But if we measure the effective concurrency achieved: We did 8 tasks in 45.36 s, so average per task = 5.67 s if evenly overlapped (which obviously is not how we ran it, since tasks themselves took 10 s; it means tasks overlapped roughly in time domain such that effectively instead of 8 tasks sequential (80 s), we compressed them to equivalent of doing each in ~5.67 s). That suggests on average ~80/45 = 1.78 tasks were running concurrently at any given moment. But actually all 8 were running concurrently for 10 s, but then for the remaining ~35 s none were doing actual benchmark (it was overhead time probably not overlapping with benchmark execution). So, the concurrency was full for 10 s, then zero for 35 s, giving an average concurrency of (8 × 10)/45 = 1.78. So indeed, 1.78 out of 8 possible concurrencies (which is that 22% efficiency earlier).
We can identify two phases in ta:
- Active benchmarking phase: ~10 s, concurrency = 8 (all devices busy).
- Orchestration phase: ~35 s, concurrency = 0 (devices idle, central doing something or waiting).
The goal would be to compress that orchestration phase or overlap it with execution. For instance, one can imagine starting to send results from devices as they finish while others still run (some overlap might have happened if one finished earlier, but since all had equal times, they finished near-simultaneously). In other workloads, if devices finish at different times, the result collection of early finishers could be overlapped with ongoing benchmarks on slower ones—that would improve efficiency.
7.5. Statistical Reliability
Since our benchmark times are extremely consistent, there is little statistical variance to analyze in the results. If we had multiple trials, we would see essentially identical times for this CPU test (unless external load or CPU frequency scaling changed things). We did ensure the devices were not throttling and were otherwise idle. The network overhead for sending the small results (few KB of text) is trivial, so differences between devices are not network-bound.
If using a different test like a random memory benchmark, times might vary run-to-run by small jitter, but overall conclusions wouldn’t change. For thoroughness, one could run multiple iterations and compute mean and standard deviation of ta and ttotal. But since ttotal is deterministic sum and ta had consistent overhead (we ran it a couple of times and got ~45–46 s each time), we can be confident these metrics are stable.
7.6. Impact of Network Scale
One might ask how the VPN and network links scale with more devices concurrently. In our test, the network load was minimal (eight devices sending at most a few kilobytes of output at roughly the same time). VPN and central server network can easily handle that. If the benchmark were something that produces a lot of data (say streaming results or logs), then concurrent results collection could saturate the central link. For example, if each device had to upload 10 MB of logs at the end, 8 devices could attempt 80 MB at once, which on a 1 Gbps network is fine (<1 s), but on a slow link could introduce a bottleneck. In that case ta might increase due to network queuing. Our design of having a separate results container with a database could also become a bottleneck if hundreds of results per second need insertion—but with 8 devices, it was fine.
7.7. Edge Resource Utilization
We should note that during the test, each edge device was running sysbench at 100% CPU for those 10 s. This is the intended load. The additional overhead on edge for communication was negligible.
8. Experiments and Evaluations
In this section, the performance of the SHEAB framework is thoroughly evaluated using a variety of benchmarks across multiple edge devices. The benchmarks cover CPU performance, memory throughput, machine learning inference, network throughput, and GPU versus CPU computational efficiency. Each benchmark was conducted using specific tools and synthetic workloads designed to reflect realistic scenarios in edge computing environments.
8.1. CPU Benchmarking
The CPU benchmarking tests were performed using the Sysbench tool, which measures latency and events per second (EPS) across various edge boards. Figure 3 illustrates the latency comparison among the tested devices. Devices such as Raspberry Pi 1 and Raspberry Pi 2B+ demonstrated the highest latencies of 41.41 ms and 38.39 ms, respectively, indicating limitations in processing efficiency. In contrast, the Raspberry Pi 5 and NVIDIA Jetson Nano exhibited significantly lower latencies (0.68 ms and 0.83 ms, respectively), showcasing their superior processing capabilities suitable for latency-sensitive applications.
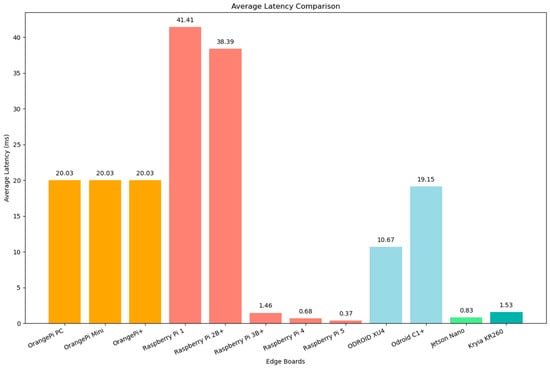
Figure 3.
CPU benchmarking “average latency”.
Figure 4 displays the events per second, a critical metric reflecting CPU throughput. Raspberry Pi 5 achieved the highest performance with 2735.82 EPS, surpassing all other devices significantly, demonstrating its suitability for demanding edge workloads. On the lower end, Orange Pi devices averaged around 49.84 EPS, reflecting their limited suitability for intensive CPU tasks.
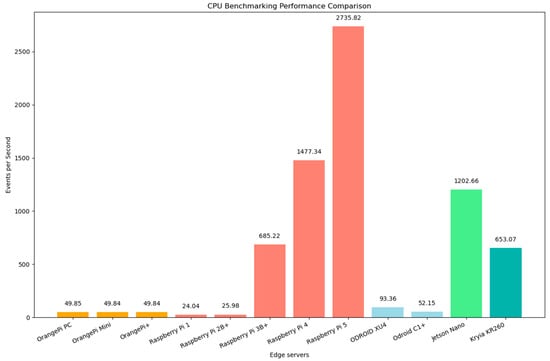
Figure 4.
CPU benchmarking “event per second”.
8.2. Memory Benchmarking
Memory benchmarking, also using Sysbench, assessed operations per second, transfer rate, total execution time, and latency (Figure 5). The Raspberry Pi 5 notably excelled, delivering 12,224.68 operations per second and a corresponding transfer rate of 12,224.68 MiB/s, substantially outperforming other evaluated devices. Notably, the Raspberry Pi 1 exhibited markedly lower performance with just 299.70 operations per second, highlighting memory bottlenecks in older hardware.
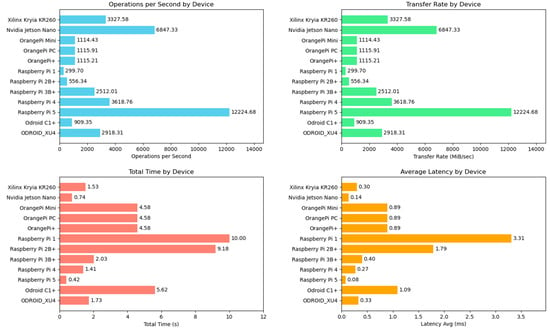
Figure 5.
Memory benchmarking.
Latency measurements further confirmed the advantages of the Raspberry Pi 5, presenting the lowest latency (0.08 ms). The substantial performance disparity underscores critical implications for real-time memory-intensive applications.
8.3. Machine Learning Inference Benchmarking
Machine Learning (ML) inference performance was evaluated using a logistic regression model trained on a synthetic dataset comprising 10,000 samples. Figure 3 highlights training durations across edge devices. Raspberry Pi 1 recorded the longest training time (1.72 s), whereas Raspberry Pi 5 completed the training in just 0.03 s. Jetson Nano, optimized for AI tasks, achieved a moderate performance at 0.22 s, demonstrating the importance of selecting appropriate hardware for edge ML tasks. The results were shown in Figure 6.
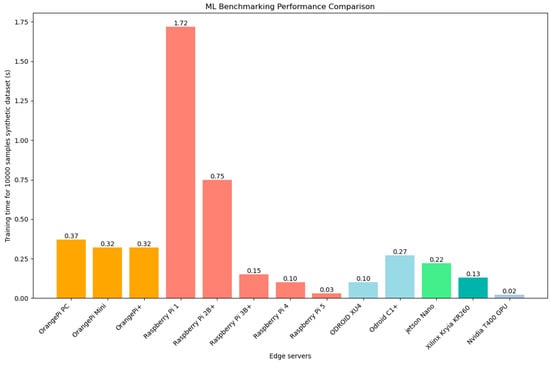
Figure 6.
ML CPU inference benchmarking.
8.4. Network Benchmarking
Network performance was evaluated using iperf3, measuring throughput capabilities (Figure 5). Devices such as Raspberry Pi 5 and Xilinx Kria KR260 reached impressive throughputs (878 Mbps and 889 Mbps, respectively), indicating robust networking capabilities critical for edge deployments involving high data transmission rates. Conversely, Raspberry Pi 1 recorded the lowest throughput at 74.7 Mbps, limiting its use in high-bandwidth applications. The benchmark results were shown in Figure 7.
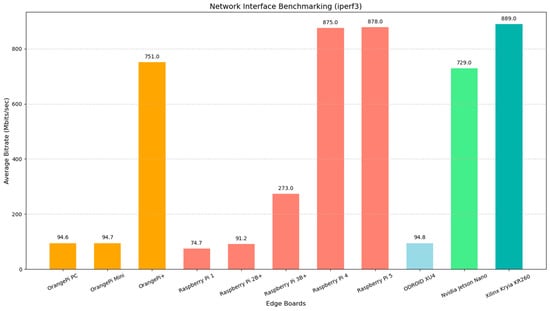
Figure 7.
Networking performance benchmarking.
8.5. GPU Versus CPU Benchmarking
GPU versus CPU computation was evaluated using a 1024 × 1024 matrix multiplication workload. Figure 6 clearly illustrates the performance advantage of GPU acceleration. The NVIDIA T400 GPU completed the computation in merely 0.05 s, significantly outperforming the CPU of the Raspberry Pi 5, which took 0.79 s. Jetson Nano, leveraging GPU computation, recorded an intermediate result at 0.35 s. This benchmark underscores the essential role of GPUs in accelerating compute-intensive tasks at the edge. The benchmark results were shown in Figure 8.
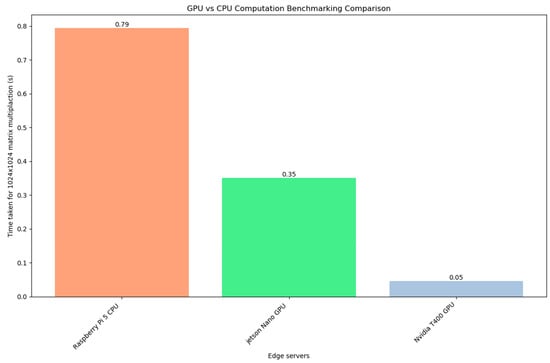
Figure 8.
GPU vs. CPU performance benchmarking.
8.6. Discussion
The comprehensive experimental results underscore critical differences in performance metrics among tested edge devices. Raspberry Pi 5 consistently demonstrated superior performance across CPU, memory, and networking benchmarks, while GPU-accelerated platforms significantly outperformed CPUs for intensive computational tasks. These findings highlight the importance of careful device selection tailored to specific edge computing workloads and requirements.
8.7. Summary of Findings
- Raspberry Pi 5 delivered the most balanced and superior performance across most benchmarks.
- Older devices like Raspberry Pi 1 and 2B+ are significantly less suitable for demanding edge applications due to latency and performance bottlenecks.
- GPU-enabled platforms like Jetson Nano and NVIDIA T400 significantly outperform traditional CPUs in computational workloads, emphasizing their value in edge deployments.
These results provide critical insights that guide effective hardware selection and optimization strategies in deploying scalable edge AI solutions.
8.8. Future Work Considerations
While our results are positive, they also highlight areas for improvement and further research, which we will detail in Section 9. Examples include:
- Reducing the orchestration overhead (perhaps by using persistent connections or a custom orchestrator instead of general-purpose Ansible) [51].
- Expanding to more diverse benchmarks (e.g., incorporating ML model inference tests which might use GPU accelerators on some devices, to see how the framework handles that).
- Integrating energy measurements: For edge, power consumption is key. We could equip devices with power meters and have the framework collect energy data during benchmarks. Automating that (maybe via networked power measurement units) could give a more holistic performance picture (not just speed, but energy efficiency).
- Benchmarking in presence of background load: In real deployments, devices might be doing something while we benchmark (or the benchmarking might itself be a stress-test). Concurrently running many devices can also test the shared network’s resilience. In one future test, we might saturate network links intentionally to see if VPN tunnels remain stable and if results can still be collected correctly.
8.9. Implications for Edge AI and Systems Research
The success of SHEAB suggests a methodological improvement for the edge computing community: when evaluating systems or devices, consider automation and concurrency to expedite experimentation. Particularly in Edge AI, where hardware is diverse and evolving, having a tool to quickly benchmark new devices (like when Raspberry Pi 5 was released, or new NVIDIA Jetson models, etc.) across a standard set of tasks in one go is extremely valuable. It speeds up the feedback loop for both researchers and practitioners.
From a systems perspective, one might draw parallels to continuous integration (CI) in software. SHEAB acts like a CI system but for performance testing across hardware. This can aid in continuously validating that edge deployments meet performance criteria after changes.
Also, our approach can help build large datasets of edge performance across hardware types and geographies, which can feed into analytical models or scheduling algorithms. For example, one could run SHEAB across 50 IoT nodes worldwide to gather latency and throughput stats, then use that data to improve an edge orchestrator’s decision-making. The easier it is to collect such data; the more empirical grounding edge computing research can have [52].
Finally, it encourages modular design—we treated the benchmarking tool as a replaceable component (via microservices and scripts). Others can plug in their own tasks. If a new AI benchmark emerges, integrating it into SHEAB means it can be run on all devices effortlessly, promoting rapid adoption and testing of new benchmarks.
9. Conclusions and Future Work
This paper presented the design and implementation of SHEAB, a novel automated framework for benchmarking edge computing devices, with a particular focus on Edge AI environments. By combining principles of secure distributed automation, parallel execution, and modular microservice architecture, SHEAB addresses a gap in existing tools, enabling efficient and scalable performance evaluation across heterogeneous edge hardware.
9.1. Conclusions
Our work makes several contributions. We demonstrated that automation can drastically reduce the time and effort required to benchmark multiple edge devices simultaneously, as evidenced by a 43.74% reduction in total benchmarking time and a speedup of 1.78× in our eight-device test scenario. We introduced the Time-to-Deploy (TTD) metric and associated formulas to quantify these gains, offering a new way to evaluate benchmarking methodologies themselves. The framework’s emphasis on security—through the integrated use of VPN tunnels, SSH authentication, and firewall restrictions—ensures that such automation does not come at the cost of exposing edge systems to vulnerabilities. We provided a detailed system design, including architecture diagrams and a formal algorithm, which can be used as a reference implementation blueprint for similar needs in the community. Additionally, our comparative analysis of related work positions SHEAB in the landscape of edge benchmarking efforts, highlighting its unique strengths (like multi-device concurrency and security-focus) relative to existing benchmarks such as EdgeBench, IoTBench, EdgeFaaSBench, and others.
The implementation and experimental validation confirm that SHEAB is not only conceptually sound but also practically effective. The approach is general enough to apply to various types of benchmarks (CPU, memory, ML inference, I/O, etc.) and various device types. It fosters reproducibility and consistency in measurements by automating the procedure and centralizing results, thereby reducing the likelihood of human error and environmental inconsistencies. In essence, SHEAB can be viewed as a foundational tool for edge computing research and operations, analogous to how continuous integration systems are foundational for large-scale software development. It automates the “boring but necessary” part of collecting performance data, freeing researchers and engineers to focus on analysis and optimization.
9.2. Future Work
The journey does not end here. We identify several avenues to extend and enhance the SHEAB framework:
- Enhanced Orchestration Efficiency: As analyzed, our current implementation has room for optimization in terms of reducing orchestration overhead. Future development could involve moving from Ansible to a more streamlined concurrency model, possibly using Golang or Python asyncio for SSH management. Alternatively, using container orchestration frameworks (like Kubernetes) where each device’s job is a pod (with Node affinity) could be explored. However, for edge devices that cannot run a full k8s, a lighter approach is needed. Another idea is to maintain persistent SSH connections to devices (via a daemon) so that repeated benchmarks incur minimal reconnection cost.
- Scalability Testing: We plan to test SHEAB with a larger pool of devices, potentially using virtual devices to simulate up to 50 or 100 nodes if physical ones are not available. This will help uncover any bottlenecks in the central coordinator and ensure the framework scales. If needed, a hierarchical approach could be used: e.g., have multiple orchestrators each handling a subset of devices (perhaps grouped by network location), coordinated by a higher-level script.
- Integration of Diverse Benchmarks: We intend to incorporate a library of benchmark workloads into SHEAB. This might include:
- o
- Microbenchmarks: CPU, memory bandwidth, storage I/O, network throughput between devices (to test device-to-device communication via the central or mesh).
- o
- AI Benchmarks: Running a set of TinyML inference tests (like the MLPerf Tiny benchmark or others) on all devices to compare AI inference latency and accuracy across hardware.
- o
- Application-level Benchmarks: E.g., deploying a simple edge application (like an MQTT broker test, or an image recognition service) on all devices to simulate how they would perform as edge servers.By doing so, SHEAB can become a one-stop solution where a user selects which tests to run and receives a full report per device.
- Dynamic Workload and Continuous Benchmarking: We consider adding features to run benchmarks continuously or on schedule, monitoring device performance over time. This could detect performance drift (if a device slows down due to wear-out or software changes). Combined with environmental sensors (temp, power), one could correlate performance with external factors.
- Energy and Thermal Measurements: To cater to edge AI’s concern for energy efficiency, we will look at integrating energy measurement. If devices have onboard power sensors or if we use smart power outlets, the framework could read those via API and include energy per task in the results. Similarly, reading CPU temperature before/after can indicate thermal throttling issues.
- Security and Fault-Tolerance Enhancements: While our security model is robust, future work could explore a zero-trust approach where even the central server does not fully trust devices. For instance, results could be signed by devices to ensure authenticity. Additionally, adding support for remote attestation (checking that the device is running a known software stack before benchmarking, to avoid compromised devices giving skewed results) could be interesting for high-assurance scenarios. Fault tolerance can be improved by perhaps queueing benchmarks to retry later if a device is temporarily unreachable, thus making the framework self-healing to network blips.
- User Interface and Visualization: A potential extension is a web-based dashboard for SHEAB. This UI could allow users to configure benchmark runs (select devices, select tests, schedule time) and then visualize results (graphs comparing devices, historical trends, etc.). This would make SHEAB more accessible to less technical users (e.g., a QA engineer who is not comfortable with command lines but needs performance data).
- Deployment as a Service: We envision packaging SHEAB such that it could be offered “as a service” in an organization. For example, an edge computing test lab could have SHEAB running, and whenever a new device is added to the lab network, an admin could trigger benchmarks. Or a device manufacturer could integrate SHEAB into their CI pipeline to automatically run performance tests on physical hardware prototypes whenever firmware changes [53].
- Comparative Studies Using SHEAB: Using the framework, we want to perform a broad comparative study of various edge devices (old and new) on a consistent set of benchmarks. This would produce a valuable dataset and possibly a journal publication on edge device performance trends. It would also serve as a proof-of-concept for how SHEAB simplifies such a study that might have been prohibitively tedious otherwise.
- Extending to Edge-Cloud Collaborative Benchmarks: Currently, SHEAB treats devices individually. But many edge scenarios involve client-edge-cloud interplay. We could extend the framework to coordinate not just device benchmarks but also end-to-end scenario tests. For instance, integrate with Edge AIBench’s notion of client-edge-cloud task. The central server could also simulate a cloud component (since it is powerful) and we can include an edge device’s interaction with it as part of a test.
9.3. Concluding Remarks
The design and successful demonstration of the SHEAB framework mark an important step towards more efficient and secure evaluation of edge computing systems. As edge deployments become larger and more complex (edge clusters, swarms of IoT devices, etc.), tools like SHEAB will be instrumental in ensuring that performance is well-understood and optimized. By open-sourcing the framework (as we intend to after some refinements) and encouraging community contributions, we hope to create a foundation that others can build upon—for example, adding new benchmarks or adapting the framework to specific verticals (industrial IoT, smart city sensors, etc.). The interplay of systems engineering (containers, orchestration, network security) and performance analysis in SHEAB exemplifies the multidisciplinary effort required in modern cyber–physical systems research. We believe that the ideas presented can spur further innovation in how researchers approach experimental evaluation in edge computing, shifting from ad hoc scripts to robust, reusable platforms.
In summary, SHEAB provides a scalable, secure, and flexible solution for automated edge benchmarking. It reduces time overhead, maintains data integrity and security, and yields reliable performance insights. This framework will aid practitioners and researchers in pushing the frontiers of Edge AI and cyber–physical systems, enabling them to focus on higher-level interpretations and optimizations while the tedious benchmarking logistics are handled automatically.
Author Contributions
Conceptualization, M.A. and S.R.R.; methodology, M.A. and S.R.R.; software, M.A.; validation, M.A. and S.R.R.; formal analysis, M.A.; investigation, M.A. and S.R.R.; resources, S.R.R.; data curation, M.A.; writing—original draft preparation, M.A.; writing—review and editing, M.A.; visualization, M.A.; supervision, S.R.R.; project administration, S.R.R.; funding acquisition, not applicable. All authors have read and agreed to the published version of the manuscript.
Funding
The APC for getting this work published was Funded by Széchenyi Istvan University’s Publication Support Program.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data underlying this article will be shared on reasonable request to the corresponding author.
Acknowledgments
The authors thank Sandor R. Repas for his supervision in this work: and Széchenyi Istvan university for the offering of the required Lab. equipment. The authors reviewed and edited the output and take full responsibility for the content.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, Y.; Wang, H.; Chen, S.; Xia, Y. A Survey on Mainstream Dimensions of Edge Computing. In Proceedings of the 2021 5th International Conference on Information System and Data Mining (ICISDM), Silicon Valley, CA, USA, 21–23 May 2021; ACM: New York, NY, USA, 2021; pp. 46–54. [Google Scholar] [CrossRef]
- Kong, L.; Tan, J.; Huang, J.; Chen, G.; Wang, S.; Jin, X.; Zeng, P.; Khan, M.; Das, S. Edge-Computing-Driven Internet of Things: A Survey. ACM Comput. Surv. 2023, 55, 1–41. [Google Scholar] [CrossRef]
- Meuser, T.; Lovén, L.; Bhuyan, M.; Patil, S.G.; Dustdar, S.; Aral, A.; Welzl, M. Revisiting Edge AI: Opportunities and Challenges. IEEE Internet Comput. 2024, 28, 49–59. [Google Scholar] [CrossRef]
- Gill, S.S.; Golec, M.; Hu, J.; Xu, M.; Du, J.; Wu, H.; Walia, G.K.; Murugesan, S.S.; Ali, B.; Kumar, M.; et al. Edge AI: A Taxonomy, Systematic Review and Future Directions. Cluster Comput. 2025, 28, 18. [Google Scholar] [CrossRef]
- Hamdan, S.; Ayyash, M.; Almajali, S. Edge-Computing Architectures for Internet of Things Applications: A Survey. Sensors 2020, 20, 6441. [Google Scholar] [CrossRef]
- Andriulo, F.C.; Fiore, M.; Mongiello, M.; Traversa, E.; Zizzo, V. Edge Computing and Cloud Computing for Internet of Things: A Review. Informatics 2024, 11, 71. [Google Scholar] [CrossRef]
- Nencioni, G.; Garroppo, R.; Olimid, R. 5G Multi-Access Edge Computing: A Survey on Security, Dependability, and Performance. IEEE Access 2023, 11, 63496–63533. [Google Scholar] [CrossRef]
- Xavier, R.; Silva, R.S.; Ribeiro, M.; Moreira, W.; Freitas, L.; Oliveira-Jr, A. Integrating Multi-Access Edge Computing (MEC) into Open 5G Core. Telecom 2024, 5, 2. [Google Scholar] [CrossRef]
- Sheikh, A.M.; Islam, M.R.; Habaebi, M.H.; Zabidi, S.A.; Bin Najeeb, A.R.; Kabbani, A. A Survey on Edge Computing (EC) Security Challenges: Classification, Threats, and Mitigation Strategies. Future Internet 2025, 17, 175. [Google Scholar] [CrossRef]
- Kolevski, D. Edge Computing and IoT Data Breaches: Security, Privacy, Trust, and Regulation. IEEE Technology and Society. Available online: https://technologyandsociety.org/edge-computing-and-iot-data-breaches-security-privacy-trust-and-regulation/ (accessed on 26 April 2025).
- Rocha, A.; Monteiro, M.; Mattos, C.; Dias, M.; Soares, J.; Magalhaes, R.; Macedo, J. Edge AI for Internet of Medical Things: A Literature Review. Comput. Electr. Eng. 2024, 116, 109202. [Google Scholar] [CrossRef]
- Rancea, A.; Anghel, I.; Cioara, T. Edge Computing in Healthcare: Innovations, Opportunities, and Challenges. Future Internet 2024, 16, 329. [Google Scholar] [CrossRef]
- Bevilacqua, R.; Barbarossa, F.; Fantechi, L.; Fornarelli, D.; Paci, E.; Bolognini, S.; Maranesi, E. Radiomics and Artificial Intelligence for the Diagnosis and Monitoring of Alzheimer’s Disease: A Systematic Review of Studies in the Field. J. Clin. Med. 2023, 12, 5432. [Google Scholar] [CrossRef]
- Akila, K.; Gopinathan, R.; Arunkumar, J.; Malar, B.S.B. The Role of Artificial Intelligence in Modern Healthcare: Advances, Challenges, and Future Prospects. Eur. J. Cardiovasc. Med. 2025, 15, 615–624. [Google Scholar] [CrossRef]
- Chen, P.; Huang, X. A Brief Discussion on Edge Computing and Smart Medical Care. In Proceedings of the 2024 3rd International Conference on Public Health and Data Science (ICPHDS ’24), New York, NY, USA, 22–24 March 2025; pp. 193–197. [Google Scholar] [CrossRef]
- Usman, M.; Ferlin, S.; Brunstrom, A.; Taheri, J. A Survey on Observability of Distributed Edge & Container-Based Microservices. IEEE Access 2022, 10, 86904–86919. [Google Scholar] [CrossRef]
- Chen, C.-C.; Chiang, Y.; Lee, Y.-C.; Wei, H. Edge Computing Management with Collaborative Lazy Pulling for Accelerated Container Startup. IEEE Trans. Netw. Serv. Manag. 2024, 12, 6437–6450. [Google Scholar] [CrossRef]
- Hebbar, A.; Thavarekere, S.; Kabber, A.; Subramaniam, K.V. Performance Comparison of Virtualization Methods. In Proceedings of the 2022 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM), Bangalore, India, 7–10 December 2022; pp. 43–47. [Google Scholar] [CrossRef]
- Haq, M.S.; Tosun, A.; Korkmaz, T. Security Analysis of Docker Containers for ARM Architecture. In Proceedings of the 2022 IEEE/ACM 7th Symposium on Edge Computing (SEC), Seattle, WA, USA, 5–8 December 2022; p. 236. [Google Scholar] [CrossRef]
- Sami, H.; Otrok, H.; Bentahar, J.; Mourad, A. AI-Based Resource Provisioning of IoE Services in 6G: A Deep Reinforcement Learning Approach. IEEE Trans. Netw. Serv. Manag. 2021, 18, 3527–3540. [Google Scholar] [CrossRef]
- Detti, A. Microservices from Cloud to Edge: An Analytical Discussion on Risks, Opportunities and Enablers. IEEE Access 2023, 11, 49924–49942. [Google Scholar] [CrossRef]
- Abdullah, O.; Adelusi, J. Edge Computing vs. Cloud Computing: A Comparative Study of Performance, Scalability, and Latency. Preprint 2025. [Google Scholar]
- Banbury, C.; Reddi, V.J.; Torelli, P.; Holleman, J.; Jeffries, N.; Kiraly, C.; Xuesong, X. MLPerf Tiny Benchmark. arXiv 2021, arXiv:2106.07597. [Google Scholar] [CrossRef]
- Communications Security Establishment (Canada). Security Considerations for Edge Devices (ITSM.80.101). Canadian Centre for Cyber Security. Available online: https://www.cyber.gc.ca/en/guidance/security-considerations-edge-devices-itsm80101 (accessed on 25 April 2025).
- Kruger, C.P.; Hancke, G.P. Benchmarking Internet of Things Devices. In Proceedings of the 2014 12th IEEE International Conference on Industrial Informatics (INDIN), Porto Alegre, Brazil, 27–30 July 2014; pp. 611–616. [Google Scholar] [CrossRef]
- Shukla, A.; Chaturvedi, S.; Simmhan, Y. RIoTBench: An IoT Benchmark for Distributed Stream Processing Systems. Concurr. Comput. Pract. Exp. 2017, 29, e4257. [Google Scholar] [CrossRef]
- Lee, C.-I.; Lin, M.-Y.; Yang, C.-L.; Chen, Y.-K. IoTBench: A Benchmark Suite for Intelligent Internet of Things Edge Devices. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 170–174. [Google Scholar] [CrossRef]
- Edge AIBench: Towards Comprehensive End-to-End Edge Computing Benchmarking. Available online: https://ar5iv.labs.arxiv.org/html/1908.01924 (accessed on 25 April 2025).
- Naman, O.; Qadi, H.; Karsten, M.; Al-Kiswany, S. MECBench: A Framework for Benchmarking Multi-Access Edge Computing Platforms. In Proceedings of the 2023 IEEE International Conference on Edge Computing and Communications (EDGE), Chicago, IL, USA, 2–8 July 2023; pp. 85–95. [Google Scholar] [CrossRef]
- Bäurle, S.; Mohan, N. ComB: A Flexible, Application-Oriented Benchmark for Edge Computing. In Proceedings of the 5th International Workshop on Edge Systems, Analytics and Networking (EdgeSys ’22), Rennes, France, 5 April 2022; pp. 19–24. [Google Scholar] [CrossRef]
- Rajput, K.R.; Kulkarni, C.D.; Cho, B.; Wang, W.; Kim, I.K. EdgeFaaSBench: Benchmarking Edge Devices Using Serverless Computing. In Proceedings of the 2022 IEEE International Conference on Edge Computing and Communications (EDGE), Chicago, IL, USA, 10–16 July 2022; pp. 93–103. [Google Scholar] [CrossRef]
- Hasanpour, M.A.; Kirkegaard, M.; Fafoutis, X. EdgeMark: An Automation and Benchmarking System for Embedded Artificial Intelligence Tools. arXiv 2025, arXiv:2502.01700. [Google Scholar] [CrossRef]
- Anwar, A.; Nadeem, S.; Tanvir, A. Edge-AI Based Face Recognition System: Benchmarks and Analysis. In Proceedings of the 2022 19th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 16–20 August 2022; pp. 302–307. [Google Scholar] [CrossRef]
- Arroba, P.; Buyya, R.; Cárdenas, R.; Risco-Martín, J.L.; Moya, J.M. Sustainable Edge Computing: Challenges and Future Directions. Softw. Pract. Exp. 2024, 54, 2272–2296. [Google Scholar] [CrossRef]
- Bozkaya, E. A Digital Twin Framework for Edge Server Placement in Mobile Edge Computing. In Proceedings of the 2023 4th International Informatics and Software Engineering Conference (IISEC), Ankara, Türkiye, 21–22 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Carpio, F.; Michalke, M.; Jukan, A. BenchFaaS: Benchmarking Serverless Functions in an Edge Computing Network Testbed. IEEE Netw. 2023, 37, 81–88. [Google Scholar] [CrossRef]
- Sodiya, E.O.; Umoga, U.J.; Obaigbena, A.; Jacks, B.S.; Ugwuanyi, E.D.; Daraojimba, A.I.; Lottu, O.A. Current State and Prospects of Edge Computing within the Internet of Things (IoT) Ecosystem. Int. J. Sci. Res. Arch. 2024, 11, 1863–1873. [Google Scholar] [CrossRef]
- Garcia-Perez, A.; Miñón, R.; Torre-Bastida, A.I.; Diaz-de-Arcaya, J.; Zulueta-Guerrero, E. Conceptualising a Benchmarking Platform for Embedded Devices. In Proceedings of the 2024 9th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 18–21 June 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Goethals, T.; Sebrechts, M.; Al-Naday, M.; Volckaert, B.; De Turck, F. A Functional and Performance Benchmark of Lightweight Virtualization Platforms for Edge Computing. In Proceedings of the 2022 IEEE International Conference on Edge Computing and Communications (EDGE), Chicago, IL, USA, 10–16 July 2022; pp. 60–68. [Google Scholar] [CrossRef]
- Hao, T.; Hwang, K.; Zhan, J.; Li, Y.; Cao, Y. Scenario-Based AI Benchmark Evaluation of Distributed Cloud/Edge Computing Systems. IEEE Trans. Comput. 2023, 72, 719–731. [Google Scholar] [CrossRef]
- Kaiser, S.; Tosun, A.Ş.; Korkmaz, T. Benchmarking Container Technologies on ARM-Based Edge Devices. IEEE Access 2023, 11, 107331–107347. [Google Scholar] [CrossRef]
- Kasioulis, M.; Symeonides, M.; Ioannou, G.; Pallis, G.; Dikaiakos, M.D. Energy Modeling of Inference Workloads with AI Accelerators at the Edge: A Benchmarking Study. In Proceedings of the 2024 IEEE International Conference on Cloud Engineering (IC2E), Pafos, Cyprus, 16–19 September 2024; pp. 189–196. [Google Scholar] [CrossRef]
- Schneider, M.; Prokscha, R.; Saadani, S.; Höß, A. ECBA-MLI: Edge Computing Benchmark Architecture for Machine Learning Inference. In Proceedings of the 2022 IEEE International Conference on Edge Computing and Communications (EDGE), Chicago, IL, USA, 10–16 July 2022; pp. 23–32. [Google Scholar] [CrossRef]
- Zhang, Q.; Han, R.; Liu, C.H.; Wang, G.; Chen, L.Y. EdgeVisionBench: A Benchmark of Evolving Input Domains for Vision Applications at Edge. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023; pp. 3643–3646. [Google Scholar] [CrossRef]
- Jo, J.; Jeong, S.; Kang, P. Benchmarking GPU-Accelerated Edge Devices. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 117–120. [Google Scholar] [CrossRef]
- Toczé, K.; Schmitt, N.; Kargén, U.; Aral, A.; Brandić, I. Edge Workload Trace Gathering and Analysis for Benchmarking. In Proceedings of the 2022 IEEE 6th International Conference on Fog and Edge Computing (ICFEC), Turin, Italy, 16–19 May 2022; pp. 34–41. [Google Scholar] [CrossRef]
- Wen, S.; Deng, H.; Qiu, K.; Han, R. EdgeCloudBenchmark: A Benchmark Driven by Real Trace to Generate Cloud-Edge Workloads. In Proceedings of the 2022 IEEE International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Chongqing, China, 5–7 August 2022; pp. 377–382. [Google Scholar] [CrossRef]
- Ganguli, M.; Ranganath, S.; Ravisundar, S.; Layek, A.; Ilangovan, D.; Verplanke, E. Challenges and Opportunities in Performance Benchmarking of Service Mesh for the Edge. In Proceedings of the 2021 IEEE International Conference on Edge Computing (EDGE), Chicago, IL, USA, 18–23 September 2021; pp. 78–85. [Google Scholar] [CrossRef]
- Brochu, O.; Spatharakis, D.; Dechouniotis, D.; Leivadeas, A.; Papavassiliou, S. Benchmarking Real-Time Image Processing for Offloading at the Edge. In Proceedings of the 2022 IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 5–8 September 2022; pp. 90–93. [Google Scholar] [CrossRef]
- Ferraz, O.; Araujo, H.; Silva, V.; Falcao, G. Benchmarking Convolutional Neural Network Inference on Low-Power Edge Devices. In Proceedings of the ICASSP 2023—IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, S.; Ren, Y.; Zhang, J.; Guan, J.; Li, B. KubeHICE: Performance-Aware Container Orchestration on Heterogeneous-ISA Architectures in Cloud-Edge Platforms. In Proceedings of the 2021 IEEE ISPA/BDCloud/SocialCom/SustainCom, New York, NY, USA, 30 September–3 October 2021; pp. 81–91. [Google Scholar] [CrossRef]
- Fernando, D.; Rodriguez, M.A.; Buyya, R. iAnomaly: A Toolkit for Generating Performance Anomaly Datasets in Edge-Cloud Integrated Computing Environments. In Proceedings of the 2024 IEEE/ACM 17th International Conference on Utility and Cloud Computing (UCC), Shanghai, China, 16–19 December 2024; pp. 236–245. [Google Scholar] [CrossRef]
- Joint Shareability and Interference for Multiple Edge Application Deployment in Mobile-Edge Computing Environment. IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/9452122 (accessed on 2 May 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).