

A Blockchain-Based Framework for Secure Data Stream Dissemination in Federated IoT Environments



Abstract
1. Introduction
- Security gap: How do we implement secure data distribution among participants in a federated environment, adhering to the data-centric security paradigm [3]? This involves ensuring robust data protection starting from the point of origin, maintaining integrity throughout its entire life cycle, and facilitating granular access control mechanisms to enforce strict data permissions.
- Identity management gap: How do we manage the identity of devices? How do we identify devices?
- Real-time data access gap: How do we enable the processing and sharing of relevant IOs based on their VoI, importance, and relevance within a specified time range?
- Resource allocation gap: How do we dynamically allocate resources to effectively manage trade-offs in a data dissemination environment while taking customer key performance indicators (KPIs) into account?
- Network integration and interoperability gap: How do we organize interconnections, especially between unclassified systems (civilian systems) and military systems?
- Resilience and centralization gap: How do we ensure data availability in constrained (partially isolated) environments?
- We have developed a novel and practical framework for the secure and dynamic dissemination of data streams within a multi-organizational federation environment utilizing Hyperledger Fabric [4], Apache Kafka as data queuing technology, along with a microservice processing logic to verify and disseminate data streams (by utilizing the Kafka Streams API library in Java [5] and the Sarama library in Go [6]);
- We have integrated a hardware-software IoT gateway with a DLT (Hyperledger Fabric) to authenticate IoT devices and verify data streams, which involves the deployment of the fingerprint enrichment layer in conjunction with the protocol forwarder (proxy) component;
- We validated the effectiveness of the proposed framework by conducting extensive performance tests in two setups: the Amazon Web Services cloud-based and the Raspberry Pi resource-constrained environment.
2. Related Work
- Securing data processed by IoT devices with the usage of distributed ledger technology and blockchain mechanisms;
- Behavior-based IoT device identification (IoT distinctive features);
- The integration of heterogeneous military and civilian systems based on IoT devices, where specific KPIs must be achieved (e.g., zero-day interoperability).
2.1. Blockchain-Based Device and Data Protection Mechanisms
2.2. Fingerprint Sampling Techniques
- Hardware/Software class: hardware and software features of the device;
- Flow class: characteristics of generated network traffic;
- RF class: characteristics of generated radio signals.
2.3. Reliable Data Stream Dissemination
2.4. Discussion
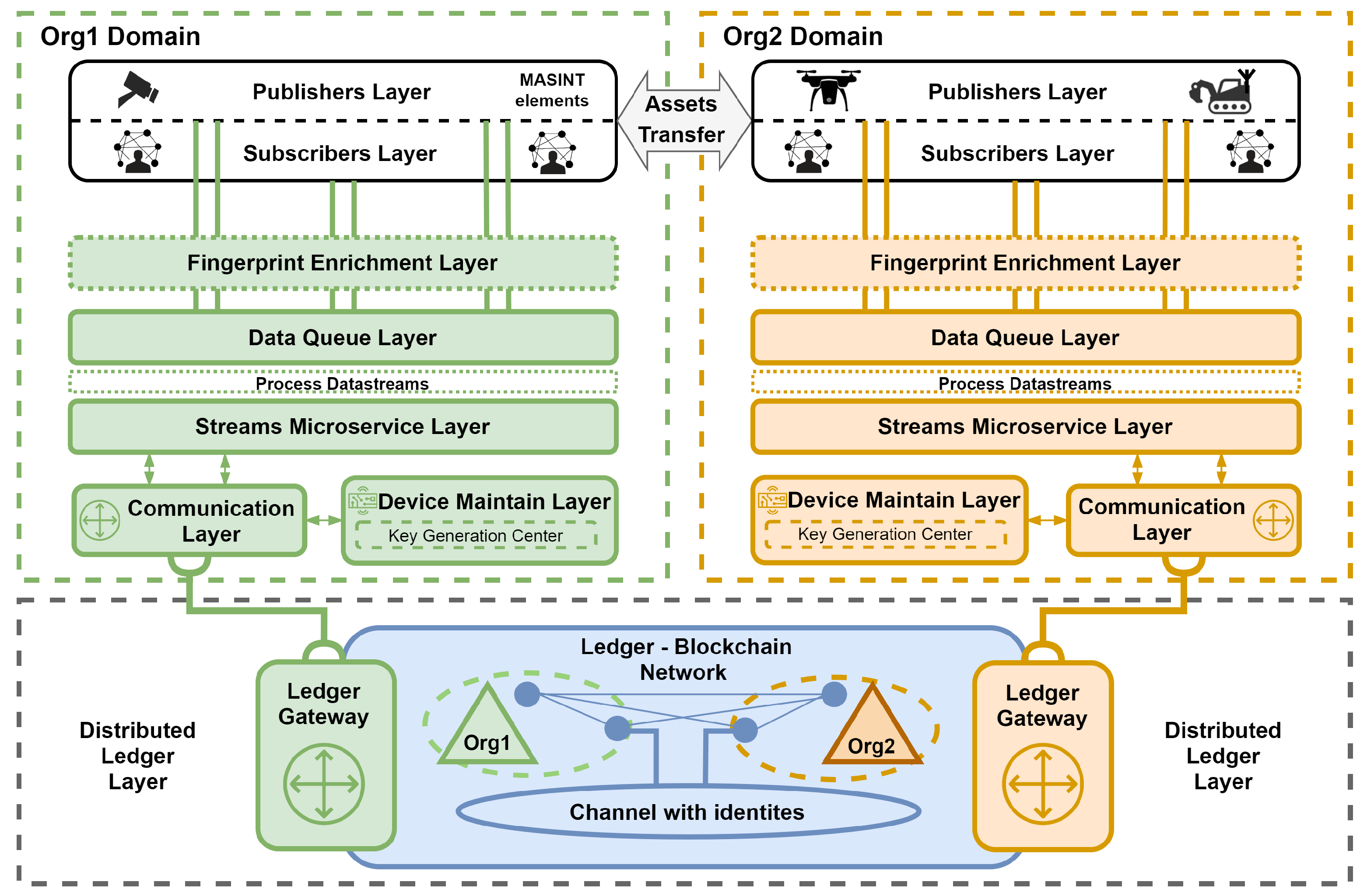
3. Framework Design
- Publisher Layer: This encompasses entities that facilitate the data-centric protection of generated (produced) data streams through the sealing process, where the sealing key is derived from the device’s fingerprint (identity) defined during the registration operation managed by the device maintain layer;
- Subscriber Layer: This is made up of authenticated and authorized entities that read (consume) available and verified data streams from the data queue layer according to the access policy (e.g., one to many);
- Data Queue layer: This is composed of distributed data queues that facilitate the acquisition, merging, storage, and replication of data streams transmitted from the publisher layer, subsequently making it accessible to the subscribers layer;
- Fingerprint Enrichment Layer: This can transport connectionless protocols like UDP by employing a protocol forwarder that converts data streams into a connection-oriented format (e.g., transmission control protocol, TCP). This layer is essential due to the constraints of the connection types supported by the technologies available for the data queue layer. Moreover, it facilitates device behavior-based authentication by utilizing analyzers to gather various features, including network and radio characteristics, and by enriching messages with entity fingerprint samples;
- Distributed Ledger Layer: This enables the interchangeable deployment of various DLT. Furthermore, it reliably stores the identities of devices belonging to organizations within the federation and retains information about entity data quality and subscriber data context dissemination [28];
- Communication Layer: This enables the streams microservice and the device maintain layer to communicate with the distributed ledger via a hardware–software IoT gateway;
- Streams Microservice Layer: This is tasked with verifying sealed data streams originating from entities within the publisher layer. Additionally, it has the capability to analyze, categorize, and disseminate streams pertinent to these entities, and enrich them (e.g., by detecting objects during image processing);
- Device Maintain Layer: This manages the device registration operation, with additional responsibilities including updating and revoking identities. The registration process is initiated with the establishment of the entity’s identity through the use of fingerprint methods.
3.1. Publisher’s Layer
3.2. Subscriber’s Layer
3.3. Data Queue Layer
- Storing and replicating sealed data streams within the layer;
- Storing invalid records to trigger a detection mechanism of potentially malicious entities;
- Intermediating within the micro-caching mechanism by linking the publisher layer (blockchain event listeners) with the streams microservice layer.
3.4. Fingerprint Enrichment Layer
3.5. Distributed Ledger Layer
- Redundant and reliable storing of all identities of devices belonging to organizations that participate in the federation;
- Redundant and reliable storing information about entities regarding the value of information and context dissemination;
- Secure handling of the chaincode (smart contracts) execution (transaction steps) during the device registration operation;
- Obtaining approvals (transaction authorizations) under endorsement policy from participating organizations;
- Generating events related to actions on the distributed ledger (blockchain);
- Being an integrated part of the verification process of devices and sealed messages.
3.6. Communication Layer
- Performing queries to the on-chain store to read the examined identity from the distributed ledger layer during the verification process;
- Participating in entity identities registering, updating, and revoking operations called by the device maintain layer;
- Broadcasting of events generated by the distributed ledger layer as a result of approved transactions and blocks.
3.7. Streams Microservice Layer
3.8. Device Maintain Layer
- Limitations arising from the heterogeneity of the environment and the need to maintain the mobility of IoT devices;
- Devices’ vulnerability to extreme environmental factors (e.g., temperature and humidity);
- Autonomy from the protocols used in the network.
4. Framework Basic Operations
4.1. Security Mechanisms and Message Types
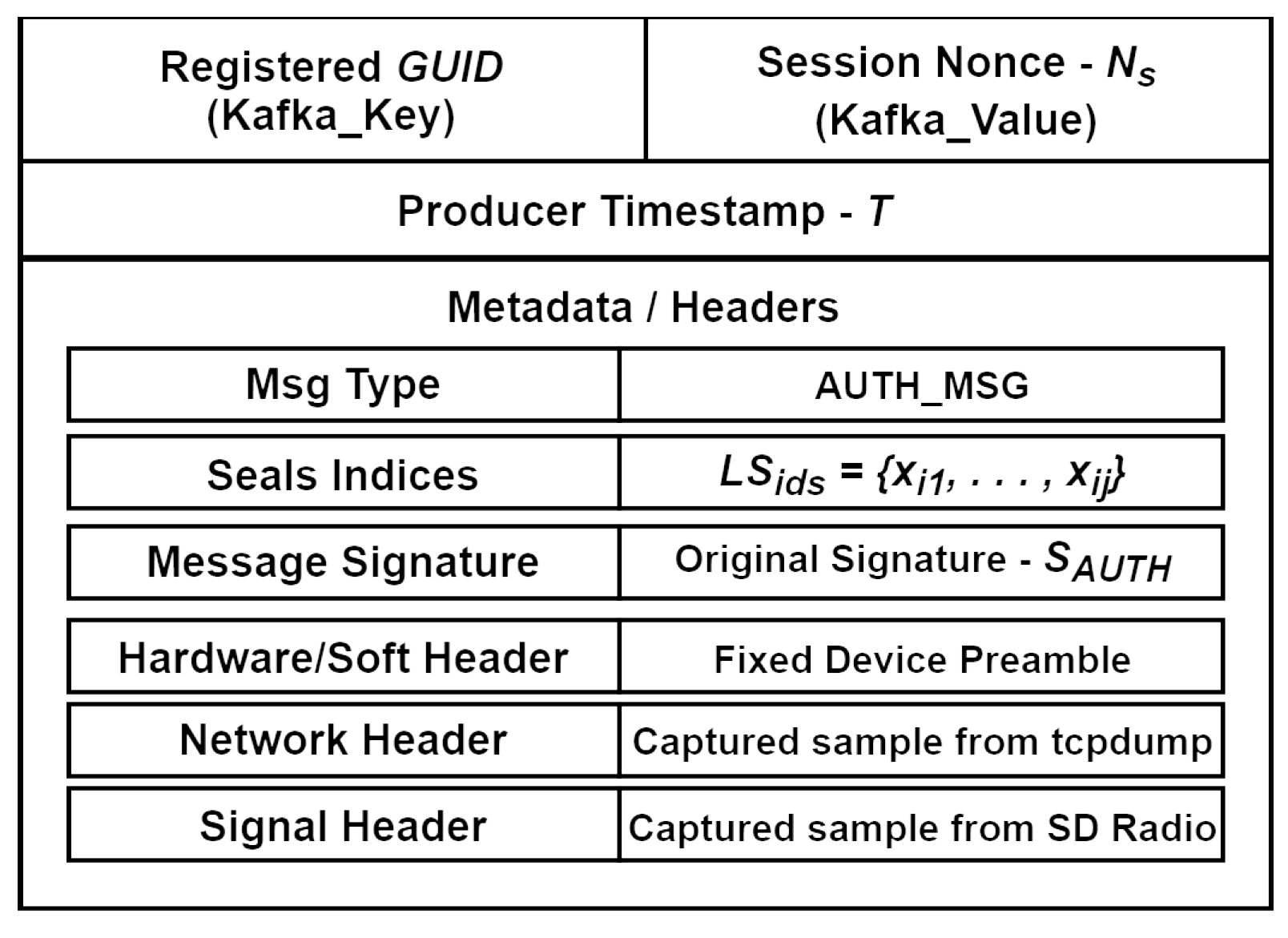
- Globally Unique Identifier, : This is assigned to the entity during the registration process in the device maintain layer. It functions as a unique identifier, ensuring that each device can be distinctly recognized within a set of registered devices. For example, it may be represented as a human-readable combination of the federated organization name, type, and number, such as ORG1-SENSOR-0001;
- Session Nonce, : This is a unique pseudo-random value generated by the entity that identifies a specific data stream, thus facilitating the correlation between the AUTH_MSG and the DATA_MSG;
- Seals Indices, : These consist of a subset of indexes for the seals selected from the secure seal store, , where the seal . For each specific seal we proposed to use a hashed exclusive OR multiplication ⊕ of the entity fingerprint sample, , recorded in the entity features store, , combined with internal parameters from the hardware security module, ;
- Timestamp, T: This is used as a protection mechanism against replay attacks. When the Kafka topic is configured to use CreateTime for timestamps, the timestamp of a record will be the time that the producer sets when the record (message) is created;
- Message Signatures, , : These are utilized to guarantee both the integrity and authenticity of the data streams. These signatures are compared to signature values calculated during the processing of messages within the streams microservice layer. The seal, , or subset of seals, , and session nonce work in conjunction with a key-derivation function to generate the key for the signature function, . The use of signatures fits naturally into the architecture of our system because of the Kafka message format autonomy (independence).


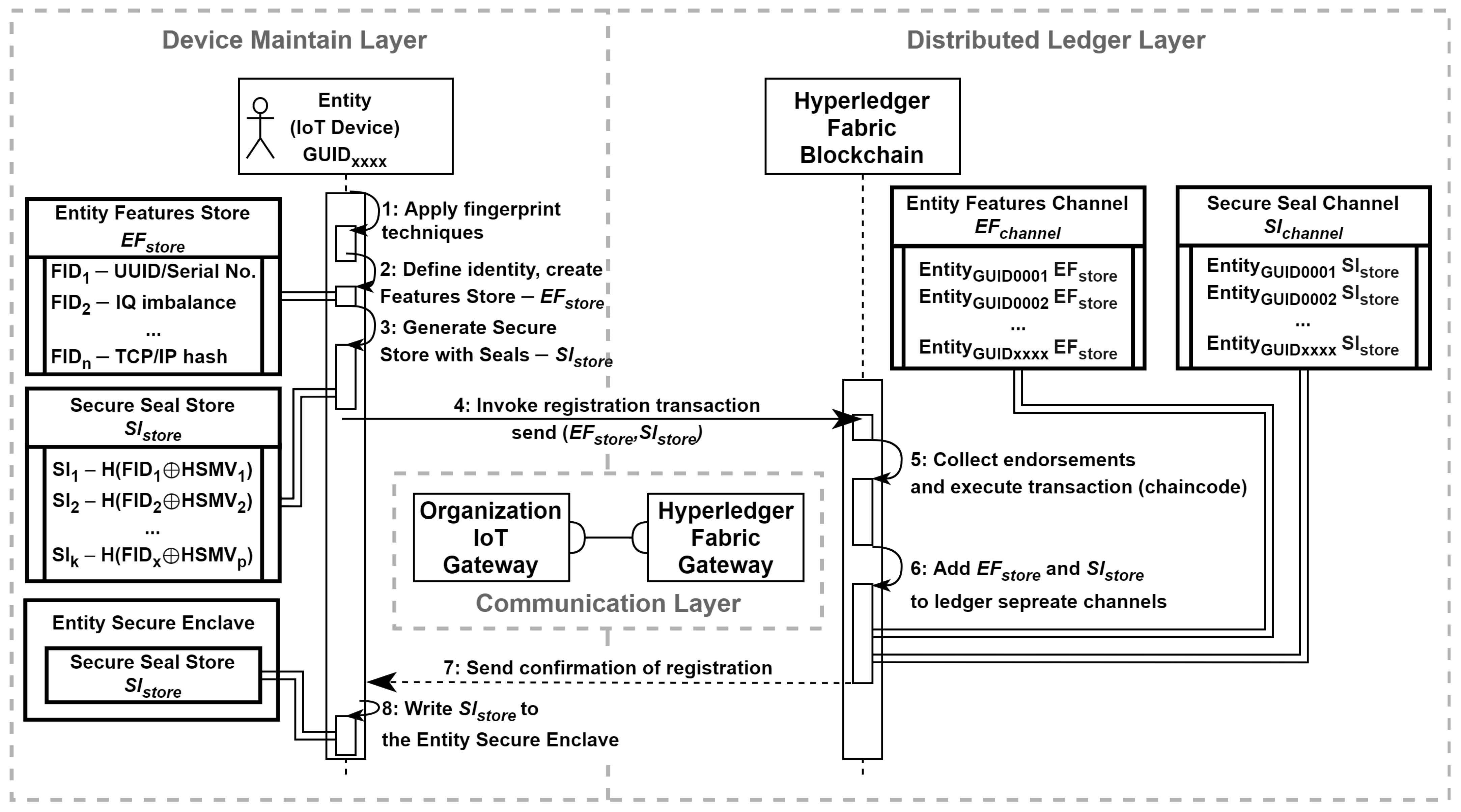
4.2. Entity Registration
- Step 1: The device registration process begins with the device maintain layer defining an entity’s identity through hybrid fingerprint techniques. This operation is conducted within a secure enclave (e.g., TEE);
- Step 2: The entity’s identity, represented by fingerprint samples, is recorded in the entity features store, ;
- Step 3: A set of seals, , is generated based on a subset of fingerprint samples from the features store. For each specific seal, , we proposed to use a hashed exclusive OR multiplication ⊕ of the feature sample, , combined with internal parameters from the hardware security module, ;
- Step 4: The chaincode is invoked, a component of the distributed ledger layer that manages the secure transaction of adding a new identity to the ledger. This transaction incorporates entity features and secure seal stores as part of its payload, .
- Step 5: The transaction is executed upon receiving the necessary approvals from the organizations specified by the endorsement policy. This step is crucial for ensuring the integrity and transparency of the ledger, as it guarantees that all identities are accurately and securely recorded;
- Step 6: The entity features and secure seal store are recorded in the distributed ledger through separate channels: an entity features channel, , and a secure seal channel, , respectively;
- Step 7: A confirmation of the registration is sent back to the device maintain layer;
- Step 8: Considering the confidential computing strategy, the is written to the entity’s secure enclave. Any cached values related to the registration process should be cleared (wiped out).
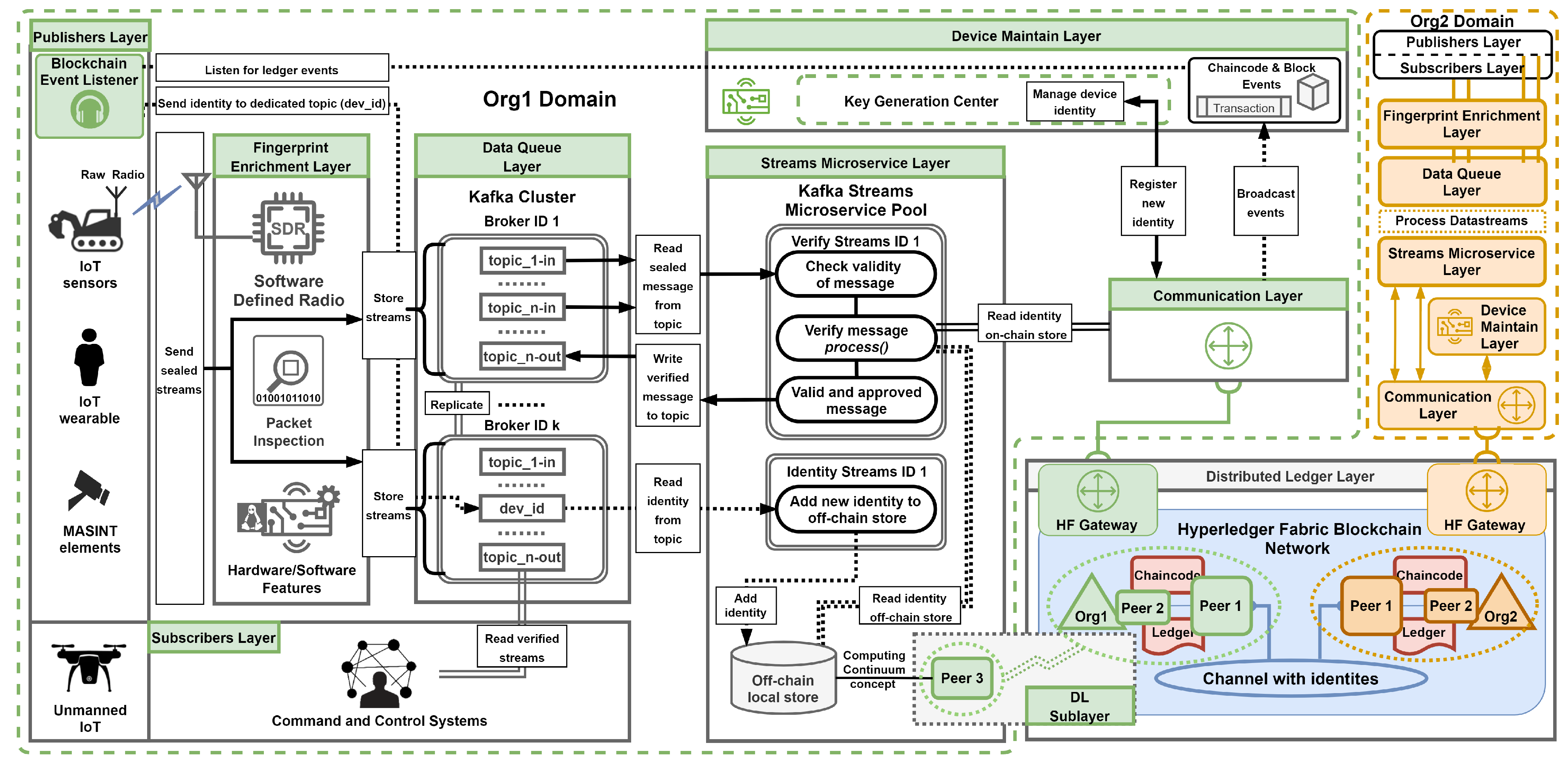
4.3. Blockchain Event Listener Application
- Step 1–4: These remain the same as for registering the entity identity top-sequence diagram (Figure 8);
- Step 5: Upon receiving the necessary approvals from the organizations specified by the endorsement policy, the transaction is executed (the distributed ledger layer);
- Step 6: The entity features and secure seal stores are recorded in the distributed ledger through separate channels: and ;
- Step 7: An application called the blockchain event listener monitors events that are emitted by the distributed ledger layer. This application represents a special entity within the publisher’s layer. As a result of the approved and executed transaction, the and the seal store are written to the event payload. Then, the event is emitted by the distributed ledger layer.
- Step 8: A confirmation of the registration is sent back to the device maintain layer;
- Step 9: The secure seal store is written to the entity’s secure enclave (the device maintain layer);
- Step 10: The blockchain event listener (the publisher’s layer) interprets the occurrence of the event, and the seal store is extracted from the event payload;
- Step 11: The seal store extracted from the event payload is written to the data queue layer (Kafka Cluster). The dedicated Kafka topic is utilized for this purpose;
- Step 12: The streams microservice layer reads the seal store from the cluster in a sequential manner;
- Step 13: During the process() method handled by the streams microservice layer, the seal store is added to the local off-chain data store and can be utilized by other streams microservices within the pool.

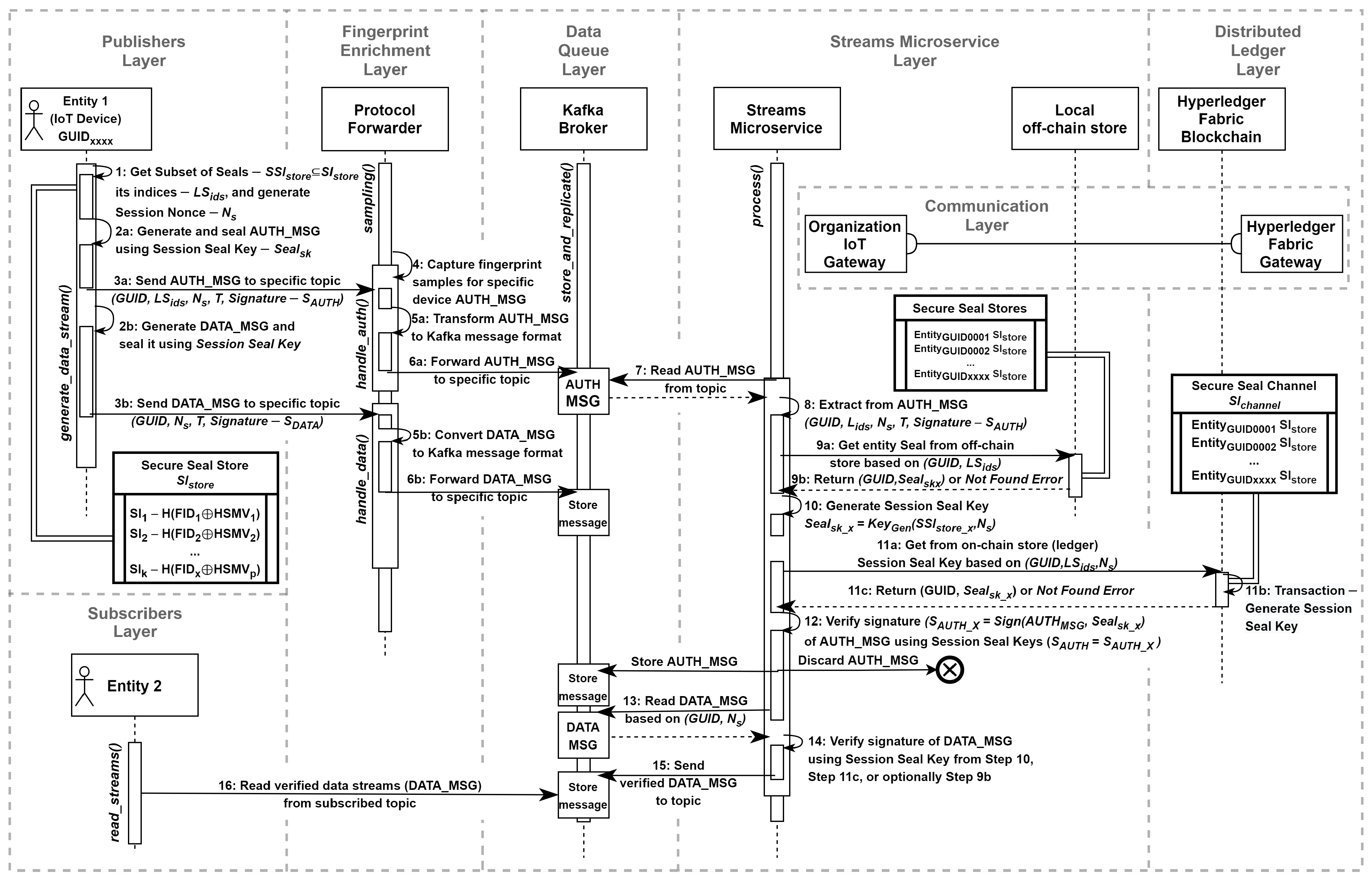
4.4. Data Streams Verification
- Step 1: When an entity (IoT device) from the publisher’s layer intends to transmit a data stream, it invokes the generate_data_stream() method. During this execution, initial parameters for the cryptographic primitive (sealing) are chosen from the secure seal store, , where the seal, , or subset of seals, , is selected along with its corresponding indices, , and a session nonce, , is generated;
- Step 2a: For the chosen seal and the session nonce, a session seal key is generated, . Next, the AUTH_MSG is crafted and sealed using a signature algorithm founded on the specified parameters: ;
- Step 2b: Subsequently, the session-related data stream messages are sealed using the session seal key generated in Step 2a: ;
- Step 3a: The sealed AUTH_MSG is transmitted through a reliable communication channel via the fingerprint enrichment layer to the data queue layer (Kafka Cluster), stored under a designated topic. The AUTH_MSG includes ;
- Step 3b: The sealed DATA_MSG messages are transmitted in the same manner as described in Step 3a. The DATA_MSG contains ;
- Step 4: Optionally, within the fingerprint enrichment layer, specialized behavior-based analyzers handle the sampling() method to capture fingerprint samples associated with a specific device’s AUTH_MSG;
- Step 5a: The handle_auth() method transforms the raw AUTH_MSG message into a structure suitable for loading into the Kafka Broker;
- Step 5b: The handle_data() method transforms the raw DATA_MSG message into a format that can be processed by the data queue layer;
- Step 6a: The data stream authentication message, AUTH_MSG, is forwarded to the data queue layer;
- Step 6b: The session-related messages, DATA_MSG, are forwarded;
- Step 7: The process() method of the streams microservice layer sequentially reads the AUTH_MSG message from the specified topic;
- Step 8: The parameters are extracted from the AUTH_MSG for subsequent verification;
- Step 9a: The micro-caching mechanism is utilized. The verify streams microservice queries local off-chain storage to retrieve the device fingerprint (identity) that sealed the message. The query is composed of the GUID and seals indices (). As an extension, a stored procedure or a trigger-like mechanism can be employed with the local off-chain storage to generate the session seal key, . In this case, the body query is extended with the session nonce parameter (), allowing for a reduction in the number of steps necessary before proceeding to Step 12. The confidential computing strategy should be implemented to ensure the strict protection of data in transit;
- Step 9b: The appropriate identity is returned, or an identity showing Not Found Error is generated. If the extension mentioned in Step 9a is applied, an alternate response of is returned;
- Step 10: If the session seal key, , is successfully generated (or obtained), the steps related to querying the distributed ledger layer (Hyperledger Fabric) are omitted, and Step 12 is executed instead;
- Step 11a: Otherwise, the identity Not Found Error results in a query via the communication layer to the Hyperledger Fabric Gateway service of the distributed ledger layer;
- Step 11b: The chaincode (transaction) is executed to generate based on the device GUID, a list of seal indices, and the session nonce ;
- Step 11c: The device GUID along with the session seal key is returned from the ledger , or a relevant error is produced;
- Step 12: Entity identities are compared by verifying the extracted signature that sealed the AUTH_MSG against the signature, , with the session seal key returned from Step 10, Step 11c, or optionally, Step 9b. If the signatures match (), the AUTH_MSG undergoing the verification process will be preserved. If they do not match, the message may either be discarded or stored in a separate queue for the identification of potentially malicious or faulty devices;
- Step 13: The streams microservice sequentially reads and verifies the session-related messages, DATA_MSGN si;
- Step 14: The session seal key from either Step 10 or Step 11c is used, and the signatures of the DATA_MSG are compared;
- Step 15: Verified DATA_MSG is sent to the appropriate topic;
- Step 16: An entity representing the subscribers layer reads the verified data streams read_streams() based on the subscribed topics and the authorization policy.
5. Security and Reliability Risk Assessment
5.1. Analysis of Attack Resilience
5.1.1. General Attacks
5.1.2. Perception Layer Attacks
- Device capture: The attacker can access the IoT device and generate messages sealed with its identity. In this situation, it is assumed that such a device’s behavioral pattern (distinctive features) will change. Consequently, it will be possible to use analytics tools (SIEM) to detect these changes, mainly related to network fingerprints. Moreover, when a compromised device is detected, it can be immediately marked and revoked from the distributed ledger. Also, security enclaves (e.g., HSM) can increase device resilience against capture and manipulation.
- Malicious devices: The attack involves adding a fake IoT device to the network. In our structure, a device is registered once in a protected environment. Therefore, we assume that the process will be coordinated by an authorized person. Therefore, it is not possible to register a fake device. If a device is not registered, it will not be authenticated and messages from such a device will be rejected, and consequently, the device will be detected and blocked.
- Device tampering: The attack consists of changing software or hardware components of the IoT device. In our framework, any changes to a unique device fingerprint would generate numerous failed verification attempts.
- Sybil attacks: The attack consists of having a multi-identity device by the IoT device. This situation is prevented via a secure registration process.
- Side-channel (timing) attacks: Attacks consist of obtaining the key by analyzing the implementation of the protocol (e.g., current power consumption and time dependencies). The framework could be susceptible to a timing attack when the device uses unique data to seal messages. In this situation, it is possible to predict from where these data are read, but not the values of these data; therefore, we believe that this attack is rather difficult to perform in practice.
5.1.3. Network Layer Attacks
- Eavesdropping: This attack involves eavesdropping on transmissions and obtaining messages (credentials). In our framework, we have separated the key used to secure the communication channel for IoT devices from the key used for the data authenticity protection mechanism. Only the registration phase is critical and must be carried out in a protected, trusted environment.
- Replay attack: This attack is based on intercepting a message and sending it later. In the case of the developed solution, it is impossible to perform this attack because each message contains a creation timestamp, which is verified. When decrypting the message, the IoT device or the gateway compares this timestamp with the current time. The disadvantage of this solution is having a correctly synchronized time on each IoT device.
- Packet injection: This attack involves injecting packets to disrupt communications. In the case of our framework, the attack can consist of duplicating transmitted packets or creating invalid packets. Since the packets are verified by the streams microservice layer in both cases, the recipient will ignore them.
- Session hijacking: This attack compromises the session key by stealing or predicting. Within our framework, it is mitigated through the session nonce, timestamps, and the device-based key used for data authenticity.
- Man-in-the-Middle: This attack consists of changing the messages sent between the IoT device and the verifying microservices. Any change to the message will prevent it from being verified due to the data authenticity protection mechanism. Moreover, invalid messages can be logged to identify faulty (malicious) devices.
5.1.4. Application Layer Attacks
- Storage attack: This attack consists of changing device identity features. To prevent this attack, access to the device should be properly secured to prevent changes to data stored in it. In our framework, if the device identity is changed, the device will not be able to authenticate itself. It is almost impossible to change data in a distributed ledger without the knowledge and consent of the organization that owns the IoT device.
- Malicious insider attack: This attack consists of using credentials by an authorized person. In the framework, access to data stored in the Hyperledger Fabric is possible only by an authenticated and authorized entity that uses an appropriate private key and a valid X.509 certificate. Each access attempt is logged. Resistance to this attack can be enhanced by using SIEM.
- Abuse of authority: The possibility of a successful attack is minimized through chaincodes designed to verify every operation performed on data stored in the distributed ledger. For this reason, each organization has, among other things, the ability to modify the permissions of its IoT devices, but unauthorized entities cannot perform this.
- Permissions modification by unauthorized users: In the framework, the modification of permissions is only possible through chaincodes; thus, any modification requires the conditions written in the chaincode to be met. If the chaincode is written correctly, only the device owner or authorized entity can modify the device’s IoT permissions.
5.2. Analysis of Fault Resilience
- Distributed ledger node failures: In our framework, we propose that each organization has a minimum of two nodes. Since the data in the blockchain are replicated, the failure of a single node does not affect the operation of the entire Hyperledger Fabric network.
- Kafka cluster (brokers) failure: In our framework, it is possible to maintain the availability of data generated by IoT devices by using the built-in synchronization mechanism and setting an appropriate replication factor.
6. Framework Evaluation
6.1. Cloud Setup
6.2. Resource-Constrained Setup
6.3. Processing Systems Benchmarking
- Configuration of the data queue layer: number of brokers, partitions, and data stream replication factor;
- Parallelization (horizontal-scaling) of stream processors (microservices);
- Kind (e.g., windowed aggregation) and type of operations (e.g., stateless);
- Number of organizations that joined a federated IoT environment and registered devices (identity count);
- Number of peers of the distributed ledger layer;
- Selected programming language for microservices and chaincodes.
6.3.1. Data Dissemination System Benchmarking
6.3.2. Distributed Ledger System Benchmarking
6.3.3. Microservice Benchmarking
6.4. Resource Utilization
6.5. Power Consumption
- Devices for testing were deployed in their unmodified state, without any overclocking;
- The lower limit for CPU temperature (throttle protection) was not modified;
- No additional devices were connected to the GPIO and USB ports; an SSH connection was used to control the devices.
6.6. Processing Scenarios
6.6.1. Scenarios of Setup I: Cloud-Based Environment
- Setup I, Scenario I: This involved verifying the input (sealed) message by comparing the extracted device identity and the identity stored in the distributed ledger.
- Setup I, Scenario II: We verify the sealed message by comparing the extracted device identity with the identity stored in the off-chain data store. In this scenario, all device identities from the ledger were synchronized and stored in the off-chain store.
6.6.2. Scenarios of Setup II: Resource-Constrained Environment
- Setup II, Scenario I: This involved verifying the sealed message by comparing the extracted device identity with the identity stored in the distributed ledger located in the data center component, while also applying the burst at startup technique.
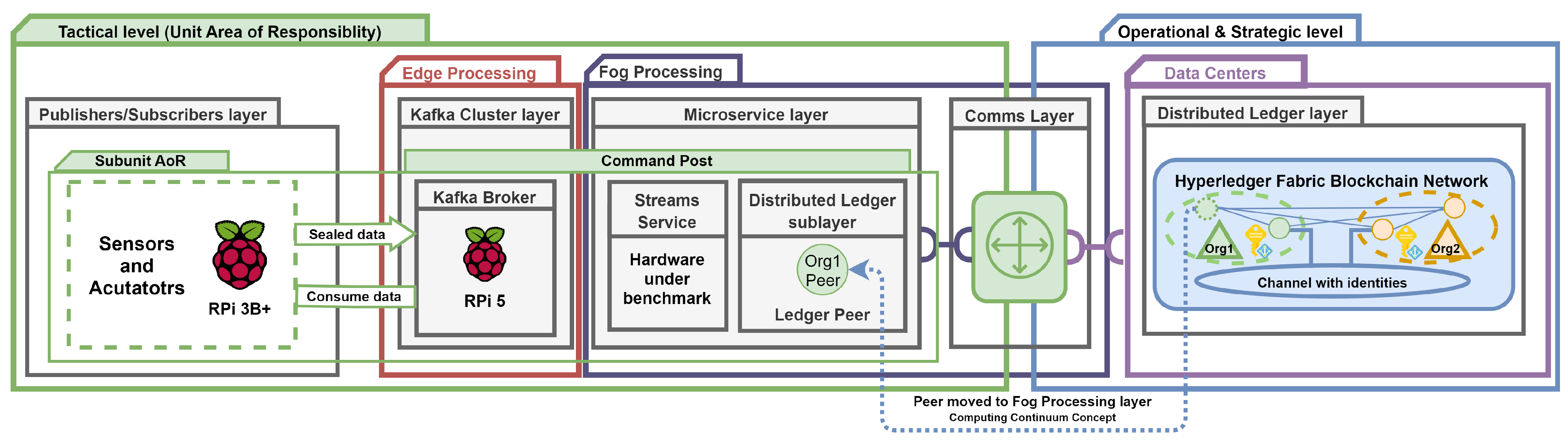
- Setup II, Scenario II: We verified the sealed message by comparing the extracted device identity with the identity stored in the ledger peer relocated to the Fog processing component (the continuum computing concept enabled). The burst at startup technique was applied.
- Setup II, Scenario III: We verified the sealed message by comparing the extracted device identity with the identity stored in the distributed ledger within the data center component. Throughout this scenario, continuous writing operations were conducted to the data queue layer, maintaining a consistent message (real-world data flow) throughput of 400 messages per second [32].
6.7. Reference Points for Experiments
6.7.1. Processing Scenarios
- Average (Avg), i.e., the average absolute deviations of data points from their mean value (Avg Dev), and minimum (Min) latency;
- Standard deviation based on the entire population (Pop Std Dev);
- Confidence intervals for the mean and standard deviation of the normal distribution ([]);
- Quantiles of order: p90, p95, and p99 (percentiles [).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| Crypt. Prim. Init | 0.003 (0.0001) | 0.001 (0.0001) | 0.001 (0.0001) | 0.005 (0.0003) | [0.0003; 0.0003; 0.0004] | [0.004 (0.0003); 0.006 (0.0002); 0.009 (0.0005)] |
| DL Query | 5.69 (0.10) | 0.89 (0.08) | 3.56 (0.07) | 1.74 (0.36) | [0.0286; 0.0341; 0.0448] | [6.95 (0.17); 7.71 (0.23); 10.96 (0.78)] |
| HMAC Validation | 0.006 (0.0002) | 0.002 (0.0001) | 0.001 (0.0001) | 0.004 (0.0004) | [0.0001; 0.0001; 0.0001] | [0.009 (0.0003); 0.012 (0.0004); 0.022 (0.0009)] |
| AES Decryption | 0.024 (0.0006) | 0.009 (0.0005) | 0.006 (0.0004) | 0.021 (0.0064) | [0.0003; 0.0004; 0.0005] | [0.041 (0.0015); 0.052 (0.0015); 0.083 (0.0028)] |
| Msg Forwarding | 0.030 (0.0007) | 0.015 (0.0005) | 0.005 (0.0008) | 0.089 (0.0073) | [0.0015; 0.0017; 0.0023] | [0.051 (0.0016); 0.077 (0.0017); 0.117 (0.0031)] |
| Full Processing | 5.76 (0.10) | 0.90 (0.08) | 3.59 (0.07) | 1.76 (0.36) | [0.0290; 0.0345; 0.0453] | [7.04 (0.17); 7.81 (0.24); 11.05 (0.79)] |
| Chaincode Exec (logs) | 1.10 (0.02) | 0.19 (0.03) | 0.00 (0.00) | 0.49 (0.06) | [0.0081; 0.0096; 0.0126] | [1.10 (0.18); 2.00 (0.00); 3.00 (0.00)] |
| gRPC Call (logs) | 2.47 (0.11) | 0.34 (0.07) | 1.51 (0.02) | 0.70 (0.19) | [0.0115; 0.0137; 0.0180] | [2.93 (0.27); 3.29 (0.42); 4.71 (0.69)] |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| Crypt. Prim. Init | 0.009 (0.0003) | 0.002 (0.0001) | 0.001 (0.0002) | 0.004 (0.0005) | [0.0001; 0.0001; 0.0001] | [0.012 (0.0004); 0.015 (0.0011); 0.029 (0.0046)] |
| DL Query | 4.23 (0.23) | 0.81 (0.15) | 2.64 (0.11) | 1.40 (0.25) | [0.0230; 0.0274; 0.0361] | [5.44 (0.54); 6.56 (0.60); 9.56 (1.31)] |
| HMAC Validation | 0.011 (0.0003) | 0.002 (0.0004) | 0.002 (0.0002) | 0.008 (0.0049) | [0.0001; 0.0002; 0.0002] | [0.012 (0.0005); 0.016 (0.001); 0.031 (0.0064)] |
| AES Decryption | 0.009 (0.0006) | 0.003 (0.0009) | 0.001 (0.0002) | 0.012 (0.0074) | [0.0002; 0.0002; 0.0003] | [0.013 (0.001); 0.018 (0.0009); 0.037 (0.0038)] |
| Msg Forwarding | 2.197 (0.0914) | 0.276 (0.0321) | 1.499 (0.0590) | 0.760 (0.1696) | [0.0125; 0.0149; 0.0196] | [2.526 (0.0845); 2.688 (0.0866); 3.813 (0.6615)] |
| Full Processing | 6.48 (0.24) | 0.95 (0.13) | 4.30 (0.17) | 1.67 (0.20) | [0.0275; 0.0327; 0.0430] | [7.87 (0.47); 9.08 (0.63); 13.12 (1.55)] |
| Chaincode Exec (logs) | 1.31 (0.12) | 0.48 (0.13) | 0.00 (0.00) | 0.86 (0.18) | [0.0141; 0.0169; 0.0222] | [1.90 (0.36); 2.9 (0.36); 4.9 (0.9)] |
| gRPC Call (logs) | 2.81 (0.16) | 0.58 (0.13) | 1.72 (0.06) | 0.99 (0.20) | [0.0163; 0.0194; 0.0255] | [3.67 (0.41); 4.60 (0.51); 6.69 (0.86)] |
6.7.2. Resource Utilization
6.7.3. Power Consumption
6.8. Benchmarks
- Processing Scenarios:
- Setup I Scenario I
- Setup II Scenario I
- Setup II Scenario II
- Resource Utilization:
- Power Consumption:
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABAC | Attribute-Based Access Control |
| ACL | Access Control List |
| AES | Advanced Encryption Standard |
| AWS | Amazon Web Services |
| AoR | Area of Responsibility |
| CC | Compute Continuum concept |
| CCTV | City Surveillance Camera |
| COTS | Commercial Off-The-Shelf |
| CP | Cold Ledger Peer Phase |
| DIL | Disconnected, Intermittent, Limited |
| DLT | Distributed Ledger Technology |
| FMN | Federated Mission Networking |
| gRPC | Remote Procedure Calls |
| GUID | Globally Unique Identifier |
| HADR | Humanitarian Assistance And Disaster Relief |
| HMAC | Keyed-Hash Message Authentication Code |
| HP | Hot Ledger Peer Phase |
| IOs | Information Objects |
| IPC | CPU Instructions per Clock |
| IoT | Internet of Things |
| JIT | Just-In-Time |
| JVM | Java Virtual Machine |
| KPIs | Key Performance Indicators |
| MQTT | MQ Telemetry Transport |
| NATO | North Atlantic Treaty Organization |
| PC | Power Consumption |
| RPi3 | Raspberry Pi 3 |
| RPi5 | Raspberry Pi 5 |
| SLap | Standalone Laptop |
| SS | Java JIT Steady State |
| TCP | Transmission Control Protocol |
| TLS | Transport Layer Security |
| UAV | Unmanned Aerial Vehicle |
| UDP | User Datagram Protocol |
| VoI | Value of Information |
| WS | Java JIT Warm-Up State |
References
- Johnsen, F.T.; Hauge, M. Interoperable, adaptable, information exchange in NATO coalition operations. J. Mil. Stud. 2022, 11, 49–62. [Google Scholar] [CrossRef]
- Zaccarini, M.; Cantelli, B.; Fazio, M.; Fornaciari, W.; Poltronieri, F.; Stefanelli, C.; Tortonesi, M. VOICE: Value-of-Information for Compute Continuum Ecosystems. In Proceedings of the 2024 27th Conference on Innovation in Clouds, Internet and Networks (ICIN), Paris, France, 11–14 March 2024; pp. 73–80. [Google Scholar] [CrossRef]
- Pióro, L.; Sychowiec, J.; Kanciak, K.; Zieliński, Z. Application of Attribute-Based Encryption in Military Internet of Things Environment. Sensors 2024, 24, 5863. [Google Scholar] [CrossRef]
- Hyperledger Fabric Documentation. Available online: https://hyperledger-fabric.readthedocs.io/ (accessed on 3 March 2025).
- Apache Kafka Streams API Documentation. Available online: https://kafka.apache.org/documentation/streams/ (accessed on 3 March 2025).
- Sarama Go Library. Available online: https://pkg.go.dev/github.com/shopify/sarama (accessed on 3 March 2025).
- Wang, X.; Zha, X.; Ni, W.; Liu, R.P.; Guo, Y.J.; Niu, X.; Zheng, K. Survey on blockchain for Internet of Things. Comput. Commun. 2019, 136, 10–29. [Google Scholar] [CrossRef]
- Kumar, R.; Khan, F.; Kadry, S.N.; Rho, S. A Survey on blockchain for industrial Internet of Things. Alex. Eng. J. 2021, 61, 6001–6022. [Google Scholar] [CrossRef]
- Alfandi, O.; Khanji, S.I.R.; Ahmad, L.; Khattak, A.M. A survey on boosting IoT security and privacy through blockchain. Clust. Comput. 2020, 24, 37–55. [Google Scholar] [CrossRef]
- Guo, S.; Wang, F.; Zhang, N.; Qi, F.; Song, Q.X. Master-slave chain based trusted cross-domain authentication mechanism in IoT. J. Netw. Comput. Appl. 2020, 172, 102812. [Google Scholar] [CrossRef]
- Xu, L.; Chen, L.; Gao, Z.; Fan, X.; Suh, T.; Shi, W.L. DIoTA: Decentralized-Ledger-Based Framework for Data Authenticity Protection in IoT Systems. IEEE Netw. 2020, 34, 38–46. [Google Scholar] [CrossRef]
- Khalid, U.; Asim, M.; Baker, T.; Hung, P.C.K.; Tariq, M.A.; Rafferty, L. A decentralized lightweight blockchain-based authentication mechanism for IoT systems. Clust. Comput. 2020, 23, 2067–2087. [Google Scholar] [CrossRef]
- Chung; Ferraiolo, D.; Kuhn, D.; Schnitzer, A.; Sandlin, K.; Miller, R.; Scarfone, K. Guide to Attribute Based Access Control (ABAC) Definition and Considerations; U.S. Department of Commerce: Washington, DC, USA, 2019. [CrossRef]
- Song, H.; Tu, Z.; Qin, Y. Blockchain-Based Access Control and Behavior Regulation System for IoT. Sensors 2022, 22, 8339. [Google Scholar] [CrossRef]
- Lu, Y.; Feng, T.; Liu, C.; Zhang, W. A Blockchain and CP-ABE Based Access Control Scheme with Fine-Grained Revocation of Attributes in Cloud Health. Comput. Mater. Contin. 2024, 78, 2787–2811. [Google Scholar] [CrossRef]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying IoT Devices in Smart Environments Using Network Traffic Characteristics. IEEE Trans. Mob. Comput. 2019, 18, 1745–1759. [Google Scholar] [CrossRef]
- Xu, Q.; Zheng, R.; Saad, W.; Han, Z. Device Fingerprinting in Wireless Networks: Challenges and Opportunities. IEEE Commun. Surv. Tutor. 2015, 18, 94–104. [Google Scholar] [CrossRef]
- Jagannath, A.; Jagannath, J.; Kumar, P.S.P.V. A Comprehensive Survey on Radio Frequency (RF) Fingerprinting: Traditional Approaches, Deep Learning, and Open Challenges. Comput. Netw. 2022, 219, 109455. [Google Scholar] [CrossRef]
- Jarosz, M.; Wrona, K.; Zieliński, Z. Distributed Ledger-Based Authentication and Authorization of IoT Devices in Federated Environments. Electronics 2024, 13, 3932. [Google Scholar] [CrossRef]
- Sanogo, L.; Alata, E.; Takacs, A.; Dragomirescu, D. Intrusion Detection System for IoT: Analysis of PSD Robustness. Sensors 2023, 23, 2353. [Google Scholar] [CrossRef]
- Chatterjee, B.; Das, D.; Maity, S.; Sen, S. RF-PUF: Enhancing IoT Security Through Authentication of Wireless Nodes Using In-Situ Machine Learning. IEEE Internet Things J. 2018, 6, 388–398. [Google Scholar] [CrossRef]
- Charyyev, B.; Gunes, M.H. IoT Traffic Flow Identification using Locality Sensitive Hashes. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Neumann, C.; Heen, O.; Onno, S. An Empirical Study of Passive 802.11 Device Fingerprinting. In Proceedings of the 2012 32nd International Conference on Distributed Computing Systems Workshops, Macau, China, 18–21 June 2012; pp. 593–602. [Google Scholar] [CrossRef]
- Jansen, N.; Manso, M.; Toth, A.; Chan, K.S.; Bloebaum, T.H.; Johnsen, F.T. NATO Core Services profiling for Hybrid Tactical Networks—Results and Recommendations. In Proceedings of the 2021 International Conference on Military Communication and Information Systems (ICMCIS), Hague, The Netherlands, 4–5 May 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Suri, N.; Fronteddu, R.; Cramer, E.; Breedy, M.R.; Marcus, K.M.; in’t Velt, R.; Nilsson, J.; Mantovani, M.; Campioni, L.; Poltronieri, F.; et al. Experimental Evaluation of Group Communications Protocols for Tactical Data Dissemination. In Proceedings of the MILCOM 2018—2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 133–139. [Google Scholar] [CrossRef]
- Rango, F.D.; Potrino, G.; Tropea, M.; Fazio, P. Energy-aware dynamic Internet of Things security system based on Elliptic Curve Cryptography and Message Queue Telemetry Transport protocol for mitigating Replay attacks. Pervasive Mob. Comput. 2020, 61, 101105. [Google Scholar] [CrossRef]
- Yang, M.; Margheri, A.; Hu, R.; Sassone, V. Differentially Private Data Sharing in a Cloud Federation with Blockchain. IEEE Cloud Comput. 2018, 5, 69–79. [Google Scholar] [CrossRef]
- Byabazaire, J.; O’Hare, G.M.P.; Collier, R.W.; Delaney, D.T. IoT Data Quality Assessment Framework Using Adaptive Weighted Estimation Fusion. Sensors 2023, 23, 5993. [Google Scholar] [CrossRef]
- Post-Quantum Cryptography PQC—Selected Algorithms: Digital Signature Algorithms. Available online: https://csrc.nist.gov/Projects/post-quantum-cryptography/selected-algorithms-2022 (accessed on 3 March 2025).
- Kul, S.; Tashiev, I.; Sentas, A.; Sayar, A. Event-Based Microservices with Apache Kafka Streams: A Real-Time Vehicle Detection System Based on Type, Color, and Speed Attributes. IEEE Access 2021, 9, 83137–83148. [Google Scholar] [CrossRef]
- Karimov, J.; Rabl, T.; Katsifodimos, A.; Samarev, R.S.; Heiskanen, H.; Markl, V. Benchmarking Distributed Stream Data Processing Systems. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018. [Google Scholar] [CrossRef]
- van Dongen, G.; den Poel, D.V. Evaluation of Stream Processing Frameworks. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1845–1858. [Google Scholar] [CrossRef]
- Bartock, M.; Souppaya, M.; Savino, R.F.; Knoll, T.; Shetty, U.; Cherfaoui, M.; Yeluri, R.; Malhotra, A.; Banks, D.; Jordan, M.; et al. Hardware-Enabled Security: Enabling a Layered Approach to Platform Security for Cloud and Edge Computing Use Cases; U.S. Department of Commerce: Washington, DC, USA, 2021. [CrossRef]
- Nakaike, T.; Zhang, Q.; Ueda, Y.; Inagaki, T.; Ohara, M. Hyperledger Fabric Performance Characterization and Optimization Using GoLevelDB Benchmark. In Proceedings of the 2020 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Toronto, ON, Canada, 2–6 May 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Swathi, P.; Venkatesan, M. Scalability improvement and analysis of permissioned-blockchain. ICT Express 2021, 7, 283–289. [Google Scholar] [CrossRef]
- Traini, L.; Cortellessa, V.; Pompeo, D.D.; Tucci, M. Towards effective assessment of steady state performance in Java software: Are we there yet? Empir. Softw. Eng. 2022, 28, 13. [Google Scholar] [CrossRef]
- Monitoring Linux with the Node Exporter. Available online: https://prometheus.io/docs/guides/node-exporter/ (accessed on 3 March 2025).
- Extra PMIC Features: RPi 4, RPi 5, and Compute Module 4. Available online: https://pip.raspberrypi.com/categories/685-whitepapers-app-notes/documents/RP-004340-WP/Extra-PMIC-features-on-Raspberry-Pi-4-and-Compute-Module-4.pdf (accessed on 3 March 2025).
- Kingman, J.F.C.; Atiyah, M.F. The single server queue in heavy traffic. Math. Proc. Camb. Philos. Soc. 1961, 57, 902–904. [Google Scholar] [CrossRef]
- Raspberry Pi Hardware—Power Supply: Typical Power Requirements. Available online: https://www.raspberrypi.com/documentation/computers/raspberry-pi.html#typical-power-requirements (accessed on 3 March 2025).
- Keval, H.U.; Sasse, M.A. to catch a thief—You need at least 8 frames per second: The impact of frame rates on user performance in a CCTV detection task. In Proceedings of the ACM Multimedia, Vancouver, BC, Canada, 27–31 October 2008. [Google Scholar] [CrossRef]
- Bekaroo, G.; Santokhee, A. Power consumption of the Raspberry Pi: A comparative analysis. In Proceedings of the 2016 IEEE International Conference on Emerging Technologies and Innovative Business Practices for the Transformation of Societies (EmergiTech), Balaclava, Mauritius, 3–6 August 2016; pp. 361–366. [Google Scholar] [CrossRef]

| Perception Layer | Network Layer | Application Layer |
|---|---|---|
| DoS/DDoS | DoS/DDoS | DoS/DDoS |
| Spoofing | Spoofing | Spoofing |
| Cryptanalysis | Cryptanalysis | Cryptanalysis |
| Device capture | Eavesdropping | Storage attack |
| Malicious device | Replay attack | Malicious insider attack |
| Device tampering | Packet injection | Abuse of authority |
| Side-channel (timing) attacks | Session hijacking | Permissions modification by unauthorized users |
| Sybil attack | Man-in-the-middle attack |
| Framework Layer | Hardware/Software Component | Description |
|---|---|---|
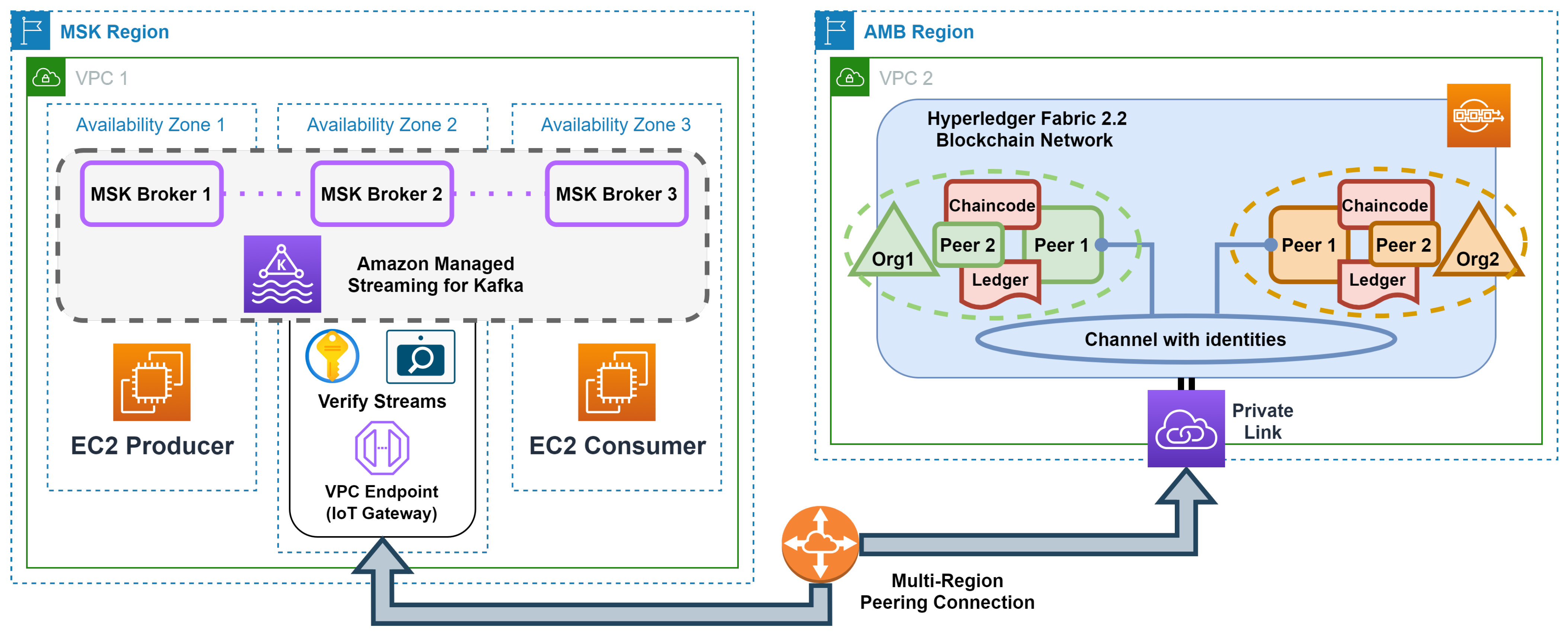
| Communication | Amazon Virtual Private Cloud (VPC) and PrivateLink interface (VPC Endpoint) | The multi-region link was set to connect two AWS regions that simulate geographical distances: the MSK region belongs to Org1 and the AMB region belongs to Org1 and Org2. Moreover, the VPC Endpoint enables the communication between the streams microservice and the distributed ledger layer. |
| Publishers/Subscribers | Two Amazon Elastic Compute Cloud (EC2) virtual machines: t2.micro (vCPU: 1 and Memory: 1 GiB) | Virtual machines were deployed in the MSK region in two isolated (availability) zones to simulate the Org1 data stream producer and consumer. |
| Data Queue | Cluster of the Amazon Managed Streaming for Apache Kafka (ver. 2.8.1) that consists of three brokers: kafka.t3.small (vCPU: 2 and Memory: 2 GiB) | To ensure durability (fault tolerance), cluster brokers were deployed in separate MSK region zones. Furthermore, each broker has a default configuration with a single partition and a replication factor of three. |
| Streams Microservice | Single EC2 virtual machine: t2.micro (vCPU: 1 and Memory: 1 GiB) | A Java microservice was deployed in the MSK region to verify data streams. |
| Distributed Ledger | Amazon Managed Blockchain Starter Edition for Hyperledger Fabric (ver. 2.2) with two nodes (peers) per organization: bc.t3.small (vCPU: 2 and Memory: 2 GiB) | Ledger peers were deployed in the AMB region, where a single channel for identities was created within the blockchain network. Each member (Org1 and Org2) of the channel has two peers to ensure durability. |
| Framework Layer | Hardware/Software Component | Description |
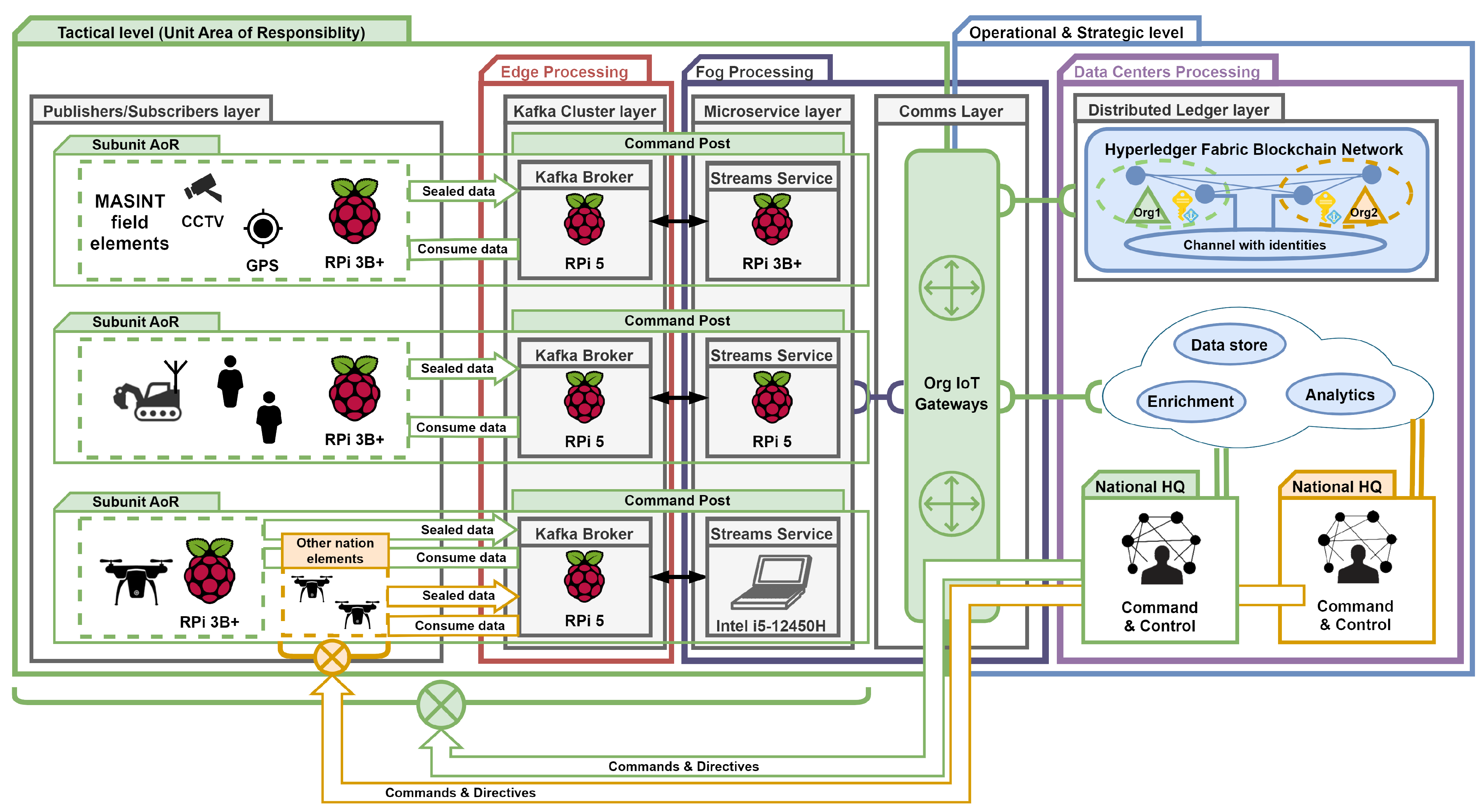
|---|---|---|
| Communication | Gigabit switch and an IEEE 802.11 router | At the Tactical level (unit area of responsibility, AoR), three zones (subunit command posts) were designated to simulate geographical distances. |
| Publishers/Subscribers | Three RPi3 (CPU: 1.4 GHz Arm Cortex A53 and Memory: 1 GiB) | Devices were deployed at each subunit AoR to be used as producers and consumers. |
| Data Queue | Cluster of the Apache Kafka that consist three brokers: RPi5 devices (CPU: 2.4 GHz Arm Cortex A76 and Memory: 8 GiB) | Cluster was deployed in the edge processing location. Furthermore, each broker was configured with a single partition and a replication factor of three. |
| Streams Microservice | Three different devices: RPi3 (CPU: 1.4 GHz Arm Cortex A53 and Memory: 1 GiB), RPi5 (CPU: 2.4 GHz Arm Cortex A76 and Memory: 8 GiB), and SLap (CPU: 3.3 GHz i5-12450H and Memory: 16 GB) | Resource-constrained devices (RPi3 and RPi5) were used to test Java and Go microservices. The SLap platform was deployed as a reference for microservice benchmarking. All devices were placed in the Fog processing location. |
| Distributed Ledger | Hyperledger Fabric Blockchain Network (ver. 2.2) with two nodes (peers) per organization: VMs (vCPU: 2 and Memory: 2 GiB) | Ledger peers were deployed on a server using virtualization technology (data centers processing location). |
| Configuration Parameter | Description |
|---|---|
| linger.ms = 0 | The produce operation was set without artificial delay, and a record was sent immediately to the Kafka Cluster. |
| acks = all | Microservice reliability was configured to complete operations only after all in-sync replicas received the record and sent back an acknowledgment. This setting includes both publish and commit times, which adds latency overhead to our microservice. |
| ––replication-factor 3 | The replication factor of a single record was set to three. Fault-tolerance KPI. |
| num.replica.fetchers = 1 | The number of replica fetcher threads per source broker was set to the default value of one. |
| enable.idempotence = true | Idempotence was set. This enables the Kafka mechanism to identify and eliminate duplicate messages by comparing the unique sequence number of each record sent to a partition. |
| listeners | There was no separate listener for replication traffic on brokers and for client (producer/consumer) traffic. |
| fetch.min.bytes = 1 | The microservice record consumer was configured to operate without incurring any additional latency, while ensuring that the processing guarantee is established as exactly once. Upon submission of a fetch request by microservice, a response is provided immediately when a single byte of data (record) becomes available from the Kafka Broker. |
| Device Name | CPU Idle (%) | RAM Usage (%) | PC (W) |
|---|---|---|---|
| SM | 98.6 | 9.8 | 2.12 (0.18) |
| B1 | 98.7 | 5.5 | 2.20 (0.14) |
| B2 | 98.2 | 5.6 | 2.25 (0.18) |
| B3 | 98.1 | 5.7 | 2.30 (0.16) |
| Device Name | CPU Idle (%) | RAM Usage (%) | PC (W) |
|---|---|---|---|
| SM + CC | 98.1 | 20.6 | 2.15 (0.22) |
| B1 | 95.2 | 16.9 | 2.83 (0.51) |
| B2 | 94.8 | 17.1 | 2.71 (0.48) |
| B3 | 94.8 | 17.1 | 2.87 (0.49) |
| Sync State | CPU Idle (%) | RAM Usage (%) | PC (W) |
|---|---|---|---|
| No Sync | 98.1 | 20.6 | 2.15 (0.22) |
| Catch Up | 62.8 | 21.0 | 3.30 (0.72) |
| Concurrent | 97.1 | 21.0 | 2.18 (0.22) |
| Identity Count | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| 10,000 | 38.3 (0.76) | 3.0 (0.00) | 32.7 (0.56) | 5.5 (0.70) | [0.2861; 0.3409; 0.448] | [44.3 (0.76); 47.7 (1.24); 56.7 (2.16)] |
| 20,000 | 39.5 (1.20) | 4.0 (0.00) | 32.2 (1.28) | 6.6 (0.60) | [0.343; 0.409; 0.538] | [46.7 (1.90); 50.7 (1.70); 61.4 (2.00)] |
| 35,000 | 39.9 (1.12) | 3.7 (0.42) | 32.6 (1.08) | 5.9 (0.54) | [0.307; 0.366; 0.481] | [46.5 (1.10); 50.5 (1.30); 60.2 (2.16)] |
| 50,000 | 38.2 (1.28) | 3.3 (0.42) | 31.7 (1.30) | 5.5 (0.60) | [0.2861; 0.3409; 0.448] | [44.6 (1.72); 47.8 (2.00); 55.7 (2.70)] |
| 100,000 | 38.6 (0.72) | 3.3 (0.42) | 32.0 (0.40) | 5.5 (0.50) | [0.2861; 0.3409; 0.448] | [44.7 (0.56); 47.8 (0.64); 55.8 (1.64)] |
| Identity Count | |||||
|---|---|---|---|---|---|
| 10,000 | 20,000 | 35,000 | 50,000 | 100,000 | |
| Scenario I | 38.86 (0.64) | 39.95 (1.39) | 40.19 (0.98) | 38.59 (1.22) | 39.15 (0.61) |
| Scenario II | 20.42 (0.77) | 21.03 (1.20) | 21.15 (1.06) | 20.39 (1.12) | 20.06 (0.69) |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| Crypt. Prim. Init | 0.007 (0.0004) | 0.003 (0.0003) | 0.002 (0.0003) | 0.024 (0.0156) | [0.0004; 0.0005; 0.0006] | [0.010 (0.0005); 0.014 (0.0004); 0.027 (0.0005)] |
| DL Query | 7.20 (0.18) | 1.10 (0.19) | 5.29 (0.06) | 3.21 (2.66) | [0.0528; 0.0629; 0.0827] | [8.80 (0.33); 9.99 (0.43); 13.83 (0.76)] |
| HMAC Validation | 0.015 (0.0004) | 0.006 (0.0003) | 0.006 (0.0010) | 0.013 (0.0017) | [0.0002; 0.0003; 0.0003] | [0.022 (0.0004); 0.03 (0.0007); 0.062 (0.0016)] |
| AES Decryption | 0.057 (0.0017) | 0.027 (0.0005) | 0.024 (0.0037) | 0.061 (0.0100) | [0.001; 0.0012; 0.0016] | [0.098 (0.0034); 0.136 (0.0021); 0.244 (0.0041)] |
| Msg Forwarding | 0.082 (0.0021) | 0.044 (0.0021) | 0.027 (0.0038) | 0.262 (0.0435) | [0.0043; 0.0051; 0.0067] | [0.144 (0.0058); 0.193 (0.0046); 0.354 (0.0247)] |
| Full Processing | 7.38 (0.18) | 1.16 (0.18) | 5.38 (0.05) | 3.31 (2.64) | [0.0544; 0.0649; 0.0853] | [9.08 (0.32); 10.34 (0.41); 14.42 (0.74)] |
| Chaincode Exec (logs) | 1.19 (0.09) | 0.34 (0.14) | 0.00 (0.00) | 0.77 (0.19) | [0.0127; 0.0151; 0.0198] | [1.50 (0.60); 2.30 (0.48); 3.70 (0.84)] |
| gRPC Call (logs) | 2.55 (0.11) | 0.47 (0.11) | 1.57 (0.09) | 0.91 (0.16) | [0.015; 0.0178; 0.0234] | [3.28 (0.4); 3.89 (0.52); 5.59 (0.68)] |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| Crypt. Prim. Init | 0.004 (0.0002) | 0.002 (0.0003) | 0.002 (0.0001) | 0.006 (0.0038) | [0.0001; 0.0001; 0.0002] | [0.006 (0.0001); 0.007 (0.0003); 0.013 (0.002)] |
| DL Query | 4.24 (0.27) | 1.26 (0.16) | 2.50 (0.07) | 1.84 (0.28) | [0.0303; 0.0361; 0.0474] | [6.25 (0.39); 7.13 (0.52); 10.12 (1.03)] |
| HMAC Validation | 0.003 (0.0002) | 0.001 (0.0004) | 0.002 (0.0001) | 0.008 (0.0063) | [0.0001; 0.0002; 0.0002] | [0.004 (0.0001); 0.005 (0.0003); 0.011 (0.0019)] |
| AES Decryption | 0.005 (0.0006) | 0.002 (0.0010) | 0.003 (0.0001) | 0.015 (0.0131) | [0.0002; 0.0003; 0.0004] | [0.006 (0.0002); 0.008 (0.0006); 0.027 (0.0086)] |
| Msg Forwarding | 1.926 (0.0622) | 0.252 (0.0387) | 1.463 (0.0193) | 0.678 (0.1895) | [0.0112; 0.0133; 0.0175] | [2.221 (0.0706); 2.391 (0.1051); 3.691 (0.8053)] |
| Full Processing | 6.18 (0.29) | 1.33 (0.16) | 4.14 (0.11) | 1.91 (0.24) | [0.0314; 0.0374; 0.0492] | [8.30 (0.44); 9.32 (0.56); 13.00 (1.46)] |
| Chaincode Exec (logs) | 1.79 (0.21) | 1.05 (0.16) | 0.00 (0.00) | 1.48 (0.31) | [0.0243; 0.029; 0.0381] | [3.50 (0.50); 4.40 (0.48); 6.60 (0.72)] |
| gRPC Call (logs) | 3.24 (0.24) | 1.13 (0.16) | 1.73 (0.05) | 1.62 (0.3) | [0.0266; 0.0318; 0.0417] | [5.13 (0.31); 5.87 (0.48); 8.24 (0.67)] |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| Crypt. Prim. Init | 0.039 (0.0015) | 0.013 (0.0017) | 0.015 (0.0013) | 0.071 (0.017) | [0.0012; 0.0014; 0.0018] | [0.052 (0.0016); 0.067 (0.0018); 0.108 (0.0022)] |
| DL Query | 20.28 (0.29) | 3.70 (0.29) | 14.50 (0.13) | 11.28 (2.42) | [0.1856; 0.2211; 0.2906] | [25.49 (0.36); 29.99 (0.50); 42.24 (1.51)] |
| HMAC Validation | 0.078 (0.0012) | 0.019 (0.0014) | 0.046 (0.0063) | 0.063 (0.0288) | [0.001; 0.0012; 0.0016] | [0.097 (0.0019); 0.133 (0.0031); 0.236 (0.0035)] |
| AES Decryption | 0.280 (0.0061) | 0.109 (0.0068) | 0.148 (0.0100) | 0.321 (0.0980) | [0.0053; 0.0063; 0.0083] | [0.457 (0.0214); 0.586 (0.0152); 0.952 (0.0144)] |
| Msg Forwarding | 0.389 (0.0103) | 0.182 (0.0056) | 0.185 (0.0157) | 0.968 (0.0928) | [0.0159; 0.019; 0.0249] | [0.647 (0.0172); 0.866 (0.0355); 1.636 (0.1188)] |
| Full Processing | 21.14 (0.28) | 3.97 (0.28) | 15.02 (0.14) | 11.56 (2.37) | [0.1902; 0.2266; 0.2978] | [26.9 (0.33); 31.54 (0.45); 44.62 (1.55)] |
| Chaincode Exec (logs) | 1.14 (0.04) | 0.25 (0.07) | 0.00 (0.00) | 0.65 (0.21) | [0.0107; 0.0127; 0.0167] | [1.40 (0.48); 2.00 (0.00); 2.90 (0.72)] |
| gRPC Call (logs) | 2.58 (0.05) | 0.36 (0.05) | 1.37 (0.17) | 0.77 (0.18) | [0.0127; 0.0151; 0.0198] | [3.06 (0.07); 3.39 (0.15); 4.70 (0.58)] |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| Crypt. Prim. Init | 0.030 (0.0005) | 0.008 (0.0007) | 0.021 (0.0002) | 0.017 (0.0058) | [0.0003; 0.0003; 0.0004] | [0.043 (0.0013); 0.054 (0.0014); 0.085 (0.0072)] |
| DL Query | 5.10 (0.18) | 0.76 (0.15) | 3.72 (0.06) | 1.40 (0.40) | [0.023; 0.0274; 0.0361] | [6.14 (0.31); 7.08 (0.54); 10.49 (2.01)] |
| HMAC Validation | 0.030 (0.0009) | 0.008 (0.0012) | 0.023 (0.0001) | 0.023 (0.0071) | [0.0004; 0.0005; 0.0006] | [0.042 (0.0013); 0.052 (0.0035); 0.086 (0.0073)] |
| AES Decryption | 0.062 (0.0018) | 0.014 (0.0026) | 0.048 (0.0003) | 0.053 (0.0436) | [0.0009; 0.001; 0.0014] | [0.080 (0.0016); 0.091 (0.0023); 0.126 (0.006)] |
| Msg Forwarding | 2.591 (0.1124) | 0.303 (0.0225) | 1.947 (0.0196) | 0.703 (0.1376) | [0.0116; 0.0138; 0.0181] | [2.988 (0.1207); 3.204 (0.1204); 4.407 (0.3333)] |
| Full Processing | 7.86 (0.21) | 0.94 (0.14) | 6.04 (0.07) | 1.65 (0.37) | [0.0271; 0.0323; 0.0425] | [9.22 (0.33); 10.21 (0.62); 14.18 (2.01)] |
| Chaincode Exec (logs) | 1.20 (0.08) | 0.33 (0.11) | 0.00 (0.00) | 0.70 (0.19) | [0.0115; 0.0137; 0.018] | [1.64 (0.46); 2.18 (0.30); 3.45 (0.68)] |
| gRPC Call (logs) | 2.67 (0.15) | 0.44 (0.09) | 1.71 (0.07) | 0.84 (0.22) | [0.0138; 0.0165; 0.0216] | [3.32 (0.25); 3.87 (0.34); 5.61 (0.81)] |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| DL Query | 7.13 (0.19) | 1.10 (0.28) | 5.77 (0.02) | 1.40 (0.84) | [0.023; 0.0274; 0.0361] | [8.30 (0.05); 9.33 (0.09); 13.04 (0.20)] |
| Chaincode Exec (logs) | 0.79 (0.02) | 0.41 (0.01) | 0.00 (0.00) | 0.57 (0.01) | [0.0094; 0.0112; 0.0147] | [1.00 (0.00); 1.00 (0.00); 2.20 (0.32)] |
| gRPC Call (logs) | 2.67 (0.02) | 0.32 (0.02) | 2.04 (0.1) | 1.2 (0.8) | [0.0197; 0.0235; 0.0309] | [3.11 (0.03); 3.43 (0.06); 4.85 (0.11)] |
| Operation | Avg | Avg Dev | Min | Pop Std Dev | Confidence Intervals [] | Percentiles [p = 0.9; p = 0.95; p = 0.99] |
|---|---|---|---|---|---|---|
| DL Query | 3.23 (0.24) | 0.22 (0.06) | 2.83 (0.21) | 0.35 (0.06) | [0.0058; 0.0069; 0.009] | [3.59 (0.15); 3.79 (0.15); 4.51 (0.25)] |
| Chaincode Exec (logs) | 0.53 (0.26) | 0.35 (0.08) | 0.00 (0.00) | 0.43 (0.05) | [0.0071; 0.0084; 0.0111] | [1.00 (0.00); 1.00 (0.00); 1.10 (0.18)] |
| gRPC Call (logs) | 2.60 (0.20) | 0.17 (0.05) | 2.27 (0.18) | 0.27 (0.05) | [0.0044; 0.0053; 0.007] | [2.90 (0.13); 3.04 (0.12); 3.51 (0.18)] |
| Device Name | CPU Idle (%) | RAM Usage (%) | PC (W) |
|---|---|---|---|
| SM | 85.2 | 16.0 | 3.11 (0.63) |
| SM + CC | 60.1 | 31.6 | 3.88 (0.58) |
| B1 | 86.0 | 17.7 | 3.34 (0.68) |
| B2 | 83.3 | 17.8 | 3.32 (0.68) |
| B3 | 91.4 | 17.7 | 3.40 (0.66) |
| Device Name | CPU Idle (%) | RAM Usage (%) | PC (W) |
|---|---|---|---|
| SM | 96.1 | 11.0 | 2.27 (0.29) |
| SM + CC | 71.2 | 27.4 | 3.17 (0.59) |
| B1 | 86.4 | 17.9 | 3.29 (0.71) |
| B2 | 85.9 | 18.1 | 3.13 (0.66) |
| B3 | 92.4 | 18.0 | 3.21 (0.57) |
| Setup I, Scenario I: Suitable for audiovisual streams processing |
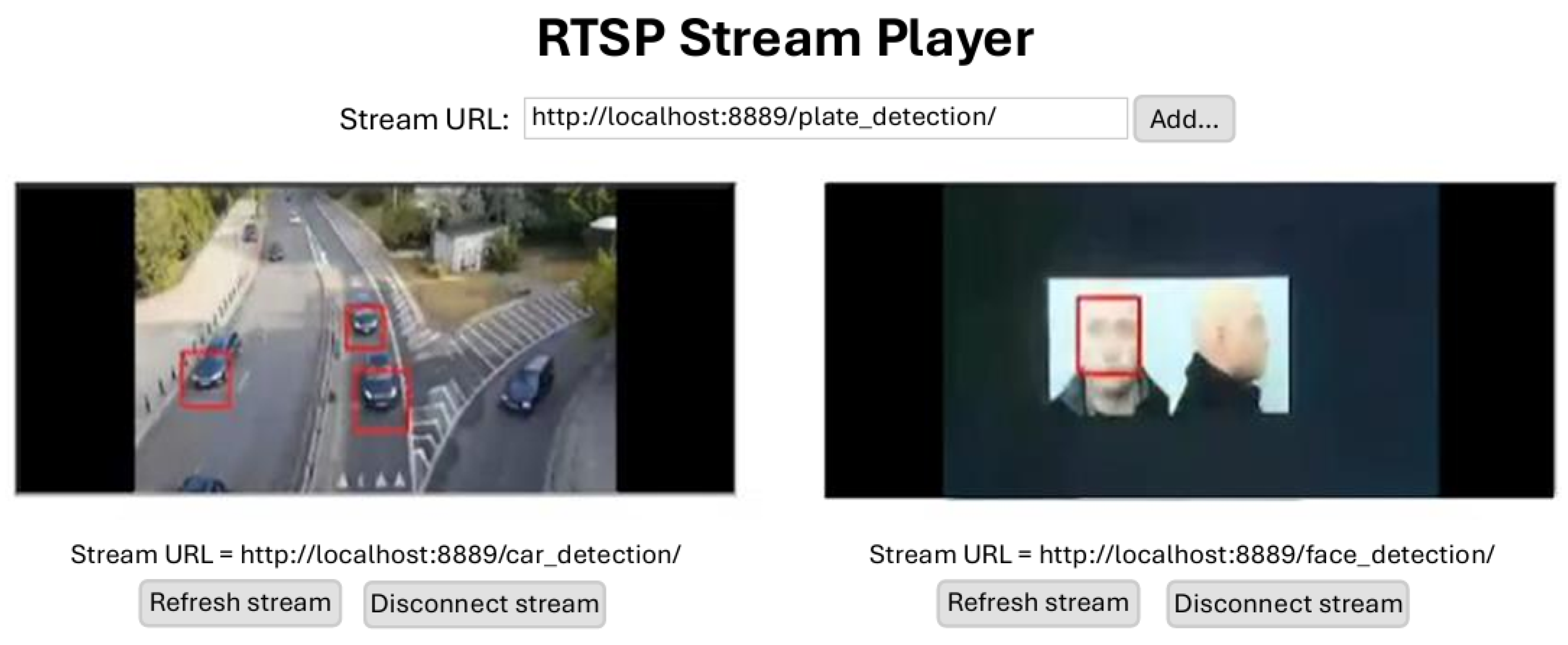
| The average time for a consumer to read the verified data stream was approximately 39 s. In the context of audiovisual streams, the measured time (1000 msg/39 s) represents about 25 frames per second (fps). Notably, the work of [41] demonstrated that CCTV cameras with a minimum 8 fps rate are required to identify objects on video correctly (Table 10). |
| Setup I, Scenario II: Microcaching with off-chain data store usage |
| The obtained results confirmed the rightness of local off-chain data store applicability as a microcaching mechanism for stream verification. The usage of the mentioned store almost doubled the reading time of data streams (Table 11). |
| Setup II, Scenario I: Resource-constrained Java microservice benchmarking |
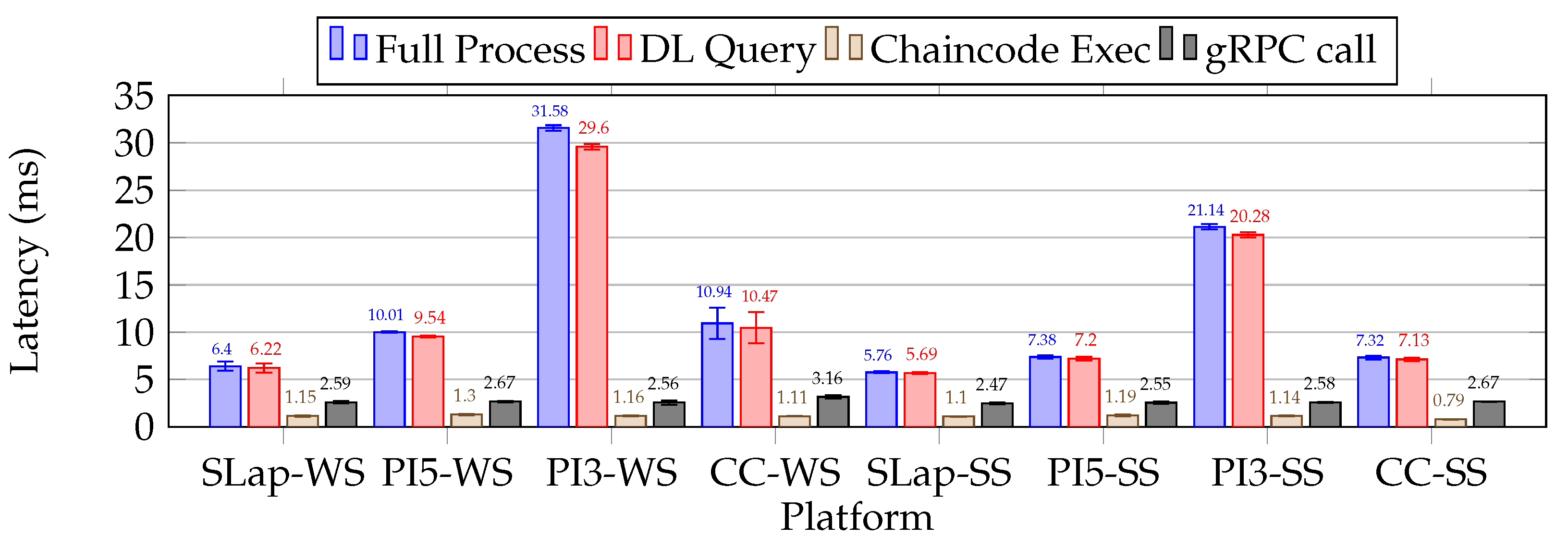
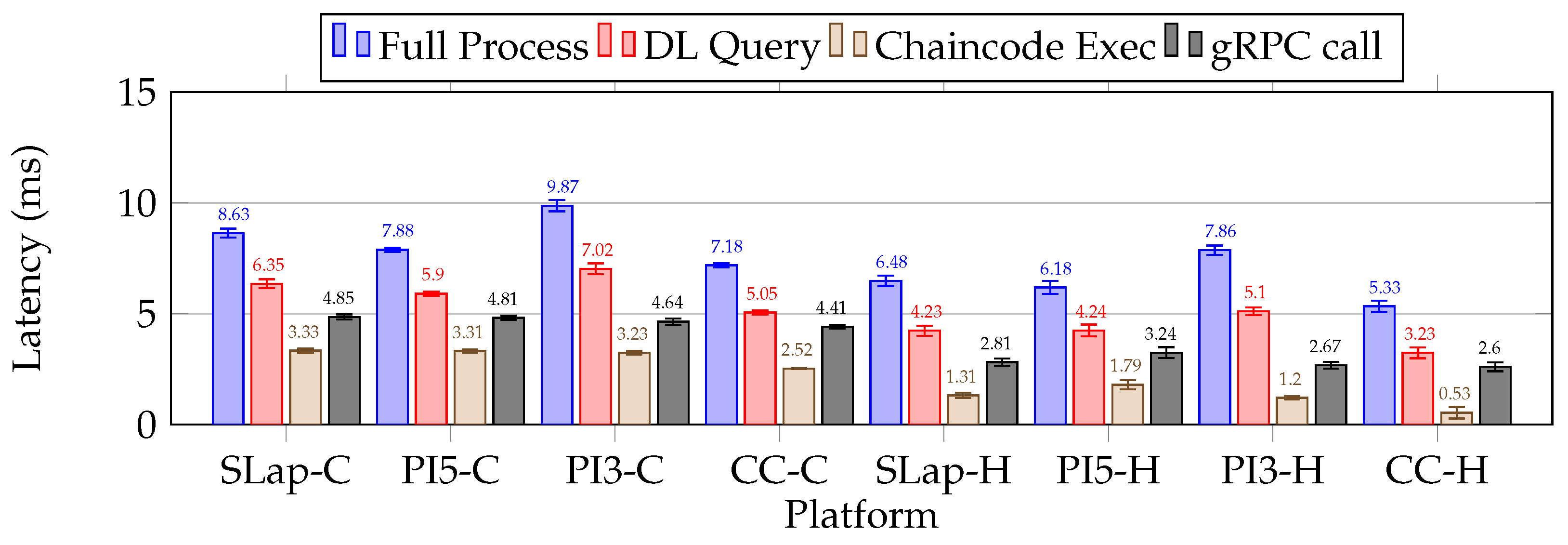
| The overall processing latency for the Java-based microservice on the RPi5 was 7.38 (±0.18) ms, which is approximately 1.62 ms longer than that on the SLap platform. Notably, 98.7% of this processing time was associated with the DL query operation. The RPi3 microservice execution exhibited a nearly three times greater latency than the RPi5 (Table 5, Table 12, and Table 14). |
| Setup II, Scenario I: Resource-constrained Go microservice benchmarking |
| For Go-based microservice execution, we observed that the RPi5 consistently outperformed both SLap and RPi3. The average time required to verify a single message on the RPi5 was 6.18 (±0.29) ms. Also, 68.6% was attributed to the DL query, while 31.2% was related to the message forwarding operation (Table 6, Table 13 and Table 15). |
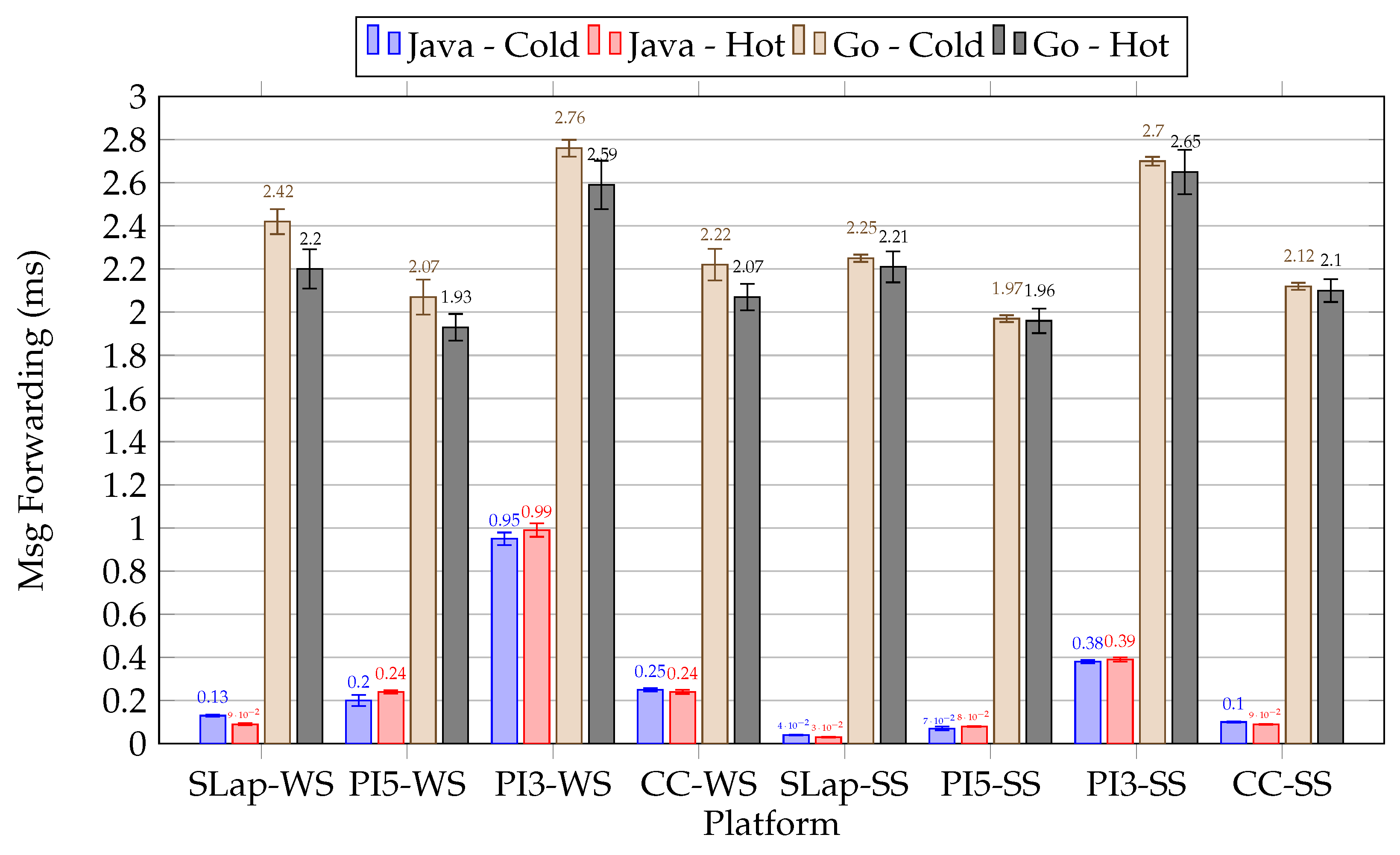
| Setup II, Scenario I: The message forwarding operation (libraries) comparison |
| We observed that when uniformly applying the configuration for the message forwarding operation, the Kafka Streams API outperforms the Sarama library. The discrepancies in latencies for stream forwarding can largely be attributed to the handling of synchronous operations and the wait time for acknowledgment responses. In contrast, the use of asynchronous data flow adversely affects reliability, which is not in alignment with the key performance indicators we have established (Figure 15). |
| Setup II, Scenario II: The computing continuum concept comparison |
| For cold and hot phases with the computing continuum enabled, the DL query operation exhibited the lowest latencies among all platforms, averaging 5.05 (±0.09) ms for CP and 3.23 (±0.24) ms for HP. Moreover, the latency for chaincode execution was more than twice as low on the CC platform compared to others. In contrast, latencies for gRPC calls remained largely consistent across the various platforms (Table 12 and Table 16; Figure 16 and Figure 17). |
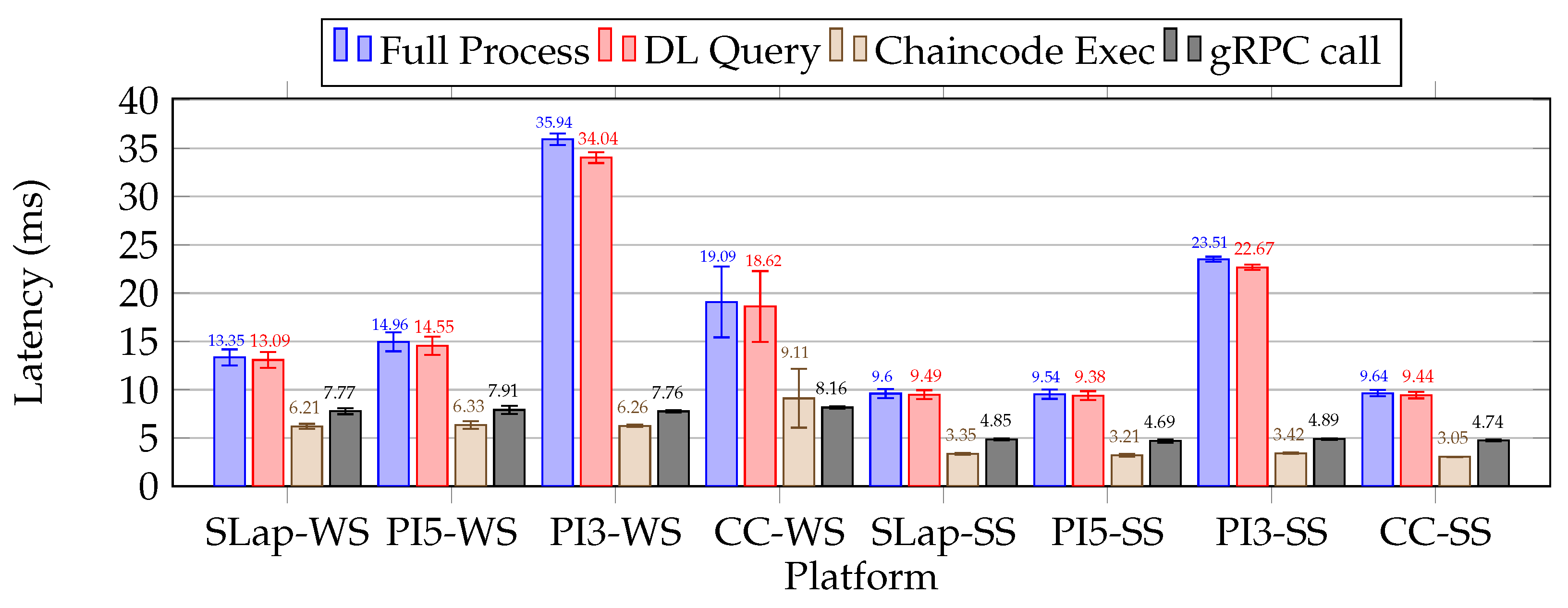
| Setup II, Scenario II: The ledger peer phase comparison |
| The phase of the ledger peer, whether it is cold or hot, combined with JVM dynamic compilation and garbage collection, results in fluctuations in internal operation latencies during the microservice warm-up state. We especially observed significant instability (deviations) in both chaincode execution and gRPC calls during testing that involved the warm-up state and the cold peer phase. We particularly noted the latency of chaincode execution, which averaged 9.11 (±3.04) ms. This was higher than the gRPC call average of 8.16 (±0.13) ms. This anomaly in the metrics can be attributed to the duration received from log entries, where the execution time for the chaincode is rounded to whole milliseconds. To mitigate this, we can estimate the duration of the warm-up state statically using tools such as the Java Microbenchmark Harness. However, one drawback of this approach is its dependence on the researcher’s coding experience, which can lead to inaccurate estimates. Alternatively, dynamic estimation methods can be employed, such as a sliding window, to compare the most recent iterations [36]. This approach can effectively reduce the duration of performance testing while maintaining an acceptable accuracy level (Table 13 and Table 17; Figure 18). |
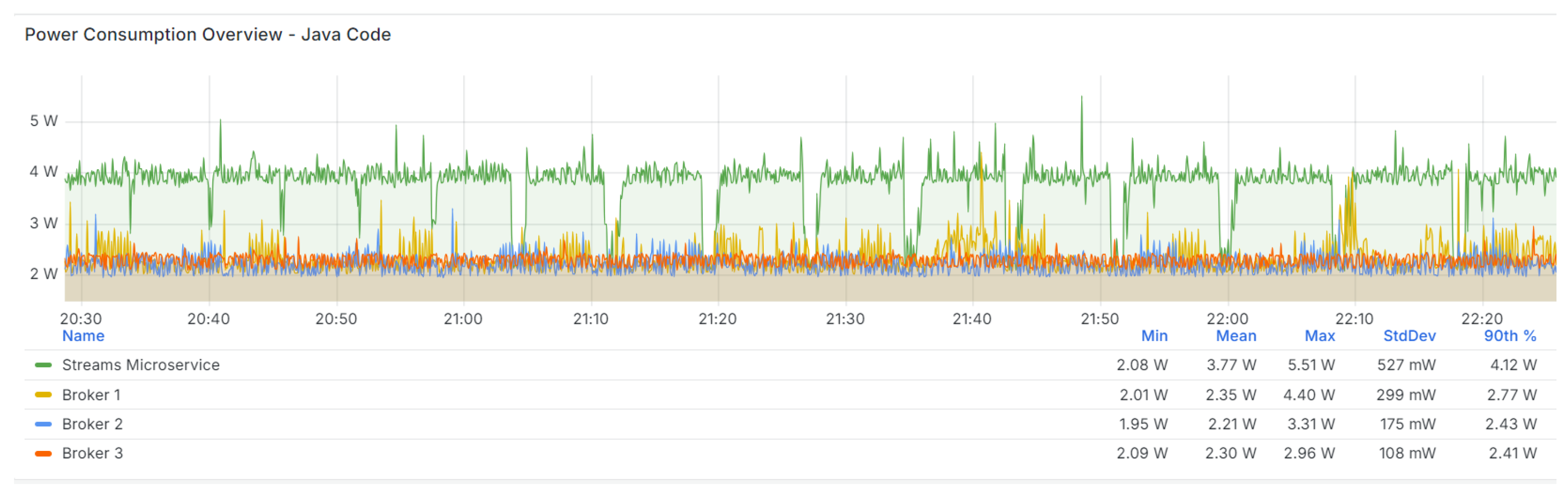
| Setup II, Scenario III: Platform Power Consumption |
| Upon comparing our results with those detailed in Bekaroo et al. [42], we found that the PC for the RPi5 under test during the idle state was nearly identical (2.20 W). Furthermore, the results for the CC concept associated with the Java microservice can be likened to activities that necessitate the use of a persistent network connection and graphic rendering (3.80 W) (Table 7, Table 8 and Table 9, Table 18, and Table 19). |
| Framework monitoring |
| As we noted earlier, several factors can influence our environment’s metrics, including the cluster’s configuration, resource usage, the settings for producing/consuming applications, and the communication medium used. Through detailed monitoring of resource utilization and power consumption with the Prometheus environment integrated into our setup, we were able to identify potential issues, such as CPU IPC decrease, queueing delays, and PC spikes. Fortunately, none of these events occurred during our experiments. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sychowiec, J.; Zieliński, Z. A Blockchain-Based Framework for Secure Data Stream Dissemination in Federated IoT Environments. Electronics 2025, 14, 2067. https://doi.org/10.3390/electronics14102067
Sychowiec J, Zieliński Z. A Blockchain-Based Framework for Secure Data Stream Dissemination in Federated IoT Environments. Electronics. 2025; 14(10):2067. https://doi.org/10.3390/electronics14102067
Chicago/Turabian StyleSychowiec, Jakub, and Zbigniew Zieliński. 2025. "A Blockchain-Based Framework for Secure Data Stream Dissemination in Federated IoT Environments" Electronics 14, no. 10: 2067. https://doi.org/10.3390/electronics14102067
APA StyleSychowiec, J., & Zieliński, Z. (2025). A Blockchain-Based Framework for Secure Data Stream Dissemination in Federated IoT Environments. Electronics, 14(10), 2067. https://doi.org/10.3390/electronics14102067