
Analysing A/O Possession in Māori-Language Tweets


Abstract
1. Introduction
Scope
2. A/O Alternation in Māori
- alienability vs. inalienability (Krupa 1964, p. 434; 2003, p. 122)
- active vs. passive (Foster 1987)
- dominance vs. subordination (Biggs 1996, p. 42), later revised to dominance vs. non-dominance (Bauer et al. 1997, p. 391; Biggs 2000, as cited in Harlow 2007, p. 168)
- inheritance vs. active production (Ryan 1974, p. 5)
| (1) | ngā | tamariki | a | te | matua |
| the.PL | children | POSS | the.SG | parent | |
| ‘The children of the parent/the parent’s children’ | |||||
| (2) | te | matua | o | ngā | tamariki |
| the.SG | parent | POSS | the.PL | children | |
| ‘The parent of the children/the children’s parent’ | |||||
| (3) | te | tuhinga | a | Rāwiri | i | tana | reta |
| the.SG | writing | POSS | David | OBJ | his | letter | |
| ‘David’s writing of his letter’ | |||||||
- Whakarākei/Adornments
- Whanaunga/Relations (of same generation or older)
- Waka/Modes of transport
- Wāhanga/Parts of someone/thing
- Whakaruruhau/Shelter7
- Whakaora/Wellbeing
- Wāhi/Places
- Whakaahua/Adjectives or qualities of someone/thing
“As a second-language speaker of te reo Māori, I was introduced to the A and O categories early as another example of how reo (language) and tikanga (customs) are intertwined. To have confidence knowing which is the correct marker to use, one has to have a good understanding of the relationships being discussed and where the mana (authority) of the relationship resides. In general, the more authoritative actor has the O category, with the more submissive character being referred to in the A category. But there are lots of nuances, with objects taking the O category in some instances, but then the same object taking the A category in other instances, depending on the different relationships that are in play. I was fortunate that when I learnt te reo Māori I was in the presence of some gifted exponents of Māori language. Once my ear became tuned, I found that I was able to defer to what sounded the best, rather than turning to specific rules about which category should be used. For me, this makes learning and speaking te reo Māori natural and more enjoyable as I am not relying on following rules, but rather I am being guided by a taonga (treasure) that has been handed down to me. Unfortunately, this does not mean I am correct all the time, but it works well enough for me to run with it!”
Research Questions
- RQ1: What semantic categories and relationships are most frequently used by Māori-language tweeters in the [possessum a/o possessor] construction?
- RQ2: To what extent do Māori-language tweeters adhere to the rules described in Māori grammars when using the [possessum a/o possessor] construction? By analysing semantic categories and relationships, can patterns of adherence to and/or deviation from these rules be identified?
- RQ3: What are the sociolinguistic profiles of the tweeters in the corpus? If notable patterns arise from RQ2, can these be linked to characteristics such as gender, number of followers, and overall proportion of Māori-language tweets?
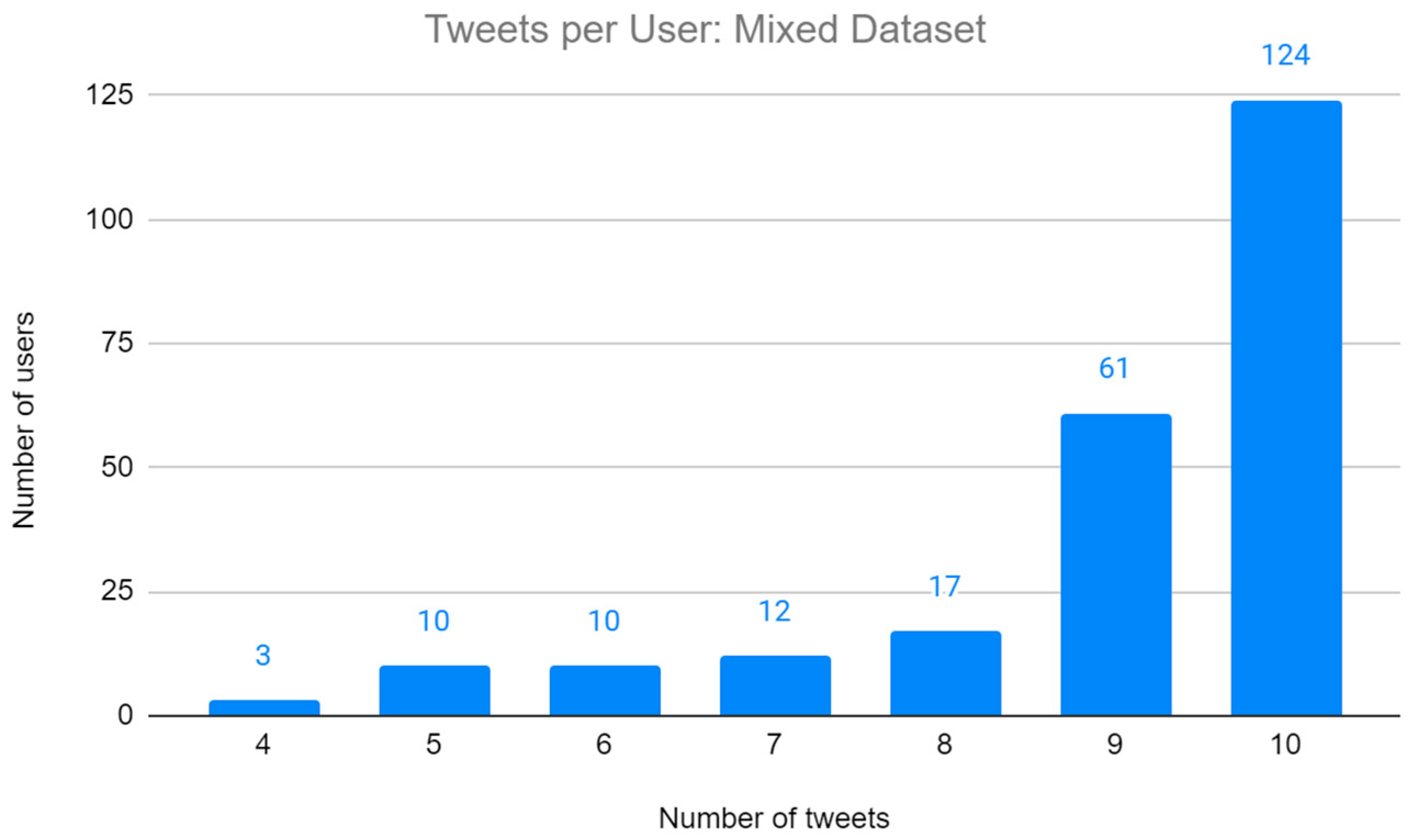
3. Data and Methods
- Non-possessive uses of a and o, including occurrences of the English indefinite article, incorrect word division (e.g., a’s that had become detached from kia), and remaining instances of the personal article;
- Tweets in which (short) a or o were used instead of (long) ā or ō, respectively;
- Formulaic phrases9 in which users did not explicitly choose a possessive marker (e.g., Te Wiki o te Reo Māori ‘Māori Language Week’);
- Tweets where the use of a or o was unclear.
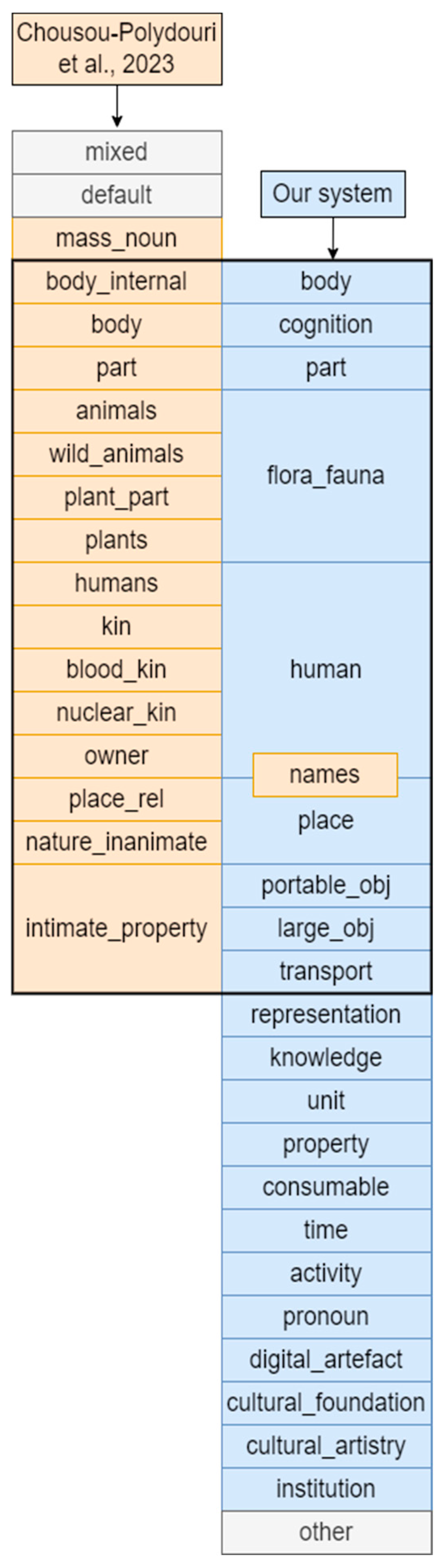
4. Semantic Classification Scheme
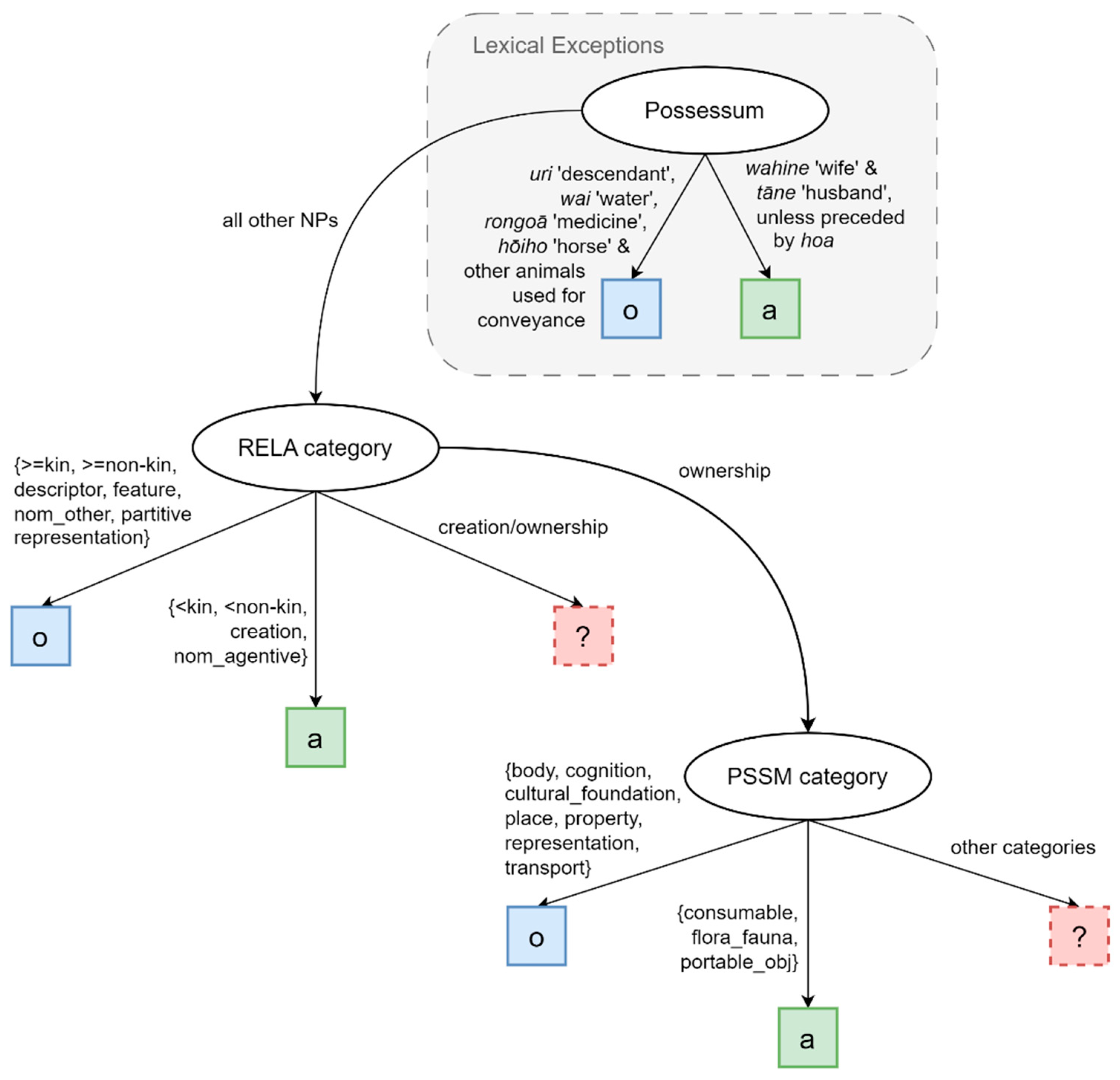
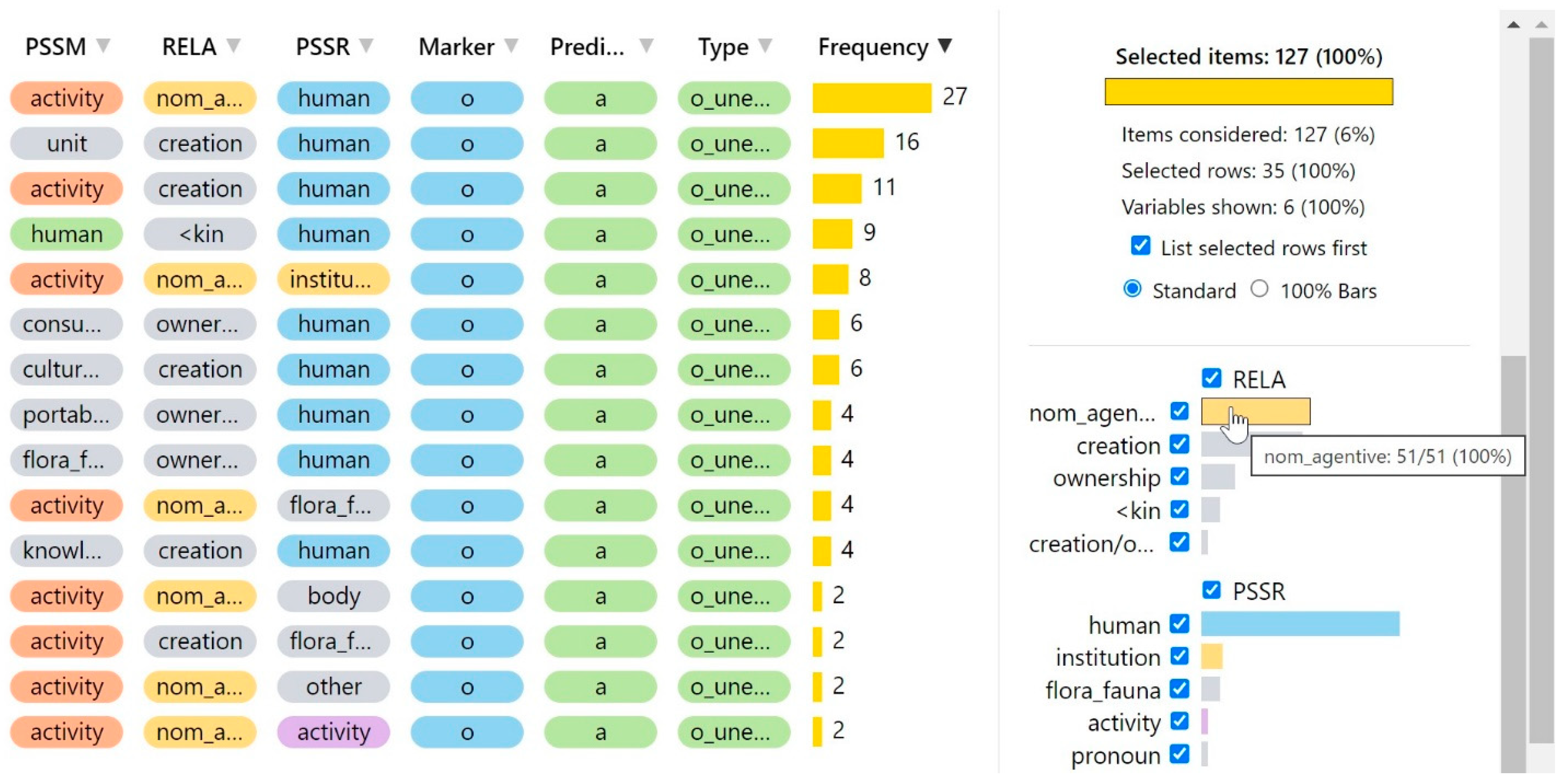
4.1. PSSM and PSSR Variables
4.2. RELA Variable
4.3. Semantic Annotation Challenges
| (4) | te | pukapuka | a | Hēmi Kelly | rāua | ko | Witi Ihimaera |
| the.SG | book | POSS | Hēmi Kelly | both | with | Witi Ihimaera | |
| <cultural_artistry> | <creation> | <human> | |||||
| ‘the book of (written by) Hēmi Kelly and Witi Ihimaera’ | |||||||
| (5) | te | pukapuka | o | Kamupene C |
| the.SG | book | POSS | C Company | |
| <cultural_artistry> | <descriptor> | <institution> | ||
| ‘the book of (about) C Company’ | ||||
| (6) | ngā | tikanga | a | Te | Pākehā |
| the.PL | customs | POSS | the.SG | European | |
| <cultural_foundation> | <creation> | <human> | |||
| ‘the customs of the European(s)’ | |||||
| (7) | ngā | tikanga | o | te | kāinga |
| the.PL | traditions | POSS | the.SG | home | |
| <cultural_foundation> | <descriptor> | <place> | |||
| ‘the traditions of the home’ | |||||
| (8) | te | tikanga | o | te | kupu |
| the.SG | meaning | POSS | the.SG | word | |
| <property> | <feature> | <unit> | |||
| ‘the meaning of the word’ | |||||
| (9) | BTW | he | aha | te | tikanga | *a | #NZTL? |
| BTW | what is | the.SG | meaning | POSS | #NZTL | ||
| <property> | <feature> | <institution> | |||||
| ‘B(y) T(he) W(ay,) what is the meaning of #NZTL?’ | |||||||
| (10) | i oho au waenganui i | te | kōrero | a | āku | tamariki |
| TENSE wake I middle of | the.SG | conversation | POSS | my | children | |
| <activity> | <nom_agentive> | <human> | ||||
| ‘I woke up in the middle of my children’s conversation [lit. the speaking of my children]’ | ||||||
| (11) | E | tika | ana | te | kōrero | a | Haimona | nei! |
| correct | the.SG | speech | POSS | Simon | PARTICLE | |||
| <unit> | <creation> | <human> | ||||||
| ‘What Haimona said [lit. the speech of Haimona] is correct!’ | ||||||||
| (12) | me | whakanui | tatou12 | ngaa | koorero | o | eenei | motu |
| should | celebrate | we | the.PL | speech | POSS | this | country | |
| <unit> | <descriptor> | <place> | ||||||
| ‘We should celebrate the [good] things said about this country’ | ||||||||
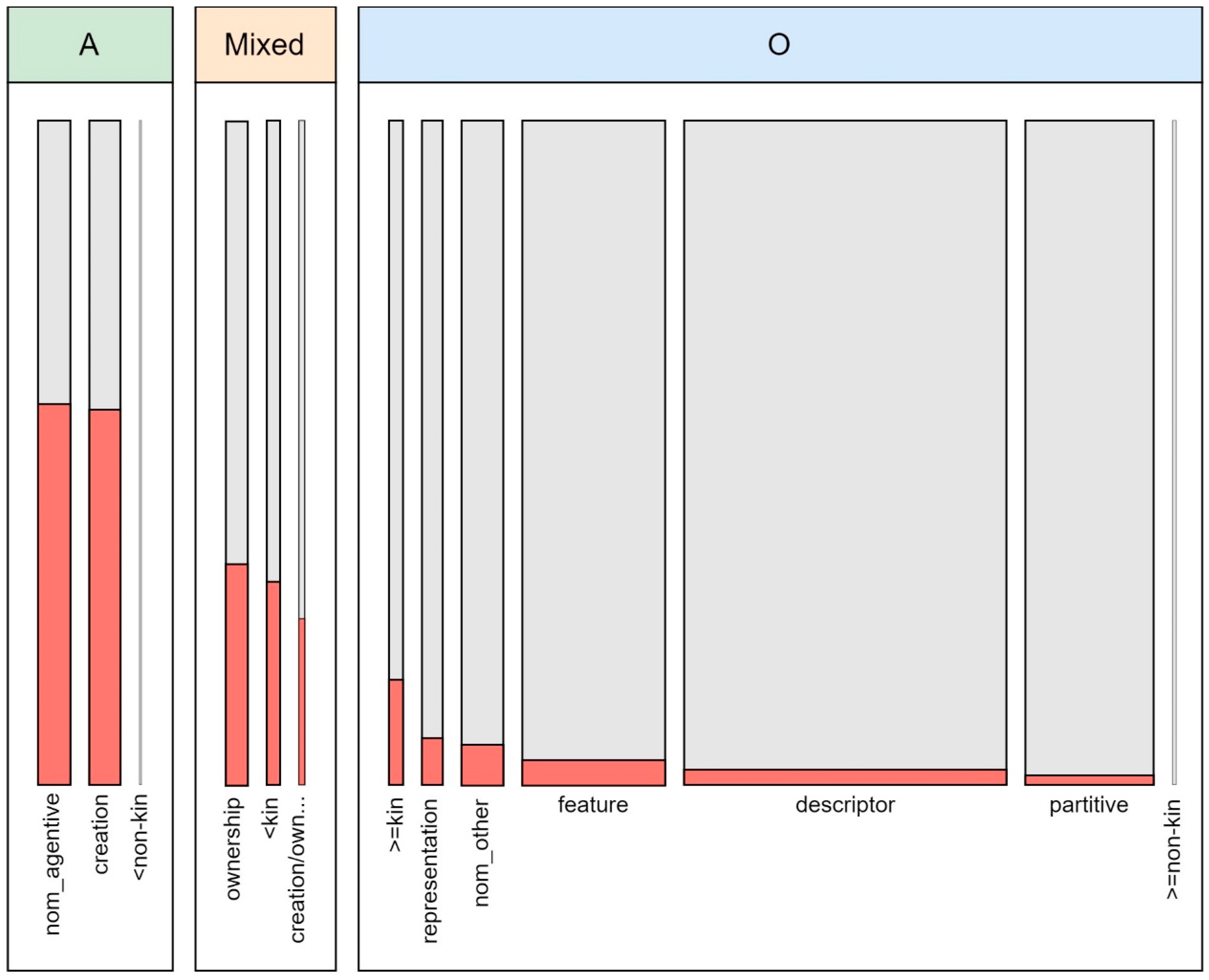
4.4. Type Variable
- Assign markers based on the RELA variable, but manually check the creation/ownership category and ignore ownership relationships. This is the most crucial step, as it applies to the largest proportion of data.
- For all ownership relationships, assign markers based on ten PSSM categories with fixed A/O forms, and manually check the rest.
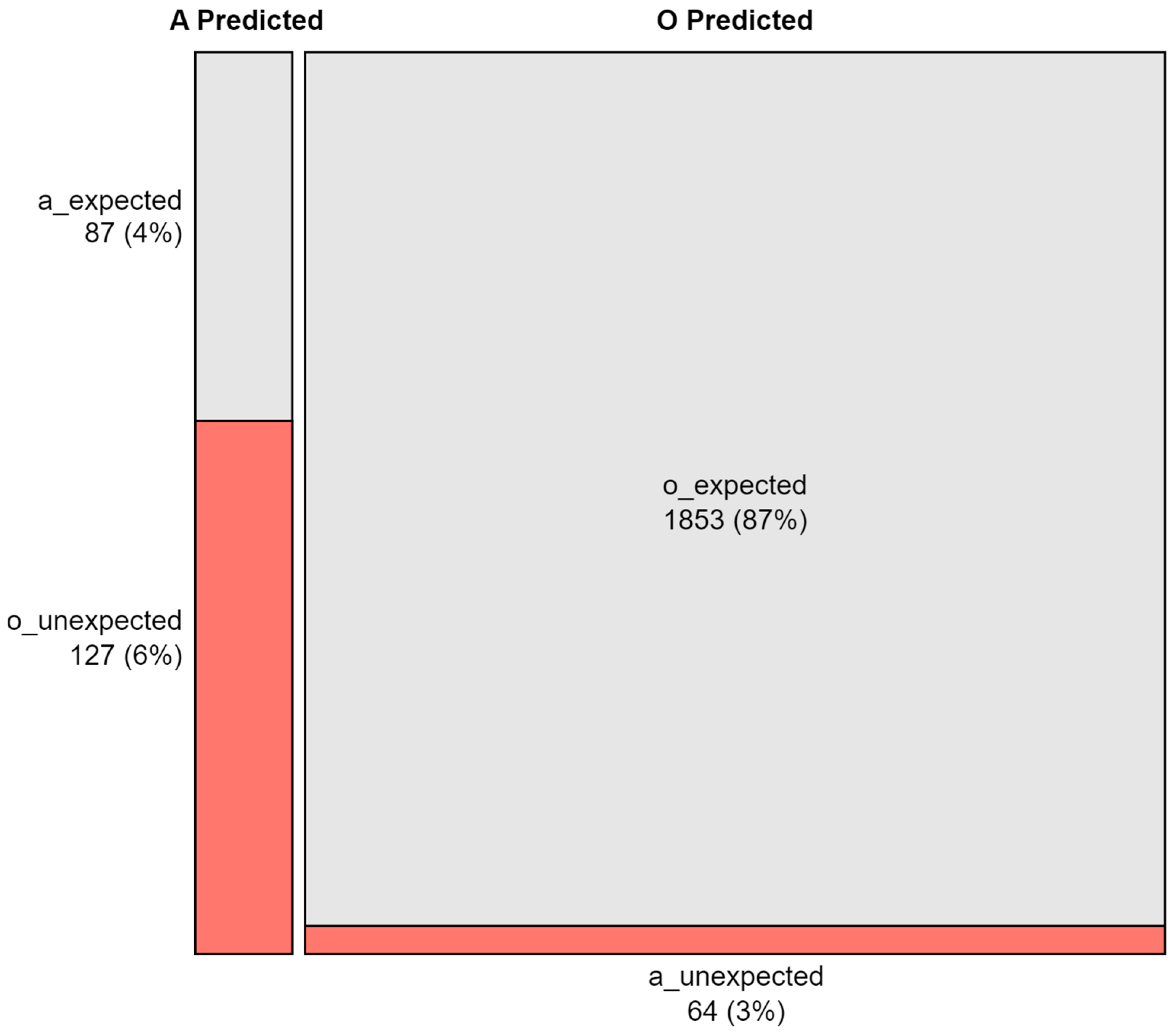
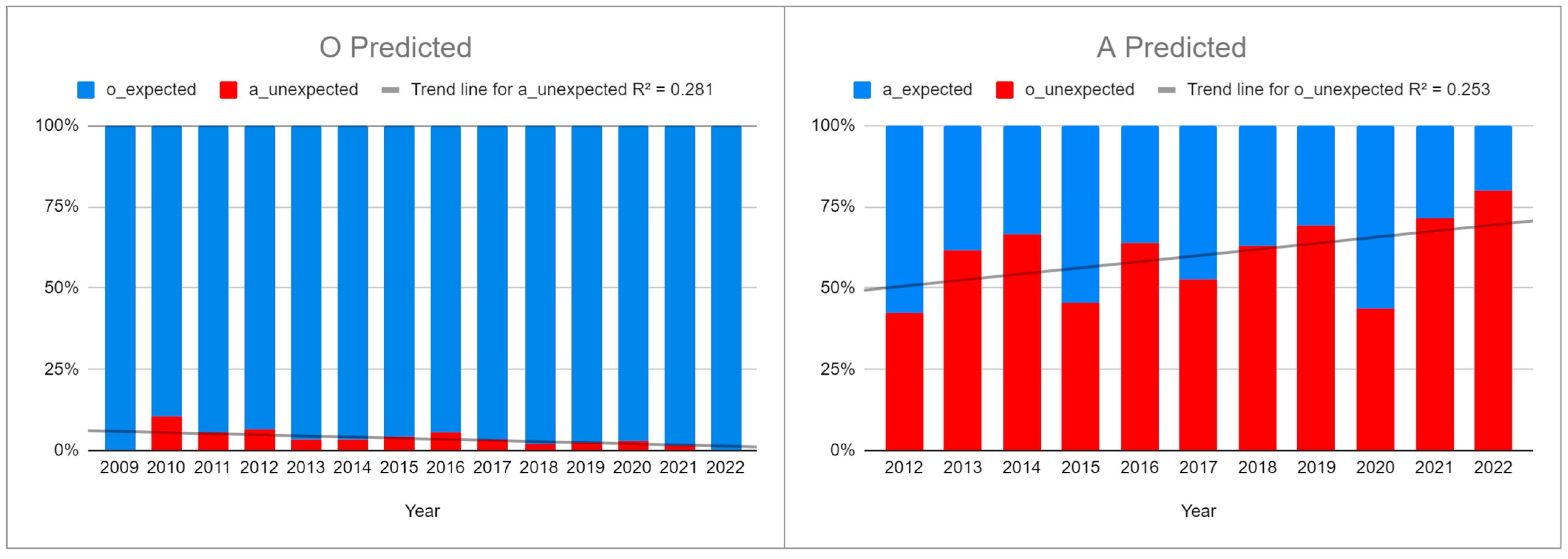
- a_expected, if both the predicted and actual markers were a;
- a_unexpected, if the predicted marker was o but the user chose a;
- o_expected, if both the predicted and actual markers were o;
- o_unexpected, if the predicted marker was a but the user chose o.
5. Results
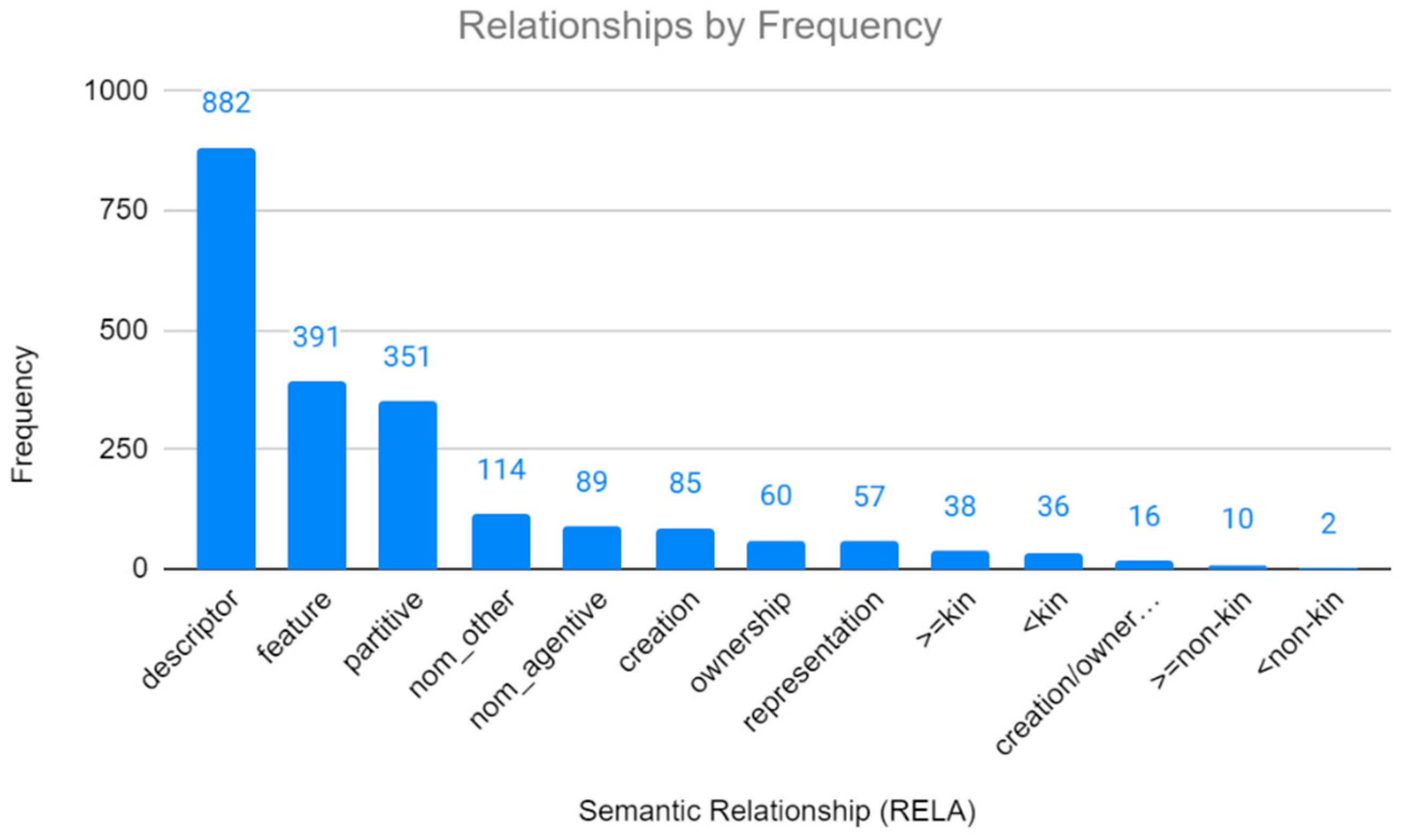
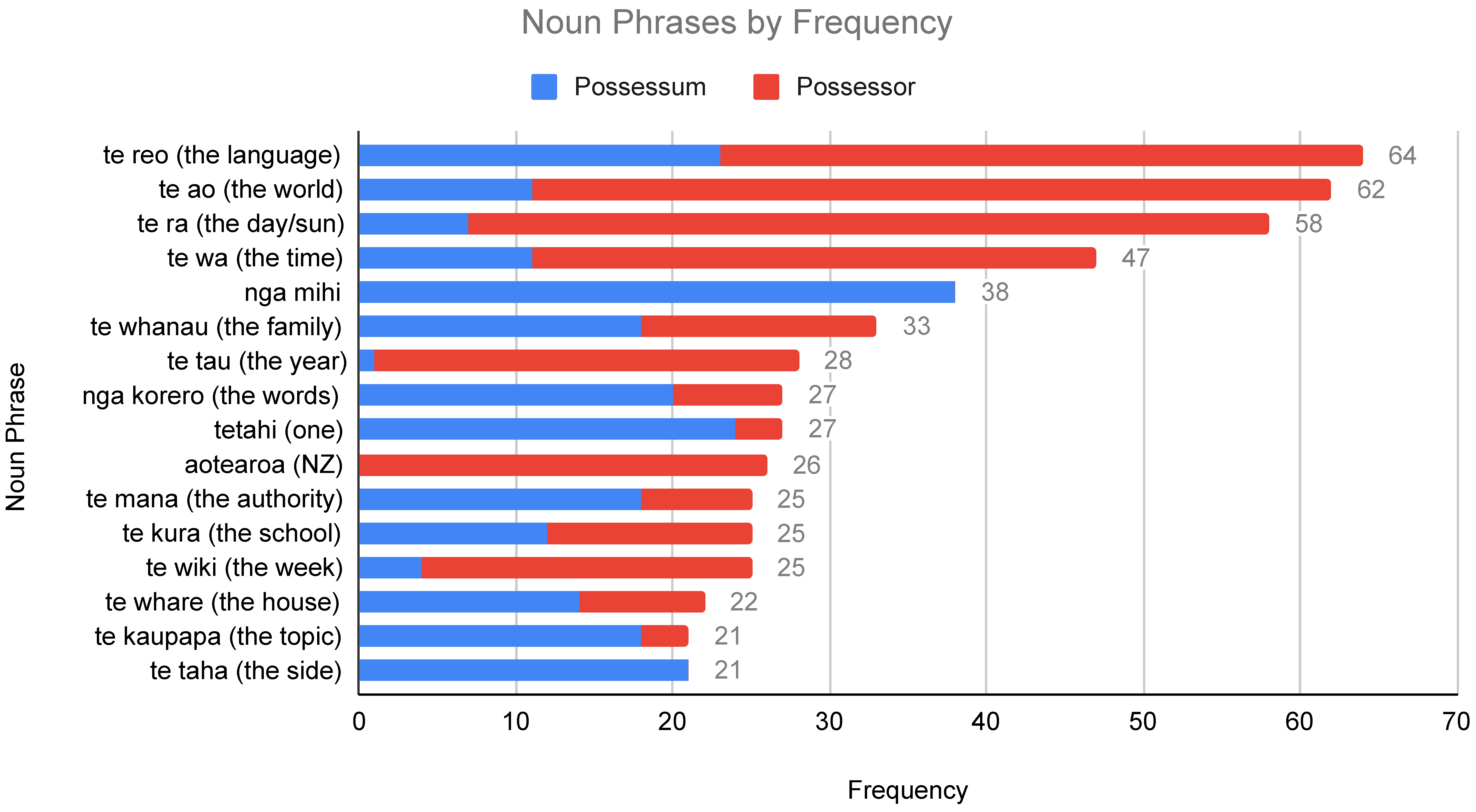
5.1. Semantic Variables by Frequency (RQ1)
5.2. Conformity with Descriptive Rules (RQ2)
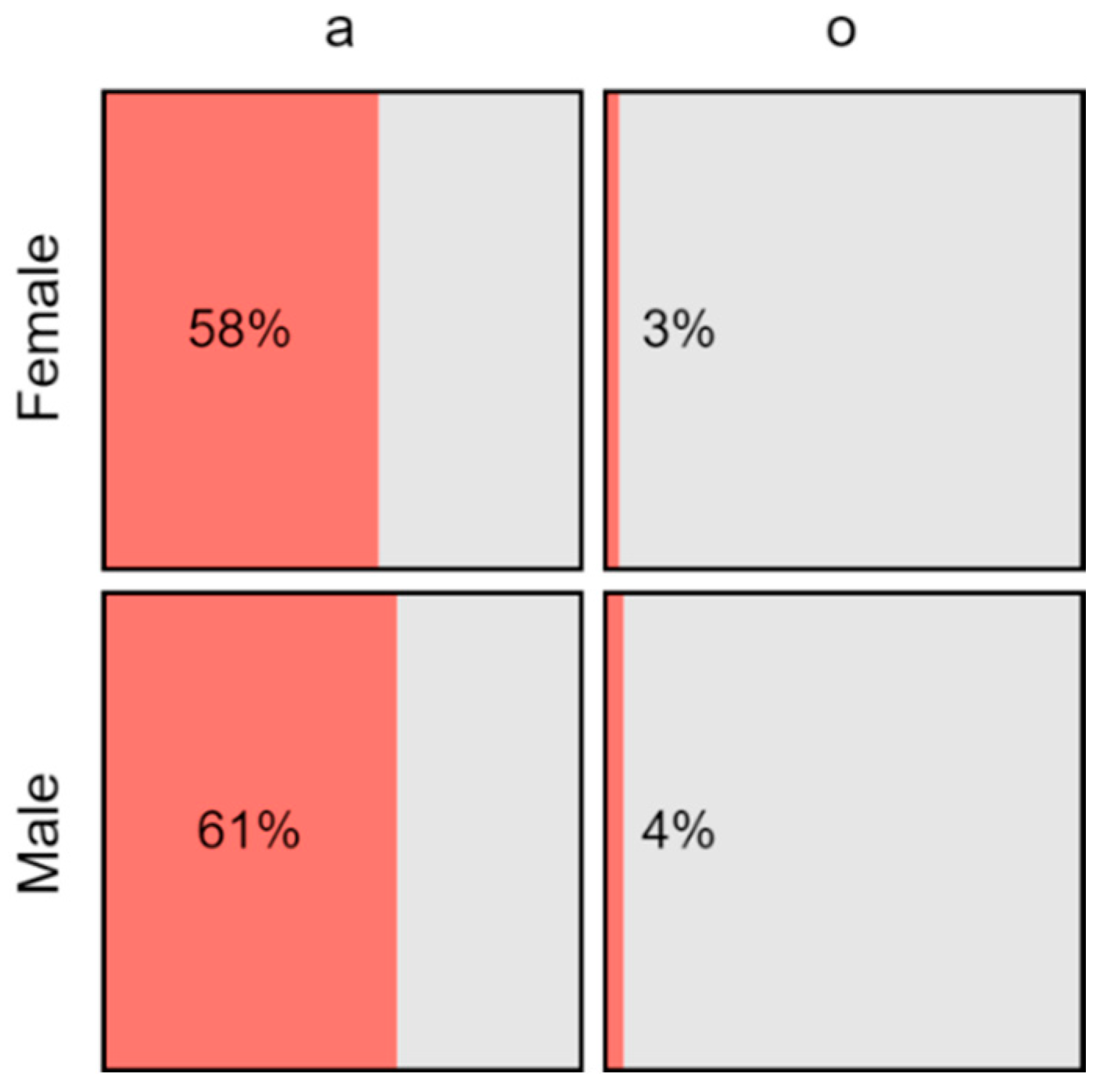
5.3. Sociolinguistic Characteristics of Tweeters (RQ3)
6. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | Throughout this article, we refer to the possessed item as the possessum, rather than the possessee. |
| 2 | |
| 3 | By way of convention, we will use small letters in italics (a/o) to refer to the alternation between (single-vowel) a or o forms in our target construction and non-italicised, capital letters (A/O) to represent the categories within the entire possessive system. |
| 4 | Since our data were collected prior to Twitter’s rebranding as X, we refer to the platform by its original name. |
| 5 | Throughout the paper, we write possessive markers in bold and use the following glosses: OBJ ‘indirect object’, PL ‘plural’, POSS ‘possessive marker’, and SG ‘singular’. Macrons (e.g., ā) denote long vowel sounds in Māori. |
| 6 | |
| 7 | This can include people who act as kaitiaki (e.g., doctor, teacher), as well as more traditional forms of shelter. |
| 8 | Information about the gender of each tweeter came from the RMT Corpus, and was primarily based on users’ self-reported pronouns. We acknowledge that Twitter users may claim identities that they do not possess or wish to possess. |
| 9 | There are still some formulaic names of entities in our data, but these represent only a small proportion of tweets and are not productively used. |
| 10 | The examples are written as they appear in our data, reflecting each speaker’s choice of possessive marker. Unexpected markers are prefixed with an asterisk. The semantic categories are given in the order <PSSM>, <RELA>, and <PSSR>, with <RELA> appearing directly beneath the possessive marker. |
| 11 | Even though links within tweets were redacted from the RMT Corpus, we still had access to the URLs for the tweets themselves and could, therefore, view them on Twitter if they were (still) publicly available. |
| 12 | We note the omission of a double-vowel in taatou, which is inconsistent with the remainder of the tweet. |
| 13 | |
| 14 | Across the whole dataset, there are 173 noun phrases that occur at least once as both possessum and possessor. |
References
- Aikhenvald, Alexandra Y. 2013. Possession and ownership: A cross-linguistic perspective. In Possession and Ownership: A Cross-Linguistic Typology. Edited by Alexandra Aikhenvald and Robert M. W. Dixon. Oxford: Oxford University Press, pp. 1–64. [Google Scholar]
- Baclawski, Kenneth. 2011. A/O Possession in Modern Māori. [Unpublished Manuscript]. Hanover: Dartmouth College. Available online: https://linguistics.berkeley.edu/~kbaclawski/Baclawski_2011_Maori_possession (accessed on 12 December 2023).
- Barlow, Michael, and Suzanne Kemmer. 2000. Usage-Based Models. Stanford: CSLI Publications. [Google Scholar]
- Bauer, Winifred, William Parker, and Te Kareongawai Evans. 1993. Maori. Abingdon: Routledge. [Google Scholar]
- Bauer, Winifred, William Parker, Te Kareongawai Evans, and Te Aroha Noti Teepa. 1997. The Reed Reference Grammar of Māori. Auckland: Reed. [Google Scholar]
- Biggs, Bruce J. 1955. The compound possessives in Maori. The Journal of the Polynesian Society 64: 341–48. [Google Scholar]
- Biggs, Bruce J. 1996. Let’s Learn Maori: A Guide to the Study of the Maori Language. Auckland: Auckland University Press. [Google Scholar]
- Biggs, Bruce J. 2000. Te Paanui A Wai-Wharariki. February 2000. Auckland: Māori Department, University of Auckland. [Google Scholar]
- Bleaman, Isaac L. 2020. Implicit standardization in a minority language community: A real-time syntactic change among Hasidic Yiddish writers. Frontiers in Artificial Intelligence 3: 1–20. [Google Scholar] [CrossRef]
- Boyce, Mary C. 2006. A Corpus of Modern Spoken Māori. Unpublished Ph.D. thesis, Victoria University of Wellington, Wellington, New Zealand. [Google Scholar]
- Capell, Arthur. 1949. The concept of ownership in the languages of Australia and the Pacific. Southwestern Journal of Anthropology 5: 169–89. [Google Scholar] [CrossRef]
- Chousou-Polydouri, Natalia, David Inman, Thomas C. Huber, and Balthasar Bickel. 2023. Multi-variate coding for possession: Methodology and preliminary results. Linguistics 61: 1365–402. [Google Scholar] [CrossRef] [PubMed]
- Christensen, Ian S. 2003. Proficiency, Use and Transmission: Maori Language Revitalisation. New Zealand Studies in Applied Linguistics 9: 41–61. [Google Scholar]
- Clark, Ross. 1976. Aspects of Proto-Polynesian Syntax, Te Reo Monograph. Auckland: Linguistic Society of New Zealand. [Google Scholar]
- Foster, John. 1987. He Whakamārama: A New Course in Māori. Auckland: Heinemann. [Google Scholar]
- Fusi, Valerio. 1985. Action and Possession in Māori Language and Culture. A Whorfian Approach. L’Homme 25: 117–45. [Google Scholar] [CrossRef]
- Goodwin, Ian, Antonia C. Lyons, Jessica Young, and Tia Neha. 2024. Young People’s Internet Use, Social Media Activity, and Engagement with Social Media Influencers. Auckland: University of Auckland, School of Cultures, Languages and Linguistics. Available online: https://researchspace.auckland.ac.nz/handle/2292/68247 (accessed on 25 July 2024).
- Greensill, Hineitimoana, Hōri Manuirirangi, and Hēmi Whaanga. 2017. Māori language resources and Māori initiatives for teaching and learning te reo Māori. In He Whare Hangarau Māori—Language, Culture & Technology. Edited by Hēmi Whaanga, Te Taka A. G. Keegan and Mark Apperley. Hamilton: Te Pua Wānanga ki te Ao/Faculty of Māori and Indigenous Studies, the University of Waikato, pp. 1–9. [Google Scholar]
- Harlow, Ray. 2000. Possessive markers in Māori. STUF-Language Typology and Universals 53: 357–70. [Google Scholar]
- Harlow, Ray. 2007. Maori: A Linguistic Introduction. Cambridge: Cambridge University Press. [Google Scholar]
- Harlow, Ray. 2015. A Māori Reference Grammar, 2nd ed. Wellington: Huia Publishers. [Google Scholar]
- Harlow, Ray, Winifred Bauer, Margaret Maclagan, Catherine Watson, Peter Keegan, and Jeanette King. 2011. Interrupted transmission and rule loss in Māori: The case of ka. Oceanic Linguistics 50: 50–64. [Google Scholar] [CrossRef]
- Haspelmath, Martin. 2017. Explaining alienability contrasts in adpossessive constructions: Predictability vs. iconicity. Zeitschrift für Sprachwissenschaft 36: 193–231. [Google Scholar] [CrossRef]
- Haspelmath, Martin. 2021. Explaining grammatical coding asymmetries: Form–frequency correspondences and predictability. Journal of Linguistics 57: 605–33. [Google Scholar] [CrossRef]
- Head, Lyndsay. 1989. Making Maori Sentences. London: Longman Paul. Available online: https://tereomaori.tki.org.nz/content/download/2780/15817/file/moe626-making-sentences-complete-100dpi.pdf (accessed on 5 August 2023).
- Higgins, Rawinia, Poia Rewi, and Vincent Olsen-Reeder, eds. 2014. The Value of the Māori Language: Te hua o te Reo Māori. Wellington: Huia Publishers, vol. 2. [Google Scholar]
- Kārena-Holmes, David. 2021. Te Reo Māori: The Basics Explained. Auckland: Oratia Media Ltd. [Google Scholar]
- Keegan, Te Taka A. G., and Daniel Cunliffe. 2014. Young people, technology and the future of te Reo Māori. In The Value of the Māori Language: Te hua o te Reo Māori. Edited by Rawinia Higgins, Poia Rewi and Vincent Olsen-Reeder. Wellington: Huia Publishers, pp. 385–98. [Google Scholar]
- Kelly, Karena. 2014. Iti Te Kupu, Nui Te Korero—The study of the little details that make the Maori language Maori. In The Value of the Maori Language: Te Hua o Te Reo Maori. Edited by Rawinia Higgins, Poia Rewi and Vincent Olsen-Reeder. Wellington: Huia Publishers, pp. 255–67. [Google Scholar]
- Kelly, Karena. 2015. Aspects of Change in the Syntax of Māori—A Corpus-Based Study. Doctoral thesis, Te Herenga Waka-Victoria University of Wellington, Wellington, New Zealand. Available online: http://researcharchive.vuw.ac.nz/handle/10063/4841 (accessed on 11 July 2023).
- King, Jeanette. 2018. Māori: Revitalization of an endangered language. In The Oxford Handbook of Endangered Languages. Edited by Kenneth L. Rehg and Lyle Campbell. Oxford: Oxford University Press, pp. 592–612. [Google Scholar]
- Krupa, Viktor. 1964. On the category of possession in Maori. Bulletin of the School of Oriental and African Studies 27: 433–35. [Google Scholar] [CrossRef]
- Krupa, Viktor. 2003. Extralinguistic basis of the category of possessivity. Asian and African Studies 12: 122–34. [Google Scholar]
- Lane, Christopher. 2024. First and second language speakers in the revitalisation of te reo Māori: A statistical analysis from Te Kupenga 2018. Te Reo 66: 28–56. [Google Scholar]
- Levshina, Natalia. 2015. How to Do Linguistics with R: Data Exploration and Statistical Analysis. Amsterdam: John Benjamins Publishing Company. [Google Scholar]
- Moorfield, John C. 1988. Te Kākano. Auckland: Longman Paul. [Google Scholar]
- Nicholas, Sally. 2010. An Investigation of the So-Called ‘Passive’ Construction in New Zealand Māori. Master’s thesis, The University of Auckland, Auckland, New Zealand. Available online: https://researchspace.auckland.ac.nz/handle/2292/7143 (accessed on 17 July 2022).
- Pierrehumbert, Janet B. 2001. Exemplar dynamics, word frequency, lenition, and contrast. In Frequency Effects and the Emergence of Linguistic Structure. Edited by Joan Bybee and Paul Hopper. Amsterdam: John Benjamins, pp. 135–57. [Google Scholar]
- Rocha, Miguel Mechi Naves, and Celmar Guimaraes da Silva. 2018. Heatmap matrix: A multidimensional data visualization technique. Paper presented by 31st Conference on Graphics, Patterns and Images (SIBGRAPI), Parana, Brazil, October 29–November 1. [Google Scholar]
- Ryan, Peter M. 1974. The New Dictionary of Modern Māori. Auckland: Heinemann. [Google Scholar]
- Ryan, Peter M. 1980. Modern Māori: Book 2. Auckland: Heinemann. [Google Scholar]
- Scannell, Kevin P. 2022. Managing data from social media: The Indigenous Tweets project. In The Open Handbook of Linguistic Data Management. Edited by Andrea L. Berez-Kroeker, Bradley McDonnell, Eve Koller and Lauren B. Collister. Cambridge: MIT Press. [Google Scholar]
- Statistics NZ. 2018. Available online: https://www.stats.govt.nz/information-releases/2018-census-totals-by-topic-national-highlights-updated (accessed on 30 March 2022).
- Stefanowitsch, Anatol. 2020. Corpus Linguistics: A Guide to the Methodology. Berlin: Language Science Press. [Google Scholar]
- Tawhara, Te Ao Marama. 2015. Kia Māori te reo Māori? An Investigation of Adult Learner Attitudes towards the Impact of English on te reo Māori. Master’s thesis, University of Otago, Dunedin, New Zealand. [Google Scholar]
- Te Kupenga. 2018. Available online: https://www.stats.govt.nz/news/more-than-1-in-6-maori-people-speak-te-reo-maori (accessed on 30 March 2022).
- Thornton, Agathe. 1998. Do a and o categories of “possession” in Maori express degrees of tapu? The Journal of the Polynesian Society 107: 381–93. [Google Scholar]
- Trye, David, Mark Apperley, and David Bainbridge. 2023. Extending the Heatmap Matrix: Pairwise analysis of multivariate categorical data. Paper presented at the 2023 27th International Conference Information Visualisation (IV), Tampere, Finland, July 25–28; Tampere: IEEE, pp. 29–36. [Google Scholar] [CrossRef]
- Trye, David, Mark Apperley, and David Bainbridge. 2024. MultiCat: A Visualisation Technique for Multidimensional Categorical Data. [Unpublished Manuscript]. Hamilton: University of Waikato. Available online: https://dgt12.github.io/files/multicat.pdf (accessed on 27 July 2024).
- Trye, David, Te Taka Keegan, Paora Mato, and Mark Apperley. 2022. Harnessing Indigenous Tweets: The Reo Māori Twitter corpus. In Lang Resources & Evaluation 56: 1229–68. [Google Scholar] [CrossRef]
- Whaanga, Hēmi, and Hineitimoana Greensill. 2014. An account of the evolution of language description of te reo Māori since first contact. In He Hiringa, He Pūmanawa: Studies on the Māori Language. Edited by Alexander Onysko, Marta Degani and Jeanette King. Wellington: Huia Publishers, pp. 7–32. [Google Scholar]
- Williams, Herbert W., and William L. Williams. 1971. First Lessons in Māori. Christchurch: Government Printer. [Google Scholar]
- Wilson, William H. 1982. Proto-Polynesian Possessive Marking. Canberra: Australian National University. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A Class (Marked) | O Class (Unmarked) |
|---|---|
| Small portable possessions | Large objects, and animals used for transport |
| Kin of lower generations (see Example 1; apart from uri, ‘descendant’), and spouses | Kin of same or higher generations (see Example 2) |
| Subjects of nominalisations of active transitive verbs (see Example 3), including derived nominals | Subjects of nominalisations of other verbs |
| Consumables, apart from water and medicine | Wai ‘water’ and rongoā ‘medicine’ |
| Animals not used for transport | Parts of whole, including body parts and clothing |
| Variable | Cohen’s Kappa | Interpretation |
|---|---|---|
| PSSM | 0.89 | Near perfect |
| PSSR | 0.88 | Near perfect |
| RELA | 0.79 | Substantial |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trye, D.; Calude, A.S.; Harlow, R.; Keegan, T.T. Analysing A/O Possession in Māori-Language Tweets. Languages 2024, 9, 271. https://doi.org/10.3390/languages9080271
Trye D, Calude AS, Harlow R, Keegan TT. Analysing A/O Possession in Māori-Language Tweets. Languages. 2024; 9(8):271. https://doi.org/10.3390/languages9080271
Chicago/Turabian StyleTrye, David, Andreea S. Calude, Ray Harlow, and Te Taka Keegan. 2024. "Analysing A/O Possession in Māori-Language Tweets" Languages 9, no. 8: 271. https://doi.org/10.3390/languages9080271
APA StyleTrye, D., Calude, A. S., Harlow, R., & Keegan, T. T. (2024). Analysing A/O Possession in Māori-Language Tweets. Languages, 9(8), 271. https://doi.org/10.3390/languages9080271