
Addressing Class Imbalance in Intrusion Detection: A Comprehensive Evaluation of Machine Learning Approaches



Abstract
1. Introduction
2. Background
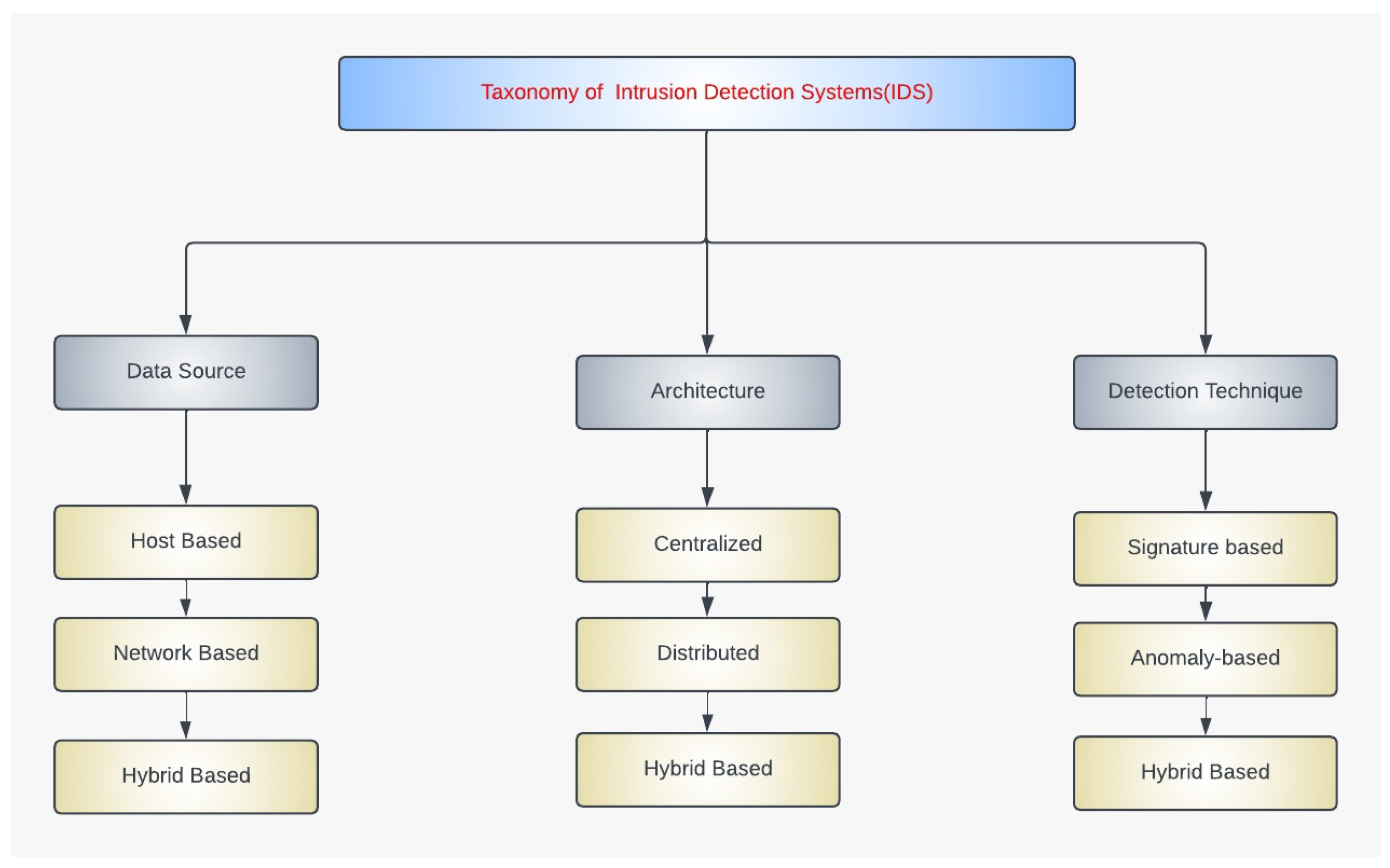
2.1. Intrusion Detection Systems
2.1.1. Data Source and Implementation
2.1.2. Architecture and Placement Strategy
2.1.3. Detection Methods
2.2. Data-Driven IDS
2.2.1. Unsupervised Learning
2.2.2. Supervised Learning
2.2.3. Deep Learning
2.2.4. Semi-Supervised Learning
2.2.5. Hybrid Learning
3. Problem Statement
Case Study
4. Class Imbalance Learning
4.1. Algorithm-Level
4.2. Data Level
4.3. Cost-Sensitive
4.4. Hybrid
5. Experimental Results
5.1. Experimental Setting
5.1.1. Scenarios
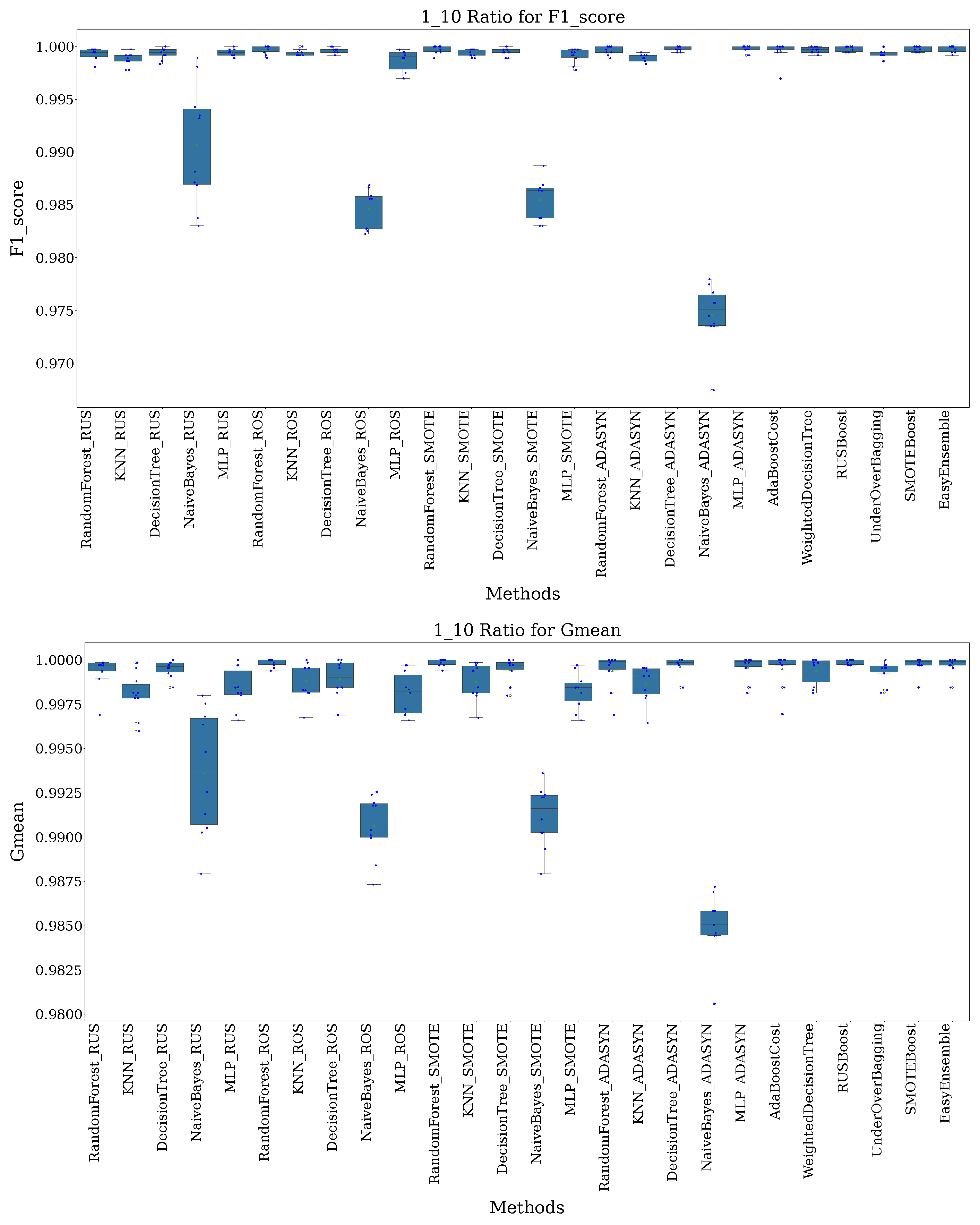
- 1:10 Ratio: In this scenario, for every 1 instance of the minority class, there are 10 instances of the majority class. The dataset has 1644 BENIGN samples and 16,443 DrDoS_DNS samples.
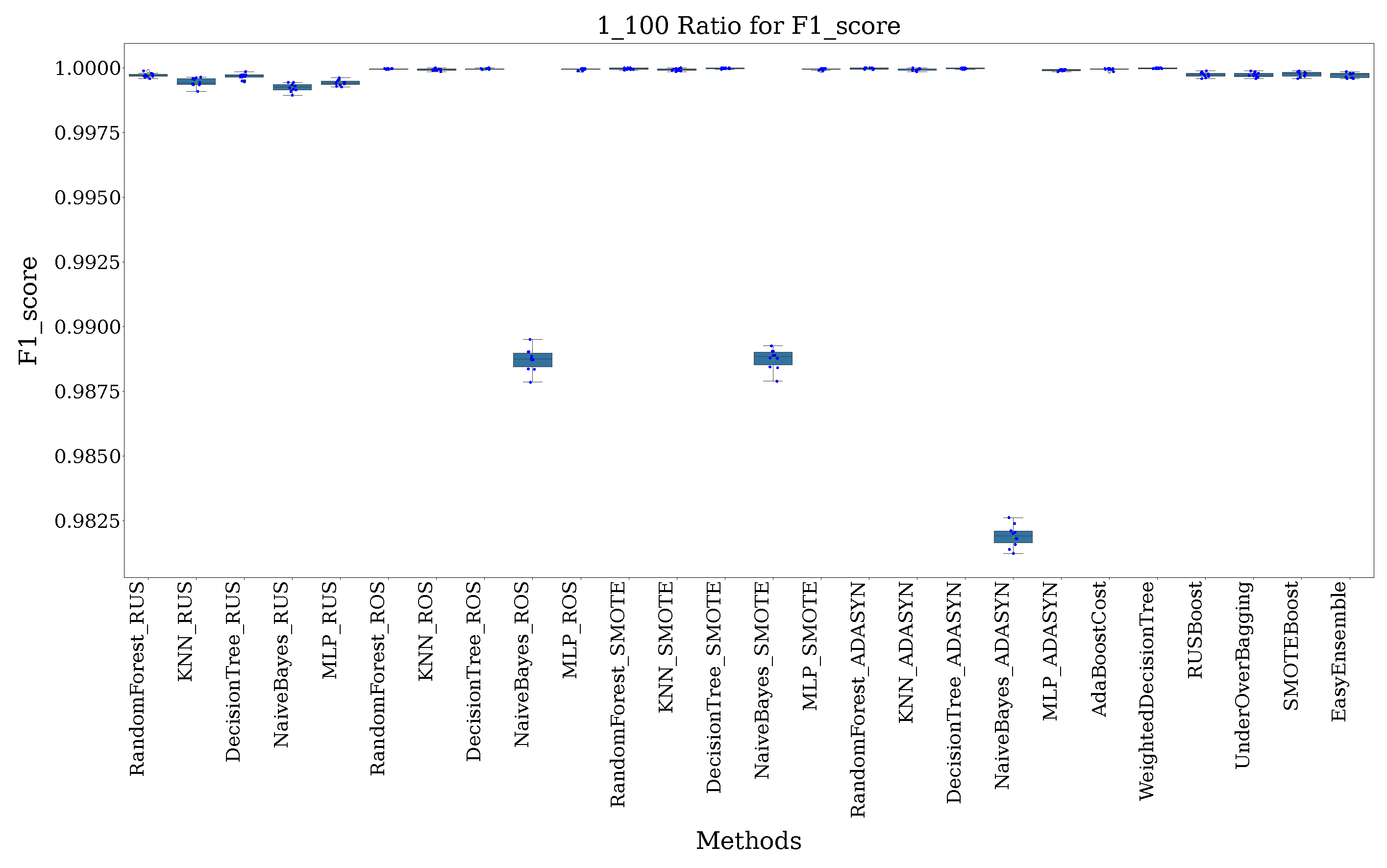
- 1:100 Ratio: At a 1 to 100 ratio, for every 1 instance of the minority class, there are 100 instances of the majority class. The dataset has 3222 BENIGN samples and 328,691 DrDoS_DNS samples.
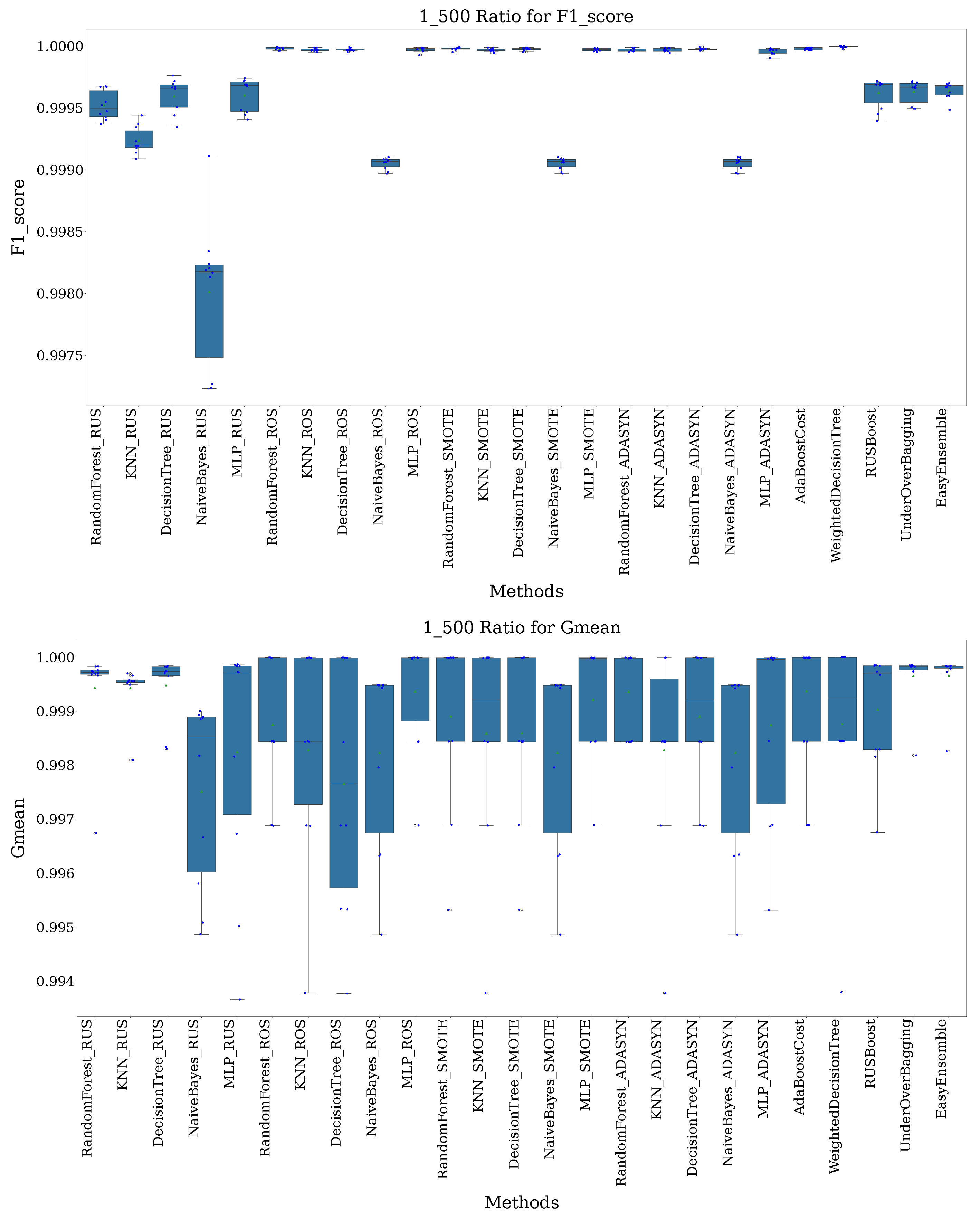
- 1:500 Ratio: With a 1 to 500 ratio, the imbalance is quite high. The dataset has 3223 BENIGN samples and 1,634,044 DrDoS_DNS samples.
- 1:1000 Ratio: This ratio is extremely imbalanced, where for every 1 instance of the minority class, there are 1000 instances of the majority class. The dataset has 3223 BENIGN samples and 3,246,951 DrDoS_DNS samples.
5.1.2. Data Processing
5.1.3. Model Training
5.1.4. Evaluation
5.2. Results’ Analysis
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Int. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, K.; Kim, D.D.; Asghar, M.R. Adversarial Machine Learning for Network Intrusion Detection Systems: A Comprehensive Survey. Commun. Surv. Tutor. 2023, 25, 538–566. [Google Scholar] [CrossRef]
- Jamalipour, A.; Murali, S. A Taxonomy of Machine-Learning-Based Intrusion Detection Systems for the Internet of Things: A Survey. IEEE Internet Things J. 2021, 9, 9444–9466. [Google Scholar] [CrossRef]
- Ou, C.M. Host-based Intrusion Detection Systems Inspired by Machine Learning of Agent-Based Artificial Immune Systems. In Proceedings of the 2019 IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), Sofia, Bulgaria, 3–5 July 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Malek, Z.S.; Trivedi, B.; Shah, A. User behavior Pattern -Signature based Intrusion Detection. In Proceedings of the 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), London, UK, 27–28 July 2020; pp. 549–552. [Google Scholar] [CrossRef]
- Nisioti, A.; Mylonas, A.; Yoo, P.; Katos, V. From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods. IEEE Commun. Surv. Tutor. 2018, 20, 3369–3388. [Google Scholar] [CrossRef]
- Sowmya, T.; Anita, E. A comprehensive review of AI based intrusion detection system. Meas. Sens. 2023, 28, 100827. [Google Scholar] [CrossRef]
- Bilot, T.; El Madhoun, N.; Al Agha, K.; Zouaoui, A. Graph Neural Networks for Intrusion Detection: A Survey. IEEE Access 2023, 11, 49114–49139. [Google Scholar] [CrossRef]
- Kiran, A.; Prakash, S.W.; Kumar, B.A.; Likhitha; Sameeratmaja, T.; Charan, U.S.S.R. Intrusion Detection System Using Machine Learning. In Proceedings of the 2023 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 23–25 January 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Gaber, T.; Awotunde, J.B.; Torky, M.; Ajagbe, S.A.; Hammoudeh, M.; Li, W. Metaverse-IDS: Deep learning-based intrusion detection system for Metaverse-IoT networks. Internet Things 2023, 24, 100977. [Google Scholar] [CrossRef]
- Fosić, I.; Žagar, D.; Grgić, K. Network traffic verification based on a public dataset for IDS systems and machine learning classification algorithms. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022; pp. 1037–1041. [Google Scholar] [CrossRef]
- Li, S.; Cao, Y.; Liu, S.; Lai, Y.; Zhu, Y.; Ahmad, N. HDA-IDS: A Hybrid DoS Attacks Intrusion Detection System for IoT by using semi-supervised CL-GAN. Expert Syst. Appl. 2024, 238, 122198. [Google Scholar] [CrossRef]
- Milosevic, M.S.; Ciric, V.M. Extreme minority class detection in imbalanced data for network intrusion. Comput. Secur. 2022, 123, 102940. [Google Scholar] [CrossRef]
- Chen, W.; Yang, K.; Yu, Z.; Shi, Y.; Chen, C.L.P. A survey on imbalanced learning: Latest research, applications and future directions. Artif. Intell. Rev. 2024, 57, 137. [Google Scholar] [CrossRef]
- Ren, H.; Tang, Y.; Dong, W.; Ren, S.; Jiang, L. DUEN: Dynamic ensemble handling class imbalance in network intrusion detection. Expert Syst. Appl. 2023, 229, 120420. [Google Scholar] [CrossRef]
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data 2021, 8, 6. [Google Scholar] [CrossRef]
- Razavi-Far, R.; Farajzadeh-Zanjani, M.; Saif, M. An Integrated Class-Imbalanced Learning Scheme for Diagnosing Bearing Defects in Induction Motors. IEEE Trans. Ind. Inform. 2017, 13, 2758–2769. [Google Scholar] [CrossRef]
- Farajzadeh-Zanjani, M.; Razavi-Far, R.; Saif, M. Efficient sampling techniques for ensemble learning and diagnosing bearing defects under class imbalanced condition. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Zhihao, P.; Fenglong, Y.; Xucheng, L. Comparison of the Different Sampling Techniques for Imbalanced Classification Problems in Machine Learning. In Proceedings of the 2019 11th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Qiqihar, China, 28–29 April 2019; pp. 431–434. [Google Scholar] [CrossRef]
- Fan, W.; Stolfo, S.J.; Zhang, J.; Chan, P.K. AdaCost: Misclassification Cost-Sensitive Boosting. In Proceedings of the Sixteenth International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 97–105. [Google Scholar]
- Rezvani, S.; Wang, X. A broad review on class imbalance learning techniques. Appl. Soft Comput. 2023, 143, 110415. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. RUSBoost: A Hybrid Approach to Alleviating Class Imbalance. IEEE Trans. Syst. Man Cybern.-Part A Syst. Humans 2010, 40, 185–197. [Google Scholar] [CrossRef]
- Moniz, N.; Ribeiro, R.; Cerqueira, V.; Chawla, N. SMOTEBoost for Regression: Improving the Prediction of Extreme Values. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–4 October 2018; pp. 150–159. [Google Scholar] [CrossRef]
- Kusdiyanto, A.Y.; Pristyanto, Y. Machine Learning Models for Classifying Imbalanced Class Datasets Using Ensemble Learning. In Proceedings of the 2022 5th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 8 December 2022; pp. 648–653. [Google Scholar] [CrossRef]
- Gu, Y.; Yang, Y.; Yan, Y.; Shen, F.; Gao, M. Learning-based intrusion detection for high-dimensional imbalanced traffic. Comput. Commun. 2023, 212, 366–376. [Google Scholar] [CrossRef]
- Tabassum, A.; Erbad, A.; Lebda, W.; Mohamed, A.; Guizani, M. FEDGAN-IDS: Privacy-preserving IDS using GAN and Federated Learning. Comput. Commun. 2022, 192, 299–310. [Google Scholar] [CrossRef]
- Yakshit; Kaur, G.; Kaur, V.; Sharma, Y.; Bansal, V. Analyzing various Machine Learning Algorithms with SMOTE and ADASYN for Image Classification having Imbalanced Data. In Proceedings of the 2022 IEEE International Conference on Current Development in Engineering and Technology (CCET), Bhopal, India, 23–24 December 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Than, S.S.M.; Soe, A.M.; Maw, A.H. Investigation of Oversampling in IoT-IDS. In Proceedings of the 2024 IEEE Conference on Computer Applications (ICCA), Yangon, Myanmar, 16 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Abdelkhalek, A.; Mashaly, M. Addressing the class imbalance problem in network intrusion detection systems using data resampling and deep learning. J. Supercomput. 2023, 79, 10611–10644. [Google Scholar] [CrossRef]
- Liu, Y.; Li, B.; Yang, S.; Li, Z. Handling missing values and imbalanced classes in machine learning to predict consumer preference: Demonstrations and comparisons to prominent methods. Expert Syst. Appl. 2024, 237, 121694. [Google Scholar] [CrossRef]
- Farajzadeh-Zanjani, M.; Hallaji, E.; Razavi-Far, R.; Saif, M. Generative-Adversarial Class-Imbalance Learning for Classifying Cyber-Attacks and Faults - A Cyber-Physical Power System. IEEE Trans. Dependable Secur. Comput. 2022, 19, 4068–4081. [Google Scholar] [CrossRef]
- Santhiappan, S.; Ravindran, B. Class Imbalance Learning. Adv. Comput. Commun. 2017, 1. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Yoo, J.; Min, B.; Kim, S.; Shin, D.; Shin, D. Study on Network Intrusion Detection Method Using Discrete Pre-Processing Method and Convolution Neural Network. IEEE Access 2021, 9, 142348–142361. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Description |
|---|---|
| Flow ID | Identifier for network flows, helping with tracking and analyzing sessions. |
| Source IP and Destination IP | Source and destination IP addresses for routing the network traffic. |
| Source Port and Destination Port | These denote the ports utilized by the source and destination. |
| Protocol | Indicates the network protocol used in a flow, such as TCP, UDP, or ICMP. |
| Timestamp | The time when the flow is observed. |
| Flow Duration | The overall duration of the flow, which can reveal the nature of communication. |
| Total Fwd Packets and Total Backward Packets | The count of sent packets in each direction offering insights into traffic volume. |
| Total Length of Fwd Packets and Total Length of Bwd Packets | The size of packets in the backward directions aiding in understanding data volume and potential content. |
| Fwd Packet Length Max/Min/Mean/Std and Bwd Packet Length Max/Min/Mean/Std | These metrics give insights into sizes in both directions assisting in detecting anomalies. |
| Flow Bytes/s and Flow Packets/s | The rate at which bytes and packets are transmitted per second, indicating usage and flow intensity. |
| Flow IAT Mean/Std/Max/Min | The average, deviation, maximum, and minimum inter-arrival times of the flow indicate its burstiness and regularity. |
| Fwd IAT Total/Mean/Std/Max/Min and Bwd IAT Total/Mean/Std/Max/Min | Similar statistics for inter-arrival times in both forward and backward directions. |
| Fwd PSH Flags and Bwd PSH Flags | Determines whether data should be pushed immediately. |
| Fwd URG Flags and Bwd URG Flags | The TCP packets with flags indicate the data of utmost importance. |
| Fwd Header Length and Bwd Header Length | Understanding the length of headers in both forward and backward packets is essential for grasping the intricacies of overhead and protocol details. |
| Fwd Packets/s and Bwd Packets/s | The rate at which packets are transmitted in both directions. |
| Min Packet Length and Max Packet Length | The recorded packet lengths in the flow vary from the smallest to the largest observed lengths. |
| Packet Length Mean/Std/Variance | Statistical measures of packet length, providing insights into the consistency and variability of packet sizes. |
| FIN Flag Count, SYN Flag Count, RST Flag Count, PSH Flag Count, ACK Flag Count, URG Flag Count, CWE Flag Count, ECE Flag Count | Counts of various TCP flags, which are crucial for understanding the control mechanisms of the TCP connections. |
| Down/Up Ratio | The ratio of download to upload, indicating the balance of traffic direction. |
| Average Packet Size | The average size of packets in the flow. |
| Avg Fwd Segment Size and Avg Bwd Segment Size | The average size of segments in forward and backward directions. |
| Fwd Avg Bytes/Bulk, Fwd Avg Packets/Bulk, Fwd Avg Bulk Rate, Bwd Avg Bytes/Bulk, Bwd Avg Packets/Bulk, Bwd Avg Bulk Rate | Bulk statistics for forward and backward directions, indicating bulk data transfer patterns. |
| Subflow Fwd Packets and Subflow Fwd Bytes, Subflow Bwd Packets and Subflow Bwd Bytes | Subflow statistics, which can help in breaking down larger flows into manageable parts for detailed analysis. |
| Init_Win_bytes_forward and Init_Win_bytes_backward | Initial window sizes for forward and backward directions, which are important for understanding the flow control mechanisms. |
| act_data_pkt_fwd and min_seg_size_forward | Active data packets in the forward direction and minimum segment size. |
| Active Mean/Std/Max/Min and Idle Mean/Std/Max/Min | Active and idle times for the flow, providing insights into the flow’s activity patterns. |
| SimillarHTTP | Indicates similarity to HTTP traffic, which is useful for identifying web-based traffic. |
| Inbound | Indicates whether the traffic is inbound. |
| Label | The class label (e.g., BENIGN or DrDoS_DNS). |
| Ratio | Benign Samples | Dr_DoS_DNS | Total Samples | Training (90%) | Testing (10%) |
|---|---|---|---|---|---|
| 1:10 | 1644 | 16,443 | 18,087 | 16,278 | 1809 |
| 1:100 | 3222 | 328,691 | 331,913 | 298,721 | 33,192 |
| 1:500 | 3223 | 1,634,044 | 1,637,267 | 1,473,540 | 163,727 |
| 1:1000 | 3223 | 3,246,951 | 3,250,174 | 2,925,157 | 325,017 |
| Algorithm | Parameter Setting |
|---|---|
| AdaBoostCost | #. estimators = 173, learning rate = 0.8387, algorithm = SAMME |
| Weighted Decision Tree | Class weight = [{0: 100, 1: 1}, {0: 10, 1: 1}, {0: 1, 1: 1}, {0: 1, 1: 10}, {0: 1, 1: 100}] |
| EasyEnsemble | #. estimators = (50, 500), sampling strategy = [‘auto’, ‘not minority’, ‘all’] |
| RUSBoost | #. estimators = 50, learning rate = 0.1, base estimator = decision tree |
| UnderOverBagging | Estimator = decision tree, sampling strategy = ‘auto’, replacement = False |
| SMOTEBoost | #. estimators = 87, learning rate = 0.4262, estimator = decision tree |
| Random Forest | #. estimators = 100, resampling methods = rus, ros, smote, adasyn |
| KNN | , Resampling methods = rus, ros, smote, adasyn |
| Decision Tree | Resampling methods = rus, ros, smote, adasyn |
| Naive Bayes | Resampling methods = rus, ros, smote, adasyn |
| MLP | Max iter = 300, resampling methods = rus, ros, smote, adasyn |
| Rank | Technique | 1:10 Ratio | 1:100 Ratio | 1:500 Ratio | 1:1000 Ratio |
|---|---|---|---|---|---|
| 1 | Random Forest (SMOTE) | 1.0000 ± 0.0000 (1) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 1 | Random Forest (ADASYN) | 1.0000 ± 0.0000 (1) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 1 | Decision Tree (ADASYN) | 1.0000 ± 0.0000 (1) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 2 | KNN (ROS) | 0.9999 ± 0.0001 (2) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 2 | KNN (ROS) | 0.9999 ± 0.0001 (2) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 2 | MLP (RUS) | 0.9999 ± 0.0001 (2) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 2 | WeightedDecision Tree | 1.0000 ± 0.0000 (1) | 0.9997 ± 0.0005 (2) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 3 | MLP (ROS) | 0.9999 ± 0.0000 (3) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 3 | MLP (ADASYN) | 0.9999 ± 0.0000 (3) | 0.9997 ± 0.0004 (1) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 4 | Decision Tree (SMOTE) | 1.0000 ± 0.0000 (1) | 0.9997 ± 0.0004 (1) | 0.9999 ± 0.0000 (2) | 0.9998 ± 0.0001 (3) |
| 5 | MLP (SMOTE) | 0.9999 ± 0.0000 (3) | 0.9996 ± 0.0004 (3) | 1.0000 ± 0.0000 (1) | 1.0000 ± 0.0000 (1) |
| 6 | Decision Tree (ROS) | 0.9999 ± 0.0000 (3) | 0.9997 ± 0.0004 (1) | 0.9999 ± 0.0000 (2) | 0.9998 ± 0.0001 (3) |
| 6 | Random Forest (ROS) | 0.9999 ± 0.0000 (3) | 0.9996 ± 0.0004 (3) | 0.9999 ± 0.0000 (2) | 1.0000 ± 0.0000 (1) |
| 7 | KNN (SMOTE) | 0.9999 ± 0.0001 (2) | 0.9996 ± 0.0004 (3) | 0.9999 ± 0.0000 (2) | 0.9997 ± 0.0002 (4) |
| 7 | KNN (RUS) | 0.9999 ± 0.0001 (2) | 0.9997 ± 0.0004 (1) | 0.9992 ± 0.0006 (6) | 0.9999 ± 0.0002 (2) |
| 7 | KNN (ADASYN) | 0.9999 ± 0.0001 (2) | 0.9996 ± 0.0004 (3) | 0.9996 ± 0.0002 (4) | 0.9999 ± 0.0002 (2) |
| 8 | AdaBoostCost | 0.9999 ± 0.0000 (3) | 0.9992 ± 0.0014 (6) | 0.9999 ± 0.0000 (2) | 0.9999 ± 0.0000 (2) |
| 9 | UnderOverBagging | 0.9999 ± 0.0000 (3) | 0.9995 ± 0.0006 (4) | 0.9998 ± 0.0001 (3) | 0.9996 ± 0.0002 (5) |
| 9 | EasyEnsemble | 0.9999 ± 0.0000 (3) | 0.9994 ± 0.0008 (5) | 0.9998 ± 0.0001 (3) | 0.9997 ± 0.0002 (4) |
| 9 | RUSBoost | 0.9997 ± 0.0001 (5) | 0.9996 ± 0.0004 (3) | 0.9998 ± 0.0001 (3) | 0.9997 ± 0.0002 (4) |
| 9 | Naive Bayes (SMOTE) | 0.9998 ± 0.0001 (4) | 0.9915 ± 0.0040 (8) | 1.0000 ± 0.0000 (1) | 0.9999 ± 0.0000 (2) |
| 10 | SMOTEBoost | 0.9998 ± 0.0001 (4) | 0.9995 ± 0.0006 (4) | 0.9996 ± 0.0002 (4) | 0.9997 ± 0.0002 (4) |
| 11 | Decision Tree (RUS) | 0.9996 ± 0.0002 (6) | 0.9996 ± 0.0004 (3) | 0.9999 ± 0.0000 (2) | 0.9994 ± 0.0002 (7) |
| 12 | Random Forest (RUS) | 0.9999 ± 0.0000 (3) | 0.9992 ± 0.0012 (7) | 0.9995 ± 0.0002 (5) | 0.9995 ± 0.0002 (6) |
| 13 | Naive Bayes (RUS) | 0.9993 ± 0.0002 (7) | 0.9888 ± 0.0044 (9) | 0.9980 ± 0.0004 (8) | 0.9985 ± 0.0004 (8) |
| 14 | Naive Bayes (ROS) | 0.9887 ± 0.0008 (8) | 0.9854 ± 0.0044(11) | 0.9985 ± 0.0004 (7) | 0.9985 ± 0.0004 (8) |
| 15 | Naive Bayes (ADASYN) | 0.9818 ± 0.0012 (9) | 0.9876 ± 0.0040(10) | 0.9911 ± 0.0009 (9) | 0.9981 ± 0.0008 (9) |
| Rank | Technique | 1:10 Ratio | 1:100 Ratio | 1:500 Ratio | 1:1000 Ratio |
|---|---|---|---|---|---|
| 1 | SMOTEBoost | 0.9999 ± 0.0002 (1) | 0.9999 ± 0.0002 (1) | 0.9997 ± 0.0004 (3) | 0.9997 ± 0.0006 (7) |
| 2 | UnderOverBagging | 0.9999 ± 0.0006 (2) | 0.9999 ± 0.0006 (2) | 0.9997 ± 0.0005 (4) | 0.9997 ± 0.0005 (6) |
| 3 | RUSBoost | 0.9998 ± 0.0010 (3) | 0.9998 ± 0.0010 (3) | 0.9998 ± 0.0010 (2) | 0.9997 ± 0.0015 (9) |
| 4 | EasyEnsemble | 0.9997 ± 0.0005 (5) | 0.9996 ± 0.0004 (4) | 0.9997 ± 0.0005 (4) | 0.9996 ± 0.0005 (13) |
| 5 | KNN (ROS) | 0.9990 ± 0.0012 (14) | 0.9990 ± 0.0012 (9) | 0.9996 ± 0.0007 (6) | 0.9997 ± 0.0002 (5) |
| 6 | KNN (SMOTE) | 0.9991 ± 0.0008 (13) | 0.9988 ± 0.0015 (11) | 0.9998 ± 0.0008 (1) | 0.9997 ± 0.0024 (11) |
| 6 | Random Forest (ADASYN) | 0.9998 ± 0.0010 (3) | 0.9991 ± 0.0008 (8) | 0.9996 ± 0.0008 (7) | 0.9994 ± 0.0014 (18) |
| 8 | Decision Tree (RUS) | 0.9995 ± 0.0010 (9) | 0.9985 ± 0.0012 (13) | 0.9995 ± 0.0006 (8) | 0.9997 ± 0.0010 (8) |
| 9 | KNN (ADASYN) | 0.9993 ± 0.0010 (12) | 0.9988 ± 0.0012 (10) | 0.9993 ± 0.0010 (16) | 0.9998 ± 0.0019 (4) |
| 10 | MLP (SMOTE) | 0.9951 ± 0.0021 (16) | 0.9985 ± 0.0027 (14) | 0.9995 ± 0.0025 (12) | 0.9998 ± 0.0016 (3) |
| 11 | Random Forest (RUS) | 0.9998 ± 0.0010 (3) | 0.9983 ± 0.0016 (17) | 0.9994 ± 0.0009 (14) | 0.9996 ± 0.0004 (12) |
| 12 | Random Forest (SMOTE) | 0.9998 ± 0.0005 (4) | 0.9995 ± 0.0010 (6) | 0.9989 ± 0.0010 (20) | 0.9994 ± 0.0014 (18) |
| 13 | Decision Tree (SMOTE) | 0.9995 ± 0.0009 (8) | 0.9982 ± 0.0025 (22) | 0.9995 ± 0.0010 (10) | 0.9997 ± 0.0020 (10) |
| 14 | KNN (RUS) | 0.9988 ± 0.0021 (15) | 0.9986 ± 0.0015 (12) | 0.9995 ± 0.0008 (9) | 0.9995 ± 0.0005 (16) |
| 15 | Decision Tree (ROS) | 0.9994 ± 0.0008 (11) | 0.9983 ± 0.0012 (16) | 0.9994 ± 0.0008 (13) | 0.9996 ± 0.0006 (14) |
| 16 | Random Forest (ROS) | 0.9997 ± 0.0010 (7) | 0.9992 ± 0.0012 (7) | 0.9987 ± 0.0012 (22) | 0.9988 ± 0.0015 (19) |
| 16 | WeightedDecision Tree | 0.9997 ± 0.0009 (6) | 0.9996 ± 0.0011 (5) | 0.9988 ± 0.0018 (21) | 0.9977 ± 0.0017 (23) |
| 18 | Decision Tree (ADASYN) | 0.9995 ± 0.0010 (9) | 0.9982 ± 0.0022 (21) | 0.9995 ± 0.0010 (10) | 0.9995 ± 0.0020 (17) |
| 19 | Naive Bayes (SMOTE) | 0.9920 ± 0.0040 (19) | 0.9982 ± 0.0022 (21) | 0.9993 ± 0.0012 (17) | 0.9998 ± 0.0012 (1) |
| 19 | Naive Bayes (RUS) | 0.9920 ± 0.0040 (19) | 0.9982 ± 0.0016 (19) | 0.9993 ± 0.0013 (18) | 0.9998 ± 0.0015 (2) |
| 21 | MLP (ADASYN) | 0.9995 ± 0.0010 (9) | 0.9977 ± 0.0037 (24) | 0.9997 ± 0.0010 (5) | 0.9980 ± 0.0025 (22) |
| 22 | Naive Bayes (ROS) | 0.9920 ± 0.0030 (18) | 0.9982 ± 0.0017 (20) | 0.9995 ± 0.0012 (11) | 0.9996 ± 0.0019 (15) |
| 23 | AdaBoostCost | 0.9995 ± 0.0011 (10) | 0.9982 ± 0.0013 (18) | 0.9993 ± 0.0013 (18) | 0.9986 ± 0.0008 (20) |
| 24 | MLP (RUS) | 0.9921 ± 0.0037 (17) | 0.9984 ± 0.0031 (15) | 0.9992 ± 0.0017 (19) | 0.9986 ± 0.0019 (21) |
| 25 | Naive Bayes (ADASYN) | 0.9870 ± 0.0124 (20) | 0.9981 ± 0.0019 (23) | 0.9994 ± 0.0012 (15) | 0.9980 ± 0.0025 (22) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shanmugam, V.; Razavi-Far, R.; Hallaji, E. Addressing Class Imbalance in Intrusion Detection: A Comprehensive Evaluation of Machine Learning Approaches. Electronics 2025, 14, 69. https://doi.org/10.3390/electronics14010069
Shanmugam V, Razavi-Far R, Hallaji E. Addressing Class Imbalance in Intrusion Detection: A Comprehensive Evaluation of Machine Learning Approaches. Electronics. 2025; 14(1):69. https://doi.org/10.3390/electronics14010069
Chicago/Turabian StyleShanmugam, Vaishnavi, Roozbeh Razavi-Far, and Ehsan Hallaji. 2025. "Addressing Class Imbalance in Intrusion Detection: A Comprehensive Evaluation of Machine Learning Approaches" Electronics 14, no. 1: 69. https://doi.org/10.3390/electronics14010069
APA StyleShanmugam, V., Razavi-Far, R., & Hallaji, E. (2025). Addressing Class Imbalance in Intrusion Detection: A Comprehensive Evaluation of Machine Learning Approaches. Electronics, 14(1), 69. https://doi.org/10.3390/electronics14010069