
Automated Real-Time Identification of Medicinal Plants Species in Natural Environment Using Deep Learning Models—A Case Study from Borneo Region



Abstract
:1. Introduction
- We have proposed a machine vision system that is capable of automating the identification of medicinal plant species in real time.
- We have developed an end-to-end computer vision system with a convolutional neural network (CNN) model to identify medicinal plant species when given an image.
- The system works in real time and can accurately identify different plant species given by simply taking a picture with a mobile camera or uploading an existing image from a device.
- The system provides a feedback mechanism and a knowledge base as a means to continuous lifelong learning of the models to produce a robust plant species identification system.
2. Materials and Methods
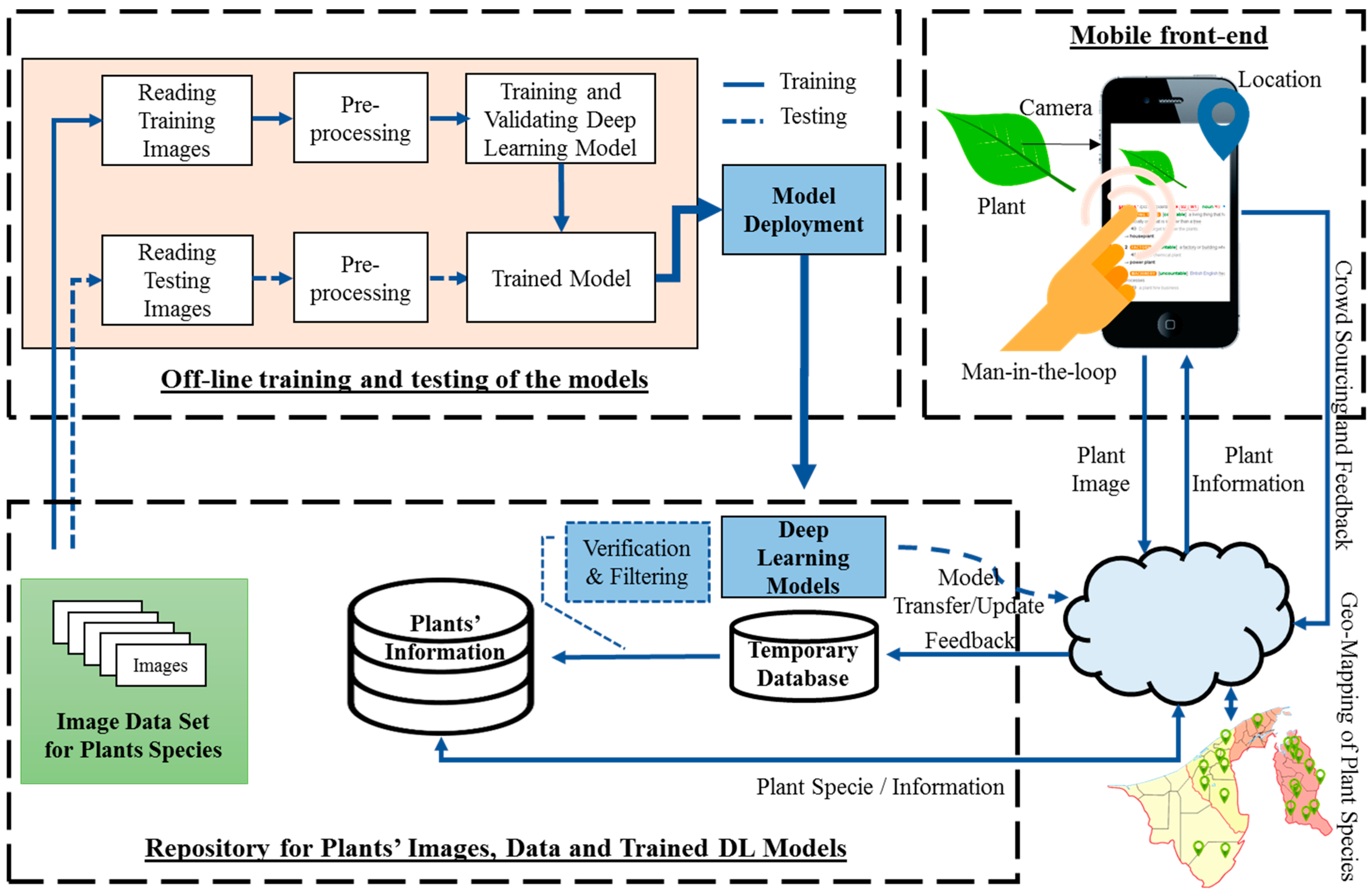
2.1. Proposed System
2.2. Classification Model
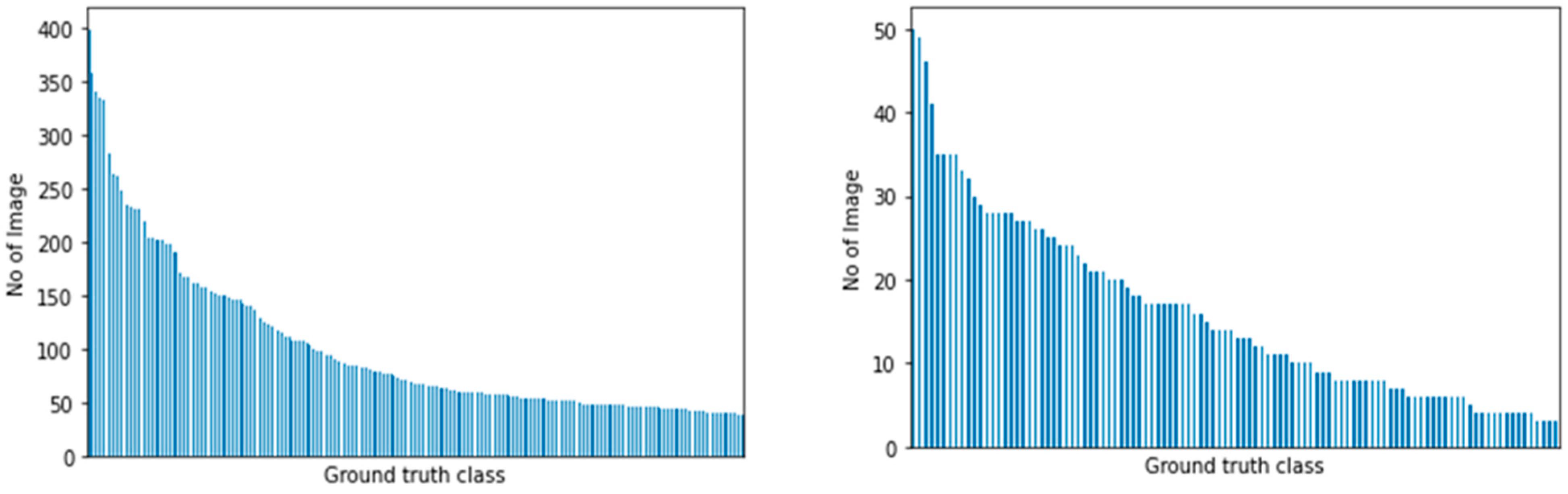
2.2.1. Datasets
PlantCLEF 2015
UBD Botanical Garden Dataset
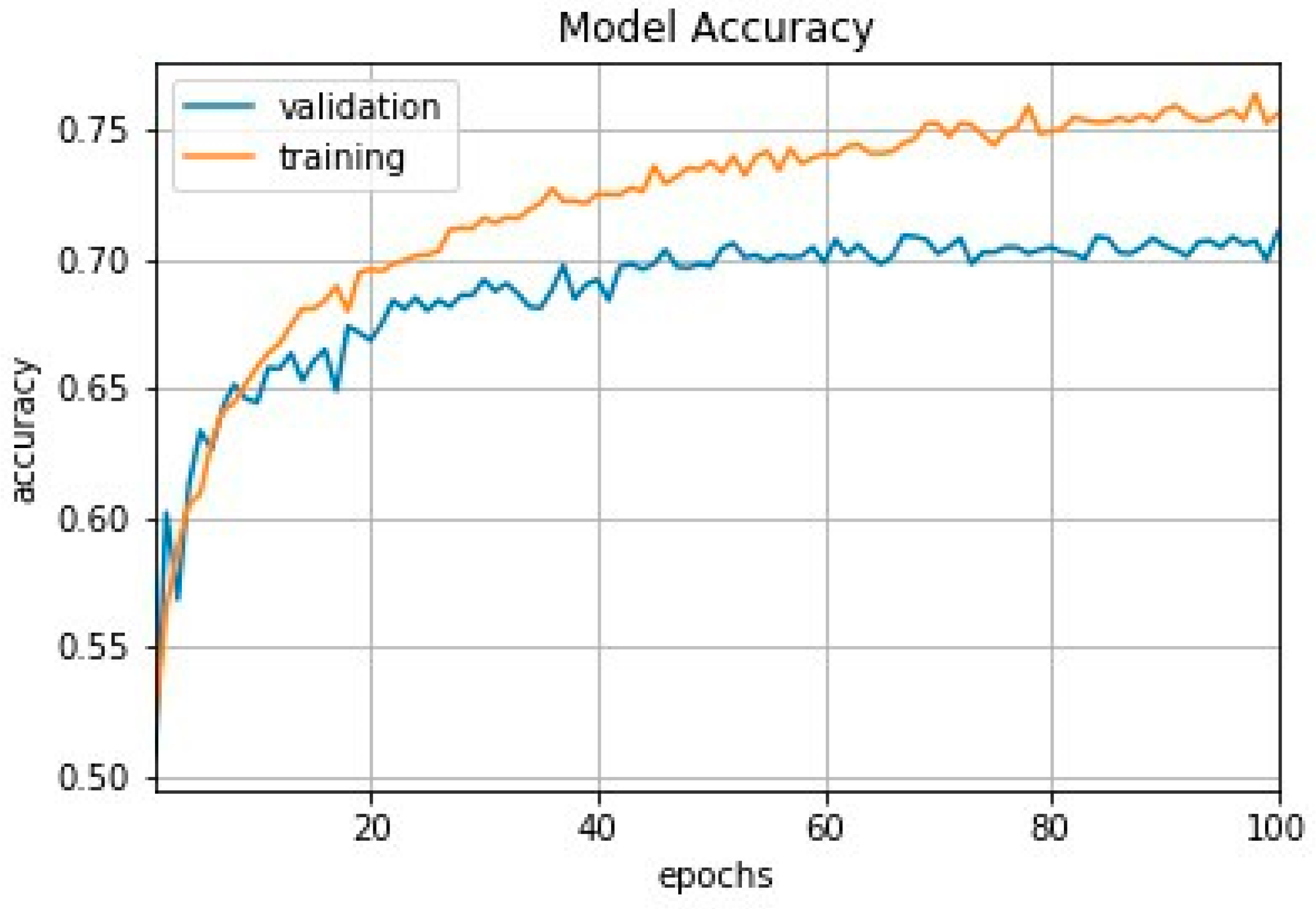
2.2.2. Training Details
Class Weighted Function
- def class_weights() #returns a dict. of class weights.
- counter = dict. containing the no. of samples per class from .
- if > 0:
- p = max(counter.values()) *
- for class in counter.keys():
- counter[class] += p
- majority = max(counter.values())
- return {class: }
Focal Loss
- As →1—meaning that the model is confident that a given sample belongs to class t—the modulating factor goes to 0 given , resulting in the down-weight of the loss of the easy examples during training.
- Parameter γ, or the focusing parameter, controls the rate at which easy examples are down-weighted. As γ [0, 5], γ = 0 is equivalent to the standard cross-entropy loss with no class weights assigned. As → 5, the modulating factor grows exponentially, resulting in the increase of down-weight of easy examples.
2.2.3. Hyperparameter Tuning
Learning Rate Finder
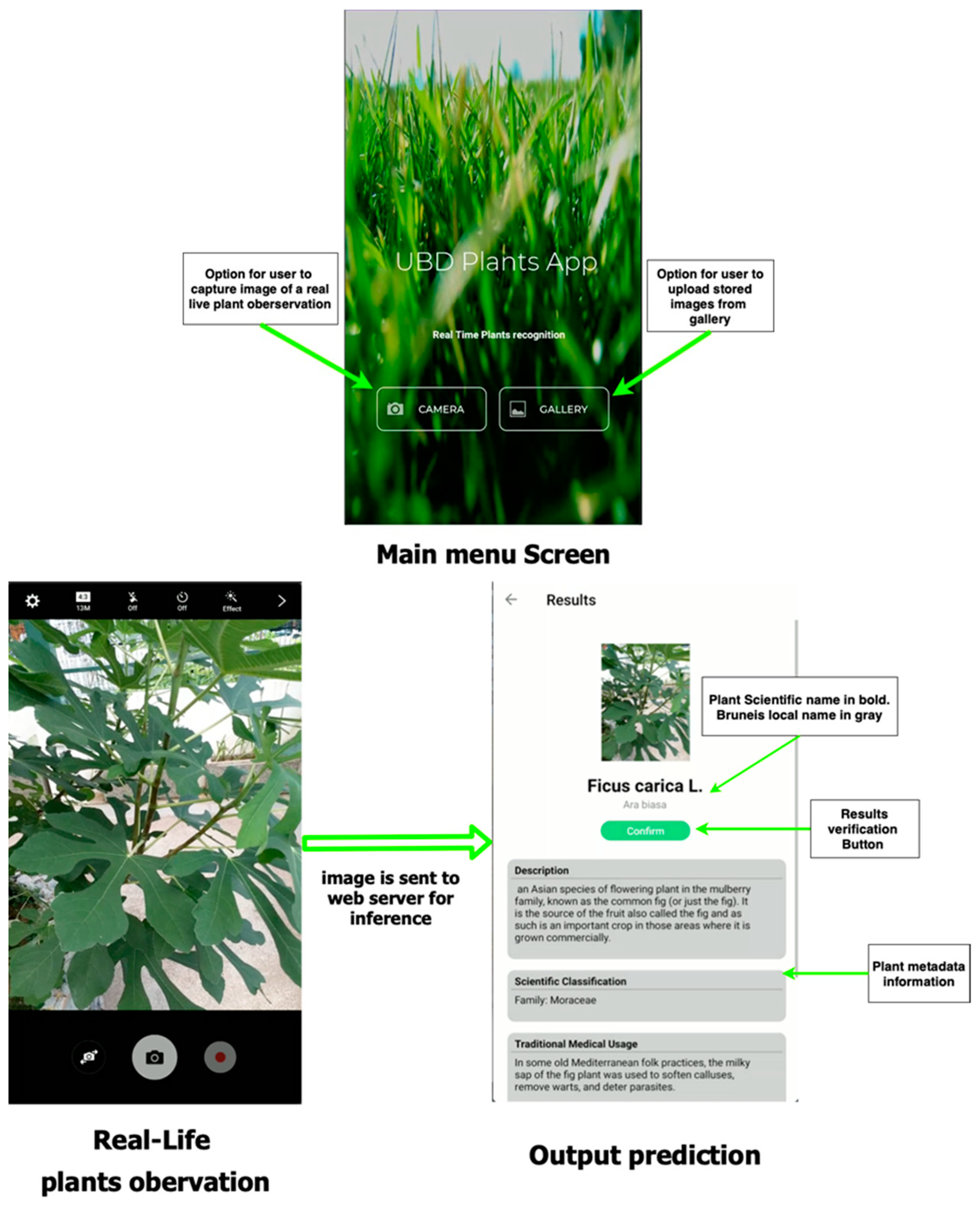
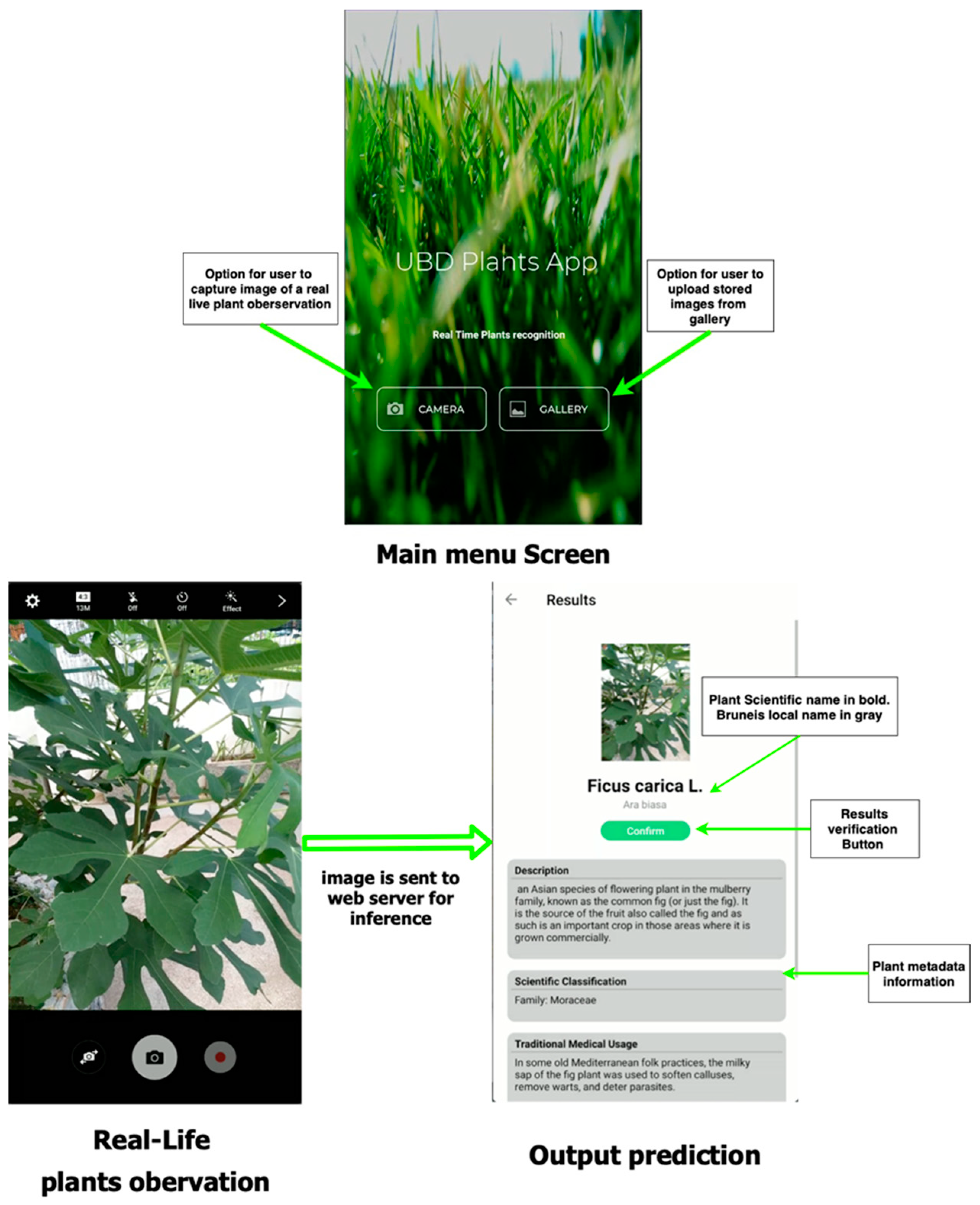
2.3. Mobile Application Details
2.3.1. Web API and Front-End
2.3.2. Species Prediction
2.3.3. User Response Information Storage
2.4. Knowledge Base
3. Experiments and Results
3.1. Offline Testing of the Classification Models (for Both Datasets)
3.2. Mobile Application Testing
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sachar, S.; Kumar, A. Survey of feature extraction and classification techniques to identify plant through leaves. Expert Syst. Appl. 2021, 167, 114181. [Google Scholar] [CrossRef]
- Elhassouny, A.; Smarandache, F. Smart mobile application to recognize tomato leaf diseases using Convolutional Neural Networks. In Proceedings of the International Conference of Computer Science and Renewable Energies (ICCSRE 2019), Agadir, Morocco, 22–24 July 2019; IEEE: Piscatway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Chakravarthy, A.S.; Raman, S. Early Blight Identification in Tomato Leaves using Deep Learning. In Proceedings of the 2020 International Conference on Contemporary Computing and Applications (IC3A), Lucknow, India, 5–7 February 2020; IEEE: Piscatway, NJ, USA, 2020; pp. 154–158. [Google Scholar] [CrossRef]
- Valdoria, J.C.; Caballeo, A.R.; Fernandez, B.I.D.; Condino, J.M.M. iDahon: An Android Based Terrestrial Plant Disease Detection Mobile Application through Digital Image Processing Using Deep Learning Neural Network Algorithm. In Proceedings of the 4th International Conference on Information Technology, Bangkok, Thailand, 24–25 October 2019; IEEE: Piscatway, NJ, USA, 2019; pp. 94–98. [Google Scholar] [CrossRef]
- Dyrmann, M.; Karstoft, H.; Midtiby, H.S. Plant species classification using deep convolutional neural network. Biosyst. Eng. 2016, 151, 72–80. [Google Scholar] [CrossRef]
- Bir, P.; Kumar, R.; Singh, G. Transfer Learning based Tomato Leaf Disease Detection for mobile applications. In Proceedings of the International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 2–4 October 2020; IEEE: Piscatway, NJ, USA, 2020; pp. 34–39. [Google Scholar] [CrossRef]
- Picon, A.; Alvarez-Gila, A.; Seitz, M.; Ortiz-Barredo, A.; Echazarra, J.; Johannes, A. Deep convolutional neural networks for mobile capture device-based crop disease classification in the wild. Comput. Electron. Agric. 2019, 161, 280–290. [Google Scholar] [CrossRef]
- Prasvita, D.S.; Herdiyeni, Y. MedLeaf: Mobile Application for Medicinal Plant Identification Based on Leaf Image. Int. J. Adv. Sci. Eng. Inf. Technol. 2013, 3, 103. [Google Scholar] [CrossRef] [Green Version]
- Muneer, A.; Fati, S.M. Efficient and Automated Herbs Classification Approach Based on Shape and Texture Features using Deep Learning. IEEE Access 2020, 8, 196747. [Google Scholar] [CrossRef]
- Herdiyeni, Y.; Wahyuni, N.K.S. Mobile application for Indonesian medicinal plants identification using fuzzy local binary pattern and fuzzy color histogram. In Proceedings of the International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 1–2 December 2012; IEEE: Piscatway, NJ, USA, 2012; pp. 301–306. [Google Scholar]
- Cheng, Q.; Zhao, H.; Wang, C.; Du, H. An Android Application for Plant Identification. In Proceedings of the 4th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 14–16 December 2018; IEEE: Piscatway, NJ, USA, 2018; pp. 60–64. [Google Scholar] [CrossRef]
- Munisami, T.; Ramsurn, M.; Kishnah, S.; Pudaruth, S. Plant Leaf Recognition Using Shape Features and Colour Histogram with K-nearest Neighbour Classifiers. Procedia Comput. Sci. 2015, 58, 740–747. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.-Q.; Ma, L.-H.; Cheung, Y.; Wu, X.; Tang, Y.; Chen, C. ApLeaf: An efficient android-based plant leaf identification system. Neurocomputing 2015, 151, 1112–1119. [Google Scholar] [CrossRef]
- Priyankara, H.A.C.; Withanage, D.K. Computer assisted plant identification system for Android. In Proceedings of the Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 7–8 April 2015; IEEE: Piscatway, NJ, USA, 2015; pp. 148–153. [Google Scholar] [CrossRef]
- Akiyama, T.; Kobayashi, Y.; Sasaki, Y.; Sasaki, K.; Kawaguchi, T.; Kishigami, J. Mobile Leaf Identification System using CNN applied to plants in Hokkaido. In Proceedings of the 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; IEEE: Piscatway, NJ, USA, 2019; pp. 324–325. [Google Scholar] [CrossRef]
- Jassmann, T.J.; Tashakkori, R.; Parry, R.M. Leaf classification utilizing a convolutional neural network. In Proceedings of the SoutheastCon 2015, Fort Lauderdale, FL, USA, 9–12 April 2015; IEEE: Piscatway, NJ, USA, 2015; pp. 1–3. [Google Scholar] [CrossRef]
- Zaid, M.; Akhtar, S.; Patekar, S.A.; Sohani, M.G. A Mobile Application for Quick Classification of Plant Leaf Based on Color and Shape. Int. J. Mod. Trends Eng. Res. 2015, 2, 2393–8161. [Google Scholar]
- Jassmann, T.J. Mobile Leaf Classification Application Utilizing A CNN. Master’s Thesis, Appalachian State University, Boone, NC, USA, 2015. [Google Scholar]
- Hussein, B.R.; Malik, O.A.; Ong, W.-H.; Slik, J.W.F. Automated Classification of Tropical Plant Species Data Based on Machine Learning Techniques and Leaf Trait Measurements. In Computational Science and Technology; Springer: Singapore, 2020; pp. 85–94. [Google Scholar] [CrossRef]
- Ngugi, L.C.; Abelwahab, M.; Abo-Zahhad, M. Tomato leaf segmentation algorithms for mobile phone applications using deep learning. Comput. Electron. Agric. 2020, 178, 105788. [Google Scholar] [CrossRef]
- Knight, D.; Painter, J.; Potter, M. Automatic Plant Leaf Classification for a Mobile Field Guide—An Android Application; Stanford University: Stanford, CA, USA, 2010. [Google Scholar]
- Petrovska, B.B. Historical review of medicinal plants’ usage. Pharmacogn. Rev. 2012, 6, 1–5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pimm, S.L.; Joppa, L.N. How many plant species are there, where are they, and at what rate are they going extinct? Ann. MO Bot. Gard. 2015, 100, 170–176. [Google Scholar] [CrossRef]
- Barthlott, W. Borneo—The Most Species-Rich Area in the World! 2005. Available online: https://phys.org/news/2005-05-borneo-species-rich-area-world.html (accessed on 19 January 2021).
- Saw, L.G.; Chua, L.S.L.; Suhaida, M.; Yong, W.S.Y.; Hamidah, M. Conservation of some rare and endangered plants from Peninsular Malaysia. Kew Bull. 2010, 65, 681–689. [Google Scholar] [CrossRef]
- Rautner, M.; Hardiono, M. Borneo: Treasure Island at Risk; WWF: Gland, Switzerland, 2005; pp. 1–80. [Google Scholar]
- Joly, A.; Göeau, H.; Glotin, H.; Spampinato, C.; Bonnet, P.; Vellinga, W.P.; Planqué, R.; Rauber, A.; Palazzo, S.; Fisher, B.; et al. LifeCLEF 2015: Multimedia life species identification challenges. In Proceedings of the 6th International Conference of the CLEF Association (CLEF’15), Toulouse, France, 8–11 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 462–483. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscatway, NJ, USA, 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection (RetinaNet). IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Policies from Data. arXiv 2019, arXiv:1805.09501. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscatway, NJ, USA, 2017; pp. 464–472. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:1711.05101. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total | Leaf | Leaf-Scan | Entire Plant | |
|---|---|---|---|---|
| Train | 18,949 | 6122 | 9522 | 3305 |
| Test | 2380 | 767 | 1190 | 423 |
| Validation | 2379 | 781 | 1134 | 464 |
| Train | 1691 |
| Test | 157 |
| Validation | 249 |
| Total | 2097 |
| Top-1 Acc. (%) | Top-5 Acc. (%) | Sensitivity (%) | Specificity (%) | |
|---|---|---|---|---|
| Baseline | 73.5 | 79.4 | 43.2 | 53.5 |
| Class weighted ) | 81.9 | 87.4 | 61.5 | 64.6 |
| Class weighted ) | 83.2 | 92.4 | 79.5 | 77.6 |
| Focal Loss ) | 83.8 | 92.2 | 76.5 | 74.6 |
| Focal Loss ) | 84.0 | 89.4 | 76.5 | 74.6 |
| Top-1 Accuracy (%) | Top-5 Accuracy (%) | Sensitivity (%) | Specificity (%) | |
|---|---|---|---|---|
| Baseline | 63.4 | 72.4 | 43.2 | 53.5 |
| Class weighted ) | 83.5 | 87.4 | 61.5 | 64.6 |
| Class weighted ) | 85.5 | 92.4 | 73.5 | 77.6 |
| Focal Loss ) | 83.5 | 92.4 | 71.5 | 77.6 |
| Focal Loss ) | 87.5 | 86.4 | 70.5 | 74.6 |
| Top-1 Accuracy (%) | Top-5 Accuracy (%) | Sensitivity (%) | Specificity (%) | |
|---|---|---|---|---|
| Focal Loss ) | 78.5 | 82.6 | 75.2 | 77.7 |
| Class weighted ) | 62.8 | 70.2 | 66.1 | 68.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malik, O.A.; Ismail, N.; Hussein, B.R.; Yahya, U. Automated Real-Time Identification of Medicinal Plants Species in Natural Environment Using Deep Learning Models—A Case Study from Borneo Region. Plants 2022, 11, 1952. https://doi.org/10.3390/plants11151952
Malik OA, Ismail N, Hussein BR, Yahya U. Automated Real-Time Identification of Medicinal Plants Species in Natural Environment Using Deep Learning Models—A Case Study from Borneo Region. Plants. 2022; 11(15):1952. https://doi.org/10.3390/plants11151952
Chicago/Turabian StyleMalik, Owais A., Nazrul Ismail, Burhan R. Hussein, and Umar Yahya. 2022. "Automated Real-Time Identification of Medicinal Plants Species in Natural Environment Using Deep Learning Models—A Case Study from Borneo Region" Plants 11, no. 15: 1952. https://doi.org/10.3390/plants11151952
APA StyleMalik, O. A., Ismail, N., Hussein, B. R., & Yahya, U. (2022). Automated Real-Time Identification of Medicinal Plants Species in Natural Environment Using Deep Learning Models—A Case Study from Borneo Region. Plants, 11(15), 1952. https://doi.org/10.3390/plants11151952