Abstract
Knowledge tracing (KT), which uses machine learning models to predict students’ future performance, has received a lot of attention in intelligence education. However, in Massive Open Online Courses (MOOCs), most of the existing KT methods can only track students’ performance in one course. In addition, when there is scant learning record data on new courses, training a new KT model becomes challenging. Furthermore, existing KT methods tend to excel in specific courses, but their generalization ability is inferior when faced with similar or distinct courses. To address these challenges, this paper proposes a MOOC-oriented cross-course knowledge tracing model (MCKT). In MCKT, we first construct two attribute relationship graphs to obtain the student and KC representations from the source course and the target course, respectively. Then, the element-wise attention mechanism is used to fuse the student representations from both courses. Next, MLPs are used to reconstruct the interaction between students and KCs in each course to enhance students’ cross-course representation. Finally, recurrent neural networks (RNNs) are used to predict the students’ performance in each course. Experiments show that our proposed approach outperforms existing KT methods in predicting students’ performance across diverse MOOCs, proving its effectiveness and superiority.
1. Introduction
The fourth industrial revolution, driven by the integration of intelligent technologies such as the Internet of Things (IoT), big data analytics, and Artificial Intelligence (AI), has transformed the way data is generated and decisions are made in both industrial and societal domains. Machine learning architectures like Transformers have become essential for automating complex analytical tasks. In industrial settings, these models learn from sensor data and operational logs to carry out tasks such as predictive maintenance and quality control. On social media and digital platforms, they process vast amounts of sequential and graph-structured interaction data to drive content recommendations and user behavior modeling. This also provides important analogies and a technical foundation for the field of education, enabling the emergence of knowledge tracing (KT) models. KT models can help intelligent tutoring systems dynamically understand the students’ mastery of knowledge, make timely adjustments to the teaching plans, and recommend relevant teaching resources for students. To study this issue in depth, many efforts have been made to devise various methods of KT. One of the most widely used is deep knowledge tracing (DKT) [1] based on the deep learning method. DKT typically employs long short-term memory networks (LSTMs) to model students’ learning interaction state. DKT converts students’ exercise-answering performance history into a time series to predict students’ answers in the next step and infer their mastery of KCs. On this basis, many deep learning-based KT models, such as CNN-KT [2], Transformer-KT [3], and GNN-KT [4], have also been proposed to improve KT models’ performance.
Although these KT models have proven to be effective, it is still difficult to play to their strengths in Massive Open Online Course (MOOC) scenarios. (i) Single-Course Limitation: The traditional KT models only track the knowledge mastery status of students in a certain course and cannot predict their performance in another course. However, MOOCs include a large number of courses, and it is common in practice for a student to study more than one course at the same time. Figure 1 show four students in course a and four students in course b, where and are enrolled in both courses (referred to as common students in this study). Students learn different KCs in different courses, but most existing KT models cannot capture the performance of a student in different courses.

Figure 1.
Schematic diagram of MOOC user learning.
(ii) Data Scarcity Issue: There is a common problem of scarcity of learning record data in MOOCs [5], which will lead to difficulty in training the KT model of a single course. KT methods rely on large amounts of historical data from students to build models and make accurate predictions. Yet, in MOOCs, especially in newly opened courses or in the educational setting of some schools, learning record data may be very limited or non-existent, making it difficult to apply training KT. (iii) Generalization Difficulty: A course in the MOOCs usually has a long learning cycle and requires students to continuously invest time. As a result, students often want to predict how they will perform on a new course before they start that course in order to make better decisions about whether to start learning or how to plan for it. Nevertheless, the existing KT models only focus on one course, lack generalization ability, and cannot be used to predict the performance of students in the new course. (iv) Lack of Video Interaction Mapping: In addition, most of the courses in MOOCs contain many instructional videos, and the task of answering questions after watching the videos is not mandatory. However, most of the existing KT models map the level of mastery of KCs based on the results of students answering exercises. Due to the lack of a method to map the mastery level of KCs according to students’ video browsing behavior, the existing KT models cannot be widely used in MOOCs. These limitations hinder the realization of robust, automated learner modeling in MOOCs—a context characterized by massive scale and data-rich interactions where such technology should offer significant value.
To overcome these hurdles and advance towards truly adaptive MOOC platforms, we propose a transfer learning-based MOOC cross-course knowledge tracing method, namely MCKT, to predict students’ learning performance in the next step of a different course. The framework of MCKT can be divided into three parts, i.e., data pre-processing, pre-training, and prediction. In the part of data pre-processing, we extract the sequence of students’ interaction with knowledge concepts (KCs) based on the interaction records between students and items (e.g., exercises and videos) in the MOOC dataset; this approach follows the classic way of dealing with knowledge tracing datasets. In the part of pre-training, two graph structures are used: (i) we use the skip-gram algorithm to obtain the initial student representation in the structure of the attribute relationship graph (ARG); (ii) we use element-wise attention and a multi-layer perception (MLP) to reconstruct the interaction relationship between the students and KCs in the Interaction Relationship Graph (IRG) structure after the cross-course method. By using the above two graph structures in the pre-training, the students’ representations not only combine the similarity of students’ attributes in the source course and the target course, but also combine their relationship with KCs in the source course. In the prediction phase, the RNNs are used to model the results of the interaction between students and KCs and predict students’ mastery of the next KC in both the source and target courses.
In summary, the contributions of this study are threefold:
- This paper proposes a MOOC-oriented cross-course KT method based on transfer learning, which predicts the status of the next stage of students’ learning in the different MOOCs with unbalanced learning records.
- This paper proposes a method to evaluate the mastery of KCs by using the information of video viewing in MOOCs so that the KT model can be applied to video viewing behavior, not only to answer exercises.
- This paper reports on the extensive experiments that were conducted in six scenarios based on two real MOOC datasets. The experiments verify that the proposed model is more effective than the existing KT methods in cross-course KT tasks.
The rest of this paper is organized as follows. Section 2 briefly reviews the related work. Section 3 introduce the problem statement. Section 4 describes the framework and the implementation of the proposed approach in detail. Extensive experimental studies to validate the effectiveness of our model and several research questions are addressed in Section 5. Section 6 concludes this work, analyzes this study’s limitations, and proposes future research directions.
2. Related Work
2.1. Knowledge Tracing
The term knowledge tracing was introduced by [6]. In a study period, the teacher can estimate the probability of the students mastering each KC. Based on the estimated probability, the teacher can propose a personalized sequence of exercises to students until they master all the KCs. In the original KT model, the probability estimation of students’ learning performance adopted the Bayesian probability formula, called Bayesian Knowledge Tracing (BKT). Lin et al. proposed the intervention-BKT model by adding intervention nodes to the original BKT model [7]. In [1], Piech et al. proposed a knowledge tracing model based on RNNs, named deep knowledge tracing (DKT). Using records of the exercises answered, the model learns to predict the probability that a student can correctly answer subsequent exercises. DKT adopts LSTM, a variant of RNNs, to perform prediction tasks, as LSTM has a good effect on sequence-based prediction. The advantage of the DKT model has been verified on other datasets, in classic programming courses [8], and in courses studied by watching videos [9]. DKT summarizes a student’s mastery level of all concepts by one hidden state, making it difficult to trace to what degree a student has mastered a certain concept. To address this issue, Zhang et al. proposed dynamic key–value memory networks (DKVMNs), which can accurately indicate the mastery state of each concept [10]. The DKVMN initializes a static matrix called key, which stores the concepts, and a dynamic matrix called value, which stores and updates the corresponding concepts’ mastery through reading and writing operations. In order to improve the interpretability, a Markov blanket-based KT model was proposed by [11], which applied interpretable machine learning techniques in a KT task.
2.2. Cross-Domain Prediction
In the field of cross-domain prediction, researchers have proposed a series of methods to solve the transfer learning problem between different domains. The existing cross-domain prediction algorithms can be divided into three categories according to the different deep transfer learning techniques: (i) Cross-domain prediction algorithms based on feature mapping can align features between the source and target domains, thereby enabling the transfer of knowledge from the source to the target domain. In this process, attention-based mechanisms are often employed to capture complex relationships among data [12]. (ii) Cross-domain prediction algorithms based on instance transfer improve the existing results or models in the transfer learning pre-trained network as a whole and weight the features of different domains to break the data sparsity effect of cross-domain prediction. (iii) The third category is cross-domain prediction algorithms based on adversarial transfer based on generative adversarial networks (GANs). This method is integrated into the cross-domain prediction problem to solve the feature domain adaptation problem. Cross-domain prediction technology has applications in various fields, such as medical services, network security, and semantic feature processing. However, in the field of education data mining, the research in cross-course personalized learning recommendation is still in its early stage. Although some progress has been made in cross-domain prediction, most existing methods only focus on transfer learning between discrete domains, ignoring transfer learning between continuous-time domains.
Recently, researchers have begun to focus on how to use the knowledge gained in one subject area by transfer learning to complement and improve the learning process in other areas. To solve the problems of domain-specific limitations and data sparsity in the current KT methods [13]. Cheng et al. proposed a three-step adaptive KT model [14], which introduced the maximum mean discrepancy (MMD), where the difference in data distribution between different domains is narrowed to achieve the effective use of knowledge between domains. However, MMD is sensitive to parameters and requires a large amount of target domain data for effective domain adaptation, and the adaptability of the model may be limited if the target domain data is extremely scarce [15]. To solve the problem of knowledge distribution bias between different courses, Huang et al. proposed a STAN framework [16], which aligned the difficulty distribution of the two domains using conditional adversarial learning and difficulty-based sampling methods. However, the embedding mechanism of these methods mainly relies on serialized coding and fails to consider the graph topology information implied by the course KCs or common students as middle-layer embeddings.
3. Problem Statement
In this section, we first review the definition of knowledge tracing. Then, we introduce the graph structure used to represent the relationships between the students and items in the MOOC. Finally, we explain the cross-course knowledge tracing in MOOC scenarios. Some important notations are listed in Table 1, and we present a more detailed explanation of their role in the context.

Table 1.
Some important notations.
Knowledge Tracing. Given the sequence of students’ learning interactions in online learning systems, knowledge tracing aims to monitor students’ changing knowledge states during the learning process and accurately predict their performance on the next items. Formally, in an intelligent education system, suppose the number of students, items, and KCs are denoted as , , and , respectively. For a student , the sequence of items (e.g., video or exercise) with which the student interacted is recorded, denoted as , where is the item that appeared at time step and indicates the corresponding score. For instance, if the answer of the exercise is correct, is 1 (or tick); otherwise, is 0 (or cross). Knowledge tracing can be formulated as follows:
where, denotes the probability of correctly answering. Interaction Relationship Graph. In the process of viewing videos or answering exercises during the course learning, there are heterogeneous relationships among students, items, and KCs [17,18]. An Interaction Relationship Graph (IRG) is denoted as , consisting of an object set and a link set . is a set of object types (e.g., student, item, or KC). is a set of relation types, and , where represents the relation interact and represents the relation contains.
As shown in Figure 1, for the IRG of course a, views the video and . requires KCs and . requires KC . From the figure, we can observe that there is a relationship between and through , and there is also a relationship between and through . The reason is that views both videos during her learning process. In the KT task, the prediction of KC mastery is more general, so in this work, the IRG is used to model the relationship between students and KCs in a MOOC.
Cross-Course Knowledge Tracing. Students often enroll in more than one course in MOOCs. As shown in Figure 1, suppose there are two courses a and b, denoted by and , where and represent students who have taken both course a and course b (i.e., Kate and Tom, referred to as ‘common students’). represents the distinct students in course a (i.e., John and Mary), and represents the distinct students in course b (i.e., James and Jone). Students enrolled in different courses are referred to as ‘distinct students’ in this paper. and represent the set of items of and separately. I signifies the set of interactions. Given the respective interaction records in these two courses, the goal of the cross-course knowledge tracing is to predict students’ mastery level of knowledge in b/a courses using the interaction data observed by a student in the a/b course.
Given a sequence of learning resources items of the course a, if student s has learned on , and the interaction recording is denoted by , then the probability of the knowledge mastery of this student on the course b is calculated as
where represents the probability of answering correctly, which usually also reflects the mastery level of student s on the corresponding KC of the course b at the next time step, and the closer its value is to 1, the higher the student’s mastery level.
4. Proposed Approach
To address the problem introduced in Section 1, this paper proposes a novel KT method for cross-course student performance prediction in MOOCs, namely MCKT. As shown in Figure 2, the framework of MCKT is divided into the three modules, i.e., the Course graph construction module, the Cross-course embedding combination module , and the Knowledge performance prediction module. At the beginning, we extract data from the MOOC dataset that can be used for cross-course KT, including students, items, the text of KCs, the KCs contained in the items, and the results of students’ interaction with the items. Then, we calculate the similarity of the textual information of students, projects, and KCs in two courses (e.g., and ) to form an attribute relationship graph (ARG). Next, an attention mechanism and the MLP are employed in the Cross-course embedding combination module to generate the cross-course fusion representations of the common students, which is combined with the features from courses a and b. Finally, all students’ representations and the interaction results are sent to the Knowledge performance prediction module to predict students’ performance.
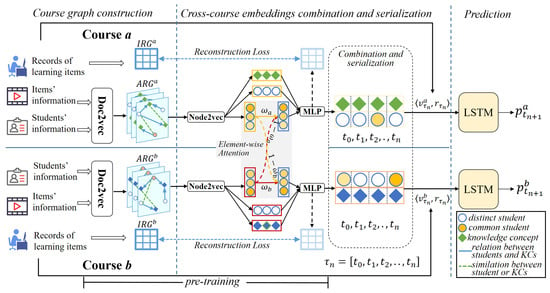
Figure 2.
The framework of MCKT taking course a and course b as examples. The and are constructed by pre-processing the dataset, and the representations of the students and KCs are obtained. Then the representations of the cross-course common students and distinct students are obtained by pre-training. Next, the cross-course representations of the students and KCs from time to are input into the prediction layer to predict the knowledge state at the step.
4.1. Data Pre-Processing
In reality, some MOOC platforms provide exercises or tasks containing KCs for the courses, such as MOOPer, which has many online exercises for each course. However, to increase utilization [5], some MOOC platforms provide learning videos that contain KCs, such as MOOC-Cube, and do not necessarily provide online exercises for all courses, nor do they force students to answer online exercises. Video-watching sequences (e.g., play, pause, fast-forward, and replay) exhibit temporal patterns that have been shown in prior research [19,20] to correlate with learning attention and self-regulation (e.g., studies on clickstream analysis for engagement inference). Therefore, converting these sequences into simulated knowledge states provides a plausible, data-driven approximation. Based on this assumption, for courses that provide only video-watching logs but no exercise response records, we follow the method described in Reference [9], which uses the processed video-watching log data as the input data.
The first step involves consolidating information from the students watching the video. The initial representation of a student is constructed from five kinds of data, i.e., the learned courses C; the learned videos V; the number of times a student watched a learned video m; the duration of each learned video l; and the average duration that the s-th student spent on each learned video . We consider that the student’s mastery level of each KC is determined by the ratio of the average duration of the corresponding video learned by them to the total duration of the video. The process of obtaining the result of the interaction is formalized as
where represents the result of the student’s interaction with video v.
In the second step, the student’s ID, the learned video’s ID, and the mastery probability of the KC in the learned video (each video contains one KC) are combined into a triplet I to form a sequence of the student’s interaction–response to the video:
where represents an interaction between the student and video v at time t.
The third step is to generate two specific representations of each student. One reflects the student’s association with the learning videos (or other items, such as exercises), denoted by ,
where is the initial data for the IRG, which is used to further generate cross-course representations in the Cross-course embedding combination module. And the other reflects the KCs and state time series of the learning interaction, which is denoted by ,
where is employed to further model the student’s mastery of KCs in the Knowledge performance prediction module.
4.2. Course Graph Construction
In this module, a weighted attribute relationship graph (ARG) for each course is formed. is input to this module. The similarity of the text representation vectors is calculated to generate edge weights between corresponding nodes. The text representations of students and KCs are derived using Doc2Vec [21] from their respective textual attributes: student ID, name, and enrolled courses for students and KC ID and textual description for knowledge components. The pairwise similarities among these resulting embedding vectors are then used to construct the weighted edges of the ARG connecting students to students, students to KCs, and KCs to KCs. The text representations’ similarities are formalized as the following Equations (7)–(9).
where s denotes the student node, k represents the KC node, are the constant coefficient matrices, and represents the relationship weight between nodes. represents the cosine similarity. Through the above steps, a weighted ARG is created for each course.
Then, the Node2vec [22] module is employed to generate the node embeddings of these two ARGs. The embedding of a node is denoted by . The Node2vec module adopts the principle of similarity of adjacent nodes, uses the central node to predict the context node, and obtains the embedding of the target node after continuous iterative optimization. Node2Vec uses the skip-gram model to learn the embedding representation of the node. The goal of the skip-gram model is to predict the node itself based on its context. The optimization objective of Node2vec is
where f is a function that maps each node u to a d-dimensional space vector, e.g., . u is the current node, is the neighbor node of the u node obtained through the paths of the ARGs, and . Stochastic gradient descent is used to optimize .
4.3. Cross-Course Embedding Combination
Considering that students are the subjects of cross-course learning behaviors and the importance of users in information systems [23], we propose to leverage the representation of students who have taken both the source and target courses as a transferable ’bridge’. Specifically, these overlapping students’ behavioral patterns in both courses are modeled and fused to establish a shared latent space, enabling knowledge transfer for new students in the target course based on their similarity to these bridge students in the source course. The representation of students in two different courses (take course a and course b as examples) are the embeddings of the student nodes in two ARGs. The task of this module is to generate the cross-course representations of students shared by course a and course b. In this module, the comment students’ representations are generated through element-wise attention [24]. Consequently, it attains high expressivity with neuron-level degrees of freedom [25]. We denote the representations of student in course a by ; we denote the representations of student in course b by . The process of cross-course feature combination is shown in the middle part of Figure 2.
The cross-course representations of students must be further processed before sequence modeling can be performed. The element-wise attention mechanism combines the common students’ embedding representations in courses a and b, and then a matrix multiplication calculation is performed on these cross-course representations. Specifically, the representation of common students in courses a and b can be expressed as follows:
where ⊙ indicates element multiplication and and are, respectively, the weight matrices of courses a and b in the element-wise attention mechanism. For distinct students and items in different courses, we only keep their embeddings and do not use the attention mechanism because they do not have double embeddings in courses a and b.
We then used two MLPs to reconstruct the non-linear relationship between students and items. We denote the representations of two kinds of students in course a i.e., , by and denote items in course a by . Then, and are input to the neural node; the result is and following Equations (13)–(16),
where is the activation function ReLU and are the learnable weights of each layer of the MLP of the student and items, respectively. The label ⊙ denotes element-wise multiplication. We use a cross-entropy loss to reconstruct the relationship between students and items, following Equations (17) and (18):
where is the predicted interaction in course a, is the activation function sigmoid, and is the inner product. is an observed interaction in course a. By this way, we can also obtain the same kind of loss in course b. The algorithm of the student cross-course representation generation is shown in Algorithm 1.
| Algorithm 1 Algorithm of the student cross-course representation generation |
Input: The s of two courses and ; The weight matrix of the course a and b in the element-wise attention mechanism and . is a termination condition. Output: Two sets of representations of students used for prediction layer. |
4.4. Knowledge Performance Prediction
In this module, an LSTM model is utilized to model students’ behavior and response sequences when learning items. Specifically, the cross-domain representations of students and KCs generated by using Algorithm 1 are integrated into to form the sequence of the learning interaction (e.g., performing exercises or watching videos) and responses containing cross-course information. Here, each student’s learning interaction records and student representations are individually spliced to form the input data. These input data are fed into the LSTM model, which predicts the student’s knowledge state at the next step. The variables are related using a simple network defined by the equations
where is the activation function . is the input weight matrix, is the loop weight matrix, is the initial state, and is the output weight matrix. and are latent bias and output bias, respectively.
We denote the actual performance of the i-th student on the j-th KC by , while the learning interaction results are obtained by Equation (3). We train the model with two strategies based on two types of label values. The first strategy is to treat as a continuous value; i.e.,
where is the normalization operation.
The other is to set to a binary value of 0 or 1; that is,
where denotes the threshold used to divide the mastery of KCs. The loss functions of these two strategies are both defined as the cross-entropy of the prediction performance p and the real one r; i.e.,
Remark: The task of transfer learning is to transfer the model from the source domain to the target domain. However, in our research scenario, a course serves as both the target and source course. In each round of iterative training, we use the two courses in the experiment as source courses for cross-training. In this way, the model we train will consist of two sub-models, each capable of performing two-way cross-domain functions.
5. Experiments
In this section, we first provide detailed information about the dataset and experiment setup. This section then provides details of the extensive experiments that were conducted across six cross-course scenarios and the in-depth analyses. Additionally, to provide a clearer understanding of the model, we address the following key research questions in the subsequent sections:
RQ1: Is MCKT more effective than existing KT models in terms of cross-course knowledge performance prediction or not?
RQ2: What impact do the constituent modules of MCKT have on its performance?
RQ3: How effective is MCKT in predicting similar or non-similar courses?
RQ4: Can MCKT predict a student’s performance in another course?
RQ5: Is there is a difference in the representation of common students and distinct students?
5.1. Overview of Datasets
Our experiments are performed on two classic MOOC platforms that contain multiple courses, i.e., MOOPer [26] and MOOC-Cube [27]. MOOPer extracts the interactive data on users’ participation in practical exercises on the EduCoder platform from 2018 to 2019 and models the attribute information of courses, practices, levels, and KCs and the interrelationships between them in a knowledge graph to construct a large-scale practice-oriented online learning dataset. MOOC-Cube is an open large-scale data repository for natural language processing, knowledge graphs, data mining, and other research areas concerned with massive open online courses. It comprises 706 MOOCs, 38,181 videos, 114,563 KCs, and 199,199 real MOOC users. This data source also contains a large-scale concept graph and related academic papers as additional resources for further utilization. We selected student video interaction data, students’ personal characteristics text, videos, and their corresponding courses’ KCs and KCs’ text. The student video interaction data includes video ID, student ID, the number of times students watch the video, the video duration, and the average length of time students watch the video, and the student’s personal characteristics text encompasses the name of the student, the title of the course, etc.; the KC’s text relates to its name and information summary.
To analyze the effect of the proposed method on courses in the same discipline and interdisciplinary courses, we select part of the course data from MOOPer and MOOC-Cube based on the discipline division to form three experiment datasets.
- Dataset I—All belong to the same disciplineCourse A comes from MOOPer’s course “C/C++ programming”. We randomly selected 20,500 interactive data items for it, including 1224 students and 26 KCs.Course B comes from MOOPer’s course “Data Structures & Algorithms (C/C++)”. We randomly selected 55,578 interactive data items for it, including 2925 students and 134 KCs.Course C comes from MOOPer’s course “Introduction to Artificial Intelligence”. We randomly selected 12,048 interactive data items for it, including 679 students and 91 KCs.
- Dataset II—From basic sciences to social sciencesCourse a comes from the MOOC-Cube course “College Physics—Mechanics and Thermal”. We randomly selected 68,131 interactive data items for it, including 5459 students and 36 KCs;Course b comes from the MOOC-Cube course “College Physics—Vibration, Waves and Optics”. We randomly selected 7350 interactive data items for it, including 516 students and 36 KCs.Course c comes from the MOOC-Cube course “Exhibition Planning and Management”. We randomly selected 103,973 interactive data items for it, including 16,256 students, and 119 KCs.
- Dataset III—From social sciences to basic sciencesCourse x comes from the MOOC-Cube course “History as a Mirror” (Chineses name is “Zi Zhi Tong Jian”). We randomly selected 94,807 interactive data items for it, including 4138 students and 56 KCs.Course y comes from the MOOC-Cube course “Rise and Fall of the Tang Dynasty”. We randomly selected 23,110 interactive data items for it, including 1230 students and 47 KCs.Course z comes from the MOOC-Cube course “College Physics-Electromagnetism”. We randomly selected 18,422 interactive data items for it, including 969 students and 85 KCs.
Table 2 provides a summary of the experimental datasets.
Table 2.
Summary of the experiment datasets.
The symbol course A → course B indicates that course A is the source course and course B is the target course. In a cross-course scenario, three courses (course A, B, and C) are divided into two scenarios for the experiment. Each scenario consists of two courses, which alternate as the source and target courses, denoted by ↔. In this way, the three datasets are pre-processed into six cross-course scenarios, .i.e.,
- Scenario1: Course A ↔ Course B;
- Scenario2: Course A ↔ Course C;
- Scenario3: Course a ↔ Course b;
- Scenario4: Course a ↔ Course c;
- Scenario5: Course x ↔ Course y;
- Scenario6: Course x ↔ Course z.
Table 3 provides a detailed overview of these six cross-course KT scenarios along with the corresponding dataset information.
Table 3.
Statistics of six cross-course KT scenarios.
5.2. Experiment Setup
We obtain using Equation (5), which is used to further generate cross-course representations, and obtain from Equation (6), which is used to input the LSTM for modeling the students’ mastery of the KCs. Furthermore, we obtain the data of the common students in the two courses. In the Course graph construction module, the Stanford CoreNLP [28] is used to compress the text information; when constructing the HGC of the courses, we set the sampling probability parameter to 0.05, and the values of the students’ mastery of KCs are all mapped to [0,1].
In the Cross-course embedding combination module, the length of the students’ representation vector is set to 8, 16, 32, 64, and 128, as a comparative experiment. The learning rate of the cross-domain training is set to 0.001, and the training batch size is set to 32. When splicing the training data, we utilize 70% of the distinct students in the source course and the common students in both the source course and target course as the training set, and the remaining 30% of the distinct students in the source course are used as the test set.
In the Knowledge performance prediction module, the max size of the parameter is set to 200. The learning rate is set to 0.001, and the training batch size is set to 8. The dimension of the hidden layer of the model can be either 100 or 50, and the number of hidden layers can be either 1 or 2. Suppose the number of KCs contained in the course corresponding to the model is n and the length of the student representation vector is m; then the dimension of the input data is , and the output one is n. The training adopts the Adam optimizer.
5.3. Baseline Methods
As far as we know, most existing KT models lack cross-domain capabilities. To better demonstrate the effectiveness of MCKT, we selected four mainstream KT models from recent years as baselines and made them have cross-domain capabilities through some methods. The specific introductions of the baselines are as follows:
- Original: After training on the source course data, the model is directly applied to the target course for prediction without cross-domain training. We select the best result for all baseline models to ensure a fair comparison.
- DKT [1]: This is a knowledge tracing model based on an RNN that uses students’ historical answer sequences as input to predict students’ answer results at each time step in the future.
- DKVMN [10]: This is a knowledge tracing model based on memory networks that employs a memory matrix to store students’ knowledge status and uses an attention mechanism to dynamically update and retrieve information in the memory matrix.
- FGKT [29]: This is a knowledge tracing model based on matrix factorization, which decomposes the student’s answer result matrix into a student ability matrix and a KC difficulty matrix to infer the student’s knowledge status.
- CKT [2]: This is an improvement on the DKT model, which uses a KC correlation matrix to model the relationship between students’ answer results and KCs, thereby more accurately predicting students’ knowledge status.
- SGKT [18]: This is a knowledge tracing model based on the session graph and relationship graph, where the session graph is used to model the students’ answering process and the relationship graph is used to model the relationship between the exercises and KCs.
- DDTCD-KT [30]: DDTCDR is a cross-domain recommendation model that uses latent orthogonal mapping to extract users’ preferences in multiple domains and retain the relationship between users in different latent spaces and combines the autoencoder method to extract the latent essence of feature information. We adapt it to the knowledge tracing task using a target-value mapping transformation (i.e., matching the user’s rating of the items to the right or wrong values of the student’s answers to the exercises) and name it DDTCD-KT.
We use the experiment settings in AdaptKT, which adds fine-tuning operations to each baseline model, endowing them with certain cross-domain capabilities. Therefore, in our experiment, the learning record data of the common students in the two courses is added to the training data of each baseline model to achieve the cross-course function of knowledge tracing. Furthermore, our model also incorporates student representations obtained from cross-course training, while other baseline models do not.
5.4. Evaluation Metrics
In the knowledge tracing dataset, 1 or 0 is usually used to indicate whether a student answered an exercise correctly or not. However, watching videos is the most common learning behavior for course learning in MOOCs. In view of this, we calculate the students’ performance on KCs based on the interactive indicator records of the students watching the videos in scenarios 3–6; and in scenarios 1–2, the students’ performance on KCs is still represented by their correct or incorrect answers to the exercises. In the experiments comparing the baseline models, to maintain the consistency of the evaluation indicators and data format, we still use 0 or 1 to indicate whether students have mastered KCs or not.
In subsequent ablation experiments and self-control experiments, we used probability to indicate the students’ performance on KCs and adjusted the evaluation indicators accordingly. For the case of using 0 and 1, we use AUC, F1, recall, and precision as the evaluation indicators. AUC is used to measure the performance of the classifier, where the closer the value is to 1, the better the performance. The F1 score comprehensively considers the precision rate and recall rate, where the closer the value is to 1, the better the overall performance is. Recall measures the number of positive examples correctly predicted by the model as a proportion of all true positive examples. Precision measures the proportion of the number of positive examples that were correctly predicted by the model out of all the samples predicted as positive examples.
When using probability values, we adopt MAE, RMSE, and R-squared as the evaluation indicators. MAE represents the average absolute difference between the predicted value and the actual value, with a smaller value indicating a lower prediction error; RMSE represents the square root of the mean square error between the predicted value and the true value, where the smaller the value, the smaller the prediction error; and R-squared measures the degree to which the model explains the dependent variable, with a value ranging from 0 to 1, where the closer the value is to 1, the stronger the explanatory power.
5.5. Performance Comparison Experiment (RQ1)
The results of the performance comparison experiments on the six scenarios are shown in Table 4, Table 5 and Table 6. The original model performs worst because it does not perform any cross-course transfer operations. Moreover, the model trained from the source course did not play a positive role in the target course, with an AUC of about 0.5, which is close to random estimation. After adding the alternating training operation using some of the source course students’ data and the common students’ data, the AUC of +co models exceeds 0.65, with the best results of the +co models underlined. However, the AUC of DDTCD-KT and the proposed MCKT are near or over 0.75, and the other performance indicators have improved too. These results also prove that the method of alternating training with rich training set content can enhance the effect of cross-course knowledge tracing.
Table 4.
Comparison of the results for scenarios 1 and 2.
Table 5.
Comparison of the results for scenarios 3 and 4.
Table 6.
Comparison of the results for scenarios 5 and 6.
5.6. Ablation Study (RQ2)
The Course graph construction and the Cross-course embedding combination are two core modules of the proposed approach, where the use of students’ cross-course representations (ccrs) and the use of common students’ data to train the prediction layer (cst) are two important parts. The ablation study evaluates the utility of these two parts. In particular, ablation studies were conducted on the cross-course representation of students and the effectiveness of training using data from the common students. They consist of the following three variants:
- MCKT-ori Removing students’ cross-course representations, and the prediction module is not trained by using the learning record data of common students.
- MCKT-cst Removing learning record data from common students’ data when training the prediction module.
- MCKT-ccr Removing students’ cross-course representations.
Removing student representations after cross-domain training. In the results in Table 7, Table 8 and Table 9, we remove the original spliced student representations and only use the data of students watching videos for training, and the AUC is about 68%. Although this is not as good as the training effect of the complete model, it is still slightly higher than DKT, CKT, FGKT, and DKVMN after adding alternate training operations. This is attributed to MCKT-cst’s continued utilization of the number of times students watch videos as auxiliary training data, which proves, from the perspective of the knowledge tracing effect, that the splicing of the number of times students watch videos has a positive effect on the performance of this knowledge tracing model.
Table 7.
Ablation results for scenarios 1–2.
Table 8.
Ablation results for scenarios 3–4.
Table 9.
Ablation results for scenarios 5–6.
Remove learning data training of common students in the source course. Judging by the results in Table 7, Table 8 and Table 9, if the step of alternating training using common student data is removed, the accuracy reduces to only about 61%. The performance of this model in cross-course transfer is even worse than that of DKT, CKT, FGKT, and DKT, which have additional alternate training steps. DKVMN is only slightly better than the original model in cross-course transfer. This is because the baseline model that adds alternate training does not have a complete student representation vector, but it also learns certain characteristics of the target course through co-students, while the model that removes the alternate training step, although it has a complete student representation, still has the training data limited to a single course, which does not allow it to learn any features of the target course. Therefore, when the model is transferred to the target course, the features learned in the source course are not well utilized.
5.7. Impact of Course Similarity on Model Performance (RQ3)
From the results of the ablation study, we know that if the transfer training step is removed, the model will not perform well for cross-course transfers due to the lack of data from the common students. To test the effect of the similarity of course content on the transfer performance of the model, we carry out related experiments on dataset I, which includes course A, course B, and course C from MOOPer. Course A and course B are both programming courses, and the content is very similar. Course C is an introductory course and its content is significantly different from course A and course B. From the results shown in Figure 3, we found that models that use data from the source courses as the primary training data achieve better prediction performance in the target course when the content of the target course is similar to that of the source course compared to two courses with significantly different content. Furthermore, when the transfer training steps are removed, the transfer effect of course A and course B will be slightly better than that of course A and course C.
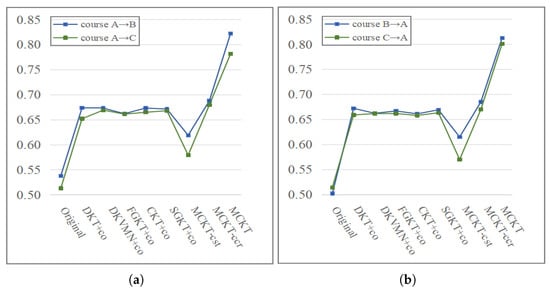
Figure 3.
Comparison of the prediction performance between two similar courses (i.e., courses A and B) and two significantly different courses (i.e., courses A and C) in scenario 1 for all models. (a) Transfer from course A to courses B and C; (b) transfer from courses B and C to course A. The results show that all the models have better prediction performance for two similar courses than two significantly different courses.
To further verify this conclusion, we conducted an additional experiment on dataset II and dataset III (see Section 5.1 for details). The goal of this experiment is to quantitatively analyze the mechanism through which course similarity influences transfer effectiveness, rather than to compare classification performance directly. Therefore, we employ MAE, RMSE, and R-squared as evaluation metrics. These metrics are suited to measure the continuous error in the model’s predicted probabilities in the target course and to elucidate the relationship between this error and course similarity. As shown in Figure 4, course a and course b (and similarly, courses x and y) represent similar course pairs, whereas course a and course c (and courses x and z) represent dissimilar pairs. Notably, when the transfer training step is omitted, the transfer effect between the similar courses (a and b) remains marginally better than that between the dissimilar ones (a and c). This result substantiates that the content and nature of the courses have a significant impact on the model’s transfer effect.
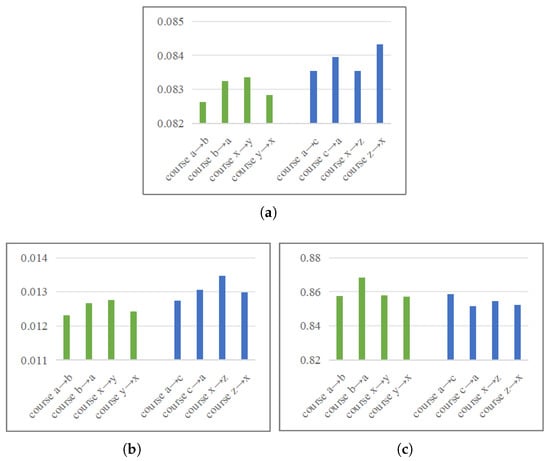
Figure 4.
Comparison of cross-course prediction performance on the group of similar courses and the group of significantly different courses on datasets II and III. (a) MAE; (b) RMSE; and (c) R-squared. The results also show that models have better prediction performance between two similar courses than between two significantly different courses.
5.8. Cross-Course Performance Evolution Description (RQ4)
The evolution description of learning performance is an important application of the knowledge tracing model, which is a visual way to dynamically trace students’ performance. This task usually employs a heat-map to show the student’s level of performance. The cross-course performance evolution description also uses a heat-map to show the strength and weakness of each student’s mastery level of each KC on the source course and the target course.
Figure 5 shows the heat-map of the students in scenario 1 whose learning performance is constantly changing on certain KCs. Figure 5 comprises three sub-figures, which show the performance evolution of the same student in source course A and two target courses, i.e., course B and course C, respectively.
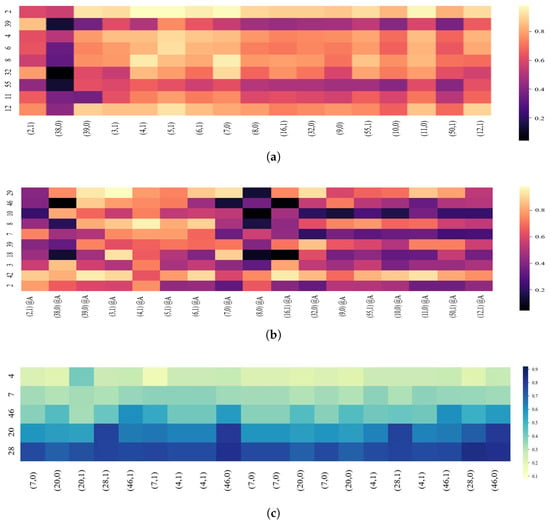
Figure 5.
Visualization of a common student’s knowledge tracing. (a) MOOPer course A; (b) MOOPer course B; and (c) MOOPer course C.
For each sub-figure in Figure 5, the label in the vertical dimension denotes KCs. The horizontal dimension shows a sequence of KCs and corresponding answers (0 indicates incorrectly answered and 1 indicates correctly answered) from the source course, where the labels refer to the KCs input into the model at each time step. The heat-map color indicates the predicted probability that the student will demonstrate the corresponding KCs correctly in the next step. We observed the evolution of the predicted values for the five KCs in source course A. As Figure 5a shows, after answering the 20 exercises, the student improves these five KCs. Furthermore, Figure 5b shows that the prediction on KC 58 in target course B also improves as the learning progresses. However, as Figure 5c shows, the student masters KCs 28 and 20 but fails to master KCs 7 and 4, and there is no noticeable improvement on KC 46.
5.9. Visualization of Student Embedding (RQ5)
We employ T-SNE to visualize the representations of common students and distinct students in six courses after dimensionality reduction, as shown in Figure 6, where the area of the two color scatters in each figure reflects the number of students in each course.
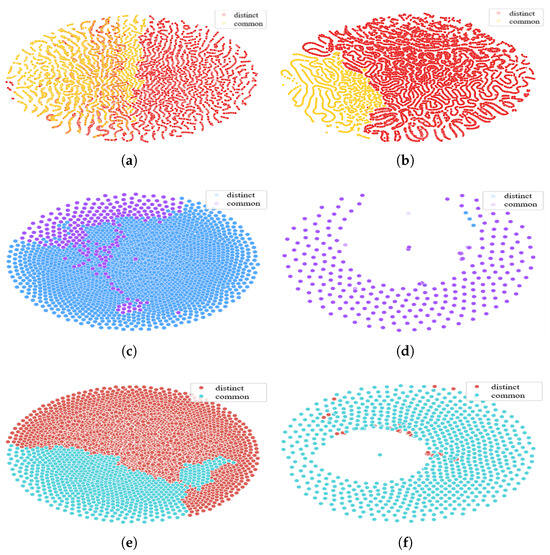
Figure 6.
Visualization of common and distinct students’ embeddings in the different courses. (a) MOOPer course A; (b) MOOPer course B; (c) MOOC-Cube course a; (d) MOOC-Cube course b; (e) MOOC-Cube course x; and (f) MOOC-Cube course y.
For instance, Figure 6a,b show the difference between the MOOPer courses A and B. The relative positions of the representations of the common students and the distinct students are similar in the low-dimensional space; that is, the representations of the common students are mostly distributed on the left side of the figure, and the representations of the distinct students are mostly distributed on the right side of the figure. Figure 6c,e show that in course a and course x of MOOC-Cube, the representation distributions of the common and distinct students are relatively clustered. In addition, Figure 6d,f show that in course b and course y of MOOC-Cube, the number of common students is much higher than that of distinct students, but the representation of the distinct students is also relatively concentrated. However, Figure 6d,f also show that the representation distribution of the distinct students overlaps more with that of the common students. A reason may be that the distinct student representations of the target course (i.e., course b and course y) are more affected by the common students when training in the cross-domain stage.
6. Conclusions and Future Work
In this paper, we propose a cross-course knowledge tracing model. Through comparative experiments with different KT models, the superiority of MCKT in performance has been demonstrated. Of course, our method still has some limitations. After enhancing the model’s cross-course learning capability, its predictive performance can be somewhat affected by information from other courses, making it difficult to surpass single-target knowledge tracing. Our next objective is to trace these effects and develop methods to filter out “noise” introduced by other courses. Here, “noise” refers not to data errors, but to irrelevant information originating from source courses, which can hinder or mislead the prediction of knowledge states in the target course during cross-domain transfer—a phenomenon commonly termed “negative transfer”. Currently, our graph embedding layer utilizes the Doc2Vec model to obtain textual representations. However, our future work will prioritize architectural simplification and efficiency. Instead of pre-training methods, we will shift our focus towards exploring end-to-end trainable and lightweight alternatives. This includes investigating unified architectures, such as fine-tuning pre-trained language models or employing graph neural networks capable of jointly processing textual and structural information in a differentiable manner. Similarly, for graph representation learning, rather than simply substituting Node2Vec with other similar sampling-based methods, we plan to explore integrating trainable graph encoding layers that can be optimized jointly with the sequential model, thereby moving towards a more streamlined, efficient pipeline. The proposed MCKT model still carries potential risks in practical applications, primarily manifested in external threats from the following two aspects: First, the multi-stage pipeline—relying on separate Doc2Vec and Node2Vec modules—creates a dependency on pre-trained, fixed representations. The performance is sensitive to the parameters of these independent stages , and any noise or bias introduced during graph construction or text processing may propagate through the model. Second, the specific architecture of the fusion MLP and the LSTM is one of many possible configurations; while ablation studies validate our design, the causal link between the fusion mechanism itself and the performance gain could be further isolated from the specific hyperparameters selected. The main external threat comes from the applicability of the courses. Our evaluation was conducted on specific MOOC datasets. Although we selected courses from different disciplines such as IT, physics, history, and management, it is ultimately impossible to cover all disciplines. In addition, the computational complexity of the current process poses a significant threat to its feasibility in real-time educational environments, where low-latency predictions are usually required.
Author Contributions
The study was conceived and designed by D.L. and Z.W., and Y.L. was responsible for the experiments, data collection, and analysis. Y.L. and Z.W. jointly drafted the manuscript. Z.W. provided critical feedback and supervised the research work. D.L. revised the manuscript to ensure the accuracy of important content. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Project of Philosophy and Social Science Planning of Guangdong Province (No. GD25CJY40), and an industry-sponsored horizontal project (No. 2541503).
Data Availability Statement
Suggested Data Availability Statements are available at https://github.com/THU-KEG/MOOCCubeX?tab=readme-ov-file (accessed on 15 October 2025), and http://data.openkg.cn/dataset/mooper (accessed on 18 October 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 505–513. [Google Scholar]
- Shen, S.; Liu, Q.; Chen, E.; Wu, H.; Huang, Z.; Zhao, W.; Su, Y.; Ma, H.; Wang, S. Convolutional Knowledge Tracing: Modeling Individualization in Student Learning Process. In Proceedings of the the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 1857–1860. [Google Scholar]
- Pu, S.; Yudelson, M.; Ou, L.; Huang, Y. Deep Knowledge Tracing with Transformers. In Proceedings of the Artificial Intelligence in Education, Ifrane, Morocco, 6–10 July 2020; pp. 252–256. [Google Scholar]
- Yang, Y.; Shen, J.; Qu, Y.; Liu, Y.; Wang, K.; Zhu, Y.; Zhang, W.; Yu, Y. GIKT: A Graph-Based Interaction Model for Knowledge Tracing. In Proceedings of the Machine Learning and Knowledge Discovery in Databases—European Conference, ECML PKDD 2020, Ghent, Belgium, 14–18 September 2020; Volume 12457, pp. 299–315. [Google Scholar]
- Feng, W.; Tang, J.; Liu, T.X. Understanding Dropouts in MOOCs. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 517–524. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model.-User-Adapt. Interact. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- Lin, C.; Chi, M. Intervention-bkt: Incorporating instructional interventions into bayesian knowledge tracing. In Proceedings of the International Conference on Intelligent Tutoring Systems, Zagreb, Croatia, 7–10 June 2016; pp. 208–218. [Google Scholar]
- Wang, L.; Sy, A.; Liu, L.; Piech, C. Deep knowledge tracing on programming exercises. In Proceedings of the Fourth ACM Conference on Learning@ Scale, Cambridge, MA, USA, 20–21 April 2017; pp. 201–204. [Google Scholar]
- Mongkhonvanit, K.; Kanopka, K.; Lang, D. Deep Knowledge Tracing and Engagement with MOOCs. In Proceedings of the 9th International Conference on Learning Analytics and Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 340–342. [Google Scholar]
- Zhang, J.; Shi, X.; King, I.; Yeung, D. Dynamic Key-Value Memory Networks for Knowledge Tracing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 765–774. [Google Scholar]
- Jiang, B.; Wei, Y.; Zhang, T.; Zhang, W. Improving the performance and explainability of knowledge tracing via Markov blanket. Inf. Process. Manag. 2024, 61, 103620. [Google Scholar] [CrossRef]
- Shukla, P.K.; Veerasamy, B.D.; Alduaiji, N.; Addula, S.R.; Sharma, S.; Shukla, P.K. Encoder only attention-guided transformer framework for accurate and explainable social media fake profile detection. Peer Peer Netw. Appl. 2025, 18, 232. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, Y.; Cen, J.; Zheng, Z.; Xu, G. A cross-domain knowledge tracing model based on graph optimal transport. World Wide Web 2025, 28, 10. [Google Scholar] [CrossRef]
- Cheng, S.; Liu, Q.; Chen, E.; Zhang, K.; Huang, Z.; Yin, Y.; Huang, X.; Su, Y. AdaptKT: A Domain Adaptable Method for Knowledge Tracing. In Proceedings of the WSDM ’22: The Fifteenth ACM International Conference on Web Search and Data Mining, Virtual, 21–25 February 2022; pp. 123–131. [Google Scholar]
- Wilson, G.; Cook, D.J. A Survey of Unsupervised Deep Domain Adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 51. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Huang, W.; Tong, S.; Huang, Z.; Liu, Q.; Chen, E.; Ma, J.; Wan, L.; Wang, S. STAN: Adversarial Network for Cross-domain Question Difficulty Prediction. In Proceedings of the IEEE International Conference on Data Mining, ICDM 2021, Auckland, New Zealand, 7–10 December 2021; pp. 220–229. [Google Scholar]
- Wu, Z.; Liang, Q.; Zhan, Z. Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph. Appl. Sci. 2023, 13, 2404. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, L.; Huang, Q.; Huang, C.; Tang, Y. SGKT: Session graph-based knowledge tracing for student performance prediction. Expert Syst. Appl. 2022, 206, 117681. [Google Scholar] [CrossRef]
- Liu, A.; Wei, Y.; Xiu, Q.; Yao, H.; Liu, J. How Learning Time Allocation Make Sense on Secondary School Students’ Academic Performance: A Chinese Evidence Based on PISA 2018. Behav. Sci. 2023, 13, 237. [Google Scholar] [CrossRef] [PubMed]
- Ozyildirim, G. Time Spent on Homework and Academic Achievement: A Meta-analysis Study Related to Results of TIMSS. Psicol. Educ. 2022, 28, 13–21. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the the 31st International Conference on International Conference on Machine Learning, ICML’14, Beijing, China, 21–26 June 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Jansen, B.J.; Jung, S.; Salminen, J. Finetuning Analytics Information Systems for a Better Understanding of Users: Evidence of Personification Bias on Multiple Digital Channels. Inf. Syst. Front. 2024, 26, 775–798. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Dengsheng, C.; Li, J.; Xu, K. AReLU: Attention-based Rectified Linear Unit. arXiv 2020, arXiv:2006.13858. [Google Scholar]
- Liu, K.; Zhao, X.; Tang, J.; Zeng, W.; Liao, J.; Tian, F.; Zheng, Q.; Huang, J.; Dai, A. MOOPer: A Large-Scale Dataset of Practice-Oriented Online Learning. In Proceedings of the Knowledge Graph and Semantic Computing: Knowledge Graph Empowers New Infrastructure Construction—6th China Conference, CCKS 2021, Guangzhou, China, 4–7 November 2021; Volume 1466, pp. 281–287. [Google Scholar]
- Yu, J.; Luo, G.; Xiao, T.; Zhong, Q.; Wang, Y.; Feng, W.; Luo, J.; Wang, C.; Hou, L.; Li, J.; et al. MOOCCube: A Large-scale Data Repository for NLP Applications in MOOCs. In Proceedings of the The 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 3135–3142. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the the 52nd Annual Meeting of the Association for Computational Linguistics, ACL 2014, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Chen, Y.; Liu, Q.; Huang, Z.; Wu, L.; Chen, E.; Wu, R.; Su, Y.; Hu, G. Tracking Knowledge Proficiency of Students with Educational Priors. In Proceedings of the the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 989–998. [Google Scholar]
- Li, P.; Tuzhilin, A. DDTCDR: Deep Dual Transfer Cross Domain Recommendation. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 331–339. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.