Abstract
Building function identification plays a crucial role in providing basic data for urban planning, management, and various intelligent applications. Today, building function identification methods using Street View Images (SVIs) have made significant progress. However, these methods use the visual features of SVIs to infer building functions, which ignores the contributions of the multiple potential semantics of SVIs, resulting in suboptimal identification accuracy. To address this issue, this study proposes a multi-semantic semi-supervised building function identification (MS-SS-BFI) method, which integrates multi-level visual semantics and spatial contextual semantics to improve building function identification from SVIs. Specifically, a location mapping module was designed to align SVIs with buildings. Additionally, a multi-level visual semantic extraction module was developed to integrate the visual semantics and visual-textual semantics of SVIs. In addition, a semi-supervised spatial interaction module was designed to characterize the spatial context of buildings. Extensive experiments on the Brooklyn dataset show that the proposed method achieves 7.98% improvement in F1-score over the state-of-the-art baseline, demonstrating superior performance and robustness. This work explores a novel approach to building function identification and provides a methodological reference for various SVI-based applications.
1. Introduction
Building function refers to the land use undertaken by an individual building unit [1]. Automatic identification of building functions plays a pivotal role across multiple domains, including urban planning, environmental monitoring, population statistics, disaster emergency response, and topographic mapping [2,3,4]. In practice, building functions are affected by many factors, including environment and human activities, making it quite a challenge to accurately identify the functions of buildings [5,6].
Street view images (SVIs) have demonstrated great potential in building function identification [7,8], benefiting from their multi-view characteristics and rich embedded socioeconomic semantics. For example, Kang et al. [9] proposed a convolutional neural network (CNN)-based method for building instance function classification using Google Street View (GSV), overcoming the limitation of remote sensing images (RSIs) that capture only rooftops. Wang et al. [10] used instance segmentation to identify urban soft-story buildings in SVIs, aiming to improve the efficiency of structural safety analysis and management. Murdoch et al. [11] employed CNNs to extract building features from SVIs and classify building categories. However, these methods follow the full-supervised learning paradigm, which requires extensive labeled image samples for training the model. Annotating samples is very labor-intensive and time-consuming, especially for some regions where buildings are structurally complex and functionally diverse.
Recently, researchers have explored semi-supervised learning methods in building function identification to address the challenge of insufficient labeled samples. These methods leverage a small number of labeled samples in conjunction with a large volume of unlabeled samples for model training. For instance, Xie et al. [12] proposed a semi-supervised framework that combines geometric, POI, and spatial features to improve building function recognition with limited labels. Skuppin et al. [13] employed a U-Net model with incomplete OSM labels to classify building functions, achieving reliable performance despite limited annotations. For SVI-based building function identification, Li et al. [14] proposed a geometry-aware semi-supervised building function recognition method that enhances classification accuracy while addressing class imbalance. However, the method focuses on inferring building functions from the visual features of SVIs, which ignores multiple potential semantics of SVIs, resulting in suboptimal identification accuracy.
To alleviate this issue, this paper proposes a multi-semantic semi-supervised building function identification (MS-SS-BFI) method, which leverages multi-level visual semantics and spatial contextual semantics to improve building function identification. Specifically, a location mapping module (LoMM) is designed to align the locations of the SVIs’ buildings. A multi-level visual semantic extraction module (ML-VSEM) is developed to integrate visual semantics and visual-textual semantics from SVIs. A semi-supervised spatial interaction module (S3IM) is introduced to characterize the spatial context of buildings. The main contributions of this paper can be summarized as follows:
- (1)
- This study highlights the importance of multiple semantics derived from SVIs for identifying building functions, and it proposes integrating multiple semantics of SVIs and the semi-supervised model to enhance identification accuracy.
- (2)
- A network is developed to identify building functions by integrating multi-level visual semantics from SVIs and incorporating spatial contextual semantics to improve the accuracy of building function identification. This study offers a methodological reference for urban applications having insufficiently labeled samples.
- (3)
- Experimental results demonstrate that the proposed method significantly improves the identification accuracy of building functions, even when the number of labeled SVIs is small.
The rest of this paper is structured as follows. Section 2 reviews related studies. Section 3 provides a detailed description of the proposed method. Section 4 outlines the experimental setting. Section 5 presents the experimental results and discussions. Section 6 summarizes this study and outlines prospects for future work.
2. Related Work
The work that relates to this paper can be classified into two categories: building function identification and semi-supervised learning methods for urban applications.
2.1. Building Function Identification
Numerous works used RSIs to identify building functions. They infer building functions by analyzing visual features such as shape, size, texture, and spatial layout. For example, Du et al. [15] proposed a building function classification method based on RSIs, which combines traditional machine learning techniques with spectral and texture features extracted from remote sensing images. Xu et al. [16] achieved building function classification based on features extracted from RSIs by deep learning models. Vasavi et al. [17] introduced a classification approach integrating U-Net and ResNet architectures, which substantially enhances classification accuracy with very high resolution. In practice, the diversity of building structures and the complexity of urban environments make it difficult to identify building functions using RSIs taken from a distance.
SVIs are typically ground-level images that provide visual information closer to buildings and rich embedded socioeconomic semantics [18,19], giving a unique advantage in building instance function identification. Laupheimer et al. [20] proposed a CNN-based approach that uses SVIs to classify building facades and identify five categories of building functions. Li et al. [14] proposed a geometry-aware framework for fine-grained building function identification based on SVIs, improving accuracy by incorporating geometric relationships between GIS and SVIs. However, these methods are focused on identifying building functions based on the visual features of SVIs, which ignores the multiple potential semantics of SVIs that are closely related to building functions.
2.2. Semi-Supervised Learning Method for Urban Applications
Semi-supervised models have made significant progress in urban applications, especially in scenarios having a low number of labeled samples. For example, Protopapadakis et al. [21] proposed a semi-supervised deep neural network based on stacking autoencoders to efficiently extract buildings from near-infrared satellite images. This approach significantly reduces the need for labeled samples, while achieving accuracy close to that of the state-of-the-art methods. Liu et al. [22] introduced an innovative semi-supervised learning framework that leverages graph convolutional networks and multimodal autoencoders to automatically classify geotagged social media content. Fouedjio et al. [23] developed a geostatistical semi-supervised learning method, which combines a small amount of labeled spatial data with a large volume of unlabeled samples to enhance spatial prediction accuracy and uncertainty estimation using pseudo-labels and geostatistical simulations. However, the previous building function identification methods have not yet been fully utilized for multiple semantics of unlabeled SVIs, which deserves further exploration.
3. Methodology
This study aims to improve building function identification by integrating multiple semantics of SVIs with the spatial context of buildings, and it proposes the multi-semantic semi-supervised building function identification (MS-SS-BFI) method. As depicted in Figure 1, the proposed method comprises four key modules: a location mapping module (LoMM) that is designed to align SVIs with buildings, a multi-level visual semantic extraction module (ML-VSEM) that extracts visual semantics and visual-textual semantics from SVIs, a semi-supervised spatial interaction module (S3IM) that integrates multi-semantics and spatial context between buildings via graph-based aggregation, and a model optimization module that trains the model and predicts the function category of each building.
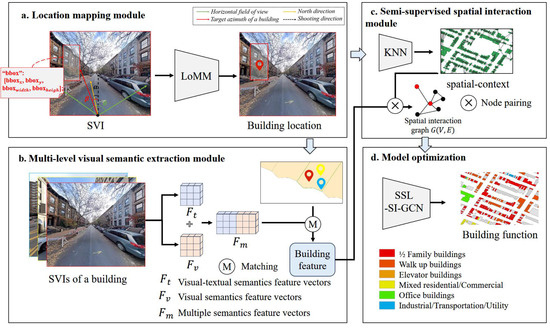
Figure 1.
An overview of the proposed method. The method consists of four modules: (a) location mapping module (LoMM), (b) multi-level visual semantic extraction module (ML-VSEM), (c) semi-supervised spatial interaction module (S3IM), and (d) model optimization.
3.1. Location Mapping Module
The recorded geographic coordinates of SVIs refer to the location of the camera, since SVIs are typically captured by vehicles traveling along roadways [24]. That is, the image coordinates reflect the shooting locations (i.e., where the SVI was taken), not the building locations (i.e., the true locations of the buildings). To align the image objects with building objects, the proposed method develops a location mapping algorithm. As illustrated in Figure 2, the algorithm is a three-step process.
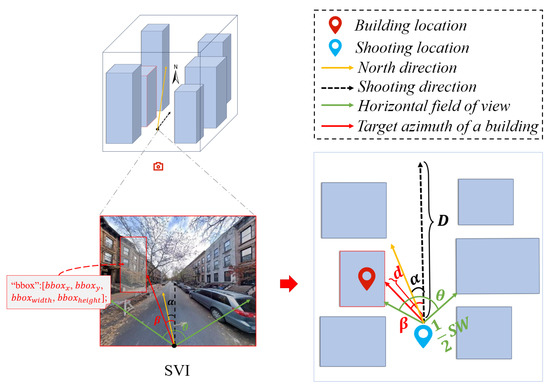
Figure 2.
Location mapping from SVIs to buildings.
Step 1. Calculating building azimuth .
The building azimuth represents the angle between the shooting direction of the SVI and true north, describing the orientation of the building facade in the image. The values of typically range from 0° to 360°, where 0° corresponds to true north, 90° to east, 180° to south, and 270° to west. can be inferred from the SVI’s shooting direction and the building’s position within the image.
The pixel position of the building in an SVI can be calculated using the bounding box annotations of the SVI, as shown in Equation (1):
where and denote the x- and y-coordinates of the bounding box’s top-left corner, respectively; and and represent the width and height of the bounding box, respectively.
The angular deviation between the building and the SVI’s shooting direction can be computed using Equation (2):
where , estimated through multi-angle observations, denotes the horizontal field of view (HFOV) of the image; and is the total number of horizontal pixels in the image. is computed as the ratio of the difference of building azimuths () to the difference in the x-coordinates of the bounding boxes’ top-left corners.
The building azimuth is derived as follows:
where represents the azimuth angle of the SVI’s shooting direction.
Step 2. Estimating the distance between shooting and building location.
The distance between the shooting and building location, d, is closely related to the absolute value of the horizontal offset angle. When the absolute offset angle approaches 0°, i.e., the SVI shooting direction aligns with the street’s longitudinal axis, the buildings appearing near the center of the image tend to be farther away, as they lie along the depth of the street. Conversely, when the offset angle approaches 90°, indicating a side-view perspective perpendicular to the street’s longitudinal direction, the buildings are located on both sides of the street and much closer to the camera, with the distance approaching approximately half the street width ().
To account for the fact that buildings captured at the far end of a street are not infinitely distant, this study introduces a hyperparameter, D, to denote the maximum distance from the SVI to the building. A nonlinear quadratic function is employed to represent distance variation as the building’s position shifts from the image edges toward the center. The distance d is computed as follows:
where is a hyperparameter representing the street width, and is the azimuthal deviation of the building relative to the shooting direction.
Step 3. Mapping shooting location to building location.
Given the geographic coordinates of the SVI shooting location, the building azimuth , and the estimated distance d, the actual geographic location of the building can be inferred by solving the forward geodesic problem. The central angle and deviation angle (in radians) are calculated by Equations (5) and (6):
where R is the radius of the Earth, d is the distance between shooting and building location, and is the building azimuth.
The building’s latitude and longitude are then derived using the Haversine formula:
where and denote the latitude and longitude of the shooting location where the SVI was taken, respectively.
The complete location mapping algorithm is presented in Algorithm 1.
| Algorithm 1 Location Mapping Algorithm |
|
3.2. Multi-Level Visual Semantic Extraction Module
Visual semantics from SVIs effectively characterize building functional features, while visual-textual semantics, derived from image captions [25], provide the scene knowledge of the SVI from pre-trained large models. These two kinds of visual semantics jointly provide complementary semantics for building function identification. As shown in Figure 3, visual semantics are first extracted using the Vision Transformer (ViT) model [26]. Subsequently, a pre-trained image captioning model generates descriptive text captions for each SVI to embed latent semantic information. Finally, the generated captions are processed by BERT [27] to extract contextualized visual-textual semantics.
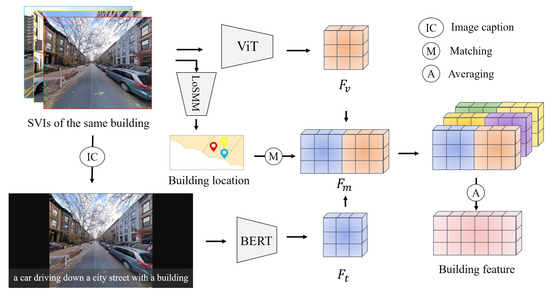
Figure 3.
An illustration of multi-level visual semantic extraction from SVIs.
Specifically, the input SVI is denoted as , where H, W, and C represent the image height, width, and number of channels, respectively. The image is first divided into N non-overlapping patches, each of size . Each patch is flattened into a 1-D vector and mapped to a high-dimensional embedding space, represented as follows:
The embedding layer transforms these image patches into D-dimensional vectors:
where is positional encoding.
The embedding vectors are processed through the Transformer encoder consisting of identical L layers. Each layer employs a residual connection and layer normalization (LN) around a multi-head self-attention (MSA) mechanism, followed by a position-wise feed-forward network (MLP):
The visual semantic feature vectors are derived from the last Transformer layer:
Subsequently, an image caption model generates a textual description for the SVI. The generation process is modeled as follows:
where denotes the hidden state of the LSTM at time step t, represents the parameters of the output layer, and is the bias term.
The textual description is fed into a pre-trained BERT model to encode into a semantic embedding. Let denote the BERT encoding function; the resulting vector representation is
Following Yang et al. [28], a concatenation-based fusion strategy integrates the visual and visual-textual semantic features. The experimental results in Section 5.5 suggest the strategy is effective.
For each building b, let denote its corresponding SVI set. The final building-level feature is obtained by aggregating the features of all SVIs in .
3.3. Semi-Supervised Spatial Interaction Module
A semi-supervised spatial interaction graph convolutional network (S3I-GCN) is designed to integrate multi-semantics with spatial context between buildings. Specifically, a spatial weight matrix is constructed to represent the spatial relationships among buildings, where n is the number of buildings. The matrix is defined as follows:
where denotes that building is spatially related to building , and represents the spatial weight between them. The spatial weight is computed using a K-nearest neighbor (KNN) spatial weighting scheme [29], where is inversely proportional to the distance between and , typically defined as follows:
where is a hyperparameter controlling the weight decay with distance, proportional to the scaling exponent of the spatial interaction, and is set to 0 to 3 according to the spatial autocorrelation theory [30].
As illustrated in Figure 4, once the spatial weight matrix M is established, a spatial interaction graph is constructed. Each node corresponds to a building instance and is associated with a feature vector . Each edge captures the spatial context between the corresponding building instances and is associated with .
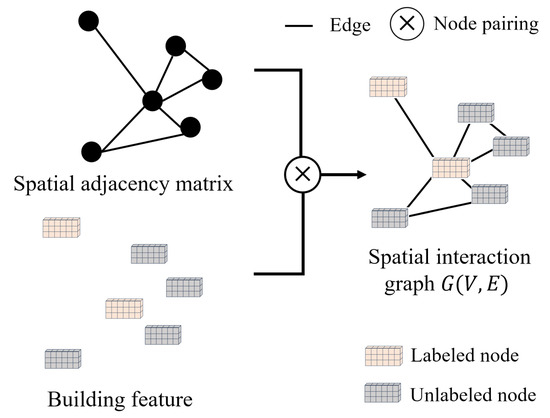
Figure 4.
Semi-supervised spatial interaction modeling.
The S3I-GCN network stacks three layers of GCN to capture the relationships between nodes and their spatial interaction in graph . Each layer learns node representations by aggregating features from neighboring nodes, as formulated in Equations (20) and (21):
where is the node feature matrix at the l-th layer; M is the adjacency matrix of the graph, indicating the connections between nodes. D is the degree matrix of the graph. is the normalized adjacency matrix, obtained by normalizing the adjacency matrix M. In semi-supervised training, the graph structure enables the propagation of label information from labeled to unlabeled nodes through feature aggregation using the matrix .
3.4. Model Optimization
In graph , the feature matrix V, which incorporates both visual and visual-textual semantic features, is fed into the S3I-GCN. The hidden representations from the k-th layer are passed through a SoftMax classifier:
where denotes the input of the first layer.
The network is trained using a cross-entropy loss function, defined as
where represents the set of labeled buildings in the training set, C is the number of building function categories, and is the ground truth label for node p and class i. Finally, the SoftMax layer outputs a probability distribution of each node over all building function categories.
4. Experimental Setting
4.1. Study Area and Datasets
This study selects Brooklyn, one of the administrative districts of New York City, as the study area. The buildings in Brooklyn are diverse in terms of type and spatial distribution. The SVIs of the study area are sourced from “Zone 2” of the OmniCity dataset [31], which provides detailed building functional categories. As shown in Figure 5, the study area covers approximately 20.09 square kilometers, and the Brooklyn dataset contains a total of 5197 SVIs. After processing by the location mapping module, 4125 unique buildings are mapped to SVIs. The SVIs and buildings are divided into a training set and a test set. The dataset is roughly divided into a training set and a test set in a 3:1 ratio. Specifically, the training set consists of 4156 images covering 3086 buildings, and the test set comprises 1041 images covering 1039 buildings. It should be noted that this paper seeks to develop a semi-supervised approach of the training model to enhance its generalization capabilities when labeled data is limited. In the experiments, the proposed method assumes that the spatial regions of training and testing data do not overlap. That is, the data used for prediction did not participate in training. Even in production scenarios where vast amounts of prediction data are available, the proposed method does not increase the training dataset size, thus alleviating computational bottlenecks of semi-supervised models.
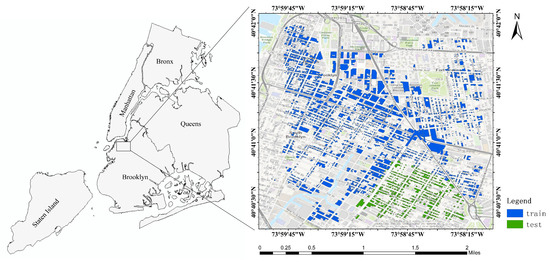
Figure 5.
Spatial distribution of buildings.
The building functional categories in the study area include six categories: 1/2 Family Buildings, Walk-Up Buildings, Elevator Buildings, Industrial/Transportation/Utility, Mixed Residential/Commercial, and Office Buildings. A detailed description of each category is listed in Table 1. Figure 6 illustrates each category with four samples.

Table 1.
Building function categories of Brooklyn.

Figure 6.
Illustration of building function.
4.2. Implementation Details
The pre-trained ViT model on the ImageNet dataset was employed to extract visual feature vectors from the SVIs. S3I-GCN stacks three GCN layers, connected using the ReLU non-linear activation function. The cross-entropy loss function was used to train the proposed model. The dimensions of the input layer, first hidden layer, second hidden layer, and output layer were set to 1536, 32, 16, and 8, respectively.
During training, a fixed random seed of 1,234,567 was used to ensure the reproducibility of results. The network was trained for 300 epochs using the Adam optimizer with an initial learning rate of 0.005 and a weight decay of 0.0005. In this study, K is set to 5, and is set to 1. The hyperparameters D and are set to 60 and 30, respectively. Following the common setup of semi-supervised learning models, 20% of the SVIs from the training set were randomly sampled as labeled samples, and the remaining images were treated as unlabeled samples.
All the experiments were conducted using the PyTorch 2.1.1 framework and performed on a NVIDIA 3090 GPU.
4.3. Baselines
This study selected four methods as baselines to investigate the performance of the proposed method, including VGG [32], ResNet [33], StructCNN [9], and GASSL [14]. VGG and ResNet are two classical deep convolutional networks for vision tasks. VGG is known for its deep architecture that effectively captures both local and global visual features. ResNet incorporates residual learning through skip connections, allowing it to extract complex patterns of urban environments. StructCNN is a task-specific method designed for building instance classification using SVIs. GASSL is a state-of-the-art semi-supervised model of building function identification. These baselines are selected to include both classical vision models and state-of-the-art methods of building instance identification, contributing to a comprehensive evaluation of the proposed method.
4.4. Evaluation Metrics
This study adopts three widely used evaluation metrics, including Precision (Pre.), Recall (Rec.), and F1-score (F1.). For a given class, Pre. indicates the proportion of correctly predicted instances of that class among all instances predicted as that class. Rec. measures the proportion of actual instances of the class that were correctly identified by the model. F1. serves as the harmonic mean of Pre. and Rec., providing a balanced assessment of the model’s performance on that specific class.
For each class c, the evaluation metrics are defined as follows:
where for each class c, , , and represent the number of true positives, false positives, and false negatives, respectively.
The overall macro-averaged metrics are then computed as follows:
where n denotes the total number of classes.
5. Results and Discussion
5.1. Overall Results
As shown in Table 2, the proposed method outperforms all the baseline models in all the evaluation metrics. Specifically, the method achieves an average Pre. of 30.45%, an average Rec. of 27.32%, and an average F1. of 27.74%, surpassing the second-best model (GASSL) by margins of 10.43%, 6.75%, and 7.98%, respectively. Additionally, the weighted F1. of the proposed method stands at 37.8%, indicating that class imbalance has affected the overall average scores. The results demonstrate the superior capability of the proposed method in accurately identifying building functions. Furthermore, the proposed method outperforms the baselines across all six building function categories in terms of Pre.; specifically, it achieves 40.00% in category C3 and 53.49% in category C2, outperforming the second-best methods by substantial margins. The improvements observed in some categories, such as C3 (i.e., Elevator Buildings), which is very challenging due to its high visual ambiguity, further highlight the effectiveness of the multiple semantics.
Table 2.
Comparison results in the Brooklyn dataset.
To further observe the performance of the proposed method, the identification results of various methods on the Brooklyn dataset are visualized, as shown in Figure 7. As illustrated in the figure, the proposed method achieves better performance compared to the baseline methods. Specifically, the baseline methods shown in columns (a) to (d) made some misidentifications. In contrast, as shown in row (e), the proposed method produces more accurate building category predictions, highlighting its superior ability when integrating multiple semantics and spatial contextual information.

Figure 7.
Visualized results of (a) ResNet, (b) VGG, (c) StructCNN, (d) GASSL, (e) the proposed method, (f) ground truth in the Brooklyn dataset.
5.2. Ablation Study
To further investigate the effect of each component within the proposed method, ablation experiments were conducted by systematically removing the following key components: (1) the location mapping module (w/o LoMM); (2) visual semantic features (w/o ); (3) visual-textual semantic features (w/o); and (4) the semi-supervised spatial interaction GCN (w/o S3I-GCN). Here, “w/o” indicates that the component is removed from the proposed method. The results are reported in Figure 8.
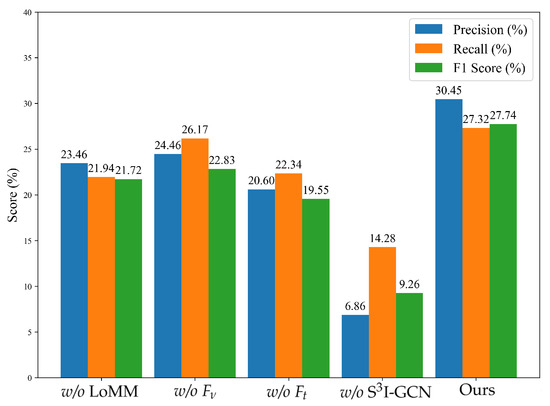
Figure 8.
Ablation experimental results on the Brooklyn dataset.
As shown in Figure 8, when the LoMM is removed, F1. drops from 27.74% to 21.72%, indicating the importance of spatial alignment between SVIs and buildings. Removing slightly decreases but retains a relatively high Rec. of 26.17%, suggesting that textual semantics alone offer some resilience in classification. In contrast, removing the causes a pronounced decline in F1. of 19.55%, highlighting the critical role of textual descriptions in enhancing semantic discrimination. Notably, removing the S3I-GCN module leads to the most substantial performance decline, with the F1. dropping sharply to 9.26%, thereby confirming its vital role in the proposed framework. This demonstrates the critical importance of modeling spatial relationships among buildings to support robust function identification. Overall, the full model achieves the best performance, confirming that each component makes a meaningful contribution and that their integration substantially boosts the effectiveness of the proposed method.
5.3. Effect of the Training Sample Size
Given that the number of labeled training samples may affect model performance, we conducted experiments using five different numbers of labeled training samples: 10%, 20%, 30%, 40%, and full supervision (i.e., all training samples are labeled). The detailed results are presented in Table 3.
Table 3.
Experimental results for different proportions of the labeled sample.
As shown in Table 3, the experimental results demonstrate that the proposed method achieved its highest F1. of 27.74% when the training sample size was 20%. Remarkably, even with only 10% of the training data, it reached 80% of the fully supervised performance, highlighting its strong applicability in low-resource scenarios. However, when the annotation ratio increased to 40%, all the evaluation metrics declined, with the F1. dropping to 23.11%. We argue this may be due to the model being trained on a large proportion of samples from the training region, which leads to overfitting and consequently lower accuracy in the test region. The results validate the effectiveness of the proposed method under limited annotated-data conditions.
5.4. Effect of GNN Models
In this study, GNNs are employed to capture and model the spatial interactions of buildings within a graph network. To evaluate the effect of different GNN models, we conduct experiments using four widely used models: Graph Convolutional Network (GCN) [34], GraphSAGE [35], Graph Attention Network (GAT) [36], and TransGNN [37].
As shown in Figure 9, GraphSAGE achieves a slightly lower Rec. of 23.22% and Pre. of 20.77%, resulting in an F1. of 18.96%. TransGNN obtains a Rec. of 24.40% and Pre. of 22.48%, resulting in an F1. of 21.06%. Overall, these results demonstrate that GCN substantially improves the model performance across multiple metrics, including Pre., Rec., and F1., by effectively capturing spatial dependencies among buildings.
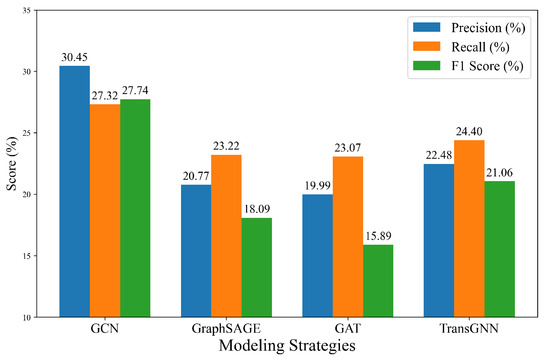
Figure 9.
Experimental results for different spatial relationship modeling strategies.
5.5. Effect of Semantic Fusion Strategy
To evaluate the influence of semantic fusion strategies, we experiment with three widely used fusion methods: feature splicing, adaptive weighted average, and feature aggregation. Their results are presented in Table 4.
Table 4.
Experimental results for different semantic fusion strategies.
Among the three strategies, feature splicing achieves the best overall performance, having a Pre. of 30.45%, a Rec. of 27.32%, and the highest F1. of 30.45%. This indicates that directly concatenating visual and textual semantic features helps retain the complementary information of the two semantics, thus enhancing their discriminative capacity. In contrast, the adaptive weighted average strategy yields a slightly lower performance, having an F1. of 23.66%. The feature aggregation strategy performs the worst, having an F1. of only 18.40%. The results show that the feature splicing strategy effectively preserves the multiple semantic features, making it more suitable for building function identification tasks.
5.6. Effect of Spatial Weight
As discussed in Section 3.3, the S3I-GCN captures the influence of surrounding geographic areas on building functions by assigning weights to the edges between nodes. To investigate the effect of calculating spatial weights, we compare two commonly used methods: KNN [29] and Queen Contiguity [38]. The results are summarized in Table 5.
Table 5.
Experimental results for different spatial weight calculation algorithms.
Table 5 shows that KNN achieves a significantly higher F1. of 27.74%, with a Pre. of 30.45% and a Rec. of 27.32%. The improvement can be attributed to the flexibility of KNN in modeling irregular spatial structures by dynamically selecting the most relevant neighbors based on distance, thereby preserving local spatial context more effectively. In contrast, the Queen Contiguity method yields an F1. of only 22.96%, with a lower Pre. of 22.99% and Rec. of 25.06%. This suggests that relying solely on topological adjacency may overlook subtle yet relevant spatial interactions, particularly in urban environments under complex spatial distributions.
5.7. Effect of Parameter D
To evaluate the influence of parameter D on the proposed method, experiments were conducted by setting D from 40 m to 80 m in 10 m increments. The detailed results are presented in Table 6. As shown in this table, the highest F1. of 17.74% is obtained when D is set to 60 m. Performance declines slightly when D takes smaller or larger values, indicating that distances are either too large or too small, increasing mapping noise.
Table 6.
Experimental results for different values of parameter D.
5.8. Experiments in Different Areas
To evaluate the robustness of the proposed method, an additional experiment in a different area, Wuhan city, is conducted. The Wuhan dataset covers an area ranging approximately from to and to , comprising a total of 537 buildings. Each building is manually classified into one of four functional categories: Retail (C1), Apartment (C2), Office Building (C3), and Others (C4). In this experiment, the model was trained directly on samples having four-category labels.
The experiments are conducted using the same settings as those in the New York dataset. As shown in Table 7, the proposed method outperforms the baselines, achieving overall Pre., Rec., and F1. values of 32.21%, 32.56% and 31.27%, respectively. The experimental results suggest that the proposed approach is robust.
Table 7.
Comparison results in the Wuhan dataset.
6. Conclusions
This study highlights the importance of multiple semantics derived from SVIs for identifying building functions, and it proposes integrating multiple semantics of SVIs and the semi-supervised model to enhance identification accuracy. Specifically, a location mapping module was designed to align SVIs with buildings. Additionally, a multi-level visual semantic extraction module was developed to integrate the visual semantics and visual-textual semantics of SVIs. A semi-supervised spatial interaction module was also designed to characterize the spatial context of buildings. Extensive experiments demonstrate that MS-SS-BFI not only achieves superior prediction accuracy but also exhibits strong robustness across various scenarios. The proposed method contributes a methodological reference for SVI-based practical applications in urban analytics, especially in situations where only a small number of labeled samples are available.
Future work will focus on developing improved fusion strategies to integrate multimodal data with SVIs, thereby further enhancing the model’s identification accuracy. Additionally, it is well worth exploring the possibility of extending the proposed model by more deeply incorporating large pre-trained models that have shown strong capabilities in various visual tasks.
Author Contributions
Conceptualization, Fang Fang and Shengwen Li; methodology, Fang Fang and Nan Min; software, Nan Min; validation, Nan Min; formal analysis, Nan Min; investigation, Nan Min; resources, Fang Fang; data curation, Nan Min, Yuxiang Zhao, Yu Wang and Sishi Gong; writing—original draft preparation, Nan Min; writing—review and editing, Fang Fang, Shengwen Li, and Shunping Zhou; visualization, Nan Min; supervision, Shengwen Li; project administration, Fang Fang; funding acquisition, Shengwen Li. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (grant No. 42371420).
Data Availability Statement
The data that support the findings of this study are available at https://figshare.com/s/85e58426fad9c8eefd11, accessed on 15 July 2025.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Steiniger, S.; Lange, T.; Burghardt, D.; Weibel, R. An Approach for the Classification of Urban Building Structures Based on Discriminant Analysis Techniques. Trans. GIS 2008, 12, 31–59. [Google Scholar] [CrossRef]
- Fonte, C.C.; Minghini, M.; Antoniou, V.; Patriarca, J.; See, L. Classification of Building Function Using Available Sources of VGI. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, IV-4, 209–215. [Google Scholar] [CrossRef]
- Smith, D.; Crooks, A. From Buildings to Cities: Techniques for the Multi-Scale Analysis of Urban Form and Function; Centre for Advanced Spatial Analysis (UCL): London, UK, 2010; Unpublished work. [Google Scholar]
- Xiao, C.; Xie, X.; Zhang, L.; Xue, B. Efficient Building Category Classification with Façade Information from Oblique Aerial Images. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2020, V-2-2020, 1309–1313. [Google Scholar] [CrossRef]
- Kang, S.; Hong, T. A Feasibility Study of Occupancy Measurement Using Environmental Sensors for Building Energy Management. Appl. Energy 2015, 149, 18–35. [Google Scholar]
- Zhong, L.; Weng, Q. Building Function Classification from High-Spatial Resolution Imagery and Geographic Data Using Deep Learning. ISPRS J. Photogramm. Remote Sens. 2019, 149, 104–116. [Google Scholar]
- Sarmadi, B.; Javed, U.; Gu, Y.; Wang, S.; Cao, S. Robust Building Identification from Street Views Using Deep Convolutional Neural Networks. Buildings 2023, 13, 578. [Google Scholar]
- Zhao, K.; Liu, Y.; Hao, S.; Lu, S.; Liu, H.; Zhou, L. Bounding Boxes Are All We Need: Street View Image Classification via Context Encoding of Detected Buildings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 13–19 June 2020; pp. 1072–1081. [Google Scholar]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X. Building Instance Classification Using Street View Images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- Wang, C.; Hornauer, S.; Yu, S.X.; McKenna, F.; Law, K.H. Instance Segmentation of Soft-Story Buildings from Street-View Images with Semiautomatic Annotation. Earthq. Eng. Struct. Dyn. 2023, 52, 2520–2532. [Google Scholar] [CrossRef]
- Murdoch, R.; Al-Habashna, A. Residential building type classification from street-view imagery with convolutional neural networks. Signal Image Video Process. 2024, 18, 1949–1958. [Google Scholar] [CrossRef]
- Xie, X.; Liu, Y.; Xu, Y.; He, Z.; Chen, X.; Zheng, X.; Xie, Z. Building Function Recognition Using the Semi-Supervised Classification. Appl. Sci. 2022, 12, 9900. [Google Scholar] [CrossRef]
- Skuppin, N.; Hoffmann, E.J.; Shi, Y.; Zhu, X.X. Building Type Classification with Incomplete Labels. Remote Sens. 2022, 14, 567. [Google Scholar]
- Li, W.; Yu, J.; Chen, D.; Lin, Y.; Dong, R.; Zhang, X.; He, C.; Fu, H. Fine-Grained Building Function Recognition with Street-View Images and GIS Map Data via Geometry-Aware Semi-Supervised Learning. Int. J. Appl. Earth Obs. Geoinf. 2025, 137, 104386. [Google Scholar] [CrossRef]
- Du, S.; Zhang, F.; Zhang, X. Semantic Classification of Urban Buildings Combining VHR Image and GIS Data: An Improved Random Forest Approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Xu, Y.; He, Z.; Xie, X.; Xie, Z.; Luo, J.; Xie, H. Building Function Classification in Nanjing, China, Using Deep Learning. Trans. GIS 2022, 26, 2145–2165. [Google Scholar] [CrossRef]
- Vasavi, S.; Somagani, H.S.; Sai, Y. Classification of Buildings from VHR Satellite Images Using Ensemble of U-Net and ResNet. Egypt. J. Remote Sens. Space Sci. 2023, 26, 937–953. [Google Scholar] [CrossRef]
- Li, Z.; Su, Y.; Zhu, C.; Zhao, W. BuildingView: Constructing Urban Building Exteriors Databases with Street View Imagery and Multimodal Large Language Models. arXiv 2024, arXiv:2409.19527. [Google Scholar]
- Liang, X.; Xie, J.; Zhao, T.; Stouffs, R.; Biljecki, F. OpenFACADES: An Open Framework for Architectural Caption and Attribute Data Enrichment via Street View Imagery. arXiv 2025, arXiv:2504.02866. [Google Scholar] [CrossRef]
- Laupheimer, D.; Tutzauer, P.; Haala, N.; Spicker, M. Neural Networks for the Classification of Building Use from Street-View Imagery. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, IV-2, 177–184. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked Autoencoders Driven by Semi-Supervised Learning for Building Extraction from Near Infrared Remote Sensing Imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Liu, P.; De Sabbata, S. A graph-based semi-supervised approach to classification learning in digital geographies. Comput. Environ. Urban Syst. 2021, 86, 101583. [Google Scholar] [CrossRef]
- Fouedjio, F.; Talebi, H. Geostatistical semi-supervised learning for spatial prediction. Artif. Intell. Geosci. 2022, 3, 162–178. [Google Scholar] [CrossRef]
- Wilson, D.; Alshaabi, T.; Van Oort, C.; Zhang, X.; Nelson, J.; Wshah, S. Object Tracking and Geo-Localization from Street Images. Remote Sens. 2022, 14, 2575. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Yang, Y.-H.; Huang, T.E.; Sun, M.; Rota Bulò, S.; Kontschieder, P.; Yu, F. Dense Prediction with Attentive Feature Aggregation. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2023; pp. 97–106. [Google Scholar]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification. In OTM Confederated International Conferences on the Move to Meaningful Internet Systems; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Chen, Y. The Distance-Decay Function of Geographical Gravity Model: Power Law or Exponential Law? Chaos Solitons Fractals 2015, 77, 174–189. [Google Scholar] [CrossRef]
- Li, W.; Lai, Y.; Xu, L.; Xiangli, Y.; Yu, J.; He, C.; Xia, G.-S.; Lin, D. OmniCity: Omnipotent City Understanding with Multi-Level and Multi-View Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 17397–17407. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, P.; Yan, Y.; Zhang, X.; Li, C.; Wang, S.; Huang, F.; Kim, S. TransGNN: Harnessing the Collaborative Power of Transformers and Graph Neural Networks for Recommender Systems. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington DC, USA, 14–18 July 2024; pp. 1285–1295. [Google Scholar]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1988. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).