Abstract
With the accelerated expansion of the Internet of Things (IoT), massive distributed and heterogeneous devices are increasingly exposed to severe security threats. Traditional centralized intrusion detection systems (IDS) suffer from significant limitations in terms of privacy preservation and communication overhead. Federated Learning (FL) offers an effective paradigm for building the next generation of distributed IDS; however, it remains vulnerable to poisoning attacks in open environments, and existing client selection strategies generally lack robustness and security awareness. To address these challenges, this paper proposes an Uncertainty-Guided Evolutionary Game-Theoretic (UEGT) Client Selection mechanism. Built upon evolutionary game theory, UEGT integrates Shapley value, gradient similarity, and data quality to construct a multidimensional payoff function and employs a replicator dynamics mechanism to adaptively optimize client participation probabilities. Furthermore, uncertainty modeling is introduced to enhance strategic exploration and improve the identification accuracy of potentially high-value clients. Experimental results under adversarial scenarios demonstrate that UEGT maintains stable convergence even under a high fraction of malicious participating clients, achieving an average accuracy exceeding 89%, which outperforms several mainstream client selection and robust aggregation methods.
1. Introduction
As the Internet of Things (IoT) technologies become broadly integrated into areas such as intelligent manufacturing, healthcare, smart transportation, and smart cities, the openness, heterogeneity, and distributed nature of IoT systems have introduced unprecedented security challenges [1]. A vast number of terminal devices are typically resource-constrained and lack unified protection mechanisms, making them vulnerable to exploitation by malicious actors. Such intrusions can lead to severe consequences, including sensitive data leakage and service disruption [2,3]. As a core component of network defense frameworks, the Intrusion Detection System (IDS) is designed to detect and respond to anomalous behaviors at an early stage, thereby serving as a critical safeguard for IoT security.
Traditional IDSs are predominantly based on centralized architectures, where data from distributed nodes are collected by a central server for unified modeling and threat analysis. However, this approach exhibits fundamental structural limitations in IoT environments [4,5]. On the one hand, centralized transmission of raw data poses severe privacy risks, particularly in highly sensitive contexts such as user behavior analysis, medical records, and industrial control systems [6,7]. On the other hand, IoT devices often operate under bandwidth and energy constraints; frequent uploads of high-dimensional data impose considerable communication overhead, which significantly degrades system efficiency and scalability [8].
To address these challenges, federated learning (FL) has increasingly been recognized as an effective framework for jointly training models without exposing raw data, thereby offering a viable solution to privacy-sensitive distributed environments [9]. In FL, clients conduct training locally using their private datasets and transmit only the updated model information to the server, which then performs the aggregation. This paradigm effectively mitigates privacy leakage and reduces communication burden, making it particularly well-suited for IoT environments characterized by heterogeneous data distributions, large-scale deployment, and limited bandwidth resources [10].
Nevertheless, the open and decentralized nature of FL also introduces new security threats, such as poisoning attacks. In typical FL architectures, the server cannot directly observe local training processes, allowing adversaries to masquerade as legitimate clients and inject malicious model updates to disrupt global convergence [6,11]. Such attacks are highly stealthy and can exert cumulative long-term effects, severely undermining system stability and reliability. More critically, the vulnerability of existing client scheduling mechanisms further amplifies these risks. Most FL systems assume client honesty and adopt random sampling or static round-robin selection, without evaluating the historical behavior or contribution of each client. Consequently, malicious participants may be repeatedly selected despite submitting anomalous updates, leading to continuous performance degradation [12,13]. Therefore, designing a security-aware and adaptively responsive client selection strategy is essential for constructing a robust federated IDS (FIDS).
In response to this challenge, we introduce an Uncertainty-Guided Evolutionary Game-Theoretic (UEGT) client selection mechanism. The proposed mechanism is grounded in Evolutionary Game Theory (EGT) and employs replicator dynamics to drive the evolution of client participation strategies [14,15,16]. It constructs a multidimensional payoff function that integrates three key indicators—Shapley value, gradient similarity, and data quality—to comprehensively evaluate the collaborative value of each client, thereby enhancing system robustness under adversarial conditions. Building upon this foundation, UEGT further incorporates a Beta distribution–based uncertainty modeling [17] to characterize the volatility and credibility of client contributions. This uncertainty is incorporated into the strategy adjustment process, serving as an auxiliary signal to guide adaptive client selection. By integrating the EGT-driven historical reward mechanism with uncertainty-based risk modeling, the system establishes a strategy adaptation framework that balances security and exploration. The hybrid design ensures that exploratory adjustments are moderately constrained, enabling the system to discover potentially high-value clients without compromising the robustness of the original EGT dynamics. This paper makes the following contributions:
- We design a UEGT-based client selection mechanism that integrates EGT with uncertainty modeling to adaptively suppress malicious clients and strategically schedule high-quality participants in FIDS.
- We design a multidimensional payoff function that combines Shapley value, gradient similarity, and data quality to enable unsupervised optimization of client participation via replicator dynamics, thereby enhancing both security and adaptability.
- The introduced uncertainty modeling captures the volatility of client contributions. Coupled with EGT, it boosts both resilience and exploration, activating potentially valuable clients while maintaining robustness.
- Experiments on the CICIoT2023 dataset show that UEGT consistently outperforms existing methods in terms of robustness and detection accuracy, even under highly adversarial environments.
2. Related Work
The rapid proliferation of IoT devices has exposed the limitations of centralized learning, including privacy risks and high communication overhead due to raw data transmission [6,10]. In response to such issues, researchers have explored the application of FL in IoT environments. Table 1 provides a summary of recent research efforts related to FL.
Rashid et al. [18] proposed an FIDS for Industrial IoT (IIoT) networks. In this approach, using the Edge-IIoTset dataset, they conducted comparative experiments between centralized learning (CL) and FL modes under various client population settings. Experimental findings revealed that although the FL approach initially performed slightly below the CL, after 50 training rounds, it achieved an accuracy of 92.49%, comparable to the centralized model’s 93.92%, demonstrating strong detection capability and privacy protection. Benameur et al. [19] proposed an IDS that combines FL and knowledge distillation (KD) to enhance IoT security. The authors adopted a teacher–student distillation mechanism to reduce model complexity and inference latency. During training, the FedAvg algorithm was used to aggregate model parameters across clients. Experimental results demonstrated that the proposed approach achieved over 96% accuracy on binary classification tasks using the Edge-IIoTset dataset. Shibly et al. [20] developed a personalized FIDS for vehicular networks. Experiments were conducted on the NAIST CAN Attack and Car-Hacking datasets. The proposed method integrates supervised and unsupervised learning frameworks, where the supervised component employs the XGBoost classifier under a federated setting, while the unsupervised component leverages autoencoders (AE) for feature extraction. Experimental results demonstrated that the XGBoost achieved 99.98% accuracy on multiclass tasks. Zhang et al. [21] proposed FedKSam*, a two-stage FIDS designed for data heterogeneity and long-tailed data environments. In the first stage (FedKSam), the framework integrates the Sharpness-Aware Minimization (SAM) optimizer with KD to incorporate global awareness into local training, thereby mitigating both local and global drift issues and significantly enhancing model representation capability. In the second stage, classifier weights are normalized to reduce inter-class vector magnitude disparities, improving discrimination under long-tailed class distributions. Moreover, Zhao et al. [22] addressed inference threats in FL by designing a secure aggregation scheme in which individual updates are cryptographically masked before transmission. Relying on hardness assumptions from Diffie–Hellman, the protocol allows the server to recover only the collective update while preventing exposure of any single participant’s model, even in the presence of colluding entities.
In the aforementioned studies, all clients in FL participate in model training and aggregation. This approach simplifies the scheduling process and enhances system-wide collaboration; however, it is often impractical in IoT environments. IoT devices often face limited bandwidth, constrained resources, and unreliable connectivity. Consequently, full participation leads to substantial communication and computation overhead, significantly reducing system efficiency and scalability [23,24]. To address these challenges, researchers have begun focusing on client selection mechanisms, in which only a subset of representative or high-quality clients participate in each communication round.
Liang et al. [25] proposed an FIDS in smart grids that enables data concentrators to locally train deep neural networks (DNN) and upload only model parameters to a central data center for aggregation. Their method introduces a client selection strategy during every training cycle, where a randomly chosen group of clients participates in the federated update process. By adjusting the participation ratio, they effectively balance convergence speed and model performance. Nobakht et al. [26] developed SIM-FED, a federated deep learning framework for IoT malware detection. During training, FedAvg is used to aggregate locally trained models from multiple clients, with a random selection mechanism that selects 10 clients from 100 IoT devices in each communication round. This design enhances model generalization and reflects the heterogeneity of IoT devices. Experiments conducted on the IoT-23 dataset demonstrated that after 10 federated training rounds, SIM-FED achieved 99.52% accuracy. Beyond random selection strategies, recent research has explored more adaptive and flexible selection mechanisms. Cho et al. [27] proposed a novel strategy termed Power-of-Choice (PoC) to accelerate convergence in FL. This method prioritizes clients with higher local losses for participation, thereby optimizing global model updates and expediting error convergence. Based on this idea, they provided a theoretical analysis of biased client selection, proving that preferentially choosing clients with larger losses can significantly reduce convergence time and improve final test accuracy.
In many studies, FL commonly assumes that all participating clients are trustworthy. However, in real-world IoT environments, client nodes may possess low-quality data or be compromised by malicious actors. Malicious clients can upload falsified model updates that disrupt the global training process and launch poisoning attacks that undermine the system’s robustness [11,28]. Therefore, designing robust client selection mechanisms capable of resisting malicious participants and poisoning attacks has become a key challenge in enhancing the security and stability of FL systems. Yin et al. [29] addressed the Byzantine attack problem in distributed learning and proposed a Trimmed Mean–based robust gradient aggregation method. This approach mitigates the influence of abnormal gradients contributed by malicious clients by discarding a portion of the largest and smallest gradient values during the aggregation of each dimension. Compared with conventional mean aggregation, the Trimmed Mean method exhibits superior robustness when some clients submit extreme or adversarial updates. Blanchard et al. [30] focused on maintaining training stability and security in distributed learning environments with malicious nodes. They noted that traditional mean-based aggregation strategies are highly vulnerable to Byzantine attacks, as even a small fraction of adversarial clients can cause the training to diverge significantly from the correct optimization direction. To address this issue, they proposed Krum, a robust aggregation strategy that selects, for each round, the gradient vector closest to the majority of other client updates for global aggregation. This design effectively mitigates the influence of Byzantine nodes without directly averaging all updates, thereby maintaining both training stability and convergence even when a portion of the clients are compromised. Cao et al. [31] proposed FLTrust, a robust FL framework designed to defend against Byzantine adversaries. By introducing a small clean dataset as a trusted reference at the server side, this method addresses the lack of a root of trust in conventional robust aggregation schemes. During each training round, the server assigns trust weights to client updates based on their directional consistency with the server’s reference update and further normalizes their magnitudes, thereby mitigating the influence of anomalous or malicious model updates.

Table 1.
Summary of recent research on FL applications.
Table 1.
Summary of recent research on FL applications.
| Ref. | Year | Dataset | Algorithm | Total Clients | Selection Strategy | Selected Clients | Poisoning Defense |
|---|---|---|---|---|---|---|---|
| [18] | 2023 | Edge-IIoTset | CNN, RNN | K = 3, 9, 15 | Full | Full | ✗ |
| [19] | 2024 | Edge-IIoTset | CNN, DNN, CNN-LSTM | K = 4 | Full | Full | ✗ |
| [20] | 2022 | NAIST CAN, Car-Hacking | CNN, XGBoost, MLP, AE | K = 3 | Full | Full | ✗ |
| [21] | 2024 | N-BaIoT | FedKSam* | K = 20 | Full | Full | ✗ |
| [22] | 2023 | MNIST, Fashion-MNIST, CIFAR-10 | CNN | K = 10, 40, 80, 100 | Full | Full | ✗ |
| [25] | 2023 | NSL-KDD | DNN | K = 50 | Random | C = 5, 10, 25, 35, 50 | ✗ |
| [26] | 2024 | IoT-23 | CNN | K = 100 | Random | C = 10 | ✗ |
| [27] | 2022 | Synthetic, FMNIST, CIFAR-10, Sent140, EMNIST, Shakespeare | Logistic Regression, MLP, CNN | K = 30, 100, 314, 500 | PoC | C = 3, 9, 8, 15 | ✗ |
| [29] | 2018 | MNIST | Logistic Regression, CNN | K = 10, 40 | Full | Full | Trimmed mean |
| [30] | 2017 | Spambase, MNIST | MLP, ConvNet | K = 20 | Full | Full | Krum |
| [31] | 2021 | MNIST, Fashion-MNIST, CIFAR-10, HAR, CH-MNIST | Logistic Regression, CNN, ResNet | K = 30, 40, 100 | Full | Full | FLTrust |
| [32] | 2021 | MNIST | Neural Network | K = 10 | Shapley | C = 5 | S-FedAvg |
| [33] | 2024 | MNIST, FMNIST, CIFAR-10 | MLP, CNN | K = 200, 300, 400 | Greedy Shapley | C = 3, 20 | ✗ |
| Our method | CICIoT2023 | DNN | K = 9 | UEGT | C = 4 | EGT |
Full indicates full participation; ✗ indicates the absence of poisoning-attack defense.
In recent years, the Shapley value, as a fundamental concept in cooperative game theory, has been widely adopted to quantify the contribution of individual clients to the global model, thereby enabling more effective client selection strategies in FL. Nagalapatti et al. [32] addressed the performance degradation arising from the inconsistency between local client data and the global learning objective, and proposed a game-theoretic relevance-aware client selection framework, termed S-FedAvg. This approach employs a small server-side validation set to estimate the marginal contribution of each client update to the global model via Shapley value computation. Based on the estimated relevance, client sampling probabilities are adaptively adjusted during the federated training process, reducing the likelihood of repeatedly selecting irrelevant or negatively contributing clients. Experimental results demonstrate that the proposed strategy enhances convergence stability and overall performance in scenarios involving irrelevant clients. Singhal et al. [33] proposed a client selection approach for FL, referred to as GreedyFed. This method employs the Shapley value to quantify the relative contributions of different clients during model training and, after an initial round-robin phase for client valuation, adopts a greedy strategy to prioritize clients with higher estimated contributions in subsequent communication rounds.
Building upon the aforementioned studies, which have provided significant insights into enhancing model performance and security in FL and client selection strategies for IoT environments, this paper proposes a UEGT mechanism. The proposed mechanism employs EGT as its core to adaptively optimize client participation probabilities through a multidimensional payoff function that integrates Shapley value, gradient similarity, and data quality. To further enhance strategic exploration and flexibility, the system incorporates a Beta distribution–based uncertainty modeling framework, which characterizes the volatility of client contributions and introduces it into the strategy evolution process.
3. Methodology
3.1. System Overview
FL offers a promising paradigm for next-generation distributed IDS, allowing clients to retain raw data locally while collaboratively training a global model. This approach balances privacy and scalability, making it well-suited for data-sensitive and heterogeneous IoT environments [34]. However, the server’s inability to observe local training exposes FL to poisoning attacks. In addition, existing client scheduling methods often rely on random sampling and naive aggregation, lacking anomaly detection and adaptive response, which compromises system robustness and security [13]. In response to these problems, we introduce the UEGT mechanism for constructing a robust and adaptive FIDS. Figure 1 illustrates the workflow of UEGT within the FIDS. Centered on EGT, the proposed mechanism formulates a multidimensional payoff function that integrates Shapley value, gradient similarity, and data quality to dynamically quantify each client’s contribution during model training. The system employs replicator dynamics to drive strategy evolution, enabling clients’ participation probabilities to self-adjust based on historical payoffs, thereby continuously optimizing scheduling behavior and mitigating the influence of malicious or unreliable nodes.
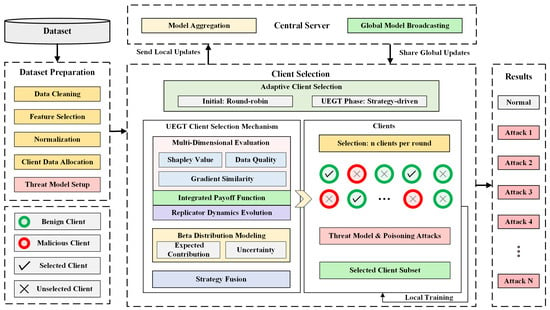
Figure 1.
Methodology flowchart.
Furthermore, UEGT incorporates a Beta distribution–based uncertainty modeling framework to jointly characterize the volatility of client behaviors and the stability of system cognition. A time-decay mechanism is further introduced to dynamically regulate uncertainty contributions over training rounds. Through the synergistic interaction between the uncertainty-driven incentive mechanism and evolutionary strategy adaptation, the proposed framework achieves a balanced trade-off between robustness and exploration capability, allowing the system to effectively identify and activate potentially high-value clients that may have been undervalued in early training stages.
3.2. Dataset and Preprocessing
3.2.1. Dataset Description
To assess the UEGT mechanism’s performance in IoT environments, the CICIoT2023 dataset was employed for experimentation [35]. This dataset represents one of the most comprehensive and widely adopted large-scale network traffic datasets in contemporary IoT security research. It was specifically developed for the design and evaluation of IDS in intelligent device ecosystems. The CICIoT2023 dataset was collected from a testbed comprising more than one hundred real IoT devices, thereby encompassing typical application scenarios such as smart homes, environmental monitoring, and remote control. The test platform simulated realistic operational conditions through a hybrid network architecture, generating high-fidelity IoT communication traffic. In terms of attack diversity, the dataset contains 33 distinct attack types grouped into seven major categories, including DDoS, information gathering, web attacks, and brute-force attacks, among others. Given the substantial size of the original dataset, a subset was randomly sampled for this study while preserving all attack categories and normal traffic. The resulting dataset consists of eight classes—seven attack types and one normal behavior category—which serves as the basis for model training and performance evaluation.
3.2.2. Data Preprocessing
To improve the IDS model’s performance and efficiency, a systematic data preprocessing pipeline was applied to the raw CICIoT2023 dataset prior to model training.
First, data cleaning was performed, including the imputation of missing values, removal of duplicate records, and elimination of invalid or irrelevant fields, ensuring the consistency and validity of the input data. Second, to mitigate the influence of feature scale disparities and prevent distributional bias during model training, all numerical features were normalized using the Z-score standardization method. This transformation standardizes each feature to zero mean and unit variance, ensuring that all features contribute equally during gradient updates. Consequently, this step effectively improves both the convergence speed and stability of the learning process. Finally, to reduce redundancy and compress the input feature space, Mutual Information (MI)–based feature selection was employed. By quantifying the information gain between each feature and the target class labels, this method identifies the most discriminative attributes from the original feature set. As a result, 29 key features were selected to construct a more compact and informative representation space, thereby enhancing the model’s generalization capability and computational efficiency.
3.3. Federated Learning Framework
This study is based on the FedAvg algorithm, which serves as the foundational framework for FL systems [9]. FedAvg is the most widely adopted optimization method in FL. Its core concept is that each client updates a local model with private data and periodically uploads model parameters to a central server for global aggregation. The overall FL process is illustrated in Figure 2.
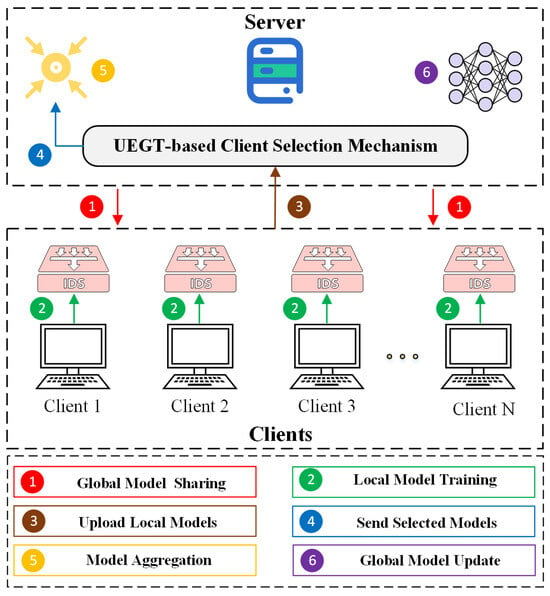
Figure 2.
FL architecture.
At the beginning of each communication round, the server randomly chooses a group of participating clients and disseminates the latest global model parameters to them. Upon receiving these parameters, each participant updates its own model on its local dataset to optimize the following objective function:
where denotes the loss function. The initial learning rate is set to , and it is dynamically adjusted according to an exponential decay schedule with :
Clients upload updates after local training, and the server performs data-proportional weighted averaging to form the global model:
3.4. Threat Model, and Poisoning Attacks
In FL environments, since the data and training processes of all clients are fully localized, the central server cannot directly observe or verify client behaviors. This black-box architecture inherently exposes the system to poisoning attacks, posing a fundamental threat to model integrity and reliability [36]. Particularly in practical deployments involving untrusted or compromised devices, adversaries may deliberately craft malicious model updates to manipulate the global training process, leading to model degradation or misleading predictions, which in turn creates severe security risks [37].
This study focuses on a representative type of poisoning attack, the label-flipping attack, as illustrated in Figure 3. This attack targets the data layer of the system, where the adversary alters the labels of most samples in its local dataset, making them inconsistent with their true semantic classes. As a result, a large volume of mislabeled data is introduced into the local training process, misleading the model into learning incorrect decision boundaries [38]. Notably, this attack requires no knowledge of the model structure and can be executed solely through the attacker’s full control of local data, giving it high stealthiness and broad applicability. During aggregation, these compromised local models propagate systematic bias into the global model, significantly degrading its generalization ability and overall security. To comprehensively evaluate the impact of this attack, we construct a high-intensity poisoning scenario in which 4 out of 9 clients are malicious in each communication round, and label flipping is applied to their local data samples. This configuration simulates an extreme adversarial environment, designed to rigorously assess the stability and robustness of the proposed client selection mechanism under strong attack conditions.
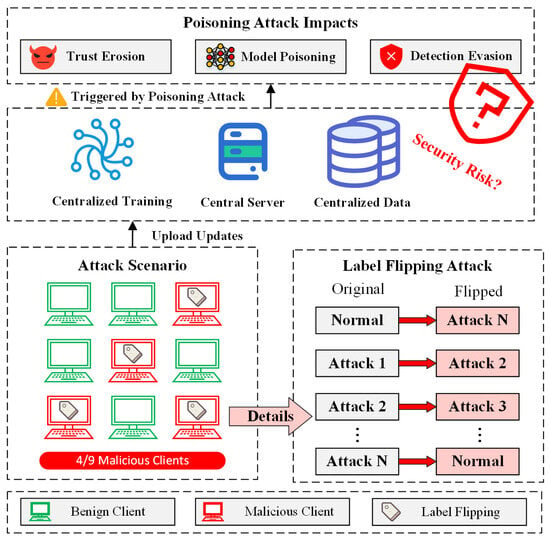
Figure 3.
Poisoning attack scenarios and impacts in FL.
3.5. Uncertainty Modeling via Beta Distribution
In FL, client selection critically influences model performance and robustness. Owing to the heterogeneity of client data, local training remains opaque to the central server. Consequently, system evaluation often depends on clients’ historical performance, which may not adapt well to dynamic environments [24].
To address these challenges, this study introduces a probabilistic uncertainty representation model based on the Beta distribution, which provides a more comprehensive characterization of clients’ behavioral stability and dynamism. By treating clients’ historical performance as random variables and leveraging Bayesian inference, the system can continuously refine its knowledge of client reliability and dynamically quantify uncertainty. This design enables a balance between exploitation and exploration in client selection. Specifically, we model each client’s contribution reliability using a Beta distribution [39]. For client i, its contribution reliability is modeled as a random variable:
where and represent the accumulated strengths of positive and negative contributions, respectively, based on the client’s historical evaluations [17]. The expected value of this distribution reflects the system’s estimate of the client’s average reliability:
which represents the client’s expected reliability or trusted contributor probability. Meanwhile, the variance quantifies the uncertainty of this estimate:
A higher variance indicates greater uncertainty in the system’s reliability estimation, whereas a smaller variance implies stability and confidence. This framework allows each client to maintain a dynamically updated reliability distribution that integrates both historical behavior and uncertainty quantification, leading to a richer behavioral representation.
During training, the system observes each client’s marginal contribution per communication round. The normalized Shapley value is employed as the observed contribution indicator, transformed from the original via:
This normalized value serves as the observed outcome used to update the Beta distribution parameters:
This update mechanism dynamically adjusts the system’s confidence in each client’s reliability. If a client performs well in a given round, increases, strengthening trust; conversely, poor performance increases , reflecting risk or unreliability. As grows, the system’s estimate stabilizes. Details on the Shapley value computation are provided in Section 3.6.1.
However, the expected reliability only reflects the client’s average performance and fails to capture the system’s epistemic uncertainty about the client’s future behavior. To quantify this uncertainty, we define the exploration value based on the standard deviation of the Beta distribution:
where is the decay factor applied to the variance, which is set to 0.95 in this study. The t denotes the number of rounds elapsed since the end of the initialization phase, and represents the exploration score of client i in the current round. This mechanism ensures sufficient exploration in the early stages while gradually converging toward a more stable selection strategy, preventing training oscillations caused by excessive emphasis on uncertainty. To ensure fairness, the exploration values are normalized as follows:
The normalized uncertainty scores are then incorporated into the client selection strategy, allowing the system to make decisions that consider not only average contributions but also risk-aware exploration.
3.6. Client Evaluation Metrics
3.6.1. Shapley Value Contribution
In an open FL environment, some clients may engage in malicious or unreliable behaviors, making it difficult for traditional averaging aggregation methods to accurately and fairly measure their true contributions to the global model. To improve the fairness and robustness of contribution evaluation, this paper introduces the Shapley value, a concept from cooperative game theory, as a quantitative metric for evaluating client contribution [40]. The Shapley value provides a theoretically grounded and equitable method for contribution allocation by assessing each participant’s marginal effect across all possible cooperation subsets [41].
Let the set of all clients be , and let the utility function represent the performance gain of the global model when a subset of clients participates in validation. Client i’s Shapley value is given by:
This formulation enumerates all possible subsets S excluding client i and computes its expected marginal contribution weighted by the probability of each subset appearing in random coalition orders. During the federated training process, the system calculates each selected client’s marginal contribution after every communication round by evaluating its effect on model performance over the validation dataset. This defines the utility function , completing the computation of the Shapley value. Subsequently, all clients’ Shapley values are normalized to facilitate comparison and are further used as dynamic inputs for the uncertainty modeling process based on the Beta distribution. These normalized values not only serve as cumulative contribution indicators but also act as crucial observational variables for quantifying uncertainty in client reliability.
3.6.2. Gradient Similarity Analysis
Gradient similarity is employed to evaluate how well a client’s update direction aligns with the anticipated trajectory of the global model’s optimization. It serves as an essential indicator for assessing client reliability and detecting anomalous behaviors [42]. In FL, the essence of model training lies in minimizing the loss function along the gradient direction. However, when certain clients, either due to corrupted data or intentional malicious behavior, upload gradients that deviate significantly from the global optimization direction as poisoning attacks, the aggregated model update may become distorted, leading to unstable or even degraded performance. Therefore, quantifying the directional consistency between a client’s gradient and the global gradient is critical for improving the system’s robustness and reliability.
In this study, cosine similarity is adopted as the metric to measure the directional alignment between client and global gradients [43]. Let the local model update gradient of client i be denoted as , and the global reference gradient as . The cosine similarity between the two is defined as follows:
where denotes the inner product, and represents the L2 norm. The value of lies within the interval . A higher value indicates stronger directional consistency between the client and the global optimization gradient, while a lower value signifies a significant deviation, potentially revealing abnormal client behavior.
3.6.3. Data Quality Estimation
Client data quality directly impacts local training efficiency and the client’s contribution to model convergence. When a client’s data aligns with the global optimization objective, it produces more representative and generalizable model parameters. In contrast, low-quality data can cause overfitting, slow convergence, or harm the global model. Thus, accurately assessing data quality is crucial for evaluating each client’s contribution to FL [44].
Training loss reflects the model’s fit to local data. Smaller training loss indicates better alignment with the global model, suggesting higher data quality [45]. In this work, average training loss serves as the proxy for data quality evaluation. Specifically, after each round of local training, the system performs a forward pass on the local dataset to evaluate the model’s performance on the client’s own data. Let denote the local model of client i, and let its local training dataset be ,with loss function . The average training loss is then defined as:
To obtain a positively correlated data quality score, the system applies an inverse transformation with a smoothing term, yielding the following formulation:
where represents the data quality score of client i, and c is a stability constant. A larger indicates higher-quality data that aligns better with the global model and contributes more effectively to optimization.
3.7. Uncertainty-Guided Evolutionary Game-Theoretic Client Selection
3.7.1. Evolutionary Game Model
To achieve dynamic optimization of client selection strategies in FL, this study introduces EGT to construct a client behavior adjustment mechanism [14]. EGT emphasizes that participants, under bounded rationality, iteratively adjust their behaviors based on local payoff feedback. Through long-term interactions, the system naturally evolves toward equilibrium strategies that exhibit strong adaptability and stability. Within this framework, each client in the FL system is regarded as a participant in the evolutionary game, and its strategy space represents its probability of participating in training.
Consider a system containing n clients. The decision variable for client i is represented as , which indicates its participation tendency in the current training round. The overall strategy vector of all clients is represented as , subject to the normalization constraint . To quantify the cooperative value of each client, a multi-dimensional payoff function is designed that integrates several evaluation indicators. The payoff function comprehensively considers the following three aspects:
- Shapley Value (): Measures the marginal contribution of a client to the overall model performance.
- Gradient Similarity (): Reflects the directional consistency between the local model update and the global optimization gradient.
- Data Quality Score (): Evaluates the quality and effectiveness of the data used to support local training.
After normalization, the payoff function of the ith client is defined as:
where , , and denote the normalized Shapley value, gradient similarity, and data quality score, respectively. The coefficients are weighting factors that satisfy the constraint . In this study, these weights are set to 0.6, 0.3, and 0.1, respectively.
3.7.2. Replicator Dynamics Strategy Updating
Under the EGT framework, replicator dynamics is a classical mechanism for strategy evolution. Its fundamental idea originates from the principle of survival of the fittest in evolutionary biology. Strategies associated with higher payoffs tend to expand within the population, whereas those with lower payoffs gradually diminish [15]. Unlike traditional game-theoretic models that rely on rational decision-making, replicator dynamics emphasizes local feedback-driven adaptation, enabling autonomous and continuous optimization without external supervision. In this study, the mechanism is employed to update clients’ participation probabilities, guiding the evolution of strategies toward system stability. The overall process is illustrated in Figure 4.
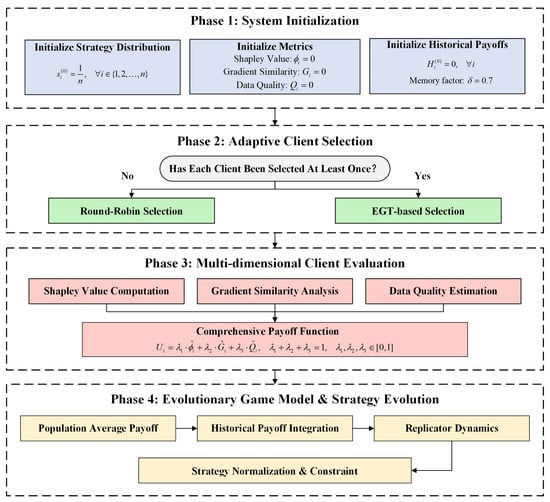
Figure 4.
Flowchart of EGT client selection mechanism.
Let the strategy distribution of clients in the tth round be denoted by:
where represents the participation probability of client i in that round.
Based on the individual payoff defined in the previous section, a historical payoff mechanism is introduced to enhance evolutionary stability and mitigate the effects of short-term fluctuations. The historical payoff is updated using an exponential moving average:
where denotes the memory factor controlling the decay rate of historical information. In this study, . After obtaining each client’s historical payoff , the system computes the average historical payoff across all clients as:
This value reflects the overall system performance under the current strategy distribution and serves as a baseline for individual strategy adjustments.
Then, the strategy of each client is updated following the replicator dynamic rule:
where is the learning rate in evolutionary dynamics, set to 0.01 in this work. This formulation embodies the dynamic law of the expansion of the superior and contraction of the inferior:
- When , client i performs better than the population average, and its participation probability increases.
- When , client i performs worse than average, and its participation probability decreases.
- The magnitude of change is proportional to reflecting the “strong get stronger” characteristic of evolutionary adaptation.
To maintain the validity of strategy proportions, the system performs a normalization step after each update:
Through payoff-driven adjustments, the proposed mechanism dynamically regulates client participation tendencies, achieving autonomous adaptation at the individual level. Without requiring external intervention, the system continuously refines the client strategy configuration, progressively approaching an evolutionarily stable state.
3.7.3. Uncertainty-Guided Strategy Selection
In the replicator dynamics–driven evolutionary game framework, the updating of client strategies primarily depends on their cumulative historical payoffs. To enhance the survival of the fittest evolution logic and further improve global model performance, it is essential to strengthen the system’s exploratory capability and adaptive diversity.
Building on the uncertainty modeling from Section 3.5, this study incorporates the Beta distribution’s variance as an uncertainty-guided incentive, allowing the system to balance exploration and exploitation during strategy evolution. The resulting UEGT mechanism combines classical payoff dynamics with uncertainty-driven exploration to better capture clients’ potential contributions, and its workflow is illustrated in Figure 5.
Figure 5.
Flowchart of UEGT client selection mechanism.
Specifically, the system first computes each client’s uncertainty score based on the variance of its Beta distribution. To mitigate the effect of extreme values, the variance is adjusted by a temporal decay factor, and the reduced uncertainty measure is defined as:
The normalized uncertainty probability distribution is then incorporated into the replicator dynamics to construct an exploration-enhanced strategy score:
where is the exploration factor, controlling the system’s reward for uncertainty-driven behavior. This allows the system to dynamically adjust client participation based on historical performance and current uncertainty. To maintain the validity and normalization of strategy distributions, the system applies the following standardization:
The proposed integration mechanism not only stabilizes strategy evolution but also introduces adaptive exploration driven by client contribution uncertainty. By dynamically balancing known and uncertain contributions, the system maintains equilibrium while actively identifying clients with latent potential.
3.8. Integration into Federated Learning Workflow
This paper proposes an FL client selection method that integrates EGT strategy updates with uncertainty modeling. At the beginning of each communication round, the system first generates a strategy distribution using the replicator dynamics mechanism, assigning each client a participation probability derived from its accumulated historical payoff. Simultaneously, an uncertainty score modeled by the Beta distribution is introduced, and the strategy is further enhanced through an exploration factor, forming an uncertainty-guided evolutionary strategy. After normalization, the fused strategy distribution is applied to actual client selection, prioritizing clients with stable contributions or high potential to participate in the current round of training. Once training is completed, the selected clients upload their locally updated models, and central node aggregates these parameters to update the global model. Subsequently, the system evaluates client contributions comprehensively based on three key metrics. The evaluation results are then mapped to strategy feedback through the payoff function, updating both the replicator strategy and the uncertainty modeling distribution, thereby completing one full evolutionary optimization cycle. The overall client selection workflow is illustrated in Algorithm 1.
Considering the limited observation data during the system’s initialization phase, the first few rounds employ a round-robin selection approach to ensure that all clients have the opportunity to participate, thereby providing sufficient baseline data for subsequent modeling. Once the strategy feedback mechanism has accumulated sufficient historical data, client selection is fully driven by the integrated evolutionary strategy, allowing the system to dynamically adjust participation probabilities according to clients’ historical behaviors and uncertainties. This design achieves more precise resource allocation and more efficient federated training.
| Algorithm 1 UEGT Client Selection for FL |
| Require: Communication rounds T, number of clients n, selected per round K, FL learning rate , EGT learning rate , payoff weights , exploration factor , uncertainty decay rate Ensure: Global model , strategies
|
4. Experiments and Evaluation
4.1. Experimental Setup
To validate the effectiveness of the UEGT mechanism within the FIDS, an FL simulation environment was constructed, employing a synchronous update mechanism. In this environment, nine independent clients were deployed, and during each communication round, the server selected four clients to participate in global model aggregation. Given that the primary objective of this work is to evaluate the security performance of UEGT under poisoning attack scenarios as well as the accuracy of client contribution quantification, the simulation settings focus mainly on validating the algorithmic logic and the game-theoretic interaction mechanisms. Accordingly, the experiments assume that the selected clients possess sufficient computational and communication resources, enabling them to complete local training and upload model updates in a timely manner. Both the global and local models were implemented using a DNN architecture. The employed DNN consisted of five hidden layers with neuron sizes of 32, 64, 128, 64, and 32, respectively.
The FL process was conducted over 40 communication rounds, where each local model performed two training iterations per round to ensure sufficient convergence under multi-round dynamic game interactions and strategy evolution. To support Shapley value computation, an independent public validation set was constructed by sampling from the original dataset without replacement. This validation set was used exclusively for evaluating the marginal contribution of each client after every communication round and was not involved in training or testing. It contained several hundred samples, representing a relatively small proportion of the total data, thereby reducing validation overhead and improving overall training efficiency. The remaining data were split 8:2 for training and testing. To ensure the effectiveness and fairness of the model training process, hyperparameter configurations were determined based on empirical settings from relevant literature and further optimized through a systematic grid search strategy. The final hyperparameter configuration is summarized in Table 2.
Table 2.
Hyperparameter setting.
To thoroughly assess the UEGT mechanism’s detection performance and robustness, several classical classification metrics were employed for model analysis.
4.2. Sensitivity and Ablation Analysis of the Payoff Function
This section provides a systematic analysis of the payoff function design in the UEGT framework from the perspective of module-wise ablation. The payoff function in UEGT consists of three independent modules, namely the Shapley value, gradient similarity, and data quality, which characterize a client’s participation value from complementary perspectives including global contribution, fairness consistency, and the reliability of local updates. To evaluate the independent contribution of each module as well as their combined effects on overall performance, we conduct a series of ablation and sensitivity experiments by intentionally retaining or removing specific modules in the payoff function and examining the resulting model performance.
4.2.1. Extreme Single-Module Ablation Analysis
We first consider an extreme single-module ablation setting, in which only one module is retained in the payoff function while all others are removed. The first three rows of Table 3 report the model performance when the payoff function is constructed using only the Shapley value (), only gradient similarity (), and only data quality (), respectively. It can be observed that when only the Shapley value module is retained, the model still achieves an average accuracy of 88.81% and an F1-score of 88.11%, which are close to the results obtained by the complete UEGT framework. This indicates that the Shapley value is capable of independently characterizing each client’s effective marginal contribution to the global model, even in the absence of auxiliary modules, thereby playing a core role in the payoff function design. In contrast, when gradient similarity alone is used as the payoff function, model performance degrades noticeably. An even more severe performance drop is observed when only the data quality module is employed. These results suggest that, without the constraint of global contribution information, the gradient similarity and data quality modules are insufficient to independently support effective client selection and incentive allocation. Their discriminative capability and stability are therefore inherently limited when used in isolation.
Table 3.
Comparison of model performance under different payoff weights.
Overall, the extreme single-module ablation results clearly demonstrate that the Shapley value is an indispensable component of the payoff function, whereas the other modules fail to achieve comparable performance when used alone.
4.2.2. Multi-Module Combination and Weight Sensitivity Analysis
Building upon the extreme single-module ablation analysis, we further investigate the performance of the payoff function when multiple modules are jointly employed. The last three rows of Table 3 present the model performance under different weight combinations of the Shapley value, gradient similarity, and data quality modules.
The system achieved its best performance when the weights were set to , , and , resulting in an average accuracy of 89.07% and an F1-score of 89.02%. These results even slightly outperform the extreme ablation case in which only the Shapley value is used. This finding indicates that, while maintaining the dominant role of the Shapley value, incorporating gradient similarity and data quality modules can effectively complement the payoff function and further enhance overall performance. As the weight of the Shapley value is gradually reduced and the weights of gradient similarity and data quality are increased, model performance exhibits a moderate downward trend. Nevertheless, the performance remains significantly superior to that achieved in the extreme ablation scenarios where gradient similarity or data quality is used alone.
It is worth emphasizing that the weight configuration , , and represents the optimal result obtained via grid search on the CICIoT2023 dataset under a label-flipping attack scenario involving 4 malicious clients out of 9 participating clients. We do not claim that this specific numerical setting is universally optimal across different datasets or attack conditions. Rather than serving as a fixed parameter choice, its primary significance lies in revealing, based on the experimental results in Table 3, the relative importance among the constituent modules of the payoff function.
By jointly considering the results of the extreme single-module ablation and the multi-module combination experiments, it can be observed that the contributions of different modules to the overall system performance are not equivalent, but instead exhibit a stable hierarchical importance relationship. Specifically, the Shapley value module is able to independently support effective client evaluation even in the absence of auxiliary information, and thus constitutes the core component of the payoff function. Compared with the data quality module, gradient similarity contributes more substantially to performance improvement; under the premise of preserving the dominant role of the Shapley value, it provides an effective complement for assessing update consistency. In contrast, the data quality module mainly acts as an additional constraint to mitigate the impact of local training instability. This hierarchical relationship remains relatively stable across different weight combinations. Accordingly, we regard the above weight configuration as a representative reference setting, whose core value lies in clarifying the ordering principle of relative importance among the modules in the payoff function design. In practical applications, the specific weights can be appropriately adjusted according to data distribution characteristics and attack types. Nevertheless, the Shapley value module should remain dominant, with gradient similarity preferentially incorporated as an auxiliary discriminative signal, and the data quality module further introduced as a complementary constraint, so as to ensure the rationality and stability of the payoff function across diverse scenarios.
From the above experimental results, it can be concluded that the modules within the UEGT payoff function serve distinct yet complementary roles in the overall framework. Specifically, the Shapley value module plays a dominant role in performance improvement, while the gradient similarity and data quality modules mainly contribute to enhancing the stability and robustness of the training process.
4.3. Client Strategy Evolution Analysis
To comprehensively evaluate the proposed UEGT mechanism, this section analyzes the evolutionary characteristics of client selection strategies throughout the training process.
4.3.1. Evolution of Client Participation Probability
To assess the effectiveness of the UEGT in guiding the evolution of client participation strategies, we first examine the changes in client participation probabilities over time. At the initial training stage, the system adopts a uniform round-robin strategy, ensuring that all clients have an equal opportunity to participate. However, as training progresses, the participation probability of each client begins to adjust according to its contribution, with the system gradually favoring high-contribution benign clients while suppressing the participation of malicious ones.
As shown in Figure 6a, the evolution of participation probability for each client during training is illustrated. With the increase in communication rounds, the participation probability of benign clients rises steadily, indicating that consistently well-performing nodes are preferentially selected for model updates. Conversely, the participation probability of malicious clients decreases progressively and eventually stabilizes at a low level. This phenomenon validates the capability of the UEGT mechanism to achieve survival of the fittest in dynamic federated environments, that is, the system adaptively reinforces the selection of high-contribution clients while diminishing reliance on adversarial participants. Figure 6b further presents the evolution of the average participation probability across all clients, reinforcing the observed trend. The participation rate of benign clients continuously increases, while that of malicious clients declines sharply. These results indicate that, after multiple communication rounds, the system effectively distinguishes clients with different contribution levels and dynamically adjusts the selection strategy based on their historical performance.
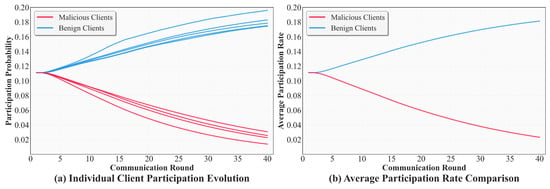
Figure 6.
Client participation probability evolution.
4.3.2. Evolution of Shapley Value and Client Contribution Modeling
In the UEGT mechanism, the system uses the Shapley value to quantify each client’s marginal contribution in every communication round and dynamically adjust its participation probability accordingly. This allows the system to more accurately assess client contributions and achieve adaptive client selection throughout training.
Figure 7 illustrates the evolution of Shapley values for all clients over the entire training process. The Y-axis represents client indices, where red labels denote malicious clients, and black labels indicate benign clients. As shown in the figure, benign clients typically exhibit relatively high Shapley values from the early training rounds, which subsequently stabilize within the range of 0 to 0.2, demonstrating strong persistence and stability. This observation indicates that the system can rapidly identify and incentivize clients with consistently positive contributions, granting them higher participation priority and effectively leveraging their input to optimize global model performance. In contrast, malicious clients generally start with low Shapley values, contributing insignificantly to the global model. As training progresses, their Shapley values decline further and frequently become negative in the mid-to-late stages. The corresponding heatmap colors gradually transition from bright to dark, reflecting a substantial decrease in contribution. This trend reveals that, through long-term observation and cumulative performance assessment, the system effectively identifies malicious behaviors and progressively suppresses their participation in subsequent rounds.
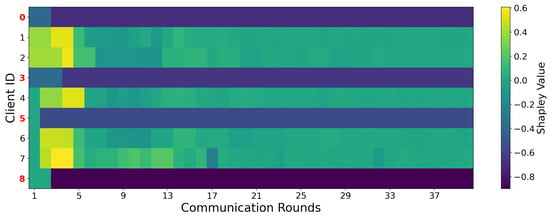
Figure 7.
Heatmap of client Shapley value evolution.
4.3.3. Strategy Evolution Driven by Multi-Dimensional Payoffs
Within the UEGT mechanism, the evolution of client selection strategies is not solely determined by Shapley values but also integrates gradient similarity and data quality as additional payoff dimensions. Figure 8 presents the average payoffs of benign and malicious clients across different communication rounds. It is important to note that the first two rounds correspond to the initial round-robin phase, during which all clients receive zero payoffs since the system has not yet begun to adjust participation probabilities based on contributions. This stage ensures that each client has the opportunity to engage in preliminary training and evaluation.
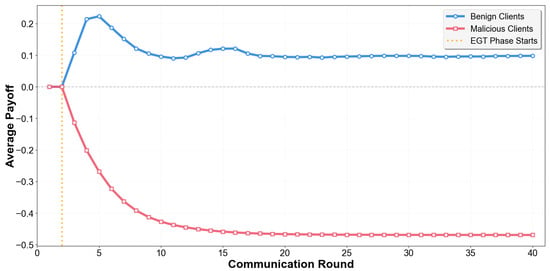
Figure 8.
Comparison of average payoff between benign and malicious clients.
Once the system transitions into the EGT-based client selection phase, client payoffs begin to diverge. The average payoff of benign clients shows a rapid increase during the early rounds, then gradually stabilizes at a positive value around 0.1, indicating their sustained contribution and strong stability in global model training. In EGT, a positive payoff signifies a client’s beneficial impact on the system, implying a higher survival likelihood and sustained participation opportunities. Conversely, the average payoff of malicious clients declines continuously, stabilizing around −0.47 after approximately the 15th round. A negative payoff indicates a client’s detrimental impact on the system and signifies its eventual elimination from the strategic game, after which it no longer affects the global model. As the number of communication rounds increases, the payoff gap between benign and malicious clients progressively widens. Initially, the difference between the two groups is minimal; however, as the system refines its contribution assessment and adaptive feedback mechanisms, the benign clients’ payoffs rise and then stabilize at a positive level, while those of malicious clients steadily decline, leading to a pronounced divergence. This process exemplifies the survival of the fittest principle inherent in the UEGT mechanism, whereby the system dynamically adjusts participation probabilities to marginalize malicious clients and retain high-contribution clients, ultimately enhancing the robustness and performance of the FL system.
4.4. Uncertainty-Guided Strategy Evolution Analysis
In FL scenarios, client selection strategies are typically updated based on historical payoffs to enhance model performance and system robustness. However, under complex conditions such as data heterogeneity and training process unobservability, strategies that overly depend on past performance may converge prematurely to local optima, causing potentially valuable clients to be consistently overlooked. This limitation can hinder further improvement of the global model. To tackle this problem, we introduce uncertainty modeling to enhance the system’s exploration capability and overall performance.
4.4.1. Comparative Analysis Between EGT and UEGT Mechanisms
From a module-ablation perspective, UEGT can be regarded as an extended form of the standard EGT mechanism with the incorporation of uncertainty-guided strategies. Accordingly, this section conducts a comparative analysis between the standard EGT and UEGT mechanisms in terms of detection performance and strategic behavior during the training process, with a particular focus on differences in model performance and client scheduling strategies. As shown in Table 4, under identical conditions of communication rounds, attack ratio, and model architecture, UEGT outperforms EGT across all performance metrics. Specifically, the average accuracy improves from 89.01% to 89.07%, while the average F1-score increases from 88.56% to 89.02%, demonstrating that UEGT achieves superior overall robustness and detection capability. It is noteworthy that UEGT’s performance improvement is not primarily due to enhanced malicious client identification. As illustrated in Figure 9, the cumulative selection counts of the four malicious clients (Clients 0, 3, 5, and 8) are nearly identical under both mechanisms, with five selections under EGT and six selections under UEGT, and only a minor discrepancy for Client 3. This indicates that both mechanisms exhibit comparable effectiveness in suppressing adversarial behaviors, and the exploratory component introduced by UEGT does not compromise its defense capability.
Table 4.
EGT and UEGT mechanism performance comparison.
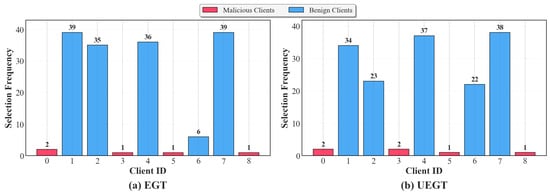
Figure 9.
Comparison of client selection frequency distributions under EGT and UEGT mechanisms.
The key factor underlying UEGT’s superior performance lies in its more intelligent client selection strategy for benign participants. During the evolutionary process, the standard EGT mechanism exhibits a strong bias toward a small subset of high-payoff nodes (e.g., Clients 1, 2, 4, and 7), which dominate participation opportunities throughout training. In contrast, Client 6, despite being a benign node with high latent contribution potential, is selected only six times under the EGT mechanism, which is an evident manifestation of strategy convergence bias. This phenomenon reflects that, when driven purely by immediate payoff optimization, EGT tends to develop path dependence, favoring nodes with early strong performance while neglecting others with delayed but significant potential. Consequently, the system becomes trapped in a locally optimal solution space, limiting further global optimization. In comparison, UEGT effectively alleviates this issue by incorporating uncertainty modeling into the strategy evolution process. This design introduces a moderate degree of exploratory behavior, enabling the system to recognize and activate previously undervalued high-potential clients. Under UEGT, Client 6’s cumulative participation count increases significantly from 6 to 22, indicating that the system successfully overcomes early convergence bias and transitions from a “locally optimal four-node combination” to a “globally optimal five-node configuration.” This structural transformation in client selection distribution represents the fundamental reason behind UEGT’s performance improvement, highlighting its ability to achieve a balanced trade-off between exploitation and exploration.
4.4.2. Analysis of the Impact of the Exploration Factor
To further investigate the influence of exploration intensity on the performance of the UEGT Mechanism, we performed comparative analyses under various settings of the exploration parameter. It is worth noting that when , the system degenerates into the standard EGT mechanism, whose performance characteristics and strategic behaviors have been thoroughly discussed in the previous section and will not be repeated here. Table 5 summarizes the average performance under different exploration factor settings.
Table 5.
Average performance of UEGT under different exploration factors.
As shown in the table, the configuration of the exploration factor affects overall system performance. When , the system exhibits a relatively conservative strategy, achieving 88.83% accuracy and 88.49% F1-score. As increases, the system’s exploratory capability is gradually enhanced. When , UEGT achieves optimal performance across all metrics, with the average accuracy improving to 89.07%, precision and recall reaching 91.83% and 89.07%, respectively, and the F1-score increasing to 89.02%. These results indicate that a moderate level of exploration helps mitigate the path dependence formed during early-stage strategy convergence, enabling the system to effectively identify and activate potentially high-value clients, thereby enhancing detection performance of the global model. However, as the exploration factor continues to increase to 0.5, 0.7, and 0.9, system performance begins to deteriorate, with the average accuracy dropping to 88.50%, 88.51%, and 87.46%, respectively. In these cases, the strategy evolution process becomes overly exploratory, causing the system to excessively favor clients with high uncertainty. This behavior increases the likelihood of introducing noise or anomalous updates, ultimately degrading the overall performance of the global model.
It should be noted that , as the exploration factor, exhibits a certain degree of scenario dependency, and its optimal value may be influenced by the specific experimental configuration. Within the exploration–exploitation trade-off framework, an excessively large exploration weight may amplify the impact of uncertainty estimation errors during the strategy evolution process, whereas an overly small exploration strength may lead to premature strategy convergence, thereby limiting the effective identification of potentially high-value clients. Consequently, the choice of in this study represents an empirically optimal result obtained via validation-set-based grid search under the current experimental setting, rather than a universally optimal constant. In practical applications, to achieve a near-optimal exploration strength, can be appropriately adjusted through lightweight validation according to the specific task scenario, enabling effective adaptation to different deployment environments. As indicated by the results in Table 5, avoiding extreme values generally yields a reasonable balance between exploration capability and training stability, while excessively large values tend to induce over-exploration and result in performance degradation.
4.5. Comparison with Baseline Strategies
4.5.1. Comparison of Average Performance Metrics
To comprehensively evaluate the performance of the UEGT Mechanism in highly adversarial environments, this study considers a diverse set of representative client selection and robust federated learning strategies as baselines, including FedAvg-Random, FedAvg-Robin [9], PoC [27], Trimmed Mean [29], Krum [30], FLTrust [31], S-FedAvg [32], and GreedyFed [33]. These methods cover a wide spectrum of design paradigms, ranging from random sampling and static round-robin scheduling to robust aggregation, preference-based selection guided by local performance metrics, and Shapley value–based client contribution assessment. All experiments were conducted under an identical experimental setting, in which 4 out of 9 clients were malicious and performed label-flipping attacks.
Table 6 summarizes the average classification performance of different client selection strategies after 40 communication rounds in a high-threat environment. Overall, UEGT consistently outperforms all baseline methods across various performance metrics, demonstrating its superior robustness and discriminative capability. Even under the highly adversarial setting, UEGT achieves an average accuracy of 89.07% and an average F1-score of 89.02%, highlighting its strong detection and classification capabilities. In contrast, FedAvg-Random and FedAvg-Robin achieve only 56.89% and 51.36% accuracy, with F1-scores of 57.62% and 54.06%, respectively. These results indicate that memoryless client scheduling strategies, which lack mechanisms for evaluating historical contribution, fail to effectively distinguish between benign and malicious clients under sustained poisoning attacks, leading to severe model degradation. The Trimmed Mean method, as a robust aggregation strategy, mitigates the impact of abnormal updates to some extent by excluding extreme values, achieving an accuracy of 59.17%, slightly outperforming random selection. Conversely, Krum performs the worst (38.90% accuracy), likely due to its distance-based aggregation mechanism being misled by collective malicious gradients in high-attack scenarios, resulting in the selection of untrustworthy clients [46]. The PoC strategy achieves 47.10% accuracy, performing between Krum and FedAvg-Robin.
Table 6.
Average classification performance of different client selection strategies under label-flipping attacks.
FLTrust, as a classical robust FL method for defending against poisoning attacks, demonstrates improved resilience compared to most traditional robust aggregation strategies, achieving an accuracy of 73.49%. This result validates the effectiveness of trust-guided mechanisms in mitigating malicious updates. However, because FLTrust heavily relies on a small trusted root dataset maintained at the server, its performance remains bounded when the proportion of malicious clients is high. GreedyFed and S-FedAvg, both of which are Shapley value–based client selection methods, achieve strong classification performance in this experiment, with accuracies of 88.60% and 88.44%, respectively. These results demonstrate that Shapley values are highly effective in characterizing client contribution, thereby substantially improving client selection quality and overall model performance. Although the performance of GreedyFed and S-FedAvg is very close to that of UEGT, both methods still exhibit certain limitations and potential risks in their client decision mechanisms. These effects will be further analyzed in subsequent sections via convergence behavior and client selection dynamics.
From the perspective of computational efficiency, UEGT’s total runtime is 504.32 s, which is slightly higher than that of most baseline methods but significantly lower than that of PoC (609.50 s). The additional computational overhead primarily arises from UEGT’s multi-dimensional metric evaluation and uncertainty modeling, particularly the Shapley value computation and the replicator dynamics-based strategy updates, which introduce extra processing during each communication round. Nevertheless, considering the significant improvement in classification performance, this computational cost is acceptable.
4.5.2. Convergence Trend Analysis
To further compare the dynamic performance evolution of different client selection strategies during the communication process, Figure 10 illustrates the accuracy trends of all methods over 40 communication rounds. As observed in the figure, the proposed UEGT mechanism exhibits the fastest convergence rate and superior stability. During the first fifteen communication rounds, its accuracy rapidly increases and stabilizes, subsequently maintaining a consistently high level above 98% with minimal fluctuations. This indicates that the uncertainty-guided strategy evolution mechanism designed in UEGT not only effectively filters out malicious clients but also ensures the stable participation of high-quality nodes, thereby significantly enhancing both the overall performance and robustness of the federated model.
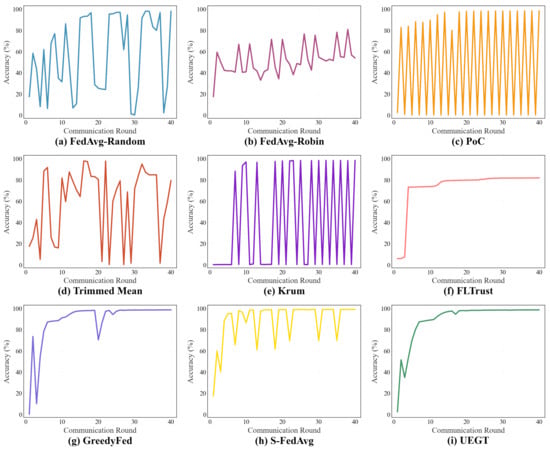
Figure 10.
Accuracy convergence trends of different client selection strategies under the highly adversarial setting.
In contrast, the FedAvg-Random and FedAvg-Robin strategies, both memoryless selection mechanisms, exhibit pronounced oscillations in accuracy throughout the entire communication process. Due to the absence of any behavior-feedback capability, these strategies frequently select malicious clients for training, causing repeated disruptions to the model and preventing effective convergence. The Trimmed Mean method demonstrates limited mitigation against abnormal updates in certain communication rounds; however, its accuracy still fluctuates considerably, showing a strong cyclical oscillation pattern. This result suggests that its robustness remains insufficient under high-proportion poisoning attacks. The Krum algorithm performs the worst, with accuracy values oscillating drastically between 0% and nearly 100%, and even dropping close to 0% for several consecutive rounds. This severe instability indicates that its distance-based aggregation mechanism becomes almost completely ineffective under the high-adversarial setting. Similarly, the PoC strategy also displays high-frequency, large-amplitude fluctuations in accuracy. Although occasional performance spikes can be observed, its overall stability is poor and average performance remains suboptimal.
The accuracy curve of FLTrust exhibits a relatively smooth and gradually convergent trend, indicating that the direction-constrained mechanism constructed based on a trusted root dataset can effectively suppress the disturbances caused by anomalous updates during the training process. However, while this mechanism limits the influence of malicious gradients, it also imposes strong constraints on the effective updates contributed by benign clients, rendering the model optimization process relatively conservative. As a result, under scenarios with a high proportion of malicious clients, the final convergence performance is noticeably constrained. The convergence curves of GreedyFed and S-FedAvg demonstrate relatively rapid accuracy improvement and maintain high accuracy levels across most communication rounds. GreedyFed exhibits relatively noticeable fluctuations only in a few communication rounds. In contrast, the accuracy curve of S-FedAvg shows multiple fluctuations during training. This behavior primarily stems from the fact that S-FedAvg maps clients’ Shapley values into relevance scores and subsequently converts them into selection probabilities via a softmax function, which allows clients with lower contributions to still be selected in certain communication rounds. In scenarios with a high proportion of malicious clients, this probabilistic selection mechanism may lead to intermittent participation of malicious nodes, thereby introducing disturbances into the model convergence process.
4.5.3. Comparison of Client Selection Distributions
To further reveal the behavioral differences among various client selection strategies, particularly their ability to identify and respond to malicious clients, this study analyzes the cumulative selection frequencies of all clients throughout the training process, as illustrated in Figure 11.
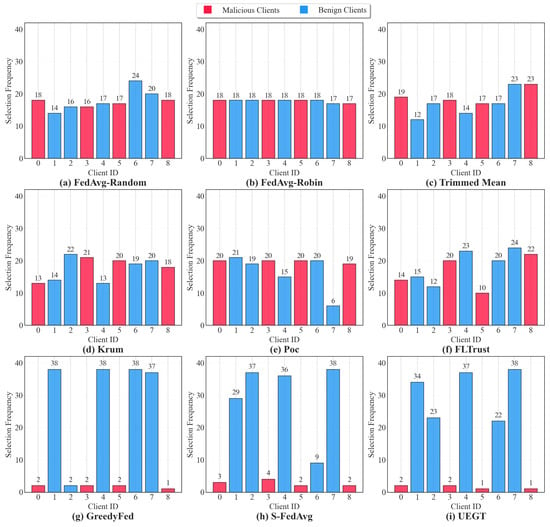
Figure 11.
Selection frequency distribution of different client selection strategies under the highly adversarial setting.
As observed, both FedAvg-Random (Figure 11a) and FedAvg-Robin (Figure 11b) lack any form of behavioral feedback. Consequently, their client selection frequencies remain nearly uniform across all nodes, with malicious and benign clients being selected with almost equal probability. This indiscriminate scheduling allows malicious clients to participate persistently in model training, severely compromising system stability and security. Although Trimmed Mean (Figure 11c) and Krum (Figure 11d) incorporate certain robustness mechanisms during the aggregation phase, their defensive effectiveness deteriorates significantly in the highly adversarial poisoning setting, where 4 out of 9 clients are malicious and perform label-flipping attacks. Malicious clients continue to be frequently selected, and in some communication rounds, even dominate participation. This behavior indicates that their defense mechanisms largely collapse under high-intensity poisoning conditions. Similarly, the PoC strategy (Figure 11e) also demonstrates weak discriminative capability, as the selection frequencies of malicious clients are comparable to those of benign ones, showing little evidence of effective suppression.
The client selection frequency distribution of FLTrust (Figure 11f) does not exhibit clear discrimination; nevertheless, its overall performance remains superior to that of defense-free FedAvg-based methods. This improvement primarily stems from the trust-constrained aggregation mechanism based on a reference gradient introduced at the aggregation stage. However, under highly adversarial settings, certain malicious gradients may still maintain positive similarity with the reference direction and thus bypass the filtering process. The accumulated effect of such gradients ultimately limits the convergence performance of FLTrust. GreedyFed (Figure 11g) and S-FedAvg (Figure 11h), as Shapley value–based client selection approaches, substantially increase the scheduling frequency of benign clients while significantly reducing the participation of malicious ones. GreedyFed relies on a greedy selection strategy that rapidly locks onto a small subset of clients with high Shapley values during the early training stage and continuously reinforces this selection preference in subsequent communication rounds, resulting in their frequent participation throughout training. Although this strategy effectively suppresses malicious clients, it may also cause potentially valuable clients to be persistently overlooked, leading to convergence toward a locally optimal client subset. S-FedAvg similarly evaluates client contributions using Shapley values and introduces a certain degree of exploration through probabilistic sampling. Nevertheless, its selection distribution remains noticeably imbalanced. Since probabilistic sampling theoretically preserves a nonzero selection probability for all clients, malicious clients may still be selected in some communication rounds.
In contrast, the proposed UEGT mechanism (Figure 11i) exhibits a distinctly structured and selective scheduling pattern. Throughout the entire training process, malicious clients are selected only rarely, participating at most two times, while benign clients are consistently prioritized, with several being selected more than 34 times. This highly differentiated distribution demonstrates that UEGT, without relying on any prior knowledge of malicious nodes, can autonomously and dynamically distinguish client reliability through its evolutionary dynamics and uncertainty-guided modeling. As a result, the mechanism achieves high-precision client selection, enabling the sustained utilization of high-quality clients and the proactive suppression of potential threats.
4.6. Discussion
The preceding experimental results clearly demonstrate that the UEGT mechanism significantly enhances the robustness and security of FIDS. Notably, even in adversarial scenarios containing a high proportion of malicious clients, UEGT consistently maintains superior detection performance, exhibiting strong resistance to attacks and excellent system stability.
From the perspective of strategy evolution, UEGT initially adopts a round-robin selection scheme to ensure that all clients have opportunities to participate in training, thereby establishing a comprehensive behavioral observation foundation for the system. As the evolutionary process progresses, the system gradually prioritizes clients with superior historical performance for model updates. Experimental results indicate that the participation probabilities of benign clients increase progressively over communication rounds, while those of malicious clients are gradually suppressed. This survival-of-the-fittest evolutionary pattern aligns well with the system’s intended security objectives, effectively mitigating the destructive effects of poisoning on the global model. By integrating uncertainty modeling into the original EGT framework, UEGT not only strengthens the preference for consistently reliable clients but also enables dynamic identification of previously underestimated high-value nodes, thereby improving both adaptability and diversity in client participation. Furthermore, comparative experiments with other client selection strategies provide strong empirical validation of UEGT’s superiority. In terms of average performance metrics, UEGT outperforms all baseline methods in key indicators such as accuracy and F1 score. Even under an extreme adversarial setting with 4 out of 9 clients being malicious, UEGT maintains an average accuracy of nearly 90% with a stable convergence trend, surpassing competing approaches. In addition, UEGT exhibits a more desirable client selection distribution. Experimental statistics show that both UEGT and standard EGT mechanisms achieve similar effectiveness in suppressing malicious clients, with the cumulative selection frequencies of attack nodes remaining at low levels. This finding indicates that the incorporation of exploration in UEGT does not compromise its security awareness. Instead, UEGT provides structural optimization in the allocation of benign client resources by successfully activating underutilized high-potential clients and preventing excessive selection concentration on a few nodes, thereby achieving a more balanced scheduling pattern and stronger generalization capability. Overall, UEGT demonstrates distinct advantages in enhancing robustness, improving system performance, and safeguarding training security. It not only extends the historical reward-driven characteristics embedded in the EGT framework but also introduces an uncertainty-based reward mechanism that grants the system greater adaptability and exploratory capacity. As a result, UEGT maintains resilient and flexible client selection behavior even in the presence of highly adversarial threat environments, providing an intelligent and secure scheduling framework for FIDS.
Nevertheless, UEGT still presents several aspects that can be further optimized. While its multi-dimensional evaluation and uncertainty modeling enhance the accuracy of client selection and improve overall system robustness, they also introduce additional computational overhead. This overhead becomes particularly significant when a large number of clients are selected in each communication round, in which case the computation of Shapley values and the subsequent strategy integration process may emerge as performance bottlenecks. Future research will therefore focus on improving computational efficiency, for example, by adopting approximate sampling-based marginal contribution estimation methods to reduce the complexity of Shapley value computation. In addition, the experiments in this study are conducted in a synchronous FL simulation environment and assume that the selected clients can consistently obtain sufficient computational and communication resources in each communication round to complete local training and model upload in a timely manner. Consequently, system-level instabilities that are prevalent in real-world IoT scenarios, including resource contention, task queuing, and queuing delays, are not considered. Under resource-constrained conditions or in the presence of concurrent multi-task execution, such instabilities may further amplify the waiting overhead inherent in synchronous mechanisms and adversely affect the timeliness and stability of historical payoff feedback during the strategy evolution process. Future work will therefore emphasize enhancing the practicality and generality of the proposed mechanism by incorporating models of resource competition and queuing delays into FL simulations. This will enable a systematic evaluation of the performance and stability of UEGT in environments that more closely resemble realistic IoT deployments, thereby further validating its feasibility for real-world implementation.
5. Conclusions
This paper proposes a UEGT client selection mechanism aimed at strengthening the robustness and detection performance of FIDS in IoT environments. The proposed mechanism is grounded in evolutionary game theory, where clients are modeled as game participants, and strategy evolution is driven by historical payoff feedback. UEGT constructs a multi-dimensional payoff function by integrating Shapley value, gradient similarity, and data quality, enabling the system to adaptively adjust each client’s participation probability through replicator dynamics. This process encourages the aggregation of strategies toward high-contribution clients, thereby achieving dynamic suppression of malicious nodes and priority scheduling of trustworthy participants. Building on this foundation, UEGT incorporates a Beta-based uncertainty modeling mechanism to capture fluctuations in client contribution. This uncertainty serves as an exploration incentive, enabling the system to reinforce participation from stable clients while still identifying and activating previously underestimated high-potential ones. Experimental results demonstrate that UEGT maintains a stable convergence trend even under extreme adversarial conditions with a high proportion of malicious clients. The proposed mechanism achieves an average accuracy exceeding 89%, outperforming conventional client selection and robust aggregation methods. UEGT not only enhances the system’s security awareness but also improves scheduling balance, exhibiting comprehensive advantages in terms of model performance and robustness.
Future research will focus on further improving the practicality and generalizability of UEGT. First, efforts will focus on optimizing computational efficiency by reducing additional overhead while preserving robustness and accuracy, thereby enabling effective operation on resource-constrained IoT devices. Furthermore, more realistic modeling of resource constraints in IoT environments will be incorporated to systematically evaluate the impact of resource contention and system instability on performance in real-world deployments.
Author Contributions
Conceptualization, H.P. and C.W.; methodology, H.P.; software, H.P.; validation, H.P. and Y.X.; formal analysis, H.P. and Y.X.; investigation, H.P. and Y.X.; resources, C.W.; writing—original draft preparation, H.P.; writing—review and editing, C.W. and Y.X.; visualization, H.P.; supervision, C.W.; project administration, H.P. and C.W.; funding acquisition, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the “Pioneer” and “Leading Goose” R&D Program of Zhejiang (2024C01066).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study used a publicly available dataset (accessed on 1 December 2025): the CICIoT2023 dataset (https://www.unb.ca/cic/datasets/iotdataset-2023.html).
Conflicts of Interest
Author Yanfeng Xiao was employed by the company China Mobile Group Huzhou Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Sadhu, P.K.; Yanambaka, V.P.; Abdelgawad, A. Internet of things: Security and solutions survey. Sensors 2022, 22, 7433. [Google Scholar] [CrossRef] [PubMed]
- Mishra, N.; Pandya, S. Internet of things applications, security challenges, attacks, intrusion detection, and future visions: A systematic review. IEEE Access 2021, 9, 59353–59377. [Google Scholar] [CrossRef]
- Mahadevappa, P.; Al-amri, R.; Alkawsi, G.; Alkahtani, A.A.; Alghenaim, M.F.; Alsamman, M. Analyzing threats and attacks in edge data analytics within IoT environments. IoT 2024, 5, 123–154. [Google Scholar] [CrossRef]
- Xu, H.; Seng, K.P.; Ang, L.M.; Smith, J. Decentralized and distributed learning for AIoT: A comprehensive review, emerging challenges, and opportunities. IEEE Access 2024, 12, 101016–101052. [Google Scholar] [CrossRef]
- Beltrán, E.T.M.; Pérez, M.Q.; Sánchez, P.M.S.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun. Surv. Tutor. 2023, 25, 2983–3013. [Google Scholar] [CrossRef]
- Chen, C.; Liu, J.; Tan, H.; Li, X.; Wang, K.I.K.; Li, P.; Sakurai, K.; Dou, D. Trustworthy federated learning: Privacy, security, and beyond. Knowl. Inf. Syst. 2025, 67, 2321–2356. [Google Scholar] [CrossRef]
- Abbas, S.R.; Abbas, Z.; Zahir, A.; Lee, S.W. Federated learning in smart healthcare: A comprehensive review on privacy, security, and predictive analytics with IoT integration. Healthcare 2024, 12, 2587. [Google Scholar] [CrossRef]
- Imteaj, A.; Thakker, U.; Wang, S.; Li, J.; Amini, M.H. A survey on federated learning for resource-constrained IoT devices. IEEE Internet Things J. 2021, 9, 1–24. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Ft. Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, S.; Mao, L.; Ning, H. Anomaly detection and defense techniques in federated learning: A comprehensive review. Artif. Intell. Rev. 2024, 57, 150. [Google Scholar] [CrossRef]
- Xu, R.; Pokhrel, S.R.; Lan, Q.; Li, G. FAIR-BFL: Flexible and incentive redesign for blockchain-based federated learning. In Proceedings of the 51st International Conference on Parallel Processing, Bordeaux, France, 29 August–1 September 2022; pp. 1–11. [Google Scholar]
- Fu, L.; Zhang, H.; Gao, G.; Zhang, M.; Liu, X. Client selection in federated learning: Principles, challenges, and opportunities. IEEE Internet Things J. 2023, 10, 21811–21819. [Google Scholar] [CrossRef]
- Smith, J.M.; Price, G.R. The logic of animal conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- Taylor, P.D.; Jonker, L.B. Evolutionary stable strategies and game dynamics. Math. Biosci. 1978, 40, 145–156. [Google Scholar] [CrossRef]
- Smith, J.M. Evolution and the Theory of Games. In Did Darwin Get It Right? Essays on Games, Sex and Evolution; Springer: Boston, MA, USA, 1982; pp. 202–215. [Google Scholar]
- Josang, A.; Ismail, R. The beta reputation system. In Proceedings of the 15th Bled Electronic Commerce Conference, Bled, Slovenia, 17–19 June 2002; Volume 5, pp. 2502–2511. [Google Scholar]
- Rashid, M.M.; Khan, S.U.; Eusufzai, F.; Redwan, M.A.; Sabuj, S.R.; Elsharief, M. A federated learning-based approach for improving intrusion detection in industrial internet of things networks. Network 2023, 3, 158–179. [Google Scholar] [CrossRef]
- Benameur, R.; Dahane, A.; Souihi, S.; Mellouk, A. A novel federated learning based intrusion detection system for iot networks. In Proceedings of the ICC 2024-IEEE International Conference on Communications, Denver, CO, USA, 9–13 June 2024; pp. 2402–2407. [Google Scholar]
- Shibly, K.H.; Hossain, M.D.; Inoue, H.; Taenaka, Y.; Kadobayashi, Y. Personalized federated learning for automotive intrusion detection systems. In Proceedings of the 2022 IEEE Future Networks World Forum (FNWF), Montreal, QC, Canada, 12–14 October 2022; pp. 544–549. [Google Scholar]
- Zhang, X.; Li, Y.; Gong, T.; Wang, Z.; Wang, F. FedKSam*: A Two-Phase Federated Learning Intrusion Detection Algorithm. In Proceedings of the 2024 43rd Chinese Control Conference (CCC), Kunming, China, 28–31 July 2024; pp. 8827–8831. [Google Scholar]
- Zhao, P.; Cao, Z.; Jiang, J.; Gao, F. Practical private aggregation in federated learning against inference attack. IEEE Internet Things J. 2022, 10, 318–329. [Google Scholar] [CrossRef]
- Khajehali, N.; Yan, J.; Chow, Y.W.; Fahmideh, M. A comprehensive overview of IoT-based federated learning: Focusing on client selection methods. Sensors 2023, 23, 7235. [Google Scholar] [CrossRef]
- Li, J.; Chen, T.; Teng, S. A comprehensive survey on client selection strategies in federated learning. Comput. Netw. 2024, 251, 110663. [Google Scholar] [CrossRef]
- Liang, H.; Liu, D.; Zeng, X.; Ye, C. An intrusion detection method for advanced metering infrastructure system based on federated learning. J. Mod. Power Syst. Clean Energy 2022, 11, 927–937. [Google Scholar]
- Nobakht, M.; Javidan, R.; Pourebrahimi, A. SIM-FED: Secure IoT malware detection model with federated learning. Comput. Electr. Eng. 2024, 116, 109139. [Google Scholar]
- Cho, Y.J.; Wang, J.; Joshi, G. Towards understanding biased client selection in federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 28–30 March 2022; pp. 10351–10375. [Google Scholar]
- Xia, G.; Chen, J.; Yu, C.; Ma, J. Poisoning attacks in federated learning: A survey. IEEE Access 2023, 11, 10708–10722. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 118–128. [Google Scholar]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. Fltrust: Byzantine-robust federated learning via trust bootstrapping. arXiv 2020, arXiv:2012.13995. [Google Scholar]
- Nagalapatti, L.; Narayanam, R. Game of gradients: Mitigating irrelevant clients in federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9046–9054. [Google Scholar]
- Singhal, P.; Pandey, S.R.; Popovski, P. Greedy shapley client selection for communication-efficient federated learning. IEEE Netw. Lett. 2024, 6, 134–138. [Google Scholar] [CrossRef]
- Kang, N.; Lim, Y.; Im, J. Optimizing Federated Learning: Addressing Key Challenges in Real-World Applications. IEEE Internet Things J. 2025, 12, 19065–19089. [Google Scholar] [CrossRef]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A real-time dataset and benchmark for large-scale attacks in IoT environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef]
- Kumar, K.N.; Mohan, C.K.; Cenkeramaddi, L.R. The impact of adversarial attacks on federated learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2672–2691. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, J.; Wang, X.; Hu, J.; Qin, Z.; Ren, K. Threats to training: A survey of poisoning attacks and defenses on machine learning systems. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Lavaur, L.; Busnel, Y.; Autrel, F. Investigating the Impact of Label-flipping Attacks against Federated Learning for Collaborative Intrusion Detection. Comput. Secur. 2025, 156, 104462. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Li, M.; Sun, H.; Huang, Y.; Chen, H. Shapley value: From cooperative game to explainable artificial intelligence. Auton. Intell. Syst. 2024, 4, 2. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, Y.; Jing, Z.; Zhou, Y.; Xin, Z. Federated Learning Poison Attack Detection Scheme Based on Gradient Similarity. In Emerging Information Security and Applications, Proceedings of the 5th International Conference, EISA 2024, Changzhou, China, 18–19 October 2024; Springer: Cham, Switzerland, 2024; pp. 20–36. [Google Scholar]
- Ren, P.; Qi, K.; Li, J.; Yan, T.; Dai, Q. CosPer: An adaptive personalized approach for enhancing fairness and robustness of federated learning. Inf. Sci. 2024, 675, 120760. [Google Scholar] [CrossRef]
- Song, S.; Li, Y.; Wan, J.; Fu, X.; Jiang, J. Data quality-aware client selection in heterogeneous federated learning. Mathematics 2024, 12, 3229. [Google Scholar] [CrossRef]
- Zeng, Y.; Teng, S.; Xiang, T.; Zhang, J.; Mu, Y.; Ren, Y.; Wan, J. A Client Selection Method Based on Loss Function Optimization for Federated Learning. Comput. Model. Eng. Sci. 2023, 137, 1047. [Google Scholar] [CrossRef]
- Campos, E.M.; Gonzalez-Vidal, A.; Hernández-Ramos, J.L.; Skarmeta, A. FedRDF: A robust and dynamic aggregation function against poisoning attacks in federated learning. IEEE Trans. Emerg. Top. Comput. 2024, 13, 48–67. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.