

Enhancing Policy Generation with GraphRAG and YouTube Data: A Logistics Case Study



Abstract
1. Introduction
2. Literature Review
2.1. Studies on Driver Shortage

{kind=link}
{kind=link}
{kind=link}
| Author | Year | Method | Contents |
|---|---|---|---|
| Beilock and Capelle [14] | 1990 | Questionnaire survey | Analysis of loyalty to occupation |
| de Croon et al. [9] | 2004 | Structural equation modeling | Analysis of psychological burden and turnover |
| Suzuki et al. [6] | 2009 | Econometrics method | Predicting truck driver turnover |
| Sersland and Nataraajan [7] | 2015 | Interview | Analysis of truck driver turnover |
| Prockl et al. [10] | 2017 | Statistical analysis | Analysis of well-being and safety environment |
| Swartz et al. [11] | 2017 | Structural equation modeling | Analysis of work attitude and safety environment |
| Belzer and Sedo [18] | 2018 | Statistical analysis | Analysis of long working hours |
| Burks and Monaco [19] | 2018 | Statistical analysis | Driver labor market analysis |
| Wijngaards et al. [12] | 2019 | Empirical sampling study | Determinants of well-being analysis |
| Hege et al. [13] | 2019 | Structural equation modeling | Survey of work–life conflicts |
| Lemke et al. [20] | 2020 | Data reviews | Impact analysis of COVID-19 |
| Wang et al. [3] | 2022 | Structural equation modeling | Study of the impact of driver shortage |
| Chandiran et al. [4] | 2023 | System dynamic model | Study of the impact of driver shortage |
| Schuster et al. [5] | 2023 | Questionnaire survey | Factor analysis of driver shortage |
| de Winter et al. [15] | 2024 | Questionnaire survey | Survey of occupational image |
| Correll [8] | 2024 | Machine learning | Predicting truck driver turnover |
2.2. Large Language Models in NLP
3. Method
3.1. Base Model and Fine-Tuning
3.2. GraphRAG-Based NLP Analysis
3.3. Performance Metrics
4. Data
4.1. Methods of Data Acquisition and Processing
4.2. Overview of Data
5. Results and Discussion
5.1. Prompts and Answers
5.2. Performance Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LLMs | Large language models |
| GraphRAG | Graph-based retrieval-augmented generation |
| NLP | Natural language processing |
| GPT | Generative pre-trained transformer |
| WC | Word count |
| TTR | Type token ratios |
| ADD | Average dependency distance |
| FKG | Flesch–Kincaid grade level |
| CS | Cosine similarity |
| AI | Artificial intelligence |
| DX | Logistics digital transformation |
| GPS | Global positioning system |
Appendix A. Pseudocode of the GraphRAG Algorithm
| Algorithm A1. GraphRAG |
| Structured Retriever: (question) - Input: Question - Processing: - Extract entities from the question (entity_chain.invoke(question)) - Search structured data in Neo4j using each entity (graph.query(entity)) - Output: structured data (result) Retriever: - Input: question, mode - Processing: - If mode is “gpt_only”, pass question directly to LLM (llm.invoke(question)) - If mode is “local” or “hybrid”, retrieve structured data (structured_retriever(question)) - If mode is “global” or “hybrid”, search for unstructured data (vector_index.search(question)) - Output: result of combining structured and unstructured data QA Chain: - Input: question, mode - Processing: - Call retriever to get data (context) based on the question - Pass the data to LLM to generate the final answer (llm.invoke(context)) - Output: final answer |
References
- Dzeparoska, K.; Lin, J.; Tizghadam, A.; Leon-Garcia, A. LLM-Based Policy Generation for Intent-Based Management of Applications. In Proceedings of the 2023 19th International Conference on Network and Service Management (CNSM), Niagara Falls, ON, Canada, 30 October–2 November 2023; pp. 1–7. [Google Scholar]
- IRU Global Truck Driver Shortage Report 2023 |IRU| World Road Transport Organisation. Available online: https://www.iru.org/resources/iru-library/global-truck-driver-shortage-report-2023 (accessed on 15 January 2025).
- Wang, M.; Wood, L.C.; Wang, B. Transportation Capacity Shortage Influence on Logistics Performance: Evidence from the Driver Shortage. Heliyon 2022, 8, e09423. [Google Scholar] [CrossRef]
- Chandiran, P.; Ramasubramaniam, M.; Venkatesh, V.G.; Mani, V.; Shi, Y. Can Driver Supply Disruption Alleviate Driver Shortages? A Systems Approach. Transp. Policy 2023, 130, 116–129. [Google Scholar] [CrossRef]
- Schuster, A.M.; Agrawal, S.; Britt, N.; Sperry, D.; Van Fossen, J.A.; Wang, S.; Mack, E.A.; Liberman, J.; Cotten, S.R. Will Automated Vehicles Solve the Truck Driver Shortages? Perspectives from the Trucking Industry. Technol. Soc. 2023, 74, 102313. [Google Scholar] [CrossRef]
- Suzuki, Y.; Crum, M.R.; Pautsch, G.R. Predicting Truck Driver Turnover. Transp. Res. Part E Logist. Transp. Rev. 2009, 45, 538–550. [Google Scholar] [CrossRef]
- Sersland, D.; Nataraajan, R. Driver Turnover Research: Exploring the Missing Angle with a Global Perspective. J. Serv. Manag. 2015, 26, 648–661. [Google Scholar] [CrossRef]
- Correll, D.H. Predicting and Understanding Long-Haul Truck Driver Turnover Using Driver-Level Operational Data and Supervised Machine Learning Classifiers. Expert Syst. Appl. 2024, 242, 122782. [Google Scholar] [CrossRef]
- de Croon, E.M.; Sluiter, J.K.; Blonk, R.W.B.; Broersen, J.P.J.; Frings-Dresen, M.H.W. Stressful Work, Psychological Job Strain, and Turnover: A 2-Year Prospective Cohort Study of Truck Drivers. J. Appl. Psychol. 2004, 89, 442–454. [Google Scholar] [CrossRef]
- Prockl, G.; Teller, C.; Kotzab, H.; Angell, R. Antecedents of Truck Drivers’ Job Satisfaction and Retention Proneness. J. Bus. Logist. 2017, 38, 184–196. [Google Scholar] [CrossRef]
- Swartz, S.M.; Douglas, M.A.; Roberts, M.D.; Overstreet, R.E. Leavin’ on My Mind: Influence of Safety Climate on Truck Drivers’ Job Attitudes and Intentions to Leave. Transp. J. 2017, 56, 184–209. [Google Scholar] [CrossRef]
- Wijngaards, I.; Hendriks, M.; Burger, M.J. Steering towards Happiness: An Experience Sampling Study on the Determinants of Happiness of Truck Drivers. Transp. Res. Part A Policy Pract. 2019, 128, 131–148. [Google Scholar] [CrossRef]
- Hege, A.; Lemke, M.K.; Apostolopoulos, Y.; Whitaker, B.; Sönmez, S. Work-Life Conflict among U.S. Long-Haul Truck Drivers: Influences of Work Organization, Perceived Job Stress, Sleep, and Organizational Support. Int. J. Environ. Res. Public Health 2019, 16, 984. [Google Scholar] [CrossRef] [PubMed]
- Beilock, R.; Capelle, R.B. Occupational Loyalties Among Truck Drivers. Transp. J. 1990, 29, 20–28. [Google Scholar]
- de Winter, J.; Driessen, T.; Dodou, D.; Cannoo, A. Exploring the Challenges Faced by Dutch Truck Drivers in the Era of Technological Advancement. Front. Public Health 2024, 12, 1352979. [Google Scholar] [CrossRef]
- Mittal, N.; Udayakumar, P.D.; Raghuram, G.; Bajaj, N. The Endemic Issue of Truck Driver Shortage—A Comparative Study between India and the United States. Res. Transp. Econ. 2018, 71, 76–84. [Google Scholar] [CrossRef]
- Hirata, E.; Matsuda, T. Examining Logistics Developments in Post-Pandemic Japan through Sentiment Analysis of Twitter Data. Asian Transp. Stud. 2023, 9, 100110. [Google Scholar] [CrossRef]
- Belzer, M.H.; Sedo, S.A. Why Do Long Distance Truck Drivers Work Extremely Long Hours? Econ. Labour Relat. Rev. 2018, 29, 59–79. [Google Scholar] [CrossRef]
- Burks, S.V.; Monaco, K. Is the U.S. Labor Market for Truck Drivers Broken? An Empirical Analysis Using Nationally Representative Data; Institute of Labor Economics (IZA): Bonn, Germany, 2018; pp. 1–47. [Google Scholar]
- Lemke, M.K.; Apostolopoulos, Y.; Sönmez, S. A Novel COVID-19 Based Truck Driver Syndemic? Implications for Public Health, Safety, and Vital Supply Chains. Am. J. Ind. Med. 2020, 63, 659–662. [Google Scholar] [CrossRef]
- Hyder, Z.; Siau, K.; Nah, F. Artificial Intelligence, Machine Learning, and Autonomous Technologies in Mining Industry. J. Database Manag. 2019, 30, 67–79. [Google Scholar] [CrossRef]
- Cascella, M.; Semeraro, F.; Montomoli, J.; Bellini, V.; Piazza, O.; Bignami, E. The Breakthrough of Large Language Models Release for Medical Applications: 1-Year Timeline and Perspectives. J. Med. Syst. 2024, 48, 22. [Google Scholar] [CrossRef]
- Yenduri, G.; Srivastava, G.; Maddikunta, P.K.; Jhaveri, R.H.; Wang, W.; Vasilakos, A.V.; Gadekallu, T.R. Generative Pre-Trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions. arXiv 2023, arXiv:2305.10435. [Google Scholar] [CrossRef]
- Rawte, V.; Sheth, A.; Das, A. A Survey of Hallucination in Large Foundation Models. arXiv 2023, arXiv:2309.05922. [Google Scholar]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Halgamuge, M.N. The Inadequacy of Reinforcement Learning From Human Feedback—Radicalizing Large Language Models via Semantic Vulnerabilities. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1561–1574. [Google Scholar] [CrossRef]
- Zhao, P.; Zhang, H.; Yu, Q.; Wang, Z.; Geng, Y.; Fu, F.; Yang, L.; Zhang, W.; Jiang, J.; Cui, B. Retrieval-Augmented Generation for AI-Generated Content: A Survey. arXiv 2024, arXiv:2402.19473. [Google Scholar]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Cheungpasitporn, W. Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications. Medicina 2024, 60, 445. [Google Scholar] [CrossRef] [PubMed]
- Hang, C.N.; Wei Tan, C.; Yu, P.-D. MCQGen: A Large Language Model-Driven MCQ Generator for Personalized Learning. IEEE Access 2024, 12, 102261–102273. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T. Retrieval-Augmented Generation for Knowledge-Intensive Nlp Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Barnett, S.; Kurniawan, S.; Thudumu, S.; Brannelly, Z.; Abdelrazek, M. Seven Failure Points When Engineering a Retrieval Augmented Generation System. In Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI, Lisbon, Portugal, 14–15 April 2024; ACM: New York, NY, USA, 2024; pp. 194–199. [Google Scholar]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Larson, J. From Local to Global: A Graph Rag Approach to Query-Focused Summarization. arXiv 2024, arXiv:2404.16130. [Google Scholar]
- Han, H.; Shomer, H.; Wang, Y.; Lei, Y.; Guo, K.; Hua, Z.; Long, B.; Liu, H.; Tang, J. RAG vs. GraphRAG: A Systematic Evaluation and Key Insights. arXiv 2025, arXiv:2502.11371. [Google Scholar]
- Hottolink 2025 Ranking of SNS Utilization in Japan and Worldwide. Available online: https://www.hottolink.co.jp/column/20250106_114872/ (accessed on 14 February 2025).
- Google YouTube Data API. Available online: https://developers.google.com/youtube/v3 (accessed on 15 January 2025).
- pukkandan; Shirt-dev; Sepro; Sawicki, S.; coletdjnz; ashonly Yt-Dlp/Yt-Dlp 2025. Available online: https://github.com/yt-dlp/yt-dlp/releases (accessed on 14 February 2025).
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Hang, C.N.; Yu, P.-D.; Tan, C.W. TrumorGPT: Query Optimization and Semantic Reasoning over Networks for Automated Fact-Checking. In Proceedings of the 2024 58th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 13–15 March 2024; pp. 1–6. [Google Scholar]
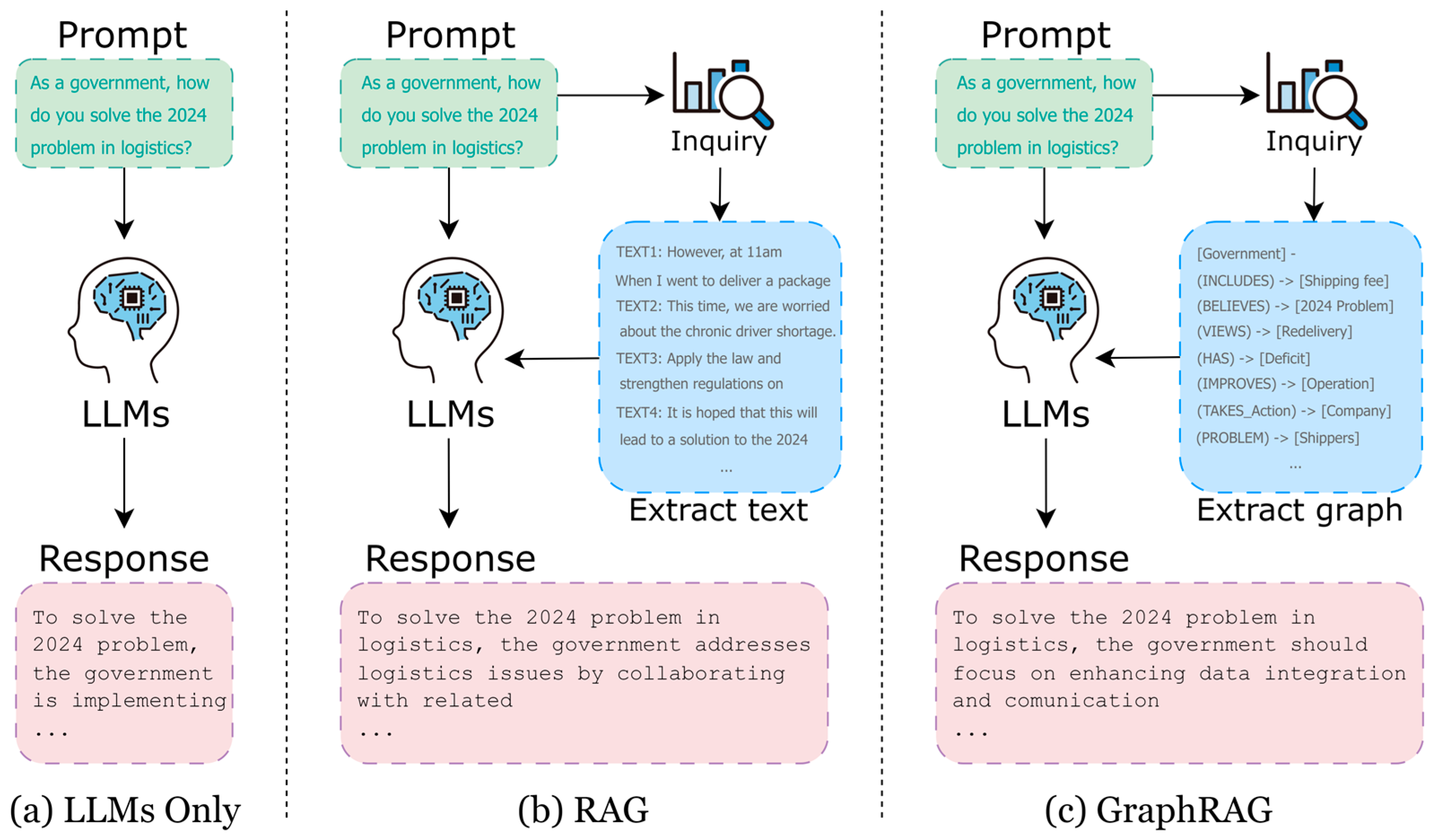
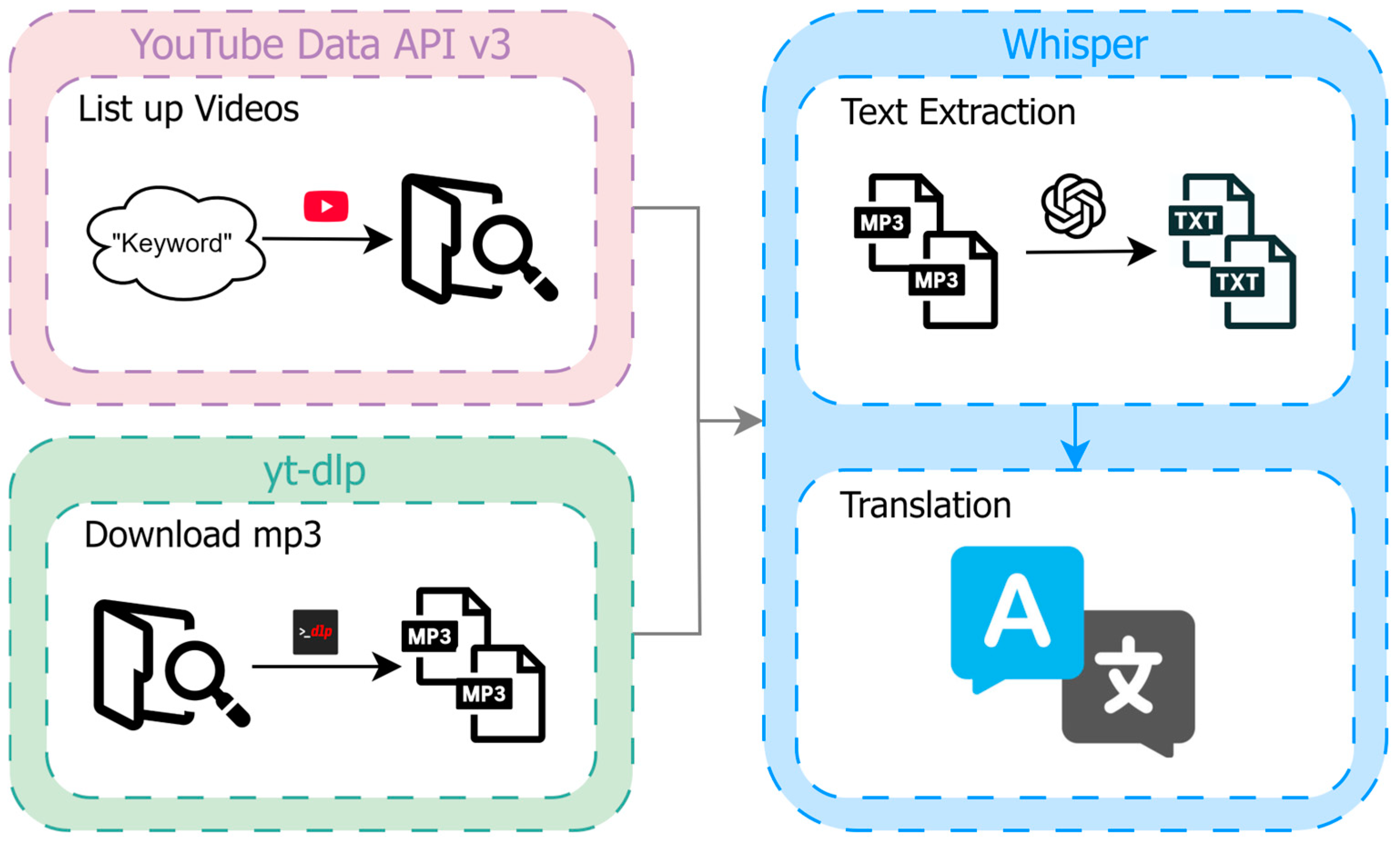
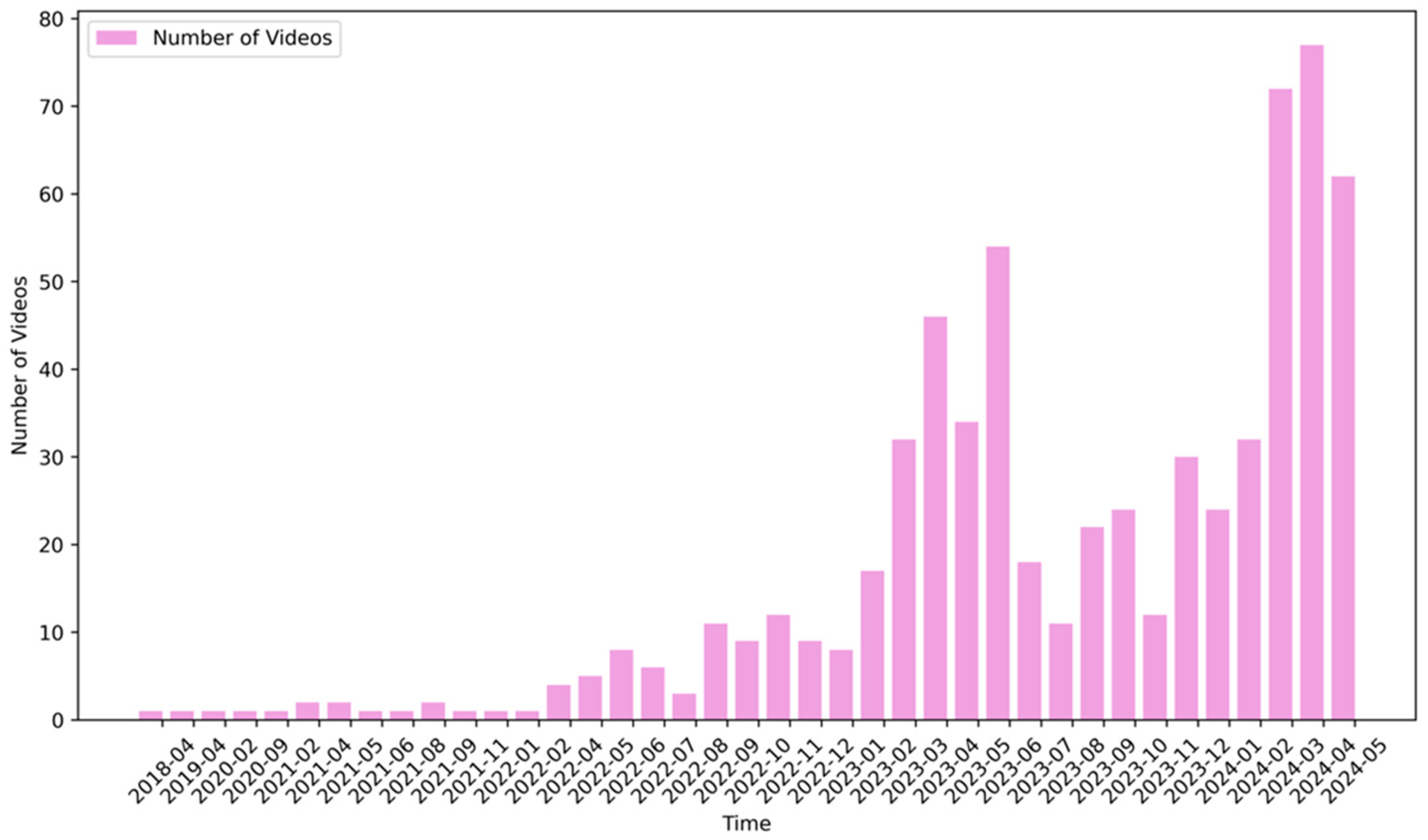
| Metrics | Value |
|---|---|
| Temperature | 0 |
| Output Node Limit | 100 |
| Fuzzy Match Score | 0.5 |
| No. | Prompts |
|---|---|
| 1 | As a logistics company, how do you solve the 2024 problem in logistics? |
| 2 | As a government, how do you solve the 2024 problem in logistics? |
| 3 | As a driver, how do you solve the 2024 problem in logistics? |
| 4 | As a consumer, how do you solve the 2024 problem in logistics? |
| Metrics | Abbreviations | Descriptions |
|---|---|---|
| Word count | WC | Total number of words in a sentence. |
| Type Token Ratios | TTR | Measures vocabulary diversity; the higher the TTR, the more diverse the vocabulary. |
| Average Dependency Distance | ADD | Measures the distance of dependencies between words in a sentence; higher ADD indicates more complex sentence structure and higher reading load. |
| Flesch–Kincaid Grade Level | FKG | Indicator for evaluating the readability of a text. |
| Cosine Similarity | CS | An index measuring the degree of similarity between texts. |
| Model | Output |
|---|---|
| I | The "2024 problem" in logistics isn’t a recognized term in the industry. If you’re referring to a specific issue expected to arise by 2024, please provide more details. However, general solutions for future logistics problems include investing in technology for better tracking and management, improving supply chain visibility, focusing on sustainability, and training staff to handle new challenges. |
| II | To address the 2024 problem in logistics, we focus on compliance measures and innovative solutions. This includes optimizing our operations through dynamic pricing strategies, enhancing delivery speed, and improving cost performance. We also leverage technology, such as robots, to streamline processes and ensure efficient order handling and delivery. Additionally, we actively participate in industry discussions, like the Supermarket Representatives Meeting, to stay aligned with market needs and collaborate with partners to develop effective strategies. |
| Ⅲ | To solve the 2024 problem in logistics, we focus on enhancing our data management by integrating structured data systems for efficient tracking and inventory management, while also leveraging unstructured data analytics to gain insights from customer feedback and market trends. This dual approach allows us to optimize our supply chain, improve decision-making, and adapt to changing demands effectively. |
| Ⅳ | To address the 2024 problem in logistics, we focus on compliance measures and innovative solutions. This includes optimizing our operations through dynamic pricing strategies, enhancing delivery speed, and improving cost performance. We also leverage technology, such as robots, to streamline processes and ensure efficient order handling and delivery. Additionally, we participate in industry discussions, like the Supermarket Representatives Meeting, to collaborate on best practices and solutions. |
| Model | Output |
|---|---|
| I | To solve the 2024 problem in logistics, the government is implementing several measures, including providing guidance and support to shippers, improving transportation efficiency through logistics digital transformation (DX) and modal shifts, and addressing labor shortages by raising wages for truck drivers. Additionally, the government is introducing regulatory measures to ensure proper transactions and reduce redelivery rates by incentivizing consumers to choose flexible delivery options. Collaborative efforts among various ministries aim to enhance the overall logistics infrastructure and resolve the challenges faced by the industry. |
| II | To solve the 2024 problem in logistics, the government addresses logistics issues by collaborating with related ministries and agencies, providing a logistics policy package, and ensuring transportation capacity. They also take action by working with transport companies, offering support mechanisms, and raising wages for truck drivers to improve operational efficiency. Additionally, the government reviews shipping charges and implements regulations to enhance the logistics industry. |
| Ⅲ | To solve the 2024 problem in logistics, the government should focus on enhancing data integration and communication between various stakeholders. This includes investing in advanced technologies for real-time tracking, optimizing supply chain processes, and ensuring compliance with regulations. Additionally, fostering collaboration between public and private sectors can improve resource allocation and efficiency. Implementing training programs for workforce development will also be crucial to adapt to evolving logistics demands. |
| Ⅳ | To solve the 2024 problem in logistics, the government addresses logistics issues by collaborating with related ministries and agencies, providing subsidies, and implementing a logistics policy package. They also ensure transportation capacity, improve operational efficiency, and raise wages for truck drivers to enhance the workforce. Additionally, the government interacts with the trucking association and requests input from shippers to develop effective solutions. |
| Model | Output |
|---|---|
| I | To solve the 2024 problem, reduce waste and protect working hours by optimizing operation plans and utilizing digital technology. Promote shift work and appropriate freight rates, and achieve sustainable logistics through safe operations and efficiency. |
| II | To solve the 2024 problem in logistics as a driver, focus on optimizing routes to reduce fuel consumption and delivery times, utilize real-time data for traffic updates, and maintain effective communication with dispatch to adapt to any changes. Additionally, prioritize efficient loading and unloading processes to enhance overall productivity. |
| Ⅲ | To solve the 2024 problem in logistics as a driver, focus on optimizing routes to reduce delivery times and costs, utilize technology for real-time tracking and communication, and ensure compliance with regulations. Additionally, prioritize efficient loading and unloading processes to enhance overall productivity. |
| Ⅳ | To solve the 2024 problem in logistics as a driver, focus on optimizing routes to reduce delivery times and costs, utilize real-time data for traffic and weather updates, and ensure efficient communication with dispatch to adapt to any changes. Additionally, prioritize vehicle maintenance to avoid breakdowns and enhance overall efficiency. |
| Model | Output |
|---|---|
| I | As a consumer, you don’t directly solve the 2024 problem in logistics. This issue pertains to the logistics industry and professionals in that field. However, you can contribute to the solution by supporting companies that implement sustainable and efficient logistics practices, providing feedback to companies about their delivery services, and opting for delivery options that reduce environmental impact. |
| II | To solve the 2024 problem in logistics as a consumer, I would focus on leveraging technology to enhance efficiency. This includes using apps for real-time tracking of shipments, opting for services that utilize predictive analytics to anticipate delays, and choosing providers that prioritize sustainability and transparency in their supply chains. Additionally, I would advocate for better communication with logistics companies to ensure timely updates and resolutions to any issues that arise. |
| Ⅲ | To solve the 2024 problem in logistics as a consumer, I would focus on leveraging technology to enhance efficiency. This includes using apps for real-time tracking of shipments, opting for services that utilize predictive analytics for better delivery estimates, and choosing companies that prioritize sustainability and transparency in their supply chains. Additionally, I would advocate for better communication with logistics providers to ensure timely updates and address any potential issues proactively. |
| Ⅳ | To solve the 2024 problem in logistics as a consumer, I would focus on leveraging technology to enhance efficiency. This includes using apps for real-time tracking of shipments, opting for services that utilize predictive analytics for better inventory management, and choosing providers that prioritize sustainability and transparency in their supply chains. Additionally, I would advocate for better communication with logistics companies to ensure timely updates and resolutions to any issues that arise. |
| Prompt | 1 | 2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Model | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅰ | Ⅱ | Ⅲ | Ⅳ |
| WC | 68 | 73 | 64 | 78 | 94 | 73 | 76 | 71 |
| TTR | 0.765 | 0.712 | 0.797 | 0.705 | 0.723 | 0.712 | 0.789 | 0.718 |
| ADD | 2.908 | 3.214 | 3.328 | 3.149 | 3.220 | 3.214 | 2.932 | 3.132 |
| FKG | 15.500 | 18.700 | 19.300 | 16.800 | 21.300 | 18.700 | 17.000 | 18.400 |
| CS | - | 0.709 | 0.660 | 0.721 | - | 0.901 | 0.810 | 0.907 |
| Prompt | 3 | 4 | ||||||
| Model | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅰ | Ⅱ | Ⅲ | Ⅳ |
| WC | 39 | 55 | 49 | 56 | 66 | 78 | 78 | 79 |
| TTR | 0.846 | 0.818 | 0.816 | 0.804 | 0.712 | 0.756 | 0.762 | 0.747 |
| ADD | 3.162 | 3.509 | 3.571 | 3.464 | 3.302 | 3.195 | 3.312 | 3.244 |
| FKG | 14.800 | 18.700 | 18.800 | 17.800 | 15.500 | 17.300 | 18.400 | 18.600 |
| CS | - | 0.706 | 0.717 | 0.690 | - | 0.776 | 0.778 | 0.776 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naganawa, H.; Hirata, E. Enhancing Policy Generation with GraphRAG and YouTube Data: A Logistics Case Study. Electronics 2025, 14, 1241. https://doi.org/10.3390/electronics14071241
Naganawa H, Hirata E. Enhancing Policy Generation with GraphRAG and YouTube Data: A Logistics Case Study. Electronics. 2025; 14(7):1241. https://doi.org/10.3390/electronics14071241
Chicago/Turabian StyleNaganawa, Hisatoshi, and Enna Hirata. 2025. "Enhancing Policy Generation with GraphRAG and YouTube Data: A Logistics Case Study" Electronics 14, no. 7: 1241. https://doi.org/10.3390/electronics14071241
APA StyleNaganawa, H., & Hirata, E. (2025). Enhancing Policy Generation with GraphRAG and YouTube Data: A Logistics Case Study. Electronics, 14(7), 1241. https://doi.org/10.3390/electronics14071241