Abstract
The rapid growth of user-generated content on social media platforms has escalated both the spread of harmful speech and the emergence of positive discourse, such as hope speech messages that offer encouragement, support, and optimism to individuals and communities facing challenges. While significant research has been conducted on detecting hate speech and toxicity, the detection of hope speech remains underexplored. In this paper, we combine several advanced deep learning architectures for hope speech detection in high-resource languages such as English. Our approach can effectively classify social media comments as either hopeful or non-hopeful speech. Experimental evaluations on the publicly available HopeEDI dataset demonstrate that our deep learning model consistently outperforms individual models, achieving weighted average F1-scores of 0.94 for the English subdataset. The results validate the effectiveness of combining complementary models to enhance performance, especially in high-resource settings.
1. Introduction
The unprecedented growth of social media has revolutionized how individuals express themselves, connect with others, and access emotional support [1]. With billions of users generating enormous volumes of content daily on platforms like YouTube, Facebook, and Twitter, these platforms have become powerful arenas for both expression and influence [2,3]. While promoting inclusivity and open discussions, this openness has also led to an increase in toxic content like hate speech, cyberbullying, and discrimination. To combat these issues, advancements in NLP are being utilized to automatically detect and reduce harmful content online.
While social media is often criticized, it plays a crucial role in fostering encouragement, compassion, and emotional strength. This positive interaction is referred to as “hope speech,” which focuses on optimism, support, and solidarity. Hope speech plays an essential role in promoting psychological well-being, countering online toxicity, and building inclusive digital communities [4]. Nevertheless, unlike hate speech detection, which has garnered substantial scholarly attention, the identification of hope speech remains underexplored [5].
Detecting hope speech is vital for promoting positive narratives online and for supporting mental health interventions [6]. Automatic identification and amplification of hope speech can not only counterbalance negative discourse but also guide platforms in surfacing content that uplifts and supports users [7]. Although current studies have explored machine learning and deep learning approaches for detecting hope speech, there remains considerable room for improvement in terms of classification accuracy, even in resource-rich languages such as English. Current methods often fail to capture subtle linguistic and contextual details effectively, highlighting a clear need for improved models specifically designed for high-resource languages, such as English.
To address the existing gap in hope speech detection, this study proposes a robust ensemble framework that integrates both conventional deep learning methods and cutting-edge transformer-based language models. Specifically, the ensemble utilizes LSTM networks, augmented with GloVe word embeddings, to capture sequential dependencies and semantic regularities in textual data. Also, this approach integrates four advanced transformer-based architectures: DistilBERT, ELECTRA, DeBERTa, and MiniLM. DistilBERT is a resource-efficient alternative to BERT. ELECTRA uses a replaced-token detection method that enhances speed and accuracy compared to BERT. DeBERTa enhances representation learning with disentangled attention mechanisms and relative position encodings, resulting in improved performance on benchmark datasets. MiniLM, with its deep self-attention distillation approach, delivers a lightweight model that retains high accuracy while minimizing inference latency. By integrating these heterogeneous models, the proposed ensemble aims to exploit complementary strengths—balancing depth, efficiency, and linguistic variations—to achieve high generalizability in detecting hope speech across high-resource languages. The effectiveness of this ensemble is evaluated using the HopeEDI dataset, which comprises English-language YouTube comments labeled as either hope speech or non-hope speech, thereby providing a reliable assessment of model performance on real user-generated content.
While the proposed framework builds on established transformer architectures, its uniqueness lies in the deliberate integration of various lightweight encoders with a calibrated stacking mechanism designed explicitly for hope speech detection. Unlike generic stacking approaches, the meta-learner in our model is optimized to weight complementary error profiles across sequential (Bi-LSTM) and contextual (transformer) representations, improving minority-class recall where single models and simple majority-voting ensembles typically underperform. This method systematically evaluates model diversity and calibrated fusion in a socially sensitive, underexplored task, demonstrating how lightweight architectures can achieve near-state-of-the-art results while enabling real-time inference. These findings extend beyond implementation, offering a transferable methodology for combining small-footprint models in other imbalanced-text classification problems. Many hope speech detection methods rely on single-model transformers or majority-vote ensembles. Still, they often miss the importance of model diversity and precise calibration of strengths, which limits their accuracy and scalability. To address these limitations, our work introduces a stacked transformer ensemble approach that explicitly enhances detection performance through three distinct contributions:
- Model diversity, by integrating heterogeneous models (sequential Bi-LSTM with GloVe embeddings and transformer-based DistilBERT, ELECTRA, DeBERTa, and MiniLM), capturing complementary linguistic signals;
- Calibrated fusion, achieved by employing logistic regression stacking to learn optimal reliability weights rather than majority voting, significantly improving minority-class (hope speech) recall; and
- Scalable inference, leveraging lightweight, distilled transformer models combined with a computationally efficient meta-classifier to ensure real-time applicability.
2. Related Work
The increasing volume of user-generated content on social media platforms has prompted extensive research in hope speech detection, as shown in Table 1. Saumya and Mishra [8] addressed hope speech detection in YouTube comments across three languages, English, Tamil, and Malayalam, as part of the LT-EDI shared task at EACL 2021 [9]. The study aimed to classify comments as either hope speech, non-hope speech, or not in the intended language. To accomplish this, they experimented with conventional machine learning models, such as SVM and LR, as well as deep learning models, including CNN, LSTM, and Bi-LSTM, and hybrid deep-learning architectures that combined CNN and LSTM models. They found that a hybrid two-parallel CNN-LSTM model was most effective for English, achieving a weighted F1-score of 0.91 on the development set. Meanwhile, a three-parallel Bi-LSTM model yielded the best performance for Tamil and Malayalam, with weighted F1-scores of 0.56 and 0.78, respectively. Their approach’s main advantage was combining GloVe and Word2Vec embeddings to capture semantic and contextual differences in comments. However, it faced lower performance in Tamil due to its complex morphology and limited lexical resources compared to English and Malayalam. The paper emphasized the need for customized linguistic resources and domain-specific embeddings to enhance the handling of low-resource languages.
Jha et al. [10] introduced a deep learning-based approach for identifying hope speech in English YouTube comments. The dataset utilized in the research was provided by the shared task “LT-EDI-ACL 2022: Hope Speech Detection for Equality, Diversity, and Inclusion [11]” specifically focusing on English-language data collected from YouTube. Several neural network architectures were evaluated, including DNN, CNN, Bi-LSTM, and GRU, as well as stacked combinations such as LSTM-CNN and LSTM-LSTM. Among these models, the DNN achieved the highest performance, reaching a macro-average F1-score of 0.67 on both the development and test datasets. The model struggled to capture the subtleties of hope speech effectively. It also did not utilize advanced pretrained embeddings or transformers, which could potentially enhance its performance.
Puranik et al. [12] presented a detection method for hope speech across social media platforms in English, Malayalam, and Tamil, employing multiple transformer-based models. The primary objective was to distinguish supportive or positive comments of hope speech from harmful content. The authors evaluated various transformer architectures, including BERT, ALBERT, DistilBERT, RoBERTa, and CharacterBERT, as well as the transfer learning model ULMFiT. The multilingual dataset used for the experimentation, HopeEDI, contained YouTube comments annotated as either hope speech or non-hope speech or comments in other languages, distributed across English (28,451 samples), Tamil (20,198 samples), and Malayalam (10,705 samples). The best-performing model for English was ULMFiT, achieving an F1-score of 0.9356 on the test set, while mBERT performed best for Malayalam (F1-score: 0.8545), and DistilBERT achieved the highest performance on Tamil data (F1-score: 0.5926). An advantage of their approach was the extensive exploration of multilingual transformer models explicitly tailored for Dravidian languages. The study identified class imbalance, particularly in English, and reduced performance in Tamil, highlighting challenges with multilingual and code-mixed texts. The authors concluded that transfer learning and transformer-based models improved hopeful speech detection.
Transformer-based models such as BERT, mBERT, and XLM-RoBERTa have become state-of-the-art for multilingual NLP [13]. Arunima et al. [14] addressed the classification of hope speech from YouTube comments in three languages: English, Tamil, and Malayalam. The research employed transformer-based models, specifically utilizing mBERT for Tamil and Malayalam and BERT for English. The dataset provided by the LT-EDI organizers included annotated comments classified into hope speech, non-hope speech, and non-language. The study achieved a weighted F1-score of 0.92 for English, 0.81 for Malayalam, and 0.46 for Tamil, ranking second, fourth, and fourteenth among teams. BERT-based models demonstrated superior contextual understanding and multilingual capabilities compared to traditional classifiers, such as SVM and LR. Key preprocessing steps, like normalizing contractions and handling out-of-vocabulary words, greatly improved recall. However, results varied by language. Tamil faced difficulties due to its complex structure and limited resources. The authors suggested that future research should focus on code-switching contexts and explore alternative transformer architectures to improve detection accuracy across different linguistic datasets.
Singh et al. [15] introduced a multilingual transformer-based approach to detect hope speech on social media platforms, particularly in YouTube comments in English, Tamil, and Malayalam. The authors focused on identifying positive and encouraging content that promotes equality, diversity, and inclusion, which is critical for balancing the dominant emphasis on removing offensive content online. Their approach leveraged multilingual transformer models, including mBERT, XLM-RoBERTa, IndicBERT, and MuRIL. The dataset used was from the shared task organized by LT-EDI-EACL 2021, comprising annotated YouTube comments categorized into hope Speech, non-hope speech, and not in the intended language. XLM-RoBERTa outperformed other transformer models, achieving F1-scores of 0.928 for English, 0.860 for Malayalam, and 0.582 for Tamil. The methodology effectively captured cross-lingual differences using multilingual transformer models and required minimal preprocessing. However, challenges arose in Tamil classification due to dataset imbalance and linguistic complexities, which are common in low-resource languages. While the approach performed well in English and Malayalam, it relied heavily on extensive hyperparameter tuning, limiting its applicability to other contexts.
Praveen Kumar et al. [16] proposed an NLP approach for identifying hope speech in YouTube comments. That approach classified sentences into two categories: hope speech and non-hope speech. The authors applied the ALBERT model, an optimized transformer-based approach that significantly reduces the number of parameters compared to traditional BERT models, thus making the approach computationally efficient. The datasets used were provided by the LT-EDI organizers and contained multilingual comments in English, Tamil, Malayalam, and Kannada. The study achieved noteworthy results, ranking first in Kannada (F1-score: 0.750), second in Malayalam (F1-score: 0.740), third in Tamil (F1-score: 0.390), and sixth in English (F1-score: 0.880). Advantages of their method included effective tokenization using IndicBERT and the use of smart batching techniques, resulting in reduced computational overhead. The study faced a major limitation: inconsistent performance across different languages. The results were particularly poor for Tamil, likely because of the language’s complexity and uneven data. The authors recommended using data augmentation in future research to enhance the model’s performance. Overall, that paper demonstrated the efficacy of transformer-based models in multilingual settings while also highlighting the challenges that remain, particularly in low-resource languages.
Recent works have attempted to bridge performance gaps. Hande et al. [17] addressed the challenge of detecting hope speech in code-mixed Kannada, a low-resource language. They proposed a DC-LM that uses both code-mixed Kannada–English text and English translations, enhancing detection performance through cross-lingual transfer. The model achieved a weighted F1-score of 0.756, surpassing traditional single-channel multilingual and monolingual BERT models. The utilized dataset consisted of 6176 annotated YouTube comments labeled as hope or not hope, with preprocessing steps that included replacing URLs, handling emojis, and removing special characters. The paper emphasized the benefits of managing multilingual data with dual inputs and cross-lingual training while also noting the potential for mistranslations from automated translation APIs that could impact model accuracy. Additionally, linguistic complexity in morphologically rich code-mixed texts posed challenges, as evidenced by occasional misclassifications during evaluation.
Yueying Zhu [18] presented an ensemble model for detecting hope speech aimed at promoting equality, diversity, and inclusion across multiple languages (English, Spanish, Kannada, Malayalam, and Tamil). The proposed ensemble approach combined three distinct neural network architectures: LSTM, a hybrid CNN with LSTM, and a bidirectional LSTM, integrated through an attention mechanism to effectively highlight key information from the inputs. This methodology was evaluated on datasets from the LT-EDI ACL 2022 shared task, comprising YouTube comments categorized as either hope speech or non-hope speech. The ensemble model achieved competitive performance, ranking highly among submitted systems, especially excelling in English (achieving a weighted F1-score of 0.88), Spanish accomplishing a weighted F1-score of 0.76, Kannada, and Malayalam, but demonstrating notably lower performance in Tamil due to language-specific complexities and imbalanced data. That approach combined various types of neural networks and utilized an attention mechanism to facilitate more comprehensible results. However, it did not work as well for Tamil, indicating that improvements are needed in data preprocessing and model design.
Kumar et al. [19] proposed an ensemble approach to classify hope speech in YouTube comments across multiple languages, including English, Spanish, Tamil, Malayalam, and Kannada. The ensemble integrated three classifiers—SVM, LR, and RF—with carefully selected features. Leveraging character-level TF-IDF features for SVM and LR and word-level TF-IDF features for RF, the ensemble was carefully designed. Extensive experiments were conducted to identify optimal feature combinations, revealing that character-level features outperformed word-level features for SVM and LR, whereas word-level features worked better for RF. Evaluations were performed on the multilingual HopeEDI dataset provided by the LT-EDI-ACL2022 shared task. The ensemble achieved macro F1-scores of 0.380 (English), 0.790 (Spanish), 0.290 (Tamil), 0.480 (Malayalam), and 0.470 (Kannada), positioning it competitively among other submissions, particularly for Dravidian languages. That approach easily integrated classical machine learning algorithms and performed well with moderate computational resources. However, it struggled with highly imbalanced datasets, particularly in Tamil, which suggests a need for more complex neural architectures or better data augmentation techniques.
García-Baena et al. [20] presented an extensive study on hope speech detection specifically for the Spanish language. The authors introduced a novel dataset, SpanishHopeEDI, constructed from Twitter data that focused on messages related to EDI. The dataset comprised 1650 manually annotated tweets classified as either hope speech or non-hope speech. Multiple machine learning methods, including traditional algorithms (e.g., SVM, LR, NB) and deep learning techniques (MLP, CNN, BiLSTM, and transformer-based models like BERT), were evaluated. Experimental results showed that fine-tuned MLP embeddings achieved the best performance. While the dataset provided a balanced representation of classes and underwent careful manual annotation, the authors acknowledged limitations in annotation complexity due to the subjective nature of defining hope speech. The paper made a significant contribution by providing a valuable Spanish resource and baseline results, thereby facilitating future research in promoting positive online discourse.
Studies are increasingly focusing on variation-rich phenomena like sarcasm, indirect speech, and sentiment conflict. For instance, Sharma et al. [21] investigated targeted hope speech and metaphor use in Hindi–English code-mixed corpora. The present study proposes a hybrid ensemble architecture integrating LSTM, DistilBERT, ELECTRA, DeBERTa, and MiniLM. This model leverages LSTM’s sequence modeling capabilities and transformer’s multilingual contextual embeddings. Empirical evaluations demonstrate that the ensemble outperforms standalone models in the English language. Paired t-tests statistically confirm its superiority, making this a scalable solution for hope speech detection in high-resource contexts. Existing hope speech detectors for English can be categorized into three types: classical machine learning pipelines using surface features (e.g., TF–IDF with LR); single deep models such as Bi-LSTM or a solitary transformer; and light ensembles—most notably the Stop the Hate, Spread the Hope (StH) system [21], which merges an LSTM with two multilingual transformers through majority voting.
Compared with these lines of work, our stacked-transformer architecture presents three notable advantages: a diversity of base estimators, calibrated fusion, and scalable inference. By combining four heterogeneous transformers with a light Bi-LSTM, the ensemble captures both token-level context (transformers) and sequential cues (LSTM), yielding broader error coverage than vote-based schemes that rely on fewer, often correlated, models. Unlike majority voting, logistic stacking learns reliability weights for each base estimator, thereby improving recall on minority hope speech without sacrificing the high precision typically associated with transformer backbones. All base estimators are distilled or small-footprint models; the meta-learner adds negligible overhead, keeping latency within the bounds of real-time moderation.
The approach is not without limitations. First, five forward passes are still required, which may be prohibitive for edge deployment. Second, the method inherits the lexical bias of its English pretraining corpora and, like related work, struggles with highly domain-specific slang. Finally, transfer to truly low-resource languages will demand either additional language-specific base estimators and high-quality labeled data.

Table 1.
Qualitative comparison of our proposed approach and related methods.
3. Proposed Method
We propose a stacked ensemble model for detecting hope speech in English. It contains five independent base estimators and a logistic regression meta-classifier. The processing pipeline has four stages, illustrated in Figure 1.
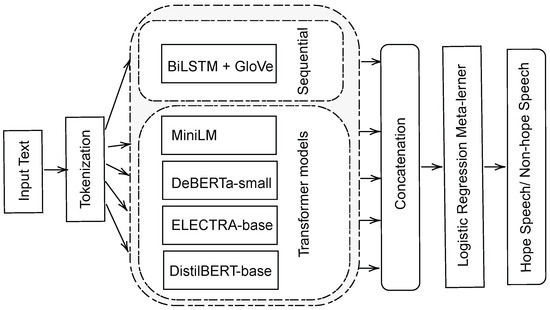
Figure 1.
Overview of the proposed stacked ensemble architecture.
3.1. Preprocessing
Tweets were lower-cased, non-alphanumeric symbols were removed, and each sequence was padded or truncated to length . The binary label mapping was
3.2. Base Estimators
We fine-tuned five transformer encoders (DistilBERT , ELECTRA , DeBERTa-v3-small , MiniLM ) and trained a Bi-LSTM base estimator . All transformers used the Adam optimizer with learning rate , batch size 16, three epochs, and the cross-entropy loss
where is the soft-max probability of class produced by base estimator k.
The Bi-LSTM model was trained separately for four epochs using Adam and sparse categorical cross-entropy.
3.2.1. Transformer Logits
Let be the contextual [CLS] vector of base estimator k. The two-class logits are
3.2.2. Bi-LSTM Logits
With fixed 100-d GloVe embeddings , the input sequence X is processed as
where GMP denotes global-max pooling.
Each transformer base model was fine-tuned independently and did not share weights. Transformer models used pretrained tokenizers with truncation and padding to length 128. The Bi-LSTM model used a Keras tokenizer limited to 20,000 vocabulary words, followed by padding and GloVe embedding lookup.
3.3. Meta-Learner (Stacking)
For each validation item , we concatenated the five base estimators’ logits,
A logistic-regression classifier with minimized
Early stopping was applied if validation accuracy failed to improve for two consecutive epochs.
3.4. Inference
For a test tweet x, we obtain the concatenated logits and predict
The meta-learner adds less than 0.01 s of latency per tweet.
Transformer base estimators capture rich contextual semantics, whereas the Bi-LSTM focuses on sequential dependencies with external GloVe embeddings. Logistic stacking provides a convex decision surface and negligible inference cost. Empirically, the ensemble surpasses each individual base estimator in weighted F1, confirming the expected reduction in bias and variance. We refer to this stacked configuration as Stack-T (Stacked Transformer Ensemble).
The hyperparameters for both the transformer models and the Bi-LSTM were determined through preliminary experiments on the development set. For all transformer-based models (DistilBERT, ELECTRA, DeBERTa, and MiniLM), we employed the Adam optimizer with a learning rate of , batch size of 16, and fine-tuned them for three epochs, which provided a stable balance between convergence and overfitting. For the Bi-LSTM model, we utilized an Adam optimizer with a learning rate of , batch size of 64, and trained it separately for four epochs. These hyperparameters were determined empirically based on validation performance and the stability of the model observed during tuning. The logistic regression-based meta-learner used regularization with a penalty of . It included an early stopping feature that halted training if validation accuracy did not improve for two consecutive epochs, helping to prevent overfitting and enhancing performance.
4. Dataset Details
HopeEDI [22] is a multilingual dataset designed to promote research on hope speech—positive, inclusive content that supports equality, diversity, and inclusion. It includes 28,451 English, 20,198 Tamil, and 10,705 Malayalam YouTube comments, manually labeled for hope speech. This is the first dataset of its kind in a multilingual setting. Annotation quality was measured using Krippendorff’s alpha, and baseline models were evaluated using precision, recall, and F1-score. The dataset is publicly available to support further research in fostering positive online discourse.
The English portion of the HopeEDI corpus was compiled from YouTube comments posted between November 2019 and June 2020 on topics closely related to equality, diversity, and inclusion—such as Women-in-STEM initiatives, COVID-19 public health discourse, and the Black Lives Matter movement. Videos were selected from channels located in predominantly English-speaking countries (Australia, Canada, Ireland, New Zealand, the UK, and the USA) to minimize dialectal interference and to ensure cultural relevance to high-resource English. Comments containing personally identifiable information were removed, and all data were distributed under an academic research license following anonymization protocols.
The resulting sub-dataset comprised 28,451 comments (46,974 sentences), containing 522,717 running words drawn from a vocabulary of 29,383 unique tokens. On average, each sentence was 18 tokens long, and each comment comprised a single sentence, reflecting the succinct style typical of social-media discourse. Three categorical labels were assigned at the comment level: hope, not hope, and other language. The distribution was markedly imbalanced—2484 hope (8.7%), 25,940 not hope (91.2%), and 27 other-language comments (0.1%)—highlighting the rarity of explicitly hopeful discourse in open platforms and motivating the ensemble approach adopted in the present study.
A team of 11 annotators with undergraduate to postgraduate training in linguistics or related disciplines performed the labeling after completing a structured calibration exercise and ethics briefing. Inter-annotator reliability, measured with Krippendorff’s = 0.63 under a nominal metric, indicated substantial agreement given the implicit semantic subtleties of hope speech. For downstream experimentation, the data were partitioned into training (22,762 comments, 80%), development (2843, 10%), and test (2846, 10%) splits, maintaining the original class ratios across folds. This stratification supports reproducible benchmarking of future architectures while preventing information leakage. Finally, it is noteworthy that although a negligible “Other-Language” category was preserved—chiefly to parallel the Tamil and Malayalam subsets—it may be safely excluded in purely English-centric modeling pipelines without loss of statistical power. Overall, the English HopeEDI sub-dataset supplies a large-scale, high-quality, and ethically curated resource for advancing positivity-oriented NLP research in high-resource settings.
To ensure a fair comparison with baseline models, all methods evaluated in this study—including DistilBERT, ELECTRA, DeBERTa, MiniLM, and Bi-LSTM—were trained and tested using the identical data splits (training: 80%, validation: 10%, and test: 10%) provided in the original HopeEDI dataset. Furthermore, baseline models employed the same preprocessing steps, including text normalization, tokenization, truncation or padding to a sequence length of 128 tokens, and lowercase conversion. Hyperparameters, such as the optimizer (Adam), learning rates, batch size, epochs, and early stopping criteria, were consistently applied across all models unless otherwise explicitly stated.
5. Results and Discussion
The proposed architecture attained a good performance. Figure 2b plots epoch-wise training accuracy for the four transformer base estimators. DistilBERT converged fast, reaching accuracy after only two epochs, whereas DeBERTa and ELECTRA required a third epoch to match that level. All models exhibited a steady reduction in loss, confirming stable optimization. Importantly, development accuracy stabilized around epoch 2 for every model, suggesting minimal risk of overfitting under the chosen early-stopping criteria.
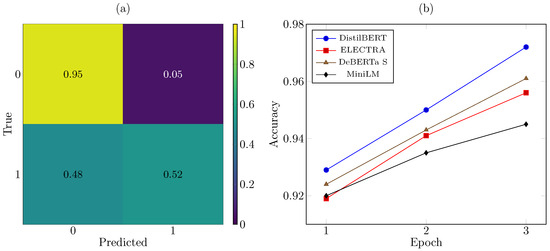
Figure 2.
(a) Confusion matrix of the stacked ensemble. (b) Epoch-wise training accuracy of transformer base estimators.
Table 2 lists precision, recall, and F1 for each base estimator on the held-out test set. ELECTRA and DeBERTa shared the highest weighted F1 (0.931), closely followed by DistilBERT (0.924), whereas MiniLM scored 0.926 and the Bi-LSTM baseline scored 0.916. Across all base estimators, class 0 (non-hope) was detected with a high F1-score (≥0.964). Class 1 (hope) remained challenging: the best individual F1 was 0.563 (ELECTRA), reflecting recall deficits (0.393–0.462). These disparities are visualized in Figure 3b: precision bars (blue) are consistently higher than recall (green), resulting in moderate harmonic means (red).
Table 2.
Individual test-set results.
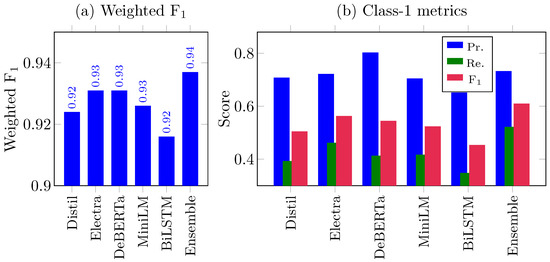
Figure 3.
(a) Weighted F1 per model. (b) Class-1 precision (Pr.), recall (Re.), and F1.
Stacking the five base estimators with logistic regression improved the weighted F1 to 0.937 and boosted class 1 F1 to 0.610, a gain of 4.7–15.6 points over single models. The confusion matrix in Figure 2a confirms this improvement: true positives for hope rise from 39–46% (individual) to 52% (ensemble), while maintaining a false-positive rate below 5%.
Misclassifications primarily occurred with short, ironic posts or context-heavy hashtags that were rare in the training set. ELECTRA contributed substantially to the ensemble’s recall gains, likely because its discriminator pretraining better captured subtle token substitutions. In contrast, DistilBERT added robustness on noisy spellings, evidenced by its lower loss trajectory (0.076 at epoch 3).
Ensembling was computationally cheap: meta-level inference (0.01 s) was negligible compared with forwarding through the base estimators. Average wall-clock latency for the full model was ∼0.19 s per tweet on a single Nvidia T4, making the system suitable for near-real-time or real-time use cases.
Comparison with Prior Hope Speech Systems
Figure 4b contrasts our stacked ensemble (Stack-T) with the most competitive English-only systems reported to date. Stack-T attained a weighted of 0.94, edging past the StH ensemble [21] of LSTM, mBERT, and XLM-RoBERTa (0.93) and surpassing earlier TF–IDF, classical neural, and single-transformer set-ups (0.86–0.92). More importantly, our model pushed the minority hope speech () to 0.610, a relative jump over the StH [21] of 0.58. The logistic meta-learner effectively re-weighted the confidence cues coming from five heterogeneous base estimators, yielding better recall for positive messages without sacrificing the already-strong precision on non-hope ().
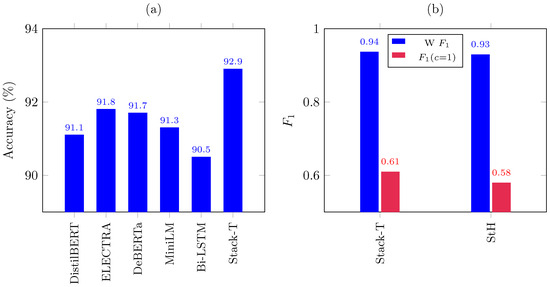
Figure 4.
(a) Bar chart of approximate accuracy for different models in hope speech detection. (b) Stack-T vs. StH [21] on two metrics (i.e., weighted and for the second class).
StH [21] already demonstrated that mixing sequence (LSTM) and contextual-embedding transformers outperformed individual models. Our contribution lies in broadening the base estimators (DistilBERT, ELECTRA, DeBERTa, MiniLM, Bi-LSTM) and in learning a calibrated stacking layer rather than relying on majority voting. The richer diversity improves discrimination of subtle supportive messages, which is reflected in the higher class-1 recall and . At the same time, inference stays lightweight: logistic regression adds s per batch.
The StH [21] pipeline combines mBERT, XLM-RoBERTa, and a Bi-LSTM via majority vote, achieving a weighted of 0.93 on the English HopeEDI benchmark. Our logistic-stacked ensemble (Stack-T) raised that to 0.94 (Figure 4b), driven mainly by an absolute three-point gain in hope speech () (0.610 vs. 0.580). Precision for supportive tweets improved only marginally, but recall climbed by six points, confirming that the additional base estimators—especially ELECTRA and DeBERTa—supplied complementary signals that the meta-learner could exploit. Although the gap may appear modest in aggregate terms, it translates into 48 extra correctly identified hope messages over the 8229-item test set, which is valuable for down-stream moderation scenarios.
To quantify the contribution of each base model, we performed experiments by systematically removing individual experts from the stacked ensemble and evaluating the effect on performance. When the Bi-LSTM was removed and only the four transformer models were retained, the ensemble achieved a weighted F1-score of 0.920 and a class-1 F1-score of 0.586. This indicates that while the Bi-LSTM contributes less to the overall weighted F1, it provides complementary sequential information that slightly boosts hope speech recall. Excluding DistilBERT while keeping ELECTRA, DeBERTa, MiniLM, and the Bi-LSTM reduced the weighted F1 to 0.932 and the class-1 F1 to 0.569, confirming that DistilBERT’s distilled embeddings help handle short or noisy texts that are otherwise misclassified. Removing ELECTRA resulted in a weighted F1-score of 0.932 and a class-1 F1-score of 0.565, showing that ELECTRA significantly enhances minority-class recall by capturing subtle supportive phrasing. Removing DeBERTa led to one of the most significant drops: the weighted F1 fell to 0.928 and class-1 F1 to 0.536, highlighting the importance of DeBERTa’s disentangled attention for contextual representation. Finally, excluding MiniLM resulted in a weighted F1 of 0.910 and class-1 F1 of 0.550, indicating that although MiniLM is lightweight, its distilled contextual features still complement the larger models and contribute to minority-class detection. With all five models combined in the stacked ensemble, the system achieved the best overall scores with a weighted F1 of 0.937 and class-1 F1 of 0.610, demonstrating that the gains are driven by true model diversity rather than a single dominant expert. The results confirm that removing any base model consistently reduces the performance of the minority class, validating the design of integrating heterogeneous encoders and a Bi-LSTM within a calibrated stacking framework.
Other ensemble fusion strategies, including bagging, boosting, and attention-based meta-layers, were not explored in this study. These methods represent promising directions for future work, as they could further enhance the integration of diverse base models and improve the performance of minority-class detection. Overall, our ensemble method performed well but struggled to detect hopeful speech (class 1), achieving an F1-score of 0.610 and a recall of about 0.52. It often misclassified short texts and struggled with irony or sarcasm due to a lack of context. To improve detection, future research should focus on utilizing external context, sarcasm-aware linguistic resources, and few-shot learning strategies to recognize subtle language patterns better. Our stacked transformer ensemble performed well with high-resource languages, such as English but may struggle with low-resource languages, like Tamil. This is primarily due to the limited availability of annotated data, class imbalances, and complex language features. Future work can focus on multilingual fine-tuning and use transfer learning from high-resource languages. Future work can also integrate data augmentation and cross-lingual distillation to address data scarcity. In future research, we should enhance the effectiveness of our model across languages.
6. Conclusions
This study introduced a stacked ensemble that fused a Bi-LSTM augmented with GloVe embeddings and four lightweight transformer encoders—DistilBERT, ELECTRA, DeBERTa-v3-small, and MiniLM—to advance automated hope speech detection in high-resource languages. Trained and evaluated on the English portion of the HopeEDI corpus, the proposed architecture attained a weighted F1 of 0.94, surpassing each constituent model and outperforming previously published English-only baselines. The gains stemmed from complementary error profiles among heterogeneous base estimators and a calibrated logistic meta-learner that privileged the most reliable logits without incurring prohibitive inference costs. Empirical analysis further showed that the ensemble markedly improved recall on the minority hope class while preserving the high precision characteristic of transformer backbones. In addition to performance improvements, this work demonstrated the feasibility of real-time moderation pipelines: all base estimators were distilled or small-footprint models, and the meta-layer added negligible latency. The findings also corroborated the value of combining sequential encoders with contextual transformers for tasks where sentiment polarity and pragmatic intent co-occur in noisy social-media text. Two principal limitations warrant future research. First, five forward passes, although lightweight, remain costly for edge deployment or extremely high-throughput streams. Model pruning, single-pass mixture-of-base estimators, or on-device distillation may mitigate this overhead. Second, the ensemble inherits lexical and cultural biases from English pretraining corpora; adapting the framework to low-resource or code-switched settings will require multilingual fine-tuning, data augmentation to address class imbalance, and rigorous fairness evaluation. Extending interpretability analyses, e.g., via attention attribution or counterfactual explanations, could further support ethical deployment. The stacked ensemble presented herein offers a scalable and effective solution for amplifying positive discourse online. This study improves hope speech detection and provides clear pathways for broader linguistic inclusion, paving the way for future work in building supportive digital communities.
Author Contributions
Conceptualization, B.A. and M.A.; methodology, B.A.; software, B.A. and M.A.; validation, B.A.; writing—original draft preparation, B.A.; writing—review and editing, B.A.; visualization, B.A. and M.A.; supervision, B.A.; project administration, B.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in this study are available in [22].
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| NLP | Natural language processing |
| LSTM | Long short-term memory |
| GloVe | Global vectors for word representation |
| mBERT | Multilingual bidirectional encoder representations from transformers |
| XLM | Cross-lingual language model |
| RoBERTa | Robustly optimized BERT pretraining approach |
| SVM | Support vector machine |
| LR | Logistic regression |
| RF | Random forest |
| NB | Naïve Bayes |
| TF-IDF | Term frequency–inverse document frequency |
| CNN | Convolutional neural network |
| MuRIL | Multilingual representations for Indian languages |
| ALBERT | A lite BERT |
| DistilBERT | Distilled version of BERT |
| ELECTRA | Efficiently learning an encoder that classifies token replacements accurately |
| DNN | Deep neural network |
| GRU | Gated recurrent unit |
| ULMFiT | Universal language model fine-tuning |
| EACL | European Chapter of Association for Computational Linguistics |
| EDI | Equality, diversity, and inclusion |
| DT | Decision tree |
| KNN | K-nearest neighbors |
| DC-LM | Dual-channel language model |
| URL | Uniform resource locator |
| API | Application programming interface |
| STEM | Science, technology, engineering, and mathematics |
References
- Omipidan, I.A.; Sanusi, B.O. Rise of social media in the digital age: Whatsapp a threat to effective communication. IMSU J. Commun. Stud. 2024, 8, 142–153. [Google Scholar] [CrossRef]
- Zhuang, W.; Zeng, Q.; Zhang, Y.; Liu, C.; Fan, W. What Makes User-Generated Content More Helpful on Social Media Platforms? Insights from Creator Interactivity Perspective. Inf. Process. Manag. 2023, 60, 103201. [Google Scholar] [CrossRef]
- Bleier, A.; Fossen, B.L.; Shapira, M. On the role of social media platforms in the creator economy. Int. J. Res. Mark. 2024, 41, 411–426. [Google Scholar] [CrossRef]
- Pepper, C.; Perez Vallejos, E.; Carter, C.J. “I Don’t Feel Like There’s Enough Awareness about the Damage That Social Media Does”: A Thematic Analysis of the Relationships between Social Media Use, Mental Wellbeing, and Care Experience. Youth 2023, 3, 1244–1267. [Google Scholar] [CrossRef]
- Balouchzahi, F.; Sidorov, G.; Gelbukh, A. Polyhope: Two-level hope speech detection from tweets. Expert Syst. Appl. 2023, 225, 120078. [Google Scholar] [CrossRef]
- Arif, M.; Tash, M.S.; Jamshidi, A.; Ullah, F.; Ameer, I.; Kalita, J.; Gelbukh, A.; Balouchzahi, F. Analyzing hope speech from psycholinguistic and emotional perspectives. Sci. Rep. 2024, 14, 23548. [Google Scholar] [CrossRef] [PubMed]
- Divakaran, S.; Girish, K.; Shashirekha, H.L. Hope on the horizon: Experiments with learning models for hope speech detection in spanish and english. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024), Co-Located with the 40th Conference of the Spanish Society for Natural Language Processing (SEPLN 2024), Valladolid, Spain, 24–27 September 2024. [Google Scholar]
- Saumya, S.; Mishra, A.K. IIIT_DWD@ LT-EDI-EACL2021: Hope Speech Detection in YouTube Multilingual Comments. In Proceedings of the First Workshop on Language Technology for Equality, Diversity and Inclusion, Kyiv, Ukraine, 19 April 2021; pp. 107–113. Available online: https://aclanthology.org/2021.ltedi-1.14 (accessed on 23 May 2025).
- Chakravarthi, B.R.; Muralidaran, V. Findings of the Shared Task on Hope Speech Detection for Equality, Diversity, and Inclusion. In Proceedings of the First Workshop on Language Technology for Equality, Diversity and Inclusion, Kyiv, Ukraine, 19 April 2021; Chakravarthi, B.R., McCrae, J.P., Zarrouk, M., Bali, K., Buitelaar, P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 61–72. [Google Scholar] [CrossRef]
- Jha, V.; Mishra, A.; Saumya, S. CURAJ_IIITDWD@ LT-EDI-ACL 2022: Hope Speech Detection in English YouTube Comments Using Deep Learning Techniques. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, Marseille, France, 23–28 May 2022; pp. 190–195. [Google Scholar] [CrossRef]
- Chakravarthi, B.R.; Muralidaran, V.; Priyadharshini, R.; McCrae, J.P.; García, M.Á.; Jiménez-Zafra, S.M.; Valencia-García, R.; Kumaresan, P.; García-Díaz, J. Overview of the Shared Task on Hope Speech Detection for Equality, Diversity, and Inclusion. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, Marseille, France, 23–28 May 2022; pp. 378–388. [Google Scholar] [CrossRef]
- Puranik, K.; Hande, A.; Priyadharshini, R.; Thavareesan, S.; Chakravarthi, B.R. IIITT@ LT-EDI-EACL2021—Hope Speech Detection: There is Always Hope in Transformers. arXiv 2021, arXiv:2104.09066. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Arunima, S.; Ramakrishnan, A.; Balaji, A.; Thenmozhi, D. ssn_diBERTsity@ LT-EDI-EACL2021: Hope Speech Detection on Multilingual YouTube Comments via Transformer Based Approach. In Proceedings of the First Workshop on Language Technology for Equality, Diversity and Inclusion, Kyiv, Ukraine, 19 April 2021; pp. 92–97. Available online: https://aclanthology.org/2021.ltedi-1.12 (accessed on 23 May 2025).
- Singh, P.; Kumar, P.; Bhattacharyya, P. CFILT IIT Bombay@ LT-EDI-EACL2021: Hope Speech Detection for Equality, Diversity, and Inclusion Using Multilingual Representation from Transformers. In Proceedings of the First Workshop on Language Technology for Equality, Diversity and Inclusion, Kyiv, Ukraine, 19 April 2021; pp. 193–196. Available online: https://aclanthology.org/2021.ltedi-1.29 (accessed on 23 May 2025).
- Vijayakumar, P.; Prathyush, S.; Aravind, P.; Angel, S.; Sivanaiah, R.; Rajendram, S.M.; Mirnalinee, T.T. SSN_ARMM@ LT-EDI-ACL2022: Hope Speech Detection for Equality, Diversity, and Inclusion Using ALBERT Model. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, Marseille, France, 23–28 May 2022; pp. 172–176. [Google Scholar] [CrossRef]
- Hande, A.; Hegde, S.U.; Sangeetha, S.; Priyadharshini, R.; Chakravarthi, B.R. The Best of Both Worlds: Dual Channel Language Modeling for Hope Speech Detection in Low-Resourced Kannada. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, Marseille, France, 23–28 May 2022; pp. 127–135. [Google Scholar] [CrossRef]
- Zhu, Y. Lps@ LT-EDI-ACL2022: An Ensemble Approach About Hope Speech Detection. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, Marseille, France, 23–28 May 2022; pp. 183–189. [Google Scholar] [CrossRef]
- Kumar, A.; Saumya, S.; Roy, P. SOA_NLP@ LT-EDI-ACL2022: An Ensemble Model for Hope Speech Detection from YouTube Comments. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, Marseille, France, 23–28 May 2022; pp. 223–228. [Google Scholar] [CrossRef]
- García-Baena, D.; García-Cumbreras, M.Á.; Jiménez-Zafra, S.M.; García-Díaz, J.A.; Valencia-García, R. Hope Speech Detection in Spanish: The LGBT Case. Lang. Resour. Eval. 2023, 57, 1487–1514. [Google Scholar] [CrossRef] [PubMed]
- Sharma, D.; Gupta, V.; Singh, V.K.; Chakravarthi, B.R. Stop the Hate, Spread the Hope: An ensemble model for hope speech detection in english and dravidian languages. Acm Trans. Asian-Low-Resour. Lang. Inf. Process. 2025. [Google Scholar] [CrossRef]
- Chakravarthi, B.R. HopeEDI: A Multilingual Hope Speech Detection Dataset for Equality, Diversity, and Inclusion. In Proceedings of the 3rd Workshop on Computational Modeling of People’s Opinions, Personality, and Emotion’s in Social Media, Barcelona, Spain, 13 December 2020; pp. 41–53. Available online: https://aclanthology.org/2020.peoples-1.5 (accessed on 23 May 2025).




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).