1. Introduction
Since smartphones were introduced, the rate of multimedia capture has surged dramatically. Digital cameras are widespread [
1], and social networks have driven extensive media creation [
2,
3,
4,
5]; more recently, there has been a significant rise in short-form video content [
6]. Additionally, the COVID-19 pandemic significantly accelerated the adoption of remote communication and collaborative technologies, such as video conferencing and virtual meetings [
7]. The concept of an enduring virtual environment where people interact, known as the metaverse, has regained traction in recent years [
8]. According to Mystakidis, the metaverse comprises interconnected, everlasting, and immersive virtual worlds [
8].
The growing engagement with metaverse platforms [
9,
10], such as Roblox [
11] and Minecraft [
12], highlights the extensive use of virtual environments. Forecasts suggest that this trend will continue to rise [
13]. Consequently, it is plausible that individuals will document their virtual world encounters just as they do in reality. Early iterations of these types of videos are available on YouTube [
14] for entertainment.
We refer to these types of recordings as
Metaverse Recordings (MVRs) [
15], such as a screen captures from a virtual world interaction as videos. Multimedia Information Retrieval (MMIR) [
16] is a computer science discipline that focuses on indexing, retrieving, and accessing Multimedia Content Objects (MMCO), including audio, video, text, and images. Given that the metaverse consists of virtual, computer-generated multimedia scenes for 3D or Virtual Reality (VR) [
17] presentation, we regard
MVRs as a novel emerging media type [
18] and explore the integration of
MVRs in MMIR [
15]. A field study [
19] revealed existing application scenarios for
MVRs in the domains of education, videoconferencing/collaboration, law enforcement in the metaverse, industrial metaverse, and personal use. For example, VR training [
20,
21] is used to train complex skills, and this training is recorded and evaluated [
22] later. Another example is the marketing domain, where shelf arrangements for virtual supermarkets are evaluated on the basis of eye-gaze recording. With a growing number of
MVRs, the need for indexing and retrieval increases, which can be supported by MMIR.
The field study also showed interest in replaying the
MVR as MMCO and an interactive 3D or VR form. In contrast to media capturing real-world scenarios, user sessions in the metaverse can be recorded inside the technical and digital space of a computer rendering a virtual world. Technically, the metaverse and virtual worlds are based on Massively Multiplayer Online Games [
23] that use 3D graphics technology, such as raytracing, photorealistic visualizations, and digital interactions between users and the metaverse. This allows for the recording of much more than just the perceivable video and audio stream as an output of the rendering process. The rendering input, referred to as
Scene Raw Data (SRD), and additional data from peripheral devices, referred to as
Peripheral Data (PD), for example, hand controller data or biosensor data, can be recorded.
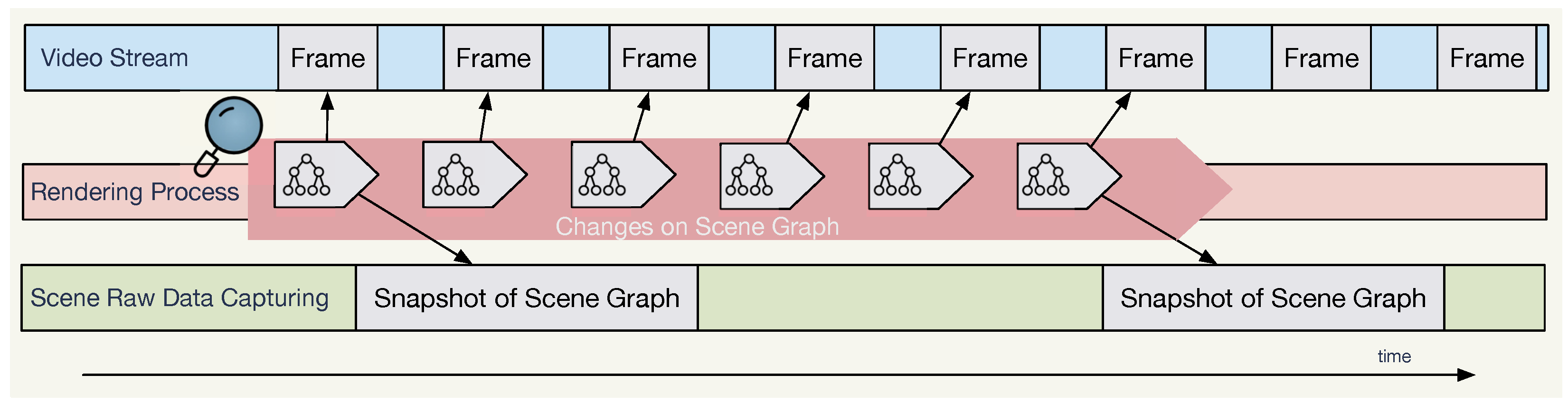
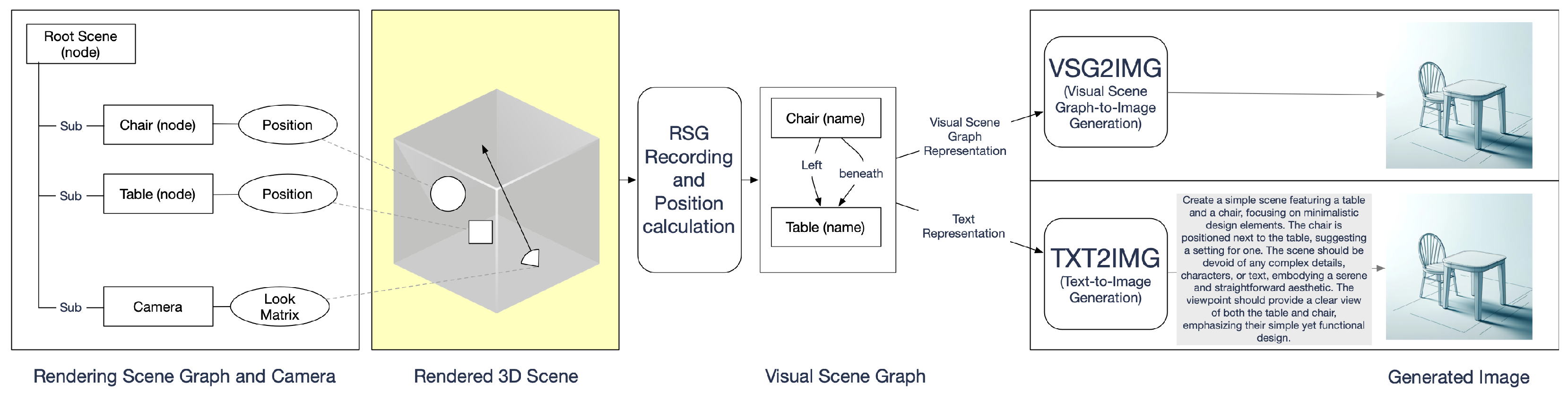
Figure 1 describes a simplified version of this recording. While the rendering process renders each frame for the video stream,
SRD can also be captured, e.g., if the position of an object in the scene changes or if a user input was processed. The information captured by this procedure can be used for indexing and querying
MVR. For example, a VR trainer can search for
MVRs in which the person being trained had a hectic activity or encountered another avatar.
One particularly interesting element of
SRD is the scene graph [
24]. It is a data structure used to organize several elements in a scene, such as 3D models or textures. The scene graph is dynamic, as it changes with rendering time; hence, it is referred to as a
Rendering Scene Graph (RSG). Metaverse Recordings with
SRD can be produced by capturing static snapshots of the
RSG during the rendering runtime using custom application code. It is difficult to record all
SRDs during runtime, since there are several bandwidth and throughput limitations. The
RSG contains relevant information that can support the retrieval of
MVRs and can be recorded individually. However, it is difficult to visually render the exact same metaverse session correctly when relying solely on the
RSG. Despite this utility, relying solely on
SRD raises important challenges in the visual reproduction of a metaverse session. For example, the presentation of the MMIR result of the retrieved
MVR containing only
SRDs is challenging, because
SRDs may only contain a lossy version of the rendered scene, e.g., lacking 3D models and textures. However, the RSG may still contain enough data to produce an image or video for visual MMIR result presentation. Recent advances in the area of artificial intelligence, particularly in generative Large Language Models (LLMs) [
25], demonstrate that only minimal information is required to generate high-quality images [
26] or short video sequences [
27]. These capabilities of generative LLMs support the presentation of MMIR results for sparse
SRD. Instead of requiring full-scale 3D or 2D resources, developers can employ
SRD to outline essential elements—object positions, user gestures, or event timestamps—and then leverage generative LLMs to reconstruct visual representations.
This article addresses the problem that MVRs with only SRD are challenging for the MMIR result presentation. It explores how SRD, particularly RSGs, can be leveraged to generate MMCO, specifically images, using LLMs for MVR-based MMIR result presentation.
As a research methodology, we employ the research framework of J. Nunamaker et al. [
28] in the remainder of the article. The framework connects the four research disciplines, observation, theory building, systems development, and experimentation, to answer the research questions. The following sections present our observation results as an overview of MMIR,
MVRs, LLM image generation, and related technologies in
Section 2. In
Section 3, we present our conceptual models for the
RSG-to-image conversion, which forms the theoretical foundation of our approach. A prototypical implementation (system development) of the conceptual model is described in
Section 4.
Section 5 presents our experiments, which evaluate the effectiveness of our prototypical implementation of the conceptual models. Finally,
Section 6 summarizes the work presented and discusses future work.
2. State of the Art and Related Work
This section introduces MMIR, MVRs, MVR recording methods, and related datasets. Next, a literature review for text-to-image generation is presented, followed by an exploratory study highlighting challenges in RSG-to-image conversion. Finally, the remaining challenges are summarized.
2.1. Multimedia Information Retrieval
Multimedia encompasses various forms of media [
29]. The focus of MMIR is on the diverse media types that an MMIR system can retrieve, including images, audio, and data from biometric sensors. Typically, the MMIR process is composed of indexing, querying, and result presentation [
30]. For indexing, features of a multimedia content object (MMCO) are extracted, typically through content analysis, referred to as feature extraction [
30]. The query interface enables users to express their search queries. The output of a search query is displayed in the result presentation. Beyond simply displaying results, a result presentation may offer interactive browsing capabilities, such as recommending related MMCOs [
30]. In video retrieval systems, preview images are often used in the result presentation, providing users the option to play the video if desired [
31].
The lack of integration for the emerging multimedia type
MVR, in particular with time series-based
SRD, in the MMIR result presentation is not covered in the MMIR literature [
15].
To provide a better understanding of MVRs, these are described next.
2.2. Metaverse Recordings
A variety of applications have been developed in the emerging landscape of the metaverse [
10,
32]. In investigating the use of
MVRs [
19], at least four distinct application domains have been identified [
15,
19]. In the
personal media use domain, people are increasingly organizing, storing, and retrieving personal memories, such as photos and videos, captured within the metaverse, while lifelogging [
33] represents an advanced extension of this practice. This feature enables users to organize collections of their digital experiences on devices such as smartphones, making it easy to access important moments. The
entertainment domain includes the creation, editing, and consumption of video, including metaverse experiences. In virtual environments, products and experiences can be presented, created, shared, and viewed as
MVR. In the entertainment domain, Video Retrieval systems are established in production and access portals. The next domain is the application of
MVR to improve
educational and training outcomes in the field of VR education and VR training [
20]. The recorded sessions are analyzed to quantitatively evaluate performance, offering a novel approach to skill development and learning.
MVR also enables the exploration of various inquiries, including behavioral studies, in the field of research by providing a rich dataset for analysis, thus expanding the horizons of scientific investigation. These applications underscore the versatility and significance of supporting
MVRs in MMIR, which is accomplished through the development of
MVR-specific MMIR. Although existing systems are capable of handling diverse types of media,
MVRs represent an emerging type of multimedia that necessitates integration. The differences in
MVRs are explained next.
2.3. Options to Produce MVRs
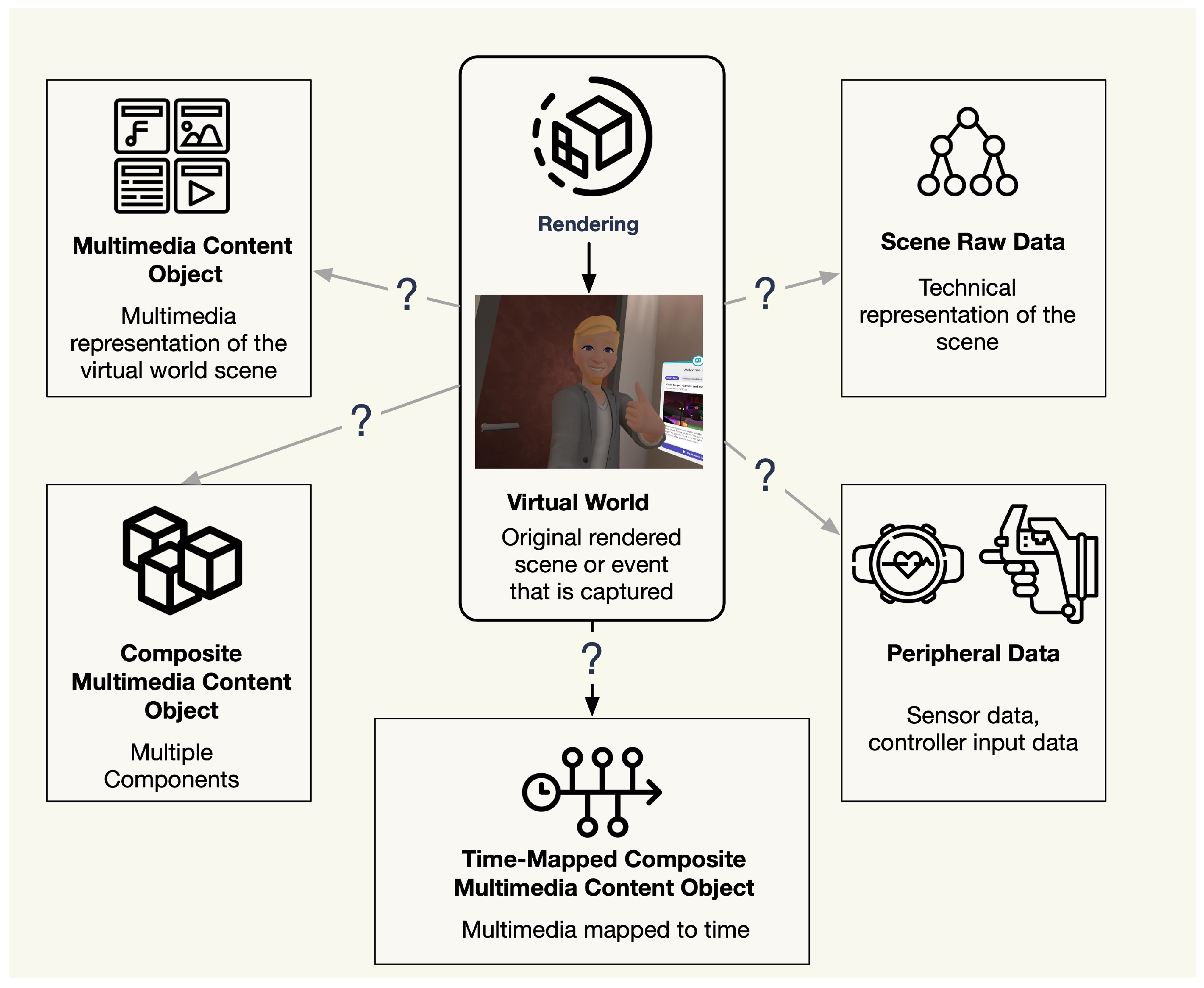
The different recording options for
MVRs raise key questions, as shown in
Figure 2, regarding their usefulness and relevance. The following paragraph examines the advantages, disadvantages, and opportunities of each recording format group.
The first group, MMCOs, can be created by directly recording sessions as videos, containing audio of the game and the voice of the user, within metaverse applications, e.g., in Roblox. This approach captures both outputs, audio and video, of the virtual environment. An alternative within this category is the use of screen recorders to capture the audio–visual output of the rendered scenes.
The second group,
SRD, captures the visual rendering input used to create the virtual scene. This can be achieved, for example, in two ways: (1) capturing the
RSG [
34], which represents the objects present in a scene, and (2) utilizing network codes to record inputs from other players, including avatar positions and actions. The capture process during the rendering process is visualized in
Figure 1. The second method could take place on a centralized server, which relays the network-transmitted information between participants and saves the virtual world state. The resulting
SRD, when combined with additional audio–visual elements such as textures and colors, offers a comprehensive view of the scene. Engage VR is a metaverse for creating virtual learning experiences [
35,
36] that allow the creation of session recordings for individuals or groups [
37]. The recordings can be stored as a file in a proprietary and undocumented file format. The playback can be controlled in time, i.e., pause, forward, and backward, and options exist to select playback of only specific elements from the recording. However, the recording does not contain the virtual world environment, models, or other
SRD, only a log of the activities of users.
The third group of recordable data is PD. Like the second group, recording Peripheral Data can be achieved by capturing it during the rendering process but also in a parallel process. A parallel process could be a fitness tracker or smartwatch, where the data are recorded in parallel and subsequently merged with the MVR. PD provides supplementary information that enriches the primary recording, which is hard to gain otherwise, for example mimics, such as smiling, or bioinformation of high heart rate from physical activity or emotions.
All data, but in particular SRD and PD, can be considered as time series data because they reflect the user session over a certain time period.
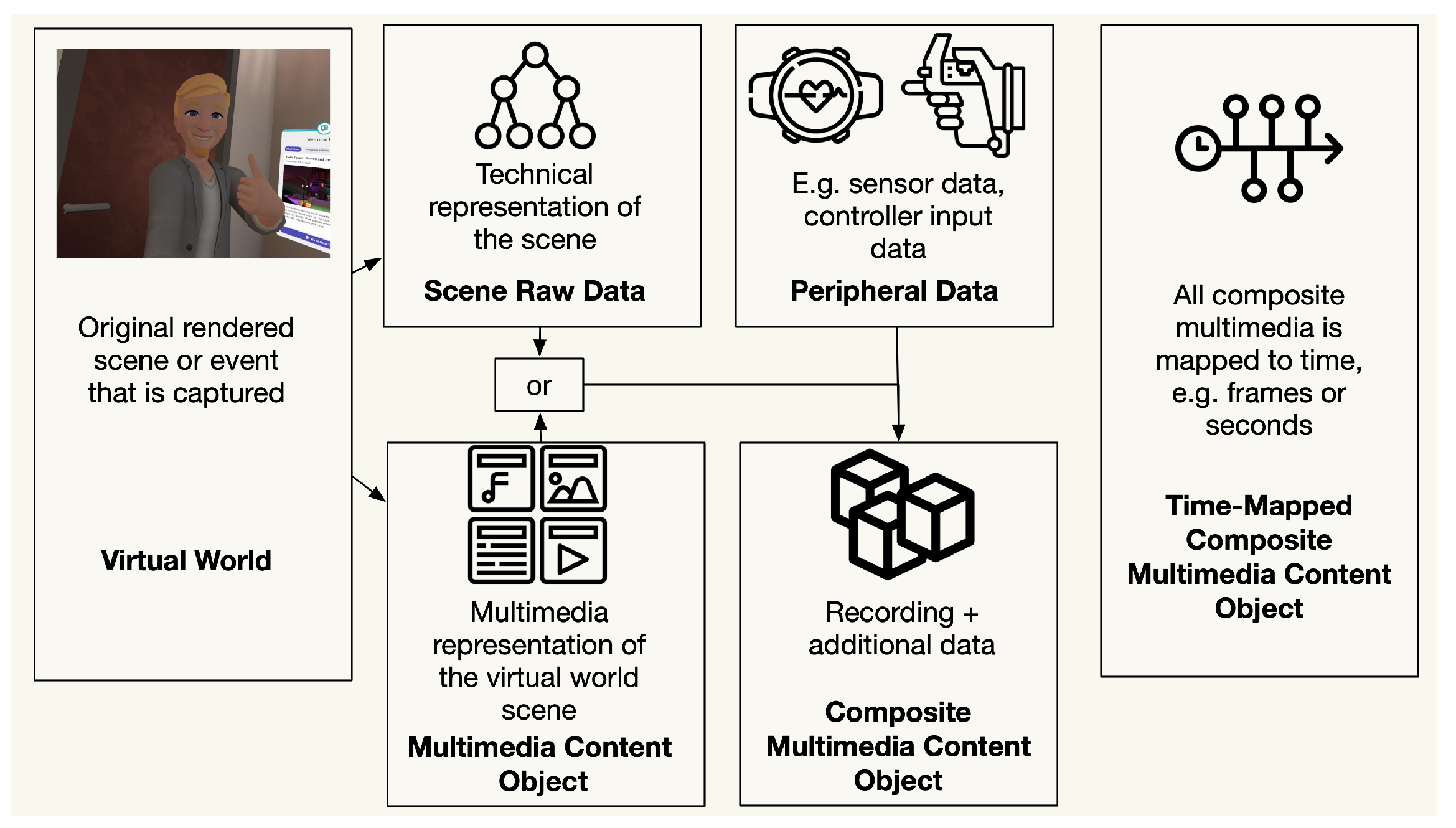
These different types can be used to support different use cases. Hence, a model of the combination of data is described and visualized in
Figure 3. If the data are combined in any form, this is defined as a
Composite Multimedia Content Object (CMMCO) [
15,
18]. If there is a common time in the data, such as a timestamp or frame number, this is defined as a
Time-mapped CMMCO (TCMMCO) [
15,
18].
With this understanding of MVRs, existing MVR datasets are described next.
2.4. The 111 Metaverse Recordings Dataset
In the field of MMIR, some datasets have emerged for Metaverse Retrieval. Abdari [
38,
39] presented a dataset for MMIR research, but it only includes constructed textual descriptions of metaverse scenes. The 256 Metaverse Recordings dataset [
40] provides video recordings [
41] of virtual worlds in the wild but lacks
SRD. We created the 111 Metaverse Records dataset [
42], which contains
MVRs including
RSGs in textual formats in the form of a system log file. The described prototype enables the production of
MVR recordings, which include
SRD and
PD, thus allowing experiments to be performed.
For the evaluation, a dataset comprising 111
MVRs from three distinct virtual environments was curated.
Figure 4 shows the three environments: Man–Tree (a), Interaction Example (b), and an object-rich city (c). The
MVRs consist of a video, a log file with extractable information, and a heart rate log file. Most of the recordings contain at least one visible object, a gesture, a trigger pressed, a player joined, or normal or high HR. The dataset and the source code are available at [
42] for reproduction and further experiments.
Building on this understanding of the problem domain, the next section presents literature research on methods for supporting multimedia generation.
2.5. Scene Graphs and Text-to-Image with Generative Artificial Intelligence
A scene graph in 3D graphics represents objects within a scene [
34]. In metaverse engines such as Unity [
43], Unreal Engine [
44], and WebXR/WebGL [
45], scene graphs are typically structured as hierarchical, unidirectional graphs or rooted trees. However, these rendering-oriented scene graphs differ from semantic scene graphs, which contain edges with meaningful relationships. To distinguish between them, this paper refers to rendering-focused scene graphs as
Rendering Scene Graphs (RSGs) and semantically enriched scene graphs as
Visual Scene Graphs (VSGs) [
46].
VSGs play a crucial role in MMIR, particularly in scene representation [
47,
48,
49] and captioning [
50]. Recent research has demonstrated that
VSGs can effectively describe a scene and serve as an input for generating images [
49,
50]. Various models leverage
VSGs for image generation, such as SG2IM [
51], which set an early benchmark in 2018. More advanced approaches, including Masked Contrastive Pre-Training [
52], SGDiff [
52], and R3CD [
53], have improved image quality. Additionally, research has explored generating 3D models from VSGs [
54].
Given this background, the question arises: Can MMCOs be created from SRD? Fundamentally, the answer is affirmative, as the renderer itself performs this function. However, rendering requires the same input as the original recording—namely, game data and user interactions. Capturing all of these data in a metaverse setting presents a significant challenge due to the high computational cost of rendering.
Since RSGs lack semantic relationships, they do not provide the same level of understanding as VSGs. This leads to the first major challenge in RSG-to-MMCO generation, referred to as the challenge of RSG lacking semantic relationships.
In addition to the VSG-to-image models, image generation can be performed with a textual description as input, referred to as text-to-image models. Popular models are Midjourney [
55], Dall-E3 [
56], or Stable Diffusion [
57]. The text input can be of any form and does not necessarily require semantic relationships. However, recreating the scene in an image requires a textual description and a prompt [
57] including details about the scene. Obtaining exact control over the generation of images from text descriptions remains a significant challenge [
58]. Research has been conducted to address this challenge. For example, [
59] attempted to gain control over positioning. Using positional information in the training of text-to-image models in prompts was explored by [
60]. Several studies address prompt optimization. Automated prompt engineering and optimization are addressed by [
61]. Even inferring, or hallucinating, parts of the
VSG to improve the resulting quality has been researched [
62]. Virtual metaverse worlds have different visual styles [
15]. LLMs can generate images in different visual styles, which is also addressed in research, e.g., ref. [
63].
Despite significant research efforts, effectively converting a VSG into a prompt remains an open challenge, and it is still unclear whether an RSG alone contains sufficient information for image generation. The lack of established methods for this conversion highlights a critical gap in current approaches. To address this, an exploratory study was conducted to systematically analyze the challenges and limitations involved.
2.6. Explorative Study
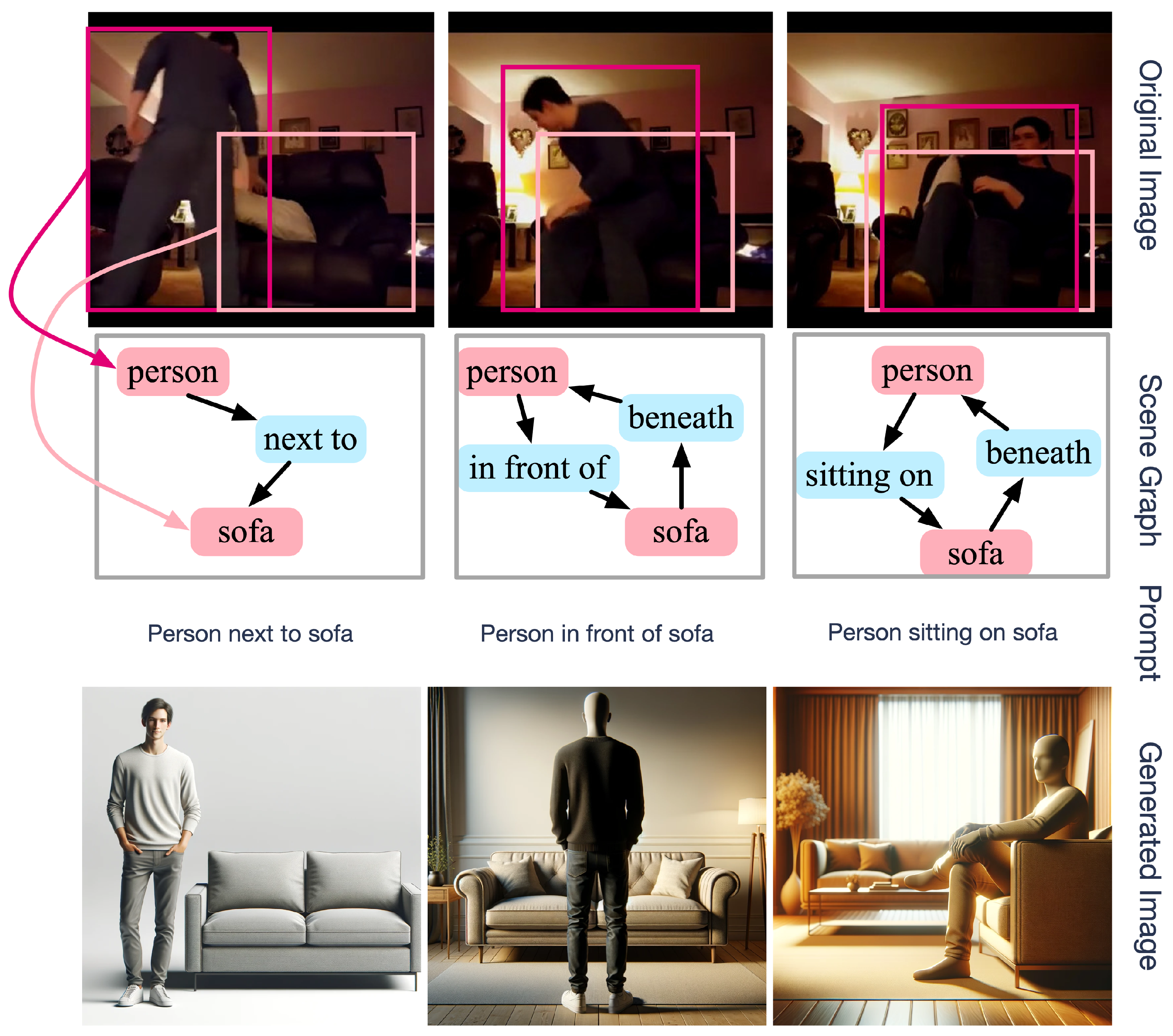
As described above, there are various methods to generate images from text and
VSGs. The
RSG-to-image conversion, beyond the lack of semantics, is maybe trivial. For example, when constructing the
VSGs from
Figure 5 as a prompt, for example, “person next to sofa”, a text-to-image model, such as Dall-E3, can produce an image containing concepts and relationships. The examples generated in
Figure 5 are not identical to the original image, but considering the information given in the prompt, the resulting images are similar.
To baseline our research, we conducted an exploratory study using the RSGs of the 111 Metaverse Records dataset as input, which discovered several challenges. Two methods are described, VSG-to-image generation, referred to as VSG2IMG, using the VSG as input, and VSG-to-text-to-image generation, referred to as VSG2TXT2IMG, converting the VSG to a text prompt first and using it as input for text-to-image models. Since prompts can have any form, the initial approach was to write them by hand in different forms.
2.6.1. Handcrafting Results
RSGandVSGwith Dall-E3: Analyzing the conversion of an
RSG from Unity, included in the 111 Metaverse Records dataset, to a
VSG reveals several problems. The scene graph contains non-visible elements such as a container node, lights, or animation scripts. These elements can be filtered out by the visibility state. Furthermore, the depth in the
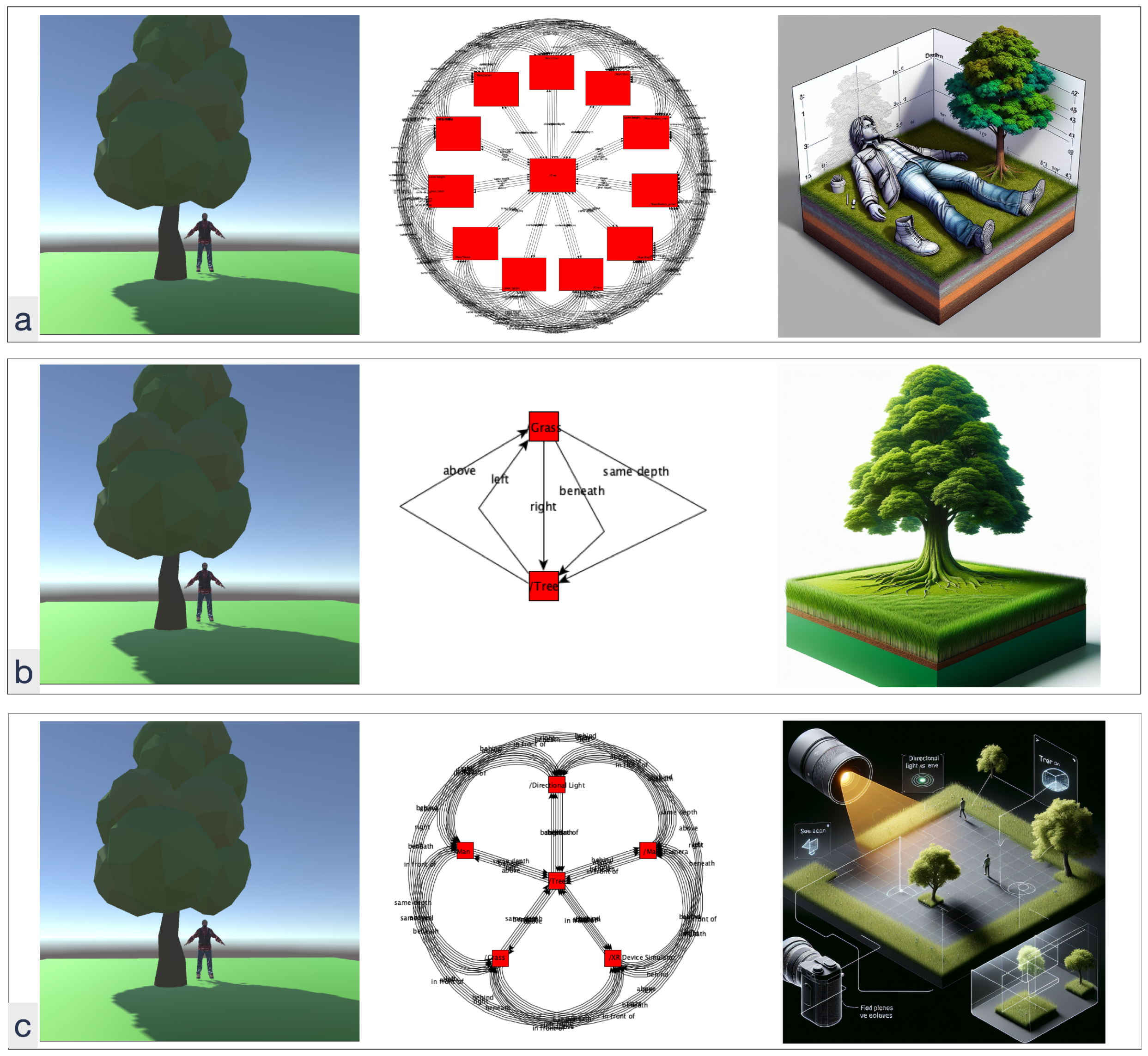
RSG can be huge for real 3D scenes. The depth is similar to a Level of Detail (LoD). Hence, filtering on the depth is possible to adjust the LoD.
Figure 6a shows the problem with such filtering; when a simple scene is filtered to LoD ≤ 1, the 3D object of the
man is subdivided into
eyes,
body, etc., which creates additional objects in the generated image. If the LoD is reduced to ≤0, the node
man is not a rendered object on this level and hence is missing in the graph and generated image, as
Figure 6b shows. Alternatively, if non-visible elements on LoD ≤ 0 are also included, technical objects are added to the scene, as demonstrated in
Figure 6c. The examples created any-to-any relationships that grow nearly exponentially with the number of nodes. Identification and reduction to predominant relationships could improve the results.
Adding more detailed information to the
VSGs, converted to text prompts, provides insufficient results, as shown in
Figure 7. Several issues were discovered that influence the quality of the result.
Due to the limitations of the original RSGs, for example, unclear names or prefixes and suffixes, experiments were carried out with manually created scene graphs. For this purpose, the node names and relationships of the example scenes captured from the application were adapted and manually converted into prompts.
VSG2IMGGeneration with SGDiff: From the recorded
MVRs, a sample
RSG was extracted and transformed into a
VSG, with manually edited node names. The resulting
VSG has been used as input for the SGDiff model. The SGDiff model was trained with the same parameters as in the original paper [
52] on the Visual Genome dataset [
65]. As shown in
Figure 8, the images produced do not show clearly recognizable objects and, hence, are not usable for evaluation. Similarly, the use of SG2IM produced unusable results. In conclusion, VSG-to-image generation remains a challenge.
With this understanding, the discovered challenges can be summarized next.
2.6.2. Discovered Challenges
The exploration of the generation of images from RSGs of the 111 Metaverse Recordings dataset discovered several significant challenges. These challenges are summarized here.
Node Naming Challenges: Problems arise from generic object descriptions; e.g., “Visual” contained the numbering of objects, e.g., “person 9”, or technical names, e.g., “bip L Toe0”. In addition, the selected labels are not in the vocabulary that corresponds to the procedures for generating images from VSGs, e.g., “Interactable Instant Pyramid” is not part of the vocabulary of the Visual Genome dataset. Non-descriptive names are referred to as the non-descriptive name challenge, and prefixes, suffixes, and numbers are referred to as the technical name challenge.
Graph Structure and Size Challenges: The size of real
RSG can be large, with more than 100 nodes on more than 10 levels; this is also called the depth of the tree, which presents a high LoD. A series of graphs was tested with three different LoDs, using 10 examples each. It was expected that the Level of Detail describing the scene would help to create more accurate replications of the original rendered images.
VSGs with semantic relationships, such as the examples in
Figure 5, create better results.
Figure 7 shows example results with different LoDs and styles. While the full LoD produced overloaded images, a reduction in the LoD produced more accurate results. Furthermore, text-to-image models have certain hard limits of maximum characters, e.g., 4000 characters for Dall-E 3 [
66], and soft limits, e.g., for not considering words further back in the prompt [
67]. This is referred to as the
text length limitation challenge. However, reducing the LoD by cutting off branches from the
RSG can inadvertently remove information essential for accurately representing some graphs. For example, if the depth is limited to 3, a larger graph is created that organizes its elements in “Base Scene”, “Structure_01”, “Exterior”, “Brick Wall”, and the level of the walls provides visually relevant information, which would be cut off. Hence, it is a conflict of objectives between the simplification and the selection of relevant information. This is referred to as the
high level of visual details challenge.
The RSG contains all elements of a scene, visible or not. For replicating the image, it makes sense to filter all invisible elements. In some occurrences, this led to the problem that a visible node has a useless name, while an invisible parent node, e.g., a container node such as “Player”, or in other cases, a cutoff subnode, would have a helpful name. In conclusion, simple filtering and limiting LoD are insufficient post-processing. This is referred to as the visibility challenge.
2.7. Summary
In conclusion, the presentation of the results of RSG-based MVRs is not addressed in the literature. An example of time-series-based SRD is static snapshots of RSGs. RSGs can be recorded, as the 111 Metaverse Records dataset demonstrates. Two image-generation methods have been found, text-to-image models and VSG-to-image models. VSGs, representing semantic concepts and relationships in images, can be used for image generation. RSGs and VSGs are different, and RSGs need to be transformed into VSGs to generate images for the presentation of results.
In an exploratory study, the following list of challenges was discovered.
The challenge that RSG lacks semantic relationships.
Non-descriptive name challenge.
Technical name challenge.
Text length limitation challenge.
High level of visual details challenge.
Visibility challenge.
With this body of knowledge, the modeling and design outlined in the next section address these challenges and introduce a formal approach to generate images from RSGs.
3. Modeling and Design
This section presents our modeling work, which follows User-Centered System Design (UCSD) [
68] and employs the Unified Modeling Language (UML) [
69]. Therefore, the modeling will start from a user perspective by outlining use cases, then dive deeper into the formal and technical requirements to address the users’s needs.
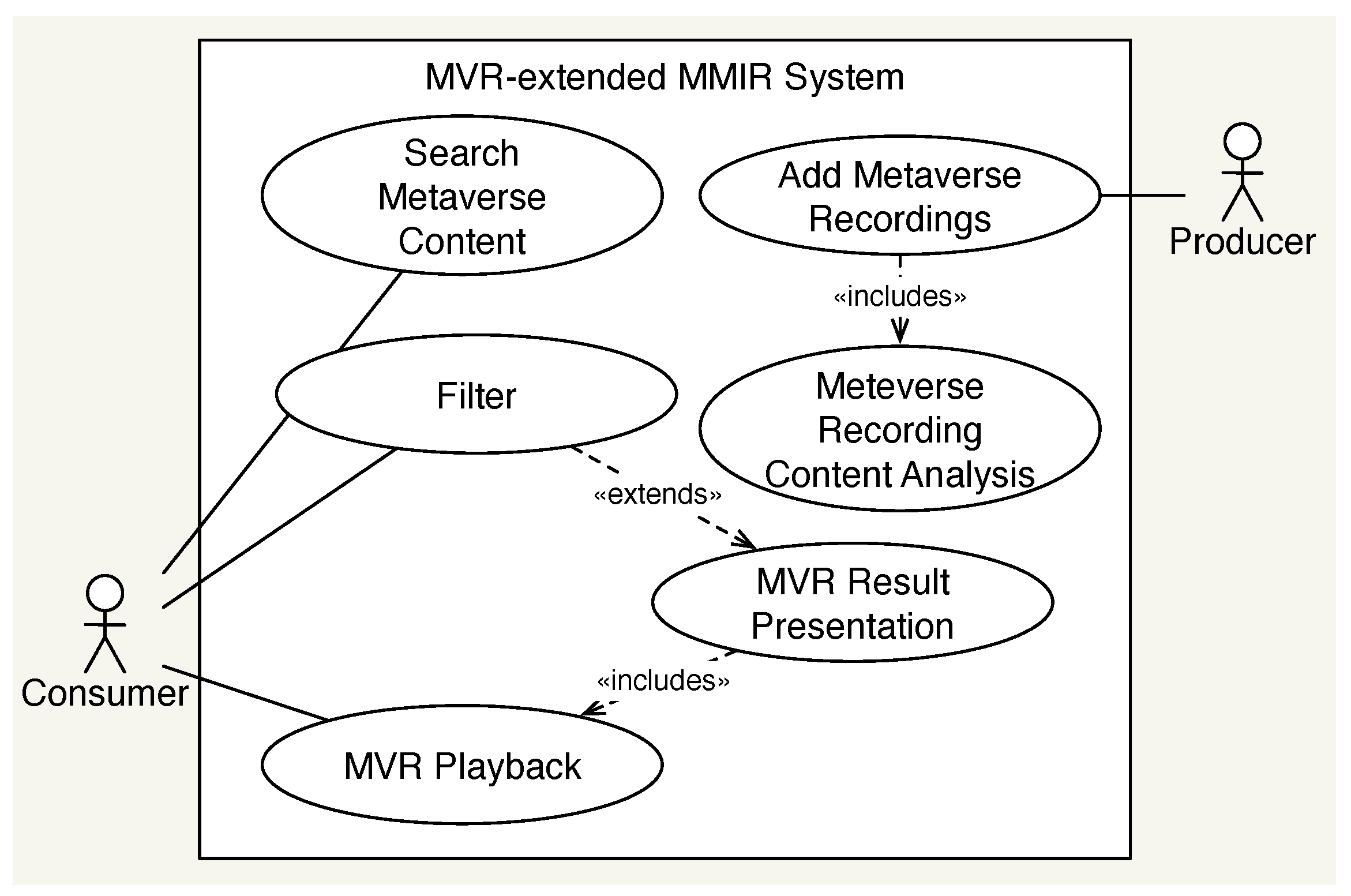
In general, MMIR can be separated into indexing by a producer and retrieval by a consumer. As shown in
Figure 9, this paper focuses on the use case
MVR Result Presentation as part of the retrieval process.
A consumer wants to inspect the retrieved results, and showing a visual presentation of the media is a common way form them to inspect them. For MVRs with an MMCO of the image or video type, these can be easily displayed and played back. If there is no MMCO, converting the SRD, especially the RSG, to an MMCO, such as an image, is a viable option.
The research presented in
Section 2 shows that a process is needed to solve the challenges described. The conceptual modeling of such processes is described in the following sections. As the literature research showed, at least two kinds of models can be used to generate the desired images, i.e., VSG-to-image and text-to-image models. For both options, a two-step process is required. As visualized in the activity diagram in
Figure 10, the first action transforms the
RSG into a
VSG model and subsequently converts it into a
VSG representation usable by VSG-to-image models (
VSG) or an intermediate text representation, i.e., a prompt, usable by text-to-image models (
VSG). The second action, Generation, executes the generation of the image.
Section 3.1 and
Section 3.2 describe the first action. For the second option, the
VSG2IMG is described in
Section 3.3 and the
VSG2TXT2IMG option is described in
Section 3.4.
3.1. Creating Semantic Relationships
RSGs are used to organize the elements in a 3D scene. The state of the
RSG can persist at runtime. The persisting data can be used as input to generate image data. As presented in
Section 2.6,
VSG-to-image methods exist and can be used. As a previous step, a transformation from an
RSG to an
VSG is required to address the challenge of a lack of semantic relationships.
The RSG represents the state of the scene at rendering time, which contains the objects O with attributes A, such as name, visibility and position. An RSG graph structure is defined as , where is the set of objects in the RSG and is a set of edges. In the case of , ; hence, an RSG is a tree. Each object has the form where is the class of the object and are the attributes of the object, such as position, tags, or name. A special node in an is the camera object, also known as the view port , which can be identified by a specific class or specific attribute.
As described, the main difference between an RSG and a VSG is the lack of a semantic relationship between nodes in an RSG. The VSG is a graph of tuple , where is the set of objects in the VSG and is a set of edges. In the case of , is an infinite set of relationships, such as “in front of”, “beneath”, “wearing” or “holding”, .
Further optional steps can improve the transformation results, such as filtering invisible objects. The LoD of a VSG can vary. VSGs describe an image. For example, an image of a motorcycle driven by a person can be described as “person riding motorcycle”, or “person wearing helmet rides motorcycle on street, motorcycle has wheels and spokes”. The second description has a higher LoD. The transformation can filter certain elements to match a desired LoD.
To address the challenge that
RSG lacks semantic relationships and transform an
RSG into a
VSG,
, one approach is to add, for example, spatial relationships, a subset of semantic relationships. The proposed process is summarized in
Figure 11, where the proposed transformation method,
, is a lossy transformation with inference. The transformation is lossy, because irrelevant attributes from the
RSG are not transformed. The mandatory step is to infer the spatial relationship
between the objects, which replaces the child relationships. This inference relies on the bounding box for each node stored as an attribute in the graph, as well as the camera position and viewport
to compute the position of objects in space.
For each node n, , to all the other nodes and the view port, is calculated by based on the position of the attribute bounding box .
This approach of the inference creates basic semantic relationships but has a limited set of values for . The conversion of the relationship requires the matching of the values of the image generation method used later, which is required to be considered in the function . More advanced steps in inference could complete the VSG by inferring relationships based on the semantic understanding of two objects and their position; for example, a hand and a tennis racket with overlapping bounding boxes could be inferred as interaction, e.g., holding. This approach is not addressed further in the context of this paper and remains part of future work. As outlined in the other challenges, O can be named in many possible ways; a conversion to requires further processing to be usable in further image generation methods, which is described in the next section.
3.2. RSG Preprocessing and Postprocessing
The challenges of a
high level of visual details,
visibility,
technical names, and
non-descriptive names are addressed by a pre- and post-processing activity, as visualized in
Figure 12. At the conceptual model level, various methods can be applied.
Examples of preprocessing activities for the challenge
of a high level of details are the filtering of invisible elements and the reduction in the visual details. Filtering out elements deeper in the
VSG is relevant, since the depth of a large
RSG from the 111 Metaverse Records dataset can be 18 with a total of 7330 elements. Derived from the samples of the 111 dataset, these layers only describe very detailed elements of animated figures, such as
BowJoint or
Thumb. Such an LoD describing the concepts in the scene is not beneficial for the generation and, hence, can be filtered out. For resembling the images, only visible objects are relevant. This filter can be applied to each function by filtering elements above the depth threshold
by restricting
n to
Nodes in a Scene Graph usually describe the element in the scene, which is in the best case a word that can be found in a language dictionary. However, numerations, such as prefixes or suffixes, are used for repeated entries.
Postprocessing can employ several methods. A whitelist or blacklist of terms can be used to filter nodes based on node names. A Text-to-Ontology Mapping [
70] can be applied, e.g., based on the vocabulary of the VSG-to-image method. A Knowledge Graph Completion [
71,
72] may reveal dominant relationships. Furthermore, developing and applying algorithms that can infer other node attributes from the
RSG, e.g., material type and affordances for objects [
73], could improve the
VSG conversion.
Based on this modeling, the described challenges of node naming and size limits have been solved.
The transformation action is now modeled. The generation action is described next.
3.3. Visual Scene Graph to Image Generation
Based on preprocessing and transformation, the
RSG in the
VSG representation is usable for
VSG but needs to be converted into the required expression of the VSG-to-image model. Many models have a closed vocabulary and a limited set of relationships and hence map the nodes and relationship types to a vocabulary.
Since the
VSG resulting from the previously explained conversions are vocabulary-free, node names not included in the vocabulary need to be inferred, e.g., by the Levenshtein distance [
74] in combination with WordNet [
75], or simply excluded.
With the described actions, the VSG-to-text model can be executed to produce the image.
Next, the second option is described.
3.4. Visual Scene Graph to Text to Image Generation
Transforming the VSG into a textual representation, now can be achieved by serializing the tuples . A prompt for text-to-image generation can have any form, and different formats are defined, e.g., GraphML. However, our exploratory study has shown that natural language prompts yield better results. Hence, the serialization method results in a natural language text. For example, each tuple may be a line, consisting of ObjectA and position ObjectB. A text-to-image model can process this information, but, as shown in the exploratory study, the challenges of text length limitation and the high level of visual details need to be addressed with current LLMs.
Leveraging the reasoning of LLMs, the use of automated prompt optimization through LLMs simplifies the prompt and adds advice for the image generation, i.e., inferring the object organization into layers.
The final prompt can be used to send it to an LLM via an API or local execution, producing the final image.
3.5. Summary
The models presented describe two options of a two-step process to transform the RSG into an image. In the first step, used by both variants, the RSG is converted into a VSG model by adding positional semantic relationships. In the second step, the resulting VSG is used as input for the image generation. In the case of the VSG option, the VSG is used as input, while in the case of the second option, it is first converted into a textual representation as input for a text-to-image model. The modeled process addresses the identified challenges by processing node naming, creating semantic relationships by positional construction, and, in the case of VSG, prompt engineering.
Based on the conceptual models, a prototypical proof-of-concept implementation can be developed to prove the model’s applicability.
4. Implementation
To validate the modeling, a prototypical application was implemented, as outlined in this section. First, the RSG-to-VSG transformation is presented, followed by the implementation of the generation options.
4.1. Rendering Scene Graph to Visual Scene Graph Transformation
To implement the first step of the conceptual modeling process, the activities of preprocessing, transformation, and postprocessing are implemented. The 111 Metaverse Records dataset contains RSGs expressed as a textual list, containing a JSON object with positional attributes. The RSG representation as a graph requires a transformation to text or to VSG.
The preprocessing, conversion, and postprocessing are described in the following sections.
4.1.1. Preprocessing
As described in
Section 2.3, the
RSG contains all information about a scene. Hence, for the deserialization of the data, as a preprocessing step, the described filter mechanisms are applied. The filter removes all elements in the
RSG that are invisible (
) and deeper than the second level (
), as shown in Listing 1.
| Listing 1. Filter function based on graph depth and visiblity state. |
![Electronics 14 01427 i001]() |
Unfortunately, many main concepts in the RSGs are in an invisible state. For example, a main concept node “man” consists of the subnodes head, torso, arms, and legs. The concept of man would be good to describe the overall concept, but it is invisible, and only subnodes are visible, but they are filtered because they are too deep in the RSG.
4.1.2. Transformation by Adding Semantics
The calculation of the positions in the 3D space based on the camera is made by projecting the camera to a world matrix on the object positions, as shown in Listing 2. With a further comparison of the positional x, y, and z values between each object, the relative position can be determined.
Compared to the conceptual model, our implementation only uses the object positions as points in space, not considering the bounding boxes as 3D objects and the resulting occlusion or varying position anchoring of 3D models.
| Listing 2. Get Positions in 3D space. |
![Electronics 14 01427 i002]() |
After the conversion, the resulting tuples of of the VSG can be printed as text, converted to a GraphML, or stored in a JSON object.
Subsequently, the postprocessing can be performed.
4.1.3. Postprocessing
Using a word list with 1500 English nouns, the complete node name is replaced if the noun matches the node name. Multiple numbered nodes, such as sm_car_01 and sm_car_02, end with ambiguous nodenames.
RSGs without nodes, e.g., when looking in the blue sky and when no object is visible, will just set as a prompt “Empty Scene”.
With the resulting VSG, the VSG and VSG generation can be performed, and the corresponding implementations are described next.
4.2. VSG2IMG with SGDiff
The
VSGs generated from the previous step are mapped to the vocabulary of the SGDiff/SG2IM vocabulary, which is defined by the Visual Genome dataset. If the elements of the tuples
do not match, the tuple is dropped. Subsequently, the generation is triggered. Experiments with SGDiff showed that the scene-graph-to-image generation is a fortuitous process, as illustrated in
Figure 13.
4.3. VSG2TXT2IMG with Stable Diffusion
To overcome the text length limitation and the challenges of the high level of visual details, the VSG-to-text transformation enhances the basic serialization of the
VSG with sophisticated optimizations. The implementation employs the OpenAI GPT-4o [
66] API to simplify the prompt, based on the idea of automatic prompt optimization. The prompt in Listing 3 was used to create an element separation in the form of the layers of foreground, midground, and background [
76].
| Listing 3. Prompt template. {} marks the insertion point of the VSG data. |
![Electronics 14 01427 i003]() |
In some cases, the input scene graph was empty, e.g., when looking in the sky, and hence, no elements in the RSG are visible. In such cases, the text added to the prompt was “Empty scene”. Otherwise, the list of tuples (object, relationship, object) was added. An example result is as follows (Listing 4).
The output of the GPT-4o request, shown in
Appendix A, is used as a prompt to send it to a text-to-image generation model. The output of GPT-4o is, as with most LLMs, not deterministic. Therefore, the output is saved as an intermediate format in order to perform validations. The Stable Diffusion 3 medium (local) and Stable Diffusion 3 large (API) models were used. The output of the generated images had to be minimally resized to match the size of the input images.
| Listing 4. An exemplary prompt for Recording 56. |
![Electronics 14 01427 i004]() |
The generated prompt is used to make a request to a text-to-image model, and the Stable Diffusion model has been selected to be used for the evaluation.
4.4. Summary
The prototypical implementation of the conceptual models was achieved for both options,
VSG and
VSG. The source code is available at [
77].
Based on the prototypical implementations, the evaluation can be performed.
5. Evaluation
This section discusses the evaluation results of our conceptual models and the prototypical implementation to test the hypothesis and answer the research questions. Quantitative experiments were performed on generating images from SRD, i.e., RSG.
For each method, VSG and VSG, experiments should generate images based on the RSGs of the 111 Metaverse Records dataset. First, the results of the VSG experiment are described, followed by the results of the VSG experiment.
5.1. Evaluation of RSG-to-VSG Transformation and VSG2TXT2IMG
The prototypical implementation of the RSG to VSG and VSG option was used to perform a qualitative evaluation of the generated images compared to the original scenes. The 111 Metaverse dataset contains 1079 RSGs. A total of 781 of them overlap in the videos. The 781 corresponding frames were extracted from the videos and used as the ground truth. The RSG-to-text script was used with two versions of the Stable Diffusion 3 models, that is, medium on a local machine with an Nvidia RTX 3090Ti, referred to as SD3-med, and large with the Stablility API, referred to as SD3-large. The results of the automatic prompt optimization, random samples, were checked, and no anomalies were found.
The SD3-med configuration was used with a maximum of 150 steps, a random seed, and an image size that corresponded to the ground truth.
The SD3-large was used with an aspect ratio of 16:9, which required an image resizing to match the size of the ground truth.
Based on the ground truth and generated images, the Inception Score (IS) [
78] and Fréchet Inception Distance (FID) [
79] scores were calculated, shown in
Table 1.
It is evident that the generated images differ significantly from the original images, even though the original objects sometimes appear in the generated image. This is visible in the example results shown in
Figure 14. For example, in Recording 56, the “man” tree contains the relevant elements, but the difference is still there.
The results between SD3-med and SD3-large were found to differ only marginally. A higher number and similarity of recognizable elements would improve the FID scores. SD3-large generates slightly more dreamy but realistic images but does not add more detailed elements to the image. The slightly better FID score of SD3-med could result from the better recognizable elements in the image. The InceptionV3 [
80,
81] image classification model used by FID and IS generally has difficulties in recognizing objects in computer-generated images. For example, in Recording 56, Frame 116, shown in
Figure 14, the classes “umbrella” and “parachute” are recognized with high probability in the original. The false positives can be seen in the figure. However, “lakeside” and “bonnet”, which were also recognized in the image generated by SD-3med, are also recognized with a low probability. Although the recognition of the class “lakeside” in the original could be argued, this is a false positive in the generated image. Therefore, it can be said that the use of InceptionV3 is generally not suitable for computer-generated images. Furthermore, the difference in metrics between SD3-med and SD3-large with respect to poor detection rates cannot be assessed without further analysis.
Compared to other image-generation methods based on
VSGs, the IS scores are comparable to SG2IM, as shown in
Table 2. SG2IM is considered the baseline, and other methods perform much better, so the IS metrics of
VSG can be considered low in comparison. If an FID value below 50 is considered good, the FID of
VSG must be categorized as poor. As already explained, this can also be attributed to the suitability of the underlying InceptionV3 model.
Since computer vision is hard, a second experiment was carried out in which a person matched the images to the originals. For the experiment, a total of 22 generated images were randomly numbered in a new order and shown to the test subject on the monitor, one after the other. A second window showed the reference images for the 22 generated images in a gallery view, through which the test subject could click. On the left-hand side, the test subject was asked to enter a maximum of one image to which they assigned the generated image. It was noted that multiple entries were allowed.
The test subject was unable to assign five images to a reference image; five images were correctly assigned, and twelve images were incorrectly assigned. This resulted in a hit rate of 23%, although it should be noted that some of the reference images were very similar, which made correct assignment more difficult. The test subject expressed two aspects that caused her difficulties in categorizing the images. First, the strong differences in the depiction of the same objects made it difficult to recognize similarities. The second problem mentioned was the similarity between some of the reference images. Repeating the process on the basis of a larger quantity and variety of the generated images could mitigate the effects of the second problem and lead to better results, but this remains an open challenge.
When comparing the images in pairs with the originals on which they are based, the semantic similarity stands out in contrast to the poor rate of correct matching. Another open challenge is to capture and quantify these similarities using suitable methods, e.g., generating VSGs from the image.
Evaluating the second option, VSG, is discussed next.
5.2. VSG2IMG with SG2IM and SGDiff
To evaluate the
VSG generation, images were generated from
VSGs, produced by the described method, using the SG2IM and SGDiff methods. Both techniques do not generate satisfactory results, as illustrated in
Figure 13. Despite following the method described in the literature, the performance did not meet expectations, suggesting that its applicability may be limited in this scenario. Reproducing the experiments of the original paper showed that image generation produced a poor result, as demonstrated in
Figure 13 with the validation data of the original paper. The limitations presented in the transformation of the
RSG to
VSG further reduce the result. These findings highlight the need for either adapting the method or exploring alternative approaches to achieve better performance, e.g., SceneGenie [
82], R3CD [
53], or CLIP-Guided Diffusion Models for Scene Graphs [
83].
5.3. Discussion
The conversion model can create an image from the graph that presents the scene, but it is not a perfect representation. The algorithms used to convert scene graphs to images were not effective. The proposed methods to address the challenges are a first approach and are insufficient.
The evaluation results demonstrate the effectiveness and limitations of our approach in generating images from SRD using RSG. While the prototypical implementation produced images that qualitatively captured some of the essential scene elements, the overall fidelity and realism of the generated images remain an area for improvement. This section discusses the key findings, challenges, and implications of the evaluation results.
The comparison between SD3-med and SD3-large reveals that while both models perform similarly, SD3-large achieves a slightly higher IS of 9.128 compared to 8.424 for SD3-med; however, the FID score for SD3-med is marginally better, suggesting that SD3-med produces images that are somewhat closer to the ground truth in terms of visual similarity.
Although both models generate plausible images, the overall performance of the conversion does not reach the level required for high-fidelity scene reconstruction. The relatively high FID scores indicate that the generated images diverge significantly from the ground truth, reinforcing the need for further refinement in the translation from scene graphs to image generation prompts.
5.3.1. Challenges in Scene-Graph-to-Image Generation
Several challenges were identified in the process of converting RSG to VSG and ultimately to images:
Naming and Vocabulary Limitations: The naming conventions used in scene graphs often do not match the generic vocabulary of pre-trained text-to-image models like Stable Diffusion 3. This mismatch leads to an inaccurate depiction of scene elements, as models may fail to recognize or correctly interpret scene descriptions.
Graph Complexity: The complexity of scene graphs, especially in terms of object relationships and visibility indicators, posed difficulties. The simple use of visibility as an indicator has proven to be insufficient when it comes to complex or densely populated scenes. Filtering out unnecessary details remains a critical challenge in improving the quality of generated images. Further details could be considered, for example, the size of the elements in the scene.
When comparing the results obtained from SD3 with those generated by SG2IM and SGDiff, it is evident that SG2IM and SGDiff struggle to produce usable results.
Figure 13 illustrates that the images generated by these methods lack coherence and do not accurately reconstruct scenes from their corresponding scene graphs. More recent advanced methods, such as SceneGenie [
82], R3CD [
53], and CLIP-Guided Diffusion Models for Scene Graphs [
83], may offer better solutions for scene-graph-based image generation, which should be explored in future work.
5.3.2. Potential for Handcrafted Improvements
An alternative approach to improve image generation results is the use of handcrafted prompts, where scene graphs are first translated into structured textual descriptions before being input into text-to-image models. Preliminary experiments with VSG-to-text-to-image pipelines, using models such as DALL-E2, suggest that such an approach might yield better results than direct VSG-to-image generation. Future research should investigate whether hybrid approaches, combining structured scene graph processing with advanced text-to-image models, could bridge the gap between structured scene representations and high-quality image synthesis.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}