To best understand how language is used for communicative purposes, as opposed to experimental tasks, where the participant is not actually communicating new information to a listener, and what types of variation are present and available to speakers, we rely on spontaneous speech from a range of speakers who vary widely in how frequently they hear and speak Russian, their attitudes toward the language and culture, and the types of input they have received. Variationist sociolinguistic methods (cf.
Labov 1984), augmented by further information necessary to understand what influences speech variation in multilingual contexts, are applied, as described in this section. The goal is to describe both the
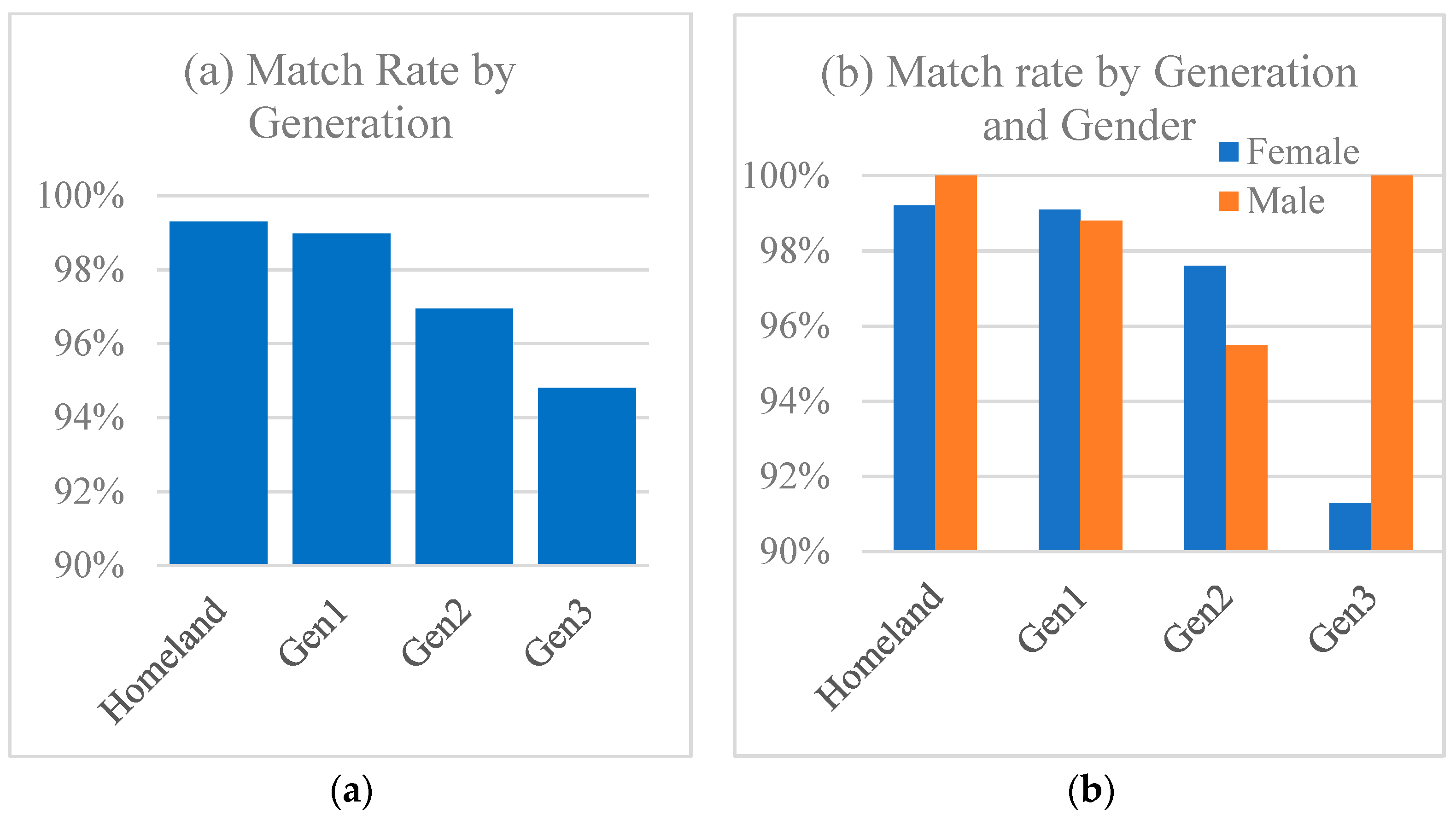
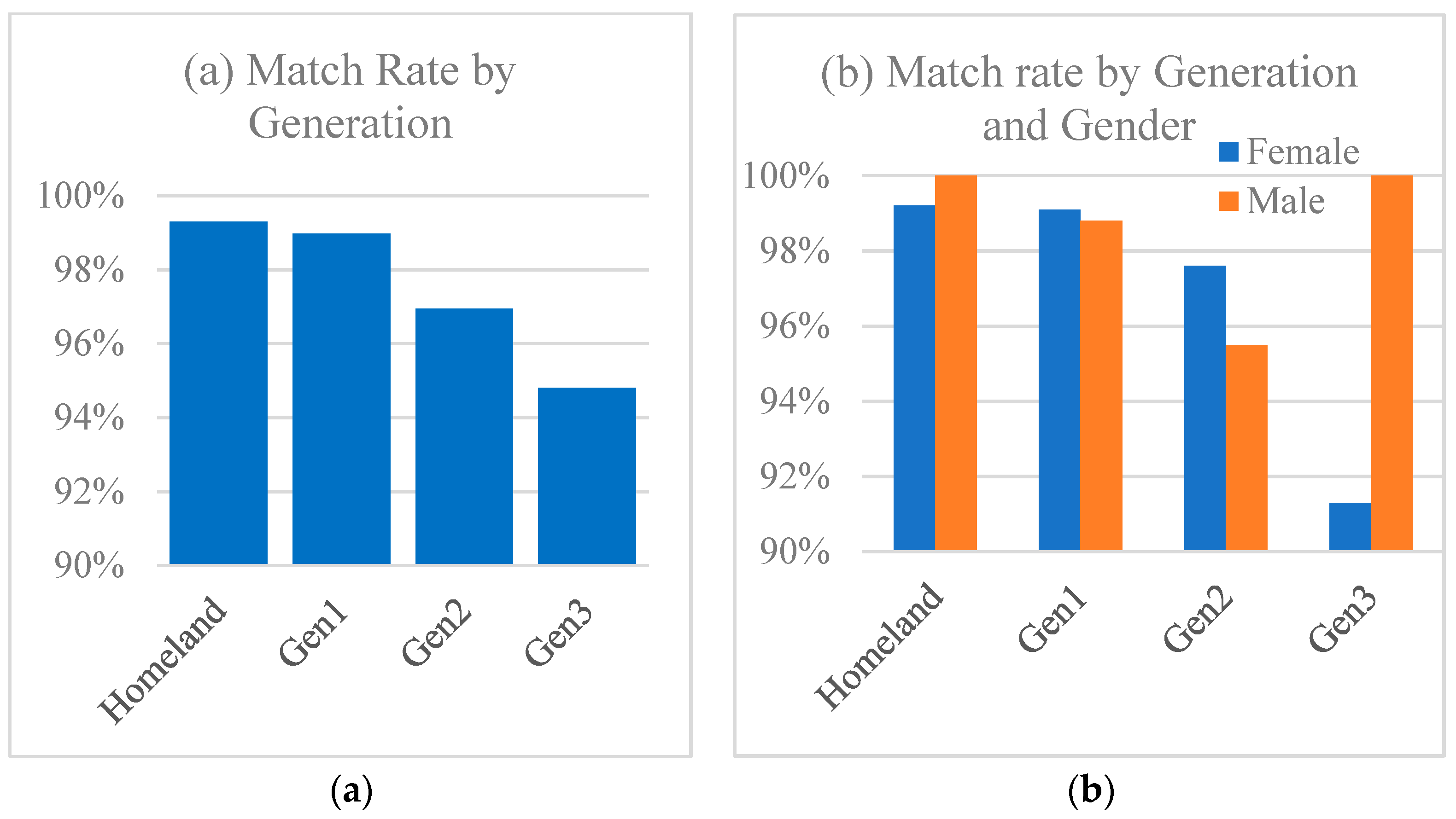
rates of match (canonical case-marking choice vs. non-canonical choice) and the
patterns of contexts in which matches occur most frequently, and how these change from one generation of speakers to the next.
2.2. Data Collection
The speech samples from the heritage speakers are from the HerLD corpus (
Nagy 2009) and are extracted from sociolinguistic interviews, each approximately an hour in length, conducted in Russian. Sociolinguistic interviews, as defined in
Labov (
1984), are conversational samples over a wide range of topics.
3 These interviews were conducted by Heritage Russian-speaking student investigators who suggested topics and facilitated the conversation to elicit the largest amount of vernacular speech, basing the conversation on the HLVC interview protocol.
4 Speakers were also asked to complete a short picture description task and an Ethnic Orientation Questionnaire.
5 From the Ethnic Orientation Questionnaire, responses were scored on a scale indicating preferences for Russian or for English/Canadian language and cultural practices in various contexts. A Principal Components Analysis reduced the responses for 37 questions to two independent axes, one focusing on the speaker’s language use and preference (EO_Language) and one describing the speaker’s family’s language and cultural preferences (EO_Family). Interestingly, the speaker’s own ethnic identification (Russian, mixed, or Canadian) did not load strongly onto either axis and is thus not considered further in this paper. Ranges for ethnic orientation (EO) scores, shown in
Table 2, indicate that these, like age, are collinear with generation.
The homeland data, part of the
Russian National Corpus (
2003), consisted of short, unscripted conversations of various types between the speaker and one or additional participants whose speech remained unanalyzed. The speakers were Moscow residents.
Table 2.
Distribution of 30 speakers.
Table 2.
Distribution of 30 speakers.
| Generation | Female | Male | EO_ Language | EO_ Family |
|---|
| | n | age range (years) | n | age range (years) | range | range |
| Homeland | 5 | unknown, but younger | 1 | unknown | NA | NA |
| Gen1 | 8 | 40–82 | 4 | 47–80 | −2.5–−0.6 | −1.3–2.8 |
| Gen2 | 6 | 12–68 | 3 | 12–56 | −2.0–3.7 | −1.6–3.7 |
| Gen3 | 2 | 25–37 | 1 | 56 | 2.9 | −0.2 |
Interviews were transcribed orthographically in ELAN, a program for time-aligned transcription and annotation (
Sloetjes and Wittenburg 2008;
Wittenburg et al. 2006). A transliteration into Latin script was used and non-standard elements of a speaker’s speech were transcribed as produced. This provides search and retrieval of instances of, for example, non-canonical case productions. Additional information on these tasks and methodology can be found in
Nagy (
2024, Chap. 4).
2.3. Variables and Coding
The dependent variable in our analyses was the choice of case marker. It was coded as binary: canonical vs. non-canonical selection of case marker, as determined by native Russian-speaking research assistants. To make this determination, each noun or pronoun in the selected portion of each interview was annotated in ELAN for both observed and prescribed cases, excluding those that are prescriptively NOM or categorically produced as match.
6 Briefly, this consisted of categorizing tokens by the context in which they appear (according to prescribed case and part of speech, that is, noun or pronoun), described in further detail below, and then calculating the majority form produced in heritage and homeland data for each context. These majority forms matched the normative forms in
Gruszczyński’s (
2002) grammar, as well as the RAs’ intuitions, and are thus labelled as canonical forms. In this way, the dependent variable is a binary choice, either
match (the token produced has the prescribed form) or
mismatch (the token produced does not have the prescribed form). An example from the data of a mismatch is in (10), a clause produced by a Gen2 speaker in which the object of the preposition в ‘in’ is in the nominative or accusative form (
nachalo) rather than the prescribed locative form (
nachale). The target nouns are bolded. In contrast, (11) demonstrates an instance of a match token, where the object of the preposition ‘in’ is in the locative form, as is prescribed.
| (10) | v | nachalo | nojabre |
| | в | нaчaлo | нoябpe |
| | In | beginning.NOM/ACC | November.LOC |
| | ‘In the beginning of November’ (R2F68C, 00:00:59) |
| (11) | ja | byla | u | nix | v | dome |
| | я | былa | y | ниx | в | дoмe |
| | 1SG.NOM | be.AGR.PERF | at | 3PL.LOC | in | house.LOC |
| | ‘I have been in their house’ (R0F20B, 00:27:15) |
Errors in marking animacy, gender, and number were not included in our analysis (and have not yet been examined in this corpus). In cases where it was not possible to determine whether the lack of match to the canonical form should be attributed to selecting the wrong case or selecting the wrong animacy, gender, or number, we coded the tokens as a mismatch. For example, if a masculine noun was produced with the feminine form of the prescribed case, it was marked as a mismatch.
Coding of tokens began 15 min into each interview or conversation recording, allowing a period of adjustment to the context and thus using data that more closely approximates the speakers’ vernacular. In ELAN, approximately 100 noun phrases were selected and annotated for a match between the prescribed and produced case (the dependent variable) for each of the 30 speakers. If fewer than 100 tokens for a speaker were found throughout this portion of the interview, then the first 15 min of the file was coded as well. This limit of 100 tokens allows for a representative sample of how each speaker talks while conserving scarce resources required to process the data, particularly the time available to heritage-language-speaking student researchers. It also avoids skewing the data if any particularly garrulous or particularly reticent speakers have different patterns from others.
7 As our focus here is an examination of nominals that are the objects of prepositions (the context studied in
Polinsky 2006), tokens were extracted from a larger data set previously coded for the work published in
Łyskawa and Nagy (
2020): tokens are included in this analysis only if they were a noun or pronoun object of a preposition with a prescribed or canonical case of ACC, DAT, GEN, INS, or LOC. Thus, of the original 3000 coded tokens (30 speakers × 100 tokens), we examine 1454 preposition + noun tokens here.
For this study, four independent linguistic variables were also coded for each token, following the method described by
Łyskawa and Nagy (
2020) who operationalized the variationist study of Slavic case systems. These are nominal form (noun or pronoun), canonical case (ACC, DAT, GEN, INS or LOC), observed case (ACC, DAT, GEN, INS, LOC or NOM), and lexical frequency of the nominal form. Factors and their levels are listed in
Table 3.
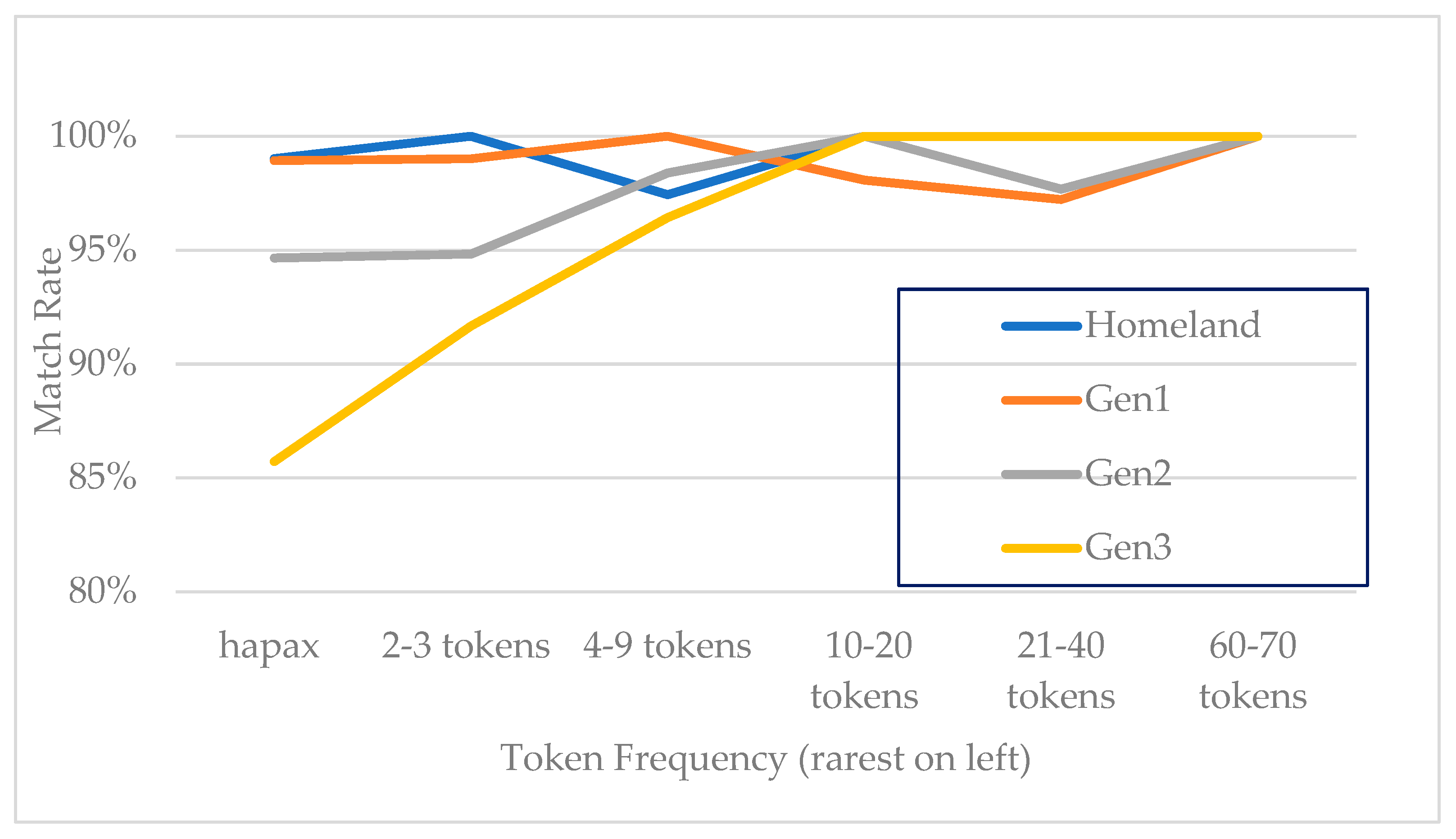
Lexical frequency was determined by counting the number of appearances of each form (not lemmatized) in the token list. Thus, it is a very local frequency. We operationalized lexical frequency in two ways, as a binned and as a continuous measure. To create the binned measure, we coded hapax legomena (single occurrences in the dataset) as the rarest category and two frequent pronouns (
мeня ‘me’ and
нac ‘us’) as the most common category. The remaining words were divided into four categories (see
Table 3). We compare models with each measure and find that the continuous measure produces a model that better fits the data. We also coded each token as a noun or pronoun and determined that this did not interact with the lexical frequency measure, except that the two most frequent tokens were both pronouns (
мeня ‘me’ and
нac ‘us’). This was meant to control for the difference in complexity of case marking on nouns compared to pronouns (
Polinsky 2006, pp. 214–17).
Finally, each token was coded according to the social characteristics of the speaker who produced it: generation, sex, age, EO_Language, EO_Family. The levels of all factors are shown in
Table 3.
Based on these factors,
Table 4 demonstrates how the example in (10) was coded. Items in the first four rows are coded for each token in ELAN. In another tier, tokens are automatically coded as match or mismatch, depending on whether the canonical and observed cases are the same. In this example, the dependent variable is entered as a mismatch because the canonical and observed cases do not match. Codes for each social factor (generation, sex, age, EO_Language, EO_Family) are added to each token after exporting the full token set from ELAN to a spreadsheet for statistical analysis (methodology described in
Nagy and Meyerhoff 2015).
Narrowing down to the context of prepositional nominals with a prescribed case other than NOM and excluding the invariant (in the dataset) nominal classes (see endnote 6), we examine 1454 tokens, each coded in ELAN for the linguistic factors.
2.4. Analysis Methods
We first examined the distribution of tokens in intersecting contexts, considering both linguistic and social factors. Since speakers will not have the same number of tokens produced in each context, given the spontaneous nature of the speech data used, and because we have an imbalance in the number of speakers representing certain categories of our three social factors, we then conducted multivariate regression analyses to show which predictors significantly affect the match rates. Logistic regression models were constructed from the dataset using Rbrul (
Johnson 2009), a package for R (
R Development Core Team 2008). Rbrul supports multivariate analyses by asking the user to select modelling methods appropriate to the data, avoiding the need for writing code. As is standard in the field of sociolinguistics, factors with a
p-value less than 0.05 were considered significant.
We compared multiple models to determine the combination of factors which best account for the patterning of our data. Models were compared through the reported AICc score (corrected Akaike Information Criterion, used for model averaging,
Burnham and Anderson 2004) to determine which combination of factors best accounts for the data distribution. The size and distribution of the dataset precludes the inclusion of Speaker or Word as random intercepts. Because ethnic orientation is collinear with generation, it is excluded from the regression models and examined subsequently. Two speakers’ data had to be excluded from the models because these speakers exhaustively represent Homeland Males and Gen3 Males, respectively, and they exhibited no variation. Categorical levels cannot be entered in logistic regression models. Thus, in the multivariate analyses in
Section 3.2, we model patterns for 29 of the 31 speakers considered in
Section 3.1.
For our examination of the effects of lexical frequency, we also calculated type/token ratios for each generation and each speaker, based on the distinct forms produced and included as tokens in the above analysis. For type/token ratios, the larger the number, the more different the words or the larger the vocabulary a group exhibits. We compare (Pearson’s) correlations of this type/token ratio, match rate, and ethnic orientation scores across speakers.




{kind=link}
{kind=link}
{kind=link}
{kind=link}