
Game on: Computerized Training Promotes Second Language Stress–Suffix Associations


Abstract
1. Introduction
2. Prosody in L2 Processing and the Role of Training
3. Linguistic Variables: Lexical Stress, Syllable Structure, and Phonotactic Probability in Spanish and English
4. Working Memory in L2 Processing
5. The Present Study
6. Methods
6.1. Participants
6.2. Materials
6.3. Procedure
7. Data Analysis
8. Results
8.1. Descriptive Statistics
8.2. General Findings
8.3. The Impact of Lexical Stress, Syllabic Structure, and Phonotactic Probability on Learners’ Performance
8.4. The Impact of WM on Learners’ Performance
9. Discussion
9.1. Lexical Stress, Syllable Structure, and Phonotactic Probability
9.2. Working Memory
9.3. Pedagogical Implications
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. GLMM and GAMM Accuracy Summaries

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Response Variable | Smooth Terms (Fixed Effects and Interactions) | Fixed Effects and Interactions | Random Effects | |||||
|---|---|---|---|---|---|---|---|---|
| Participant ID | Sentence ID | |||||||
| Estimate | Std. Error | p-Value | Variance | Std. Deviation | Variance | Std. Deviation | ||
| Accuracy | Stress (paroxytone) | −0.044 | 0.049 | 0.377 | 0.019 | 0.139 | 0.072 | 0.269 |
| Accuracy | Syllable struct (CVC) | −0.041 | 0.049 | 0.405 | 0.019 | 0.139 | 0.072 | 0.269 |
| Accuracy | wm_score | 0.039 | 0.034 | 0.245 | 0.018 | 0.133 | 0.072 | 0.269 |
| Accuracy | log_phono_freq | 0.806 | 0.995 | 0.418 | 0.019 | 0.139 | 0.072 | 0.269 |
| Accuracy | wm_score: paroxytone CV | −0.078 | 0.126 | 0.537 | 0.018 | 0.134 | 0.070 | 0.265 |
| wm_score: oxytone CVC | −0.068 | 0.127 | 0.590 | |||||
| wm_score: paroxytone CVC | −0.306 | 0.124 | 0.014 * | |||||
| wm_score: paroxytone CV: level | 0.007 | 0.015 | 0.620 | |||||
| wm_score: oxytone CVC: level | 0.011 | 0.015 | 0.461 | |||||
| wm_score: paroxytone CVC: level | 0.030 | 0.014 | 0.037 * | |||||
| Response Variable | Smooth Terms (Fixed Effects and Interactions) | S(Fixed Effects and Interactions) | S(Participant ID) | S(Sentence ID) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EDF | Ref.df | F | EDF | Ref.df | F | EDF | Ref.df | F | ||
| Accuracy | s(Level) | 1.015 | 1.029 | 0.707 | 15.083 | 19 | 83.916 *** | 118.531 | 191 | 322.035 *** |
| Accuracy | s(Level, by = Stress, oxytone) | 1.005 | 1.01 | 3.296 | 15.058 | 19 | 83.803 *** | 118.157 | 191 | 319.152 *** |
| s(Level, by = Stress, paroxytone) | 3.675 | 4.554 | 14.401 ** | |||||||
| Accuracy | s(Level, by = syllable_struct, CV) | 1.016 | 1.032 | 1.29 | 15.147 | 19 | 86.03 ** | 118.155 | 191 | 319.55 *** |
| s(Level, by = syllable_struct, CVC) | 1.01 | 1.02 | 5.69 * | |||||||
| Accuracy | s(Level, by = wm_score) | 2.413 | 2.713 | 2.786 | 14.061 | 18 | 74.146 *** | 118.484 | 191 | 320.139 *** |
| Accuracy | s(Level, by = log_phono_freq) | 1.015 | 1.029 | 0.707 | 15.083 | 19 | 83.916 | 118.531 | 191 | 320.761 *** |
Appendix B. GAMM RT Summaries
| Response Variable | Smooth Terms (Fixed Effects and Interactions) | Fixed Effects and Interactions | Random Effects | |||||
|---|---|---|---|---|---|---|---|---|
| Participant ID | Sentence ID | |||||||
| Estimate | Std. Error | p-Value | Variance | Std. Deviation | Variance | Std. Deviation | ||
| log_rt_ms | Stress (paroxytone) | −0.019 | 0.019 | 0.324 | 0.040 | 0.199 | 0.009 | 0.096 |
| log_rt_ms | Syllable struct (CVC) | −0.044 | 0.019 | 0.019 * | 0.040 | 0.199 | 0.009 | 0.094 |
| log_rt_ms | wm_score | −0.051 | 0.189 | 0.791 | 0.041 | 0.202 | 0.009 | 0.096 |
| log_rt_ms | log_phono_freq | 0.153 | 0.377 | 0.686 | 0.040 | 0.199 | 0.009 | 0.097 |
| log_rt_ms | wm_score: paroxytone CV | −0.104 | 0.054 | 0.054 | 0.018 | 0.134 | 0.070 | 0.265 |
| wm_score: oxytone CVC | −0.099 | 0.054 | 0.069 | |||||
| wm_score: paroxytone CVC | −0.128 | 0.053 | 0.015 * | |||||
| wm_score: paroxytone CV: level | −0.004 | 0.006 | 0.511 | |||||
| wm_score: oxytone CVC: level | −0.007 | 0.006 | 0.300 | |||||
| wm_score: paroxytone CVC: level | −0.001 | 0.006 | 0.936 | |||||
| Response Variable | Smooth Terms (Fixed Effects and Interactions) | S(Fixed Effects and Interactions) | S(Participant ID) | S(Sentence ID) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EDF | Ref.df | F | EDF | Ref.df | F | EDF | Ref.df | F | ||
| log_rt_ms | s(Level) | 7.073 | 8.095 | 25.730 *** | 18.619 | 19.000 | 56.316 *** | 101.652 | 191.000 | 1.336 *** |
| log_rt_ms | s(Level, by = Stress, oxytone) | 6.186 | 7.310 | 16.085 *** | 18.616 | 19.000 | 55.774 ** | 100.968 | 191.000 | 1.303 *** |
| s(Level, by = Stress, paroxytone) | 5.599 | 6.727 | 16.141 *** | |||||||
| log_rt_ms | s(Level, by = syllable_struct, CV) | 6.024 | 7.158 | 13.891 *** | 18.618 | 19.000 | 56.189 *** | 101.911 | 191.000 | 1.322 *** |
| s(Level, by = syllable_struct, CVC) | 5.755 | 6.887 | 16.953 *** | |||||||
| log_rt_ms | s(Level, by = wm_score) | 5.334 | 6.33 | 5.191 *** | 17.605 | 18.000 | 52.182 *** | 102.908 | 191.000 | 1.384 *** |
| log_rt_ms | s(Level, by = log_phono_freq) | 8.052 | 9.078 | 21.485 *** | 18.608 | 19.000 | 55.081 *** | 101.515 | 190.000 | 1.337 *** |
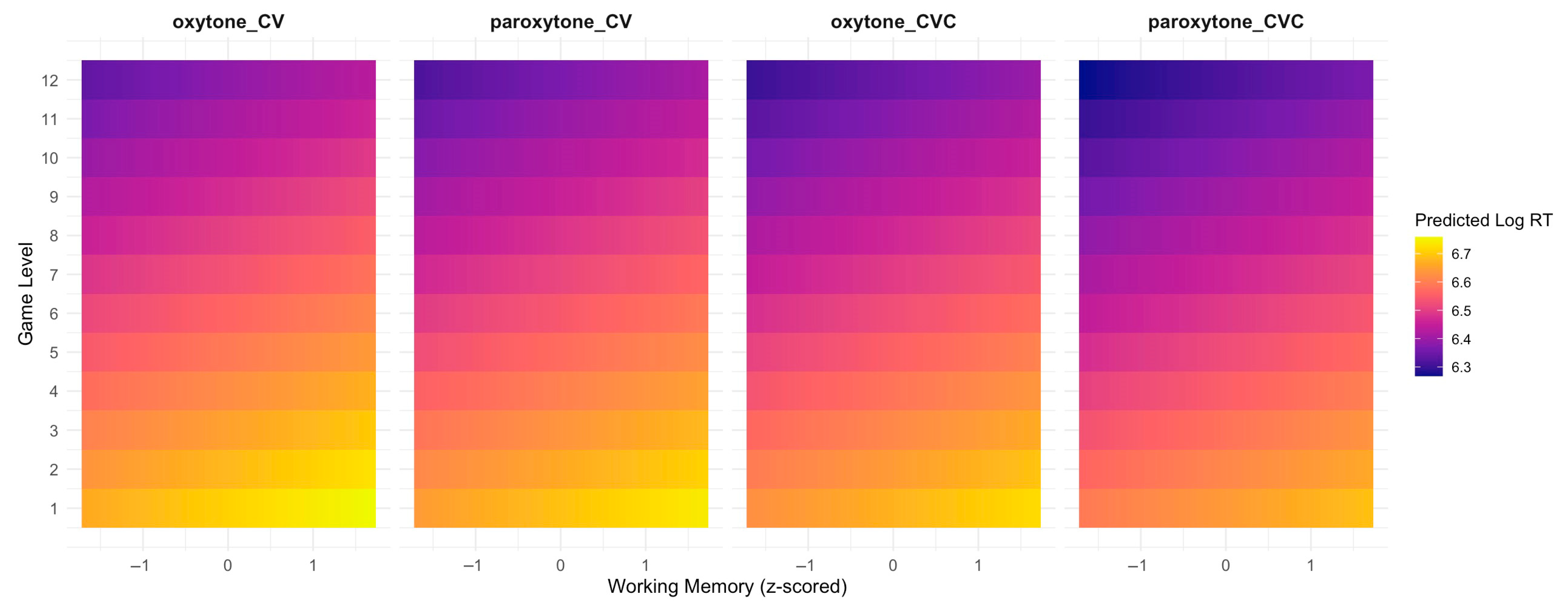
| 1 | A prediction plot displays model-estimated (fitted) values of the dependent variable, holding all other predictors constant. The shaded band marks the 95% confidence interval around those estimates. |
References
- Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. [Google Scholar] [CrossRef]
- Boersma, P., & Weenink, D. (2018). Praat: Doing phonetics by computer [Computer software]. Available online: http://www.praat.org (accessed on 1 September 2023).
- Bovolenta, G., & Marsden, E. (2021). Expectation violation enhances the development of new abstract syntactic representations: Evidence from an artificial language learning study. Language Development Research, 193–243. [Google Scholar] [CrossRef]
- Chrabaszcz, A., Winn, M., Lin, C. Y., & Idsardi, W. J. (2014). Acoustic cues to perception of word stress by English, Mandarin, and Russian speakers. Journal of Speech, Language, and Hearing Research, 57(4), 1468–1479. [Google Scholar] [CrossRef] [PubMed]
- Cooper, N., Cutler, A., & Wales, R. (2002). Constraints of lexical stress on lexical access in English: Evidence from native and non-native listeners. Language and Speech, 45(3), 207–228. [Google Scholar] [CrossRef]
- Corsi, P. M. (1972). Human memory and the medial temporal region of the brain [Unpublished doctoral dissertation, McGill University]. [Google Scholar]
- Cowan, N. (2017). The many faces of working memory and short-term storage. Psychonomic Bulletin & Review, 24(4), 1158–1170. [Google Scholar] [CrossRef]
- Cutler, A. (1986). Forbear is a homophone: Lexical prosody does not constrain lexical access. Language and Speech, 29(3), 201–220. [Google Scholar] [CrossRef]
- Cutler, A. (2012). Native listening: Language experience and the recognition of spoken words. MIT Press. [Google Scholar] [CrossRef]
- Cutler, A., Dahan, D., & van Donselaar, W. (1997). Prosody in the comprehension of spoken language: A literature review. Language and Speech, 40(2), 141–201. [Google Scholar] [CrossRef]
- Cutler, A., & Pasveer, D. (2006). Explaining cross-linguistic differences in effects of lexical stress on spoken-word recognition. In R. Hoffman, & H. Mixdorff (Eds.), Speech prosody. TUD Press. [Google Scholar]
- DeKeyser, R. M., & Criado, R. (2012). Automatization, skill acquisition, and practice in second language acquisition. In C. Chapelle (Ed.), The encyclopedia of applied linguistics (pp. 4501–4504). Wiley-Blackwell. [Google Scholar] [CrossRef]
- Durand López, E. M. (2021). Morphological processing and individual frequency effects in L1 and L2 Spanish. Lingua, 257, 103093. [Google Scholar] [CrossRef]
- Dussias, P. E., Kroff, J. R. V., Tamargo, R. E. G., & Gerfen, C. (2013). When gender and looking go hand in hand: Grammatical gender processing in L2 Spanish. Studies in Second Language Acquisition, 35(2), 353–387. [Google Scholar] [CrossRef]
- Face, T. L. (2005). Syllable weight and the perception of Spanish stress placement by second language learners. Journal of Language and Learning, 3(1), 90–103. [Google Scholar]
- Faretta-Stutenberg, M., & Morgan-Short, K. (2018). The interplay of individual differences and context of learning in behavioral and neurocognitive second language development. Second Language Research, 34(1), 67–101. [Google Scholar] [CrossRef]
- Fernandez, K. (2024). Dinosaur verb game. Available online: https://testenvdinosaur-game.web.app (accessed on 15 April 2024).
- Flege, J. E., & Bohn, O.-S. (2021). The revised speech learning model (SLM-r). In Second language speech learning (pp. 3–83). Cambridge University Press. [Google Scholar] [CrossRef]
- Foltz, A. (2021). Using prosody to predict upcoming referents in the L1 and the L2: The role of recent exposure. Studies in Second Language Acquisition, 43(4), 753–780. [Google Scholar] [CrossRef]
- Foote, R. (2011). Integrated knowledge of agreement in early and late English–Spanish bilinguals. Applied Psycholinguistics, 32(1), 187–220. [Google Scholar] [CrossRef]
- Gosselke Berthelsen, S., Horne, M., Brännström, K. J., Shtyrov, Y., & Roll, M. (2018). Neural processing of morphosyntactic tonal cues in second-language learners. Journal of Neurolinguistics, 45, 60–78. [Google Scholar] [CrossRef]
- Gosselke Berthelsen, S., Horne, M., Shtyrov, Y., & Roll, M. (2022). Native language experience shapes pre-attentive foreign tone processing and guides rapid memory trace build-up: An ERP study. Psychophysiology, 59(8), e14042. [Google Scholar] [CrossRef]
- Gosselke Berthelsen, S., & Roll, M. (2023). Computer-Aided L2 prosody acquisition and its potential in second language learning. ASLA:s Skriftserie, 30, 157–182. [Google Scholar] [CrossRef]
- Grüter, T., Lew-Williams, C., & Fernald, A. (2012). Grammatical gender in L2: A production or a real-time processing problem? Second Language Research, 28(2), 191–215. [Google Scholar] [CrossRef]
- Hamrick, P., & Pandža, N. B. (2014). Competitive lexical activation during ESL spoken word recognition. International Journal of Innovation in English Language Teaching and Research, 3(2), 159–177. [Google Scholar]
- Hed, A., Schremm, A., Horne, M., & Roll, M. (2019). Neural correlates of second language acquisition of tone-grammar associations. The Mental Lexicon, 14(1), 98–123. [Google Scholar] [CrossRef]
- Holt, L. L., & Lotto, A. J. (2006). Cue weighting in auditory categorization: Implications for first and second language acquisition. The Journal of the Acoustical Society of America, 119(5), 3059–3071. [Google Scholar] [CrossRef]
- Hopp, H. (2013). Grammatical gender in adult L2 acquisition: Relations between lexical and syntactic variability. Second Language Research, 29(1), 33–56. [Google Scholar] [CrossRef]
- Hualde, J. I. (2005). The sounds of Spanish with audio CD. Cambridge University Press. [Google Scholar]
- Huettig, F. (2015). Four central questions about prediction in language processing. Brain Research, 1626, 118–135. [Google Scholar] [CrossRef] [PubMed]
- Huettig, F., & Janse, E. (2016). Individual differences in working memory and processing speed predict anticipatory spoken language processing in the visual world. Language, Cognition and Neuroscience, 31(1), 80–93. [Google Scholar] [CrossRef]
- Ito, K., & Speer, S. R. (2008). Anticipatory effects of intonation: Eye movements during instructed visual search. Journal of Memory and Language, 58, 541–573. [Google Scholar] [CrossRef]
- Izura, C., Cuetos, F., & Brysbaert, M. (2014). Lextale-Esp: A test to rapidly and efficiently assess the Spanish vocabulary size. Psicológica, 35(1), 49–66. [Google Scholar]
- Kaan, E., & Grüter, T. (2021). Prediction in second language processing and learning: Advances and directions. In E. Kaan, & T. Grüter (Eds.), Prediction in second language processing and learning (pp. 1–24). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Kutas, M., DeLong, K. A., & Smith, N. J. (2011). A look around at what lies ahead: Prediction and predictability in language processing. In M. Bar (Ed.), Predictions in the brain: Using our past to generate a future (pp. 190–207). Oxford University Press. [Google Scholar] [CrossRef]
- Li, S. (2010). The effectiveness of corrective feedback in SLA: A meta-analysis. Language Learning, 60(2), 309–365. [Google Scholar] [CrossRef]
- Loewen, S., Isbell, D. R., & Sporn, Z. (2020). The effectiveness of app-based language instruction for developing receptive linguistic knowledge and oral communicative ability. Foreign Language Annals, 53(2), 209–233. [Google Scholar] [CrossRef]
- Lord, G. (2007). The role of the lexicon in learning second language stress patterns. Applied Language Learning, 17(1/2), 1–14. [Google Scholar]
- Lozano-Argüelles, C., Sagarra, N., & Casillas, J. (2023). Interpreting experience and working memory effects on L1 and L2 morphological prediction. Frontiers in Language Sciences, 1, 1065014. [Google Scholar] [CrossRef]
- Luce, P. A., & Pisoni, D. B. (1998). Recognizing spoken words: The neighborhood activation model. Ear and Hearing, 19, 1–36. [Google Scholar] [CrossRef]
- MacDonald, M. C., Just, M. A., & Carpenter, P. A. (1992). Working memory constraints on the processing of syntactic ambiguity. Cognitive Psychology, 24(1), 56–98. [Google Scholar] [CrossRef] [PubMed]
- Mifka-Profozic, N. (2015). Effects of corrective feedback on L2 Acquisition of tense-aspect verbal morphology. LIA: Language, Interaction and Acquisition, 6(1), 149–180. [Google Scholar] [CrossRef]
- Mitsugi, S., & MacWhinney, B. (2015). The use of case marking for predictive processing in second language Japanese. Bilingualism: Language and Cognition, 19(1), 19–35. [Google Scholar] [CrossRef]
- Morales-Font, A. (2014). El acento. In R. A. Nuñez, S. Colina, & T. G. Bradley (Eds.), Fonología generativa contemporánea de la lengua Española (pp. 235–265). Georgetown University Press. [Google Scholar]
- Nakamura, C., Arai, M., & Mazuka, R. (2012). Immediate use of prosody and context in predicting a syntactic structure. Cognition, 125(2), 317–323. [Google Scholar] [CrossRef]
- Nicholas, H., Lightbown, P. M., & Spada, N. (2001). Recasts as feedback to language learners. Language Learning, 51(4), 719–758. [Google Scholar] [CrossRef]
- Norris, D., Cutler, A., McQueen, J. M., & Butterfield, S. (2006). Phonological and conceptual activation in speech comprehension. Cognitive Psychology, 53(2), 146–193. [Google Scholar] [CrossRef]
- Ortega-Llebaria, M., Gu, H., & Fan, J. (2013). English speakers’ perception of Spanish lexical stress: Context-driven L2 stress perception. Journal of Phonetics, 41(3–4), 186–197. [Google Scholar] [CrossRef]
- Perdomo, M., & Kaan, E. (2021). Prosodic cues in second-language speech processing: A visual world eye-tracking study. Second Language Research, 37(2), 349–375. [Google Scholar] [CrossRef]
- Pufahl, I., & Rhodes, N. C. (2011). Foreign language instruction in U.S. schools: Results of a national survey of elementary and secondary schools. Foreign Language Annals, 44(2), 258–288. [Google Scholar] [CrossRef]
- R Core Team. (2023). R: A language and environment for statistical computing. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 15 March 2024).
- Reichle, R. V., Tremblay, A., & Coughlin, C. E. (2013). Working-memory capacity effects in the processing of non-adjacent subject-verb agreement: An event-related brain potentials study. In Selected proceedings of the 2011 second language research forum. Cascadilla Proceedings Project. [Google Scholar]
- Rızaoğlu, F., & Gürel, A. (2020). Second language processing of English past tense morphology: The role of working memory. International Review of Applied Linguistics in Language Teaching, 60(3), 825–853. [Google Scholar] [CrossRef]
- Roll, M., Söderström, P., Mannfolk, P., Shtyrov, Y., Johansson, M., van Westen, D., & Horne, M. (2015). Word tones cueing morphosyntactic structure: Neuroanatomical substrates and activation time-course assessed by EEG and fMRI. Brain and Language, 150, 14–21. [Google Scholar] [CrossRef] [PubMed]
- Saffran, J. R., Johnson, E. K., Aslin, R. N., & Newport, E. (1999). Statistical learning of tone sequences by human infants and adults. Cognition, 70(1), 27–52. [Google Scholar] [CrossRef] [PubMed]
- Sagarra, N., & Casillas, J. V. (2018). Suprasegmental information cues morphological anticipation during L1/L2 lexical access. Journal of Second Language Studies, 1(1), 31–59. [Google Scholar] [CrossRef]
- Sagarra, N., & Herschensohn, J. (2010). The role of proficiency and working memory in gender and number agreement processing in L1 and L2 Spanish. Lingua, 120(8), 2022–2039. [Google Scholar] [CrossRef]
- Schremm, A., Hed, A., Horne, M., & Roll, M. (2017). Training predictive L2 processing with a digital game: Prototype promotes acquisition of anticipatory use of tone-suffix associations. Computers & Education, 114, 206–221. [Google Scholar] [CrossRef]
- Schremm, A., Söderström, P., Horne, M., & Roll, M. (2016). Implicit acquisition of tone-suffix connections in L2 learners of Swedish. The Mental Lexicon, 11(1), 55–75. [Google Scholar] [CrossRef]
- Soto-Faraco, S., Sebastián-Gallés, N., & Cutler, A. (2001). Segmental and suprasegmental mismatch in lexical access. Journal of Memory and Language, 45(3), 412–432. [Google Scholar] [CrossRef]
- Söderström, P., Horne, M., & Roll, M. (2017). Stem tones pre-activate suffixes in the brain. Journal of Psycholinguistic Research, 46, 271–280. [Google Scholar] [CrossRef]
- Tokowicz, N., & MacWhinney, B. (2005). Implicit and explicit measures of sensitivity to violations in second language grammar: An event-related potential investigation. Studies in Second Language Acquisition, 27(2), 173–204. [Google Scholar] [CrossRef]
- Tremblay, A. (2008). Is second language lexical access prosodically constrained? Processing of word stress by French Canadian second language learners of English. Applied Psycholinguistics, 29(4), 553–584. [Google Scholar] [CrossRef]
- Tremblay, A., Broersma, M., & Coughlin, C. E. (2017). The functional weight of a prosodic cue in the native language predicts the learning of speech segmentation in a second language. Bilingualism: Language and Cognition, 21(3), 640–652. [Google Scholar] [CrossRef]
- Vitevitch, M. S., & Luce, P. A. (1998). When words compete: Levels of processing in perception of spoken words. Psychological Science, 9(4), 325–329. [Google Scholar] [CrossRef]
- Vitevitch, M. S., & Luce, P. A. (1999). Probabilistic phonotactics and neighborhood activation in spoken word recognition. Journal of Memory and Language, 40(3), 374–408. [Google Scholar] [CrossRef]
- Vitevitch, M. S., & Luce, P. A. (2004). Spanish phonotactic probability calculator. Department of Psychology, University of Kansas. Available online: https://calculator.ku.edu/phonotactic/Spanish/words (accessed on 1 March 2024).
- Vitevitch, M. S., Luce, P. A., Charles-Luce, J., & Kemmerer, D. (1997). Phonotactics and syllable stress: Implications for the processing of spoken nonsense words. Language and Speech, 40(1), 47–62. [Google Scholar] [CrossRef]
- Vitevitch, M. S., Luce, P. A., Pisoni, D. B., & Auer, E. T. (1999). Phonotactics, neighborhood activation, and lexical access for spoken words. Brain and Language, 68(1–2), 306–311. [Google Scholar] [CrossRef]
- Vitevitch, M. S., Stamer, M. K., & Sereno, J. A. (2008). Word length and lexical competition: Longer is the same as shorter. Language and Speech, 51(4), 361–383. [Google Scholar] [CrossRef]
- Weber, A., Grice, M., & Crocker, M. W. (2006). The role of prosody in the interpretation of structural ambiguities: A study of anticipatory eye movements. Cognition, 99, B63–B72. [Google Scholar] [CrossRef]
- Wood, S. (2023). Mgcv: Mixed GAM computation vehicle with automatic smoothness estimation (R package version 1.9.1). Available online: https://CRAN.R-project.org/package=mgcv (accessed on 15 March 2024).











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernandez, K.; Sagarra, N. Game on: Computerized Training Promotes Second Language Stress–Suffix Associations. Languages 2025, 10, 170. https://doi.org/10.3390/languages10070170
Fernandez K, Sagarra N. Game on: Computerized Training Promotes Second Language Stress–Suffix Associations. Languages. 2025; 10(7):170. https://doi.org/10.3390/languages10070170
Chicago/Turabian StyleFernandez, Kaylee, and Nuria Sagarra. 2025. "Game on: Computerized Training Promotes Second Language Stress–Suffix Associations" Languages 10, no. 7: 170. https://doi.org/10.3390/languages10070170
APA StyleFernandez, K., & Sagarra, N. (2025). Game on: Computerized Training Promotes Second Language Stress–Suffix Associations. Languages, 10(7), 170. https://doi.org/10.3390/languages10070170