Abstract
Deep learning-based vehicle detection methods have achieved impressive performance in favorable conditions. However, their effectiveness declines significantly in adverse weather scenarios, such as fog, rain, and low-illumination environments, due to severe image degradation. Existing approaches often fail to achieve efficient integration between image enhancement and object detection, and typically lack adaptive strategies to cope with diverse degradation patterns. To address these challenges, this paper proposes a novel end-to-end detection framework, You Only Look Once-Dynamic Enhancement Routing (YOLO-DER), which introduces a lightweight Dynamic Enhancement Routing module. This module adaptively selects the optimal enhancement strategy—such as dehazing or brightness correction—based on the degradation characteristics of the input image. It is jointly optimized with the YOLOv12 detector to achieve tight integration of enhancement and detection. Extensive experiments on BDD100K, Foggy Cityscapes, and ExDark demonstrate the superior performance of YOLO-DER, yielding mAP50 scores of 80.8%, 57.9%, and 85.6%, which translate into absolute gains of +3.8%, +2.3%, and +2.9% over YOLOv12 on the respective datasets. The results confirm its robustness and generalization across foggy, rainy, and low-light conditions, providing an efficient and scalable solution for all-weather visual perception in autonomous driving.
1. Introduction
In recent years, deep learning-based object detection methods have achieved remarkable progress in various application scenarios, including autonomous driving, intelligent surveillance, and traffic perception [1,2]. However, under adverse weather conditions, such as fog, rain, and nighttime, images often suffer from degradation issues, including low contrast, blurred edges, and intensified noise, which severely degrade the performance of mainstream detection models [3,4]. These limitations hinder the models from meeting real-world requirements for robustness and accuracy, particularly in safety-critical tasks, such as traffic monitoring.
However, existing detection frameworks often fail to maintain accurate and stable vehicle detection performance under visual degradation caused by fog, rain, and low-light conditions. This limitation directly affects the reliability of vision-based perception modules employed in autonomous driving, intelligent traffic light control, and visual monitoring systems. Therefore, the core research problem of this paper lies in improving detection robustness under uncertain visual conditions while maintaining real-time efficiency. To address this issue, we propose the YOLO-DER framework, which introduces a dynamic enhancement routing mechanism and an entropy-aware feature optimization strategy to ensure consistent detection reliability and stable performance across diverse real-world environments.
Among all types of adverse weather, fog, rain, and low-light conditions are the most common and representative [5]. Influenced by atmospheric scattering, occlusions, and water vapor, images captured in such environments often suffer from reduced visibility, color distortion, and edge blurring [6]. These characteristics significantly weaken the model’s ability to extract edge and texture features. To address this issue, some existing studies have attempted to combine image enhancement techniques—such as dehazing, brightness enhancement, or style transfer—with object detection tasks [7,8]. However, several limitations remain. First, the enhancement and detection processes are usually executed independently, lacking joint optimization. Second, most enhancement strategies are static or pre-defined, without the ability to adapt to different levels of degradation at the instance level. Third, current methods often overlook the diverse feature distributions caused by different weather types, which limits their ability to extract degradation-specific features. These issues are especially pronounced in real-world applications where weather conditions are dynamic and often co-occur, rendering static enhancement strategies ineffective for robust perception.
To address these challenges, this paper proposes a unified detection framework named YOLO-DER, which integrates dynamic enhancement selection and instance-adaptive degradation modeling. Specifically, a lightweight Dynamic Enhancement Routing (DER) module is embedded into the backbone of YOLOv12. This module dynamically selects the most suitable enhancement path based on learned degradation features, enabling deep coupling between image enhancement and object detection at the feature level. Unlike prior adaptive-enhancement detectors, such as IA-YOLO, GDIP, and D-YOLO—which typically rely on fixed enhancement operators, binary gating, or single-stage adaptation—our approach explicitly models a compact degradation descriptor from global feature statistics and employs a soft, continuous routing mechanism across multiple enhancement branches. Furthermore, YOLO-DER introduces a complementary EnhanceNet module that refines local structures using degradation-conditioned cues (e.g., fog and brightness severity), and the two modules are jointly integrated at multiple backbone stages in a fully end-to-end manner. This design provides finer-grained adaptivity and more stable cross-weather generalization than sequential or single-level enhancement schemes.
To validate the effectiveness of the proposed method, comprehensive experiments were conducted on several publicly available benchmark datasets representing typical adverse weather conditions, including BDD100K, Foggy Cityscapes, and ExDark [9]. The results demonstrate that YOLO-DER achieves superior accuracy and robustness under foggy, rainy, and nighttime conditions, while maintaining stable performance in clear weather, exhibiting excellent cross-domain generalization capability [10].
The main contributions of this paper are summarized as follows:
- We propose a dynamic image enhancement routing mechanism that adaptively selects the optimal enhancement strategy based on image degradation characteristics, enabling tight integration between image enhancement and object detection (see Section 3.2).
- We develop a unified object detection framework based on YOLOv12, named YOLO-DER, which integrates both image enhancement and detection modules within an end-to-end architecture, significantly improving detection robustness and accuracy in foggy and low-light environments (see Section 3).
- We conduct extensive experiments on representative public datasets, including Foggy Cityscapes, ExDark, and BDD100K. The results demonstrate that our proposed method significantly outperforms existing state-of-the-art detection methods and exhibits strong generalization capability (see Section 4).
The remainder of this paper is organized as follows: Section 2 reviews related work on object detection and image enhancement. Section 3 details the proposed YOLO-DER framework. Section 4 presents the experimental setup and analyzes the results. Finally, Section 5 concludes the paper and discusses future research directions.
2. Related Work
2.1. Object Detection
Object detection methods are broadly categorized into two-stage and one-stage frameworks. Two-stage detectors, Faster R-CNN [11] and Mask R-CNN [12], provide strong accuracy through region proposals, while one-stage detectors—including YOLO [13], SSD [14], and RetinaNet [15]—offer real-time performance via dense prediction. Despite substantial progress, both paradigms remain vulnerable to degradation from low illumination, haze, rain, and occlusion, motivating detection models that can better handle adverse conditions.
2.2. Object Detection Under Adverse Conditions
Research on adverse-weather detection focuses on mitigating degradation-induced performance drops. Prior works explore causal modeling to reduce weather-domain shifts [16], multi-scale semantic enhancement for robustness [17], nighttime detection benchmarks with joint enhancement [18], and restoration–detection joint optimization [19]. Domain-alignment methods [20] further alleviate cross-weather discrepancies. While effective, these approaches often rely on global enhancement or handcrafted priors, limiting their adaptiveness under diverse and mixed degradations.
2.3. Adaptive Image Preprocessing
Numerous image enhancement techniques have been designed for haze removal [21,22], color attenuation [23], semantic-guided enhancement [3], and illumination adjustment [24]. Recent detector-coupled enhancement frameworks improve robustness by learning differentiable enhancement modules. IA-YOLO [25] jointly optimizes enhancement parameters with YOLOv3, while GDIP [26] employs gated differentiable operators to dynamically adjust enhancement strength. However, most existing modules use a single enhancement path and struggle to generalize across complex, heterogeneous weather patterns.
2.4. Dynamic Routing Mechanisms
Dynamic routing has gained traction for enabling adaptive processing conditioned on input degradation. Dynamic enhancement networks [27], dual-path designs such as D-YOLO [28], and image-adaptive parameter prediction [25] demonstrate the benefits of selective processing. Style-aware adaptation frameworks [29], as well as video-level routing like UniWRV, extend these ideas to more diverse scenarios. While effective, many such designs incur high computational overhead or offer limited enhancement granularity, leaving space for lightweight and fine-grained routing suitable for real-time adverse-weather detection.
3. Methods
In this section, we introduce the proposed end-to-end detection framework for adverse weather conditions. Section 3.1 provides an overview of the network architecture. Section 3.2 presents the Dynamic Enhancement Routing (DER) mechanism for adaptive degradation modeling, followed by Section 3.3, which details the static enhancement subnetwork (EnhanceNet). Finally, Section 3.5 formulates the unified loss function used for joint optimization.
3.1. Overview of the Unified Network
Figure 1 illustrates the overall YOLO-DER framework, which extends the YOLOv12 baseline by embedding image enhancement modules into the backbone feature extraction [30]. Unlike preprocessing-based approaches, YOLO-DER performs degradation modeling and restoration in the feature domain, thereby enhancing robustness under fog, rain, and low-illumination. The network consists of three components: an enhanced backbone, a neck for multi-scale fusion, and detection heads [31].
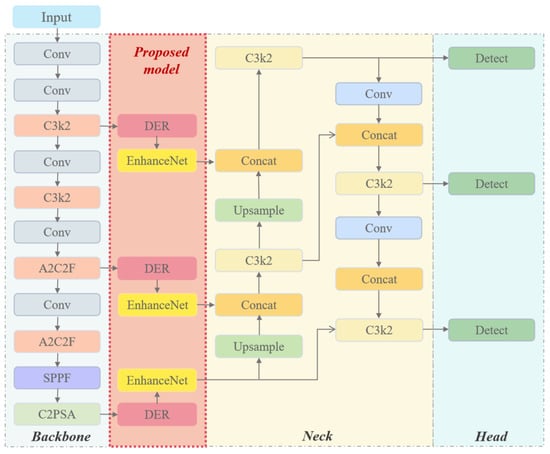
Figure 1.
Overall architecture of the proposed YOLO-DER framework, which consists of three core components: a backbone for feature extraction, a neck for multi-scale feature fusion, and a head for object detection.
Within the backbone, the proposed Dynamic Enhancement Routing (DER) modules are inserted at multiple stages to adaptively select enhancement pathways according to the estimated degradation level. The refined features are further processed by the EnhanceNet module for fine-grained structural restoration. Multi-scale features are fused through an FPN-style neck and fed into detection heads at three resolutions. This unified design improves adverse-weather robustness while maintaining real-time efficiency, with spatial awareness enhanced by CoordConv layers. For optimization, Varifocal Loss is adopted for classification to improve foreground–background discrimination [32], and CIoU Loss is employed for bounding box regression [33].
3.2. Dynamic Enhancement Routing (DER)
Most existing detectors perform enhancement via static preprocessing, ignoring per-sample degradation diversity. To overcome this limitation, building on the above observations and YOLOv10–transformer-based automated non-PPE detection framework proposed by SeunghyeonWang [34], we propose DER, which dynamically adjusts enhancement pathways based on learned degradation descriptors, as shown in Figure 2.
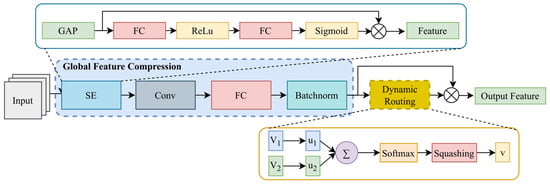
Figure 2.
Architecture of the proposed Dynamic Enhancement Routing (DER) module, which comprises two key components: Global Feature Compression and Dynamic Weight Generation.
Global Feature Compression. Given a feature map , DER extracts its global degradation signature [35]:
where denotes global average pooling. The resulting descriptor Z encodes brightness, contrast, and haze-level cues for adaptive routing.
Dynamic Weight Generation.A two-layer perceptron transforms Z into normalized weights for N enhancement paths:
where , , denotes ReLU, and are learnable biases. The normalized weights act as soft routing gates, guiding the fusion of multiple enhancement paths in proportion to the degradation intensity. DER is embedded in three backbone stages for hierarchical adaptation [36].
3.3. Static Image Enhancement Subnetwork (EnhanceNet)
Adverse weather often causes low brightness, poor contrast, and haze-induced blur [37]. To refine intermediate features degraded by these effects, we propose EnhanceNet, a lightweight, multi-branch enhancement subnetwork operating in parallel with DER, as shown in Figure 3.
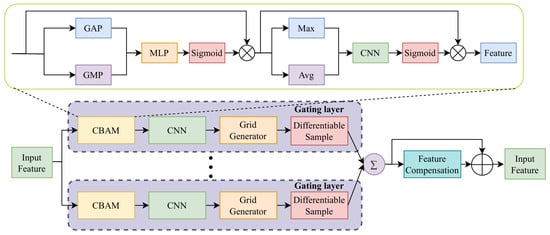
Figure 3.
Architecture of the proposed EnhanceNet, which comprises two key components: differentiable enhancement formulation, soft quality gating, and quantification of adverse conditions.
Differentiable Enhancement Formulation.For a feature map at stage l, EnhanceNet consists of five differentiable branches:
- (1)
- Tone:
- (2)
- Contrast:
- (3)
- Detail:
- (4)
- White-balance:
- (5)
- Identity:where refers to lightweight MLPs predicting adaptive parameters from pooled features, and denotes a differentiable Gaussian blur [38].
Soft Quality Gating. The importance of each branch is adaptively determined through a Convolutional Block Attention Module (CBAM)-inspired attention gate:
The enhanced feature is aggregated as
where is a learnable fusion weight.
Quantification of Adverse Conditions. Fog and low-light conditions are quantitatively modeled to ensure reproducibility. Fog severity is derived from the atmospheric scattering model:
and low-illumination severity is defined as
where is mean luminance in the Y-channel, and is a reference brightness (). Images are labeled as foggy or dark if or (, ). These severities also condition the gating network, allowing for EnhanceNet to emphasize specific branches under measured degradation [39].
Efficiency and Complementarity. EnhanceNet contributes less than 10% additional parameters and ∼3 ms inference overhead. It provides local structural refinement complementary to DER’s global routing, jointly forming a unified, quantitative enhancement framework for adverse-weather detection.
3.4. Entropy-Aware Feature Modulation
In addition to adaptive enhancement, both DER and EnhanceNet implicitly regulate the entropy distribution of intermediate feature maps, helping stabilize detection under fog, rain, and low-illumination. Specifically, the degradation descriptor in DER (Equations (1)–(4)) summarizes global feature statistics that are strongly correlated with feature entropy, allowing for the routing module to assign higher weights to enhancement paths that reduce uncertainty in high-entropy degradations, such as haze or scattering [40].
Similarly, the degradation-conditioned parameters used by EnhanceNet (Equations (10) and (11)) modulate local tone, contrast, and detail, suppressing noise amplification in low-SNR regions while enhancing informative edges. Together, these two modules jointly shape the entropy of feature representations during forward propagation, reducing randomness in fog-affected features and compensating for information loss under low-light conditions. This perspective provides a unified interpretation of how YOLO-DER improves robustness across diverse degradation types.
3.5. Loss Function
To jointly optimize detection and enhancement, a unified multi-task loss is designed:
where denotes the Varifocal Loss for classification, is the Complete IoU Loss for bounding box regression, and supervises feature-level enhancement. The balancing coefficients , , and are empirically set to 1.0, 5.0, and 0.1, respectively.
The enhancement supervision ensures that refined features preserve structural details. It is implemented using a Smooth L1 loss:
where and denote the enhanced and reference feature values at pixel p and channel c, and N is the total number of pixels. This loss constrains the enhanced representation to be perceptually consistent with high-quality reference features, reducing structural distortion while maintaining discriminative content. Through this joint optimization, YOLO-DER achieves balanced adaptation across high-entropy (foggy) and low-entropy (dark) scenes, improving both robustness and detection accuracy [41].
4. Experimental Settings and Results
This section provides a comprehensive experimental evaluation of the proposed YOLO-DER framework under diverse adverse weather conditions. The experiments are structured to verify three aspects: (1) detection performance improvement under adverse weather scenarios, including foggy, rainy, and low-illumination conditions; (2) the contribution of each enhancement component (DER and EnhanceNet); and (3) the framework’s generalization and real-time capability.
4.1. Datasets
Three representative datasets—BDD100K, Foggy Cityscapes, and ExDark—were selected to comprehensively evaluate the framework across varied weather and illumination conditions. A summary is provided in Table 1.

Table 1.
Summary of datasets used in the experiments.
BDD100K: This large-scale dataset contains over 100,000 driving scenes captured across U.S. highways and city streets. It includes diverse conditions—daytime, nighttime, rain, and fog—making it ideal for studying illumination and weather variability [44]. We retained only the “Car” class and adopted the official 7:1:1 train/val/test split, removing unlabeled samples to ensure consistent supervision. This dataset mainly validates cross-weather generalization of the proposed model.
Foggy Cityscapes: Constructed by applying a physically-based scattering model to the Cityscapes dataset, Foggy Cityscapes simulates different fog densities using depth maps. It contains the same annotation structure and splits as the original Cityscapes [45]. This dataset allows for a controlled evaluation of model robustness against haze-level degradation.
ExDark: Designed for extremely low-light scenes, ExDark includes 7363 real-world nighttime images with varying illumination levels, often containing significant noise and low signal-to-noise ratios. It provides a challenging benchmark for assessing the ability of YOLO-DER to preserve semantic and structural consistency under illumination deficiency.
4.2. Experimental Settings
In this study, we adopt YOLOv12-S as the baseline one-stage detector because it achieves a favorable balance between detection accuracy and real-time performance, which is crucial for robust vehicle detection under complex weather conditions. In addition, YOLOv12 employs a modular CSPDarknet-style backbone, making it convenient to insert the proposed Dynamic Enhancement Routing (DER) and EnhanceNet modules at the feature level without modifying the original detection head. Therefore, YOLOv12 is chosen as the baseline detector to highlight the performance gains brought by the degradation-aware enhancement mechanism while preserving real-time efficiency.
All experiments were implemented using PyTorch 2.2 on an NVIDIA RTX 4090 GPU with CUDA 12.2. The YOLOv12 backbone was pretrained on MS COCO and fine-tuned on each target dataset. Input images were resized to , and random horizontal flips and photometric (brightness/contrast) augmentations were applied. We also follow YOLOv12’s default settings for warm-up (3 epochs with warm-up momentum 0.8 and a bias learning rate of 0.0) and loss weights (box/class/DFL gains of 7.5/0.5/1.5).
Training was conducted for 300 epochs with a batch size of 6. We employed Stochastic Gradient Descent (SGD) with a weight decay of and a momentum of 0.937. The learning rate followed a cosine annealing schedule, gradually increasing from to and decaying smoothly thereafter. To enhance training stability, gradient clipping (threshold = 10) and mixed-precision training were applied. The parameters of DER and EnhanceNet were initialized using Xavier uniform initialization. Each experiment was repeated three times, and we report the mean results for statistical reliability.
4.3. Evaluation Metrics
We adopted Precision, Recall, F1-score, and mAP50 to comprehensively measure detection accuracy and robustness [46].
Since this study focuses on a single target class (Car), mAP50 represents the Average Precision at IoU = 0.5, serving as a unified performance metric.
4.4. Quantitative Results
We compared YOLO-DER with recent state-of-the-art (SOTA) detectors across three benchmark datasets (Table 2, Table 3 and Table 4). The model’s processing efficiency is shown in the Table 5.
Table 2.
A quantitative comparison with SOTA methods on the Foggy Cityscapes dataset.
Table 3.
Quantitative comparison with SOTA methods on the BDD100K dataset.
Table 4.
Quantitative comparison with SOTA methods on the ExDark dataset.
Table 5.
Inference efficiency on an NVIDIA RTX 4090 (FP16, batch size 1). Latency is averaged over 200 images.
Foggy Cityscapes: As shown in Table 2, YOLO-DER achieves a mAP50 of 57.9%, comparable to SCAN (57.3%) while yielding higher Precision (65.1%) and Recall (56.9%). These results indicate that DER effectively compensates for haze-induced contrast loss, improving the detection of partially occluded or low-visibility vehicles.
BDD100K: From Table 3, YOLO-DER delivers the strongest overall performance, exceeding Enhanced YOLOv8 by +3.0% in mAP50 and +6.3% in Precision. The gains suggest that the proposed dual enhancement design adapts reliably to heterogeneous illumination conditions and provides more stable feature representations than feature-blending approaches such as AQT (BlenDA).
ExDark: As shown in Table 4, YOLO-DER achieves 85.6% mAP50 and 87.2% F1-score, outperforming DENet and EMV-YOLO. The improvements highlight the model’s ability to recover informative structures under extreme low-light while preserving object boundaries.
Across all datasets, YOLO-DER provides consistent accuracy improvements with a small runtime cost of 3 ms, maintaining real-time compatibility and demonstrating efficient integration of adaptive enhancement within the detection pipeline.
Figure 4 illustrates that the YOLOv12 detector often misses small or low-contrast objects, whereas YOLO-DER recovers them more reliably under fog and nighttime conditions. The improved robustness is attributable to better suppression of noise and enhanced preservation of structural cues. Figure 5 shows qualitative results on BDD100K, ExDark, and Foggy Cityscapes, including dense-fog and heavy-rain examples. The proposed method delivers stable detection under low illumination and adverse weather, exhibiting precise localization and fewer false alarms than the baselines. It also retains object structures under severely degraded visibility, reflecting strong resilience to contrast loss and noise. Minor confidence degradation appears only for distant or heavily occluded targets, indicating the remaining difficulty of extreme low-visibility conditions. Overall, the visualization verifies both the robustness and the practical limits of the approach.

Figure 4.
Qualitative comparison of detection results on the BDD100K, ExDark, and Foggy Cityscapes datasets.

Figure 5.
Qualitative comparison of detection results on BDD100K, ExDark, and Foggy Cityscapes, with additional extreme-condition examples (e.g., dense fog and heavy rain) to highlight robustness.
4.5. Ablation Study
To assess the individual and combined effects of DER and EnhanceNet, we perform ablation experiments on BDD100K, Foggy Cityscapes, and ExDark. The quantitative results for the first two datasets are reported in Table 6, while ExDark results are visualized in Figure 6.
Table 6.
Ablation study of the proposed DER and EnhanceNet modules on BDD100K and Foggy Cityscapes, evaluated using mAP50, Precision, Recall, and F1-score.
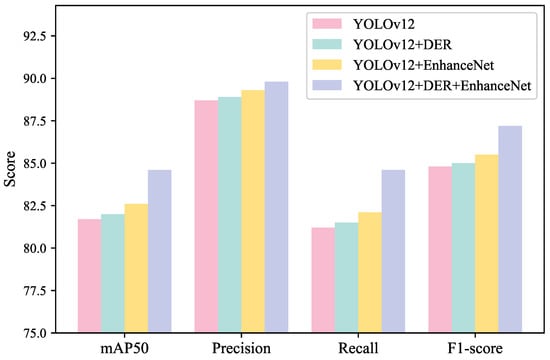
Figure 6.
Comparative ablation study of different components on the ExDark dataset.
Quantitative Analysis on BDD100K and Foggy Cityscapes.As shown in Table 6, adding the DER module yields consistent but moderate gains (e.g., +0.3% mAP50 on BDD100K), indicating that the routing mechanism provides a lightweight adjustment to feature enhancement under varying degradation levels. Introducing EnhanceNet alone leads to larger improvements (+1.1% and +1.5% mAP50), reflecting the contribution of learnable multi-branch refinement to restoring local contrast and structural cues. The full configuration (DER+EnhanceNet) achieves the best performance (+3.8% on BDD100K, +2.6% on Foggy Cityscapes), demonstrating that global routing and local enhancement operate in a complementary manner.
Visual Analysis on ExDark.Figure 6 shows a consistent upward trend in all metrics across module combinations. DER mainly stabilizes predictions by adjusting feature exposure levels, while EnhanceNet improves texture visibility in dark regions. The complete model achieves notable Recall and F1-score gains (+2.4% and +2.1%), highlighting improved recovery of low-illumination details and more reliable detection under severe darkness.
Validation of Degradation Metrics.We further evaluate whether the fog- and brightness-severity metrics (Equations (10) and (11)) correlate with human perception. A total of 50 images were randomly sampled, and three annotators rated the degradation levels on a 1–5 scale. As shown in Table 7, the metrics achieve correlations above 0.80, indicating that both measures capture changes in visibility and illumination in a manner consistent with human judgments. These results support the use of the proposed metrics as auxiliary cues within the enhancement module.
Table 7.
Correlation between our degradation metrics and human perceptual ratings.
Discussion.Across all datasets, the ablation results show that DER provides global degradation-aware modulation, whereas EnhanceNet improves localized feature quality, and their combination yields the most stable gains. The improvements are achieved with moderate computational overhead, suggesting that adaptive enhancement can be integrated into real-time detectors without sacrificing efficiency. Future work will explore lightweight extensions for embedded platforms, multimodal variants, and more explicit modeling of weather-induced feature uncertainty.
5. Conclusions
In conclusion, we present YOLO-DER, an end-to-end dynamic enhancement routing framework that effectively improves object detection under adverse weather conditions. By integrating a lightweight, learnable enhancement routing module with the YOLOv12 detector, the model adaptively selects optimal enhancement strategies—such as dehazing or brightness correction—based on the degradation characteristics of input images. Interpreted as an entropy-regulation mechanism, YOLO-DER mitigates randomness in high-entropy conditions (e.g., fog and rain) and compensates for information loss in low-entropy scenes (e.g., low-illumination), thus preserving discriminative semantic features. Extensive experiments demonstrate its superior performance, achieving mAP50 scores of 80.8%, 57.9%, and 85.6% on the BDD100K, Foggy Cityscapes, and ExDark datasets, respectively. These results confirm that YOLO-DER delivers strong robustness, generalization, and real-time capability, offering a practical and scalable solution for all-weather visual perception in autonomous driving applications.
Future work.The limitation of our work is that we do not perform systematic hyperparameter optimization beyond using a common YOLOv12-based configuration across all experiments. Prior studies, such as Automated Non-PPE Detection on Construction Sites Using YOLOv10 and Transformer Architectures for Surveillance and Body-Worn Cameras with Benchmark Datasets [34], have shown that careful hyperparameter tuning can further improve performance, which we leave as an interesting direction for future research.
Author Contributions
Methodology and software, R.G.; writing—review and editing, M.H.O.; supervision, M.M. and M.H.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep Learning for Person Re-Identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef]
- Huang, S.-C.; Le, T.-H.; Jaw, D.-W. Dsnet: Joint Semantic Learning for Object Detection in Inclement Weather Conditions. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2623–2633. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Y.; He, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. Yolov5-Fog: A Multiobjective Visual Detection Algorithm for Fog Driving Scenes Based on Improved Yolov5. IEEE Trans. Instrum. Meas. 2022, 71, 2515612. [Google Scholar] [CrossRef]
- Tiwari, A.K.; Pattanaik, M.; Sharma, G. Low-Light Detection Transformer (Ldetr): Object Detection in Low-Light and Adverse Weather Conditions. Multimed. Tools Appl. 2024, 83, 84231–84248. [Google Scholar] [CrossRef]
- Tan, K.; Oakley, J.P. Enhancement of Color Images in Poor Visibility Conditions. In Proceedings of the 2000 International Conference on Image Processing (Cat. No. 00CH37101), Vancouver, BC, Canada, 10–13 September 2000. [Google Scholar]
- Park, D.; Lee, B.H.; Chun, S.Y. All-in-One Image Restoration for Unknown Degradations Using Adaptive Discriminative Filters for Specific Degradations. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Valanarasu, J.M.J.; Yasarla, R.; Patel, V.M. Transweather: Transformer-Based Restoration of Images Degraded by Adverse Weather Conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Loh, Y.P.; Chan, C.S. Getting to Know Low-Light Images with the Exclusively Dark Dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Z.; Qi, G.; Hu, G.; Zhu, Z.; Huang, X. Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism. Remote Sens. 2024, 16, 644. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28, Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montréal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, H.; Xiao, L.; Cao, X.; Foroosh, H. Multiple Adverse Weather Conditions Adaptation for Object Detection via Causal Intervention. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 1742–1756. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.-M. Yolo-Ms: Rethinking Multi-Scale Representation Learning for Real-Time Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef]
- Xiao, Y.; Jiang, A.; Ye, J.; Wang, M.-W. Making of Night Vision: Object Detection under Low-Illumination. IEEE Access 2020, 8, 123075–123086. [Google Scholar] [CrossRef]
- Sun, S.; Ren, W.; Wang, T.; Cao, X. Rethinking Image Restoration for Object Detection. Adv. Neural Inf. Process. Syst. 2022, 35, 4461–4474. [Google Scholar]
- Zhang, S.; Tuo, H.; Hu, J.; Jing, Z. Domain Adaptive Yolo for One-Stage Cross-Domain Detection. In Proceedings of the 13th Asian Conference on Machine Learning, Virtual, 17–19 November 2021. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-Net: All-in-One Dehazing Network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-Adaptive Yolo for Object Detection in Adverse Weather Conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022. [Google Scholar]
- Kalwar, S.; Patel, D.; Aanegola, A.; Konda, K.R.; Garg, S.; Krishna, K.M. Gdip: Gated Differentiable Image Processing for Object Detection in Adverse Conditions. arXiv 2022, arXiv:2209.14922. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, X.; Zhang, K.; Gong, L.; Xie, H.; Wang, F.L.; Wei, M. Togethernet: Bridging Image Restoration and Object Detection Together via Dynamic Enhancement Learning. Comput. Graph. Forum 2022, 41, 465–476. [Google Scholar] [CrossRef]
- Chu, Z. D-Yolo: A Robust Framework for Object Detection in Adverse Weather Conditions. arXiv 2024, arXiv:2403.09233. [Google Scholar]
- Jeon, M.; Seo, J.; Min, J. Da-Raw: Domain Adaptive Object Detection for Real-World Adverse Weather Conditions. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Ji, Y.; Ma, T.; Shen, H.; Feng, H.; Zhang, Z.; Li, D.; He, Y. Transmission Line Defect Detection Algorithm Based on Improved YOLOv12. Electronics 2025, 14, 2432. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, W.; Zhang, W.; Yang, L.; Wang, J.; Ni, H.; Guan, T.; He, J.; Gu, Y.; Tran, N.N. A multi-feature fusion and attention network for multi-scale object detection in remote sensing images. Remote Sens. 2023, 15, 2096. [Google Scholar] [CrossRef]
- Zhao, Q.; Wu, Y.; Yuan, Y. Ship target detection in optical remote sensing images based on E2YOLOX-VFL. Remote Sens. 2024, 16, 340. [Google Scholar]
- Dong, C.; Duoqian, M. Control distance IoU and control distance IoU loss for better bounding box regression. Pattern Recognit. 2023, 137, 109256. [Google Scholar] [CrossRef]
- Wang, S. Automated Non-PPE Detection on Construction Sites Using YOLOv10 and Transformer Architectures for Surveillance and Body Worn Cameras with Benchmark Datasets. Sci. Rep. 2025, 15, 27043. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, X.; Wang, Q.; Lv, J.; Chen, L.; Du, Y.; Du, L. An area-efficient CNN accelerator supporting global average pooling with arbitrary shapes. In Proceedings of the 2024 IEEE 6th International Conference on AI Circuits and Systems (AICAS), Abu Dhabi, United Arab Emirates, 22–25 April 2024. [Google Scholar]
- Chen, G.; Du, C.; Yu, Y.; Hu, H.; Duan, H.; Zhu, H. A Deepfake Image Detection Method Based on a Multi-Graph Attention Network. Electronics 2025, 14, 482. [Google Scholar] [CrossRef]
- Gao, R.; bin Omar, M.H.; bin Mahmuddin, M. Vehicle detection method in adverse weather conditions based on multitask deep learning. In Proceedings of the Fourth International Symposium on Control Engineering and Robotics (ISCER 2025), Lappeenranta, Finland, 4–5 September 2025. [Google Scholar]
- Huang, Z.; Zhang, Z.; Lan, C.; Zha, Z.J.; Lu, Y.; Guo, B. Adaptive frequency filters as efficient global token mixers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023. [Google Scholar]
- Gan, Y.; Wu, C.; Ouyang, D.; Tang, S.; Ye, M.; Xiang, T. LESEP: Boosting adversarial transferability via latent encoding and semantic embedding perturbations. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 3368–3382. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, Q.; Qu, S. Evaluation of railway transportation performance based on CRITIC-relative entropy method in China. J. Adv. Transp. 2023, 2023, 5257482. [Google Scholar] [CrossRef]
- Gan, Y.; Xiao, X.; Xiang, T.; Wu, C.; Ouyang, D. SFCM-AEG: Source-Free Cross-Modal Adversarial Example Generation. IEEE Trans. Multimed. 2025, 27, 6262–6272. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic Foggy Scene Understanding with Synthetic Data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Ortiz Castelló, V.; Salvador Igual, I.; del Tejo Catalá, O.; Perez-Cortes, J.C. High-profile vru detection on resource-constrained hardware using yolov3/v4 on bdd100k. J. Imaging 2020, 6, 142. [Google Scholar] [CrossRef]
- Bi, Q.; You, S.; Gevers, T. Generalized foggy-scene semantic segmentation by frequency decoupling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Maxwell, A.E.; Pourmohammadi, P.; Poyner, J.D. Mapping the topographic features of mining-related valley fills using mask R-CNN deep learning and digital elevation data. Remote Sens. 2020, 12, 547. [Google Scholar] [CrossRef]
- Zhao, Z.; Guo, Y.; Shen, H.; Ye, J. Adaptive Object Detection with Dual Multi-Label Prediction. In European Conference on Computer Vision; Springer: Berlin, Germany, 2020. [Google Scholar]
- Zhang, W.; Wang, J.; Wang, Y.; Wang, F.-Y. Parauda: Invariant Feature Learning with Auxiliary Synthetic Samples for Unsupervised Domain Adaptation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20217–20229. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-Cnn for Object Detection in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xu, M.; Wang, H.; Ni, B.; Tian, Q.; Zhang, W. Cross-Domain Detection via Graph-Induced Prototype Alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, J.; Xu, R.; Liu, X.; Ma, J.; Li, B.; Zou, Q.; Ma, J.; Yu, H. Domain Adaptation Based Object Detection for Autonomous Driving in Foggy and Rainy Weather. arXiv 2023, arXiv:2307.09676. [Google Scholar] [CrossRef]
- Hnewa, M.; Radha, H. Integrated Multiscale Domain Adaptive Yolo. IEEE Trans. Image Process. 2023, 32, 1857–1867. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Liu, X.; Yao, X.; Yuan, Y. Scan: Cross Domain Object Detection with Semantic Conditioned Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Oxford, UK, 19–21 May 2022. [Google Scholar]
- Seemakurthy, K.; Bosilj, P.; Aptoula, E.; Fox, C. Domain Generalised Fully Convolutional One Stage Detection. In Proceedings of the International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Huang, T.; Huang, C.-C.; Ku, C.-H.; Chen, J.-C. Blenda: Domain Adaptive Object Detection through Diffusion-Based Blending. In Proceedings of the ICASSP 2024—IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Chen, H.; Min, B.W.; Zhang, H. A Study on a Target Detection Model for Autonomous Driving Tasks. IEEE Internet Things J. 2024, 18, 3447–3459. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).