Shared or Separate Representations? The Spanish Palatal Nasal in Early Spanish/English Bilinguals


Abstract
1. Introduction
1.1. Nasal Consonants in Spanish and English
| 1. | /m/ | cama | /ˈkama/ | ‘bed’; |
| /n/ | cana | /ˈkana/ | ‘gray hair’; | |
| /ɲ/ | caña | /ˈkaɲa/ | ‘cane’. |
| 2. | canyon | /ˈkænjn̩/; |
| onion | /ˈʌnjn̩/; | |
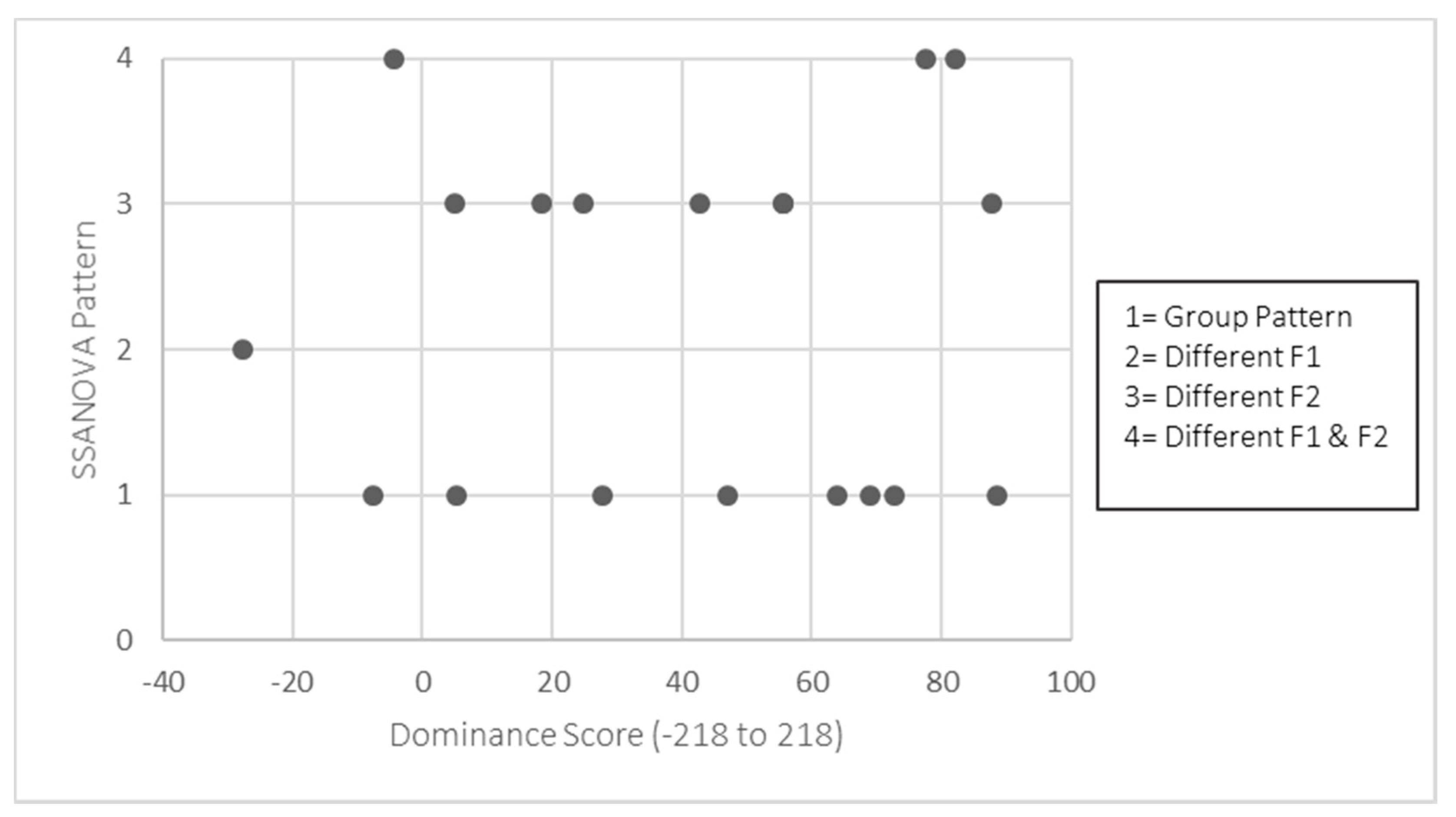
| lanyard | /ˈlænjɹ̩d/. |
1.2. Research Question and Predictions
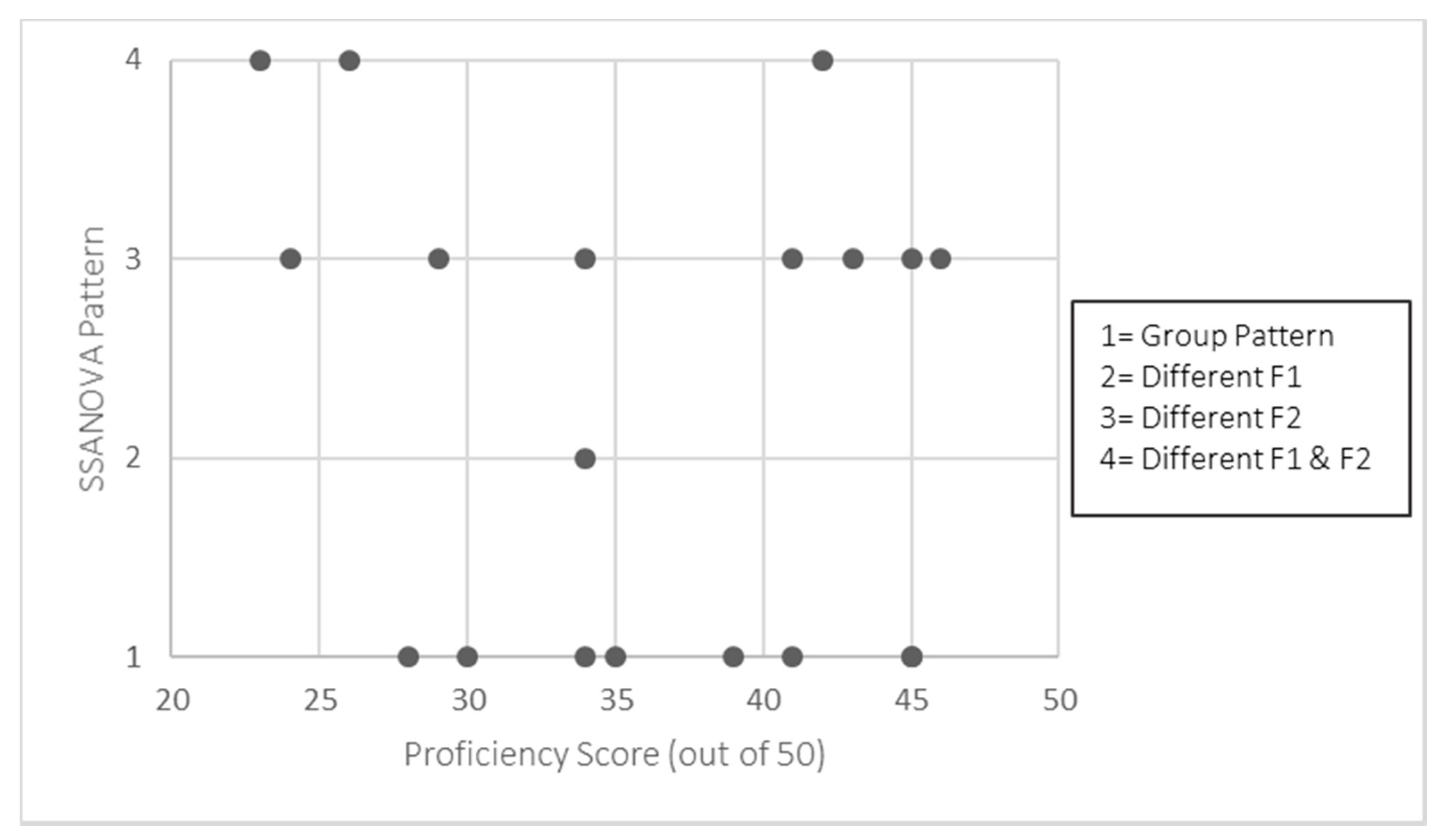
2. Materials and Methods
2.1. Participants
2.2. Materials and Procedure
2.3. Analysis
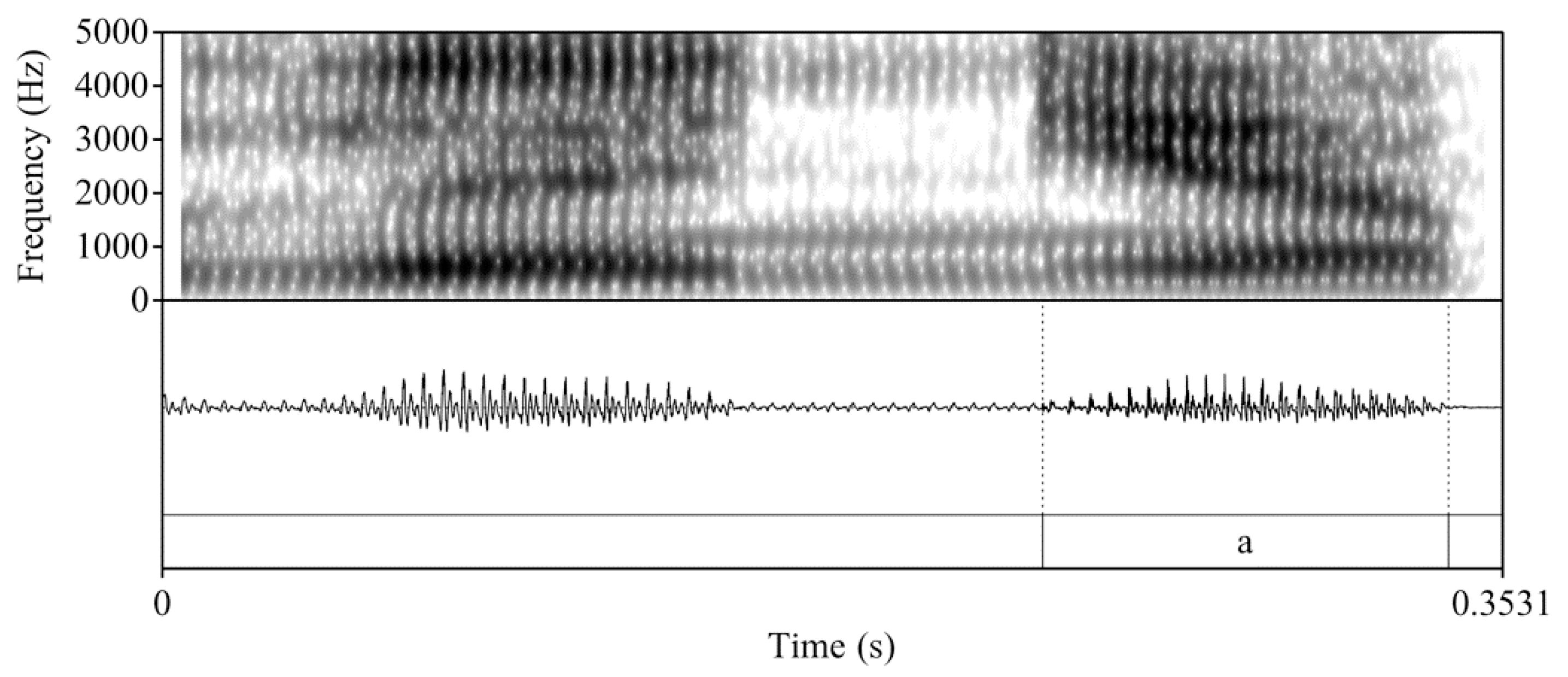
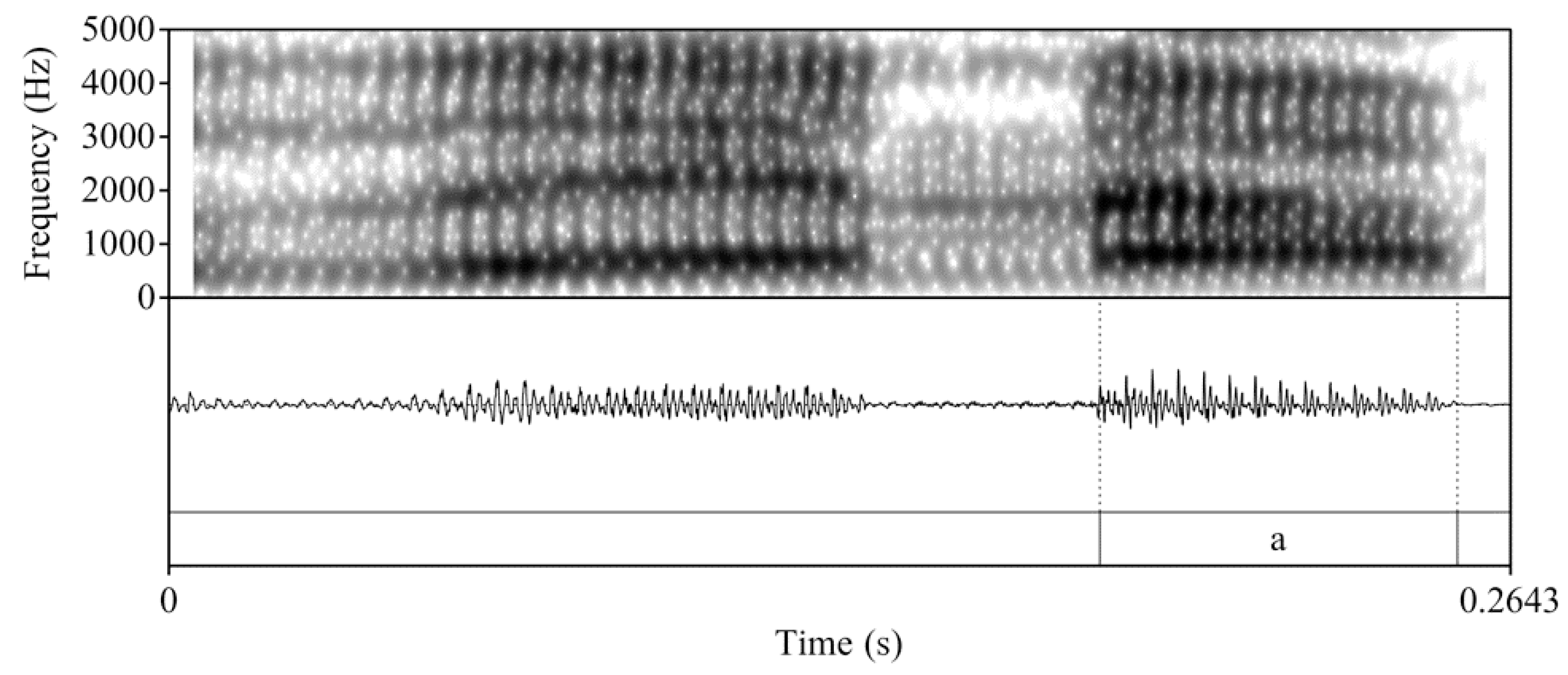
2.3.1. Acoustic Analysis
2.3.2. Statistical Analysis
3. Results
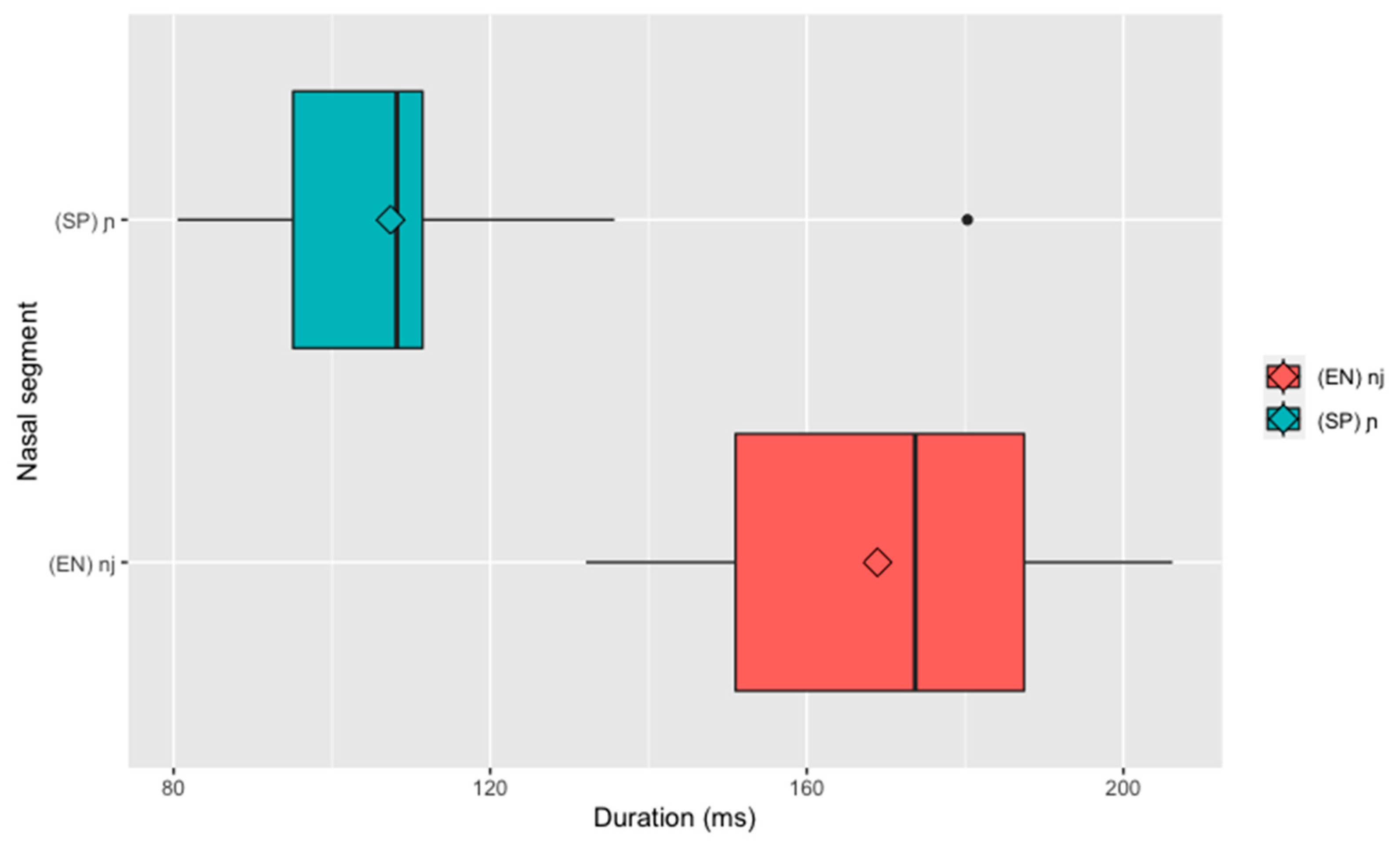
3.1. Duration Results
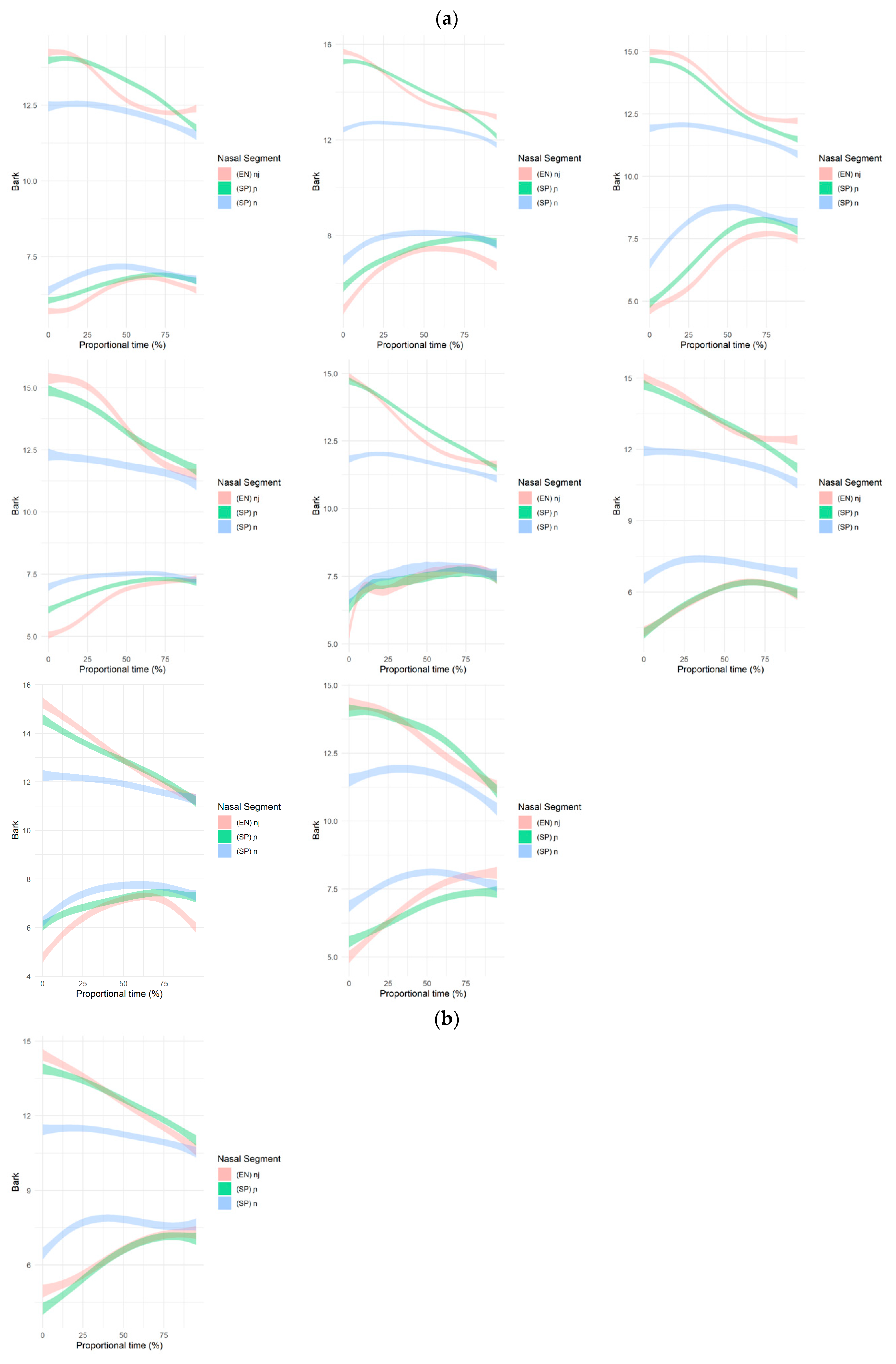
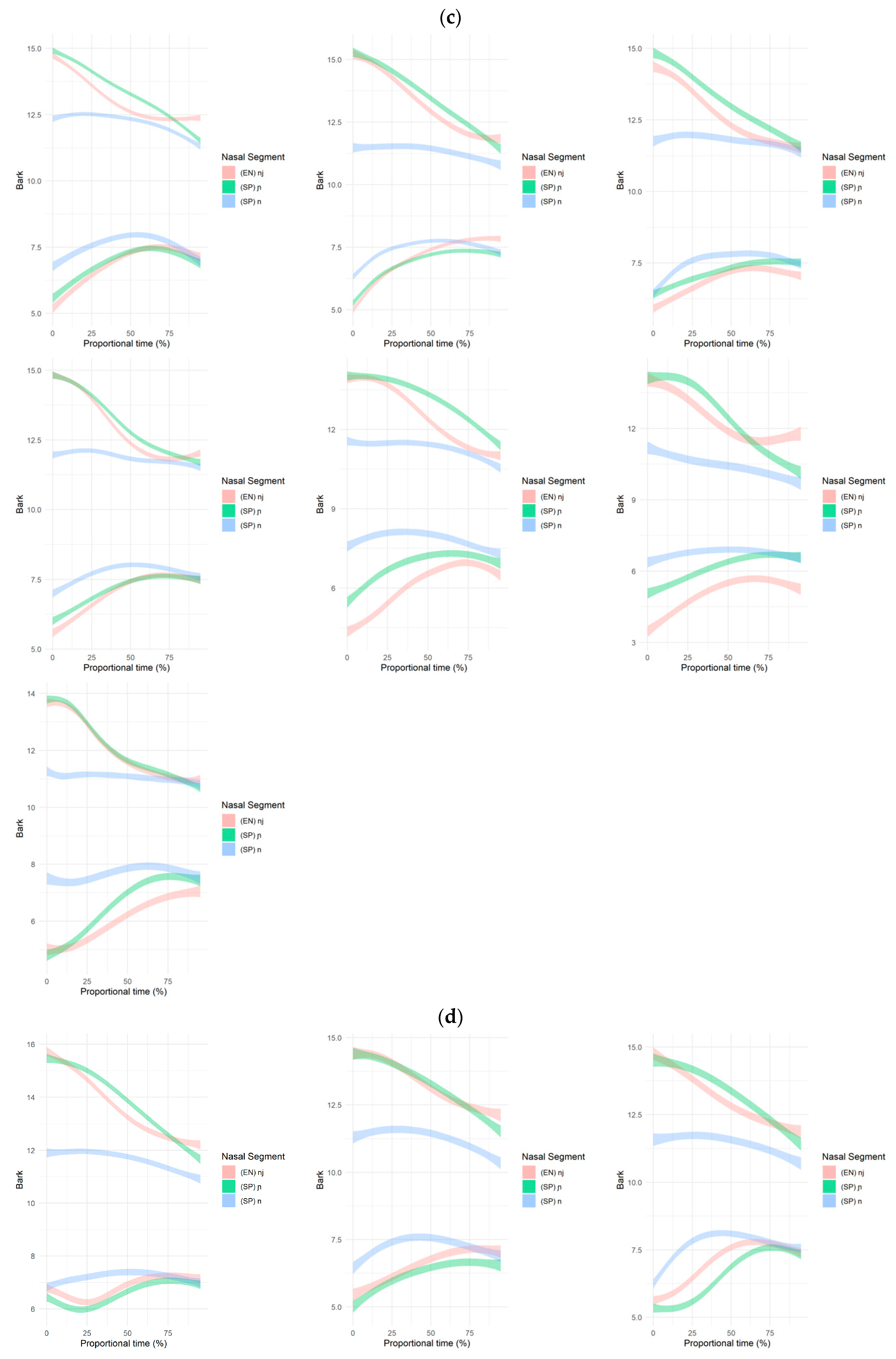
3.2. Formant Structure Results
4. Discussion
4.1. Summary
4.2. Separate Representations and Age of Acquisition
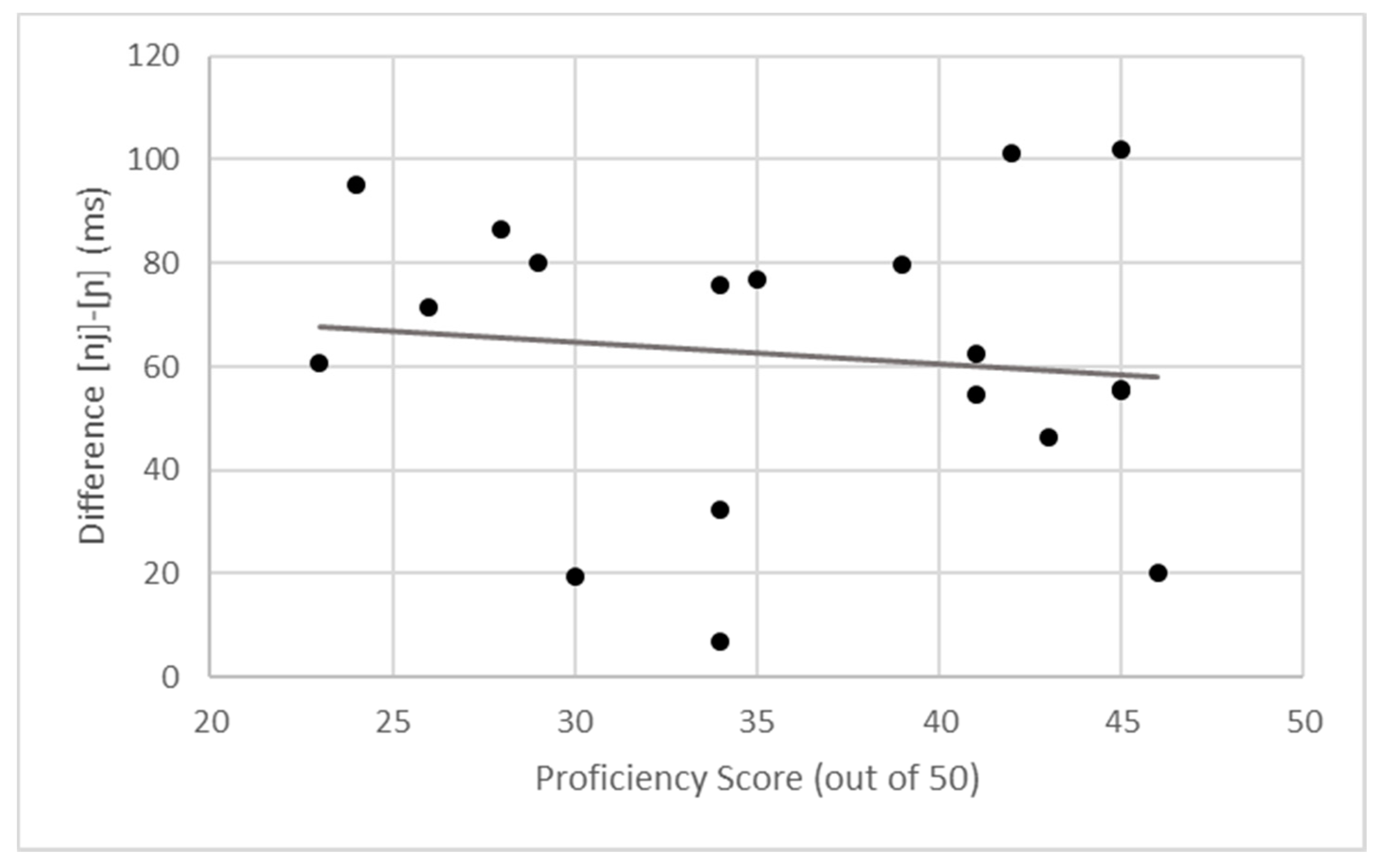
4.3. Individual Variation
4.4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spanish Mode | English Mode | |||
|---|---|---|---|---|
| Critical (C)CV.ɲa (Spanish) (C)CVn.ja (English) | reña | [reɲa] | renya | [ɹɛnjə] |
| boña | [boɲa] | bonya | [bɑnjə] | |
| broña | [bɾoɲa] | bronya | [bɹɑnjə] | |
| droña | [dɾoɲa] | dronya | [dɹɑnjə] | |
| feña | [feɲa] | fenya | [fɛnjə] | |
| poña | [poɲa] | ponya | [pʰɑnjə] | |
| foña | [foɲa] | fonya | [fɑnjə] | |
| loña | [loɲa] | lonya | [lɑnjə] | |
| deña | [deɲa] | denya | [dɛnjə] | |
| beña | [beɲa] | benya | [bɛnjə] | |
| Control (C)CV.na | bena | [bena] | benna | [bɛnə] |
| dena | [dena] | denna | [dɛnə] | |
| lona | [lona] | lonna | [lɑnə] | |
| fona | [fona] | fonna | [fɑnə] | |
| pona | [pona] | ponna | [pʰɑnə] | |
| fena | [fena] | fenna | [fɛnə] | |
| drona | [dɾona] | dronna | [dɾɑnə] | |
| brona | [bɾona] | bronna | [bɾɑnə] | |
| quena | [kena] | renna | [ɹɛnə] | |
| jona | [xona] | bonna | [bɑnə] | |
| Distractor | nela | [nela] | talla | [tʰælə] |
| neda | [neð̞a] | tamma | [tʰæmə] | |
| dera | [deɾa] | tulla | [tʰʌlə] | |
| gada | [gað̞a] | bura | [bɚə] | |
| meba | [meβ̞a] | lekka | [lɛkə] | |
| bera | [beɾa] | meppa | [mɛpə] | |
| doda | [doð̞a] | maffa | [mæfə] | |
| bora | [boɾa] | ponka | [pʰɑnkə] | |
| doba | [doβ̞a] | cromma | [kʰɹɑmə] | |
| gora | [goɾa] | neppa | [nɛpə] | |
| gera | [geɾa] | zappa | [zæpə] | |
| pada | [pað̞a] | ficka | [fɪkə] | |
| fala | [fala] | vatta | [væɾə] | |
| deda | [deð̞a] | virta | [vɚɾə] | |
| seba | [seβ̞a] | zanta | [zæntə] | |
| poba | [poβ̞a] | thappa | [θæpə] | |
| dola | [dola] | thurpa | [θɚpə] | |
| teba | [teβ̞a] | drotta | [dɹɑɾə] | |
| dela | [dela] | vecka | [vɛkə] | |
| bada | [bað̞a] | stucka | [stʌkə] | |
Appendix B


References
- Abrahamsson, Niclas, and Kenneth Hyltenstam. 2009. Age of onset and nativelikeness in a second language: Listener perception versus linguistic scrutiny. Language Learning 59: 249–306. [Google Scholar] [CrossRef]
- Amengual, Mark. 2016. Acoustic correlates of the Spanish tap-trill contrast: Heritage and L2 Spanish speakers. Heritage Language Journal 13: 88–112. [Google Scholar] [CrossRef]
- Amengual, Mark. 2018. Asymmetrical interlingual influence in the production of Spanish and English laterals as a result of competing activation in bilingual language processing. Journal of Phonetics 69: 12–28. [Google Scholar] [CrossRef]
- Antoniou, Mark, Michael Tyler, and Catherine Best. 2012. Two ways to listen: Do L2 dominant bilinguals perceive stop voicing according to language mode? Journal of Phonetics 40: 582–94. [Google Scholar] [CrossRef] [PubMed]
- Barlow, Jessica A. 2014. Age of acquisition and allophony in Spanish-English bilinguals. Frontiers in Psychology 5: 288. [Google Scholar] [CrossRef] [PubMed]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed]
- Birdsong, David. 2016. Dominance in bilingualism: Foundations of measurement, with insights from the study of handedness. In Language Dominance in Bilinguals: Issues of Measurement and Operationalization. Edited by Jeanine Treffers-Daller and Carmen Silva-Corvalán. Cambridge: Cambridge University Press, pp. 85–105. [Google Scholar]
- Birdsong, David, Libby M. Gertken, and Mark Amengual. 2012. Bilingual Language Profile: An Easy-to-Use Instrument to Assess Bilingualism. Austin: COERLL, University of Texas at Austin. [Google Scholar]
- Boersma, Paul, and David Weenink. 2019. Praat: Doing Phonetics by Computer (Version 6.1.22) [Computer Program]. Available online: http://www.praat.org/ (accessed on 31 October 2020).
- Bongiovanni, Silvina. 2019. An acoustical analysis of the merger of /ɲ/ and /nj/ in Buenos Aires Spanish. Journal of the International Phonetic Association, 1–25. [Google Scholar] [CrossRef]
- Chang, Charles. 2020. Phonetics and Phonology. In The Cambridge Handbook of Heritage Languages and Linguistics. Edited by Silvina Montrul and Maria Polinsky. Cambridge: Cambridge University Press. Available online: https://drive.google.com/file/d/1Pbks63JsZwcfyaUgjm-yB1EbwWGcmhil/view (accessed on 31 October 2020).
- Chang, Charles, Erin F. Haynes, Yao Yao, and Russell Rhodes. 2009. A tale of five fricatives: Consonantal contrast in heritage speakers of mandarin. University of Pennsylvania Working Papers in Linguistics 15: 37–43. [Google Scholar]
- Chang, Charles, Yao Yao, Erin F. Haynes, and Russell Rhodes. 2011. Production of phonetic and phonological contrast by heritage speakers of mandarin. The Journal of the Acoustical Society of America 129: 3964–80. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Andrew. 2019. Age of arrival does not affect childhood immigrants’ acquisition of ongoing sound change: Evidence from Korean Americans. In Proceedings of the 19th International Congress of Phonetic Sciences. Edited by Sasha Calhoun, Paola Escudero, Marija Tabain and Paul Warren. Canberra: Australasian Speech Science and Technology Association Inc., pp. 2213–17. [Google Scholar]
- Colina, Sonia. 2009. Spanish Phonology: A Syllabic Perspective. Washington: Georgetown University Press. [Google Scholar]
- De Houwer, Annick. 2011. Language input environments and language development in bilingual acquisition. Applied Linguistics Review 2: 221–40. [Google Scholar] [CrossRef]
- DeKeyser, Robert. 2012. Age effects in second language learning. In The Routledge Handbook of Second Language Acquisition. Edited by Susan Gass and Alison Mackey. New York: Routledge, pp. 442–60. [Google Scholar]
- Díaz-Campos, Manuel. 2004. Context of learning in the acquisition of Spanish second language phonology. Studies in Second Language Acquisition 26: 249–73. [Google Scholar] [CrossRef]
- Flege, James E. 1995. Second language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 233–72. [Google Scholar]
- Flege, James E., and Ocke-Schwen Bohn. 2020. The revised speech learning model (slm-r). In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, in press. [Google Scholar]
- Flege, James E., Ian R. A. MacKay, and Diane Meador. 1999. Native Italian speakers’ perception and production of English vowels. The Journal of the Acoustical Society of America 106: 2973–87. [Google Scholar] [CrossRef] [PubMed]
- Fujimura, Osamu. 1962. Analysis of nasals consonants. The Journal of the Acoustical Society of America 34: 1865–75. [Google Scholar] [CrossRef]
- Godson, Linda. 2003. Phonetics of Language Attrition: Vowel Production and Articulatory Setting in the Speech of Western Armenian Heritage Speakers. Ph.D. thesis, University of California, San Diego. [Google Scholar]
- Godson, Linda. 2004. Vowel production in the speech of western Armenian heritage speakers. Heritage Language Journal 2: 44–69. [Google Scholar]
- Hirst, Daniel. 2012. Analyse_tier.praat. Available online: http://uk.groups.yahoo.com/group/praat-users/files/Daniel_Hirst/analyse_tier.praat (accessed on 13 October 2015).
- IBM Corp. 2019. IBM SPSS Statistics for Macintosh, Version 26.0. Armonk: IBM Corp. [Google Scholar]
- Kang, Yoonjung, Sneha George, and Rachel Soo. 2016. Cross-language influence in the stop voicing contrast in heritage Tagalog. Heritage Language Journal 13: 184–218. [Google Scholar] [CrossRef]
- Keating, Gregory D., Jill Jegerski, and Bill VanPatten. 2016. Online processing of subject pronouns in monolingual and heritage bilingual speakers of Mexican Spanish. Bilingualism: Language and Cognition 19: 36–49. [Google Scholar] [CrossRef]
- Kirkham, Sam. 2017. Ethnicity and phonetic variation in Sheffield English liquids. Journal of the International Phonetic Association 47: 17–35. [Google Scholar] [CrossRef]
- Knightly, Leah M., Sun-ah Jun, Janet S. Oh, and Terry kit-fong Au. 2003. Production benefits of childhood overhearing. The Journal of the Acoustical Society of America 114: 465–74. [Google Scholar] [CrossRef]
- Ladefoged, Peter. 2005. A Course in Phonetics, 5th ed. Boston: Thomson. [Google Scholar]
- Leal, Tania, Jason Rothman, and Roumyana Slabakova. 2015. Discourse-sensitive clitic-doubled dislocations in heritage Spanish. Lingua 155: 85–97. [Google Scholar] [CrossRef]
- Lein, Tatjana, Tanja Kupisch, and Joost van de Weijer. 2016. Voice onset time and global foreign accent in german–french simultaneous bilinguals during adulthood. International Journal of Bilingualism 20: 732–49. [Google Scholar] [CrossRef]
- Martínez Celdrán, Eugenio, and Ana María Fernández Planas. 2007. Manual de Fonética Española: Articulaciones y Sonidos de Español. Madrid: Editorial Ariel. [Google Scholar]
- Massone, Maria Ignacia. 1988. Estudio acústico y perceptivo de las consonantes nasales y líquidas del español [Acoustic and perceptual study of Spanish nasal and liquid consonants]. Estudios de Fonética Experimental 3: 13–34. [Google Scholar]
- Mayr, Robert, and Aysha Siddika. 2018. Inter-generational transmission in a minority language setting: Stop consonant production by Bangladeshi heritage children and adults. International Journal of Bilingualism 22: 255–84. [Google Scholar] [CrossRef]
- McCarthy, Kathleen M., Bronwen Evans, and Merle Mahon. 2013. Acquiring a second language in an immigrant community: The production of Sylheti and English stops and vowels by London-Bengali speakers. Journal of Phonetics 41: 344–58. [Google Scholar] [CrossRef]
- McCloy, Daniel, and August McGrath. 2012. SemiAutoFormantExtractor.praat. Available online: https://github.com/drammock/praat-semiauto/blob/master/SemiAutoFormantExtractor.praat (accessed on 10 February 2018).
- Melgar de González, Maria. 1976. Cómo Detectar al niño con Problemas de Habla [How to Detect a Child with Speech Problems]. Mexico City: Trillas. [Google Scholar]
- Montrul, Silvina, and Maria Polinsky. 2019. Introduction to heritage language development. In The Oxford Handbook of Language Attrition. Edited by Monika Schmid and Barbara Köpke. Oxford: Oxford University Press, pp. 419–33. [Google Scholar]
- Nagy, Naomi, and Alexei Kochetov. 2013. Voice onset time across the generations: A cross-linguistic study of contact-induced change. In Multilingualism and Language Contact in Urban Areas: Acquisition—Development—Teaching—Communication. Edited by Peter Siemund, Ingrid Gogolin, Monica Edith Schulz and Julia Davydova. Amsterdam: John Benjamins, pp. 19–38. [Google Scholar]
- Nance, Claire. 2014. Phonetic variation in Scottish Gaelic laterals. Journal of Phonetics 47: 1–17. [Google Scholar] [CrossRef]
- Newport, Elissa, Daphne Bavelier, and Helen Neville. 2001. Critcal thinking about critical periods: Perspectives on a critical period for language acquisition. In Language, Brain and Cognitive Development: Essays in Honor of Jacques Mehler. Edited by Emmanuel Dupoux. Cambridge: MIT Press, pp. 481–502. [Google Scholar]
- Plonsky, Luke, and Frederick Oswald. 2014. How big is “big”? Interpreting effect sizes in l2 research. Language Learning 64: 878–912. [Google Scholar] [CrossRef]
- Potowski, Kim. 2020. University of Illinois at Chicago, Chicago, IL, USA. Personal communication, August 10.
- R Core Team. 2020. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 31 October 2020).
- Recasens, Daniel. 2013. On the articulatory classification of (alveolo) palatal consonants. Journal of the International Phonetic Association 43: 1–22. [Google Scholar] [CrossRef]
- Ronquest, Rebecca. 2012. An Acoustic Analysis of Heritage Spanish Vowels. Ph.D. thesis, Indiana University, Bloomington. [Google Scholar]
- Scovel, Thomas. 2000. A critical review of the critical period research. Annual Review of Applied Linguistics 20: 213–23. [Google Scholar] [CrossRef]
- Shea, Christine. 2019. Dominance, proficiency, and Spanish heritage speakers’ production of English and Spanish vowels. Studies in Second Language Acquisition 41: 123–49. [Google Scholar] [CrossRef]
- Simonet, Miquel. 2014. Phonetic consequences of dynamic cross-linguistic interference in proficient bilinguals. Journal of Phonetics 43: 26–37. [Google Scholar] [CrossRef]
- Simonet, Miquel, and Mark Amengual. 2020. Increased language co-activation leads to enhanced cross-linguistic phonetic convergence. International Journal of Bilingualism 24: 208–21. [Google Scholar] [CrossRef]
- Simonet, Miquel, Marcos Rohena-Madrazo, and Mercedes Paz. 2008. Preliminary evidence for incomplete neutralization of coda liquids in Puerto Rican Spanish. In Selected Proceedings of the 3rd Conference on Laboratory Approaches to Spanish Phonology. Edited by Laura Colantoni and Jeffrey Steele. Somerville: Cascadilla Proceedings Project, pp. 72–86. [Google Scholar]
- Solis-Barroso, Cecilia, and Sara Stefanich. 2019. Measuring language dominance in early Spanish/English bilinguals. Languages 4: 62. [Google Scholar] [CrossRef]
- Stefanich, Sara, and Jennifer Cabrelli. 2016. L2 Acquisition of the Spanish palatal nasal. Paper presented at New Sounds 2016: 8th International Conference on Second Language Speech, Aarhus, Denmark, June 10–12. [Google Scholar]
- Trofimovich, Pavel, and Wendy Baker. 2006. Learning second language suprasegmentals: Effect of L2 experience on prosody and fluency characteristics of l2 speech. Studies in Second Language Acquisition 28: 1–30. [Google Scholar] [CrossRef]
- van Leussen, Jan Willem, and Paola Escudero. 2015. Learning to perceive and recognize a second language: The L2LP model revised. Frontiers in Psychology 6: 1000. [Google Scholar] [CrossRef] [PubMed]
- Yao, Yao, and Charles Chang. 2016. On the cognitive basis of contact-induced sound change: Vowel merger reversal in Shanghainese. Language 92: 433–67. [Google Scholar] [CrossRef]
| 1 | A note on notation: although category representations are often represented in the literature using brackets, we use slashes when referring to phonemic inventories and representations in the speaker’s grammar. |
| 2 | We employ this phonemic notation following Bongiovanni (2019), recognizing that the glide in this sound sequence in Spanish is not phonemic and that this notation conflates phonetic and phonological representations. |
| 3 | In light of the unreliability of acoustic analysis of nasal consonants (see, e.g., Fujimura 1962, cited in Bongiovanni 2019, p. 4), Bongiovanni (2019) limited her analysis to the following vocalic portion. |
| 4 | Following authors such as Birdsong (2016) and Solis-Barroso and Stefanich (2019), we recognize the gradient nature of the different dimensions of dominance and treat the variable as scalar rather than categorical. |
| 5 | Spanish alveolar data are reported for contextual comparison; we have excluded the English alveolar data, as they are not relevant to the research question. |
| 6 | To determine the effect of individual differences in speech rate on the outcome, a separate model was fit to z-score-transformed data; the model yielded the same main effect of language (F(1,41.942) = 70.524, p < 0.001). For ease of interpretation, we report the duration data herein in ms. |
| 7 | One factor that may contribute to why the data do not evidence merged categories, such as those in the voiced stop data in Kang et al. (2016) and the acoustically similar vowel data in Godson (2003), is that some similar crosslinguistic pairs might be “easier” to keep separate. Recall from Section 1.1 that Spanish also has a /n+j/ sequence that contrasts with /ɲ/ in pairs, such as uranio /uɾanjo/ ‘uranium’ and huraño /uɾaɲo/ ‘unsociable’. Although the only experimental data on this contrast we are aware of is from Buenos Aires Spanish, in which there is a near-merger of /ɲ/ and /nj/, Bongiovanni (2019) found that, even in that case, while the participants did not accurately perceive the difference, their productions were acoustically distinct despite the contrast’s low functional load. We posit that one possibility is that the early Spanish bilinguals in this study successfully developed these separate representations early on, and that doing so facilitated the acquisition of the /n+j/ sequence in English. Comparisons of the /n+j/ productions in English versus Spanish mode will inform whether there is a single representation of the /n+j/ sequence or two, thus providing a more complete picture of the crosslinguistic relationship of these similar sounds. |
| 8 | Reanalysis of the L2 data from Stefanich and Cabrelli (2016), which will include the measurement of the same acoustic indices (FV duration and formant contours), is in progress. |
| 9 | Both groups of bilinguals are overall English dominant, strengthening our conclusion that it is not merely language dominance alone that contributes to the interaction (or lack thereof) between systems. Further, given that language dominance is thought to be fluid and changeable across a bilingual’s lifespan (e.g., De Houwer 2011), it makes sense that dominance would not be a determining factor in system interaction. |
| 10 | As pointed out by an anonymous reviewer, another interpretation of the higher F2 values could be that these speakers are producing a more constricted dorsopalatal realization, given that dorsopalatal constriction narrowing and F2 are positively correlated. |
| 11 | As evident in Appendix B, while the individual data fall into the four patterns, there is variation in the degree of spline overlap (i.e., acoustic distance). Without a principled way to quantitatively determine acoustic difference in the formant trajectories, however, we limit our discussion to the categorical patterns and include the individual SSANOVA for readers’ reference. |
| 12 | We also note that we only measured our participants’ proficiency in the heritage language (here, Spanish), as our participants attended school and are dominant in the majority language (here English). Future research could also measure proficiency in the majority language in addition to that of the heritage language to see what patterns might surface. |









| English | Spanish | |||
|---|---|---|---|---|
| M | SD | M | SD | |
| Friends | 0.82 | 0.15 | 0.18 | 0.15 |
| Family | 0.41 | 0.25 | 0.59 | 0.23 |
| School/Work | 0.78 | 0.13 | 0.20 | 0.14 |
| English | Spanish | |||
|---|---|---|---|---|
| M | SD | M | SD | |
| Speaking | 5.75 | 0.55 | 4.35 | 1.27 |
| Understanding | 5.95 | 0.22 | 5.00 | 0.97 |
| Reading | 5.85 | 0.87 | 4.05 | 1.32 |
| Writing | 5.75 | 0.44 | 3.65 | 1.27 |
| n | English | Example | Spanish | Example | |||
|---|---|---|---|---|---|---|---|
| Critical | 10 | (C)CVn.ja | /dɛnjɑ/ [ˈdɛn.jə] | ‘denya’ | (C)CV.ɲa | /deɲa/ [ˈde.ɲa] | deña |
| Control | 10 | (C)CV.na | /dɛnɑ/ [ˈdɛ.nə] | ‘denna’ | (C)CV.na | /dena/ [ˈde.na] | dena |
| Distractor | 20 | (C)CV.CV | /lɛkɑ/ [ˈlɛ.kə] | ‘lecka’ | (C)CV.CV | /meba/ [ˈme.β̞a] | meba |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stefanich, S.; Cabrelli, J. Shared or Separate Representations? The Spanish Palatal Nasal in Early Spanish/English Bilinguals. Languages 2020, 5, 50. https://doi.org/10.3390/languages5040050
Stefanich S, Cabrelli J. Shared or Separate Representations? The Spanish Palatal Nasal in Early Spanish/English Bilinguals. Languages. 2020; 5(4):50. https://doi.org/10.3390/languages5040050
Chicago/Turabian StyleStefanich, Sara, and Jennifer Cabrelli. 2020. "Shared or Separate Representations? The Spanish Palatal Nasal in Early Spanish/English Bilinguals" Languages 5, no. 4: 50. https://doi.org/10.3390/languages5040050
APA StyleStefanich, S., & Cabrelli, J. (2020). Shared or Separate Representations? The Spanish Palatal Nasal in Early Spanish/English Bilinguals. Languages, 5(4), 50. https://doi.org/10.3390/languages5040050