Abstract
In this paper, the real-time decentralized integrated sensing, navigation, and communication co-optimization problem is investigated for large-scale mobile wireless sensor networks (MWSN) under limited energy. Compared with traditional sensor network optimization and control problems, large-scale resource-constrained MWSNs are associated with two new challenges, i.e., (1) increased computational and communication complexity due to a large number of mobile wireless sensors and (2) an uncertain environment with limited system resources, e.g., unknown wireless channels, limited transmission power, etc. To overcome these challenges, the Mean Field Game theory is adopted and integrated along with the emerging decentralized multi-agent reinforcement learning algorithm. Specifically, the problem is decomposed into two scenarios, i.e., cost-effective navigation and transmission power allocation optimization. Then, the Actor–Critic–Mass reinforcement learning algorithm is applied to learn the decentralized co-optimal design for both scenarios. To tune the reinforcement-learning-based neural networks, the coupled Hamiltonian–Jacobi–Bellman (HJB) and Fokker–Planck–Kolmogorov (FPK) equations derived from the Mean Field Game formulation are utilized. Finally, numerical simulations are conducted to demonstrate the effectiveness of the developed co-optimal design. Specifically, the optimal navigation algorithm achieved an average accuracy of when tracking the given routes.
1. Introduction
Coordinating a large number of mobile robots equipped with multi-modal sensors for information gathering in extreme environments (such as in underwater and underground workspaces where communication, computation, and power are limited) is a critically needed capability in many emerging applications [1]. For instance, state-of-the-art multi-agent simultaneous localization and mapping (SLAM) techniques [2] heavily rely on the scalability and robustness of mobile wireless sensor networks (MWSNs), particularly when the agent population is large. Furthermore, modern monitoring systems [3] have widely adopted robot-assisted large-scale wireless sensor networks. In such practical deployments, a MWSN typically consists of a single computationally capable remote station responsible for task planning, along with numerous low-cost mobile sensing robots characterized by limited energy and communication capabilities [4]. The agents’ navigation trajectories directly influence communication quality, since the channel attenuation depends on each agent’s position relative to the remote station.
This paper considers MWSNs comprising a fixed remote station and a large number of low-cost mobile sensors. The remote station acts as an intelligent coordinator, generating navigation plans and broadcasting them to the sensing agents. The agents, in turn, are tasked with following the assigned trajectories and transmitting collected data back to the remote station.
While utilizing low-cost mobile sensors significantly reduces deployment costs, it also introduces substantial challenges in both robot control and communication, especially as the number of agents increases [5]. Recent multi-agent navigation methods [6], for instance, often require real-time position information from neighboring agents to compute control policies, causing the computational complexity to scale with the number of agents. This scalability issue is widely known as the “Curse of Dimensionality” [7].
In addition, most low-cost robots are incapable of full-duplex point-to-point communication. As a result, data sharing among large populations of robots with low latency and minimal packet loss becomes infeasible. Simultaneously, the volume of sensed data is enormous (e.g., in multi-agent SLAM), and the number of agents requiring uplink communication with the remote station is high. Thus, maintaining the desired quality of service (QoS) becomes challenging, particularly due to the difficulty in coordinating transmission power among agents. Traditional wireless transmission power allocation schemes focus on optimizing the signal-to-interference-plus-noise ratio (SINR) in either centralized or distributed settings [8]. However, many practical MWSNs function as self-organizing (i.e., “ad hoc”) networks [9], requiring decentralized solutions.
To address these challenges, this paper adopts the framework of Mean Field Game (MFG) theory, a decentralized decision-making paradigm for large-population multi-agent systems. In our previous studies [10,11], MFGs were successfully applied to multi-agent tracking tasks. The theoretical foundation of MFGs was introduced by Lasry and Lions [12,13] under the umbrella of stochastic non-cooperative game theory. The core concept is that an individual agent’s influence on the collective behavior can be effectively summarized via a local impact index derived from the population distribution. Specifically, it is shown in [12,13] that when the number of agents approaches infinity, each agent’s influence can be captured using a probability density function (PDF) of all agent states. This transforms the original large-scale multi-agent game into an equivalent two-player game: a local agent versus the population influence, significantly reducing computational complexity.
To compute the optimal decentralized control, a value function must be minimized, which accounts for the agent’s local state and the PDF of the population. As established in classical optimal control theory [14], this value function satisfies the Hamilton–Jacobi–Bellman (HJB) equation, which is solved backward in time. Simultaneously, the evolution of the agents’ state distribution is governed by the Fokker–Planck–Kolmogorov (FPK) equation [12], which is solved forward in time. Consequently, the optimal decentralized solution in an MFG framework is obtained by solving the coupled HJB–FPK system.
It was shown by [15] that the solution to this coupled PDE system converges to an -Nash equilibrium, which is regarded as the optimal solution for large-scale non-cooperative games. A complete and rigorous derivation of the -Nash equilibrium was first provided in [16] and later formalized through the Nash Certainty Equivalence Principle in [15]. Despite its theoretical elegance, solving the coupled HJB–FPK equations remains a formidable challenge due to their bidirectional structure and strong coupling [17].
Recently, adaptive reinforcement learning approaches have emerged to approximate the solution of the HJB equation in a forward-in-time manner [18,19]. To extend this capability to the coupled HJB–FPK system, I applied a novel Actor–Critic–Mass (ACM) algorithm for the decentralized co-optimization of navigation and transmission power in large-scale MWSNs. Specifically, three neural networks are designed:
- Mass Neural Network (Mass NN): Approximates the population-level PDFs of agents’ tracking errors and transmission power.
- Critic Neural Network (Critic NN): Estimates the value function, which quantifies tracking accuracy and QoS performance.
- Actor Neural Network (Actor NN): Learns the optimal control input for navigation and transmission power adjustment in real time.
The main contributions of this paper are as follows:
- The decentralized co-optimization problem is formulated for MWSNs as two interconnected Mean Field Games: one for optimal navigation and one for transmission power control. The MFG framework effectively mitigates the “Curse of Dimensionality” associated with large-scale multi-agent systems.
- The data-driven Actor–Critic–Mass (ACM) reinforcement learning algorithm is developed to learn the optimal solution of the MWSN control online, enabling real-time implementation in uncertain and dynamic environments.
- The proposed novel MWSN algorithm is fully decentralized, requiring no inter-agent communication, making it highly scalable and communication-efficient for large populations of mobile agents.
2. Related Work
Research on large-scale multi-agent decision-making has increasingly focused on reinforcement learning and Mean Field Game (MFG) theory as two complementary tools for addressing the curse of dimensionality. Traditional MARL methods often suffer from scalability issues, as the number of interactions grows quadratically with the number of agents. Mean field approximations mitigate this challenge by replacing explicit pairwise interactions with population-level distributions, thereby reducing the computational burden while preserving critical coupling effects.
Recent studies have advanced actor–critic algorithms within MFG frameworks to provide scalable solutions in continuous state and action spaces. For example, Liang et al. [20] propose online and offline actor–critic schemes that converge to mean field equilibria in continuous-time settings. Similarly, Angiuli et al. [21] introduce a unified deep reinforcement learning architecture that approximates infinite-horizon mean field control problems using neural parameterizations of distributions. These works highlight the feasibility of coupling reinforcement learning with MFG theory, though most focus on simplified environments without strong real-time constraints.
Another important direction addresses safety and robustness in mean field control. Bogunovic et al. [22] design Safe-M3-UCRL, a model-based mean field reinforcement learning algorithm that enforces global safety constraints through log-barrier methods, demonstrating applications in shared mobility networks. Complementarily, Zaman et al. [23] propose a minimax mean field framework to handle environmental uncertainty, where gradient descent–ascent reinforcement learning converges to robust equilibria. While these works ensure stability in uncertain systems, they do not explicitly consider the dual challenges of trajectory tracking and communication in wireless sensor networks.
In parallel, researchers have pursued decentralized MARL approaches that eschew centralized coordination. Jiang et al. [24] provide a comprehensive survey of decentralized MARL, highlighting advances in independent actor–critic algorithms. Gabler et al. [25] demonstrate the effectiveness of decentralized actor–critic methods in sparse-reward cooperative tasks, showing that independent learners can rival centralized baselines. Gu [26] further emphasizes localized training strategies to reduce communication overhead. These approaches align with the requirements of mobile wireless sensor networks, where communication bandwidth is limited, but they typically neglect the continuous evolution of agent state distributions modeled by mean field dynamics.
Domain-specific applications also illustrate the flexibility of actor–critic methods in large agent systems. Alam et al. [27] survey actor–critic frameworks in UAV swarm networks, emphasizing architectural diversity, from recurrent to transformer-based models, to handle non-stationary environments. Xu et al. [28] apply mean field MARL to UAV-assisted V2X communications, achieving scalable resource allocation in vehicular networks. Emami et al. [29] leverage MFG-inspired reinforcement learning for age-of-information minimization in UAV swarms. These studies demonstrate the adaptability of MARL–MFG approaches to communication-constrained systems, but do not yet provide a unified solution for navigation and transmission co-optimization.
Our work builds directly on these foundations by integrating actor–critic learning with a novel Mass Neural Network that explicitly models the population distribution through Fokker–Planck dynamics. Unlike prior actor–critic MFG formulations [20,21], which approximate equilibria offline or in simplified dynamics, our ACM framework learns solutions online in stochastic environments. Moreover, while safety-focused methods [22,23] constrain system-level objectives, our approach targets the dual optimization of navigation and transmission power, which is critical for energy-constrained wireless sensor networks. Finally, by eliminating inter-agent communication, our decentralized ACM algorithm extends decentralized MARL advances [24,25] into a setting where scalability and robustness are simultaneously required.
3. Preliminaries
Before presenting the proposed Actor–Critic–Mass (ACM) algorithm, this section provides the necessary theoretical background on Mean Field Game (MFG) theory and the structure of the reinforcement learning framework adopted in this study. Specifically, we first review the fundamental principles of MFGs that enable scalable decision-making in large populations of interacting agents by coupling the Hamilton–Jacobi–Bellman (HJB) and Fokker–Planck–Kolmogorov (FPK) equations. Then, we introduce the ACM framework, which extends the classical actor–critic structure with an additional mass neural network to capture the evolution of the population density. This section thus establishes the mathematical foundations required for formulating the decentralized optimization problems and implementing the proposed algorithm in later sections.
3.1. Mean Field Game Theory
Mean Field Game (MFG) theory provides a mathematical framework for modeling decision-making in large populations of interacting agents. Instead of analyzing all pairwise interactions, which becomes intractable as the number of agents grows, MFG approximates the aggregate influence of the population using a probability density function (PDF) of states. This approximation reduces the original high-dimensional multi-agent problem into a tractable two-player game: a representative agent versus the mean field. The optimal strategy for each agent is then determined by solving a coupled system of partial differential equations: the Hamilton–Jacobi–Bellman (HJB) equation, which characterizes the optimal value function backward in time, and the Fokker–Planck–Kolmogorov (FPK) equation, which evolves the population state distribution forward in time. The equilibrium solution of this system corresponds to an -Nash equilibrium, ensuring near-optimality when the agent population is large. This formulation forms the foundation for decentralized and scalable control in large-scale multi-agent systems.
3.2. The ACM Structure
The proposed Actor–Critic–Mass (ACM) framework extends the classical actor–critic reinforcement learning structure by introducing an additional mass network to capture the evolution of the population distribution. Specifically, the critic neural network approximates the value function defined by the Hamilton–Jacobi–Bellman (HJB) equation, enabling the evaluation of long-term performance for a given state and policy. The actor neural network outputs the local control action, which is updated by minimizing the residual of the critic-estimated value gradient. In parallel, the mass neural network approximates the probability density function (PDF) of agent states by learning the solution to the Fokker–Planck–Kolmogorov (FPK) equation. The three networks are coupled: the actor depends on the critic’s value gradient, the critic requires the mass distribution to capture population-level coupling effects, and the mass network evolves based on the actor’s control inputs. This closed-loop interaction allows decentralized agents to approximate the coupled HJB–FPK system online, ensuring convergence toward an -Nash equilibrium.
4. Problem Formulation
Consider N (for example, ) mobile sensing robots, named “agents”, operating in an n-dimensional workspace where a remote station guides this massive team of sensing robots to search a designated area. A reference navigation trajectory (i.e., ) is first broadcast to all robots. For simplicity, the area and the reference trajectory are denoted by the same notation . The robots are required to follow the received reference trajectory. Once the mobile sensing robot finishes tracking one trajectory, it will transmit sensed data back to the remote station and then receive a new navigation trajectory. During surveillance and data communication, mobile sensing agents will experience channel fading, shadowing effects, and interference from each other. Overall, to optimize the mobile wireless sensor network for all robots, two objectives need to be co-optimized, i.e., (1) tracking the reference trajectories effectively, considering the interference from other agents, and (2) transmitting back the sensed data efficiently and achieving the desired signal-to-interference-plus-noise ratio (SINR), even with an uncertain environment. As shown in Figure 1, the task is defined as two different scenarios, i.e., (1) Scenario 1: tracking control; (2) Scenario 2: transmission power allocation. These two scenarios run asynchronously to fulfill the two aforementioned objectives as depicted in the flow chart in Figure 2.
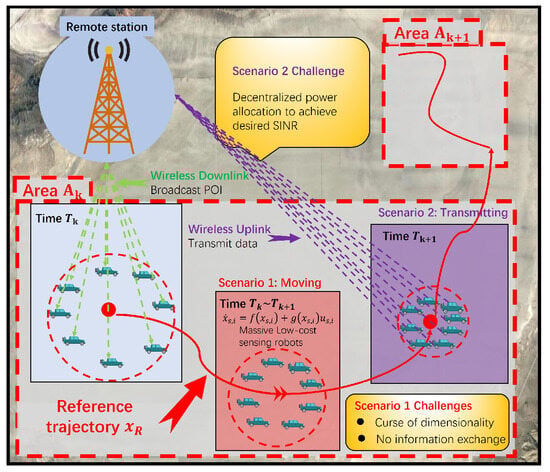
Figure 1.
An illustration of the low-cost MWSN. At time , the remote station wants to detect the area , and therefore a reference trajectory is broadcast to a massive group of sensing robots. Then the robot team tracks the reference trajectory through decentralized optimal tracking control. When the area is fully detected, all sensing robots transmit the collected information back to the remote station. Then, a new area (reference trajectory) is broadcast once the data transmission is completed.
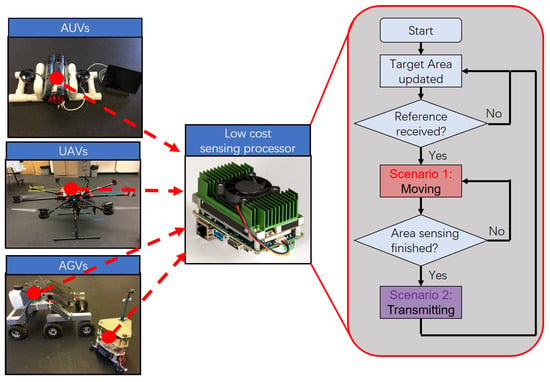
Figure 2.
Low-cost mobile robots (e.g., AUVs, UAVs, and AGVs) have limited communication and computational resources. Hence, they alternate between two asynchronous modes: (1) Scenario 1—navigation; and (2) Scenario 2—data transmission. The workflow is illustrated in this figure.
4.1. Scenario 1: Optimal Navigation Formulation
Consider the motion dynamics of robot i in a team comprising N homogeneous robots as a stochastic differential equation:
where and are smooth and Lipchitz nonlinear equations representing the agent’s states and motion control input, respectively. The functions and describe the robot’s motion dynamics. The term denotes a set of independent Wiener processes representing environmental noise, while is the constant diffusion matrix for these processes.
Next, at any time , the tracking error can be represented as , where is the current reference trajectory. The tracking error dynamics is thus derived as
where , and .
Remark 1.
The error dynamics in Equation (2) follow from the affine transformation . Since the Jacobian is the identity and the Hessian vanishes, Itô’s lemma reduces to , with the extra term absorbed into .
To track the reference trajectory in an optimal manner, a value function is proposed for any given time duration as follows:
where is the augmented tracking error matrix including all agents. The motion energy and states value is defined as
and the coupling function is an arbitrary Lipschitz function which represents the cost caused by other agents.
The value function (3) penalizes the tracking error, motion control input, and the coupling cost between other agents and local agent i. It is also worth noting that although the cost function summarizes the running cost over a finite time duration (i.e., ), the problem is still an infinite time optimal control problem. Instead of a predefined value, the end time is determined by the time of all agents reaching the POI. Thus, the end time has no specific restriction applied. Another important assumption is that the time required for transmitting information is significantly less than the time for required moving, meaning that the transmitting time can be ignored when I consider the optimal tracking problem.
4.2. Scenario 2: Optimal Transmission Power Allocation Formulation
Next, the channel fading model is discussed. In wireless communication, the transmitted signal loss between the remote station and individual robot is related to the distance of the signal path [30,31]. Moreover, Ref. [32] shows that the power attenuation can be described as a stochastic differential equation (SDE) if the lognormal channel fading model is adopted. If we let the denote the position of the fixed remote station, then the distance between robot i and the remote station (i.e, transmitted path distance) can be represented as . Therefore, the dynamic equation of is derived as
where and .
Letting denote the power attenuation (loss) of the link between robot i and the remote station, this can be calculated by a function of the path distance [32]. Thus, the actual received power at the remote station is . To guarantee the quality of service (QoS), which is measured by the signal-to-interference-plus-noise ratio (SINR), the transmitter’s power for individual robots needs to be coordinated. In other words, the consensus for transmission power needs to be achieved for all agents. According to related research [8,33,34,35,36], the SINR in a large population of users can be defined as
where is the interference and denotes the variance power of the noise at its receiver node.
In (6), we approximate the aggregate interference coupling coefficient as . This assumption is not meant to describe all heterogeneous fading environments but serves as a tractable large-system surrogate that captures the dominant scaling behavior of interference with respect to the number of active users. When transmitters experience independent small-scale fading and random phases, the aggregate interference at a receiver can be modeled as a sum of N weakly correlated random variables. Under normalized transmitted power, each term contributes to the total interference, and as N increases, the law of large numbers implies that the total interference remains bounded while the effective contribution of each interferer decays proportionally to . This observation is consistent with shot-noise models of large wireless networks, where the interference field converges to a finite mean despite an increasing number of interferers [37,38]. In symmetric multi-user systems with homogeneous power control or scheduling, the interference power is effectively shared among N users, leading to an average cross-coupling that also scales inversely with N. Furthermore, the same approximation is adopted in other large-scale communication literatures such as [8].
The objective of communication QoS requires that the SINR is higher than or equal to a desired threshold, i.e., . Meanwhile, the power allocation objective is to minimize the total power consumption for all users, i.e., . Based on [8], the solution of the total power minimization subject to the QoS constraint is defined as
which is equivalent to
With the assumption that , (8) can be calculated as
Without loss of generality, the transmission power of the ith robot can be modeled and described similarly as in [8], i.e.,
where represents the transmission power and represents the power-control command generated by the base station or scheduler to regulate user i’s transmitted power in real time. In practice, this control corresponds to the standard closed-loop power-control signal used in modern systems (e.g., LTE or 5G NR), which adjusts the transmitted power at sub-millisecond intervals based on SINR feedback. The stochastic differential equation formulation serves as the continuous-time limit of this discrete process, where the drift term governed by models the deterministic adjustment of power and the diffusion term captures random channel fluctuations and measurement noise. This abstraction preserves the bounded, feedback-driven nature of practical power-control loops while enabling tractable stochastic analysis. Furthermore, provides the random noise from the transmitter.
Therefore, the communication value function can be defined for each robot at time with transmitting time as
with
where and represent the sets of all users’ power and the power loss of the ith agent, respectively, is the coupling term that forces the transmitter to achieve the desired SINR, represents the penalty of abrupt power adjustment, and represents the additional penalty of high power. Although the integration in (11) is to infinity, the transmission stops when the remote station receives all data.
The objective of an individual robot is to find the optimal control and such that the value functions (3) and (11) are minimized. It is easy to observe from (3) and (11) that the coupling terms and require the current information from other robots, which is unattainable. To overcome these difficulties, Mean Field Games are applied where coupling functions are replaced by a function that is related to the PDF of all agents’ state information.
5. Mean Field Type Control
Mean Field Game (MFG) theory [12] is an emerging technique that can effectively solve the stochastic decision-making and control problem with a large population of agents in a decentralized manner. In Mean Field Games, the information is encoded into a probability density function (PDF) which can be computed by a partial differential equation (PDE) named the Fokker–Planck–Kolmogorov (FPK) equation. The computed PDF overcomes the difficulty of collecting information from all other agents, as well as reducing the dimensions of the optimal control problem. In this section, the tasks in Scenarios 1 and 2 are formulated into two non-cooperative Mean Field Games. Then, a series of neural networks are designed and activated asynchronously to approximate the optimal solution. For example, when the robot is in Scenario 1, three NNs for Scenario 1 are activated, whereas Scenario 2’s NNs remain unchanged. The block diagram of the Actor–Critic–Mass (ACM) structure is demonstrated in Figure 3.
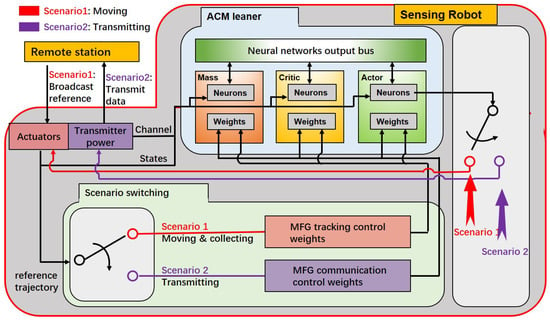
Figure 3.
Block diagram of the Actor–Critic–Mass (ACM) architecture. Two sets of actor, critic, and mass neural networks are constructed to estimate the optimal control strategies for Scenario 1 and Scenario 2, respectively. These two sets are activated alternately based on the current scenario. Each neural network continuously interacts with the environment and updates its synaptic weights using real-time feedback, enabling online learning and adaptation.
5.1. Mean Field Power Allocation Games and Solution Learning
I first formulate Scenario 2 as a mean field type of transmission power allocation problem and derive the Actor–Critic–Mass structure to learn the optimal solution. As mentioned in the previous section, the coupling term requires the current transmission power of other robots, which is unattainable. Therefore, I propose using the PDF to replace all agents’ transmission power and power loss .
Given a wireless channel, the PDFs of the power loss and transmission power for all robots, i.e., and , are used to compute the joint PDF of the received power of the i-th robot, i.e., , with . Assuming , the SINR constraint can be replaced with the expected value as follows:
While changes, is fixed since the all agents remain still. Since the mobility and power allocation are separately considered, I consider the and p as independent random variables and .
To solve the optimal strategy which minimizes the value function, the HJB equation can be obtained. According to the optimal control theory [39], the HJB equation is given as
where
The optimal power adjustment strategy for individual agents can be represented as
To solve the HJB, i.e., Equation (16), the attenuation mass distribution and the transmission power mass distribution are needed. Recalling the Mean Field Game (MFG) [13], the probability density function (PDF) can be attained by solving the FPK equation:
The expected value can be calculated by substituting the monotonic power attenuation function . Furthermore, the PDF of the transmitted path loss in (5), , can also be solved by the following FPK equation:
where is the motion control of the robot that is known in Scenario 2 and is the initial transmitted path loss distribution.
Finally, the optimal strategy based on a Mean Field Game for all agents is officially defined. Considering the aforementioned value function (14), the optimization of the transmission power allocation for N players, i.e., Scenario 2, can be formulated as a non-cooperative game.
In Scenario 2, each mobile sensing robot (player) tries to minimize the value function given in (14) by computing a dynamic transmission power adjustment rate . Since the coupling effect is considered in the value function, the Nash Equilibrium is the optimal strategy for individual agents, while the number of agents is infinite. Let denote the set of transmission power for all mobile sensing robots at time t. Define a mapping to represent the power adjustment strategy set for agent i. I further denote as the set of transmission power other than that for agent i. Then, the optimal strategy equilibrium, i.e., the Nash Equilibrium, can be defined as follows.
Definition 1 ( Nash Equilibrium (NE) of Scenario 2).
Given power set and action set at any time t, the Nash Equilibrium (NE) of the N-player non-cooperative power allocation game is a strategy set that is generated by and satisfies the following conditions:
where .
According to recent studies [15,40], the solution to the coupled Hamilton–Jacobi-Bellman (HJB) and Fokker–Planck–Kolmogorov (FPK) equations yields an -Nash equilibrium, where .
Remark 2.
Unlike conventional distributed control methods, which require precise real-time information from neighboring agents, the Mean Field Game (MFG)-based decentralized control framework allows each agent to make decisions based on local information and the aggregate effect of the entire multi-agent system (MAS). This aggregate influence is captured through the probability density function (PDF) of agents’ transmission powers, denoted by . Notably, this PDF can be computed using the FPK equation [12], without requiring direct access to other agents’ instantaneous states or actions.
To determine the optimal transmission power, one must simultaneously solve the coupled Hamilton–Jacobi–Bellman (HJB) and Fokker–Planck–Kolmogorov (FPK) equations. However, this is inherently challenging: the HJB equation, i.e., Equation (16), is a backward-in-time partial differential equation (PDE), whereas the FPK equation, Equation (19), evolves forward in time. This opposing temporal structure makes the real-time solution of the mean field design highly complex.
To address this challenge, a novel online adaptive reinforcement learning framework, termed the Actor–Critic–Mass (ACM) architecture, is proposed. In this framework, three neural networks—the actor, the critic, and the mass network—are constructed to approximate the solutions to Equation (18), Equation (16), and Equation (19), respectively.
Assuming ideal neural network weights , , and , respectively, the optimal value function, control policy, and mass distribution can be approximated as follows:
where , , and are bounded, continuous activation functions, and , , and denote the neural network approximation errors.
Correspondingly, the learned approximations for the value function, power control strategy, and mass distribution are expressed as
where , , and represent the online-estimated basis functions corresponding to each approximated quantity.
Substituting the neural network approximations in Equation (23) into the original HJB equation (16), the optimal control law (18), and the FPK equation (19), the equations no longer hold exactly. Instead, residual errors are introduced, which are then used to update the critic, actor, and mass networks over time. These residuals are defined as follows:
The residual terms in Equations (24)–(26) are obtained by substituting the neural network approximations into the original HJB, FPK, and optimal control equations, respectively, and represent the resulting approximation errors when these equations are not exactly satisfied.
According to Equation (22), these approximation errors vanish when the ideal neural network weights are reached. Hence, a gradient descent-based update law is applied to minimize the residuals and iteratively learn the optimal weights in Equation (22):
where , , and denote the learning rates for the critic, mass, and actor networks, respectively.
5.2. Mean Field Optimal Navigation Games
As shown in [10], the decentralized navigation problem for large-scale mobile sensor networks can be formulated as a mean-field-type optimal tracking control problem. Let denote the time-varying probability density function (PDF) of the agents’ tracking errors at time t. It is assumed that the coupling function depends on the distribution of tracking errors and can be expressed as . With this, the cost function in Equation (3) becomes
To minimize this cost, the corresponding Hamilton–Jacobi–Bellman (HJB) equation can be derived as in [10]:
where the Hamiltonian is given by
Solving the HJB equation yields the optimal cost-to-go function and control policy. The optimal control input is given by
Meanwhile, the tracking error distribution evolves according to the Fokker–Planck–Kolmogorov (FPK) equation:
where denotes differentiation with respect to the second argument. Solving the coupled HJB–FPK equations yields the -Nash equilibrium for Scenario 1.
To avoid solving the coupled PDEs directly, I employ a mean field reinforcement learning approach to approximate the optimal value function, control policy, and distribution. These are represented using neural networks as follows:
The weights of the neural networks are updated via gradient descent using the residual errors from the HJB, FPK, and control equations:
5.3. Convergence of Neural Network Weights
To ensure the reliability of the proposed learning framework, it is essential to analyze the convergence properties of the neural networks. Given the structural similarity between the neural networks used in Scenario 1 and Scenario 2, I focus our analysis on Scenario 2 without loss of generality.
Recall the update laws defined in Equations (27)–(29). The weight estimation errors of the actor, critic, and mass networks can be expressed as
where the weight estimation error is defined as , with , , and representing the respective errors for the critic, mass, and actor networks.
Firstly, a lemma regarding the closed-loop dynamics is proposed.
Lemma 1.
Consider the continuous-time system described by Equation (10). There exists an optimal mean field-type control input such that the resulting closed-loop system dynamics,
satisfy the inequality
where is a positive constant.
Based on this lemma, the performance of the Actor–Critic–Mass (ACM) learning algorithm in Scenario 2 can be analyzed through the following theorem.
Theorem 1 (Closed-loop Stability).
Let the initial control input be admissible, and suppose the actor, critic, and mass neural network weights are initialized within a compact set. Assume the neural network weight update laws are given by Equations (27)–(29). Then, there exist the positive constants , , and such that the transmission power and the weight estimation errors , , and of the critic, mass, and actor networks, respectively, are all uniformly ultimately bounded (UUB). Moreover, the estimated value function , mass function , and control input are also UUB. If the neural networks are sufficiently expressive (i.e., with enough neurons and a properly designed architecture), the reconstruction errors can be made arbitrarily small. Under such ideal conditions, the system state and the weight estimation errors , , and will asymptotically converge to zero, ensuring asymptotic stability of the closed-loop system.
Proof.
A brief proof sketch is provided: Consider the transmission power dynamics in Equation (10) and the neural network approximations in Equation (23). Let the ideal network weights be , , and , and their online estimates be , , and . Define the corresponding weight estimation errors as , , and . The residual errors , , and are defined in Equations (24)–(26) as the deviations obtained when the approximated neural networks are substituted into the corresponding Hamilton–Jacobi–Bellman (HJB), Fokker–Planck–Kolmogorov (FPK), and optimal control equations, respectively. The update laws in Equations (27)–(29) minimize these residuals through gradient descent with learning rates , , and . To analyze convergence, consider the following Lyapunov candidate function:
where is a constant and is the transmission power of agent i. Differentiating along the trajectories of the closed-loop system and substituting the learning laws (27)–(29) yields
where are constants and denotes the bounded neural network approximation errors introduced in Equation (22). The inequality shows that is negative definite up to a small residual term proportional to , implying that both the transmission power and the weight estimation errors remain uniformly ultimately bounded (UUB). Under the standard universal approximation theorem, if the neural networks are sufficiently expressive such that the approximation errors can be made arbitrarily small, then and the system trajectories asymptotically converge to the optimal solution . This establishes the stability and convergence results stated in Theorem 1. □
The performance for the mean field navigation game can be similarly obtained. Furthermore, the algorithm can be summarized as a pseudocode in Algorithm 1.
| Algorithm 1 ACM for Mean Field Navigation (Scenario 1) and Power Control (Scenario 2) |
|
6. Simulations
To validate the effectiveness of the proposed Actor–Critic–Mass (ACM) algorithm and its scalability in large-scale mobile wireless sensor networks, a series of numerical simulations are conducted. The simulations are designed to evaluate both navigation and communication performance under decentralized control. Specifically, the tracking accuracy, convergence of the mean field learning process, and communication quality of service (QoS) compared with a baseline decentralized algorithm are analyzed. The following subsections describe the simulation setup, performance metrics, and comparative results in detail.
Simulation Setup
The performance of the proposed decentralized multi-agent reinforcement learning algorithm is evaluated using a network of 1000 mobile wireless sensors. The simulation is conducted within a 6 × 5 m2 workspace. All agents are randomly initialized within this area, and a remote station is located at the origin.
The mobile sensors are tasked with tracking four distinct trajectories corresponding to four areas of interest. Each trajectory , for , is defined as
where denotes the activation time for trajectory k.
Each mobile sensor spends 20 s navigating along each reference trajectory. After completing the navigation for one area, the agent spends 15 s transmitting its collected data back to the remote station. The overall simulation timeline is illustrated in Figure 4, where denotes the tracking phase for area k and denotes the corresponding data transmission phase.
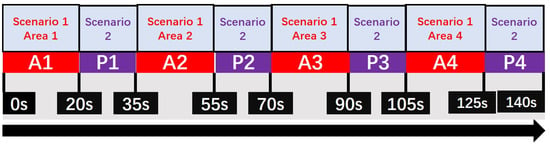
Figure 4.
Timeline of scenarios. stands for transmission location 1, and so on.
The desired transmission SINR is set to , and the noise variance for all agents is . The diffusion coefficients are set as and . The cost function parameters are chosen as , , , and . The mean field coupling function from Equation (30) is defined as
The initial distribution of agents’ positions is modeled as a Gaussian:
The simulation parameters are summarized in Table 1. A flow chart of the simulation process is provided in Figure 5. The actor, critic, and mass neural networks for both scenarios are updated separately. As shown, each agent starts by operating individually and alternates between the navigation and communication phases. In the navigation phase, the agent observes its state , estimates the population distribution by solving the Fokker–Planck–Kolmogorov (FPK) equation, and computes the value function from the Hamilton–Jacobi–Bellman (HJB) equation. A new optimal control action is then generated and implemented to update the agent’s trajectory. Similarly, in the communication phase, the agent observes its relative distance to the remote station, updates the power distribution via the FPK equation, and evaluates the value function using the HJB equation to produce the optimal transmission power . The new actions from both phases are implemented iteratively, allowing each agent to adapt its motion and power in real time until convergence to the mean field equilibrium occurs.

Table 1.
Simulation parameters.
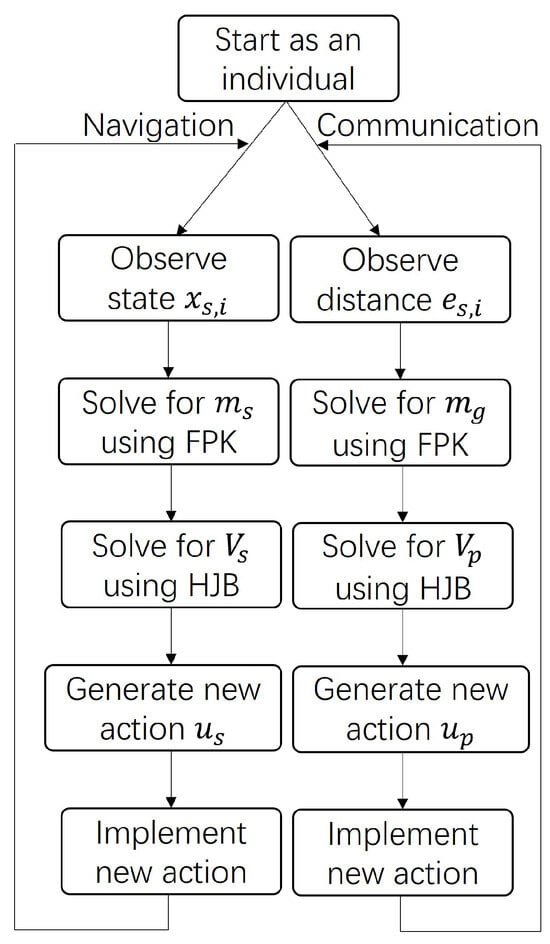
Figure 5.
The flow chart of the algorithm.
To approximate the solutions of the HJB equations [Equations (31) and (16)], the FPK equations [Equations (34) and (19)], and the optimal control policies and , I design and deploy three neural networks: Critic NN, Mass NN, and Actor NN.
Figure 6 illustrates the trajectories of all mobile sensors throughout the simulation. The blue curves represent the desired reference trajectories, while the data transmission points are indicated by red squares. The thin colored curves correspond to the individual trajectories of the 1000 mobile sensing agents. It can be clearly observed that the agents successfully track the desired paths with high accuracy. The detailed tracking error average and the percentage are included in Table 2. On average, the four areas achieved accuracy at the end of each stage.
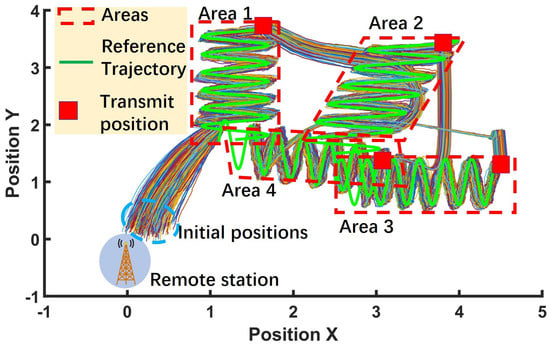
Figure 6.
The overall trajectory for all sensing robots in Scenario 1. The red squares represent the transmitting points. The green curve represents the tracking reference.
Table 2.
Trajectory tracking errors by time.
In addition, Figure 7b shows the time evolution of the normalized average tracking error across all agents. The tracking error remains bounded and converges close to zero, demonstrating effective trajectory tracking performance. However, due to the inherent stochasticity in the agents’ motion dynamics, the tracking error does not converge exactly to zero, which is consistent with the presence of system noise. The state density plot is shown in Figure 8 and displays similar behavior.
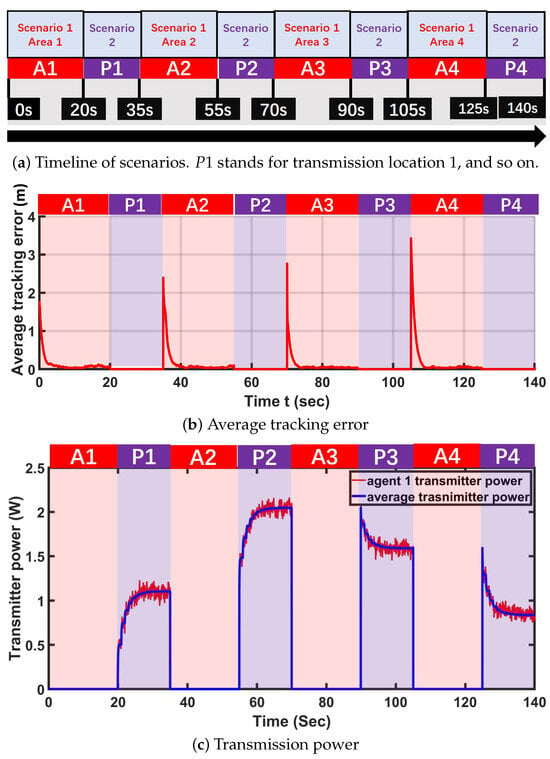
Figure 7.
(a) Time evolution of scenarios. This reveals the process of the sensing networks’ workflow with respect to time. (b) Time evolution of the normalized tracking error on the x axis (red curve) and y axis (blue curve). (c) Time evolution of the transmission power for a single agent (red curve) and the population average (blue curve).
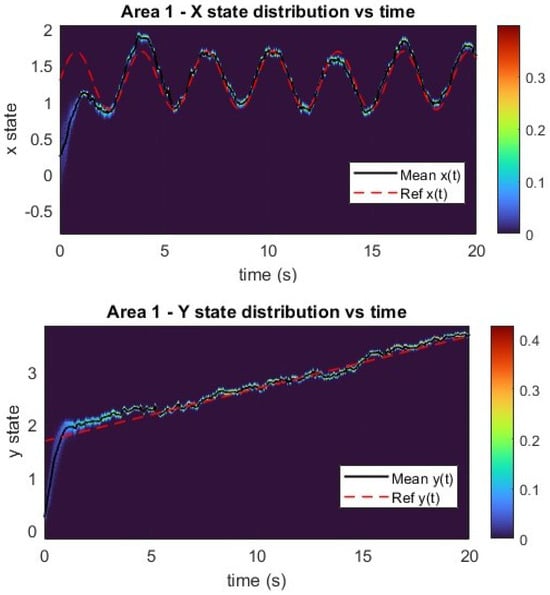
Figure 8.
Navigation state density distribution evolution.
To further analyze the learning performance at the individual agent level, I examine the HJB equation residual of Robot 1 in Scenario 1 (i.e., navigation). Figure 9 plots the HJB residual over time in a stationary setting, where both the HJB and FPK equations are assumed to be time-invariant. In this scenario, the mass neural network is updated every 1 s to compute , which is then used to update the critic neural network. As shown in Figure 9, the HJB residual converges to zero within approximately 1 s. Moreover, the HJB error distribution among all robots is plotted in Figure 10.
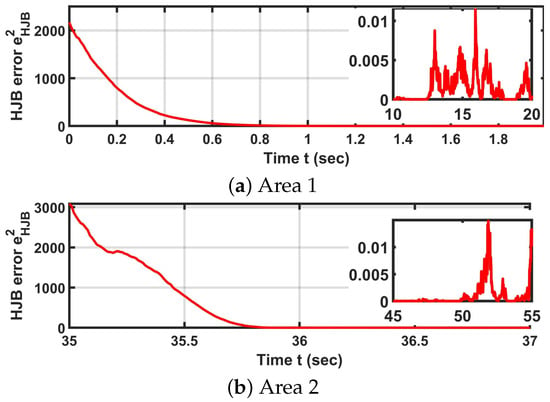
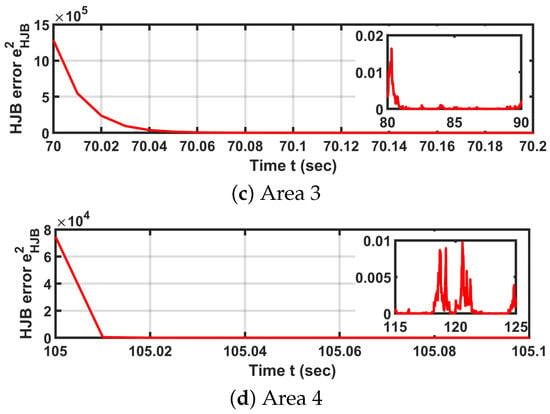
Figure 9.
The plots of Robot 1’s HJB equation error, which is also the critic NN error. The small figure on the right part of each plot is the HJB error in the last 10 s of moving in each area.
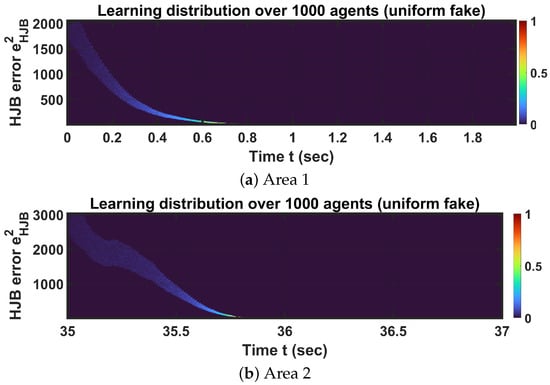
Figure 10.
The plots of all robots’ HJB error distributions.
Given the convergence of both the tracking error and the HJB residual, it can be concluded that the actor, critic, and mass networks successfully converge in Scenario 1. This implies that the learned control policy, value function, and tracking error distribution converge to the solution of the mean field equation system. Therefore, the learned control policy represents the unique solution to the -Nash equilibrium.
Next, I analyze the performance of the Actor–Critic–Mass (ACM) algorithm in Scenario 2 (i.e., transmission). Similarly to Scenario 1, a set of three neural networks is employed to solve the coupled HJB–FPK equation system for decentralized optimal transmission power control. The evolution of the signal-to-interference-plus-noise ratio (SINR) during data transmission is shown in Figure 11. Furthermore, the SINR distribution is also plotted in Figure 12. As observed, the SINR converges to the desired target of , confirming the effectiveness of the ACM algorithm in transmission tasks.
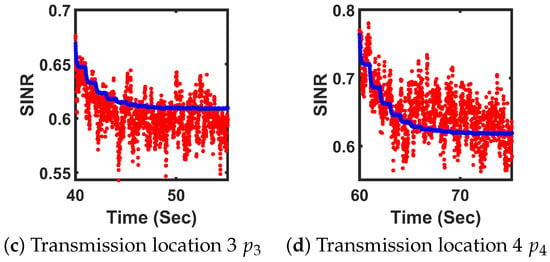
Figure 11.
The plots of the average SINR and Robot 1’s SINR in all transmission locations. The red dots show Robot 1’s SINR and the blue dots represent the average SINR among all robots.
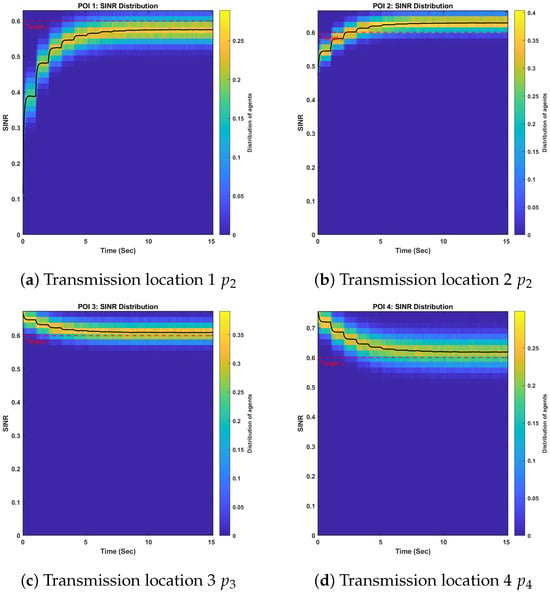
Figure 12.
SINR distribution plot.
Interestingly, at transmission locations and , the initial SINR values are higher but subsequently decrease and stabilize near the target value. This behavior arises from the value function design in Equation (14), which penalizes high power outputs due to the energy constraints of the low-cost mobile sensing robots. Figure 7c further illustrates that during data transmission at and , the robot actively minimizes its SINR to reduce power consumption at the transmitter.
This power-saving behavior will next be compared with the performance of an alternative decentralized game theoretic method, namely the Parallel Update Algorithm (PUA) introduced in [41].
7. Results and Analysis
To evaluate the effectiveness of the proposed ACM algorithm, it is compared with the Parallel Update Algorithm (PUA) introduced in [41]. The parameters for the PUA algorithm are selected as , , and , ensuring that the target SINR is achieved.
The transmission process in area is simulated using both the proposed ACM algorithm and the PUA algorithm. As shown in Figure 13, both methods achieve the target SINR. Furthermore, the total transmission power consumption across all agents converges to the same level, confirming that both algorithms reach a Nash equilibrium, as established in [41]. This validates the capability of the ACM algorithm to learn the optimal decentralized transmission strategy.
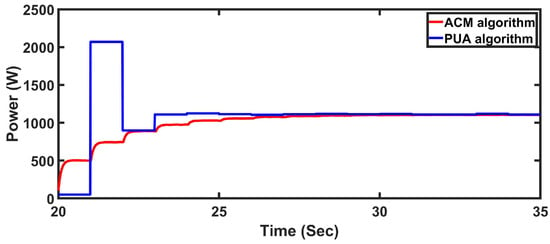
Figure 13.
The transmitters’ power summation for all mobile sensing robots in Scenario 2. The red curve represents the ACM algorithm. The blue curve represents the PUA algorithm.
However, it is important to highlight key differences. The ACM algorithm updates neural network weights continuously, while the PUA algorithm performs updates every 1 s. The ACM algorithm uses less power than the PUA algorithm. Despite its slower update frequency, PUA converges faster to the Nash equilibrium. This is because the PUA algorithm does not explicitly account for the population influence (i.e., the mass effect), leading to a more aggressive strategy.
Nevertheless, Figure 13 clearly shows that the PUA algorithm results in higher transmission power levels compared to the ACM algorithm, particularly during the transmission intervals at and . Such power profiles are not ideal for energy-constrained mobile sensors. In contrast, the ACM algorithm, by modeling and responding to the mean field, promotes more energy-efficient behavior.
To evaluate the overall performance, a composite cost function that penalizes both SINR deviation and power consumption is defined:
The values of for both algorithms are plotted in Figure 14. The results demonstrate that the ACM algorithm achieves superior performance by maintaining SINR requirements while minimizing power consumption.
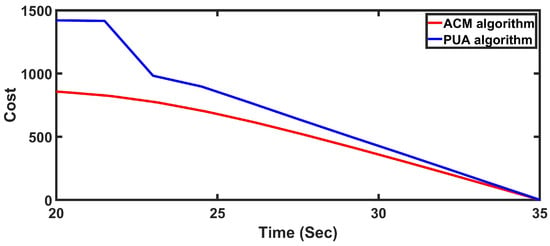
Figure 14.
The transmitters’ cost for all sensing robots in Scenario 2. The red curve represents the ACM algorithm. The blue curve represents the PUA algorithm.
Notably, at approximately 21 s in Figure 13, the PUA algorithm exhibits an overshoot in total power. This behavior stems from its lack of coordination and foresight—each agent increases its transmission power independently, without considering the collective dynamics. In contrast, the ACM algorithm anticipates these interactions by estimating the power distribution (via the mass NN), thereby avoiding destructive competition.
This comparison highlights a fundamental advantage of Mean Field Games: they serve as an implicit coordination mechanism in non-cooperative multi-agent systems. Through mass feedback, each agent adapts to the aggregate behavior of the population without requiring explicit communication, enabling convergence to a socially efficient -Nash equilibrium. Moreover, this feature significantly reduces communication overheads and channel usage, making ACM particularly well-suited for large-scale mobile sensor networks.
8. Discussion
The proposed Actor–Critic–Mass (ACM) algorithm demonstrates scalable, decentralized optimization for large-scale mobile wireless sensor networks (MWSNs). By jointly solving the Hamilton–Jacobi–Bellman (HJB) and Fokker–Planck–Kolmogorov (FPK) equations through reinforcement learning, the ACM enables each agent to learn optimal control policies without inter-agent communication. The simulation results confirm that ACM maintains the desired signal-to-interference-plus-noise ratio (SINR) while minimizing transmission power, offering energy-efficient performance under dynamic network conditions.
Compared with recent reinforcement learning approaches, ACM provides comparable or superior energy savings while avoiding centralized coordination. El Jamous et al. [42] achieved energy-efficient WiFi power control using deep RL but relied on a global critic and full state feedback. Choi et al. [43] reported up to 70% power savings in 5G H-CRANs through centralized interference coordination, whereas ACM attains similar gains using only local feedback and the learned mean field distribution. Likewise, Soltani et al. [44] demonstrated efficiency improvements in MARL-based routing but required synchronized updates, in contrast to ACM’s asynchronous and fully distributed updates.
The observed convergence of the HJB residuals and SINR trajectories aligns with mean field control theory, which predicts -Nash convergence as [15]. Unlike earlier mean field control formulations that depend on offline PDE solutions [45], ACM learns the evolving population density online, achieving faster adaptation under stochastic conditions. This emergent, energy-aware coordination behavior is comparable to that seen in other MFG-based cooperative systems such as autonomous driving [46].
9. Conclusions
This paper presents a novel decentralized co-optimization framework for mobile sensing and communication in large-scale wireless sensor networks, based on Mean Field Game (MFG) theory. The proposed Actor–Critic–Mass (ACM) algorithm leverages three neural networks—Actor NN, Critic NN, and Mass NN—to approximate the solution of the coupled Hamilton–Jacobi–Bellman (HJB) and Fokker–Planck–Kolmogorov (FPK) equations online. Two value functions are formulated to capture both navigation and communication objectives. Minimizing these functions ensures that the desired SINR is maintained and that the sensing agents accurately follow designated trajectories. The ACM algorithm achieved trajectory tracking accuracy and uses less power than the PUA algorithm. The resulting optimal policies are shown to approximate an -Nash equilibrium. Compared with traditional centralized and distributed optimization algorithms, the ACM framework significantly reduces communication overhead and computational complexity, enabling scalable, real-time implementation. Numerical simulations validate the effectiveness and efficiency of the approach, demonstrating high tracking accuracy and energy-efficient transmission.
Limitations: Despite these promising results, several simplifying assumptions constrain the present study. First, all agents were assumed to be homogeneous with identical dynamics and sensing capabilities; extending the framework to heterogeneous agents with distinct models and cost functions remains an open challenge. Second, communication latency, packet loss, and synchronization issues were neglected, yet such factors can significantly influence decentralized learning and coordination performance in practice. Third, the convergence guarantees rely on the infinite-population (mean field) limit, while practical deployments involve finite populations whose deviations from the mean field warrant further theoretical characterization. Future work will relax these assumptions by incorporating asynchronous updates, heterogeneous agent dynamics, and realistic wireless channel models to more accurately capture large-scale multi-agent behaviors in real-world environments.
Future Perspectives: Building on these results, several promising directions remain open. First, extending the ACM framework to heterogeneous multi-agent systems, where agents differ in sensing and communication capabilities, would improve applicability to realistic networks. Second, incorporating safety constraints, robustness against adversarial disturbances, and energy awareness into the MFG formulation is essential for deployment in safety-critical domains. Third, coupling ACM with online system identification or adaptive learning strategies could enhance robustness to dynamic or partially observed environments. Finally, exploring hierarchical and multi-layered networked systems—such as UAV–AUV–ground cooperative networks—offers a path toward general-purpose autonomous sensing and communication in real-world applications.
In practical deployments, additional challenges such as sensor drifts, intermittent communication, and packet loss can significantly affect system performance. Small but accumulating sensor drifts may distort the agents’ state estimates and consequently the learned mean field distribution. Future work will therefore incorporate online calibration mechanisms and adaptive filtering to mitigate such errors. Similarly, communication failures or delays can cause asynchronous updates among agents, leading to instability in distributed learning. To address this, we plan to integrate resilient consensus and delay compensation strategies into the ACM framework, allowing agents to maintain stability even under partial or delayed information exchange. These efforts will be validated through experiments on the planned large-scale mobile sensing testbed to ensure robustness under realistic operating conditions.
Funding
This research was funded by NASA EPSCoR award #80NSSC23M0170 and NASA Wyoming Space Grant #80NSSC20M0113.
Data Availability Statement
Data are contained within the article.
Acknowledgments
This article is a revised and expanded version of a paper entitled “Decentralized multi-agent reinforcement learning for large-scale mobile wireless sensor network control using mean field games”, which was presented at 2024 33rd International Conference on Computer Communications and Networks (ICCCN) [47]. The author has used AI tools to improve the grammar.
Conflicts of Interest
The author declares no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACM | Actor–Critic–Mass |
| FPK | Fokker–Planck–Kolmogorov |
| HJB | Hamilton–Jacobi–Bellman |
| MFG | Mean Field Game |
| MWSN | Mobile Wireless Sensor Network |
| NN | Neural Network |
| PDE | Partial Differential Equation |
| Probability Density Function | |
| PUA | Parallel Update Algorithm |
| QoS | Quality of Service |
| SINR | Signal-to-Interference-plus-Noise Ratio |
| SLAM | Simultaneous Localization and Mapping |
| UUB | Uniformly Ultimately Bounded |
| AGV | Automated Guided Vehicle |
| AI | Artificial Intelligence |
| AUV | Autonomous Underwater Vehicle |
| MAS | Multi-Agent System |
| POI | Point of Interest |
| UAV | Unmanned Aerial Vehicle |
| UCRL | Upper-Confidence Reinforcement Learning |
| V2X | Vehicle-to-Everything |
References
- Liu, L.; Zheng, Z.; Zhu, S.; Chan, S.; Wu, C. Virtual-Mobile-Agent-Assisted Boundary Tracking for Continuous Objects in Underwater Acoustic Sensor Networks. IEEE Internet Things J. 2024, 11, 9171–9183. [Google Scholar] [CrossRef]
- Huang, P.; Zeng, L.; Chen, X.; Luo, K.; Zhou, Z.; Yu, S. Edge Robotics: Edge-Computing-Accelerated Multirobot Simultaneous Localization and Mapping. IEEE Internet Things J. 2022, 9, 14087–14102. [Google Scholar] [CrossRef]
- Fernández-Jiménez, F.J.; Dios, J.R.M.d. A Robot–Sensor Network Security Architecture for Monitoring Applications. IEEE Internet Things J. 2022, 9, 6288–6304. [Google Scholar] [CrossRef]
- Lee, J.S.; Jiang, H.T. An Extended Hierarchical Clustering Approach to Energy-Harvesting Mobile Wireless Sensor Networks. IEEE Internet Things J. 2021, 8, 7105–7114. [Google Scholar] [CrossRef]
- Su, Y.; Guo, L.; Jin, Z.; Fu, X. A Mobile-Beacon-Based Iterative Localization Mechanism in Large-Scale Underwater Acoustic Sensor Networks. IEEE Internet Things J. 2021, 8, 3653–3664. [Google Scholar] [CrossRef]
- Wang, D.; Chen, H.; Lao, S.; Drew, S. Efficient Path Planning and Dynamic Obstacle Avoidance in Edge for Safe Navigation of USV. IEEE Internet Things J. 2024, 11, 10084–10094. [Google Scholar] [CrossRef]
- Ma, C.; Li, A.; Du, Y.; Dong, H.; Yang, Y. Efficient and scalable reinforcement learning for large-scale network control. Nat. Mach. Intell. 2024, 6, 1006–1020. [Google Scholar] [CrossRef]
- Huang, M.; Caines, P.E.; Charalambous, C.D. Stochastic power control for wireless systems: Classical and viscosity solutions. In Proceedings of the 40th IEEE Conference on Decision and Control (Cat. No. 01CH37228), Orlando, FL, USA, 4–7 December 2001; Volume 2, pp. 1037–1042. [Google Scholar]
- Kafetzis, D.; Vassilaras, S.; Vardoulias, G.; Koutsopoulos, I. Software-defined networking meets software-defined radio in mobile ad hoc networks: State of the art and future directions. IEEE Access 2022, 10, 9989–10014. [Google Scholar] [CrossRef]
- Zejian, Z.; Xu, H. Decentralized Adaptive Optimal Tracking Control for Massive Multi-agent Systems: An Actor-Critic-Mass Algorithm. In Proceedings of the 58th IEEE Conference on Decision and Control, Nice, France, 11–13 December 2019. [Google Scholar]
- Zejian, Z.; Xu, H. Decentralized Adaptive Optimal Control for Massive Multi-agent Systems Using Mean Field Game with Self-Organizing Neural Networks. In Proceedings of the 58th IEEE Conference on Decision and Control, Nice, France, 11–13 December 2019. [Google Scholar]
- Guéant, O.; Lasry, J.M.; Lions, P.L. Mean field games and applications. In Paris-Princeton Lectures on Mathematical Finance 2010; Springer: Berlin/Heidelberg, Germany, 2011; pp. 205–266. [Google Scholar]
- Lasry, J.M.; Lions, P.L. Mean field games. Jpn. J. Math. 2007, 2, 229–260. [Google Scholar] [CrossRef]
- Prag, K.; Woolway, M.; Celik, T. Toward data-driven optimal control: A systematic review of the landscape. IEEE Access 2022, 10, 32190–32212. [Google Scholar] [CrossRef]
- Huang, M.; Caines, P.E.; Malhamé, R.P. Large-population cost-coupled LQG problems with nonuniform agents: Individual-mass behavior and decentralized ε-Nash equilibria. IEEE Trans. Autom. Control 2007, 52, 1560–1571. [Google Scholar] [CrossRef]
- Huang, M.; Sheu, S.; Sun, L. Mean field social optimization: Feedback person-by-person optimality and the dynamic programming equation. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC), Jeju, Republic of Korea, 14–18 December 2020. [Google Scholar]
- Cardaliaguet, P.; Porretta, A. An Introduction to Mean Field Game Theory; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–158. [Google Scholar]
- Liu, M.; Zhao, L.; Lopez, V.; Wan, Y.; Lewis, F.; Tseng, H.E.; Filev, D. Game-Theoretic Decision-Making for Autonomous Driving; CRC Press: Boca Raton, FL, USA, 2025; pp. 236–272. [Google Scholar]
- Wei, X.; Zhao, J.; Zhou, L.; Qian, Y. Broad Reinforcement Learning for Supporting Fast Autonomous IoT. IEEE Internet Things J. 2020, 7, 7010–7020. [Google Scholar] [CrossRef]
- Liang, S.; Wang, X.; Huang, J. Actor–Critic Reinforcement Learning Algorithms for Mean Field Games in Continuous Time, State, and Action Spaces. arXiv 2024, arXiv:2401.00052. [Google Scholar] [CrossRef]
- Angiuli, A.; Subramanian, J.; Perolat, J.; Carpentier, A.; Geist, M.; Pietquin, O. Deep Reinforcement Learning for Mean Field Control and Games. arXiv 2023, arXiv:2309.10953. [Google Scholar]
- Bogunovic, I.; Pirotta, M.; Rosolia, U. Safe-M3-UCRL: Safe Mean-Field Multi-Agent Reinforcement Learning under Global Constraints. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS), Auckland, New Zealand, 6–10 May 2024; pp. 973–981. [Google Scholar]
- Zaman, A.; Ratliff, L.; Mesbahi, M. Robust Multi-Agent Reinforcement Learning via Mean-Field Games. In Proceedings of the 41st International Conference on Machine Learning (ICML), Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Jiang, Y.; Xu, K.; Wu, Y.; Zhang, M. A Survey of Fully Decentralized Multi-Agent Reinforcement Learning. arXiv 2024, arXiv:2306.02766. [Google Scholar]
- Gabler, L.; Scheller, S.; Albrecht, S.V. Decentralized Actor–Critic Reinforcement Learning for Cooperative Tasks with Sparse Rewards. Front. Robot. AI 2024, 11, 1229026. [Google Scholar]
- Gu, Y. Centralized training with hybrid execution in multi-agent reinforcement learning via predictive observation imputation. Artif. Intell. 2025, 348, 104404. [Google Scholar] [CrossRef]
- Alam, S.; Khan, M.; Zhang, W. Actor–Critic Frameworks for UAV Swarm Networks: A Survey. Drones 2025, 9, 153. [Google Scholar] [CrossRef]
- Xu, C.; Li, P.; Sun, X. Mean-Field Multi-Agent Reinforcement Learning for UAV-Assisted V2X Communications. arXiv 2025, arXiv:2502.01234. [Google Scholar]
- Emami, N.; Joo, C.; Kim, S.C. Age of Information Minimization Using Multi-Agent UAVs Based on AI-Enhanced Mean Field Resource Allocation. IEEE Trans. Wirel. Commun. 2024, 73, 13368–13380. [Google Scholar] [CrossRef]
- Mostofi, Y.; Malmirchegini, M.; Ghaffarkhah, A. Estimation of communication signal strength in robotic networks. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 1946–1951. [Google Scholar]
- Malmirchegini, M.; Mostofi, Y. On the spatial predictability of communication channels. IEEE Trans. Wirel. Commun. 2012, 11, 964–978. [Google Scholar] [CrossRef]
- Charalambous, C.D.; Menemenlis, N. Stochastic models for long-term multipath fading channels and their statistical properties. In Proceedings of the 38th IEEE Conference on Decision and Control (Cat. No. 99CH36304), Phoenix, AZ, USA, 7–10 December 1999; Volume 5, pp. 4947–4952. [Google Scholar]
- Huang, M.; Malhamé, R.P.; Caines, P.E. Stochastic power control in wireless communication systems: Analysis, approximate control algorithms and state aggregation. In Proceedings of the 42nd IEEE International Conference on Decision and Control (IEEE Cat. No. 03CH37475), Maui, HI, USA, 9–12 December 2003; Volume 4, pp. 4231–4236. [Google Scholar]
- Huang, M.; Caines, P.E.; Malhamé, R.P. Individual and mass behaviour in large population stochastic wireless power control problems: Centralized and Nash equilibrium solutions. In Proceedings of the 42nd IEEE International Conference on Decision and Control (IEEE Cat. No. 03CH37475)), Maui, HI, USA, 9–12 December 2003; Volume 1, pp. 98–103. [Google Scholar]
- Aziz, M.; Caines, P.E. Computational investigations of decentralized cellular network optimization via mean field control. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 5560–5567. [Google Scholar]
- Aziz, M.; Caines, P.E. A mean field game computational methodology for decentralized cellular network optimization. IEEE Trans. Control Syst. Technol. 2016, 25, 563–576. [Google Scholar] [CrossRef]
- Haenggi, M.; Ganti, R.K. Interference in large wireless networks. Found. Trends Netw. 2009, 3, 127–248. [Google Scholar] [CrossRef]
- Baccelli, F.; Błaszczyszyn, B. Stochastic geometry and wireless networks: Volume II applications. Found. Trends Netw. 2010, 4, 1–312. [Google Scholar] [CrossRef]
- Jiang, Y.; Fan, J.; Chai, T.; Lewis, F.L.; Li, J. Tracking control for linear discrete-time networked control systems with unknown dynamics and dropout. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4607–4620. [Google Scholar] [CrossRef] [PubMed]
- Nourian, M.; Caines, P.E. ϵ-Nash mean field game theory for nonlinear stochastic dynamical systems with major and minor agents. SIAM J. Control Optim. 2013, 51, 3302–3331. [Google Scholar] [CrossRef]
- Alpcan, T.; Başar, T.; Srikant, R.; Altman, E. CDMA uplink power control as a noncooperative game. Wirel. Netw. 2002, 8, 659–670. [Google Scholar] [CrossRef]
- El Jamous, Z.; Davaslioglu, K.; Sagduyu, Y.E. Deep reinforcement learning for power control in next-generation wifi network systems. In Proceedings of the MILCOM 2022—2022 IEEE Military Communications Conference (MILCOM), Rockville, MD, USA, 28 November–2 December 2022; pp. 547–552. [Google Scholar]
- Choi, H.; Kim, T.; Lee, S.; Choi, H.S.; Yoo, N. Energy-Efficient Dynamic Enhanced Inter-Cell Interference Coordination Scheme Based on Deep Reinforcement Learning in H-CRAN. Sensors 2024, 24, 7980. [Google Scholar] [CrossRef]
- Soltani, P.; Eskandarpour, M.; Ahmadizad, A.; Soleimani, H. Energy-Efficient Routing Algorithm for Wireless Sensor Networks: A Multi-Agent Reinforcement Learning Approach. arXiv 2025, arXiv:2508.14679. [Google Scholar]
- Wu, Y.; Wu, J.; Huang, M.; Shi, L. Mean-field transmission power control in dense networks. IEEE Trans. Control Netw. Syst. 2020, 8, 99–110. [Google Scholar] [CrossRef]
- Zhang, H.; Lu, C.; Tang, H.; Wei, X.; Liang, L.; Cheng, L.; Ding, W.; Han, Z. Mean-field-aided multiagent reinforcement learning for resource allocation in vehicular networks. IEEE Internet Things J. 2022, 10, 2667–2679. [Google Scholar] [CrossRef]
- Zhou, Z.; Qian, L.; Xu, H. Decentralized multi-agent reinforcement learning for large-scale mobile wireless sensor network control using mean field games. In Proceedings of the 2024 33rd International Conference on Computer Communications and Networks (ICCCN), Kailua-Kona, HI, USA, 29–31 July 2024; pp. 1–6. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).