
MLBSNet: Mutual Learning and Boosting Segmentation Network for RGB-D Salient Object Detection

Abstract
1. Introduction
- We propose a mutual learning and boost segmentation network (MLBSNet) that completes the deep optimization, feature fusion, and information inference process through the deep prediction and saliency goal inference stages. The five RGB-D SOD datasets yield excellent experimental results and outperform the state-of-the-art models.
- We introduce a deep optimization module (DOM) to obtain more accurate depth information through similarity learning, which provides more effective complementary features for fusion.
- We designed the semantic alignment module (SAM) with a graph attention mechanism to eliminate the variability between the neighboring features of a single modality. The output features are then fed into a cross-modal integration (CMI) module to collect cross-modal complementary information.
- We build a simple and effective separate–reconstruct decoder (SRD) that not only avoids information loss caused by up-sample but also integrates rich multi-source features.
2. Related Work
RGB-D Salient Object Detection
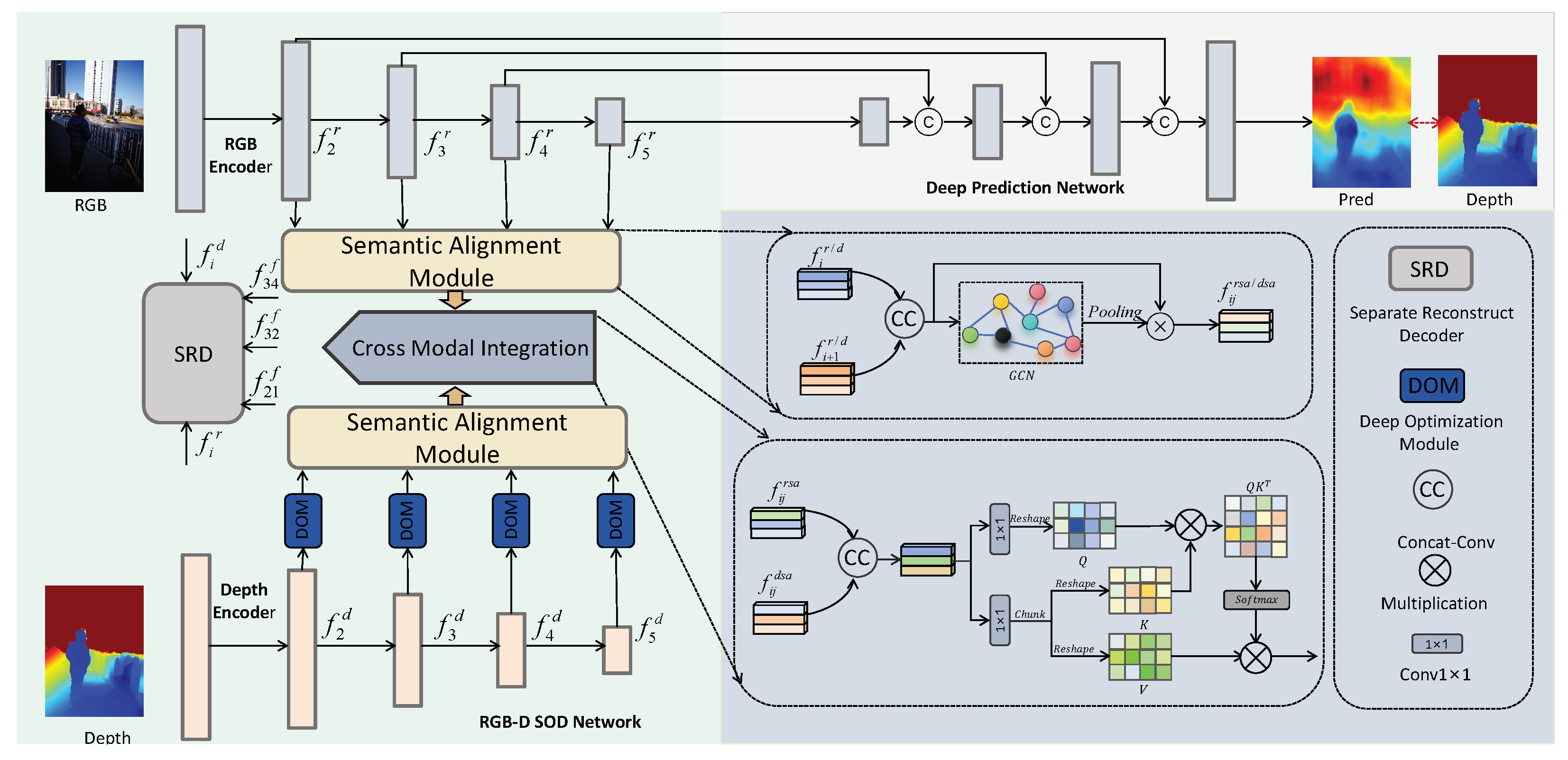
3. Proposed Methods
3.1. Architecture Overview
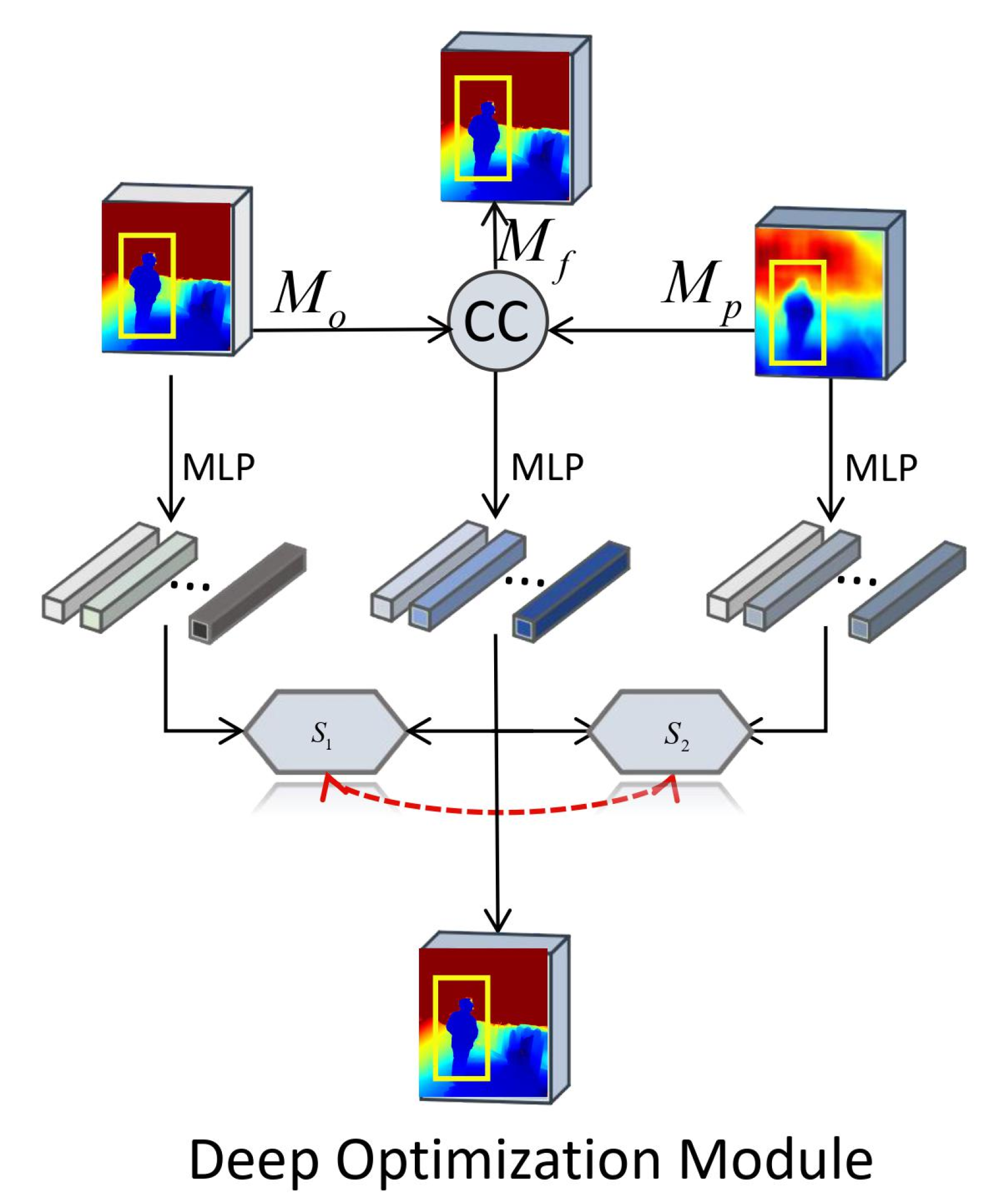
3.2. Depth Optimization Module (DOM)
3.3. Semantic Alignment Module (SAM)
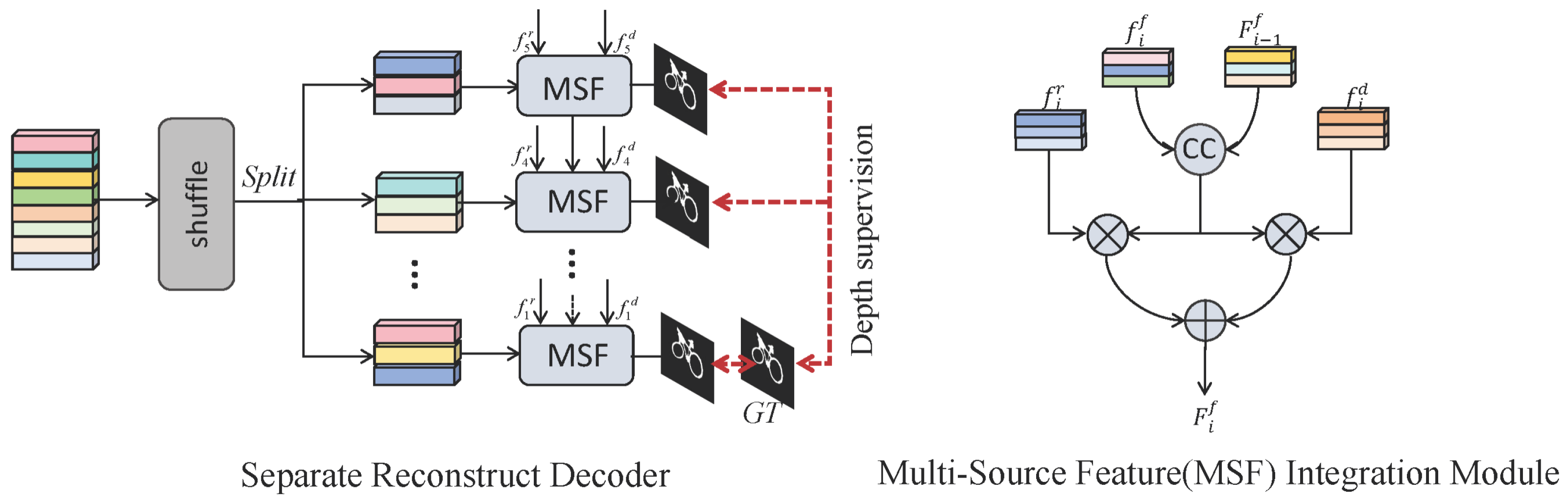
3.4. Cross-Modal Integration (CMI) Module
3.5. Separate–Reconstruct Decoder (SRD)
3.6. Supervision
4. Experiments
4.1. Experimental Protocol
4.2. Comparison with State-of-the-Art Models
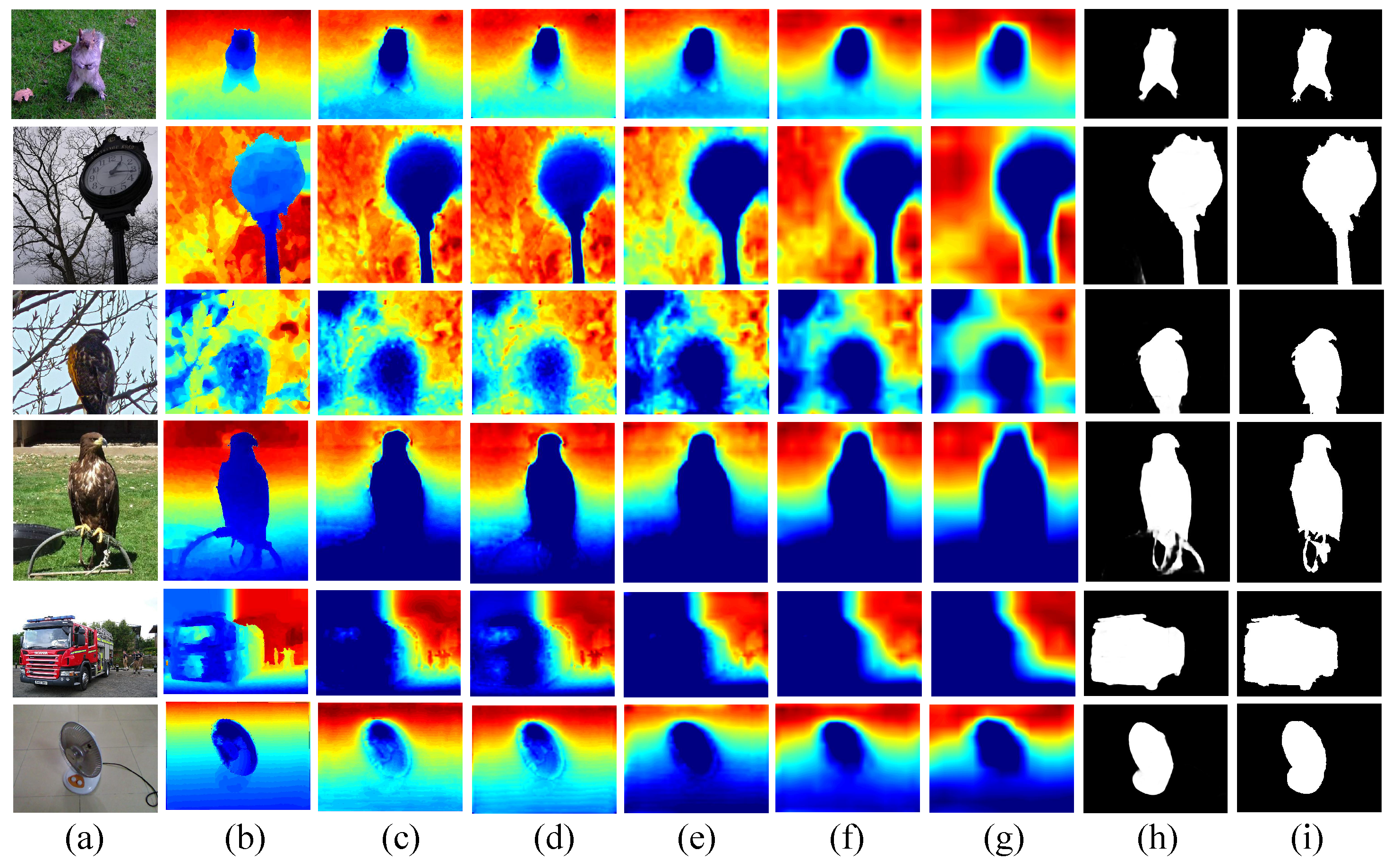
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, G.; Li, M.; Zhang, J.; Lin, X.; Ji, H.; Chang, S.F. Video event extraction via tracking visual states of arguments. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 3136–3144. [Google Scholar]
- Athar, A.; Hermans, A.; Luiten, J.; Ramanan, D.; Leibe, B. Tarvis: A unified approach for target-based video segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18738–18748. [Google Scholar]
- Bai, Y.; Chen, D.; Li, Q.; Shen, W.; Wang, Y. Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11514–11524. [Google Scholar]
- Chai, J.C.L.; Ng, T.S.; Low, C.Y.; Park, J.; Teoh, A.B.J. Recognizability Embedding Enhancement for Very Low-Resolution Face Recognition and Quality Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9957–9967. [Google Scholar]
- Chen, C.; Ye, M.; Jiang, D. Towards Modality-Agnostic Person Re-Identification with Descriptive Query. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15128–15137. [Google Scholar]
- Lee, M.; Park, C.; Cho, S.; Lee, S. Spsn: Superpixel prototype sampling network for rgb-d salient object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 630–647. [Google Scholar]
- Zhou, J.; Wang, L.; Lu, H.; Huang, K.; Shi, X.; Liu, B. Mvsalnet: Multi-view augmentation for rgb-d salient object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 270–287. [Google Scholar]
- Wu, Z.; Allibert, G.; Meriaudeau, F.; Ma, C.; Demonceaux, C. HiDAnet: RGB-D Salient Object Detection via Hierarchical Depth Awareness. arXiv 2023, arXiv:2301.07405. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Wang, J.; Zhou, Z.; An, Z.; Jiang, Q.; Demonceaux, C.; Sun, G.; Timofte, R. Object Segmentation by Mining Cross-Modal Semantics. arXiv 2023, arXiv:2305.10469. [Google Scholar]
- Zhang, W.; Ji, G.P.; Wang, Z.; Fu, K.; Zhao, Q. Depth quality-inspired feature manipulation for efficient RGB-D salient object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 731–740. [Google Scholar]
- Ji, W.; Li, J.; Yu, S.; Zhang, M.; Piao, Y.; Yao, S.; Bi, Q.; Ma, K.; Zheng, Y.; Lu, H.; et al. Calibrated RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9471–9481. [Google Scholar]
- Zhang, Q.; Qin, Q.; Yang, Y.; Jiao, Q.; Han, J. Feature Calibrating and Fusing Network for RGB-D Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1493–1507. [Google Scholar] [CrossRef]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Wei, J.; Peng, C.; Zhang, W.; Qin, H. Improved saliency detection in RGB-D images using two-phase depth estimation and selective deep fusion. IEEE Trans. Image Process. 2020, 29, 4296–4307. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, Y.; Li, J.; Chen, X. Is depth really necessary for salient object detection? In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1745–1754. [Google Scholar]
- Wu, Z.; Gobichettipalayam, S.; Tamadazte, B.; Allibert, G.; Paudel, D.P.; Demonceaux, C. Robust rgb-d fusion for saliency detection. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czechia, 12–15 September 2022; pp. 403–413. [Google Scholar]
- Song, M.; Song, W.; Yang, G.; Chen, C. Improving RGB-D salient object detection via modality-aware decoder. IEEE Trans. Image Process. 2022, 31, 6124–6138. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.; Ren, P.; Yin, B.; Wang, F.; Li, H. CATNet: A Cascaded and Aggregated Transformer Network For RGB-D Salient Object Detection. IEEE Trans. Multimed. 2023, 26, 2249–2262. [Google Scholar] [CrossRef]
- Wen, H.; Yan, C.; Zhou, X.; Cong, R.; Sun, Y.; Zheng, B.; Zhang, J.; Bao, Y.; Ding, G. Dynamic selective network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 9179–9192. [Google Scholar] [CrossRef]
- Ji, W.; Yan, G.; Li, J.; Piao, Y.; Yao, S.; Zhang, M.; Cheng, L.; Lu, H. DMRA: Depth-induced multi-scale recurrent attention network for RGB-D saliency detection. IEEE Trans. Image Process. 2022, 31, 2321–2336. [Google Scholar] [CrossRef]
- Cheng, Y.; Fu, H.; Wei, X.; Xiao, J.; Cao, X. Depth enhanced saliency detection method. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xiamen, China, 10–12 July 2014; pp. 23–27. [Google Scholar]
- Ciptadi, A.; Hermans, T.; Rehg, J.M. An In Depth View of Saliency. In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013; pp. 1–11. [Google Scholar]
- Piao, Y.; Rong, Z.; Zhang, M.; Ren, W.; Lu, H. A2dele: Adaptive and attentive depth distiller for efficient RGB-D salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9060–9069. [Google Scholar]
- Zhang, C.; Cong, R.; Lin, Q.; Ma, L.; Li, F.; Zhao, Y.; Kwong, S. Cross-modality discrepant interaction network for RGB-D salient object detection. In Proceedings of the ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2094–2102. [Google Scholar]
- Liao, G.; Gao, W.; Jiang, Q.; Wang, R.; Li, G. Mmnet: Multi-stage and multi-scale fusion network for rgb-d salient object detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2436–2444. [Google Scholar]
- Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; Yang, Q. RGBD salient object detection via deep fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef]
- Zhang, J.; Fan, D.P.; Dai, Y.; Anwar, S.; Saleh, F.S.; Zhang, T.; Barnes, N. UC-Net: Uncertainty inspired RGB-D saliency detection via conditional variational autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8582–8591. [Google Scholar]
- Han, J.; Chen, H.; Liu, N.; Yan, C.; Li, X. CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion. IEEE Trans. Cybern. 2017, 48, 3171–3183. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, F.; Wang, C.; Sun, F.; He, J. Learning Saliency-Aware Correlation Filters for Visual Tracking. Comput. J. 2022, 65, 1846–1859. [Google Scholar] [CrossRef]
- Feng, G.; Meng, J.; Zhang, L.; Lu, H. Encoder deep interleaved network with multi-scale aggregation for RGB-D salient object detection. Pattern Recognit. 2022, 128, 108666. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, W.; Wang, H.; Li, S.; Li, X. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1407–1417. [Google Scholar]
- Cong, R.; Lin, Q.; Zhang, C.; Li, C.; Cao, X.; Huang, Q.; Zhao, Y. CIR-Net: Cross-modality interaction and refinement for RGB-D salient object detection. IEEE Trans. Image Process. 2022, 31, 6800–6815. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Fu, H.; Chen, G.; Zhou, Y.; Fan, D.P.; Shao, L. Specificity-preserving RGB-D saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4681–4691. [Google Scholar]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and cross-scale adaptive fusion network for detecting salient objects in RGB-D images. IEEE Trans. Multimed. 2021, 24, 2192–2204. [Google Scholar] [CrossRef]
- Jin, W.D.; Xu, J.; Han, Q.; Zhang, Y.; Cheng, M.M. CDNet: Complementary depth network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 3376–3390. [Google Scholar] [CrossRef] [PubMed]
- Te, G.; Liu, Y.; Hu, W.; Shi, H.; Mei, T. Edge-aware graph representation learning and reasoning for face parsing. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 258–274. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H. Joint learning of salient object detection, depth estimation and contour extraction. IEEE Trans. Image Process. 2022, 31, 7350–7362. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Fan, D.P.; Dai, Y.; Yu, X.; Zhong, Y.; Barnes, N.; Shao, L. RGB-D saliency detection via cascaded mutual information minimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4338–4347. [Google Scholar]
- Fan, D.P.; Zhai, Y.; Borji, A.; Yang, J.; Shao, L. BBS-Net: RGB-D salient object detection with a bifurcated backbone strategy network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 275–292. [Google Scholar]
- Ju, R.; Ge, L.; Geng, W.; Ren, T.; Wu, G. Depth saliency based on anisotropic center-surround difference. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1115–1119. [Google Scholar]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. RGBD salient object detection: A benchmark and algorithms. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part III 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 92–109. [Google Scholar]
- Li, N.; Ye, J.; Ji, Y.; Ling, H.; Yu, J. Saliency detection on light field. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2806–2813. [Google Scholar]
- Niu, Y.; Geng, Y.; Li, X.; Liu, F. Leveraging stereopsis for saliency analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 454–461. [Google Scholar]
- Perazzi, F.; Krahenbuhl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Kulshreshtha, A.; Deshpande, A.; Meher, S.K. Time-frequency-tuned salient region detection and segmentation. In Proceedings of the IEEE International Advance Computing Conference, Ghaziabad, India, 22–23 February 2013; pp. 1080–1085. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Xiao, F.; Pu, Z.; Chen, J.; Gao, X. DGFNet: Depth-guided cross-modality fusion network for RGB-D salient object detection. IEEE Trans. Multimed. 2023, 26, 2648–2658. [Google Scholar] [CrossRef]
- Li, A.; Mao, Y.; Zhang, J.; Dai, Y. Mutual information regularization for weakly-supervised RGB-D salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 397–410. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Shao, L.; Han, J. Learning selective mutual attention and contrast for RGB-D saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9026–9042. [Google Scholar] [CrossRef]
- Zeng, Z.; Liu, H.; Chen, F.; Tan, X. AirSOD: A Lightweight Network for RGB-D Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1656–1669. [Google Scholar] [CrossRef]
- Bi, H.; Zhang, J.; Wu, R.; Tong, Y.; Jin, W. Cross-modal refined adjacent-guided network for RGB-D salient object detection. Multimed. Tools Appl. 2023, 82, 37453–37478. [Google Scholar] [CrossRef]
- Zhang, Z.; Lin, Z.; Xu, J.; Jin, W.D.; Lu, S.P.; Fan, D.P. Bilateral attention network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 1949–1961. [Google Scholar] [CrossRef] [PubMed]
- Fu, K.; Fan, D.P.; Ji, G.P.; Zhao, Q.; Shen, J.; Zhu, C. Siamese network for RGB-D salient object detection and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5541–5559. [Google Scholar] [CrossRef] [PubMed]
- Ji, W.; Li, J.; Zhang, M.; Piao, Y.; Lu, H. Accurate RGB-D salient object detection via collaborative learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 52–69. [Google Scholar]
- Ju, R.; Liu, Y.; Ren, T.; Ge, L.; Wu, G. Depth-aware salient object detection using anisotropic center-surround difference. Signal Process. Image Commun. 2015, 38, 115–126. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Metric | D3Net20 | BBSNet20 | CoNet20 | JLDCF21 | DCF21 | BiANet21 | EMANet22 | SPSN22 | SMAC22 | AirSOD22 | HINet23 | MRVI23 | DGFNet23 | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NJU2K | 0.950 | - | 0.953 | ||||||||||||
| 0.920 | 0.920 | 0.925 | |||||||||||||
| 0.931 | 0.939 | ||||||||||||||
| 0.032 | 0.029 | ||||||||||||||
| NLPR | 0.958 | 0.957 | - | ||||||||||||
| 0.930 | 0.926 | ||||||||||||||
| 0.925 | 0.927 | ||||||||||||||
| 0.023 | 0.022 | ||||||||||||||
| DES | 0.973 | - | - | 0.974 | |||||||||||
| 0.937 | - | 0.940 | |||||||||||||
| 0.942 | 0.942 | - | 0.943 | ||||||||||||
| 0.017 | - | 0.016 | |||||||||||||
| SIP | - | - | 0.932 | - | 0.930 | ||||||||||
| - | 0.891 | - | - | 0.895 | |||||||||||
| 0.903 | 0.903 | - | 0.910 | - | - | 0.910 | |||||||||
| - | 0.043 | - | - | 0.041 | |||||||||||
| STERE | 0.941 | - | - | 0.942 | |||||||||||
| 0.911 | - | 0.912 | |||||||||||||
| 0.919 | - | 0.920 | |||||||||||||
| 0.039 | 0.039 | 0.035 | - | 0.035 |
| Virants | NJU2K | SIP | ||||||
|---|---|---|---|---|---|---|---|---|
| w/o DOM | 0.935 | 0.923 | 0.951 | 0.030 | 0.904 | 0.885 | 0.920 | 0.047 |
| w/o SAM | 0.936 | 0.923 | 0.951 | 0.031 | 0.908 | 0.889 | 0.924 | 0.045 |
| w/o CIM | 0.937 | 0.922 | 0.950 | 0.031 | 0.907 | 0.889 | 0.923 | 0.045 |
| w/o SRD | 0.926 | 0.914 | 0.944 | 0.034 | 0.907 | 0.891 | 0.930 | 0.044 |
| Ours | 0.939 | 0.925 | 0.953 | 0.029 | 0.910 | 0.895 | 0.930 | 0.041 |
| SIP | DES | NJU2K | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 0.888 | 0.906 | 0.922 | 0.938 | 0.941 | 0.971 | 0.920 | 0.933 | 0.949 | |
| ✓ | 0.886 | 0.904 | 0.922 | 0.933 | 0.938 | 0.968 | 0.922 | 0.936 | 0.950 | |
| ✓ | ✓ | 0.895 | 0.910 | 0.930 | 0.940 | 0.943 | 0.974 | 0.925 | 0.939 | 0.953 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, C.; Wang, J.; Ge, B. MLBSNet: Mutual Learning and Boosting Segmentation Network for RGB-D Salient Object Detection. Electronics 2024, 13, 2690. https://doi.org/10.3390/electronics13142690
Xia C, Wang J, Ge B. MLBSNet: Mutual Learning and Boosting Segmentation Network for RGB-D Salient Object Detection. Electronics. 2024; 13(14):2690. https://doi.org/10.3390/electronics13142690
Chicago/Turabian StyleXia, Chenxing, Jingjing Wang, and Bing Ge. 2024. "MLBSNet: Mutual Learning and Boosting Segmentation Network for RGB-D Salient Object Detection" Electronics 13, no. 14: 2690. https://doi.org/10.3390/electronics13142690
APA StyleXia, C., Wang, J., & Ge, B. (2024). MLBSNet: Mutual Learning and Boosting Segmentation Network for RGB-D Salient Object Detection. Electronics, 13(14), 2690. https://doi.org/10.3390/electronics13142690