Abstract
The main purpose of this study is to generate defect images of body parts using a GAN (generative adversarial network) and compare and analyze the performance of the YOLO (You Only Look Once) v7 and v8 object detection models. The goal is to accurately judge good and defective products. Quality control is very important in the automobile industry, and defects in body parts directly affect vehicle safety, so the development of highly accurate defect detection technology is essential. This study ensures data diversity by generating defect images of car body parts using a GAN and through this, compares and analyzes the object detection performance of the YOLO v7 and v8 models to present an optimal solution for detecting defects in car parts. Through experiments, the dataset was expanded by adding fake defect images generated by the GAN. The performance experiments of the YOLO v7 and v8 models based on the data obtained through this approach demonstrated that YOLO v8 effectively identifies objects even with a smaller amount of data. It was confirmed that defects could be detected. The readout of the detection system can be improved through software calibration.
1. Introduction
The automotive industry is one of the cornerstone sectors of modern society, in which safety and reliability are of paramount importance. Particularly, the quality of body components is directly linked to a vehicle’s safety, making its management a crucial factor in ensuring product reliability. Defects in body parts can cause accidents, leading to significant human casualties and economic losses. Consequently, the development of technologies for effectively detecting and identifying defects during the manufacturing process has become an essential task within the automotive industry [,]. Defects in body components can arise from various causes, and such defects not only degrade product performance but can also lead to safety incidents.
Therefore, defect detection technology plays a crucial role in the manufacturing process by preemptively identifying and eliminating defective products, thereby enhancing the final product’s quality and ensuring safety. This study aims to demonstrate the possibility of generating fake images of parts with various defects within a group of images of defective parts using the generative adversarial network (GAN) algorithm. By supplementing the collection of defect images manually with generative images, which can produce fine defects that are hard to identify through GANs, this approach offers a novel avenue for enhancing defect detection methodologies [,,].
In the field of object detection, the YOLO model, particularly its latest versions, YOLO v7 and v8, has garnered significant attention due to its fast processing speed and high accuracy. These versions offer improvements in accuracy and processing speed compared to those of their predecessors, greatly expanding the applicability of real-time object detection. This progress represents a substantial advancement in the application of object detection technologies across various industrial sectors.
In this study, the aim is to compare and analyze the performance of generative adversarial network (GAN)-based technologies and object detection technologies utilizing YOLO v7 and v8 models for detecting defects in automotive body parts. Thanks to its ability to generate images that closely resemble real ones, a GAN can be used to enhance the diversity of a training dataset by generating images of defective automotive body parts. This can be particularly useful in situations in which the availability of training data is limited [,].
As a first step, a process utilizing GAN models is developed to accurately detect defects in automotive body parts. In this phase, the images generated by the GAN are used to augment the training data for the defect detection model, ensuring the model can learn various forms and sizes of defects [].
In the second phase, a direct comparison and analysis of the performance of YOLO v7 and v8 models are conducted. This comparison focuses on accuracy, processing speed, and practical applicability. Given the nature of detecting defects in automotive body parts, a high accuracy and rapid processing speed are crucial. Through this comparison, a superior model for detecting defects in automotive body parts can be identified, and optimization strategies for a defect detection system based on the chosen model can be explored.
This study aims to significantly enhance the accuracy and efficiency of manufacturing quality control by effectively detecting and classifying various defects that may occur in the automotive manufacturing process. Given the automotive industry’s demand for high levels of precision and safety, advancements in defect detection technology directly lead to production cost reductions, product quality improvements, and an increase in consumer satisfaction.
Artificial-intelligence-based image processing technologies, particularly defect detection techniques utilizing GAN and YOLO models, play a crucial role in meeting these requirements. These technologies are capable of processing a vast amount of image data at a high speed and accurately identifying defects of various shapes and sizes. This enables the real-time detection of defects during the manufacturing process and immediate corrective actions to be taken, thereby improving overall manufacturing efficiency. The findings of this study are not limited to the automotive industry; AI-based image processing technologies can be applied to quality control in various other industries, including medical, aviation, and electronics manufacturing.
Customized defect detection systems can be developed by learning the specific requirements and types of defects that occur in each industry sector. This will significantly contribute to maintaining consistent product quality and minimizing losses that may occur during the production process.
2. Related Research
2.1. Recent Trends in Metal Surface Defect Detection Research
Early research in metal surface defect classification primarily utilized signal processing techniques. Methods such as Fourier transform and wavelet transform were employed to analyze changes in signals over time or space for defect detection. While these approaches were useful for basic defect detection, they often failed to fully represent the diverse characteristics of defects. Their reliance on a consistent feature extraction method resulted in a decreased accuracy and insufficient handling of anomalies. To address these issues, machine learning-based classification algorithms like support vector machines (SVMs) were introduced. These methods marked an improvement in performance compared to that of signal processing techniques but still faced the limitation of manually identifying features specific to defects. The manual feature extraction process is time-consuming and requires expert knowledge. The introduction of deep learning technologies has contributed significantly to overcoming these limitations. Convolutional neural networks (CNNs) have the ability to automatically extract features of defects from image data, eliminating the cumbersome process of manual feature extraction and achieving a higher accuracy and efficiency. CNNs learn the spatial hierarchical structure within images, enabling the effective recognition of complex features.
Recently, the focus has shifted beyond merely classifying defects to accurately determining their location and size. Object detection algorithms, such as YOLO (You Only Look Once) and R-CNNs (Region-based Convolutional Neural Networks), are being utilized for this purpose. These algorithms can identify objects (in this case, defects on metal surfaces) within images and accurately pinpoint their locations, significantly enhancing the efficiency and accuracy of the detection process.
Furthermore, advancements in these technologies hold the potential to significantly enhance the automation of manufacturing processes and the efficiency of quality control by enabling the implementation of real-time defect detection systems [].
2.2. Generative Adversarial Network
Generative adversarial networks (GANs) represent a field within machine learning, characterized by a competitive structure between two neural networks aiming to enhance each other’s performance. This framework was first introduced in 2014. The core idea of GANs involves pitting two neural networks against each other, a generator and a discriminator, to produce highly realistic synthetic data.
Figure 1 presents the fundamental structure of generative adversarial networks (GANs) along with their applications in the industrial sector. The architecture of GANs facilitates the generation of images, which can be further utilized for data augmentation in systems such as YOLO. The application of this methodology in the industrial domain can significantly enhance areas such as defect detection [,].
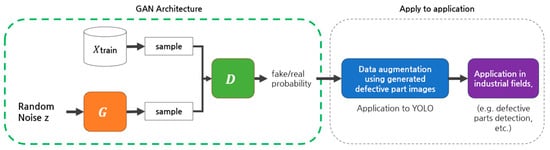
Figure 1.
GAN model structure and application in industry.
The generator (G) receives random noise (z) as input, which acts as an initial ‘seed’, and uses this to generate fake data. For instance, in image generation tasks, it produces synthetic images. This process continuously learns to create data that are indistinguishable from real data. The generator’s goal is to deceive the discriminator into recognizing the synthetic data it produces as genuine. This process can be represented by the following equation.
Here, represents the generator, and denotes the parameters of the generator. The generator takes noise as input to produce fake images as output.
The discriminator takes as input both the real images and fake images produced by the generator and discriminates whether they are real or fake. This process can be expressed by the following equation.
Here, represents the discriminator, and denotes the parameters of the discriminator. These two neural networks engage in competition and learn by minimizing the following objective function.
Here, denotes the expectation, represents the distribution of real data, and signifies the distribution of random noise. During this process, the discriminator becomes increasingly powerful, and in response, the generator evolves to produce more sophisticated fake data. Once the training of a GAN is complete, it gains the ability to generate synthetic data that are nearly indistinguishable from real data. Through this competitive learning process, GANs are capable of producing high-quality data that closely resemble real data [].
2.3. YOLO
YOLO is a prominent real-time detection model widely used in the field of object recognition, adopting a CNN-based approach that processes an entire image in a single pass. This characteristic makes it more efficiently optimized than traditional object detection methods. YOLO has evolved through continuous updates, with various versions developed from YOLO v5 to YOLO v7 and up to YOLO v8. Notably, YOLO v8 has garnered attention as a model that is focused on lightweight design, emphasizing accuracy and speed among the updates thus far [,,].
3. Method
3.1. GAN-Based Car Body Part Defect Detection Process
The proposed study introduces a process that effectively detects and identifies defects in automobile body parts by combining generative adversarial networks (GANs) and the You Only Look Once (YOLO) algorithm. Beyond manually augmenting data for defective part images through GANs, this study innovatively enhances defect detection performance in the final manufacturing process by augmenting data with generated images and utilizing them for improved defect detection in automobile parts. The images generated are labeled and prepared as training data, after which a CNN-based YOLO algorithm is employed for defect detection. YOLO, an algorithm capable of detecting and classifying objects in images in real time, can identify multiple objects within an image with a single inference. This capability is especially beneficial for swiftly and accurately identifying defects in vehicle body parts.
YOLO predicts the class of each object and the accuracy of the bounding box (confidence score) by drawing bounding boxes around the objects. In this system, defects in vehicle body parts are considered as objects, allowing for the detection and classification of these defects to accurately identify their type and location. This approach significantly enhances the accuracy and efficiency of identifying defects in body parts and can contribute to improved quality control in the manufacturing process.
The integration of GAN-generated images with real images as training data for the YOLO model represents a novel and effective strategy for enhancing its defect detection performance. This approach allows the model to learn from a more diverse and comprehensive dataset, leading to improved generalization and robustness.
Figure 2 illustrates the process of detecting defects in vehicle body parts using a GAN-based approach. Furthermore, the process efficiently identifies defects in vehicle body parts by combining fake images generated by GAN with real images, utilizing the real-time object detection algorithms YOLO v7 and v8. This approach represents a novel and effective strategy for enhancing the defect detection performance in the final manufacturing process.
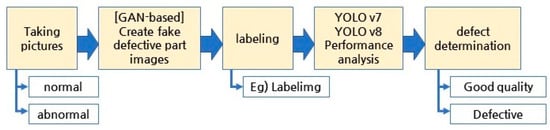
Figure 2.
GAN-based car body part defect detection process.
3.2. SW UI Design
In this research, an AI-based real-time object detection and defect identification system is developed that is equipped with a user-friendly interface, implemented using Python-based GUI (graphical user interface) programming tools. The system adheres to the model–view–controller (MVC) architectural pattern, with a particular emphasis on the design of the user interface in the view component, enabling users to intuitively understand and utilize the system. Figure 3 illustrates the design of the GUI program performing AI-based real-time object detection and defect identification.
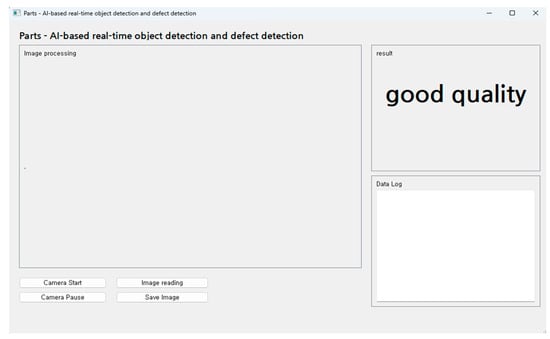
Figure 3.
Parts—AI-based real-time object detection and defect detection GUI.
The real-time object detection functionality in this system was achieved by integrating OpenCV (Open Source Computer Vision Library) with YOLO v8, a state-of-the-art real-time object detection algorithm capable of identifying and classifying multiple objects in an image with a single forward pass. Through this technological amalgamation, the system can accurately detect and interpret parts or objects of interest in real time for the user. The user interface of the system was designed with the utmost priority placed on user convenience. The results of object detection are presented to the user in a visually clear manner, and the interface includes elements designed to provide additional information if necessary.
4. Experiments
This study aims to identify defects in vehicle body parts by capturing photographs of actual defective parts and creating a dataset based on these images to train a deep learning model. By directly capturing and labeling photographs of defective body parts, the model is enabled to accurately identify various defects that may occur in real-world scenarios.
A total of 49 photographs were utilized to train the model, with 29 designated for training, 10 for testing, and 10 for validation purposes. This division follows the common practice of splitting the dataset into training, testing, and validation sets in a 6:2:2 ratio, which aids in accurately evaluating the model’s performance in real-world conditions and preventing overfitting.
Additionally, to facilitate the training of the model for defect identification in vehicle body parts, videos of both good and defective parts were prepared. The recorded videos, each less than five minutes in length, focus on demonstrating how vehicle body parts move and develop defects in real working environments. This approach enables the model to develop the capability to identify defects not only in static images but also in dynamic environments. The types of defects prepared for the model training include nut defects and tears. Nut defects encompass missing or damaged nuts used to secure vehicle body parts, while tears include rips or cracks in body parts.
Figure 4 is presented to compare and analyze the appearance of part 1 and part 2. In (a) and (b) shown in Figure 4, the defects are not marked separately. In Figure 5 and Figure 6, the defective parts of the car body are marked. What is noteworthy in this study is the experimental approach using YOLO and GANs. In the YOLO experiment, the model was used to label nut defect images, and then a performance comparison and analysis between the YOLO v7 and YOLO v8 algorithms were conducted. This allowed us to evaluate how accurately each version of the YOLO algorithm can detect and classify nut defects.

Figure 4.
(a) View of body part 1, (b) View of body part 2.

Figure 5.
Results of applying a GAN to abnormal cases for part 1.

Figure 6.
Results of applying a GAN to abnormal cases for part 2.
For part 1 and part 2, 1999 images were generated through the GAN for 20,000 epochs, and among them, 12 well-learned images were selected and labeled. A total of 24 GAN images were labeled. In this experiment, two types of loss functions were employed: BCELoss and CrossEntropyLoss. BCELoss is suitable for binary classification problems, whereas CrossEntropyLoss is used for multi-class classification issues. The labeling of both the real and synthetic images generated by the GAN was conducted using the Labellmg program.
Subsequently, by training the YOLO algorithm on these images, an artificial intelligence model capable of distinguishing between real and synthetic images was developed. The effectiveness and accuracy of the developed model were assessed through experiments using video footage of defective and non-defective parts. This evaluation aimed to determine the model’s ability to accurately identify and classify various types of defects that could occur in actual manufacturing and inspection processes.
The artificial intelligence model developed in this study was trained using the YOLO algorithm, and the training results were distributed in the .pt file format, which was integrated into a GUI program. This GUI program is designed to enable users to easily utilize the AI model for identifying defective parts. To accommodate cases in which the trained model may not perfectly identify all types of defects, a specific logic has been implemented to allow the software to make determinations of defects.
While acknowledging the limitations of its object detection capabilities, the design of this system was crucial to incorporate various conditional variables to ensure its effectiveness. For instance, it includes logic that determines whether a part should be classified as good (or normal) or defective based on a certain threshold of object detection failures. This design allows the system to adapt to a wide range of scenarios that may arise in actual manufacturing environments.
This design allows the system to adapt to a wide range of scenarios that may arise in actual manufacturing environments. Various scenarios refer to problems that may occur in a factory, such as detecting defects or controlling defects in electrical systems.
For instance, the methodology includes a comparative operation that determines whether parts should be classified as acceptable (or normal) or defective based on a specific threshold of object detection failures. Specifically, if the number of object detections falls within a predefined limit and does not meet the criteria for being considered a fault detection, the part is deemed normal.
In detail, the system was tested on photographs and videos of defective parts taken under various lighting conditions and backgrounds. The computer used for the experiments was equipped with a high-performance GPU, enabling complex image processing and rapid defect detection. The software environment utilized the Python programming language and the PyTorch framework, while the GUI was developed using PyQt to provide a user-friendly interface.
This experimental environment is designed to maximize the performance of the artificial intelligence model, and it is expected to be highly effective when applied to defect detection processes in manufacturing industries. Through the GUI, users can easily identify defective parts, and the implementation of defect judgment logic will enhance quality control in manufacturing processes.
4.1. Experimental Environment
The experimental setup for this study is detailed in Table 1, utilizing PyTorch 2.12 for the training and development of the artificial intelligence model. PyTorch, a widely used open-source machine learning library, offers excellent performance in developing complex AI models and computations. Furthermore, Cuda 12.1 was used for GPU acceleration. Additionally, the environment was configured as follows to facilitate the training of the GANs and YOLO.

Table 1.
Training/testing setup environment—GPU server.
4.2. Results
To assess the progression of the GAN training, we conducted visual inspections instead of using traditional metrics, such as accuracy. This approach was chosen because it is challenging to evaluate the performance of generative models solely through objective metrics. By visually inspecting the generated images, we could directly assess how similar the generated images are to real images. Visual inspections can be conducted by an average person.
Additionally, Table 2 summarizes the metrics representing the competitive relationship between the generator (G) and the discriminator (D) throughout the training process. As training progresses, the generator increasingly produces images that are difficult to distinguish from real ones, prompting the discriminator to continuously learn to more accurately identify these images. The loss values of G and D exhibit constant fluctuations during this process, indicating an ongoing advancement of both networks through their competition.
Table 2.
‘Part 1’ image GAN learning results (partial summary).
In this study, experiments were conducted on the datasets for part 1 and part 2 using the basic structure of a GAN, known as a simple GAN, which consists of two parts: a generator and a discriminator. These two networks compete and learn from each other, with the generator attempting to create fake images that resemble real images, and the discriminator striving to distinguish between real and fake images. Figure 5 and Figure 6 visually demonstrate the qualitative changes in the images generated from the part 1 and part 2 datasets through this learning process.
The visual inspection results indicate that, over time, the generated images reach a qualitative level that makes them difficult to distinguish from real images. This suggests that despite its basic structure, the simple GAN, with sufficient training and an appropriate dataset, is capable of generating highly realistic images. However, enhancements in pixel or resolution quality might require the implementation of more advanced GAN models or modifications in the neural network architecture.
Subsequently, the generated fake images were labeled alongside the real images. Figure 7 demonstrates the labeling process conducted using the Labellmg program, formatted to comply with the YOLO standards. Training was carried out with both real and fake images using YOLO v7 and v8.

Figure 7.
Labeling defective areas with the Labellmg program.
This paper introduces a novel training methodology that integrates generative adversarial networks (GANs) with the YOLO v7 and YOLO v8 object detection frameworks to enhance the system’s detection accuracy. The proposed approach is divided into six distinct stages, each contributing to the overall efficacy of the object detection system.
In the initial stage, real images are fed into a GAN for training. This process allows the GAN to learn the distribution of the input data, enabling it to generate new images that are visually similar to the original dataset.
Upon completion of the GAN training, the second stage involves the generation of synthetic images. These images are produced at various epochs, allowing for the selection of the most realistic outputs for further processing.
The third stage focuses on the selection and enlargement of certain synthetic images. This step is crucial for ensuring that the generated images are of sufficient quality and resolution for object detection tasks.
In the fourth stage, the real images, along with the selected synthetic images, undergo a labeling process using the Labellmg tool. This manual annotation step is essential for creating accurate ground truth data for the training of object detection models.
The fifth stage entails the training of either the YOLO v7 or YOLO v8 framework using the labeled images and corresponding annotation files. Both YOLO versions are renowned for their efficiency and accuracy in detecting objects across various domains.
Finally, the sixth stage involves the evaluation of object detection performance.
The resolution of the image used for labeling was 640 × 480 or higher for the actual image and 240 × 240 for the fake image. The resolution of the fake image can increase depending on the memory of the GPU used.
Due to the limited number of images in the automotive body defect dataset, there were challenges in obtaining significant graphs.
In this study, training, testing, and validation were conducted under the same conditions using YOLO v7 and v8. The results indicated that while YOLO v7 failed to detect objects, YOLO v8 successfully recognized them. Figure 8 illustrates a scenario in which YOLO v7 was unable to identify objects.

Figure 8.
YOLO v7 learning prediction results (training).
In this study, the performance measurement results for defect_nut1 and defect_nut2 using YOLO v8 are summarized in Table 3.
Table 3.
Training performance results with YOLO v8.
Although the performance was diminished due to the scarcity of image training data, it was observed that the system could partially execute the detection function for the defective parts.
One of the most widely used performance evaluation metrics in object detection and instance segmentation tasks is the mAP50 (the mean average precision at IoU = 0.50). This metric is utilized to assess how well a model makes predictions. This metric measures the mean average precision (mAP) across various intersection over union (IoU) threshold values. The IoU quantifies the overlap between predicted bounding boxes and actual bounding boxes, serving as a critical factor in assessing accuracy in object detection. Specifically, the mAP50-95 calculates the average precision for each IoU threshold, with increments from 0.50 to 0.95 in steps of 0.05, and then takes the average of these values. This is utilized to assess how precisely a model can detect objects across a range of precision levels.
Figure 9 illustrates the results when trained with fewer than 50 images using YOLO v8. It can be observed that the performance of the mAP50 and mAP50-95 graphs is suboptimal. In the present study, enhancements to the performance depicted in Graph 9 can be achieved by increasing the quantity of training images and conducting additional tasks such as labeling.
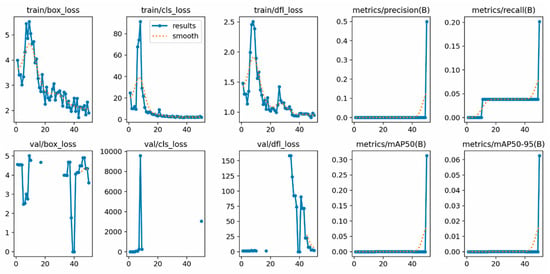
Figure 9.
YOLO V8 training results (dataset with less than 50 images).
In the implementation described earlier, Figure 2 outlines the design of a GUI that incorporates video processing technology with a PyTorch-based YOLO v8 learning model for defect detection. Figure 10 is not directly related to defect detection but shows an experiment to evaluate object detection performance assuming that a sufficient dataset is secured for YOLO v8.
Figure 10.
Failure to detect objects using YOLO v7.
Figure 11 presents the results of an experiment using YOLO v8, conducted with a dataset of 2550 images provided by Roboflow. It demonstrates the variation in confidence values for the static images identified as ‘crush’ defects, which range from 0.3 to 0.9. This variability underscores the model’s capacity to discern defects with varying degrees of confidence across a broad spectrum of test images [].

Figure 11.
Validation set training results in YOLO v8 (partial).
Figure 12 is the result of object detection in a defective product video using YOLO v8. Error detection was captured in the order of (a) to (d). Figure 12 illustrates the results of using YOLO v8 for object detection in videos of defective products. The sequence from (a) to (d) captures the process of error detection. Initially, malfunctions occurred due to insufficient training data. However, as the model was further trained, it progressively demonstrated an improved ability to detect defective areas.
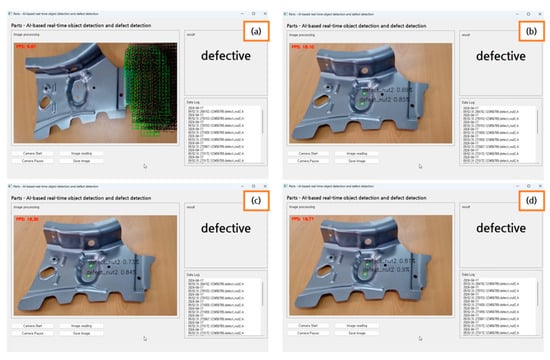
Figure 12.
Detection of defective vehicle bodies using video analysis. (a) Underfitting; (b) Fault detection; (c) Fault detection; and (d) Fault detection.
Two nut holes were accurately detected, with the classification of “defect_nut2” showing confidence levels of 0.69% and 0.85% in Figure 12a. When the video closely matched the training images, “defect_nut2” exhibited confidence levels of 0.73% and 0.84% in case (b). In instances (c) and (d), the confidence levels were, respectively, 0.73% and 0.84% and 0.81% and 0.9%. One method to enhance confidence levels involves increasing the quantity of training images.
There exists an ensemble technique, which involves combining multiple models to perform predictions. This approach can enhance overall performance by leveraging the strengths of different models. The phenomenon of defect_nut2 being excessively generated, marked as number 1 in Figure 12, can be considered a case of underfitting. To address this issue, it is necessary to increase the number of images and, concurrently, extend the labeling work to match the increased number of images for improvement.
In Figure 12, the instances marked as (b), (c), and (d) were considered defective due to the detection of two holes. Figure 13 presents the results from using YOLO v8 for object detection in videos of non-defective products. While some occurrences of defect_nut2 were detected, they did not exceed a predetermined count. By comparing the quantity of occurrences in the data structure when defect_nut2 is in a flaw-free state, it was verified whether the nuts were correctly attached [].
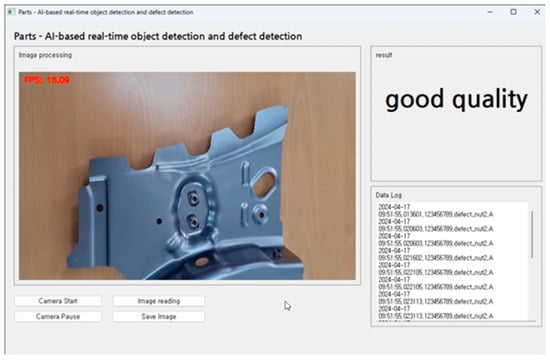
Figure 13.
Non-defective vehicle body detection using video.
4.3. Future Research
This study particularly utilizes a GAN to generate images of vehicle body parts with realistic defects. Utilizing the generated data, the object detection performances of the latest versions of the YOLO algorithm, namely YOLO v7 and YOLO v8, are compared and analyzed. The first aspect of this research focuses on the use of GANs for data augmentation. Obtaining images of actual defective vehicle body parts is challenging, and datasets are often small in size. By leveraging a GAN to create high-quality synthetic images of defective parts, the aim is to expand the training dataset and enhance the generalization ability of the model.
Secondly, the augmented image data obtained allow for a performance comparison between YOLO v7 and v8. This comparison is conducted across various aspects including accuracy, detection speed, and real-time processing capabilities.
Thirdly, the system’s feasibility in real-world applications is evaluated. Beyond just a performance assessment under laboratory conditions, its potential for deployment in actual manufacturing settings is examined. This necessitates an experimental design that takes into account the complexity and diversity of real-world environments.
Fourthly, system integration and optimization are achievable. Considering factors such as system stability, scalability, and user-friendliness, solutions that can be easily implemented into actual manufacturing processes are developed. This research aims to enhance the accuracy and efficiency of defect detection in vehicle body parts, ultimately contributing to improved quality control in manufacturing and reducing the costs and time associated with defects.
5. Conclusions
In this study, an analysis was conducted comparing the performance of object detection using YOLO v7 and YOLO v8, as well as exploring a defect detection process for vehicle body parts based on a GAN. The experimental results demonstrated the feasibility of generating synthetic images of defective parts using a GAN, and it was observed that the quality of images improved with an increase in epochs.
In the application of the YOLO algorithm, it was observed that YOLO v7 exhibited low detection rates with a small dataset of images. In contrast, YOLO v8 demonstrated the ability to perform object detection even with limited training images. There were instances of inaccurate recognition and underfitting during image training. These issues can be addressed either by compensating for this with software logic or by acquiring additional images to enhance the training process.
Author Contributions
Conceptualization, D.-Y.J. and N.-H.K.; methodology, D.-Y.J., Y.-J.O. and N.-H.K.; software, D.-Y.J.; validation, D.-Y.J., Y.-J.O. and N.-H.K.; formal analysis, D.-Y.J.; investigation, D.-Y.J.; resources, N.-H.K.; data curation, D.-Y.J.; writing—original draft preparation, D.-Y.J.; writing—review and editing, D.-Y.J.; visualization, D.-Y.J.; supervision, N.-H.K.; project administration, N.-H.K.; funding acquisition, N.-H.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Innovative Human Resource Development for Local Intellectualization program through the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (IITP-2024-00156287).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available as they were purchased.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pham, D.L.; Chang, T.W. A YOLO-based real-time packaging defect detection system. Procedia Comput. Sci. 2023, 217, 886–894. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q. Machine vision inspection of electrical connectors based on improved Yolo v3. IEEE Access 2020, 8, 166184–166196. [Google Scholar] [CrossRef]
- Yang, G.; Song, C.; Yang, Z.; Cui, S. Bubble detection in photoresist with small samples based on GAN augmentations and modified YOLO. Eng. Appl. Artif. Intell. 2023, 123, 106224. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection, and cycle learning ensemble (GAN-CIRCLE). Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Chen, S.H.; Lai, Y.W.; Kuo, C.L.; Lo, C.Y.; Lin, Y.S.; Lin, Y.R.; Tsai, C.C. A surface defect detection system for golden diamond pineapple based on CycleGAN and YOLOv4. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 8041–8053. [Google Scholar] [CrossRef]
- Lee, S.-H.; Shin, Y.-S.; Choi, O.-K.; Kim, S.-J.; Kang, J.-M. YOLO-Based Detection of Metal Surface Defects. J. Korean Inst. Intell. Syst. 2022, 32, 275–285. [Google Scholar] [CrossRef]
- Tang, T.W.; Kuo, W.H.; Lan, J.H.; Ding, C.F.; Hsu, H.; Young, H.T. Anomaly detection neural network with dual auto-encoders GAN and its industrial inspection applications. Sensors 2020, 20, 3336. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L. Surface defect detection methods for industrial products: A review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Nguyen, H.-V.; Bae, J.-H.; Lee, Y.-E.; Lee, H.-S.; Kwon, K.-R. Comparison of pre-trained YOLO models on steel surface defects detector based on transfer learning with GPU-based embedded devices. Sensors 2022, 22, 9926. [Google Scholar] [CrossRef]
- Andrea, M.C.; Lee, C.K.; Kim, Y.S.; Noh, M.J.; Moon, S.I.; Shin, J.H. Computer Vision-Based Car Accident Detection using YOLOv8. J. Korea Ind. Inf. Syst. Res. 2024, 29, 91–105. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A modified YOLO for detection of steel surface defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).