Abstract
For classifying brain tumors with small datasets, the knowledge-based transfer learning (KBTL) approach has performed very well in attaining an optimized classification model. However, its successful implementation is typically affected by different hyperparameters, specifically the learning rate (LR), batch size (BS), and their joint influence. In general, most of the existing research could not achieve the desired performance because the work addressed only one hyperparameter tuning. This study adopted a Cartesian product matrix-based approach, to interpret the effect of both hyperparameters and their interaction on the performance of models. To evaluate their impact, 56 two-tuple hyperparameters from the Cartesian product matrix were used as inputs to perform an extensive exercise, comprising 504 simulations for three cutting-edge architecture-based pre-trained Deep Learning (DL) models, ResNet18, ResNet50, and ResNet101. Additionally, the impact was also assessed by using three well-known optimizers (solvers): SGDM, Adam, and RMSProp. The performance assessment showed that the framework is an efficient framework to attain optimal values of two important hyperparameters (LR and BS) and consequently an optimized model with an accuracy of 99.56%. Further, our results showed that both hyperparameters have a significant impact individually as well as interactively, with a trade-off in between. Further, the evaluation space was extended by using the statistical ANOVA analysis to validate the main findings. F-test returned with p < 0.05, confirming that both hyperparameters not only have a significant impact on the model performance independently, but that there exists an interaction between the hyperparameters for a combination of their levels.
1. Introduction
Brain tumors, which appear as a collection of anomalous cells growing inside or around the brain, are one of the most well-known and imperative causes of the increase in fatalities among adults and children [1]. A precise and early diagnosis of a brain tumor is the key to a successful course of treatment. Among imaging modalities, MRI is the most extensively utilized non-invasive approach that succor radiologists and physicians in the discernment, diagnosis, and classification of brain tumors [2,3,4]. The radiologist approaches brain tumor classification in two ways: (i) by categorizing the normal and anomalous magnetic resonance (MR) images and (ii) by scrutinizing the types and stages of the anomalous MR images [2].
Since brain tumors show a high level of dissimilarities related to size, shape, and intensity [5] and tumors from various neurotic types might show comparatively similar appearances [6], therefore the classification into different types and stages has become quite a wide research topic [7,8]. Manual classification of comparatively similar appearing brain tumor MR images is quite a challenging task, which relies upon the skills of radiologists and their availability. Despite the radiologist’s skills, the human visual system always bounds the analysis as the knowledge contained in an MR image surpasses the visual system’s capacity of the human to perceive. Thus, the computer was used as the second eye to understand the MR images.
DL models trained on a dataset for a certain classification task are difficult to effectively reuse and generalize [9]. Therefore, a new model from scratch has to be rebuilt even for a similar task that requires considerable computational power and time. At the same time, if sufficient data are not available for similar tasks, the developed algorithm may have difficulty in attaining the desired performance or might even fail to complete the tasks. In case of a shortage of data, KBTL techniques have shown good performance for the classification problem [10]. KBTL is a technique that uses the knowledge of a pre-trained DL model to retrain the model with the available dataset for a targeted classification problem. However, to obtain an optimized model for the intended classification problem, it is challenging to select an existing pre-trained DL model, hyperparameters’ optimum values, and an optimization algorithm (solver).
All existing pre-trained deep learning models have the hyperparameter’s values set and the most fundamental task in implementing KBTL is to tune these hyperparameters to obtain the optimal performance. Therefore, hyperparameter tuning has become a challenging and the most critical problem for implementing KBTL to obtain an optimized model for the targeted classification problem. The tuning of hyperparameters is an optimization problem that makes solvers efficient and the objective function of optimization is ultimately the model’s black-box function. The optimization problem in implementing KBTL is finding a set of model hyperparameter values that are consistent with the knowledge of the used pre-trained model and give the best accuracy for the classification problem.
Traditional techniques to find the optimal values such as the grid search method have scalability issues. Therefore, interest in determining more effective optimization strategies has recently increased [11]. In one of our recent research studies [10], we proposed a framework to implement KBTL for the brain tumor classification task. To obtain an optimized model, the framework compared the performances of 11 different state-of-the-art existing DL models that were retrained with the brain tumor dataset with three different solvers: SGDM, RMSProp, and Adam. To determine the optimal hyperparameter values, the framework took inputs from the Cartesian product matrix consisting of 16 pairs generated to serve as the foundation of the framework using unique values of the two most important hyperparameters BS and LR. The pairs were formed using individual hyperparameter values taken from the literature rather than making a grid for a particular range. The framework proved to be an efficient framework that reduced the computational complexity (as the search space consisted of very limited hyperparameter values and corresponding pairs) and consequently the time to reach to the optimal values of the hyperparameters, ultimately providing us with ResNet18 [12], an optimized model with optimal hyperparameter values (BS = 32 and LR = 0.01) for the SGDM solver which achieved 99.56% accuracy. ResNet50 [12] and ResNet 101 [12] also provided us more or less the same accuracies, 99.56% and 99.35% respectively, but could not be considered as optimized models because of other measuring parameters (see Section 4.1) such as testing accuracies and the convergence time. ResNet architecture-based DL models proved to be the best models for brain tumor classification in comparison to other pre-trained DL models such as AlexNet [13], GoogleNet(s) [14], VGGNet(s) [15], SqueezeNet [16], MobileNet [17], and InceptionV3 [18]. A comparative study of these models’ performances with their optimal parameters are presented in Section 4.1. "Simulated Results".
Despite the significant success this framework has achieved, it is still unable to answer questions such as: how significant each hyperparameter is to the model Which hyperparameter interactions are significant How do the responses to these queries connect to the features of the dataset being examined To answer these questions, a statistical approach is adopted in this study to contribute to extending the scope of the research work presented in [10].The research contributions of this study are as follows:
- In comparison to the previous research, for better interpretation, an extended version of a (8 × 7) Cartesian product matrix is generated to evaluate and validate the impact of hyperparameters (LR and BS). The matrix consists of the 56 most effective two-tuple hyperparameters used as an input to perform an extensive exercise, comprising 504 simulations for three cutting-edge architecture-based pre-trained Deep Learning (DL) models, ResNet18, ResNet50, and ResNet101. Additionally, the impact was also assessed by using three well-known optimizers (solvers): SGDM, Adam, and RMSProp.
- A dataset comprising 504 DL model accuracies against each pair of hyperparameters (LR, BS). The accuracies represent model performances trained for brain tumor multi-classification.
- Validation of the simulated results regarding the significant impact of hyperparameters individually as well as interactively using statistical ANOVA analysis.
The rest of the paper is divided into five sections. Section 2 presents a brief literature review related to the tuning and the significant impact of hyperparameters. Section 3 describes the materials and methods used to analyze simulated data and its statistical analysis. Section 4 discusses the experimental setup and results analysis. In the end, the conclusion and future work are discussed in Section 5.
2. Literature Review
Over the years, research on the improvement and development of new optimization techniques has played a vital role in effectively utilizing the knowledge of pre-trained deep learning models to implement KBTL for the targeted classification problem. Many research efforts have contributed to addressing the impact of the hyperparameters [10,19,20,21,22], especially the learning rate and batch size, on the network performance either in terms of the accuracy of the model or the convergence time. Very few researchers have extended their work to perform a statistical analysis to examine the significance of each hyperparameter individually as well as their interactive effect on the network performance [19,20].
I. Kandel and M. Castelli [20] used the Patch Camelyon histopathologic dataset to identify the metastatic tissues in the lymph node section. The set is larger than the dataset CIFAR10 and smaller than the dataset ImageNet. The authors compared the performance of the VGG16 DL model in which five different batch sizes [16, 32, 64, 128, 256] and two different learning rates [0.001 0.0001] were used. The authors concluded that the network’s performance was significantly influenced by the learning rate and batch size. The learning rate and batch size had a high correlation: when the learning rates were high, bigger batch sizes performed better than those with low learning rates. The authors advised choosing small batch sizes with a low learning rate. In addition, they advised the use of lower batch sizes initially (often 32 or 64), having in mind that small batch sizes need small learning rates. The authors concluded the study based on experiments performed with very limited values of the hyperparameters, especially learning rates. Moreover, the authors did not perform any statistical test to find the correlation between hyperparameters and their significance on the model performance.
Using the CIFAR-10 and MNIST datasets, Radiuk et al. [19] experimented to examine the batch size impact on the performance of a pre-existing DL model for image classification. The author evaluated a batch size range (16–1024) with a power of two, along with 50, 100, 150, 200, and 250 batch sizes. For the MNIST dataset, the author used a LeNet architecture, while for the CIFAR-10 dataset, he used a customized model based on five convolutional layers. The SGD optimizer with initial learning rates of 0.0001 and 0.001 was used for the CIFAR-10 dataset and the MNIST dataset, respectively for both networks. The 1024 batch size produced the highest accuracy for both datasets, whereas the batch size 16 produced the lowest results. According to the author’s investigation, the batch size had a significant influence on the model performance, which showed that the bigger the batch size, the better the model performance. The author, in this research, investigated the impact of only one hyperparameter i.e., batch size, and kept fixed other hyperparameters such as learning rate.
In [21] the author found that 32 is an appropriate default setting for the batch size. He also noted that a bigger batch size would speed up the network processing but would need fewer updates to attain convergence. According to the author, an appropriate batch size helps in reducing the convergence time but not network performance. On the other hand, the authors in [22] investigated the effect of batch size on two state-of-the-art models: AlexNet [13] and ResNet [12]. Authors used batch sizes ranging from and examined their effect on three datasets: ImageNet [23], CIFAR10 [24], and CIFAR100 [24]. The research study concluded that batch sizes between 2 and 32 produced good results and added that small batch sizes are more robust than high batch sizes.
Usmani et al. [10], presented a framework to implement KBTL for brain tumor classification. The authors assessed the performance of the framework by taking hyperparameters’ inputs from a Cartesian product matrix in a pair combination of two-tuple. The two most important hyperparameters, learning rate and batch size, were contributed to tune the 11 state-of-the-art pre-trained DL models and found that ResNet architectures performed the best among all for the targeted brain tumor classification task. The Cartesian product matrix comprised of only 16 pairs built using individual hyperparameter values gathered from the literature instead of creating a full grid for a certain range for optimization. Since the authors picked up very selective values from the literature, making the whole process much less computationally expensive, they were able to assess the framework with two inputs in parallel allowing for the examination of their combined effect on the network performance. The authors performed a comparative analysis to find the best-performing model, but the study required a statistical analysis to further investigate the significance of both hyperparameters individually as well as their interactive effect. The statistical analysis may have justified controlling the learning rate and batch size in parallel to find the best model for brain tumor classification.
3. Materials and Methods
3.1. KBTL Implementation
As discussed in the Introduction, we have adopted a Cartesian-based framework, from one of our most recent research studies [10], to implement KBTL, presented in Figure 1.
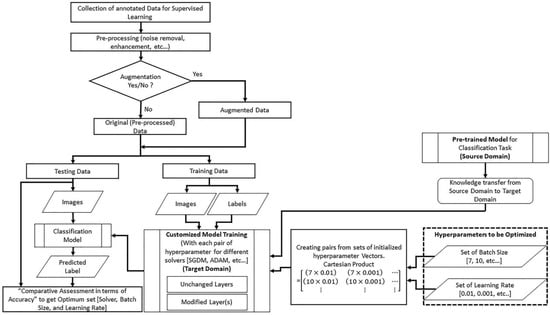
Figure 1.
The framework to implement KBTL.
Any pre-trained classification model with its learned parameters can be used after customization. The framework is based on an idea to input hyperparameters in the form of ordered pairs (batch size and learning rate). The ordered pair can be defined as a 2-tuple element of a matrix constructed using the concept of the Cartesian product of two initialized sets of the batch size and learning rate. The following subsections discuss the step-by-step implementation of the transfer learning technique using the adopted framework.
3.1.1. Dataset
Exactly 3064 MR images from a publicly available dataset of 233 patients with brain tumors were used [25]. This collection contained three different types of brain tumor MR images, including 1426 slices of gliomas, 708 slices of meningiomas, and 930 slices of pituitary tumors. Each type of tumor proportion in the dataset is shown in Figure 2 [10]. These data, which are accessible in .mat file (Matlab data format), include a patient ID, a label for the image, the picture as a 512 by 512 matrix, a tumor mask, and discrete point coordinates on the tumor border.
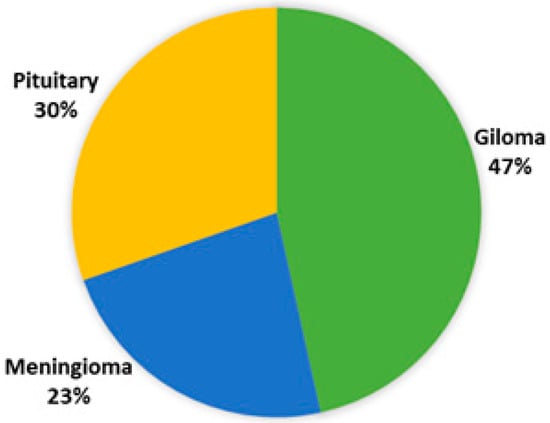
Figure 2.
The percentage of different type of tumors in the dataset.
3.1.2. Preprocessing
Data preprocessing, which includes contrast enhancement and normalization, is necessary for medical image analysis. The dataset was first normalized to the intensity values and then mapped to the 256 levels of grayscale using Equation (1):
where represents any one of the 8-bit grayscale pixel values between 0 and 255 against at position . The variables and are the maximum and minimum pixel intensity in the original image, respectively. Figure 3 shows the original and enhanced images and Figure 4 presents one sample of each type of tumor.
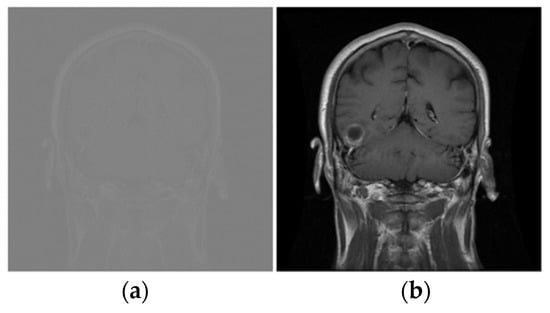
Figure 3.
The original and Enhanced Image. (a) Image in dataset; (b) Enhanced Image.
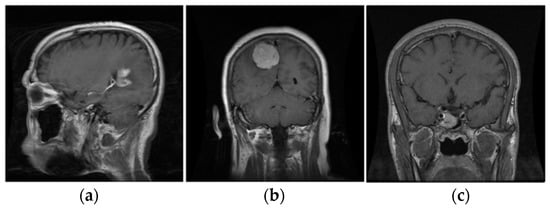
Figure 4.
The three types of tumors. (a) Glioma; (b) Meningioma; (c) Pituitary.
The enhanced resultant images were resized and concatenated three times, as per the standard input image size of the pre-trained DL models, to create channels. All three variants of ResNet: ResNet18, ResNet50, and ResNet101, the best-performing pre-trained DL models [10] for brain tumor classification, have a standard input image size of .
3.1.3. Pre-Trained DL Models
There were many state-of-the-art pre-trained DL models for the classification task. In this research, the idea behind the adopted framework was domain adaptation, in which transfer learning allowed us to utilize the network and knowledge in terms of network weights of pre-trained DL models, from a source domain, to retrain it using new training data for another classification task in the target domain. The data size and similarity between the target and source domain tasks were important parameters for the pre-trained model selection. Because almost all pre-trained existing DL models are trained on millions of natural images, choosing one pre-trained model directly to implement the transfer learning technique for the classification of brain tumors was quite difficult. We assumed, based on the availability of state-of-the-art pre-trained DL models, that the source domain and target domain were different but the task in both domains was similar i.e., classification task. Since we were extending the scope of the research of [10] through statistical analysis, therefore, for better interpretation, we had to increase the simulated results in terms of accuracy to evaluate and validate the hyperparameter effect individually as well as interactively. For this purpose, in this study we were using only the best-performing models based on ResNet architecture: ResNet18, ResNet50, and ResNet101. Figure 5 shows the network architecture of the ResNet18 model.
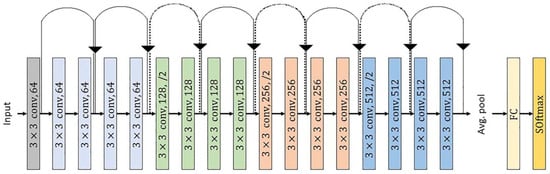
Figure 5.
The ResNet18 architecture [26].
The ResNet18 network architecture consists of 18 layers including 17 convolutional layers plus one fully connected layer and an additional softmax layer to perform the classification task. In this study, we used ResNet18 as a network, already trained on ImageNet dataset to classify 1000 objects, for the initialization of weights, and KBTL was performed. KBTL was implemented by replacing the last fully connected (FC) layer with the new FC layer to match the number of classes, which was 3 three for our task. After replacing the layer, the modified network was retrained for our target domain brain tumor multi-classification task. The modified network was trained with different hyperparameter settings, discussed in the next section, and a comparative analysis was performed to find the optimal hyperparameters, ultimately to obtain an optimized model with the highest accuracy. Since ResNet50 and ResNet101 have the same foundation as ResNet18 and both networks are deeper than ResNet18, therefore, we also used these networks to extend our evaluation space and to validate the significance of hyperparameters in the model performance.
3.1.4. Model Training with Hyperparameters
The optimization problem in implementing KBTL, using the classification framework [10], is finding a set of two most important model hyperparameters’ values i.e., the optimal values for the learning rate and batch size that are consistent with knowledge of the used pre-trained model and give the best accuracy for the classification problem. Mathematically, the problem is defined as:
where is representing the cost function and are the two optimal values of learning rate and batch size that help in minimizing the cost function using the solvers: SGDM, Adam, and RMSprop. Mathematically, is defined in Equation (2) as the training average cost with dataset size.
There are three options to compute the gradient updates: utilizing the complete dataset images , using a single image, or a sample of size between 1 and . The three methods are known as batch gradient descent, stochastic gradient descent, and mini-batch gradient descent respectively. The image sample size utilized to update the gradients each time in one iteration is indicated by the hyperparameter batch size .
Networks using SGDM solver [27] can update their weights according to Equation (3):
where, and is representing the learning rate and are the weights being updated.
The Adam [27] is a relatively straightforward method using first-order gradients that is computationally efficient and has a low memory demand for stochastic optimization. The technique calculates the rate of adaptive learning for each gradient training parameter. For this solver, the weights can be updated using Equation (4):
where ; ; and where the value of indicates how much information from the previous update is required, is the first momentum, which is the running average of the gradients, and is the second momentum, which is the running average of the squared gradients. The first and second momentums after bias correction are and .
The weight updated equation for RMSprop [27] is as follows:
where, . RMSprop divides the learning rate by an average of the squared gradients that decays exponentially. The above equations show that the batch size and learning rate have an impact on each other, and they can have a huge impact on the network performance.
In our previous research work [10], we initialized two different sets and for both hyperparameters, consisting of possible values based on their available values in various studies [46, 50, 53, 62, 68, 69]. We defined and for the batch size and learning rate, respectively. A matrix of size , containing 2-tuple elements, was generated by taking the Cartesian product of two initialized sets X and Y. The Cartesian product of two sets X and Y is the set of all ordered pairs and can be defined as:
It can be generalized to an -ary Cartesian product over sets of different hyperparameters:
In our case, we transformed the Cartesian product vector into a matrix for a better understanding, as described in Equation (8):
Each element of the Cartesian product matrix is applied as a pair of inputs for two hyperparameters to retrain the modified network architecture against each pre-trained deep learning model with our dataset for the brain tumor classification task. Each modified network architecture was evaluated for the three most popular solvers: SGDM, ADAM, and RMSProp. An extensive comparative assessment was conducted in terms of accuracy to obtain the optimal values of batch size and learning rate, along with the most appropriate solver.
3.2. Analysis of Variance (ANOVA)
ANOVA is a group of statistical models and their accompanying estimation technique for examining the differences between means. A two-way ANOVA, an extension of ANOVA, is used when data are collected for a quantitative dependent variable (performance) at multiple levels of two independent controlling categorical variables (learning rate and batch size). The categorical variables are called factors and model performances at each row/column factors are known as treatments. ANOVA is based on the total variance law, according to which the variance observed in a given variable is divided into parts attributed to various variation sources [28]. In this study, we used ANOVA to evaluate the significance of the LR and BS factors and their interaction on model performance.
3.2.1. Factor Effects Model
Consider the two categorical variables (factors) with levels with levels , and representing the treatment observation at the factor’s level . Equation (9) [29] represents the Factor effects model:
where, represents the overall mean:
represents the level of : ,
represents the level of :
is the main effect due to factor :
is the main effect due to factor
and represents the interaction effect between factors and and can be defined as:
These equations also describe the relationship between the factor effects model parameters and cell means .
3.2.2. Estimates for the Factor Effects Model
Equation (10) represents the overall mean and each group’s means estimation by the overall mean of all treatments/outputs and by the mean of the treatments within that group, respectively.
, the main effect due to factor can be estimated using Equation (10b):
, the main effect due to factor can be estimated using Equation (10c):
, the interaction effect in between factors and that can be estimated using Equation (10d):
3.2.3. Sum of Squares (SS) for ANOVA Table
SS (total) defines the sum of squares for the overall data, corrected for the overall mean of all accuracies. Equation (11) describes the SS (total), mathematically.
where,
3.2.4. Degree of Freedom (df) for ANOVA Table
The degree of freedom (df) is the number of independent pieces of information. Mathematically,
3.2.5. Mean Square (MS) for ANOVA Table
The ratio of the Sum of Squares (SS) and Degree of freedom (df) gives the corresponding Mean Square (MS). Mathematically,
3.2.6. Hypotheses for Two-Way ANOVA
Test for LR Effect:
Null Hypotheses
Alternate Hypotheses
The F-statistics for the LR effect test is
and under the null hypotheses, this follows an F distribution with .
Test for BS Effect:
Null Hypotheses
Alternate Hypotheses
The F-statistics for the BS effect test is
and under the null hypotheses, this follows an F distribution with .
Test for LR and BS Interaction Effect:
Null Hypotheses
Alternate Hypotheses
The F-statistics for the LR and BS interaction effect test is
and under the null hypotheses, this follows an F distribution with .
3.2.7. F-Statistics for the Tests
F-statistics gives p-values, calculated using the F distribution with . A indicates that the tested effect due to factors LR and BS, either as individuals or with an interaction in between, is statistically significant. Table 1 summarizes all the statistical parameters involved in the statistical analysis.

Table 1.
The two-way ANOVA Table, with the individual and interaction effect of LR (column) and BS (rows) [30].
4. Experimental Setup and Results Analysis
For brain tumor classification, we used the experimental setup based on the methodology described in Section 3, implemented and investigated using a system equipped with NVIDIA GEFORCE GTX 1080—8 GB Graphics and MATLAB 2020. The dataset was divided into 70%, 15%, and 15% for training, validation, and testing of the model, respectively. After customizing all pre-trained deep learning models, experiments were performed with each pair of inputs from the Cartesian product-based matrix of the batch size and learning rate for the three most popular solvers.
To evaluate and validate the impact of both hyperparameters, we increased the number of samples in the specified ranges [10] of the LR and BS to obtain a detailed output distribution for better interpretation. This study used an extended Cartesian product matrix, consisting of 56 two-tuple hyperparameters generated from the following two vectors:
and
4.1. Simulated Results
An extensive exercise, comprising 504 simulations on the best-performing [10] three cutting-edge architecture-based pre-trained DL models, ResNet18, ResNet50, and ResNet101 were performed. Additionally, the impact was also assessed by using three well-known optimization algorithms (solvers): the adaptive moment estimation (Adam), the stochastic gradient descent with momentum (SGDM), and the root mean squared propagation (RMSProp). The three best-performing ResNet variants were selected with the help of a comparative analysis in which three ResNet variants were compared with other start-of-the-art classification models as presented in Table 2. The parameters to compare were the number of epochs utilized in convergence, number of iterations, validation accuracy, training time, and confusion matrix. All three variants of ResNet, especially ResNet18, outperformed all other networks with parameters {SGDM, 32, 0.01} by achieving 99.56% accuracy when using our framework for brain tumor classification. This was due to the ResNet working principle of building a deeper network compared to other networks and its capability to solve the vanishing gradient problem simultaneously. Figure 6a,b depict the training-validation accuracy and loss curve and the confusion matrix while training, validating, and testing ResNet18, the best-performing model. In addition to the ultimate accuracy measurement, utilizing three other measures: precision, recall, and specificity, the framework was further evaluated. Table 3 summarizes the performance measures related to the above-mentioned measuring parameters for the average of all classes and each class separately as well for all deep learning networks presented in Table 2. The comparison shows that ResNet18 outperforms all the others in all the measuring fields. Figure 6 clearly describes the condition that we had achieved a solution of our optimization problem, defined in Section 3.1.4, with the optimal hyperparameters’ values () using the SGDM solver. The solution, ultimately, provided us with an optimized model with the highest accuracy of 99.56% for the brain tumor classification problem.
Table 2.
A comparative study of the models with their optimal parameters [10].
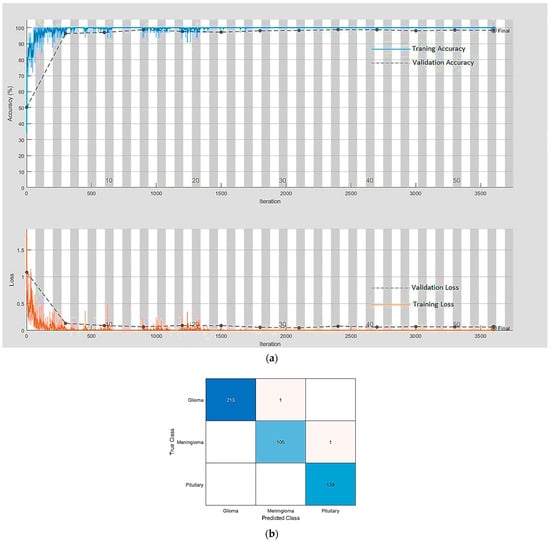
Figure 6.
(a) The training-validation accuracy and loss for the best-performing model. (b) The confusion matrix for the best-performing model.
Table 3.
A comparative study of the models in terms of performance metrics [10].
In this study, as discussed above, we extended the scope of the research by performing a statistical analysis to evaluate and validate the effect of the hyperparameters. All three models with three different solvers were simulated with each pair (LR, and BS) from the extended Cartesian product matrix for 100 epochs. Seven LRs and eight BSs in the form of pairs resulted in 56 test accuracies with one solver for one model. Table 4 presents all three models’ performances in terms of accuracies for the three solvers.
Table 4.
ResNet architecture-based models’ performances in term of accuracies (percentage).
Furthermore, Figure 7 shows boxplots, demonstrating the collected results’ distribution for the ResNet18 DL model retrained on our brain tumor dataset with solvers SGDM, Adam, and RMSProp. On the left side, each boxplot exhibits a distribution of measured accuracies for the given range of BSs at each specific LR starting from 0.00001 to 0.01. On the right side, each boxplot exhibits a distribution of the measured accuracies for the given range of LRs at each specific BS starting from 2 to 64. Each boxplot represents the lower quartile, median, and upper quartile, and whiskers extend to the end of the sample range to display the maximum and minimum accuracies.
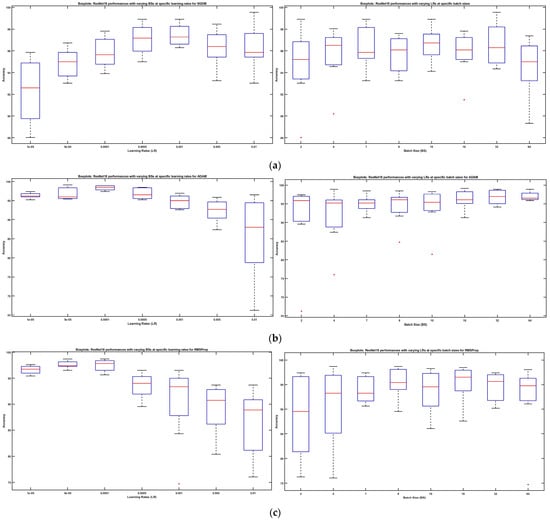
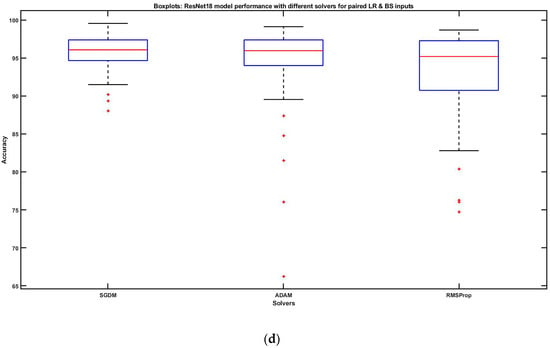
Figure 7.
(a) ResNet18 performances with SGDM: varying BSs at specific LRs (left side), varying LRs at specific BSs (right side). (b) ResNet18 performances with ADAM: varying BSs at specific LRs (left side), varying LRs at specific BSs (right side). (c) ResNet18 performances with RMSProp: varying BSs at specific LRs (left side), varying LRs at specific BSs (right side). (d) ResNet18 model performances with three solvers for paired hyperparameter inputs.
On increasing the LRs, the parameters of the boxplots display a nonlinear behavior. When referring to SGDM, the maximum accuracy of 99.56% i.e., the highest value of the whiskers, was observed with LR = 0.01 while the maximum dispersion was observed with the lowest value of LR = 0.00001. On the other hand, with Adam, the maximum value of the whiskers (accuracy = 99.13%) was observed with LR = 0.00005, whereas the greatest dispersion was depicted with LR = 0.01. RMSProp informed of a behavior similar to Adam, with the greatest dispersion being at the highest value of LR and the maximum performance being at LR = 0.00005. Similarly, on the right side of Figure 7, boxplots about the increase in the batch size reveal a nonlinear pattern. Conclusively, it is quite evident from the boxplots that increasing/decreasing the LRs and BS did not increase/decrease the model performance in a hierarchical fashion, rather there seemed to be a trade-off in-between.
Figure 7d reveals the joint impact of LR and BS on the data set while comparing the model performances using SGDM, Adam, and RMSProp. We observed that concerning the brain tumor classification, SGDM had the most optimum performance in comparison to Adam and RMSProp as it reached the maximum accuracy and has the lowest dispersion too. The dispersion of outputs was gradually increasing in Adam and RMSProp, respectively. Although the whiskers maxima and the upper quartile were almost the same for all three solvers, the lower quartile was gradually decreasing. Conclusively, the experimental results show that both hyperparameters (LR and BS) had a significant impact individually as well as interactively, with a trade-off in between.
Similar experiments were performed for ResNet50, and ResNet101 models to collect the relevant data in terms of accuracies for the defined values of LR and BS. Simulation results revealed the same effect of LR and BS on the model performance as shown by ResNet18.
A performance comparison is presented in Table 5 between our work and other existing state-of-the-art research studies that used the same brain tumor dataset for multi-type tumor classification. The comparison was mainly based on the performance metric “accuracy” with the support of three other parameters: “precision,” “recall,” and “specificity.” The comparison showed that the transfer learning technique, implemented through our proposed framework for brain tumor classification, outperformed all existing approaches based on traditional image processing [5,31], CNN [32,33], and transfer learning [34,35,36,37,38,39,40].
Table 5.
The comparison of the framework with the related work based on the same dataset.
4.2. Statistical Analysis
The discussion in this section validates our experimental results using two-way ANOVA. The analysis was performed using the collected data in terms of test accuracies, shown in Table 4 as well as in Figure 7 boxplots. Each accuracy represented an output against each pair of LR and BS for the ResNet18 model with solvers SGDM, Adam, and RMSProp. The statistical analysis has validated our experimental findings: (1) LR showed a significant impact on the model performance, (2) BS showed a significant impact on the model performance, and (3) there was an interaction effect of LR and BS on the model performance.
In addition to the representation of data as boxplots, a sample of data to describe how it was used in the analysis is shown in Table 6.
Table 6.
The dataset sample (the ResNet model’s performances (accuracies) with SGDM) organized for ANOVA statistics [30].
The columns of the matrix represent the LRs and the rows represent the BSs. In this analysis, we replicated each experiment three times, as per the ANOVA statistics, for a balanced design. The first three rows correspond to ResNet18, ResNet50, and ResNet101, respectively for BS = 2 and the next three rows represent the performances for all three models with BS = 4. The response values are the model performances in terms of accuracy at each (LR, BS) paired value.
Table 7 shows the parameters obtained through the ANOVA analysis. The parameter shows the p-values: for the LRs, BSs, and the interaction effect between LR and BS, respectively. These values indicate that LRs and BSs affected the model performance individually as well as there was an interaction between the two hyperparameters. Further, we have also performed multiple comparison tests to investigate whether the model performance differed between pairs of LRs or not. The test helped us in finding the significant impact on the model performance due to an increase/decrease in the LR.
Table 7.
The two-way ANOVA, individual and interaction effect of LR (column) and BS (rows).
Table 8 shows the multiple comparisons of the means of accuracies associated with each LR. Seven LRs are representing seven groups to compare.
Table 8.
The two-way ANOVA, multiple comparisons of LR’s (column-wise) means.
Column 1 and column 2 of Table 3 show the LR’s associated groups that are compared. Column number 4 shows the difference between the calculated group means. Column numbers 3 and 5 represent the lower and upper limits, respectively, for the 95% confidence interval for the true mean difference. The last column consists of the p-value for a hypothesis testing that the difference between the corresponding group means is equal to zero. It is very clear from Table 4 that the larger group mean difference resulted in a p-value < 0.05. The p-values in Table 4 that are very small, indicate that the model performance varied across LRs. Conclusively, the LR had a significant impact on the model performance.
Similarly, another multiple comparison was performed to investigate the impact of BS on the model performance. Table 9 shows the multiple comparisons of the means of accuracies associated with each BS. There are eight accuracies groups associated with eight BSs. The small p-values < 0.05 indicate that the model performance differed between two BSs and the group means were significantly different from each other. It is concluded that BS had a significant impact on the model performance.
Table 9.
Two-way ANOVA, multiple comparisons of BS’s (row-wise) means.
Kandel et al. [20] used five different BS(s) and two LR(s) to investigate these hyperparameters’ influence on the network’s performance. The author concluded that the performance was significantly influenced by the learning rate and batch size; the learning rate and batch size had a high correlation. The author advised choosing small batch sizes with a low learning rate. According to a Masters et al. [22] statement, small BS(s) should be used. The author did not comment on the influence of LR while Radiuk [19] said that a higher BS should be used with a large LR to obtain a better performance. All these research studies used very limited experiments with few LR(s) and BS(s) that could not guarantee the exact pattern. In our case, we performed an extensive exercise with a larger number of LR(s) and BS(s) to find the pattern. From our simulation results, presented in Table 4, it is quite clear that both hyperparameters have a significant influence on the model performance with a trade-off in-between. Further, the ANOVA statistical test also proved that both hyperparameters not only have an individual significant effect on the model performance but also an interaction exists in-between.
5. Conclusions and Future Work
The successful implementation of KBTL is completely based on the tuning of hyperparameters such as the LR and BS. In addition to the challenging task of selecting an optimal value for hyperparameters, there is another issue to find their significant impact, independently as well as interactively, on the model performance. In this study, a Cartesian product matrix, consisting of 56 pairs of LR and BS, was used to input the three best-performing ResNet architecture-based DL models for brain tumor classification. In the first phase, an extensive experiment comprising 504 simulations was performed, and results in terms of the accuracy were collected for further investigation. The initial study revealed that increasing/decreasing the LRs and BS did not increase/decrease the model performance in a hierarchical fashion, rather there seemed to be a trade-off in-between. Further, the experimental results showed that both hyperparameters (LR and BS) had a joint significant impact on the model performance. In the second phase, the results were validated using the statistical ANOVA analysis. The F-test returned all three results, with , stating both hyperparameters (LR and BS) not only have a significant impact on the model performance independently, but there exists an interaction between LR and BS for a combination of their levels. In addition to these findings, multiple comparison tests for different LRs and different BSs concluded that each LR and BS had an independent impact on the model performance. Further, the non-linear pattern for accuracy on increasing/decreasing LR and BS suggested that there should be a trade-off between LR and BS to obtain the maximum accuracy, ultimately helping to find the optimal values of LR and BS and the optimum model for brain tumor classification.
This study can be further extended by using more than two hyperparameters in the Cartesian product matrix to obtain their optimal values. Moreover, researchers are invited to further validate the methodology by using other dataset(s) for not only brain tumor classification but also in other classification problems. The limitation of this research was the GPU specifications that allowed for the evaluation and validation of the framework for the batch sizes up to 64.
Author Contributions
Conceptualization, I.A.U., M.T.Q., R.Z., F.S.A., O.S. and K.D.; methodology, I.A.U., M.T.Q., R.Z., F.S.A., O.S. and K.D.; software, I.A.U., M.T.Q., R.Z., F.S.A. and O.S.; validation, I.A.U., F.S.A. and O.S.; formal analysis, I.A.U., M.T.Q. and R.Z.; investigation, I.A.U. and K.D.; resources, M.T.Q., R.Z., F.S.A., O.S. and K.D.; data curation, I.A.U., F.S.A. and O.S.; writing—original draft preparation, I.A.U.; writing—review and editing, M.T.Q., R.Z., F.S.A., O.S. and I.A.U.; supervision, M.T.Q.; project administration, F.S.A. and O.S.; funding acquisition, F.S.A. and O.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R319), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
Dataset used for statistical analysis will be available on request from the corresponding author.
Acknowledgments
Authors would like to give thanks for the support of Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R319), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Selvanayaki, K.; Karnan, M. CAD system for automatic detection of brain tumor through magnetic resonance image-a review. Int. J. Eng. Sci. Technol. 2010, 2, 2. [Google Scholar]
- Brindle, K.M.; Izquierdo-García, J.L.; Lewis, D.Y.; Mair, R.J.; Wright, A.J. Brain Tumor Imaging. J. Clin. Oncol. 2017, 35, 2432–2438. [Google Scholar] [CrossRef] [PubMed]
- Wen, P.Y.; Macdonald, D.R.; Reardon, D.A.; Cloughesy, T.F.; Sorensen, A.G.; Galanis, E.; DeGroot, J.; Wick, W.; Gilbert, M.R.; Lassman, A.B.; et al. Updated Response Assessment Criteria for High-Grade Gliomas: Response Assessment in Neuro-Oncology Working Group. J. Clin. Oncol. 2010, 28, 1963–1972. [Google Scholar] [CrossRef]
- Drevelegas, A. Imaging of Brain Tumors with Histological Correlations; Springer: Berlin/Heidelberg, Germany, 2011; pp. 13–33. [Google Scholar]
- Cheng, J.; Huang, W.; Cao, S.; Yang, R.; Yang, W.; Yun, Z.; Wang, Z.; Feng, Q. Enhanced performance of brain tumor classification via tumor region augmentation and partition. PloS ONE 2015, 10, e0140381. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Yang, W.; Huang, M.; Huang, W.; Jiang, J.; Zhou, Y.; Yang, R.; Zhao, J.; Feng, Y.; Feng, Q.; et al. Retrieval of Brain Tumors by Adaptive Spatial Pooling and Fisher Vector Representation. PLoS ONE 2016, 11, e0157112. [Google Scholar] [CrossRef]
- Kumar, S.; Dabas, C.; Godara, S. Classification of Brain MRI Tumor Images: A Hybrid Approach. Procedia Comput. Sci. 2017, 122, 510–517. [Google Scholar] [CrossRef]
- Mohan, G.; Subashini, M.M. MRI based medical image analysis: Survey on brain tumor grade classification. Biomed. Signal Process. Control 2018, 39, 139–161. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, W.; Tao, L.; Ma, J. Transfer Learning Strategies for Deep Learning-based PHM Algorithms. Appl. Sci. 2020, 10, 2361. [Google Scholar] [CrossRef]
- Usmani, I.A.; Qadri, M.T.; Zia, R.; Aziz, A.; Saeed, F. Cartesian Product Based Transfer Learning Implementation for Brain Tumor Classification. Comput. Mater. Contin. 2022, 73, 4369–4392. [Google Scholar] [CrossRef]
- Bahmani, M.; Shawi, R.E.; Potikyan, N.; Sakr, S. To tune or not to tune? An Approach for Recommending Important Hyperparameters. arXiv 2021, arXiv:2108.13066. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Radiuk, P.M. Impact of Training Set Batch Size on the Performance of Convolutional Neural Networks for Diverse Datasets. Inf. Technol. Manag. Sci. 2017, 20, 20–24. [Google Scholar] [CrossRef]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 7 January 2023).
- Cheng, J. Brain Tumor Dataset, Version 5. 2017. Available online: https://doi.org/10.6084/m9.figshare.1512427.v5 (accessed on 2 April 2017).
- Ramzan, F.; Khan, M.U.G.; Rehmat, A.; Iqbal, S.; Saba, T.; Rehman, A.; Mehmood, Z. A Deep Learning Approach for Automated Diagnosis and Multi-Class Classification of Alzheimer’s Disease Stages Using Resting-State fMRI and Residual Neural Networks. J. Med. Syst. 2019, 44, 37. [Google Scholar] [CrossRef]
- Yaqub, M.; Feng, J.; Zia, M.; Arshid, K.; Jia, K.; Rehman, Z.; Mehmood, A. State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images. Brain Sci. 2020, 10, 427. [Google Scholar] [CrossRef]
- Wu, S.; Hu, X.; Zheng, W.; He, C.; Zhang, G.; Zhang, H.; Wang, X. Effects of reservoir water level fluctuations and rainfall on a landslide by two-way ANOVA and K-means clustering. Bull. Eng. Geol. Environ. 2021, 80, 5405–5421. [Google Scholar] [CrossRef]
- Rouder, J.N.; Schnuerch, M.; Haaf, J.M.; Morey, R.D. Principles of Model Specification in ANOVA Designs. Comput. Brain Behav. 2022, 1–14. [Google Scholar] [CrossRef]
- Mahajan, R.; Kishore, K.; Jaswal, V. The challenges of interpreting ANOVA by dermatologists. Indian Dermatol. Online J. 2022, 13, 109. [Google Scholar] [CrossRef] [PubMed]
- Ismael, M.R.; Abdel-Qader, I. Brain tumor classification via statistical features and back-propagation neural network. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 0252–0257. [Google Scholar]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N. Brain tumor type classification via capsule networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3129–3133. [Google Scholar]
- Pashaei, A.; Sajedi, H.; Jazayeri, N. Brain tumor classification via convolutional neural network and extreme learning machines. In Proceedings of the 2018 8th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 25–26 October 2018; pp. 314–319. [Google Scholar]
- Sajjad, M.; Khan, S.; Muhammad, K.; Wu, W.; Ullah, A.; Baik, S.W. Multi-grade brain tumor classification using deep CNN with extensive data augmentation. J. Comput. Sci. 2018, 30, 174–182. [Google Scholar] [CrossRef]
- Swati, Z.N.K.; Zhao, Q.; Kabir, M.; Ali, F.; Ali, Z.; Ahmed, S.; Lu, J. Brain tumor classification for MR images using transfer learning and fine-tuning. Comput. Med. Imaging Graph. 2019, 75, 34–46. [Google Scholar] [CrossRef] [PubMed]
- Deepak, S.; Ameer, P. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. 2019, 111, 103345. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, K.; Khan, S.; Del Ser, J.; de Albuquerque, V.H.C. Deep Learning for Multigrade Brain Tumor Classification in Smart Healthcare Systems: A Prospective Survey. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 507–522. [Google Scholar] [CrossRef]
- Noreen, N.; Palaniappan, S.; Qayyum, A.; Ahmad, I.; Imran, M.; Shoaib, M. A Deep Learning Model Based on Concatenation Approach for the Diagnosis of Brain Tumor. IEEE Access 2020, 8, 55135–55144. [Google Scholar] [CrossRef]
- Sekhar, A.; Biswas, S.; Hazra, R.; Sunaniya, A.K.; Mukherjee, A.; Yang, L. Brain Tumor Classification Using Fine-Tuned GoogLeNet Features and Machine Learning Algorithms: IoMT Enabled CAD System. IEEE J. Biomed. Health Inform. 2021, 26, 983–991. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I.; Akram, F.; Imran, M. A Deep Learning-Based Framework for Automatic Brain Tumors Classification Using Transfer Learning. Circuits Syst. Signal Process. 2020, 39, 757–775. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).