1. Introduction
Wheat (
Triticum aestivum L.), as one of the most important food crops in the world [
1,
2], occupies a crucial position in our agricultural production and food security [
3,
4]. The formation of wheat yield in the field mainly depends on two key agronomic traits—the number of ears per unit area and the thousand grain weight [
5,
6]—of which the number of ears per unit area is the most decisive yield-constituting factor. Therefore, accurate counting of wheat ears in the field is of great theoretical and practical significance for dynamic monitoring of wheat growth, yield prediction and evaluation, and optimization of the breeding process.
In the traditional method of wheat spike detection and counting, manual surveying has long dominated the techniques employed [
7,
8,
9]. However, there are many obvious drawbacks of manual surveying, such as low efficiency, making it difficult to ensure accurate results and introducing strong subjectivity to the prediction results; these factors make it difficult to meet the needs of modern agriculture for efficient and accurate wheat spike counting [
10]. With the rapid development of computer technology, the method of counting wheat ears based on image processing and machine learning came into being, providing a new turnaround for the work of counting wheat ears. However, in practical applications, due to the complexity and variability of the field environment, there are large differences in the shape, color, and scale of wheat ears, which bring many challenges to the realization of high-throughput wheat ear detection and counting [
3,
11].
Satellite remote sensing technology, as a non-invasive monitoring approach, can efficiently obtain multi-spectral information of crops on a regional scale, providing data support for agricultural needs at different spatial and temporal resolutions, and it is increasingly widely used in the fields of fine crop management and yield modeling [
12,
13,
14,
15]. Many scholars have carried out in-depth research in this field and achieved remarkable results. For example, Wang et al. [
16] proposed HyperSIGMA, a hyperspectral intelligent understanding model, to address the problems of weak cross-task generalization and poor cross-scene mobility in traditional hyperspectral image processing models, and they verified its excellent performance on multiple hyperspectral image datasets. Ileana et al. [
17] combined remote sensing technology with the M5P model tree algorithm to estimate rapeseed oil yield. Chen et al. [
18] used hyperspectral remote sensing technology to predict potato underground yield traits with the help of structural equation modeling, which provided a new method for precision agriculture. Zhao et al. [
19] proposed a winter wheat extraction method based on multi-task learning and visual transformer for GF-2 remote sensing data, which effectively improves the accuracy of winter wheat extraction by fusing normalized vegetation index and surface temperature data. These research results have achieved remarkable results in agricultural crop characterization and promoted the development of precision agriculture. However, the application potential of satellite remote sensing in agricultural monitoring is constrained by its inherent technical limitations. Its low spatial resolution and temporal revisit frequency make it difficult to meet the demand for high spatial and temporal accuracy in fine agricultural management, which may lead to problems such as bias in characterization and identification during critical periods and difficulty in accurately counting important agronomic traits. In addition, the acquisition of multi-spectral information is highly dependent on favorable meteorological conditions [
20,
21], while wheat has large differences in individual morphology during the tasseling period, and the spatial distribution and visibility of wheat ears in the field change rapidly, which further reduce the feasibility of using multi-spectral data to achieve reliable and synchronized wheat ear counting. Therefore, the development of an efficient and automated high-throughput wheat spike counting technology has become a critical need to advance the wheat breeding process.
Visible light imaging systems carried by UAVs have received extensive attention in scientific research and engineering applications due to their significant advantages such as high mobility, high timeliness, and excellent spatial resolution [
22,
23,
24,
25,
26]. With the continuous progress of computer vision technology, counting methods based on UAV images have gradually been applied in the automatic counting of various crops. At present, the mainstream counting methods are mainly categorized into two types: the rectangular box style detection model and the dense counting model based on density regression [
27]. Among them, the dense counting model based on density regression shows better performance in handling the counting task in dense situations. However, the method can only output the numerical results of counting, and it cannot obtain the specific coordinates and location information of the target through the detection box as in the detection model, which limits its application in precision agriculture to a certain extent [
28,
29]. Therefore, the method based on detection counting has gradually become a research hotspot in precision agriculture. Numerous scholars have carried out in-depth research in this field and achieved fruitful results. For example, Lin et al. [
30] used a new cascaded convolutional neural network to extract regions of interest from visible and multi-spectral images acquired by unmanned aerial systems, and they realized the detection and counting of grain ears under different field conditions. Guo et al. [
31] proposed a deep learning algorithm based on natural image segmentation for automatically calculating the fruiting rate in response to the problem of spatial overlapping of rice grains that makes counting difficult. Li et al. [
28] proposed a lightweight wheat ear detection model called RT-WEDT, which aims to improve the accuracy and efficiency of wheat ear detection and counting in a complex farmland environment. To enhance the model’s representation ability in complex agricultural scenarios, researchers have also introduced the attention mechanism as a core enhancement method: Firozeh [
32] et al. used data rebalancing and the YOLOv8-SE attention module to solve the class imbalance and small-target problems in tomato flower/fruit/bud detection. Yan [
33] et al., based on improved YOLOv11 (APYOLO) and DeepSORT, combined MSCA attention and EnMPDIoU loss to achieve apple detection and yield estimation in occluded and overlapping environments.
Although the above methods have shown good performance in detecting and counting various crops, in the actual field environment, due to the differences in the growth patterns of different wheat ears and the influence of factors such as wind and light, the wheat ear images often have problems such as occlusion and sticking, inconsistent scale, and being difficult to distinguish from the background, which bring great challenges to the work of counting wheat ears [
34,
35]. Previous studies have specifically conducted empirical exploration in dense occlusion scenarios: They proposed AO-DETR, introduced category-to-category one-to-one matching (CSA) and forward dense anchor boxes (LFDs) into the DETR-DINO framework, significantly alleviating the feature coupling and edge blurring caused by overlapping X-ray contraband features [
36], as well as the lightweight YOLO-PDGT algorithm based on YOLOv8—under the synergy of a simplified neck, accelerated convolution, and enhanced small-target detection ability through triplet attention, achieving real-time detection and counting of unripe pomegranates [
37]. In view of this, this study has proposed an innovative approach. First, hybrid feature extraction is realized by splicing the spatial and frequency domains, which improves the feature extraction capability of the target in the complex background. Second, the GHSDConv and CSPDWOK structures are designed to construct the multi-scale sequence feature fusion module MFEP, which aims to improve the model’s detection capability for targets of different scales. Finally, considering the growing demand for high accuracy and fast response in precision agriculture and the realistic need to reduce the hardware cost, this study adopts the channel pruning technique based on Layer-Adaptive Magnitude Pruning (LAMP) scoring based on a lightweight backbone network in order to reduce the model parameters and runtime memory. The main innovations of this paper are as follows:
(1) The FM module is introduced to transform the bottleneck layer in C2f to realize hybrid feature extraction by splicing spatial and frequency domains, which significantly improves the feature extraction capability of wheat to be tested in complex scenes.
(2) The multi-scale feature enhancement pyramid (MFEP) is designed by combining GHSDConv, which is used to efficiently obtain low-level detail information, and CSPDWOK, which constructs a multi-scale semantic fusion structure. This improves the model’s ability to detect targets at different scales while balancing the expression of small-target details and the context modeling of large targets.
(3) The channel pruning technique based on LAMP scoring is adopted to reduce the model parameters and runtime memory and realize the lightweight characteristic of the model under the premise of guaranteeing the model’s performance, which reduces the hardware cost and meets the demands of precision agriculture for high accuracy and fast responsiveness.
2. Dataset
In this paper, the 2021 version of the global wheat head detection (GWHD) [
38] dataset was used as the training dataset for the model. The dataset consists of 6422 wheat head images (JPG format) taken in Asia, North America, Europe, and Oceania, and it contains 275,187 bounding box labels. It covers 60+ wheat varieties (including spring-type, winter-type, local varieties, and modern high-yield varieties). Samples were taken throughout the growth period from the time of wheat head emergence to the complete ripening stage, ensuring that the dataset contains different head shapes, colors, and densities. The imaging conditions were classified according to weather and light conditions: 45% for sunny days, 38% for cloudy days, and 17% for backlighting. This ensures the diversity of scenes and environments. The image specifications include a resolution of 1024 × 1024 pixels taken from heights ranging from 1.8 m to 3 m.
The global wheat sheaf dataset is rich in genetic and environmental diversity, which makes it ideal for use as a source of training data for neural networks and helps to improve the accuracy of wheat sheaf detection. According to the principle of machine learning data partitioning, if the dataset bounding box is in the order of , considering that a larger validation set can provide more samples for the evaluation of the model configurations and thus be more conducive to the adjustment of the optimal parameters in training, the global wheat sheaf dataset was randomly partitioned into a training set, a validation set, and a test set in the ratio of 7:2:1.
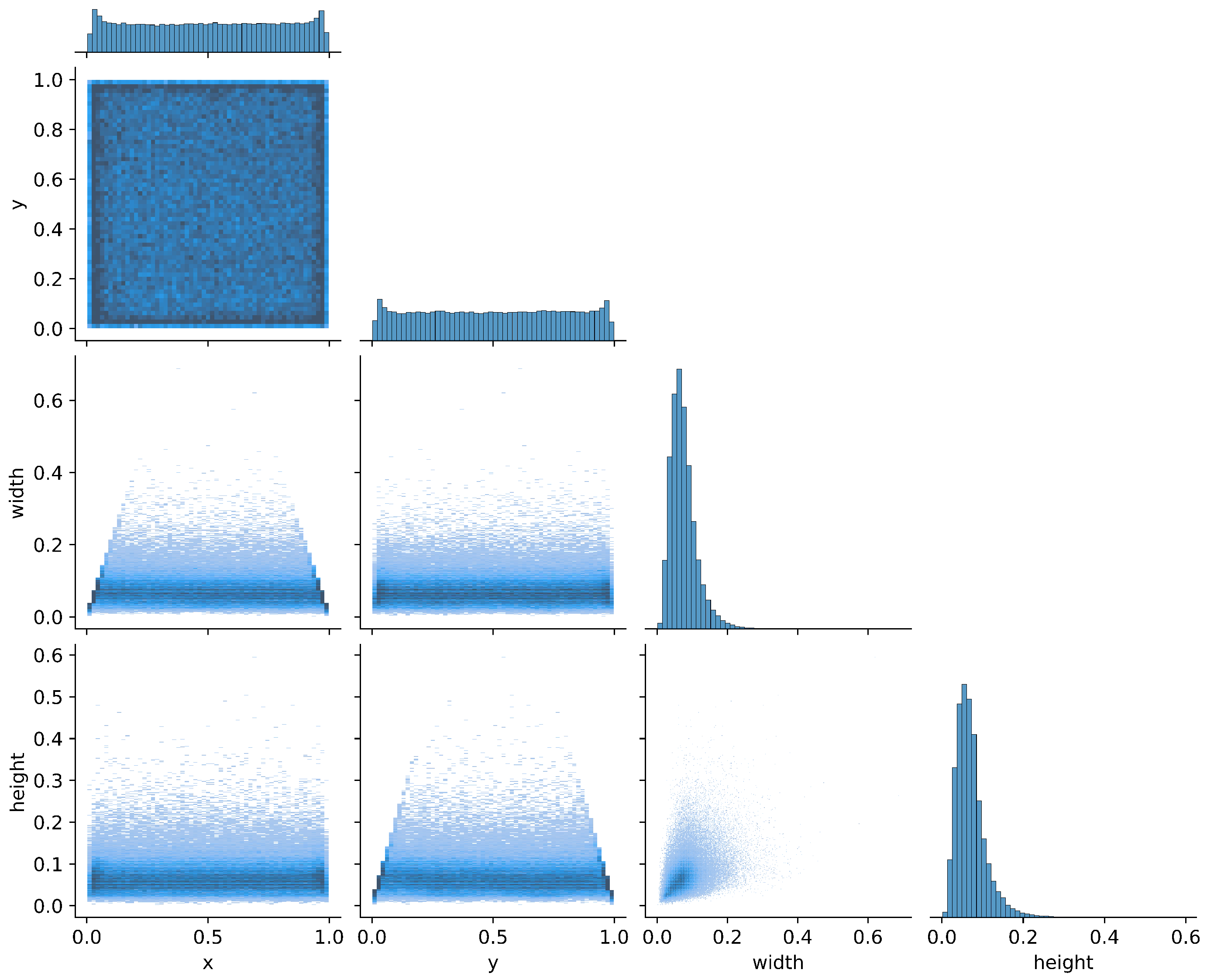
Figure 1 illustrates the distribution of the center points (x, y), widths, and heights of the rectangular boxes. The center points (x, y) are relatively uniformly distributed across the image, indicating a lack of distinct target concentration areas and a more dispersed distribution. The widths and heights are predominantly concentrated within smaller numerical ranges, with the heights exhibiting a near-normal distribution around a mean value, while the widths have a broader distribution but are still predominantly small. This suggests that the dataset contains targets of varying sizes, with most being relatively small and randomly positioned without significant spatial clustering.
6. Conclusions
In order to realize accurate detection of wheat and facilitate the subsequent realization of lightweight accurate counting of wheat, this paper proposes an improved wheat detection and counting model based on RT-DETR, and the main conclusions are as follows: The lightweight network CSPDarknet was adopted as the backbone network of RT-DETR to improve the feature extraction efficiency, and the FM module was introduced to modify the bottleneck in C2f to realize hybrid feature extraction through spatial and frequency domain splicing to improve the feature extraction capability of wheat to be tested in complex scenes. Second, the GHSDConv and CSPDWOK structures were designed to construct the multi-scale sequence feature fusion module MFEP, which aims to improve the model’s detection capability for targets of different scales. In addition, a loss function named CML_loss has been created specifically for dense small-object detection in scenes with overlapping and occluded objects. It aims to mitigate the missing detection box problem caused by overlapping and occlusion. Finally, channel pruning based on LAMP scoring was performed to reduce the model parameters and runtime memory. The accuracy of the improved model reached 90.5, and the , , , , and were improved by 1.5%, 2.1%, 3.6%, 1.4%, and 1.9% over the initial values. Comparing the more advantageous lightweight CNN networks in recent years, the results of CML-RTDETR were 0.5 and 0.9 percentage points higher than YOLOv8n, and YOLO10n, respectively. Compared with the classical Retinanet and CenterNet, the was 6.0 percentage points and 2.8 percentage points higher, respectively. Since models such as the CNN lack shallow feature maps to recognize localized small-target wheat ears, and CML-RTDETR obtains multi-scale fusion features through GHSDConv, the detection accuracy values of most CNN models were much lower than that of CML-DETR on small targets. Compared with the Transfomer-based RT-DETR series, the number of parameter of the model proposed in this paper is only a half of theirs, which has a large advantage in terms of parameters and is equal to them in terms of metrics.
However, the actual field environment is much more complex: The diversity in morphology and texture brought about by variety differences, as well as the significant fluctuations in resolution caused by differences in collection equipment and shooting distance, all significantly reduce the robustness and generalization ability of the model. In the future, we will do the following: carry out systematic evaluations on an expanded dataset covering multiple varieties, multiple resolutions, and multiple climate zones to quantify the specific impacts of these factors on the detection performance and design and implement an adaptive illumination normalization module to suppress the illumination disturbances caused by strong light, shadows, and color bias, further improving the stability and accuracy of the model in complex lighting conditions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}