1. Introduction
Space object detection is a fundamental task in supporting close-proximity operations involving non-cooperative spacecraft with known trajectories and clearly visible geometries. Such detection capabilities play a crucial role in monitoring non-cooperative spacecraft [
1,
2], preventing collisions with space debris [
3,
4], and supporting space mission planning [
5,
6]. First, in close-range scenarios, non-cooperative spacecraft, particularly those considered potentially adversarial, pose significant risks due to their unpredictable behavior and lack of communication with existing tracking infrastructure. In these contexts, visual detection systems enable real-time situational awareness, thereby supporting timely risk assessment and the formulation of effective response strategies. Such capabilities are critical for maintaining the safety and operational stability of space assets in increasingly congested and contested orbital environments. Moreover, the rapidly increasing amount of space debris poses a serious threat to the safety of spacecraft in orbit [
7]. Avoiding collisions with space debris requires highly accurate detection systems capable of sensing debris, thereby providing guidance for subsequent threat avoidance measures. Furthermore, perception serves as a foundational element in the planning and execution of various close-range space operations, including autonomous docking, inspection, and servicing tasks [
8,
9]. Reliable detection systems contribute to the early identification of infeasible objectives or operational constraints, thereby improving mission efficiency and safety. In light of these considerations, this paper presents a robust and efficient space object detection method designed for close-proximity scenarios involving known targets under complex visual conditions. The proposed method aims to provide accurate object localization while maintaining real-time performance, offering a dependable visual perception foundation for autonomous navigation and mission planning in near-field space environments.
However, space object detection currently faces three major challenges. First, interference from other celestial bodies and sensor noise introduce substantial noise into the images, complicating the detection process and degrading the detection accuracy [
10]. The low lighting conditions in space result in poor contrast between the spacecraft and their background in the images captured by cameras, making it difficult to extract meaningful features. Second, spacecraft are constrained by limited onboard resources, including computational power, energy, and storage capacity, yet there is a requirement for rapid response, which requires fast and accurate detection within the constraints of limited computational and storage resources. Achieving a balance between performance and resource efficiency remains a fundamental challenge for onboard detection technologies. Lastly, the vast operational space and large measurement scales lead to the frequent prevalence of small objects [
11]. These small objects occupy only a tiny fraction of the entire image, often exhibiting low resolution and indistinct features, making them particularly challenging to detect. Addressing these challenges is essential for advancing space object detection capabilities and ensuring mission success in complex and dynamic orbital environments.
Spacecraft images are frequently contaminated with noise caused by background interference and sensor noise. Given the limited onboard resources, traditional image processing techniques, such as mean filtering, median filtering, and Gaussian filtering, are commonly employed for noise reduction due to their simplicity and low computational requirements. However, these methods often compromise critical edge and texture details, which are essential for accurate detection. To overcome this limitation, bilateral filtering [
12,
13] is considered as a more suitable approach, which can preserve edge and texture features for subsequent detection tasks while effectively removing noise.
Low-contrast images captured in space present significant challenges for space object detection, as inadequate lighting often obscures critical features [
14]. Some enhancement techniques, such as linear transformation, Gamma correction, and histogram adjustment, can improve contrast but may struggle with uneven lighting or significant noise. Inspired by [
15,
16], contrast-limited adaptive histogram equalization (CLAHE) provides a more effective solution by enhancing local contrast while limiting noise amplification. By processing small image regions independently, CLAHE effectively highlights spacecraft features and improves overall image clarity, enabling more accurate detection.
Object detection algorithms can generally be classified into two categories based on whether explicit regions of interest are generated: two-stage and one-stage algorithms [
17,
18]. Two-stage algorithms, such as Region-based Convolutional Neural Networks (R-CNNs) [
19], Faster Region-based Convolutional Neural Networks (Faster R-CNNs) [
20], and Region-based Fully Convolutional Networks (R-FCNs) [
21], first generate candidate regions and then classify them. In contrast, one-stage algorithms like You Only Look Once (YOLO) [
22], Single Shot MultiBox Detector (SSD) [
23], and RetinaNet [
24] directly predict object locations and categories in a single step. One-stage algorithms typically require only a single forward pass to extract features, making them faster in detection and better suited for the real-time requirements of space object detection. The study in [
25] shows that integrating EfficientDet with EfficientNet-v2 enhances space object detection and classification on the SPARK dataset, outperforming existing methods, while also highlighting the potential of YOLO-based detectors on this challenging dataset in this work. YOLO, as a representative of one-stage object detection algorithms, stands out for its efficiency and real-time processing capability, with its architecture evolving to improve accuracy, speed, and robustness from YOLOv1 [
22] to YOLO11 [
26]. The study in [
3] employs YOLOv8 for space debris detection and achieves excellent performance on its synthetically generated images. The study in [
27] also builds upon YOLOv8, approaching the problem from the perspective of cross-scale feature fusion, and likewise achieves promising detection performance for space debris. Compared with these studies, the method used in this work is based on YOLO11, whose structural improvements over previous YOLO versions enhance detection performance. Additionally, further architectural modifications are made to the original YOLO11 to improve its ability to detect small objects, which frequently appear in space object detection tasks.
Small object detection remains a significant challenge in space object detection [
28,
29]. To tackle this issue, most typical approaches focus on network architecture and data augmentation [
30]. In terms of network architecture, Feature Pyramid Networks (FPN) [
31] and their variants [
32] are commonly employed. These methods focus on efficient and effective feature fusion, enhancing the representation of small objects across different feature layers. Other approaches include various data augmentation techniques, and previous work has mainly concentrated on using handcrafted data augmentation strategies [
33] to enable the model to learn multi-scale features. In this work, to address the challenge of small object detection, targeted structural improvements are made to YOLO11, and a loss-guided online data augmentation method is proposed to further optimize the detection process for small objects.
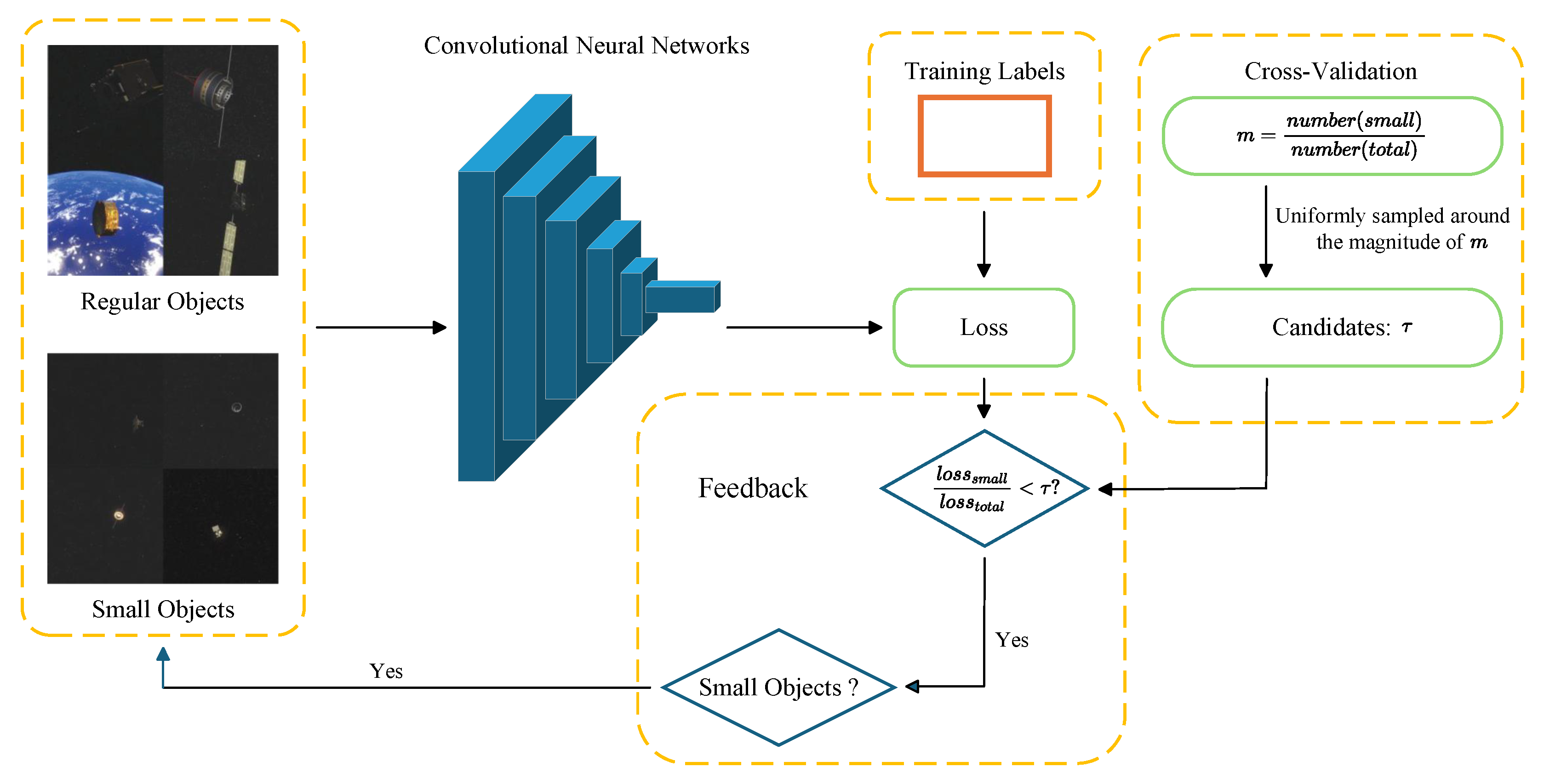
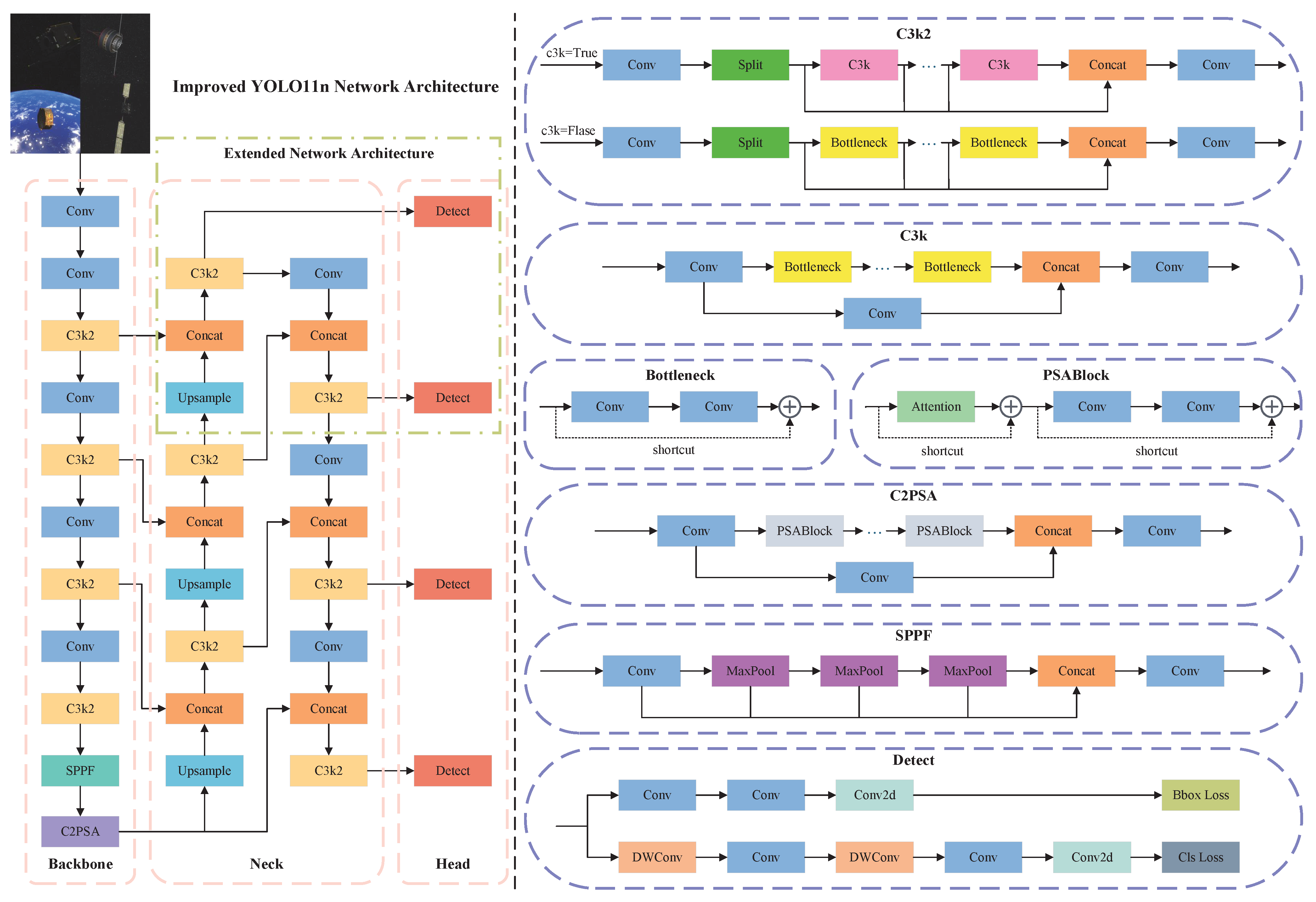
Building on the insights discussed above, YOLO11 serves as the baseline, with several improvements introduced for the space object detection scenario. The main contributions of this paper can be summarized as follows:
A complete object detection framework tailored to the characteristics of space targets is proposed, encompassing image preprocessing, data augmentation, and network architecture enhancements. The experimental results demonstrate that the proposed algorithm effectively improves detection performance.
A loss-guided online data augmentation technique is proposed, along with improvements to the YOLO11 network structure, to address the challenge of small object detection in the dataset.
In the following,
Section 2 introduces SPARK-2022, a space object detection dataset, highlighting its design and relevance to the field.
Section 3 presents our proposed method, which integrates bilateral filtering, CLAHE, loss-guided online data augmentation, and architecture improvements to YOLO11. Experimental results and conclusions are discussed in
Section 4 and
Section 5, respectively.
2. SPARK-2022 Dataset
The SPARK-2022 dataset [
34,
35], developed by the University of Luxembourg for the Spark Challenge 2022, is specifically designed for space object detection. It consists of 88,000 RGB images with a resolution of 1024 × 1024, representing 10 classes of spacecraft and 1 class of space debris. The dataset is split into a training set of 66,000 images—a validation set of 11,000 images, and a test set of 11,000 images—with an equal distribution of each class across all subsets. The 10 spacecraft classes include smart_1, cheops, lisa_pathfinder, proba_3_ocs, proba_3_csc, soho, earth_observation_sat_1, proba_2, xmm_newton, and double_star, and the space debris includes components from the Space Shuttle’s external fuel tank, orbital docking systems, damaged communication dishes, thermal protection tiles, and connectors. The histograms of bounding box sizes in the training set of the dataset are presented in
Figure 1. The horizontal axis represents the proportion of the bounding box area relative to the entire image, while the vertical axis indicates the corresponding frequency. It can be observed that small objects are widely present in the dataset.
To comprehensively simulate a wide range of space environmental conditions, the dataset leverages extensive domain randomization techniques and is generated within a highly realistic space simulation environment. This approach ensures the inclusion of data from diverse orbital scenarios, varying levels of background noise, and different sensor configurations. Moreover, the dataset encompasses a broad spectrum of sensing conditions, ranging from typical to extreme and challenging scenarios. These challenging conditions include low signal-to-noise ratios (SNR) and high image contrast, which are characteristic features of actual space imagery. This design philosophy enables the dataset to capture the complexities and variability inherent in real-world space environments. Notably, the Earth, placed at the center of all orbital scenario 3D environments, is represented by a realistic model composed of 16,000 polygons and high-resolution textures. Surrounding space textures are sourced from a detailed panoramic image of the Milky Way galaxy. The model also features intricate elements such as dynamic clouds, cloud shadows, and atmospheric scattering effects, contributing to a highly immersive visual effect.
Figure 2 presents sample images from the dataset.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}