1. Introduction and Background
A crucial part of the listening process entails identifying meaningful linguistic units in a continuous speech signal. Lexical identification in continuous speech is a complex task because sounds in the speech signal overlap with each other in time and space, even across word boundaries, and word boundaries are rarely marked explicitly in the acoustic signal. During the early stages of speech processing, listeners can parse the speech signal into prelexical phonological units that can be used to access the lexicon and activate lexical items (see
Floccia et al. 2012;
Pallier et al. 2001;
McQueen et al. 2006). Although some accounts propose that the prelexical phonological units into which the speech stream is parsed are syllable-sized perceptual units (see
Savin and Bever 1970), the specific nature of these units is yet to be determined. Guided by cross-linguistic evidence, many models of lexical processing include the availability of multiple perceptual units that can be used during prelexical processing (e.g.,
Dupoux 1993;
Gaskell and Marslen-Wilson 1997;
Goldinger and Azuma 2003;
McClelland and Elman 1986).
Cross-linguistic evidence suggests that among other factors, phonetic and phonological differences across languages may influence the types of perceptual routines in which listeners engage. Segmentation routines may vary based on the type of rhythm of a given language (
Ramus et al. 1999). Native speakers of languages commonly classified as “syllable-timed” (i.e., languages whose rhythmic structure revolves around the syllable and whose syllables have a roughly equivalent duration; see
Conlen 2016;
Liu and Takeda 2021), like Spanish, Italian, French, and Portuguese, use a syllable-like prelexical unit to parse the speech signal, and they take advantage of syllabic information for lexical segmentation (e.g.,
Floccia et al. 2012;
Mehler et al. 1981;
Sebastián-Galles et al. 1992). On the other hand, native speakers of languages classified as “stress-timed” (i.e., languages in which stressed syllables are spread out consistently with equal amounts of time in between; see
Conlen 2016;
Liu and Takeda 2021), like English, Dutch, and German, rely on patterns of lexical stress for speech segmentation during prelexical processing (e.g.,
Cutler et al. 1986;
Dupoux 1993;
Cutler and Norris 1988;
Mehler et al. 1981).
Although available studies on lexical segmentation report differences in the segmentation routines of speakers of syllable-timed and stress-timed languages, there is compelling evidence that argues against this rhythm class typology based on timing distinctions (for reviews, see
Arvaniti and Rodriquez 2013;
Fletcher 2010;
Loukina et al. 2011). Studies have found evidence against the view that timing is the base of speech rhythm and instead suggest that factors such as speaking rate and
F0 play a more consistent role than timing in discrimination between languages (see
Arvaniti and Rodriquez 2013). The reported differences in segmentation of languages like Spanish in comparison to languages like English may well be due to timing distinctions, differences in speaking rate, or differences in the complexity and predictability of their syllable patterns, which could facilitate using syllable structure as a cue for segmentation in some languages but not in others. Regardless of the nature of the distinction, studies have found evidence of syllabic segmentation in languages commonly classified as syllable-timed but not in languages commonly classified as stress-timed (see
Cutler et al. 1986;
Dupoux 1993;
Mehler et al. 1981). The present study uses this classification based on timing to build upon prior evidence in segmentation studies.
It is still unclear how bilinguals and second language (L2) learners who speak a syllable-timed language and a stress-timed language carry out lexical segmentation and what prelexical units they use to achieve it. The present study investigated lexical segmentation in L1 speakers and L2 learners of Spanish through a syllable detection paradigm (
Mehler et al. 1981). The study tested whether L2 learners of Spanish exhibit evidence of the use of segmentation routines that are motivated only by the phonological structure of their stress-timed L1 (English), or whether they develop speech segmentation routines that are specific to the phonological structure of their syllable-timed L2 (Spanish). The current study extends previous research to examine the influence of phonetic/phonological factors such as syllable structure and consonant sonority in prelexical processing.
Early models of lexical processing assumed that the syllable had a central role in speech recognition and that syllable-like units mediated the mapping of the speech signal onto the lexicon. For example, the Standard Syllabic Model (
Mehler et al. 1981) and the Cascade Syllabic Model (
Dupoux 1993) used a restrictive approach to speech processing which was centered around the syllable. Their assumptions were mostly based on evidence from syllable-timed languages like Italian, Spanish, and French (e.g.,
Mehler et al. 1981), but they lacked support from stress-timed languages like English (e.g.,
Bradley et al. 1993;
Cutler et al. 1986). A more dynamic model that accounts for cross-linguistic differences is the Semi-Syllables Model (
Dupoux 1993), which assumes different perceptual units depending on the phonological properties of each language. For example, Spanish speakers may use syllable-like units, whereas English speakers may use feet or other stress-based units. Evidence of the availability of different perceptual units is found in studies reporting that segmentation routines vary across languages based on their phonological composition, and that listeners can develop language-specific segmentation routines (e.g.,
Bradley et al. 1993;
Cutler et al. 1992;
Detey and Nespoulous 2008;
Katayama 2015). In the present study, the Semi-Syllables Model (
Dupoux 1993) can account for differences in the segmentation routines of Spanish L1 and English L1 subjects and the presence of language-specific segmentation.
More recent models of speech processing do not include syllabic units as universal perceptual units. They allow for the availability of different perceptual units across languages and processing levels (e.g.,
Luce et al. 2000;
Marslen-Wilson and Welsh 1978;
Marslen-Wilson 1987;
Norris 1994;
Shook and Marian 2013). While most models assume a prelexical level of representation, the perceptual units at this level differ in nature. Importantly, a few models explicitly incorporate the role of syllable structure in the mapping of the speech signal onto the lexicon (e.g.,
Luce et al. 2000;
Shook and Marian 2013). Although the syllable is not a central unit in these models, syllable structure helps modulate lexical activation and access to different degrees.
There is abundant evidence of the use of syllabic information in speech segmentation in native speakers of syllable-timed languages (e.g., French:
Cutler et al. 1986;
Mehler et al. 1981; Catalan:
Sebastián-Galles et al. 1992; Spanish:
Bradley et al. 1993; Portuguese:
Morais et al. 1989; Italian:
Floccia et al. 2012; see
Simonet 2019 for a review). Many of these studies reported that under specific conditions, monolingual speakers exhibit a target-type-by-word-type interaction in syllable detection in monitoring tasks. In a monitoring task, participants listen to lists of words as they see a specific target syllable or fragment on the screen. They are asked to detect the words that begin with the syllable or fragment that they see on the screen. A target-type-by-word-type interaction is observed when participants respond faster, or more accurately, to targets that match the syllabic structure of the first syllable of the carrier word than to targets that do not match the structure of the first syllable of the carrier word. For example, French monolinguals respond faster to the fragment “ba” in the word “balance” than in the word “balcon”, and they respond faster to the fragment “bal” in the word “balcon” than in the word “balance” (
Mehler et al. 1981).
This sensitivity to matching/mismatching syllabic information in the target-type-by-word-type interaction has been interpreted as evidence of syllabic segmentation during prelexical processing. However, studies have failed to replicate this interaction in stress-timed languages like Dutch and English (e.g., English:
Cutler et al. 1986; Dutch:
Zwitserlood 1989), suggesting that speech segmentation is language-specific and that syllabic segmentation occurs only in speakers of syllable-timed languages, while speakers of stress-timed languages use non-syllabic segmentation routines. These results are more consistent with the premises of the Semi-Syllables Model (
Dupoux 1993), which assumes different perceptual units across different languages.
Considering that monolingual speakers employ segmentation routines that are specific to the phonology of their specific language, it is then relevant to examine whether L2 learners and bilinguals employ the same segmentation routines for both of their languages or develop different language-specific routines for each of their languages. Bilinguals present an interesting scenario because they deal with two different linguistic systems, each of which has its own phonological structure with different rhythmic patterns. Studying L2 segmentation routines allows us to investigate to what extent L2 segmentation routines are restricted by the L1, whether it is possible to develop different language-specific segmentation routines, and what factors influence the development of L2 segmentation routines, among other matters that remain unclear.
Studies addressing bilingual speech segmentation in syllable-timed languages are scarce, and those available have provided mixed findings. Available evidence suggests that L2 segmentation is constrained by the phonology of the L1 or the dominant language (
Cutler et al. 1989,
1992). For instance,
Cutler et al. (
1992) tested French–English and English–French early bilinguals in three tasks: two fragment-monitoring tasks (in English and French) and a word-spotting task in English. The results of the French fragment-monitoring task revealed that only the French-dominant early bilinguals exhibited the target-type-by-word-type interaction, which is typically observed in French monolinguals. However, results of the English fragment-monitoring task yielded no target-type-by-word-type interaction for any of the groups. The results of the word-spotting task in English indicated that only the English-dominant early bilinguals used lexical stress to segment the speech signal, which is commonly observed in English monolinguals.
Cutler et al. (
1992) showed that rhythm-based language-specific segmentation routines may be mutually exclusive. The early bilinguals in this study exhibited evidence of the segmentation routine that was motivated by their dominant language only. French-dominant participants behaved like French monolinguals and exhibited syllable-based segmentation; and English-dominant participants behaved like English monolinguals. However, the lack of syllabic effects for French-dominant bilinguals with English words shows that these bilinguals employed two different segmentation routines, a syllable-based routine for French and a non-syllable-based routine for English. Thus, bilinguals with a syllable-timed L1 can develop unmarked non-syllabic segmentation routines for L2 perception whereas bilinguals with a stress-timed L1 seem to not develop syllabic routines for an L2 (
Cutler et al. 1986,
1989), which highlights the role of language dominance and L1 type in the development of L2 segmentation strategies.
Further evidence from Spanish–English bilinguals reveals differences in the segmentation routines employed by Spanish-dominant bilinguals and Spanish monolinguals.
Bradley et al. (
1993) tested Spanish monolinguals and English monolinguals in two fragment-monitoring tasks, one in Spanish and one in English. Additionally, they also tested Spanish–English early bilinguals (Spanish-dominant) in a fragment-monitoring task in Spanish. The results showed no target-type-by-word-type interaction for English monolinguals in any of the tasks. On the other hand, a target-type-by-word-type interaction was observed with Spanish monolinguals in the Spanish task but not in the English task. Spanish–English bilinguals did not exhibit a target-type-by-word-type interaction with Spanish words. These results contrast with previous evidence indicating that French monolinguals use syllable-based segmentation even for English words (
Cutler et al. 1986), suggesting that syllabic routines in Spanish monolinguals might not be as stable as in French monolinguals because they only exhibit syllabic influence in Spanish and not in English. In addition, the lack of syllabic effects in the Spanish–English bilinguals in
Bradley et al. (
1993) conflicts with the results for the French–English bilinguals in
Cutler et al. (
1992). These bilinguals did not exhibit the syllabic effects typically attributed to speakers with a syllable-timed L1. Importantly, the bilinguals in
Bradley et al. (
1993) had been living in an English-speaking country for an extended period of time. The difference between the performance of Spanish monolinguals and Spanish–English bilinguals with Spanish stimuli could indicate that either syllabic segmentation in Spanish is unstable and could easily be abandoned, or acquisition of a stress-timed L2, coupled with extended immersion in the L2 context, may cause listeners to modify their approach to input representation and abandon syllabic routines even for L1 materials.
In addition to syllable structure, phonetic information may affect speech segmentation as well. The Syllable Onset Segmentation Hypothesis (henceforth SOSH;
Content et al. 2000) suggests that syllabic information aids speech segmentation by providing possible points of alignment for the detection of possible word onsets. Since locating word boundaries implies establishing syllable boundaries, SOSH claims that speech segmentation is affected by syllable structure. Syllable onsets constitute reliable points of alignment for the lexical search process because syllable onsets often coincide with word onsets and are more salient in the signal than offsets. Consequently, detecting syllable onsets and detecting syllable offsets in the speech signal involve different processes and constraints. Syllable onset detection is more reliable and effective than syllable offset detection. In fact, in word-spotting tasks, listeners identify target words faster and more accurately when the onset aligns with a syllable onset than when the offset aligns with a syllable offset (see
Dumay et al. 2002). On the other hand, syllable offset detection is influenced by the level of sonority of intervocalic consonants (
Content et al. 2001). A common scale for sonority includes vowels > approximants (glides and liquids) > nasals > fricatives > affricates > stops, with vowels being the most sonorous sounds and stops being the least sonorous. According to SOSH, more sonorous intervocalic consonants are more likely to be assigned as codas (offset of the previous syllable), while less sonorous consonants are more likely to be assigned as onsets. Thus, L2 listeners are more likely to place a syllable boundary before less sonorous intervocalic consonants and after more sonorous intervocalic consonants.
Intervocalic consonant sonority typically affects segmentation when listeners are engaged in detection of a syllable offset, but not in detection of a syllable onset. Monolingual speakers of Spanish commonly assign single intervocalic consonants as onsets rather than offsets. Based on SOSH, English-speaking L2 learners of Spanish are more likely to exhibit native-like Spanish segmentation with less sonorous intervocalic consonants than with more sonorous intervocalic consonants. In other words, one can predict that English-speaking L2 learners of Spanish are more likely to assign fricative intervocalic consonants (e.g., /s/ in “basura”) as onsets of the following syllable (ba.su.ra) while liquid intervocalic consonants (e.g., /l/ in “balance”) are more likely to be assigned as offsets of the previous syllable (bal.an.ce). The present study manipulates syllable structure and intervocalic consonant sonority to further study patterns in segmentation of L2 Spanish in English-speaking L2 learners of Spanish and Spanish-speaking L2 learners of English. In addition, the present study includes L2 learners of different levels of proficiency to examine how segmentation routines develop as L2 acquisition progresses.
The Present Study
The present study investigates lexical segmentation in L1 and L2 Spanish. Available evidence of syllabic effects in segmentation of Spanish comes from studies addressing early bilinguals (e.g.,
Bradley et al. 1993), but studies on segmentation in adult L2 learners of Spanish are scarce. This study examines lexical segmentation in adult Spanish-speaking L2 learners of English and English-speaking L2 learners of Spanish. Studying these two groups of L2 learners provides an opportunity to assess whether listeners with a stress-timed L1 (English) develop language-specific routines for segmentation of a syllable-timed L2 (Spanish) and whether listeners with a syllable-timed L1 (Spanish) modify their segmentation routines with acquisition of a stress-timed L2 (English). In addition, while studies using word-spotting tasks have highlighted the role of consonant sonority in segmentation of French (
Dumay et al. 2002), the role of consonant sonority in segmentation of Spanish is still unclear. The current study also explores the influence of phonetic/phonological factors such as intervocalic consonant sonority and syllable structure in lexical segmentation of Spanish to test how acoustic-phonetic information modulates syllable detection and syllabic effects. Notably, available studies on syllabic effects in segmentation have not addressed possible effects of language proficiency in segmentation routines. The present study includes subjects with different levels of proficiency to examine how L2 segmentation routines vary with higher L2 proficiency. This study is driven by the following research questions:
RQ1: Are L2 learners sensitive to matching/mismatching syllable structure during a fragment-monitoring task in Spanish?
RQ2: Does intervocalic consonant sonority modulate L2 learners’ sensitivity to matching/mismatching syllable structure during a fragment-monitoring task in Spanish?
RQ3: Does L2 proficiency modulate L2 learners’ sensitivity to syllable structure during a fragment-monitoring task in Spanish?
The first research question examines whether Spanish–English learners and English–Spanish learners are sensitive to syllable structure during syllable detection in Spanish. Previous studies suggest that segmentation routines in bilinguals are constrained by the phonological composition of their first or dominant language (
Carroll 2004;
Cutler et al. 1989,
1992). Specifically, speakers with a stress-timed L1 do not typically develop L2 syllable-based segmentation routines, and it is unclear whether acquisition of an L2 is related to a modification of segmentation routines even for L1 materials. Following previous studies, the present study predicted that Spanish–English learners are likely to show sensitivity to matching/mismatching syllable structure, but English–Spanish learners are not. If syllabic effects are observed in the English–Spanish group, the results will serve as evidence that L2 learners can develop two separate language-specific segmentation routines, and that with L2 acquisition, English–Spanish learners can develop a segmentation routine that is not motivated by their L1.
The second research question asks whether intervocalic consonant sonority modulates L2 learners’ sensitivity to syllable structure in syllable detection in Spanish. SOSH (
Content et al. 2000) predicts that the sonority of intervocalic consonants modulates whether they are assigned as onsets or offsets, thus affecting syllabification and segmentation. Evidence consistent with this claim has been observed with French monolinguals (
Dumay et al. 2002), but evidence of sonority effects in L2 and bilingual segmentation is scarce. Based on SOSH and previous studies, the present study predicted that English– Spanish learners are more likely to exhibit syllabic effects, which resemble the effects in Spanish monolinguals, with less sonorous intervocalic consonants.
Finally, the third research question explores the role of L2 proficiency in syllable detection in Spanish. It is still unclear whether L2 proficiency modulates the development of L2-specific segmentation routines and whether the effects of consonant sonority and syllable structure in segmentation vary as a function of L2 proficiency. The present study predicted that higher proficiency in Spanish results in more sensitivity to matching/mismatching syllable structure.
3. Results
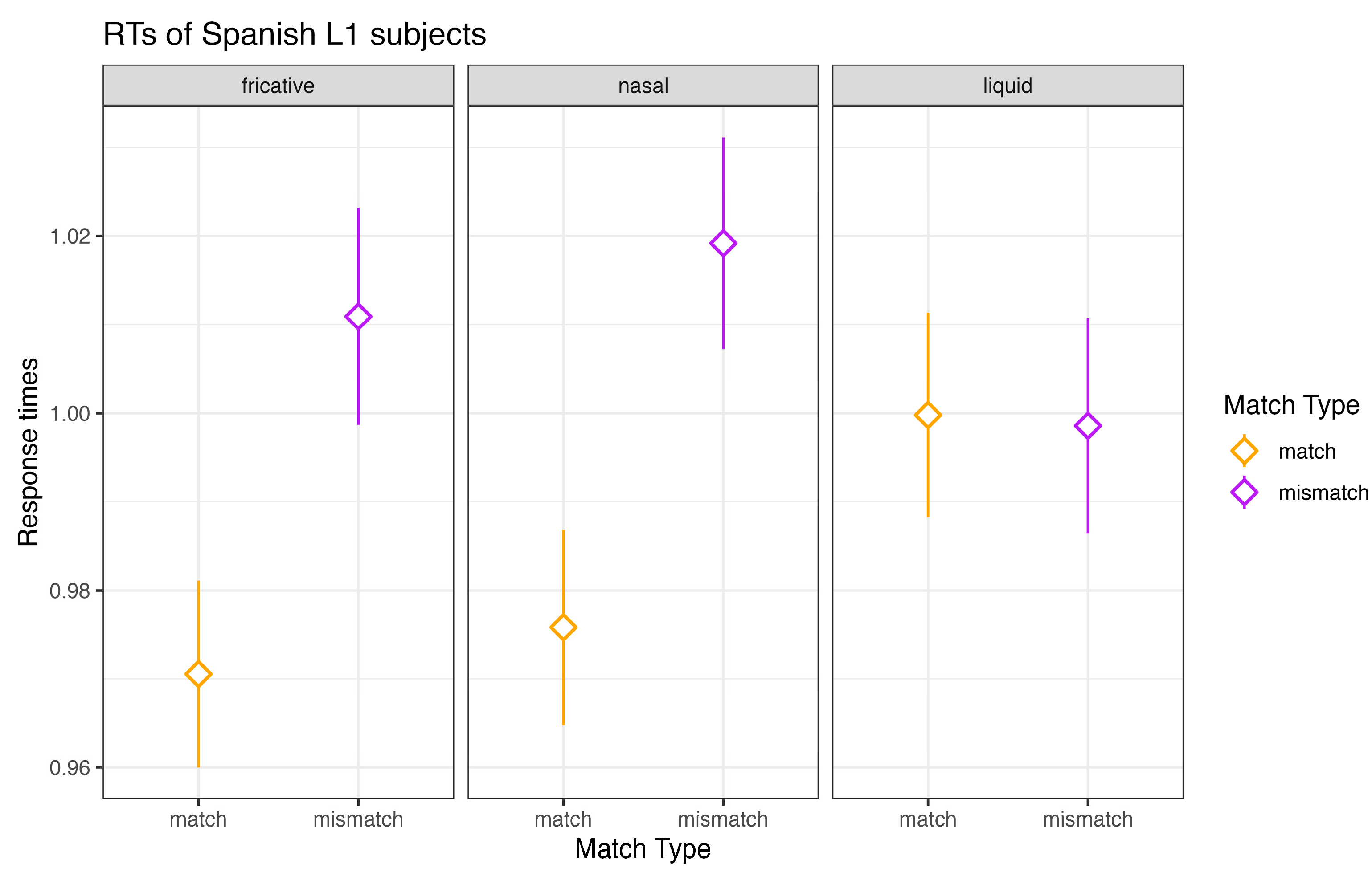
This section presents the results of the Spanish L1–English L2 subjects followed by the results of the English L1–Spanish L2 subjects. Spanish L1 subjects identified the target fragment correctly (i.e., they identified the word that contained the target sequence correctly) in over 90% of the instances. The analysis of RTs of correct responses revealed a main effect of
match type (
χ2(1) = 17.51,
p < 0.001) and a significant interaction between
match type and
sonority (
χ2(2) = 6.04,
p = 0.04). Overall, Spanish L1 subjects responded to the match condition (e.g.,
pa—
paloma) about 31 ms faster than to the mismatch condition (e.g.,
pal—
paloma) (
SE = ±0.008). However, this effect was modulated by consonant sonority. Pairwise comparisons revealed that Spanish L1 subjects responded faster to the match condition when the intervocalic consonant of the carrier word was a fricative (
p = 0.02) or a nasal (
p = 0.003). With a fricative intervocalic consonant, Spanish L1 subjects responded to the match condition approximately 42 ms faster than to the mismatch condition (
SE = ±0.013). With a nasal intervocalic consonant, Spanish L1 subjects responded to the match condition approximately 48 ms faster (
SE = ±0.013).
Figure 3 shows mean RTs in milliseconds of Spanish L1 subjects as a function of
match type and
sonority. RTs in this plot are aggregated across both target fragment structures and word types (CV or CVC).
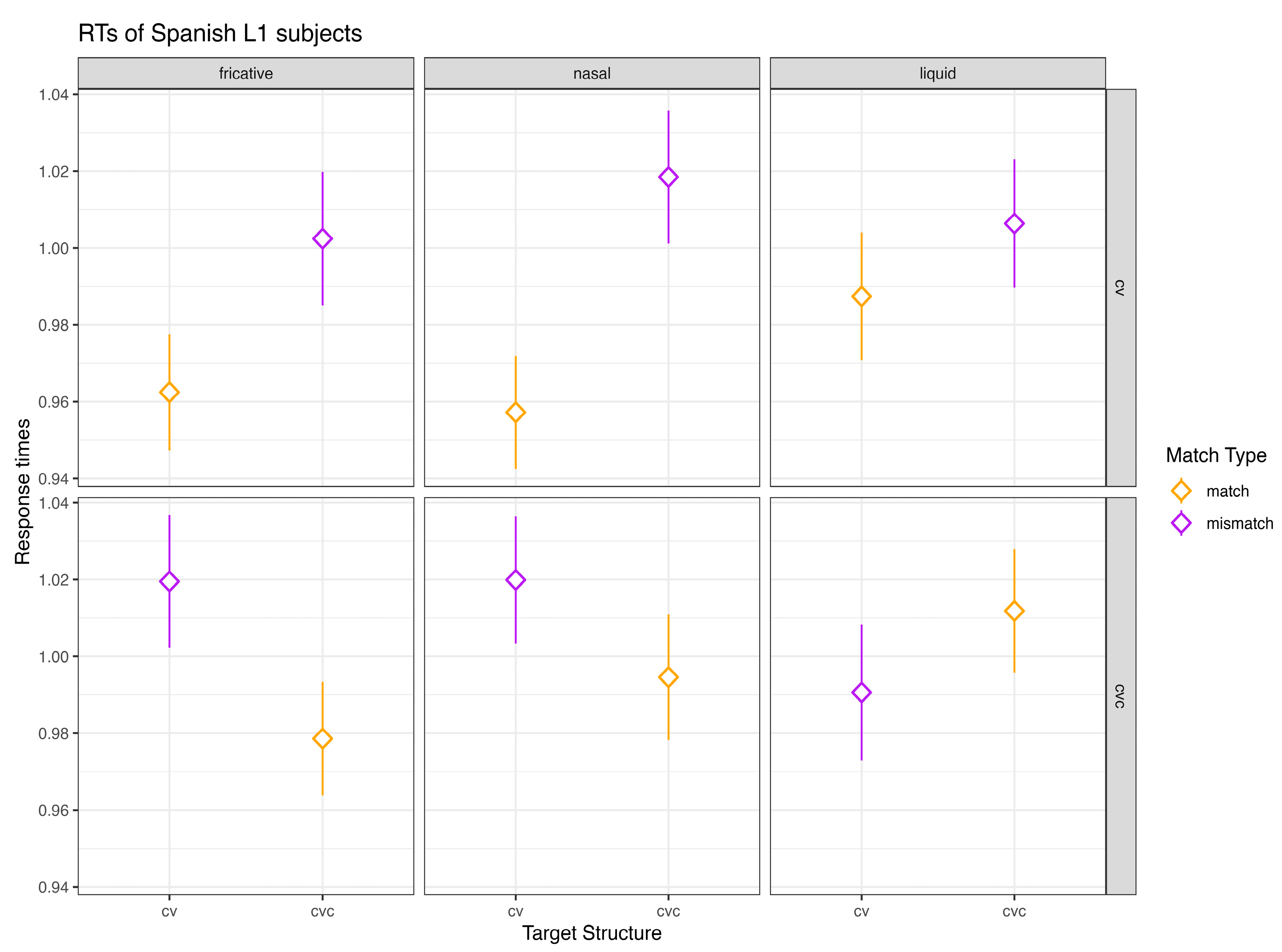
Figure 4 shows mean RTs in milliseconds as a function of
match type,
sonority, and
item structure (CV words and CVC words).
Figure 4 shows that Spanish L1 subjects responded faster to matching syllable structure regardless of consonant sonority when the target word had a CV first syllable (e.g.,
pa—
pa.lo.ma). When the target word had a CVC first syllable (e.g.,
pal.me.ra), Spanish L1 subjects benefited from matching syllable structure with a fricative or a nasal consonant but not with a liquid consonant. A summary of the final model used to make inferences on the data of Spanish L1 subjects can found in
Table 1.
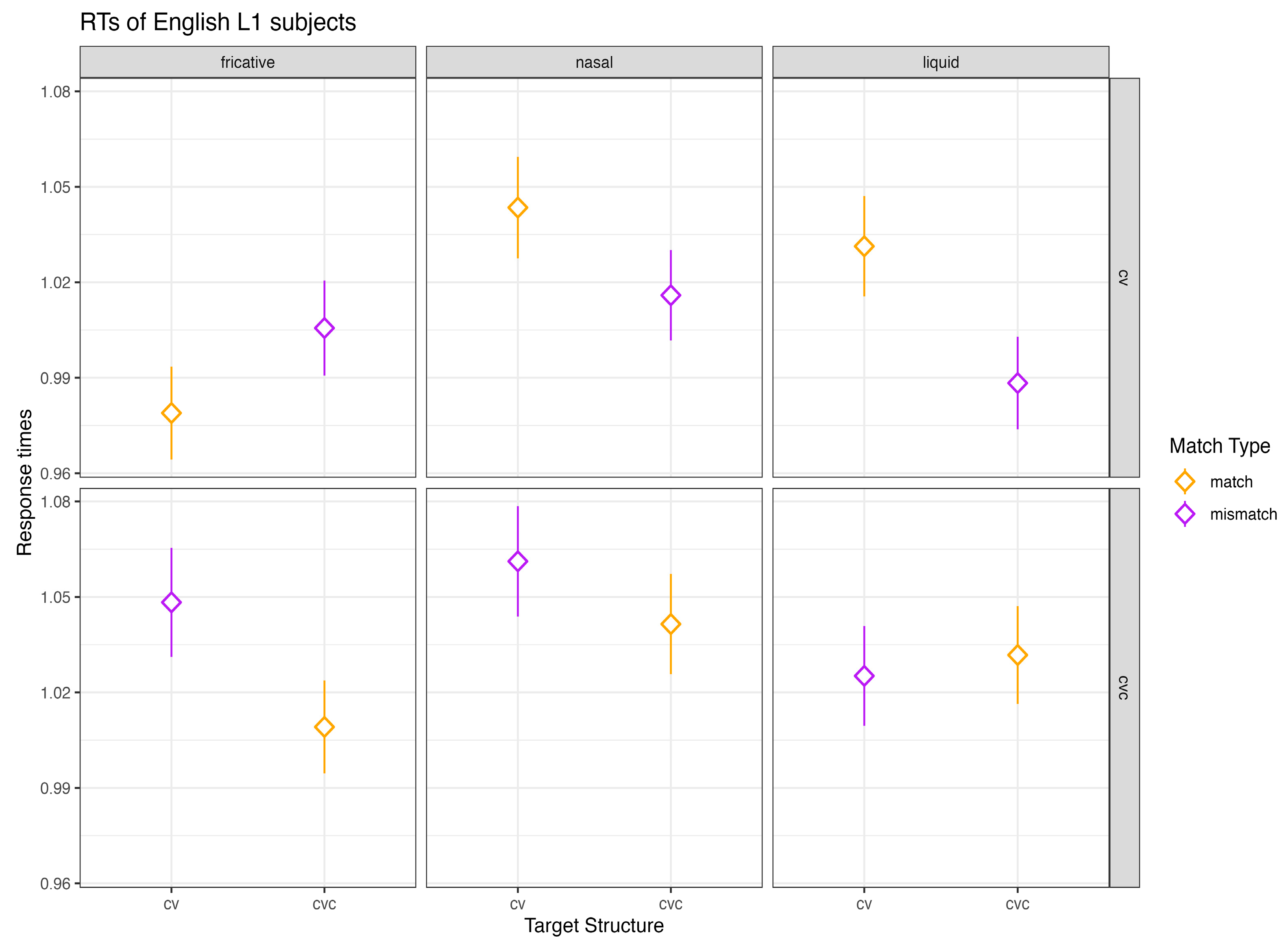
Regarding English L1–Spanish L2 subjects, they also exhibited high accuracy rates, detecting target fragments correctly in over 90% of the instances overall. The analysis of RTs of correct responses revealed no main effects of
match type,
sonority, or
proficiency. However, the models revealed a significant interaction between
match type and
sonority (
χ2(2) = 6.12,
p = 0.04). Pairwise comparisons revealed that English L1 subjects responded faster to the match condition only when the intervocalic consonant of the carrier word was a fricative (
p = 0.04). With a fricative intervocalic consonant, they responded to the match condition approximately 37 ms faster than to the mismatch condition (
SE = ±0.013) for both CV and CVC words. Interestingly, although not statistically significant, there was a trend for English L1 subjects to respond about 25 ms faster to the mismatch condition than to the match condition in CV words with a liquid intervocalic consonant and to a lesser degree with a nasal intervocalic consonant (see
Figure 5). Spanish L2 proficiency did not yield any significant effects on the response times of English L1 subjects. However, there was a trend for overall RTs to decrease as proficiency increased. Post hoc analyses yielded a significant negative correlation between overall RTs and L2 proficiency, but the correlation was not strong (
r(3383) = −0.22,
p < 0.001). For words with a fricative intervocalic consonant, English L1 subjects seemed to benefit more from matching syllable structure with higher L2 proficiency.
Figure 5 shows mean RTs in milliseconds of English L1 subjects as a function of
match type and
sonority with RTs aggregated across target and word type.
Figure 6 shows mean RTs as a function of
match type,
sonority, and
item structure (CV words and CVC words).
Figure 6 shows a shift in the pattern of RTs in CV words across levels of consonant sonority, with matching syllable structure facilitating target detection in words with a fricative consonant and mismatching structure facilitating target detection in words with a nasal or liquid consonant. A summary of the final model used to make inferences on the data of English L1 subjects can found in
Table 2.
4. Discussion
The present study investigated lexical segmentation of Spanish in English-speaking L2 learners of Spanish and Spanish-speaking L2 learners of English. More specifically, the study examined whether L2 learners exhibit the use of language-specific segmentation when monitoring syllabic fragments in Spanish. The study used a fragment-monitoring task to test whether L2 learners were sensitive to matching/mismatching syllable structure and assess the influence of intervocalic consonant sonority and L2 proficiency on lexical segmentation of Spanish.
The first research question focused on L2 learners’ sensitivity to matching/mismatching syllable structure during segmentation of Spanish. Previous studies showed that segmentation routines in bilinguals are constrained by the phonological composition of their first or dominant language, with English L1 speakers having more difficulty to develop L2-specific syllable-based segmentation routines (
Bradley et al. 1993;
Carroll 2004;
Cutler et al. 1989,
1992;
Dupoux 1993). The results of the current study are in line with previous findings since Spanish L1 subjects and English L1 subjects benefited from matching syllable structure in different ways. Participants identified target syllables faster when they matched the structure of the first syllable of the carrier word, but this effect of matching/mismatching syllable structure was modulated by consonant sonority, affecting RTs of Spanish L1 subjects and English L1 subjects differently. When including all target and word types, Spanish L1 subjects responded faster to the match condition with a fricative and a nasal intervocalic consonant, but not with a liquid; and English L1 subjects responded faster to the match condition only with a fricative intervocalic consonant. When looking at the interplay of target type, word type, and consonant sonority, Spanish L1 subjects responded faster to matching syllable structure across all levels of sonority when the carrier word had a CV first syllable. English L1 subjects, on the other hand, responded faster to matching syllable structure with CV words with a fricative consonant, and they responded faster to mismatching syllable structure with CV words with a nasal or liquid consonant. Both groups exhibited different patterns which corresponds to the L1/L2 status of Spanish and the type of segmentation strategies that are motivated by participants’ L1.
The presence of syllabic effects in the Spanish L1–English L2 subjects in the present study is consistent with previous studies that reported syllabic effects in L1 speakers of languages with predictable syllable patterns like Spanish (e.g.,
Bradley et al. 1993), French (e.g.,
Cutler et al. 1989,
1992;
Dumay et al. 2002;
Mehler et al. 1981), Portuguese (e.g.,
Morais et al. 1989), and Italian (e.g.,
Floccia et al. 2012). However, these results differ from the results of
Bradley et al. (
1993), where Spanish-dominant early bilinguals did not exhibit syllabic effects in Spanish. The discrepancy may correspond to differences in the age and mode of acquisition and L2 immersion since the participants of the present study acquired L2 English after puberty through formal instruction, while those in
Bradley et al. (
1993) lived immersed in the context of the L2 since early childhood, which may have influenced the segmentation strategies that they employed. Importantly, the presence of syllabic effects in English L1–Spanish L2 subjects in the present study differs from previous studies claiming that L1 speakers of stress-based languages like English are unable to develop syllable-based segmentation routines for an L2 (e.g.,
Carroll 2004;
Cutler et al. 1989,
1992). In the present study, differences in syllabic structure between the target and the carrier word affected RTs of English L1 subjects, but the pattern varied based on consonant sonority, highlighting the role of phonetic information in speech segmentation.
The second research question focused on the role of consonant sonority in speech segmentation. The Syllable Onset Segmentation Hypothesis (SOSH;
Content et al. 2000) predicts that the sonority of intervocalic consonants modulates whether they are assigned as onsets or offsets. Less sonorous intervocalic consonants are syllabified into the next syllable as onsets (e.g., “pa.
sa.je”), and more sonorous intervocalic consonants are more likely to be syllabified into the previous syllable as codas (e.g., “ba
l.an.ce”), thus affecting syllabification and segmentation. Evidence consistent with this claim has been observed with French monolinguals (
Dumay et al. 2002), but evidence in L2 learners and bilinguals is scarce. The results of the current study are in line with the assumptions of SOSH. Intervocalic consonant sonority modulated the effects of matching/mismatching syllable structure in the same direction as predicted by SOSH. Spanish L1 subjects exhibited stronger syllabic effects overall with the less sonorous consonants, and English L1 subjects benefited from matching syllable structure only with the least sonorous consonant. As the level of sonority increased, English L1 subjects displayed a reversed effect, which can be explained by the influence of sonority in syllabification assumed by SOSH. English L1 subjects may have employed different syllabification for words with more sonorous intervocalic consonants, which does not match syllabification patterns expected for Spanish, causing the reversed effect. If, according to SOSH, English L1 subjects syllabified more sonorous consonants (liquids and nasals) as offsets of the previous syllable (e.g., “
pal.o.ma” and “
con.e.jo”), the mismatch condition in the present study actually represented a match for English L1 subjects (e.g., “pal—
pal.o.ma”). Consequently, what the present study coded as mismatching structure actually facilitated target detection due to English L1 subjects applying different syllabification to words with more sonorous consonants.
The last research question asked about the role of L2 proficiency in segmentation of Spanish. In this study, L2 proficiency did not yield any significant effects or interactions. However, there was a trend for English L1–Spanish L2 subjects to detect target sequences faster as L2 proficiency increased, but their sensitivity to matching/mismatching information did not vary as much as a function of L2 proficiency. In general, there was a trend for English L1–Spanish L2 subjects to respond faster to the match condition than to the mismatch condition with fricative intervocalic consonants, and as proficiency increased, the difference in RTs for match/mismatch became bigger. This trend could point to the possibility of higher L2 proficiency increasing sensitivity to syllable structure, but further research is needed. Additionally, in the case of liquid intervocalic consonants, the results showed that English–Spanish learners responded faster to the mismatch condition at lower levels of proficiency, but as proficiency increased, there was a slight shift in the opposite direction to observe faster responses to the match condition at higher levels of proficiency. A similar pattern was observed for nasal intervocalic consonants but to a lesser degree. The trend could suggest that the effects of consonant sonority predicted by SOSH, especially those that do not match the syllabification typically used in L2 Spanish (with more sonorous consonants), can shift with higher L2 proficiency and begin to resemble patterns observed in L1 speakers of Spanish. Future research is needed to disentangle the influence of L2 proficiency in L2 segmentation.
The results of the present study support syllabic models of speech segmentation such as the Standard Syllabic Model (
Dupoux 1993;
Mehler et al. 1981), the Cascade Syllabic Model (
Dupoux 1993), and the Semi-Syllables Model (
Dupoux 1993) with regard to the influence of syllable structure in speech segmentation. The present study does not claim that the syllable has a privileged role in speech perception, as some of these models state, but the results suggest that syllable structure is involved in the process of speech segmentation even for L2 learners with a stress-timed L1. Likewise, although the results of the present study do not provide word recognition data, they could also inform models of spoken-word recognition. The Cohort Model (
Marslen-Wilson and Tyler 1980;
Marslen-Wilson and Welsh 1978;
Marslen-Wilson 1987) assumes that during lexical access, only lexical items that coincide with the onset of the incoming input are co-activated as a cohort. If syllable structure is involved in this process, the Cohort Model could account for the results of the present study because subjects responded faster when the target syllable coincided with the structure of the first syllable of the incoming carrier word. Based on the Cohort Model, one could assume that in a fragment-monitoring task, listeners more easily activate lexical items that are in the cohort pre-activated by the target syllable shown on the screen. Similarly, the results of this study are also in line with the PARSYN model (
Luce et al. 2000), which is an instantiation of the Neighborhood Activation Model (NAM) (
Luce and Pisoni 1998). PARSYN assumes that lexical activation flows in a bottom-up fashion and that at lower levels of recognition, pre-lexical information such as syllable structure affects the activation of lexical items, with mismatching information being inhibited. These models, however, do not account for the interactions between syllable structure and consonant sonority observed in segmentation and syllabification in the present study. Future models should take into account the influence of phonetic and phonological factors within and across languages to explain the processes involved in speech segmentation in bilingual and multilingual individuals.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}