Abstract
Graph-based retrieval-augmented generation (GraphRAG) represents an innovative advancement in natural language processing, leveraging the power of large language models (LLMs) for complex tasks such as policy generation. This research presents a GraphRAG model trained on YouTube data containing keywords related to logistics issues to generate policy proposals addressing these challenges. The collected data include both video subtitles and user comments, which are used to fine-tune the GraphRAG model. To evaluate the effectiveness of this approach, the performance of the proposed model is compared to a standard generative pre-trained transformer (GPT) model. The results show that the GraphRAG model outperforms the GPT model in most prompts, highlighting its potential to generate more accurate and contextually relevant policy recommendations. This study not only contributes to the evolving field of LLM-based natural language processing (NLP) applications but also explores new methods for improving model efficiency and scalability in real-world domains like logistics policy making.
1. Introduction
Recent advancements in large language models (LLMs) have had a major impact on policy generation in various domains. Researchers are actively exploring innovative methods to improve the decision-making capabilities of LLMs without the need for extensive fine-tuning. For example, LLM-based policy generation has been proposed for intent-based management [1]. Despite the potential in improving decision making and task generalization, real-word applications remain limited.
To bridge this gap, we experiment with generating policy recommendation to address the logistics challenges using Japan as a case study, which is a pressing issue due to the need for sustainable and resilient solutions.
The logistics sector has moved from a cost deflationary phase to a cost inflationary era. In Japan, transportation capacity has exceeded logistics demand since the 1990s, largely due to deregulation. However, since around 2017, there has been growing concern about a looming logistics and courier crisis. Unlike past fluctuations caused by temporary supply and demand imbalances, the current logistics crisis stems from a sustained decline in transportation capacity, leading to delivery delays and operational challenges. As a critical component of one of the world’s largest economies, Japan’s trucking industry plays a vital role in maintaining its ultra-convenient consumer culture.
By 2021, Japan’s domestic freight volume reached 4.3 billion tons and 405 billion ton-miles annually, with trucks handling about 90% of total freight by weight and 50% by ton-miles. The rise of e-commerce and increasing demand from manufacturers seeking to minimize excess inventory are expected to drive commercial freight down to 3.2 billion tons in 2030. However, commercial freight capacity is projected to decline from 2.6 billion tons in 2020 to 2.0 billion tons in 2030, primarily due to a shrinking truck driver workforce. The number of truck drivers is expected to fall from 662,000 in 2020 to 519,000 in 2030, a decline of nearly 30% from 2015 levels. In April 2024, a new regulation capping truck drivers’ annual overtime at 960 hours was implemented, exacerbating the existing driver shortage—an issue widely referred to as the "2024 problem".
The driver shortage issue is not unique to Japan. A study by the International Road Transport Union [2] warns that if no action is taken to recruit more drivers, there could be a global shortage of more than 7 million drivers by 2028 in the 36 countries surveyed. The most commonly cited reasons include an aging workforce, long working hours, and low wages.
To address the issue, this study introduces a graph-based retrieval-augmented generation (GraphRAG) approach for policy generation aimed at addressing logistics challenges, such as the truck driver shortage, using Japan as a case study. The results show that the proposed model outperforms a GPT-only model for most of the prompts. In addition, this study leverages a large textual dataset by integrating both subtitle and comment data extracted from relevant YouTube videos, allowing for a more comprehensive analysis.
This study makes several important contributions. It is the first application of GraphRAG in logistics analysis, pioneering its use to analyze textual data derived from YouTube. The results highlight the potential of AI-driven methods in policy making. Using a large-scale natural language processing (NLP) approach, it captures public discourse and industry insights in real time. It also categorizes solutions by stakeholder (logistics companies, governments, drivers, and consumers) for a comprehensive approach to the labor shortage. Finally, it provides insights for optimizing GraphRAG’s search strategies (local, global, and hybrid) for logistics applications.
The study is structured as follows: Section 2 reviews previous research, Section 3 introduces the dataset, Section 4 presents the proposed methodology, Section 5 details experiments and results to evaluate the RAG effectiveness of the approach and discusses the findings, and Section 6 presents the conclusion.
2. Literature Review
2.1. Studies on Driver Shortage
Research on truck driver shortages has been approached from a variety of perspectives and methodologies. Table 1 summarizes the major studies that have examined this issue. Wang et al. [3], Chandiran et al. [4], and Schuster et al. [5] have analyzed the societal impacts and contributing factors behind the truck driver shortage using specially developed models. Meanwhile, Suzuki et al [6], Sersland et al. [7], and Corell [8] have used interview surveys and economic indicators to predict truck driver turnover.
Other studies, such as those by De Croon et al. [9], Prockl et al. [10], Swartz et al. [11], Wijngaards et al. [12], and Hage et al. [13], have examined the psychological aspects of truck drivers, particularly their well-being and its influence on turnover. In contrast, Beilock et al. [14] and de Winter et al. [15] have focused on job retention, examining the motivations and factors behind drivers’ career decisions.
By using different research approaches, studies of the truck driver shortage aim to understand its social, economic, and psychological dimensions. Addressing this challenge requires aligning the goals of three key stakeholders: truck drivers, industry, and government [16].
In Japan, since the economic recession of the 1990s, companies have increasingly sought to reduce operating costs, including logistics costs. This trend has continued to the present day. Understanding public and industry perspectives on logistics challenges such as driver shortages is critical to shaping policy and practical responses, particularly in balancing supply and demand in the logistics sector [17].

Table 1.
Summary of the literature on truck driver shortages.
Table 1.
Summary of the literature on truck driver shortages.
| Author | Year | Method | Contents |
|---|---|---|---|
| Beilock and Capelle [14] | 1990 | Questionnaire survey | Analysis of loyalty to occupation |
| de Croon et al. [9] | 2004 | Structural equation modeling | Analysis of psychological burden and turnover |
| Suzuki et al. [6] | 2009 | Econometrics method | Predicting truck driver turnover |
| Sersland and Nataraajan [7] | 2015 | Interview | Analysis of truck driver turnover |
| Prockl et al. [10] | 2017 | Statistical analysis | Analysis of well-being and safety environment |
| Swartz et al. [11] | 2017 | Structural equation modeling | Analysis of work attitude and safety environment |
| Belzer and Sedo [18] | 2018 | Statistical analysis | Analysis of long working hours |
| Burks and Monaco [19] | 2018 | Statistical analysis | Driver labor market analysis |
| Wijngaards et al. [12] | 2019 | Empirical sampling study | Determinants of well-being analysis |
| Hege et al. [13] | 2019 | Structural equation modeling | Survey of work–life conflicts |
| Lemke et al. [20] | 2020 | Data reviews | Impact analysis of COVID-19 |
| Wang et al. [3] | 2022 | Structural equation modeling | Study of the impact of driver shortage |
| Chandiran et al. [4] | 2023 | System dynamic model | Study of the impact of driver shortage |
| Schuster et al. [5] | 2023 | Questionnaire survey | Factor analysis of driver shortage |
| de Winter et al. [15] | 2024 | Questionnaire survey | Survey of occupational image |
| Correll [8] | 2024 | Machine learning | Predicting truck driver turnover |
2.2. Large Language Models in NLP
Artificial intelligence (AI) has received a great deal of attention in various fields and industries [21]. Over time, AI has gone through several stages of development and periods of stagnation known as AI winters. However, its global prominence skyrocketed after OpenAI released the chat generative pre-trained transformer (ChatGPT) in late 2022. The GPT family leverages massive datasets and LLMs trained with deep learning techniques to generate human-like text [22].
Built on a transformer architecture, GPT processes large amounts of text data to generate coherent responses based on user input [23]. While it excels at understanding context and handling diverse queries, its primary limitation is knowledge rigidity. It relies on pre-existing training data and cannot incorporate real-time updates. In addition, it struggles with factually accurate responses when confronted with unseen information, often producing misleading or incorrect content through inference. These limitations pose challenges for applications requiring high reliability [24,25].
To address these issues, retrieval-augmented generation (RAG) has been introduced. RAG extends the capabilities of GPT by retrieving external documents and databases to generate more factually grounded responses [26]. This approach is particularly useful for tasks involving real-time news updates and specialized knowledge domains. Miao et al. applied RAG in nephrology to improve its practical application. The authors created a specialized GPT model with RAG and demonstrated its potential in providing customized, accurate medical advice [27]. Hang et al. introduced an LLM and RAG integrated MCQGen framework for automated multiple-choice question generation. The authors suggest that MCQGen is effective at producing high-quality questions for different educational needs and learning styles, thus enhancing personalized learning [28]. However, RAG has its own challenges. It does not inherently consider document structure or interrelationships, which can lead to inefficient information integration. In addition, its effectiveness is highly dependent on data quality and retrieval accuracy, and incorrect retrievals can still lead to misleading results [29,30].
GraphRAG was proposed to address the limitations of standard RAG; it extends traditional RAG by more effectively integrating both retrieval and generation processes [31]. It employs three different search strategies: (a) local search, (b) global search, and (c) hybrid search, each offering different trade-offs in search coverage, computational efficiency, and result completeness. Figure 1 illustrates the differences in generation methods between LLMs only, RAG, and GraphRAG.
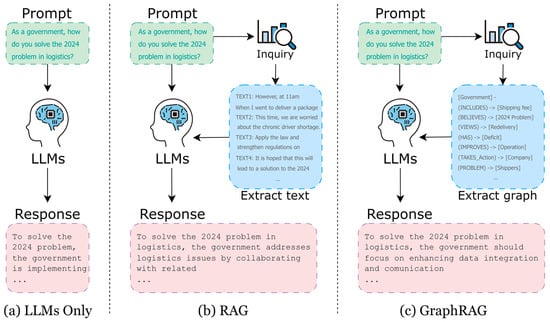
Figure 1.
Differences in generation method.
Local search focuses on retrieving information from nodes closely related to the query, scanning only the surrounding nodes within a predefined depth. This method enables fast retrieval with minimal computational cost because it relies on local graph structures. However, its limited scope may result in missing globally optimal nodes, which limits the completeness of the results.
Global search, on the other hand, scans the entire graph to identify the most relevant nodes based on embedding similarity and other search techniques. This approach improves comprehensiveness by uncovering relationships and insights that local search may miss. However, it requires more processing power and longer processing times, making it less efficient for real-time applications.
Hybrid search combines the best of both approaches. It starts with a fast local search to gather immediately relevant information and then expands to a global search to retrieve additional insights that may have been missed. This method ensures highly accurate search results by maintaining a balance between local relevance and global context [32]. However, it is more complex to implement, and the computational cost can be significant due to the dual search process.
As described above, there is a tradeoff between search coverage and computational cost in the GraphRAG generation method. Overall, RAG-based techniques, especially GraphRAG, enhance factual grounding by integrating external document retrieval, making them highly suitable for real-time logistics analysis.
3. Method
3.1. Base Model and Fine-Tuning
We compared VectorRAG and GraphRAG and chose the latter for the following reasons. VectorRAG has a strong focus on semantic search, identifying documents that are conceptually related to the query, even without exact keyword matches. GraphRAG, on the other hand, is characterized by its ability to retrieve information by exploiting relationships and connections between entities. There are a few other contemporary RAG technologies, such as Hybrid RAG and Light RAG. Hybrid RAG has a primary focus on improving retrieval quality. While it applies both neural and keyword-based retrieval, it has increased computational cost, complexity in implementation and tuning, and risk of conflicting results. Light RAG has its primary focus on reducing computational cost; for this reason, it has disadvantages such as low retrieval accuracy, limited knowledge depth, and is less effective for large-scale data such as the data applied in this study.
To fine-tune GraphRAG for logistics policy generation, we first used a pre-trained version of GraphRAG as our base model. The model was adapted for policy generation by incorporating domain-specific logistics datasets obtained from YouTube. We made modifications to the input processing and output generation layers to handle domain-specific constraints and goals (Table 2). For GPT tuning, the temperature was set to 0 to ensure more definite and consistent answers. The number of nodes used to generate responses was limited to 100 to balance the thoroughness of search results with response speed. In addition, fuzzy matching was used as the search mechanism in GraphRAG. This technique allows searches based on partial matches and similarities between queries and node names. Cosine similarity was used to calculate the fuzzy match score, with a threshold set at 0.5. This approach effectively combines flexible natural language understanding with the relational structure of the graph, improving both the accuracy and practical utility of information retrieval and response generation.
Table 2.
Tuning Metrics.
For fine-tuning, data obtained from YouTube videos are used. YouTube was selected for two main reasons. First, as Japan’s largest online video platform, it has a usage rate of 87.9% across all generations [33]. Second, it provides multiple perspectives, capturing both video creators’ viewpoints and audience comments, making it a valuable two-sided source of information.
The search keywords included “2024 problem in logistics” and “logistics crisis” in Japanese, which were retrieved using YouTube Data API v3 [34]. In total, 3037 videos and corresponding comment data were collected. Whisper v3 large was then applied for speech-to-text conversion. Finally, the data were translated to English and structured for NLP handling. The details of data collection are described in Section 4.
3.2. GraphRAG-Based NLP Analysis
GraphRAG was used to generate responses to four prompts employing four methods, namely (I) GPT-only, (II) local search, (III) global search, and (IV) hybrid search, to generate policy recommendations.
GraphRAG works by using a graph-structured knowledge base that stores domain-specific entities and their relationships. When a query is received, it is first mapped to a relevant subgraph using a graph traversal technique. The retrieval process starts by identifying the nodes most relevant to the query through a search of the graph, which may involve traversing edges, analyzing node labels, and considering relationships within the graph. The goal of this process is to find the subgraph that best matches the semantic content of the query.
The information retrieval from the graph is guided by a scoring function based on cosine similarity, which measures the closeness between the query vector and the node representations. Let us denote the query vector as and the node vector as . The similarity score between the query and each node is computed as follows:
where and represents the dot product of the query and node vectors, and and are the magnitudes of the respective vectors. Nodes with a similarity score above a defined threshold (e.g., 0.5) are retrieved as the most relevant for the query. The pseudocode for the Algorithm A1 is presented in Appendix A.
GraphRAG was created using neo4j desktop as the database and GPT 4o-mini as the LLM. The four prompts are designed from the perspective of four key stakeholders: logistics companies, government agencies, truck drivers, and consumers (Table 3). It is important to note that consumers are also a key stakeholder because they are the recipients of logistics services. The shortage of truck drivers directly affects delivery times, which in turn affects customer satisfaction. Therefore, the consumer perspective should be a key consideration in policy making.
Table 3.
Overview of prompts.
3.3. Performance Metrics
The performance of each model is evaluated using five metrics. Paraphrase-MiniLM-L6-v2 was applied to embed sentences for the calculation of cosine similarity (Table 4).
Table 4.
Performance evaluation metrics.
4. Data
4.1. Methods of Data Acquisition and Processing
Data collection process is outlined in Figure 2. It consists of the following steps:
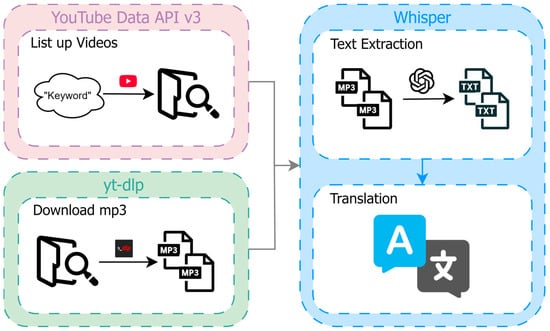
Figure 2.
Data collection process.
(a) YouTube Data API v3 is used to create a list of videos related to the truck driver shortage. The search keywords include “2024 problem in logistics” and “logistics crisis” in Japanese.
(b) Duplicate or irrelevant videos were removed.
(c) Based on the video list, a comment dataset was created using YouTube Data API v3 [34]. The dataset included the video ID, date and time of posting, comment content, number of likes, and username.
(d) Based on the video list, the audio data of the videos were collected using yt-dlp [35]. The audio data were also converted into text data using whisper v3 large [36].
(e) All collected text data were converted to English text.
The Python programming language version 3.13.1 was used to convert these data into a structured format for further training and analysis. In contrast to the existing literature, which primarily analyzes data from video comments, our study includes both comment data and text data, which are converted from audio for analysis.
4.2. Overview of Data
A total of 3037 videos were listed as a result of the collection; the number of YouTube videos peaked between February and June 2021 and again between February and May 2024 (Figure 3). This is likely related to the increased attention surrounding the increase in the overtime premium rate from 25% to 50% for overtime exceeding 60 hours per month in small and medium enterprises beginning 1 April 2023. The second peak is likely related to the introduction of a cap on overtime work of 960 hours per year from 1 April 2024. The introduction of a driver hours and pay policy has led to an increased number of related videos being uploaded.
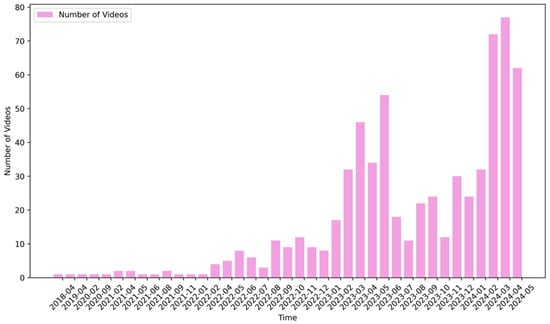
Figure 3.
Numbers of videos.
5. Results and Discussion
5.1. Prompts and Answers
Following the definition explained in Section 3.2, the prompts are run in each of the four models, namely (I) GPT-only, (II) local search, (III) global search, and (IV) hybrid search, and the results are shown in Table 5, Table 6, Table 7 and Table 8.
Table 5.
Output of "As a logistics company, how do you solve the 2024 problem in logistics?"
Table 6.
Output of "As a government, how do you solve the 2024 problem in logistics?"
Table 7.
Output of "As a driver, how do you solve the 2024 problem in logistics?"
Table 8.
Output of "As a consumer, how do you solve the 2024 problem in logistics?"
The intuitive impression is that the GPT model (I) generates broader, more general proposals, while RAG-based models (II, III, and IV) provide more specific and targeted suggestions. Quantitative performance evaluation is discussed in Section 5.2.
5.2. Performance Evaluation
The performance of each model, as measured by the metrics described in Section 3.3, is shown in Table 9. The results indicate that overall model III (Global Search) outperforms the other models, especially for Prompts 1, 3, and 4. Interestingly, for Prompt 2 (government), model 1 (GPT only) outperforms GraphRAG models. This may be because GPT tends to excel at understanding broader, context-rich scenarios. On the other hand, RAG could be more useful when factual accuracy or transparent source traceability is the top priority. In a government policy recommendation context, the best model may combine both: using a retrieval-based system like GraphRAG for fact-based grounding and taking advantage of GPT’s capabilities for higher-level synthesis and creativity in policy design.
Table 9.
Performance metrics (bold indicates best performance).
6. Conclusions
This study offers a new perspective on Japan’s truck driver shortage by using GraphRAG to analyze large amounts of text data from YouTube videos and comments. Going beyond traditional statistical analysis, it provides an alternative approach to understanding logistics challenges. Four models were used to generate responses to four prompts representing the perspectives of logistics companies, governments, drivers, and consumers. In three out of four cases, GraphRAG outperformed the GPT model, demonstrating higher vocabulary density, better readability, and greater similarity in responses.
This study contributes in the following ways. First, it is the first application of GraphRAG in logistics analysis. It pioneers the use of GraphRAG to analyze textual data retrieved from YouTube for logistics-related issues. The results demonstrate the potential of AI-driven methods in policy making. Second, the application of a large-scale NLP approach provides a rich and diverse dataset that captures public discourse and industry insights in real time. Third, the research categorizes solutions based on different logistics stakeholders (logistics companies, governments, drivers, and consumers), providing a holistic approach to addressing labor shortages. Fourth, by comparing different search strategies (local, global, and hybrid) within GraphRAG, the study provides insights into optimizing retrieval-augmented generation models for logistics applications.
This study has several limitations. First, the dataset is based on social media data. While YouTube provides a broad dataset, it may contain biases, misinformation, or exaggerated opinions that affect the validity of the conclusions. Second, the use of GraphRAG, particularly hybrid search, increases computational costs and may not be easily scalable for real-time logistics applications. Third, the study does not compare the results with official logistics data or expert surveys, which limits the validation of its conclusions.
Future studies should combine GraphRAG with official industry reports, global positioning system (GPS) tracking, and transportation network datasets for more comprehensive insights. It would be worthwhile to develop improved methods for validating and interpreting AI-generated insights to increase industry confidence and adoption. To address potential biases or rumors in SNS data, future studies could incorporate LLM-based fact-checking tools such as TrumorGPT [37]. Finally, further research should assess how AI-driven analytics can shape government regulations and industry standards for sustainable logistics.
Author Contributions
Conceptualization, H.N. and E.H.; methodology, H.N. and E.H.; software, H.N.; validation, H.N. and E.H.; data curation, H.N.; writing—original draft preparation, H.N. and E.H.; writing—review and editing, E.H.; visualization, H.N.; supervision, E.H.; funding acquisition, E.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by JSPS KAKENHI Grant Numbers JP 23K04076.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors thank the editor and referees for helping to improve this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LLMs | Large language models |
| GraphRAG | Graph-based retrieval-augmented generation |
| NLP | Natural language processing |
| GPT | Generative pre-trained transformer |
| WC | Word count |
| TTR | Type token ratios |
| ADD | Average dependency distance |
| FKG | Flesch–Kincaid grade level |
| CS | Cosine similarity |
| AI | Artificial intelligence |
| DX | Logistics digital transformation |
| GPS | Global positioning system |
Appendix A. Pseudocode of the GraphRAG Algorithm
| Algorithm A1. GraphRAG |
| Structured Retriever: (question) - Input: Question - Processing: - Extract entities from the question (entity_chain.invoke(question)) - Search structured data in Neo4j using each entity (graph.query(entity)) - Output: structured data (result) Retriever: - Input: question, mode - Processing: - If mode is “gpt_only”, pass question directly to LLM (llm.invoke(question)) - If mode is “local” or “hybrid”, retrieve structured data (structured_retriever(question)) - If mode is “global” or “hybrid”, search for unstructured data (vector_index.search(question)) - Output: result of combining structured and unstructured data QA Chain: - Input: question, mode - Processing: - Call retriever to get data (context) based on the question - Pass the data to LLM to generate the final answer (llm.invoke(context)) - Output: final answer |
References
- Dzeparoska, K.; Lin, J.; Tizghadam, A.; Leon-Garcia, A. LLM-Based Policy Generation for Intent-Based Management of Applications. In Proceedings of the 2023 19th International Conference on Network and Service Management (CNSM), Niagara Falls, ON, Canada, 30 October–2 November 2023; pp. 1–7. [Google Scholar]
- IRU Global Truck Driver Shortage Report 2023 |IRU| World Road Transport Organisation. Available online: https://www.iru.org/resources/iru-library/global-truck-driver-shortage-report-2023 (accessed on 15 January 2025).
- Wang, M.; Wood, L.C.; Wang, B. Transportation Capacity Shortage Influence on Logistics Performance: Evidence from the Driver Shortage. Heliyon 2022, 8, e09423. [Google Scholar] [CrossRef]
- Chandiran, P.; Ramasubramaniam, M.; Venkatesh, V.G.; Mani, V.; Shi, Y. Can Driver Supply Disruption Alleviate Driver Shortages? A Systems Approach. Transp. Policy 2023, 130, 116–129. [Google Scholar] [CrossRef]
- Schuster, A.M.; Agrawal, S.; Britt, N.; Sperry, D.; Van Fossen, J.A.; Wang, S.; Mack, E.A.; Liberman, J.; Cotten, S.R. Will Automated Vehicles Solve the Truck Driver Shortages? Perspectives from the Trucking Industry. Technol. Soc. 2023, 74, 102313. [Google Scholar] [CrossRef]
- Suzuki, Y.; Crum, M.R.; Pautsch, G.R. Predicting Truck Driver Turnover. Transp. Res. Part E Logist. Transp. Rev. 2009, 45, 538–550. [Google Scholar] [CrossRef]
- Sersland, D.; Nataraajan, R. Driver Turnover Research: Exploring the Missing Angle with a Global Perspective. J. Serv. Manag. 2015, 26, 648–661. [Google Scholar] [CrossRef]
- Correll, D.H. Predicting and Understanding Long-Haul Truck Driver Turnover Using Driver-Level Operational Data and Supervised Machine Learning Classifiers. Expert Syst. Appl. 2024, 242, 122782. [Google Scholar] [CrossRef]
- de Croon, E.M.; Sluiter, J.K.; Blonk, R.W.B.; Broersen, J.P.J.; Frings-Dresen, M.H.W. Stressful Work, Psychological Job Strain, and Turnover: A 2-Year Prospective Cohort Study of Truck Drivers. J. Appl. Psychol. 2004, 89, 442–454. [Google Scholar] [CrossRef]
- Prockl, G.; Teller, C.; Kotzab, H.; Angell, R. Antecedents of Truck Drivers’ Job Satisfaction and Retention Proneness. J. Bus. Logist. 2017, 38, 184–196. [Google Scholar] [CrossRef]
- Swartz, S.M.; Douglas, M.A.; Roberts, M.D.; Overstreet, R.E. Leavin’ on My Mind: Influence of Safety Climate on Truck Drivers’ Job Attitudes and Intentions to Leave. Transp. J. 2017, 56, 184–209. [Google Scholar] [CrossRef]
- Wijngaards, I.; Hendriks, M.; Burger, M.J. Steering towards Happiness: An Experience Sampling Study on the Determinants of Happiness of Truck Drivers. Transp. Res. Part A Policy Pract. 2019, 128, 131–148. [Google Scholar] [CrossRef]
- Hege, A.; Lemke, M.K.; Apostolopoulos, Y.; Whitaker, B.; Sönmez, S. Work-Life Conflict among U.S. Long-Haul Truck Drivers: Influences of Work Organization, Perceived Job Stress, Sleep, and Organizational Support. Int. J. Environ. Res. Public Health 2019, 16, 984. [Google Scholar] [CrossRef] [PubMed]
- Beilock, R.; Capelle, R.B. Occupational Loyalties Among Truck Drivers. Transp. J. 1990, 29, 20–28. [Google Scholar]
- de Winter, J.; Driessen, T.; Dodou, D.; Cannoo, A. Exploring the Challenges Faced by Dutch Truck Drivers in the Era of Technological Advancement. Front. Public Health 2024, 12, 1352979. [Google Scholar] [CrossRef]
- Mittal, N.; Udayakumar, P.D.; Raghuram, G.; Bajaj, N. The Endemic Issue of Truck Driver Shortage—A Comparative Study between India and the United States. Res. Transp. Econ. 2018, 71, 76–84. [Google Scholar] [CrossRef]
- Hirata, E.; Matsuda, T. Examining Logistics Developments in Post-Pandemic Japan through Sentiment Analysis of Twitter Data. Asian Transp. Stud. 2023, 9, 100110. [Google Scholar] [CrossRef]
- Belzer, M.H.; Sedo, S.A. Why Do Long Distance Truck Drivers Work Extremely Long Hours? Econ. Labour Relat. Rev. 2018, 29, 59–79. [Google Scholar] [CrossRef]
- Burks, S.V.; Monaco, K. Is the U.S. Labor Market for Truck Drivers Broken? An Empirical Analysis Using Nationally Representative Data; Institute of Labor Economics (IZA): Bonn, Germany, 2018; pp. 1–47. [Google Scholar]
- Lemke, M.K.; Apostolopoulos, Y.; Sönmez, S. A Novel COVID-19 Based Truck Driver Syndemic? Implications for Public Health, Safety, and Vital Supply Chains. Am. J. Ind. Med. 2020, 63, 659–662. [Google Scholar] [CrossRef]
- Hyder, Z.; Siau, K.; Nah, F. Artificial Intelligence, Machine Learning, and Autonomous Technologies in Mining Industry. J. Database Manag. 2019, 30, 67–79. [Google Scholar] [CrossRef]
- Cascella, M.; Semeraro, F.; Montomoli, J.; Bellini, V.; Piazza, O.; Bignami, E. The Breakthrough of Large Language Models Release for Medical Applications: 1-Year Timeline and Perspectives. J. Med. Syst. 2024, 48, 22. [Google Scholar] [CrossRef]
- Yenduri, G.; Srivastava, G.; Maddikunta, P.K.; Jhaveri, R.H.; Wang, W.; Vasilakos, A.V.; Gadekallu, T.R. Generative Pre-Trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions. arXiv 2023, arXiv:2305.10435. [Google Scholar] [CrossRef]
- Rawte, V.; Sheth, A.; Das, A. A Survey of Hallucination in Large Foundation Models. arXiv 2023, arXiv:2309.05922. [Google Scholar]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Halgamuge, M.N. The Inadequacy of Reinforcement Learning From Human Feedback—Radicalizing Large Language Models via Semantic Vulnerabilities. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1561–1574. [Google Scholar] [CrossRef]
- Zhao, P.; Zhang, H.; Yu, Q.; Wang, Z.; Geng, Y.; Fu, F.; Yang, L.; Zhang, W.; Jiang, J.; Cui, B. Retrieval-Augmented Generation for AI-Generated Content: A Survey. arXiv 2024, arXiv:2402.19473. [Google Scholar]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Cheungpasitporn, W. Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications. Medicina 2024, 60, 445. [Google Scholar] [CrossRef] [PubMed]
- Hang, C.N.; Wei Tan, C.; Yu, P.-D. MCQGen: A Large Language Model-Driven MCQ Generator for Personalized Learning. IEEE Access 2024, 12, 102261–102273. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T. Retrieval-Augmented Generation for Knowledge-Intensive Nlp Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Barnett, S.; Kurniawan, S.; Thudumu, S.; Brannelly, Z.; Abdelrazek, M. Seven Failure Points When Engineering a Retrieval Augmented Generation System. In Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI, Lisbon, Portugal, 14–15 April 2024; ACM: New York, NY, USA, 2024; pp. 194–199. [Google Scholar]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Larson, J. From Local to Global: A Graph Rag Approach to Query-Focused Summarization. arXiv 2024, arXiv:2404.16130. [Google Scholar]
- Han, H.; Shomer, H.; Wang, Y.; Lei, Y.; Guo, K.; Hua, Z.; Long, B.; Liu, H.; Tang, J. RAG vs. GraphRAG: A Systematic Evaluation and Key Insights. arXiv 2025, arXiv:2502.11371. [Google Scholar]
- Hottolink 2025 Ranking of SNS Utilization in Japan and Worldwide. Available online: https://www.hottolink.co.jp/column/20250106_114872/ (accessed on 14 February 2025).
- Google YouTube Data API. Available online: https://developers.google.com/youtube/v3 (accessed on 15 January 2025).
- pukkandan; Shirt-dev; Sepro; Sawicki, S.; coletdjnz; ashonly Yt-Dlp/Yt-Dlp 2025. Available online: https://github.com/yt-dlp/yt-dlp/releases (accessed on 14 February 2025).
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Hang, C.N.; Yu, P.-D.; Tan, C.W. TrumorGPT: Query Optimization and Semantic Reasoning over Networks for Automated Fact-Checking. In Proceedings of the 2024 58th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 13–15 March 2024; pp. 1–6. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).