Abstract
Speaker recognition has become a critical component of human–robot interaction (HRI), enabling personalized services based on user identity, as the demand for home service robots increases. In contrast to conventional speech recognition tasks, recognition in home service robot environments is affected by varying speaker–robot distances and background noises, which can significantly reduce accuracy. Traditional approaches rely on hand-crafted features, which may lose essential speaker-specific information during extraction like mel-frequency cepstral coefficients (MFCCs). To address this, we propose a novel speaker recognition technique for intelligent robots that combines SincNet-based raw waveform processing with an adaptive neuro-fuzzy inference system (ANFIS). SincNet extracts relevant frequency features by learning low- and high-cutoff frequencies in its convolutional filters, reducing parameter complexity while retaining discriminative power. To improve interpretability and handle non-linearity, ANFIS is used as the classifier, leveraging fuzzy rules generated by fuzzy c-means (FCM) clustering. The model is evaluated on a custom dataset collected in a realistic home environment with background noise, including TV sounds and mechanical noise from robot motion. Our results show that the proposed model outperforms existing CNN, CNN-ANFIS, and SincNet models in terms of accuracy. This approach offers robust performance and enhanced model transparency, making it well-suited for intelligent home robot systems.
1. Introduction
The demand for home service robots has been increasing globally as they make human life more convenient [1]. According to the global market research firm Fact.MR, the global home robot market was valued at USD 12.1 billion in 2022, with a compound annual growth rate (CAGR) of 20.6%. It is projected to reach USD 95.1 billion by 2033 [2]. Additionally, the personal robot market is expected to grow at a CAGR of 7.8% by 2030, according to a market research report by ResearchAndMarkets [3]. With the growing use of robots, the human–robot interaction (HRI), which refers to communication between humans and robots, has garnered significant attention, and speech-related technologies that play a crucial role in the interaction are actively being researched [4,5,6,7,8,9].
Speech is the most fundamental form of human communication. An individual’s speech signal has unique characteristics depending on the vocal organ and speaking style, and contains various information such as the speaker’s identity [10]. For a robot to communicate effectively with a person, the first step is to recognize the person’s identity. By identifying the speaker, robots can provide personalized services, including tasks like playing music based on individual preferences or checking personal schedules. In households with children, robots can recognize a child’s speech and monitor their language development. The technology used to recognize a person’s identity is known as speaker recognition, and numerous studies on speaker recognition using speech have been conducted in recent years. Speaker recognition involves training a model on a database containing speeches from multiple speakers. When a speech sample is input into the trained model, the speaker with the highest score is recognized.
With the advancement of artificial intelligence (AI), deep learning-based speaker recognition research has been widely conducted [5,9,11,12,13,14,15,16]. In most deep learning studies using speech, features are extracted from the speech data before being input into the model. Commonly used features include Fast Fourier Transform (FFT), spectrograms, and mel-frequency cepstral coefficients (MFCCs). In the process of feature extraction from speech data, unstructured or fine-grained information can be lost, and the performance of the model can vary significantly due to the manual tuning of various hyperparameters for feature extraction. To address these issues, several studies have been conducted where raw speech signals are used as input, allowing the model to learn features directly from the data [11,12,13,14,15,16].
Various deep learning-based methods have been studied for speaker recognition. However, many models require a large number of parameters to learn the non-linear characteristics of speech, and they suffer from the black-box problem, limiting their interpretability. To address this, the present study proposes a speaker recognition model designed for home service robots, which ensures both performance and interpretability with fewer parameters. In this study, we propose the SincNet-ANFIS model, which can secure both interpretability and performance with a small number of parameters by extending the existing SincNet-based speaker recognition model [12]. SincNet is a convolutional neural network (CNN) architecture that uses Sinc filters in the first layer, allowing the network to learn relevant features directly from raw speech signals without the need for manual feature extraction. Since these filters are learnable, the model can be applied to noisy and variable speech signals that are commonly encountered in home environments. To improve interpretability and reduce parameter complexity, we fuse the adaptive neural-fuzzy inference system (ANFIS) in the final classification step. The fusion of SincNet and ANFIS enables robust processing of non-linear and uncertain data. The proposed model is evaluated using a Korean speaker recognition dataset tailored to a robot environment, and compared with baseline models including CNN, CNN-ANFIS, and SincNet.
This paper is structured as follows: In Section 2, we introduce the related work. Section 3 provides a detailed description of the SincNet-ANFIS model architecture. Section 4 presents the database used and discusses the experimental results. Section 5 provides a discussion of the findings. Finally, Section 6 concludes the paper and outlines potential future work.
2. Related Work
Traditional speech processing methods extract features such as MFCCs and spectrograms, which often lead to the loss of fine-grained information. To address this issue, recent studies have explored techniques that integrate deep learning with fuzzy systems to enhance the robustness of learning non-linear characteristics in speech signals. This section provides a structured review of these advancements, focusing on three key areas: end-to-end models in speech processing, fuzzy inference systems for signal processing, and hybrid models that combine deep learning models with fuzzy inference systems.
2.1. End-to-End Deep Learning Models for Speech Processing
Feature extraction methods in speech processing can result in the loss of unstructured or fine-grained information, and the manual tuning of hyperparameters during this process may significantly impact model performance [13]. To overcome these limitations, deep learning models that directly use raw speech signals as input have been actively studied.
Jung [14] proposed RawNet, a speaker verification model with a front-end that extracts speaker feature vectors from raw speech signals and a back-end that functions as a classifier. This model improves upon a previous architecture that combined CNNs with long short-term memory (LSTM) units. In the front-end, a conventional CNN structure was enhanced with a gated recurrent unit (GRU) layer to capture temporal dependencies. Experiments were conducted using the VoxCeleb1 database without data augmentation to ensure fair comparison, and the model achieved an equal error rate (EER) that was 3.5% lower than that of baseline models. However, since the entire raw speech signal is used as input during inference, the model requires substantial computational resources, limiting its applicability in real-time processing. Jung [15] proposed a Res2Net-based RawNet3 model that enhances the time-frequency representation of raw speech signals using complex filters. The filters are optimized through the training process, and to effectively process the raw speech signal sequence, max pooling operations are employed to prevent overfitting and improve computational efficiency. The experimental results demonstrate high performance with an EER of 0.89. However, when using the DINO (Distillation with NO labels) framework, if the hyperparameters are not appropriately tuned, the model’s output may converge to a single representation. Baevski [16] proposed a self-supervised learning model that learns from unlabeled raw speech data and achieves high performance using a small amount of labeled data for fine-tuning. In this model, a CNN encoder extracts feature vectors directly from the raw waveform, and a transformer module is employed to reconstruct masked portions of the speech signal using global contextual information. However, due to the memory-intensive nature of transformer-based architectures, this approach is not well-suited for real-time speaker recognition systems. Ravanelli [11] introduced SincNet, a speaker recognition model that uses raw speech signals as input by replacing the first convolutional layer of a conventional CNN with a Sinc filter. By allowing the model to learn directly from raw time-domain waveforms, it can capture a wide range of speech characteristics. In contrast to standard convolutional filters, which learn all filter parameters, SincNet constrains learning to just two parameters per filter, enabling the model to extract essential frequency band information with a significantly reduced number of parameters.
2.2. Fuzzy Inference Systems for Signal Processing
Recent studies have focused on using Fuzzy Inference Systems (FISs) to effectively learn and classify non-linear features in signal processing. FIS enhances robustness in tasks such as recognition and classification in speech and signal-related applications, making it well-suited for speaker recognition systems in home service robots.
Ton-That [17] proposed a Speech Emotion Recognition (SER) model using a Fuzzy Inference System (FIS). MFCC features are extracted from the speech signal and used as inputs to the FIS based on Fuzzy Associative Memory (FAM). The FAM-based FIS consists of n input variables and one output variable, organized into five layers. Among the five layers, the fuzzification layer converts the input variables into fuzzy sets and calculates the membership values for each input. In the inference layer, the output values are computed based on fuzzy rules, and the final output is calculated in the Defuzzification layer. Savchenko [18] proposed a speech control system using a Fuzzy Logic System (FLS). To address the limitations of the existing Phonetic Decoding (PD) method, fuzzy logic was introduced, representing each vowel as a fuzzy set. Fuzzy membership values are used to flexibly estimate the probability that a specific frame belongs to a particular phoneme, achieving better performance than previous DNN-based methods. However, a limitation of this approach is that higher recognition accuracy is achieved only when all vowels are stressed during speech commands. Shahnawazuddin [19] proposed a speaker-independent Automatic Speech Recognition (ASR) system using limited speech data. Most ASR systems, which typically use adult speech data, exhibit lower recognition accuracy for children’s speeches. To address this issue, Fuzzy Classification of Spectral Bins (FCSBs) was used to classify the speech signal’s spectrum into fuzzy sets. Experimental results demonstrated that the system, trained on adult data, was also able to effectively recognize children’s speech.
2.3. Hybrid Models Combining Deep Learning Models and Fuzzy Inference Systems
Deep learning has made significant advancements in various fields that deal with large-scale databases. While deep learning performs well when precise data is available, it has the disadvantage of being a “black box,” where the rationale behind the results cannot be explained. Fuzzy systems, on the other hand, use IF-THEN rules and logical reasoning to handle vague and uncertain data, providing insight into the inference process behind the results. By integrating fuzzy logic with deep learning, it becomes possible to handle uncertain data while also making the inference process explainable. Research combining deep learning and fuzzy inference systems has progressed as follows.
Latifi [20] proposed a hybrid model for recognizing characters through EEG signal classification. To address the limitation that deep learning alone cannot handle complex and uncertain signals, Type-2 fuzzy logic was integrated between CNN and RNN. Features extracted from EEG signals are fuzzified using Type-2 Gaussian membership functions, and the fuzzified values are then combined based on Takagi-Sugeno-Kang (TSK) fuzzy rules. The model parameters are adjusted using the Parallel Swarm Optimization (PSO) algorithm. Afterward, the model is trained using an RNN to recognize characters. Experiments were conducted using three databases: BCI Competition III-Dataset II, BCI Competition II-Dataset IIb, and another EEG database. The model achieved an average accuracy of 96.2% after 15 epochs, outperforming existing models. However, due to the complex model structure, real-time application on mobile or wearable devices may be challenging. Asif [21] proposed a deep fuzzy framework that combines deep learning and fuzzy logic to classify complex and subjective emotions. The DENS database, which contains 24 emotions and uses EEG signals, was employed in the study. Short-Time Fourier Transform (STFT) features were used as input, and CNN and LSTM were used to learn spatial and temporal features, respectively. The emotions were then classified into three dimensions (low, medium, high) and fuzzified using Type-2 Gaussian membership functions. The use of fuzzy logic enhanced the model’s interpretability through membership degrees, and the model achieved a higher performance of 96.09% accuracy compared to when fuzzy logic was not used. However, additional research is needed regarding emotional changes over time. Chen [22] proposed a Fuzzy Deep Neural Network (FDNN) to improve a robot’s ability to recognize human emotions and understand emotional intentions. The input data was clustered using the fuzzy c-means algorithm. The databases used include facial expression-based emotion data (eNTERFACE), audio-based emotion data (SEMAINE), and multimodal emotion recognition data (AVEC 2014). FDNN uses Sparse Autoencoders (SAEs) to extract features from high-dimensional input data, and the fuzzy layer fuzzifies the input features using Gaussian functions. Multiple membership functions are applied to each input, and IF-THEN fuzzy rules are constructed. The final output is derived using the softmax function. Performance evaluation showed that the FDNN outperformed existing models in terms of accuracy, making it suitable for real-world applications in mobile robots. Ahmadzadeh Nobari Azar [23] proposed an EEG signal-based emotion classification system using CNN and fuzzy logic. The DEAP database was used, containing EEG recordings from 36 participants while watching videos designed to evoke specific emotions. Features were extracted using FFT and used as input to the model. Since CNN alone cannot optimize the extracted features from time-series data, fuzzy logic was incorporated to enhance the features. The proposed model extracts EEG signal features through convolutional layers, and in the fuzzy layer, feature vectors are transformed into fuzzy space. Experimental results showed that adding fuzzy logic improved the accuracy by more than 9% compared to using conventional CNN. Baradaran [24] proposed an EEG-based emotion recognition model using Type-2 fuzzy systems and CNN. CNN was used to extract features from EEG signals after preprocessing, and a Type-2 fuzzy activation function was used to determine emotion classes. The DEAP database was also used, and the experimental results showed a high accuracy of 98.2% in distinguishing between positive and negative emotions. However, the integration of Type-2 fuzzy logic with deep CNNs increases computational complexity, which may make real-time emotion recognition difficult. Vega [25] proposed EEG-TCFNet for building a brain–computer interface (BCI) for smart home interaction. EEG-TCFNet is a model that combines EEG-Net with Temporal Convolutional Network (TCN). The model consists of CNN, TCN, LSTM, Fuzzy Neural Block (FNB), and a softmax layer. The first convolutional layer filters frequencies, while the second convolutional layer learns spatial filtering. In the third convolutional layer, feature maps are individually summarized and then combined. The LSTM layer further learns temporal information, and FNB is used to extract and integrate fuzzy features that are robust to noise. Comparing the model’s performance with LeNet, LeNet-FNB, TCNet, TCNet-FNB, and TCNet-LSTM, the model achieved the highest accuracy of 98.6% for subject S01. Overall, the model outperformed existing studies for eight out of nine subjects. However, reducing the four-dimensional emotional space to two dimensions results in a loss of emotional complexity.
Deep learning has demonstrated excellent performance in analyzing and learning from large-scale data; however, the learning process is opaque, which limits the interpretability of the data. Fuzzy logic, on the other hand, excels in handling ambiguous data and provides interpretability, but it faces challenges in processing large-scale data. Therefore, recent research has been actively focused on developing models that combine the learning capability of deep learning with the interpretability of fuzzy logic. Various studies have shown that integrating fuzzy logic concepts into deep learning not only enhances interpretability, but also improves performance [20,21,22]. One common approach in deep learning models involves converting features of speech data into image-like forms for input. However, this method suffers from the problem of information loss during the feature extraction process. To address this, the SincNet model is used in this study, enabling the model to learn directly from raw speech signals. SincNet, which uses Sinc filters in the first layer of a conventional CNN model, updates the low-pass and high-pass cutoff frequencies of the Sinc filters as learnable parameters during training, allowing the model to extract important frequency bands. In contrast to CNNs, where all filter parameters are learned in the convolutional layers, SincNet uses only two learnable parameters in the Sinc layer, allowing it to learn with fewer parameters. However, to learn the non-linear characteristics of speech data, many parameters are still used in the layers following the Sinc filter. Therefore, this paper proposes a model that integrates ANFIS layers instead of the multiple fully connected layers typically found in SincNet. This approach allows the model to learn non-linear features with fewer parameters and solves the black-box problem of deep learning by making the speaker recognition inference process interpretable. ANFIS uses fuzzy IF-THEN rules, enabling qualitative analysis through human-like reasoning. The proposed model aims to achieve accurate speaker recognition by learning features directly from speech signals recorded in a robotic environment using the SincNet model, followed by speaker classification through the ANFIS layer.
3. Speaker Recognition Model Based on SincNet-ANFIS
The SincNet-ANFIS model uses raw speech signals as input to extract features and classify speakers. The speech waveform input to the model has its features extracted through Sinc filters, and speaker classification is performed using ANFIS. Finally, the final output is computed through a softmax function.
3.1. SincNet
SincNet is a model that uses Sinc filters in the first layer of a CNN [11]. As shown in Figure 1, SincNet consists of a Sinc layer, two convolutional blocks, three fully connected blocks, and a softmax layer. Each convolutional block is composed of a convolutional layer, a batch normalization layer, and a max pooling layer, while each fully connected block consists of a fully connected layer and a batch normalization layer. After preprocessing, the raw speech data is convolved in a sliding manner through a Sinc filter. This process allows SincNet to directly learn features from raw speech waveforms. The Sinc filter, which passes specific frequency bands, highlights certain frequency ranges in the raw speech waveform. Once a raw speech signal is input, a feature map is generated by stacking the outputs corresponding to the number of filters. The convolutional layers then learn temporal features within the emphasized frequency bands using convolutional filters. After that, the Leaky ReLU activation function is applied to two convolutional blocks and three FC blocks to enable the model to learn diverse and complex features. Finally, the softmax function is used to classify the final speaker classes.
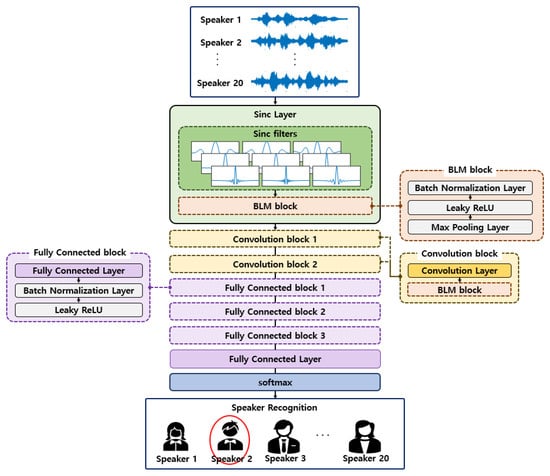
Figure 1.
Structure of SincNet.
Both CNNs and SincNet generate initial filters when speech data () is input, and optimize these filters through the training process. In CNNs, the convolutional layer extracts features through the convolution operation shown in Equation (1). The convolutional filter is represented as an array of weights rather than a specific mathematical shape, as illustrated in Figure 2a. Since it is difficult to specify the exact frequency bands to be extracted, and because the weights and biases of each filter must be learned to update the filters, CNNs require a large number of parameters. In contrast, the Sinc filter functions as a band-pass filter, allowing only specific frequency bands to pass through. As described in Equation (2), it is calculated by subtracting the high-pass cutoff frequency () from the low-pass cutoff frequency (), thus allowing only the frequency band between these two values to pass through. Each band-pass filter is computed based on the Sinc function, which is defined in Equation (3). The parameters and are set to be learnable, with the filter being initialized with specified values and updated during the training process. Since only these two parameters are learned, the Sinc filter uses significantly fewer parameters compared to convolutional filters. The Sinc filter, as shown in Figure 2b, has a clearly defined frequency band to be extracted.
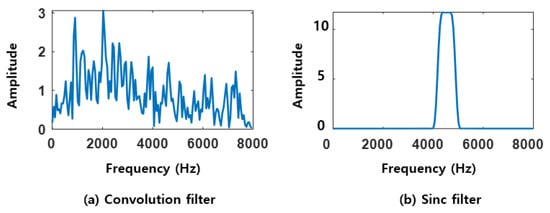
Figure 2.
Visualization of convolution filter and Sinc filter.
Side lobes refer to signals that occur outside the desired frequency band when extracting components from a specific frequency band. Since side lobes are not ideal for the desired frequency band, minimizing them can improve the performance of the filter [26]. To pass the important frequency components and suppress unnecessary ones, a Hamming window was applied to the Sinc filter before performing the convolution operation. The Hamming window is defined by Equation (4) according to [27]. Here, is a specific index, is the length of the window, and is the weight for each index. The function with the applied Hamming window is given by Equation (5).
In this paper, 90 Sinc filters with a length of 150 samples each were generated. The parameters and were set to be learnable, and during training, these two weights are optimized. The layer using Sinc filters requires fewer parameters to be learned compared to a conventional convolutional layer. A typical convolutional layer with filters of length has learnable parameters, whereas the Sinc layer requires only learnable parameters. For a layer consisting of 90 filters of length 150, a conventional convolutional layer would use parameters. However, by using Sinc filters, this paper utilizes only parameters. Furthermore, in contrast to CNNs, where the number of parameters scales with the filter length, SincNet’s parameter count remains unchanged regardless of the length of the Sinc filters. By using fewer parameters, SincNet trains faster than conventional convolutional neural networks while achieving similar performance to existing models.
The filter update process is as follows. When speech data is input into the SincNet model, initial parameter values are used for computation, and a Sinc filter is generated by applying a Hamming window. The input speech data and Sinc filter undergo a convolution operation to generate the output feature map. The resulting features pass through subsequent layers after the Sinc filter, and the two parameter values that define the filter are updated based on the loss function of the output. When the next speech data is input, the filter is computed using the updated parameter values.
3.2. ANFIS
A fuzzy control system is a type of system that utilizes fuzzy theory to convert expert knowledge and experience into linguistic rules for control purposes. This approach effectively represents human-like ambiguous reasoning and offers the advantage of quantifying expert knowledge. While fuzzy systems provide interpretable inference processes, they are limited in terms of learning capabilities. In contrast, artificial neural networks (ANNs) are capable of learning data patterns to predict outcomes for new input data, and they exhibit excellent performance when handling large-scale databases. However, the internal mechanisms of the learning process are often opaque, leading to the so-called “black-box” problem.
The limitations of fuzzy systems and neural networks can be complementarily addressed through hybrid models that combine both approaches. Numerous studies have been conducted based on this idea. In this paper, we employ one such hybrid model, the adaptive neuro-fuzzy inference system (ANFIS), to conduct our experiments. ANFIS, proposed by Jang [28], is a hybrid model that integrates the powerful learning capabilities of neural networks with the rule-based reasoning of fuzzy systems. It is effective in solving non-linear and complex problems by adjusting the parameters of the premise part through the backpropagation algorithm. As illustrated in Figure 3, ANFIS consists of five layers and is designed to minimize the error between the predicted output and the target output using input–output training data. In particular, the fourth layer of Figure 3 fuses current information with initial knowledge to achieve a more robust learning performance.
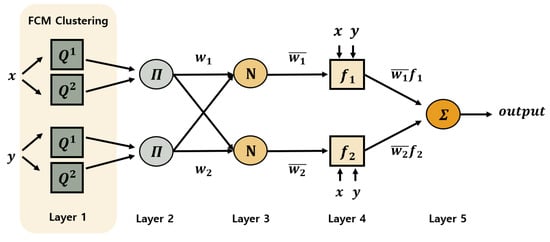
Figure 3.
Structure of ANFIS.
The first layer is the fuzzification layer, which generates membership degrees in linguistic terms and outputs membership values as defined in Equation (6). In this study, the fuzzy c-means (FCM) clustering method [29] is used to partition the input data into multiple fuzzy cluster sets.
Here, and denote the input to cluster , and represents the fuzzy set associated with cluster . The functions and are the membership functions, and Gaussian membership functions are used to calculate the membership degrees.
The second layer is the rule layer, which outputs the weight of each fuzzy rule by multiplying the membership values obtained from the first layer, as shown in Equation (7). This weight represents the firing strength of the corresponding fuzzy rule.
The third layer is the normalization layer, which normalizes the firing strengths of all the rules, as described in Equation (8).
The fourth layer is the defuzzification layer, which calculates the output by multiplying the normalized firing strength by the output function of the consequent part, as shown in Equation (9).
Here, represent the consequent parameters, which are optimized through the learning process to minimize error.
The fifth layer computes the final output using a weighted average method based on the inputs from the previous layer, as defined in Equation (10).
3.3. SincNet-ANFIS
SincNet reduces the number of parameters by using Sinc filters instead of convolutional filters. However, this reduction accounts for only a portion of the model’s total parameters, and a significant number of parameters are still required. In the proposed SincNet-ANFIS model, the three fully connected (FC) layers of the original SincNet are replaced with ANFIS to address the limitations of the FC layers. While FC layers demand a large number of parameters and substantial computational resources during training, ANFIS can effectively learn the non-linear characteristics of speech with fewer parameters and provides better interpretability. In this paper, ANFIS is used instead of the three fully connected blocks, as shown in Figure 4.
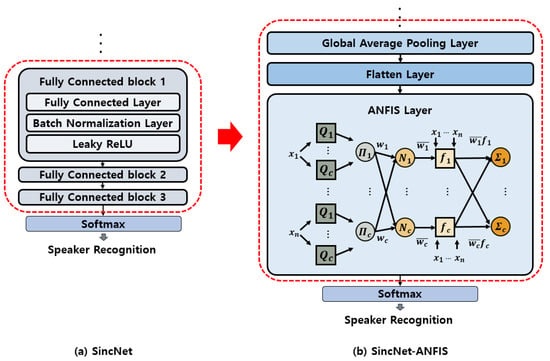
Figure 4.
Comparison of classification layers of SincNet and SincNet-ANFIS.
Figure 5 illustrates the proposed SincNet-ANFIS model for speaker recognition in a robot environment. Raw speech signals are preprocessed and segmented into 200 ms frames, which are then used as input to the model. The speech signal passes through 90 Sinc filters and a convolution operation, followed by two convolutional blocks. The first convolutional layer uses 60 filters, while the second uses eight filters to match the dimensionality required for input to the ANFIS layer. Each block employs a Leaky ReLU activation function to introduce non-linearity. The resulting speech features, with eight channels after the second convolutional layer, are converted into a one-dimensional vector using a global average pooling layer followed by a flatten layer. In the ANFIS layer, features of size [1 × 8] are input, and the initial parameters of the Gaussian membership functions are set using the FCM clustering algorithm. Each input data can belong to multiple clusters, and the number of clusters is set to eight based on experiments. In the first layer of ANFIS, the eight inputs generate membership values for eight rules through the membership functions. In the second layer, the membership values for each input are multiplied by the corresponding rules, generating the firing strength for the eight rules. These values are normalized in the third layer. In the fourth layer, the conclusion parameters are used to calculate the degree of contribution of each rule for 20 speakers based on the inputs. After that, in the fifth layer, the scores for each rule are summed to produce the final score for the 20 speakers. Finally, the softmax layer outputs the speaker class for the input data, and the parameters of the Sinc filter and ANFIS are updated based on the loss value calculation.
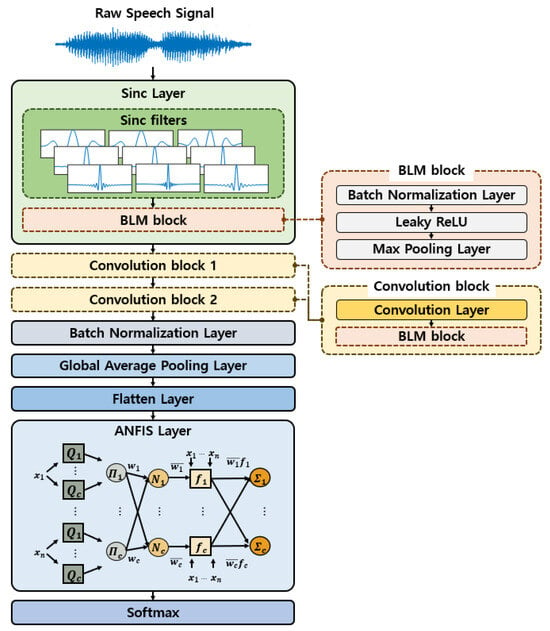
Figure 5.
Structure of SincNet-ANFIS.
In the proposed framework, SincNet is employed for efficient feature extraction from raw speech signals, and the extracted representations are directly passed to the ANFIS layer for classification. This sequential integration allows the complementary strengths of both components to be fully utilized: while SincNet reduces parameter complexity and preserves essential frequency information, ANFIS effectively captures non-linear patterns and improves interpretability through fuzzy rules.
4. Experiments and Results
4.1. Database
The database used in this study was obtained from the Electronics and Telecommunications Research Institute (ETRI) and is employed for speaker recognition [30]. The database includes 20 speakers, consisting of 10 male and 10 female speakers, and was recorded using a robotic Weber as shown in Figure 6. Each speech sample is a single-channel, 16-bit Wav file with a sampling frequency of 16 kHz. The recordings were made in a real-home environment testbed. The database contains background noise, such as the sound of the robot moving and TV noise, with a signal-to-noise ratio (SNR) greater than 15 dB, ensuring that the human speech is louder than the surrounding noise.

Figure 6.
Robot Weber.
Considering that the distance between the robot and the speaker is not always constant, the speech data were collected at distances of 1 m, 2 m, and 3 m. The training database contains 20 sentences from each of the 20 speakers at different distances, while the test database includes 10 sentences from each distance. Each sentence is approximately 2 s long and represents everyday conversational phrases. Table 1 shows the total number of data samples and speech duration.

Table 1.
Number of databases and time.
4.2. Data Preprocessing
The raw speech waveform is divided into segments of equal length through a preprocessing step and used as input to the model. The speech signal is divided into 0.2 s segments, with an overlap of 0.04 s to minimize information loss at the segmentation boundaries. The sampling rate is set to 16,000 Hz, and the data preprocessing is conducted in two ways: one where silent segments are not removed and one where the silent segments at the beginning and end of the speech are removed. In the case of removing silence, the start and end indices of the speech segments are detected, and only the speech portions are extracted and segmented. Table 2 shows the number of segmented data samples after preprocessing. The number of segments varies according to the length of the speech data. When silence is not removed, the data is divided into 15,800 training samples and 8464 test samples. When silence is removed, the data is divided into 11,984 training samples and 6838 test samples.
Table 2.
Number of database.
4.3. Experimental Setup
The hardware and software used in the experiments are shown in Table 3. The hardware includes an NVIDIA GeForce RTX 3060 Ti, 64 GB RAM, and an Intel® Core™ i7-12700F processor, while the software includes Windows 11 and MATLAB R2024b.
Table 3.
Experimental setup.
To ensure that all experiments were conducted under identical conditions, the hyperparameters are summarized in Table 4. Training was performed using the Adam (Adaptive Moment Estimation) optimizer with a mini-batch size of 256. The hyperparameters, including the length and number of Sinc filters as well as other training parameters, were determined based on the findings of our previous work [12], where extensive experiments were conducted to identify suitable configurations for speaker recognition in robotic environments. For consistency and fair comparison, the same parameter settings were applied in this study, as they had already demonstrated stable convergence and high recognition accuracy.
Table 4.
Training hyperparameters.
4.4. Experimental Results
To evaluate the speaker recognition performance of the proposed SincNet-ANFIS model, three baseline models—CNN, CNN-ANFIS, and SincNet [12]—were selected for comparison. All experiments were conducted using a speaker recognition database for robotics, which includes speech samples from 20 speakers. To assess the impact of preprocessing, experiments were carried out under two conditions: with and without silence removal. The primary metric used for this comparison was accuracy, and the results are presented in Table 5. Among the four models, three showed improved accuracy when silence segments were removed, indicating that eliminating silent portions from speech signals enhances the overall data quality.
Table 5.
Accuracy comparison with and without silent interval removal.
In the ANFIS layer, it is known that an excessive number of fuzzy rules may result in meaningless rules and overfitting, whereas too few rules may lead to poor interpretability and reduced classification performance. Therefore, the number of fuzzy rules was empirically determined. As shown in Table 6, the best performance of SincNet-ANFIS was achieved when eight fuzzy rules were used.
Table 6.
Accuracy of SincNet-ANFIS based on the number of rules.
Table 7 shows the accuracy of the four models under different speaker-to-microphone distances. Interestingly, better performance was observed at 2 m and 3 m compared to 1 m. This result suggests that background noise was relatively lower at longer distances, which helped improve recognition accuracy.
Table 7.
Accuracy of speaker recognition model by distance.
The performance of the models was evaluated using accuracy, precision, recall, and F1-score. Accuracy is defined as the ratio of correctly predicted samples to the total number of predictions. Precision indicates the proportion of true positives among all positive predictions. Recall refers to the proportion of true positives among all actual positive samples. F1-score is the harmonic mean of precision and recall. The detailed performance metrics are summarized in Table 8.
Table 8.
Model performance comparison.
Additionally, confusion matrices were used to visualize classification performance. A confusion matrix compares the actual class labels with the predicted class labels. The diagonal elements represent correctly classified instances. Figure 7, Figure 8, Figure 9 and Figure 10 illustrate the confusion matrices for each model. The proposed SincNet-ANFIS model demonstrates the highest values across all evaluation metrics, confirming its superior performance. These results also suggest that incorporating ANFIS into conventional deep learning models leads to performance improvements. Moreover, integrating the ANFIS layer into SincNet significantly reduced model complexity. The total number of trainable parameters decreased from 4,846,600 (SincNet alone) to 31,156 (SincNet-ANFIS), and the training time was reduced from approximately 10 h to 3 h and 20 min.
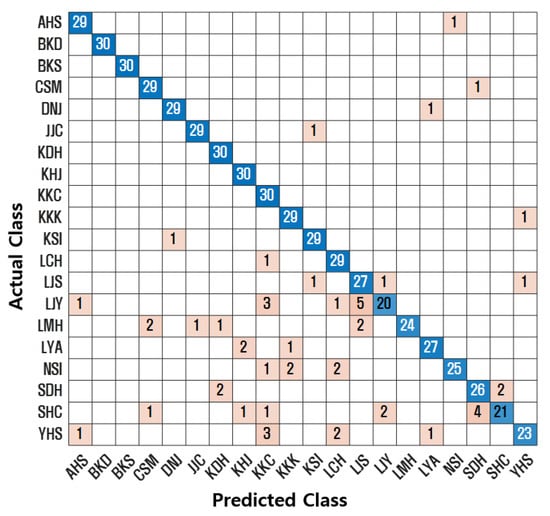
Figure 7.
Confusion matrix for CNN.
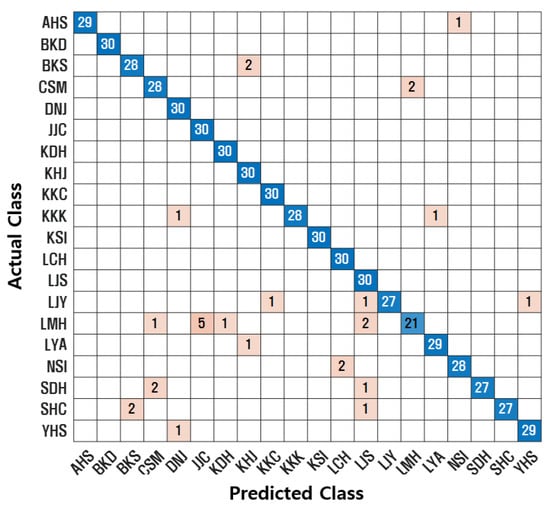
Figure 8.
Confusion matrix for CNN-ANFIS.
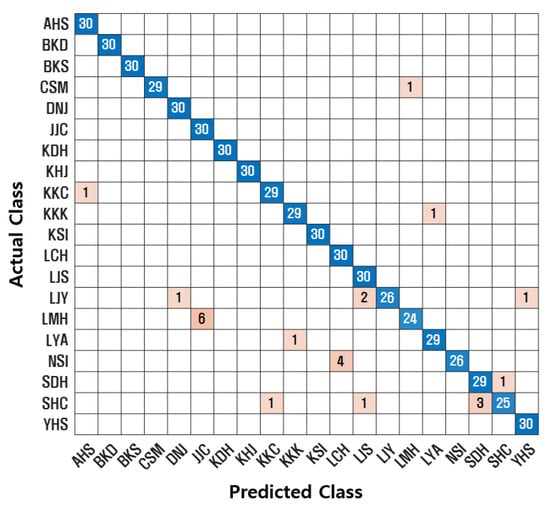
Figure 9.
Confusion matrix for SincNet.
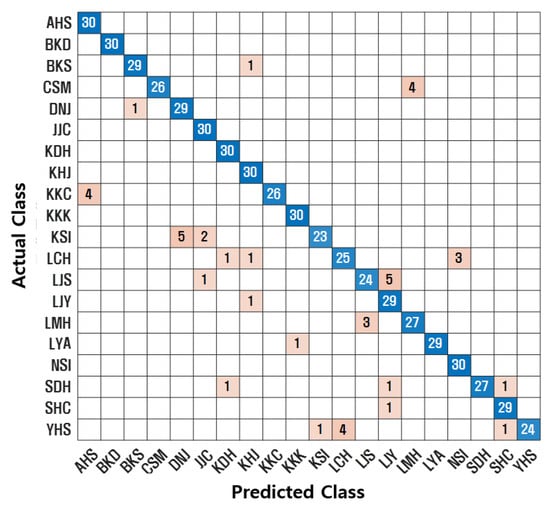
Figure 10.
Confusion matrix for SincNet-ANFIS.
Figure 11 and Figure 12 show the frequency domain visualizations of 9 out of the 90 filters learned by the CNN and SincNet-ANFIS models, respectively. As can be observed, the convolutional filters of the trained CNN model do not clearly reveal the target frequency bands, making them less interpretable. In contrast, the filters from the SincNet-ANFIS model exhibit well-defined and interpretable frequency bands, clearly indicating the dominant frequency components extracted by the model.
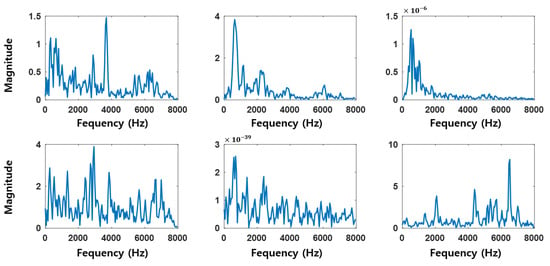
Figure 11.
Convolutional filters of the trained CNN.
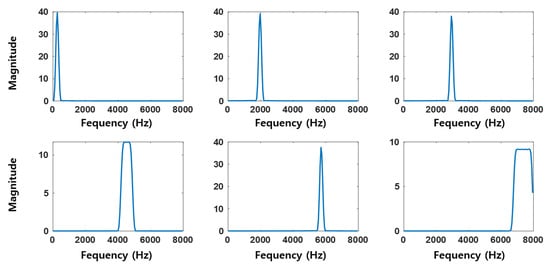
Figure 12.
Sinc filters of the trained SincNet-ANFIS.
Each input speech signal is processed through 90 filters, resulting in 90 filtered feature outputs via convolution operations. Figure 13 and Figure 14 represent the complete set of 90 outputs visualized as a single feature map. In Figure 13, the feature map generated by the CNN convolutional filters shows widespread activation across all filters, resembling noise. In contrast, Figure 14 derived from the Sinc filters shows distinct and concentrated activations in specific filters. This indicates that the SincNet-ANFIS model effectively captures important frequency bands, highlighting its capability to extract more interpretable and relevant features from the input signal.
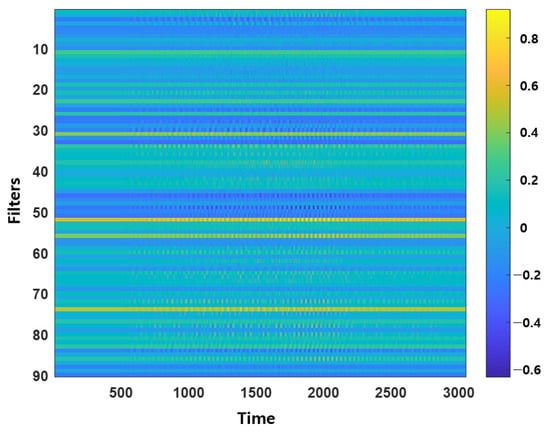
Figure 13.
Feature map through the convolutional filter.
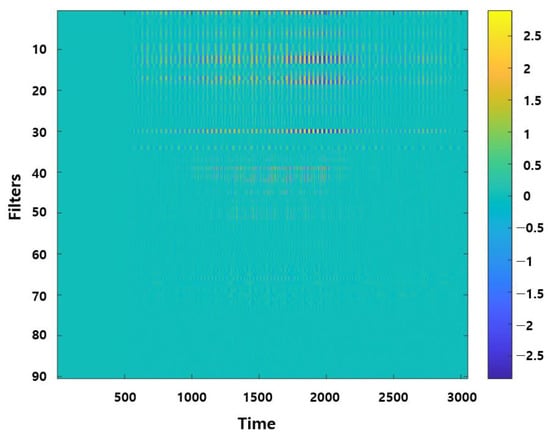
Figure 14.
Feature map through the Sinc filter.
The learnable parameters—the low-cutoff and high-cutoff frequencies—are updated during the training process. As the parameters are optimized, the starting frequencies of the 90 Sinc filters are adjusted accordingly, as illustrated in Figure 15. It can be observed that the filters, which were initially generated uniformly, are updated through training to focus on extracting more informative and task-relevant frequency bands.
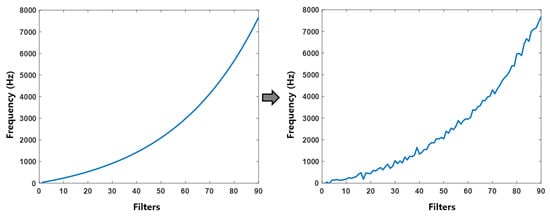
Figure 15.
Change in the starting frequency of Sinc filters.
5. Discussion
In this section, we discuss the main research findings and their implications for the proposed SincNet-ANFIS in the context of speaker recognition for home robot environments.
The experimental results show that the proposed model consistently outperforms conventional CNN, CNN-ANFIS, and SincNet models in terms of accuracy, precision, recall, and F1-score. In particular, by replacing multiple fully connected layers with ANFIS, the number of parameters was reduced by nearly fifteen-fold while achieving comparable or superior performance. This not only demonstrates the computational efficiency of the approach but also highlights improved interpretability, as the fuzzy rules provide transparent reasoning for classification outcomes.
Recent studies in speaker recognition (e.g., ECAPA-TDNN [31], RawNet3 [15], and wav2vec-based models [32]) have achieved remarkable performance on large-scale benchmark datasets. However, these methods are typically trained and evaluated in controlled environments or on publicly available datasets. In contrast, the customized dataset employed in this study reflects background noise specific to real home environments, such as TV sound and robot operation noise. The proposed model also achieved high recognition rates under varying speaker-to-robot distances of 1 m, 2 m, and 3 m, with the best performance observed at longer distances where the impact of near-field noise interference is reduced. These results demonstrate that the proposed framework can deliver robust performance in noisy, real-world human–robot interaction (HRI) scenarios.
Recent studies that integrate deep learning with fuzzy inference systems [33,34] indicate growing interest in improving interpretability and robustness. This study contributes to this trend and is distinctive in that it explicitly applies such a hybrid model to a real-world home robot scenario. Despite its strong performance, this study has certain limitations. The dataset comprises 20 Korean speakers, which may not fully capture the variability of larger and more diverse populations. While this is reasonable for home-centered applications, future research should validate generalization on larger, multilingual datasets. In addition, further work is needed to explore rule optimization techniques to enhance both efficiency and accuracy.
In summary, the proposed SincNet-ANFIS framework presents a promising approach for achieving reliable and interpretable speaker recognition in intelligent home service robots. By maintaining high accuracy and low computational cost even in realistic noisy environments, this work contributes to the development of practical HRI systems capable of delivering personalized and context-aware services.
6. Conclusions
In this paper, we propose a SincNet-ANFIS fusion model for speaker recognition and compare its performance with other models. The method of converting features extracted from speech data into image-like forms for input into deep learning models may result in the loss or distortion of important information during the feature extraction process. To address this issue, SincNet is employed to directly train and extract features from raw speech waveforms, thereby eliminating the need for separate feature extraction procedures. SincNet trains with fewer parameters in the Sinc layer, but many parameters are still required in subsequent layers to learn non-linear features. To overcome this challenge, we used ANFIS layers instead of multiple fully connected layers to effectively train non-linear features. By fusion of ANFIS, the model was able to handle ambiguous data and achieve high accuracy with fewer parameters. In typical home environments where robots are used, various types of noise may be present. Therefore, a testbed considering real home environment noise was established, and the database acquired from this setup was used. The database used in the experiments is a Korean speaker recognition database, consisting of speech recordings from 20 speakers using sentences in everyday life. The proposed SincNet-ANFIS model achieved the highest accuracy of 96%, outperforming three other models: CNN, CNN-ANFIS, and SincNet. The number of parameters was reduced by approximately 15 times compared to using only SincNet, and the training time was shortened by 6 h and 40 min when ANFIS was incorporated. Through this study, we confirmed that the proposed model can accurately recognize speakers even in noisy environments. Furthermore, the straightforward integration of SincNet and ANFIS ensures a balance between simplicity and performance. By avoiding overly complex fusion mechanisms, the model remains computationally efficient while still achieving superior accuracy and interpretability, making it well suited for intelligent home service robots operating under resource constraints. In future studies, we will focus on selecting rules to further improve speaker recognition accuracy.
Author Contributions
Conceptualization, S.-H.K. and K.-C.K.; methodology, S.-H.K., T.-W.K. and K.-C.K.; software, S.-H.K. and K.-C.K.; validation, S.-H.K., T.-W.K. and K.-C.K.; formal analysis, S.-H.K. and K.-C.K.; investigation, S.-H.K., T.-W.K. and K.-C.K.; resources, S.-H.K. and K.-C.K.; data curation, S.-H.K., T.-W.K. and K.-C.K.; writing—original draft preparation, S.-H.K.; writing—review and editing, K.-C.K.; visualization, S.-H.K. and K.-C.K.; supervision, K.-C.K.; project administration, K.-C.K.; funding acquisition, K.-C.K. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by a research fund from Chosun University, 2025.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, S.-A.; Liu, Y.-Y.; Chen, Y.-C.; Feng, H.-M.; Shen, P.-K.; Wu, Y.-C. Voice interaction recognition design in real-life scenario mobile robot applications. Appl. Sci. 2023, 13, 3359. [Google Scholar] [CrossRef]
- Artificial Intelligence Times. Personal Service Robots Armed with Artificial Intelligence. Global Market Expected to Reach 56 Trillion KRW by 2030. Available online: https://www.aitimes.kr/news/articleView.html?idxno=18582 (accessed on 6 December 2020).
- HouseHold Robot Market Outlook (2023 to 2033). (n.d.). Fact.MR. Available online: https://www.factmr.com/report/household-robot-market (accessed on 26 July 2025).
- Wang, W.; Seraj, F.; Meratnia, N.; Havinga, P.J. Speaker counting model based on transfer learning from SincNet bottleneck layer. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications (PerCom), Austin, TX, USA, 23–27 March 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Kozhirbayev, Z.; Erol, B.A.; Sharipbay, A.; Jamshidi, M. Speaker recognition for robotic control via an iot device. In Proceedings of the 2018 World Automation Congress (WAC), Stevenson, WA, USA, 3–6 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Ding, I.-J.; Shi, J.-Y. Kinect microphone array-based speech and speaker recognition for the exhibition control of humanoid robots. Comput. Electr. Eng. 2017, 62, 719–729. [Google Scholar] [CrossRef]
- Tuasikal, D.A.A.; Fakhrurroja, H.; Machbub, C. Voice activation using speaker recognition for controlling humanoid robot. In Proceedings of the 2018 IEEE 8th International Conference on System Engineering and Technology (ICSET), Bandung, Indonesia, 15–16 October 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Saakshara, K.; Pranathi, K.; Gomathi, R.; Sivasangari, A.; Ajitha, P.; Anandhi, T. Speaker recognition system using Gaussian mixture model. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Warohma, A.M.; Hindersah, H.; Lestari, D.P. Speaker Recognition Using MobileNetV3 for Voice-Based Robot Navigation. In Proceedings of the 2024 11th International Conference on Advanced Informatics: Concept, Theory and Application (ICAICTA), Singapore, 28–30 September 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Kinnunen, T.; Li, H. An overview of text-independent speaker recognition: From features to supervectors. Speech Commun. 2010, 52, 12–40. [Google Scholar] [CrossRef]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Kim, S.-H.; Jo, A.-H.; Kwak, K.-C. SincNet-Based Speaker Identification for Robotic Environments with Varying Human–Robot Interaction Distance. Electronics 2024, 13, 4836. [Google Scholar] [CrossRef]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with rawnet2. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Jung, J.-W.; Heo, H.-S.; Kim, J.-H.; Shim, H.-J.; Yu, H.-J. Rawnet: Advanced end-to-end deep neural network using raw waveforms for text-independent speaker verification. arXiv 2019, arXiv:1904.08104. [Google Scholar]
- Jung, J.-W.; Kim, Y.; Heo, H.-S.; Lee, B.-J.; Kwon, Y.; Chung, J.S. Pushing the limits of raw waveform speaker recognition. arXiv 2022, arXiv:2203.08488. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Ton-That, A.H.; Cao, N.T. Speech emotion recognition using a fuzzy approach. J. Intell. Fuzzy Syst. 2019, 36, 1587–1597. [Google Scholar]
- Savchenko, A.V.; Savchenko, L.V. Savchenko. Towards the creation of reliable voice control system based on a fuzzy approach. Pattern Recognit. Lett. 2015, 65, 145–151. [Google Scholar] [CrossRef]
- Shahnawazuddin, S.; Adiga, N.; Sai, B.T.; Ahmad, W.; Kathania, H.K. Developing speaker independent ASR system using limited data through prosody modification based on fuzzy classification of spectral bins. Digit. Signal Process. 2019, 93, 34–42. [Google Scholar] [CrossRef]
- Latifi, F.; Hosseini, R.; Sharifi, A. Fuzzy deep learning for modeling uncertainty in character recognition using EEG signals. Appl. Soft Comput. 2024, 159, 111575. [Google Scholar] [CrossRef]
- Asif, M.; Ali, N.; Mishra, S.; Dandawate, A.; Tiwary, U.S. Deep fuzzy framework for emotion recognition using eeg signals and emotion representation in type-2 fuzzy vad space. arXiv 2024, arXiv:2401.07892. [Google Scholar] [CrossRef]
- Chen, L.; Su, W.; Wu, M.; Pedrycz, W.; Hirota, K. A fuzzy deep neural network with sparse autoencoder for emotional intention understanding in human–robot interaction. IEEE Trans. Fuzzy Syst. 2020, 28, 1252–1264. [Google Scholar] [CrossRef]
- Ahmadzadeh Nobari Azar, N.; Cavus, N.; Esmaili, P.; Sekeroglu, B.; Aşır, S. Detecting emotions through EEG signals based on modified convolutional fuzzy neural network. Sci. Rep. 2024, 14, 10371. [Google Scholar] [CrossRef]
- Baradaran, F.; Farzan, A.; Danishvar, S.; Sheykhivand, S. Automatic emotion recognition from EEG signals using a combination of type-2 fuzzy and deep convolutional networks. Electronics 2023, 12, 2216. [Google Scholar] [CrossRef]
- Vega, C.F.; Quevedo, J.; Escandón, E.; Kiani, M.; Ding, W.; Andreu-Perez, J. Fuzzy temporal convolutional neural networks in P300-based Brain–computer interface for smart home interaction. Appl. Soft Comput. 2022, 117, 108359. [Google Scholar] [CrossRef]
- Harris, F.J. On the use of windows for harmonic analysis with the discrete Fourier transform. Proc. IEEE 2005, 66, 51–83. [Google Scholar] [CrossRef]
- Charbit, M. (Ed.) Digital Signal and Image Processing Using Matlab; John Wiley & Sons: Hoboken, NJ, USA, 2010; Volume 666. [Google Scholar]
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Kwak, K.C.; Kim, H.J.; Bae, K.S.; Yoon, H.S. Speaker identification and verification for intelligent service robots. In Proceedings of the International Conference on Artifical Intelligence (ICAI), Las Vegas, NV, USA, 25–28 June 2007. [Google Scholar]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar] [CrossRef]
- Vaessen, N.; Van Leeuwen, D.A. Fine-tuning wav2vec2 for speaker recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Tanveer, M.; Sajid, M.; Akhtar, M.; Quadir, A.; Goel, T.; Aimen, A.; Mitra, S.; Zhang, Y.-D.; Lin, C.T.; Del Ser, J. Fuzzy deep learning for the diagnosis of Alzheimer's disease: Approaches and challenges. IEEE Trans. Fuzzy Syst. 2024, 32, 5477–5492. [Google Scholar] [CrossRef]
- Zheng, Y.; Xu, Z.; Wang, X. The fusion of deep learning and fuzzy systems: A state-of-the-art survey. IEEE Trans. Fuzzy Syst. 2021, 30, 2783–2799. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).