
AI and Evolutionary Computation for Intelligent Aviation Health Monitoring


Abstract

1. Introduction
1.1. Background and Motivation
1.2. Related Works
1.3. Research Gap, Contributions, and Paper Structure
2. Materials and Methods
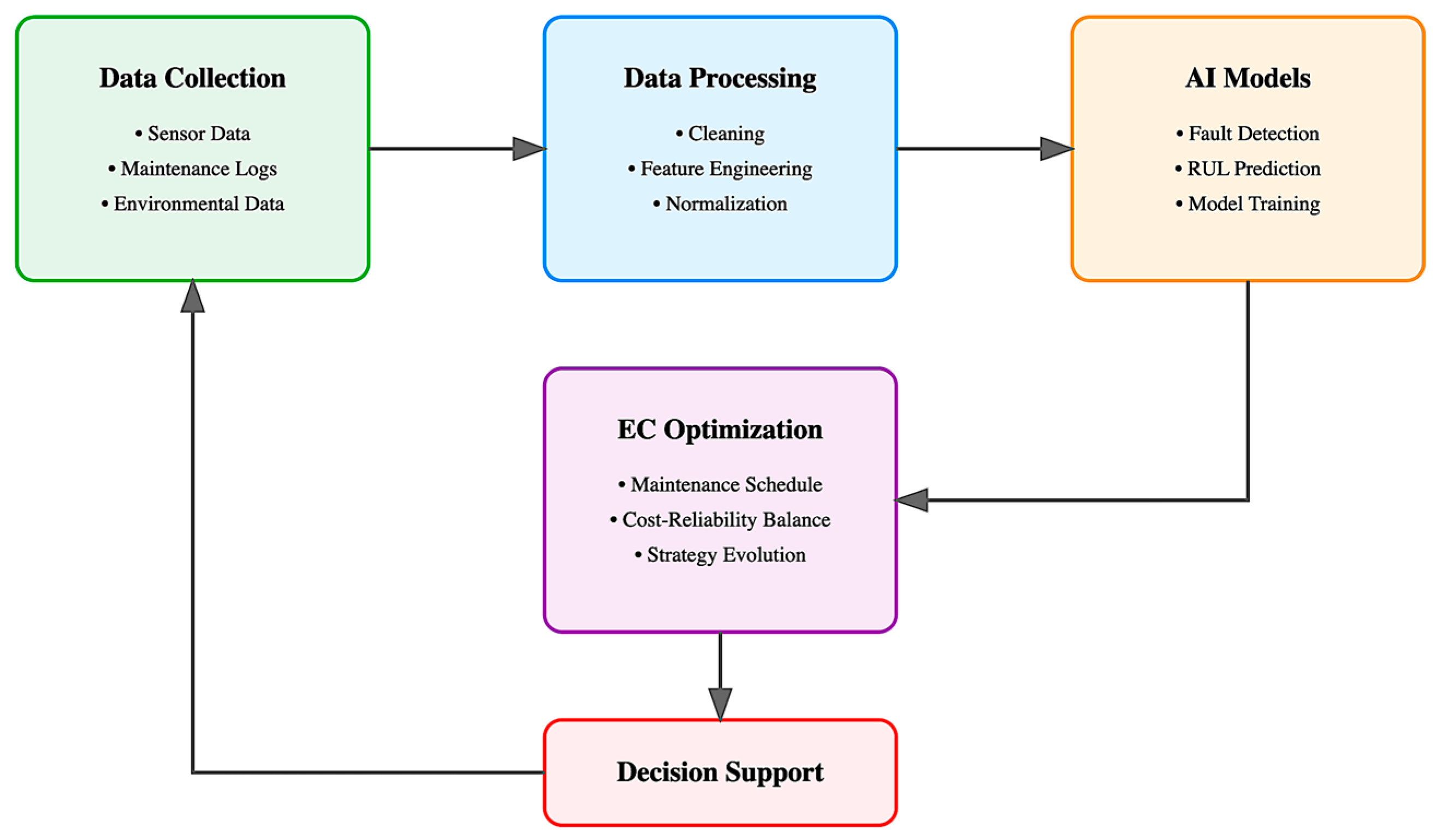
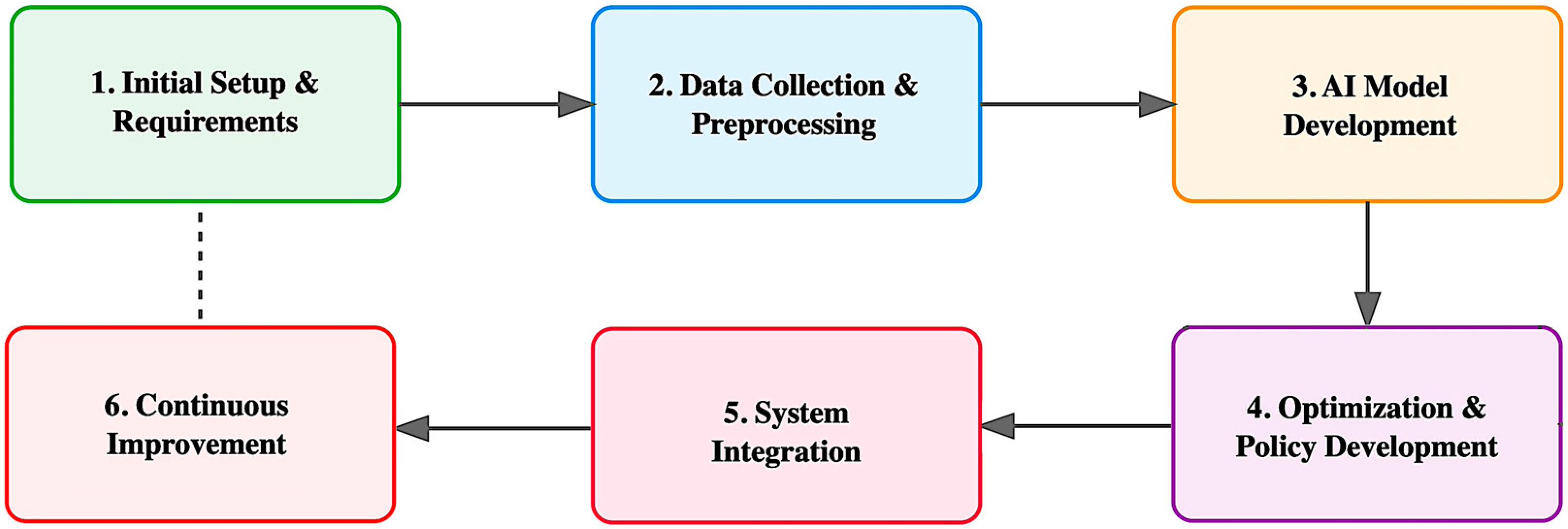
2.1. AI/EC Framework Development Methodology
2.2. Data Collection
2.3. Data Preprocessing
2.4. Feature Engineering and Selection
2.5. Differentiation Between Fault Detection and Remaining Useful Life Prediction
- Fault Detection as a Classification/Anomaly Detection Task
- Supervised learning (e.g., random forest, support vector machines, neural networks) requires labeled historical fault data to train a classifier capable of distinguishing failure modes.
- Clustering (e.g., K-Means, DBSCAN) identifies anomalies by grouping similar operational patterns and flagging outliers as potential faults.
- Autoencoder-based anomaly detection learns a compressed representation of normal behavior and detects faults when reconstruction errors exceed a predefined threshold.
- 2.
- RUL Prediction as a Regression-Based Temporal Forecasting Task
- Recurrent neural networks (RNNs) and long short-term memory (LSTM) networks—well-suited for sequential data modeling, learning from historical degradation patterns to predict future failure points.
- Kalman filters are state-space models that provide real-time updates on system health based on sensor data.
- Survival analysis (e.g., Weibull distribution models) estimates the probability of failure over time based on operational history.
- 3.
- Integration of Fault Detection and RUL Prediction in the Proposed Framework
- The fault detection model first identifies system anomalies. If a fault is detected, the system transitions to predictive maintenance mode.
- The RUL prediction model estimates the time remaining before failure, allowing for proactive maintenance scheduling.
- The two models share extracted feature representations, ensuring consistency between classification-based fault identification and regression-based lifespan estimation.
2.6. AI Model Development
- Classification loss (cross-entropy)
- Regression loss (mean squared error)
- Anomaly detection loss (reconstruction error)
- Classification metrics
- Regression metrics
- Anomaly detection metrics
- Class weights which modify the loss function to assign higher weights to minority classes
- Data augmentation which generates synthetic samples using methods like SMOTE
2.7. Multi-Objective Optimization and Predictive Maintenance
- Reducing the costs of inspections, repairs, and replacements.
- Ensuring the system remains operational for as long as possible.
- Reducing the probability of critical failures by addressing faults proactively.
- Identifying potential faults early using anomaly detection models or classification algorithms.
- Estimating the RUL of components based on sensor data, operational conditions, and historical trends.
- Optimizing when and how maintenance actions are performed to minimize costs and downtime while maintaining reliability.
- Representing maintenance decisions, such as repair schedules or thresholds for fault intervention.
- Assessing the quality of each solution based on the objectives.
- Applying crossover and mutation to generate diverse solutions and explore the solution space.
- Maintenance cost
- System downtime
- Reliability maximization
- Pareto optimization. The solution to the multi-objective optimization problem is a Pareto front
- Evolutionary algorithm implementation:
- o
- Solutions are represented as chromosomes.
- o
- A population of solutions is generated.
- o
- Each solution is evaluated using
- o
- Crossover and mutation introduce diversity.
- o
- Non-dominated solutions are selected to form the next generation.
3. Results
3.1. System Integration and Architecture
3.2. Dataset Characteristics and Feature Selection
- Number of Extracted Features (Numerical and Categorical)
- Numerical features (48 total):
- o
- Time-domain statistical features (18 features): Mean, variance, standard deviation, skewness, kurtosis, root mean square (RMS), peak-to-peak amplitude, signal energy, entropy, interquartile range, crest factor, shape factor, impulse factor, margin factor, slope, zero-crossing rate, range, and median absolute deviation.
- o
- Frequency-domain features (12 features): Fourier-transform coefficients, dominant frequency component, spectral entropy, power spectral density in selected frequency bands, wavelet decomposition coefficients.
- o
- Domain-specific features (18 features): Residual error from a degradation model, moving average trend deviation, slope of feature degradation, cumulative damage index, trend-based anomaly detection scores, and autoregressive model parameters.
- Categorical features (three total). These represent operating states of the system (normal, warning, faulty), encoded using one-hot encoding for integration with machine learning models.
- 2.
- Number of Selected Features
- Selected Numerical Features (19 total):
- o
- Time-domain statistical features (eight features): Mean, standard deviation, root mean square (RMS), skewness, kurtosis, peak-to-peak amplitude, entropy, and zero-crossing rate.
- o
- Frequency-domain features (six features): Dominant frequency component, spectral entropy, power spectral density in low and mid-frequency bands, wavelet transform coefficient at level 3, and spectral centroid.
- o
- Domain-specific features (five features): Cumulative damage index, residual error from degradation model, moving average trend deviation, trend-based anomaly detection score, and autoregressive model parameter.
- Selected Categorical Features (three total). These represent the system’s operational condition (normal, warning, or fault) and were retained to provide contextual information during model training and prediction.
- 3.
- Number of Training Samples
- Training set: 3500 samples (70% of the total dataset)—Used for model learning and parameter optimization.
- Validation set: 750 samples (15%)—Used for hyperparameter tuning and to prevent overfitting.
- Testing set: 750 samples (15%)—Used to evaluate final model performance on unseen data.
- 4.
- Feature Distributions
3.3. Simulation Experiment
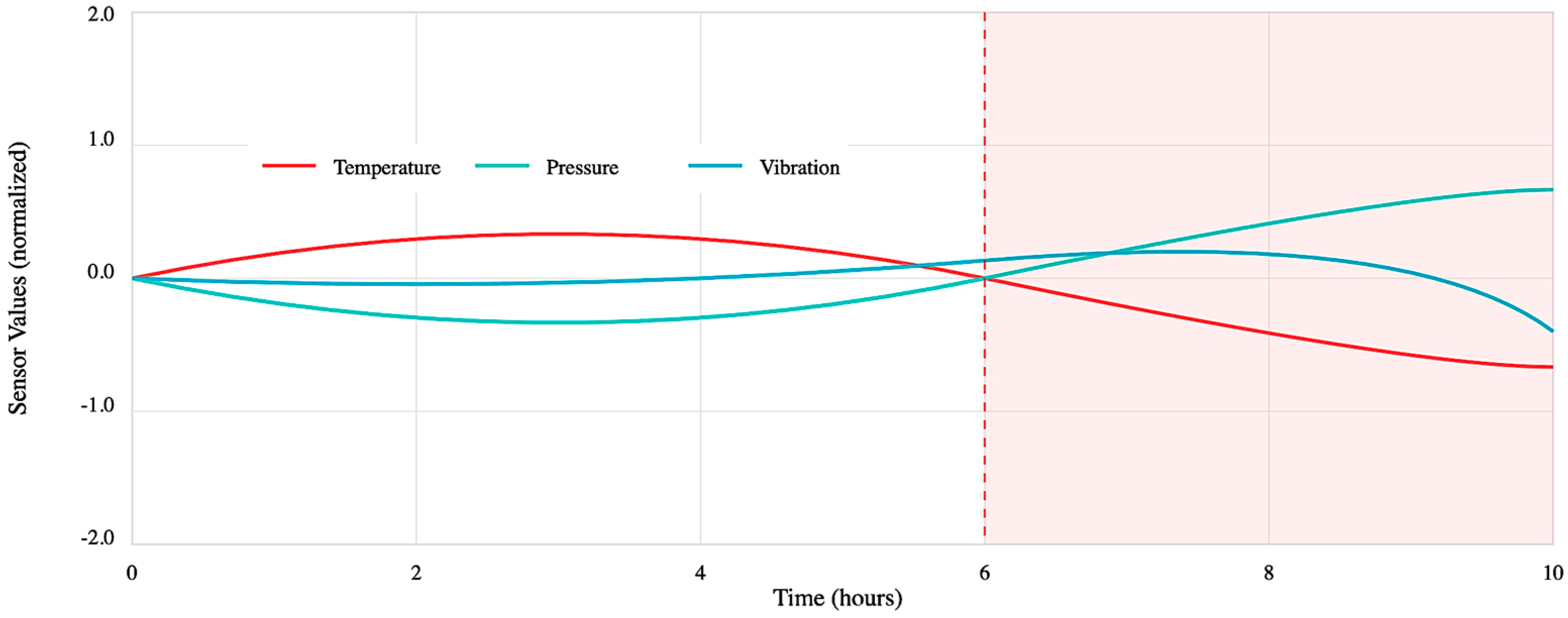
3.3.1. Methodology of the Simulation Experiment
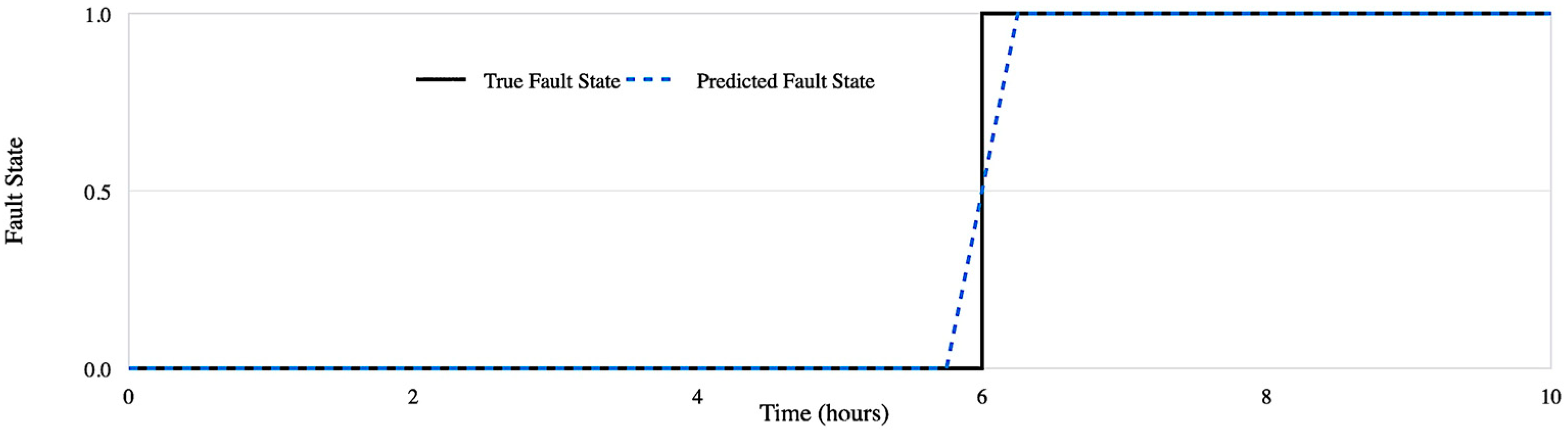
3.3.2. Fault Detection Model
3.3.3. Remaining Useful Life Prediction Model
3.3.4. Parameter Settings in the Design Algorithm
- AI Model Parameter Settings
- Fault detection model (random forest classifier)
- o
- Number of trees: 100
- o
- Maximum depth: None (fully grown trees)
- o
- Minimum samples per split: 2
- o
- Feature subset size: sqrt (number of features)
- o
- Bootstrapping: Enabled
- Remaining useful life prediction model (random forest regressor)
- o
- Number of trees: 200
- o
- Maximum depth: 20
- o
- Minimum samples per leaf: 5
- o
- Feature subset size: log2 (number of features)
- Neural network for fault classification (alternative model for comparison)
- o
- Architecture: 3-layer feedforward neural network
- o
- Activation functions: ReLU (hidden layers), Sigmoid (output layer)
- o
- Optimizer: Adam
- o
- Learning rate: 0.001
- o
- Epochs: 100
- o
- Batch size: 64
- 2.
- Evolutionary Algorithm Parameter Settings
- Genetic Algorithm (for feature selection and hyperparameter tuning)
- o
- Population size: 50
- o
- Crossover rate: 0.8
- o
- Mutation rate: 0.05
- o
- Selection mechanism: Tournament selection (size = 3)
- o
- Termination criteria: 50 generations or convergence (fitness variance < 0.01)
- Multi-Objective Optimization (NSGA-II) for Maintenance Scheduling
- o
- Population size: 100
- o
- Crossover probability: 0.9
- o
- Mutation probability: 1/number of decision variables
- o
- Number of generations: 200
- o
- Pareto dominance sorting method: Crowding distance
3.3.5. Results of Simulation Experiment
- Analysis of Fault Detection Performance in Aircraft Health Monitoring System
- 2.
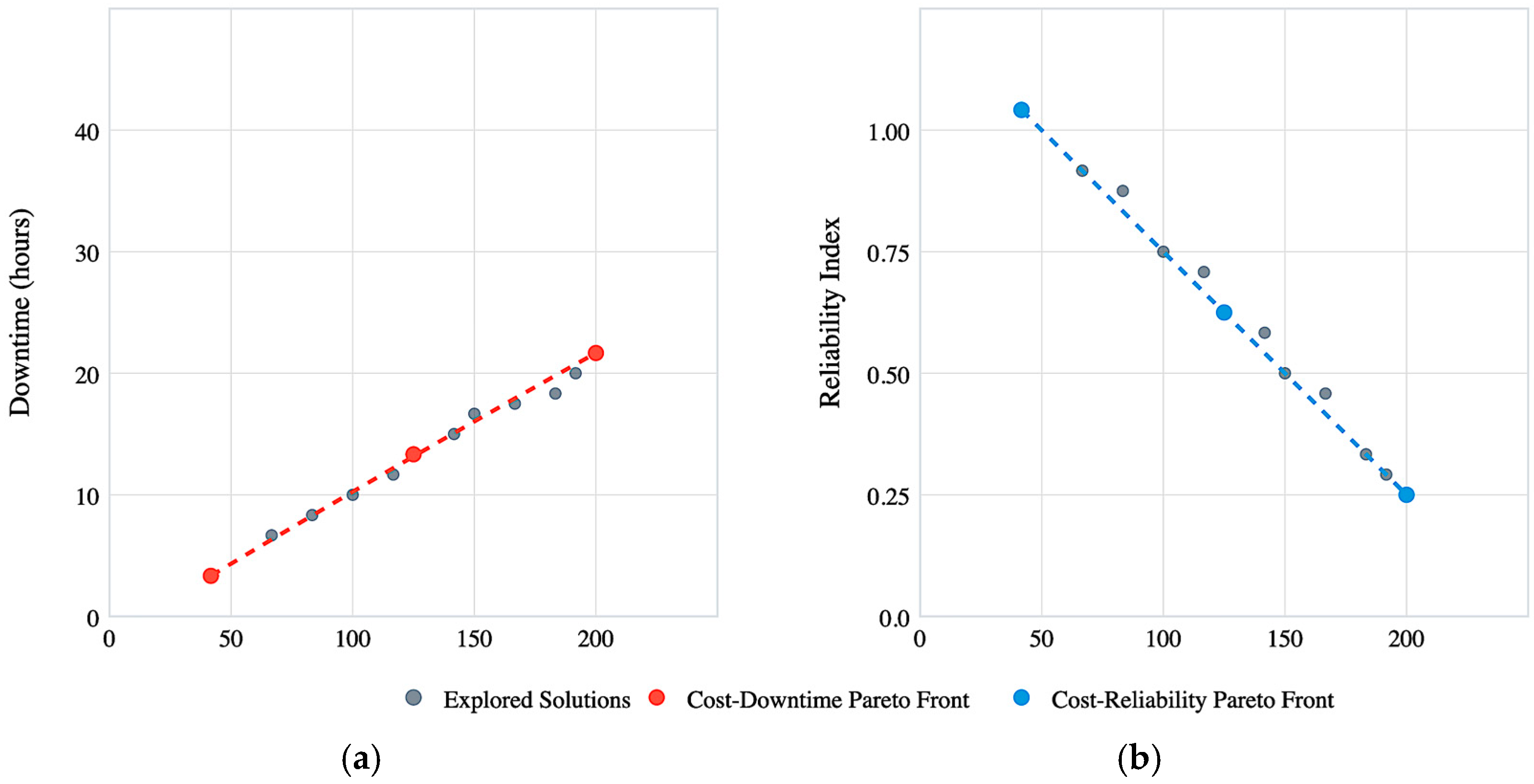
- Multi-objective Pareto Optimization Analysis for Aircraft Maintenance Strategy
- 3.
- Fault Detection Performance through Confusion Matrix Heatmap
- 4.
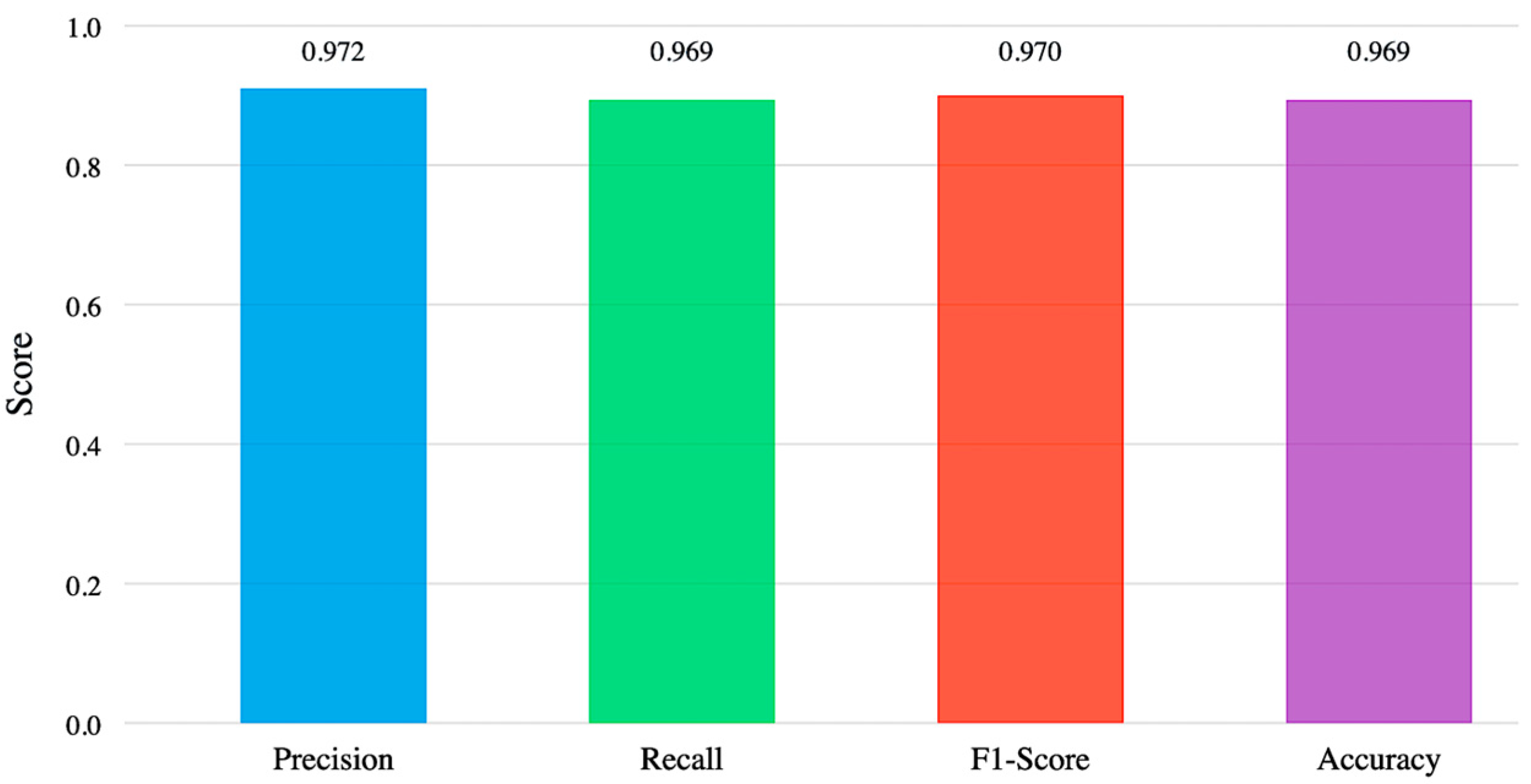
- Analysis of Classification Performance Metrics for Aircraft Fault Detection System
- 5.
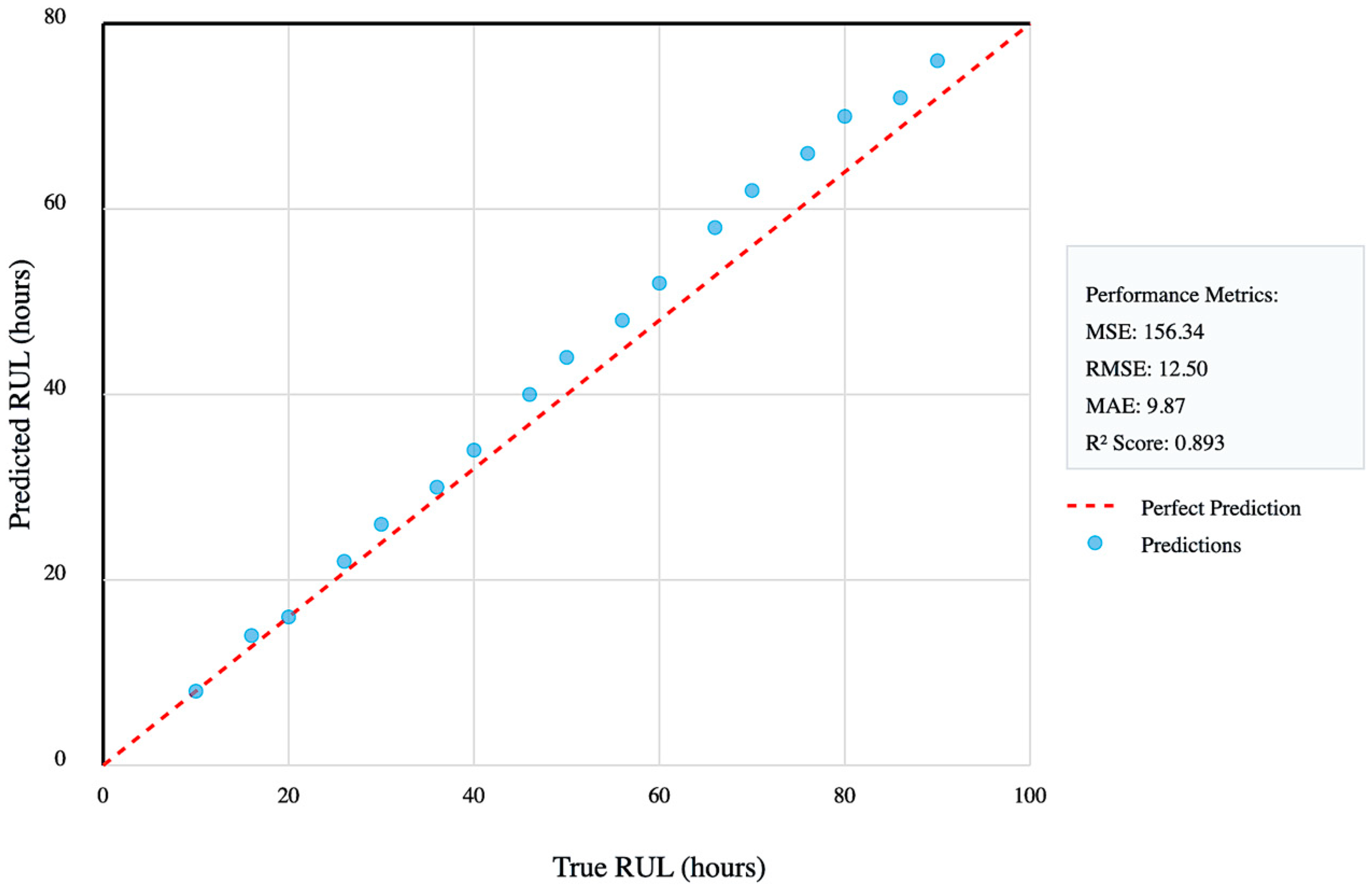
- Analysis of RUL Prediction Performance
- 6.
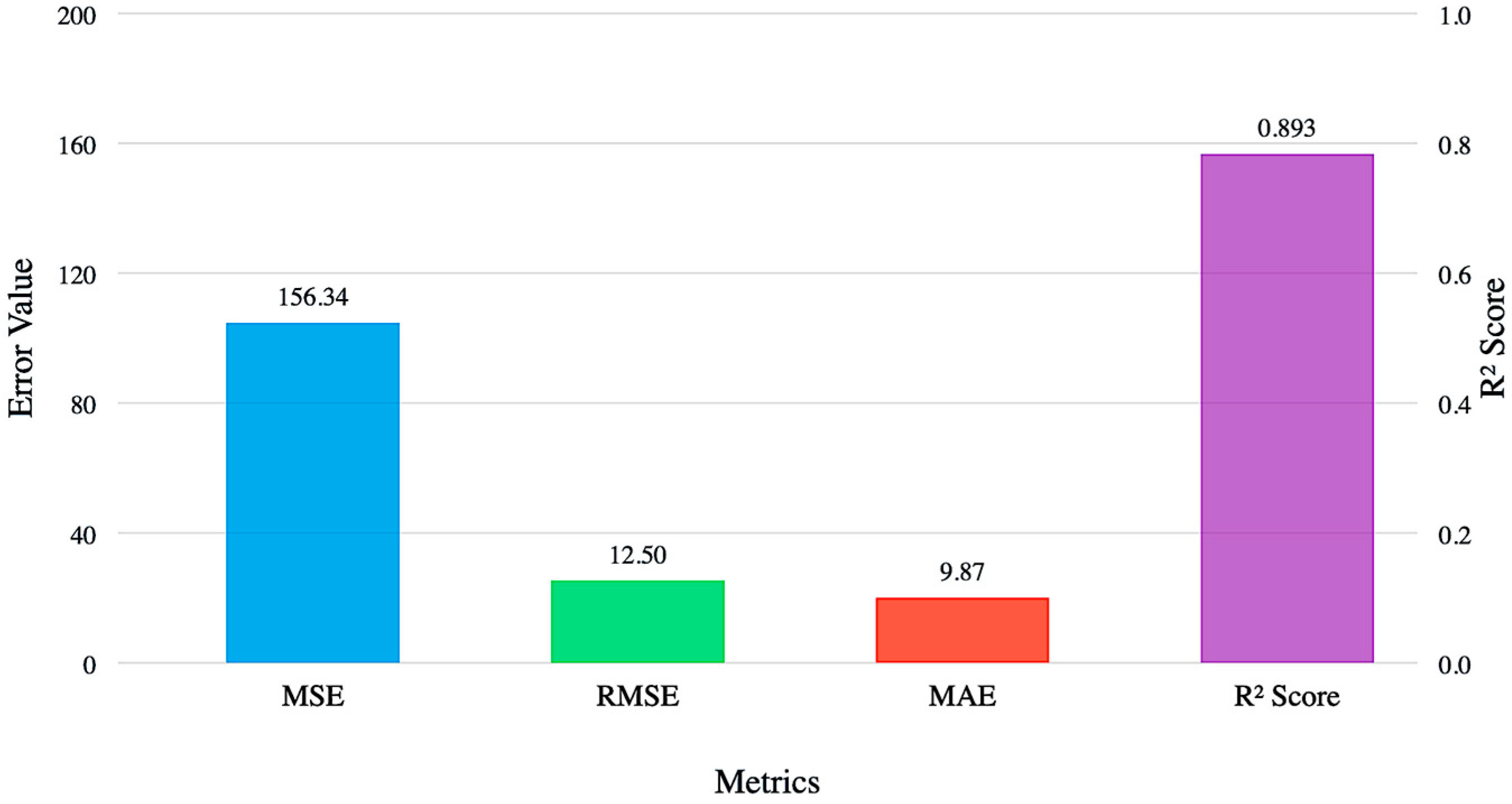
- Comparative Analysis of RUL Estimation Performance Metrics
4. Discussion
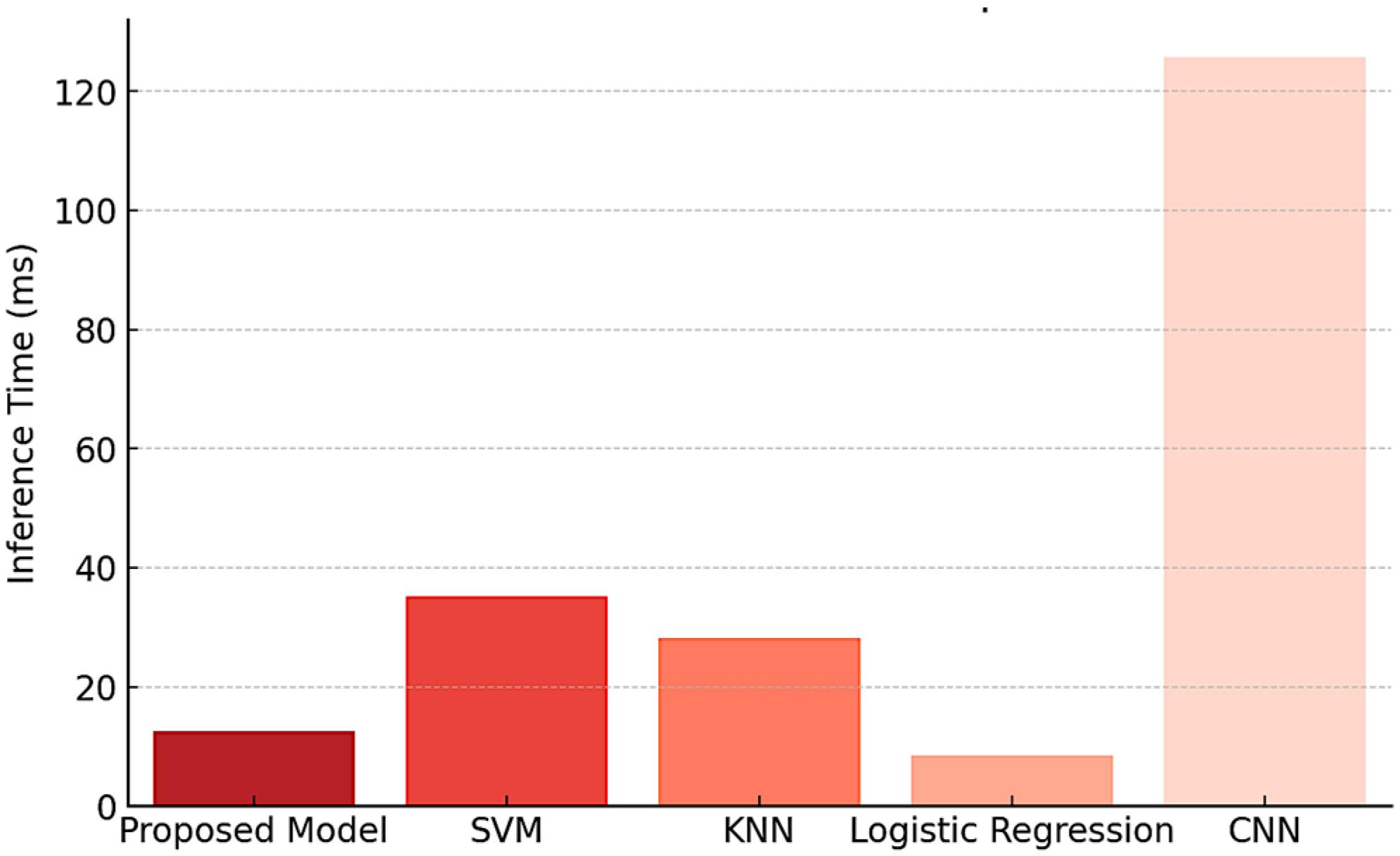
4.1. Comparative Analysis with Existing Fault Detection Methods
- Support Vector Machine (SVM)—A widely used classification algorithm for fault detection due to its robustness in high-dimensional spaces.
- K-Nearest Neighbors (KNNs)—A distance-based classification approach commonly employed for anomaly detection.
- Logistic Regression (LR)—A standard probabilistic classification method used as a baseline in binary fault classification.
- Convolutional Neural Networks (CNNs)—A deep learning-based approach capable of feature extraction and fault classification in complex datasets.
4.2. Implementation Plan
4.3. Evaluation and Validation
4.4. Expected Outcomes
4.5. Challenges in Integrating EC and AI for AHM and Management
4.6. Future Directions of Research
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Basora, L.; Bry, P.; Olive, X.; Freeman, F. Aircraft Fleet Health Monitoring with Anomaly Detection Techniques. Aerospace 2021, 8, 103. [Google Scholar] [CrossRef]
- Cicirello, V.A. Evolutionary Computation: Theories, Techniques, and Applications. Appl. Sci. 2024, 14, 2542. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992; ISBN 978-0262082136. [Google Scholar]
- Eiben, A.; Smith, J. Introduction to Evolutionary Computing, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2015; ISBN 978-3662448731. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998; ISBN 978-0262631853. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef] [PubMed]
- Langdon, W.B.; Poli, R. Foundations of Genetic Programming; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies—A comprehensive introduction. Nat. Comput. Int. J. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential Evolution: A Survey of the State-of-the-Art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Bilal; Pant, M.; Zaheer, H.; Garcia-Hernandez, L.; Abraham, A. Differential Evolution: A review of more than two decades of research. Eng. Appl. Artif. Intell. 2020, 90, 103479. [Google Scholar] [CrossRef]
- Yao, X.; Liu, Y.; Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 1999, 3, 82–102. [Google Scholar] [CrossRef]
- Cicirello, V.A. A Survey and Analysis of Evolutionary Operators for Permutations. In Proceedings of the 15th International Joint Conference on Computational Intelligence, Rome, Italy, 13–15 November 2023; pp. 288–299. Available online: https://www.scitepress.org/Link.aspx?doi=10.5220/0012204900003595 (accessed on 26 December 2024).
- Osaba, E.; Del Ser, J.; Cotta, C.; Moscato, P. Memetic Computing: Accelerating optimization heuristics with problem-dependent local search methods. Swarm Evol. Comput. 2022, 70, 101047. [Google Scholar] [CrossRef]
- Larrañaga, P.; Bielza, C. Estimation of Distribution Algorithms in Machine Learning: A Survey. IEEE Trans. Evol. Comput. 2024, 28, 1301–1321. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Uusitalo, S.; Kantosalo, A.; Salovaara, A.; Takala, T.; Guckelsberger, C. Creative collaboration with interactive evolutionary algorithms: A reflective exploratory design study. Genet. Program. Evolvable Mach. 2023, 25, 4. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evol. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1996, 26, 29–41. [Google Scholar] [CrossRef]
- Dasgupta, D. Advances in artificial immune systems. IEEE Comput. Intell. Mag. 2006, 1, 40–49. [Google Scholar] [CrossRef]
- Siarry, P. (Ed.) Metaheuristics; Springer Nature: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Hoos, H.H.; Stützle, T. Stochastic Local Search: Foundations and Applications; Morgan Kaufmann: San Francisco, CA, USA, 2005. [Google Scholar]
- Harada, T.; Alba, E. Parallel Genetic Algorithms: A Useful Survey. ACM Comput. Surv. 2020, 53, 86. [Google Scholar] [CrossRef]
- Cicirello, V.A. Impact of Random Number Generation on Parallel Genetic Algorithms. In Proceedings of the 31st International Florida Artificial Intelligence Research Society Conference, Melbourne, FL, USA, 21–23 May 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 2–7. [Google Scholar]
- Luque, G.; Alba, E. Parallel Genetic Algorithms: Theory and Real World Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Rudolph, G. Convergence analysis of canonical genetic algorithms. IEEE Trans. Neural Netw. 1994, 5, 96–101. [Google Scholar] [CrossRef]
- Rudolph, G. Convergence of evolutionary algorithms in general search spaces. In Proceedings of the IEEE International Conference on Evolutionary Computation, Nagoya, Japan, 20–22 May 1996; pp. 50–54. [Google Scholar] [CrossRef]
- He, J.; Yao, X. Drift analysis and average time complexity of evolutionary algorithms. Artif. Intell. 2001, 127, 57–85. [Google Scholar] [CrossRef]
- Karafotias, G.; Hoogendoorn, M.; Eiben, A.E. Parameter Control in Evolutionary Algorithms: Trends and Challenges. IEEE Trans. Evol. Comput. 2015, 19, 167–187. [Google Scholar] [CrossRef]
- Cicirello, V.A. On Fitness Landscape Analysis of Permutation Problems: From Distance Metrics to Mutation Operator Selection. Mob. Netw. Appl. 2023, 28, 507–517. [Google Scholar] [CrossRef]
- Pimenta, C.G.; de Sá, A.G.C.; Ochoa, G.; Pappa, G.L. Fitness Landscape Analysis of Automated Machine Learning Search Spaces. In Proceedings of the Evolutionary Computation in Combinatorial Optimization: 20th European Conference, EvoCOP 2020, Held as Part of EvoStar 2020, Seville, Spain, 15–17 April 2020; Springer: Cham, Switzerland, 2020; pp. 114–130. [Google Scholar] [CrossRef]
- Huang, Y.; Li, W.; Tian, F.; Meng, X. A fitness landscape ruggedness multiobjective differential evolution algorithm with a reinforcement learning strategy. Appl. Soft Comput. 2020, 96, 106693. [Google Scholar] [CrossRef]
- Jones, T.; Forrest, S. Fitness Distance Correlation as a Measure of Problem Difficulty for Genetic Algorithms. In Proceedings of the 6th International Conference on Genetic Algorithms, Pittsburgh, PA, USA, 15–19 July 1995; pp. 184–192. Available online: https://sfi-edu.s3.amazonaws.com/sfi-edu/production/uploads/sfi-com/dev/uploads/filer/bf/eb/bfeb9cb0-100f-44d9-a35f-e95243dba350/95-02-022.pdf (accessed on 26 December 2024).
- Cicirello, V.A. The Permutation in a Haystack Problem and the Calculus of Search Landscapes. IEEE Trans. Evol. Comput. 2016, 20, 434–446. [Google Scholar] [CrossRef]
- Scott, E.O.; Luke, S. ECJ at 20: Toward a General Metaheuristics Toolkit. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Prague, Czech Republic, 13–17 July 2019; ACM Press: New York, NY, USA, 2019; pp. 1391–1398. [Google Scholar] [CrossRef]
- Cicirello, V.A. Chips-n-Salsa: A Java Library of Customizable, Hybridizable, Iterative, Parallel, Stochastic, and Self-Adaptive Local Search Algorithms. J. Open Source Softw. 2020, 5, 2448. [Google Scholar] [CrossRef]
- Jenetics. Jenetics—Genetic Algorithm, Genetic Programming, Evolutionary Algorithm, and Multi-Objective Optimization. 2024. Available online: https://jenetics.io/ (accessed on 26 December 2024).
- Bell, I.H. CEGO: C++11 Evolutionary Global Optimization. J. Open Source Softw. 2019, 4, 1147. [Google Scholar] [CrossRef]
- Gijsbers, P.; Vanschoren, J. GAMA: Genetic Automated Machine learning Assistant. J. Open Source Softw. 2019, 4, 1132. [Google Scholar] [CrossRef]
- Detorakis, G.; Burton, A. GAIM: A C++ library for Genetic Algorithms and Island Models. J. Open Source Softw. 2019, 4, 1839. [Google Scholar] [CrossRef]
- de Dios, J.A.M.; Mezura-Montes, E. Metaheuristics: A Julia Package for Single- and Multi-Objective Optimization. J. Open Source Softw. 2022, 7, 4723. [Google Scholar] [CrossRef]
- Izzo, D.; Biscani, F. dcgp: Differentiable Cartesian Genetic Programming made easy. J. Open Source Softw. 2020, 5, 2290. [Google Scholar] [CrossRef]
- Simson, J. LGP: A robust Linear Genetic Programming implementation on the JVM using Kotlin. J. Open Source Softw. 2019, 4, 1337. [Google Scholar] [CrossRef]
- Tarkowski, T. Quilë: C++ genetic algorithms scientific library. J. Open Source Softw. 2023, 8, 4902. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Liang, J.; Ban, X.; Yu, K.; Qu, B.; Qiao, K.; Yue, C.; Chen, K.; Tan, K.C. A Survey on Evolutionary Constrained Multiobjective Optimization. IEEE Trans. Evol. Comput. 2023, 27, 201–221. [Google Scholar] [CrossRef]
- Tian, Y.; Si, L.; Zhang, X.; Cheng, R.; He, C.; Tan, K.C.; Jin, Y. Evolutionary Large-Scale Multi-Objective Optimization: A Survey. ACM Comput. Surv. 2021, 54, 174. [Google Scholar] [CrossRef]
- Li, M.; Yao, X. Quality Evaluation of Solution Sets in Multiobjective Optimisation: A Survey. ACM Comput. Surv. 2019, 52, 26. [Google Scholar] [CrossRef]
- Sohail, A. Genetic Algorithms in the Fields of Artificial Intelligence and Data Sciences. Ann. Data Sci. 2023, 10, 1007–1018. [Google Scholar] [CrossRef]
- Li, N.; Ma, L.; Yu, G.; Xue, B.; Zhang, M.; Jin, Y. Survey on Evolutionary Deep Learning: Principles, Algorithms, Applications, and Open Issues. ACM Comput. Surv. 2023, 56, 41. [Google Scholar] [CrossRef]
- Telikani, A.; Tahmassebi, A.; Banzhaf, W.; Gandomi, A.H. Evolutionary Machine Learning: A Survey. ACM Comput. Surv. 2021, 54, 161. [Google Scholar] [CrossRef]
- Li, N.; Ma, L.; Xing, T.; Yu, G.; Wang, C.; Wen, Y.; Cheng, S.; Gao, S. Automatic design of machine learning via evolutionary computation: A survey. Appl. Soft Comput. 2023, 143, 110412. [Google Scholar] [CrossRef]
- Espejo, P.G.; Ventura, S.; Herrera, F. A Survey on the Application of Genetic Programming to Classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 40, 121–144. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Zhou, X.; Qin, A.K.; Sun, Y.; Tan, K.C. A Survey of Advances in Evolutionary Neural Architecture Search. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Virtually, 28 June–1 July 2021; pp. 950–957. [Google Scholar] [CrossRef]
- Papavasileiou, E.; Cornelis, J.; Jansen, B. A Systematic Literature Review of the Successors of “NeuroEvolution of Augmenting Topologies”. Evol. Comput. 2021, 29, 1–73. [Google Scholar] [CrossRef]
- Fogel, G.B.; Corne, D.W. (Eds.) Evolutionary Computation in Bioinformatics; Morgan Kaufmann: San Francisco, CA, USA, 2003. [Google Scholar]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Survey on Genetic Programming and Machine Learning Techniques for Heuristic Design in Job Shop Scheduling. IEEE Trans. Evol. Comput. 2023, 28, 147–167. [Google Scholar] [CrossRef]
- Kerschke, P.; Hoos, H.H.; Neumann, F.; Trautmann, H. Automated Algorithm Selection: Survey and Perspectives. Evol. Comput. 2019, 27, 3–45. [Google Scholar] [CrossRef] [PubMed]
- Bi, Y.; Xue, B.; Mesejo, P.; Cagnoni, S.; Zhang, M. A Survey on Evolutionary Computation for Computer Vision and Image Analysis: Past, Present, and Future Trends. IEEE Trans. Evol. Comput. 2023, 27, 5–25. [Google Scholar] [CrossRef]
- Jayasena, A.; Mishra, P. Directed Test Generation for Hardware Validation: A Survey. ACM Comput. Surv. 2024, 56, 132. [Google Scholar] [CrossRef]
- Sobania, D.; Schweim, D.; Rothlauf, F. A Comprehensive Survey on Program Synthesis with Evolutionary Algorithms. IEEE Trans. Evol. Comput. 2023, 27, 82–97. [Google Scholar] [CrossRef]
- Arcuri, A.; Galeotti, J.P.; Marculescu, B.; Zhang, M. EvoMaster: A Search-Based System Test Generation Tool. J. Open Source Softw. 2021, 6, 2153. [Google Scholar] [CrossRef]
- Tan, Z.; Luo, L.; Zhong, J. Knowledge transfer in evolutionary multi-task optimization: A survey. Appl. Soft Comput. 2023, 138, 110182. [Google Scholar] [CrossRef]
- Zhao, H.; Ning, X.; Liu, X.; Wang, C.; Liu, J. What makes evolutionary multi-task optimization better: A comprehensive survey. Appl. Soft Comput. 2023, 145, 110545. [Google Scholar] [CrossRef]
- Singh, R. Are We Ready for NDE 5.0. In Handbook of Nondestructive Evaluation 4.0, 1st ed.; Springer: Cham, Switzerland, 2021; pp. 1–18. [Google Scholar] [CrossRef]
- Tsakalerou, M.; Nurmaganbetov, D.; Beltenov, N. Aircraft Maintenance 4.0 in an era of disruptions. Procedia Comput. Sci. 2022, 200, 121–131. [Google Scholar] [CrossRef]
- Vargas, J.; Calvo, R. Joint Optimization of Process Flow and Scheduling in Service-Oriented Manufacturing Systems. Materials 2018, 11, 1559. [Google Scholar] [CrossRef]
- Kabashkin, I.; Misnevs, B.; Zervina, O. Artificial Intelligence in Aviation: New Professionals for New Technologies. Appl. Sci. 2023, 13, 11660. [Google Scholar] [CrossRef]
- Abdelghany, E.S.; Farghaly, M.B.; Almalki, M.M.; Sarhan, H.H.; Essa, M.E.-S.M. Machine Learning and IoT Trends for Intelligent Prediction of Aircraft Wing Anti-Icing System Temperature. Aerospace 2023, 10, 676. [Google Scholar] [CrossRef]
- Gao, Z.; Mavris, D.N. Statistics and Machine Learning in Aviation Environmental Impact Analysis: A Survey of Recent Progress. Aerospace 2022, 9, 750. [Google Scholar] [CrossRef]
- Brandoli, B.; de Geus, A.R.; Souza, J.R.; Spadon, G.; Soares, A.; Rodrigues, J.F., Jr.; Komorowski, J.; Matwin, S. Aircraft Fuselage Corrosion Detection Using Artificial Intelligence. Sensors 2021, 21, 4026. [Google Scholar] [CrossRef]
- Yang, R.; Gao, Y.; Wang, H.; Ni, X. Fuzzy Neural Network PID Control Used in Individual Blade Control. Aerospace 2023, 10, 623. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Y. Data-Driven Exhaust Gas Temperature Baseline Predictions for Aeroengine Based on Machine Learning Algorithms. Aerospace 2023, 10, 17. [Google Scholar] [CrossRef]
- Chen, J.; Qi, G.; Wang, K. Synergizing Machine Learning and the Aviation Sector in Lithium-Ion Battery Applications: A Review. Energies 2023, 16, 6318. [Google Scholar] [CrossRef]
- Baumann, M.; Koch, C.; Staudacher, S. Application of Neural Networks and Transfer Learning to Turbomachinery Heat Transfer. Aerospace 2022, 9, 49. [Google Scholar] [CrossRef]
- Quadros, J.D.; Khan, S.A.; Aabid, A.; Alam, M.S.; Baig, M. Machine Learning Applications in Modelling and Analysis of Base Pressure in Suddenly Expanded Flows. Aerospace 2021, 8, 318. [Google Scholar] [CrossRef]
- Papakonstantinou, C.; Daramouskas, I.; Lappas, V.; Moulianitis, V.C.; Kostopoulos, V. A Machine Learning Approach for Global Steering Control Moment Gyroscope Clusters. Aerospace 2022, 9, 164. [Google Scholar] [CrossRef]
- Leite, D.; Andrade, E.; Rativa, D.; Maciel, A.M.A. Fault Detection and Diagnosis in Industry 4.0: A Review on Challenges and Opportunities. Sensors 2025, 25, 60. [Google Scholar] [CrossRef]
- Song, Y.; Huang, H.; Wang, H.; Wei, Q. Leveraging Swarm Intelligence for Invariant Rule Generation and Anomaly Detection in Industrial Control Systems. Appl. Sci. 2024, 14, 10705. [Google Scholar] [CrossRef]
- Xu, M.; Cao, L.; Lu, D.; Hu, Z.; Yue, Y. Application of Swarm Intelligence Optimization Algorithms in Image Processing: A Comprehensive Review of Analysis, Synthesis, and Optimization. Biomimetics 2023, 8, 235. [Google Scholar] [CrossRef] [PubMed]
- Abbal, K.; El-Amrani, M.; Aoun, O.; Benadada, Y. Adaptive Particle Swarm Optimization with Landscape Learning for Global Optimization and Feature Selection. Modelling 2025, 6, 9. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, L.; Li, M.; Chen, M.; Zhao, J.; Chu, F.; Li, W.J. A High-Accuracy Fault Detection Method Using Swarm Intelligence Optimization Entropy. IEEE Trans. Instrum. Meas. 2025, 74, 3501113. [Google Scholar] [CrossRef]
- Domínguez-Monferrer, C.; Ramajo-Ballester, A.; Armingol, J.M.; Cantero, J.L. Spot-checking machine learning algorithms for tool wear monitoring in automatic drilling operations in CFRP/Ti6Al4V/Al stacks in the aircraft industry. J. Manuf. Syst. 2024, 77, 96–111. [Google Scholar] [CrossRef]
- Caggiano, A.; Mattera, G.; Nele, L. Smart Tool Wear Monitoring of CFRP/CFRP Stack Drilling Using Autoencoders and Memory-Based Neural Networks. Appl. Sci. 2023, 13, 3307. [Google Scholar] [CrossRef]
- SHAP Documentation Team. Welcome to the SHAP Documentation. Available online: https://shap.readthedocs.io/en/latest/ (accessed on 26 December 2024).
- What Is Local Interpretable Model-Agnostic Explanations (LIME)? Available online: https://c3.ai/glossary/data-science/lime-local-interpretable-model-agnostic-explanations/ (accessed on 26 December 2024).
- Tian, Y.; Zhang, Y.; Zhang, H. Recent Advances in Stochastic Gradient Descent in Deep Learning. Mathematics 2023, 11, 682. [Google Scholar] [CrossRef]
- Cheng, H.; Ai, Q. A Cost Optimization Method Based on Adam Algorithm for Integrated Demand Response. Electronics 2023, 12, 4731. [Google Scholar] [CrossRef]
- Wen, X.; Song, Q.; Qian, Y.; Qiao, D.; Wang, H.; Zhang, Y.; Li, H. Effective Improved NSGA-II Algorithm for Multi-Objective Integrated Process Planning and Scheduling. Mathematics 2023, 11, 3523. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, H.; Zhao, J.; Li, Z. An Improved MOEA/D Algorithm for the Solution of the Multi-Objective Optimal Power Flow Problem. Processes 2023, 11, 337. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Examples | Key Characteristics |
|---|---|---|
| Operational Data | Temperature, vibration, pressure | High-frequency, large volume, time-series |
| Maintenance Data | Inspection logs, repair records | Structured, links operations to interventions |
| Failure Data | Fault patterns, cascading events | Sparse, crucial for fault detection and classification |
| Environmental Data | Weather, flight conditions | Auxiliary input, context-dependent granularity |
| Historical Data | Long-term trends, cumulative cycles | Enables trend analysis and RUL estimation |
| Simulated Data | Digital twin outputs, synthetic faults | Fills data gaps, controlled testing environment |
| Derived Features | Statistical and frequency-domain metrics | Domain-specific, enhances model accuracy |
| Diagnostic/Prognostic Labels | Health states, failure types, RUL labels | Annotated, essential for supervised learning |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Inference Time (ms) |
|---|---|---|---|---|---|
| Proposed Model (Random Forest + Genetic Algorithm) | 96.5 | 95.8 | 97.2 | 96.5 | 12.5 |
| Support Vector Machine (SVM) | 89.4 | 88.6 | 90.1 | 89.3 | 35.2 |
| K-Nearest Neighbors (KNNs) | 85.7 | 84.3 | 86.2 | 85.2 | 28.1 |
| Logistic Regression (LR) | 81.2 | 79.8 | 80.5 | 80.1 | 8.4 |
| Convolutional Neural Networks (CNNs) | 93.1 | 92.3 | 94.0 | 93.1 | 125.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabashkin, I. AI and Evolutionary Computation for Intelligent Aviation Health Monitoring. Electronics 2025, 14, 1369. https://doi.org/10.3390/electronics14071369
Kabashkin I. AI and Evolutionary Computation for Intelligent Aviation Health Monitoring. Electronics. 2025; 14(7):1369. https://doi.org/10.3390/electronics14071369
Chicago/Turabian StyleKabashkin, Igor. 2025. "AI and Evolutionary Computation for Intelligent Aviation Health Monitoring" Electronics 14, no. 7: 1369. https://doi.org/10.3390/electronics14071369
APA StyleKabashkin, I. (2025). AI and Evolutionary Computation for Intelligent Aviation Health Monitoring. Electronics, 14(7), 1369. https://doi.org/10.3390/electronics14071369