1. Introduction
As an important source of information, numerous images are digitally stored and transmitted on the Internet. Since most of the human communication relies on natural language, enabling computers to describe the visual world can bring a wide range of possible applications, such as natural human-computer interaction, child education, information retrieval, and assistance for visually impaired people.
Image captioning is a comprehensive task in computer vision (CV) [
1] and natural language processing (NLP) [
2], which can complete multi-modal conversion from image to text. The algorithm automatically generates corresponding descriptive texts according to an input image. The task can be specifically described as:
represents an input image of a given group
.
represents the target word sequence where
is the word extracted from the dataset. The training goal of the model is to maximize the likelihood
to complete a multimodal mapping from image
to describing sentence
.
As a challenging and meaningful area of artificial intelligence, automatically generating image descriptions are attracting more and more attention. The goal of image captioning is to generate linguistically plausible sentences that are semantically true to the content of the image. Therefore, image description has two basic aspects: visual understanding and language processing [
3]. To ensure that the generated sentences are grammatically and semantically correct, CV and NLP techniques should be used to deal with the problems generated by the corresponding modalities and to properly integrate them.
With the booming growth of data scale and computing capability, machine learning based on data and hardware begins to show unique advantages, which directly promote the prosperity of artificial intelligence in various application areas. Under the pioneering research of many outstanding scholars, deep learning with the kernel structure of neural network emerged. It has made extraordinary progress in CV, NLP and speech recognition [
4]. In 2012, many participants of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [
5] adopted a Convolutional Neural Network (CNN) [
6] in their successful and innovative programs, which attracted widespread attention in academia and industry. Deep learning began to become popular and quickly introduced into many other classic CV tasks, including image classification, object recognition and object detection [
5]. At the same time, excellent deep learning models in NLP such as Word2Vec [
7] and GloVe [
8] have been proposed. The performance of other NLP tasks has also been generally improved, such as sentiment analysis, text summarization and machine translation.
Since Alex and his mentor took the first place with the 16.4% top-5 error rate in ILSVRC2012 [
9], the dominance of CNN in CV was established. VGGNet [
10], developed by the Visual Geometry Group of University of Oxford and Google DeepMind, built a highly scalable neural network by repeatedly stacking
small convolution kernels and
maximum pooling layers. This structure reduced training parameters using small convolution kernels. With this advantage, the number of feature maps could be greatly increased, and more information could be extracted. In 2014, the 22-layer Inception V1 model [
11] reduced the top-5 error rate to 6.67% in the ILSVRC2014 competition. The structure of GoogLeNet was deeply influenced by the structure of the Network-in-Network model proposed by Lin et al. [
12], which was characterized using the Inception module to build small network architecture within the model, so that the convolutional neural network could be deeper and wider and the number of training parameters was reduced. Besides, an additional classifier was used in the network to effectively solve the gradient disappearance problem. ResNet [
13] proposed by He et al. introduced identity mapping in the residual network to solve the training problem under deep layers. It was inspired by the idea of the Highway Network [
14], which added a direct connection next to the convolution channel. The straight-through channel could accelerate the training of the super-neural network and the accuracy of the model was greatly improved.
Traditional methods of image captioning are retrieval-based methods [
15] and template-based methods [
16]. Farhadi et al. [
3] detected objects to form a triple of scene elements and infer the final text relying on description templates. Devlin et al. [
15] discussed and summarized some characteristics of retrieval-based methods and the key issues that needed to be paid attention to in the image description tasks through experiments. They determined the key factors for the excellent description effect of this method. However, these two methods are too dependent on the training corpora and the generated text descriptions are lack diversity.
The early machine learning based image processing method uses some image processing operators to extract the features of the image, which adopts Support Vector Machine (SVM) [
17] as a classifier to get the target of the image and then use the obtained target and its attributions as the foundation for a generated sentence. This approach overly relies on the extraction of image features and the rules of generating sentences. The difficulty of training large datasets limits the captioning effect.
Based on significant advances of encoder–decoder structure in machine translation [
18,
19], a generative model called Neural Image Caption (NIC) [
20] was proposed. Vinyals et al. replaced the encoder Recurrent Neural Network (RNN) by a deep CNN and took an image as input. They improved the initial NIC model in the first MSCOCO competition with image model fine tuning and beam size reduction, which achieved overall improvement on different metrics [
21]. With a similar idea, Karpathy et al. introduced a ranking model that combined visual and language modalities through a common, multimodal embedding, where the multimodal RNN model was utilized to generate descriptions of images [
22]. Li and her team of Stanford University made an image semantic description system similar to NIC, called Neuraltalk, which used other models to map image regions to sentence segments [
23]. Xu et al. [
24] first introduced the attention mechanism of human visual system into the image description generation algorithm. Different from the NIC, the model used the feature map of the last convolutional layer of CNN as the image feature. At the decoding stage, the attention mechanism allowed the model to dynamically select particular image region features that needed attention.
Recently, some optimization algorithms of neural networks were related to image captioning. The multi-threaded learning control mechanism could minimize the training time of CNN [
19]. Cao et al. [
25] presented Bag-LSTM to obtain more text-related image features by feedback propagation. In addition, Yan et al. [
26] proposed a hierarchical attention mechanism via using both the global CNN features and the local object features for improved results.
Despite these advancements, the realization of these refined methods has been accompanied with complicated network structures and the growing number of parameters. The captioning models then may lose controllability and effectiveness. In addition, it has limited ability to adapt the network architectures to other datasets and tasks. To address these above issues, we propose a simple end-to-end image captioning model with extended CNN architecture. In order to improve the accuracy of the CNN model, the widely used method is to deepen or widen the network. However, as the number of hyper-parameters increases (like channel and filter size), the difficulty of network design and computational overhead will also increase. Therefore, we propose an extended CNN structure based on residual learning to obtain rich representations of input images. The learned representations of each image are transmitted into language model to generate sentence.
Overall, the main contributions of this paper are:
We develop a novel encoder–decoder framework to increase the accuracy of predicted sentences for image captioning via focusing on visual features.
We first propose a new multi-branch CNN model based on residual learning for image captioning. The simple design consists of blocks of the same topology, which could improve the effect of feature extraction while reducing complexity and the number of parameters.
Through comprehensive experiments, we validate the effectiveness of our model on three benchmark datasets: Flickr8k [
27], Flickr30k [
28] and MSCOCO [
29]. Our method achieves state-of-the-art performance, showing competitive image captioning results on adopted evaluation metrics.
We perform an extensive analysis of our expanded model, which could be easily used in other tasks because of its modularized architecture.
2. Model
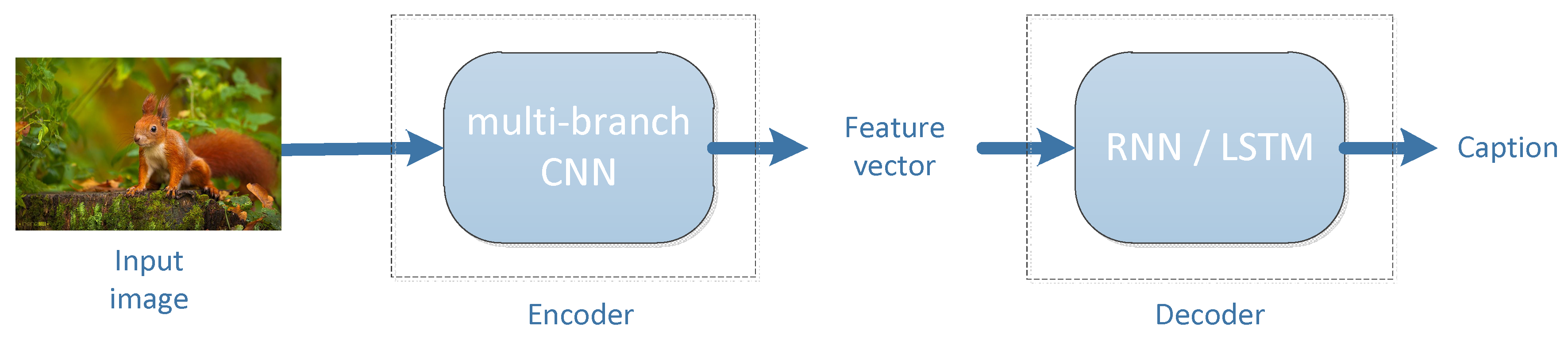
In this paper, we propose a neural framework to generate descriptions from images. Inspired by the encoder–decoder model of machine translation, it is possible to replace the RNN encoding the source text in machine translation with CNN to encode the image, which aims to get a caption of the image.
Figure 1 illustrates the overview of our proposed image captioning model. The extended CNN structure we presented works as the encoder. This multi-branch expansion approach improves the accuracy without increasing the complexity of structure and also reduces the number of hyper-parameters. Then the extracted feature vector from CNN is utilized as an input to the RNN decoder to generate captions. The improved network has a large receptive field that is important for learning the complex relationship of object categories.
2.1. ResNet
Most previous deep convolutional neural networks for image feature extraction are VGG and ResNet. VGGNet explores the relationship between the depth of the convolutional neural network and its performance. By repeatedly stacking small convolution kernels and maximum pooling layers, deep CNNs of 16 to 19 layers are successfully constructed. It is generally believed that the deeper the neural network (more complex, more parameters), the stronger the expressive ability. With this basic principle, the CNN classification network has evolved from the AlexNet of 7-layers to the VGGNet of 16 to 19 layers, even the GoogLeNet of 22 layers. However, we later found that after the depth of deep CNN reached a certain extent, the increase of layers did not lead to further improvement in classification performance. On the contrary, it would cause the network convergence to become slower and the classification accuracy of the test dataset to become worse.
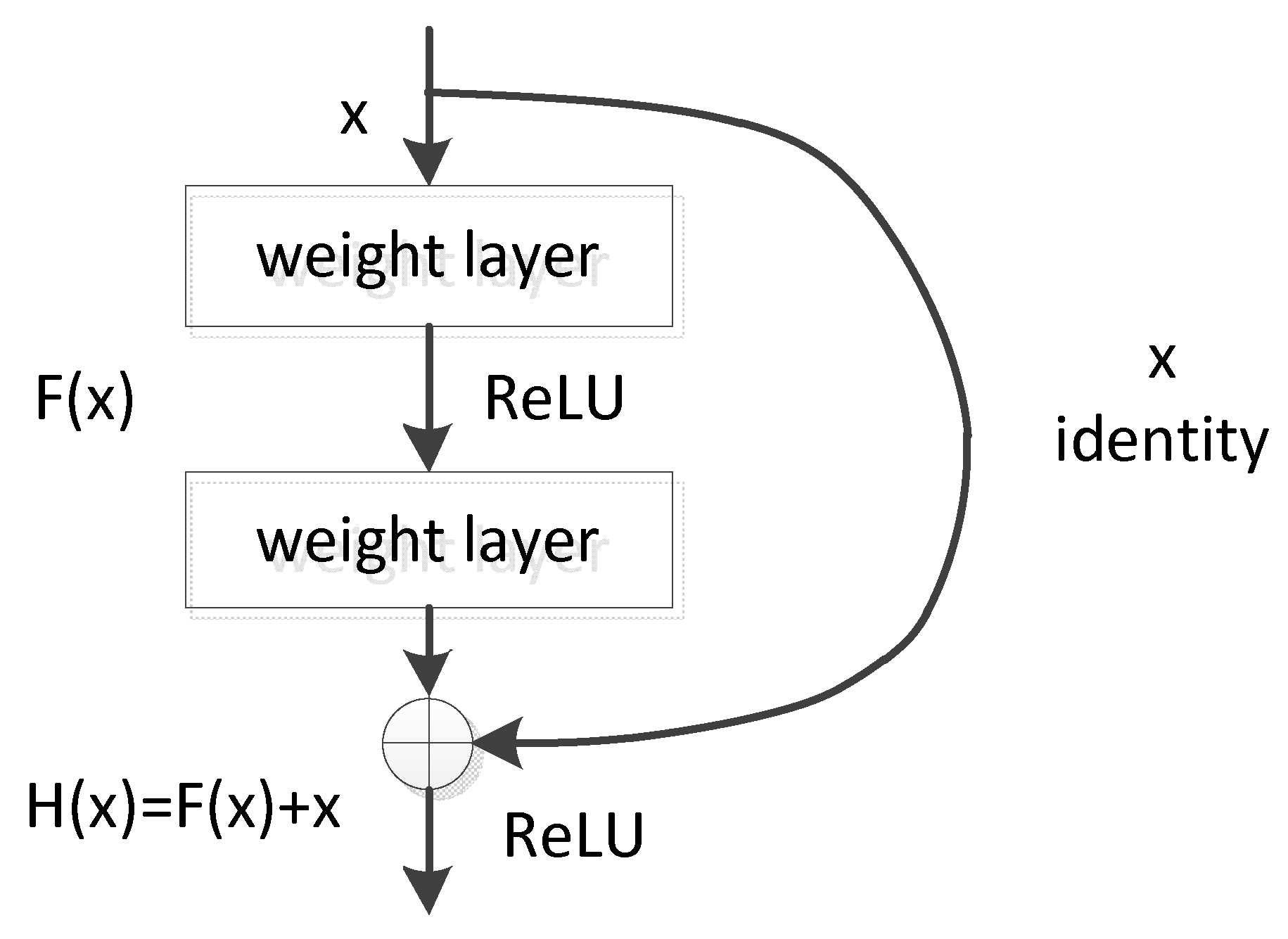
The residual learning of ResNet can solve the problem that the accuracy does not increase but decrease when the network reaches a certain depth. The main idea of ResNet is to add a direct connection channel to the network, which is the core concept of the Highway Network. The previous network structure is a non-linear transformation of the performance inputs, while the Highway Network allows retaining a certain proportion of the output of the previous network layer. The idea of ResNet is very similar to that of the Highway Network, which allows the original input information to be directly transmitted to the later layer, as shown in
Figure 2.
Figure 2 shows the principle of deep residual learning. Denoting a stacked layers network as
, the output of this network block with
as an input will be
. Generally, CNN such as AlexNet or VGG will directly learn the expression of the parameter function
through training, thereby directly learning
. Residual learning is aimed to learn the residual mapping between input and output
. The original mapping H(x) is rewritten into
. Although both forms could approximate the desired functions, it is easier to learn and optimize the residual one.
Traditional convolutional networks or fully connected networks often have the problems of information loss, gradient disappearance and gradient explosion during transmission, which will lead to the deep network unable to train. ResNet solves the problem to a certain extent via bypassing the input information directly to the output to protect the integrity of information. The entire network only needs to learn the difference between the input and output, simplifying the learning objectives and difficulties. The biggest difference between ResNet and VGG is that ResNet has many bypasses that connect the input directly to the back layers. This structure is also called shortcut or skip connection.
2.2. Multi-Branch CNN
In the field of image captioning, the commonly used CNN are VGG and ResNet, which are also widely applied in image classification and image detection. We improved the encoder part of image captioning model by adopting the idea of stacking modules of VGG/ResNet to build a deep neural network. By repeatedly stacking modules of the same topology, we can reduce the selection of hyper-parameters and reduce the risk of over-adapting the hyper-parameters to certain datasets.
In the process of building a neural network, the most straightforward way to improve network performance is to increase the depth and width. Depth refers to the number of layers of the network and width refers to the number of channels per layer. However, these approaches bring some disadvantages: (1) It is prone to overfitting. As the depth and width continue to increase, the parameters that need to be learned are also increasing, and huge parameters are likely to cause overfitting. (2) Simply stacking large convolutional layers consumes a mass of computational resources. (3) It is difficult to optimize the model because the deeper the network is, the easier the gradient disappears.
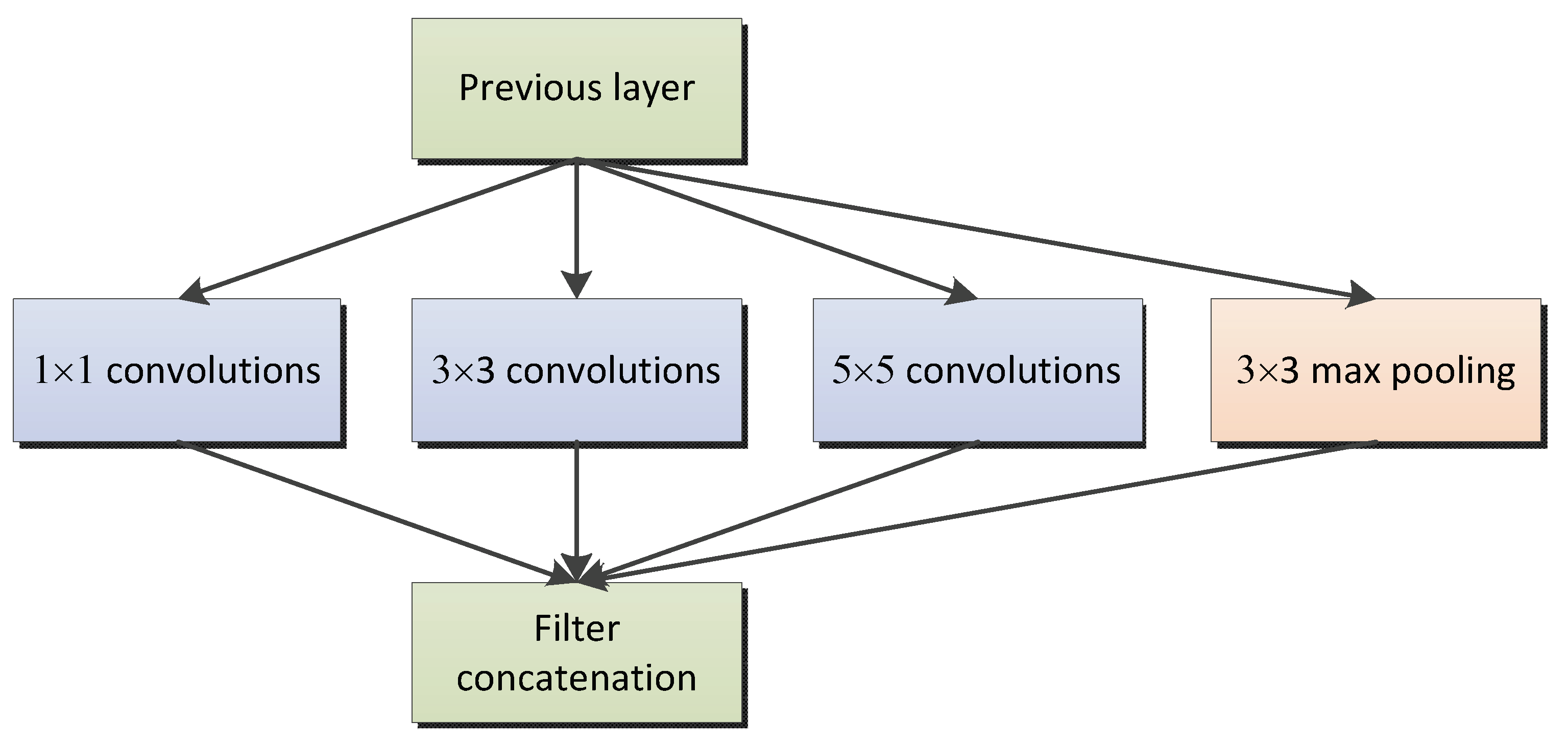
According to [
11], running filters with multiple sizes on the same level makes the network essentially “wider” rather than “deeper.” Unlike traditional convolutional neural networks, the Inception module could set multiple paths. Each path could have different operations and the same operation could also set different kernels, size and stride (see
Figure 3).
The complexity of the Inception architecture makes it difficult to modify and apply to different tasks. If we just simply expand the scale of the structure, the advantages of computing will disappear, and it is difficult to update to new situations while maintaining efficiency.
Therefore, we propose to improve ResNet with the multi-path idea of the Inception network.
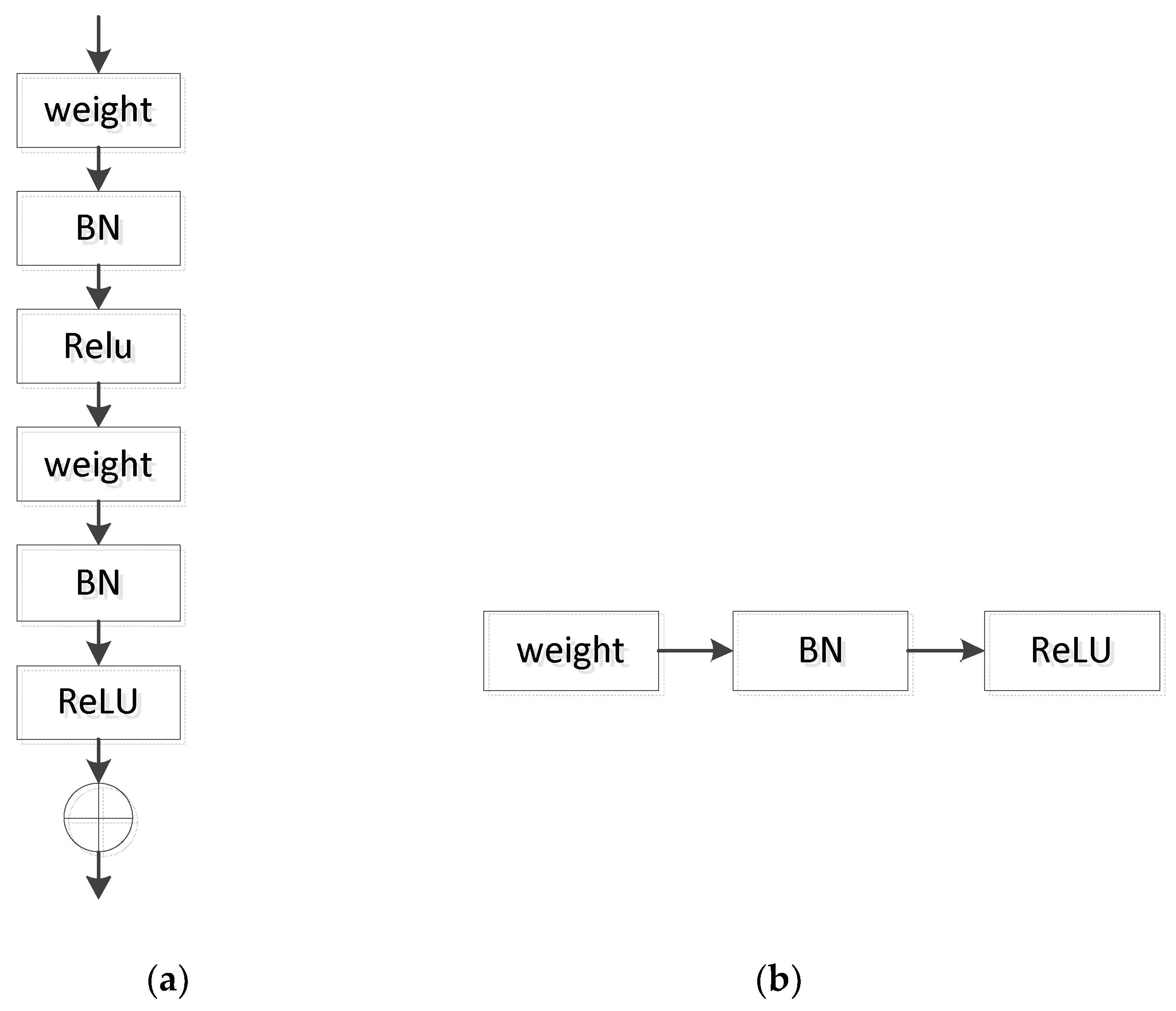
Figure 4a is a residual block in ResNet, in which BN (Batch Normalization) [
30] and ReLU (Rectified Linear Unit) [
31] act as activation functions.
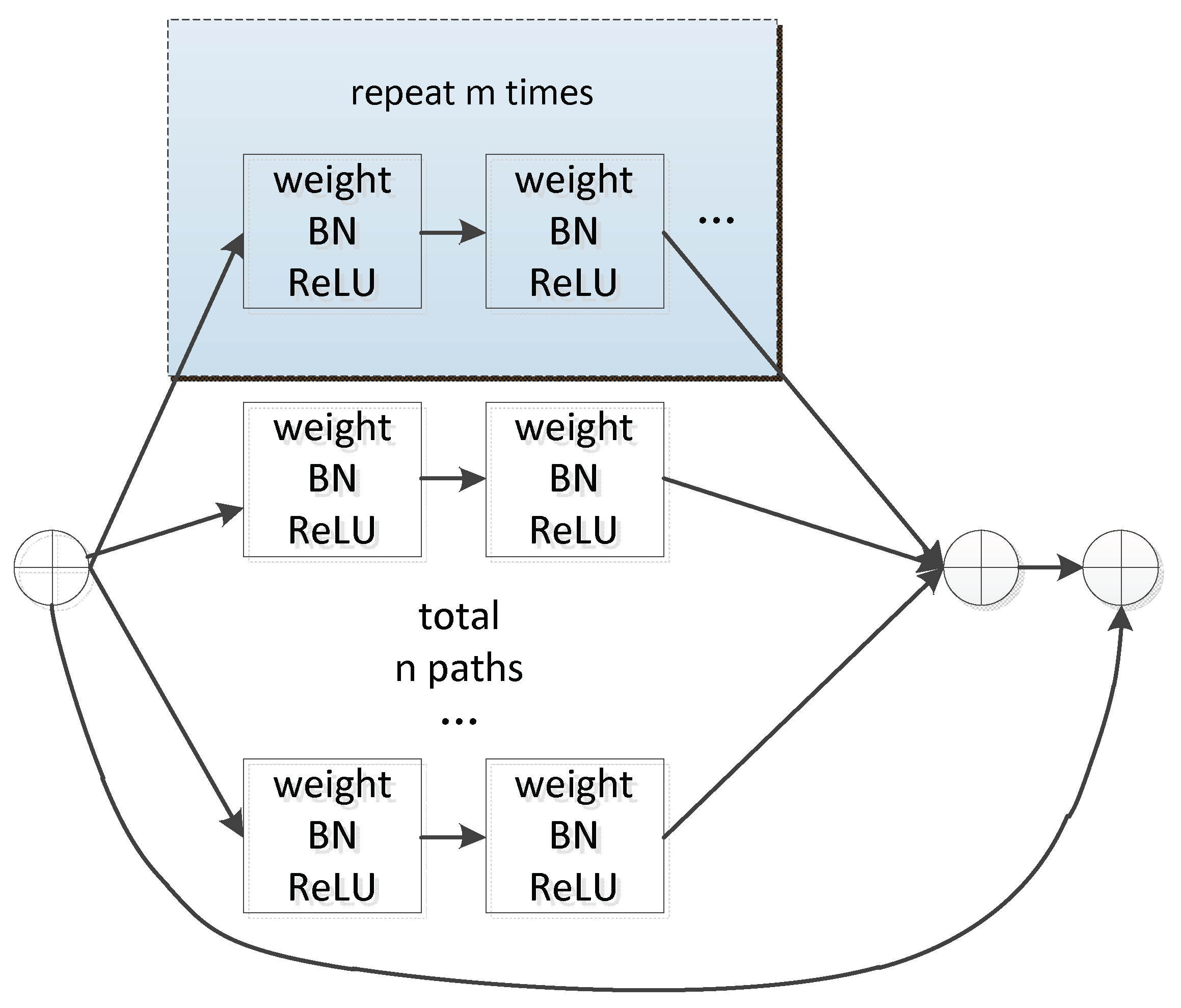
Figure 4b shows a unit in the residual block. We expand the network structure of
Figure 4a by stacking blocks of the same topology in parallel to obtain a new CNN of unit*m_n, as shown in
Figure 5, where m is the number of convolutional layers and n is the number of extended paths. Since the topology of each sub-block is the same, the network structure is more concise and modular while maintaining the network capacity.
The improved ResNet by extending the residual module is shown in
Figure 6. The improved encoder CNN can extract image features through multiple paths, which can reduce the loss of image information of various parts and extract deeper image features.
2.3. LSTM
The recurrent neural network is a mature technology in NLP and plays an important role in machine translation and speech recognition. RNN can adequately mine the semantic information in time-series data and use the previous information to assist the current task [
32]. In RNN, the output at the current time will remain in the network, and the output of the next time will be determined jointly by combining the input at the next time and the output of current time. RNN is as important in deep learning as convolutional neural network.
However, traditional RNN tends to face the challenge of long-term dependencies. The main reason is that RNN shares parameters in time dimension and repeatedly applies the same operation in the long time series. The deepened network structure is easy to have gradient disappearance or gradient explosion in the process of exploiting backpropagation and gradient descent algorithm. Therefore, the gradient cannot be effectively transmitted to the front network layer after multi-layer propagation during the training process, which makes RNN unable to capture the impact of long-distance information.
To overcome the potential issue of vanishing gradient faced by RNN, Hochreiter et al. [
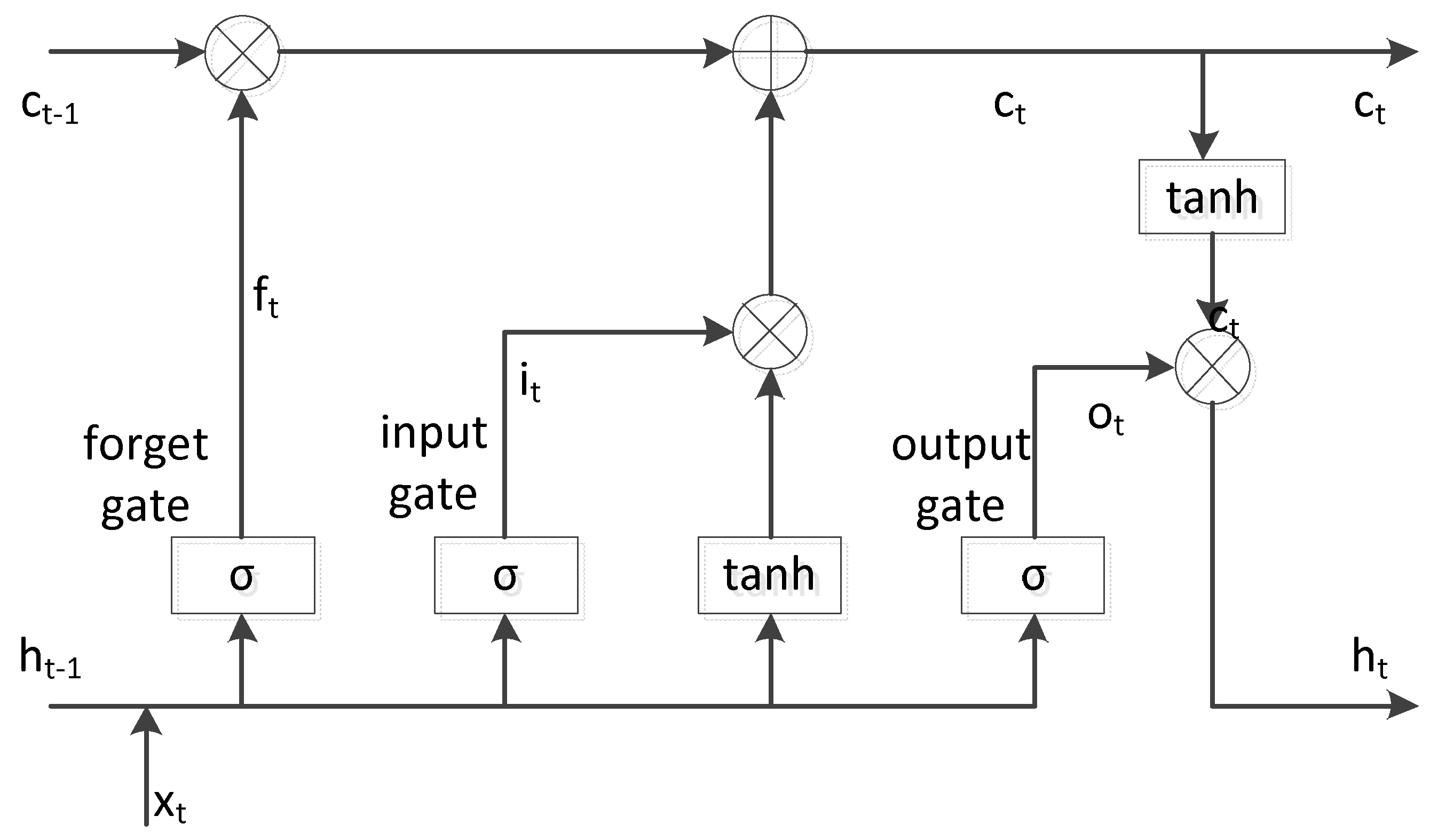
33] improved the RNN with an architecture called Long Short-Term Memory (LSTM). LSTM is a special kind of RNN, which memorizes the information flowing through the network through the memory cell and controls the information updating process through three special “gate” structures. LSTM is easier to learn long-term dependencies than simple recurrent architecture and can effectively capture context information in long sequences. It achieves good application effect in speech recognition, machine translation, image description generation and other application fields. Usually, a recurrent neural network has the form of a chain structure of repeating neural network modules. In ordinary RNN, the repeating modules just simply apply a nonlinear calculation after affine transformation. To replace hidden units in traditional RNN, LSTM introduced well-designed gate units to control information flow. In addition to calculating the hidden state
, LSTM maintains a memory cell state
, which selectively adds, retains or deletes information via gate units. The LSTM structure is shown in
Figure 7.
The calculation formula for each state update and output during the forward propagation of LSTM are as follows:
where
represents the current input vector at time
, and
and
represent the hidden layer states at time
and time
, respectively.
,
,
represent the weight and offset of the input gate and the input gate determines how much of the current input is to enter the memory cell.
,
,
represent the weight and offset of the forget gate and the forget gate controls the network to discard useless information.
,
,
respectively represent the weight and offset of the output gate and the output gate determines the current output based on the current input and the information in the latest memory cell.
represents the sigmoid function, which obtains a probability value between 0 and 1 to control the degree of update of the cell states.
indicates element-wise multiplication.
3. Experiments and Result
3.1. Evaluation Metrics
There is no standard evaluation method in image captioning tasks, yet the generation results can be measured by calculating the correspondence between the reference description and the prediction description. Therefore, we use Bilingual Evaluation Understudy (BLEU, B@1, B@2, B@3, B@4) [
34], Metric for Evaluation of Translation with Explicit Ordering (METEOR) [
35] and Consensus-based Image Description Evaluation (CIDEr) [
36] as evaluation metrics. The three evaluation metrics will be presented in detail below.
• BLEU
BLEU (Bilingual Evaluation Understudy) is a quality score metric developed to evaluate the prediction results of machine translation systems. This evaluation method counts the matching n-grams of the candidate translation and the reference text, where n means the number of ordered words in comparison (1-g compares each word and 2-g compares each word pair). It measures the n-gram correlation between prediction descriptions and reference sentences based on the accuracy analysis. The closer the prediction description and the reference description are, the higher the BLEU score is. In BLEU@N (N = 1, 2, 3, 4), N represents the length of the n-gram. The longer the n-gram, the more difficult it is to match. If only calculate BLEU for N = 1, it is easy to obtain a relatively high evaluation on a description of low quality. Thus, we calculated four levels of BLEU scores in the actual comparison.
• METEOR
METEOR (Metric for Evaluation of Translation with Explicit Ordering) is a more rigorous evaluation metric than BLEU. It is initially used to evaluate machine translation effects and can also be applied to image captioning tasks. METEOR evaluates a description by computing a score based on explicit word-to-word matches between the generated description and a reference sentence. This method obtains the final score by calculating unigram precision and unigram recall, then combining the precision and recall by a harmonic-mean to get Fmean. METEOR can solve the inconsistency problem between the accuracy scores and the generated results of BLEU and has high correlation with human judgments than BLEU. It has greatly improved the correlation with human judgements at the segment level and sentence level.
• CIDEr
CIDEr (Consensus-based Image Description Evaluation) is an automatic evaluation metric that designed specifically for image captioning. It measures the consistency of image captioning by calculating the TF-IDF (Term Frequency-Inverse Document Frequency) weight of each n-gram. CIDEr is a combination of BLEU and vector space models. It treats each sentence as a document and then calculates the average cosine similarity between the candidate sentence and the reference sentence. The advantage of CIDEr is that different n-grams have different weights depending on TF-IDF, because more common n-grams in the entire corpus contain a smaller amount of information. The main evaluation point of image captioning is to see if the model has captured key information, thus it is necessary to reduce the weight of n-grams with less importance.
There are some other evaluation metrics we did not present in our experiments because of some limitations. ROUGE (Recall Oriented Understudy for Gisting Evaluation) [
37] from text summarization tends to reward long sentences with high recall. Unfortunately, it has been shown to correlate weakly with human judgment. SPICE (Semantic Propositional Image Caption Evaluation) [
38] evaluates the similarity of scene graphs constructed from the candidate and reference sentence. It correlates well with human judgments, but fails to capture the syntactic structure of a sentence and it is not widely used in classic image captioning method.
3.2. Datasets
We performed experiments on the following datasets.
Flickr8k, Flickr30k and MSCOCO are classic datasets of image captioning field. The Flickr8k dataset is a popular dataset composed of 8000 images in total collected from Flickr. Each image in the dataset is accompanied with five reference captions annotated by humans. Similar to Flickr8k, the Flickr30k dataset contains 31,000 images collected from Flickr, together with five reference sentences provided by human annotators. MSCOCO contains images of nature and common objects. Images of MSCOCO are in more complicated background with a large number of objects of small size. Each image of MSCOCO2014 has been annotated with five to seven descriptive sentences that are relatively visual and unbiased.
These datasets were divided into a training set, a validation set and a test set, respectively. The statistics of datasets are shown in
Table 1:
In order to avoid overfitting, we explored using a pre-trained encoder CNN on our model. Convolutional neural network requires large-scale label data to train a large number of parameters. The advantages of the convolutional neural network are not reflected well with a small database. In this case, we considered pretraining CNN on the large-scale dataset ImageNet to complete the corresponding tasks. ImageNet is a large-scale visualization database for visual object recognition software research and is widely used in deep learning. The pre-trained CNN on ImageNet has strong generalization ability and can be utilized in many research fields such as image classification, object location and object detection.
3.3. Implementation Details
All the experiments were conducted on a server embedded with NVIDIA RTX 2080Ti GPU and installed with the Ubuntu 16.04 operating system. We first trained the encoder CNN on ImageNet to avoid overfitting. The input image from ImageNet was resized to 224 × 224 randomly according to the scale and aspect ratio augmentation. Down-sampling of conv3, 4, and 5 was implemented by stride-2 convolutions in the 3 × 3 layer of the first block in each stage. Batch normalization was performed right after the convolutions and ReLU was performed right after each BN, except for the output of the block where ReLU was performed after the adding to the shortcut. Gradient descent was an effective approach to optimize the algorithm and minimize the cost of the function. BDG (Batch Gradient Descent) calculates all instances for each iteration to achieve global optimum, but it can take a long time for large amounts of data. Thus, we used SDG (Stochastic Gradient Descent) [
39] with a mini-batch size of 256 for our large-scale dataset. In SDG, a few instances are selected randomly instead of the whole dataset for each iteration, which makes the update and learning much faster. The initial learning rate was set to 0.1. The momentum of the stochastic gradient descent was set to 0.9 and the weight decay was set to 0.001. The weights were initialized as in [
40].
We trained the language model following the work of NIC. For Flickr8k, mini-batch size was set to 16, and for Flickr30k and MSCOCO, mini-batch size was set to 64. The learning rate was initialized with 0.0001 for Flickr8k and Flickr30k and 0.0005 for MSCOCO. The feature vector of the input image extracted from pre-trained CNN was linearly transformed to match the input dimension of LSTM. The dimension of the hidden layer of LSTM was set to 512 and the embedding dimensions of words and images were also set to 512.
We trained all sets of weights using stochastic gradient descent with a fixed learning rate. All weights were randomly initialized except for the CNN weights, which were left unchanged since changing them led to a negative impact. The maximum iteration period was set to 25 epochs. The BN layer was introduced to the decoder part of the model to speed up the convergence of model training. After the loss fell below two and stabilized, we add the CNN part in to train together. The caption generation process was ceased until a predefined max length of generated sentence was reached. Training the model took 70 h total on 2 GPUs.
3.4. Results
We compared the proposed method with state-of-the-art image captioning models. (1) Deep VS [
22], NIC [
20] and m-RNN [
41] are end-to-end multimodal networks that adopt pre-trained CNN like VGG or ResNet as an encoder and RNN as a language model. (2) Soft-attention and hard attention [
24] introduced two alternative attention-based mechanisms to the image caption generator. Soft deterministic attention was trained by standard back-propagation methods and hard stochastic attention was trained by maximizing a variational lower bound. (3) A spatial attention model was able to extract spatial image features and an adaptive attention mechanism [
42] could use visual sentinel instead of a single hidden state to provide a fallback option to the decoder. (4) SCA-CNN [
43] incorporated spatial attention and channel-wise attention in CNN to implement every feature entry in the multi-layer feature maps.
We empirically found our multi-branch model performed better, as illustrated in
Table 2,
Table 3 and
Table 4.
Table 2 shows results on the Flickr8k dataset. In
Table 3, we present the results of the same experiments on Flickr30k Entities, adding spatial and adaptive attention mechanisms for comparison.
Table 4 shows the performance of our method on MSCOCO.
We notice that the proposed method outperformed all compared approaches in terms of evaluation metrics, testifying that we are capable of generating image captions effectively. The outperformance of our method was due to the fact that our advanced CNN architecture extracted image features completely and effectively, which reveals that our model is more efficient to extract complete visual-semantic information.
We provided some qualitative examples in
Figure 8 for a better understanding of our model. The average inference time for each image is about 240 ms for each image. The first three images are successful and the last one shows failure examples. Even in cases where the model produces inaccurate sentences, our generated results focused on reasonable regions of images. For instance, the inaccurate generated sentence of the fourth image may have been due to the deviation of object recognition. At the testing time, we set maximum length of a generated caption to 20 words. The object recognition was influenced by many factors in complicated scenes and images which are difficult to be fully described, which needs to be further improved in future research.
Image captioning is a complex and high-level task. Our proposed multi-branch CNN architecture has a better performance in extracting advanced image features without increasing the depth of the network. However, the feature extraction via CNN still would lose some important information of images. It could not be applied well to some domains that require high precision for image features, such as medical image analysis, which requires the extraction of subtle visual features. Therefore, how to ensure that CNN loses less useful information and discards inferences is the issue we need to study in the next stage.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}