



Support Vector Machine Chains with a Novel Tournament Voting



Abstract
1. Introduction
2. Related Work
3. Proposed Method
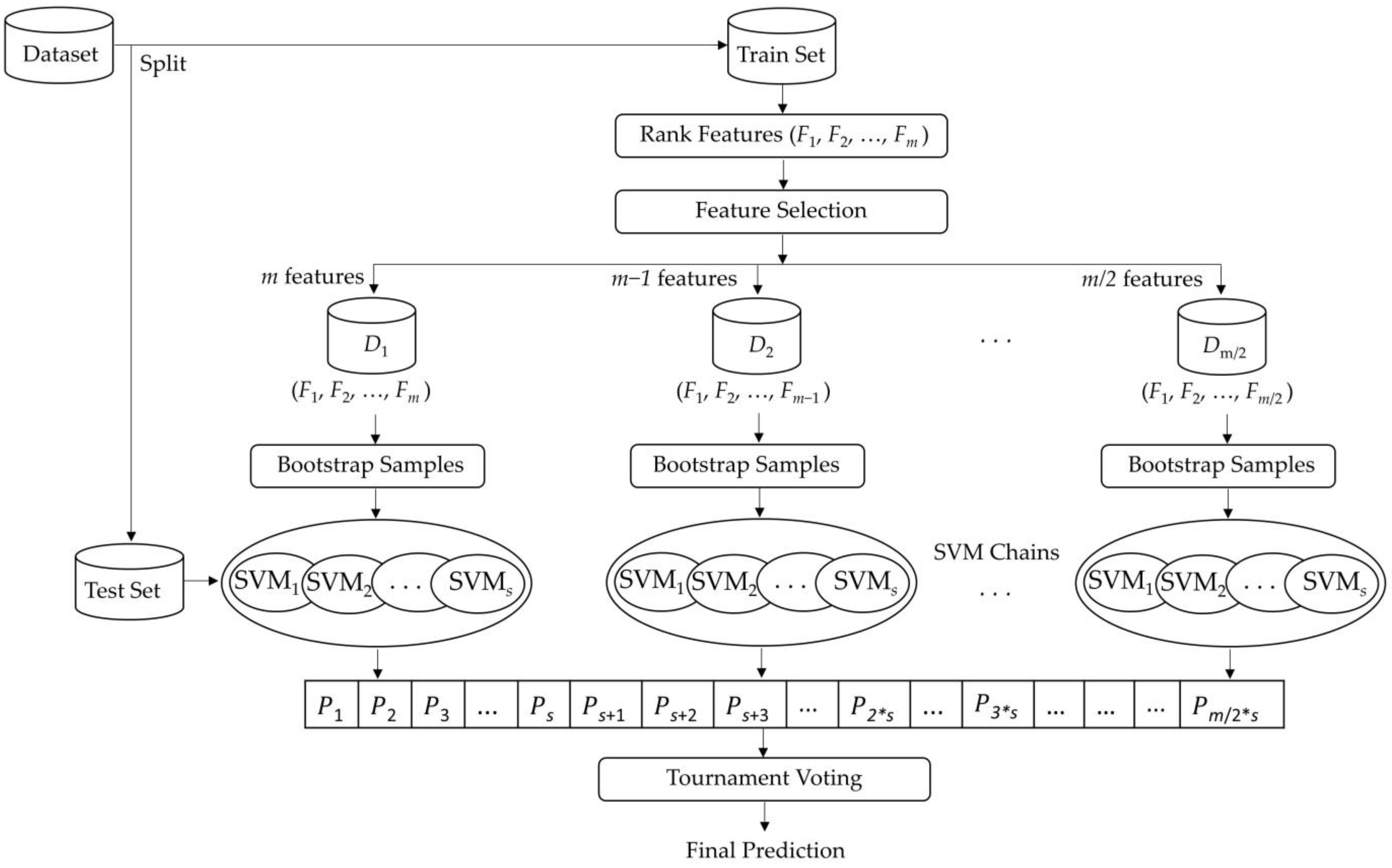
3.1. Support Vector Machine Chains (SVMC)
3.2. Formal Description
| Algorithm 1: Support Vector Machine Chains (SVMC). |
| Inputs: D: dataset m: number of features s: chain size T: test set Outputs: C: the predicted class labels |
| Begin for to Calculate mutual information () for feature end for Sort features in descending order according to scores for to = with features for to = Generate a new set from with bootstrapping = SVM() end for end for C foreach in for to for to .Add end for end for .Add() end for End Algorithm |
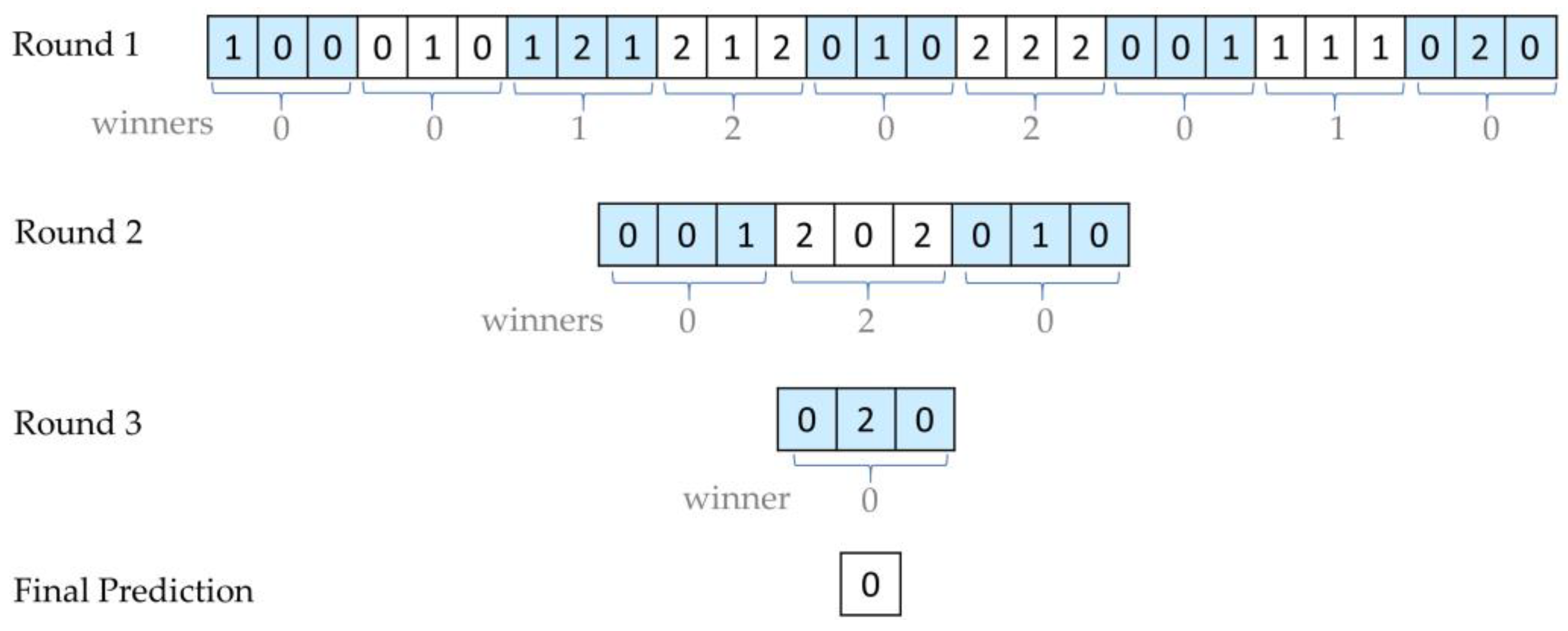
| Algorithm 2: Tournament Voting. |
| Inputs: P: array of predicted class labels t: the number of candidates in the group Output: c: final class label |
| Begin if length() = 1 c = [0] return c else Divide into with the size of for in = mode .Add() end for return endif End Algorithm |
- Since SVMC is an ensemble-learning-based method, it tends to produce a better success rate than a single SVM model. Although some models make incorrect predictions, other models in the ensemble are predisposed to correct these errors.
- Most significantly, the rank-based feature elimination strategy in SVMC makes the data less redundant, thus reducing the possibility of decision making based on unimportant and irrelevant features.
- The proposed tournament voting aims to achieve correct outcomes by excluding incorrect answers in local groups. It benefits from the strengths of a group of classifiers while overcoming the weaknesses of one classifier in the group.
- The SVMC handles feature selection, sampling, and model fusion on its own. During the construction of chain classifiers, various subspaces of the dataset are assessed along with sample and feature selection. Therefore, it benefits from the advantages of providing diversity.
- Many application domains, such as bioinformatics and text mining, usually have many input features, often of several hundreds, where many of them include only a small amount of information. In the analysis of such high-dimensional data, feature selection based on their importance can provide higher accuracy than using all features or choosing features randomly.
- Another advantage of SVMC is its implementation simplicity. The algorithm is essentially an enhanced ensemble learning algorithm that involves chaining together multiple SVM classifiers in a special structure.
- If it is required, SVMC can be easily parallelized. It is suitable for distributed and parallel environments.
4. Experimental Studies
4.1. Dataset Description
4.2. Experimental Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Method | Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dermatology | Ecoli | Hepatitis | Ionosphere | Iris | Spectf Heart | Wine | |||||
| [25] | 2022 | C5.0 | 94.90 | - | 75.95 | 89.20 | 93.40 | - | 92.00 | ||
| CTree | 93.40 | 79.10 | 90.50 | 94.10 | 89.70 | ||||||
| RPART | 92.80 | 78.90 | 87.00 | 93.00 | 88.90 | ||||||
| Tree | 92.30 | 80.80 | 87.40 | 93.60 | 92.10 | ||||||
| BSNSING | 91.50 | 79.80 | 85.90 | 94.50 | 91.10 | ||||||
| [29] | 2021 | Uniform KNN | - | 81.47 | - | 81.92 | 91.14 | - | 89.65 | ||
| Weighted KNN | 82.97 | 82.10 | 92.34 | 91.39 | |||||||
| KNNGNN | 81.51 | 91.62 | 94.27 | 94.78 | |||||||
| [32] | 2018 | SVM | - | 60.41 | - | - | 90.66 | - | 85.39 | ||
| KNN | 54.16 | 84.66 | 79.77 | ||||||||
| C4.5 | 55.65 | 92.66 | 41.01 | ||||||||
| CBCC-IM-EUC | 83.78 | 94.66 | 97.15 | ||||||||
| [33] | 2018 | C4.5 | 94.10 | 82.83 | 79.22 | 89.74 | 94.73 | - | 93.20 | ||
| CC4.5 | 94.07 | 82.95 | 77.63 | 88.95 | 94.73 | 92.98 | |||||
| AdaptiveCC4.5 | 93.96 | 81.72 | 80.62 | 88.27 | 94.13 | 92.47 | |||||
| [30] | 2018 | AR-NSGEP | 95.41 | 71.10 | 87.23 | 87.35 | 96.53 | - | 94.60 | ||
| [31] | 2016 | No TSS | 96.62 | 78.00 | 86.08 | 89.17 | 93.33 | 79.49 | 96.08 | ||
| GGA | 97.30 | 80.92 | 87.64 | 90.85 | 96.52 | 83.10 | 97.07 | ||||
| CHC | 93.29 | 78.89 | 83.59 | 90.63 | 92.67 | 76.44 | 96.67 | ||||
| SSGA | 97.42 | 80.42 | 88.33 | 91.04 | 94.00 | 82.31 | 96.88 | ||||
| [26] | 2016 | PSEL | 97.51 | 83.42 | - | 93.62 | 94.87 | 81.06 | 96.96 | ||
| Random Subspace | 96.98 | 84.38 | 93.36 | 94.67 | 79.40 | 96.33 | |||||
| Random Forest | 97.37 | 85.30 | 93.53 | 95.13 | 81.12 | 97.69 | |||||
| MultiBoostAB | 50.25 | 64.59 | 91.20 | 95.20 | 80.83 | 91.91 | |||||
| AdaBoostM1 | 50.25 | 64.59 | 92.37 | 95.33 | 80.15 | 91.35 | |||||
| Bagging | 96.09 | 83.06 | 92.20 | 94.60 | 80.72 | 95.05 | |||||
| CECMP | 94.81 | 82.82 | 91.45 | 93.73 | 79.85 | 91.40 | |||||
| CEREP | 95.06 | 82.42 | 89.94 | 93.67 | 78.76 | 91.46 | |||||
| RTBoost | 92.55 | 77.11 | 88.38 | 94.20 | 73.74 | 92.86 | |||||
| [28] | 2015 | IV-KNN | - | 82.76 | 84.67 | 84.32 | 94.67 | 76.05 | 96.60 | ||
| [34] | 2015 | PMC | 98.00 | 76.19 | 87.10 | 93.73 | 96.00 | 72.51 | 97.55 | ||
| KNN | 96.90 | 80.67 | 82.51 | 85.18 | 94.00 | 68.18 | 95.49 | ||||
| CNN | 95.78 | 67.89 | 82.33 | 89.17 | 92.67 | 64.07 | 96.63 | ||||
| [35] | 2015 | eW KNN | - | - | - | - | 92.77 | - | 96.12 | ||
| dW KNN | 95.40 | 96.75 | |||||||||
| dW-ABC KNN | 94.11 | 97.04 | |||||||||
| [27] | 2011 | NN | 85.68 | - | - | 85.24 | 95.20 | 72.81 | 71.57 | ||
| K-NN | 85.68 | 83.71 | 94.80 | 79.10 | 67.39 | ||||||
| K-MRS | 85.68 | 83.71 | 95.20 | 79.77 | 68.75 | ||||||
| K-MMS | 85.08 | 84.90 | 94.53 | 79.47 | 69.63 | ||||||
| K-NCN | 89.89 | 92.25 | 96.27 | 79.32 | 71.22 | ||||||
| Average | 90.69 | 76.86 | 82.44 | 88.82 | 93.97 | 77.65 | 89.33 | Overall Average | 85.68 | ||
| SVMC (proposed method) | 98.30 | 87.80 | 89.16 | 94.60 | 96.66 | 83.11 | 98.30 | Overall Average | 92.56 | ||
5. Conclusions and Future Work
- It proposes a novel method, called support vector machine chains (SVMC), that has a structure in which the training SVM model is included in the chain by reducing the attributes in the dataset by one at each iteration.
- It proposes a novel voting mechanism, called tournament voting, in which the outputs of classifiers compete in groups, the common result in each group gradually moves to the next round, and, in the last round, the winning class label is assigned as the final prediction.
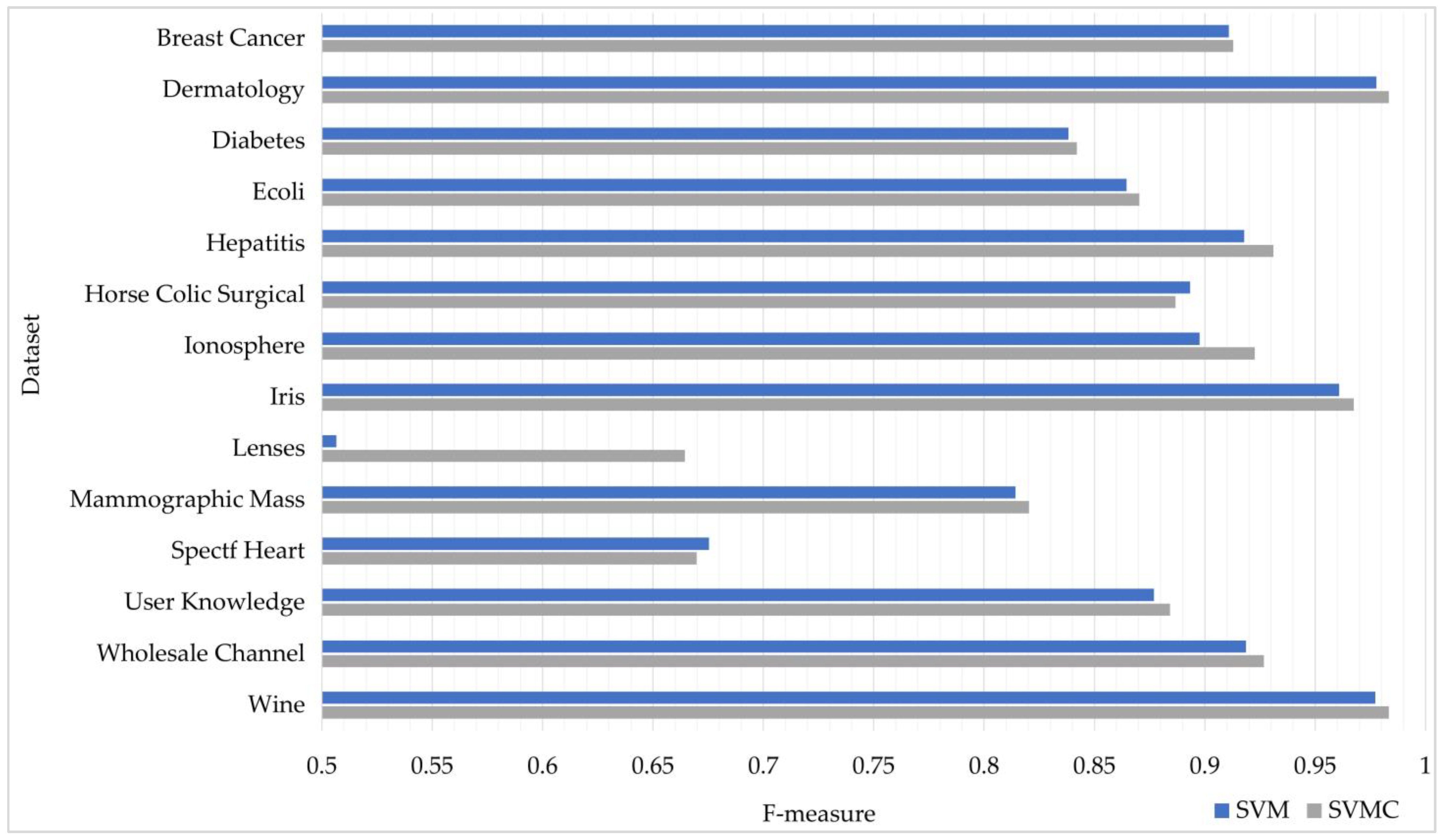
- The results of the experiments showed the superiority of SVMC (88.11%) over SVM (86.71%) in terms of average accuracy on the same datasets.
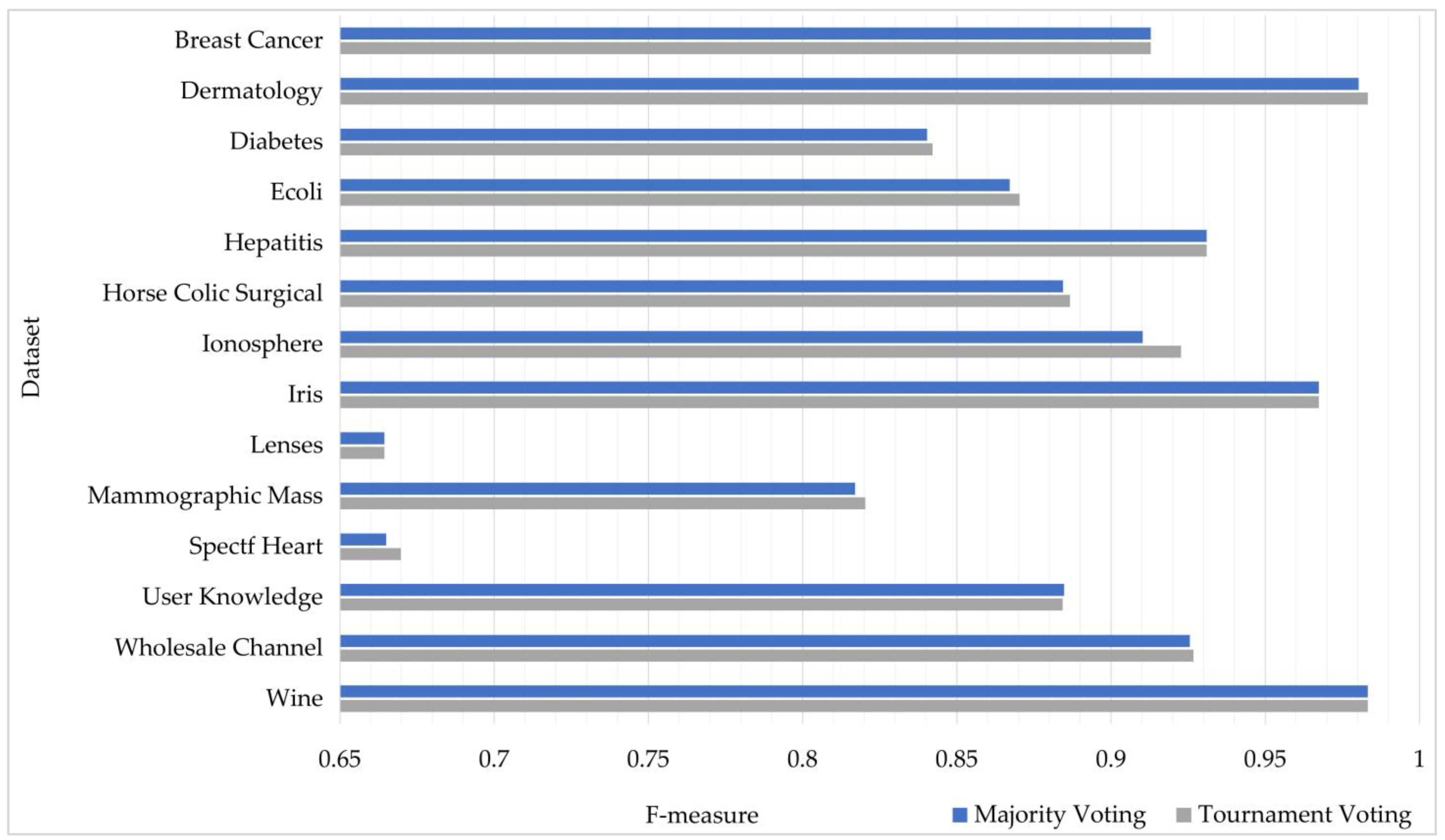
- The proposed tournament voting achieved higher accuracy than the standard majority voting in terms of the accuracy, recall, precision, and F-measure metrics when they were tested and compared on 14 well-known benchmark datasets.
- The proposed method outperformed the state-of-the-art methods, with a 6.88% improvement in average accuracy.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rojo-Álvarez, J.L.; Martínez-Ramón, M.; Muñoz-Marí, J.; Camps-Valls, G. Support Vector Machine and Kernel Classification Algorithms. In Digital Signal Processing with Kernel Methods; IEEE: Manhattan, NY, USA, 2018; pp. 433–502. [Google Scholar] [CrossRef]
- Elsadig, M.A.; Altigani, A.; Elshoush, H.T. Breast cancer detection using machine learning approaches: A comparative study. Int. J. Electr. Comput. Eng. 2023, 13, 736–745. [Google Scholar] [CrossRef]
- Zhou, C.; Song, J.; Zhou, S.; Zhang, Z.; Xing, J. COVID-19 Detection Based on Image Regrouping and Resnet-SVM Using Chest X-Ray Images. IEEE Access 2021, 9, 81902–81912. [Google Scholar] [CrossRef]
- Adarsh, V.; Kumar, P.A.; Lavanya, V.; Gangadharan, G. Fair and Explainable Depression Detection in Social Media. Inf. Process. Manag. 2023, 60, 103168. [Google Scholar] [CrossRef]
- Song, T.; Bodin, C.; Coulon, O. Ensemble learning for the detection of pli-de-passages in the superior temporal sulcus. Neuroimage 2023, 265, 119776. [Google Scholar] [CrossRef] [PubMed]
- Hayder, I.M.; Al Ali, G.A.N.; Younis, H.A. Predicting reaction based on customer’s transaction using machine learning approaches. Int. J. Electr. Comput. Eng. 2023, 13, 1086–1096. [Google Scholar] [CrossRef]
- Shakil, S.; Arora, D.; Zaidi, T. An optimal method for identification of finger vein using supervised learning. Meas. Sensors 2023, 25, 100583. [Google Scholar] [CrossRef]
- Maincer, D.; Benmahamed, Y.; Mansour, M.; Alharthi, M.; Ghonein, S.S.M. Fault Diagnosis in Robot Manipulators Using SVM and KNN. Intell. Autom. Soft Comput. 2022, 35, 1957–1969. [Google Scholar] [CrossRef]
- Puertas, G.; Cazón, P.; Vázquez, M. A Quick Method for Fraud Detection in Egg Labels Based on Egg Centrifugation Plasma. Food Chem. 2023, 402, 134507. [Google Scholar] [CrossRef]
- Malek, N.H.A.; Yaacob, W.F.W.; Wah, Y.B.; Md Nasir, S.A.; Shaadan, N.; Indratno, S.W. Comparison of Ensemble Hybrid Sampling with Bagging and Boosting Machine Learning Approach for Imbalanced Data. Indones. J. Elec. Eng. Comput. Sci. 2023, 29, 598–608. [Google Scholar] [CrossRef]
- Al Duhayyim, M.; Alotaibi, S.S.; Al-Otaibi, S.; Al-Wesabi, F.N.; Othman, M.; Yaseen, I.; Rizwanullah, M.; Motwakel, A. An Intelligent Hazardous Waste Detection and Classification Model Using Ensemble Learning Techniques. Comput. Mater. Contin. 2023, 74, 3315–3332. [Google Scholar] [CrossRef]
- Bawa, A.; Samanta, S.; Himanshu, S.K.; Singh, J.; Kim, J.J.; Zhang, T.; Chang, A.; Jung, J.; DeLaune, P.; Bordovsky, J.; et al. A Support Vector Machine and Image Processing Based Approach for Counting Open Cotton Bolls and Estimating Lint Yield from UAV Imagery. Smart Agri. Tech. 2023, 3, 100140. [Google Scholar] [CrossRef]
- Yu, L.; Yue, W.; Wang, S.; Lai, K.K. Support vector machine based multiagent ensemble learning for credit risk evaluation. Exp. Syst. Appl. 2010, 37, 1351–1360. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Salama, M.; Abdelkader, H.; Abdelwahab, A. A Novel Ensemble Approach for Heterogeneous Data with Active Learning. Int. J. Eng. Bus. Manag. 2022, 14, 18479790221082605. [Google Scholar] [CrossRef]
- Khadse, V.M.; Mahalle, P.N.; Shinde, G.R. A Novel Approach of Ensemble Learning with Feature Reduction for Classification of Binary and Multiclass IoT Data. Turk. J. Comput. Math. Edu. 2021, 12, 2072–2083. [Google Scholar]
- Noor, A.; Ucąr, M.K.; Polat, K.; Assiri, A.; Nour, R.; Masciari, E. A Novel Approach to Ensemble Classifiers: FsBoost-Based Subspace Method. Math. Probl. Eng. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Rojarath, A.; Songpan, W. Cost-sensitive Probability for Weighted Voting in an Ensemble Model for Multi-Class Classification Problems. Appl. Intell. 2021, 51, 4908–4932. [Google Scholar] [CrossRef]
- Bhuiyan, M.; Islam, M.S. A New Ensemble Learning Approach to Detect Malaria from Microscopic Red Blood Cell Images. Sensors Int. 2023, 4, 100209. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Pham, H. Optimizing Ensemble Weights and Hyperparameters of Machine Learning Models for Regression Problems. Mach. Learn. Appl. 2022, 7, 100251. [Google Scholar] [CrossRef]
- Chongya, S.; Kang, Y.; Alexander, P.; Jin, L. Rank-based Chain-Mode Ensemble for Binary Classification. Int. J. Comput. Syst. Eng. 2020, 14, 153–158. [Google Scholar]
- Tuysuzoglu, G.; Birant, D. Enhanced bagging (eBagging): A novel approach for ensemble learning. Int. Arab J. Inf. Tech. 2020, 17, 515–528. [Google Scholar] [CrossRef]
- Abdoli, M.; Akbari, M.; Shahrabi, J. Bagging Supervised Autoencoder Classifier for credit scoring. Expert Syst. Appl. 2023, 213, 118991. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI (University of California Irvine) Machine Learning Repository. 2019. Available online: https://archive.ics.uci.edu/ml (accessed on 20 April 2023).
- Liu, Y. bsnsing: A decision tree induction method based on recursive optimal boolean rule composition. arXiv 2022, arXiv:2205.15263. [Google Scholar] [CrossRef]
- Yu, Z.; Wang, D.; You, J.; Wong, H.S.; Wu, S.; Zhang, J.; Han, G. Progressive subspace ensemble learning. Pattern Recognit. 2016, 60, 692–705. [Google Scholar] [CrossRef]
- Altiņcay, H. Improving the K-Nearest Neighbour Rule: Using Geometrical Neighbourhoods and Manifold-Based Metrics. Expert Systems 2011, 28, 391–406. [Google Scholar] [CrossRef]
- Derrac, J.; Chiclana, F.; García, S.; Herrera, F. An Interval Valued K-Nearest Neighbors Classifier. In Proceedings of the 2015 Conference of the International Fuzzy Systems Association and the European Society for Fuzzy Logic and Technology, Gijón, Spain, 30 June 2015. [Google Scholar]
- Kang, S. K-nearest Neighbor Learning with Graph Neural Networks. Mathematics 2021, 9, 830. [Google Scholar] [CrossRef]
- Guerrero-Enamorado, A.; Morell, C.; Ventura, S. A Gene Expression Programming Algorithm for Discovering Classification Rules in the Multi-Objective Space. Int. J. Comp. Intell. Syst. 2018, 11, 540–559. [Google Scholar] [CrossRef]
- Verbiest, N.; Derrac, J.; Cornelis, C.; García, S.; Herrera, F. Evolutionary wrapper approaches for training set selection as preprocessing mechanism for support vector machines: Experimental evaluation and support vector analysis. Appl. Soft Comp. J. 2015, 38, 10–22. [Google Scholar] [CrossRef]
- Yelipe, U.R.; Porika, S.; Golla, M. An efficient approach for imputation and classification of medical data values using class-based clustering of medical records. Comput. Elec. Eng. 2018, 66, 487–504. [Google Scholar] [CrossRef]
- Abellán, J.; Mantas, C.J.; Castellano, J.G. AdaptativeCC4.5: Credal C4.5 with a Rough Class Noise Estimator. Expert Syst. Appl. 2018, 92, 363–379. [Google Scholar] [CrossRef]
- Sreeja, N.K.; Sankar, A. Pattern matching based classification using Ant Colony Optimization based feature selection. Appl. Soft Comp. J. 2015, 31, 91–102. [Google Scholar] [CrossRef]
- Yigit, H. ABC-based distance-weighted kNN algorithm. J. Exp. Theor. Artif. Intell. 2015, 27, 189–198. [Google Scholar] [CrossRef]




| No. | Dataset | #Class | #Feature | #Instance | Categoric | Numeric |
|---|---|---|---|---|---|---|
| 1 | Breast Cancer | 2 | 30 | 569 | √ | |
| 2 | Dermatology | 6 | 34 | 366 | √ | √ |
| 3 | Diabetes | 2 | 9 | 768 | √ | |
| 4 | Ecoli | 4 | 8 | 336 | √ | |
| 5 | Hepatitis | 2 | 20 | 155 | √ | √ |
| 6 | Horse Colic Surgical | 2 | 28 | 300 | √ | √ |
| 7 | Ionosphere | 2 | 35 | 355 | √ | √ |
| 8 | Iris | 3 | 5 | 150 | √ | |
| 9 | Lenses | 3 | 5 | 24 | √ | |
| 10 | Mammographic Mass | 2 | 6 | 961 | √ | |
| 11 | Spectf Heart | 2 | 45 | 349 | √ | |
| 12 | User Knowledge | 5 | 6 | 403 | √ | |
| 13 | Wholesale Channel | 2 | 8 | 440 | √ | √ |
| 14 | Wine | 3 | 14 | 178 | √ |
| Dataset | SVM | SVMC (Proposed) | ||||
|---|---|---|---|---|---|---|
| Accuracy (%) | Precision | Recall | Accuracy (%) | Precision | Recall | |
| Breast Cancer | 91.37 | 0.9209 | 0.9137 | 91.55 ● | 0.9225 | 0.9155 |
| Dermatology | 97.76 | 0.9814 | 0.9776 | 98.30 ● | 0.9863 | 0.9830 |
| Diabetes | 77.59 | 0.7920 | 0.8912 | 77.99 ● | 0.7912 | 0.9008 |
| Ecoli | 87.21 | 0.8728 | 0.8721 | 87.80 ● | 0.8773 | 0.8780 |
| Hepatitis | 86.80 | 0.8781 | 0.9750 | 89.16 ● | 0.9001 | 0.9750 |
| Horse Colic Surgical | 85.66 | 0.8584 | 0.9337 | 85.00 | 0.8562 | 0.9215 |
| Ionosphere | 93.18 | 0.9640 | 0.8437 | 94.60 ● | 0.9663 | 0.8859 |
| Iris | 96.00 | 0.9698 | 0.9600 | 96.66 ● | 0.9748 | 0.9666 |
| Lenses | 60.00 | 0.4861 | 0.6000 | 70.00 ● | 0.6944 | 0.7000 |
| Mammographic Mass | 80.43 | 0.8268 | 0.8040 | 81.06 ● | 0.8319 | 0.8118 |
| Spectf Heart | 82.52 | 0.6628 | 0.7069 | 83.11 ● | 0.6678 | 0.6877 |
| User Knowledge | 88.57 | 0.8912 | 0.8857 | 89.81 ● | 0.8950 | 0.8981 |
| Wholesale Channel | 89.09 | 0.9103 | 0.9295 | 90.22 ● | 0.9164 | 0.9387 |
| Wine | 97.71 | 0.9829 | 0.9771 | 98.30 ● | 0.9862 | 0.9830 |
| Average | 86.71 | 0.8570 | 0.8764 | 88.11 | 0.8762 | 0.8890 |
| Dataset | SVMC (Majority Voting) | SVMC (Tournament Voting) (Proposed) | ||||
|---|---|---|---|---|---|---|
| Accuracy (%) | Precision | Recall | Accuracy (%) | Precision | Recall | |
| Breast Cancer | 91.55 | 0.9225 | 0.9155 | 91.55 ● | 0.9225 | 0.9155 |
| Dermatology | 98.03 | 0.9837 | 0.9803 | 98.30 ● | 0.9863 | 0.9830 |
| Diabetes | 77.73 | 0.7886 | 0.9003 | 77.99 ● | 0.7912 | 0.9008 |
| Ecoli | 87.50 | 0.8755 | 0.8750 | 87.80 ● | 0.8773 | 0.8780 |
| Hepatitis | 89.16 | 0.9001 | 0.9750 | 89.16 ● | 0.9001 | 0.9750 |
| Horse Colic Surgical | 84.66 | 0.8523 | 0.9209 | 85.00 ● | 0.8562 | 0.9215 |
| Ionosphere | 94.03 | 0.9652 | 0.8643 | 94.60 ● | 0.9663 | 0.8859 |
| Iris | 96.66 | 0.9748 | 0.9666 | 96.66 ● | 0.9748 | 0.9666 |
| Lenses | 70.00 | 0.6944 | 0.7000 | 70.00 ● | 0.6944 | 0.7000 |
| Mammographic Mass | 80.64 | 0.8271 | 0.8099 | 81.06 ● | 0.8319 | 0.8118 |
| Spectf Heart | 82.53 | 0.6533 | 0.6961 | 83.11 ● | 0.6678 | 0.6877 |
| User Knowledge | 89.81 | 0.8896 | 0.8981 | 89.81 ● | 0.8950 | 0.8981 |
| Wholesale Channel | 90.00 | 0.9107 | 0.9424 | 90.22 ● | 0.9164 | 0.9387 |
| Wine | 98.30 | 0.9862 | 0.9830 | 98.30 ● | 0.9862 | 0.9830 |
| Average | 87.90 | 0.8731 | 0.8877 | 88.11 | 0.8762 | 0.8890 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atik, C.; Kut, R.A.; Yilmaz, R.; Birant, D. Support Vector Machine Chains with a Novel Tournament Voting. Electronics 2023, 12, 2485. https://doi.org/10.3390/electronics12112485
Atik C, Kut RA, Yilmaz R, Birant D. Support Vector Machine Chains with a Novel Tournament Voting. Electronics. 2023; 12(11):2485. https://doi.org/10.3390/electronics12112485
Chicago/Turabian StyleAtik, Ceren, Recep Alp Kut, Reyat Yilmaz, and Derya Birant. 2023. "Support Vector Machine Chains with a Novel Tournament Voting" Electronics 12, no. 11: 2485. https://doi.org/10.3390/electronics12112485
APA StyleAtik, C., Kut, R. A., Yilmaz, R., & Birant, D. (2023). Support Vector Machine Chains with a Novel Tournament Voting. Electronics, 12(11), 2485. https://doi.org/10.3390/electronics12112485