1. Introduction
One of the defining characteristics of human language is that an element in a sentence can appear in a different position than the one in which it is interpreted, e.g., in long-distance extraction:
| 1. | Who do you think [that I saw __]? |
In this example, the question word
who has been displaced to the front of the matrix clause, but it is interpreted as the direct object of the main verb in the embedded clause. The link between these two positions is called a filler-gap dependency and such dependencies are in principle unbounded. However,
Ross (
1967) identified a range of structures that (to varying degrees) block extraction which he termed “islands”. It has since become common to distinguish between weak (or selective) and strong (or absolute) islands (e.g.,
Kluender 1998;
Szabolcsi 2006;
Szabolcsi and Lohndal 2017), depending on the degree to which it is possible to extract from such structures.
Island effects are widespread across the languages of the world and they have been used as an argument for the existence of innate linguistic principles. The language-acquiring child is allegedly not exposed to these types of extractions and the lack of negative evidence has been taken to suggest that certain constraints on filler-gap dependencies are part of universal grammar, either as principles or parameters.
Effects of repeated exposure (satiation, priming, and/or training effects) have been widely attested in the literature on island structures (
Chaves and Putnam 2020;
Christensen et al. 2013;
Snyder 2000,
2022). Such effects may suggest that the constructions in question are in fact not illicit, but rather that they are unusual and/or highly complex, giving rise to initial processing difficulty and resulting in decreased acceptability, which is then ultimately ameliorated as speakers adapt to them.
In the syntax literature, finite adjunct clauses have traditionally been assumed to be strong islands cross-linguistically, as exemplified in (2) from
Szabolcsi (
2006, p. 481):
| 2. | *Which topic did you leave [because Mary talked about __]? |
The ungrammaticality of (2) has been accounted for under the
Condition on Extraction Domain (CED,
Huang 1982, p. 505). This constraint states that a phrase can only be extracted out of a domain that is properly governed, and hence both subjects and adjuncts should be island environments (cf. the Empty Category Principle,
Chomsky 1981, p. 205ff;
Haegeman 1994, p. 442). The CED has been thought to be an innate, universal principle (along with a number of other island constraints, subsequently subsumed under e.g., subjacency, Chomsky 1973), given the learnability problem imposed by the purported lack of negative evidence in the input during language acquisition. However, counterexamples abound in the Mainland Scandinavian (MSc.) languages. Recent studies on Norwegian (
Kush et al. 2019;
Bondevik et al. 2020) have found that topicalization (but not
wh-movement) out of conditional adjunct clauses headed by
om (‘if’) appears to be possible. In addition,
Müller (
2017) found that topicalization from adjunct clauses headed by
om (‘if’) and
efter (‘after’) in Swedish yielded acceptability ratings on the upper end of the scale, provided that the matrix and the adjunct clause event can be interpreted to be in a causal, coherent relation e.g., (3a), rather than in a purely temporal one e.g., (3b).
| 3. | a. | Det där röda vinet | mådde | jag | lite | illa |
| | | this there red wine.the | felt | I | a.little | sick |
| | | [efter | att | jeg | hade | druckit | ___ | sist]. |
| | | after | that | I | had | drunk | | last |
| | | ‘I felt a little sick after I had drunk that red wine last time.’ |
| | b. | Det röda | kan | vi | ju | gå | ut | på | stan |
| | | the red | can | we | prt1 | go | out | on | town.the |
| | | [efter | att | vi | har | druckit | ___]. |
| | | after | that | we | have | drunk | |
| | | ‘We can go out on the town after we have drunk the red wine.’ |
However, other types of adjunct clauses—specifically, clauses introduced by
fordi ‘because’ in Norwegian and
eftersom ‘because’ in Swedish—were found to be much less permissive in terms of extraction in these studies in the sense that most participants rated topicalization from them on the low end of the scale (
Bondevik et al. 2020;
Müller 2017). This has given rise to conjectures that different types of adjunct clauses, or adjunct clauses headed by different complementizers, may vary with regard to extraction possibilities (
Bondevik 2018, p. 201;
Bondevik et al. 2020;
Müller 2017,
2019). Moreover, the studies by
Kush et al. (
2018,
2019) and
Bondevik et al. (
2020), among others, suggest that topicalization from adjunct clauses is easier to accept than question formation by
wh-extraction, indicating that the acceptability of extraction might also depend on the type of extraction (see also
Lindahl 2017;
Müller 2019; and
Abeillé et al. 2020 for suggestions along these lines).
Another factor that has been suggested to be important for the felicity of at least some island extractions in MSc. in formal acceptability studies is whether the stimulus sentences are preceded by one or more sentences providing a facilitating context. More specifically, some of the formal studies of adjunct or relative clause extraction in MSc. have yielded acceptability ratings that are unexpectedly low, given the examples provided in the literature and the informal observations reporting such structures to be acceptable in MSc. (e.g.,
Christensen and Nyvad 2014;
Kush et al. 2018). It has been suggested that these unexpectedly low ratings can be partly explained by the lack of contextual cues in formal settings (e.g.,
Tutunjian et al. 2017;
Wiklund et al. 2017, p. 207;
Kush et al. 2018;
Müller 2019, p. 209;
Bondevik et al. 2020). Contextual cues may be required for the felicity of at least some of these extractions if for instance a context is necessary to license certain interpretational properties of the extracted phrase, such as D(iscourse) linking or specificity (
Pesetsky 1987;
Szabolcsi 2006). The licensing of such interpretational properties has been claimed to be relevant for the felicity of weak island extractions (see e.g.,
Starke 2001;
Szabolcsi 2006;
Abrusán 2014). In a recent study on Norwegian,
Kush et al. (
2019) found support for the beneficial effect of context on ratings for at least some adjunct clause extractions: A significant island effect (in terms of the factorial definition of island effects developed by
Sprouse 2007) was observed for decontextualized extraction from conditional adjuncts, but no significant island effect occurred once a contextual preamble was added to the stimuli sentences. In fact, the participants in this study rejected sentences involving contrastive topicalization from complement clauses, uncontroversially considered to be grammatical, presumably at least in part because they were presented in vacuo. More general evidence in favor of the facilitative role of supporting context for the comprehension of fronted elements is presented by
Engelkamp and Zimmer (
1983),
Kristensen et al. (
2014), and
Lau et al. (
2020), but see
Bernardy et al. (
2018). The question remains whether English sentences such as (2) can be ameliorated by being presented in a facilitating context.
Kush et al. (
2018) found significant inter-individual variation relating to the acceptability judgements of sentences involving
wh-movement out of embedded polar questions in Norwegian (headed by
om ‘if’), including a large number of participants not exhibiting any island sensitivity to this type of extraction.
Kush et al. (
2018) conclude that this pattern of inter-participant variation is incompatible with embedded questions being syntactic islands in Norwegian and they argue that the variability in acceptability is actually indicative of extra-syntactic factors being at play. Similarly,
Bondevik et al. (
2020) and
Kush et al. (
2019) found both inter- and intra-participant variation as well as variation between and within adjunct types in Norwegian.
The above-mentioned studies (
Bondevik et al. 2020;
Kush et al. 2018,
2019;
Müller 2017) indicate that adjunct clauses in the MSc. languages display a non-uniform behavior when it comes to their island sensitivity, and that the possibility of extraction is affected by various factors, including the type of adjunct clause, the type of extraction dependency, contextual facilitation, and semantic coherence
2. These findings seem to call for a re-evaluation of the situation in English regarding adjunct islandhood. To date, only few formal acceptability studies of extraction from finite adjunct clauses in English exist, and almost all of them focus on
wh-extraction from only one type of adjunct clause and do not provide any contextual facilitation (e.g.,
Sprouse 2009;
Sprouse et al. 2012;
Michel and Goodall 2013). Though
Sprouse et al. (
2016) also investigated extraction by relativization from
if-adjuncts, they did not compare it to extraction from other types of adjunct clauses. In order to adequately evaluate whether English finite adjunct clauses really are uniformly strong islands, as reported in the traditional literature (and to allow for a fair comparison between English and MSc. adjunct islands), an investigation that tests adjunct clause extraction in English controlling for the above-mentioned factors (type of adjunct, dependency type, presence/absence of supporting context, and coherence) is necessary. In this paper, we present a study that aims to fill (parts of) this gap, by testing extraction in the form of relativization from three different types of finite adjunct clauses in English (
if-,
when-, and
because-clauses) in the presence of supporting context.
We chose to test extraction in the form of relativization rather than topicalization since topicalization is a fairly marked structure in English compared to the MSc. languages (e.g.,
Engdahl 1997;
Poole 2017, p. 15). There are some indications that relativization behaves on a par with topicalization in that both seem to facilitate extraction from certain islands, compared to
wh-movement.
Sprouse et al. (
2016) compared
wh-extraction and relativization out of adjunct clauses in English and found that relativization from
if-clauses does not result in island effects in terms of the factorial definition of islands (although ratings for both relativization and question formation remained relatively low). Recently,
Abeillé et al. (
2020) showed that relativization (but not question formation) from subject islands in English as well as in French received ratings on par with grammatical controls. Moreover, there are indications that spontaneously produced cases of adjunct clause extractions primarily feature relativization from the adjunct: to see whether any authentic examples of adjunct island extraction can be found in English,
Müller and Eggers (
2022) conducted an exploratory corpus study on adjunct extraction using the
Corpus of Contemporary American English (COCA;
Davies 2008). All cases of adjunct clause extraction found in naturalistic English in their study involved relativization from the island, such as the examples in (4), both from COCA.
| 4. | a. | Many of the exercises are ones that I would be surprised if even 1 percent of |
| | | | healthy women can do. |
| | b. | Now, those are things that I feel very warm when I look at, and I wouldn’t |
| | | | want to live in a house that they—a house that didn’t have room for those. |
On a purely syntactic account, the level of acceptability of extraction out of finite adjunct clauses should be uniform across adjunct types, given that they have the same syntactic structure and that they are assumed to be adjoined to the matrix clause in the same way. Furthermore, gradient acceptability of extraction from adjunct clauses is not predicted by the CED either.
As an alternative to purely syntactic accounts of island constraints,
Chaves and Putnam (
2020) propose that a host of islands traditionally assumed to be of syntactic nature are instead “Relevance Islands”: the filler must be “relevant for the main action that the proposition conveys” and if it is not, unacceptability ensues as a natural consequence, without the need for postulating constraints in the syntax (
Chaves and Putnam 2020, p. 120; in line with other semantic or discourse-pragmatic accounts such as
Erteschik-Shir 1973;
Deane 1991). Prima facie, even a semantico-pragmatic account of island effects such as the one proposed by Chaves and Putnam would predict uniformly low acceptability of adjunct clause extraction since adjunct clauses are typically used to express backgrounded or presupposed information (see also e.g.,
Van Valin 1994;
Erteschik-Shir 2006;
Goldberg 2013, p. 203 for accounts in a similar vein).
2. Predictions
In light of the counterexamples to supposed universal constraints found in the MSc. languages,
Christensen and Nyvad (
2019,
2022) re-examined
wh-islands and relative clause extraction in English in order to investigate whether the same island-insensitivity and graded acceptability could also be demonstrated for English. However, the results support the hypothesis that the syntactic configurations in question (embedded
wh-questions and relative clauses) are strong islands in this language, as is standardly assumed in the syntactic literature (but see
Vincent et al. 2022). Given this compatibility of experimental findings in English with the standard assumptions in the syntax literature (the
Wh-Island Constraint and the Complex NP Constraint, respectively), our predictions regarding extraction from adjunct clauses are based on the CED, which treats all adjunct clauses as a coherent class in terms of islandhood, potentially ruling out any scope for variation:
Prediction 1. Adjunct clauses are strong islands, i.e., their acceptability level is consistently low.
Prediction 2. There is no variation in acceptability as a function of adjunct clause type.
Prediction 3. There is no between-participant variation.
Prediction 4. There is no trial effect. The acceptability of extraction is not positively correlated with repeated exposure over time in the experiment, regardless of the type of adjunct clause.
We included subject islands and coordinate structure islands as fillers and as points of comparison, given that these structures are also assumed to be strong islands in English, but with different strengths. The Subject Condition (
Ross 1967;
Chomsky 1973) has been proposed not to be active across all types of constructions:
Kush et al. (
2018,
2019) found substantial island effects in the acceptability rating of constructions involving movement out of subject phrases. However, extraction from subjects has been demonstrated to be grammatical in certain instances, depending on referential processing (
Culicover and Winkler 2022;
Culicover et al. 2022), discourse function (
Abeillé et al. 2020), and repeated exposure (
Chaves and Putnam 2020, p. 221). The Coordinate Structure Constraint, on the other hand, appears to hold cross-linguistically, and no robust counterexamples seem to have been identified (
Chaves and Putnam 2020, p. 72).
3 This way, we had two different points of comparison in terms of patterns of ungrammaticality.
3. Materials and Methods
Our design was based on a 2 × 2 stimulus design with the structure outlined in
Table 1, with ±Island and ±Extraction as the two factors; this is similar to the factorial design introduced by
Sprouse (
2007) and subsequently employed by e.g.,
Sprouse et al. (
2011,
2016) and
Bondevik et al. (
2020). In addition, our design had a Complementizer factor with four different levels:
that,
if,
when, and
because.
That-clauses are not assumed to be islands, since they are complement clauses, whereas the other three types introduce adjunct clauses. This design gave us eight target types (see
Table 1), which we used as the levels for a Type factor for our statistical model in order to test for interactions between extraction and the four clause types.
Each target stimulus sentence was preceded by a short facilitating context. We constructed the materials in such a way that all eight types could be preceded by the same context, as shown in (5):
| 5. | | Context: In the latest workout routine I designed for Emma, I really wanted to make it impossible for her and included another set of particularly brutal pull-ups. |
| | | Non-island structure, [-Extraction]: |
| | a. | It’s obvious that I was surprised that she actually completed this exercise. |
| | | Island structure, [-Extraction]: |
| | b. | It’s obvious that I would be surprised if she actually completed this exercise. |
| | c. | It’s obvious that I was surprised when she actually completed this exercise. |
| | d. | It’s obvious that I was surprised because she actually completed this exercise. |
| | | Non-island structure, [+Extraction]: |
| | e. | This is the exercise that I was surprised that she actually completed __. |
| | | Island structure, [+Extraction]: |
| | f. | This is the exercise that I would be surprised if she actually completed __ |
| | g. | This is the exercise that I was surprised when she actually completed __. |
| | h. | This is the exercise that I was surprised because she actually completed __. |
Distinct from the factorial design introduced by
Sprouse (
2007) and subsequently employed by e.g.,
Sprouse et al. (
2011, p. 201;
2016),
Bondevik et al. (
2020), the main matrix clauses of the stimulus sentences are not minimally different, but they are as minimally different as they can be. The sentences without extraction (the baseline versions) all begin with
It’s obvious that… or
It’s clear that…, whereas the sentences with extraction all begin with
This is the X that… (where
the X is the extracted filler). The stimulus set was created this way because we prioritized having relativization out of the adjunct clauses (see
Section 1 above). There is no direct unextracted counterpart to relativization that our [+Extraction] sentences could be compared to, but the
It’s obvious that… or
It’s clear that… constructions used for the matrix in our baseline sentences are as similar as possible in terms of length and complexity to the cleft structure used in the relativization condition. Note that both matrix structures add very little to the overall structure and meaning (we used pronouns and copula
be). We acknowledge that this makes the ±Extraction contrast not minimally different, but there are no a priori reasons to suspect that these small differences would affect the acceptability ratings.
As illustrated in (5) and in
Table 1, we wanted to compare three different types of adjunct islands:
if-clauses,
when-clauses and
because-clauses. The adjunct clauses and non-island
that-clauses were embedded under adjectival psych-predicates such as
be surprised or
be happy, which can be expected to trigger a causal and thus semantically coherent reading of the matrix and embedded event. The presence of a causal, coherent relation between the matrix and the adjunct clause has previously been shown to facilitate extraction from adjuncts (
Truswell 2011;
Tanaka 2015;
Müller 2019). In order to allow for a felicitous use of the
if-clauses, the verbal structure in the matrix clause was slightly altered in the conditions involving
if-adjuncts (5b,f) compared to the other conditions: instead of past tense
was, the structure
would be + psych-adjective was used, signaling the hypothetical.
Twenty-four sets of items of the type in (5) were constructed and distributed across eight lists in a Latin square design. In this way, each list contained only one version of the same scenario; since each participant saw only one list, each participant was exposed to three tokens of each type. The order of sentences on each list was randomized. As mentioned in the introduction, we also added two types of fillers: eight sets involving extraction from NP subjects, filler 1, as in (6), and eight sets involving extraction from coordinate structures, filler 2, as in (7). The NP subjects and the coordinate structures were embedded in the same four clause types that we used in target items, i.e., non-island
that-clauses, and adjunct clauses introduced by
if,
when, and
because (see
Table 1). Each of these conditions with extraction was compared to the corresponding version without extraction, resulting in eight control conditions that could easily be compared to our target items. (The entire stimulus set is available online, see Data Availability Statement).
| 6. | | Filler 1. |
| | | Context: My team has developed a COVID-19 vaccine in record time, and I think we deserve some recognition. |
| | | Subject island + non-island that-clause, [-Extraction]: |
| | a. | It’s clear that we were pleased that our vaccine against this virus finally got the Nobel Prize. |
| | | Subject island + adjunct island, [-Extraction]: |
| | b. | It’s clear that we would be pleased if our vaccine against this virus finally got the Nobel Prize. |
| | c. | It’s clear that we were pleased when our vaccine against this virus finally got the Nobel Prize. |
| | d. | It’s clear that we were pleased because our vaccine against this virus finally got the Nobel Prize. |
| | | Subject island + non-island that-clause, [+Extraction]: |
| | e. | This is the virus that we were pleased that our vaccine against __ finally got the Nobel Prize. |
| | | Subject island + adjunct island, [+Extraction]: |
| | f. | This is the virus that we would be pleased if our vaccine against __ finally got the Nobel Prize. |
| | g. | This is the virus that we were pleased when our vaccine against __ finally got the Nobel Prize. |
| | h. | This is the virus that we were pleased because our vaccine against __ finally got the Nobel Prize. |
| . | | Filler 2. |
| | | Context: I had promised a friend to watch his pets for a week. Unfortunately, I accidentally left the front door open just a bit too long and both his cat and his prize-winning show dog ran out. |
| | | Coordinate structure island + non-island that-clause, [-Extraction]: |
| | a. | It’s obvious that I was ashamed that I actually lost both the cat and this dog in one day. |
| | | Coordinate structure island + adjunct island, [-Extraction]: |
| | b. | It’s obvious that I would be ashamed if I actually lost both the cat and this dog in one day. |
| | c. | It’s obvious that I was ashamed when I actually lost both the cat and this dog in one day. |
| | d. | It’s obvious that I was ashamed because I actually lost both the cat and this dog in one day. |
| | | Coordinate structure island + non-island that-clause, [+Extraction]: |
| | e. | This is the dog that I was ashamed that I actually lost both the cat and __ in one day. |
| | | Coordinate structure island + adjunct island, [+Extraction]: |
| | f. | This is the dog that I would be ashamed if I actually lost both the cat and __ in one day. |
| | g. | This is the dog that I was ashamed when I actually lost both the cat and __ in one day. |
| | h. | This is the dog that I was ashamed because I actually lost both the cat and __ in one day. |
Participants were instructed to base their rating only on the sentence following the context. The context in our stimuli was constructed so that it triggered a cohesive interpretation of the extracted DP in the discourse in the [+Extraction] conditions.
Participants were recruited via professional connections and through various social media platforms and were randomly assigned to one of the eight presentation lists. They rated the sentences using an online questionnaire created with Google Forms. Judgments were given on a seven-point Likert scale ranging from 1 = ‘completely unacceptable’ to 7 = ‘completely acceptable’. The participants had the opportunity to leave comments on every test sentence.
4. Results
A total of 235 native speakers of English (188 female, 41 male, 6 other) participated in the experiment on a voluntary basis. Participant age ranged from 18 to 74 years (mean = 33.19, SD = 10.79). The level of education in years (including e.g., primary and secondary school, college, university, PhD, etc.) ranged from 9 to 30 years (mean = 18.00, SD = 3.19). The number of participants per list ranged between 24 and 39 (list 1 = 25, list 2 = 28, list 3 = 30, list 4 = 29, list 5 = 39, list 6 = 32, list 7 = 24, list 8 = 28).
Prior to analysis, we removed one of the target sets (a set of 8 sentences with the same context) because it turned out the that [−Extraction] sentence (as in (5a) above) was pragmatically illicit. Since we wanted to use that [−Extraction] as baseline for the island effect size measure (i.e. the DD-score in Figure 4 below), including this in the analysis would skew the result.
Table 2 contains the mean acceptability scores for all the conditions.
Extraction from adjunct clauses (target sentences as in (5) above), extraction from embedded subjects (filler type 1, as in (6)), and extraction from the second conjunct in a coordinate structure (filler 2, as in (7)) were analyzed using separate mixed-effects models. (We had no prior hypotheses about statistical differences between the three, and since the three sentence types were not minimally different, direct comparisons would also be inappropriate).
4.1. Target Type: Adjunct Islands
The model contained acceptability as an outcome variable and type as a predictor (with sliding contrasts) and random intercepts for participant and item, and random slopes for type and trial by participant, and random slopes for trial by item. The summary of the results is provided in
Table 3.
The results and sliding pairwise comparisons for the eight target sentence types are also shown in
Figure 1A. The acceptability ratings for the four baseline conditions [−Ex] all had a rating above 5 on the 7-point scale. There was a significant drop in acceptability between the [−Ex] and [+Ex] types, indicating a significant negative main effect of extraction, [−Ex] > [+Ex], as shown by the contrast between
because [−Ex] and
that [+Ex] (
p < 0.001, see also
Figure 1). (Running the same model without sliding contrasts showed significant differences between
that [−Ex] and
that [+Ex] (
p < 0.001) as well as between
that [−Ex] and
if/when [−Ex], while the difference between
that [−Ex] and
because [−Ex] was not significant). Within the [+Ex] types, while the ratings for
that and
if did not differ from each other, they were both rated significantly higher than
when, which was rated significantly higher than
because.
4.2. Filler Type 1: Subject Islands
As in the target condition, the model had acceptability as outcome variable and type as predictor (with sliding contrasts). However, the only convergent model had no random slopes, only random intercepts for participant and item. The model is summarized in
Table 4.
The results and sliding pairwise comparisons for the eight sentence types are also shown in
Figure 1B. There were no significant differences between the four baseline [−Ex] types, which were all rated in the top range. In contrast, the four [+Ex] sentence types were all in the lower range, and they were all significantly different from the [−Ex] types. In other words, there was a clear and significant negative main effect of extraction. There was also a marginally significant difference between
if [+Ex] and
when [+Ex] (
p = 0.082).
4.3. Filler Type 2: Coordinate Structure
The converging model contained acceptability as outcome variable and type as predictor (with sliding contrasts) and random intercepts for participant and item, and random slopes for trial by participant and item. The model is summarized in
Table 5.
See also
Figure 1C for the results and sliding pairwise comparisons for the eight sentence types. Similar to the findings for filler 1, the acceptability ratings for the four baseline conditions [−Ex] were all in the top range, whereas the four [+Ex] sentence types were all in the lower range. There was a marginal difference between
that [−Ex] and
if [−Ex] and a significant difference between
when [−Ex] and
because [−Ex]. As with filler 1, the most dramatic effect is the negative main effect of extraction, as indicated by the difference between
because [−Ex] and
that [+Ex] (
p < 0.001).
Figure 1.
Mean (raw) acceptability ratings. *** p < 0.001, ** p < 0.01, marginal: · p < 0.1.
Figure 1.
Mean (raw) acceptability ratings. *** p < 0.001, ** p < 0.01, marginal: · p < 0.1.
To see if the general acceptability pattern in the target condition (
Figure 1A) was consistent across the 23 sets (or contexts, see
Section 2), we plotted acceptability by type and participant for each set. As can be seen in
Figure 2, the overall patterns look quite similar.
Next, in order to obtain an impression of the between-participant variation, we plotted the mean responses from each participant for the target sentences, see
Figure 3. Although most of them show the same pattern with a downward slope from left to right, there is also a lot of variation. To control for this inter-participant variation (which is actually also taken into consideration as a random effect in the mixed-effects model) and to inspect it further, we applied
z-transformation (next section).
Figure 2.
Mean (raw) acceptability ratings by type (see
Figure 2) for each of the 24 target sets.
Figure 2.
Mean (raw) acceptability ratings by type (see
Figure 2) for each of the 24 target sets.
Figure 3.
Mean (raw) acceptability ratings by type for each of the 235 participants.
Figure 3.
Mean (raw) acceptability ratings by type for each of the 235 participants.
4.4. Standardized (z-Transformed) Acceptability Ratings
For direct comparison with
Sprouse et al. (
2012,
2016) and a number of other studies, we
z-score transformed the ratings by participant to control for potential individual scale bias, such as using only one end of the scale or a larger or smaller range (see also
Kush et al. 2018,
2019;
Bondevik et al. 2020). A
z-transformed rating represents the number of standard deviations the raw (non-transformed) rating is from that participant’s mean rating. As with the raw scores, the z-transformed results were analyzed using a linear mixed effects model with sliding contrasts. The model contained type as a predictor and random intercepts for participant and item, and random slopes for type and trial by participant, and random slopes for trial by item. The summary of the results is provided in
Table 6 and plotted in
Figure 4A. Note that the general acceptability pattern as well as the significant contrasts are the same as for the non-transformed ratings, compare
Figure 1A and
Figure 4A, and
Table 3 and
Table 6.
To test for a superadditive ‘island effect’, we calculated the differences-in-differences (DD) score for each [+Ex] condition by subtracting the D score for
that, measured as the difference in rating between
that [–Ex] and
that [+Ex] (i.e., the extraction effect for the non-island type), from the D scores for the three adjunct island types:
if,
when, and
because, see
Figure 4C,D (
Sprouse et al. 2012;
Kush et al. 2018,
2019;
Bondevik et al. 2020). DD score proves a standardized measure of the island effect size which can be used for comparisons between different island types across experiments and languages. According to
Kush et al. (
2019, p. 401), “DD scores for island effects typically fall within the range of 0.75–1.25”, and “any intermediate-sized island effect bears closer scrutiny”. To test for significance, we analyzed the
z-transformed ratings again using a linear mixed-effects model, this time with fixed effects of Complementizer and Extraction and their interaction, and random intercepts for participant and item, and random slopes for type and trial by participant, and random slopes for trial by item, first with
that as intercept (summarized in
Table 7), then with
when as intercept (summarized in
Table 8). (For
when, the model had to be simplified such that it included random slopes only for extraction by participant).
Figure 4A shows the mean of the
z-transformed acceptability ratings for the target condition, with and without extraction (compare
Figure 1), 4B the extraction effects for the four complementizers, 4C the extraction effect sizes (all significant,
p < 001, and
that,
if, and
when significantly different form each other,
p < 0.001), and 4D the DD scores indicating island effects. The DD score for
if is only marginally significant (cf. Comp =
if x Extraction,
p = 0.080, in
Table 7), whereas the DD scores for
when and
because were significant (Comp =
when x Extraction and Comp =
because x Extraction in
Table 7, both
p < 0.001). As indicated by Comp =
if x Extraction,
p < 0.001, in
Table 8, the DD scores for
if and
when were significantly different from each other (and
when and
because were not, cf. Comp =
because x Extraction,
p = 0.287). Note that the DD scores are all smaller than 0.75, which, according to
Kush et al. (
2019, p. 401), is the lower threshold value for typical island effects.
In line with
Kush et al. (
2019) and
Bondevik et al. (
2020), in order to examine the underlying judgment pattern for each of the mean scores shown in
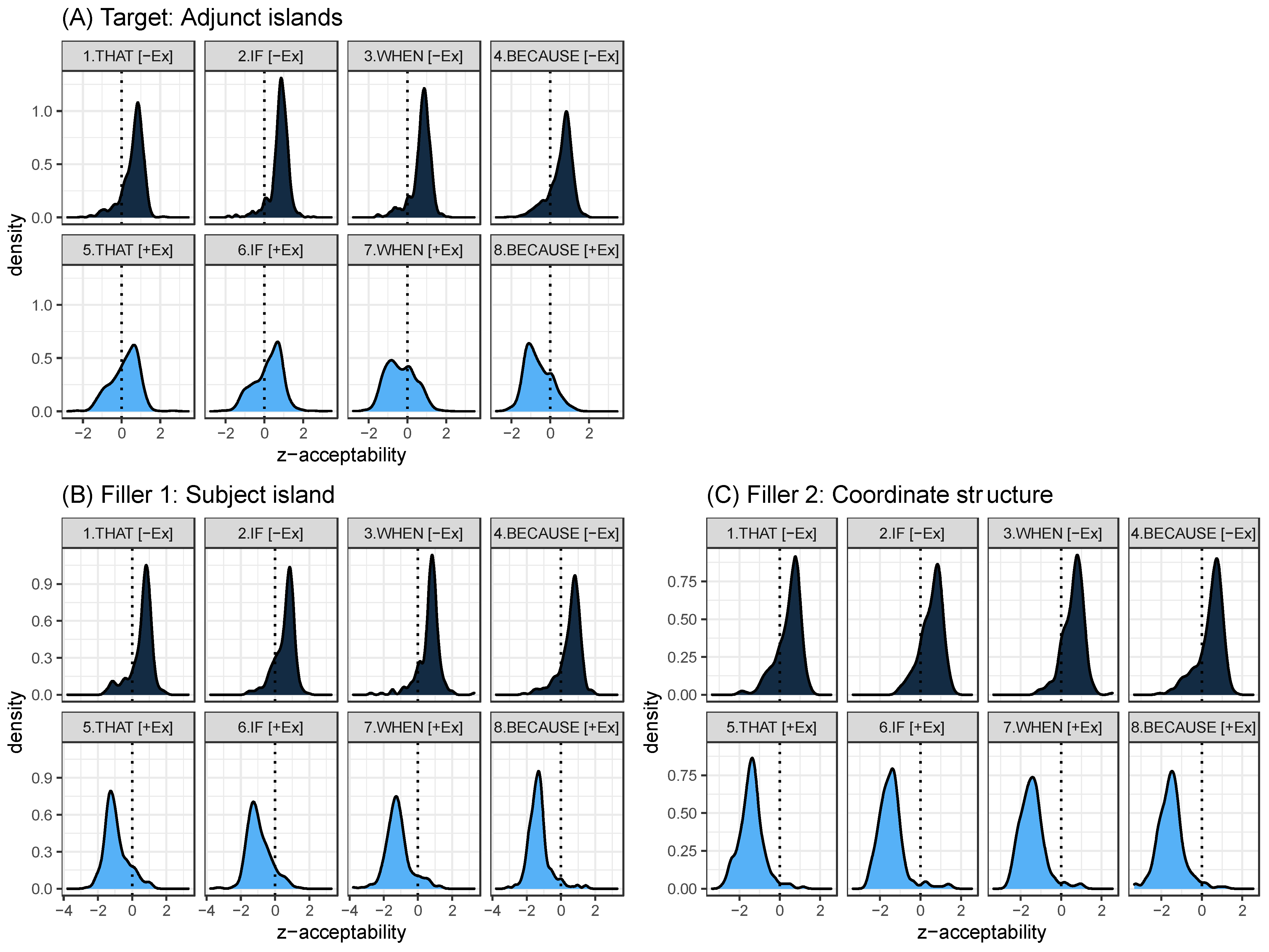
Figure 1, we investigated the distribution of acceptability ratings by condition, as shown in the density plots in
Figure 5. Uniform syntactic islands should show a unimodal distribution narrowly centered around
z = −1, indicating that the participants consistently rated them as unacceptable. This is indeed the case for the two filler types with extraction (
Figure 5B,C, light blue). The distribution of ratings for extractions from subject islands and coordinate structures is clearly skewed toward the left. Conversely, unambiguously well-formed types should show a unimodal distribution centered narrowly around
z = +1, indicating that the participants consistently rated them as completely acceptable. Indeed, this is the case for all the baseline [−Ex] sentence types (
Figure 5, dark blue): the ratings are clearly skewed towards the right. The same goes for extraction from complement clauses headed by
that, though the distribution is more even and flat than the corresponding baselines (it is less pointy, suggesting more inter-participant variation). That leaves the three adjunct island extractions:
if,
when, and
because. Extraction from
if shows the same pattern as extraction from
that, suggesting that extraction from
if is equally acceptable (as shown in
Figure 1 and
Table 3). Extraction from
because shows the inverse pattern, with a somewhat less pointy but clearly left-skewed unimodal distribution suggestive of islandhood. Finally,
when stands out with a left-skewed but somewhat ‘flatter’ or even distribution, tending towards being bimodal with peaks at
z = −1 and
z = 0.
Figure 4.
(A) Mean z-transformed acceptability ratings. (B) Extraction effect. (C) Extraction effect size (difference between [+Ex] and [–Ex]). (D) Island effect size measured in DD scores (Complementizer x Extraction interaction) between that and the other three complementizers). *** p < 0.001, ** p < 0.01, * p < 0.05, marginal: · p < 0.1.
Figure 4.
(A) Mean z-transformed acceptability ratings. (B) Extraction effect. (C) Extraction effect size (difference between [+Ex] and [–Ex]). (D) Island effect size measured in DD scores (Complementizer x Extraction interaction) between that and the other three complementizers). *** p < 0.001, ** p < 0.01, * p < 0.05, marginal: · p < 0.1.
4.5. Trial Effects
In order to test for trial effects, in particular positive correlations between repeated exposure of type and acceptability ratings, we plotted the mean acceptability (across participants on each list) of each occurrence of the four extraction types in the target category, see
Figure 6A.
That,
when, and
because showed a positive effect of trial, but the effect was only significant for
when: in the course of the experiment, extraction across
when increased 0.6 points on the 7-point scale (R
2 = 0.17,
p < 0.05).
Under the (standard) assumption that adjunct clauses headed by
if,
when, and
because have the same syntactic structure, we combined the three sets to see if their combined number of trials i.e., (9) would show a significant effect. This was not the case (
p > 0.1, see
Figure 6B).
4
Figure 6.
(A) Acceptability as a function of repetition (trial) of extractions from complement clauses headed by that and from adjunct clauses headed by if, when and because in the target category. Grey shading: 95% confidence interval. (B) Trial effect of extraction from target adjunct clauses headed by either if, when or because. Grey shading: 95% confidence interval.
Figure 6.
(A) Acceptability as a function of repetition (trial) of extractions from complement clauses headed by that and from adjunct clauses headed by if, when and because in the target category. Grey shading: 95% confidence interval. (B) Trial effect of extraction from target adjunct clauses headed by either if, when or because. Grey shading: 95% confidence interval.
5. Discussion
We investigated the acceptability of extraction from three different types of finite adjunct clauses (
if-,
when- and
because-clauses) in English. Extraction was tested in the form of relativization (rather than
wh-extraction) and in the presence of supporting context, since previous studies on island constructions in MSc. indicate that type of extraction dependency and contextual facilitation appear to have an impact on the possibility of at least some island extractions. Our study thus allowed us to examine whether finite adjunct clauses in English indeed constitute uniformly strong islands, as the traditional literature suggests, even when the potentially facilitating role of dependency type and context is taken into consideration. We predicted consistently low ratings for relativization from adjunct clauses, with no variation in acceptability across different adjunct clause types, and no trial effects. These predictions were not confirmed: the three different types of adjunct clauses tested in this study displayed a rather non-uniform behavior with regard to their acceptability. Specifically, extraction from
when- and
because-clauses both yielded significantly lower ratings than extraction from
if-clauses.
If-clauses appeared to pattern with non-island
that-clauses instead, in that extraction from both
if- and
that-clauses yielded ratings above the middle range, and a similar, right-skewed distribution of acceptability ratings (as can be seen in the density plots in
Figure 5). These findings suggest that, at least for relativization,
if-adjuncts are not absolute islands in English. However,
when- and
because-clauses in turn yielded not only significantly different ratings with extraction, but these structures also resulted in somewhat different acceptability distributions (with
because showing a left-skewed distribution, whereas extraction from
when resulted in a flatter distribution, cf.
Figure 5). This picture is corroborated by a difference in the effects of repeated exposure: only
when-clause extraction yielded a significant trial effect in our experiment, whereas the other clause types did not.
When-clause extraction thus seems to stand out, both in terms of showing a trial effect and in showing a rather flat, somewhat bimodal distribution of acceptability ratings. This suggests that the reduced acceptability levels of the three clause types have different underlying causes (see also
Snyder 2022).
Our finding that extraction from non-island
that-clauses and from
if-clauses both yielded positive and non-distinct ratings suggests that at least for relativization,
if-clauses behave similarly to
that-clauses in English in that they do not seem to universally block extraction. This finding challenges the strong island status of
if-adjuncts. On the other hand, there was a statistically significant difference between
that [−Ex] and
if [−Ex], indicating that the baseline conditions for
that- and
if-clauses may not have been as minimally different as we intended. Some of the comments left by the participants in Google Forms reveal that a few participants were bothered by
that occurring twice in relatively close proximity in our
that-condition, as in (8). Both instances are actually optional, and some participants would prefer the sentences in which (at least) the first
that was left out.
| 8. | It’s obvious that I was surprised that she actually completed this exercise. |
The comments furthermore indicate that in a few items, the context provided by us may have been more felicitous with the conditional structure used in the
if-clauses than with the indicative
that-clause. Both of these circumstances could explain why our baseline
that-clauses were rated significantly worse than the baseline
if-clauses. Nevertheless, our conclusion that
if-clauses do not appear to be absolute islands for relativization in English is supported by our finding that extraction from
if-clauses yielded acceptability ratings that were clearly above the middle range and showed a right-skewed distribution of ratings, characteristic of acceptable sentences. These findings echo those of
Kush et al. (
2019), who found that the acceptability level of structures involving topicalization out of a conditional adjunct in Norwegian was on a par with the acceptability of topicalizing from a non-island embedded clause.
In the following sections, we discuss our findings in relation to dependency type (
Section 5.1), the role of semantics and pragmatics in extractability (
Section 5.2), processing factors (
Section 5.3), and variation between complementizers and the internal structure of adjunct clauses (
Section 5.4).
5.1. Extraction and Dependency Type
Our finding that adjuncts are not uniformly strong islands might similarly call for more fine-grained classifications or for a differentiated approach not only within the group of constructions traditionally referred to as adjunct islands, but also concerning the effect of dependency type on extractability. The fact that extraction from an
if-clause appears to be rather acceptable in English may tell us something quite significant not only about the importance of applying a suitable context in this type of experiment, but also about the potential role of the type of dependency that links the filler and the gap. Previous experiments investigating extraction from finite
if-clauses in English have primarily tested
wh-extraction, and consistently yielded very low ratings for this type of extraction (e.g.,
Sprouse et al. 2012;
Sprouse et al. 2016). A possible reason for the relatively high acceptability of extraction from
if-adjuncts in our study is that extraction was in the form of relativization rather than question formation, and that extraction out of adjuncts may be possible for some dependencies such as relativization, but not for
wh-movement. If this assumption is on the right track, the results from our study contribute to a growing body of evidence that extraction possibilities seem to differ across dependency types (for English, see
Sprouse et al. 2016;
Abeillé et al. 2020; for Norwegian, see
Kush et al. 2019).
This difference in extraction dependencies is unexpected under traditional syntactic accounts of adjunct islands such as the CED: since
wh-movement, topicalization and relativization are all instances of A’-dependencies, they should adhere to the same syntactic locality conditions. However, a syntactic analysis of this phenomenon may nevertheless be possible under the framework of
Relativized Minimality (RM;
Rizzi 1990), specifically under newer incarnations of RM called
featural RM (e.g.,
Starke 2001;
Rizzi 2013;
Villata et al. 2016). Featural RM accounts for island effects in terms of feature-based intervention effects: a constituent cannot be extracted if the movement path crosses an intervening element that has the same featural specifications as the moved element. However, intervention effects can be overcome if the extracted phrase is more richly specified in morphosyntactic features than the potential intervener. An intervention account along these lines could potentially be applied to adjunct islands, in particular in the light of previous suggestions that some adjunct clauses (including conditional [
if] and temporal clauses [
when]) involve movement of an operator to the left periphery of the adjunct clause (e.g.,
Demirdache and Uribe-Etxebarria 2004;
Bhatt and Pancheva 2006;
Haegeman 2010,
2012). A potential asymmetry between different extraction dependencies into adjunct clauses could thus be accounted for under the assumption that the operator involved in the adjunct clause in question creates an intervention effect for
wh-movement, but not for relativization across it. Such an account presupposes that relativization differs from
wh-extraction in involving movement of an element that carries a richer feature specification than the operator present in the relevant adjunct clause (see also
Sprouse et al. 2016 for a proposal along those lines).
A problem that this type of analysis faces is that it is not obvious how the featural setup of the relative operator (in relativization) or of the wh-phrase (in wh-movement) interacts with the type of operators that have been suggested to move in adjunct clauses in order to create (or overcome) intervention effects. Assuming that the proposed operators in if- and when-adjunct clauses differ in their feature specifications, it might provide a partial explanation of their different acceptability ratings. Crucially, however, in order to account for the gradience across all three types of adjuncts in our experiment, we would be forced to stipulate some kind of operator in because-clauses.
5.2. The Role of Semantics and Pragmatics in Extractability
Gradient acceptability may, however, not be surprising under a discourse-based account, such as the ones proposed recently by e.g.,
Chaves and Putnam (
2020) (for a range of island phenomena) and
Abeillé et al. (
2020) (for subject islands specifically), echoing the longstanding idea that backgroundedness (
Goldberg 2005) or pragmatic dominance (
Erteschik-Shir 1973) are determining factors when it comes to extractability.
More specifically,
Goldberg (
2005, p. 135) argues that “Backgrounded Constructions are Islands” (BCI), which according to her definition means that it should be difficult to extract from a constituent that is neither primary topic nor part of the potential focus domain (
Goldberg 2005, p. 130). Similarly,
Abeillé et al. (
2020) suggest a pragmatic account termed the
Focus-Background Conflict (FBC) constraint, arguing that the island effects attested for certain constructions are due to the discourse clash that occurs when a focused element is part of a backgrounded constituent. They specifically apply this constraint to subject islands, where it can account for the relative acceptability of relativization from DP subjects in English and French, compared to
wh-extraction from the same constituents:
Wh-movement, but not relativization, puts the fronted element into focus, which clashes with the backgrounded nature of subjects. (Note, however, the very low scores for relativization from subjects in our experiment, cf.
Figure 1B). An approach of this nature could be extended to cover the apparent possibility of relativizing from some adjunct clauses that seem to resist
wh-extraction, given that adjunct clauses also typically express backgrounded information.
The three adjunct clause types in our stimuli are not discourse-functionally equivalent but have different semantico-pragmatic profiles. If, when, and because all introduce backgrounded adjunct clauses in the sense that the filler refers to a single member of a set in the context, but they differ in terms of veridicality and presupposition: when- and because-clauses are veridical (they have positive polarity and a positive truth value), whereas if-clauses are not (they cannot be assigned a truth value). Furthermore, when-clauses and because-clauses (at least central ones) are presupposed, if-clauses are not (as they are not veridical).
What our data ultimately suggest is that the concept of
gradience needs to be properly integrated into an account of island phenomena. Given that the acceptability of extracting from
if-,
when-, and
because-clauses exhibits surprising variation, we still need to identify what exactly determines the differences in the acceptability of extraction from the adjunct clauses under investigation. According to
Goldberg (
2013, pp. 224–25), “backgrounded constituents of a sentence are not part of what is asserted by the sentence”, and backgroundedness is gradient and independent of truth value, as being true is “not a requirement”. In other words, to some extent, ‘backgrounded’ means ‘not asserted’. One possible way of explaining the variation in the data while maintaining the basic assumptions of the BCI or the FBC could be to appeal to the idea of gradience in backgroundedness: the
because-clauses could be argued to be somehow more ‘asserted’ than the
when-clauses which in turn could be said to be more ‘asserted’ than the
if-clauses (where
asserted means ascribed a truth value). In that case, the clash between the adjunct clause and the filler-gap dependency relation by way of relativization should be greater for the
because-clauses than e.g., the
if-clauses, and this could give us the differences in acceptability found in the present study. It might be argued, then, that the more asserted a clause is, the less acceptable the extraction is predicted to be.
If-clauses are not asserted, and they have no truth-value, and therefore, they would be predicted to be permeable and allow for extraction. However, a problem is, then, that the extractions from
when-adjunct clauses in our experiment are much more acceptable than expected under this assumption; in a sense, our
when-clauses are too ‘good’ (acceptable) to be ‘true’ (asserted), while our
because-clauses are too ‘true’ (asserted) to be ‘good’ (acceptable). However, it is not clear that the relevant factor distinguishing between the three adjunct clause types is necessarily degree of assertion and/or backgroundedness (and, in any case, both terms still need to be properly defined and operationalized in terms of scalability). Other contenders might be degree of factivity (
Kiparsky and Kiparsky 1970) or projectivity (
Tonhauser et al. 2018)
5, realis/irrealis (
Elliott 2000;
Palmer 2001), veridicality (
Giannakidou 1998), or indeed relevance, which we turn to now.
6As mentioned above,
Chaves and Putnam (
2020) argue that many island constraints traditionally assumed to be of a syntactic nature (e.g., the CED) can be reduced to “Relevance Islands”: since adjuncts typically convey backgrounded information, extraction from them tends to violate a pragmatic principle requiring the referent that is singled out by the extraction to be sufficiently relevant for the main action, event, or state of affairs (as originally observed for extractions from complex subjects by (
Kluender 2004). However, this pragmatic constraint can, according to
Chaves and Putnam (
2020, p. 91), be circumvented if extraction occurs in the form of relativization, since relatives ”express assertions rather than backgrounded information”.
Chaves and King (
2019) found a “positive correlation between the plausibility of the proposition (as expressed by a declarative clause) and the extractability of a deeply embedded referent therein” (
Chaves and Putnam 2020, p. 222). The difference in acceptability between the three types of adjunct island complementizers found in the present study might thus be related to the proposition that they create. It seems reasonable to assume that the semantic plausibility of a proposition plays a role in connection with extractability. It is, of course, important that the corresponding declarative or non-extracted version of a sentence be plausible and felicitous (i.e., coherent) in order for extraction to be acceptable (see also
Engdahl 1997;
Kehl 2022). However, more specifically, the more prototypical and coherent the relations between the “semantic components” are, the easier it is to conceive of a referent as relevant to the main event and hence to extract it (
Chaves and Putnam 2020, pp. 222–23). This approach may account for some of the variability attested at the participant level, given that the likelihood of an extracted referent being considered relevant to the main event by the comprehender may be a matter of degree and thus subject to between-participant variation. However, our results suggest rather uniform interpretations across participants, except for extraction from adjunct clauses headed by
when (see
Figure 3 and
Figure 5).
Furthermore, the account presented in
Chaves and Putnam (
2020) suffers from the same problems that other semantico-pragmatic accounts have, namely the difficulty in operationalizing the approach in a falsifiable way. In fact, one of the few tools that they do suggest makes only partially correct predictions. Specifically,
Chaves and Putnam (
2020, p. 235) suggest that the acceptability of extracting from an adjunct clause is correlated with the inter-clausal semantic relations hierarchy in
Van Valin (
2005, pp. 208–9), according to which causal relations express a tighter semantic link or a higher degree of cohesion than purely temporal relations. However, as mentioned above, all three adjunct clause types in our study were embedded under psych-predicates that trigger a causal reading of the events in the matrix and embedded clause. If a causal reading is equally available for all three types of adjunct clauses in our study, they should rank equally high on Van Valin’s hierarchy of semantic relations and also allow extraction equally easily, which is not what we found. Possibly,
when-clauses can be argued to express a smaller degree of cohesion than
if- and
because-clauses since the causal relation is not explicitly encoded in
when-clauses but must be inferred pragmatically.
If- and
because-clauses, on the other hand, linguistically encode causation by means of the introducing element (
if and
because). This would explain why extraction from
when-clauses scored significantly lower ratings than extraction from
if-clauses in our study. However, it leaves unexplained why extraction from
because-clauses was rated significantly worse than both
if- and
when-clause extraction.
7 5.3. Processing Factors
When- and
if-clauses may, however, differ from
because-clauses in terms of processing, given that they can occur as a complement or argument. In examples such as (9a) and (9b), the matrix verb
appreciate appears to select
if- and
when-clauses which hence function as arguments in the superordinate clause. Crucially, however, this is not possible with
because-clauses, (9b) and (10b) (see
Teleman et al. 1999, pp. 568–93 for a similar observation in relation to Swedish). (Examples (9a) and (10a) are from COCA).
| 9. | a. | I would appreciate if you can post a link to my article to everyone in your |
| | | network |
| | b. | *I appreciate because you can post a link to my article to everyone in your |
| | | network. |
| 10. | a. | Sir, we always appreciate when you come on. |
| | b. | *Sir, we always appreciate because you come on. |
Based on these data, it seems possible that speakers may be able to assign a structural parse to some sentences involving
if- and
when-clauses where the
if- or
when-clause has the status of an argument or complement (similar to the
that-clauses used in our stimuli), whereas this is not an option for
because-clauses. While the selectional properties of predicative adjectives are different from those of transitive verbs such as
appreciate, it may be the case that the parser, holding a filler, postulates an intermediate attachment site at the left edge of the adjunct clause, for example via the principle of
Attach Anyway (
Fodor and Inoue 1998). This phenomenon is reminiscent of the effects of matrix verb compatibility found for long-distance dependencies: when it is plausible that the filler originates in the matrix clause and intermediate attachment is possible, the resulting acceptability level is higher than if the matrix verb is not compatible with the filler (see
Christensen et al. 2013 and references cited there). This in turn lends credence to the CED: while it seems nearly impossible to salvage a purely syntactic version of CED, the latter may be couched in processing or computational terms instead. It is simply easier to parse extractions from complements than adjuncts, and the data in our study may at least partially be explained as a misparse of the adjunct clauses as complement clauses, thus a local ambiguity leading to a global (positive) effect on acceptability. The variation found between
if,
when and
because might be due to the frequency with which they occur as complement clauses (for instance, COCA returns 2.130 hits for “appreciate that” with
that specified as a complementizer, 200 for “appreciate if” and 103 for “appreciate when”, while there are no hits of the relevant type for “appreciate because”). The possibility of extracting from adjunct clauses may thus be modulated by frequency, as the parser may use probabilistic knowledge in the online processing of the structures involving extraction from adjunct clauses in the sense that it may temporarily postulate intermediate attachment of
if- and
when-clauses as complements rather than adjuncts, based on previous exposure, and perhaps this may ameliorate the acceptability level overall. Future research, e.g., using G-Maze (
Witzel et al. 2012), could investigate the online processing of these structures and whether the comprehender has a slower reaction time at the complementizer
because than for
if and
when, which would lend support to the idea that the syntactic integration is more difficult, potentially resulting in a decrease in acceptability.
On the other hand, the potential amelioration of temporarily interpreting adjuncts as complements would be the opposite of what has been observed for garden-path resolution. Studies on parsing and ambiguity resolution has shown that garden-path sentences are particularly difficult because the position where the ambiguous constituent is initially integrated does not contain the (correct) target position (
Pritchett 1992). In a (non-garden path) sentence such as
She knew Tom liked Cats,
Tom is temporarily attached as direct object of
knew, but has to be reanalyzed as the subject of the embedded clause in the object position. In the garden-path sentence
While she dressed Tom made a sandwich,
Tom is again first analyzed as object, but has to be reanalyzed as the subject of the matrix clause in which
while she dressed is embedded. This reanalysis is effortful and costly, leading to a severe reduction in acceptability.
5.4. Variation between Complementizers and the Internal Structure of Adjunct Clauses
As discussed in
Section 5.1, the variation in acceptability as a function of the choice of complementizer (
if,
when,
because) is difficult to explain under a purely syntactic account (or solely under a processing account, see
Section 5.3) given that the underlying structure of the adjunct island constructions is generally assumed to be basically the same. However, some have argued that different types of adjunct clauses are adjoined at different positions. For instance,
Haegeman (
2012) distinguishes between
central and
peripheral adverbial clauses, which contrast in their relation to the clause that they modify, as the central adverbial clauses are event structuring (modifying the matrix clause at the event level), while the peripheral ones are discourse structuring. In other words, central adjunct clauses modify the event encoded in the host proposition, while peripheral adjunct clauses provide a contextually accessible background assumption contributing evidence for the relevance of the matrix domain (
Badan and Haegeman 2022). They differ in attachment height, such that peripheral adjuncts are adjoined to CP, central ones to TP or
vP (
Haegeman 2012, p. 171), and correspondingly, in their degree of opacity for syntactic operations. However, all three types of adjunct clauses used in this study (
if-,
when- and
because-adjuncts) are central adjunct clauses that are merged at the same height according to
Haegeman’s (
2012, p. 164) classification. Other proposals connect differences in attachment height to differences in whether or not the adjunct can be interpreted as being in a coherent (e.g., causal) single-event relation with the matrix clause (e.g.,
Ernst 2001;
Narita 2011;
Truswell 2011;
Sheehan 2013;
Brown 2017). However, since all of our target sentences were construed to trigger a semantically coherent interpretation between the matrix and adjunct clause events, these proposals cannot capture the differences across different adjunct clauses observed in our study.
There are some indications that causal adjuncts (
because-clauses) have more elaborate syntactic structures than conditional (
if-clauses) and temporal adjuncts (
when-clauses). In terms of
Haegeman’s (
2012) classification, causal clauses are merged at the same height as other central adjunct clauses, but seem to display the internal syntax of peripheral adverbial clauses (
Müller 2019, p. 98). For example, causal clauses can contain epistemic modal markers, which are usually only possible in peripheral clauses (
Ros 2005, p. 98). Causal clauses are also compatible with V2 word order in the MSc. languages, see
Teleman (
1967) for Swedish,
Julien (
2015) for Norwegian, and
Nyvad et al. (
2017, p. 462) for Danish. Based on this evidence, it has been suggested that causal clauses are root-like in that they can encode independent illocutionary force (
Müller 2019), which is also in line with the observation that causal clauses may be asserted independently (
Hooper and Thompson 1973;
Sawada and Larson 2004), whereas temporal and conditional clauses are considered non-assertive (see also
Section 5.2).
An account that may be compatible with the presented facts is the
cP/CP-distinction first proposed by
Nyvad et al. (
2017) for Danish: these authors propose an account which credits evident island extractability in Danish (and presumably the other Mainland Scandinavian languages) to the possibility of CP-recursion. Given the apparent acceptability of the structures in question, the grammar must be able to generate them (i.e., the syntax must provide a licit hierarchical representation), and given that cross-clausal filler-gap dependencies adhere to the principle of successive-cyclic movement (e.g.,
Chomsky 1973;
1995,
2001;
Den Dikken 2009;
van Urk 2020;
Davis 2021), an ‘escape hatch’ must be present. The latter may be provided by
cP (“little
cP”), a projection found in embedded clauses, which hosts functional elements such as complementizers and which can also be recursive, thus accounting for both the widespread use of complementizer stacking and otherwise unexplained island extractability in e.g., Danish. “Big” CP, on the other hand, hosts lexical elements such as finite verbs in (embedded and main clause) V2. Under this analysis, CPs are always finite, they carry illocutionary force (or illocutionary potential) and they are strong islands. Hence, in this framework, CPs are root clauses or root-like clauses. A similar observation is made in connection with
Haegeman’s (
2002) proposal that (root-like) peripheral adjunct clauses may have a Force projection, allowing embedded topicalization and V2, while central adjunct clauses do not. See
Haegeman (
2012, p. 155) for examples of the impossibility of argument fronting in central
if- and
when-clauses in English.
It may hence be the case that significantly decreased acceptability found for extraction from
because-clauses (as compared to
if- and
when-clauses) is due to the internal syntax of the
because-clauses being more complex compared to
if- and
when-clauses. Whether that is the result of the
because-clauses having a Force projection, a root-like C-projection or simply a feature encoding illocutionary force is still an open question, as is the question of how similar English really is to the Mainland Scandinavian languages when it comes to island extractability: while the Mainland Scandinavian languages appear to be able to extract fillers from embedded questions (e.g.,
Christensen et al. 2013), relative clauses (e.g.,
Lindahl 2017) and adjunct clauses (e.g.,
Müller 2019) more or less independently of dependency type (i.e., topicalization,
wh-movement or relativization), English may be more limited in its range of possibilities.
Overall, however, relativization out of adjunct clauses appears to be possible in English when presented with a supporting context.
If-,
when- and
because-clauses may thus not be strong islands after all, and they do not form a uniform class, as they seem to have different profiles in our data: the acceptability of extraction from
if-clauses was not significantly different from that of
that-clauses, even though the two types of structures are viewed as islands (adjuncts) and non-islands (complements), respectively. With regards to the
when-clauses, they stand out in a different way: the density plot (acceptability distribution) for this clause type is flatter and slightly bimodal, indicating more variation between participants. In addition, there was a trial effect for the
when-clauses such that the participants in the study found extraction significantly better over time, but not for
because-clauses, which suggests different underlying causes for reductions in acceptability (
Snyder 2022). Following
Sprouse (
2007, p. 124), this trial effect suggests that extraction from
when-clauses is licit, since only grammatical structures should exhibit priming effects (see also
Christensen et al. 2013;
Christensen and Nyvad 2014). The acceptability of
because-clauses did not improve significantly over time, but the DD-score for this structure type was actually below the threshold of 0.75 for islandhood proposed by
Kush et al. (
2019).
In short, none of the adjunct clause types showed clear signs of strong islandhood. The present study also illustrates the importance of applying different types of statistical analyses. Without this type of ‘profiling’, the multifactorial profiles of extraction from English adjunct clauses would go undetected. We suspect that the acceptability ratings result from interactions between subtle syntactic contrasts, pragmatics, and processing factors. It is very difficult, if not impossible, to tease apart the exact contribution of each of the individual factors to the observed pattern of acceptability.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}