


A Programmable SRv6 Processor for SFC


Abstract
:1. Introduction
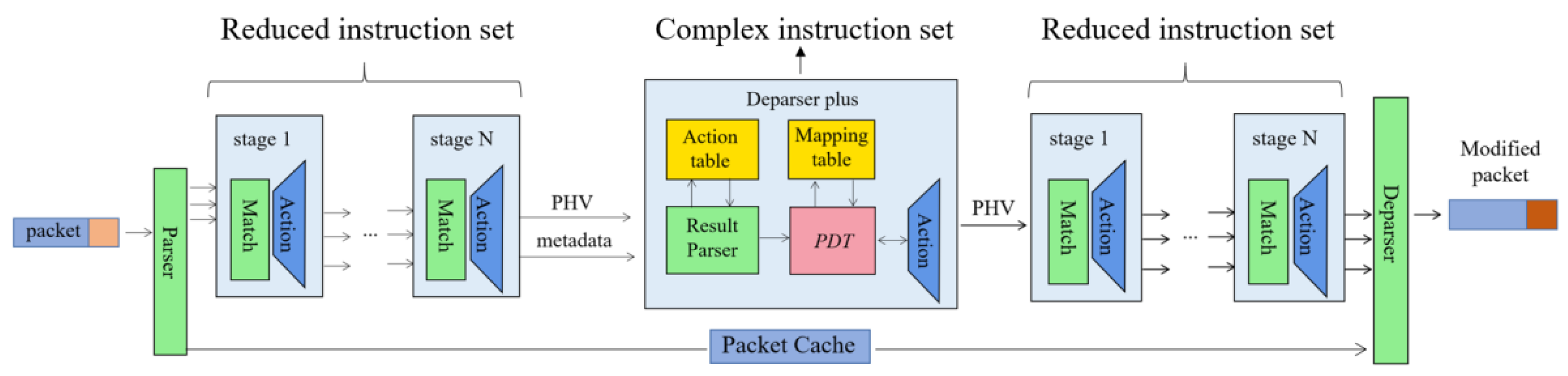
- The idea of CacheP4 comes from the repeated entry matching of packets in the same stateless packet flow when the forwarding device forwards packets on the data plane [3]. CacheP4 speeds up packet forwarding by avoiding such repeated matching. Inspired by CacheP4, we believe that it is not necessary to place the MAT cache at the starting position of RMT, but rather that we should regard this fast path as a multi-level pipeline, that is, with each processing stage as a level of cache, and add a slow path at the end for complex stateful packet processing. We can regard the slow path as a Cache ALU for the RMT architecture and use CacheP4 for reference to extend the deparser as a deparser plus, based on the RMT architecture. The RMT architecture is mainly responsible for simple stateless processing, so it is an example of pipeline architecture in the traditional model of dedicated network processor (NP) forwarding. Deparser plus is mainly responsible for complex and stateful operations, such as encapsulation of message headers and insertion of protocol headers, using a complex instruction set, and it also makes use of the run-to-completion (RTC) architecture of the NP forwarding model. A comparison of the RTC and pipeline architectures is shown in Table 1. The combination of the RTC and pipeline architectures enables the design of a protocol-independent packet processing architecture.
- We used ingress RMT, deparser plus, and egress RMT to form a pipeline architecture called a programmable SRv6 (segment routing IPv6) processor, because we designed it primarily for the segment identifier (SID) processing of SRv6. It can support parsing and processing packets of different lengths, such as SRv6, multi-protocol label switching (MPLS), virtual extensible local area network (VXLAN), multiple semantics for segment IDs (SIDs), and micro SID (uSID) compression and decompression. This paper also investigates the use of programmable SRv6 processor in application scenarios, such as segment routing over UDP (SRoU), in-band network telemetry (INT), and service function chain (SFC) orchestration.
- We test the deparser plus module on the Corundum platform using SRv6 packets to verify that the extended deparser plus can perform operations on packets using different instructions depending on the SID.
2. Related Work
2.1. Network Virtualization
2.2. Programmable Data Plane
3. Protocol-Independent Pipeline Design
3.1. Overall Architecture of Programmable SRv6 Processor
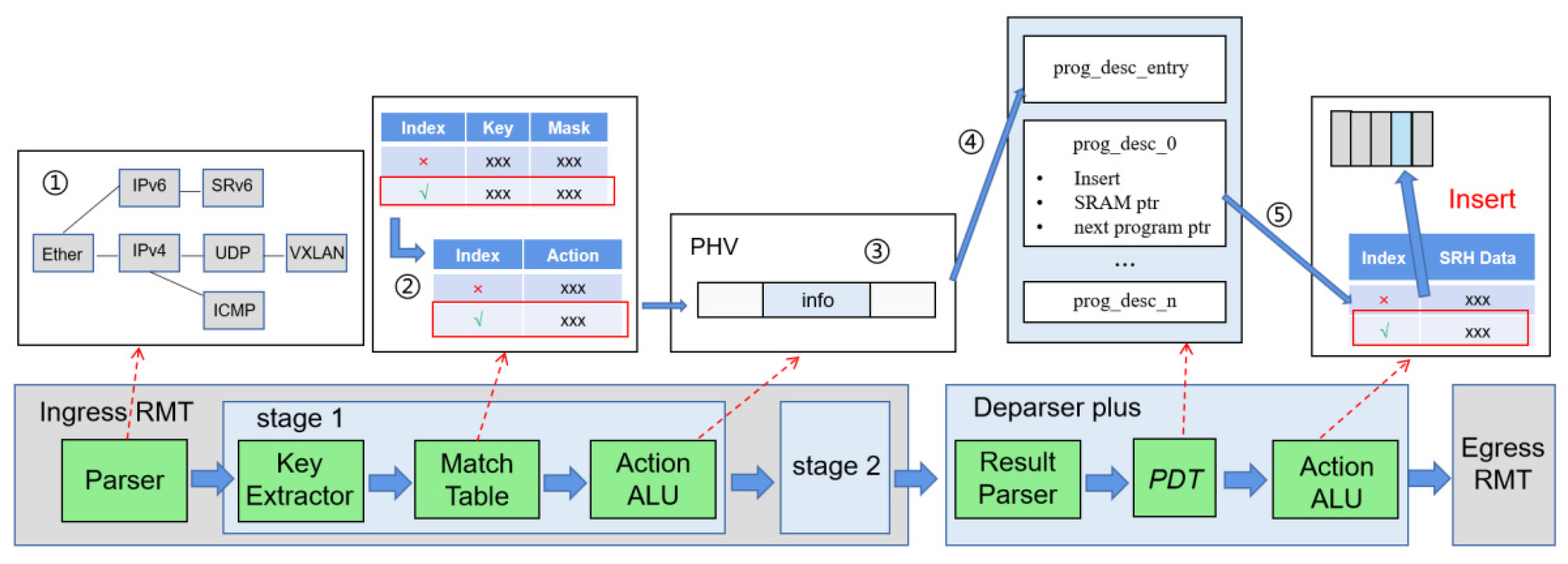
3.2. Programmable MAT
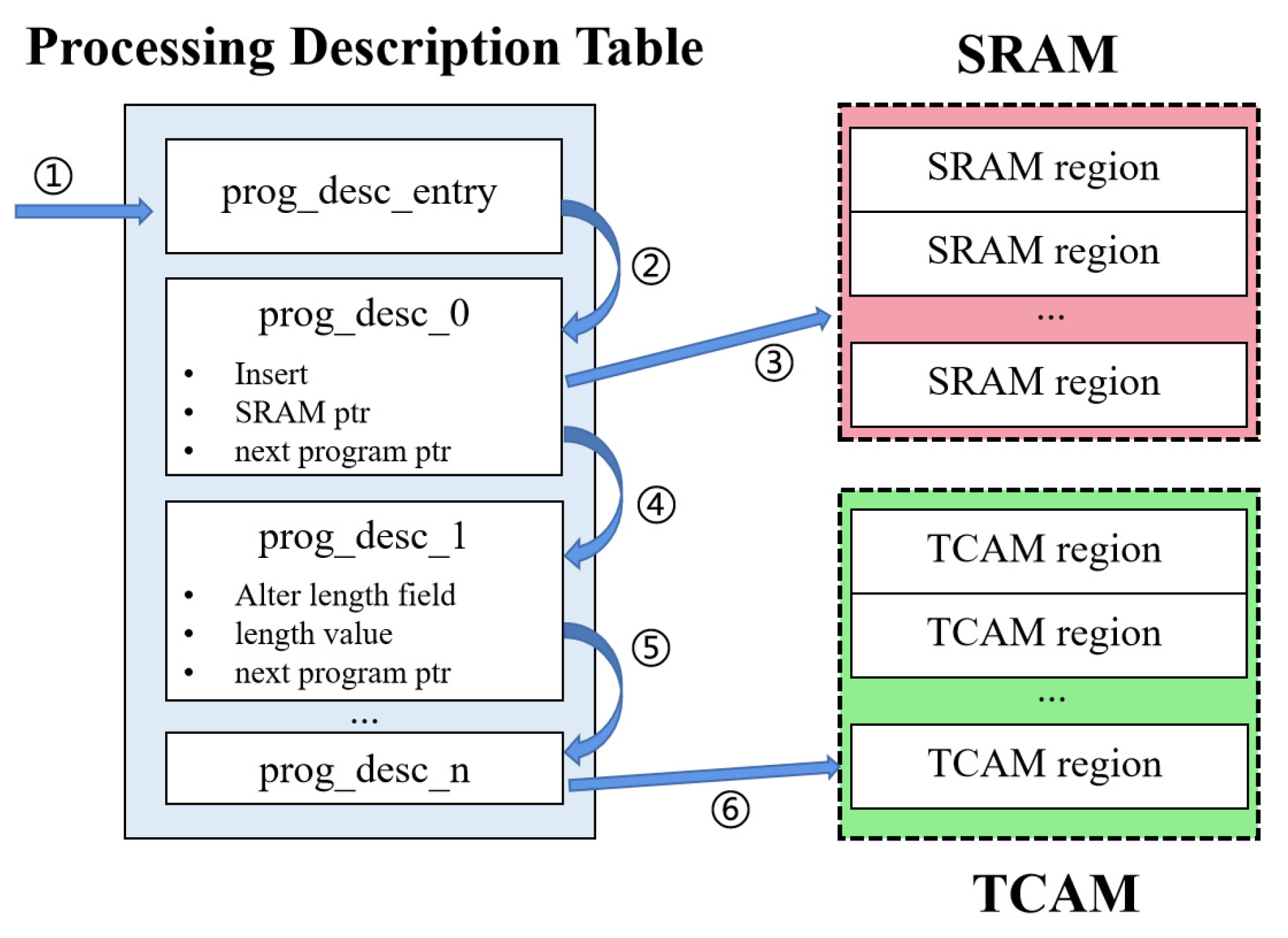
3.3. Protocol-Independent Programmable Deparser Plus
3.4. Programmable SR Forwarding for Network Slice
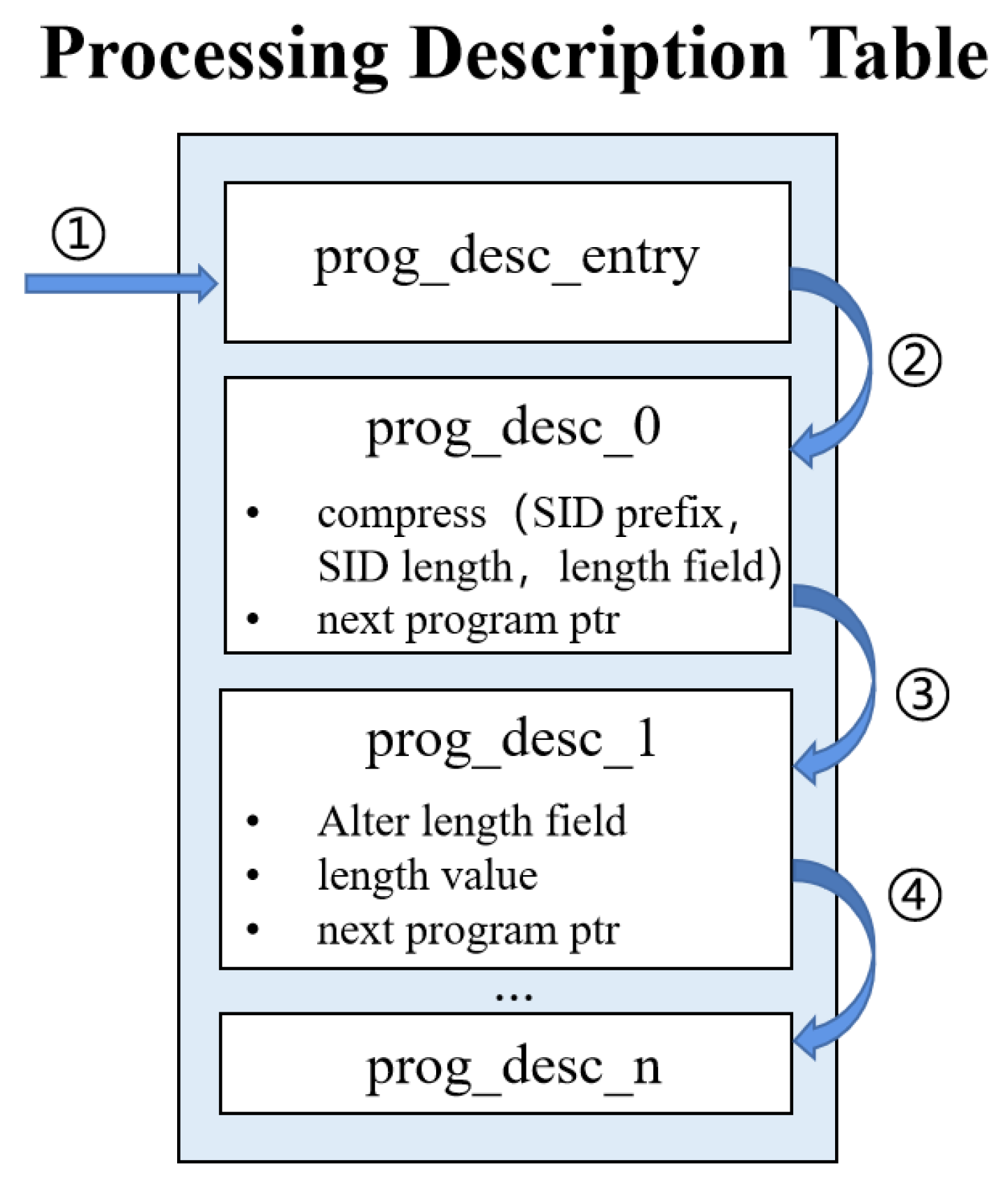
3.4.1. SRv6 Mapping in Processor
| Algorithm 1. The pseudo code of SRv6. |
| Input:packet |
| Output:modified _ packet |
| 1. if (hop _ limit == 0) drop (packet); |
| 2. else if (SRH){ |
| 3. if (Des _ IP == Local _ IP){ |
| 4. if (Segment _ Left == 0 ){ |
| 5. Des _ IP = Segment _ List [0]; |
| 6. Delete (SRH); |
| 7. hop _ limit --; |
| 8. Submit (modified _ packet); |
| 9. } |
| 10. else { |
| 11 Des _ IP = Segment _ List [Segment _ Left]; |
| 12 Segment _ Left --; |
| 13 hop _ limit --; |
| 14 out _ port = Look _ up (FIB, Des _ IP); |
| 15 Des _ MAC = Look _ up (ADJ, Des _ IP); |
| 16 Forward (out _ port, modified _ packet); |
| 17 } |
| 18 else { |
| 19 hop _ limit --; |
| 20 out _ port = Look _ up (FIB, Des _ IP); |
| 21 Des _ MAC = Look _ up (ADJ, Des _ IP); |
| 22 Forward (out_port, modified_packet); |
| 23 } |
| 24 } |
| 25 else { |
| 26 flow _ id = Look _ up (Flow _ table); |
| 27 if (flow _ id == IPv6){ |
| 28 out _ port = Look _ up (FIB, Des _ IP); |
| 29 Des _ MAC = Look _ up (ADJ, Des _ IP); |
| 30 Forward (out _ port, modified _ packet); |
| 31 } |
| 32 else if (flow _ id == source _ SRv6){ |
| 33 instruction = Look _ up (Action _ table, flow _ id) |
| 34 Config (PDT, instruction); |
| 35 SRH = Look_up (Mapping _ table, instruction [index]); |
| 36 Insert (PHV, SRH, offset, SRH _ length); |
| 37 payload _ length = payload _ length + SRH _ length; |
| 38 Des _ IP = Segment _ List [ Segment _ Left ]; |
| 39 Segment _ Left --; |
| 40 out _ port = Look _ up (FIB, Des _ IP); |
| 41 Des _ MAC = Look _ up (ADJ, Des _ IP); |
| 42 Forward (out _ port, modified _ packet); |
| 43 } |
| 44 } |
3.4.2. Multiple Semantics and Function for SID
3.4.3. Support for uSID
4. Application and Validation
4.1. Prototype System
4.2. Application Scenarios for Prototype System
4.3. Performance Analysis
4.4. Remarks
5. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Bosshart, P.; Gibb, G.; Kim, H.S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Ma, Z.; Bi, J.; Zhang, C.; Zhou, Y.; Dogar, A.B. Cachep4: A behavior-level caching mechanism for p4. In Proceedings of the SIGCOMM Posters and Demos, Los Angeles, CA, USA, 21–25 August 2017; pp. 108–110. [Google Scholar]
- Chowdhury, N.M.M.K.; Boutaba, R. A survey of network virtualization. Comput. Netw. 2010, 54, 862–876. [Google Scholar] [CrossRef]
- Sadeeq, M.M.; Abdulkareem, N.M.; Zeebaree, S.R.; Ahmed, D.M.; Sami, A.S.; Zebari, R.R. IoT and Cloud computing issues, challenges and opportunities: A review. Qubahan Acad. J. 2021, 1, 1–7. [Google Scholar] [CrossRef]
- Baykara, M.; DAŞ, R. SoftSwitch: A centralized honeypot-based security approach using software-defined switching for secure management of VLAN networks. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 3309–3325. [Google Scholar] [CrossRef]
- Salazar-Chacón, G.; Naranjo, E.; Marrone, L. Open networking programmability for VXLAN Data Centre infrastructures: Ansible and Cumulus Linux feasibility study. Rev. Ibérica De Sist. E Tecnol. De Inf. 2020, E32, 469–482. [Google Scholar]
- Ezra, P.J.; Misra, S.; Agrawal, A.; Oluranti, J.; Maskeliunas, R.; Damasevicius, R. Secured communication using virtual private network (VPN). In Cyber Security and Digital Forensics; Springer: Singapore, 2022; pp. 309–319. [Google Scholar]
- Wijethilaka, S.; Liyanage, M. Survey on network slicing for Internet of Things realization in 5G networks. IEEE Commun. Surv. Tutor. 2021, 23, 957–994. [Google Scholar] [CrossRef]
- Barakabitze, A.A.; Ahmad, A.; Mijumbi, R.; Hines, A. 5G network slicing using SDN and NFV: A survey of taxonomy, architectures and future challenges. Comput. Netw. 2020, 167, 106984. [Google Scholar] [CrossRef]
- Hawilo, H.; Liao, L.; Shami, A.; Leung, V.C. NFV/SDN-based vEPC solution in hybrid clouds. In Proceedings of the 2018 IEEE Middle East and North Africa Communications Conference (MENACOMM), Jounieh, Lebanon, 18–20 April 2018; pp. 1–6. [Google Scholar]
- Pujolle, G. Fabric, SD-WAN, vCPE, vRAN, vEPC; Wiley: Hoboken, NJ, USA, 2020. [Google Scholar]
- Ventre, P.L.; Salsano, S.; Polverini, M.; Cianfrani, A.; Abdelsalam, A.; Filsfils, C.; Camarillo, P.; Clad, F. Segment routing: A comprehensive survey of research activities, standardization efforts, and implementation results. IEEE Commun. Surv. Tutor. 2020, 23, 182–221. [Google Scholar] [CrossRef]
- P4 Runtime. Available online: https://p4.org/p4-runtime/ (accessed on 7 September 2022).
- Kaufmann, A.; Peter, S.; Sharma, N.K.; Anderson, T.; Krishnamurthy, A. High performance packet processing with flexnic. In Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems, Atlanta, GA, USA, 2–6 April 2016; pp. 67–81. [Google Scholar]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Wang, T.; Yang, X.; Antichi, G.; Sivaraman, A.; Panda, A. Isolation Mechanisms for {High-Speed}{Packet-Processing} Pipelines. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022; pp. 1289–1305. [Google Scholar]
- Chole, S.; Fingerhut, A.; Ma, S.; Sivaraman, A.; Vargaftik, S.; Berger, A.; Mendelson, G.; Alizadeh, M.; Chuang, S.T.; Keslassy, I.; et al. drmt: Disaggregated programmable switching. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 1–14. [Google Scholar]
- Xing, J.; Hsu, K.F.; Kadosh, M.; Lo, A.; Piasetzky, Y.; Krishnamurthy, A.; Chen, A. Runtime programmable switches. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022; pp. 651–665. [Google Scholar]
- Intel Infrastructure Processing Unit for Data Centers. Available online: https://www.intel.com/content/www/us/en/newsroom/news/infrastructure-processing-unit-data-center.html#gs.abuzma (accessed on 12 September 2022).
- NetXtreme® Ethernet Adapters. Available online: https://www.broadcom.com/how-to-buy/hardware-partners/ethernet-network-adapters/broadcom (accessed on 12 September 2022).
- CONNECTX-5 Product Brief. Available online: https://www.nvidia.com/en-us/networking/ethernet/connectx-5/ (accessed on 12 September 2022).
- Yang, M.; Baban, A.; Kugel, V.; Libby, J.; Mackie, S.; Kananda, S.S.R.; Wu, C.H.; Ghobadi, M. Using trio: Juniper networks’ programmable chipset-for emerging in-network applications. In Proceedings of the ACM SIGCOMM 2022 Conference, Amsterdam, The Netherlands, 22–26 August 2022; pp. 633–648. [Google Scholar]
- Exploration of Cloud Native Routing Architecture. Available online: https://www.136.la/jingpin/show-121807.html (accessed on 12 September 2022).
- Tan, L.; Su, W.; Zhang, W.; Lv, J.; Zhang, Z.; Miao, J.; Liu, X.; Li, N. In-band network telemetry: A survey. Comput. Netw. 2021, 186, 107763. [Google Scholar] [CrossRef]
- Sun, G.; Li, Y.; Yu, H.; Vasilakos, A.V.; Du, X.; Guizani, M. Energy-efficient and traffic-aware service function chaining orchestration in multi-domain networks. Future Gener. Comput. Syst. 2019, 91, 347–360. [Google Scholar] [CrossRef]
- Segment Routing with MPLS Data Plane. Available online: https://datatracker.ietf.org/doc/html/rfc8660 (accessed on 8 September 2022).
- Wu, Y.; Zhou, J. Dynamic Service Function Chaining Orchestration in a Multi-Domain: A Heuristic Approach Based on SRv6. Sensors 2021, 21, 6563. [Google Scholar] [CrossRef] [PubMed]
- Tulumello, A.; Mayer, A.; Bonola, M.; Lungaroni, P.; Scarpitta, C.; Salsano, S.; Abdelsalam, A.; Camarillo, P.; Dukes, D.; Clad, F.; et al. Micro SIDs: A solution for efficient representation of segment IDs in SRv6 networks. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Izmir, Turkey, 2–6 November 2020; pp. 1–10. [Google Scholar]
- Cheng, W.; Liu, Y.; Jiang, W.; Zhang, G.; Yang, F.; Han, T. G-SID: SRv6 Header Compression Solution. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020; pp. 126–130. [Google Scholar]
- Forencich, A.; Snoeren, A.C.; Porter, G.; Papen, G. Corundum: An open-source 100-gbps nic. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Fayetteville, AR, USA, 3–6 May 2020; pp. 38–46. [Google Scholar]
- Spirent Quint-Speed High-Speed Ethernet Test Modules. Available online: https://assets.ctfassets.net/wcxs9ap8i19s/12bhgz12JBkRa66QUG4N0L/af328986e22b1694b95b290c93ef6c21/Spirent_fX3_HSE_Module_datasheet.pdf (accessed on 7 September 2022).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pipeline | RTC | |
|---|---|---|
| Operation mode | Decompose a function (larger than a module-level function) into multiple independent phases, with data passing through queues between phases. | A program is typically divided into several logical functions, but these logical functions run on the same CPU core. |
| Development | Once the chip is designed, the processing ability it supports is fixed. | New features can be added later through software code. |
| Performance | High efficiency. There are cache consistency issues across multiple cores. | Efficiency is low. There are dependency issues in the process. |
| Scalability | Not good | Good |
| Operation | Description | Format |
|---|---|---|
| insert | Insert data in the corresponding position of the packet header | {opcode, offset, mapping table index, inserted data length, packet length field offset} |
| delete | Delete data in the corresponding position of the packet header | {opcode, offset, deleted data length, packet length field offset} |
| compress | Compress the corresponding fields in the packet header | {opcode, SID prefix, SID length, packet length field offset} |
| decompress | Decompress the corresponding fields in the packet header | {opcode, uSID prefix, uSID length, packet length field offset} |
| encapsulate | Encapsulate header | {opcode, encapsulated info, offset of altered field, altered field info, packet length field offset} |
| decapsulate | Decapsulate packet header | {opcode, offset of encapsulated info, offset of altered field, altered field, packet length field offset} |
| alter | Alter action table | {opcode, action table index, instruction length, altered instruction} |
| VXLAN | SRoU | INT | SFC | |
|---|---|---|---|---|
| Principle | Data frames in the virtual network are encapsulated into packets in the physical network for transmission | This is essentially putting the SRH into the UDP payload | As the telemetry packet passes through the switching device, the telemetry instruction tells the network device with network telemetry capability what network state information should be collected and written | Network traffic passes through these service points in a predetermined order required by the business logic |
| Information written | VXLAN header | SRH | INT header and metadata | SFC header |
| Layer of the network | L2 over L4 | L4 | L7 | L4-L7 |
| Application scenarios | VMs communication and seamless Layer 2 extension over IP networks | To solve the problem of NAT in an IPv4 network, NAT traversal and stateless forwarding of relay node are implemented | Network operation and maintenance visualization, fault location, network measurement, congestion control, path decision, and flow engineering | Service resource pooling, dynamic creation, and automatic deployment of NFV resource pools, and flexible orchestration of tenant services |
| Utilization | Deparser Plus | Corundum |
|---|---|---|
| CLB LUTs | 3281 (0.28%) | 61,460 (5.20%) |
| CLB Registers | 2297 (0.10%) | 38,739 (1.69%) |
| F7 Muxes | 495 (0.08%) | 5315 (0.86%) |
| CLB | 665 (0.45%) | 7340 (4.97%) |
| Block RAM Tile | 16 (0.74%) | 315 (14.58%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Lv, G.; Wang, J.; Yang, X. A Programmable SRv6 Processor for SFC. Electronics 2022, 11, 2920. https://doi.org/10.3390/electronics11182920
Liu Z, Lv G, Wang J, Yang X. A Programmable SRv6 Processor for SFC. Electronics. 2022; 11(18):2920. https://doi.org/10.3390/electronics11182920
Chicago/Turabian StyleLiu, Zhongpei, Gaofeng Lv, Jichang Wang, and Xiangrui Yang. 2022. "A Programmable SRv6 Processor for SFC" Electronics 11, no. 18: 2920. https://doi.org/10.3390/electronics11182920
APA StyleLiu, Z., Lv, G., Wang, J., & Yang, X. (2022). A Programmable SRv6 Processor for SFC. Electronics, 11(18), 2920. https://doi.org/10.3390/electronics11182920