
Construction of Journal Knowledge Graph Based on Deep Learning and LLM


Abstract
1. Introduction
- We construct the journal knowledge graph by integrating structured, semi-structured, and unstructured data with the BERT-BiLSTM-CRF model for entity and relation extraction.
- We propose JKG-LLM, a journal knowledge graph-based question-answering system that enhances response accuracy through retrieval-augmented generation.
2. The Construction of Journal Knowledge Graph
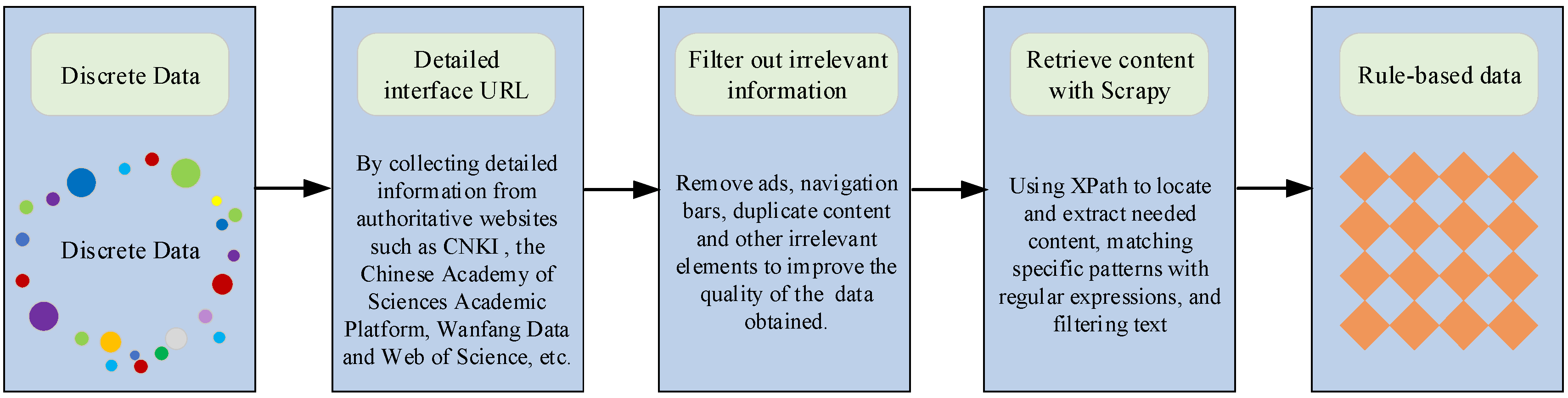
2.1. Dataset Acquisition
2.2. Knowledge Extraction
2.3. Knowledge Fusion
2.4. Ontology Construction
2.5. Knowledge Storage and Visualization
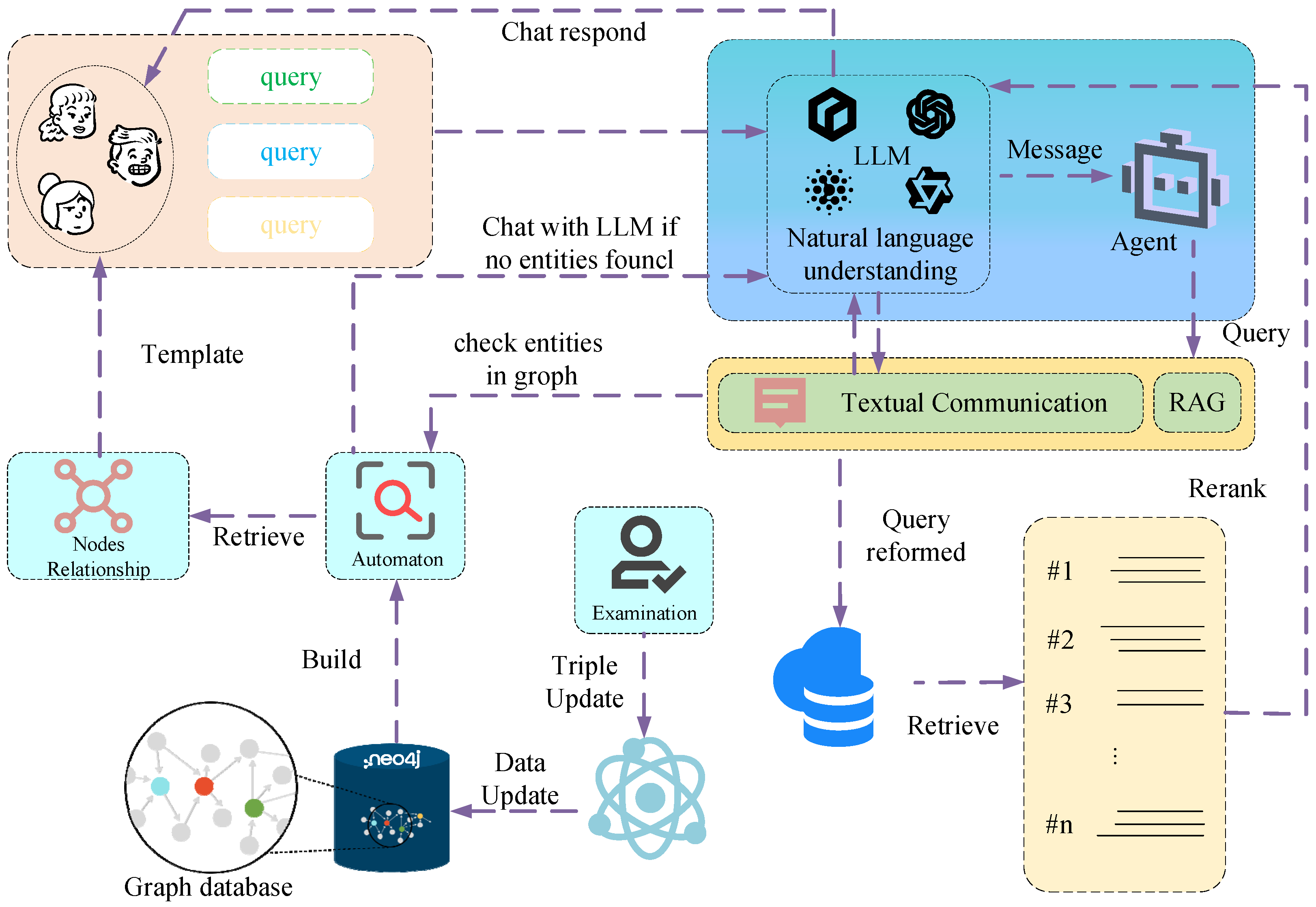
3. The Question Answering System Based on Journal Knowledge Graph
3.1. Knowledge Query
- MATCH (n)
- WHERE n.Source= ‘Proceedings of the IEEE’
- RETURN n
3.2. Question Answering
- MATCH (j:Journal)-[:OWNS]->(m:Major)
- WHERE m.name = “Database” AND j.WOS_partition = “Q1”
- RETURN j.name AS journal_name
4. Experiment
4.1. Datasets
4.2. Experimental Environment and Parameter Settings
4.3. Model Evaluation Metrics
4.4. Result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Suchanek, F.; Kasneci, G.; Weikum, G. YAGO: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; Xiao, Y. CN-DBpedia: A never-ending Chinese knowledge extraction system. In Proceedings of the 30th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; pp. 428–438. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Liu, Q.; Li, Y.; Duan, H.; Qin, Z. Knowledge graph construction techniques. J. Comput. Res. Dev. 2016, 53, 582–600. [Google Scholar]
- Zhang, S.; Wang, Z.; Wang, Z. Prediction of wheat stripe rust based on knowledge graph and bidirectional long short-term memory network. Trans. Chin. Soc. Agric. Eng. 2020, 36, 172–178. [Google Scholar]
- Wang, C.; Zhao, S.; Yan, T.; Song, S.; Ma, W.; Liu, K.; Wang, M. Hierarchical label-enhanced contrastive learning for Chinese NER. IEEE Trans. Neural Netw. Learn. Syst. 2025, 1–11. [Google Scholar] [CrossRef]
- Downey, D.; Broadhead, M.; Etzioni, O. Locating complex named entities in Web text. In Proceedings of the 20th International Joint Conferences on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2007; pp. 2733–2739. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web enhanced lexicons. In Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; pp. 188–191. [Google Scholar]
- Alex, G.; Jürgen, S.; Framewise, P. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. In Proceedings of the 2005 International Joint Conference on Neural Networks (IJCNN), Montreal, QC, Canada, 31 July–4 August 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 2047–2052. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and accurate entity recognition with iterated dilated convolutions. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2670–2680. [Google Scholar]
- Qiu, Q.; Xie, Z.; Wu, L.; Tao, L. GNER: A generative model for geological named entity recognition without labeled data using deep learning. Earth Space Sci. 2019, 6, 931–946. [Google Scholar] [CrossRef]
- Žukov-Gregorič, A.; Bachrach, Y.; Coope, S. Named entity recognition with parallel recurrent neural networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 69–74. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Yang, P.; Dong, W. Chinese named entity recognition method based on BERT embedding. Comput. Eng. 2020, 46, 40–45+52. [Google Scholar]
- Chen, Y.; Qi, X.; Huang, C.; Zheng, J. A data fusion method for maritime traffic surveillance: The fusion of AIS data and VHF speech information. Ocean. Eng. 2024, 311, 118953. [Google Scholar] [CrossRef]
- Zhu, S.; Jiang, Z.; Yan, W.; Gao, L.; Zhang, H. A knowledge graph-based intelligent planning method for remanufacturing processes of used parts. J. Eng. Des. 2025, 1–28. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. Comput. Sci. 2013, 1301, 4–8. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9–18. [Google Scholar]
- Tunstall, L.; Beeching, E.; Lambert, N.; Rajani, N.; Rasul, K.; Belkada, Y.; Huang, S.; Werra, L.; Fourrier, C.; Habib, N.; et al. Zephyr: Direct distillation of lm alignment. arXiv 2023, arXiv:2310.16944. [Google Scholar]
- Siino, M.; Tinnirello, I. Prompt engineering for identifying sexism using GPT mistral 7B. In Proceedings of the CLEF 2024: Conference and Labs of the Evaluation Forum, Grenoble, France, 9–12 September 2024. [Google Scholar]
- Abdin, M.; Aneja, J.; Awadalla, H.; Awadallah, A.; Awan, A.; Bach, N.; Bahree, A.; Bakhtiari, A.; Bao, J.; Behl, H.; et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv 2024, arXiv:2404.14219. [Google Scholar]
- Chung, H.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 2024, 25, 1–53. [Google Scholar]
- Baker, P. ChatGPT Für Dummies; John Wiley & Sons: Hoboken, NJ, USA, 2025. [Google Scholar]
- Glm, T.; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. ChatGLM: A family of large language models from GLM-130B to GLM-4 All tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]
- Grattafiori, A.; Dubeya, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Raiaan, M.; Mukta, M.; Fatema, K.; Fahad, N.M.; Sakib, S.; Jannat, M.M.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large language models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Yang, H.; Liu, X.; Dan, W. FinGPT: Open-source financial large language models. arXiv 2023, arXiv:2306.06031. [Google Scholar] [CrossRef]
- Cui, J.; Li, Z.; Yan, Y.; Chen, B.; Yuan, L. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv 2024, arXiv:2306.16092. [Google Scholar]
- Nie, Y.; Kong, Y.; Dong, X.; Mulvey, J.; Poor, H.; Wen, Q.; Zohren, S. A survey of large language models for financial applications: Progress, prospects and challenges. arXiv 2024, arXiv:2406.11903. [Google Scholar]
- Zhou, S.; Liu, K.; Li, D.; Fu, C.; Ning, Y.; Ji, W.; Liu, X.; Xiao, B.; Wei, R. Augmenting general-purpose large-language models with domain-specific multimodal knowledge graph for question-answering in construction project management. Adv. Eng. Inform. 2025, 65, 103142. [Google Scholar] [CrossRef]
- Sun, J.; Xu, C.; Tang, L.; Wang, S.; Lin, C.; Gong, Y.; Ni, L.; Shum, H.; Guo, J. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024; pp. 1–9. [Google Scholar]
- Jiang, J.; Zhou, K.; Dong, Z.; Ye, K.; Zhao, W.; Wen, J. Structgpt: A general framework for large language model to reason over structured data. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 1–7. [Google Scholar]
- Feng, C.; Zhang, X.; Fei, Z. Knowledge solver: Teaching llms to search for domain knowledge from knowledge graphs. arXiv 2023, arXiv:2309.03118,. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Hou, Y.; Jeffrey, R.; Liu, H.; Zhang, R. Improving dietary supplement information retrieval: Development of a retrieval-augmented generation system with large language models. J. Med. Internet Res. 2025, 27, e67677. [Google Scholar] [CrossRef]
- Hang, C.; Tan, C.; Yu, P. MCQGen: A large language model-driven MCQ generator for personalized learning. IEEE Access 2024, 12, 102261–102273. [Google Scholar] [CrossRef]
- Mansurova, A.; Mansurova, A.; Nugumanova, A. QA-RAG: Exploring LLM reliance on external knowledge. Big Data Cogn. Comput. 2024, 8, 115. [Google Scholar] [CrossRef]
- Wang, J.; Guo, Y. Scrapy-based crawling and user-behavior characteristics analysis on Taobao. In Proceedings of the 2012 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Sanya, China, 10–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 44–52. [Google Scholar]
- Lin, H.; Wang, Y.; Jia, Y.; Zhang, P.; Wang, W. A review of knowledge fusion methods for network big data. Chin. J. Comput. 2017, 40, 1–27. [Google Scholar]
- Tian, L.; Zhang, Z.; Zhang, J.; Zhou, W.; Zhou, X. A review of knowledge graphs representation, construction, inference and knowledge hypergraph theory. J. Comput. Appl. 2021, 41, 2161–2186. [Google Scholar]
- Topsakal, O.; Akinci, T.C. Creating large language model applications utilizing langchain: A primer on developing llm apps fast. Int. Conf. Appl. Eng. Nat. Sci. 2023, 1, 1050–1056. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity | Relation | Attribute |
|---|---|---|
| International Journal of Computer Vision | Acceptance Difficulty | Fairly Difficult |
| International Journal of Computer Vision | Press | Springer US |
| International Journal of Computer Vision | WOS partition | Q 1 |
| International Journal of Computer Vision | Review Cycle | About 4.5 months |
| International Journal of Computer Vision | Major Category | Computer Science |
| Class | Data Property | Description |
|---|---|---|
| Domain | name | Name of the academic discipline, e.g., ”Computer Science” |
| Major | name | Specific research direction within a discipline, e.g., “Deep Learning” |
| Journal | Keywords, Cycle, Research fields, CAS partition, Acceptance difficulty, Indexing, Journal metrics, Journal count, ISSN, EISSN, Impact factor, H-index, Abstract, Official website, Contact information, Publisher, Research directions, Publication region, Annual article count, Gold OA article percentage, WOS partition, Warning list, CAS major partition, CAS minor partition, TOP journal, Review journals, SCI indexed, PMC link | Various attributes of journals |
| Citation Score | SNIP | Source Normalized Impact per Paper (Scopus SNIP) |
| Impact Factor | Last five-year impact factor, Annual impact factor | Annual impact factor |
| CAS partition | CAS major Partition, CAS minor Partition | Classification of the journal in the CAS (Chinese Academy of Sciences) system |
| Website | Journal website, Submission website | Websites related to the journal and its submission process |
| WOS partition | Discipline category | Discipline category in the Web of Science (WOS) |
| Publisher | Publication language, Publication year, Publication cycle, Publication region | Details about the publisher, including language, year, cycle, and region |
| Citation score | SNIP, SJR | Source Normalized Impact per Paper (SNIP), SCImago Journal Rank (SJR) |
| Object Property | Domain | Range |
|---|---|---|
| Contains | Domain | Major |
| Owns | Major | Journal |
| Owns | Journal | Keywords, Cycle, Research fields, CAS partition, Acceptance difficulty, Indexing, Journal metrics, Journal count, ISSN, EISSN, H-index, Abstract, Official website, Contact information, Publisher, Research directions, Publication region, Annual article count, Gold OA article percentage, WOS partition, Warning list, TOP journal, Review journals, SCI indexed, PMC link |
| Owns | CAS partition | CAS major Partition, CAS minor Partition |
| Owns | CAS major Partition | CAS Major Partition Rank |
| Owns | CAS minor Partition | CAS Minor Partition Rank |
| Submits to | website | Submission website, Journal website |
| Partition | WOS partition | Discipline category |
| Publication language | Publisher | Publication language |
| Publication year | Publisher | Year |
| Publication cycle | Publisher | Publication cycle |
| Publication region | Publisher | Region |
| SNIP metric | Citation score | SNIP |
| SJR metric | Citation score | SJR |
| Last five-year impact factor | Impact factor | Impact factor (last five years) |
| Annual impact factor | Impact factor | Impact factor (annual) |
| LLM | Question: I Have an Article in the Database Field and Would Like to Submit It to a SCI Zone 1 Journal. Can You Recommend Two Journals for Me? | Real Partition | Q&A Results | Applicable Scenarios |
|---|---|---|---|---|
| Generate Reply | ||||
| ChatGPT | The International Journal on Very Large Data Bases, ACM Transactions on Database Systems | Q2 Q2 | × | General Q&A |
| JKG-LLM | Advanced Engineering Informatics, Information Processing and Management | Q1 Q1 | √ | Domain-specific journal recommendations |
| ChatGLM | ACM Transactions on Database Systems, IEEE Transactions on Knowledge and Data Engineering | Q2 Q1 | × | General Q&A |
| Qwen | IEEE Transactions on Knowledge and Data Engineering, ACM Transactions on Database Systems | Q1 Q2 | × | General Q&A |
| 01.AI | Effectiveness of Journals Funded by Category D of the China Science and Technology Journal International Influence Enhancement Program—Inclusion in SCIE/SSCI, Impact Analysis of Chinese Scientific and Technical Journals Indexed by Scopus | Two articles | × | General Q&A |
| Ernie Bot | ACM Transactions on Database Systems, The VLDB Journal | Q2 Q2 | × | General Q&A |
| Deepseek | IEEE Transactions on Knowledge and Data Engineering, ACM Transactions on Database Systems | Q1 Q2 | × | General Q&A |
| OpenAlex | PubMed, PubMed Central | Error | × | Domain Q&A |
| Parameter Category | Value |
|---|---|
| Embedding_dim | 100 |
| Max_seq_len | 256 |
| Hidden_dim | 512 |
| Batch_size | 32 |
| Learning_rate | 2 × 10−5 |
| Optimizer | Adam |
| Drop out | 0.1 |
| Epoch | 50 |
| Model | P | R | F1 | ACC |
|---|---|---|---|---|
| IDCNN-CRF | 75.62% | 67.85% | 69.12% | 68.59% |
| BiLSTM-CRF | 79.75% | 70.42% | 72.01% | 71.21% |
| BiLSTM-Attention-CRF | 80.12% | 72.10% | 73.69% | 72.89% |
| BERT-BiLSTM-CRF | 82.38% | 73.75% | 76.69% | 75.19% |
| Error Types | Example |
|---|---|
| Incorrect Entity Linking | “Journal of Economic Perspectives is an economics journal focusing on macroeconomic directions, published by American Economic Association.”, “American Economic Association” should be recognized as a publisher entity, but the BERT-BiLSTM-CRF model incorrectly labels it as “O”. |
| Incorrect Triple Generation | “Quantum is a physics journal focusing on quantum mechanics, published by Verein zur Forderung des Open Access Publizierens in den Quantenwissenschaften”. “Quantum” should be labeled as “B-JOURNAL”, but the model incorrectly predicted it as “B-DOMAIN”, leading to a misclassification error. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, J.; Niu, J. Construction of Journal Knowledge Graph Based on Deep Learning and LLM. Electronics 2025, 14, 1728. https://doi.org/10.3390/electronics14091728
Zuo J, Niu J. Construction of Journal Knowledge Graph Based on Deep Learning and LLM. Electronics. 2025; 14(9):1728. https://doi.org/10.3390/electronics14091728
Chicago/Turabian StyleZuo, Jiankun, and Jiaojiao Niu. 2025. "Construction of Journal Knowledge Graph Based on Deep Learning and LLM" Electronics 14, no. 9: 1728. https://doi.org/10.3390/electronics14091728
APA StyleZuo, J., & Niu, J. (2025). Construction of Journal Knowledge Graph Based on Deep Learning and LLM. Electronics, 14(9), 1728. https://doi.org/10.3390/electronics14091728