
Measuring the Similarity of Metro Stations Based on the Passenger Visit Distribution



Abstract
:1. Introduction
2. Materials and Methods
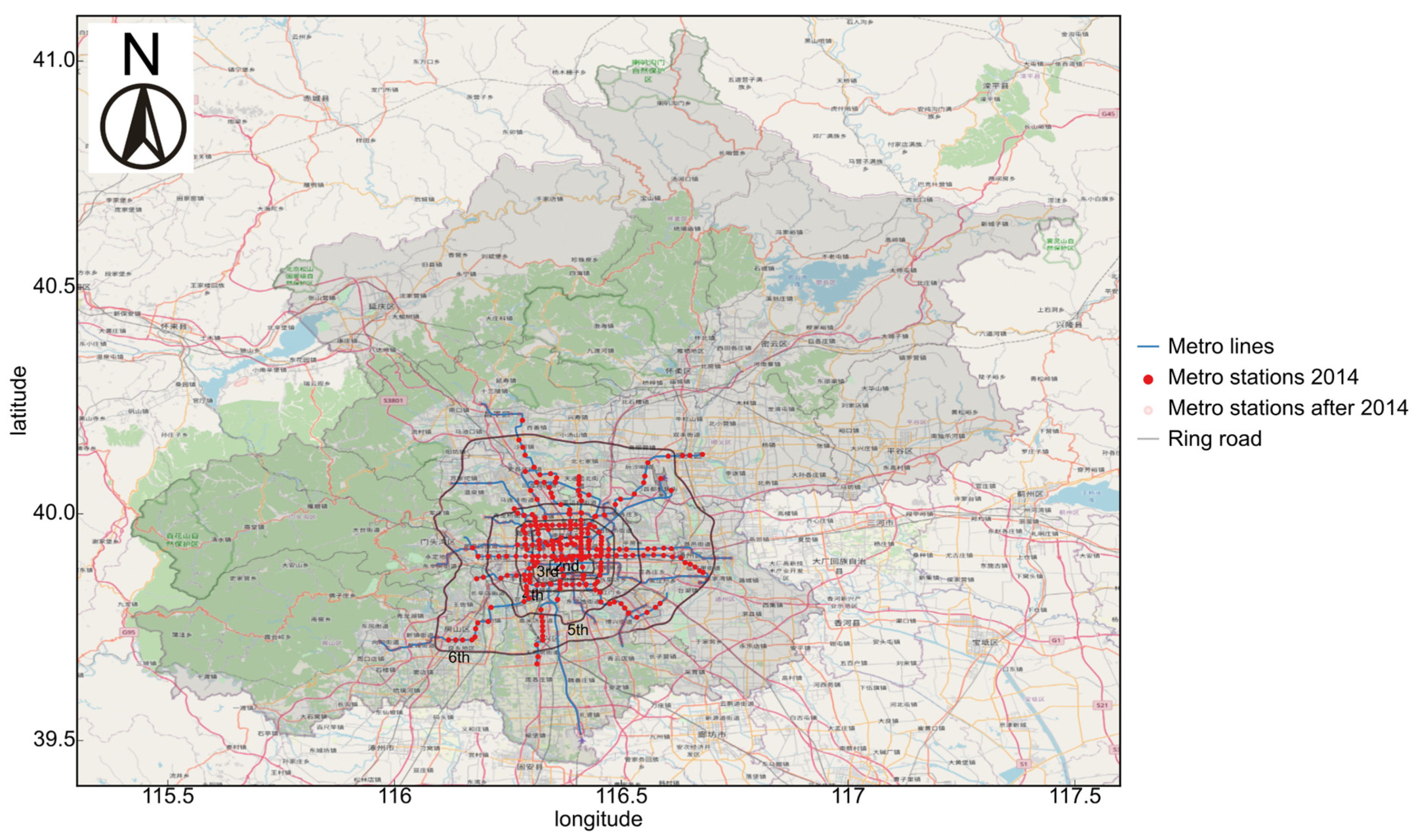
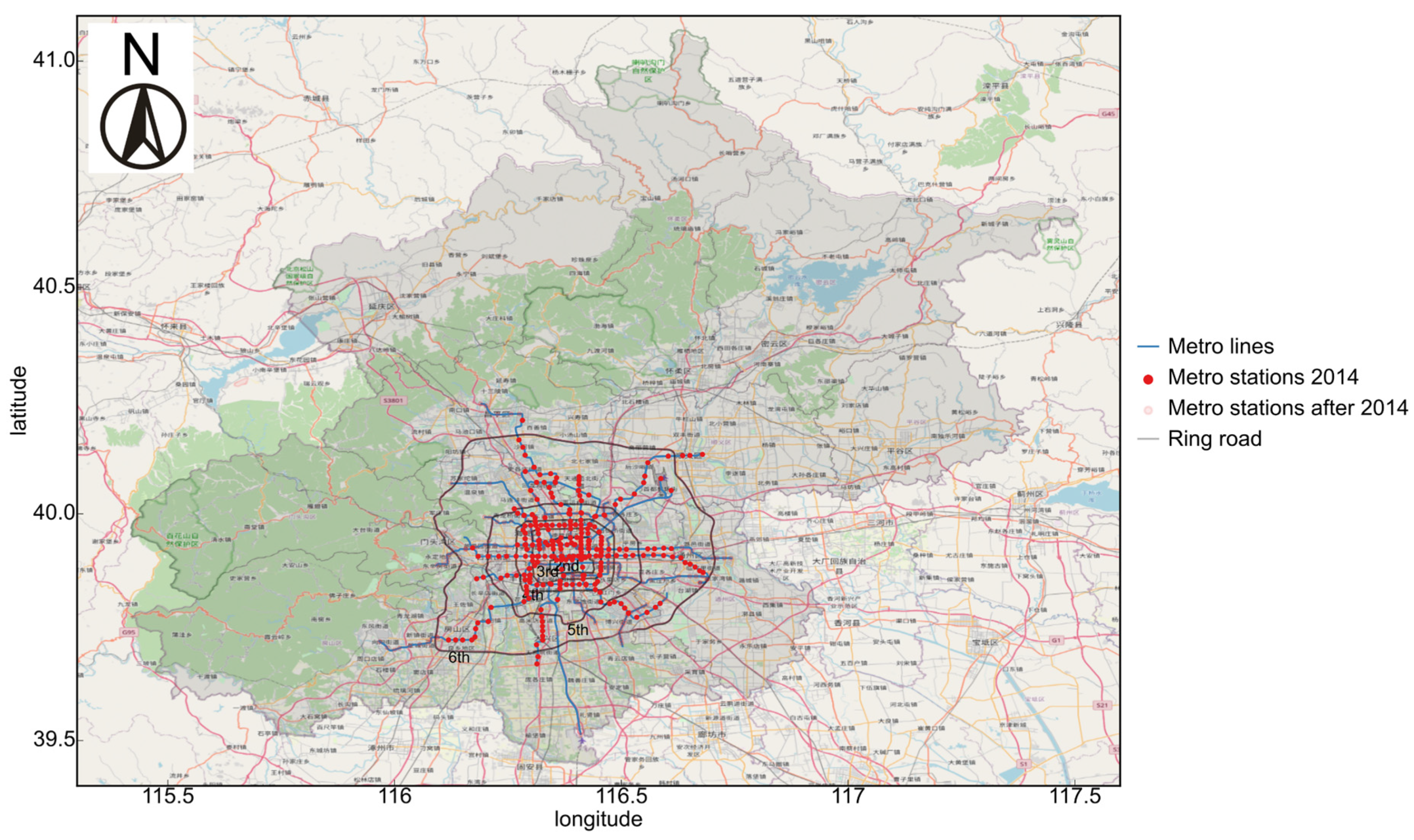
2.1. The Study Area and AFC Data
2.2. Measuring the Similarity of Distributions
2.2.1. KL Divergence and Sorensen Similarity Index
2.2.2. Wasserstein Distance
2.2.3. Definition of the Cost Function
2.3. Clustering Based on Proposed Distribution Similarity
2.3.1. Recap of Clustering Methods
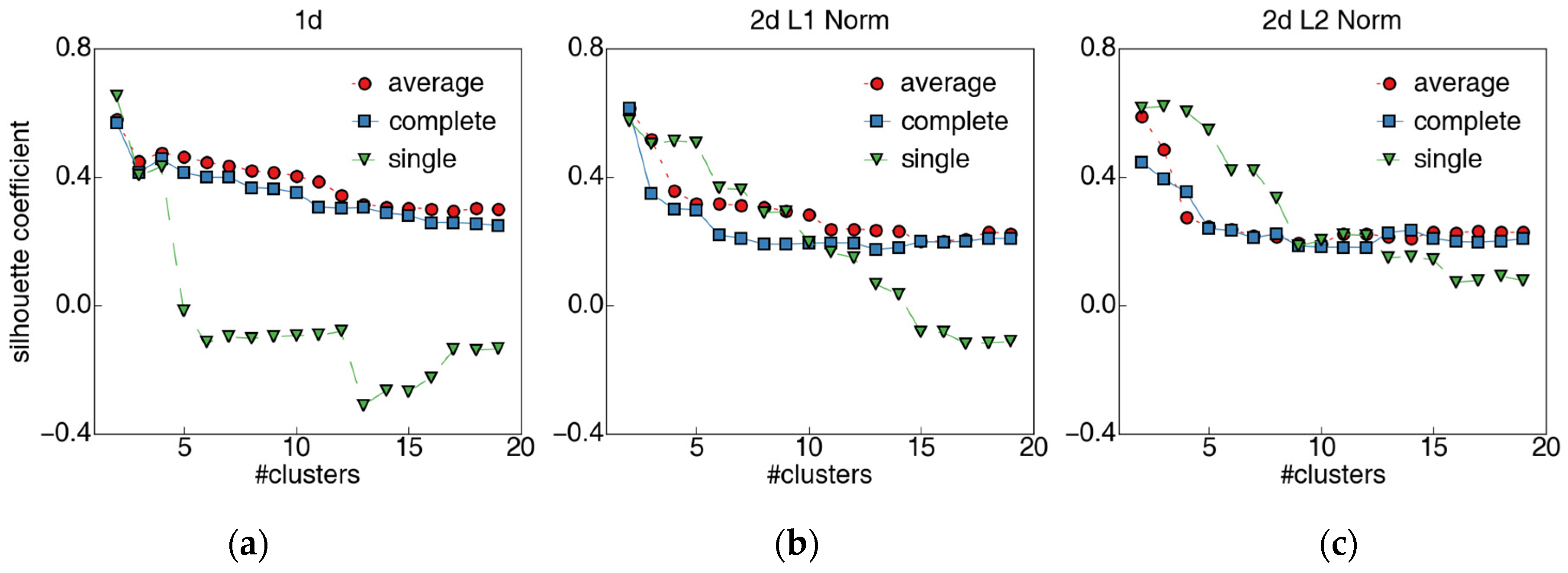
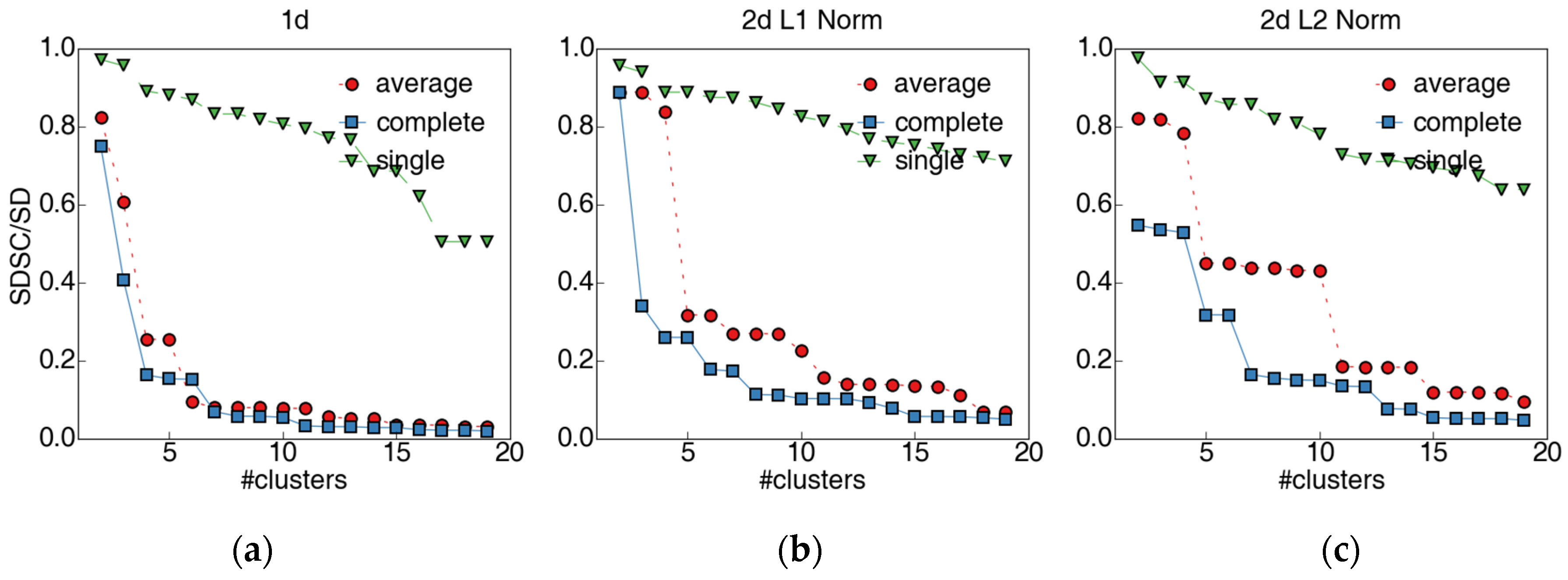
2.3.2. Clustering Evaluation Index
3. Results
3.1. Constructing Passenger’s Visit Count Distribution
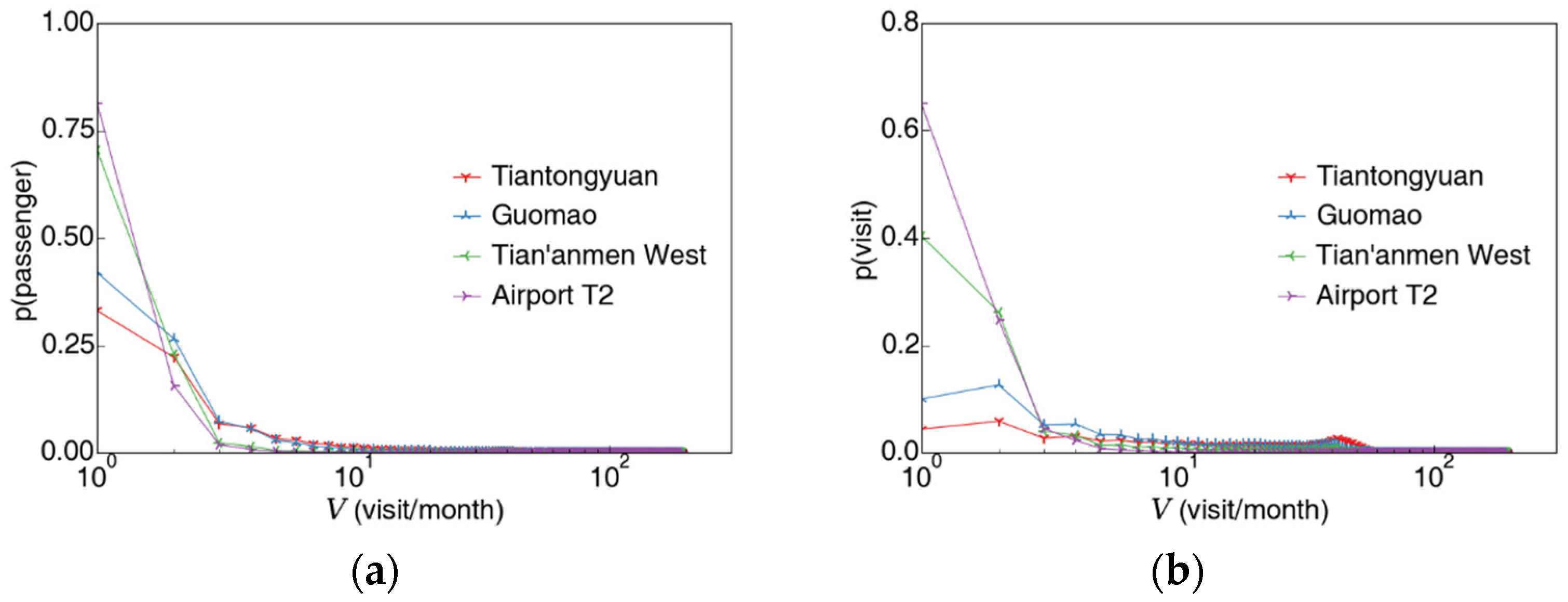
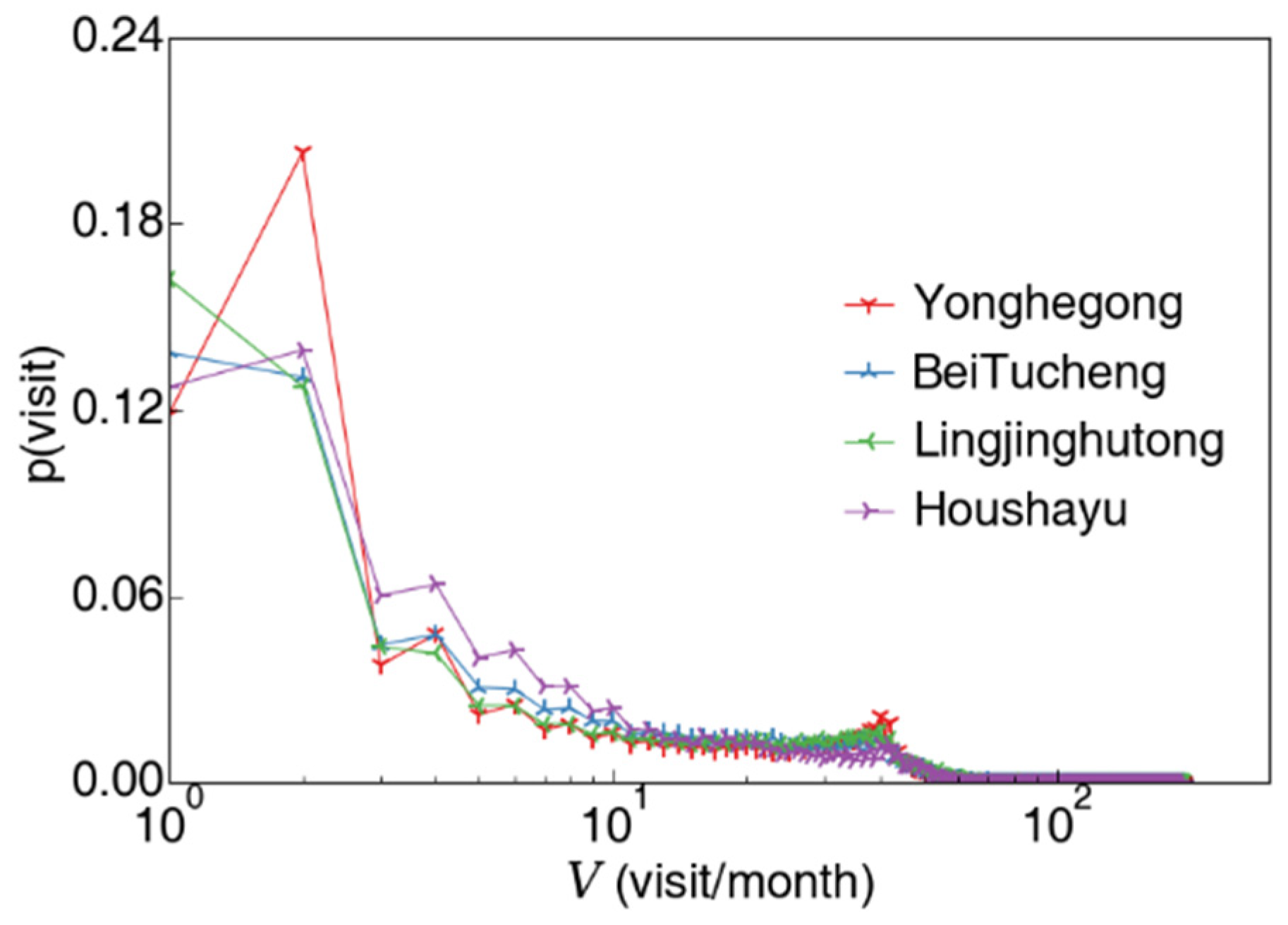
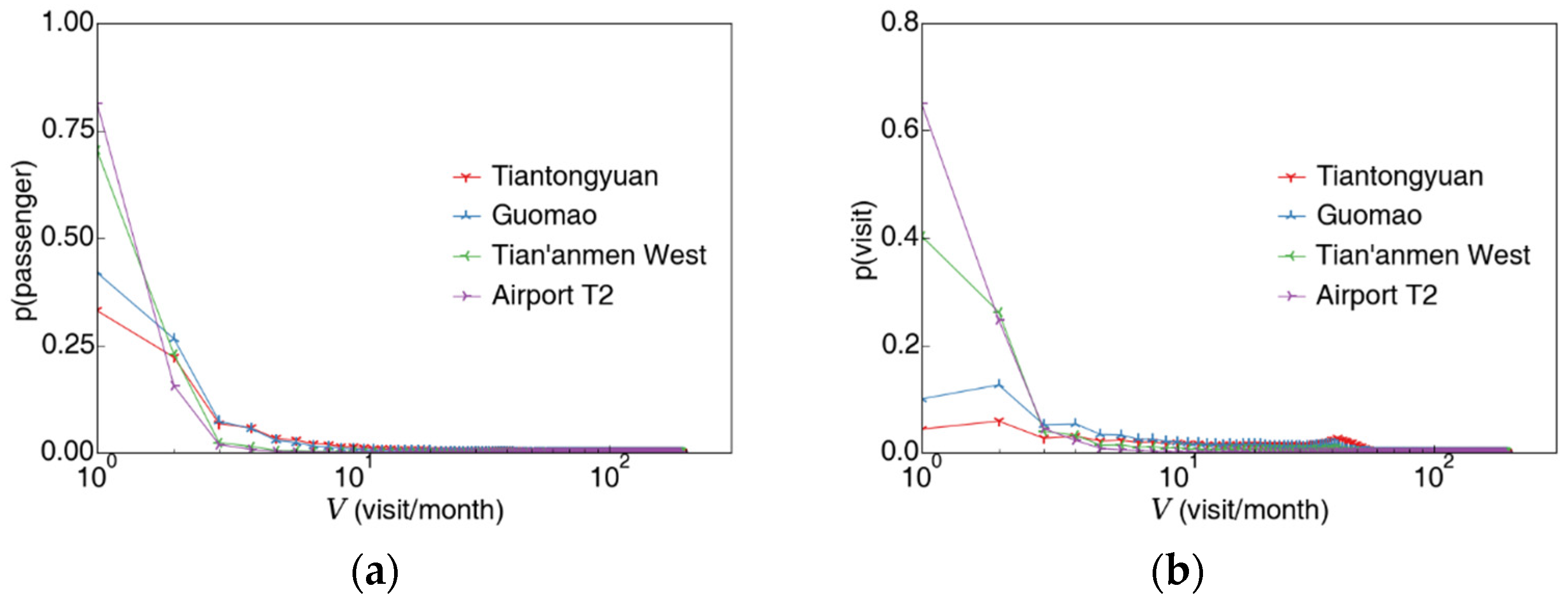
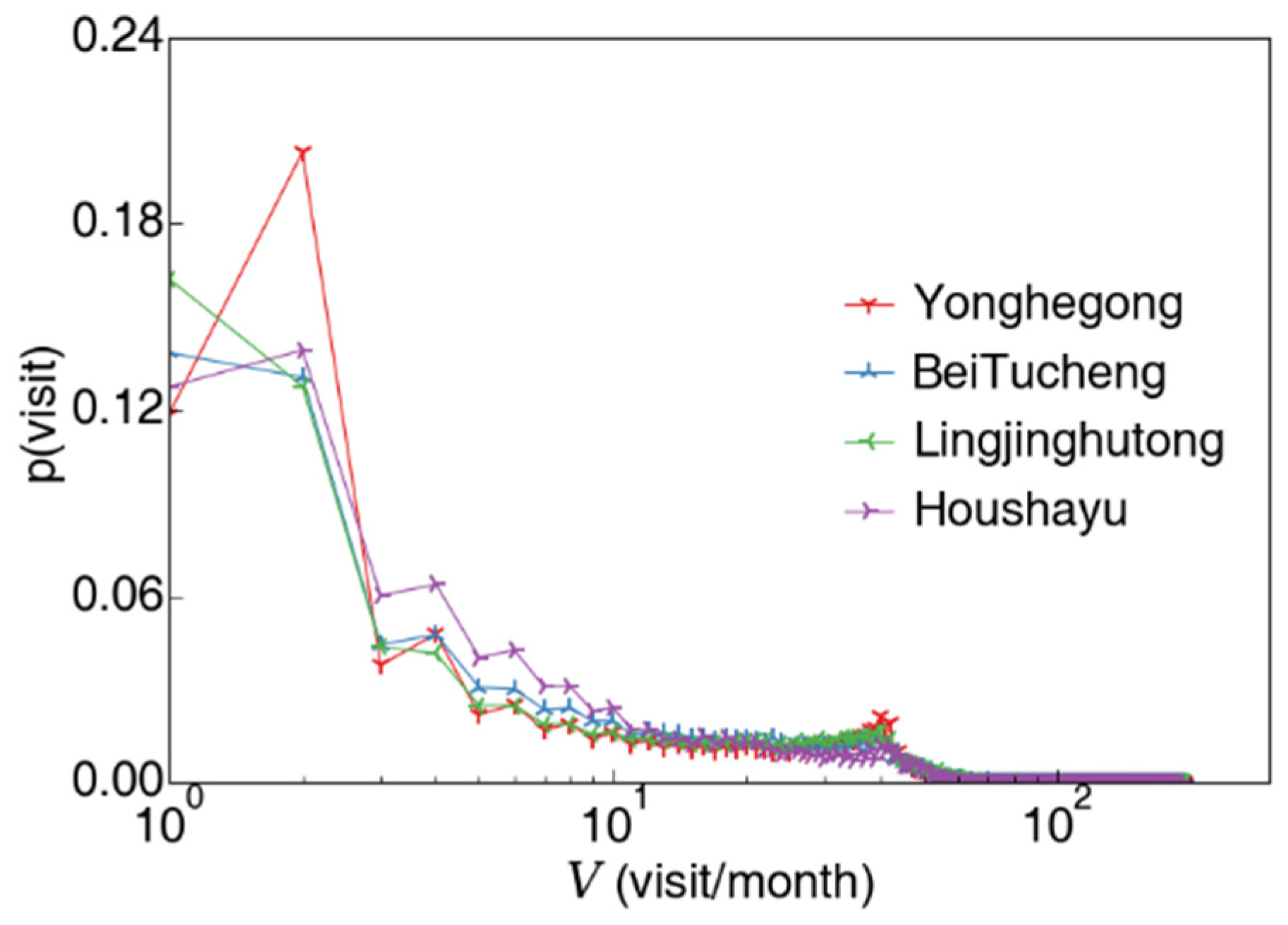
3.1.1. Passenger’s Visit Count to a Certain Station
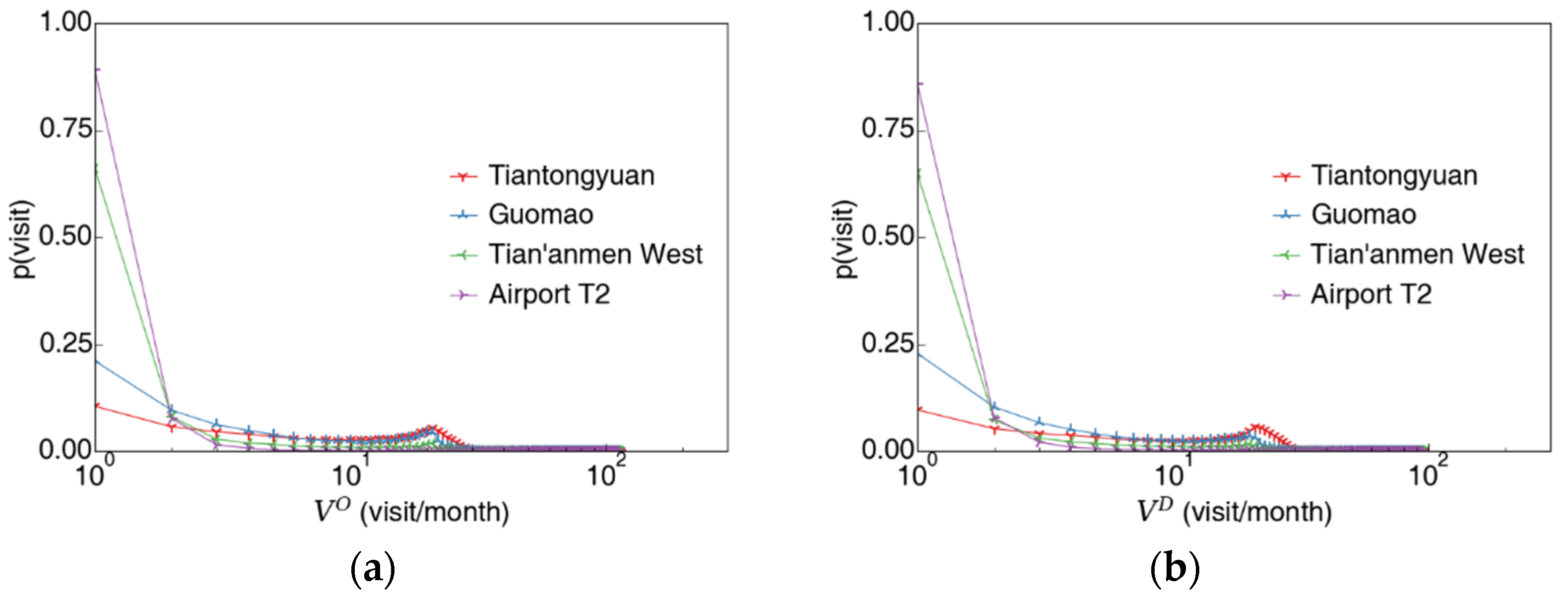
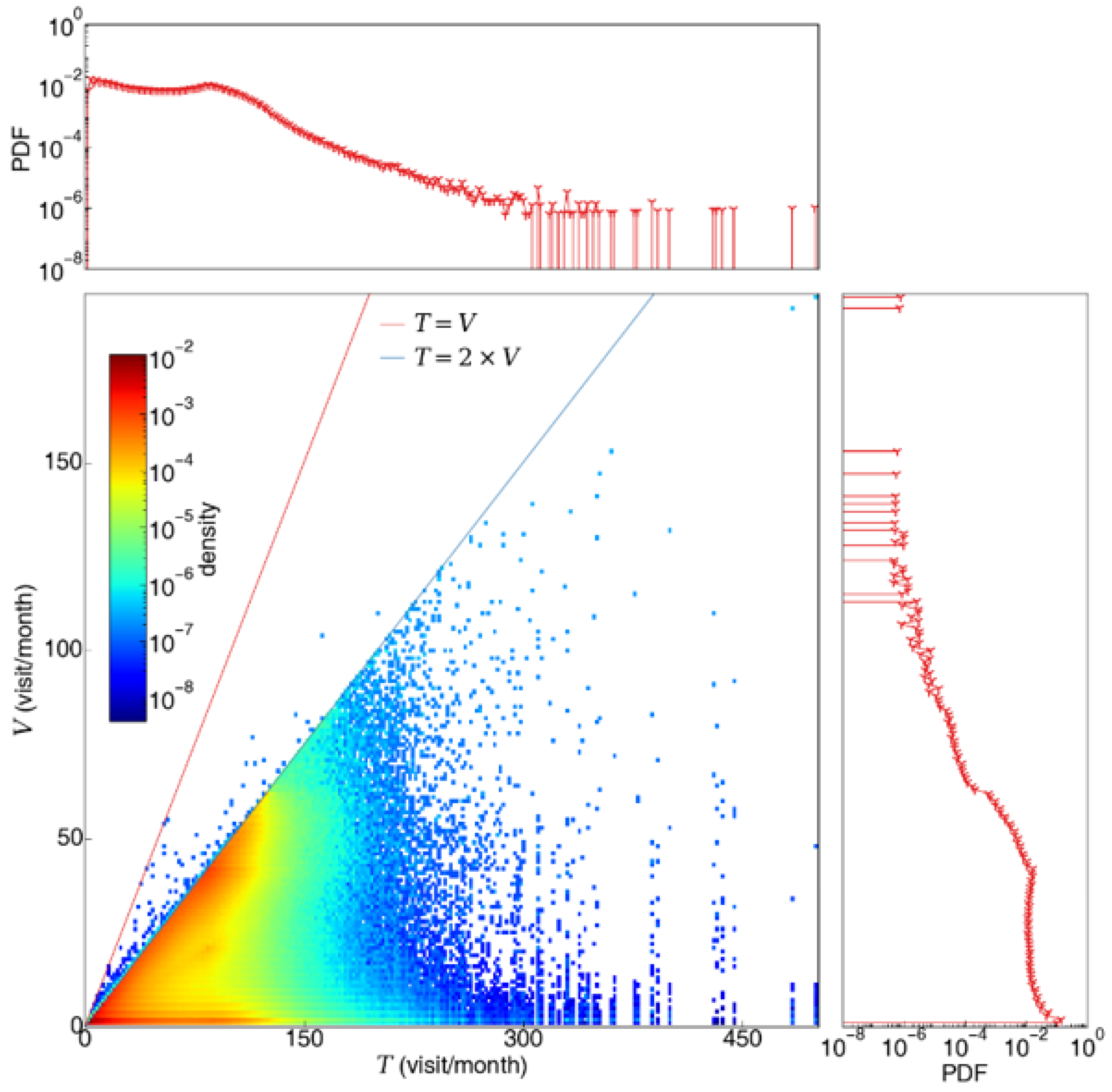
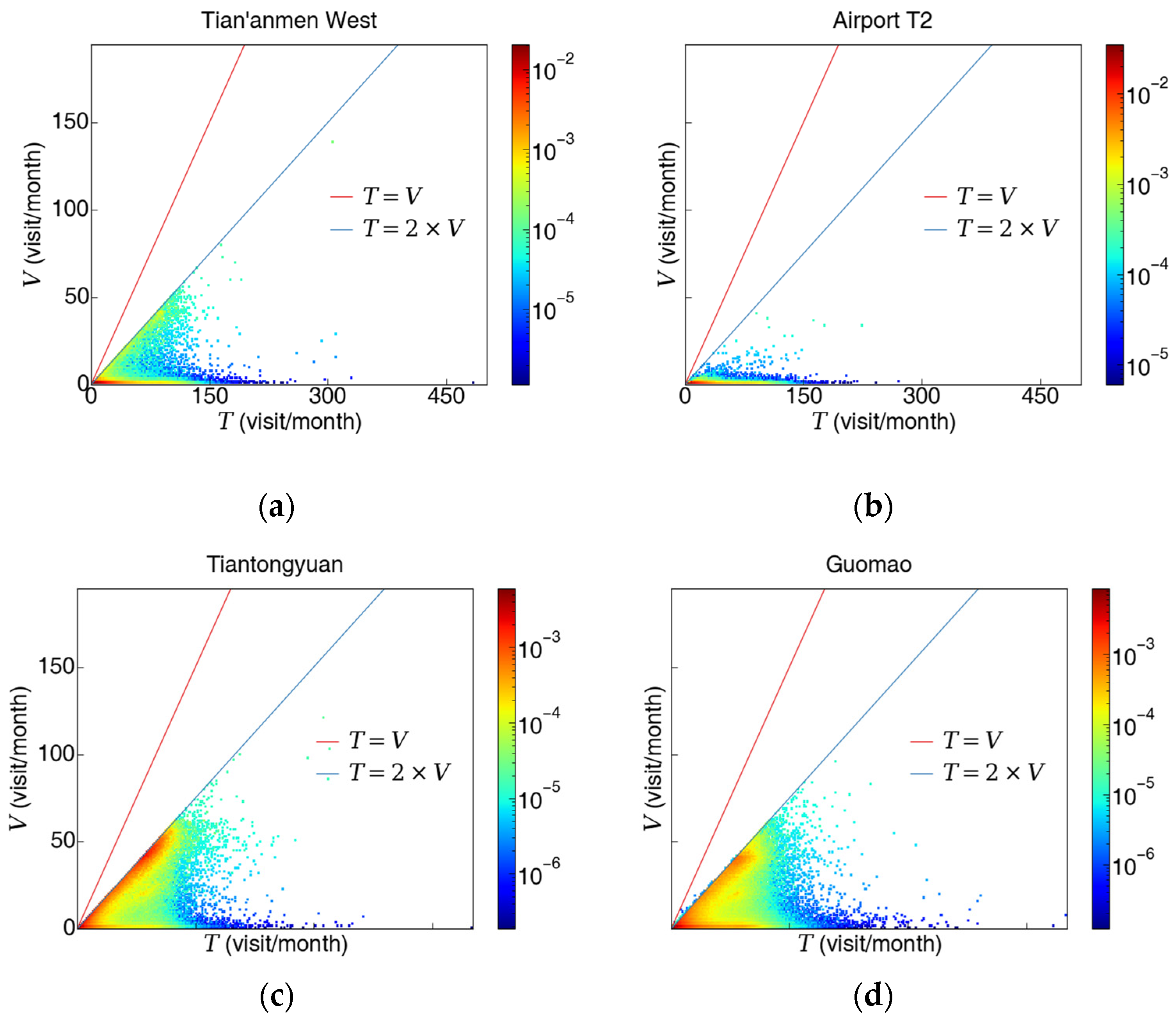
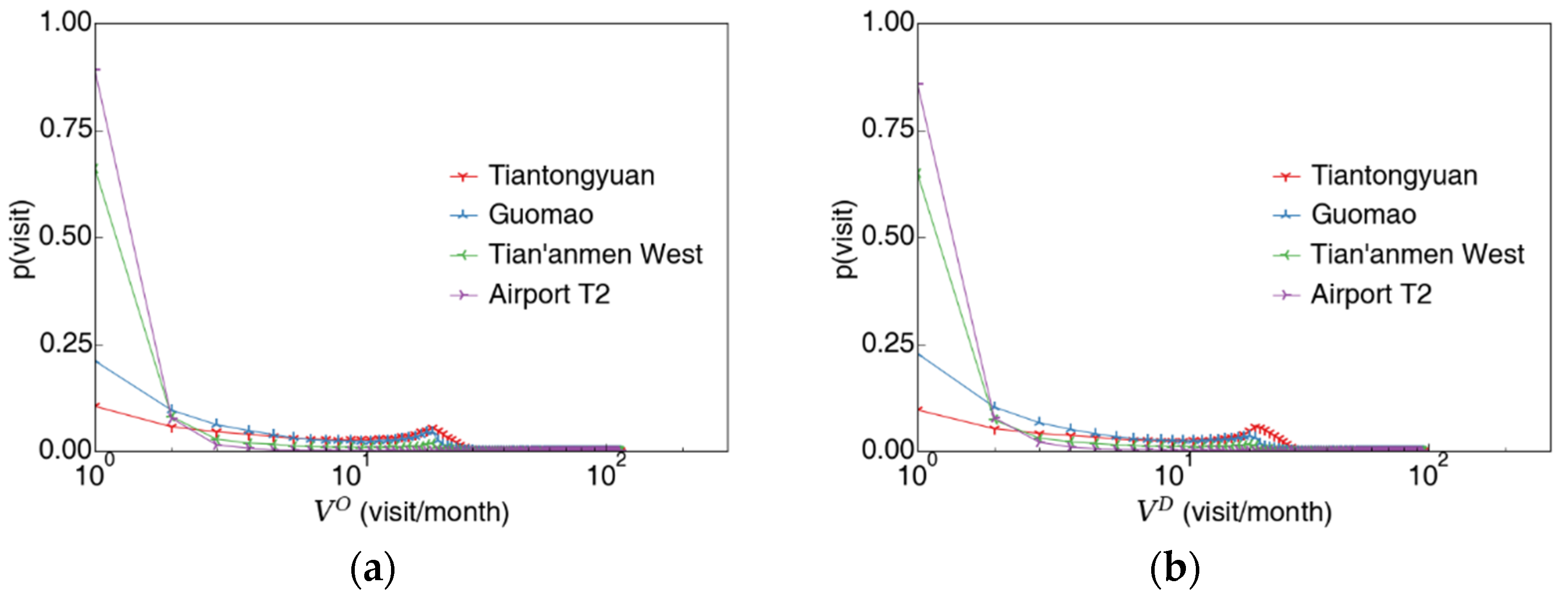
3.1.2. Passenger’s Station-Specific Visit Count and Total Visit Count
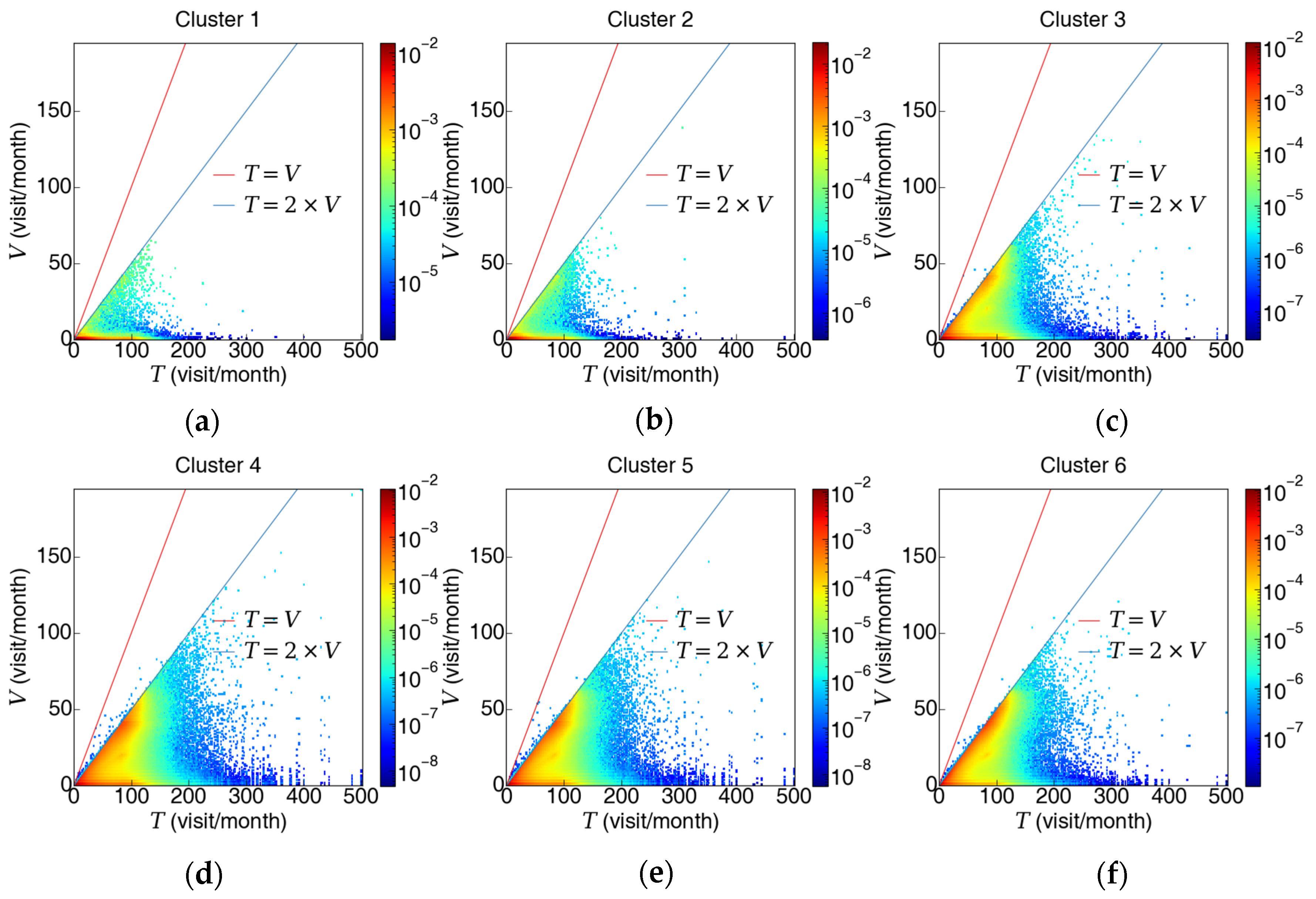
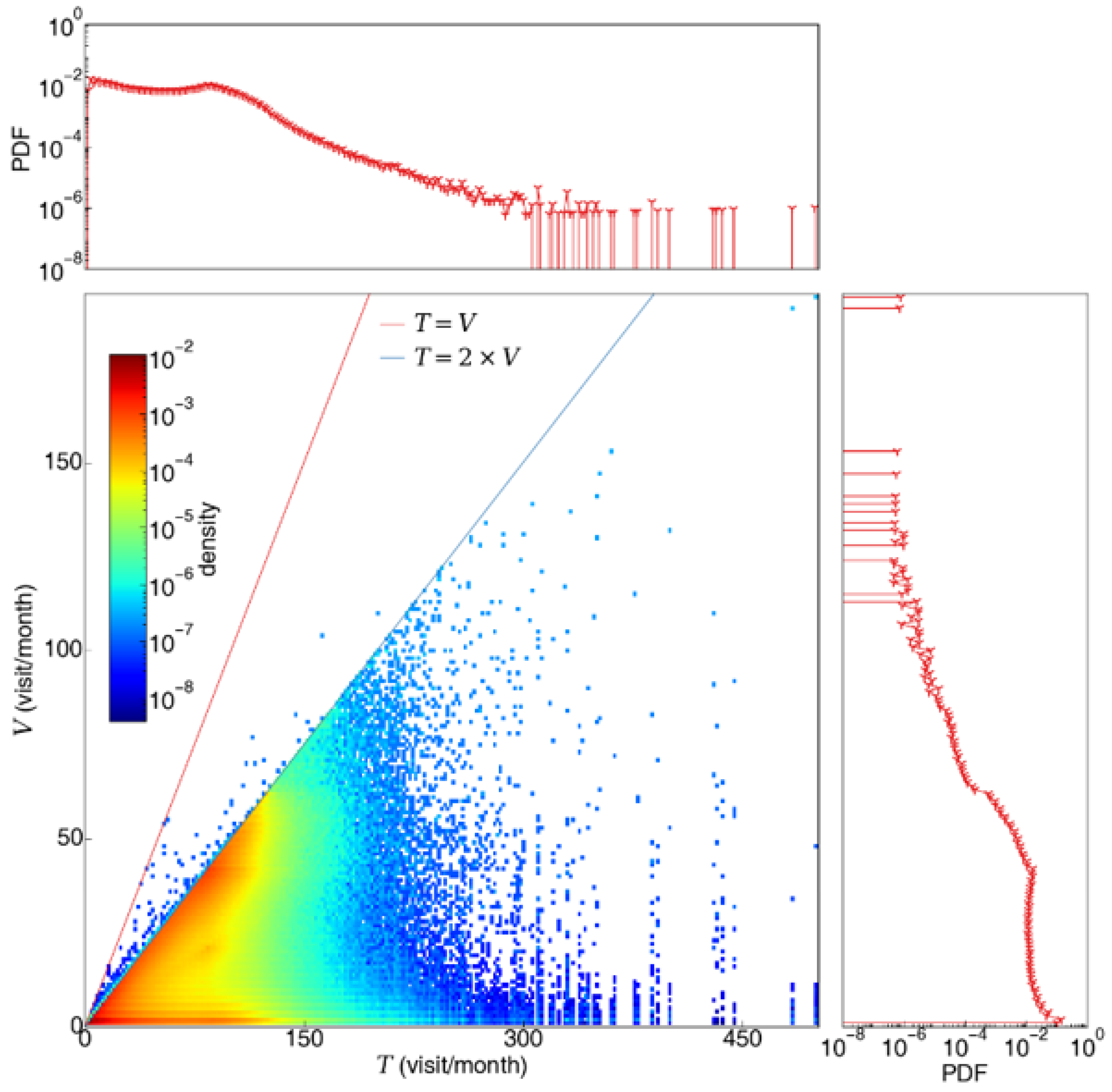
3.2. Illustrating the Advantage of Wasserstein Distance
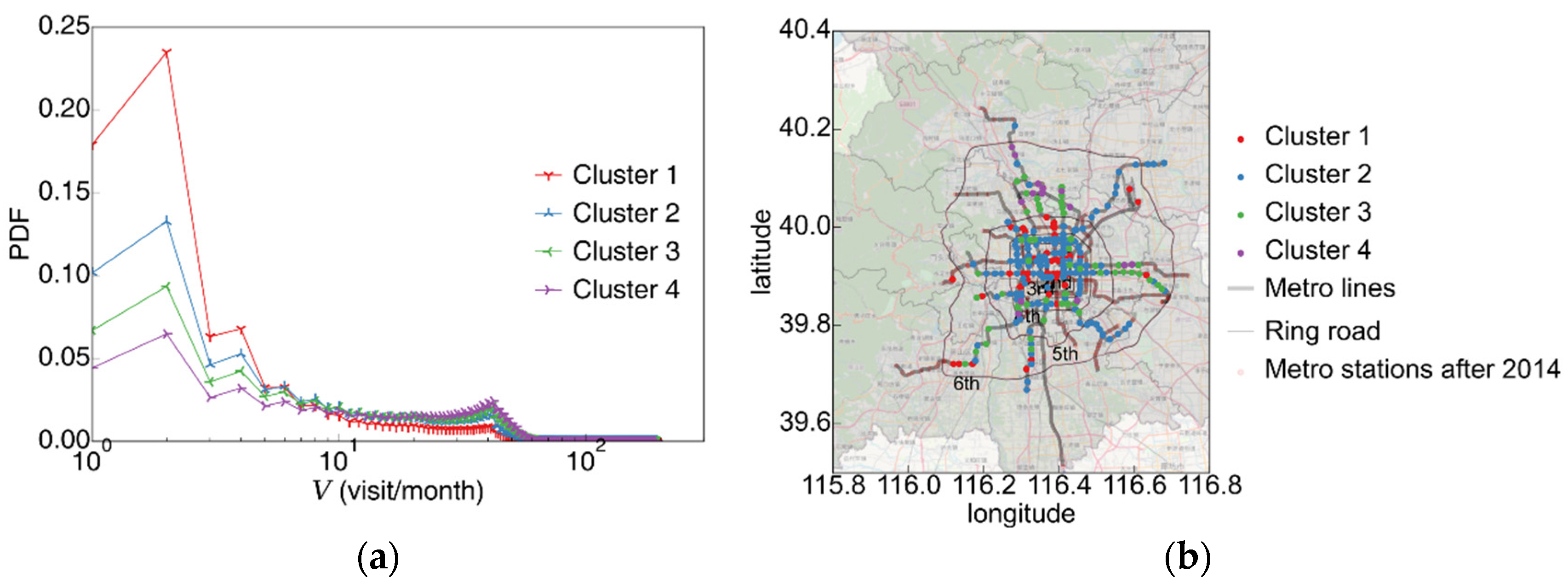
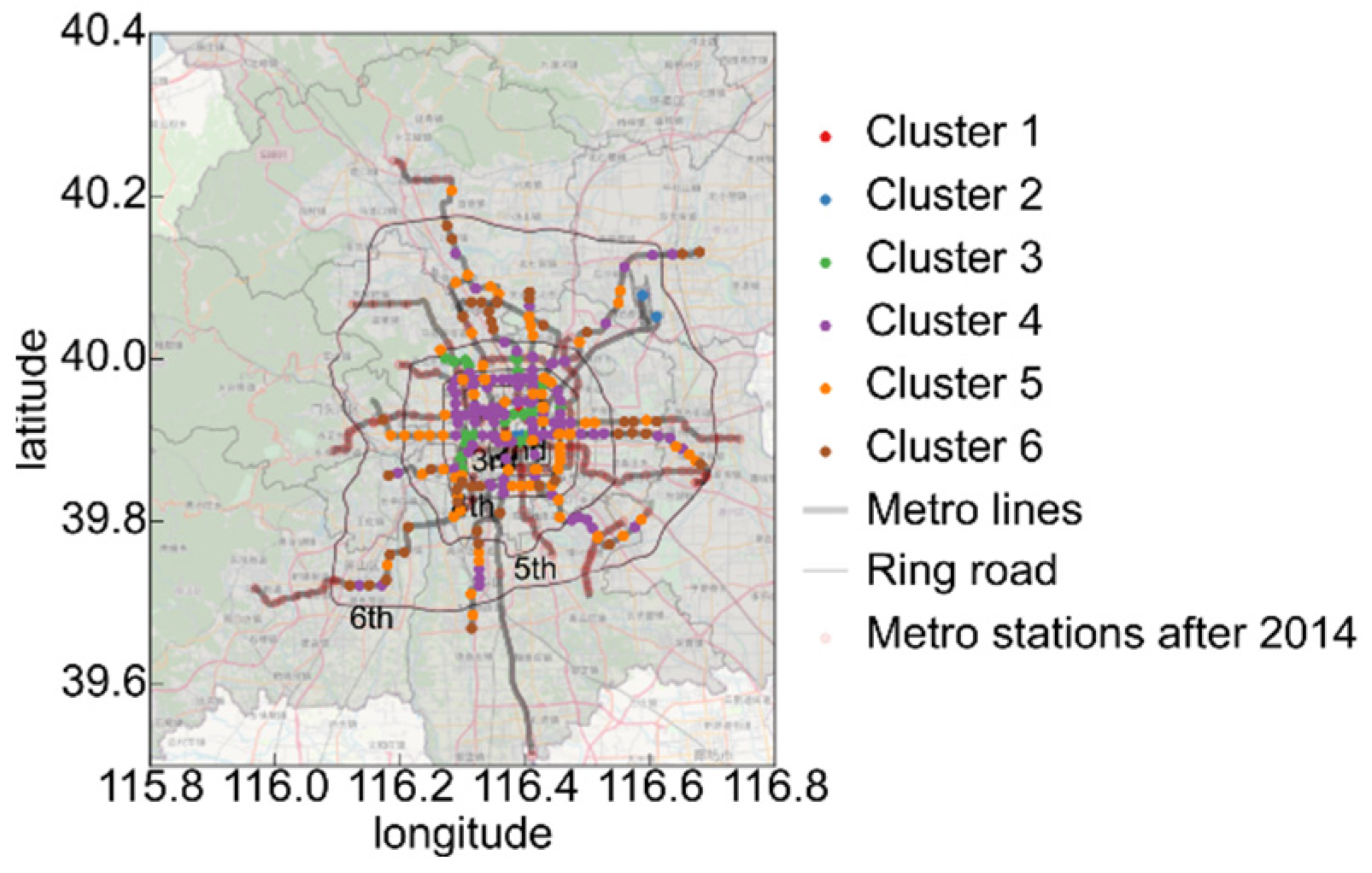
3.3. Clustering Stations Based on Distribution Distance
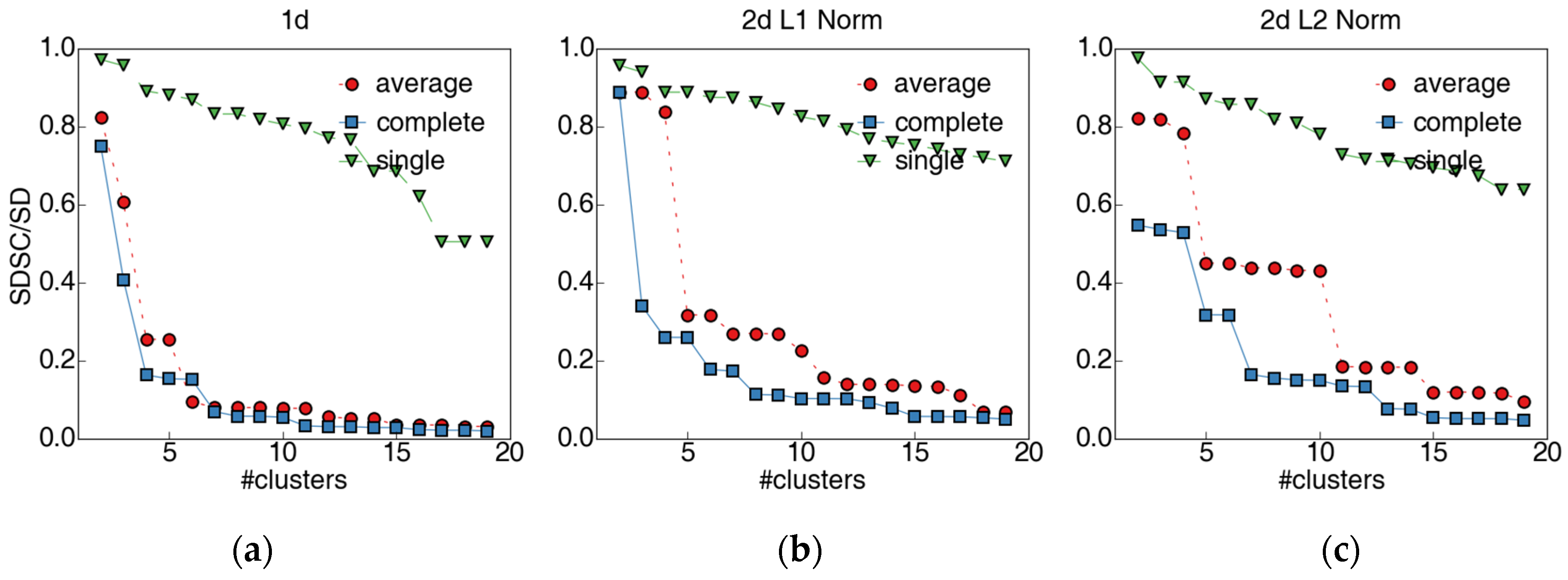
3.3.1. Selection of the Linkage Metric and the Number of Clusters
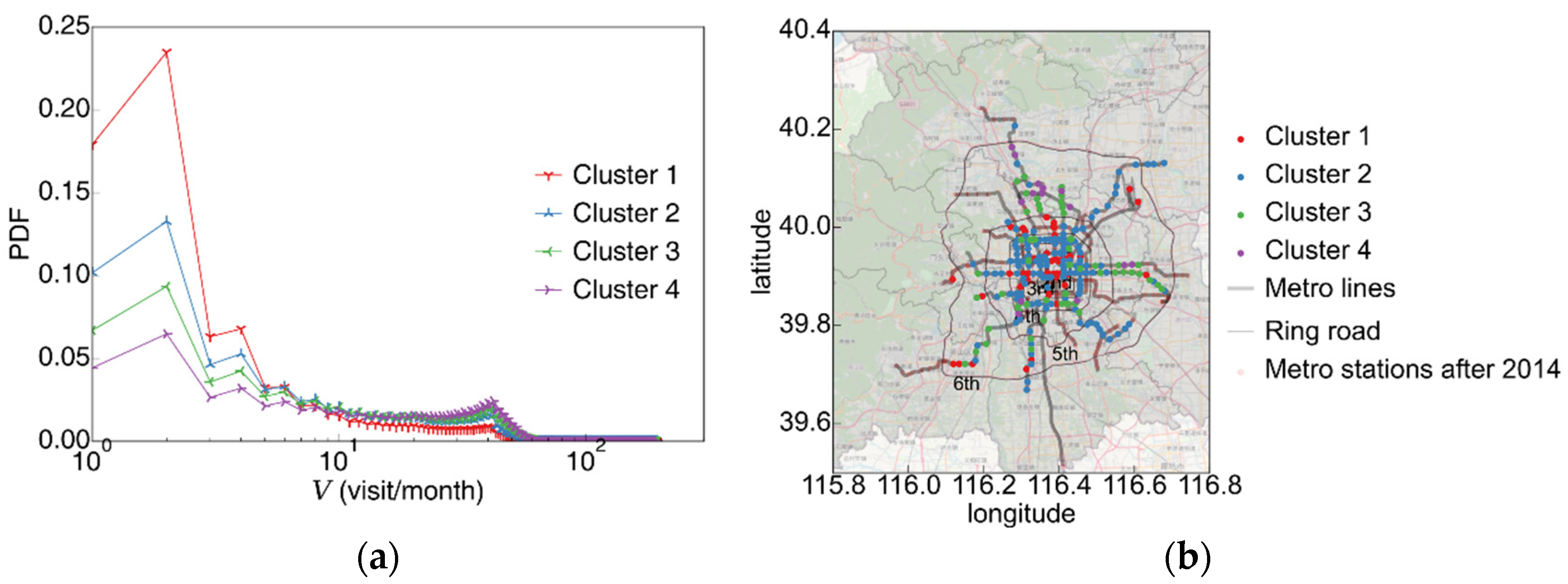
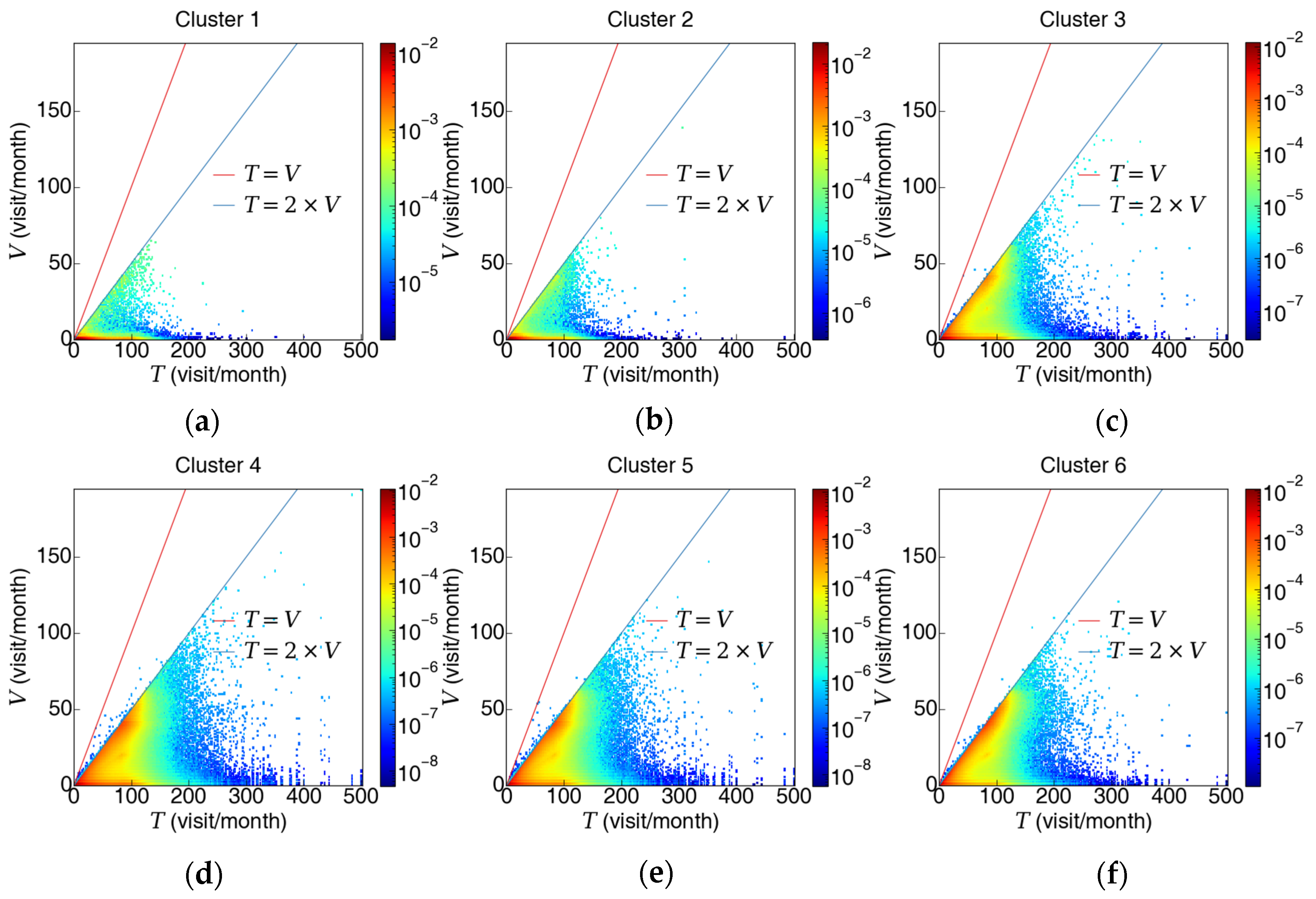
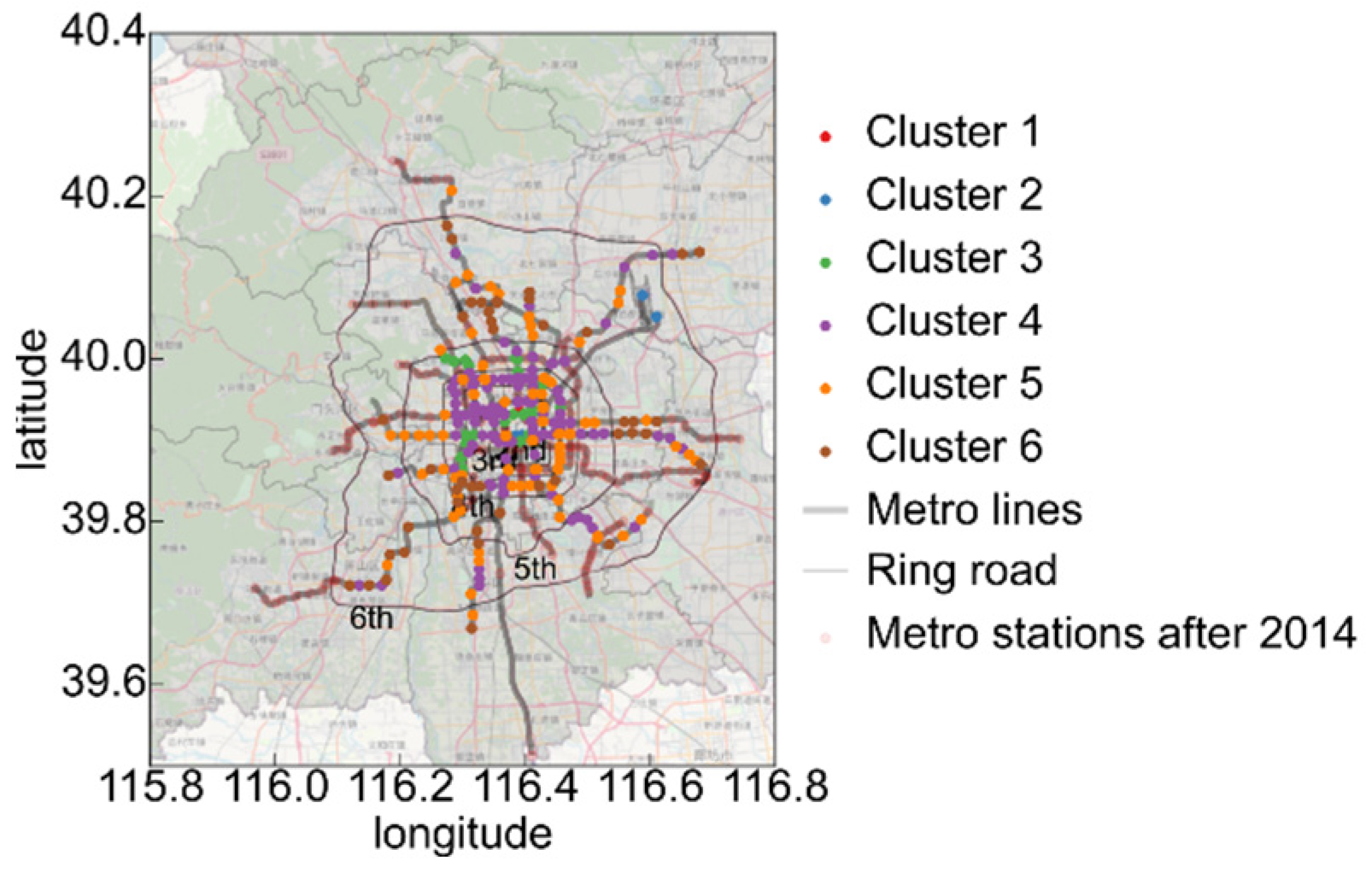
3.3.2. Analysis of Station Visit Distribution Clustering
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
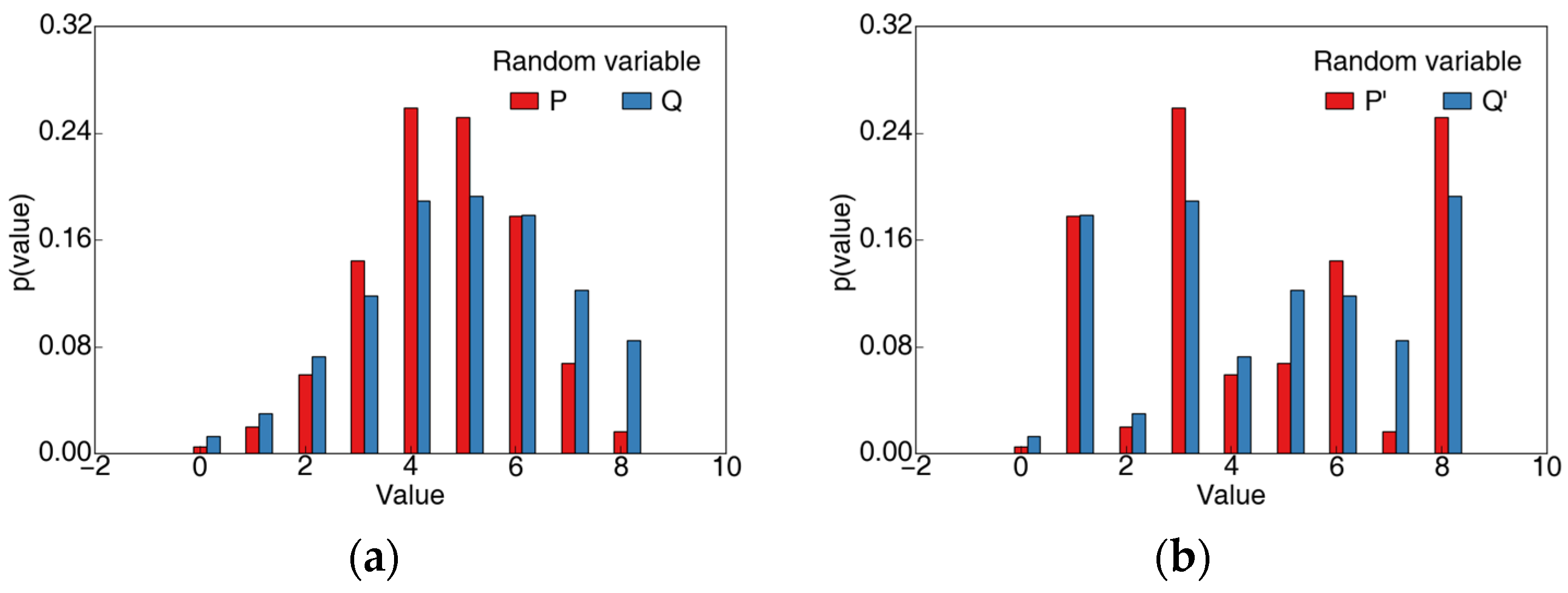
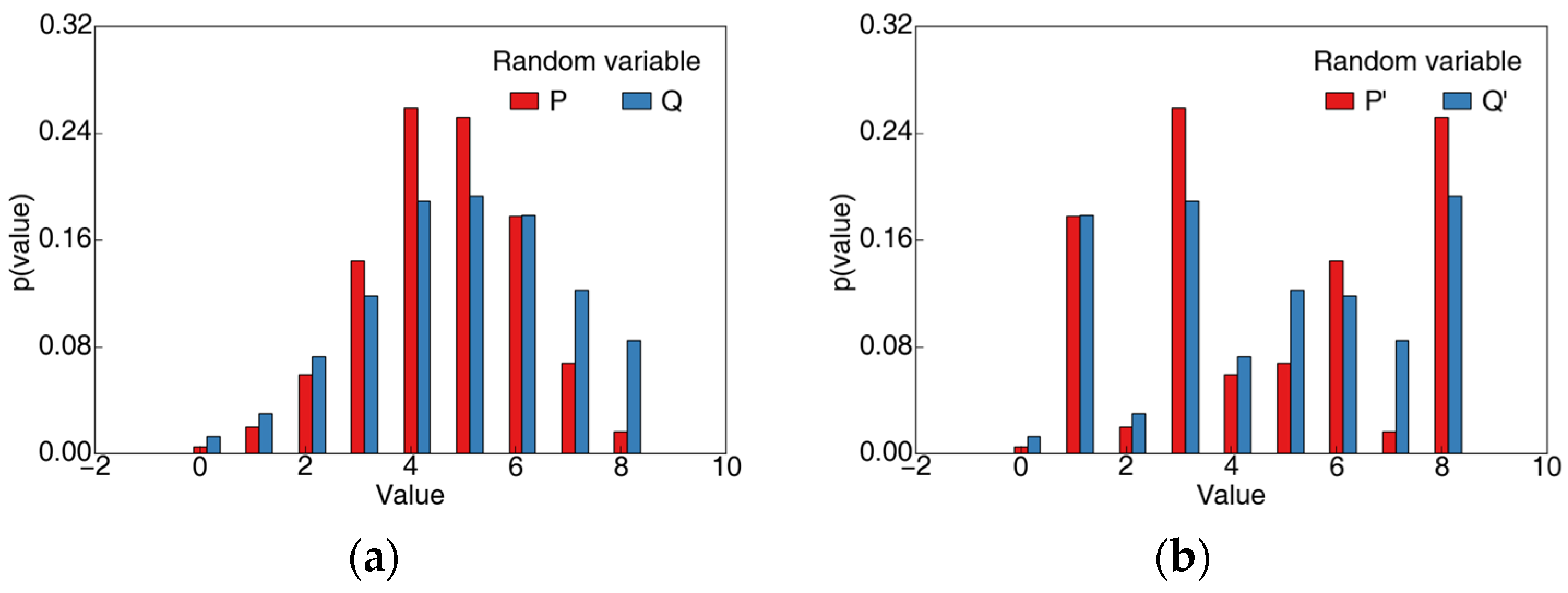
Appendix A.1. The same KL Divergence and Sorensen Similarity for Different Similarity

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Random Variables | ||||||
|---|---|---|---|---|---|---|
| Mean | 4.530 | 4.851 | 4.560 | 4.551 | 0.071 | 0.002 |
| Index | ||||
|---|---|---|---|---|
| Value | 0.085 | 0.118 | 0.085 | 0.118 |
| Index | ||||
|---|---|---|---|---|
| Value | 0.384 | 0.384 | 0.384 | 0.384 |
Appendix A.2. The Wasserstein Distance Can Distinguish Different Similarity
| Index | ||||
|---|---|---|---|---|
| Value | 0.442 | 0.209 | 0.442 | 0.209 |
Appendix A.3. Proof to the Validity of Wasserstein Distance as a Similarity Measure
References
- Beijing Statistical Yearbook. Available online: http://Nj.Tjj.Beijing.Gov.Cn/Nj/Main/2020-Tjnj/Zk/Indexch.Htm (accessed on 15 November 2021).
- Wu, J.; Li, D.; Si, S.; Gao, Z. Special Issue: Reliability Management of Complex System. Front. Eng. Manag. 2021, 8, 477–479. [Google Scholar] [CrossRef]
- Kang, L.; Meng, Q. Two-Phase Decomposition Method for the Last Train Departure Time Choice in Subway Networks. Transp. Res. Part B-Methodol. 2017, 104, 568–582. [Google Scholar] [CrossRef]
- Liu, L.; Hou, A.; Biderman, A.; Ratti, C.; Chen, J. Understanding Individual and Collective Mobility Patterns From Smart Card Records: A Case Study in Shenzhen. In Proceedings of the 2009 12th International IEEE Conference on Intelligent Transportation Systems, St. Louis, MO, USA, 4–7 October 2009; IEEE: Manhattan, NY, USA, 2009; pp. 1–6. [Google Scholar]
- Pelletier, M.-P.; Trepanier, M.; Morency, C. Smart Card Data Use In Public Transit: A Literature Review. Transp. Res. Part C-Emerg. Technol. 2011, 19, 557–568. [Google Scholar] [CrossRef]
- Ma, X.; Wu, Y.-J.; Wang, Y.; Chen, F.; Liu, J. Mining Smart Card Data For Transit Riders’ Travel Patterns. Transp. Res. Part C-Emerg. Technol. 2013, 36, 1–12. [Google Scholar] [CrossRef]
- Long, Y.; Thill, J. Combining Smart Card Data and Household Travel Survey to Analyze Jobs-Housing Relationships in Beijing. Comput. Environ. Urban Syst. 2015, 53, 19–35. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Liu, C.; Wen, H.; Wang, Y.; Wu, Y.-J. Understanding Commuting Patterns Using Transit Smart Card Data. J. Transp. Geogr. 2017, 58, 135–145. [Google Scholar] [CrossRef]
- Liu, J.; Shi, W.; Chen, P. Exploring Travel Patterns During The Holiday Season-A Case Study of Shenzhen Metro System During the Chinese Spring Festival. ISPRS Int. J. Geo-Inf. 2020, 9, 651. [Google Scholar] [CrossRef]
- Hasan, S.; Schneider, C.M.; Ukkusuri, S.V.; González, M.C. Spatiotemporal Patterns Of Urban Human Mobility. J. Stat. Phys. 2013, 151, 304–318. [Google Scholar] [CrossRef] [Green Version]
- Lei, D.; Chen, X.; Cheng, L.; Zhang, L.; Ukkusuri, S.; Witlox, F. Inferring Temporal Motifs for Travel Pattern Analysis Using Large Scale Smart Card Data. Transp. Res. Part C-Emerg. Technol. 2020, 120, 102810. [Google Scholar] [CrossRef]
- El Mahrsi, M.K.; Come, E.; Oukhellou, L.; Verleysen, M. Clustering Smart Card Data For Urban Mobility Analysis. IEEE Trans. Intell. Transp. Syst. 2017, 18, 712–728. [Google Scholar] [CrossRef]
- Deng, Y.; Wang, J.; Gao, C.; Li, X.; Wang, Z.; Li, X. Assessing Temporal-Spatial Characteristics of Urban Travel Behaviors from Multiday Smart-Card Data. Phys. A-Stat. Mech. Its Appl. 2021, 576, 126058. [Google Scholar] [CrossRef]
- Zhao, J.; Qu, Q.; Zhang, F.; Xu, C.; Liu, S. Spatio-Temporal Analysis Of Passenger Travel Patterns In Massive Smart Card Data. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3135–3146. [Google Scholar] [CrossRef]
- He, L.; Agard, B.; Trepanier, M. A Classification of Public Transit Users with Smart Card Data Based on Time Series Distance Metrics and A Hierarchical Clustering Method. Transp. A-Transp. Sci. 2020, 16, 56–75. [Google Scholar] [CrossRef]
- Yang, Y.; Heppenstall, A.; Turner, A.; Comber, A. Who, Where, Why and When? Using Smart Card and Social Media Data to Understand Urban Mobility. ISPRS Int. J. Geo-Inf. 2019, 8, 271. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Yang, Y.; Lv, W. Understand Group Travel Behaviors in an Urban Area Using Mobility Pattern Mining. In Proceedings of the IEEE 10th International Conference on Ubiquitous Intelligence and Computing, UIC 2013 and IEEE 10th International Conference on Autonomic and Trusted Computing, ATC 2013, Vietri sul Mare, Italy, 18–21 December 2013; IEEE: Manhattan, NY, USA, 2013; pp. 127–133. [Google Scholar] [CrossRef]
- Sun, L.; Axhausen, K.W. Understanding Urban Mobility Patterns With A Probabilistic Tensor Factorization Framework. Transp. Res. Part B Methodol. 2016, 91, 511–524. [Google Scholar] [CrossRef]
- Beijing Municipal Bureau Statistics Beijing Statistical Yearbook. Available online: http://Nj.Tjj.Beijing.Gov.Cn/Nj/Main/2021-Tjnj/Zk/Indexch.Htm (accessed on 22 December 2021).
- Dong, H.; Wu, M.; Ding, X.; Chu, L.; Jia, L.; Qin, Y.; Zhou, X. Traffic Zone Division Based on Big Data from Mobile Phone Base Stations. Transp. Res. Part C Emerg. Technol. 2015, 58, 278–291. [Google Scholar] [CrossRef]
- Shen, P.; Ouyang, L.; Wang, C.; Shi, Y.; Su, Y. Cluster and Characteristic Analysis of Shanghai Metro Stations Based on Metro Card and Land-Use Data. Geo-Spat. Inf. Sci. 2020, 23, 352–361. [Google Scholar] [CrossRef]
- Xiong, L.; Chen, X.; Huang, T.K.; Schneider, J.; Carbonell, J.G. Temporal Collaborative Filtering with Bayesian Probabilistic Tensor Factorization. In Proceedings of the 10th Siam International Conference on Data Mining, SDM 2010, Columbus, OH, USA, 29 April–1 May 2010; SIAM: Philadelphia, PA, USA, 2010; pp. 211–222. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Thanou, D.; Frossard, P.; Vandergheynst, P. Learning Laplacian Matrix in Smooth Graph Signal Representations. IEEE Trans. Signal Process. 2016, 64, 6160–6173. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.-F.; Rao, N.; Dhillon, I.S. Temporal Regularized Matrix Factorization for High-Dimensional Time Series Prediction. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Xu, J. Map Sensitivity vs. Map Dependency: A Case Study of Subway Maps’ Impact on Passenger Route Choices in Washington DC. Behav. Sci. 2017, 7, 72. [Google Scholar] [CrossRef] [Green Version]
- Lei, B.; Xu, J.; Li, M.; Li, H.; Li, J.; Cao, Z.; Hao, Y.; Zhang, Y. Enhancing Role of Guiding Signs Setting in Metro Stations with Incorporation of Microscopic Behavior of Pedestrians. Sustainability 2019, 11, 6109. [Google Scholar] [CrossRef] [Green Version]
- Shiwakoti, N.; Tay, R.; Stasinopoulos, P.; Woolley, P.J. Passengers’ Awareness and Perceptions of Way Finding Tools in a Train Station. Saf. Sci. 2016, 87, 179–185. [Google Scholar] [CrossRef]
- Hong, L.; Gao, J.; Zhu, W. Simulating Emergency Evacuation at Metro Stations: An Approach Based on Thorough Psychological Analysis. Transp. Lett.-Int. J. Transp. Res. 2016, 8, 113–120. [Google Scholar] [CrossRef]
- Faroqi, H.; Mesbah, M.; Kim, J. Behavioural Advertising In The Public Transit Network. Res. Transp. Bus. Manag. 2019, 32, 100421. [Google Scholar] [CrossRef]
- Raveau, S.; Guo, Z.; Munoz, J.C.; Wilson, N.H.M. A Behavioural Comparison of Route Choice on Metro Networks: Time, Transfers, Crowding, Topology and Socio-Demographics. Transp. Res. Part A-Policy Pract. 2014, 66, 185–195. [Google Scholar] [CrossRef]
- Zhu, Y.; Hu, C.; Xu, D.; Tang, J. Research on Optimization for Passenger Streamline of Hubs. Procedia-Soc. Behav. Sci. 2014, 138, 776–782. [Google Scholar] [CrossRef] [Green Version]
- Lotan, T. Effects of Familiarity on Route Choice Behavior in the Presence of Information. Transp. Res. Part C-Emerg. Technol. 1997, 5, 225–243. [Google Scholar] [CrossRef]
- Openstreetmap. Available online: https://www.openstreetmap.org/ (accessed on 22 December 2021).
- Bradski, G. The Opencv Library. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A Survey of Clustering Algorithms for Big Data: Taxonomy and Empirical Analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms For Hierarchical Clustering: An Overview, II. Wiley Interdiscip. Rev.-Data Min. Knowl. Discov. 2017, 7, E1219. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.-T. A Review of Clustering Techniques and Developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to The Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1984, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]


| Hashed CardID | Entrance Station | Exit Station | Entrance Time | Exit Time |
|---|---|---|---|---|
| -3445825934149650544 | BaGou | Beijing West Railway Station | 2014/3/9 11:35:00 | 2014/3/9 12:10:42 |
| -3445825934149650544 | Beijing West Railway Station | BaGou | 2014/3/13 21:17:00 | 2014/3/13 21:54:15 |
| -3445825934149650544 | Renmin University | Beijing West Railway Station | 2014/3/24 12:11:00 | 2014/3/24 12:34:42 |
| -3445825934149650544 | Beijing West Railway Station | HuoQiYing | 2014/3/26 7:03:00 | 2014/3/26 7:29:13 |
| -3445825934149650544 | BaGou | NanLuoGuXiang | 2014/3/29 9:35:00 | 2014/3/29 10:09:34 |
| -3445825934149650544 | BeiXinQiao | BaGou | 2014/3/29 12:07:00 | 2014/3/29 12:44:32 |
| Hashed CardID | Station | Count |
|---|---|---|
| -3445825934149650544 | BaGou | 4 |
| -3445825934149650544 | Beijing West Railway Station | 4 |
| -3445825934149650544 | Renmin University | 1 |
| -3445825934149650544 | HuoQiYing | 1 |
| -3445825934149650544 | NanLuoGuXiang | 1 |
| -3445825934149650544 | BeiXinQiao | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, K.; Yin, H.; Qu, Y.; Wu, J. Measuring the Similarity of Metro Stations Based on the Passenger Visit Distribution. ISPRS Int. J. Geo-Inf. 2022, 11, 18. https://doi.org/10.3390/ijgi11010018
Zhu K, Yin H, Qu Y, Wu J. Measuring the Similarity of Metro Stations Based on the Passenger Visit Distribution. ISPRS International Journal of Geo-Information. 2022; 11(1):18. https://doi.org/10.3390/ijgi11010018
Chicago/Turabian StyleZhu, Kangli, Haodong Yin, Yunchao Qu, and Jianjun Wu. 2022. "Measuring the Similarity of Metro Stations Based on the Passenger Visit Distribution" ISPRS International Journal of Geo-Information 11, no. 1: 18. https://doi.org/10.3390/ijgi11010018
APA StyleZhu, K., Yin, H., Qu, Y., & Wu, J. (2022). Measuring the Similarity of Metro Stations Based on the Passenger Visit Distribution. ISPRS International Journal of Geo-Information, 11(1), 18. https://doi.org/10.3390/ijgi11010018