
Neural Machine Translation of Electrical Engineering Based on Integrated Convolutional Neural Networks

Abstract
:1. Introduction
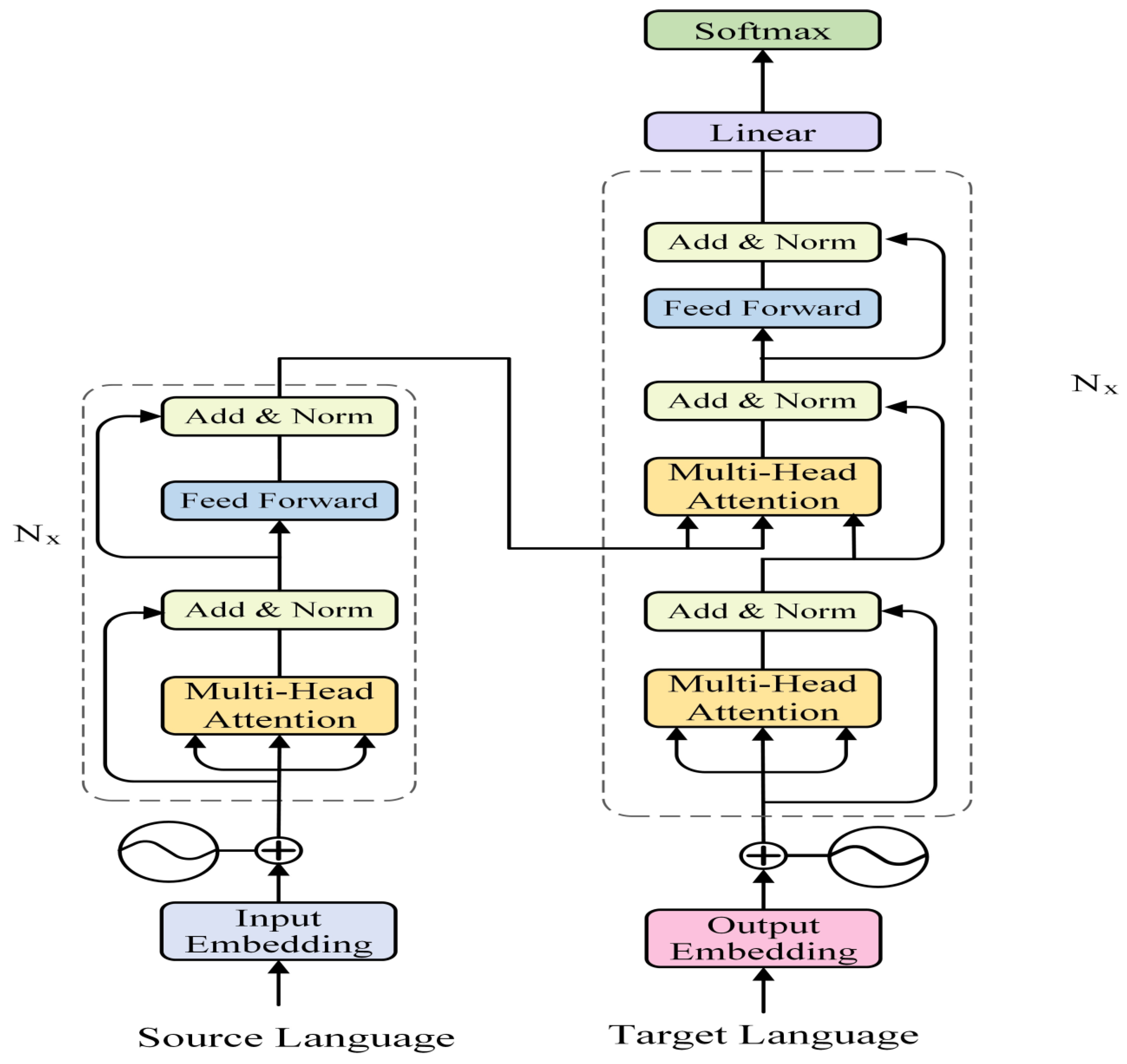
2. Model
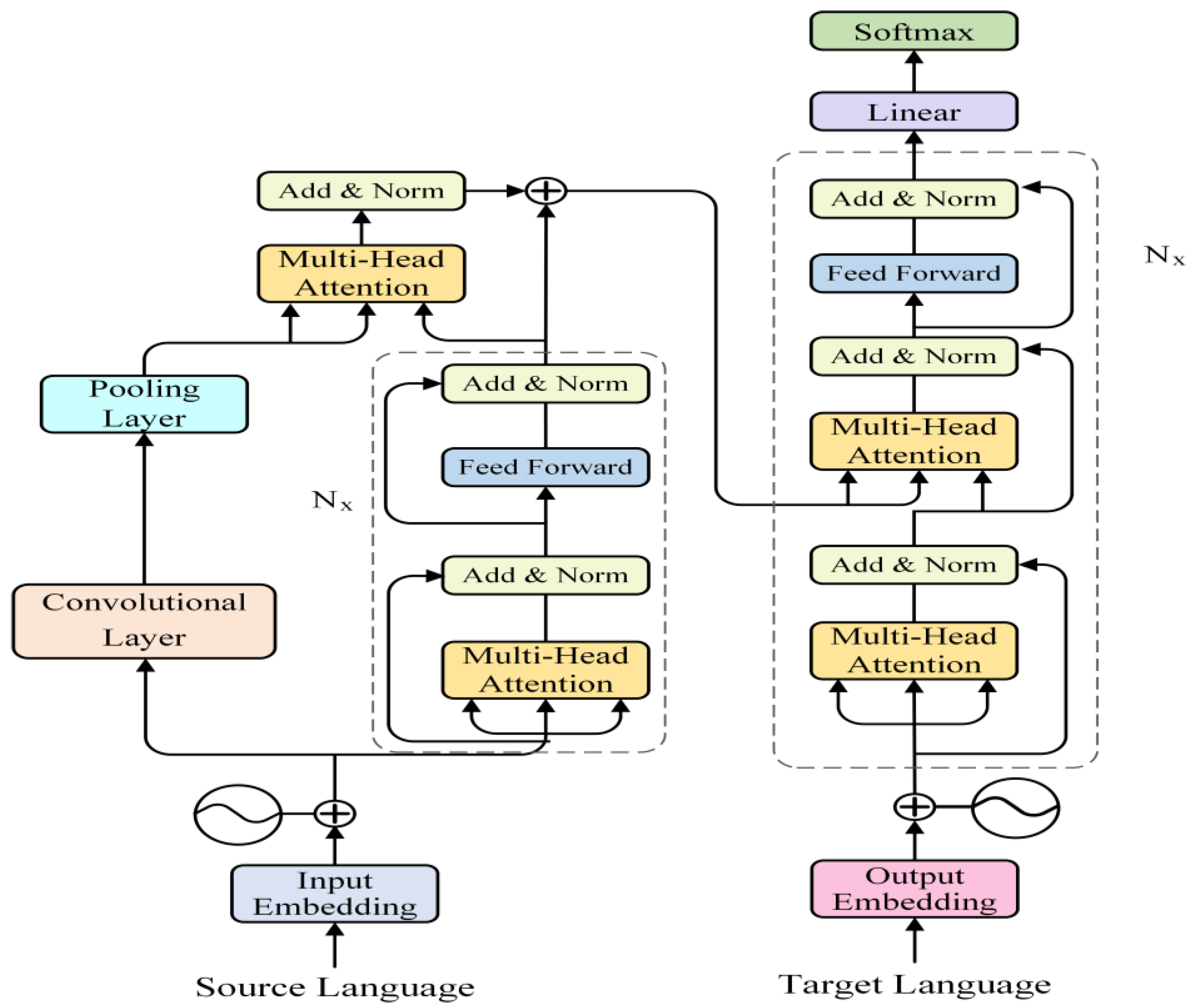
3. Source-Side-CNN-Transformer
3.1. Embedding and Positional Encoding
3.2. Encoder
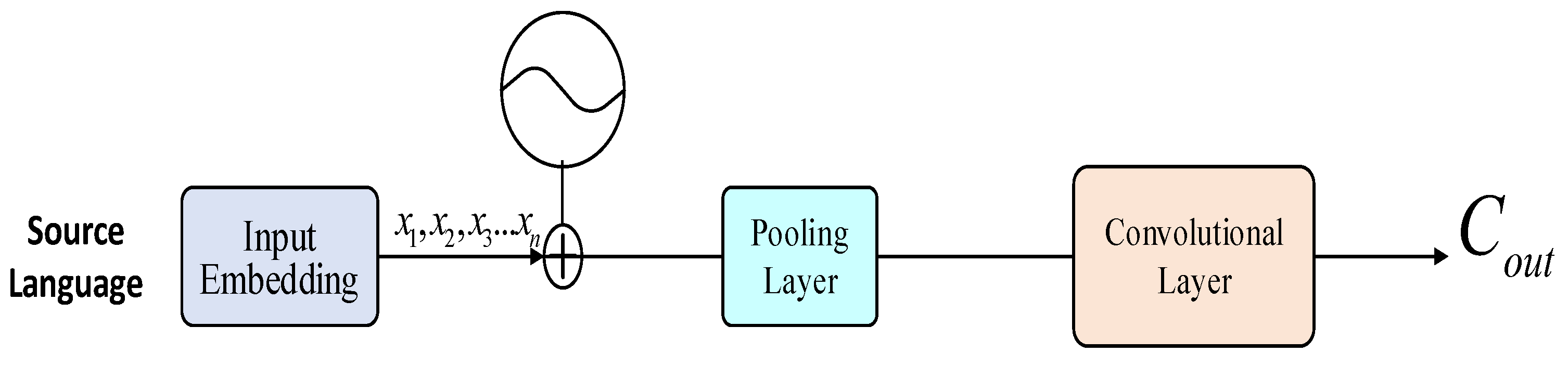
3.3. Feature Extraction Layer
3.3.1. Convolutional Layer
3.3.2. Pooling Layer
3.4. Attention Fusion Layer
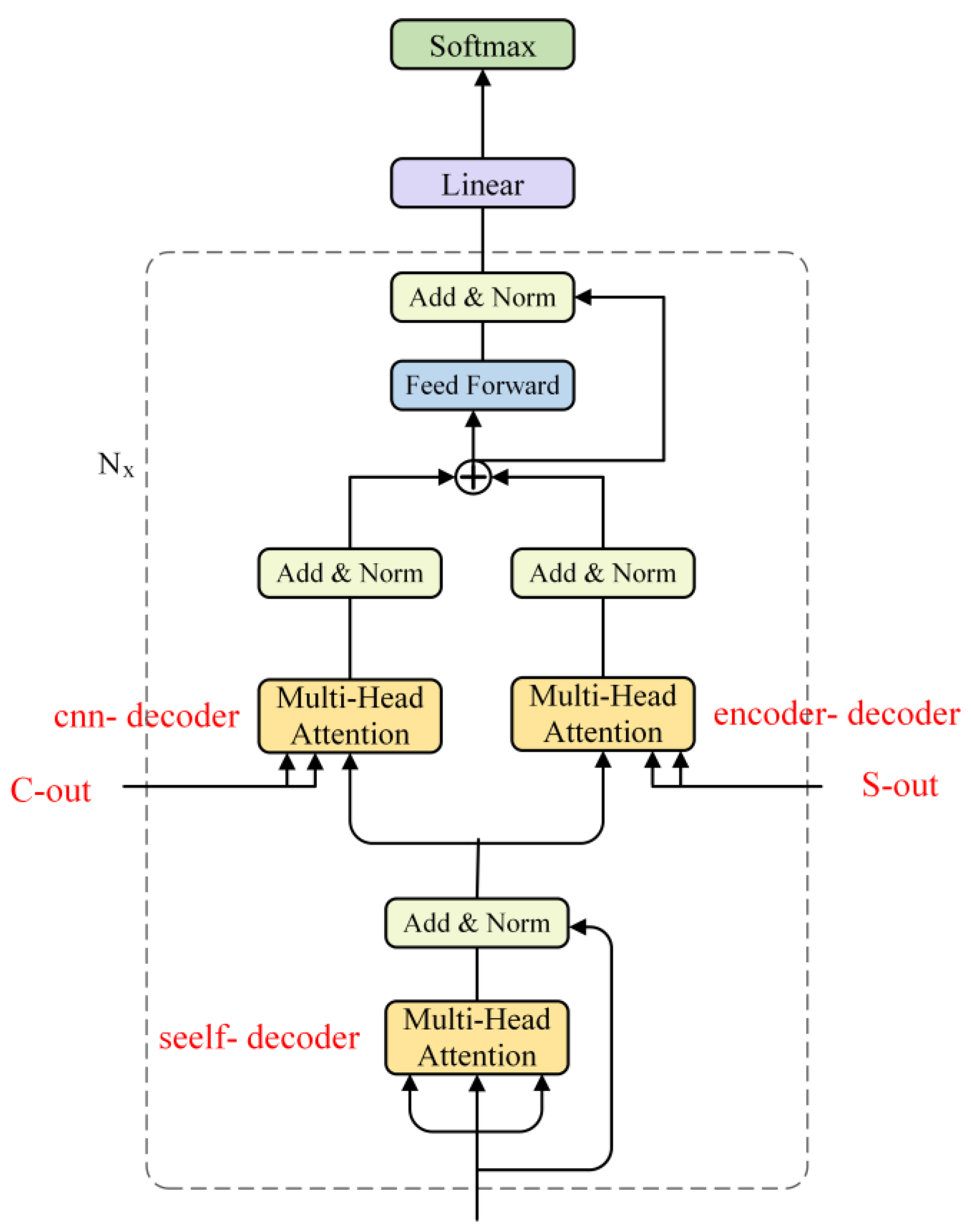
3.5. Decoder
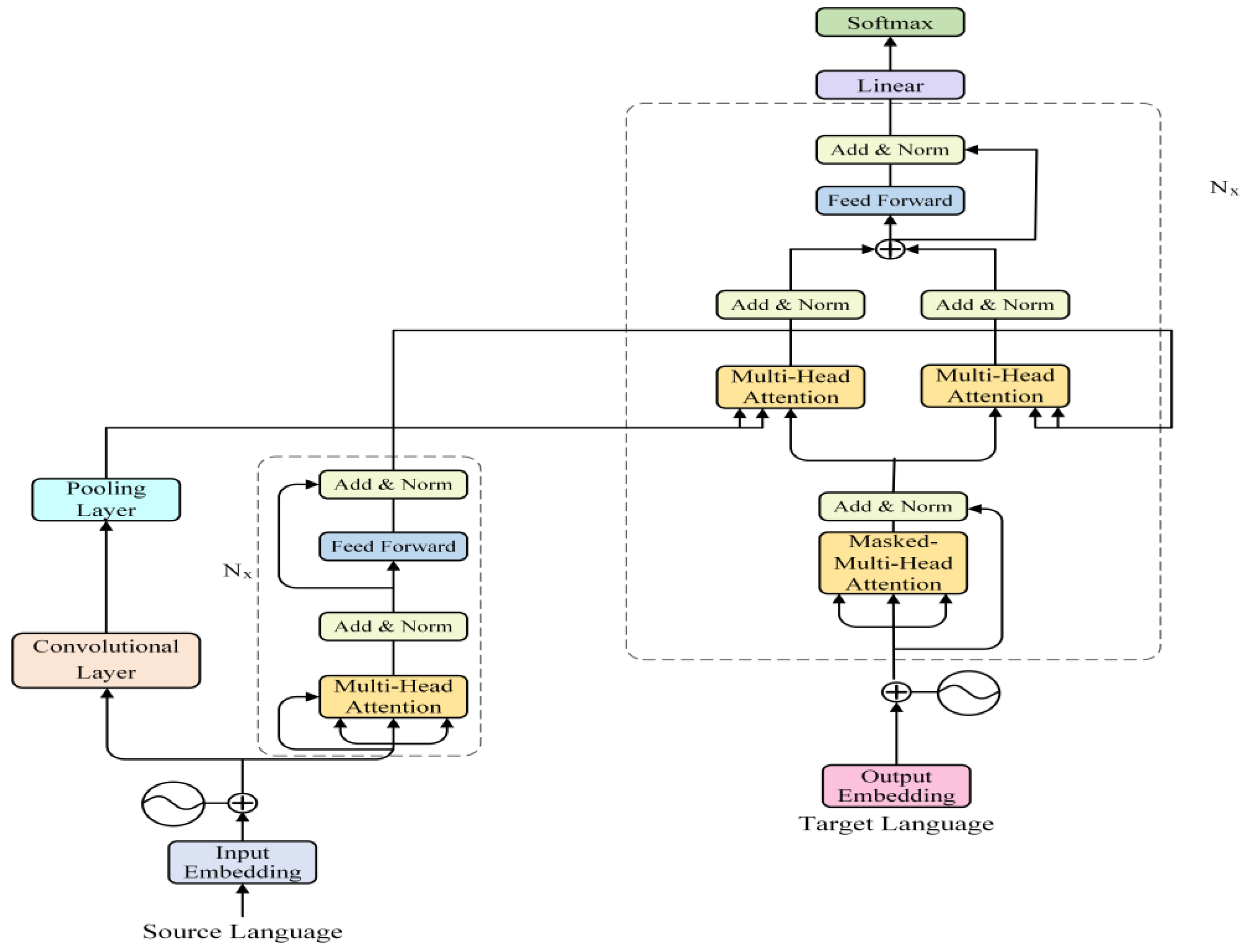
4. Target-Side-CNN-Transformer
4.1. Encoder
4.2. Decoder
5. Experiment
5.1. Dataset
5.2. Parameter Settings
5.3. Experiment and Analysis
5.3.1. Source-Side Model Experiment
5.3.2. Target-Side Model Experiment
5.3.3. Ablation Experiment
5.3.4. Comparison Experiment
5.3.5. Extended Experiment
5.3.6. Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–17 August 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Tonja, A.L.; Kolesnikova, O.; Gelbukh, A.; Sidorov, G. Low-Resource Neural Machine Translation Improvement Using Source-Side Monolingual Data. Appl. Sci. 2023, 13, 1201. [Google Scholar] [CrossRef]
- Mahsuli, M.M.; Khadivi, S.; Homayounpour, M.M. LenM: Improving Low-Resource Neural Machine Translation Using Target Length Modeling. Neural Process. Lett. 2023, 1–32. [Google Scholar] [CrossRef]
- Pham, N.L.; Pham, T.V. A Data Augmentation Method for English-Vietnamese Neural Machine Translation. IEEE Access 2023, 11, 28034–28044. [Google Scholar]
- Laskar, S.R.; Paul, B.; Dadure, P.; Manna, R.; Pakray, P.; Bandyopadhyay, S. English–Assamese neural machine translation using prior alignment and pre-trained language model. Comput. Speech Lang. 2023, 82, 101524. [Google Scholar] [CrossRef]
- Park, Y.H.; Choi, Y.S.; Yun, S.; Kim, S.H.; Lee, K.J. Robust Data Augmentation for Neural Machine Translation through EVALNET. Mathematics 2022, 11, 123. [Google Scholar] [CrossRef]
- Dhar, P.; Bisazza, A.; van Noord, G. Evaluating Pre-training Objectives for Low-Resource Translation into Morphologically Rich Languages. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 4933–4943. [Google Scholar]
- Gong, L.; Li, Y.; Guo, J.; Yu, Z.; Gao, S. Enhancing low-resource neural machine translation with syntax-graph guided self-attention. Knowl. Based Syst. 2022, 246, 108615. [Google Scholar]
- Hlaing, Z.Z.; Thu, Y.K.; Supnithi, T.; Netisopakul, P. Improving neural machine translation with POS-tag features for low-resource language pairs. Heliyon 2022, 8, e10375. [Google Scholar] [CrossRef] [PubMed]
- Ghannay, S.; Favre, B.; Esteve, Y.; Camelin, N. Word embedding evaluation and combination. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 300–305. [Google Scholar]
- Levy, O.; Goldberg, Y. Neural word embedding as implicit matrix factorization. Adv. Neural Inform. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Gulcehre, C.; Firat, O.; Xu, K.; Cho, K.; Barrault, L.; Lin, H.C.; Bougares, F.; Schwenk, H.; Bengio, Y. On using monolingual corpora in neural machine translation. arXiv 2015, arXiv:1503.03535. [Google Scholar]
- Wang, Y.; Xia, Y.; Tian, F.; Gao, F.; Qin, T.; Zhai, C.X.; Liu, T.Y. Neural machine translation with soft prototype. Adv. Neural Inform. Process. Syst. 2019, 32, 1–10. [Google Scholar]
- Cao, Q.; Xiong, D. Encoding gated translation memory into neural machine translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October 31–4 November 2018; pp. 3042–3047. [Google Scholar]
- Bimal, K. Modern Power Electronics and AC Drives; Prentice-Hall: Hoboken, NJ, USA, 2001. [Google Scholar]
- Bimal, K. Modern Power Electronics and AC Drive; Wang, C.; Zhao, J.; Yu, Q.; Cheng, H., Translators; Machinery Industry Press: Beijing, China, 2005. [Google Scholar]
- Wang, Q.; Glover, J.D. Power System Analysis and Design (Adapted in English); Machinery Industry Press: Beijing, China, 2009. [Google Scholar]
- Glover, J.D. Power System Analysis and Design (Chinese Edition); Wang, Q.; Huang, W.; Yan, Y.; Ma, Y., Translators; Machinery Industry Press: Beijing, China, 2015. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. Opennmt: Open-Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Chen, K.; Wang, R.; Utiyama, M.; Sumita, E.; Zhao, T. Neural machine translation with sentence-level topic context. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1970–1984. [Google Scholar] [CrossRef]
- Hu, S.; Li, X.; Bai, J.; Lei, H.; Qian, W.; Hu, S.; Zhang, C.; Kofi, A.S.; Qiu, Q.; Zhou, Y.; et al. Neural Machine Translation by Fusing Key Information of Text. CMC Comput. Mater. Contin. 2023, 74, 2803–2815. [Google Scholar] [CrossRef]
- Chen, K.; Wang, R.; Utiyama, M.; Sumita, E. Integrating prior translation knowledge into neural machine translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 30, 330–339. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | |
|---|---|
| CNN_height | 3 |
| CNN_width | 512 |
| Input_channel | 1 |
| Output_channel | 1 |
| Pooling | Max_pooling |
| Pooling_height | 2 |
| Pooling_width | 1 |
| Act_function | ReLU |
| Num_fliter | 51,200 |
| Model | BLEU/% | |
|---|---|---|
| SSCT-Max-Pooling | 35.88 | – |
| SSCT-Avg-Pooling | 35.35 | −0.53 |
| TSCT-Max-pooling | 35.37 | – |
| TSCT-Avg-Pooling | 34.86 | −0.51 |
| Parameters | |
|---|---|
| Baseline | Transformer |
| Word_max_length | 100 |
| Hidden_size | 512 |
| Word_vec_size | 512 |
| dropout | 0.1 |
| Optimizer | Adam |
| Learning_rate | 2 |
| Label_smoothing | 0.1 |
| Beam_size | 5 |
| Enc_layer | 6 |
| Dec_layer | 6 |
| Transformer_ff | 2048 |
| Src_vocab_size | 44,000 |
| Tgt_vocab_size | 44,000 |
| Batch_size | 64 |
| Train_steps | 25,000 |
| Vaild_steps | 1000 |
| Report_every | 100 |
| seed | 1234 |
| adam_beta2 | 0.998 |
| Model | BLEU/% | |
|---|---|---|
| Baseline | 34.25 | – |
| SSCT | 35.88 | +1.63 |
| Model | BLEU/% | |
|---|---|---|
| Baseline | 34.25 | – |
| TSCT | 35.37 | +1.12 |
| Model | BLEU/% | |
|---|---|---|
| SSCT | 35.88 | – |
| SST | 34.79 | −1.09 |
| Model | BLEU/% | |
|---|---|---|
| TSCT | 35.37 | – |
| TST | 34.50 | −0.87 |
| Model | BLEU/% | Time/min | |
|---|---|---|---|
| Baseline | 34.25 | 141 | – |
| Sentence-level | 34.93 | 203 | +0.68 |
| Key Information Fusion | 34.97 | 479 | +0.72 |
| Pos Fusion | 35.27 | 471 | +1.02 |
| SSCT | 35.88 | 179 | +1.63 |
| Prior Knowledge | 34.82 | 486 | +0.57 |
| Method | tool | Extraction Time/min | Processing Time/min | Execution Time/min |
|---|---|---|---|---|
| Key Information | YAKE | 133 | 143 | 203 |
| Pos Fusion | Stanford Tagger | 121 | 157 | 193 |
| Prior Knowledge | Stanford CoreNLP | 139 | 158 | 189 |
| Dataset | Model | BLEU/% | |
|---|---|---|---|
| WMT2017(CN-EN) | Baseline | 22.82 | – |
| SSCT | 24.09 | +1.27 | |
| TSCT | 23.57 | +0.75 |
| Source text | A Configuration Scheme of Two Automatic Bus Transfer Equipment for 10 kV Sections in a Substation with Three Main Transformers |
| Reference | 在一个有两台主变压器的变电站中,针对10千伏区段的两个自动母线转换设备的配置方案。 |
| Translation of baseline model | |
| 两台主变压器转换电站10 kV段2台自动母线传输设备配置方案/Configuration scheme of two main transformers converting power station with two automatic bus transmission equipment in the 10 kV section | |
| Translation of Source-Side-CNN-model | |
| 为一个具有两台主变压器的变电站,设计10千伏范围的两个自动母线转换设备的装置方案。/Designing a device scheme for two automatic busbar transfer devices within the 10 kV range for a substation equipped with two main transformers. | |
| Translation of Target-Side-CNN-model | |
| 在两台主变压器的变电站中,为10千伏区段的两个自动主线转换设备的设计的配置方案。/Configuration scheme for two automatic busbar transfer devices designed for the 10 kV section in a substation with three main transformers. | |
| Source text | The paper puts forward impact factor analysis of the reliability in bulk power system using power flow tracing method on the basic of power flow tracing load-shedding model. |
| Reference | 本文在潮流跟踪负荷削减模型基础上,提出了大电力系统可靠性影响因素分析的潮流跟踪法。 |
| Translation of baseline model | |
| 在潮流跟踪负荷减少模型的基础上提出了电子系统的可靠性影响因素分析的潮流跟随法。/Based on the load reduction model of power flow tracking, a power flow following method for the analysis of reliability influencing factors of electronic systems is proposed. | |
| Translation of Source-side-CNN-model | |
| 这篇文章在潮流跟踪负荷削减模型的削减基础上提出了适用于大电力系统可靠性影响因素分析的潮流跟踪法。/This article proposes a load flow tracking method for analyzing the reliability impact factors in large-scale power systems, based on the load reduction model. | |
| Translation of Target-side-CNN-model | |
| 本文在削减模型的基础上提出了较大的电力系统可靠性影响因素分析的潮流跟踪法。/The present study introduces the load flow tracking method for analyzing the reliability impact factors in large-scale power systems, building upon an existing load reduction model. | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Chen, Y.; Zhang, J. Neural Machine Translation of Electrical Engineering Based on Integrated Convolutional Neural Networks. Electronics 2023, 12, 3604. https://doi.org/10.3390/electronics12173604
Liu Z, Chen Y, Zhang J. Neural Machine Translation of Electrical Engineering Based on Integrated Convolutional Neural Networks. Electronics. 2023; 12(17):3604. https://doi.org/10.3390/electronics12173604
Chicago/Turabian StyleLiu, Zikang, Yuan Chen, and Juwei Zhang. 2023. "Neural Machine Translation of Electrical Engineering Based on Integrated Convolutional Neural Networks" Electronics 12, no. 17: 3604. https://doi.org/10.3390/electronics12173604
APA StyleLiu, Z., Chen, Y., & Zhang, J. (2023). Neural Machine Translation of Electrical Engineering Based on Integrated Convolutional Neural Networks. Electronics, 12(17), 3604. https://doi.org/10.3390/electronics12173604